Natural-gradient learning for spiking neurons
- Department of Physiology, University of Bern, Switzerland
- Kirchhoff-Institute for Physics, Heidelberg University, Germany
Abstract
In many normative theories of synaptic plasticity, weight updates implicitly depend on the chosen parametrization of the weights. This problem relates, for example, to neuronal morphology: synapses which are functionally equivalent in terms of their impact on somatic firing can differ substantially in spine size due to their different positions along the dendritic tree. Classical theories based on Euclidean-gradient descent can easily lead to inconsistencies due to such parametrization dependence. The issues are solved in the framework of Riemannian geometry, in which we propose that plasticity instead follows natural-gradient descent. Under this hypothesis, we derive a synaptic learning rule for spiking neurons that couples functional efficiency with the explanation of several well-documented biological phenomena such as dendritic democracy, multiplicative scaling, and heterosynaptic plasticity. We therefore suggest that in its search for functional synaptic plasticity, evolution might have come up with its own version of natural-gradient descent.
Editor's evaluation
The natural gradient has a long and rich history in machine learning. Here, the authors derive a biologically plausible implementation of natural-gradient-based plasticity for spiking neurons, which renders learning invariant under dendritic transformations. This new synaptic learning rule makes several very interesting experimental predictions with respect to the interplay of homo- and heterosynaptic plasticity, and with regard to the scaling of plasticity by the presynaptic variance.
https://doi.org/10.7554/eLife.66526.sa0Introduction
Understanding the fundamental computational principles underlying synaptic plasticity represents a long-standing goal in neuroscience. To this end, a multitude of top-down computational paradigms have been developed, which derive plasticity rules as gradient descent on a particular objective function of the studied neural network (Rosenblatt, 1958; Rumelhart et al., 1986; Pfister et al., 2006; D’Souza et al., 2010; Friedrich et al., 2011).
However, the exact physical quantity to which these synaptic weights correspond often remains unspecified. What is frequently simply referred to as (the synaptic weight from neuron to neuron i) might relate to different components of synaptic interaction, such as calcium concentration in the presynaptic axon terminal, neurotransmitter concentration in the synaptic cleft, receptor activation in the postsynaptic dendrite or the postsynaptic potential (PSP) amplitude in the spine, the dendritic shaft or at the soma of the postsynaptic cell. All these biological processes can be linked by transformation rules, but depending on which of them represents the variable with respect to which performance is optimized, the network behavior during training can be markedly different.
As an example we consider the parametrization of the synaptic strength either as PSP amplitude in the soma, , or as PSP amplitude in the dendrite, (see also Figure 1 and Sec. ‘The naive Euclidean gradient is not parametrization-invariant’). Reparametrizing the synaptic strength in this way implies an attenuation factor for each single synapse, but different factors are assigned across the positions on the dendritic tree. As a consequence, the weight vector will follow a different trajectory during learning depending on whether the somatic or dendritic parametrization of the PSP amplitude was chosen.
Figure 1
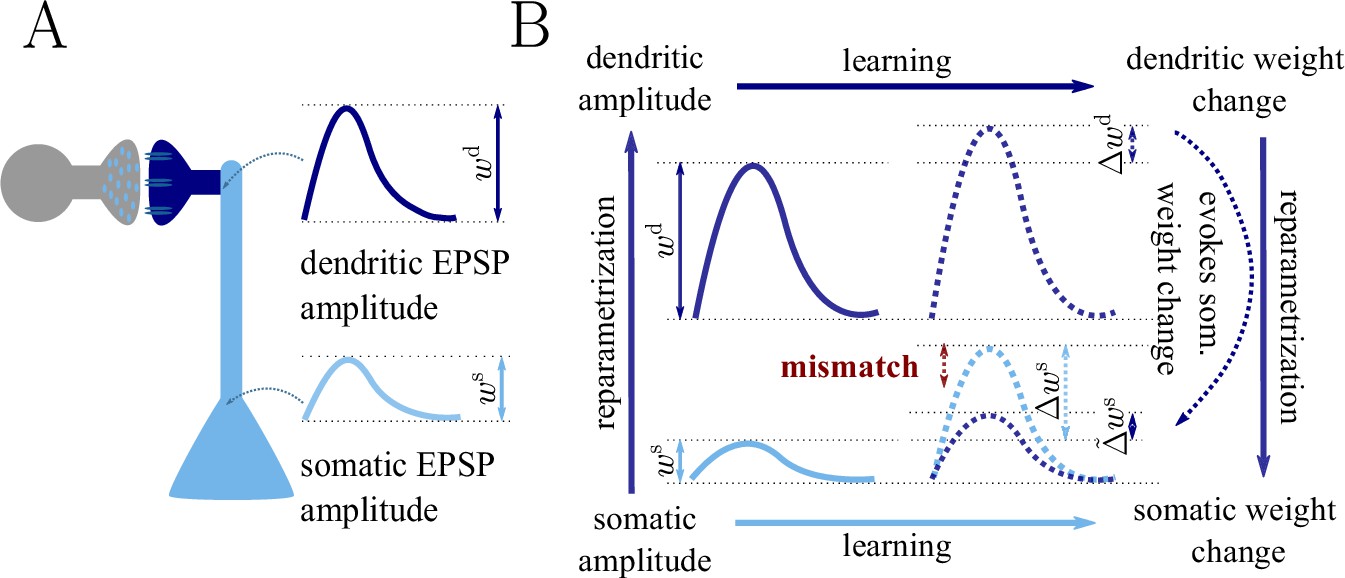
Classical gradient descent depends on chosen parametrization.
(A) The strength of a synapse can be parametrized in various ways, for example, as the EPSP amplitude at either the soma or the dendrite . Biological processes such as attenuation govern the relationship between these variables. Depending on the chosen parametrization, Euclidean-gradient descent can yield different results. (B) Phenomenological correlates. EPSPs before learning are represented as continuous, after learning as dashed curves. The light blue arrow represents gradient descent on the error as a function of the somatic EPSP (also shown in light blue). The resulting weight change leads to an increase in the somatic EPSP after learning. The dark blue arrows track the calculation of the same gradient, but with respect to the dendritic EPSP (also shown in dark blue): (1) taking the attenuation into account in order to compute the error as a function of , (2) calculating the gradient, followed by (3) deriving the associated change in , again considering attenuation. Due to the attenuation entering the calculation twice, the synaptic weights updates, as well as the associated evolution of a neuron’s output statistics over time, will differ under the two parametrizations.
It certainly could be the case that evolution has favored a parametrization-dependent learning rule, along with one particular parametrization over all others, but this would necessarily imply sub-optimal convergence for all but a narrow set of neuron morphologies and connectome configurations. An invariant learning rule on the other hand would not only be mathematically unambiguous and therefore more elegant, but could also improve learning, thus increasing fitness.
In some aspects, the question of invariant behavior is related to the principle of relativity in physics, which requires the laws of physics – in our case: the improvement of performance during learning – to be the same in all frames of reference. What if neurons would seek to conserve the way they adapt their behavior regardless of, for example, the specific positioning of synapses along their dendritic tree? Which equations of motion – in our case: synaptic learning rules – are able to fulfill this requirement?
The solution lies in following the path of steepest descent not in relation to a small change in the synaptic weights (Euclidean-gradient descent), but rather with respect to a small change in the input-output distribution (natural-gradient descent). This requires taking the gradient of the error function with respect to a metric defined directly on the space of possible input-output distributions, with coordinates defined by the synaptic weights. First proposed in Amari, 1998, but with earlier roots in information geometry (Amari, 1987; Amari and Nagaoka, 2000), natural-gradient methods (Yang and Amari, 1998; Rattray and Saad, 1999; Park et al., 2000; Kakade, 2001) have recently been rediscovered in the context of deep learning (Pascanu and Bengio, 2013; Martens, 2014; Ollivier, 2015; Amari et al., 2019; Bernacchia et al., 2018). Moreover, Pascanu and Bengio, 2013 showed that the natural-gradient learning rule is closely related to other machine learning algorithms. However, most of the applications focus on rate-based networks which are not inherently linked to a statistical manifold and have to be equipped with Gaussian noise or a probabilistic output layer interpretation in order to allow an application of the natural gradient. Furthermore, a biologically plausible synaptic plasticity rule needs to make all the required information accessible at the synapse itself, which is usually unnecessary and therefore largely ignored in machine learning.
The stochastic nature of neuronal outputs in-vivo (see, e.g. Softky and Koch, 1993) provides a natural setting for plasticity rules based on information geometry. As a model for biological synapses, natural gradient combines the elegance of invariance with the success of gradient-descent-based learning rules. In this manuscript, we derive a closed-form synaptic learning rule based on natural-gradient descent for spiking neurons and explore its implications. Our learning rule equips the synapses with more functionality compared to classical error learning by enabling them to adjust their learning rate to their respective impact on the neuron’s output. It naturally takes into account relevant variables such as the statistics of the afferent input or their respective positions on the dendritic tree. This allows a set of predictions which are corroborated by both experimentally observed phenomena such as dendritic democracy and multiplicative weight dynamics and theoretically desirable properties such as Bayesian reasoning (Marceau-Caron and Ollivier, 2007). Furthermore, and unlike classical error-learning rules, plasticity based on the natural gradient is able to incorporate both homo- and heterosynaptic phenomena into a unified framework. While theoretically derived heterosynaptic components of learning rules are notoriously difficult for synapses to implement due to their non-locality, we show that in our learning rule they can be approximated by quantities accessible at the locus of plasticity. In line with results from machine learning, the combination of these features also enables faster convergence during supervised learning.
Results
The naive Euclidean gradient is not parametrization-invariant
We consider a cost function on the neuronal level that, in the sense of cortical credit assignment (see e.g. Sacramento et al., 2017), can relate to some behavioral cost of the agent that it serves. The output of the neuron depends on the amplitudes of the somatic PSPs elicited by the presynaptic spikes. We denote these ‘somatic weights’ by , and may parametrize the neuronal cost as .
However, dendritic PSP amplitudes can be argued to offer a more unmitigated representation of synaptic weights, so we might rather wish to express the cost as . These two parametrizations are related by an attenuation factor (between 0 and 1):
(1)
In general, this attenuation factor depends on the synaptic position and is therefore described by a vector that is multiplied component-wise with the weights. For clarity, we assume a simplified picture in which we neglect, for example, the spread of PSPs as they travel along dendritic cables. However, our observations regarding the effects of reparametrization hold in general.
It may now seem straightforward to switch between the somatic and dendritic representation of the cost by simply substituting variables, for example
(2)
To derive a plasticity rule for the somatic and dendritic weights, we might consider gradient descent on the cost:
(3)
At first glance, this relation seems reasonable: dendritic weight changes affect the cost more weakly then somatic weight changes, so their respective gradient is more shallow by the factor . However, from a functional perspective, the opposite should be true: dendritic weights should experience a larger change than somatic weights in order to elicit the same effect on the cost. This conflict can be made explicit by considering that somatic weight changes are, themselves, attenuated dendritic weight changes: . Substituting this into Equation 3 leads to an inconsistency: . To solve this conundrum, we need to shift the focus from changing the synaptic input to changing the neuronal output, while at the same time considering a more rigorous treatment of gradient descent (see also Surace et al., 2020).
The natural-gradient plasticity rule
We consider a neuron with somatic potential (above a baseline potential ) evoked by the spikes of presynaptic afferents firing at rates . The presynaptic spikes of afferent i cause a train of weighted dendritic potentials locally at the synaptic site. The denotes the unweighted synaptic potential (USP) train elicited by the low-pass-filtered spike train . At the soma, each dendritic potential is attenuated by a potentially nonlinear function that depends on the synaptic location:
(4)
The somatic voltage above baseline thus reads as
(5)
We further assume that the neuron’s firing follows an inhomogeneous Poisson process whose rate
(6)
depends on the current membrane potential through a nonlinear transfer function . In this case, spiking in a sufficiently short interval is Bernoulli-distributed. The probability of a spike occurring in this interval (denoted as ) is then given by
(7)
which defines our generalized linear neuron model (Gerstner and Kistler, 2002). Here, we used as a shorthand notation for the USP vector . The full input-output distribution then reads
(8)
where the probability density of the input is independent of synaptic weights (see also Sec. ‘Detailed derivation of the natural-gradient learning rule’). In the following, we drop the time indices for better readability.
In view of this stochastic nature of neuronal responses, we consider a neuron that strives to reproduce a target firing distribution . The required information is received as teacher spike train that is sampled from (see Sec. ‘Sketch for the derivation of the somatic natural-gradient learning rule’ for details). In this context, plasticity may follow a supervised-learning paradigm based on gradient descent. The Kullback-Leibler divergence between the neuron’s current and its target firing distribution
(9)
represents a natural cost function which measures the error between the current and the desired output distribution in an information-theoretic sense. Minimizing this cost function is equivalent to maximizing the log-likelihood of teacher spikes, since does not depend on . Using naive Euclidean-gradient descent with respect to the synaptic weights (denoted by ) results in the well-known error-correcting rule (Pfister et al., 2006),
(10)
which is a spike-based version of the classical perceptron learning rule (Rosenblatt, 1958), whose multilayer version forms the basis of the error-backpropagation algorithm (Rumelhart et al., 1986). On the single-neuron level, a possible biological implementation has been suggested by Urbanczik and Senn, 2014, who demonstrated how a neuron may exploit its morphology to store errors, an idea that was recently extended to multilayer networks (Sacramento et al., 2017; Haider et al., 2021).
However, as we argued above, learning based on Euclidean-gradient descent is not unproblematic. It cannot account for synaptic weight (re)parametrization, as caused, for example, by the diversity of synaptic loci on the dendritic tree. Equation 10 represents the learning rule for a somatic parametrization of synaptic weights. For a local computation of Euclidean gradients using a dendritic parametrization, weight updates decrease with increasing distance towards the soma (Equation 3), which is likely to harm the convergence speed toward an optimal weight configuration. With the multiplicative USP term in Equation 10 being the only manifestation of presynaptic activity, there is no mechanism by which to take into account input variability. This can, in turn, also impede learning, by implicitly assigning equal importance to reliable and unreliable inputs. Furthermore, when compared to experimental evidence, this learning rule cannot explain heterosynaptic plasticity, as it is purely presynaptically gated.
In general, Euclidean-gradient descent is well-known to exhibit slow convergence in non-isotropic regions of the cost function (Ruder, 2016), with such non-isotropy frequently arising or being aggravated by an inadequate choice of parametrization (see Ollivier, 2015 and Figure 2). In contrast, natural-gradient descent is, by construction, immune to these problems. The key idea of natural gradient as outlined by Amari is to follow the (locally) shortest path in terms of the neuron’s firing distribution. Argued from a normative point of view, this is the only ‘correct’ path to consider, since plasticity aims to adapt a neuron’s behavior, that is, its input-output relationship, rather than some internal parameter (Figure 2). In the following, we therefore drop the index from the synaptic weights to emphasize the parametrization-invariant nature of the natural gradient.
Figure 2

The natural gradient represents the true gradient direction on the manifold of neuronal input-output distributions.
(A) During supervised learning, the error between the current and the target state is measured in terms of a cost function defined on the neuron’s output space; in our case, this is the manifold formed by the neuronal output distributions . As the output of a neuron is determined by the strength of incoming synapses, the cost depends indirectly on the afferent weight vector . Since the gradient of a function depends on the distance measure of the underlying space, Euclidean-gradient descent, which follows the gradient of the cost as a function of the synaptic weights , is not uniquely defined, but depends on how is parametrized. If, instead, we follow the gradient on the output manifold itself, it becomes independent of the underlying parametrization. Expressed in a specific parametrization, the resulting natural gradient contains a correction term that accounts for the distance distortion between the synaptic parameter space and the output manifold. (B–C) Standard gradient descent learning is suited for isotropic (C), rather than for non-isotropic (B) cost functions. For example, the magnitude of the gradient decreases in valley regions where the cost function is flat, resulting in slow convergence to the target. A non-optimal choice of parametrization can introduce such artefacts and therefore harm the performance of learning rules based on Euclidean-gradient descent. In contrast, natural-gradient learning will locally correct for distortions arising from non-optimal parametrizations (see also Figure 3).
Figure 3
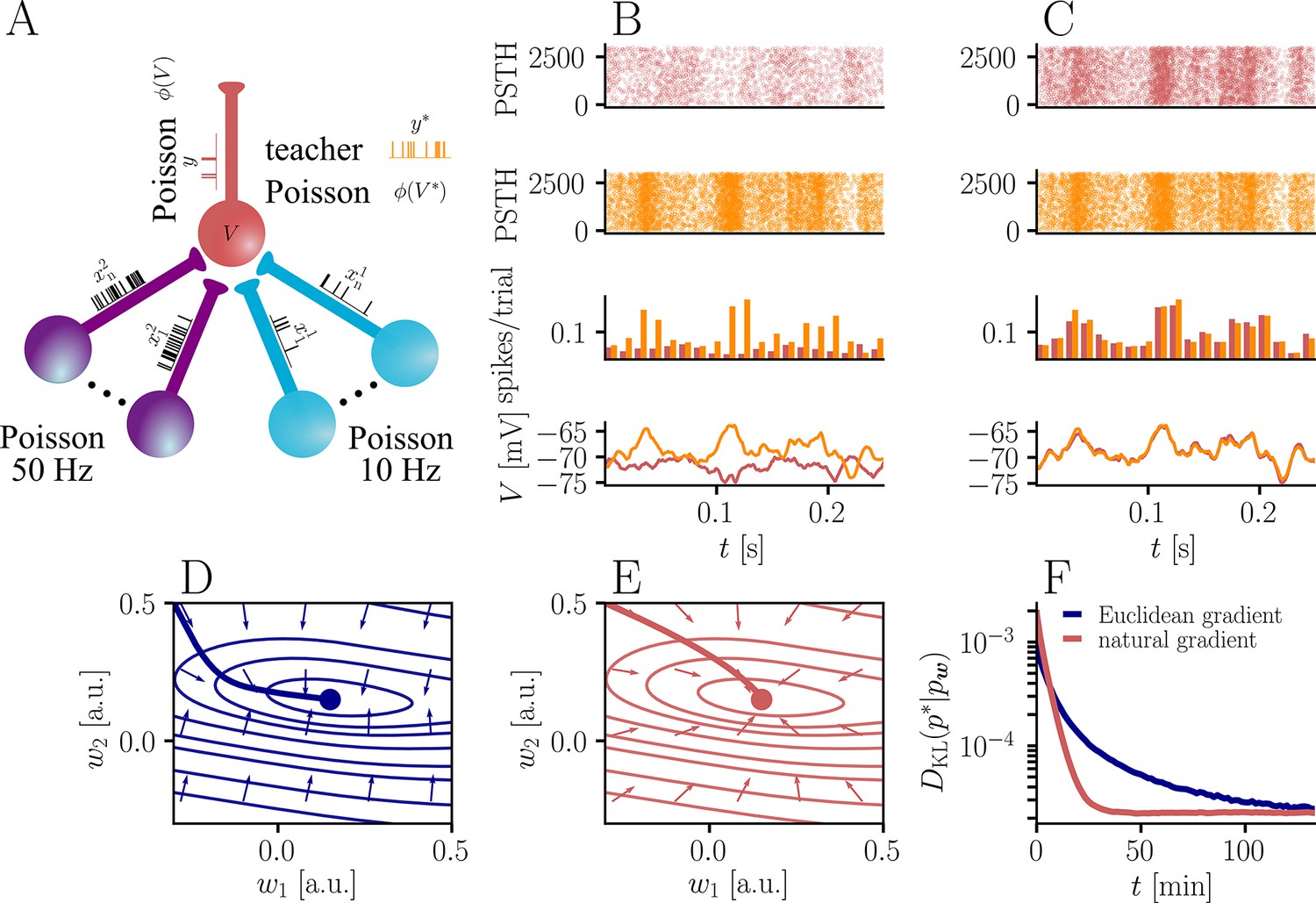
Natural-gradient plasticity speeds up learning in a simple regression task.
(A) We tested the performance of the natural gradient rule in a supervised learning scenario, where a single output neuron had to adapt its firing distribution to a target distribution, delivered in form of spikes from a teacher neuron. The latter was modeled as a Poisson neuron firing with a time-dependent instantaneous rate, where represents a randomly chosen target weight vector. The input consisted of Poisson spikes from afferents, half of them firing at 10 Hz and 50 Hz, respectively. For our simulations, we used afferents, except for the weight path plots in (D) and (E), where the number of afferents was reduced to for illustration purposes. (B–C) Spike trains, PSTHs and voltage traces for teacher (orange) and student (red) neuron before (B) and after (C) learning with natural-gradient plasticity. During learning, the firing patterns of the student neuron align to those of the teacher neuron. The structure in these patterns comes from autocorrelations in this instantaneous rate. These, in turn, are due to mechanisms such as the membrane filter (as seen in the voltage traces) and the nonlinear activation function. (D–E) Exemplary weight evolution during Euclidean-gradient (D) and natural-gradient (E) learning given afferents with the same two rates as before. Here, corresponds to in panel A (10 Hz input) and to (50 Hz input). Thick solid lines represent contour lines of the cost function . The respective vector fields depict normalized negative Euclidean and natural gradients of the cost , averaged over 2000 input samples. The thin solid lines represent the paths traced out by the input weights during learning averaged over 500 trials. (F) Learning curves for afferents using natural-gradient and Euclidean-gradient plasticity. The plot shows averages over 1000 trials with initial and target weights randomly chosen from a uniform distribution . Fixed learning rates were tuned for each algorithm separately to exhibit the fastest possible convergence to a root mean squared error of 0.8 Hz in the student neuron’s output rate.
For the concept of a locally shortest path to make sense in terms of distributions, we require the choice of a distance measure for probability distributions. Since a parametric statistical model, such as the set of our neuron’s realizable output distributions, forms a Riemannian manifold, a local distance measure can be obtained in form of a Riemannian metric. The Fisher metric (Rao, 1945), an infinitesmial version of the , represents a canonical choice on manifolds of probability distributions (Amari and Nagaoka, 2000). On a given parameter space, the Fisher metric may be expressed in terms of a bilinear product with the Fisher information matrix
(11)
The Fisher metric locally measures distances in the -manifold as a function of the chosen parametrization. We can then obtain the natural gradient (which intuitively may be thought of as ‘’) by correcting the Euclidean gradient with the distance measure above:
(12)
This correction guarantees invariance of the gradient under reparametrization (see also Sec. ‘Reparametrization and the general natural-gradient rule’). The natural-gradient learning rule is then given as . Calculating the right-hand expression for the case of Poisson-spiking neurons (for details, see Detailed derivation of the natural-gradient learning rule and Inverse of the Fisher Information Matrix), this takes the form
(13)
where is an arbitrary weight parametrization that relates to the somatic amplitudes via a component-wise rescaling
(14)
Note that the attenuation function in Equation 4 represents a special case of Equation 14 for dendritic amplitudes.
We used the shorthand , , and for three scaling factors introduced by the natural gradient that we address in detail below. For easier reading, we use a shorthand notation in which multiplications, divisions and scalar functions of vectors apply component-wise.
Equation 13 represents the complete expression of our natural-gradient rule, which we discuss throughout the remainder of the manuscript. Note that, while having used a standard sigmoidal transfer function throughout the paper, Equation 13 holds for every sufficiently smooth .
Natural-gradient learning conserves both the error term and the USP contribution from classical gradient-descent plasticity. However, by including the relationship between the parametrization of interest and the somatic PSP amplitudes , natural-gradient-based plasticity explicitly accounts for reparametrization distortions, such as those arising from PSP attenuation during propagation along the dendritic tree. Furthermore, natural-gradient learning introduces multiple scaling factors and new plasticity components, whose characteristics will be further explored in dedicated sections below (see also Sec. ‘Global scaling factor’ and ‘Empirical Analysis of and ’ for more details).
First of all, we note the appearance of two scaling factors (more details in ‘Input and output-specific scaling’). On one hand, the size of the synaptic adjustment is modulated by a global scaling factor , which adjusts synaptic weight updates to the characteristics of the output non-linearity, similarly to the synapse-specific scaling by the inverse of . Furthermore also depends on the output statistics of the neuron, harmonizing plasticity across different states in the output distribution (see Sec. ‘Global scaling factor’). On the other hand, a second, synapse-specific learning rate scaling accounts for the statistics of the input at the respective synapse, in the form of a normalization by the afferent input rate , where is a constant that depends on the PSP kernel (see Sec. ‘Neuron model’). Unlike the global modulation introduced by , this scaling only affects the USP-dependent plasticity component. Just as for Euclidean-gradient-based learning, the latter is directly evoked by the spike trains arriving at the synapse. Therefore, the resulting plasticity is homosynaptic, affecting only synapses which receive afferent input.
However, in the case of natural-gradient learning, this input-specific adaptation is complemented by two additional forms of heterosynaptic plasticity (Sec. ‘Interplay of homosynaptic and heterosynaptic plasticity’). First, the learning rule has a bias term which uniformly adjusts all synapses and may be considered homeostatic, as it usually opposes the USP-dependent plasticity contribution. The amplitude of this bias does not exclusively depend on the afferent input at the respective synapse, but is rather determined by the overall input to the neuron. Thus, unlike the USP-dependent component, this heterosynaptic plasticity component equally affects both active and inactive synaptic connections. Furthermore, natural-gradient descent implies the presence of another plasticity component which adapts the synapses depending on their current weight. More specifically, connections that are already strong are subject to larger changes compared to weaker ones. Since the proportionality factor only depends on global variables such as the membrane potential, this component also affects both active and inactive synapses.
The full expressions for , , and are functions of the membrane potential, its mean and its variance, which represent synapse-local quantities. In addition, and also depend on the total input and the total instantaneous presynaptic rate . However, under reasonable assumptions such as a high number of presynaptic partners and for a large, diverse set of empirically tested scenarios, we have shown that these factors can be reduced to simple functions of variables that are fully accessible at the locus of individual synapses:
(15)
where , are constants (Sec. ‘Global scaling factor’ and ‘Empirical Analysis of and ’). The above learning rule along with closed-form expressions for these factors represent the main analytical findings of this paper.
In the following, we demonstrate that the additional terms introduced in natural-gradient-based plasticity confer important advantages compared to Euclidean-gradient descent, both in terms of of convergence as well as with respect to biological plausibility. More precisely, we show that our plasticity rule improves convergence in a supervised learning task involving an anisotropic cost function, a situation which is notoriously hard to deal with for Euclidean-gradient-based learning rules (Ruder, 2016). We then proceed to investigate natural-gradient learning from a biological point of view, deriving a number of predictions that can be experimentally tested, with some of them related to in vivo observations that are otherwise difficult to explain with classical gradient-based learning rules.
Natural-gradient plasticity speeds up learning
Non-isotropic cost landscapes can easily be provoked by non-homogeneous input conditions. In nature, these can arise under a wide range of circumstances, for elementary reasons that boil down to morphology (the position of a synapse along a dendrite can affect the attenuation of its afferent input) and function (different afferents perform different computations and thus behave differently). To evaluate the convergence behavior of our learning rule and compare it to Euclidean-gradient descent, we considered a very generic situation in which a neuron is required to map a diverse set of inputs onto a target output.
In order to induce a simple and intuitive anisotropy of the error landscape, we divided the afferent population into two equally sized groups of neurons with different firing rates (Figure 3A, firing rates were chosen as 10 Hz for group one and 50 Hz for group 2). The input spikes were low-pass-filtered with a difference of exponentials (see Sec. ‘Neuron model for details’). This resulted in an asymmetric cost function (KL-divergence between the student and the target firing distribution, Equation 9), as visible from the elongated contour lines (Figure 3D and E). We further chose a realizable teacher by simulating a different neuron with the same input populations connected via a predefined set of target weights . For the weight path plots in Figure 3D and E fixed target weight was chosen, whereas for the learning curve in Figure 3F, the target weight components were randomly sampled from a uniform distribution on (see Sec. ‘Supervised Learning Task’ for further details). Figure 3B and C shows that our natural-gradient rule enables the student neuron to adapt its weights to reproduce the teacher voltage and thereby its output distribution.
In the following, we compare learning in two student neurons, one endowed with Euclidean-gradient plasticity (Equation 10, Figure 3D) and one with our natural-gradient rule (Equation 13, Figure 3E). To better visualize the difference between the two rules, we used a two-dimensional input weight space, that is, one neuron per afferent population. While the negative Euclidean-gradient vectors stand, by definition, perpendicular to the contour lines of , the negative natural-gradient vectors point directly towards the target weight configuration . Due to the anisotropy of induced by the different input rates (see also Figure 2B), Euclidean-gradient learning starts out by mostly adapting the high-rate afferent weight and only gradually begins learning the low-rate afferent. In contrast, natural gradient adapts both synaptic weights homogeneously. This is clearly reflected by paths traced by the synaptic weights during learning.
Overall, this lead to faster convergence of the natural-gradient plasticity rule compared to Euclidean-gradient descent. In order to enable a meaningful comparison, learning rates were tuned separately for each plasticity rule in order to optimize their respective convergence speed. The faster convergence of natural-gradient plasticity is a robust effect, as evidenced in Figure 3F by the average learning curves over 1,000 trials.
In addition to the functional advantages described above, natural-gradient learning also makes some interesting predictions about biology, which we address below.
Democratic plasticity
As discussed in the introduction, classical gradient-based learning rules do not usually account for neuron morphology. Since attenuation of PSPs is equivalent to weight reparametrization and our learning rule is, by construction, parametrization-invariant, it naturally compensates for the distance between synapse and soma. In Equation 13, this is reflected by a component-wise rescaling of the synaptic changes with the inverse of the attenuation function , which is induced by the Fisher information metric (see also Figure 8 and the corresponding section in the Materials and methods). Under the assumption of passive attenuation along the dendritic tree, we have
(16)
where di denotes the distance of the ith synapse from the soma. More specifically, , where λ represents the electrotonic length scale. We can write the natural-gradient rule as
(17)
For functionally equivalent synapses (i.e. with identical input statistics), synaptic changes in distal dendrites are scaled up compared to proximal synapses. As a result, the effect of synaptic plasticity on the neuron’s output is independent of the synapse location, since dendritic attenuation is precisely counterbalanced by weight update amplification.
We illustrate this effect with simulations of synaptic weight updates at different locations along a dendritic tree in Figure 4. Such ‘democratic plasticity’, which enables distal synapses to contribute just as effectively to changes in the output as proximal synapses, is reminiscent of the concept of ‘dendritic democracy’ (Magee and Cook, 2000). These experiments show increased synaptic amplitudes in the distal dendritic tree of multiple cell types, such as rat hippocampal CA1 neurons; dendritic democracy has therefore been presumed to serve the purpose of giving distal inputs a ‘vote’ on the neuronal output. Still, experiments show highly diverse PSP amplitudes in neuronal somata (Williams and Stuart, 2002). Our plasticity rule refines the notion of democracy by asserting that learning itself rather than its end result is rescaled in accordance with the neuronal morphology.
Figure 4
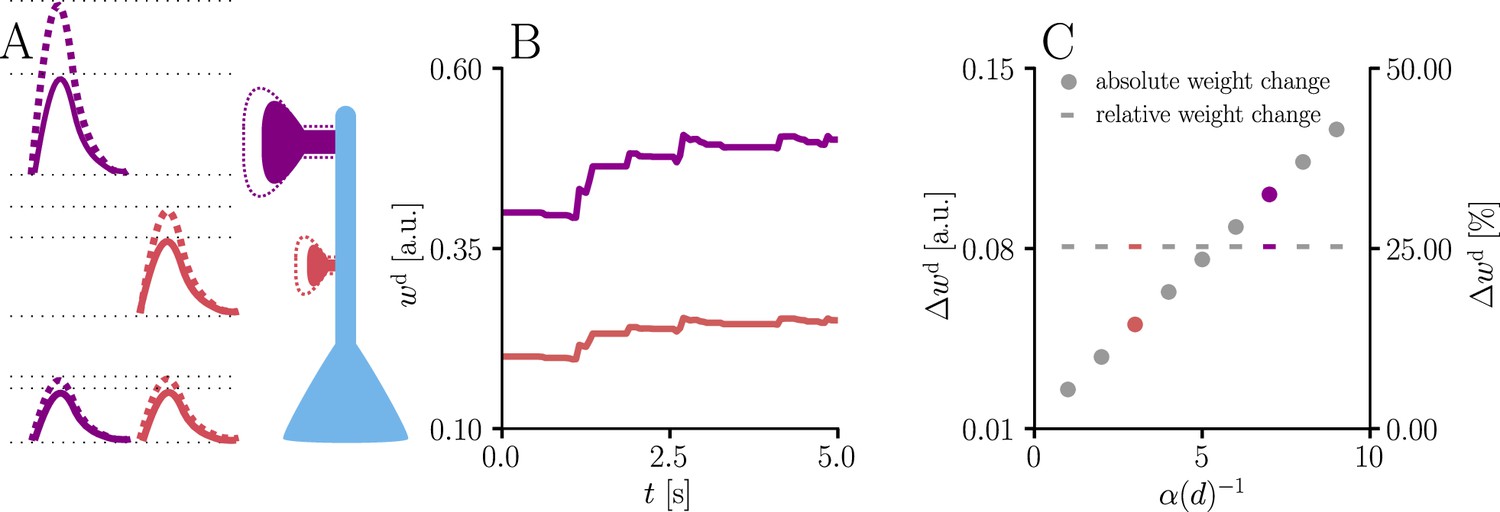
Natural-gradient learning scales synaptic weight updates depending on their distance from the soma.
We stimulated a single excitatory synapse with Poisson input at 5 Hz, paired with a Poisson teacher spike train at 20 Hz. The distance d from soma was varied between 0 μm and 460 μm and attenuation was assumed to be linear and proportional to the inverse distance from soma. To make weight changes comparable, we scaled dendritic PSP amplitudes with in order for all of them to produce the same PSP amplitude at the soma. (A) Example PSPs before (solid lines) and after (dashed lines) learning for two synapses at 3 μm and 7 μm. Application of our natural-gradient rule results in equal changes for the somatic PSPs. (B) Example traces of synaptic weights for the two synapses in (A). (C) Absolute and relative dendritic amplitude change after 5 s as a function of a synapse’s distance from the soma.
Whether such democratic plasticity ultimately leads to distal and proximal synapses having the same effective vote at the soma depends on their respective importance towards reaching the target output. In particular, if synapses from multiple afferents that encode the same information are randomly distributed along the dendritic tree, then democratic plasticity also predicts dendritic democracy, as the scaling of weight changes implies a similar scaling of the final learned weights. However, the absence of dendritic democracy does not contradict the presence of democratic plasticity, as afferents from different cortical regions might target specific positions on the dendritic tree (see, e.g., Markram et al., 2004). Furthermore, also with democratic plasticity in place, the functional efficacy of synapses at different locations on the dendritic tree will change differently based on different initial conditions. The experimental findings by Froemke et al., 2005, who report an inverse relationship between the amount of plasticity at a synapse and its distance from soma, are therefore completely consistent with the predictions of our learning rule, since they compared synapses that were not initially functionally equivalent.
Note also that dendritic democracy could, in principle, be achieved without democratic plasticity. However, this would be much slower than with natural-gradient learning, especially for distal synapses, as discussed in Sec. ‘Natural-gradient plasticity speeds up learning’.
Input and output-specific scaling
In addition to undoing distortions induced by, for example, attenuation, the natural-gradient rule predicts further modulations of the homosynaptic learning rate. The factor in Equation 13 represents an output-dependent global scaling factor (for both homo- and heterosynaptic plasticity):
(18)
Together with the factor in Equation 13, the effective scaling of the learning rule is approximately . In other words, it increases the learning rate in regions where the sigmoidal transfer function is flat (see also Sec. ‘Global scaling factor’). This represents an unmediated reflection of the philosophy of natural-gradient descent, which finds the steepest path for a small change in output, rather than in the numeric value of some parameter. The desired change in the output requires scaling the corresponding input change by the inverse slope of the transfer function.
Furthermore, synaptic learning rates are inversely correlated to the USP variance (Figure 5). In particular, for the homosynaptic component, the scaling is exactly equal to
(19)
Figure 5

Natural-gradient learning scales approximately inversely with input variance.
(A–C) Exemplary USPs and (D–F) their distributions for three different scenarios between which the USP variance is varied. In each scenario, a neuron received a single excitatory input with a given rate and synaptic time constant . The soma always received teacher spikes at a rate of 80 Hz. To enable a meaningful comparison, the mean USP was conserved by appropriately rescaling the height of the USP kernel (see Sec. ‘Neuron model’). (A,D) Reference simulation. (B,E) Reduced synaptic time constant, resulting in an increased USP variance . (C,F) Reduced input rate, resulting in an increased USP variance . (G) Synaptic weight changes over 5 s for the three scenarios above. (H) Total synaptic weight change after as a function of USP variance. Each data point represents a different pair of and . The three scenarios above are marked with their respective colors.
(see Equation 13 and Sec. ‘Neuron model’). In other words, natural-gradient learning explicitly scales synaptic updates with the (un)reliability – more specifically, with the inverse variance – of their input. To demonstrate this effect in isolation, we simulated the effects of changing the USP variance while conserving its mean. Moreover, to demonstrate its robustness, we independently varied two contributors to the input reliability, namely input rates (which enter directly) and synaptic time constants (which affect the PSP-kernel-dependent scaling constant ). Figure 5 shows how unreliable input leads to slower learning, with an inverse dependence of synaptic weight changes on the USP variance. We note that this observation also makes intuitive sense from a Bayesian point of view, under which any information needs to be weighted by the reliability of its source. Furthermore, the approximately inverse scaling with the presynaptic firing rate is qualitatively in line with observations from Aitchison and Latham, 2014 and Aitchison et al., 2021, although our interpretation and precise relationship is different.
Interplay of homosynaptic and heterosynaptic plasticity
One elementary property of update rules based on Euclidean-gradient descent is their presynaptic gating, that is, all weight updates are scaled with their respective synaptic input . Therefore, they are necessarily restricted to homosynaptic plasticity, as studied in classical LTP and LTD experiments (Bliss and Lomo, 1973; Dudek and Bear, 1992). As discussed above, natural-gradient learning retains a rescaled version of this homosynaptic contribution, but at the same time predicts the presence of two additional plasticity components. Contrary to homosynaptic plasticity, these components also adapt synapses to currently non-active afferents, given a sufficient level of global input. Due to their lack of input specificity, they give rise to heterosynaptic weight changes, a form of plasticity that has been observed in hippocampus (Chen et al., 2013; Lynch et al., 1977), cerebellum (Ito and Kano, 1982), and neocortex (Chistiakova and Volgushev, 2009), mostly in combination with homosynaptic plasticity. A functional interpretation of heterosynaptic plasticity, to which our learning rule also alludes, is as a prospective adaptation mechanism for temporarily inactive synapses such that, upon activation, they are already useful for the neuronal output.
Our natural-gradient learning rule Equation 13 can be more summarily rewritten as
(20)
where the three additive terms represent the variance-normalized homosynaptic plasticity, the uniform heterosynaptic plasticity and the weight-dependent heterosynaptic plasticity:
(21)
(22)
(23)
with the common proportionality factor composed of the learning rate, the output-dependent global scaling factor, the postsynaptic error, a sensitivity factor and the inverse attenuation function, in order of their appearance. The effect of these three components is visualized in Figure 6B. The homosynaptic term is experienced only by stimulated synapses, while the two heterosynaptic terms act on all synapses. The first heterosynaptic term introduces a uniform adjustment to all components by the same amount, depending on the global activity level. For a large number of presynaptic inputs, it can be approximated by a constant (see Sec. ‘Empirical analysis of and ’). Furthermore, it usually opposes the homosynaptic change, which we address in more detail below.
Figure 6
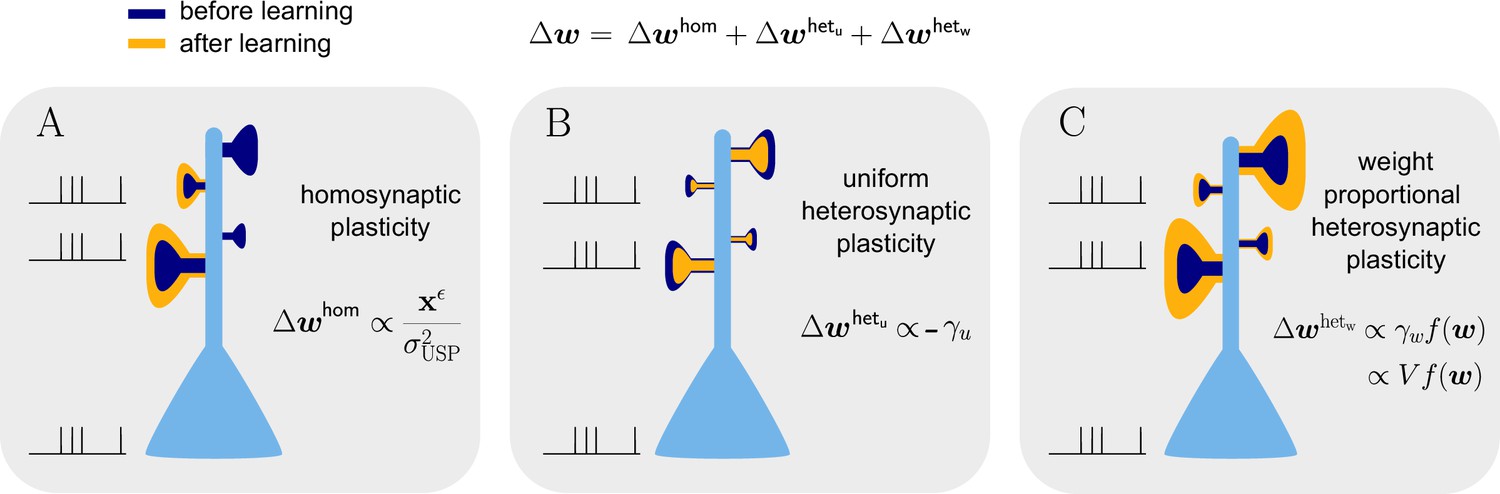
Natural-gradient learning combines multiple forms of plasticity.
Spike trains to the left of the neuron represent afferent inputs to two of the synapses and teacher input to the soma. The two synapses on the right of the dendritic tree receive no stimulus. The teacher is assumed to induce a positive error. (A) The homosynaptic component adapts all stimulated synapses, leaving all unstimulated synapses untouched. (B) The uniform heterosynaptic component changes all synapses in the same manner, only depending on global activity levels. (C) The proportional heterosynaptic component contributes a weight change that is proportional to the current synaptic strength. The magnitude of this weight change is approximately proportional to a product of the current membrane potential above baseline and the weight vector.
In contrast, the contribution of the second heterosynaptic term is weight-dependent, adapting all synapses in proportion to their current strength. This corresponds to experimental reports such as Loewenstein et al., 2011, which found in vivo weight changes in the neocortex to be proportional to the spine size, which itself is correlated with synaptic strength (Asrican et al., 2007). Our simulations in Sec. ‘Empirical Analysis of and ’ show that is roughly a linear function of the membrane potential (more specifically, its deviation with respect to its baseline), which is reflected by the last approximation in Equation 21. Since the latter can be interpreted as a scalar product between the afferent input vector and the synaptic weight vector, it implies that spikes transmitted by strong synapses have a larger impact on this heterosynaptic plasticity component compared to spikes arriving via weak synapses. Thus, weaker synapses require more persistent and strong stimulation to induce significant changes and ‘override the status quo’ of the neuron. Since, following a period of learning, afferents connected via weak synapses can be considered uninformative for the neuron’s target output, this mechanism ensures a form of heterosynaptic robustness towards noise.
The homo- and heterosynaptic terms exhibit an interesting relationship. To illustrate the nature of their interplay, we simulated a simple experiment (Figure 7A) with varying initial synaptic weights for both active and inactive presynaptic afferents. Stimulated synapses (Figure 7B) are seen to undergo strong potentiation (LTP) for very small initial weights; the magnitude of weight changes decreases for larger initial amplitudes until the neuron’s output matches its teacher, at which point the sign of the postsynaptic error term flips. For even larger initial weights, potentiation at stimulated synapses therefore turns into depression (LTD), which becoms stronger for higher initial values of the stimulated synapses’ weights. This is in line with the error learning paradigm, in which changes in synaptic weights seek to reduce the difference between a neuron’s target and its output.
Figure 7
Interplay of homo- and heterosynaptic plasticity in natural-gradient learning.
(A) Simulation setup. Five out of 10 inputs received excitatory Poisson input at 5 Hz. In addition, we assumed the presence of tonic inhibition as a balancing mechanism for keeping the neuron’s output within a reasonable regime. Afferent stimulus was paired with teacher spike trains at 20 Hz and plasticity at both stimulated and unstimulated synapses was evaluated in comparison with their initial weights. For simplicity, initial weights within each group were assumed to be equal. (B) Weight change of stimulated weights (both homo- and heterosynaptic plasticity are present). These weight changes are independent of unstimulated weights. Equilibrium (dashed black line) is reached when the neuron’s output matches its teacher and the error vanishes. For increasing stimulated weights, potentiation switches to depression at the equilibrium line. (C) Weight change of unstimulated weights (only heterosynaptic plasticity is present). For very high activity caused by very large synaptic weights, heterosynaptic plasticity always causes synaptic depression. Otherwise, plasticity at unstimulated synapses behaves exactly opposite to plasticity at stimulated synapses. Increasing the size of initial stimulated weights results in a change from depression to potentiation at the same point where potentiation turns into depression at stimulated synapses. (D) Direct comparison of plasticity at stimulated and unstimulated synapses. The light green area (O1, O2) represents opposing signs, dark green (S) represents the same sign (more specifically, depression). Their shared equilibrium is marked by the dashed green line and represents the switch from positive to negative error. (E–G) Relative weight changes of synaptic weights for stimulated and unstimulated synapses during learning, with initial weights picked from the different regimes indicated by the crosses in (B, C, D).
For unstimulated synapses (Figure 7C), we observe a reversed behavior. For small weights, the negative uniform term dominates and plasticity is depressing. As for the homosynaptic case, the sign of plasticity switches when the weights become large enough for the error to switch sign. Therefore, in the regime where stimulated synapses experienced potentiation, unstimulated synapses are depressed and vice-versa. This reproduces various experimental observations: on one hand, potentiation of stimulated synapses has often been found to be accompanied by depression of unstimulated synapses (Lynch et al., 1977), such as in the amygdala (Royer and Paré, 2003) or the visual cortex (Arami et al., 2013); on the other hand, when the postsynaptic error term switches sign, depression at unstimulated synapses transforms into potentiation (Wöhrl et al., 2007; Royer and Paré, 2003).
While plasticity at stimulated synapses is unaffected by the initial state of the unstimulated synapses, plasticity at unstimulated synaptic connections depends on both the stimulated and unstimulated weights. In particular, when either of these grow large enough, the proportional term overtakes the uniform term and heterosynaptic plasticity switches sign again. Thus, for very large weights (top right corner of Figure 7C), heterosynaptic potentiation transforms back into depression, in order to more quickly quench excessive output activity. This behavior is useful for both supervised and unsupervised learning scenarios (Zenke and Gerstner, 2017), where it was shown that pairing Hebbian terms with heterosynaptic and homeostatic plasticity is crucial for stability.
In summary, we can distinguish three plasticity regimes for natural-gradient learning (Figure 7D–G). In two of these regimes, heterosynaptic and homosynaptic plasticity are opposed (O1, O2), whereas in the third, they are aligned and lead to depression (S). The two opposing regimes are separated by the zero-error equilibrium line, at which plasticity switches sign.
Discussion
As a consequence of the fundamentally stochastic nature of evolution, it is no surprise that biology withstands confinement to strict laws. Still, physics-inspired arguments from symmetry and invariance can help uncover abstract principles that evolution may have gradually discovered and implemented into our brains. Here, we have considered parametrization invariance in the context of learning, which, in biological terms, translates to the fundamental ability of neurons to deal with diversity in their morphology and input-output characteristics. This requirement ultimately leads to various forms of scaling and heterosynaptic plasticity that are experimentally well-documented, but can not be accounted for by classical paradigms that regard plasticity as Euclidean-gradient descent. In turn, these biological phenomena can now be seen as a means to jointly improve and accelerate error-correcting learning.
Inspired by insights from information geometry, we applied the framework of natural gradient descent to biologically realistic neurons with extended morphology and spiking output. Compared to classical error-correcting learning rules, our plasticity paradigm requires the presence of several additional ingredients. First, a global factor adapts the learning rate to the particular shape of the voltage-to-spike transfer function and to the desired statistics of the output, thus addressing the diversity of neuronal response functions observed in vivo (Markram et al., 2004). Second, the homosynaptic component of plasticity is normalized by the variance of presynaptic inputs, which provides a direct link to Bayesian frameworks of neuronal computation (Aitchison and Latham, 2014; Jordan et al., 2020). Third, our rule contains a uniform heterosynaptic term that opposes homosynaptic changes, downregulating plasticity and thus acting as a homeostatic mechanism (Chen et al., 2013; Chistiakova et al., 2015). Fourth, we find a weight-dependent heterosynaptic term that also accounts for the shape of the neuron’s activation function, while increasing its robustness towards noise. Finally, our natural-gradient-based plasticity correctly accounts for the somato-dendritic reparametrization of synaptic strengths.
These features enable faster convergence on non-isotropic error landscapes, in line with results for multilayer perceptrons (Yang and Amari, 1998; Rattray and Saad, 1999) and rate-based deep neural networks (Pascanu and Bengio, 2013; Ollivier, 2015; Bernacchia et al., 2018). Importantly, our learning rule can be formulated as a simple, fully local expression, only requiring information that is available at the locus of plasticity.
We further note an interesting property of our learning rule, which it inherits directly from the Fisher information metric that underlies natural gradient descent, namely invariance under sufficient statistics (Cencov, 1972). This is especially relevant for biological neurons, whose stochastic firing effectively communicates information samples rather than explicit distributions. Thus, downstream computation is likely to require a reliable sample-based, that is, statistically sufficient, estimation of the afferent distribution’s parameters, such as the sample mean and variance. This singles out our natural-gradient approach from other second-order-like methods as a particularly appealing framework for biological learning.
Many of the biological phenomena predicted by our invariant learning rule are reflected in existing experimental results. Our democratic plasticity can give rise to dendritic democracy, as observed by Magee and Cook, 2000. Moreover, it also relates to results by Letzkus et al., 2006 and Sjöström and Häusser, 2006 which describe a sign switch of synaptic plasticity between proximal and distal sites that is not easily reconcilable with naive gradient descent. As the authors themselves speculate, the most likely reason is the (partial) failure of action potential backpropagation through the dendritic tree. In some sense, this is a mirror problem to the issue we discuss here: while we consider the attenuation of input signals, these experimental findings could be explained by an attenuation of the output signal. A simple way of incorporating this aspect into our learning rule (but also into Euclidean rules) is to apply a (nonlinear) attenuation function to the teacher signal (Equations 10 and 13). At a certain distance from the soma, this attenuation would become strong enough to switch the sign of the error term and thereby also, for example, LTP to LTD. However, addressing this at the normative level of natural gradient descent as opposed to a direct tweak of the learning rule is less straightforward.
Our rule also requires heterosynaptic plasticity, which has been observed in neocortex, as well as in deeper brain regions such as amygdala and hippocampus (Lynch et al., 1977; Engert and Bonhoeffer, 1997; White et al., 1990; Royer and Paré, 2003; Wöhrl et al., 2007; Chistiakova and Volgushev, 2009; Arami et al., 2013; Chen et al., 2013; Chistiakova et al., 2015), often in combination with homosynaptic weight changes. Moreover, we find that heterosynaptic plasticity generally opposes homosynaptic plasticity, which qualitatively matches many experimental findings (Lynch et al., 1977; White et al., 1990; Royer and Paré, 2003; Wöhrl et al., 2007) and can be functionally interpreted as an enhancement of competition. For very large weights, heterosynaptic plasticity aligns with homosynaptic changes, pushing the synaptic weights back to a sensible range (Chistiakova et al., 2015), as shown to be necessary for unsupervised learning (Zenke and Gerstner, 2017). In supervised learning it helps speed up convergence by keeping the weights in the operating range.
These qualitative matches of experimental data to the predictions of our plasticity rule provide a well-defined foundation for future, more targeted experiments that will allow a quantitative exploration of the relationship between heterosynaptic plasticity and natural gradient learning. In contrast to the mostly deterministic protocols used in the referenced literature, such experiments would require a Poisson-like, stochastic stimulation of the student neuron. To further facilitate a quantitative analysis, the experimental setup should, in particular, allow a clear separation between student and teacher, for example via a pairing protocol (see e.g. Royer and Paré, 2003, but note that their protocol was deterministic).
A further prediction that follows from our plasticity rule is the normalization of weight changes by the presynaptic variance. We would thus anticipate that increasing the variance in presynaptic spike trains (through, e.g. temporal correlations) should reduce LTP in standard plasticity induction protocols. Also, we expect to observe a significant dependence of synaptic plasticity on neuronal response functions and output statistics. For example, flatter response functions should correlate with faster learning, in contrast to the inverse correlation predicted by classical learning rules derived from Euclidean-gradient descent. These propositions remain to be tested experimentally.
By following gradients with respect to the neuronal output rather than the synaptic weights themselves, we were able to derive a parametrization-invariant error-correcting plasticity rule on the single-neuron level. Error-correcting learning rules are an important ingredient in understanding biological forms of error backpropagation (Sacramento et al., 2017). In principle, our learning rule can be directly incorporated as a building block into spike-based frameworks of error backpropagation such as (Sporea and Grüning, 2013; Schiess et al., 2016). Based on these models, top-down feedback can provide a target for the somatic spiking of individual neurons, toward which our learning rule could be used to speed up convergence.
Explicitly and exactly applying natural gradient at the network level does not appear biologically feasible due to the existence of cross-unit terms in the Fisher information matrix . These terms introduce non-localities in the natural-gradient learning rule, in the sense that synaptic changes at one neuron depend on the state of other neurons in the network. However, methods such as the unit-wise natural-gradient approach (Ollivier, 2015) could be employed to approximate the natural gradient using a block-diagonal form of . The resulting learning rule would not exhibit biologically implausible co-dependencies between different neurons in the network, while still retaining many of the advantages of full natural-gradient learning. For spiking networks, this would reduce global natural-gradient descent to our local rule for single neurons.
Materials and methods
Neuron model
Request a detailed protocolWe chose a Poisson neuron model whose firing rate depends on the somatic membrane potential above the resting potential . They relate via a sigmoidal activation function
(24)
with , and a maximal firing rate . This means the activation function is centered at −60 mV, saturating around −50 mV. Note that the derivation of our learning rule does not depend on the explicit choice of activation function, but holds for arbitrary monotonically increasing, positive functions that are sufficiently smooth. For the sake of simplicity, refractoriness was neglected. For the same reason, we assumed synaptic input to be current-based, such that incoming spikes elicit a somatic membrane potential above baseline given by
(25)
where
(26)
denotes the unweighted synaptic potential (USP) evoked by a spike train
(27)
of afferent i, and wi is the corresponding synaptic weight. Here, denote the firing times of afferent i, and the synaptic response kernel is modeled as
(28)
where is a scaling factor with units , and unless specified otherwise, we chose . For slowly changing input rates, mean and variance of the stationary unweighted synaptic potential are then given as (Petrovici, 2016)
(29)
and
(30)
with
(31)
Equations 29 and 30 are exact for constant input rates. Note that it is Equation 30 that induces the inverse dependence of the homosynaptic term on the input rate discussed around Equation 19.
Unless indicated otherwise, simulations were performed with a membrane time constant and a synaptic time constant . Hence, USPs had an amplitude of 60 mV and were normalized with respect to area under the curve and multiplied by the synaptic weights. Initial and target weights were chosen such that the resulting average membrane potential was within operating range of the activation function. As an example, in Figure 3F, the average initial excitatory weight was 0.005, corresponding to an EPSP amplitude of 300V.
In Figure 5, the scaling factor was additionally normalized proportionally to the input rate ri at the synapse in order to keep the mean USP constant and allow a comparison based solely on the variance.
Sketch for the derivation of the somatic natural-gradient learning rule
Request a detailed protocolThe choice of a Poisson neuron model implies that spiking in a small interval is governed by a Poisson distribution. For sufficiently small interval lengths , the probability of having a single spike in becomes Bernoulli with parameter . The aim of supervised learning is to bring this distribution closer to a given target distribution with density . The latter is delivered in form of a teacher spike train
(32)
where the probability of having a teacher spike (denoted as ) in is Bernoulli with parameter
(33)
Note that to facilitate the convergence analysis, in Figure 3 we chose a realizable teacher generated by a given set of teacher weights .
We measure the error between the desired and the current input-output spike distribution in terms of the Kullback-Leibler divergence given in Equation 9, which attains its single minimum when the two distributions are equal. Note that while the is a standard measure to characterize ‘how far’ two distributions are apart, its behavior can sometimes be slightly unintuitive since it is not a metric. In particular, it is not symmetric and does not satisfy the triangle inequality.
Classical error learning follows the Euclidean gradient of this cost function, given as the vector of partial derivatives with respect to the synaptic weights. A short calculation (Sec. ‘Detailed derivation of the natural-gradient learning rule’) shows that the resulting Euclidean-gradient-descent learning rule is given by Equation 10. By correcting the vector of partial derivatives for the distance distortion between the manifold of input-output distributions and the synaptic weight space, given in terms of the Fisher information matrix , we obtain the natural gradient (Equation 12). We then followed an approach by Amari, 1998 to derive an explicit formula for the product on the right hand side of Equation 12.
In Sec. ‘Detailed derivation of the natural-gradient learning rule’, we show that given independent input spike trains, the Fisher information matrix defined in Equation 11 can be decomposed with respect to the vector of input rates and the current weight vector as
(34)
Here,
(35)
is the covariance matrix of the unweighted synaptic potentials, and are coefficients (see Equation 82 for their definition) depending on the mean and variance of the membrane potential, and on the total rate
(36)
Through repeated application of the Sherman-Morrison-Formula, the inverse of can be obtained as
(37)
Here the coefficients , which are defined in Equation 102, are again functions of mean and variance of the membrane potential, and of the total rate. Consequently, the natural-gradient rule in terms of somatic amplitudes is given by
(38)
Note that the formulas for,
(39)
arise from the product of the inverse Fisher information matrix and the Euclidean gradient, using and . Due to the complicated expressions for (Equation 82), Equation 39 only provides limited information about the behavior of and . Therefore, we performed an empirical analysis based on simulation data (Sec. ‘Empirical analysis of and ’; Figure 11). In a stepwise manner we first evaluated under various conditions, which revealed that the products with g2 and g3 in Equation 39 are neglible in most cases compared to the other terms, hence
(40)
Furthermore, for a sufficient number of input afferents, we can approximate . Since , by the central limit theorem we have
(41)
for large and . Moreover, while the variance of g4 across weight samples increases with the number and firing rate of input afferents, its mean stays approximately constant across conditions. This lead to the approximation
(42)
where is constants across weights, input rates and the number of input afferents.
To evaluate the quality of our approximations, we tested the performance of learning in the setting of Figure 3 when and were replaced by their approximations (Equations 112; 113). The test was performed for several input patterns (Sec. ‘Evaluation of the approximated natural-gradient rule’, Sec. ‘Performance of the approximated learning rule’). It turned out that a convergence behavior very similar to natural-gradient descent could be achieved with , which worked much better in practice than . For a choice of 0.05 which was close to the mean of worked well.
For these input rate configurations and choices of constants, we additionally sampled the negative gradient vectors for random initial weights and USPs (Sec. ‘Evaluation of the approximated natural-gradient rule’, Sec. ‘Performance of the approximated learning rule’) and compared the angles and length difference between natural-gradient vectors and the approximation to the ones between natural and Euclidean gradient.
Reparametrization and the general natural-gradient rule
Request a detailed protocolTo arrive at a more general form of the natural-gradient learning rule, we consider a parametrization of the synaptic weights which is connected to the somatic amplitudes via a smooth component-wise coordinate change , such that . A Taylor expansion shows that small weight changes then relate via the derivative of
(43)
On the other hand, we can also express the cost function in terms of , with , and directly calculate the Euclidean gradient of in terms of . By the chain rule, we then have
(44)
Plugging this into Equation 43, we obtain an inconsistency: . Hence the predictions of Euclidean-gradient learning depend on our choice of synaptic weight parametrization (Figure 1).
In order to obtain the natural-gradient learning rule in terms of , we first express the Fisher Information Matrix in the new parametrization, starting with Equation 60
(45)
(46)
(47)
(48)
Inserting both Equation 44 and Equation 47 into Equation 12, we obtain the natural-gradient rule in terms of (Equation 13). As illustrated in Figure 8, unlike for Euclidean-gradient descent, the result is consistent with Equation 43.
Figure 8
Natural-gradient descent does not depend on chosen parametrization.
Mathematical derivation and phenomenological correlates. EPSPs before learning are represented as continuous, after learning as dashed curves. The light blue arrow represents gradient descent on the error as a function of the somatic EPSP (also shown in light blue). The resulting weight change leads to an increase in the somatic EPSP after learning. The dark blue arrows track the calculation of the same gradient, but with respect to the dendritic EPSP (also shown in dark blue): (1) taking the attenuation into account in order to compute the error as a function of , (2) calculating the gradient, followed by (3) deriving the associated change in , again considering attenuation. (A) For Euclidean-gradient descent. (B) For natural-gradient descent. Unlike for Euclidean-gradient descent, the factor is compensated, since its inverse enters via the Fisher information. This leads to the synaptic weights updates, as well as the associated evolution of a neuron’s output statistics over time, being equal under the two parametrizations.
Simulation details
All simulations were performed in python and used the numpy and scipy packages. Differential equations were integrated using a forward Euler method with a time step of 0.5 ms.
Supervised learning task
Request a detailed protocolA single output neuron was trained to spike according to a given target distribution in response to incoming spike trains from n independently firing afferents. To create an asymmetry in the input, we chose one half of the afferents’ firing rates as 10 Hz, while the remaining afferents fired at 50 Hz. The supervision signal consisted of spike trains from a teacher that received the same input spikes. To allow an easy interpretation of the results, we chose a realizable teacher, firing with rate , where for some optimal set of weights . However, our theory itself does not include assumptions about the origin and exact form of the teacher spike train.
For the learning curves in Figure 3F, initial and target weight components were chosen randomly (but identically for the two curves) from a uniform distribution on , corresponding to maximal PSP amplitudes between −600 μV and 600 μV for the simulation with input neurons. Learning curves were averaged over 1000 initial and target weight configurations. In addition, the minimum and maximum values are shown in Figure 9, as well as the mean Euclidean distance between student and teacher weights and between student and teacher firing rates. We did not enforce Dales’ law, thus about half of the synaptic input was inhibitory at the beginning but sign changes were permitted. This means that the mean membrane potential above rest covered a maximal range [−30 mV, 30 mV]. Learning rates were optimized as for the natural-gradient-descent algorithm and for Euclidean-gradient descent, providing the fastest possible convergence to a residual root mean squared error in output rates of 0.8 Hz. To confirm that the convergence behavior of both natural-gradient and Euclidean-gradient learning is robust, we varied the learning rate between and and measured the time until the first reached a value of (Figure 9). Here for Euclidean-gradient descent and for natural-gradient descent.
Figure 9

Further convergence analysis of natural-gradient-descent learning.
Unless stated otherwise, all simulation parameters are the same as in Figure 3. (A) In addition to the average learning curves from Figure 3F (solid lines), we show the minimum and maximum values (semi-transparent lines) during learning. (B) Plot of the mean Euclidean distance between student and teacher weight. Note that a smaller distance in weights does not imply a smaller , nor a smaller distance in firing rates. This is due to the non-linear relationship between weights and firing rates. (C) Development of mean Euclidean distance between student and teacher firing rate during learning. (D) Robustness of learning against perturbations of the firing rate. We varied the learning rate for natural-gradient and Euclidean-gradient descent relative to the learning rate used in the simulations for Figure 3F (EGD: , NGD: ), and measured the time until the first reached a value of .
Per trial, the expectation over USPs in the cost function was evaluated on a randomly sampled test set of 50 USPs that resulted from input spike trains of 250 ms. The expectation over output spikes was calculated analytically.
For the weight path simulation with two neurons (Figure 3D–E), we chose a fixed initial weight , a fixed target weight , and learning rates and . Weight paths were averaged over 500 trials of 6000s duration each.
The vector plots in Figure 3D–E display the average negative normalized natural and Euclidean-gradient vectors across 2000 USP samples per synapse () on a grid of weight positions on , with the first coordinate of the gridpoints in and the second in . Each USP sample was the result of a spike train at rate and respectively. The contour lines were obtained from 2000 samples of the along a grid on (distance between two grid points in one dimension: ) and displayed at the levels 0.001, 0.003, 0.005, 0.009, 0.015, 0.02, 0.03, 0.04.
For the plots in Figure 3B–C, we used initial, final, and target weights from a sample of the learning curve simulation. We then randomly sampled input spike trains of 250 ms length and calculated the resulting USPs and voltages according to Equation 26 and Equation 25. The output spikes shown in the raster plot were then sampled from a discretized Poisson process with . We then calculated the PSTH with a bin size of 12.5 ms.
Distance dependence of amplitude changes
Request a detailed protocolA single excitatory synapse received Poisson spikes at 5 Hz, paired with Poisson teacher spikes at 20 Hz. The distance from the soma was varied between 0 μm and 460 μm. Learning was switched on for 5 s with an initial weight corresponding to 0.05 at the soma, corresponding to a PSP amplitude of 3 mV. Initial dendritic weights were scaled up with the proportionality factor depending on the distance from the soma, in order for input spikes to result in the same somatic amplitude independent of the synaptic position. Example traces are shown for and .
Variance dependence of amplitude changes
Request a detailed protocolWe stimulated a single excitatory synapse with Poisson spikes, while at the same time providing Poisson teacher spike trains at 80 Hz. To change USP variance independently from mean, unlike in the other exercises, the input kernel in Equation 28 was additionally normalized by the input rate. USP variance was varied by either keeping the input rate at 10 Hz while varying the synaptic time constant between 1 ms and 20 ms, or fixing at 20 ms and varying the input rate between 10 Hz and 50 Hz.
Comparison of homo- and heterosynaptic plasticity
Out of excitatory synapses of a neuron, we stimulated 5 by Poisson spike trains at 5 Hz, together with teacher spikes at 20 Hz, and measured weight changes after 60 s of learning. To avoid singularities in the homosynaptic term of learning rule, we assumed in the learning rule that unstimulated synapses received input at some infinitesimal rate, thus effectively setting . Initial weights for both unstimulated and stimulated synapses were varied between and . For reasons of simplicity, all stimulated weights were assumed to be equal, and tonic inhibition was assumed by a constant shift in baseline membrane potential of -5 mV. Example weight traces are shown for initial weights of and for both stimulated and unstimulated weights. The learning rate was chosen as .
For the plots in Figure 7B C, we chose the diverging colormap matplotlib.cm.seismic in matplotlib. The colormap was inverted such that red indicates negative values representing synaptic depression and blue indicates positive values representing synaptic potentiation. The colormap was linearly discretized into 500 steps. To avoid too bright regions where colors cannot be clearly distinguished, the indices 243–257 were excluded. The colorbar range was manually set to a symmetric range that includes the max/min values of the data. In Figure 7D, we only distinguish between regions where plasticity at stimulated and at unstimulated synapses have opposite signs (light green), and regions where they have the same sign (dark green).
Approximation of learning-rule coefficents
Request a detailed protocolWe sampled the values for from Equation 82 for different afferent input rates. The input rate was varied between 5 Hz and 55 Hz for neurons. The coefficients were evaluated for randomly sampled input weights (20 weight samples of dimension , each component sampled from a uniform distribution ).
In a second simulation, we varied the number of afferents between 10 and 200 for a fixed input rate of 20 Hz, again for randomly sampled input weights (20 weight samples of dimension , each component sampled from a uniform distribution ).
In a next step, we compared the sampled values of g1 as a function of the total input rate to the values of the approximation given by ( between 5 Hz and 55 Hz, between 10 and 200 neurons, 20 weight samples of dimension , each component sampled from a uniform distribution ).
Afterwards, we plotted the sampled values of as a function of the approximation (Equation 111, between 5 Hz and 55 Hz, , 20 weight samples of dimension , each component sampled from a uniform distribution , 20 USP-samples of dimension for each rate/weight-combination).
Next, we investigated the behavior of as a function of ( between 5 Hz and 55 Hz, , 20 weight samples of dimension , each component sampled from a uniform distribution , 20 USP-samples of dimension for each rate/weight-combination), and in last step, as a function of with a constant .
Evaluation of the approximated natural-gradient rule
Request a detailed protocolWe evaluated the performance of the approximated natural-gradient rule in Equation 114 (with and ) compared to Euclidean-gradient descent and the full rule in Equation 13 in the learning task of Figure 3 under different input conditions (n=100, Group 1: / Group 2: 30 Hz, Group 1: 10 Hz/ Group 2: 50 Hz, Group 1: 20 Hz/ Group 2: 20 Hz, Group 1: 20 Hz/ Group 2: 40 Hz). The learning curves were averaged over 1000 trials with input and target weight components randomly chosen from a uniform distribution on . Learning rate parameters were tuned individually for each learning rule and scenario according to Table 1. All other parameters were the same as for Figure 3F.
Table 1
Learning rates.
| r1 | r2 | |||
|---|---|---|---|---|
| 10 Hz | 30 Hz | 0.000655 | 0.00055 | 0.00000110 |
| 10 Hz | 50 Hz | 0.000600 | 0.00045 | 0.00000045 |
| 20 Hz | 20 Hz | 0.000650 | 0.00053 | 0.00000118 |
| 20 Hz | 40 Hz | 0.000580 | 0.00045 | 0.00000055 |
For the angle histograms in Figure 12A-B, we simulated the natural, Euclidean and approximated natural weight updates for several input and initial weight conditions. Similar to the setup in Figure 3 we separated the input afferents in two groups firing at different rates (Group1/Group2: 10 Hz/10 Hz, 10 Hz/30 Hz, 10 Hz/50 Hz, 20 Hz/20 Hz, 20 Hz/40 Hz). For each input pattern, 100 Initial weight components were sampled randomly from a uniform distribution , while the target weight was fixed at . For each initial weight, 100-long input spike trains were sampled and the average angle between the natural-gradient weight update and the approximated natural-gradient weight update at was calculated. The same was done for the average angle between the natural and the Euclidean weight update.
Detailed derivation of the natural-gradient learning rule
Request a detailed protocolHere, we summarize the mathematical derivations underlying our natural-gradient learning rule (Equation 13). While all derivations in Sec. ‘Detailed derivation of the natural-gradient learning rule’ and Sec. ‘Inverse of the Fisher Information Matrix’ are made for the somatic parametrization and can then be extended to other weight coordinates as described in Sec. ‘Reparametrization and the general natural-gradient rule’, we drop the index in for the sake of readability.
Supervised learning requires the neuron to adapt its synapses in such a way that its input-output distribution approaches a given target distribution with density . For a given input spike pattern , at each point in time, the probability for a Poisson neuron to fire a spike during the interval (denoted as ) follows a Bernoulli distribution with a parameter , depending on the current membrane potential. The probability density of the binary variable yt on {0, 1}, describing whether or not a spike occurred in the interval , is therefore given by
(49)
and we have
(50)
where denotes the probability density of the unweighted synaptic potentials . Measuring the distance to the target distribution in terms of the Kullback-Leibler divergence, we arrive at
(51)
Since the target distribution does not depend on the synaptic weights, the negative Euclidean gradient of the equals
(52)
We may then calculate
(53)
(54)
(55)
(56)
where Equation 55 follows from the fact that and for Equation 56 we neglected the term of order which is small compared to the remainder. Plugging Equation 56 into Equation 52 leads to the Euclidean-gradient descent online learning rule, given by
(57)
Here,
(58)
is the teacher spike train. We obtain the negative natural gradient by multiplying Equation 57 with the inverse Fisher information matrix, since
(59)
with the Fisher information matrix at being defined as
(60)
Exploiting that, just like for the target density, the density of the USPs does not depend on , so
(61)
(62)
we can insert the previously derived formula Equation 56 for the partial derivative of the log-likelihood. Hence, using the tower property for expectation values and the definition of (Equation 49, Equation 50), Equation 60 transforms to
(63)
(64)
(65)
(66)
(67)
In order to arrive at an explicit expression for the natural-gradient learning rule, we further decompose the Fisher information matrix, which will then enable us to find a closed expression for its inverse.
Inspired by the approach in Amari, 1998, we exploit the fact that a positive semi-definite matrix is uniquely defined by its values as a bivariate form on any basis of . Choosing a basis for which the bilinear products with are of a particularly simple form, we are able to decompose the Fisher Information Matrix by constructing a sum of matrices whose values as a bivariate form on the basis equal are equal to those of . Due to the structure of this particular decomposition, we may then apply well-known formulas for matrix inversion to obtain .
Consider the basis such that the vectors are orthogonal to each other. Here, denotes the covariance matrix of the USPs which in the case of independent Poisson input spike trains is given as
(68)
In this case, the matrix square root reduces to the component-wise square root. Note that for any with , the random variables and are uncorrelated, since
(69)
(70)
(71)
We make the mild assumptions of having small afferent populations firing at the same input rate, and that the basis is constructed in such way that the basis vectors are not too close to the coordinate axes, such that the products are not dominated by a single component. Then, for sufficiently large , every linear combination of the random variables and is approximately normally distributed, thus, the two random variables follow a joint bivariate normal distribution. Furthermore, uncorrelated random variables that are jointly normally distributed are independent. Since functions of independent random variables are also independent, this allows us to calculate all products of the form for , as we can transform the expectation of products
(72)
into products of expectations. Taking into account that and , we arrive at
(73)
(74)
(75)
(76)
Here, denote the generalized voltage moments given as
(77)
(78)
(79)
The integral formulas follow from the fact that for a large number of input afferents, and under the mild assumption of all synaptic weights roughly being of the same order of magnitude, the membrane potential approximately follows a normal distribution with mean and variance . Here, and is given by Equation 31, see Sec. ‘Neuron model’.
Based on the above calculations, we construct a candidate for a decomposition of . We start with the matrix , since its easy to see that
(80)
Exploiting the orthogonal properties according to which we constructed to carefully add more terms such that also the other identities in Equation 73 hold, we arrive at
(81)
Here,
(82)
To check that indeed , it suffices to check the values of as a bilinear form on the basis .
Inverse of the Fisher information matrix
Request a detailed protocolAs the expectation of the outer product of a vector with itself, is per construction symmetric and positive semidefinite. From the previous calculations, it follows that for elements of a basis of the products are strictly positive. Hence is positive definite and thus invertible. We showed that,
We introduce the notation.
(83)
Then,
(84)
For the following calculations, we will repeatedly use the identities
(85)
By the Sherman-Morrison-Woodbury formula, the inverse of an invertible rank one correction of an invertible matrix A is given by
(86)
Applying this to invert , as a first step, we consider the term and identify and . Its inverse is given by
(87)
with
(88)
Applying the Sherman-Morrison-Woodbury formula a second time, this time with and , we obtain
(89)
Here,
(90)
(91)
Plugging in the definitions of M3 and M1, and using that
(92)
we arrive at
(93)
(94)
(95)
(96)
(97)
(98)
(99)
After resorting the terms and grouping, we obtain the inverse of the Fisher Information Matrix as
(100)
(101)
with
(102)
(103)
(104)
(105)
Note that instead of applying the Sherman-Morrison-Woodbury formula twice one could also directly use the version for rank-2 corrections, known as the Woodbury identity (Max, 1950). This can be seen by rewriting Equation 84 as
(106)
with
and
By the Woodbury identity for rank-2 corrections, we then have
with .
Analysis of the learning rule coefficients
In order to gain an intuitive understanding of Equation 13 and to judge its suitability as an in-vivo plasticity rule, we require insights into the behavior of the coefficients and under various circumstances.
Global scaling factor
Request a detailed protocolThe global scaling factor is given as
(107)
The above formula reveals that is closely tied to the firing nonlinearity of the neuron, as well as the statistics of output. The scaling by the inverse slope of the output nonlinearity amplifies the synaptic update in regions where a small change in weight and thus in the membrane potential would not lead to a noticeable change in output distribution. A further scaling with additionally amplifies the synaptic change in high-output regimes (Figure 10). This is in line with the spirit of natural gradient that ensures that the size of the synaptic weight update is homogeneous in terms of change rather than in absolute weight terms. Furthermore, the rescaling is based on the average output statistics, which the synapse might have access to via backpropagating action potentials (Stuart et al., 1997), rather than an instantaneous value.
Figure 10

Global learning rate scaling as a function of the mean membrane potential.
We sampled the global learning rate factor (blue) for various conditions. In line with Equation 107, is boosted in regions where the transfer function is flat, that is, is small. The global scaling factor is additionally increased in regions where the transfer function reaches high absolute values.
Empirical analysis of and
Request a detailed protocolWhile the formula for provides a rather good intuition of this coefficients’ behavior, from the derivations in the previous sections, it becomes clear that such a straightforward interpretation is not readily available from the formulas for and . Defined as
(108)
and
(109)
where are given in Equation 102, these coefficients depend, apart from the membrane potential and its first and second moments, on the total input and its mean the total rate. This raises the question whether the synapse, which in general only has limited access to global quantities, can implement and . We therefore used an empirical analysis through simulations to obtain a more detailed insight.
As a starting point, we sampled for various input conditions (Figure 11A–D, refer to Sec. ‘Approximation of learning-rule coefficents’ for simulation details). Here, we varied the afferent input rate between and for neurons and evaluated the value of the respective coefficient for a randomly sampled input weight. In a second simulation (Figure 11E–H, Sec. ‘Approximation of learning-rule coefficents’), we varied the number of afferent inputs between 10 and 200 neurons for fixed input rate , again with randomly chosen input weights. This revealed an approximately inverse proportional relationship between the average input rate and and g3 respectively. Furthermore, these coefficients seemed to be approximately inversely proportional to the number of afferent inputs. However, this was not true for g4, whose mean seemed to stay approximately constants across input rates, although the scattering across the mean value (for different weight samples) increased.
Figure 11
Learning rule coefficients can be approximated by simpler quantities.
(A)-(D) Samples values for for different afferent input rates. (E)-(H) In a second simulation, we varied the number of afferent inputs. (I) Comparison of the sampled values of (blue) as a function of the total input rate to the values of the approximation given by . (J) Sampled values of (blue) as a function of the approximation s (Equation 111). The proximity of the sampled values to the diagonal indicates that may indeed serve as an approximation for . (K) Sampled values of (blue) as a function of . The proximity of the sampled values to the diagonal indicates that serves as an approximation for . (L) Same as (K), but with replaced by a constant .
While the value of the membrane potential stays bounded also for a large number of inputs (due to the normalization of the synaptic weight range with ), the total sum of USPs increases with an increasing number of inputs. Therefore, for large enough , the term can be neglected, so
(110)
A closer look at the behavior of g1 shows that, for a sufficiently large number of neurons or high input rates, , which we verified by simulations (Figure 11I, Sec. ‘Approximation of learning-rule coefficents’). In consequence,
(111)
To verify this approximation, we sampled the values of for various conditions (Figure 11J, Sec. ‘Approximation of learning-rule coefficents’) and compared them against the approximation in Equation 111, which confirmed our approximation. Since the input rate is the mean value of the USP, assuming large enough populations with the same input rate and a sufficient number of input afferents, by the central limit theorem we have
(112)
with . However, in practice, for , a learning behavior much closer to natural gradient was obtained when was slightly smaller than 1 such as (Sec. ‘Quadratic transfer function’).
As a starting point to approximate , we noticed that the mean of g4 stayed approximately constant when varying the input rate or the number of input afferents. On the other hand, g2 rapidly tends to zero in those cases, so we assumed that stays either constant or goes to zero in the limit of large n. Since seemed to be rather small compared to g4, we hypothesized , which was confirmed by simulations (Figure 11K, Sec. ‘Approximation of learning-rule coefficents’). As a second step (Figure 11L, Sec. ‘Approximation of learning-rule coefficents’), since g4 seemed to be constant in the mean, we approximated
(113)
where simulations with , close to the mean of g4 showed a learning behavior close to natural-gradient learning (Figure 12C–F). Replacing and in Equation 13 by the expressions in Equation 112 and Equation 113, we obtain the approximated natural-gradient rule
(114)
Figure 12
Natural-gradient learning can be approximated by a simpler rule in many scenarios.
(A) Mean Fisher angles between true and approximated weight updates (orange) and between natural and Euclidean weight updates (blue), for . Results for several input patterns were pooled (group1/group2: 10 Hz/10 Hz 10 Hz/30 Hz, 10 Hz/50 Hz, 20 Hz/20 Hz, 20 Hz/40 Hz). Initial weights and input spikes were sampled randomly (100 randomly sampled initial weight vectors per input pattern; for each, angles were averaged over 100 input spike train samples per afferent). (B) Same as (A), but angles measured in the Euclidean metric. (C–F) Comparison of learning curves for natural gradient (red), Euclidean gradient (blue) and approximation (orange) for afferents. Simulations were performed in the setting of Figure 3, under multiple input conditions. (C) Group one firing with 10 Hz, group two firing at 30 Hz. (D) Group one firing with 10 Hz, group two firing at 50 Hz. (E) Group one firing with 20 Hz, group two firing at 20 Hz. (F) Group one firing with 20 Hz, group two firing at 40 Hz.
Performance of the approximated learning rule
Request a detailed protocolSimulations of natural, Euclidean and approximated natural-gradient weight updates for several input patterns and randomly sampled initial conditions (Sec. ‘Evaluation of the approximated natural-gradient rule’) showed that the average angles (both in the Euclidean metric and in the Fisher metric) between the true and approximated natural-gradient weight update were small compared to the average angle between Euclidean and natural-gradient weight update (Figure 12A–B). This was confirmed by the learning curves for several tested input conditions in the setting of Figure 3, since the performance of the approximation lay in between the natural and the Euclidean gradient’s performance (Figure 12C–F, simulation details: Sec. ‘Evaluation of the approximated natural-gradient rule’). It can hence be regarded as a trade-off between optimal learning speed, parameter invariance and biological implementability. Note that plugging the above calculations into Equation 13 still keeps invariance under coordinate-wise smooth parameter changes.
Quadratic transfer function
Request a detailed protocolWhile for all our simulations, we used the sigmoidal transfer function given in Equation 24, the derivations that lead to Equation 100 also hold for other choices of transfer function. A particularly simple and thereby instructive result can be obtained for a transfer function that satisfies
(115)
This is the case for a rectified quadratic transfer function
(116)
where is the Heaviside step function. To prevent issues with division by zero and to ensure that Equation 115 holds for all relevant membrane voltages , we assume . Then, Equation 67 reduces to
(117)
where the right side no longer depends on , thus yielding . Furthermore, we have
(118)
(119)
(120)
and therefore (see Equation 82). Plugging this into Equation 81, we obtain
(121)
with defined in Equation 35. Inverting this using the Sherman-Morrison-Woodbury Formula, we arrive at
(122)
Inserting this version of the Fisher information matrix into Equation 12, we get and (see Equation 107 and 109), thus obtaining a simplified version of the natural-gradient learning rule as
(123)
(124)
with as in Equation 36. This is in line with our empirical approximation for for the case of the sigmoidal transfer function (Equation 111). It is interesting to note that, for a large number of inputs, we have and the average of the parenthesis in Equation 123, taken in isolation, reduces to zero. However, this does not mean that, on average, there is no plasticity. Instead, we can say that, for a quadratic activation regime, the natural gradient is purely driven by the correlation between the postsynaptic error and the (normalized and centered) presynaptic input.
Continuous-time limit
Request a detailed protocolUnder the Poisson-process assumption, firing a spike in one of the time bins is independent from the spikes in other bins, therefore the probability for firing in two disjunct time intervals and is given as
(125)
Since , we have
(126)
(127)
so the Fisher information matrix is additive.
In the continuous-time limit, where the interval is decomposed as , with and , we have . Therefore,
(128)
Then, under the assumption that is small and firing rates are approximately constant on , for the Fisher information matrix, we have
(129)
(130)
Data availability
The data used to generate the figures and the simulation code are available on GitHub, (copy archived at swh:1:rev:4da5611348ea969aff461886f85842fe36a8571a).
References
-
Synaptic plasticity as Bayesian inferenceNature Neuroscience 24:565–571.https://doi.org/10.1038/s41593-021-00809-5
-
BookDifferential geometrical theory of StatisticsIn: Amari S, editors. In Differential Geometry in Statistical Inference. Hayward: Institute of Mathematical Statistics. pp. 19–94.
-
Natural Gradient Works Efficiently in LearningNeural Computation 10:251–276.https://doi.org/10.1162/089976698300017746
-
ConferenceFisher information and natural gradient learning in random deep networksIn The 22nd International Conference on Artificial Intelligence and Statistics. pp. 694–702.
-
BookMethods of Information Geometry. Translations of Mathematical MonographsAmerican Mathematical Society.
-
Synaptic strength of individual spines correlates with bound Ca2+-calmodulin-dependent kinase IIThe Journal of Neuroscience 27:14007–14011.https://doi.org/10.1523/JNEUROSCI.3587-07.2007
-
ConferenceExact natural gradient in deep linear networks and its application to the nonlinear caseAdvances in Neural Information Processing Systems. pp. 5941–5950.
-
BookOptimal Decision Rules and Optimal InferenceAmerican Mathematical Society, Rhode Island. Translation from Russian.
-
Heterosynaptic plasticity prevents runaway synaptic dynamicsThe Journal of Neuroscience 33:15915–15929.https://doi.org/10.1523/JNEUROSCI.5088-12.2013
-
Heterosynaptic plasticity in the neocortexExperimental Brain Research 199:377–390.https://doi.org/10.1007/s00221-009-1859-5
-
Homeostatic role of heterosynaptic plasticity: models and experimentsFrontiers in Computational Neuroscience 9:89.https://doi.org/10.3389/fncom.2015.00089
-
Spatio-temporal credit assignment in neuronal population learningPLOS Computational Biology 7:e1002092.https://doi.org/10.1371/journal.pcbi.1002092
-
BookSpiking Neuron Models: Single Neurons, Populations, PlasticityCambridge University Press.https://doi.org/10.1017/CBO9780511815706
-
ConferenceLatent equilibrium: A unified learning theory for arbitrarily fast computation with arbitrarily slow neuronsAdvances in Neural Information Processing Systems.
-
ConferenceA natural policy gradientAdvances in Neural Information Processing Systems. pp. 1531–1538.
-
Learning rules for spike timing-dependent plasticity depend on dendritic synapse locationThe Journal of Neuroscience 26:10420–10429.https://doi.org/10.1523/JNEUROSCI.2650-06.2006
-
ConferenceNatural Langevin dynamics for neural networksIn International Conference on Geometric Science of Information. pp. 451–459.https://doi.org/10.1007/978-3-319-68445-1
-
Interneurons of the neocortical inhibitory systemNature Reviews. Neuroscience 5:793–807.https://doi.org/10.1038/nrn1519
-
Riemannian metrics for neural networks I: feedforward networksInformation and Inference 4:108–153.https://doi.org/10.1093/imaiai/iav006
-
Information and the accuracy attainable in the estimation of statistical parametersBulletin of Calcutta Mathematical Society 37:81–91.
-
Analysis of natural gradient descent for multilayer neural networksPhysical Review E 59:4523–4532.https://doi.org/10.1103/PhysRevE.59.4523
-
The perceptron: A probabilistic model for information storage and organization in the brainPsychological Review 65:386–408.https://doi.org/10.1037/h0042519
-
Somato-dendritic Synaptic Plasticity and Error-backpropagation in Active DendritesPLOS Computational Biology 12:e1004638.https://doi.org/10.1371/journal.pcbi.1004638
-
The highly irregular firing of cortical cells is inconsistent with temporal integration of random EPSPsThe Journal of Neuroscience 13:334–350.
-
Supervised learning in multilayer spiking neural networksNeural Computation 25:473–509.https://doi.org/10.1162/NECO_a_00396
-
Action potential initiation and backpropagation in neurons of the mammalian CNSTrends in Neurosciences 20:125–131.https://doi.org/10.1016/s0166-2236(96)10075-8
-
On the choice of metric in gradient-based theories of brain functionPLOS Computational Biology 16:e1007640.https://doi.org/10.1371/journal.pcbi.1007640
-
Acute and long-term effects of MK-801 on direct cortical input evoked homosynaptic and heterosynaptic plasticity in the CA1 region of the female ratThe European Journal of Neuroscience 26:2873–2883.https://doi.org/10.1111/j.1460-9568.2007.05899.x
-
Hebbian plasticity requires compensatory processes on multiple timescalesPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 372:20160259.https://doi.org/10.1098/rstb.2016.0259
Article and author information
Author details
Funding
European Union 7th Framework Programme (604102)
- Walter Senn
Horizon 2020 Framework Programme (720270)
- Walter Senn
- Mihai A Petrovici
Horizon 2020 Framework Programme (785907 and 945539)
- Walter Senn
- Mihai A Petrovici
Swiss National Fonds (personal grant 310030L_156863 (WS))
- Walter Senn
Swiss National Fonds (Sinergia grant CRSII5_180316)
- Walter Senn
Manfred Stärk Foundation (personal grant)
- Mihai A Petrovici
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work has received funding from the European Union 7th Framework Programme under grant agreement 604102 (HBP), the Horizon 2020 Framework Programme under grant agreements 720270, 785907 and 945539 (HBP) and the SNF under the personal grant 310030L_156863 (WS) and the Sinergia grant CRSII5_180316. Calculations were performed on UBELIX (http://www.id.unibe.ch/hpc), the HPC cluster at the University of Bern. We thank Oliver Breitwieser for the figure template, and Simone Surace and João Sacramento, as well as the other members of the Senn and Petrovici groups for many insightful discussions. We are also deeply grateful to the late Robert Urbanczik for many enlightening conversations on gradient descent and its mathematical foundations. Furthermore, we wish to thank the Manfred Stärk Foundation for their ongoing support.
Copyright
© 2022, Kreutzer et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,575
- views
-
- 236
- downloads
-
- 10
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 10
- citations for umbrella DOI https://doi.org/10.7554/eLife.66526
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Natural-gradient learning for spiking neurons
eLife 11:e66526.
https://doi.org/10.7554/eLife.66526




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}