Dopamine enhances model-free credit assignment through boosting of retrospective model-based inference
- Max Planck UCL Centre for Computational Psychiatry and Ageing Research, University College London, United Kingdom
- The Wellcome Trust Centre for Neuroimaging, Institute of Neurology, University College London, United Kingdom
- Department of Child and Adolescent Psychiatry, Psychotherapy and Psychosomatics, University of Würzburg, Germany
- Department of Psychiatry and Psychotherapy, Technische Universität Dresden, Germany
- Department of Psychiatry and Psychotherapy, Charité Universitätsmedizin Berlin, Germany
- Max Planck Institute for Biological Cybernetics, Germany
- University of Tübingen, Germany
Figures
Figure 1
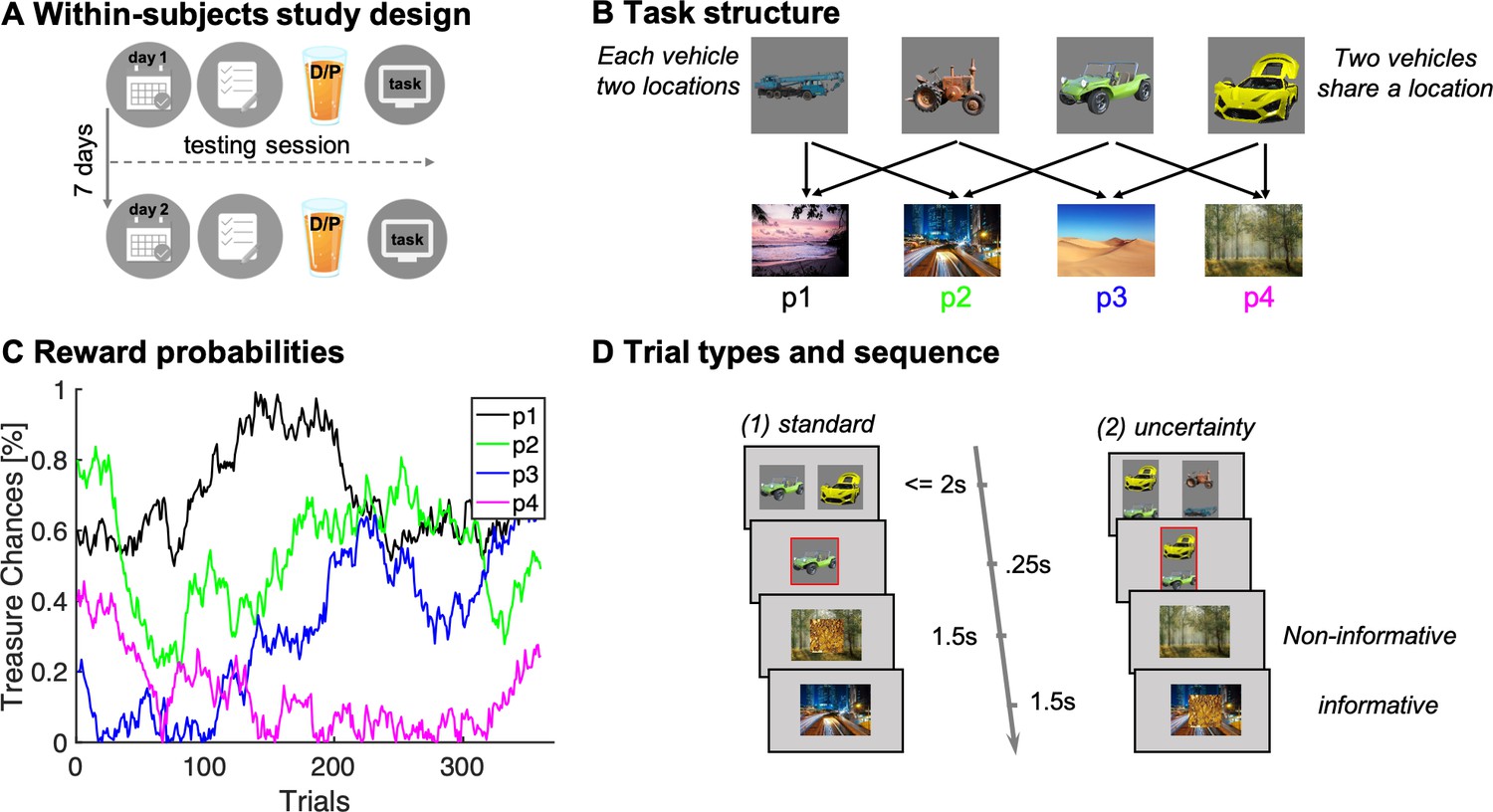
Study and task design.
(A) Illustration of within-subjects design. On each of 2 testing days, approximately 7 days apart, participants started with either a medical screening and brief physical exam (day 1) or a working memory test (day 2). Subsequently they drank an orange squash containing either levodopa ("D") or placebo ("P"). (B) Task structure of the Magic Castle Game. Following a choice of vehicle, participants ‘travelled’ to two associated destinations. Each vehicle shared a destination with another vehicle. At each destination, participants could win a reward (10 pence) with a probability that drifted slowly as Gaussian random walks, illustrated in (C). (D) Depiction of trial types and sequences. (1) On standard trials (2/3 of the trials), participants made a choice out of two options in trial n (max. choice 2 s). The choice was then highlighted (0.25 s) and participants subsequently visited each destination (0.5 s displayed alone). Reward, if obtained, was overlaid to each of the destinations for 1 s. (2) On uncertainty trials, participants made a choice between two pairs of vehicles. Subsequently, the ghost nominates, unbeknown to the participant, one vehicle out of the chosen pair. Firstly, the participant is presented the destination shared by the chosen pair of vehicles (here the forest) and this destination is therefore non-informative about the ghost’s nominee. Secondly, the destination unique to the ghost-nominated vehicle is then shown (the highway). This second destination is informative because it enables inference of the ghost’s nominee with perfect certainty based on a model-based (MB) inference that relies on task transition structure. Trial timing was identical for standard and uncertainty trials.
Figure 2
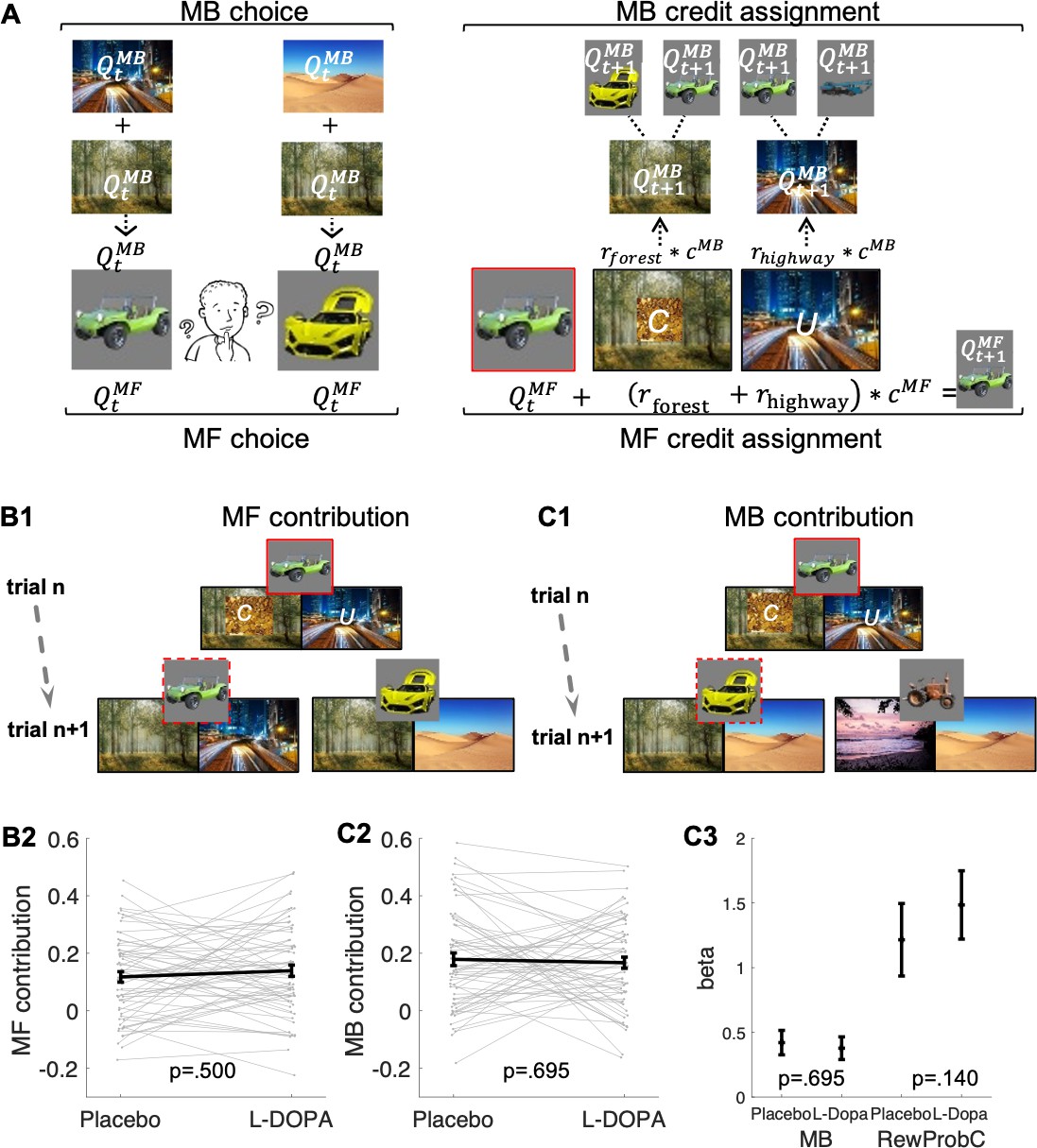
Model-free (MF) and model-based (MB) contributions.
(A) Left panel: Illustration of MF and MB values at choice in standard trials. MB values are computed prospectively based on the sum of values of the two destinations associated with each of the two vehicles offered for choice (here highway and forest for green antique car; desert and forest for yellow racing car). Right panel: MF vs. MB credit assignment (MFCA vs. MBCA) in standard trials. MFCA only updates the chosen vehicle (here green antique car) based on the sum of rewards at each destination (here forest and highway). MBCA updates separately the values for each of the two destinations (forest and highway). Each of these updates will prospectively affect equally the values of the vehicle pair associated with that destination (updated MB value for forest influences MB value of the yellow racing car and the green antique car while the updated MB value for highway influences the MB value of the green antique car and the blue crane). Forgetting of Q values was left out for simplicity (see Materials and methods and see Appendix 1—figure 1 for validating simulations). (B1) Illustration of MF choice repetition. We consider only standard trials n + 1 that offer for choice the standard trial n chosen vehicle (e.g., green antique car) alongside another vehicle (e.g., yellow racing car), sharing a common destination (forest). Following choice of a vehicle in trial n (framed in red, here the green antique car), participants visited two destinations of which one can be labelled on trial n + 1 as common to both offered vehicles (C, e.g., forest, which was also rewarded in the example) and the other labelled as unique (U, e.g., city highway, unrewarded in this example) to the vehicle chosen on trial n (the green antique car). The trial n common destination reward effect on the probability to repeat the previously chosen vehicle (dashed frame in red, e.g., the green antique car) constitutes an MF choice repetition. (B2) The empirical reward effect for the common destination (i.e., the difference between rewarded and unrewarded on trial n, see Appendix 1—figure 2 for a more detailed plot of this effect) on repetition probability in trial n + 1 is plotted for placebo and levodopa (L-Dopa) conditions. There was a positive common reward main effect and this reward effect did not differ significantly between placebo and levodopa conditions. (C1) Illustration of the MB contribution. We considered only standard trials n + 1 that excluded from the choice set the standard trial n chosen vehicle (e.g., green antique car, framed in red). One of the vehicles offered on trial n + 1 shared one destination in common with the trial n chosen vehicle (e.g., yellow racing car, sharing the forest, and we term its choice a generalization). A reward (on trial n) effect for the common destination on the probability to generalize on trial n + 1 (e.g., by choice of the yellow racing car, dashed frame in red) constitutes a signature of MB choice generalization. (C2) The empirical reward effect at the common destination (i.e., the difference between rewarded and unrewarded, see Appendix 1—figure 2 for a more detailed plot of this effect) on generalization probability is plotted for placebo and levodopa conditions. (C3) In the regression analysis described in the text, we also include the current (subject- and trial-specific) state of the drifting reward probabilities (at the common destination) because we previously found this was necessary to control for temporal auto correlations in rewards (Moran et al., 2019). For completeness, we plot beta regression weights of reward vs. no reward at the common destination (indicated as MB) and for the common reward probability (RewProbC) each for placebo and levodopa conditions. No significant interaction with drug session was observed. Error bars correspond to SEM reflecting variability between participants.
Figure 3
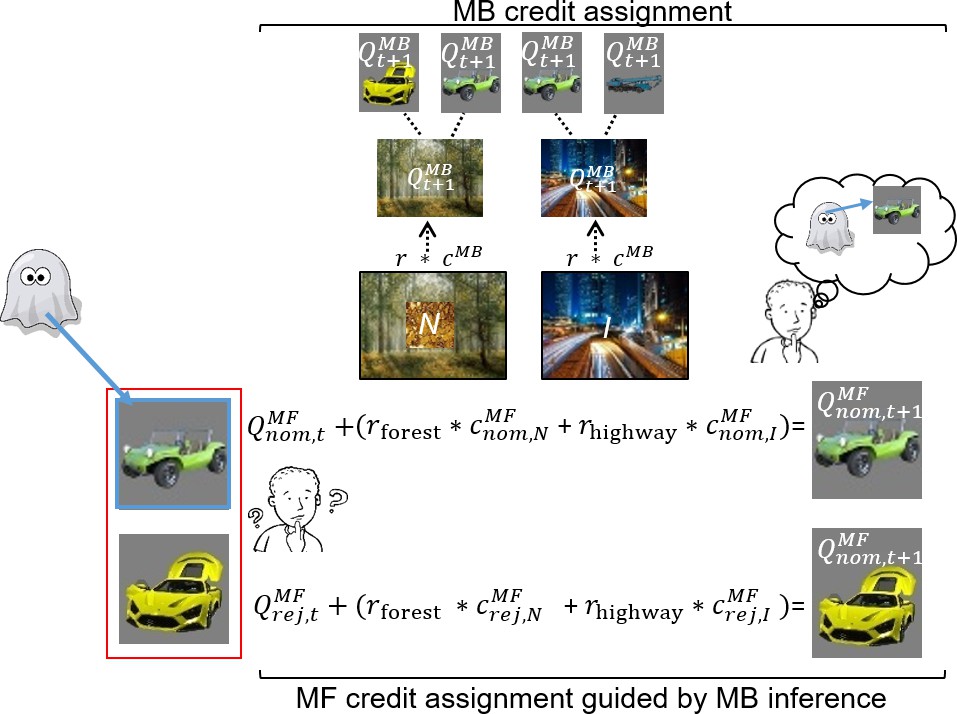
Illustration of model-free (MF) credit assignment (MFCA) guided by model-based (MB) inference and MB credit assignment (MBCA) in uncertainty trials.
The ghost, unbeknown to the participants, nominates a vehicle (e.g., green antique car). The ghost’s nomination does not matter for MBCA because it updates values for each of the destinations (here forest and highway) separately, which will prospectively effect on all associated vehicle values (here green antique car, yellow racing car, and blue crane). With respect to MFCA guided by MB inference, participants are in state uncertainty and have a chance belief about the ghost-nominated vehicle. The firstly presented destination (the forest) holds no information about the ghost-nominated vehicle (the green antique car), the non-informative (‘N’) destination. Thus, participants remain in state uncertainty. The destination presented second (here the highway) enables retrospective MB inference about the ghost’s nomination (the green antique car) and is therefore informative (‘I’). This retrospective MB inference enables preferential MFCA for the ghost-nominated vehicle (here green antique car) based on the sum of rewards at each destination (without such inference MFCA can only occur equally for the ghost-nominated and -rejected vehicles). Forgetting of Q values was left out for simplicity (see Materials and methods and see Appendix 1—figure 3 for validating simulations).
Figure 4
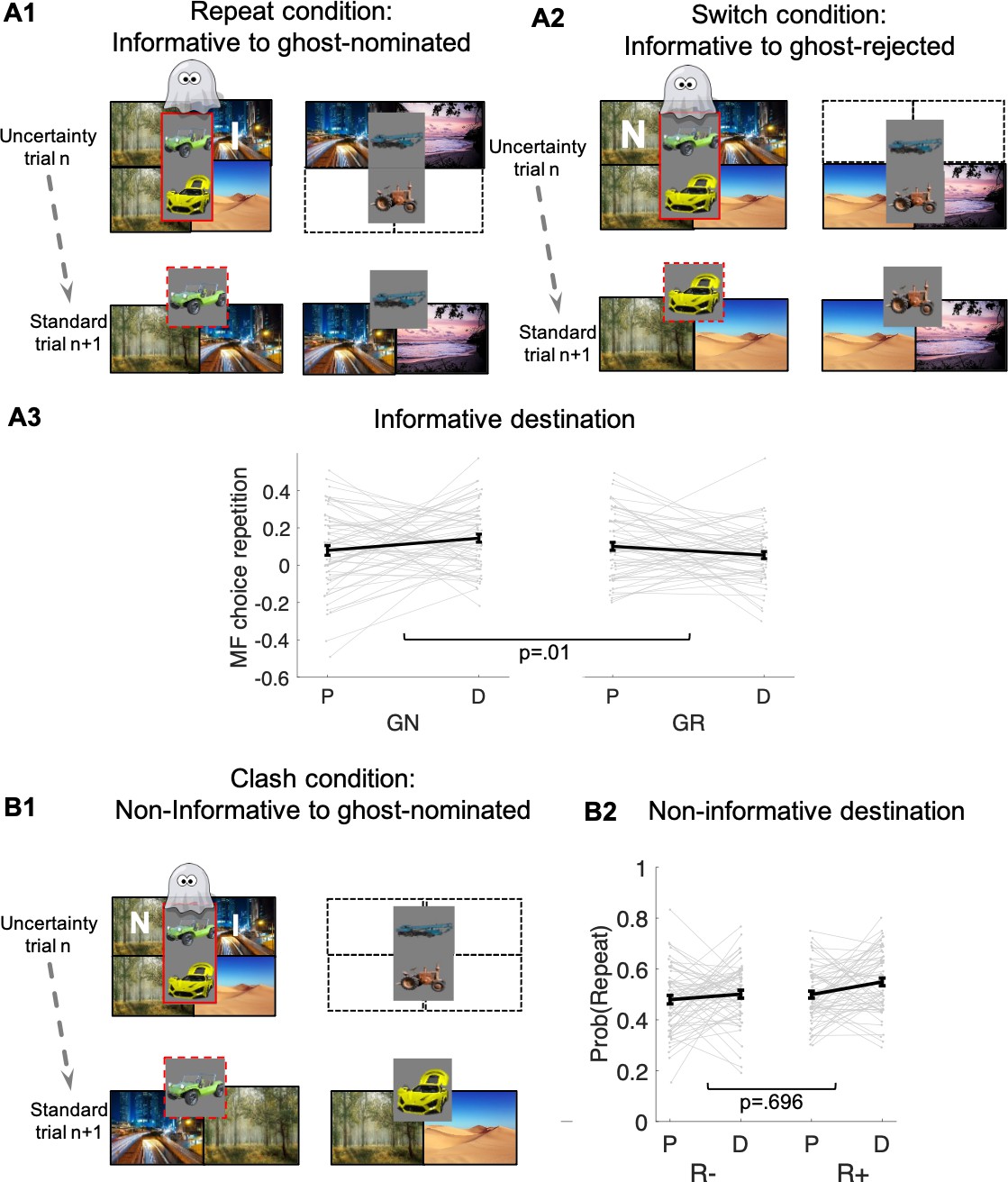
Guidance of model-free (MF) credit-assignment (CA) by retrospective model-based (MB) inference.
(A1) Illustration of the repeat condition. The ghost-nominated vehicle (e.g., green antique car) is offered for choice in standard trial n + 1 alongside a vehicle from the non-chosen pair (e.g., blue building crane). A higher probability to repeat the ghost-nominated vehicle in standard trial n + 1 after a reward as compared to no reward at the informative destination, the highway, constitutes model-free credit assignment (MFCA) for the ghost’s nomination (GN, the green antique car). (A2) Illustration of the switch condition. The ghost-rejected vehicle (e.g., the yellow racing car) is offered for choice in standard trial n + 1 alongside a vehicle from the non-chosen pair (e.g., brown farming tractor). A higher probability to choose the ghost-rejected vehicle in standard trial n + 1 after a reward as compared to no reward at the informative destination constitutes MFCA for the ghost’s rejection (GR). Both ghost-based assignments depend on retrospective model-based (MB) inference. (A3) Preferential effect of retrospective MB inference on MFCA (effects of GN > GR) based on the informative destination is enhanced under levodopa (L-Dopa; "D") as compared to placebo ("P"). This is indicated by a significant trial type (GN/GR) × drug (placebo/ levodopa) interaction (also see Appendix 1—figure 4 and Appendix 1—figure 5 for more detailed plots). (B1) Illustration of the clash condition. The previously chosen pair (green antique and yellow racing car) is offered for choice in standard trial n + 1. A higher probability to repeat the ghost-nominated vehicle (the green antique car) in standard trial n + 1 following reward (relative to non-reward) at the non-informative destination (the forest) constitutes a signature of preferential MFCA for GN (the green antique car) over GR (the yellow racing car). (B2) Choice repetition in clash trial is plotted as a function of L-Dopa ("D") vs. placebo ("P") and reward (R+: reward; R−: no-reward, see Appendix 1—figure 6 for a more detailed plot). While there was a main effect for drug, there was no interaction of non-informative reward × drug, providing no evidence that drug modulated MFCA based on the non-informative outcome. Error bars correspond to SEM reflecting variability between participants.
Figure 5
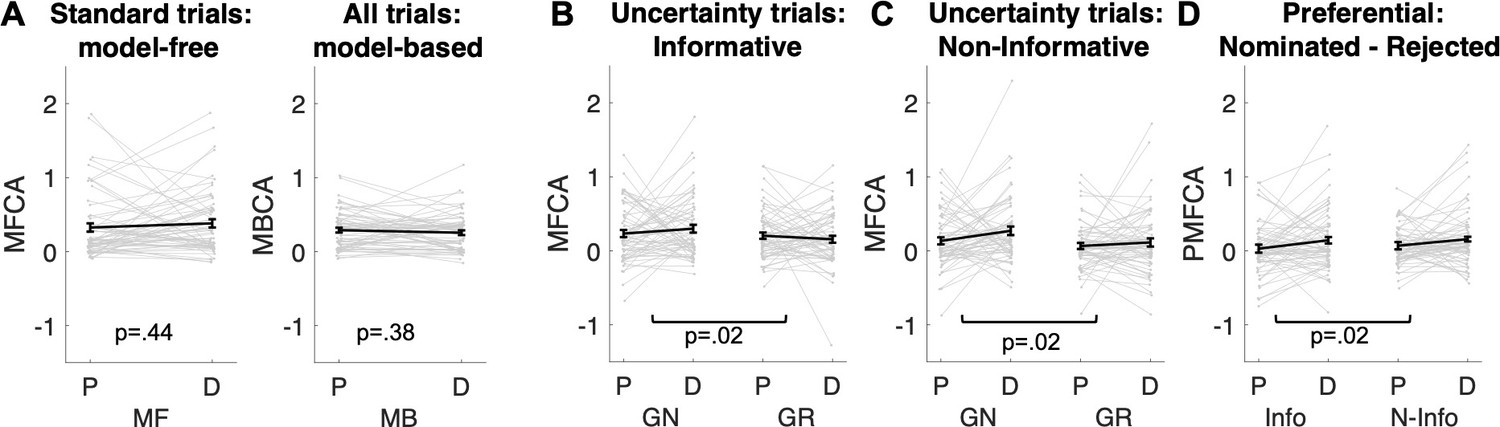
Analyses based on estimated credit assignment (CA) parameters from computational modelling (for model comparisons, based on the current and the Moran et al., 2019) data, see Appendix 1—figure 7 and Appendix 1—figure 8; for parameter recoverability, see Appendix 1—figure 9.
(A) Model-free and model-based credit assignment parameters (MFCA; MBCA) did not differ significantly for placebo (P) and levodopa (D) conditions. (B) MFCA parameters based on the informative destination for the ghost-nominated (GN) and the ghost-rejected (GR) destinations as a function of drug condition. (C) Same as B but for the non-informative destination. (D) The extent to which MFCA prefers the ghost-nominated over the ghost-rejected vehicle for each destination and drug condition. We name this preferential MFCA (PMFCA). Error bars correspond to SEM reflecting variability between participants.
Figure 6
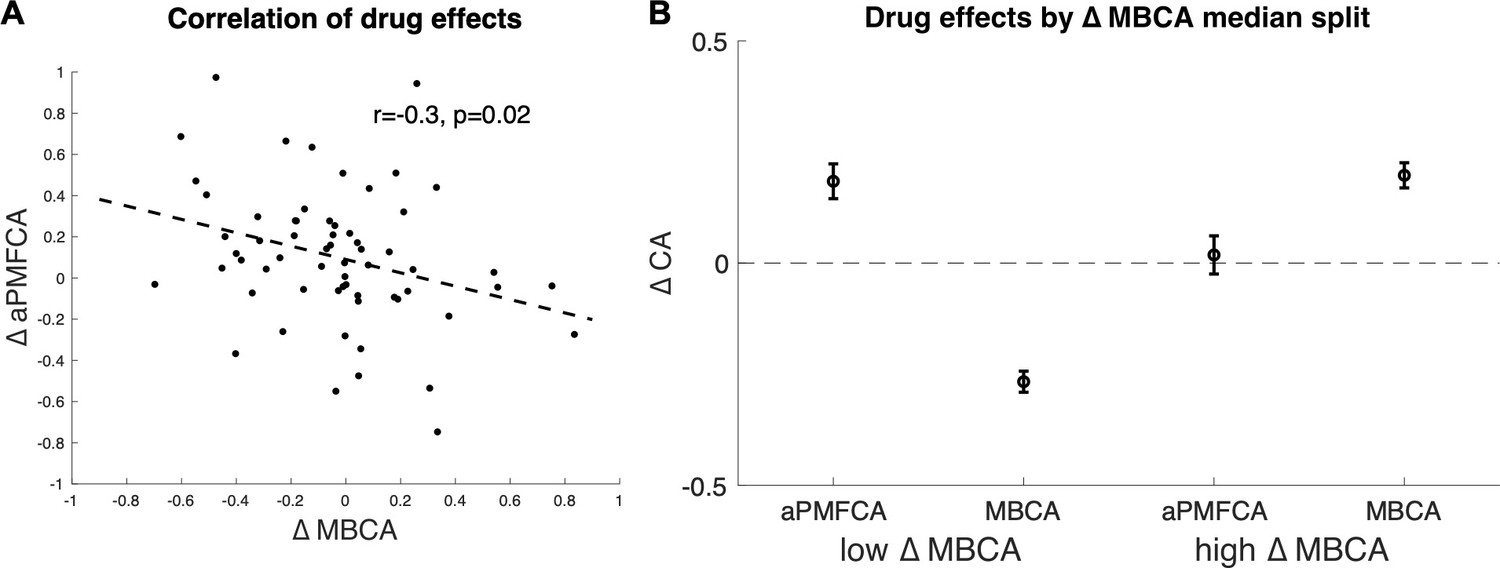
Inter-individual differences in drug effects in model-based credit assignment (MBCA) and in preferential model-based credit assignment (MFCA), averaged across informative and non-informative destinations (aPMFCA).
(A) Scatter plot of the drug effects (levodopa minus placebo; ∆aPMFCA, ∆MBCA). Dashed regression line and Pearson r correlation coefficient (see Appendix 1—figure 10 for an analysis that controls for parameter trade-off). (B) Drug effects in credit assignment (∆CA) based on a median on ∆MBCA. Error bars correspond to SEM reflecting variability between participants. See Appendix 1—figure 11, for a report on inter-individual differences in drug effects related to working memory.
Appendix 1—figure 1
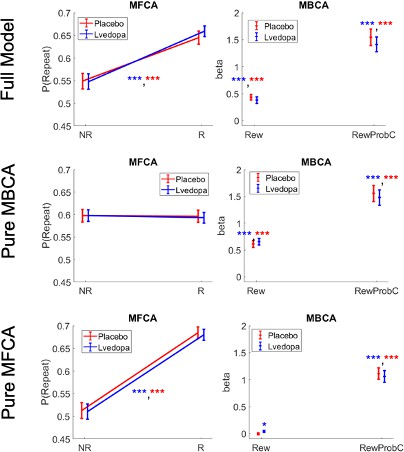
Simulations for standard trials based on the full model and sub-models.
NR = no reward, R = reward. Rew = reward at the common destination, RewProBC = reward probability at the common destination.
Appendix 1—figure 2

Empirical probabilities of model-agnostic model-free (MF) (A and B) and model-based (MB) (C and D) choice contribution under placebo and levodopa (L-Dopa).
U-Non = no reward at unique destination, U-Rew = reward at unique destination, C-Non = no reward at common destination, C-Rew = reward at common destination.
Appendix 1—figure 3
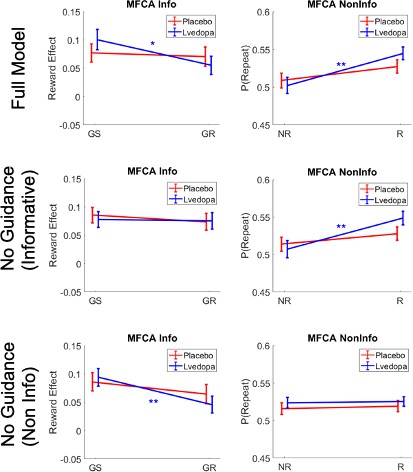
Simulations for uncertainty trials based on the full model and sub-models.
GS = ghost-selected, GR = ghost-rejected.
Appendix 1—figure 4
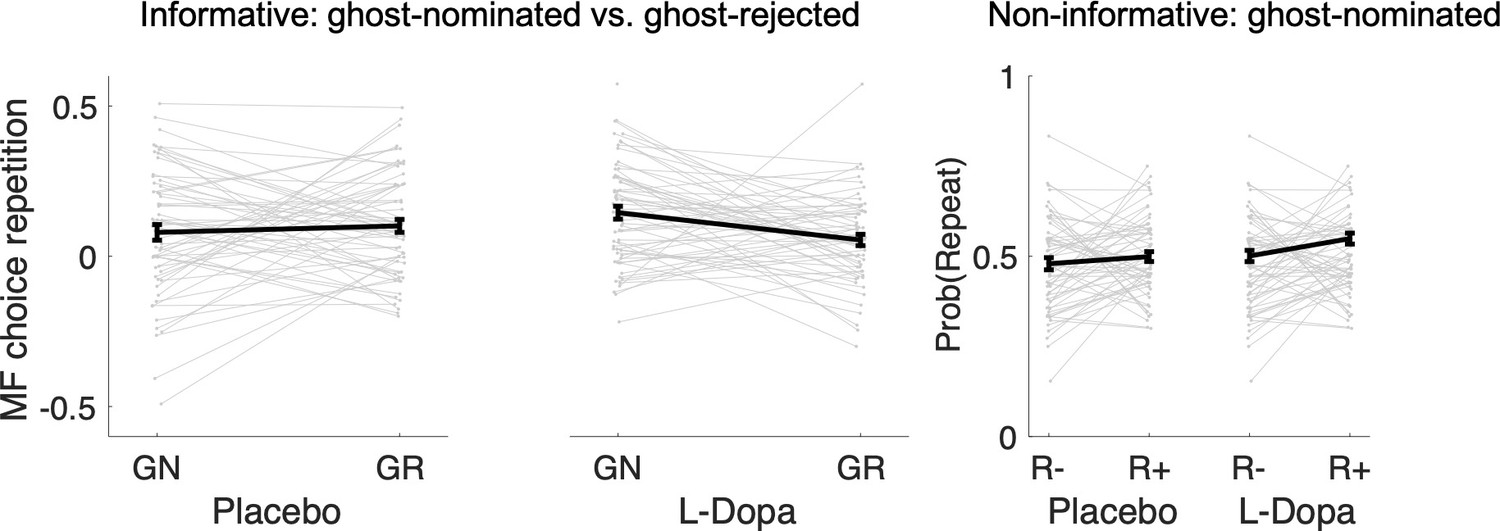
Same data as plotted in Figure 4 in the main manuscript but individual variability reflects differences in task conditions.
GN = ghost-nominated, GR = ghost-rejected, R− = no reward, R+ = reward.
Appendix 1—figure 5

Retrospective model-based (MB) inference using the informative destination based on repeat and switch signatures after uncertainty trials.
I-Non = no reward at informative destination, I-Rew = reward at informative destination, N-Non = no reward at non-informative destination, N-Rew = reward at non-informative destination.
Appendix 1—figure 6
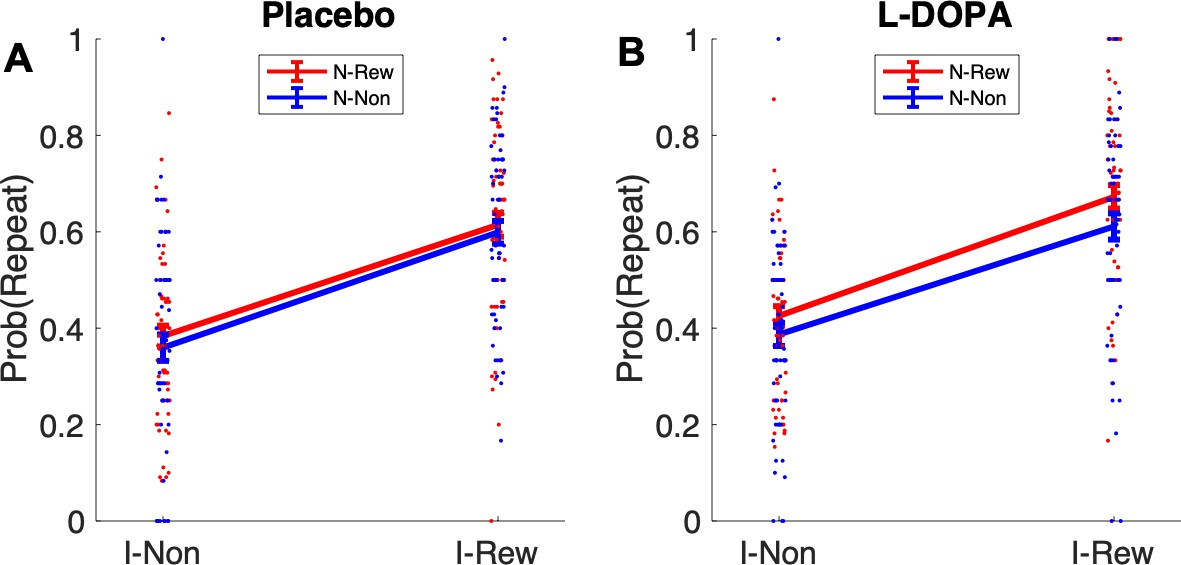
Retrospective model-based (MB) inference using the non-informative destination based on choice repetition in ‘clash’ trials n + 1 following an uncertainty trial n.
I-Non = no reward at informative destination, I-Rew = reward at informative destination, N-Non = no reward at non-informative destination, N-Rew = reward at non-informative destination.
Appendix 1—figure 7
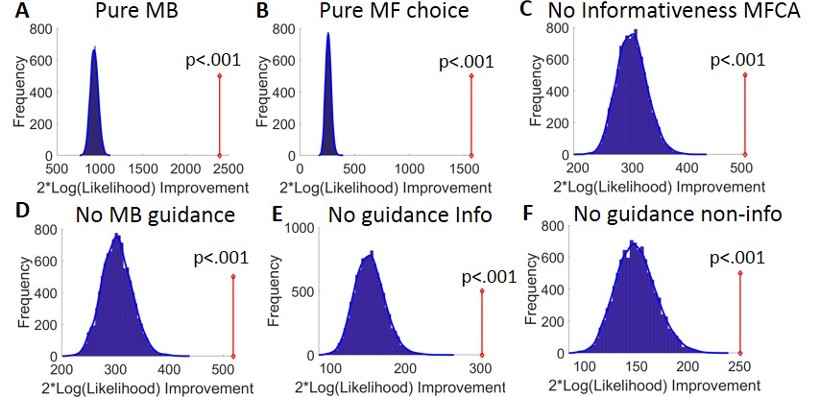
Model comparison results.
(A) Results of the bootstrap-GLRT model comparison for the pure model-based (MB) sub-model. The blue bars show the histogram of the group twice log-likelihood improvement (model vs. sub-model) for synthetic data simulated using the sub-model (10,000 simulations). The blue line displays the smoothed null distribution (using Matlab’s ‘ksdensity’). The red line shows the empirical group twice log-likelihood improvement. p-Value reflects the proportion of 10,000 simulations that yielded an improvement in likelihood that was at least as large as the empirical improvement. (B–E) Same as (A), but for the pure model-free (MF) choice, the no informativeness effects on MF credit assignment (MFCA), the no MB guidance for MFCA, the no MB guidance for the informative destination, and the no MB guidance for the non-informative destination sub-models.
Appendix 1—figure 8
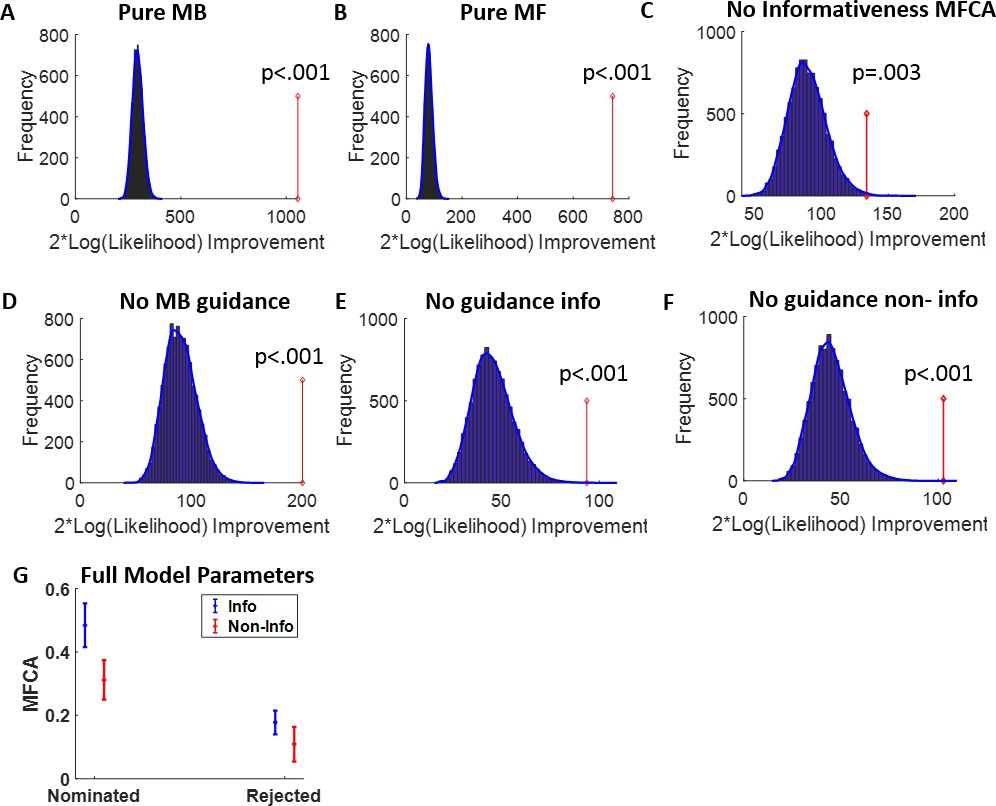
Reanalysis of Moran et al., 2019, based on the current models.
(A–F) As Appendix 1—figure 7 but for the data of Moran et al., 2019. Each of the sub-models was rejected at the group level in favour of the full model. (G) Full-model uncertainty trials model-based credit assignment (MFCA) parameters as a function of outcome informativeness (blue/red) and nomination. Using a mixed effects model, we found a significant interaction effect between informativeness and nomination (b = 0.10, t = 2.05, p = 0.042) implying the nomination effect on MFCA was stronger for the informative than the non-informative outcome. Simple effect analysis showed significant positive nomination effects for both the informative outcome (blue; b = 0.2, F(1,156) = 28.16, p = 4e-7) and the non-informative outcome (red; b = 0.31, F(1,156) = 12.36, p = 6e-4). Thus, this analysis supports the conclusions from Moran et al., 2019, that retrospective model-based (MB) inference guides MFCA on uncertainty trials for both outcomes. Note that Moran et al., 2019, did not separate MFCA for the informative and non-informative outcomes.
Appendix 1—figure 9

Parameter recoverability.
For each of the 2*62 full-model parameter combinations, 1000 synthetic (simulated) datasets were created by simulating the full model on experimental sessions as in the true experiment. Then the full model was fit to each of these generated datasets. For each credit assignment (CA) parameter we plot the recovered against the generating parameters, report the Spearman correlation and impose black diagonals where ‘recovered = generating’. (A) Model-free CA (MFCA) on standard trials, (B–E) MFCA on uncertainty trials; (B) informative outcome, ghost-nominated, (C) informative outcome, ghost-rejected, (D) non-informative outcome, ghost-nominated, (E) non-informative outcome, ghost-rejected, (F) model-based CA (MBCA).
Appendix 1—figure 10
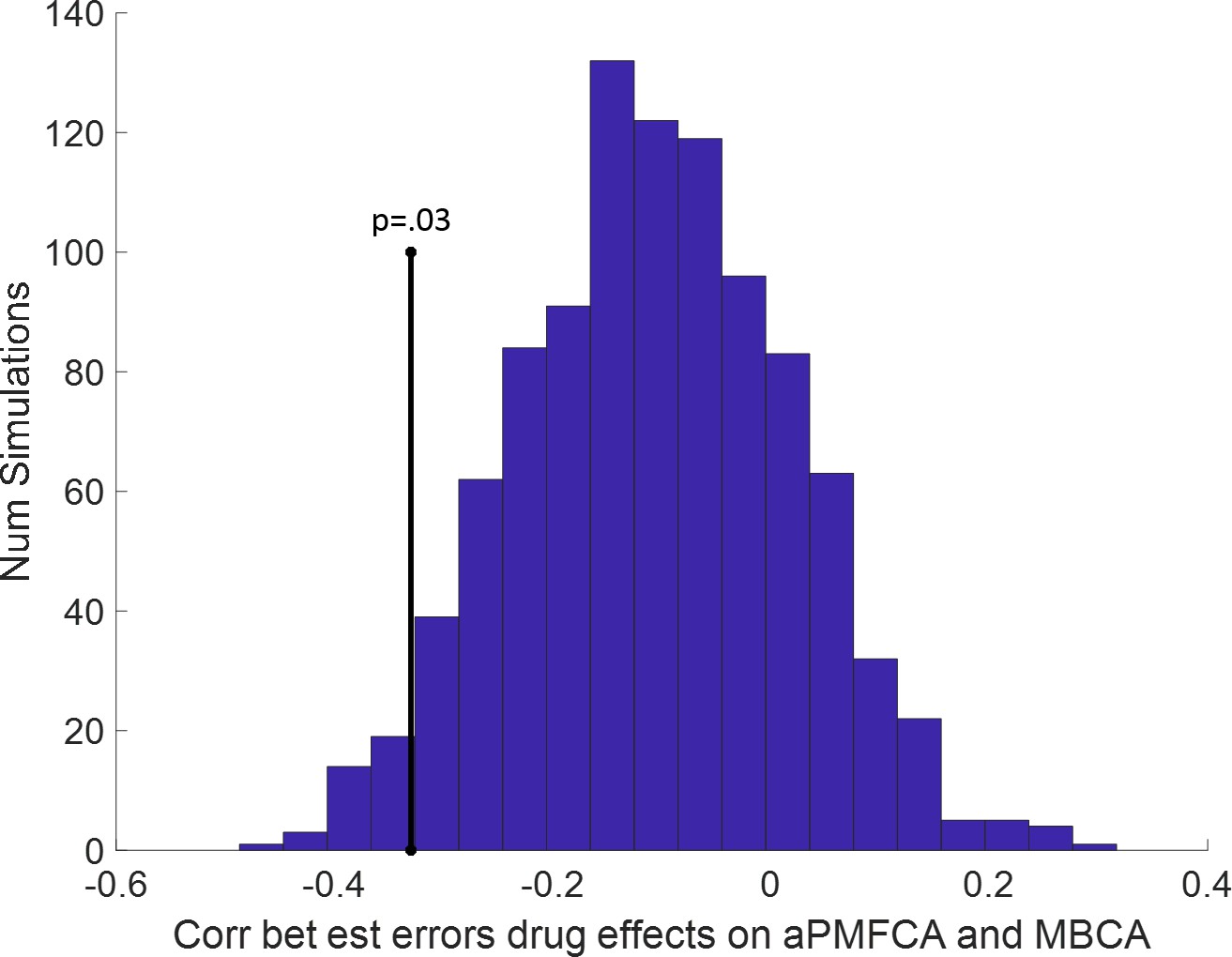
Trade-off between parametric drug effects on averaged preferential model-free credit assignment (aPMFCA) and model-based credit assignment (MBCA).
Based on our parameter recovery simulations (see Appendix 1—figure 9), we also calculated for each participant and each simulation estimation errors (est errors) for drug effects on aPMFCA and MBCA (as differences between fitted and generating drug effects). Next for each simulation index (i = 1,2,…,1000) we calculated the group-level Spearman correlation between these two estimation errors. The histogram of these correlations is plotted. There is weak negative trade-off between estimation errors of drug effects on aPMFCA and MBCA. Importantly, the negative empirical correlation (vertical black line) was still significant even after controlling for this trade-off (p = 0.03; calculated as the proportion of simulations with correlation ≤ empirical correlation).
Appendix 1—figure 11
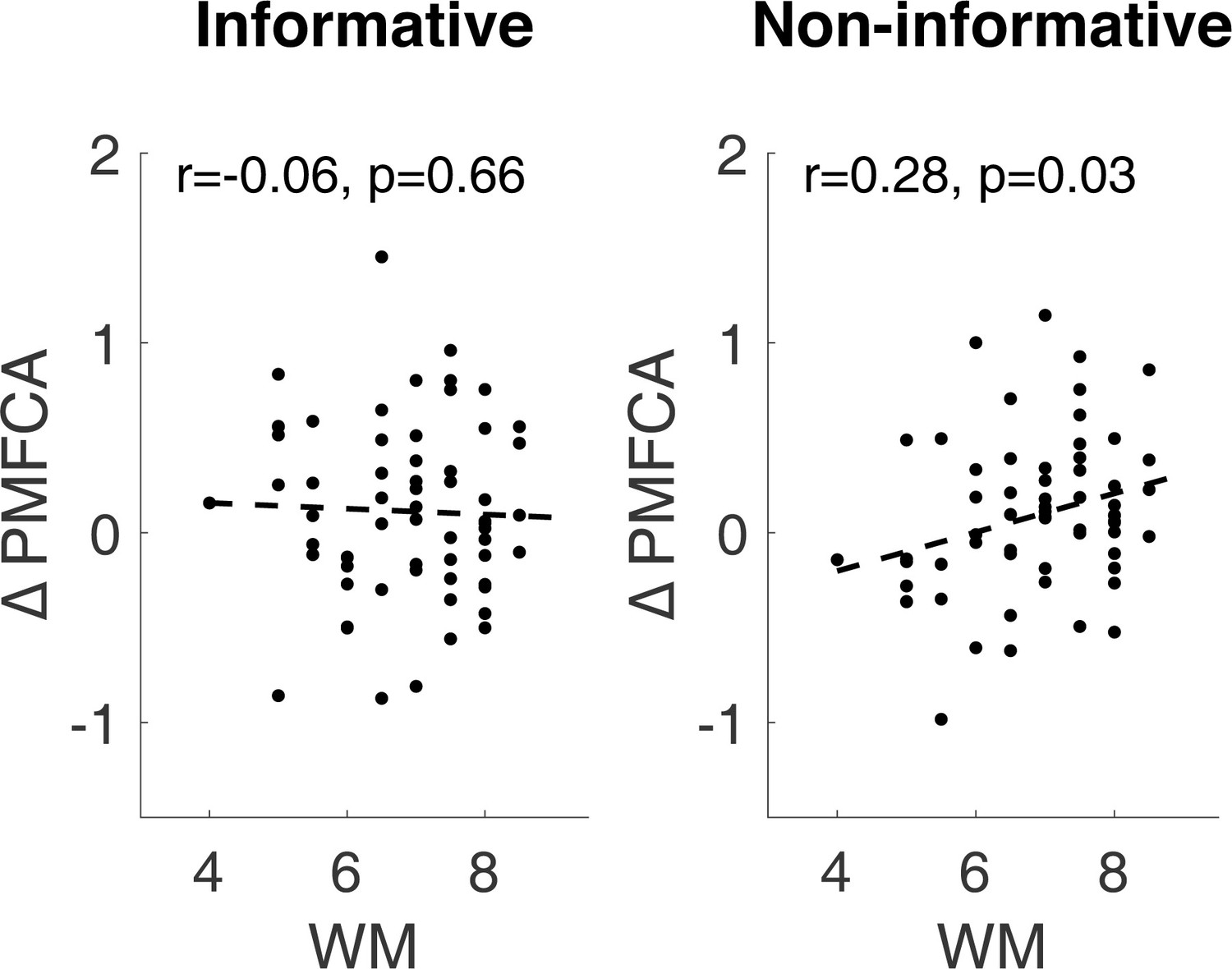
Scatter plots of the drug effect (levodopa minus placebo) on preferential model-free credit assignment (∆PMFCA) based on the informative destination reward and for the non-informative destination reward against working memory (WM).
Tables
Appendix 1—table 1
Mixed effects models on model-agnostic choice data from standard trials.
| Name | Estimate | SE | t-Stat | DF | p-Value | Lower CI | Upper CI |
|---|---|---|---|---|---|---|---|
| MF choice (standard trials)REPEAT ~ 1 + C*U*DRUG*ORDER + (C + U + DRUG + ORDER | PART) | |||||||
| (Intercept) | 0.34 | 0.06 | 5.55 | 480 | 0.000 | 0.22 | 0.46 |
| C (common) | 0.67 | 0.07 | 9.14 | 480 | 0.000 | 0.53 | 0.82 |
| U (unique) | 1.54 | 0.09 | 17.40 | 480 | 0.000 | 1.36 | 1.71 |
| DRUG | 0.03 | 0.07 | 0.46 | 480 | 0.643 | –0.11 | 0.18 |
| ORDER | 0.07 | 0.07 | 0.91 | 480 | 0.365 | –0.08 | 0.21 |
| C*U | 0.19 | 0.11 | 1.72 | 480 | 0.085 | –0.03 | 0.40 |
| C*DRUG | 0.07 | 0.11 | 0.67 | 480 | 0.500 | –0.14 | 0.29 |
| U*DRUG | 0.06 | 0.11 | 0.56 | 480 | 0.577 | –0.15 | 0.27 |
| C*ORDER | 0.12 | 0.11 | 1.09 | 480 | 0.277 | –0.10 | 0.33 |
| U*ORDER | –0.11 | 0.11 | –0.99 | 480 | 0.321 | –0.32 | 0.11 |
| DRUG*ORDER | –0.25 | 0.25 | –1.02 | 480 | 0.310 | –0.73 | 0.23 |
| C*U*DRUG | 0.14 | 0.22 | 0.64 | 480 | 0.524 | –0.29 | 0.57 |
| C*U*ORDER | 0.13 | 0.22 | 0.59 | 480 | 0.554 | –0.30 | 0.56 |
| C*DRUG*ORDER | –0.02 | 0.29 | –0.06 | 480 | 0.952 | –0.60 | 0.56 |
| U*DRUG*ORDER | –0.18 | 0.35 | –0.51 | 480 | 0.610 | –0.87 | 0.51 |
| C*U*DRUG*ORDER | –0.22 | 0.44 | –0.50 | 480 | 0.618 | –1.08 | 0.64 |
| MB choice (standard trials)GENERALIZE ~ C*P*DRUG*ORDER + (C + P + DRUG + ORDER | PART) | |||||||
| (Intercept) | 0.30 | 0.04 | 6.96 | 7177 | 0.000 | 0.22 | 0.38 |
| C (common) | 0.40 | 0.06 | 6.22 | 7177 | 0.000 | 0.27 | 0.52 |
| P (common reward probability) | 1.33 | 0.21 | 6.39 | 7177 | 0.000 | 0.92 | 1.74 |
| DRUG | –0.13 | 0.08 | –1.65 | 7177 | 0.099 | –0.29 | 0.03 |
| ORDER | –0.13 | 0.08 | –1.57 | 7177 | 0.116 | –0.29 | 0.03 |
| C*P | –0.23 | 0.23 | –1.01 | 7177 | 0.311 | –0.67 | 0.21 |
| C*DRUG | 0.05 | 0.12 | 0.39 | 7177 | 0.695 | –0.19 | 0.28 |
| P*DRUG | –0.34 | 0.23 | –1.48 | 7177 | 0.140 | –0.79 | 0.11 |
| C*ORDER | –0.06 | 0.12 | –0.52 | 7177 | 0.606 | –0.30 | 0.17 |
| P*ORDER | 0.16 | 0.23 | 0.70 | 7177 | 0.482 | –0.29 | 0.61 |
| DRUG*ORDER | –0.24 | 0.17 | –1.41 | 7177 | 0.158 | –0.58 | 0.09 |
| C*P*DRUG | –0.08 | 0.45 | –0.18 | 7177 | 0.856 | –0.97 | 0.80 |
| C*P*ORDER | 0.57 | 0.45 | 1.26 | 7177 | 0.207 | –0.31 | 1.45 |
| C*DRUG*ORDER | –0.38 | 0.25 | –1.48 | 7177 | 0.140 | –0.87 | 0.12 |
| P*DRUG*ORDER | 0.46 | 0.83 | 0.55 | 7177 | 0.583 | –1.18 | 2.09 |
| C*P*DRUG*ORDER | 1.40 | 0.91 | 1.54 | 7177 | 0.123 | –0.38 | 3.17 |
Appendix 1—table 2
Mixed effects models on model-agnostic choice data from uncertainty trials.
| Name | Estimate | SE | t-Stat | DF | p-Value | Lower CI | Upper CI |
|---|---|---|---|---|---|---|---|
| Preferential MFCA for the informative destination (ghost-nominated, ‘repeat trials’ > ghost-rejected, ‘switch trials’)MFCA ~ NOM*DRUG*ORDER + (NOM + DRUG + ORDER | PART) | |||||||
| (Intercept) | 0.10 | 0.01 | 8.27 | 239 | 0.000 | 0.07 | 0.12 |
| NOM (nomination) | 0.03 | 0.02 | 1.57 | 239 | 0.117 | –0.01 | 0.08 |
| DRUG | 0.01 | 0.02 | 0.40 | 239 | 0.687 | –0.04 | 0.06 |
| ORDER | 0.00 | 0.02 | 0.13 | 239 | 0.895 | –0.04 | 0.05 |
| NOM*DRUG | 0.11 | 0.04 | 2.73 | 239 | 0.007 | 0.03 | 0.19 |
| NOM*ORDER | 0.02 | 0.04 | 0.51 | 239 | 0.613 | –0.06 | 0.10 |
| DRUG*ORDER | –0.03 | 0.05 | –0.73 | 239 | 0.467 | –0.12 | 0.06 |
| NOM*DRUG*ORDER | –0.01 | 0.09 | –0.04 | 239 | 0.966 | –0.18 | 0.17 |
| MFCA for non-informative destination (ghost-nominated > ghost-rejected, ‘clash trials’)REPEAT ~ N*I*DRUG*ORDER + (N*I*DRUG + ORDER | PART) | |||||||
| (Intercept) | 0.05 | 0.04 | 1.27 | 479 | 0.203 | –0.03 | 0.12 |
| N (non-informative) | 0.13 | 0.07 | 1.96 | 479 | 0.051 | 0.00 | 0.26 |
| I (informative) | 1.01 | 0.10 | 9.95 | 479 | 0.000 | 0.81 | 1.21 |
| DRUG | 0.16 | 0.07 | 2.31 | 479 | 0.021 | 0.02 | 0.29 |
| ORDER | 0.03 | 0.07 | 0.41 | 479 | 0.684 | –0.10 | 0.16 |
| N*U | 0.08 | 0.14 | 0.57 | 479 | 0.568 | –0.19 | 0.35 |
| N*DRUG | 0.05 | 0.13 | 0.39 | 479 | 0.696 | –0.21 | 0.31 |
| I*DRUG | 0.03 | 0.15 | 0.24 | 479 | 0.810 | –0.25 | 0.32 |
| N*ORDER | –0.05 | 0.13 | –0.34 | 479 | 0.733 | –0.30 | 0.21 |
| I*ORDER | 0.06 | 0.14 | 0.43 | 479 | 0.664 | –0.22 | 0.35 |
| DRUG*ORDER | –0.20 | 0.15 | –1.37 | 479 | 0.171 | –0.49 | 0.09 |
| N*I*DRUG | 0.07 | 0.29 | 0.26 | 479 | 0.798 | –0.49 | 0.64 |
| N*I*ORDER | 0.25 | 0.29 | 0.86 | 479 | 0.388 | –0.32 | 0.81 |
| N*DRUG*ORDER | –0.47 | 0.26 | –1.80 | 479 | 0.072 | –0.99 | 0.04 |
| I*DRUG*ORDER | –0.12 | 0.41 | –0.31 | 479 | 0.759 | –0.92 | 0.67 |
| N*I*DRUG*ORDER | 0.86 | 0.55 | 1.56 | 479 | 0.119 | –0.22 | 1.94 |
Appendix 1—table 3
Mixed effects models on parameters of the computational model.
| Name | Estimate | SE | t-Stat | DF | p-Value | Lower CI | Upper CI |
|---|---|---|---|---|---|---|---|
| MFCA for ghost-nominated vs. ghost-rejected and informative vs. non-informativeMFCA ~ NOM*INFO*DRUG*ORDER + (NOM*INFO*DRUG + ORDER | PART) | |||||||
| (Intercept) | 0.18 | 0.02 | 7.60 | 480 | 0.000 | 0.14 | 0.23 |
| NOM (nomination) | 0.10 | 0.03 | 3.72 | 480 | 0.000 | 0.05 | 0.15 |
| INFO (informativeness) | 0.08 | 0.04 | 2.19 | 480 | 0.029 | 0.01 | 0.15 |
| DRUG | 0.05 | 0.05 | 0.94 | 480 | 0.347 | –0.05 | 0.16 |
| ORDER | 0.04 | 0.05 | 0.73 | 480 | 0.463 | –0.06 | 0.15 |
| NOM*INFO | –0.03 | 0.05 | –0.57 | 480 | 0.567 | –0.12 | 0.06 |
| NOM*DRUG | 0.10 | 0.04 | 2.43 | 480 | 0.015 | 0.02 | 0.18 |
| INFO*DRUG | –0.08 | 0.07 | –1.16 | 480 | 0.247 | –0.22 | 0.06 |
| NOM*ORDER | 0.02 | 0.04 | 0.37 | 480 | 0.715 | –0.07 | 0.10 |
| INFO*ORDER | 0.10 | 0.07 | 1.42 | 480 | 0.157 | –0.04 | 0.23 |
| DRUG*ORDER | –0.09 | 0.10 | –0.98 | 480 | 0.328 | –0.28 | 0.10 |
| NOM*INFO*DRUG | 0.02 | 0.07 | 0.33 | 480 | 0.738 | –0.12 | 0.17 |
| NOM*INFO*ORDER | –0.01 | 0.07 | –0.08 | 480 | 0.934 | –0.15 | 0.14 |
| NOM*DRUG*ORDER | –0.06 | 0.11 | –0.60 | 480 | 0.551 | –0.27 | 0.15 |
| INFO*DRUG*ORDER | 0.16 | 0.14 | 1.10 | 480 | 0.272 | –0.12 | 0.44 |
| NOM*INFO*DRUG*ORDER | 0.10 | 0.19 | 0.55 | 480 | 0.585 | –0.26 | 0.47 |
| Preferential MFCA for informative vs. non-informativePMFCA ~ INFO*DRUG*ORDER + (INFO + DRUG + ORDER | PART) | |||||||
| (Intercept) | 0.10 | 0.03 | 3.71 | 240 | 0.000 | 0.05 | 0.15 |
| INFO (informativeness) | –0.03 | 0.05 | –0.57 | 240 | 0.568 | –0.12 | 0.07 |
| DRUG | 0.10 | 0.04 | 2.39 | 240 | 0.017 | 0.02 | 0.18 |
| ORDER | 0.02 | 0.04 | 0.36 | 240 | 0.720 | –0.07 | 0.10 |
| INFO*DRUG | 0.02 | 0.07 | 0.34 | 240 | 0.734 | –0.12 | 0.17 |
| INFO*ORDER | –0.01 | 0.07 | –0.08 | 240 | 0.933 | –0.15 | 0.14 |
| DRUG*ORDER | –0.06 | 0.11 | –0.60 | 240 | 0.552 | –0.27 | 0.15 |
| INFO*DRUG*ORDER | 0.10 | 0.19 | 0.55 | 240 | 0.585 | –0.27 | 0.47 |
Appendix 1—table 4
Distribution of parameters from the full computational model.
| Cond. | % | MFCA standard | MFCA info-nom | MFCA info-rej | MFCA non-info-nom | MFCA non-info-rej | MBCA | Perseveration- standard | perseveration-nominated | forget_MF | forget_MB | forget_Pers |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Placebo | 25 | 0.053 | –0.056 | –0.026 | –0.070 | –0.074 | 0.059 | –0.197 | –0.093 | 0.002 | 0.038 | 0.010 |
| 50 | 0.147 | 0.168 | 0.149 | 0.048 | 0.030 | 0.273 | 0.042 | 0.071 | 0.058 | 0.148 | 0.123 | |
| 75 | 0.364 | 0.479 | 0.391 | 0.333 | 0.204 | 0.454 | 0.383 | 0.353 | 0.519 | 0.521 | 0.428 | |
| Levodopa | 25 | 0.060 | –0.025 | –0.073 | –0.011 | –0.098 | 0.026 | –0.086 | –0.047 | 0.019 | 0.022 | 0.008 |
| 50 | 0.272 | 0.165 | 0.130 | 0.178 | 0.070 | 0.278 | 0.098 | 0.084 | 0.190 | 0.127 | 0.089 | |
| 75 | 0.574 | 0.517 | 0.383 | 0.390 | 0.291 | 0.367 | 0.346 | 0.374 | 0.598 | 0.508 | 0.492 |
Additional files
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Dopamine enhances model-free credit assignment through boosting of retrospective model-based inference
eLife 10:e67778.
https://doi.org/10.7554/eLife.67778




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}