Synaptic learning rules for sequence learning
- Institute for Theoretical Biology, Department of Biology, Humboldt-Universität zu Berlin, Germany
- Bernstein Center for Computational Neuroscience Berlin, Germany
- Einstein Center for Neurosciences Berlin, Germany
Abstract
Remembering the temporal order of a sequence of events is a task easily performed by humans in everyday life, but the underlying neuronal mechanisms are unclear. This problem is particularly intriguing as human behavior often proceeds on a time scale of seconds, which is in stark contrast to the much faster millisecond time-scale of neuronal processing in our brains. One long-held hypothesis in sequence learning suggests that a particular temporal fine-structure of neuronal activity — termed ‘phase precession’ — enables the compression of slow behavioral sequences down to the fast time scale of the induction of synaptic plasticity. Using mathematical analysis and computer simulations, we find that — for short enough synaptic learning windows — phase precession can improve temporal-order learning tremendously and that the asymmetric part of the synaptic learning window is essential for temporal-order learning. To test these predictions, we suggest experiments that selectively alter phase precession or the learning window and evaluate memory of temporal order.
Introduction
It is a pivotal quality for animals to be able to store and recall the order of events (‘temporal-order learning’, Kahana, 1996; Fortin et al., 2002; Lehn et al., 2009; Bellmund et al., 2020) but there is only little work on the neural mechanisms generating asymmetric memory associations across behavioral time intervals (Drew and Abbott, 2006). Putative mechanisms need to bridge the gap between the faster time scale of the induction of synaptic plasticity (typically milliseconds) and the slower time scale of behavioral events (seconds or slower). The slower time scale of behavioral events is mirrored, for example, in the time course of firing rates of hippocampal place cells (O'Keefe and Dostrovsky, 1971), which signal when an animal visits certain locations (‘place fields’) in the environment. The faster time scale is given by the temporal properties of the induction of synaptic plasticity (Markram et al., 1997; Bi and Poo, 1998) — and spike-timing-dependent plasticity (STDP) is a common form of synaptic plasticity that depends on the millisecond timing and temporal order of presynaptic and postsynaptic spiking. For STDP, the so-called ‘learning window’ describes the temporal intervals at which presynaptic and postsynaptic activity induce synaptic plasticity. Such precisely timed neural activity can be generated by phase precession, which is the successive across-cycle shift of spike phases from late to early with respect to a background oscillation (Figure 1). As an animal explores an environment, phase precession can be observed in the activity of hippocampal place cells with respect to the theta oscillation (O'Keefe and Recce, 1993; Buzsáki, 2002; Qasim et al., 2021). Phase precession is highly significant in single trials (Schmidt et al., 2009; Reifenstein et al., 2012) and occurs even in first traversals of a place field in a novel environment (Cheng and Frank, 2008). Interestingly, phase precession allows for a temporal compression of a sequence of behavioral events from the time scale of seconds down to milliseconds (Figure 1; Skaggs et al., 1996; Tsodyks et al., 1996; Cheng and Frank, 2008), which matches the widths of generic STDP learning windows (Abbott and Nelson, 2000; Bi and Poo, 2001; Froemke et al., 2005; Wittenberg and Wang, 2006). This putative advantage of phase precession for temporal-order learning, however, has not yet been quantified. To assess the benefit of phase precession for temporal-order learning, we determine the synaptic weight change between pairs of cells whose activity represents two events of a sequence. Using both analytical methods and numerical simulations, we find that phase precession can dramatically facilitate temporal-order learning by increasing the synaptic weight change and the signal-to-noise ratio by up to an order of magnitude. We thus provide a mechanistic description of associative chaining models (Lewandowsky and Murdock, 1989) and extend these models to explain how to store serial order.
Figure 1
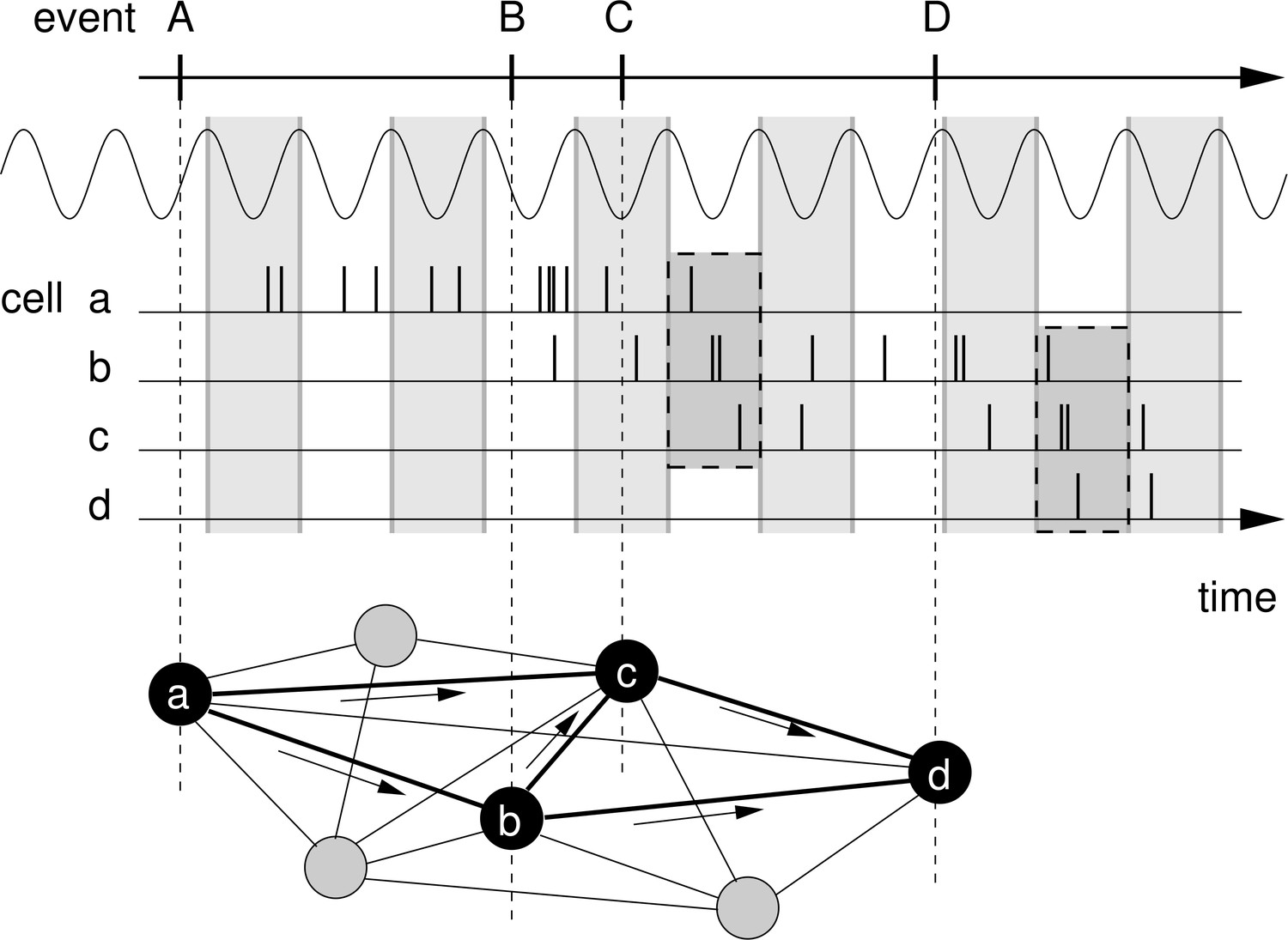
Rationale for temporal-order learning via phase precession.
Top: Behavioral events (A to D) happen on a time scale of seconds. Middle: These events are represented by different cells (a–d), which fire a burst of stochastic action potentials in response to the onset of their respective event. We assume that each cell shows phase precession with respect to the LFP’s theta oscillation (every second cycle is marked by a greay box). When the activities of multiple cells overlap, the sequence of behavioral events is compressed in time to within one theta cycle (two examples highlighted in the dashed, shaded boxes). Bottom: This faster time scale can be picked up by STDP and strengthen the connections between the cells of the sequence. Figure adapted from Korte and Schmitz, 2016.
Results
To address the question of how behavioral sequences could be encoded in the brain, we study the change of synapses between neurons that represent events in a sequence. We assume that the temporal order of two events is encoded in the asymmetry of the efficacies of synapses that connect neurons representing the two events (Figure 1). After the successful encoding of a sequence, a neuron that was activated earlier in the sequence has a strengthened connection to a neuron that was activated later in the sequence, whereas the connection in the reverse direction may be unchanged or is even weakened. As a result, when the first event is encountered and/or the first neuron is activated, the neuron representing the second event is activated. Consequently, the behavioral sequence could be replayed (as illustrated by simulations for example in Tsodyks et al., 1996; Sato and Yamaguchi, 2003; Leibold and Kempter, 2006; Shen et al., 2007; Cheng, 2013; Chenkov et al., 2017; Malerba and Bazhenov, 2019; Gillett et al., 2020) and the memory of the temporal order of events is recalled (Diba and Buzsáki, 2007; Schuck and Niv, 2019). We note, however, that in what follows we do not simulate such a replay of sequences, which would depend also on a vast number of parameters that define the network; instead, we rather focus on the underlying change in connectivity, which is the very basis of replay, and draw connections to ‘replay’ in the Discussion.
Let us now illustrate key features of the encoding of the temporal order of sequences. To do so, we consider the weight change induced by the activity of two sequentially activated cells and that represent two behavioral events (dashed lines in Figure 2A). Classical Hebbian learning (Hebb, 1949), where weight changes depend on the product of the firing rates fi and fj, is not suited for temporal-order learning because the weight change is independent of the order of cells:
Figure 2

Model of two sequentially activated phase-precessing cells.
(A) Oscillatory firing-rate profiles for two cells (solid blue and cyan lines). The black curve depicts the population theta oscillation. For easier comparison of the two different frequencies, the population activity’s troughs are continued by thin gray lines, and the peaks of the cell-intrinsic theta oscillation are marked by dots. Dashed lines depict the underlying Gaussian firing fields without theta modulation. (B) Phase precession of the two cells (same colors as in A). The compression factor describes the phase shift per theta cycle for an individual cell (). For the temporal separation of the firing fields and the theta frequency , the phase difference between the cells is . The dots depict the times of the maxima in (A). (C) Resulting cross-correlation for the two firing rates from (A). The solid red curve shows the full cross-correlation. The dashed line depicts the cross-correlation without theta-modulation. The gray region indicates small ( ms) time lags. (D) Same as in (C), but zoomed in. Note that the first peak of the theta modulation is at a positive non-zero time lag, reflecting phase precession. The dashed black curve shows the approximation of the cross-correlation for the analytical treatment (Materials and methods, Equation 17). (E) Synaptic learning window. The gray region indicates the region in which the learning window is large, and this region is also indicated in (C) and (D). Positive time lags correspond to postsynaptic activity following presynaptic activity. Parameters for all plots: s, Hz, s, ms, , , .
Therefore, a classical Hebbian weight change is symmetric, that is, . This result can be generalized to learning rules that are based on the product of two arbitrary functions of the firing rates. We note that, although not suited for temporal-order learning, Hebbian rules are able to achieve more general ‘sequence learning’, where an association between sequence elements is created — independent of the order of events. To become sensitive to temporal order, we use spike-timing dependent plasticity (STDP; Markram et al., 1997; Bi and Poo, 1998). For STDP, average weight changes depend on the cross-correlation function of the firing rates (example in Figure 2C,D),
which is anti-symmetric: . Assuming additive STDP, that is, weight changes resulting from pairs of pre- and postsynaptic action potentials are added, the average synaptic weight change between the two cells in a sequence can then be calculated explicitly (Kempter et al., 1999):
(1)
where is the STDP learning window (example in Figure 2E). We aim solve Equation 1 for given firing rates fi and fj. To do so, we assume that the synaptic weight is generally small and thus only has a weak impact on the cross-correlation of the cells during encoding, that is, for the ‘encoding’ of a sequence the cross-correlation function is dominated by feedforward input, whereas the recurrent inputs are neglected.
Next, let us show that the symmetry of is essential for temporal-order learning. Any learning window can be split up into an even part , with , and an odd part , with , such that . For even learning windows, one can derive from Equation 1 and the anti-symmetry of that weight changes are symmetric, that is, ; therefore, only the odd part of is useful for learning temporal order.
To further explore requirements for encoding the temporal order of a sequence of events, we restrict our analysis to odd learning windows. We then can relate the weight change to the essential features of . To do so, we integrate Equation 1 by parts (with replaced by ),
(2)
with the primitive and the derivative . Because can be assumed to have finite support (note that ), the first term in Equation 2 vanishes. Also the learning window has finite support, and therefore we can restrict the integral in the second term in Equation 2 to a finite region of width around zero:
(3)
where describes the width of the learning window (gray region in Figure 2E). The integral in Equation 3 can be interpreted as the cross-correlation’s slope around zero, weighted by the symmetric function ; interestingly, features of for , for example whether side lobes of the correlation function are decreasing or not, are irrelevant.
As a generic example of sequence learning, let us consider the activities of two cells and that encode two behavioral events, for example the traversal of two place fields of two hippocampal place cells. In general, the cells’ responses to these events are called ‘firing fields’. We model these firing fields as two Gaussian functions and that have the same width but different mean values 0 and (we note that and are measured in units of time, that is, seconds; Figure 2A, dashed curves). In this case of identical Gaussian shapes of the two firing fields, the cross-correlation is also a Gaussian function, denoted by , but with mean and width (dashed curve in Figure 2C). The value s, which we use in the example of Figure 2, matches experimental findings on place cells (O'Keefe and Recce, 1993; Geisler et al., 2010).
It is widely assumed that phase precession facilitates temporal-order learning (Skaggs et al., 1996; Dragoi and Buzsáki, 2006; Schmidt et al., 2009), but it has never been quantitatively shown. To test this hypothesis and to calculate how much phase precession contributes to temporal-order learning, we consider Gaussian firing fields that exhibit oscillatory modulations with theta frequency (Figure 2A, solid curves). The time-dependent firing rate of cell is described by , that is, a Gaussian that is multiplied by a sinusoidal oscillation; see also Equation 11 in Materials and methods. Phase precession occurs with respect to the population theta, which oscillates at a frequency of that is slightly smaller than , with a ‘compression factor’ that is usually small: (Dragoi and Buzsáki, 2006; Geisler et al., 2010). This compression factor describes the average advance of the firing phase — from theta cycle to theta cycle — in units of the fraction of a theta cycle; thus determines the slope of phase precession (Figure 2B). A typical value is , which accounts for ‘slope-size matching’ of phase precession (Geisler et al., 2010); that is, is inversely proportional to the field size of the firing field, and the total range of phase precession within the firing field is constant and equals . If there are multiple theta oscillation cycles within a firing field (), which is typical for place cells, the cross-correlation is a theta modulated Gaussian (solid curve in Figure 2C; see also Equation 15 in Materials and methods).
The generic shape of the cross-correlation in Figure 2C allows for an advanced interpretation of Equation 3, which critically depends on the width of the learning window . We distinguish here two limiting cases: narrow learning windows (), that is, the width of the learning window is much smaller than a theta cycle and the width of a firing field, and wide learning windows (), that is, the width of the learning window exceeds the width of a firing field. Let us first consider narrow learning windows. Only later in this manuscript, we will turn to the case of wide learning windows.
Dependence of temporal-order learning on the overlap of firing fields for narrow learning windows ()
We first show formally that sequence learning with narrow learning windows requires that the two firing fields do overlap, that is, their separation should be less than or at least similar to the width of the firing fields. In Equation 3, which was derived for odd learning windows, the weight change is determined by around in a region of width . For narrow learning windows (), this region is small compared to a theta oscillation cycle and much smaller than the width of a firing field. Because the envelope of the cross-correlation is a Gaussian with mean and width , the slope scales with the Gaussian factor . The weight change therefore strongly depends on the separation of the firing fields. When the two firing fields do not overlap (), the factor quickly tends to zero, and sequence learning is not possible. On the other hand, when the two firing fields do have considerable overlap () we have . In this case, sequence learning may be feasible with narrow learning windows. In this section, we will proceed with the mathematical analysis for overlapping fields, which allows us to assume .
For overlapping firing fields (), let us now consider the fine structure of the cross-correlation for , as illustrated in Figure 2D. Importantly, phase precession causes the first positive peak (i.e. for ) of to occur at time with (Dragoi and Buzsáki, 2006; Geisler et al., 2010); phase precession also increases the slope around , which could be beneficial for temporal-order learning according to Equation 3. To quantify this effect, we calculated the cross-correlation’s slope at (see also Equation 18 in Materials and methods):
(4)
How does depend on the temporal separation of the firing fields? If the two fields overlap entirely () the sequence has no defined temporal order, and thus is zero. For at least partly overlapping firing fields () and typical phase precession where , we will show in the next paragraph (and explain in Materials and methods in the text below Equation 18) that the second addend in Equation 4 dominates the other two. In this case, is much higher as compared to the cross-correlation slope in the absence of phase precession (), leading to a clearly larger synaptic weight change for phase precession. The maximum of is mainly determined by this second addend (multiplied by ) and it can be shown (see Materials and methods) that this maximum is located near .
The increase of induced by phase precession can be exploited by learning windows that are narrower than a theta cycle (e.g. gray regions in Figure 2C,D,E). To quantify this effect, let us consider a simple but generic shape of a learning window, for example, the odd STDP window with time constant and learning rate (Figure 2E); this STDP window is narrow for . Equations 3 and 4 then lead to (see Materials and methods, Equation 19) the average weight change
(5)
where depicts the number of spikes per field traversal. Note that, according to Equation 3, the weight change in Equation 5 can be interpreted as a time-averaged version of near from Equation 4. Thus, Equations 4 and 5 have a similar structure, but Equation 5 includes multiple incidences of the term that account for this averaging. This term is small for narrow learning windows () and can thus be neglected () in this limiting case; however, for typical biological values of ms and Hz, the peculiar structure of the -containing factor in the third addend in the square brackets is the reason why this addend can be neglected compared to the first one; as a result, the cases of ‘phase locking’ () and ‘no theta’ (only the first addend remains) are basically indistinguishable. Moreover, for narrow odd learning windows, in Equation 5 inherits a number of properties from in Equation 4: the second addend still remains the dominant one for ; inherited are also the absence of a weight change for fully overlapping fields ( for ), the maximum weight change for , and for (Figure 3A). Furthermore, the prefactor in Equation 5 suggests that the average weight change increases with increasing width of the learning window, but we emphasize that this increase is restricted to (as we assumed for the derivation), which prohibits a generalization of the quadratic scaling to large ; the exact dependence on will be explained later.
Figure 3
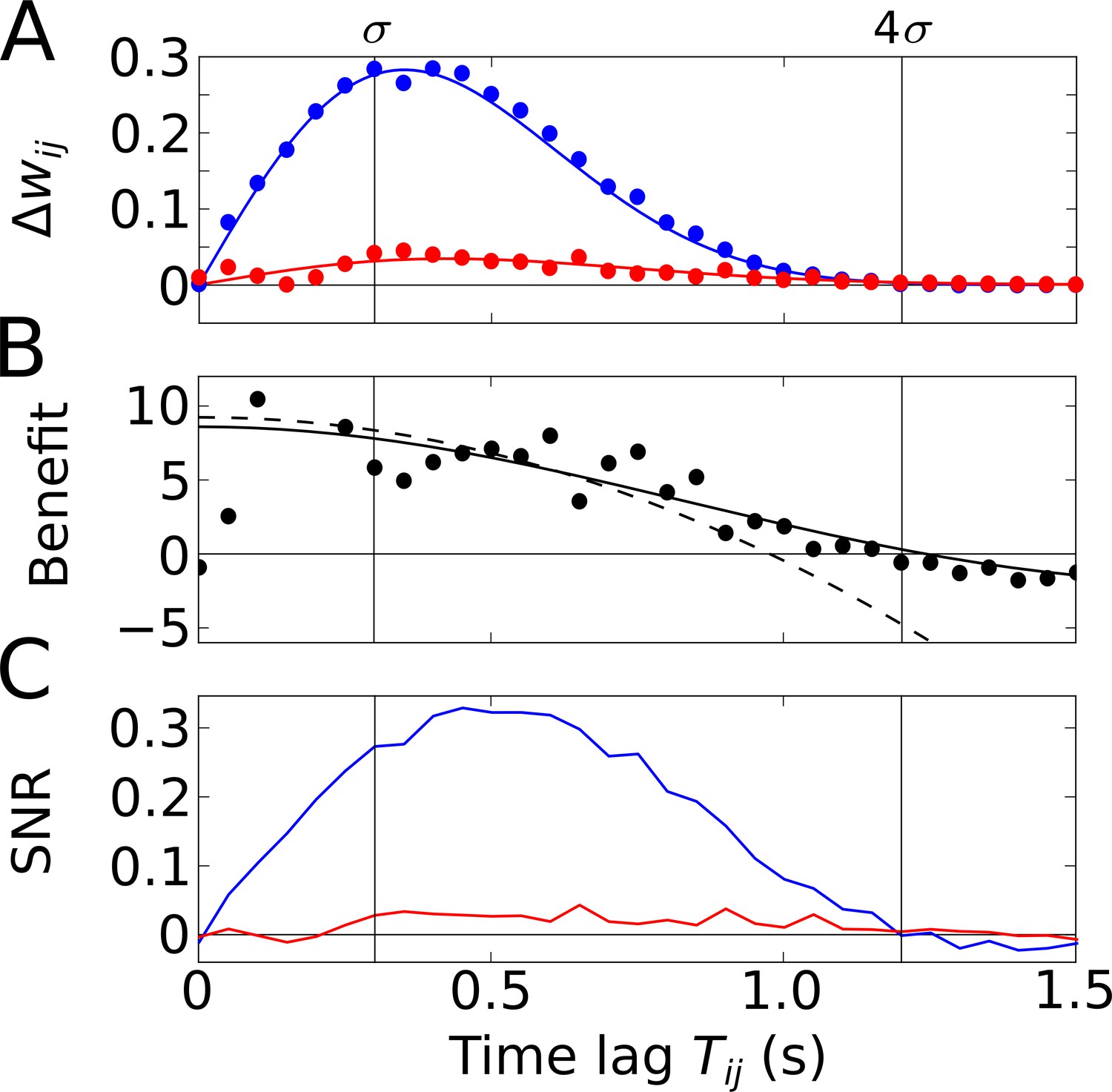
Temporal-order learning for narrow learning windows ().
(A) The average synaptic weight change depends on the temporal separation between the firing fields. Phase precession (blue) yields higher weight changes than phase locking (red). Simulation results (circles, averaged across 104 repetitions) and analytical results (lines, Equation 5) match well. The vertical lines mark time lags of and , respectively, where approximates the total field width. (B) The benefit of phase precession is determined by the ratio of the average weight changes of two scenarios from (A). The solid and dashed lines depict the analytical expression for the benefit (Equation 20) and its approximation for small (Equation 7), respectively. (C) Signal-to-noise ratio (SNR) of the weight change as a function of the firing-field separation . The SNR is defined as the mean weight change divided by the standard deviation across trials in the simulation. Colors as in (A). Parameters for all plots: Hz, s, ms, , , .
To quantify how much better a sequence can be learned with phase precession as compared to phase locking, we use the ratio of the weight change with phase precession () and the weight change without phase precession (Figure 3A), and define the benefit of phase precession as
(6)
By inserting Equation 5 in Equation 6, we can explicitly calculate the benefit of phase precession (see Equation 20 in Materials and methods and solid line in Figure 3B). For and (see Materials and methods) the benefit is well approximated by a Taylor expansion up to third order in (dashed line in Figure 3B),
(7)
The maximum of as a function of is obtained for (fully overlapping fields), but the average weight change is zero at this point. We note, however, that decays slowly with increasing , so can be used to approximate the benefit for small field separations (i.e. largely overlapping fields). For narrow () odd STDP windows and slope-size matching (), we find the maximum , which has an interesting interpretation: If we relate to the field size of a Gaussian firing field through and if we relate the frequency to the period of a theta oscillation cycle through , we obtain , that is, the maximum benefit of phase precession is about the number of theta oscillation cycles in a firing field. The example in Figure 3B (with firing fields in Figure 2A) has the maximum benefit and the benefit remains in this range for partly overlapping firing fields (). We thus conclude that phase precession can boost temporal-order learning by about an order of magnitude for typical cases in which learning windows are narrower than a theta oscillation cycle and overlapping firing fields are an order of magnitude wider than a theta oscillation cycle.
So far, we have considered ‘average’ weight changes that resulted from neural activity that was described by a deterministic firing rate. However, neural activity often shows large variability, that is, different traversals of the same firing field typically lead to very different spike trains. To account for such variability, we have simulated neural activity as inhomogeneous Poisson processes (see Materials and methods for details). As a result, the change of the weight of a synapse, which depends on the correlation between spikes of the presynaptic and the postsynaptic cells, is a stochastic variable. It is important to consider the variability of the weight change (‘noise’) in order to assess the significance of the average weight change. For this reason, we utilize the signal-to-noise ratio (SNR), that is, the mean weight change divided by its standard deviation (see Materials and methods for details). To do so, we perform stochastic simulations of spiking neurons and calculate the average weight change and its variability across trials. This is done for phase-precessing as well as phase-locked activity. To connect this approach to our previous results, we confirm that the average weight changes estimated from many fields traversals matches well the analytical predictions (Figure 3A and B, see Materials and methods for details).
The SNR shown in Figure 3C summarizes how reliable is the learning signal in a single traversal of the two firing fields — for the assumed odd learning window. The SNR further depends on and follows a similar shape as the weight changes in Figure 3A. For phase precession, there is a maximum SNR that is slightly shifted to larger ; for phase locking, SNR is always much lower. For the synapse connecting two cells with firing fields as in Figure 2A where , we find an SNR of 0.27, which is insufficient for a reliable representation of a sequence.
To allow reliable temporal-order learning, one possible solution is to increase the number of spikes per field traversal (, as shown in Appendix 1). Another possibility is to increase the number of synapses. In Materials and methods we show that where is the number of identical and uncorrelated synapses. Therefore, to achieve for , one needs synapses.
In summary, for narrow, odd learning windows (), temporal-order learning could benefit tremendously from phase precession as long as firing fields have some overlap. Average weight changes and the SNR are highest, however, for clearly distinct but still overlapping firing fields. It should be noted that any even component of the learning window would increase the noise and thus further decrease the SNR.
Dependence of temporal-order learning on the width of the learning window for overlapping firing fields
To investigate how temporal-order learning for an odd learning window depends on its width, we vary the parameter and quantify the average synaptic weight change and the SNR both analytically and numerically. We first study overlapping firing fields (Figure 4) and later consider non-overlapping firing fields (Figure 5).
Figure 4
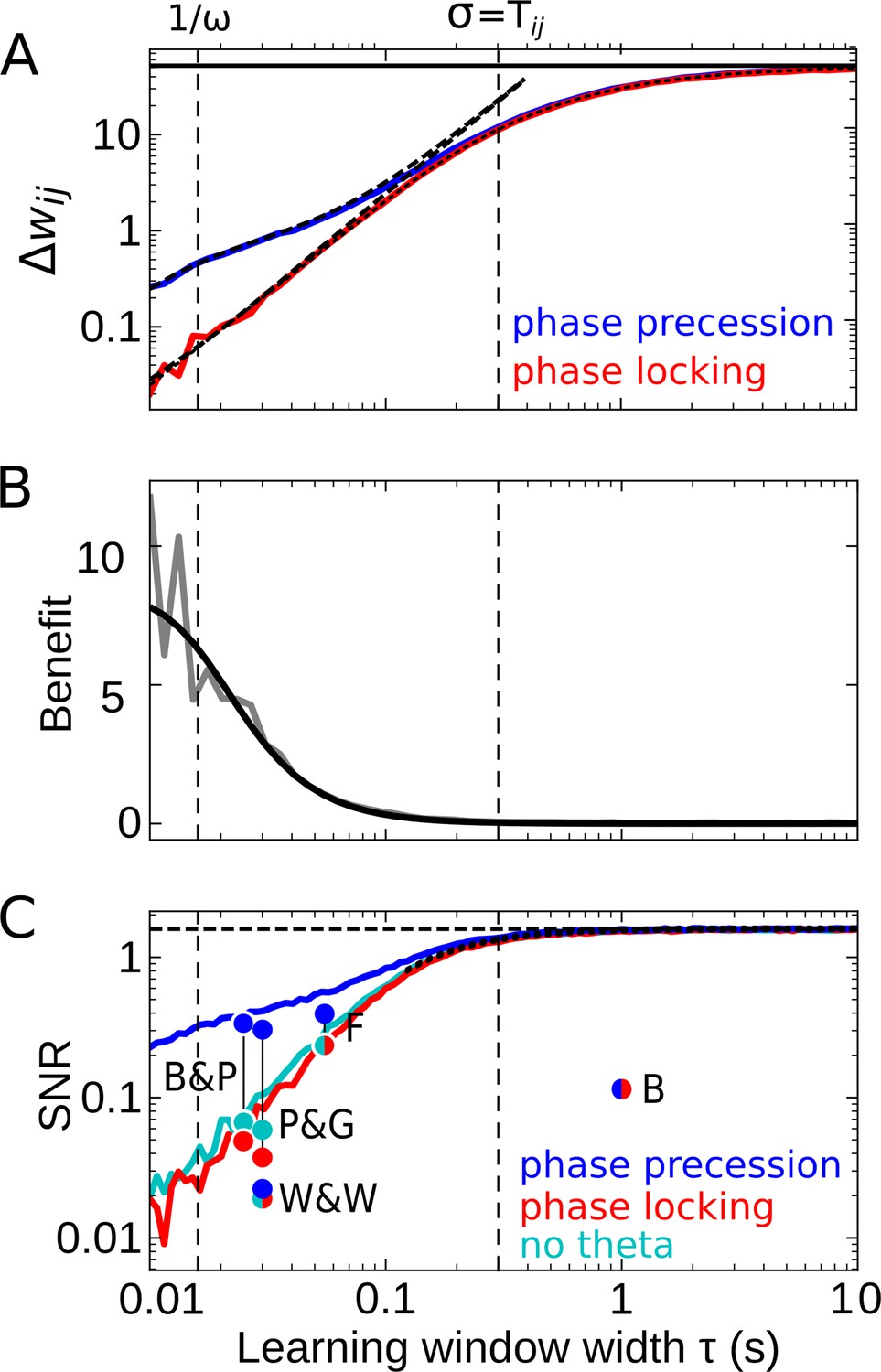
Effect of the learning-window width on temporal-order learning for overlapping fields (here: ).
(A) Average weight change as a function of width (for the asymmetric window in Equation 14) for phase precession and phase locking (colored curves). The solid black line depicts the theoretical maximum for large (, Equation 8). The dashed curves show the analytical small-tau approximations (Equation 5). The dotted curve depicts the analytical approximation for the ’no theta’ case (Equation A2-46 in Appendix 2). The vertical dashed lines mark s and the value of , respectively. (B) The benefit of phase precession is largest for narrow learning windows, and it approaches 0 for wide windows. Simulations (gray line) and analytical result (black line, small-tau approximation from Equation 20) match well. (C) The signal-to-noise ratio (SNR; phase precession: blue, phase locking: red, no theta: cyan) takes into account that only the asymmetric part of the learning window is helpful for temporal-order learning. For large , all three coding scenarios induce the same SNR. The horizontal dashed black line depicts the analytical limit of the SNR for large and overlapping firing fields (, Equation A1-17 of Appendix 1). The dotted black line depicts the analytical expression for the ’no theta’ case (Equation A2-48 in Appendix 2, the curve could not be plotted for s due to numerical instabilities). Dots represent the SNR for experimentally observed learning windows. The learning windows were taken from ‘B&P’, Bi and Poo, 2001: their Figure 1, ‘F’, Froemke et al., 2005: their Figure 1D bottom, ‘W&W’, Wittenberg and Wang, 2006: their Figure 3, ‘P&G’, Pfister and Gerstner, 2006: their Table 4, ‘All to All’, ‘minimal model’, and ‘B’, Bittner et al., 2017: their Figure 3D. For ‘B&P’, ‘F’, and ‘B’, the position of the dots on the horizontal axis was estimated as the average time constants for positive and negative lobes of the learning windows. Wittenberg and Wang modeled their learning rule by a difference of Gaussians — we approximated the corresponding time constant as 30 ms. For the triplet rule by Pfister and Gerstner, we used the average of three time constants: the two pairwise-interaction time constants (as in Bi and Poo) and the triplet-potentiation time constant. Parameters for all plots: s, Hz, s, , , . Colored/gray curves and dots are obtained from stochastic simulations; see Materials and methods for details.
Figure 5
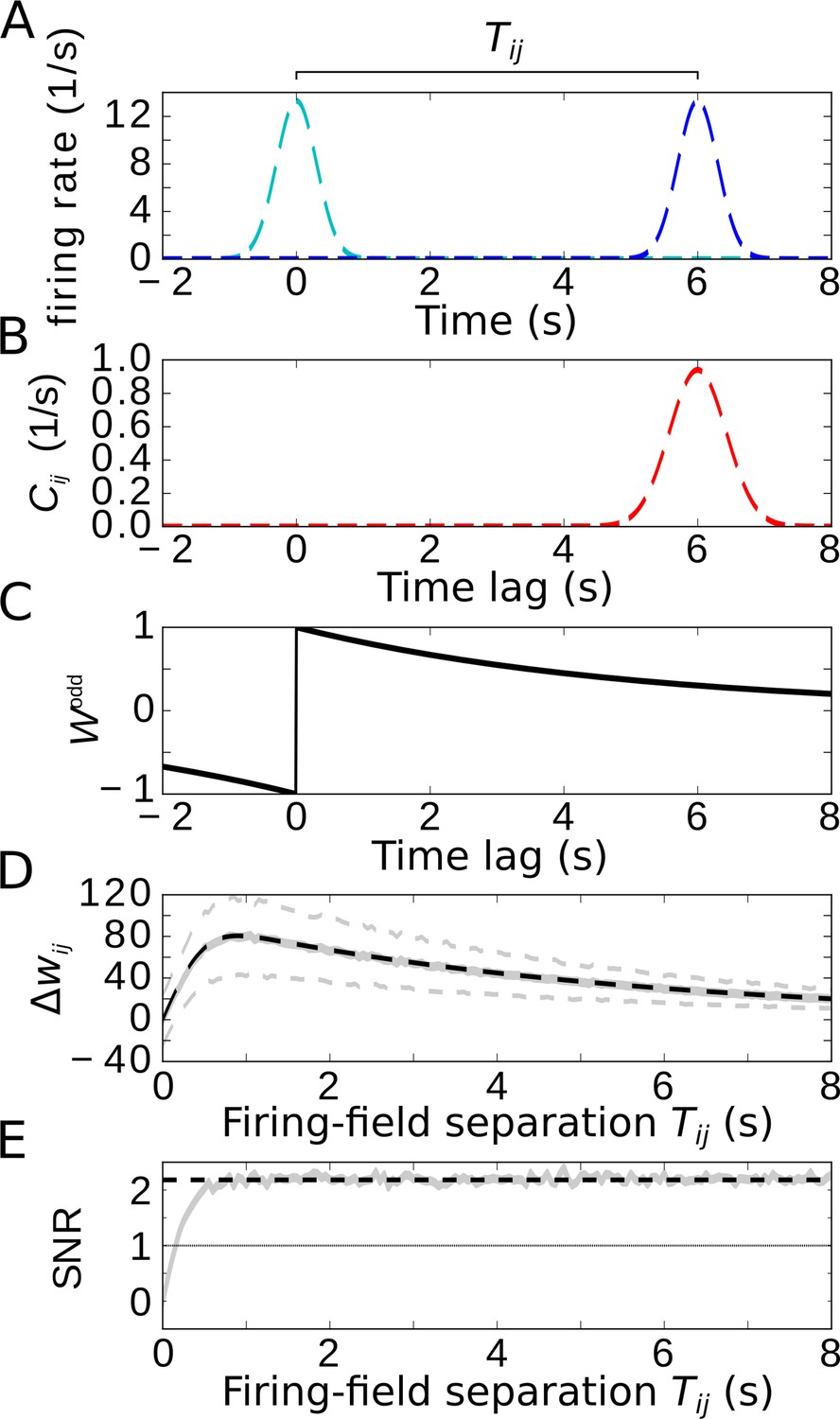
Temporal-order learning for non-overlapping firing fields using wide, asymmetric learning windows.
(A) Firing rates of two example cells with non-overlapping firing fields. (B) Cross-correlation of the two cells from (A). (C) Asymmetric learning window with large width ( s). (D) Resulting weight change for wide learning window and non-overlapping firing fields. The solid gray line depicts the average weight change. The dashed gray lines represent ±1 standard deviation across 1000 repetitions of stochastic spiking simulations. The analytical curve (dashed black line, Equation 9) matches the simulation results. (E) SNR of the weight change. Results of the stochastic simulations are shown by the gray curve. The SNR saturates for larger , which fits the analytical expectation (dashed black line, Equation 10). Parameters, unless varied in a plot: s, s, s, , .
For partly overlapping firing fields (e.g. ), we find numerically that the average synaptic weight change (the ‘learning signal’) increases monotonically for increasing and saturates (colored curves in Figure 4A). This is because for increasing the overlap between the learning window and the cross-correlation function grows, and this overlap begins to saturate as soon as the learning window is wider than , that is, the value at which the cross-correlation assumes its maximum (cmp. dashed curve in Figure 2C). To analytically calculate the saturation value of for large learning-window widths (), we can approximate the learning window as a step function (see Materials and methods for details) and find the maximum
(8)
that provides an upper bound to the weight change for overlapping firing fields (solid line in Figure 4A). For (and actually well beyond this region), the analytical small-tau approximation of (Equation 5, dashed curves in Figure 4A) matches the numerical results well.
The results in Figure 4A confirm that is increased by phase precession for narrow learning windows but is independent of phase precession for . Thus, the benefit becomes small for large (Figure 4B) because, for large enough , the theta oscillation completes multiple cycles within the width of the learning window. To better understand this behavior, let us return to Equation 1: if the product of a wide learning window and the cross-correlation is integrated to obtain the weight change, the oscillatory modulation of the cross-correlation (e.g. as in Figure 2C) becomes irrelevant; similarly, according to Equation 3, the particular value of the derivative near can be neglected. Consequently, for phase precession and phase locking as well as the scenario of firing fields that are not theta modulated yield the same weight change (Figure 4A), and the benefit approaches 0 (Figure 4B). Wide learning windows thus ignore the temporal (theta) fine-structure of the cross-correlation.
How noisy is this learning signal across trials? Figure 4C shows that for odd learning windows the SNR increases with increasing and, for , approaches a constant value. This constant value is the same for phase precession, phase locking, or no theta oscillations at all. Taken together, for large enough , the advantage of phase precession vanishes. For small enough , phase precession increases the SNR, which confirms and generalizes the results in Figure 3C. Remarkably, the SNR for ‘phase locking’ is lower than the one for ‘no theta’, which means that theta oscillations without phase precession degrade temporal-order learning, even though theta oscillations as such were emphasized to improve the modification of synaptic strength in many other cases (e.g. Buzsáki, 2002; D'Albis et al., 2015).
Figure 4C predicts that a large yields the biggest SNR, and thus wide learning windows are the best choice for temporal-order learning; however, we note that this conclusion is restricted to odd (i.e. asymmetric) learning windows. An additional even (i.e. symmetric) component of a learning window would increase the noise without affecting the signal, and thus would decrease the SNR (dots in Figure 4C). It is remarkable that the only experimentally observed instance of a wide window (with s in Bittner et al., 2017) has a strong symmetric component, which leads to a low SNR (dot marked ‘B’ in Figure 4C).
Taken together, we predict that temporal-order learning would strongly benefit from wide, asymmetric windows. However, to date, all experimentally observed (predominantly) asymmetric windows are narrow (e.g. Bi and Poo, 2001; Froemke et al., 2005; Wittenberg and Wang, 2006; see Abbott and Nelson, 2000; Bi and Poo, 2001 for reviews).
Temporal-order learning for wide learning windows ()
We finally restrict our analysis to wide learning windows, which allows us then to also consider non-overlapping firing fields (Figure 5A, we again use two Gaussians with widths and separation ). To allow for temporal-order learning in this case, the spikes of two non-overlapping fields can only be ‘paired’ by a wide enough learning window. As already indicated in Figure 4, phase precession does not affect the weight change for such wide learning windows where the width of the learning window obeys (note that we always assumed many theta oscillation cycles within a firing field, that is, ). Furthermore, Figure 4 indicated that only the asymmetric part of the learning window contributes to temporal-order learning. For the analysis of temporal-order learning with non-overlapping firing fields and wide learning windows, we thus ignore any theta modulation and phase precession and evaluate, again, only the odd STDP window . In this case, the weight change (Equation 1) is still determined by the cross-correlation function and the learning window (examples in Figure 5B,C). The resulting weight change as a function of the temporal separation of firing fields is shown in Figure 5D: with increasing , the weight quickly increases, reaches a maximum, and slowly decreases. The initial increase is due to the increasing overlap of the Gaussian bump in with the positive lobe of the learning window. The decrease, on the other hand, is dictated by the time course of the learning window. For , these two effects can be approximated by
(9)
in which the error function describes the overlap of the cross-correlation with the learning window and the exponential term describes the decay of the learning window (dashed black curve in Figure 5D, see also Equation 25 in Materials and methods for details).
How does the SNR of the weight change depend on the separation of firing fields? For , the signal is zero and thus also the SNR. As increases, both signal and noise increase, but quickly settle on a constant ratio. The value of the SNR height of this plateau can be approximated by
(10)
(dashed line in Figure 5E), where is the number of spikes within a firing field (Equation 11). For , we find , allowing for temporal-order learning with a single synapse. We note that this conclusion is limited to asymmetric STDP windows. A symmetric component (like in Bittner et al., 2017) decreases the SNR and makes temporal-order learning less efficient.
Taken together, temporal-order learning can be performed with wide STDP windows, and phase precession does not provide any benefit; but temporal-order learning requires a purely asymmetric plasticity window. For non-overlapping firing fields, wide learning windows are essential to bridge a temporal gap between the fields.
Discussion
In this report, we show that phase precession facilitates the learning of the temporal order of behavioral sequences for asymmetric learning windows that are shorter than a theta cycle. To quantify this improvement, we use additive, pairwise STDP and calculate the expected weight change for synapses between two activated cells in a sequence. We confirm the long-held hypothesis (Skaggs et al., 1996) that phase precession bridges the vastly different time scales of the slow sequence of behavioral events and the fast STDP rule. Synaptic weight changes can be an order of magnitude higher when phase precession organizes the spiking of multiple cells at the theta time scale as compared to phase-locking cells.
Other mechanisms and models for sequence learning
As an alternative mechanism to bridge the time scales of behavioral events and the induction of synaptic plasticity, Drew and Abbott, 2006 suggested STDP and persistent activity of neurons that code for such events. The authors assume regularly firing neurons that slowly decrease their firing rate after the event and show that this leads to a temporal compression of the sequence of behavioral events. For stochastically firing neurons, this approach is similar to ours with two overlapping, unmodulated Gaussian firing fields. In this case, sequence learning is possible, but the efficiency can be improved considerably by phase precession.
Sato and Yamaguchi, 2003 as well as Shen et al., 2007 investigated the memory storage of behavioral sequences using phase precession and STDP in a network model. In computer simulations, they find that phase precession facilitates sequence learning, which is in line with our results. In contrast to these approaches, our study focuses on a minimal network (two cells), but this simplification allows us to (i) consider a biologically plausible implementation of STDP, firing fields, and phase precession and (ii) derive analytical results. These mathematical results predict parameter dependencies, which is difficult to achieve with only computer simulations.
Related to our work is also the approach by Masquelier and colleagues Masquelier et al., 2009 who showed that pattern detection can be performed by single neurons using STDP and phase coding, yet they did not include phase precession. They consider patterns in the input whereas, in our framework, it might be argued that patterns between input and output are detected instead.
Noisy activity of neurons and prediction of the minimum number of synapses for temporal-order learning
To account for stochastic spiking, we use Poisson neurons. We find that a single synapse is not sufficient to reliably encode a minimal two-neuron sequence in a single trial because the fluctuations of the weight change are too large. Fortunately, the SNR scales with , that is, the square root of the number of identical, but independent synapses and the number of spikes per field traversal of the neurons. For generic hippocampal place fields and typical STDP, we predict that about 14 synapses are sufficient to reliably encode temporal order in a single traversal. Interestingly, peak firing rates of place fields are remarkably high (up to 50 spikes/s; e.g. O'Keefe and Recce, 1993, Huxter et al., 2003). Taken together, in hippocampal networks, reliable encoding of the temporal order of a sequence is possible with a low number of synapses, which matches simulation results on memory replay (Chenkov et al., 2017).
Width, shape, and symmetry of the STDP window are critical for temporal-order learning
Various widths have been observed for STDP learning windows (Abbott and Nelson, 2000; Bi and Poo, 2001). We show that for all experimentally found STDP time constants phase precession can improve temporal-order learning. However, for learning windows much wider than a theta oscillation cycle, the benefit of phase precession for temporal-order learning is small. Wide learning windows, where the width can be even on a behavioral time scale of s (Bittner et al., 2017) or larger, could, on the other hand, enable the association of non-overlapping firing fields. Alternatively, non-overlapping firing fields might also be associated by narrow learning windows if additional cells (with firing fields that fill the temporal gap) help to bridge a large temporal difference, much like 'time cells' in the hippocampal formation (reviewed in Eichenbaum, 2014).
STDP windows typically have symmetric and asymmetric components (Abbott and Nelson, 2000; Mishra et al., 2016). We find that only the asymmetric component supports the learning of temporal order. In contrast, the symmetric component strengthens both forward and backward synapses by the same amount and thus contributes to the association of behavioral events independent of their temporal order. For example, the learning window reported by Bittner et al., 2017 shows only a mild asymmetry and is thus unfavorable to store the temporal order of behavioral events. Only long, predominantly asymmetric STDP windows would allow for effective temporal-order learning (Figure 4).
Generally, the shape of STDP windows is subject to neuromodulation; for example, cholinergic and adrenergic modulation can alter its polarity and symmetry (Hasselmo, 1999). Also dopamine can change the symmetry of the learning window (Zhang et al., 2009). Therefore, sequence learning could be modulated by the behavioral state (attention, reward, etc.) of the animal.
Key features of phase precession for temporal order-learning: generalization to non-periodic modulation of activity
For STDP windows narrower ( ms) than a theta cycle ( ms), we argue that the slope of the cross-correlation function at zero offset controls the change of the weight of the synapse connecting two neurons; and we show that phase precession can substantially increase this slope. This result predicts that features of the cross-correlation at temporal offsets that are larger than the width of the learning window are irrelevant for temporal-order learning. It is thus conceivable to boost temporal-order learning even without phase precession, which is weak if theta oscillations are weak, as for example in bats (Ulanovsky and Moss, 2007) and humans (Herweg and Kahana, 2018; Qasim et al., 2021). In this case, temporal-order learning may instead benefit from two other phenomena that could create an appropriate shape of the cross-correlation: (i) Spiking of cells is locked to common (aperiodic) fluctuations of excitability. (ii) Each cell responds the faster to an increase in its excitability the longer ago its firing field has been entered, which may be mediated by a progressive facilitation mechanism. Together, these phenomena can make the cross-correlation exhibit a steeper slope around zero and could even give rise to a local maximum at a positive offset. This temporal fine structure is superimposed on a slower modulation, which is related to the widths of the firing fields. In summary, a progressively decreasing delay of spiking with respect to non-rhythmic fluctuations in excitation generalizes the notion of phase precession. Interestingly, synaptic short-term facilitation, which could generate the described fine structure of the cross-correlation, has also been proposed as mechanism underlying phase precession (Leibold et al., 2008).
Model assumptions
In our model, we assumed that recurrent synapses (e.g. between neurons representing a sequence) are plastic but weak during encoding, such that they have a negligible influence on the postsynaptic firing rate; and that the feedforward input dominates neuronal activity. These assumptions seem justified as Hasselmo, 1999 indicated that excitatory feedback connections may be suppressed during encoding to avoid interference from previously stored information (see also Haam et al., 2018). Furthermore, neuromodulators facilitate long-term plasticity (reviewed, e.g. by Rebola et al., 2017), which also supports our assumptions.
The assumption of weak recurrent connections implies that these connections do not affect the dynamics. Consequently (and in contrast to Tsodyks et al., 1996), we thus hypothesize that phase precession is not generated by the local, recurrent network (see also, e.g. Chadwick et al., 2016); instead, we assume that phase precession is inherited from upstream feedforward inputs (Chance, 2012; Jaramillo et al., 2014) or generated locally by a cellular/synaptic mechanism (Magee, 2001; Harris et al., 2002; Mehta et al., 2002; Thurley et al., 2008). After temporal-order learning was successful, the resulting asymmetric connections could indeed also generate phase precession (as demonstrated by the simulations in Tsodyks et al., 1996), and this phase precession could then even be similar to the one that has initially helped to shape synaptic connections. Finally, inherited or local cellularly/synaptically generated phase precession and locally network-generated phase precession could interact (as reviewed, for example in Jaramillo and Kempter, 2017).
We assumed in our model that the widths of the two firing fields that represent two events in a sequence are identical (see, e.g. Figure 2A). But firing fields may have different widths, and in this case a slope-size matched phase precession would fail to reproduce the timing of spikes required for the learning of the correct temporal order of the two events. For example, the learned temporal order of events (timed according to field entry) would even be reversed if two fields with different sizes are aligned at their ends. How could the correct temporal order nevertheless be learned in our framework? In the hippocampus, theta oscillations are a traveling wave (Lubenov and Siapas, 2009; Patel et al., 2012) such that there is a positive phase offset of theta oscillations for the wider firing fields in the more ventral parts of the hippocampus. This traveling-wave phenomenon could preserve the temporal order in the phase-precession-induced compressed spike timing, as also pointed out earlier (Leibold and Monsalve-Mercado, 2017; Muller et al., 2018).
Our results on learning rules for sequence learning rely on pairwise STDP in which pairs of presynaptic and postsynaptic spikes are considered. Conversely, triplet STDP considers also motifs of three spikes (either 2 presynaptic - 1 postsynaptic or 2 postsynaptic - 1 presynaptic) (Pfister and Gerstner, 2006). Triplets STDP models can reproduce a number of experimental findings that pairwise STDP could not, for example the dependence on the repetition frequency of spike pairs (Sjöström et al., 2001). To investigate the influence of triplet interactions on sequence learning, we implemented the generic triplet rule by Pfister and Gerstner, 2006. We used their ‘minimal’ model, which was regarded as the best model in terms of number of free parameters and fitting error; for the parameters they obtained from fitting the triplet STDP model to hippocampal data, we found only mild differences to our results (see, e.g. Figure 4C). Differences are small because the fitted time constant of the triplet term (40 ms) is smaller than typical inter-spike intervals ( ms, minimum in field centers) in our simulations.
Replay of sequences and storage of multiple and overlapping sequences
A sequence imprinted in recurrent synaptic weights can be replayed during rest or sleep (Wilson and McNaughton, 1994; Nádasdy et al., 1999; Diba and Buzsáki, 2007; Peyrache et al., 2009; Davidson et al., 2009), which was also observed in network-simulation studies (Matheus Gauy et al., 2020; Malerba and Bazhenov, 2019; Gillett et al., 2020). Replay could thus be a possible readout of the temporal-order learning mechanism. However, replay depends on the many parameters of the network, and a thorough investigation of is beyond the scope of this manuscript. Therefore, we focus on synaptic weight changes that represent the formation of sequences in the network, which underlies replay, and we do not simulate replay.
We have considered the minimal example of a sequence of two neurons. Sequences can contain many more neurons, and the question arises how two different sequences can be told apart if they both contain a certain neuron, but proceed in different directions — as they might do for sequences of spatial or non-spatial events (Wood et al., 2000). In this case, it may be beneficial to not only strengthen synapses that connect direct successors in the sequence but also synapses that connect the second-to-next neuron. In this way, the two crossing sequences could be disambiguated, and the wider context in which an event is embedded becomes associated, which is in line with retrieved-context theories of serial-order memory (Long and Kahana, 2019). More generally, it is an interesting question of how many sequences can be stored in a network of a given size. Gillett et al., 2020 were able to analytically calculate the storage capacity for the storage of sequences in a Hebbian network.
In conclusion, our model predicts that phase precession enables efficient and robust temporal-order learning. To test this hypothesis, we suggest experiments that modulate the shape of the STDP window or selectively manipulate phase precession and evaluate memory of temporal order.
Materials and methods
Experimental design: model description
Request a detailed protocolWe model the time-dependent firing rate of a phase precessing cell (two examples in Figure 2A) as
(11)
where the scaling factor determines the number of spikes per field traversal and is a Gaussian function that describes a firing field with center at and width . The firing field is sinusoidally modulated with theta frequency (but the sinusoidal modulation is not a critical assumption, see Discussion), with typically many oscillation cycles in a firing field (). The compression factor can be used to vary between phase precession (), phase locking (), and phase recession () because the average population activity of many such cells oscillates at frequency of (Geisler et al., 2010; D'Albis et al., 2015), which provides a reference frame to assign theta phases (Figure 2A). Usually, with typical values (Geisler et al., 2010); for a pair of cells with overlapping firing fields (centers separated by ) the phase delay is (Figure 2B).
To quantify temporal-order learning, we consider the average weight change of the synapse from cell to cell , which is (Kempter et al., 1999)
(12)
where is the cross-correlation between the firing rates fi and fj of cells and , respectively (Figure 2C,D):
(13)
denotes the synaptic learning window, for example the asymmetric window
(14)
where is the time constant and is the learning rate (Figure 2E).
For the following calculations, we make two assumptions that are reasonable in the hippocampal formation (O'Keefe and Recce, 1993; Bi and Poo, 2001; Geisler et al., 2010) :
The theta oscillation has multiple cycles within the Gaussian envelope of the firing field in Equation 11 ().
The window is short compared to the theta period ().
Analytical approximation of the cross-correlation function
Request a detailed protocolTo explicitly calculate the cross-correlation as defined in Equation 13, we plug in the firing-rate functions (Equation 11) for the two neurons:
The first term (out of four) describes the cross-correlation of two Gaussians, which results in a Gaussian function centered at and with width . For the second term, we note that the product of two Gaussians yields a function proportional to a Gaussian with width , and then use assumption (i). When integrated, the second term’s contribution to is negligible because the cosine function oscillates multiple times within the Gaussian bump, that is, positive and negative contributions to the integral approximately cancel. The same argument applies to the third term. For the fourth term, we use the trigonometric property . We set , and find
Again, we use assumption (i) and neglect the first addend on the right-hand side. Notably, the cosine function in the second addend is independent of the integration variable . Taken together, we find
(15)
Thus, the cross-correlation can be approximated by a Gaussian function (center at , width ) that is theta modulated with an amplitude scaled by the factor .
To further simplify Equation 15, we note that the time constant of the STDP window is usually small compared to the theta period (assumption (ii), Figure 2C,D,E). Structures in for thus have a negligible effect on the synaptic weight change. Therefore, we can focus on the cross-correlation for small temporal lags. In this range, we approximate the (slow) Gaussian modulation of (Figure 2C,D, dashed red line) by a linear function, that is,
(16)
Inserting this result in Equation 15, we approximate the cross-correlation function for as (Figure 2D, dashed black line)
(17)
In the Results, we show that the slope of the cross-correlation function at is important for temporal-order learning. From Equation 17 we find
(18)
which has three addends within the square brackets. Let us estimate the relative size of the second and third terms with respect to the first one. The third term is at most of the order of 0.5 because . For the second addend, we note that approaches 1 for and remains in this range for . This condition is fulfilled for if we assume slope-size matching of phase precession (Geisler et al., 2010), that is, . Then, the size of the second addend is dictated by the factor , which is large according to assumption (i). In other words, for typical phase precession and , the second addend is much larger than the other two.
To further understand the structure of , which is also shaped by the prefactors in front of the square brackets, we first note that is zero for fully overlapping firing fields (). On the other hand, for very large field separations (), the Gaussian term causes to become zero. The prefactors have a maximum at . The maximum’s exact location is slightly shifted by the second addend but remains near . This peak will be important because it is inherited by the average weight change (Equation 3).
Average weight change
Request a detailed protocolHaving approximated the cross-correlation function and its slope at zero (Equations 17,18), we are now ready to calculate the average synaptic weight change (Equation 3) for the assumed STDP window (Equation 14). Standard integration methods yield
(19)
Because is a temporal average of for small (see interpretation of Equation 3), the weight change’s structure resembles the previously discussed structure of . The averaging introduces additional factors proportional to , but for [assumption (ii)] those have only minor effects on the relative size of the three addends. The second term still dominates. Importantly, for and the position of the peak at is inherited from (Figure 3A).
The benefit of phase precession
Request a detailed protocolTo quantify the benefit of phase precession, we consider the expression , because describes the overall weight change (including phase precession), and serves as the baseline weight change due to the temporal separation of the firing fields (without phase precession). We subtract 1 to obtain when the weight changes are the same with and without phase precession. From Equation 19 we find
(20)
To better understand the structure of , we Taylor-expand it in up to the third order and assume [assumption (ii)]. The result is
(21)
Thus, assumes a maximum for and slowly decays for small (Figure 3B). Using slope-size matching (), the maximal benefit is
(22)
where depicts the total field size and is the period of the theta oscillation. Thus, the number of theta cycles per firing field determines the benefit for small separations of the firing fields.
Average weight change for wide learning windows
Request a detailed protocolIn this paragraph we relax assumption (ii), that is, we consider wide asymmetric learning windows (Equation 14 with ). Furthermore, we neglect any theta-oscillatory modulation of the firing fields in Equation 11 and, thus, in Equation 15.
First, for non-overlapping fields (), the learning window can be approximated to be constant near the peak of the Gaussian bump of . We can thus rewrite Equation 1 as
(23)
Second, for overlapping fields (), the Gaussian bump of partly lies on the negative lobe of . We can approximate , and the average weight change in Equation 1 then reads
(24)
Combining the two limiting cases in Equations 23 and 24 yields
(25)
Signal-to-noise ratio
Request a detailed protocolTo correctly encode the temporal order of behavioral events, the average weight change of a forward synapse needs to be larger than the average weight change of the corresponding backward synapse. We thus define the signal-to-noise ratio as
where std() denotes the standard deviation and , are the weight changes for trial , the averages across trials being and . This expression for the SNR ‘punishes’ the non-sequence-specific strengthening of backward synapses. Specifically, for a symmetric (even) learning window, because the numerator (which represents the ‘signal’) is zero. On the other hand, a perfectly asymmetric learning window, like the one used throughout this study (Equation 14), yields , because . Asymmetric learning windows thus recover the classical definition of the SNR as the ratio between the average weight change and the standard deviation of the weight change.
We note that the generalized definition above can be used to calculate the SNR for arbitrary windows, such as the learning window from Bittner et al., 2017, Figure 4C.
Assuming an asymmetric window and uncorrelated synapses with the same mean and variance of the weight change, we can write the signal-to-noise ratio as
because the variance of the sum can be decomposed into the sum of variances and covariances. All covariances are zero because synapses are uncorrelated. This leaves a sum of variances, which are identical. Therefore, the standard deviation, and consequently also the SNR, scale with .
Numerical simulations
Request a detailed protocolTo numerically simulate the synaptic weight change, spikes were generated by inhomogeneous Poisson processes with rate functions according to Equation 11. For every spike pair, the contribution to the weight change was calculated according to Equation 14. We repeated the simulations for trials, and the mean weight change as well as the standard deviation across trials and the SNR were estimated. All simulations were implemented in Python 3.8 using the packages NumPy (RRID:SCR_008633) and SciPy (RRID:SCR_008058). Matplotlib (RRID:SCR_008624) was used for plotting; Inkscape (RRID:SCR_014479) was used for final adjustments to the Figures. The Python code is available at https://gitlab.com/e.reifenstein/synaptic-learning-rules-for-sequence-learning (Reifenstein and Kempter, 2021; copy archived at swh:1:rev:157c347a735a090f591a2b77a71b90d7de65bca5).
Appendix 1
The signal-to-noise ratio of
A synapse with weight is assumed to connect neuron to neuron . Here, we aim to derive the signal-to-noise ratio (SNR) of the weight changes , which is defined as (Materials and methods)
(A1-1)
where is the average signal. The noise is described by the standard deviation of the weight change,
Signal and noise are generated by additive STDP and spiking activity that is modeled by two inhomogeneous Poisson processes with rates and that have finite support. The average weight change is calculated by where is the synaptic learning window and depicts the cross-correlation function . From Kempter et al., 1999, we use
(A1-2)
where and are the presynaptic and postsynaptic spike trains, respectively. To simplify, we set and . Furthermore, we are interested in paired STDP and thus set . For , Equation A1-2 reduces to
(A1-3)
Because both spike trains are drawn from different Poisson processes, and are statistically independent, and therefore we can simplify
Moreover, in a spike train the spikes at different times are uncorrelated,
and
As and are realizations of inhomogeneous Poisson processes with rates and , respectively, we find
and
We insert these expressions into Equation A1-3:
(A1-4)
where
To explicitly calculate the SNR, we parameterize the firing rates as
(A1-5)
and
(A1-6)
See main text for definitions of symbols. Furthermore, we assume with
(see Equation 14 in Materials and methods) and
In what follows we consider a limiting case of wide learning windows, for which we can explicitly calculate the SNR. The results obtained in this case match well to the numerical simulations for wide learning windows (Figures 4 and 5 in the main text).
Wide learning windows
For wide windows (formally: , ), we can approximate and and neglect the sinusoidal modulations of fi and fj in Equation A1-5 and A1-6; phase precession does not affect the SNR in this case.
The following calculations are similar for odd and even windows. We elaborate the calculations in detail for odd windows and use ‘±’ and ‘’ to include the similar calculations for even windows. The top symbol (‘+’ and ‘—’, respectively) corresponds to odd windows; the bottom symbol corresponds to even windows.
To start, we split the third and fourth integral in Equation A1-4 into positive and negative time lags and , respectively:
(A1-7)
We rewrite as
which has four addends and occurs in four integrals in Equation A1-7. Thus, there are 16 terms we need to evaluate. We label these terms (1.i) to (1.iv) for the first integral, (2.i) to (2.iv) for the second integral and so on until (4.iv).
For the term (1.i) we find
(A1-8)
The first integral is . The second integral can be solved by taking the derivative with respect to :
Term (1.i) (Equation A1-8) thus reads:
For (2.i) we find
Term (3.i) is symmetric to (2.i) and thus yields the same result. For (4.i) we find (in analogy to the term (1.i)):
We sum the contributions (1.i) to (4.i) for the odd learning window:
(A1-11)
Let us continue with the second term of , which is labeled by ‘(ii)’, and consider the first (of four) integrals in Equation A1-7, that is, we continue with contribution (1.ii):
with
which will be solved later for special cases. Note that depends on because depends on . For (2.ii) we find:
For (3.ii) we find the same:
For (4.ii) we find:
Summing contributions (1.ii) to (4.ii) for the odd window yields:
(A1-12)
We continue with contribution (1.iii):
Contribution (1.iii) is non-zero if the argument of the delta function in the last integral (across ) is zero for some , which varies from 0 to . The argument of the delta function is thus zero for some if , which we can rewrite as and then use it in the integral across , which leads to
with . D will be evaluated later for special cases.
Similarly to (1.iii), we treat (2.iii):
For (3.iii) we find:
with , which we will evaluate later for special cases.
Finally, for (4.iii) we find
To sum the four contributions (1.iii) to (4.iii) for the odd window, we note that the first terms (square brackets) of (1.iii) and (2.iii) cancel, as well as the first terms of (3.iii) and (4.iii). We thus obtain:
We continue with contribution (1.iv):
By similar arguments, (2.iv) yields:
(3.iv) yields
(4.iv) yields
We sum the contributions (1.iv) and (4.iv) and obtain . We now collect all terms for the odd window:
So far, we have calculated the second moment of . In order to determine the variance, we need to calculate the average weight change for the odd window:
(A1-13)
The variance thus reads:
(A1-14)
For the signal-to-noise ratio, we note that the definition from Equation A1-1, for odd learning windows, simplifies to
because for odd learning windows.
We insert Equation A1-13 and A1-14 and find
To obtain the final result, we have to evaluate , , and . We distinguish the two cases and to approximate these three terms:
1. :
(A1-15)
because the Gaussian function fj is shifted far into the positive lobe of the error function.
Thus,
(A1-16)
This number (for ) is indicated as the analytical comparison in Figure 5E. For large A, the SNR (Equation A1-16) approaches .
2. :
all of which we calculated numerically.
It follows:
(A1-17)
This number is plotted as the large-tau approximation in Figure 4C. For large , we find .
Even windows
As argued in the main text, for even windows, the weight change contains no information about the order of events because . This can be seen from Equation A1-1 of Appendix 1. The SNR is zero for purely even windows because the signal is zero. Nonetheless, we can calculate the variance of the weight change. To do so, we collect all terms of for even windows (indicated by the bottom symbol of all occurences of ‘±’ and ‘’ in the previous section). Again, we assume wide windows ().
Collecting the terms (1.i) to (4.i) yields
Similarly, we sum the terms (1.ii) to (4.ii):
We continue to collect the contributions (1.iii) to (4.iii):
Finally, summing (1.iv) to (4.iv) yields the same result as for the odd window: .
Overall,
Together with
the variance reads:
We now insert these variances in the denominator of Equation A1-1:
which, assuming , is twice the noise as for odd windows (, Equation A1-16).
In summary, for a complex learning window with even and odd contributions, the signal solely depends on the odd part, whereas both parts, even and odd, contribute to the noise. Any even contribution thus only decreases the SNR.
Appendix 2
Calculating SNR for learning windows of arbitrary width
We again consider odd learning windows of the shape
(A2-1)
As in the case of wide learning windows, we again consider the second moment of the weight change (similar to Equation A1-4 of Appendix 1):
(A2-2)
We write F similarly as before, neglecting the theta modulation of the firing rate:
(A2-3)
with
(A2-4)
and
(A2-5)
We label the addends of Equation A2-2 as and the addends of Equation A2-3 as . In evaluating the second moment of the weight change, we realize that many integrands have similar forms, that is, products of exponentials, error functions, and delta functions. Consequently, we will first state the integral identities we use, and will then explicitly derive the term as an example. The other terms can be evaluated in a similar manner.
Integral identities
For the evaluation of the second moment of the weight change, many integrands consist of exponential functions containing linear and squared terms. To tackle these integrals, we use Albano et al., 2011
(A2-6)
The second recurring form of integrals is
(A2-7)
Substituting
we can rewrite
(A2-8)
We now use an integral identity by Ng and Geller, 1969 (their section 4.3, eq. 13):
(A2-9)
which yields the desired solution ():
(A2-10)
Example: deriving the term (2.iii)
For the term (), we have
(A2-11)
When applying the sifting property of the Dirac delta function, we note that the integral over is nonzero for , that is, for . Thus we have:
(A2-12)
The integral over can be evaluated by using Equation A2-6, which yields:
(A2-13)
The second part of the integral over (involving the error function) will be solved numerically. For this purpose, we define as:
(A2-14)
For the first part of the integral over in Equation A2-13, we again use Equation A2-6, which results in:
(A2-15)
The first part of the integral over can be solved by applying Equation A2-6 in the limit of . For the second part we use Equation A2-10.
(A2-16)
We now observe that defining D2 in the following way:
(A2-17)
allows us to write as:
(A2-18)
Addends of the second moment
By similar logic, all four addends of Equation A2-2 (with four parts each) can be obtained. We list the results here:
First Addend
(A2-21)
(A2-22)
Second Addend
with the integral terms:
(A2-27)
(A2-28)
(A2-29)
Third Addend
with the integral terms:
(A2-34)
(A2-35)
(A2-36)
(A2-37)
Fourth Addend
(A2-38)
(A2-39)
(A2-40)
By collecting all 16 terms, we will obtain the average squared weight change. To calculate the variance, we also need the squared average weight change, which we will calculate in the next section.
Average weight change
The average weight change for odd learning windows is given by (cmp. Equation 1 in the main text):
(A2-41)
We again neglect the theta modulation of the firing fields. Evaluating the first addend yields:
(A2-42)
The second addend can be similarly evaluated:
(A2-43)
The average weight change thus reads:
(A2-44)
Equation A2-44 might show numerical instabilities for small . These instabilities can be fixed using the following approximation for the error function proposed by Abramowitz, 1974:
(A2-45)
where , , , . Along with a new set of variables
the approximation yields
(A2-46)
Note that the exponential with the term vanishes when , and only one addend contains the term for . Therefore, this approximation results in improved numerical stability for small . Equation A2-46 is shown in Figure 4A.
Variance and signal-to-noise ratio of the weight change
With all of the above results, we are now ready to state the variance and signal-to-noise ratio of the weight change:
(A2-47)
The signal-to-noise ratio is then given by:
(A2-48)
Equation A2-48 (with the variance from Equation A2-47 and the mean from Equation A2-44) is shown in Figure 4C. We observe that the analytical solution fits the numerical solution well for s but numerical instabilities cause it to diverge for s.
The numerical instability for s is likely due to a combination of two factors: the exponential terms become very large for small tau, and large arguments in the error function cause the terms () to be very close to zero. The product of the two is numerically unstable for small tau. Unfortunately, unlike in the case of the average weight change, we did not find an approximation which canceled out these exponential terms in the noise.
Data availability
Code and data are available at https://gitlab.com/e.reifenstein/synaptic-learning-rules-for-sequence-learning (copy archived at https://archive.softwareheritage.org/swh:1:rev:157c347a735a090f591a2b77a71b90d7de65bca5).
References
-
Synaptic plasticity: taming the beastNature Neuroscience 3 Suppl:1178–1183.https://doi.org/10.1038/81453
-
BookHandbook of Mathematical Functions, With Formulas, Graphs, and Mathematical TablesUSA: Dover Publications, Inc.
-
The integrals in Gradshteyn and Ryzhik. Part 19: The error functionSCIENTIA Series A Mathematical Sciences 21:25–42.
-
Sequence memory in the Hippocampal-Entorhinal regionJournal of Cognitive Neuroscience 32:2056–2070.https://doi.org/10.1162/jocn_a_01592
-
Synaptic modification by correlated activity: hebb's postulate revisitedAnnual Review of Neuroscience 24:139–166.https://doi.org/10.1146/annurev.neuro.24.1.139
-
Hippocampal phase precession from dual input componentsJournal of Neuroscience 32:16693–16703.https://doi.org/10.1523/JNEUROSCI.2786-12.2012
-
The CRISP theory of hippocampal function in episodic memoryFrontiers in Neural Circuits 7:88.https://doi.org/10.3389/fncir.2013.00088
-
Memory replay in balanced recurrent networksPLOS Computational Biology 13:e1005359.https://doi.org/10.1371/journal.pcbi.1005359
-
Forward and reverse hippocampal place-cell sequences during ripplesNature Neuroscience 10:1241–1242.https://doi.org/10.1038/nn1961
-
Time cells in the hippocampus: a new dimension for mapping memoriesNature Reviews Neuroscience 15:732–744.https://doi.org/10.1038/nrn3827
-
Critical role of the hippocampus in memory for sequences of eventsNature Neuroscience 5:458–462.https://doi.org/10.1038/nn834
-
Neuromodulation: acetylcholine and memory consolidationTrends in Cognitive Sciences 3:351–359.https://doi.org/10.1016/S1364-6613(99)01365-0
-
Spatial representations in the human brainFrontiers in Human Neuroscience 12:297.https://doi.org/10.3389/fnhum.2018.00297
-
Modeling inheritance of phase precession in the hippocampal formationJournal of Neuroscience 34:7715–7731.https://doi.org/10.1523/JNEUROSCI.5136-13.2014
-
Phase precession: a neural code underlying episodic memory?Current Opinion in Neurobiology 43:130–138.https://doi.org/10.1016/j.conb.2017.02.006
-
Associative retrieval processes in free recallMemory & Cognition 24:103–109.https://doi.org/10.3758/BF03197276
-
Hebbian learning and spiking neuronsPhysical Review E 59:4498–4514.https://doi.org/10.1103/PhysRevE.59.4498
-
Cellular and system biology of memory: timing, molecules, and beyondPhysiological Reviews 96:647–693.https://doi.org/10.1152/physrev.00010.2015
-
A specific role of the human hippocampus in recall of temporal sequencesJournal of Neuroscience 29:3475–3484.https://doi.org/10.1523/JNEUROSCI.5370-08.2009
-
Traveling Theta Waves and the Hippocampal Phase CodeScientific Reports 7:7678.https://doi.org/10.1038/s41598-017-08053-3
-
Hippocampal contributions to serial-order memoryHippocampus 29:252–259.https://doi.org/10.1002/hipo.23025
-
Dendritic mechanisms of phase precession in hippocampal CA1 pyramidal neuronsJournal of Neurophysiology 86:528–532.https://doi.org/10.1152/jn.2001.86.1.528
-
Circuit mechanisms of hippocampal reactivation during sleepNeurobiology of Learning and Memory 160:98–107.https://doi.org/10.1016/j.nlm.2018.04.018
-
Oscillations, phase-of-firing coding, and spike timing-dependent plasticity: an efficient learning schemeJournal of Neuroscience 29:13484–13493.https://doi.org/10.1523/JNEUROSCI.2207-09.2009
-
Cortical travelling waves: mechanisms and computational principlesNature Reviews Neuroscience 19:255–268.https://doi.org/10.1038/nrn.2018.20
-
Replay and time compression of recurring spike sequences in the hippocampusThe Journal of Neuroscience 19:9497–9507.https://doi.org/10.1523/JNEUROSCI.19-21-09497.1999
-
A table of integrals of the Error functionsJournal of Research of the National Bureau of Standards, Section B: Mathematical Sciences 73B:1.https://doi.org/10.6028/jres.073B.001
-
Replay of rule-learning related neural patterns in the prefrontal cortex during sleepNature Neuroscience 12:919–926.https://doi.org/10.1038/nn.2337
-
Triplets of spikes in a model of spike timing-dependent plasticityJournal of Neuroscience 26:9673–9682.https://doi.org/10.1523/JNEUROSCI.1425-06.2006
-
Operation and plasticity of hippocampal CA3 circuits: implications for memory encodingNature Reviews Neuroscience 18:208–220.https://doi.org/10.1038/nrn.2017.10
-
SoftwareSynaptic learning rules for sequence learning , version swh:1:rev:157c347a735a090f591a2b77a71b90d7de65bca5Software Heritage.
-
Memory encoding by theta phase precession in the hippocampal networkNeural Computation 15:2379–2397.https://doi.org/10.1162/089976603322362400
-
Single-trial phase precession in the hippocampusJournal of Neuroscience 29:13232–13241.https://doi.org/10.1523/JNEUROSCI.2270-09.2009
-
BookTheta Phase Precession Enhance Single Trial Learning in an STDP NetworkIn: Wang R, Shen E, Gu F, editors. Advances in Cognitive Neurodynamics ICCN 2007 . Springer. pp. 109–114.https://doi.org/10.1007/978-1-4020-8387-7_21
-
Phase precession through synaptic facilitationNeural Computation 20:1285–1324.https://doi.org/10.1162/neco.2008.07-06-292
-
Hippocampal cellular and network activity in freely moving echolocating batsNature Neuroscience 10:224–233.https://doi.org/10.1038/nn1829
-
Malleability of spike-timing-dependent plasticity at the CA3-CA1 synapseJournal of Neuroscience 26:6610–6617.https://doi.org/10.1523/JNEUROSCI.5388-05.2006
Article and author information
Author details
Eric Torsten Reifenstein

Funding
Deutsche Forschungsgemeinschaft (01GQ1705)
- Richard Kempter
Deutsche Forschungsgemeinschaft (GRK 1589/2)
- Richard Kempter
Deutsche Forschungsgemeinschaft (SPP 1665)
- Richard Kempter
Deutsche Forschungsgemeinschaft (SFB 1315)
- Richard Kempter
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work was funded by the Deutsche Forschungsgemeinschaft (DFG, German Research Foundation; Grants GRK 1589/2, SPP 1665, SFB 1315 - project-ID 327654276) and the German Federal Ministry for Education and Research (BMBF; Grant 01GQ1705). We thank Lukas Kunz, Natalie Schieferstein, Tiziano D’Albis, Paul Pfeiffer, and Adam Wilkins for helpful discussions and feedback on the manuscript. ETR and RK designed the research. ETR, IBK, and RK performed the research, wrote and discussed the manuscript. ETR, IBK, and RK declare no conflict of interest.
Copyright
© 2021, Reifenstein et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,374
- views
-
- 334
- downloads
-
- 35
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 35
- citations for umbrella DOI https://doi.org/10.7554/eLife.67171
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Synaptic learning rules for sequence learning
eLife 10:e67171.
https://doi.org/10.7554/eLife.67171




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}