A proteome-wide genetic investigation identifies several SARS-CoV-2-exploited host targets of clinical relevance
- Wellcome Sanger Institute, Wellcome Genome Campus, United Kingdom
- Open Targets, Wellcome Genome Campus, United Kingdom
- European Molecular Biology Laboratory, European Bioinformatics Institute (EMBL-EBI), Wellcome Genome Campus, United Kingdom
- Bristol-Myers Squibb, United States
- Medical Research Council (MRC) Integrative Epidemiology Unit, Department of Population Health Sciences, University of Bristol, United Kingdom
- Clinical Trial Service Unit and Epidemiological Studies Unit (CTSU), Nuffield Department of Population Health, University of Oxford, United Kingdom
- Medical Research Council Population Health Research Unit (MRC PHRU), Nuffield Department of Population Health, University of Oxford, United Kingdom
- Icelandic Heart Association, Iceland
- Faculty of Medicine, University of Iceland, Iceland
- Department of Biology, York Biomedical Research Institute, Hull York Medical School, University of York, United Kingdom
Figures
Figure 1
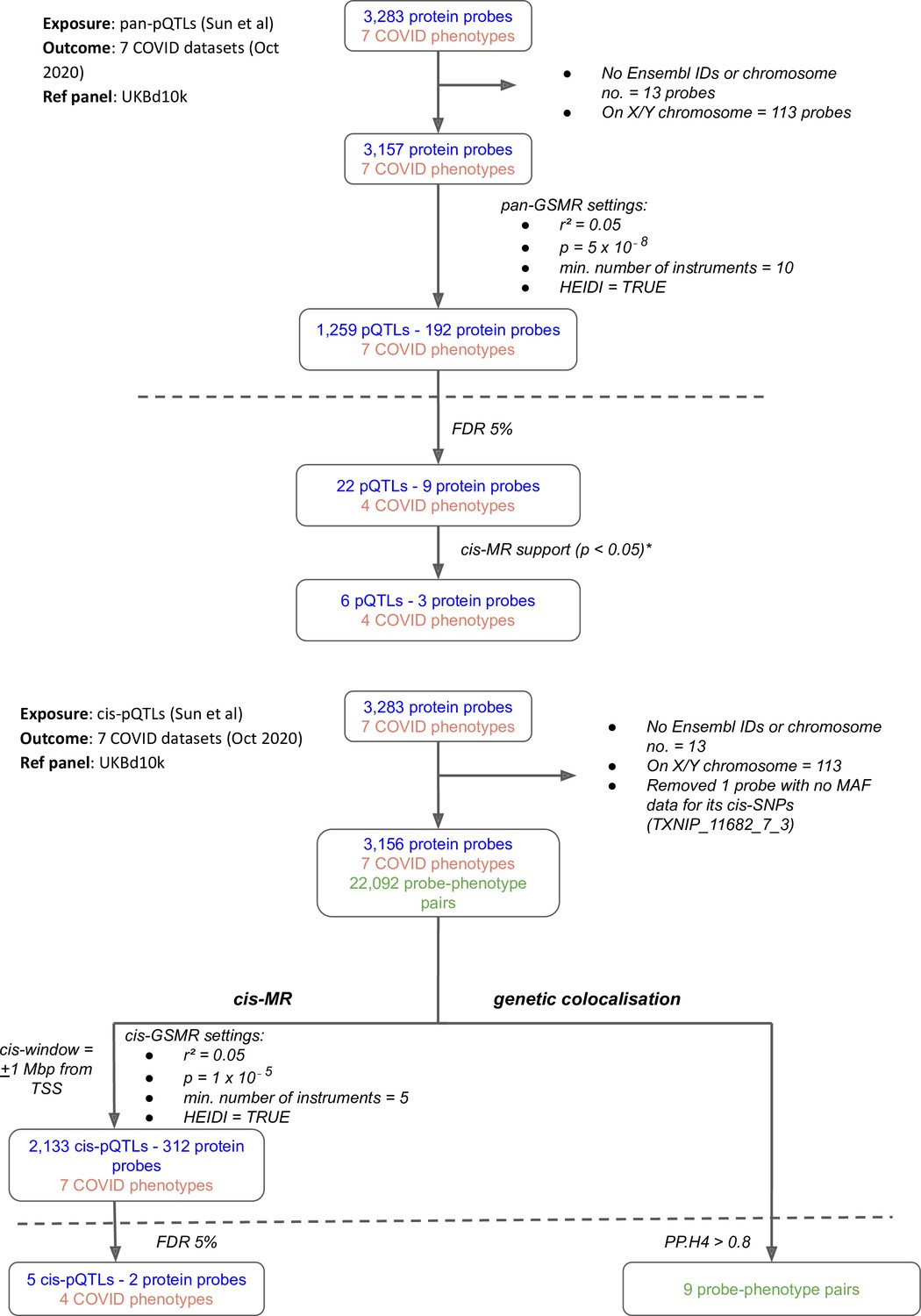
Flowcharts illustrating the process of (A) pan-Mendelian randomisation (MR) and (B) cis-MR and genetic colocalisation.
Both pan- and cis-MR methods used (Sun et al., 2018) as the source of genetic instruments and the UK Biobank downsampled 10k (UKBd10k) individual genotype data as reference panel. We selected near-independent genetic instruments and performed two sample MR analysis using generalised summary data-based Mendelian randomisation that adjusted for residual correlation between instruments. Genetic colocalisation analysis was used to estimate posterior probabilities of shared causal genetic signal between protein and outcomes. A posterior probability of shared causal genetic signal of more than 0.6 (i.e. a PP.H4 or posterior probability for hypothesis 4 > 0.6) was used as evidence of genetic colocalisation. The dashed line separates analysis (above the line) from target curation (below the line). *Only three proteins with pan-MR evidence of association with COVID also had cis-MR evidence support at nominal cis-MR p-value<0.05.
Figure 2
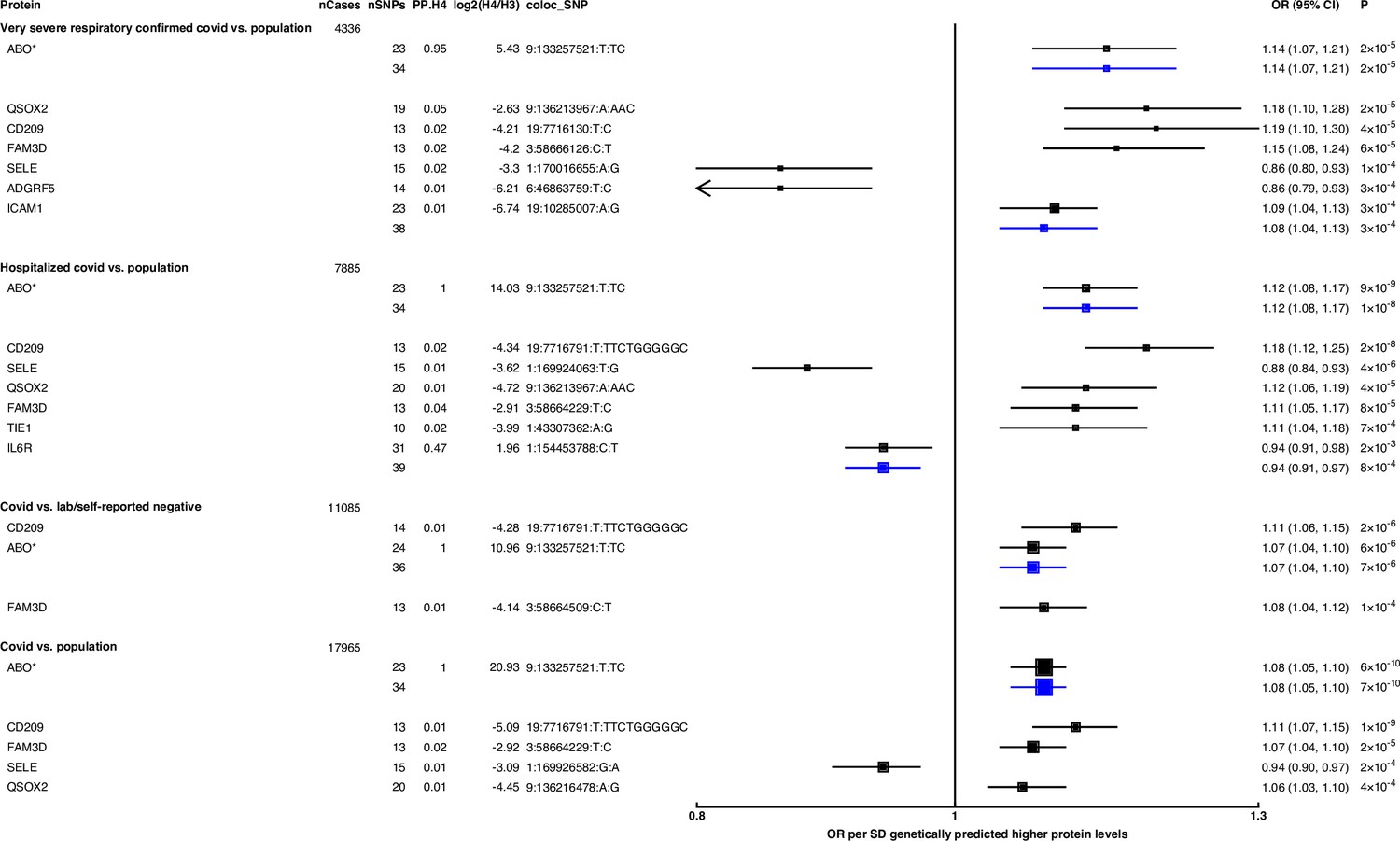
Forest plot illustrating associations of genetically predicted plasma protein concentrations with selected COVID-19 phenotypes.
The black point estimates represent odds ratios (ORs) of COVID-19 outcome per standard deviation (SD) increase of genetically predicted protein abundance using genetic instruments from across the genome (pan-Mendelian randomisation [pan-MR]). The blue point estimates represent OR of COVID outcome per SD increase of genetically predicted protein abundance using genetic instruments near or in the gene encoding the protein (cis-MR). Error bars represent 95% confidence intervals (95% CI). The areas of the squares are proportional to the inverse of the variance of the log ORs. For each COVID phenotype, pan-MR associations at FDR 5% were retained. Each row under a COVID phenotype represents a pQTL and includes the number of cases in the COVID phenotype (nCases), the number of SNPs used as genetic instruments for the protein (nSNPs), the posterior probability that protein and COVID traits colocalise (PP.H4), the posterior probability evidence for vs. against shared causal variants (log2(H4/H3)), and the candidate colocalising signal (coloc_SNP). * denotes proteins that have coloc_SNP that are either missense variants or in linkage disequilibrium with missense variants, rendering their effect estimates potentially biased.
Figure 3

Proteome-wide association of the ABO signal (rs8176719-insC) in (A) Sun et al. and (B) Emilsson et al. datasets.
The x-axis represents the chromosome for the gene encoding the protein. The y-axis represents the p-value of the per-allele association of rs8176719-insC (or an SNP in high linkage disequilibrium at r2 >0.8 with rs8176719-insC) with the proteins in Sun et al. and Emilsson et al. datasets. The red triangles point downwards and denote the inverse association of the ABO signal with the protein. The blue triangles point upwards and denote the positive association of the ABO signal with the protein. Only proteins that were considered significant at the study-specific Bonferroni-corrected p-value thresholds are displayed in this plot and tabulated in Supplementary file 6. (Supplementary file 6 also reports associations from an additional protein dataset – Suhre et al.).
Figure 4
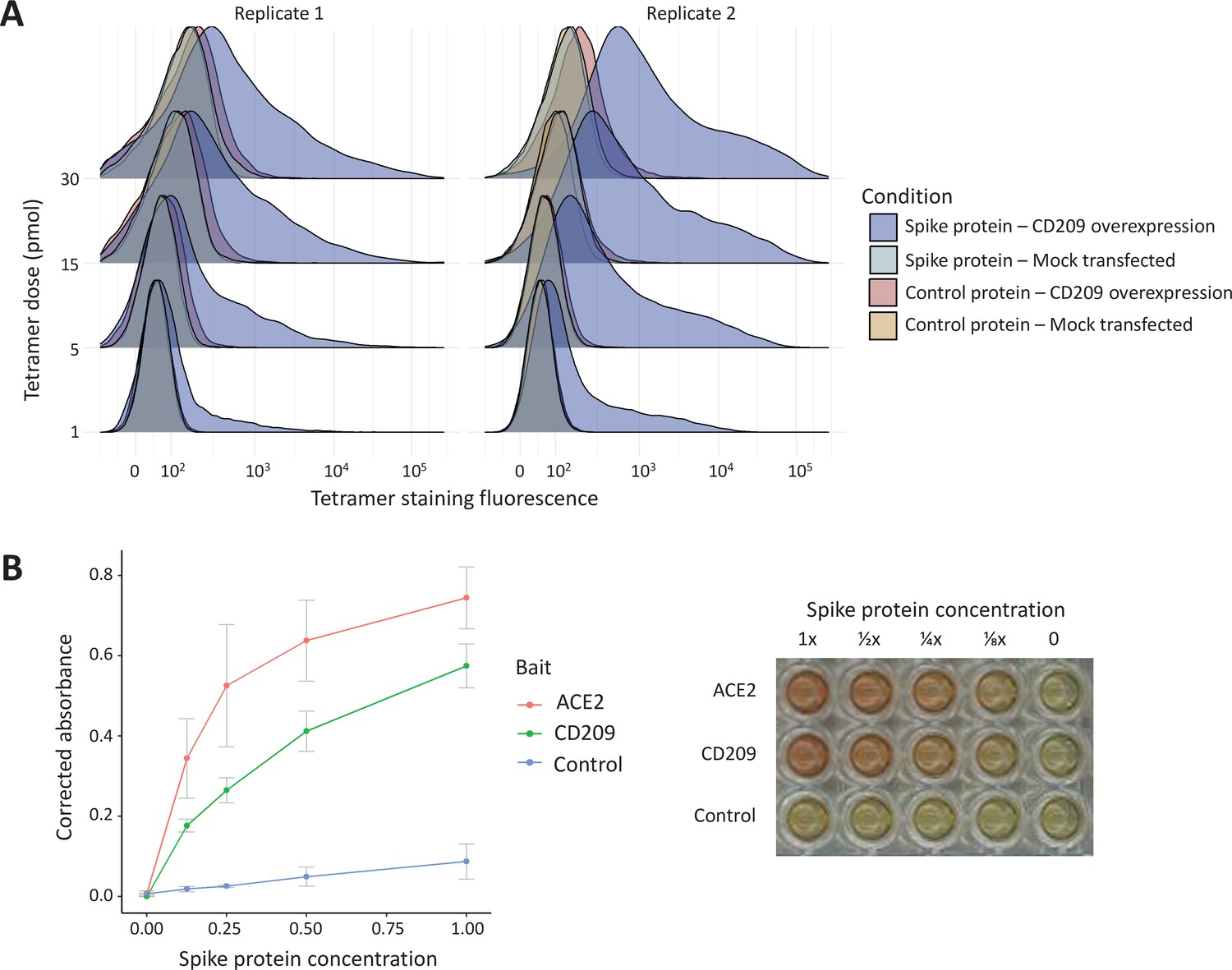
In vitro binding experiments with purified SARS-CoV-2 spike protein confirm human CD209 as a functional binding target.
(A) Human cell lines overexpressing cell-surface CD209 protein gain the ability to specifically bind SARS-CoV-2 spike. The density plots represent flow cytometry measurements of HEK293 cells stained with fluorescently conjugated tetramers of SARS-CoV-2 spike protein or a tag-only protein control. Blue distributions are cells with surface CD209, while red are control-transfected cells. Light shades indicate a negative control tetramer that was used for staining, while dark shades are stained with spike protein. (B) Purified recombinant CD209 ectodomains interact with the spike protein of SARS-CoV-2 in an in vitro binding assay. A dilution series of purified spike protein was applied over immobilised CD209, ACE2 (positive control), or a negative control protein. A plot of quantified absorbance is displayed alongside a representative assay plate. Error bars are standard deviations of two replicates.
Figure 5

Forest plot illustrating associations of genetically predicted plasma protein concentrations that colocalised with the selected COVID-19 phenotypes (PP.H4 > 0.6).
The black point estimates represent odds ratios (ORs) of COVID-19 outcome per standard deviation (SD) increase of genetically predicted protein abundance using single-SNP colocalising signals (coloc_SNP). Error bars represent the 95% confidence interval around the estimates. The areas of the squares are proportional to the inverse of the variance of the log ORs. * denotes proteins that have coloc_SNP that are either missense variants or in linkage disequilibrium with missense variants, rendering their effect estimates potentially biased.
Figure 6
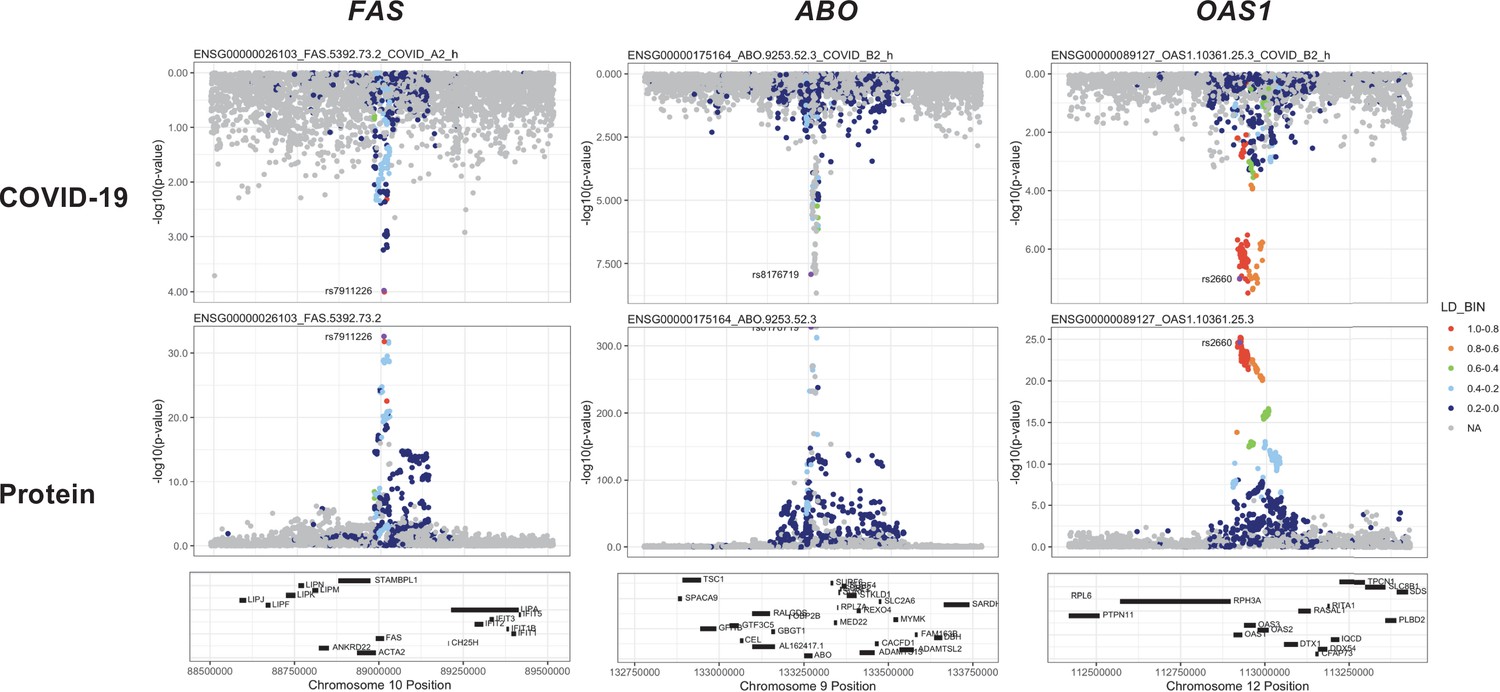
Regional association plots arranged to mirror the genetic associations of the colocalising proteins (FAS, ABO, and OAS1) with their respective COVID-19 phenotypes.
The top panels represent genetic associations of the selected COVID-19 phenotypes, and the bottom panels represent genetic associations of the protein from the Sun et al. dataset. The x-axis in each panel represents the genomic locations in or around the genes encoding FAS, ABO, and OAS1. The y-axis in each panel represents the p-value of the genetic associations.
Tables
Key resources table
| Reagent type (species) or resource | Designation | Source or reference | Identifiers | Additional information |
|---|---|---|---|---|
| Cell line (Homo sapiens) | HEK293-E | Yves Durocher, PMID:11788735 | RRID:CVCL_6974 | |
| Transfected construct (Homo sapiens) | pCMV6-CD209 | Origene | Cat.# SC304915 | Plasmid for CD209 cDNA expression in cell-based binding assay |
| Transfected construct (Homo sapiens) | pTT3-ACE2-BLH | PMID:33432067 | Plasmid for recombinant ACE2 extracellular domain, for plate-based assays as the immobilised form | |
| Transfected construct (Homo sapiens) | pTT3-CD209-BLH | This paper | Plasmid for recombinant CD209 extracellular domain for plate-based assays as the immobilised form | |
| Transfected construct (Homo sapiens) | pTT3-Cd4d3+ d4 | Addgene | RRID:Addgene_32402 | Plasmid for recombinant tag control (Cd4 domains 3 and 4) |
| Transfected construct (Homo sapiens) | pTT3-SPIKE-COMP-BLac | This paper | Plasmid for recombinant SARS-CoV-2 spike extracellular domain for plate-based assays as the soluble form | |
| Transfected construct (Homo sapiens) | pTT3-BirA-FLAG | Addgene | RRID:Addgene_64395 | Biotin ligase plasmid for recombinant protein biotinylation |
| Peptide, recombinant protein | Streptavidin R-phycoerythrin | BioLegend | Cat.# 405245 | For tetramer staining in cell-based binding assay |
| Chemical compound, drug | DAPI (4',6-diamidino-2-phenylindole) | BioLegend | Cat.# 422801 | 1 μM for flow cytometry live/dead staining |
| Chemical compound, drug | D-biotin | Sigma-Aldrich | Cat.# 2031 | 100 μM supplemented to cell culture media for biotinylation |
| Software, algorithm | R (version 4.0.3) | R Foundation | www.r-project.orgRRID:SCR_001905 | Analysis and generating plots |
Table 1
Summary of proteins reported in our study and the different sources of evidence supporting their prioritisation.
| Protein | Supported by multi-instrument pan-MR | Supported by multi-instrument cis-MR | Supported by GC and single-SNP cis-MR | Experimental support | Existing drugs | Previously reported | ||
|---|---|---|---|---|---|---|---|---|
| No. of cis-acting SNPs | No. of trans-acting SNPs | Trans-acting gene(s)* | ||||||
| ABO | 93 | 0 | None | ✓ | ✓ | x | x | ✓ |
| QSOX2 | 16 | 63 | ABO, OBP2B, ADAMTS13 | x | x | x | x | x |
| CD209 | 8 | 45 | ABO, SURF6 | x | x | ✓ | x | ✓ |
| FAM3D | 8 | 44 | ABO, SULT2B1, FAM83E, NTN5, FUT2 | x | x | x | x | x |
| SELE | 0 | 60 | ABO, FAM118B, RALGDS,OBP2B, ADAMTS13, SURF1 | x | x | x | ✓ | x |
| ADGRF5 | 5 | 9 | ABO, IL6ST, ADAMTS13 | x | x | x | x | x |
| ICAM1 | 71 | 1 | ABO | ✓ | x | x | ✓ | x |
| TIE1 | 2 | 18 | ABO, ST3GAL6, GBGT1, SURF6 | x | x | x | x | x |
| IL6R | 62 | 0 | None | ✓ | x | x | ✓ | ✓ |
| FAS | No | No | No | x | ✓ | x | x | x |
| OAS1 | No | No | No | x | ✓ | x | x | ✓ |
| THBS3 | No | No | No | x | ✓ | x | x | x |
-
Detailed description of each column is provided in Supplementary file 9.
-
*
Where trans-acting SNPs are used, genes assigned to SNPs with the highest variant-to-gene scores in Open Targets Genetics were used for annotation. GC: genetic colocalisation; MR: Mendelian randomisation.
Additional files
-
Supplementary file 1
Definitions of COVID outcomes.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp1-v2.xlsx
-
Supplementary file 2
Summary of proteins prioritised by pan-Mendelian randomisation.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp2-v2.xlsx
-
Supplementary file 3
Pan-Mendelian randomisation outcomes at p<0.05, each association divided into cis- or trans-pQTLs.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp3-v2.xlsx
-
Supplementary file 4
Cis-Mendelian randomisation outcomes at p<0.05.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp4-v2.xlsx
-
Supplementary file 5
Evaluation of pan-Mendelian randomisation association of protein probes that have passed the 5% FDR.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp5-v2.xlsx
-
Supplementary file 6
Protein-wide association studies (at study-specific Bonferroni thresholds) of the ABO signal using three proteomic datasets (Sun et al., Emilsson et al., Suhre et al.).
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp6-v2.xlsx
-
Supplementary file 7
Proteome-wide genetic colocalisation results.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp7-v2.xlsx
-
Supplementary file 8
Phenome-wide association study (p<0.05) from Open Targets Genetics portal for each colocalising variant.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp8-v2.xlsx
-
Supplementary file 9
Key to Table 1.
- https://cdn.elifesciences.org/articles/69719/elife-69719-supp9-v2.xlsx
-
Transparent reporting form
- https://cdn.elifesciences.org/articles/69719/elife-69719-transrepform1-v2.docx
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
A proteome-wide genetic investigation identifies several SARS-CoV-2-exploited host targets of clinical relevance
eLife 10:e69719.
https://doi.org/10.7554/eLife.69719




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}