Science Forum: Consensus-based guidance for conducting and reporting multi-analyst studies
- ELTE Eotvos Lorand University, Hungary
- Karolinska Institutet, Sweden
- Stockholm University, Sweden
- Tilburg University, Netherlands
- University of Groningen, Netherlands
- Utrecht University, Netherlands
- University Medical Center Groningen, University of Groningen, Netherlands
- Friesland Mental Health Care Services, Netherlands
- University of California Los Angeles, United States
- National Bureau of Economic Research, United States
- University of Amsterdam, Netherlands
- Dartmouth College, United States
- University of Münster, Germany
- University of Rennes, CNRS, Inria and Inserm, France
- McLean Hospital, United States
- Harvard Medical School, United States
- University of Missouri, United States
- National University of Singapore, Singapore
- University of New South Wales, Australia
- Stockholm School of Economics, Sweden
- University of Innsbruck, Austria
- University Hospital Basel, Switzerland
- Monash University, Australia
- University of Wisconsin-Madison, United States
- Ludwig-Maximilians-University, Germany
- Maastricht University, Netherlands
- Princeton University, United States
- University of Victoria, Canada
- Université Paris-Saclay, France
- Neurospin, CEA, France
- Amsterdam University, Netherlands
- University of Bristol, United Kingdom
- Center for Open Science, United States
- University of Virginia, United States
- Stanford University, United States
- University of Basel, Switzerland
- Tel Aviv University, Israel
- ESMT Berlin, Germany
- University College London, United Kingdom
- University of Sussex, United Kingdom
- University of Illinois, United States
- University of Alberta, Canada
- Lund University, United States
- University of Massachusetts Amherst, United States
- INSEAD, Singapore
Abstract
Any large dataset can be analyzed in a number of ways, and it is possible that the use of different analysis strategies will lead to different results and conclusions. One way to assess whether the results obtained depend on the analysis strategy chosen is to employ multiple analysts and leave each of them free to follow their own approach. Here, we present consensus-based guidance for conducting and reporting such multi-analyst studies, and we discuss how broader adoption of the multi-analyst approach has the potential to strengthen the robustness of results and conclusions obtained from analyses of datasets in basic and applied research.
Introduction
Empirical investigations often require researchers to make a large number of decisions about how to analyze the data. However, the theories that motivate investigations rarely impose strong restrictions on how the data should be analyzed. This means that empirical results typically hinge on analytical choices made by just one or a small number of researchers, and raises the possibility that different – but equally justifiable – analytical choices could lead to different results (Figure 1).
Figure 1
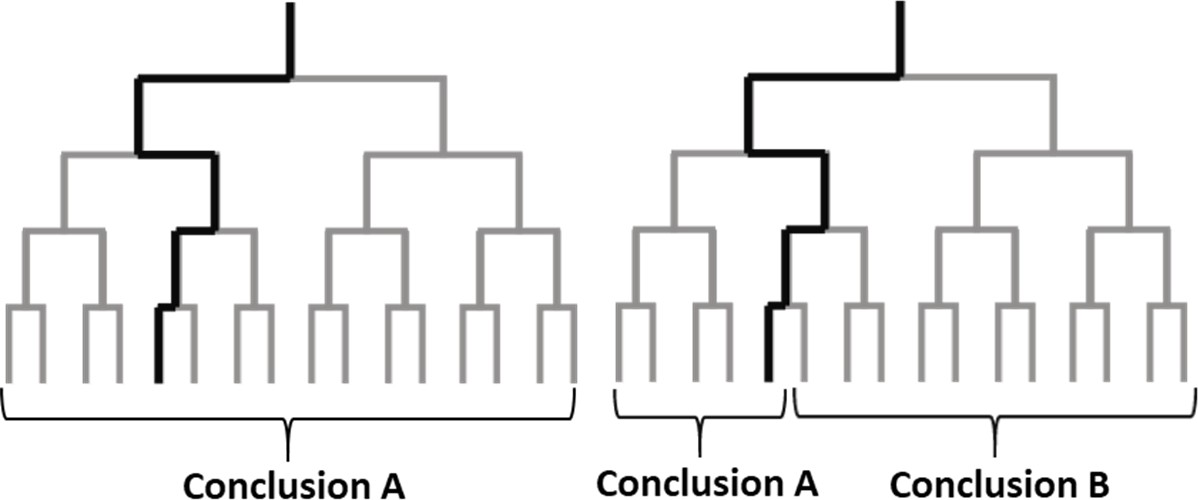
Analysis choices and alternative plausible paths.
The analysis of a large dataset can involve a sequence of analysis choices, as depicted in these schematic diagrams. The analyst first must decide between two options at the start of the analysis (top), and must make three additional decisions during the analysis: this leads to 16 possible paths for the analysis (grey lines). The left panel shows an example in which all possible paths lead to the same conclusion; the right panel shows an example in which some paths lead to conclusion A and other paths lead to conclusion B. Unless we can test alternative paths, we cannot know if the results obtained by following one particular path (thick black line) are robust, or if other plausible paths would lead to different results.
This "analytical variability" may be particularly high for datasets that were not initially collected for research purposes (such as electronic health records) because data analysts might know relatively little about how those data were collected and/or generated. However, when analyzing such datasets – and when making decisions based on the results of such analyses – it is important to be aware that the results will be subject to higher levels of analytical variability than the results obtained from analyses of data from, say, clinical trials. A recent example of the perils of analytical variability is provided by two articles in the journal Surgery that used the same dataset to investigate the same question: does the use of a retrieval bag during laparoscopic appendectomy reduce surgical site infections? Each paper used reasonable analysis, but there were notable differences between them in how they addressed inclusion and exclusion criteria, outcome measures, sample sizes, and covariates. As a result of these different analytical choices, the two articles reached opposite conclusions: one paper reported that using a retrieval bag reduced infections (Fields et al., 2019), and the other reported that it did not (Turner et al., 2019; see also Childers and Maggard-Gibbons, 2021). This and other medical examples (de Vries et al., 2010; Jivanji et al., 2020; Shah et al., 2021) illustrate how independent analysis of the same data can reach different, yet justifiable, conclusions.
The robustness of results and conclusions can be studied by evaluating multiple distinct analysis options simultaneously (e.g., vibration of effects [Patel et al., 2015] or multiverse analysis [Steegen et al., 2016]), or by employing a "multi-analyst approach" that involves engaging multiple analysts to independently analyze the same data. Rather than exhaustively evaluating all plausible analyses, the multi-analyst approach examines analytical choices that are deemed most appropriate by independent analysts. Botvinik-Nezer et al., 2020a, for example, asked 70 teams to test the same hypotheses using the same functional magnetic resonance imaging dataset. They found that no two teams followed the same data preprocessing steps or analysis strategies, which resulted in substantial variability in the teams’ conclusions. This and other work (Bastiaansen et al., 2020; van Dongen et al., 2019; Salganik et al., 2020; Silberzahn et al., 2018; Dutilh et al., 2018; Fillard et al., 2011; Starns et al., 2019; Maier-Hein et al., 2017; Poline et al., 2006) confirms how results can depend on analytic choices.
Although the multi-analyst approach will be new to many researchers, it has been in use since the 19th century. In 1857, for example, the Royal Asian Society asked four scholars to independently translate a previously unseen inscription to verify that the ancient Assyrian language had been deciphered correctly. The almost perfect overlap between the solutions indicated that “they have Truth for their basis” (Fox Talbot et al., 1861). The same approach can be used to analyze data today. With just a few co-analysts, the multi-analyst approach can be informative about the analytic robustness of results and conclusions. When the results of independent data analyses converge, more confidence in the conclusions is warranted. However, when the results diverge, confidence will be reduced, and scientists can examine the reasons for these discrepancies and identify potentially meaningful moderators of the results. With enough co-analysts, it is possible to estimate the variability among analysis strategies and attempt to identify factors explaining this variability.
The multi-analyst approach is still rarely used, but we argue that many disciplines could benefit from its broader adoption. To help researchers overcome practical challenges, we provide consensus-based guidance (including a checklist) to help researchers surmount the practical challenges of preparing, conducting, and reporting multi-analyst studies.
Methods
To develop this guidance, we recruited a panel of 50 methodology experts who followed a preregistered ‘reactive-Delphi’ expert consensus procedure (McKenna, 1994). We adopted this procedure to ensure that the resulting guidance represents the shared thinking of relevant experts and that it incorporates their topic-related insights. The applied consensus procedure and its reporting satisfy the recommendations of CREDES (Jünger et al., 2017), a guidance on conducting and reporting Delphi studies. A flowchart of the Delphi expert consensus procedure is available at https://osf.io/pzkcs/.
Preparation
Preregistering the project
Before the start of the project, on 11 November 2020, a research plan was compiled and uploaded to a time-stamped repository at https://osf.io/dgrua. During the project, we followed the preregistered plan in all respects except implementing slight changes in the wording of the survey questions to improve comprehension and not using R to analyze our results. We declared that we would share the R code and codebook of our analyses, but the project ultimately did not require us to conduct analyses in R. Instead, we shared our code in Excel and ODS format at https://osf.io/h36qy/.
Creating the initial multi-analyst guidance draft
Before the expert consensus process, the first three authors and the last author (henceforth: proposers) created an initial multi-analyst guidance draft after brainstorming and reviewing all the previously published multi-analyst-type projects they were aware of Bastiaansen et al., 2020; van Dongen et al., 2019; Salganik et al., 2020; Silberzahn et al., 2018; Botvinik-Nezer et al., 2020a; Dutilh et al., 2018; Fillard et al., 2011; Starns et al., 2019; Maier-Hein et al., 2017; Poline et al., 2006. This initial document is available here: https://osf.io/kv8jt/.
Recruiting experts
The proposers contacted 81 experts to join the project. The contacted experts included all the organizers of previous multi-analyst projects known at the time (Bastiaansen et al., 2020; van Dongen et al., 2019; Salganik et al., 2020; Silberzahn et al., 2018; Botvinik-Nezer et al., 2020a; Dutilh et al., 2018; Fillard et al., 2011; Starns et al., 2019; Maier-Hein et al., 2017; Poline et al., 2006), as well as the members of the expert panel from another methodological consensus project (Aczel et al., 2020). The previous projects were identified by conducting an unsystematic literature search and by surveying researchers in social media. Of the 81 experts, 3 declined our invitation and 50 accepted the invitation and participated in the expert consensus procedure (their names are available at https://osf.io/fwqvp/), while 28 experts did not respond to our call.
Preparatory rounds
Upon joining the project, the experts received a link to the preparatory online survey (available at https://osf.io/kv8jt/) which included the initial Multi-Analyst Guidance draft where they had the option to comment on each of the items and the overall content of the guidance.
Based on the feedback received from the preparatory online survey, the proposers updated and revised the initial Multi-Analyst Guidance. This updated document was uploaded to an online shared document and was sent out to the experts who had the option to edit and comment on the content. Again, based on feedback, the proposers revised the content of the document, and this new version was included in the expert consensus survey.
Consensus survey
The expert consensus questionnaire was sent out individually to each expert first on 8 February 2021 in the following Qualtrics survey available at https://osf.io/wrpnq/. The consensus survey approach had the advantage of minimizing potential biases in the experts’ judgments: the questions were posed in a neutral way, experts all received the same questions, and experts did not see the responses of the other experts or any reaction of the project organizers. The survey contained the ten recommended practices grouped into the following five stages:( i) recruiting co-analysts; (ii) providing the dataset, research questions, and research tasks; (iii) conducting the independent analyses; (iv) processing the results; (v) reporting the methods and results. The respondents were asked to rate each of the ten recommended practices on a nine-point Likert-type scale (‘I agree with the content and wording of this guidance section’ ranging from “1-Disagree” to “9-Agree”). Following each section, the respondents could leave comments regarding the given item.
The preregistration indicated consensus on the given item if the interquartile range of its ratings was two or smaller. It defined support for an item if the median rating was six or higher (as in Aczel et al., 2020).
Each recommended practice found support and consensus from the 48 experts who completed ratings in our first round. For each item, the median rating was eight or higher with an interquartile range of two or lower. Thus, following our preregistration, there was no need to conduct additional consensus-survey rounds; all of the items were eligible to enter the guidance with consensual support. This high level of consensus might have been due to the experts’ involvement in the preparatory round of the project. The summary table of the results is available at https://osf.io/qc7a8/.
Finalizing the manuscript
The proposers drafted the manuscript and supplements. All texts and materials were sent to the expert panel members. Each contributor was encouraged to provide feedback on the manuscript, the report, and the suggested final version of the guidance. After all discussions, minor wording changes were implemented, as documented at https://osf.io/e39j4/. No contributor objected to the content and form of the submitted materials and all approved the final item list.
Multi-analyst guidance
The final guidance includes ten recommended practices (Table 1) concerning the five main stages of multi-analyst studies. To further assist researchers in documenting multi-analyst projects, we also provide a modifiable reporting template (Supplementary file 1), as well as a reporting checklist (Supplementary file 2).
Table 1
Recommended practices for the main stages of the multi-analyst method.
| Stage | Recommended practices |
|---|---|
| Recruiting co-analysts | 1. Determine a minimum target number of co-analysts and outline clear eligibility criteria before recruiting co-analysts. We recommend that the final report justifies why these choices are adequate to achieve the study goals. 2. When recruiting co-analysts, inform them about (a) their tasks and responsibilities; (b) the project code of conduct (e.g., confidentiality/ non-disclosure agreements); (c) the plans for publishing the research report and presenting the data, analyses, and conclusion; (d) the conditions for an analysis to be included or excluded from the study; (e) whether their names will be publicly linked to the analyses; (f) the co-analysts’ rights to update or revise their analyses; (g) the project time schedule; and (h) the nature and criteria of compensation (e.g., authorship). |
| Providing datasets, research questions, and research tasks | 3. Provide the datasets accompanied with a codebook that contains a comprehensive explanation of the variables and the datafile structure. 4. Ensure that co-analysts understand any restrictions on the use of the data, including issues of ethics, privacy, confidentiality, or ownership. 5. Provide the research questions (and potential theoretically derived hypotheses that should be tested) without communicating the lead team’s preferred analysis choices or expectations about the conclusions. |
| Conducting the independent analyses | 6. To ensure independence, we recommend that co-analysts should not communicate with each other about their analyses until after all initial reports have been submitted. In general, it should be clearly explained why and at what stage co-analysts are allowed to communicate about the analyses (e.g., to detect errors or call attention to outlying data points). |
| Processing the results | 7. Require co-analysts to share with the lead team their results, the analysis code with explanatory comments (or a detailed description of their point-and-click analyses), their conclusions, and an explanation of how their conclusions follow from their results. 8. The lead team makes the commented code, results, and conclusions of all non-withdrawn analyses publicly available before or at the same time as submitting the research report. |
| Reporting the methods and results | 9. The lead team should report the multi-analyst process of the study, including (a) the justification for the number of co-analysts; (b) the eligibility criteria and recruitment of co-analysts; (c) how co-analysts were given the data sets and research questions; (d) how the independence of analyses was ensured; (e) the numbers of and reasons for withdrawals and omissions of analyses; (f) whether the lead team conducted an independent analysis; (g) how the results were processed; (h) the summary of the results of co-analysts; (i) and the limitations and potential biases of the study. 10. Data management should follow the FAIR principles (Wilkinson et al., 2016), and the research report should be transparent about access to the data and code for all analyses (Aczel et al., 2020). |
In addition to the Multi-analyst Guidance and Checklist, we provide practical considerations that can support the organization and execution of multi-analyst projects. This section contains various clarifications, recommendations, practical tools, and optional extensions, covering the five main stages of a multi-analyst project.
Recruiting co-analysts
Choosing co-analysts
The term co-analyst refers to one researcher or team of researchers working together in a multi-analyst project. Researchers can collaborate on the analyses, but if they do, we recommend that they submit the analyses as one co-analyst team, in order to ensure the independence of the analyses across teams. Researchers from the same lab or close collaborators should be able to submit separate reports in the multi-analyst project as long as they do not discuss their analyses with each other until the project rules allow that. The lead team may conduct an analysis themselves depending on the study goals and the design of the project (e.g., to set a performance baseline for comparing submitted models). Alternatively, the lead team may choose not to conduct an analysis themselves; in any case, they are expected to be transparent about their level of involvement as well as the timing (e.g., whether they conducted their analyses with or without knowing the results of the crowd of analysts).
Researchers should carefully consider both the breadth and depth of statistical and research-area expertise required for their project and should justify their choices about the required qualifications, skills, and credentials for analysts in the project. If the aim of the study is to explore what factors influence researchers’ analytical choices, then it can be useful to seek “natural variation” (representativeness) within an expert community or to maximize diversity of the co-analysts along the dimensions where they might differ the most in their choices (e.g., experience, background, discipline, interest in the findings, intellectual allegiance to different theories, paradigmatic viewpoints).
Deciding on the number of co-analysts
To decide on the desired number of co-analysts, one has to consider which of the two main purposes of the multi-analyst method applies to the given project:
Checking the robustness of the conclusions
The aim here is solely to check whether different analysts obtain the same conclusions. Confidence in the stability of the conclusions decreases with divergent results and increases with convergent results. Many projects can achieve this aim by recruiting only one additional analyst, or a handful of further analysts. For example, the above-mentioned two analyses of the same dataset published in the journal Surgery (Fields et al., 2019; Turner et al., 2019) were sufficient to detect that the analytical space allows for opposite conclusions.
Assessing the variability of the analyses
Those who wish to estimate the variability among the different analysis strategies often need to satisfy stricter demands. For example, studies that aim to assess how much the results vary among the analysts will require a larger number of co-analysts. When determining the number of co-analysts in such cases, the same factors need to be taken into consideration as in standard sample size estimation methods. For example, Botvinik-Nezer et al. (Botvinik-Nezer et al., 2020a) presented the analyses of 70 teams to demonstrate the divergence of results when analyzing a functional magnetic resonance imaging dataset.
Recruiting co-analysts
Depending on the specific goal of the research, the recruitment of co-analysts can happen in several ways. Co-analysts can be recruited before or after obtaining the dataset. With stricter eligibility criteria, co-analysts can be invited individually from among topic experts or statistical experts. Follow-up open invitations can ask experts to suggest others to be invited. Alternatively, the lead team can open the opportunity to anyone to join the project as a co-analyst within the expert community (e.g., in professional society mailing lists and on social media), where expertise can be defined as the topic requires it.
It is important to note that whenever the co-authors’ behavior is the subject of the study then they should be regarded similarly to human participants respecting ethical and data protection regulations. Useful templates for project advertisement and analyst surveys can be found in Silberzahn et al., 2018; Schweinsberg et al., 2021.
Providing the dataset, research questions, and research tasks
Providing the dataset
The lead team can invite the co-analysts to conduct data preprocessing (in addition to the main analysis). If the lead team decides to conduct the preprocessing themselves, showing their preprocessing methods can be informative to the co-analysts, but also has the potential to influence them if the preprocessing reflects some preference of methods or expectations of outcomes.
Before providing the dataset, the lead team should ensure that data management will comply with legal (e.g., the General Data Protection Regulation (GDPR) in the European Union) and ethical regulations applying to all teams (see Lundberg et al., 2019). If the dataset contains personal information, a version should be provided where data can no longer be related to an individual. An alternative is to provide a simulated dataset and ask the co-analysts to provide code to analyze the data (Drechsler, 2011; Quintana, 2020). The lead team can then run the code on the actual data.
It is important that the co-analysts understand not just the available dataset but also any ancillary information that might affect their analyses (e.g., prior exclusion of outliers or handling of missing data in the blinded dataset). Providing a codebook that is accessible and understandable for researchers with different backgrounds is essential (Kindel et al., 2019).
Providing the research question
The provided research question(s) should motivate the analysis conducted by the co-analysts. The research questions should be conveyed without specifying preferred analysis choices or expectations about the conclusions. Depending on the purpose of the project, the research questions can be more or less specific. While more specific research questions limit the analytical freedom of the co-analysts, less specific ones better explore the ways researchers can diverge in their operationalization of their question. A research question (e.g., “Is happiness age-dependent?”) can be more specific when, for example, it is formulated as a directional hypothesis (e.g., “Are young people more happy than old ones?”) or when the constructs are better operationalized (e.g., by defining what counts as young and happy).
Providing the task
The multi-analyst approach can leave the operationalization of the research question to the co-analysts so that they can translate the theoretical question into the measurement. Taking this approach can reveal the operational variations of a question, but it can also make it difficult to compare the statistical results.
Requesting results in terms of standardized metrics (e.g., t-values, standardized beta, Cohen’s d) makes it easier to compare results between co-analysts. The requested metric can be determined from the aim of the analysis (e.g., hypothesis testing, parameter estimation). It needs to be borne in mind, however, that this request might bias the analysis strategies towards using methods that easily provide such a metric. A practical tool with instructions on reporting effect estimates can be found in Parker et al., 2020.
Co-analysts should be asked to keep a record of any code, derivatives etc. that were part of the analysis, at least until the manuscript is submitted and all relevant materials are (publicly) shared.
As an extension, the co-analysts can be asked to record considered but rejected analysis choices and the reasoning behind their choices (e.g., by commented code, log-books, or dedicated solutions such as DataExplained [Schweinsberg et al., 2021]). These logs can reflect where and why co-analysts diverge in their choices.
Robustness, or multiverse analyses (in the sense that each team is free to provide a series of outcomes instead of a single one) can also be part of the task of the co-analysts so that multiple analyses are conducted under alternative data analysis preprocessing choices.
Communication with co-analysts
In projects with many co-analysts, keeping contact via a dedicated email address and automating some of the messages (e.g., automated emails when teams finished a stage in the process) can help streamline the communication and make the process less prone to human errors. For co-analyst teams with multiple members, it can be helpful for each team to nominate one member as the representative for communications.
If further information is provided to a co-analyst following specific questions, it can be useful to make sure the same information is provided to all teams, for example via a Q&A section of the project website, hosting weekly office hours where participants could ask questions, or via periodic email with updates.
Conducting the independent analyses
Preregistering the process and statistical analyses
We can distinguish meta- and specific preregistrations. Meta-preregistrations concern the plan of the whole multi-analyst project. It is good practice for the lead team to preregister how they would process, handle, and report the results of the co-analysts in order to prevent result-driven biases. This can be done in the form of a Registered Report at journals that invite such submissions (Chambers, 2013). Any metascientific questions, such as randomization of co-analysts to different conditions with variations in instructions or data, or covariates of interest for studying associations to analytic variability, should be specified.
Specific preregistrations concern the analysis plans of the co-analysts. Requiring co-analysts to prepare a specific preregistration for each analysis can be a strategy to prevent overfitting and undisclosed flexibility. It makes sense to require it from either all or none of the teams in order to maintain equal treatment among them (unless the effect of preregistration is a focus of the study).
Requiring specific preregistrations may be misaligned with the goals of the project when the aim is to explore how the analytic choices are formed during the analyses, independent of initial plans. Under such circumstances, requiring specific preregistrations may be counterproductive. Nevertheless, the lead team can record their meta-preregistration that lays down the details of the multi-analyst project.
There are alternative solutions to prevent researchers from being biased by their data and results. For example, co-analysts could be provided with blinded datasets (Dutilh et al., 2018; Starns et al., 2019; Gøtzsche, 1996), simulated datasets (Quintana, 2020), or with a subset of the data (e.g., 11).
Processing the results
Collecting the results
To facilitate summarizing the co-analysts’ methods, results, and conclusions, the lead team can collect results through provided templates or survey forms that can structure analysts’ reports. It is practical to ask the co-analysts at this stage to acknowledge that they did not communicate or cooperate with other co-analysts regarding the analysis in the project. It can also be helpful for the lead team if the co-analysts explain how their conclusions were derived from the results. In case preregistration was employed for any analyses, the template can also collect any deviations from the preregistered plan for inclusion in an online supplement.
To collect analytic code, it may be useful to require a container image (Boettiger, 2015; Nüst et al., 2020) or a portable version of the code that handles issues like software package availability (Liu and Salganik, 2019) (for a guideline see Elmenreich et al., 2019).
Validating the results
The lead team is recommended to ensure that each analyst’s codes/procedures reproduce that analyst’s submitted results. Computational reproducibility can be ascertained by running the code or repeating the analytic process by the lead team, but independent experts or the other co-analysts can also be invited to undertake this task (Hurlin and Perignon, 2019; Pérignon et al., 2019).
The project can leverage the crowd by asking co-analysts to review others’ analyses, or the lead team can employ external statistical experts to assess analyses and detect major errors. The lead team can decide to omit analyses with major errors. In that case, the reasons for omission should be documented, and for transparency, the results of the omitted analyses should be included in an online supplement.
After all the analyses have been submitted and validated, the co-analysts could have the option in certain projects to inspect the work of the other analysts and freely withdraw their own analyses. This can be appropriate if seeing other analyses makes them aware of major mistakes or shortcomings in their analytic procedures. A potential bias in this process is that co-analysts might lose confidence in their analyses after seeing other, more senior, or more expert co-analysts’ work. One way to decrease this potential bias is to follow a multi-stage process: after the first round of analyses is submitted, co-analysts could be allowed to see each other’s analysis steps/code without knowing the identity of the co-analyst or the results of their analysis. It is the lead team’s decision whether they allow co-analysts to correct or update their analyses after an external analyst or the co-analysts themselves find issues in their analyses.
Importantly, it is a minimum expectation that from the start of the project, the co-analysts should know about the conditions for their analyses to be included in, or omitted from, the study. All withdrawals, omissions, and updates of the results should be transparent in subsequent publications, for example in the supplementary materials.
Reporting the methods and results
Recording contributorship
Using CRediT taxonomy can transparently record organizers’ and co-analysts’ contributions to the study. Practical tools (e.g., tenzing Holcombe et al., 2020) can make this task easier. Co-analysts can be invited to be co-authors and/or be compensated for their contribution in other ways (e.g., prizes, honorariums). Expectations for contribution and authorship should be communicated clearly at the outset.
Presenting the methods and results
Beyond a descriptive presentation of results in a table or graph, the reporting of the results of multi-analyst projects is not straightforward and remains an open area of research. Published reports of multi-analyst projects have adopted several effective methods for presenting results. For binary outcomes, Botvinik-Nezer et al. used a table with color coding (i.e., a binary heat map) to visualize outcomes across all teams (Botvinik-Nezer et al., 2020b). They overlaid each teams’ confidence in their findings and added additional information about analytical paths in adjacent columns (Supplementary file 1, Table 1). For a project with a relatively small number of effect sizes for continuous outcomes, Schweinsberg et al. used interval plots combined with an indication of analytical choices underlying each estimate (Schweinsberg et al., 2021; Figure 3). Olsson Collentine et al. used funnel plots (Figure 2 in Olsson-Collentine et al., 2020), and Patel et al. used volcano plots to depict numerous, diverse outcomes with an intuitive depiction of clustering, akin to a multiverse analysis (Figures 1 and 2 in Patel et al., 2015).
If the main purpose is to estimate variability of analyses, it is interesting to investigate and report factors that might influence variability in the chosen analytic approaches and in the results obtained by these analytical approaches. If, on the other hand, the main purpose is to investigate the robustness of conclusions by assessing the degree to which different analysts obtain the same results, it is advisable to focus more on methods that produce only a single answer to the research question of interest. When each analysis team can provide multiple, distinct responses to the same research question, it becomes more difficult to explore how conclusions depend on the analysis choices because the individual analyses are no longer independent of each other.
The analytical approach of each co-analyst can be divided into discrete choices concerning, for instance, data preprocessing steps and decisions in model specification. If it is possible to recombine the individual choices (which will not always be the case as certain data preprocessing steps or method choices may only make sense if the aim is to fit a certain class of models), it may be worthwhile to create a larger set of possible analytical approaches that is made up of all possible combinations. In this case, the descriptive results of the multi-analyst project can be combined with a multiverse type approach (e.g., vibration of effects [Patel et al., 2015], multiverse analysis [Steegen et al., 2016], or specification curve [Simonsohn et al., 2020]) to quantify and compare the variability in results that can be explained by the different analytical choices (Patel et al., 2015; Liu et al., 2021). Additionally, this larger set of possible combinations can be helpful to present the results in an interactive user interface in which readers can explore how the results change as a function of certain analytical choices (Liu et al., 2021; Dragicevic et al., 2019). Finally, dividing the co-analysts' analytical approaches into individual choices may ultimately help in providing a unique answer to the research question of interest while accounting for the uncertainty in the choice of the analytical approach. While there are so far no approaches that would allow the derivation of a unique result that integrates all uncertain decisions, it may be a promising area of research to extend Bayesian approaches that account for model uncertainty (Hoeting et al., 1999) and measurement error (Richardson and Gilks, 1993).
To support the reporting of Multi-Analyst projects, we provide a freely modifiable Reporting Template available from here: https://osf.io/h9mgy/.
Limitations
The present work does not cover all aspects of multi-analyst projects. For instance, the multi-analyst approach outlined here entails the independent analysis of one or more datasets, but it should be acknowledged that other crowd-sourced analysis approaches might not require such independence of the analyses. Some of our practical considerations reflect disagreement and/or uncertainty within our expert panel, so they remain underspecified. Those include how to determine the number or eligibility of co-analysts for a project, how best to assess the validity of each analysis; and how to measure robustness of conclusions. Therefore, we emphasize that this consensus-based guidance is a first step towards the broader adoption of the multi-analyst approach in empirical research, and we hope and expect that our recommendations will be developed further in response to user feedback. Users of this guidance can provide feedback and suggestions for revisions at https://forms.gle/2fVqZAD3KKHVUDKq7.
Conclusions
This guidance document aims to facilitate adoption of the multi-analyst approach in both basic and clinical research. Although the multi-analyst approach is at an incipient stage of adoption, we believe that the scientific benefits greatly outweigh the extra logistics required, especially for projects with high relevance for clinical practice and policy making. The approach should have particular relevance when it indicates that applying different analysis strategies to a given dataset may lead to conflicting results. The multi-analyst approach allows a systematic exploration of the analytical space to assess whether the reported results and conclusions are dependent on the chosen analysis strategy, ultimately improving the transparency, reliability, and credibility of research findings.
We hope that our guidance here and in guideline databases will make it easier for researchers to adopt this approach to empirical analyses. We encourage journals and funders to consider recommending or requesting independent analyses whenever it is crucial to know whether the conclusions are robust to alternative analysis strategies.
Data availability
All anonymized data as well as the survey materials are publicly shared on the Open Science Framework page of the project: https://osf.io/4zvst/. Our methodology and data-analysis plan were preregistered. The preregistration document can be accessed at: https://osf.io/dgrua.
References
-
A consensus-based transparency checklistNature Human Behaviour 4:4–6.https://doi.org/10.1038/s41562-019-0772-6
-
An introduction to Docker for reproducible researchACM SIGOPS Operating Systems Review 49:71–79.https://doi.org/10.1145/2723872.2723882
-
The unconscious thought effect in clinical decision making: an example in diagnosisMedical Decision Making 30:578–581.https://doi.org/10.1177/0272989X09360820
-
ConferenceIncreasing the transparency of research papers with explorable multiverse analysesProceedings of the 2019 CHI Conference on Human Factors in Computing Systems. pp. 1–15.https://doi.org/10.1145/3290605.3300295
-
BookSynthetic Datasets for Statistical Disclosure Control: Theory and ImplementationSpringer Science & Business Media.https://doi.org/10.1007/978-1-4614-0326-5
-
The quality of response time data inference: A blinded, collaborative assessment of the validity of cognitive modelsPsychonomic Bulletin & Review 26:1051–1069.https://doi.org/10.3758/s13423-017-1417-2
-
Comparative translations of the inscription of Tiglath Pileser IJournal of the Royal Asiatic Society of Great Britain & Ireland 18:150–219.https://doi.org/10.1017/S0035869X00013666
-
Blinding during data analysis and writing of manuscriptsControlled Clinical Trials 17:285–290.https://doi.org/10.1016/0197-2456(95)00263-4
-
Reproducibility certification in economics researchSSRN Electronic Journal 1:3418896.https://doi.org/10.2139/ssrn.3418896
-
Boba: Authoring and visualizing multiverse analysesIEEE Transactions on Visualization and Computer Graphics 27:1753–1763.https://doi.org/10.1109/TVCG.2020.3028985
-
The Delphi technique: a worthwhile research approach for nursing?Journal of Advanced Nursing 19:1221–1225.https://doi.org/10.1111/j.1365-2648.1994.tb01207.x
-
Ten simple rules for writing Dockerfiles for reproducible data sciencePLOS Computational Biology 16:e1008316.https://doi.org/10.1371/journal.pcbi.1008316
-
Assessment of vibration of effects due to model specification can demonstrate the instability of observational associationsJournal of Clinical Epidemiology 68:1046–1058.https://doi.org/10.1016/j.jclinepi.2015.05.029
-
A Bayesian approach to measurement error problems in epidemiology using conditional independence modelsAmerican Journal of Epidemiology 138:430–442.https://doi.org/10.1093/oxfordjournals.aje.a116875
-
Same data, different conclusions: Radical dispersion in empirical results when independent analysts operationalize and test the same hypothesisOrganizational Behavior and Human Decision Processes 165:228–249.https://doi.org/10.1016/j.obhdp.2021.02.003
-
Many analysts, one data set: Making transparent how variations in analytic choices affect resultsAdvances in Methods and Practices in Psychological Science 1:337–356.https://doi.org/10.1177/2515245917747646
-
Specification curve analysisNature Human Behaviour 4:1208–1214.https://doi.org/10.1038/s41562-020-0912-z
-
Assessing theoretical conclusions with blinded inference to investigate a potential inference crisisAdvances in Methods and Practices in Psychological Science 2:335–349.https://doi.org/10.1177/2515245919869583
-
Increasing transparency through a multiverse analysisPerspectives on Psychological Science 11:702–712.https://doi.org/10.1177/1745691616658637
-
Multiple perspectives on inference for two simple statistical scenariosThe American Statistician 73:328–339.https://doi.org/10.1080/00031305.2019.1565553
Decision letter
-
Peter RodgersSenior and Reviewing Editor; eLife, United Kingdom
In the interests of transparency, eLife publishes the most substantive revision requests and the accompanying author responses.
Decision letter after peer review:
Thank you for submitting your article "Consensus-based guidance for conducting and reporting multi-analyst studies" to eLife for consideration as a Feature Article. Your article has been reviewed by three peer reviewers, and the evaluation has been overseen by the Peter Rogers, eLife Features Editor. The following individuals involved in review of your submission have agreed to reveal their identity: Florian Naudet; Ioana Cristea.
The reviewers and editors have discussed the reviews and we have drafted this decision letter to help you prepare a revised submission.
Summary:
The report describes a consensus-based guideline for multi-analyst studies. Overall, the manuscript provides very helpful suggestions, but I have some doubts about how much such a resource-intensive tool (beyond the rather simple version of independent reproducibility checks) will actually be used by researchers. As it stands now, the audience for such a guideline is both highly select and also I would imagine very limited (at least for now). On the other hand, as demonstrated by several papers the authors cite (such as Botvinik-Nezer et al.), the approach can have profound consequences for the practices of an entire field. However, there are a number of points that need to be addressed to make the article suitable for publication.
Essential revisions:
Section on Methods (for the expert consensus procedure)
1. Line 129: Please provide a reference for the "reactive Delphi" expert consensus procedure. Also, please comment on whether or not you followed any existing guidelines (eg CREDES) for reporting Delphi survey studies.
2. More information is needed on the process of recruiting experts. How was the list of existing many-analyst studies collected (e.g., systematic search, word of mouth)? What was the criteria for selecting "experts on research methodology"? What reasons were given by those experts who declined to get involved? Is there a minimal number of experts required for these kind of Delphi surveys? And what was the rationale for including only experts, and not a wider sample of people who might use the guideline in the future?
3. What was the rationale behind the threshold for expert consensus which was preregistered as IQR <= 2 and median >=6 (https://osf.io/dgrua)? I'm curious about why a minimum level of satisfaction wasn't sought (e.g. items 6 and 8 both have a response of "1", indicating maximum disagreement).
4. I think that more could be said in the text about the results of the consensus panel, and that consensus ratings for each item should at least be described in the main manuscript and not just by referencing a link to OSF.
5. It was a bit surprising to me that so there was so little disagreement between the expert panel on virtually all points of the guideline. This could be due to the fact that all the components of the guideline, with few exceptions, are pretty standard in terms of transparency and thus hard to disagree on (or might reflect that the relatively few multi-analyst studies conducted so far were conducted with an exceptionally high degree of rigor and transparency.) Please comment on this lack of disagreement.
Related to this, I found the section on "Practical Considerations" more nuanced and I assume there could have been some areas of disagreement in assembling this section. It would be interesting if the authors could reflect on some of these disagreements by, for instance, emphasizing points of discussion that were more controversial or where there was a more coagulated minority opinion, if any.
6. Sub-section on "Deciding on the number of co-analysts" (Lines 220-235).
My understanding is that the number of analysts needed may depend on the research question and also on the complexity of the dataset that would be analyzed. I would expect more discussion and guidance here. Currently, I don't think that this sub-section is really useful. Providing some examples would also be very helpful.
Section on Practical considerations
7. This section includes links/references for a couple of tools for any researchers who are considering embarking on their first many-analyst project (eg "instructions for reporting an effect estimate" and tenzing): it would be helpful to includes links/references for more such tools and resources, such as templates for providing the research task to many-analysts, a guide to automating emails, or a tutorial on using container images.
8. Line 271: Please provide examples of the standardized metrics that might be used for reporting results, and comment on how one might select one metric over another.
9. Please add a sub-section on "Providing the Research Questions" to the section "Providing the Dataset, Research Questions, and Research Tasks".
10. Sub-section on "Presenting the methods and results". Please give three or four examples of publications where the authors have done a good job of presenting their methods and results: please also cite the relevant figure(s) and/or table(s) for each example.
Other sections
11. Please add a paragraph to the "Conclusions" section on how you plan to disseminate these guidelines (eg, via the EQUATOR Network?)
12. There are guidelines on developing reporting guidelines for health research (eg Moher et al. 2010 Guidance for developers of health research reporting guidelines. DOI: https://doi.org/10.1371/journal.pmed.1000217). Please comment on whether or not you followed any such guidelines.
Improving the supplementary data
13. These comments are for the supplementary data file https://osf.io/qc7a8/ downloaded on 25 August 2021.
i) The excel formulas to calculate the Median and IQR are missing the rows for experts 45-49 (row 44 is blank, maybe this caused an error?). E.g. the formula in cell B53 is "=MEDIAN(B2:B44)", when it should be "=MEDIAN(B2:B50)". Fixing the formulas doesn't substantially change the results.
ii) There are no data descriptions provided in the excel file. It is not hard to work out what all the numbers and column headings mean by going back to the manuscript, but, given this is a conduct guideline and the last item is about the FAIR principles, it would be nice to lead by example and provide detailed metadata to make the document easy to re-use.
iii) Not all the data has been made publicly available. The registration page (https://osf.io/dgrua) said "All collected raw and processed anonymous data will be publicly shared on the OSF page of the project." Instead, only partial, processed data from the final consensus survey are provided (the free-text comments are not included). It would be great to see two raw files exported from Qualtrics (with names removed/anonymized): one for the preparatory survey, and one for the consensus survey.
https://doi.org/10.7554/eLife.72185.sa1Author response
Summary:
The report describes a consensus-based guideline for multi-analyst studies. Overall, the manuscript provides very helpful suggestions, but I have some doubts about how much such a resource-intensive tool (beyond the rather simple version of independent reproducibility checks) will actually be used by researchers. As it stands now, the audience for such a guideline is both highly select and also I would imagine very limited (at least for now). On the other hand, as demonstrated by several papers the authors cite (such as Botvinik-Nezer et al.), the approach can have profound consequences for the practices of an entire field. However, there are a number of points that need to be addressed to make the article suitable for publication.
We appreciate these thoughts and believe that the scientific benefits greatly outweigh the extra logistics required, especially for projects with high relevance of important theoretical or policy making questions. The guidelines, checklist, and reporting template that we disseminate here were designed to decrease the burden of those who plan to conduct multi-analyst projects.
Essential revisions:
Section on Methods (for the expert consensus procedure)
1. Line 129: Please provide a reference for the "reactive Delphi" expert consensus procedure. Also, please comment on whether or not you followed any existing guidelines (eg CREDES) for reporting Delphi survey studies.
We reviewed the CREDES Guideline and now indicate that our approach meets those recommendations. We added a citation for this method on page 4. We also added clarification where needed (e.g., rationale behind using a Delphi-procedure, more information on the expert panel, discussion of how our approach affects potential biases).
2. More information is needed on the process of recruiting experts. What was the criteria for selecting "experts on research methodology"?
The contacted experts included all the organisers of known multi-analyst projects at the time as well as members of an expert panel of another methodological consensus project (Aczel, B., Szaszi, B., Sarafoglou, A., Kekecs, Z., Kucharský, Š., Benjamin, D.,.… and Wagenmakers, E. J. (2020). A consensus-based transparency checklist. Nature Human Behaviour, 4, 4-6.). We clarified it on page 5.
How was the list of existing many-analyst studies collected (e.g., systematic search, word of mouth)?
We conducted an unsystematic literature search and then asked those who had contributed to multi-analyst studies whether they knew of other examples in the literature. A social media call also allowed us to gather a range of multi-analyst studies.
https://mobile.twitter.com/BalazsAczel/status/1301801254348300288. We describe this approach on page 5.
What reasons were given by those experts who declined to get involved?
Three invited experts declined, noting their lack of insight in the topic. 28 invitees did not respond to our call. We now document these non-responses and declined invitations in the manuscript on page 5.
Is there a minimal number of experts required for these kind of Delphi surveys?
Murphy et al’s (1998) investigation of this question found that the reliability of group judgements increases substantially with every additional panel member up to 6 members. Beyond 12 members, the added benefits to reliability become minimal. But, a larger group can increase the diversity of perspectives and makes the result somewhat more robust. We had 50 members in our expert panel.
Murphy, M. K., Black, N. A., Lamping, D. L., McKee, C. M., Sanderson, C. F., Askham, J., and Marteau, T. (1998). Consensus development methods, and their use in clinical guideline development. Health technology assessment (Winchester, England), 2(3), i–88.
And what was the rationale for including only experts, and not a wider sample of people who might use the guideline in the future?
As the multi-analyst approach concerns specific methodological issues, we sought input primarily from researchers with relevant expertise and experience. In the manuscript, we emphasize that this guidance is a first step toward the broader adoption of the multi-analyst approach. We hope that our recommendations will be developed further based on feedback from adopters. We added a survey link to page 14 to collect such feedback and suggestions.
3. What was the rationale behind the threshold for expert consensus which was preregistered as IQR <= 2 and median >=6 (https://osf.io/dgrua)? I'm curious about why a minimum level of satisfaction wasn't sought (e.g. items 6 and 8 both have a response of "1", indicating maximum disagreement).
We used those thresholds based on this consensus paper:
https://www.nature.com/articles/s41562-019-0772-6. We judged that coherence (IQR) and summary level of support (median) are better indicators of the panel’s general thinking than are outlier values. We now cite this reference on page 5.
4. I think that more could be said in the text about the results of the consensus panel, and that consensus ratings for each item should at least be described in the main manuscript and not just by referencing a link to OSF.
We have improved the prose in that section. The paragraphs now are in page 5-6:
“The preregistration indicated consensus on the given item if the interquartile range of its ratings was 2 or smaller. […] The summary table of the results is available at https://osf.io/qc7a8/”.
As we had relatively high agreement with low variance for each item, we would prefer not to include information on each item in the paper. If the editor feels it’s essential, we could add a table (such as the one below) to the manuscript, but we felt that it would provide limited additional information beyond the description in the text.
Author response table 1
| Item1 | Item2 | Item3 | Item4 | Item5 | Item6 | Item7 | Item8 | Item9 | Item10 | |
|---|---|---|---|---|---|---|---|---|---|---|
| Median ratings | 8 | 9 | 9 | 9 | 9 | 9 | 8.5 | 9 | 9 | 9 |
| Interquar-tile range | 2 | 1 | 1 | 0 | 1.25 | 1.25 | 1.25 | 1 | 1 |
5. It was a bit surprising to me that so there was so little disagreement between the expert panel on virtually all points of the guideline. This could be due to the fact that all the components of the guideline, with few exceptions, are pretty standard in terms of transparency and thus hard to disagree on (or might reflect that the relatively few multi-analyst studies conducted so far were conducted with an exceptionally high degree of rigor and transparency.) Please comment on this lack of disagreement.
The high level of agreement might be due to the fact that we had a Preparatory Round before the consensus ratings. During this round, the experts could comment on each item and the overall content of the guidance. Based on their feedback, the core team updated and revised the initial draft. Then, the experts had a new option to edit and comment on the content. As a result, the item list that they rated had already incorporated many of their insights. We now discuss this procedure more fully and note that it could contribute to the high levels of agreement. (See quote in previous reply.)
Related to this, I found the section on "Practical Considerations" more nuanced and I assume there could have been some areas of disagreement in assembling this section. It would be interesting if the authors could reflect on some of these disagreements by, for instance, emphasizing points of discussion that were more controversial or where there was a more coagulated minority opinion, if any.
Thank you for this suggestion. We have added discussion of these disagreements to our Limitations section on page 13-14:
“Some of our practical considerations reflect disagreement and/or uncertainty within our expert panel, so they remain underspecified. […] Therefore, we emphasise that this consensus-based guidance is a first step towards the broader adoption of the multi-analyst approach in empirical research, and we hope and expect that our recommendations will be developed further in response to user feedback.”
6. Sub-section on "Deciding on the number of co-analysts" (Lines 220-235).
My understanding is that the number of analysts needed may depend on the research question and also on the complexity of the dataset that would be analyzed. I would expect more discussion and guidance here. Currently, I don't think that this sub-section is really useful. Providing some examples would also be very helpful.
We see value in drawing attention to the two distinct motivations for employing a multi-analyst approach – they have different requirements. We have added examples to each subsection on page 8.
Section on Practical considerations
7. This section includes links/references for a couple of tools for any researchers who are considering embarking on their first many-analyst project (eg "instructions for reporting an effect estimate" and tenzing): it would be helpful to includes links/references for more such tools and resources, such as templates for providing the research task to many-analysts, a guide to automating emails, or a tutorial on using container images.
We added references to further templates and guidelines on pages 9 and 11.
8. Line 271: Please provide examples of the standardized metrics that might be used for reporting results, and comment on how one might select one metric over another.
We added examples and explanations on page 10.
9. Please add a sub-section on "Providing the Research Questions" to the section "Providing the Dataset, Research Questions, and Research Tasks".
Done.
10. Sub-section on "Presenting the methods and results". Please give three or four examples of publications where the authors have done a good job of presenting their methods and results: please also cite the relevant figure(s) and/or table(s) for each example.
We badded the following paragraph to this subsection with examples and relevant figure numbers on pages 12-13:
“Published reports of multi-analyst projects have adopted several effective methods for presenting results For binary outcomes, Botvinik-Nezer et al. (39) used a table with colour coding (i.e., a binary heat map) to visualise outcomes across all teams. […] Olsson Collentine et al. (40) (Figure 2) used funnel plots and Patel et al. (7) (Figures 1 and 2) used volcano plots to depict numerous, diverse outcomes with an intuitive depiction of clustering (akin to a multiverse analysis).”
Other sections
11. Please add a paragraph to the "Conclusions" section on how you plan to disseminate these guidelines (eg, via the EQUATOR Network?)
Added it on page 14.
12. There are guidelines on developing reporting guidelines for health research (eg Moher et al. 2010 Guidance for developers of health research reporting guidelines. DOI: https://doi.org/10.1371/journal.pmed.1000217). Please comment on whether or not you followed any such guidelines.
We reviewed CREDES, a guideline for conducting and reporting Delphi studies, and added the following sentence to the manuscript on page 4:
“The applied consensus procedure and its reporting satisfy the recommendations of the CREDES (21) guideline on conducting and reporting Delphi studies.”
Improving the supplementary data
13. These comments are for the supplementary data file https://osf.io/qc7a8/ downloaded on 25 August 2021.
i) The excel formulas to calculate the Median and IQR are missing the rows for experts 45-49 (row 44 is blank, maybe this caused an error?). E.g. the formula in cell B53 is "=MEDIAN(B2:B44)", when it should be "=MEDIAN(B2:B50)". Fixing the formulas doesn't substantially change the results.
We really appreciate your thorough review of the accompanying code! Because of the blank row, our calculation included a mistake. We fixed the formulas and updated the supplementary materials and main text accordingly. Fixing the formulas does not substantially change the results.
ii) There are no data descriptions provided in the excel file. It is not hard to work out what all the numbers and column headings mean by going back to the manuscript, but, given this is a conduct guideline and the last item is about the FAIR principles, it would be nice to lead by example and provide detailed metadata to make the document easy to re-use.
We added detailed meta-data to the data file to make it easier to use.
iii) Not all the data has been made publicly available. The registration page (https://osf.io/dgrua) said "All collected raw and processed anonymous data will be publicly shared on the OSF page of the project." Instead, only partial, processed data from the final consensus survey are provided (the free-text comments are not included). It would be great to see two raw files exported from Qualtrics (with names removed/anonymized): one for the preparatory survey, and one for the consensus survey.
We have added the anonymized raw files to the OSF page.
https://doi.org/10.7554/eLife.72185.sa2Article and author information
Author details
Jojanneke A Bastiaansen

Rotem Botvinik-Nezer
Noah NN van Dongen
Johnny B van Doorn
Morton Ann Gernsbacher
Magnus Johannesson
Jean-Francois Mangin
Russell A Poldrack
Don van Ravenzwaaij
Martin Schweinsberg
Funding
Netherlands Organisation for Scientific Research (406-17-568)
- Alexandra Sarafoglou
Natural Sciences and Engineering Research Council of Canada (BP-546283-2020)
- Samuel St-Jean
Fonds de Recherche du Québec - Nature et Technologies (290978)
- Samuel St-Jean
European Research Council (726361)
- Jelte Wicherts
- Olmo R van den Akker
European Research Council (681466)
- Yoram K Kunkels
VIDI fellowship organisation (016.Vidi.188.001)
- Don van Ravenzwaaij
VENI fellowship grant (Veni 191G.037)
- Laura F Bringmann
National Science Foundation (1760052)
- Matthew J Salganik
Weizmann Institute of Science (Israel National Postdoctoral Award Program for Advancing Women in Science)
- Rotem Botvinik-Nezer
John Templeton Foundation, Templeton World Charity Foundation, Templeton Religion Trust, and Arnold Ventures
- Brian A Nosek
Institut Européen d'Administration des Affaires
- Eric Luis Uhlmann
European Research Council (640638)
- Noah NN van Dongen
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Publication history
- Received:
- Accepted:
- Accepted Manuscript published:
- Version of Record published:
Copyright
© 2021, Aczel et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,981
- views
-
- 383
- downloads
-
- 47
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 47
- citations for umbrella DOI https://doi.org/10.7554/eLife.72185
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Science Forum: Consensus-based guidance for conducting and reporting multi-analyst studies
eLife 10:e72185.
https://doi.org/10.7554/eLife.72185




{kind=link}