Are single-peaked tuning curves tuned for speed rather than accuracy?
- Division of Information Science and Engineering, KTH Royal Institute of Technology, Sweden
- Division of Computational Science and Technology, KTH Royal Institute of Technology, Sweden
Abstract
According to the efficient coding hypothesis, sensory neurons are adapted to provide maximal information about the environment, given some biophysical constraints. In early visual areas, stimulus-induced modulations of neural activity (or tunings) are predominantly single-peaked. However, periodic tuning, as exhibited by grid cells, has been linked to a significant increase in decoding performance. Does this imply that the tuning curves in early visual areas are sub-optimal? We argue that the time scale at which neurons encode information is imperative to understand the advantages of single-peaked and periodic tuning curves, respectively. Here, we show that the possibility of catastrophic (large) errors creates a trade-off between decoding time and decoding ability. We investigate how decoding time and stimulus dimensionality affect the optimal shape of tuning curves for removing catastrophic errors. In particular, we focus on the spatial periods of the tuning curves for a class of circular tuning curves. We show an overall trend for minimal decoding time to increase with increasing Fisher information, implying a trade-off between accuracy and speed. This trade-off is reinforced whenever the stimulus dimensionality is high, or there is ongoing activity. Thus, given constraints on processing speed, we present normative arguments for the existence of the single-peaked tuning organization observed in early visual areas.
Editor's evaluation
This fundamental study provides important insight into coding strategies in sensory areas. The study was well done, and the analysis and simulations were highly convincing. This study should be of particular interest to anybody who cares about efficient coding.
https://doi.org/10.7554/eLife.84531.sa0Introduction
One of the fundamental problems in systems neuroscience is understanding how sensory information can be represented in the spiking activity of an ensemble of neurons. The problem is exacerbated by the fact that individual neurons are highly noisy and variable in their responses, even to identical stimuli (Arieli et al., 1996). A common feature of early sensory representation is that the neocortical neurons in primary sensory areas change their average responses only to a small range of features of the sensory stimulus. For instance, some neurons in the primary visual cortex respond to moving bars oriented at specific angles (Hubel and Wiesel, 1962). This observation has led to the notion of tuning curves. Together, a collection of tuning curves provides a possible basis for a neural code.
A considerable emphasis has been put on understanding how the structure of noise and correlations affect stimulus representation given a set of tuning curves (Shamir and Sompolinsky, 2004; Averbeck and Lee, 2006; Franke et al., 2016; Zylberberg et al., 2016; Moreno-Bote et al., 2014; Kohn et al., 2016). More recently, the issue of local and catastrophic errors, dating back to the work of Shannon (Shannon, 1949), has been raised in the context of neuroscience (e.g. Xie, 2002; Sreenivasan and Fiete, 2011). Intuitively, local errors are small estimation errors that depend on the trial-by-trial variability of the neural responses and the local shapes of the tuning curves surrounding the true stimulus condition (Figure 1a bottom plot, see s1). On the other hand, catastrophic errors are very large estimation errors that depend on the trial-by-trial variability and the global shape of the tuning curves (Figure 1a bottom plot, see s2). While a significant effort has been put into studying how stimulus tuning and different noise structures affect local errors, less is known about the interactions with catastrophic errors. For example, Fisher information is a common measure of the accuracy of a neural code (Brunel and Nadal, 1998; Abbott and Dayan, 1999; Guigon, 2003; Moreno-Bote et al., 2014; Benichoux et al., 2017). The Cramér-Rao bound states that a lower limit of the minimal mean squared error (MSE) for any unbiased estimator is given by the inverse of Fisher information (Lehmann and Casella, 1998). Thus, increasing Fisher information reduces the lower bound on MSE. However, because Fisher information can only capture local errors, the true MSE might be considerably larger in the presence of catastrophic errors (Xie, 2002; Kostal et al., 2015; Malerba et al., 2022), especially if the available decoding time is short (Bethge et al., 2002; Finkelstein et al., 2018).
Figure 1
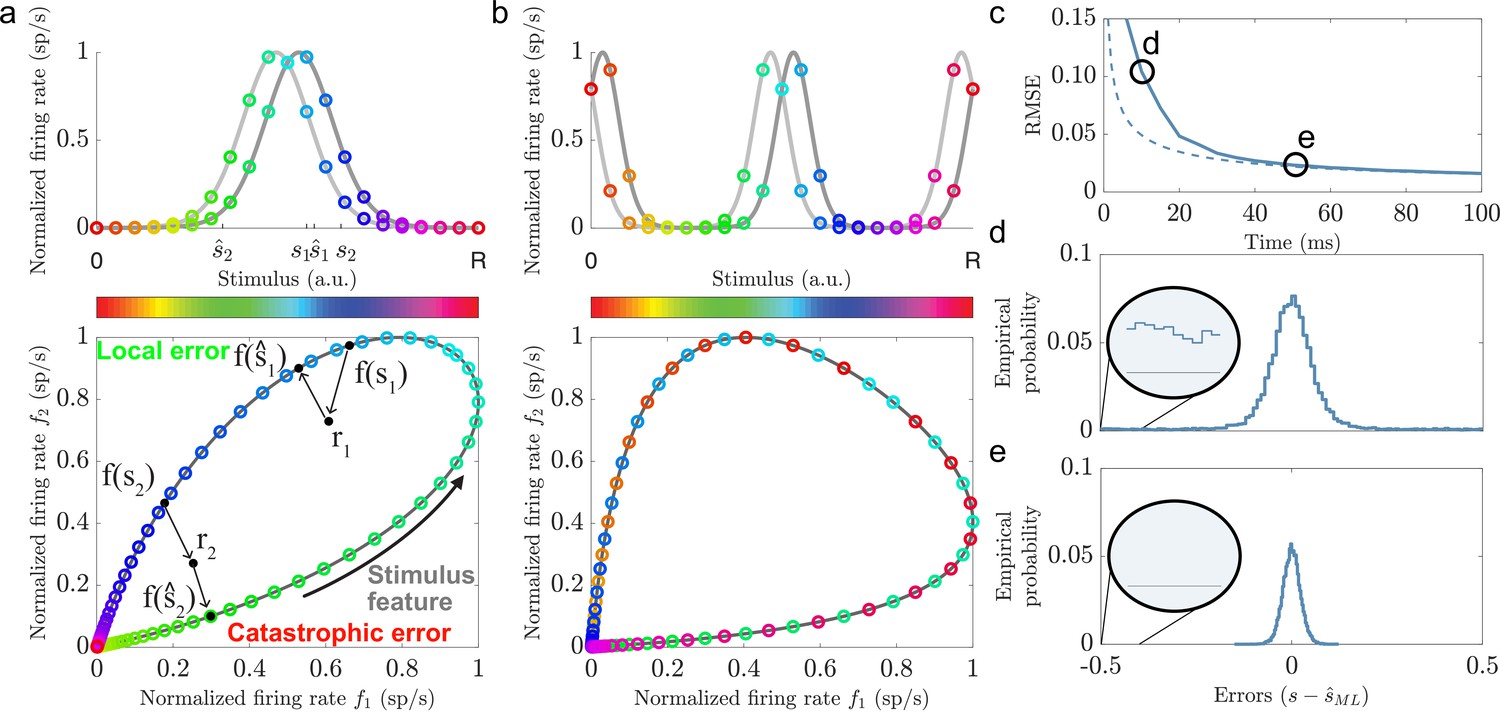
Illustrations of local and catastrophic errors.
(a) Top: A two-neuron system encoding a single variable using single-peaked tuning curves (). Bottom: The tuning curves create a one-dimensional activity trajectory embedded in a two-dimensional neural activity space (black trajectory). Decoding the two stimulus conditions, s1 and s2, illustrates the two types of estimation errors that can occur due to trial-by-trial variability, local () and catastrophic (). (b) Same as in (a) but for periodic tuning curves (). Notice that the stimulus conditions are intermingled and that the stimulus can not be determined from the firing rates. (c) Time evolution of the root mean squared error (RMSE) using maximum likelihood estimation (solid line) and the Cramér-Rao bound (dashed line) for a population of single-peaked tuning curves (, , average evoked firing rate sp/s, and sp/s). For about 50 ms the RMSE is significantly larger than the predicted lower bound. (d) The empirical error distributions for the time point indicated in (c), where the RMSE strongly deviates from the predicted lower bound. Inset: A non-zero empirical error probability spans the entire stimulus domain. (e) Same as in (d) when the RMSE roughly converges to the Cramér-Rao bound. Notice the absence of large estimation errors.
A curious observation is that the tuning curves in early visual areas predominately use single-peaked firing fields, whereas grid cells in the entorhinal cortex are known for their periodically distributed firing fields (Hafting et al., 2005). It has been shown that the multiple firing locations of grid cells increase the precision of the neural code compared to single-peaked tuning curves (Sreenivasan and Fiete, 2011; Mathis et al., 2012; Wei et al., 2015). This raises the question of why periodic firing fields are not a prominent organization of early visual processing too?
The theoretical arguments in favor of periodic tuning curves have mostly focused on local errors under the assumption that catastrophic errors are negligible (Sreenivasan and Fiete, 2011). However, given the response variability, it takes a finite amount of time to accumulate a sufficient number of spikes to decode the stimulus. Given that fast processing speed is a common feature of visual processing (Thorpe et al., 1996; Fabre-Thorpe et al., 2001; Rolls and Tovee, 1994; Resulaj et al., 2018), it is crucial that each neural population in the processing chain can quickly produce a reliable stimulus-evoked signal. Therefore, the time required to produce signals without catastrophic errors will likely put fundamental constraints on any neural code, especially in early visual areas.
Here, we contrast Fisher information with the minimal decoding time required to remove catastrophic errors (i.e. the time until Fisher information becomes a reasonable descriptor of the MSE). We base the results on the maximum likelihood estimator for uniformly distributed stimuli (i.e., the maximum a posteriori estimator) using populations of tuning curves with different numbers of peaks. We show that the minimal decoding time tends to increase with increasing Fisher information in the case of independent Poissonian noise to each neuron. This suggests a trade-off between the decoding accuracy of a neural population and the speed by which it can produce a reliable signal. Furthermore, we show that the difference in minimal decoding time grows with the number of jointly encoded stimulus features (stimulus dimensionality) and in the presence of ongoing (non-specific) activity. Thus, single-peaked tuning curves require shorter decoding times and are more robust to ongoing activity than periodic tuning curves. Finally, we illustrate the issue of large estimation errors and periodic tuning in simple spiking neural network model tracking either a step-like stimulus change or a continuously time-varying stimulus.
Results
Shapes of tuning curves, Fisher information, and catastrophic errors
To enable a comparison between single-peaked and periodic (multi-peaked) tuning curves, we consider circular tuning curves responding to a D-dimensional stimulus, , according to
(1)
where ai is the peak amplitude of the stimulus-related tuning curve , is a width scaling parameter, defines the spatial period of the tuning curve, determines the location of the peak(s) in the :th stimulus dimension, and determines the amount of ongoing activity (see Figure 1a–b, top panels). The parameters are kept fixed for each neuron, thus ignoring any effect of learning or plasticity. In the following, the stimulus domain is set to for simplicity. To avoid boundary effects, we assume that the stimulus has periodic boundaries (i.e. and are the same stimulus condition) and adjust any decoded value to lie within the stimulus domain, for example,
(2)
see Materials and methods - ’Implementation of maximum likelihood estimator’ for details.
We assume that the stimulus is uniformly distributed across its domain and that its dimensions are independent. This can be seen as a worst-case scenario as it maximizes the entropy of the stimulus. In a single trial, we assume that the number of emitted spikes for each neuron is conditionally independent, and follows a Poisson distribution, given some stimulus-dependent rate . Thus, the probability of observing a particular activity pattern, , in a population of neurons given the stimulus-dependent rates and decoding time, , is
(3)
Given a model of neural responses, the Cramér-Rao bound provides a lower bound on the accuracy by which the population can communicate a signal as the inverse of the Fisher information. For sufficiently large populations, using the population and spike count models in Equation 1 and Equation 3, Fisher information is given by (for and for all neurons, see Sreenivasan and Fiete, 2011 or Appendix 2 - 'Fisher information and the Cramér-Rao bound' for details)
(4)
where denotes the sample average of the squared inverse of the (relative) spatial periods across the population, and denotes the modified Bessel functions of the first kind. Equation 4 (and similar expressions) suggests that populations consisting of periodic tuning curves, for which , are superior at communicating a stimulus signal than a population using tuning curves with only single peaks, where . However, (inverse) Fisher information only predicts the amount of local errors for an efficient estimator. Hence, the presence of catastrophic errors (Figure 1a, bottom) can be identified by large deviations from the predicted MSE for an asymptotically efficient estimator (Figure 1c–d). Therefore, we define minimal decoding time as the shortest time required to approach the Cramér-Rao bound (Figure 1c and e).
Periodic tuning curves and stimulus ambiguity
To understand why the amount of catastrophic error can differ with different spatial periods, consider first the problem of stimulus ambiguity that can arise with periodic tuning curves. If all tuning curves in the population share the same relative spatial period, , then the stimulus-evoked responses can only provide unambiguous information about the stimulus in the range . Beyond this range, the response distributions are no longer unique. Thus, single-peaked tuning curves () provide unambiguous information about the stimulus. Periodic tuning curves (), on the other hand, require the use of tuning curves with two or more distinct spatial periods to resolve the stimulus ambiguity (Fiete et al., 2008; Mathis et al., 2012; Wei et al., 2015). In the following, we assume the tuning curves are organized into discrete modules, where all tuning curves within a module share spatial period (Figure 1b) mimicking the organization of grid cells (Stensola et al., 2012). For convenience, assume that where is the number of modules. Thus, the first module provides the most coarse-grained resolution of the stimulus interval, and each successive module provides an increasingly fine-grained resolution. It has been suggested that a geometric progression of spatial periods, such that for some spatial factor , may be optimal for maximizing the resolution of the stimulus while reducing the required number of neurons (Mathis et al., 2012; Wei et al., 2015). However, trial-by-trial variability can still cause stimulus ambiguity and catastrophic errors - at least for short decoding times, as we show later, even when using multiple modules with different spatial periods.
(Very) Short decoding times - when both Fisher information and MSE fails
While it is known that Fisher information is not an accurate predictor of the MSE when the decoding time is short (Bethge et al., 2002), less has been discussed about the issue of MSE. Although MSE is often interpreted as a measure of accuracy, its insensitivity to rare outliers makes it a poor measure of reliability. Therefore, comparing MSE directly between populations can be a misleading measure of reliability if the distributions of errors are qualitatively different. If the amounts of local errors differ, lower MSE does not necessarily imply fewer catastrophic errors. This is exemplified in Figure 2, comparing a single-peaked and a periodic population encoding a two-dimensional stimulus using the suggested optimal scale factor, (Wei et al., 2015). During the first ms, the single-peaked population has the lowest MSE of the two populations despite having lower Fisher information (Figure 2a). Furthermore, comparing the error distribution after the periodic population achieves a lower MSE (the black circle in Figure 2a) shows that the periodic population still suffers from rare errors that span the entire stimulus range (Figure 2b–c, insets). As we will show, a comparison of MSE, as a measure of reliability, only becomes valid once catastrophic errors are removed. Here we assume that catastrophic errors should strongly affect the usability of a neural code. Therefore, we argue that the first criterion for any rate-based neural code should be to satisfy its constraint on decoding time to avoid catastrophic errors.
Figure 2
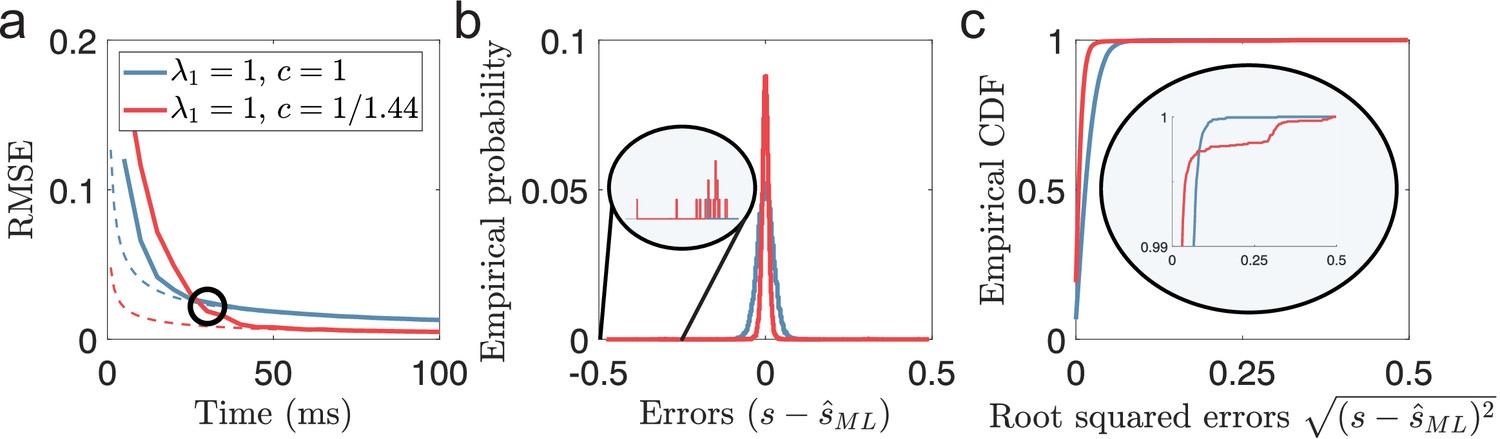
(Very) Short decoding times when both Fisher information and MSE fails.
(a) Time evolution of root mean squared error (RMSE), averaged across trials and stimulus dimensions, using maximum likelihood estimation (solid lines) for two populations (blue: , , red: , ). Dashed lines indicate the lower bound predicted by Cramér-Rao. The black circle indicates the point where the periodic population has become optimal in terms of MSE. (b) The empirical distribution of errors for the time indicated by the black circle in (a). The single-peaked population (blue) has a wider distribution of errors centered around 0 compared to the periodic population (red), as suggested by having a higher MSE. Inset: Zooming in on rare error events reveals that while the periodic population has a narrower distribution of errors around 0, it also has occasional errors across large parts of the stimulus domain. (c) The empirical CDF of the errors for the same two populations as in (b). Inset: a zoomed-in version (last 1%) of the empirical CDF highlights the heavy-tailed distribution of errors for the periodic population. Parameters used in the simulations: stimulus dimensionality , the number of modules , number of neurons , average evoked firing rate sp/s, ongoing activity sp/s, and width parameter . Note that the estimation errors for the two stimulus dimensions are pooled together.
Minimal decoding times in populations with two modules
How does the choice of spatial periods impact the required decoding time to remove catastrophic errors? To get some intuition, we first consider the case of populations encoding a one-dimensional stimulus using only two different spatial scales, and . From the perspective of a probabilistic decoder (Seung and Sompolinsky, 1993; Deneve et al., 1999; Ma et al., 2006), assuming that the stimulus is uniformly distributed, the maximum likelihood (ML) estimator is Bayesian optimal (and asymptotically efficient). The maximum likelihood estimator aims at finding the stimulus condition which is the most likely cause of the observed activity, , or
(5)
where is called the likelihood function. The likelihood function equals the probability of observing the observed neural activity, , assuming that the stimulus condition was . In the case of independent Poisson spike counts (or at least independence across modules), each module contributes to the joint likelihood function with individual likelihood functions, Q1 and Q2 (Wei et al., 2015). Thus, the joint likelihood function can be seen as the product of the two individual likelihood functions, where each likelihood is -periodic
(6)
In this sense, each module provides its own ML-estimate of the stimulus, and . Because of the periodicity of the tuning curves, there can be multiple modes for each of the likelihoods (e.g. Figure 3a and b, top panels). For the largest mode of the joint likelihood function to also be centered close to the true stimulus condition, the distance between and must be smaller than between any other pair of modes of Q1 and Q2. Thus, to avoid catastrophic errors, must be smaller than some largest allowed distance which guarantees this relation (see Equations 25–30 for calculation of assuming the stimulus is in the middle of the domain). As varies from trial to trial, we limit the probability of the decoder experiencing catastrophic errors to some small error probability, , by imposing that
(7)
Assuming that the estimation of each module becomes efficient before the joint estimation, Equation 7 can be reinterpreted as a lower bound on the required decoding time before the estimation based on the joint likelihood function becomes efficient
(8)
where is the inverse of the error function and refers to the time-normalized Fisher information of module (see Materials and methods for derivation). Thus, the spatial periods of the modules influence the minimal decoding time by determining: (1) the largest allowed distance between the estimates of the modules and (2) the variances of the estimations given by the inverse of their respective Fisher information.
Figure 3 with 2 supplements see all
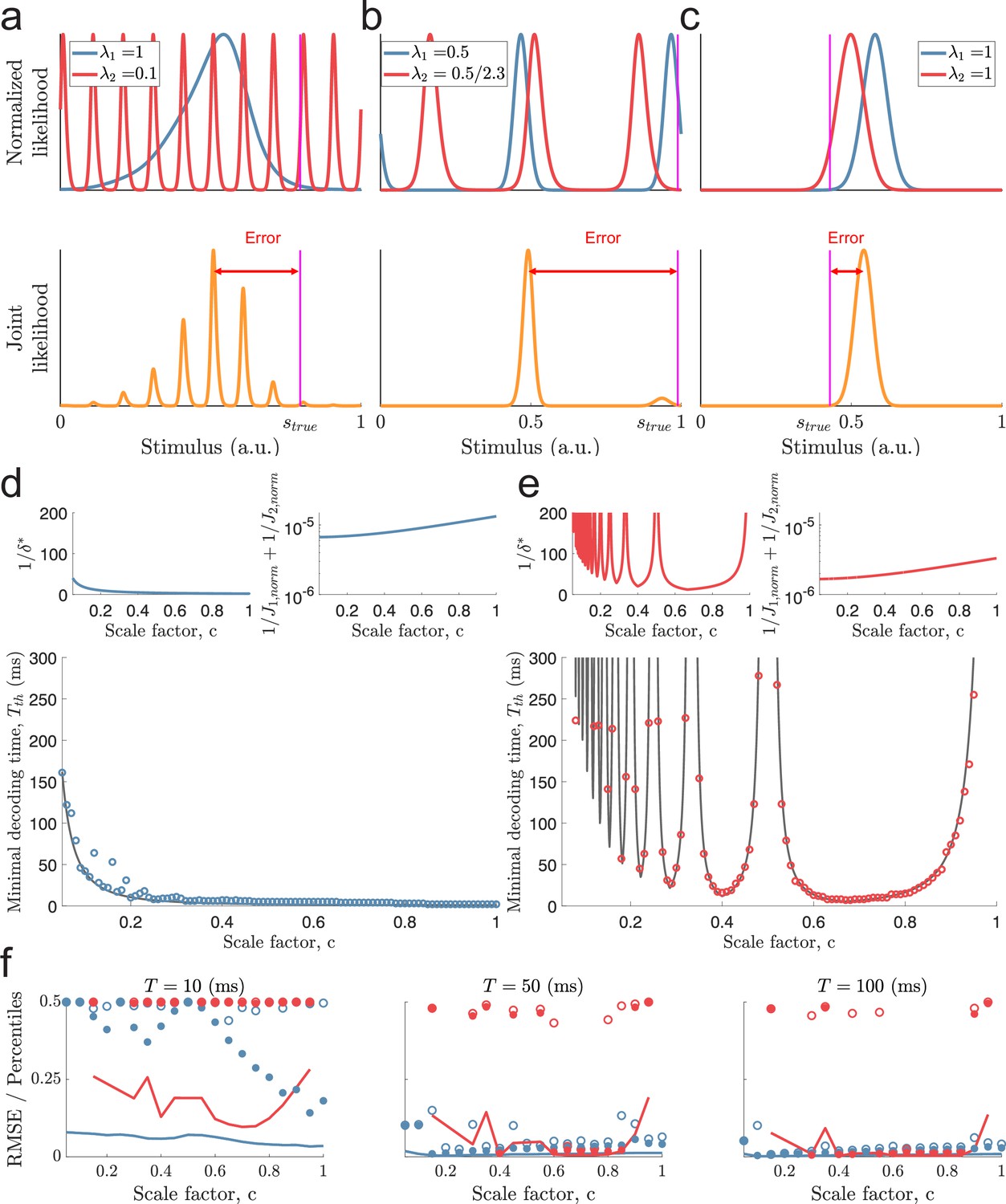
Catastophic errors and minimal decoding times in populations with two modules.
(a) Top: Sampled individual likelihood functions of two modules with very different spatial periods. Bottom: The sampled joint likelihood function for the individual likelihood functions in the top panel. (b–c) Same as in (a) but for spatial periods that are similar but not identical and for a single-peaked population, respectively. (d) Bottom: The dependence of the scale factor c on the minimal decoding time for . Blue circles indicate the simulated minimal decoding times, and the black line indicates the estimation of the minimal decoding times according to Equation 8, with . Top left: The predicted value of . Top right: The inverse of the Fisher information. (e) Same as (d) but for . (f) RMSE (lines), the 99.8th percentile (filled circles), and the maximal error (open circles) of the error distribution for several choices of scale factor, , and decoding time. The color code is the same as in panels (d-e). The parameters used in (d-f) are: population size , number of modules , scale factors , width parameter , average evoked firing rate sp/s, ongoing activity sp/s, and threshold factor .
To give some intuition of the approximation, if the spatial periods of the modules are very different, , then there exist many peaks of Q2 around the peak of Q1 (Figure 3a). Additionally, there can be modes of Q1 and Q2 far away from the true stimulus close together. Thus, can create a highly multi-modal joint likelihood function where small deviations in and can cause a shift, or a change, of the maximal mode of the joint likelihood. To avoid this, must be small, leading to longer decoding times by Equation 8. Furthermore, suppose the two modules have similar spatial periods , or is close to a multiple of . In that case, the distance between the peaks a few periods away is also small, again leading to longer decoding times (Figure 3b). In other words, periodic tuning suffers from the dilemma that small shifts in the individual stimulus estimates can cause catastrophic shifts in the joint likelihood function. Although these might be rare events, the possibility of such errors increases the probability of catastrophic errors. Thus, assuming , both small and large scale factors can lead to long decoding times. When , however, only small-scale factors pose such problems, at least unless the stimulus is close to the periodic edge (i.e. or , see Figure 3—figure supplement 1). On the other hand, compared to single-peaked tuning curves, periodic tuning generally leads to sharper likelihood functions, increasing the accuracy of the estimates once catastrophic errors are removed (e.g., compare the widths of the joint likelihood functions in Figure 3a–c).
To test the approximation in Equation 8, we simulated a set of populations ( neurons) with different spatial periods. The populations were created using identical tuning parameters except for the spatial periods, whose distribution varied across the populations, and the amplitudes, which were adjusted to ensure an equal average firing rate (across all stimulus conditions) for all neurons (see Materials and methods for details on simulations). As described above, the spatial periods were related by a scale factor . Different values of were tested for the largest period being either or . Furthermore, only populations with unambiguous codes over the stimulus interval were included (i.e. for ; Mathis et al., 2012). Note, however, that there is no restriction on the periodicity of the tuning curves to align with the periodicity of the stimulus (i.e. does not need to be an integer). For each population, the minimal decoding time was found by gradually increasing the decoding time until the empirical MSE was lower than twice the predicted lower bound (i.e. , see Equation 10 and Materials and methods for details). Limiting the probability of catastrophic errors to , Equation 8 is a good predictor of the minimal decoding time (Figure 3d–e, bottom panels, coefficient of determination and for and , respectively). For both and , the minimal decoding time increases overall with decreasing scale factor, (see Figure 3d–e). However, especially for , the trend is interrupted by large peaks (Figure 3e). For , there are deviations from the predicted minimal decoding time for small scale factors, . They occur whenever is slightly below a multiple of , and get more pronounced when increasing the sensitivity to the threshold factor (see Figure 3—figure supplement 2). We believe one cause of these deviations is the additional shifts across the periodic boundary (as in Figure 3—figure supplement 1) that can occur when is just below , etc.
To confirm that the estimated minimal decoding times have some predictive power on the error distributions, we re-simulated a subset of the populations for various decoding times, , using 15,000 randomly sampled stimulus conditions (Figure 3f). Both the RMSE and outlier errors (99.8th percentile and the maximal error, that is, 100th percentile) agree with the shape of minimal decoding times, suggesting that a single-peaked population is good at removing large errors at very short time scales.
Minimal decoding times for populations with more than two modules
From the two-module case above, it is clear that the choice of scale factor influences the minimal decoding time. However, Equation 8 is difficult to interpret and is only valid for two-module systems (). To approximate how the minimal decoding time scales with the distribution of spatial periods in populations with more than two modules, we extended the approximation method first introduced by Xie (Xie, 2002). The method was originally used to assess the number of neurons required to reach the Cramér-Rao bound for single-peaked tuning curves with additive Gaussian noise for the ML estimator. In addition, it only considered encoding a one-dimensional stimulus variable. We adapted this method to approximate the required decoding time for stimuli with arbitrary dimensions, Poisson-distributed spike counts, and tuning curves with arbitrary spatial periods. In this setting, the scaling of minimum decoding time with the spatial periods, , can be approximated as (see Materials and methods for derivation)
(9)
where and indicate the sample average across the inverse spatial periods (squared or cubed, respectively) in the population, is the average evoked firing rate across the stimulus domain, and (or ) is a function of (see Materials and methods for detailed expression). The last approximation holds with equality whenever all tuning curves have an integer number of peaks. The derivation was carried out assuming the absence of ongoing activity and that the amplitudes within each population are similar, . Importantly, the approximation also assumes the existence of a unique solution to the maximum likelihood equations. Therefore, it is ill-equipped to predict the issues of stimulus ambiguity. Thus, going back to the two-module cases, Equation 9 cannot capture the additional effects of or when is close to a multiple of , as in Figure 3d–e. On the other hand, complementing the theory presented in Equation 8, Equation 9 provides a more interpretable expression of the scaling of minimal decoding time. For , the minimal decoding time, , is expected to increase with decreasing scale factor, (see Equation 47). The scaling should also be similar for different choices of . Furthermore, assuming all other parameters are constant, the minimal decoding time should grow roughly exponentially with the number of stimulus dimensions.
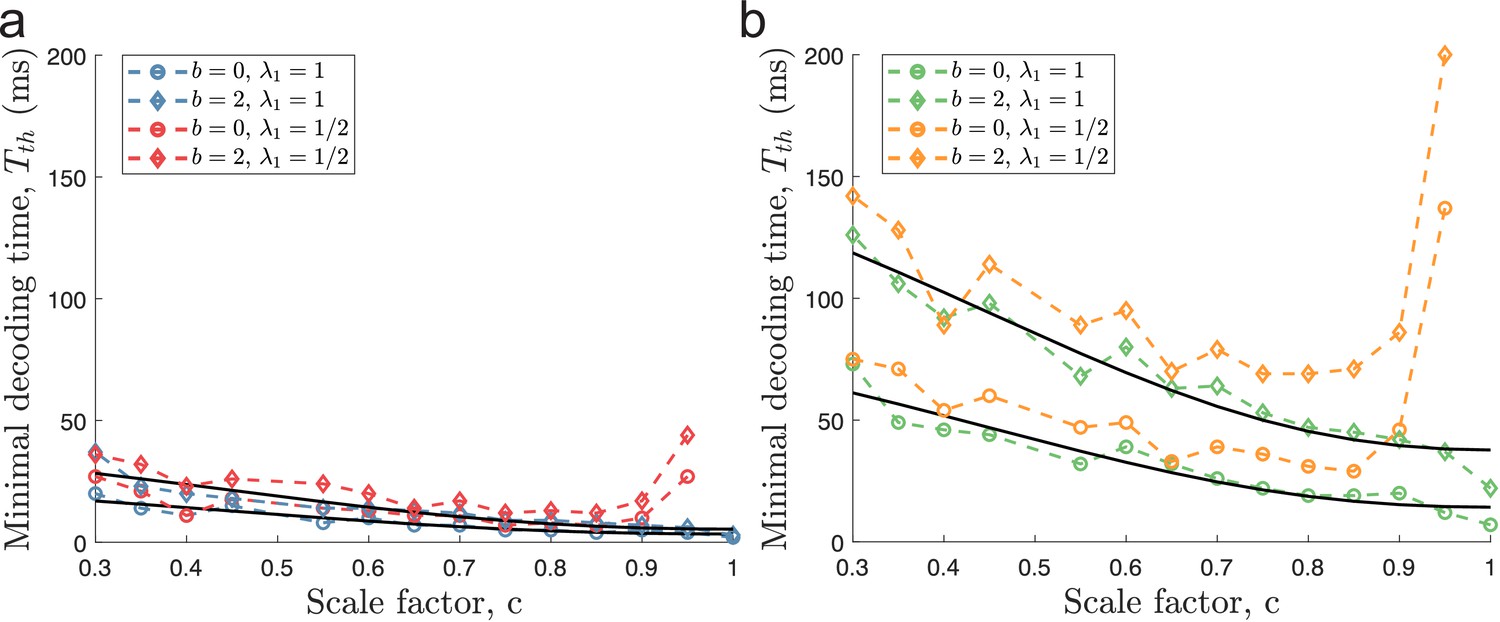
To confirm the validity of Equation 9, we simulated populations of tuning curves across modules. Again, the spatial periods across the modules were related by a scale factor, (Figure 4a). To avoid the effects of , we limited the range of the scale factor to . The upper bound on was kept (for ) to include entirely single-peaked populations. Again, the assumption of homogeneous amplitudes in Equation 9 was dropped in simulations (Figure 4b, left column) to ensure that the average firing rate across the stimulus domain is equal for all neurons (see Figure 4b, right column, for the empirical average firing rates). This had little effect on Fisher information, where the theoretical prediction was based on the average amplitudes across all populations with the same and stimulus dimensionality (see Figure 4c, inset). As before, Fisher information grows with decreasing scale factor, , and with decreasing spatial period . As expected, increasing the stimulus dimensionality decreases Fisher information if all other parameters are kept constant. On the other hand, the minimal decoding time increases with decreasing spatial periods and increases with stimulus dimensionality (Figure 4c). The increase in decoding time between and is also very well predicted by Equation 9, at least for (Figure 4—figure supplement 1a). In these simulations, the choice of width parameter is compatible with experimental data (Ringach et al., 2002), but similar trends were found for a range of different width parameters (although the differences become smaller for small , see Figure 4—figure supplement 1b–d).
Figure 4 with 6 supplements see all
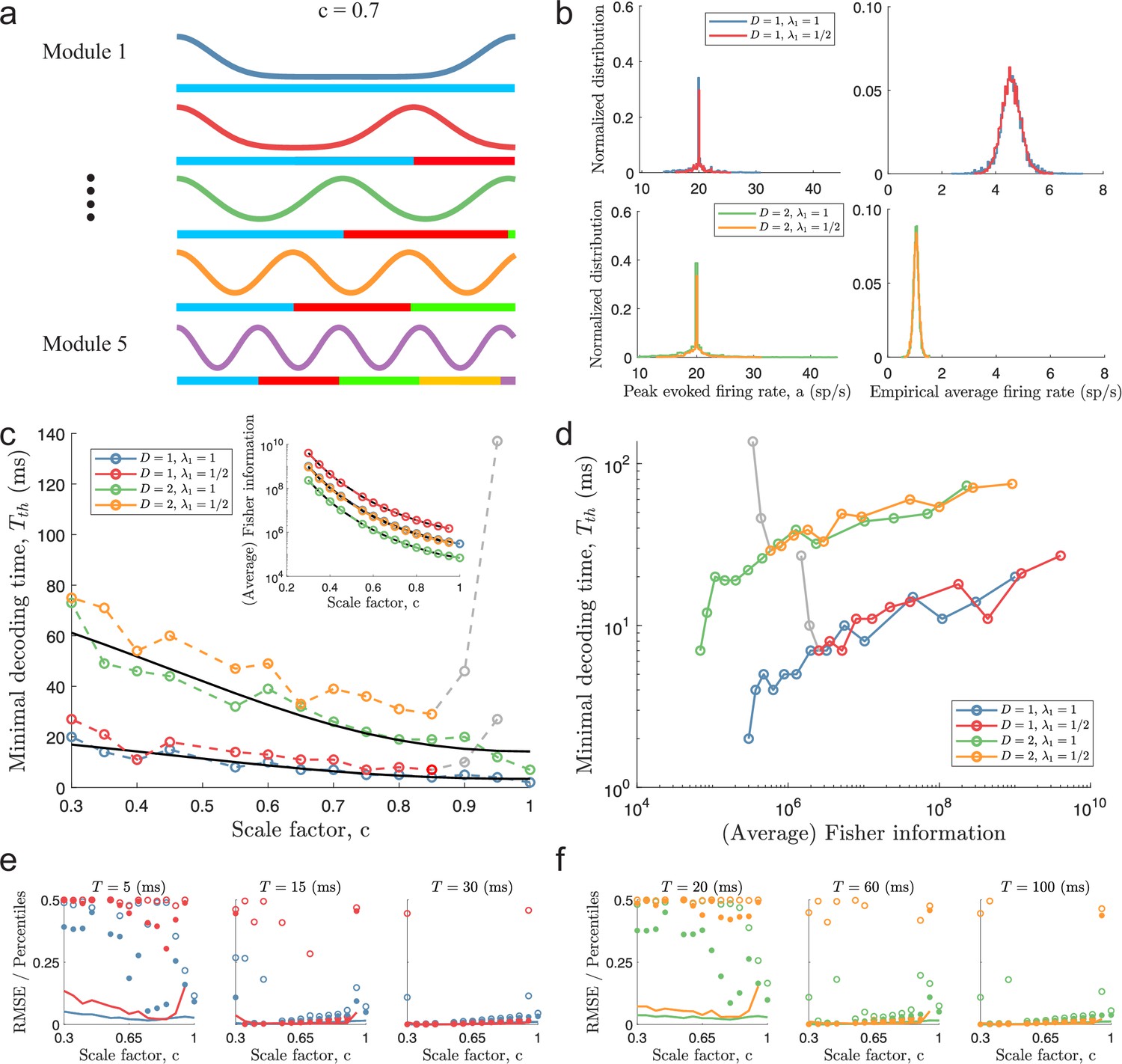
Minimal decoding times for populations with five modules.
(a) Illustration of the likelihood functions of a population with modules using scale factor . (b) The peak stimulus-evoked amplitudes of each neuron (left column) were selected such that all neurons shared the same expected firing rate for a given stimulus condition (right column). (c) Inset: Plot of average Fisher information as a function of the scale factor (colored lines: estimations from simulation data, black lines: theoretical approximations). Main plot: Plot of minimal decoding time as a function of scale factor . Minimal decoding time tends to increase with decreasing grid scales (colored lines: estimated minimal decoding time from simulations, black lines: fitted theoretical predictions using Equation 47). The gray color corresponds to points with large discrepancies between the predicted and the simulated minimal decoding times. (d) Plot of the average Fisher information against the minimal decoding time. Points colored in gray are the same as in panel (c). (e) RMSE (lines), the 99.8th percentile (filled circles), and the maximal error (open circles) of the error distribution when decoding a 1-dimensional stimulus for several choices of decoding time. The color code is the same as above. (f) same as (e) but for a two-dimensional stimulus. Note that the error distributions across stimulus dimensions are pooled together. Parameters used in panels (a-d): population size , number of modules , scale factors , width parameter , average evoked firing rate sp/s, ongoing activity sp/s, and threshold factor .
From Equation 9, we fitted two constants, K1 (regressor) and K2 (intercept), using least square regression across populations sharing the same largest period, , and stimulus dimensionality, (see Equation 47). Within the simulated range of scale factors, the regressions provide reasonable fits for the populations with (Figure 4c, coefficient of determination and for and , respectively). For the populations with , Equation 9 becomes increasingly unable to predict the behavior of the minimal decoding time as approaches 1 (see the red and yellow lines in Figure 4c–d). On the other hand, as was suggested above, the scaling of the minimal decoding time with is, in fact, similar for and whenever is less than . As suggested by Figure 4d, there is also a strong correlation between Fisher information and minimal decoding time, again indicating a speed-accuracy trade-off. Furthermore, similar results are obtained when either decreasing the threshold factor to (Figure 4—figure supplement 2) or changing the minimal decoding time criterion to a one-sided Kolmogorov–Smirnov test (KS-test) between the empirical distribution of errors and the Gaussian error distribution predicted by the Cramér-Rao bound (Figure 4—figure supplement 3, using an ad-hoc Bonferroni-type correction for multiple sequential testing, , where is the th time comparison and is the significance level.)
To further illustrate the relationship between minimum decoding time and the distribution of catastrophic errors, we re-simulated the same populations using fixed decoding times, evaluating the RMSE together with the 99.8th and 100th (maximal error) percentiles of the root squared error distributions across 15,000 new uniformly sampled stimuli (Figure 4e–f). As suggested by the minimal decoding times, there is a clear trade-off between minimizing RMSE over longer decoding times and removing outliers, especially the maximal error, over shorter decoding times. Figure 4—figure supplement 4 shows the time evolution for a few of these populations.
Additionally, to verify that the minimal decoding times are good predictors of the decoding time necessary to suppress large estimation errors, we compared the same error percentiles as in Figure 4e–f (i.e. the 99.8th and 100th percentiles) against the minimal decoding times, , estimated in Figure 4c. For each population, we expect a strong reduction in the magnitude of the largest errors when the decoding time, , is larger than the minimal decoding time, . Figure 5 shows a clear difference in large estimation errors between populations for which and populations with (circles to the left and right of the magenta lines in Figure 5, respectively). Thus, although only using the difference between MSE and Fisher information, our criterion on minimal decoding time still carries important information about the presence of large estimation errors.
Figure 5
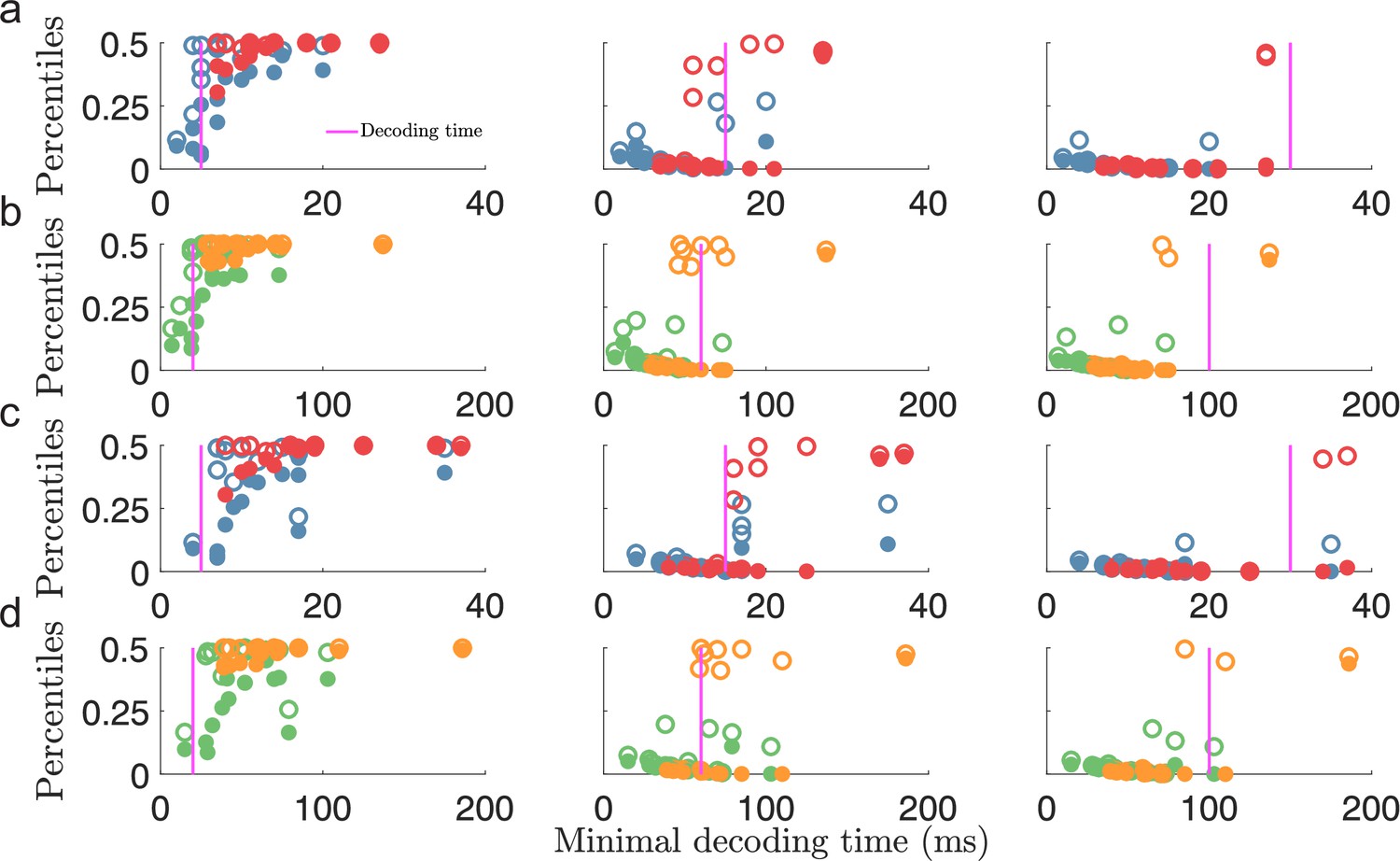
Minimal decoding time predicts the removal of large estimation errors.
(a) The 99.8th percentile (filled circles) and the maximal error (i.e., 100th percentile, open circles) of the root squared error distributions for against the estimated minimal decoding time for the corresponding populations () for various choices of decoding time, (indicted by the vertical magenta lines). (b) same as (a) but for . (c-d) Same as for (a-b) but for . Note that the plots (a) and (c), or (b) and (d), illustrate the same percentile data only remapped on the x-axis by the different minimal decoding times from the different threshold factors . Color code: same as in Figure 4.
To summarize, while periodic tuning curves provide lower estimation errors for long decoding times by minimizing local errors (Figure 4c, inset), a population of single-peaked tuning curves is faster at producing a statistically reliable signal by removing catastrophic errors (Equation 9 and Figure 4c). Generalizing minimal decoding times to an arbitrary number of stimulus dimensions reveals that the minimal decoding time also depends on the stimulus dimensionality (Figure 4c, compare lines for and ). Interestingly, however, the approximation predicts that although minimal decoding time grows with increasing stimulus dimensionality, the minimal required spike count might be independent of stimulus dimensionality, at least for populations with integer spatial frequencies, that is, integer number of peaks (see Equation A5.4). The populations simulated here have non-integer spatial frequencies. However, the trend of changes in the mean spike count is still just slightly below 1 (indicating that slightly fewer spikes across the population are needed with increasing , see Figure 4—figure supplement 5). Thus, as the average firing rate decreases with the number of encoded features (Figure 4b, right column), the increase in minimal decoding time for stimuli of higher dimensionality can be primarily explained by requiring a longer time to accumulate the sufficient number of spikes across the population. Lastly, to rule out that the differences in minimal decoding time cannot be explained by the periodicity of the tuning curves not aligning to that of the stimulus, we also simulated populations with different combinations of integer peaks (Figure 4—figure supplement 6). Again, the same phenomenon is observed: periodic tuning curves increase the required decoding time to remove catastrophic errors. This also highlights that the approximation of minimal decoding time does not require the spatial periods to be related by a scale factor, .
Effect of ongoing activity
Many cortical areas exhibit ongoing activity, that is, activity that is not stimulus-specific (Snodderly and Gur, 1995; Barth and Poulet, 2012). Thus, it is important to understand the impact of ongoing activity on the minimal decoding time, too. Unfortunately, because our approximation of the minimal decoding times did not include ongoing activity, we relied on simulations to study the effect of such non-specific activity.
When including independent ongoing (background) activity at 2 spikes/s to all neurons for the same populations as in Figure 4, minimal decoding times were elevated across all populations (Figure 6). Furthermore, the minimal decoding time increased faster with decreasing in the presence of ongoing activity compared to the case without ongoing activity (ratios of fitted regressors using Equation 47 were approximately 1.69 and 1.72 for and , respectively). Similar results are found using (Figure 6—figure supplement 1) or the alternative criterion on minimal decoding time based on one-sided KS-tests described earlier (Figure 6—figure supplement 2). Thus, ongoing activity can have a substantial impact on the time required to produce reliable signals. Figure 6 suggests that areas with ongoing activity are less suited for periodic tuning curves. Especially, the combination of multidimensional stimuli and ongoing activity leads to much longer minimal decoding times for tuning curves with small spatial periods (). For example, when encoding a two-dimensional stimulus, only the populations with , and , could remove catastrophic errors in less than 40ms when ongoing activity at 2 sp/s was present. Thus, the ability to produce reliable signals at high speeds severely deteriorates for periodic tuning curves in the presence of non-specific ongoing activity.
Figure 6 with 2 supplements see all
Ongoing activity increases minimal decoding time.
(a) The case of encoding a one-dimensional stimulus () with or without ongoing activity at 2 sp/s (diamond and circle shapes, respectively). (b) The case of a two-dimensional stimulus () under the same conditions as for (a). In both conditions, ongoing activity increases the time required for all populations to produce reliable signals, but the effect is strongest for . The parameters used in the simulations are: population size , number of modules , scale factors , width parameter , average evoked firing rate sp/s, ongoing activity sp/s, and threshold factor .
This result has an intuitive explanation. The amount of catastrophic errors depends on the probability that the trial variability reshapes the neural activity to resemble the possible activities for a distinct stimulus condition (see Figure 1a). From the analysis presented above, periodic tuning curves have been suggested to be more susceptible to such errors. Adding ongoing activity does not reshape the stimulus-evoked parts of the tuning curves but only increases the trial-by-trial variability. Thus, by this reasoning, it is not surprising that the systems which are already more susceptible also are even more negatively affected by the increased variability induced by ongoing activity. The importance of Figure 6 is that even ongoing activity as low as 2 sp/s can have a clearly visible effect on minimal decoding time.
Implications for a simple spiking neural network with sub-optimal readout
Until this point, the arguments about minimal decoding time have relied on rate-based tuning curves encoding static stimuli. To extend beyond static stimuli and to exemplify the role of decoding time for spiking neurons, we simulated simple two-layer feed-forward spiking neural networks to decode time-varying stimulus signals. The first layer () corresponds to the tuning curves (without connections between the simulated neurons). The stimulus-specific tuning of the Poissonian inputs to these neurons is either fully single-peaked, creating a population of single-peaked tuning curves, or periodic with different spatial periods, creating a population of periodic tuning curves (Figure 7a, see Materials and methods for details). The second layer instead acts as a readout layer (, allowing a weak convergence of inputs from the first layer). This layer receives both stimulus-specific excitatory input from the first layer and external non-specific Poissonian excitation (corresponding to background activity). The connection strength between the first and second layers depends on the difference in preferred stimulus conditions between the pre- and post-synaptic neurons. Such connectivity could, for example, be obtained by unsupervised Hebbian learning. Because the tuning curves in the first layer can be periodic, they can also connect strongly to several readout neurons. We introduced lateral inhibition among the readout neurons (without explicitly modeling inhibitory neurons) to create a winner-take-all style of dynamics. The readout neurons with large differences in preferred stimulus inhibit each other more strongly. Decoding is assumed to be instantaneous and based on the preferred stimulus condition of the spiking neuron in the readout layer. However, to compare the readouts, we averaged the stimulus estimates in sliding windows.
Figure 7
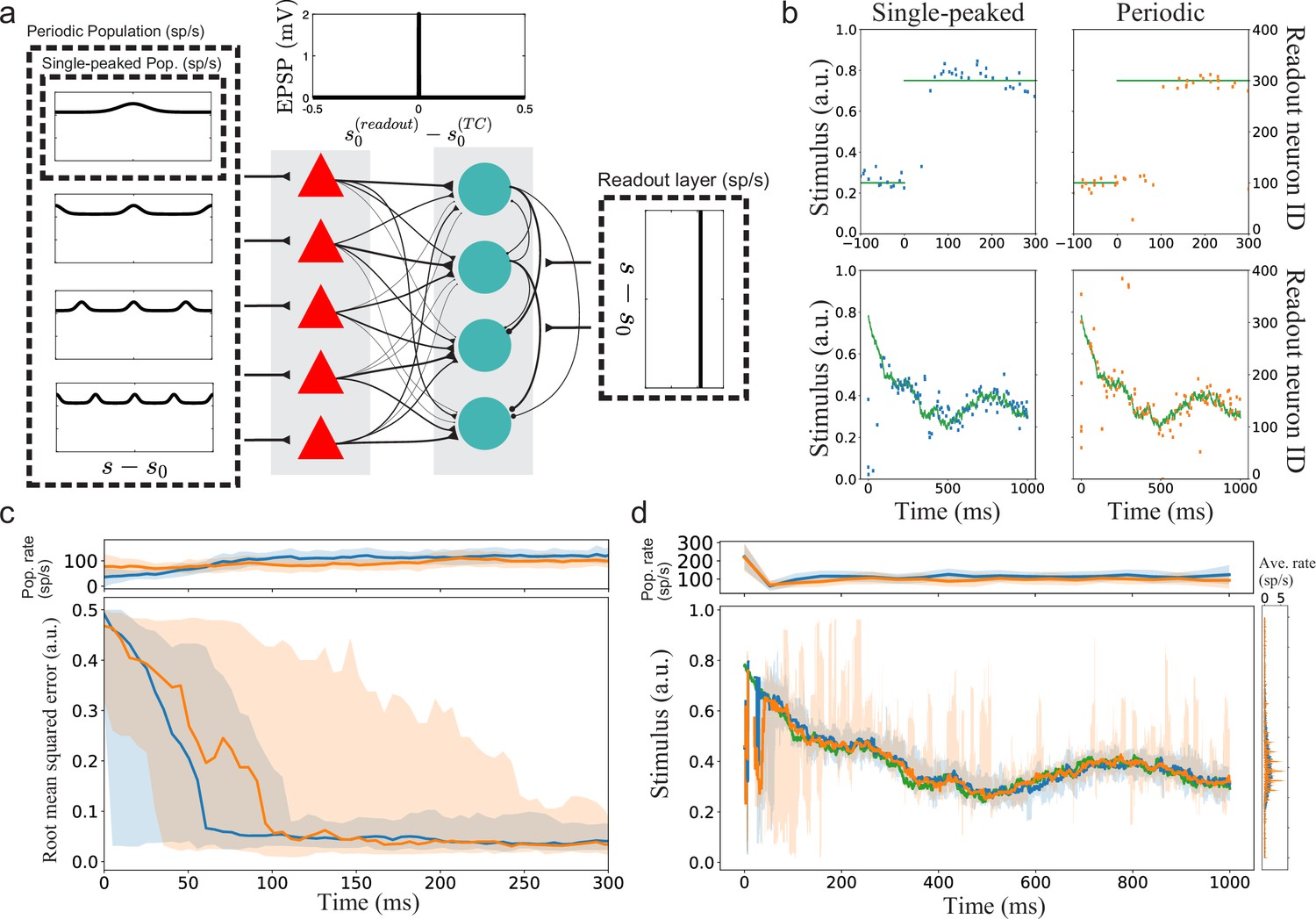
Implications for a simple spiking neural network with suboptimal readout.
(a) Illustration of the spiking neural networks (SNNs). (b) Example of single trials. Top row: Two example trials for step-like change in stimulus (green line). The left and right plots show the readout activity for the single-peaked (blue) and periodic SSNs (orange), respectively. Note that the variance around true stimulus is larger for the single-peaked SNN (i.e. larger local errors) but that there are fewer very large errors than for the periodic SNN. Bottom row: Same as for the top row but with a continuously time-varying stimulus. (c) Bottom: The median RMSE (thick lines) over all trials in a sliding window (length 50ms) for the single-peaked (blue) and periodic (orange) SNNs. The shadings correspond to the regions between the 5th and 95th percentiles. Top: The instantaneous population firing rates of the readout layers and the standard deviations (same color code as in the bottom panel). (d) Bottom left: The median estimated stimulus across trials in a sliding window (length 10ms) for the single-peaked (blue) and periodic (orange) SNNs. Shaded areas again correspond to the regions between the 5th and 95th percentiles. The true stimulus is shown in green. Bottom right: the average firing rate of each neuron, arranged according to the preferred stimulus condition. Top: The instantaneous population firing rates of the readout layers and the standard deviations. See Materials and methods for simulation details and Table 1, Table 2, Table 3 for all parameters used in the simulation.
We tested two different types of time-varying stimuli: (1) a step-like change from to (Figure 7b top row, green trace) and (2) a continuously time-varying stimulus drawn from an Ornstein–Uhlenbeck process (Figure 7b bottom row, green trace; see Materials and methods). In the case of a step-like stimulus change, the readout layer for the single-peaked population required a shorter time to switch states than the periodic network (Figure 7c). The shorter switching time is consistent with the hypothesis that single-peaked tuning curves have shorter minimal decoding times than periodic tuning curves. In these simulations, the difference is mainly due to some neurons in the first layer of the periodic network responding both before and after the step change. Thus, the correct readout neurons (after the change) must compensate for the hyper-polarization built up before the change and the continuing inhibitory input from the previously correct readout neurons (which still get excitatory inputs). Note that there are only minor differences in the population firing rates between the readout layers, confirming that this is not a consequence of different excitation levels but rather of the structures of excitation.
The continuously time-varying stimulus could be tracked well by both networks. However, averaging across trials shows that SNNs with periodic tuning curves have larger sporadic fluctuations (Figure 7d). This suggests that decoding with periodic tuning curves has difficulties in accurately estimating the stimulus without causing sudden, brief periods of large errors. To make a statistical comparison between the populations, we investigated the distributions of root mean squared error (RMSE) across trials. In both stimulus cases, there is a clear difference between the network with single-peaked tuning curves and the network with periodic ones. For the step-like change in stimulus condition, a significant difference in RMSE arises roughly 100 ms after the stimulus change (Figure 8a). For the time-varying stimulus, using single-peaked tuning curves also results in significantly lower RMSE compared to a population of periodic tuning curves (Figure 8b, RMSE calculated across the entire trial).
Figure 8
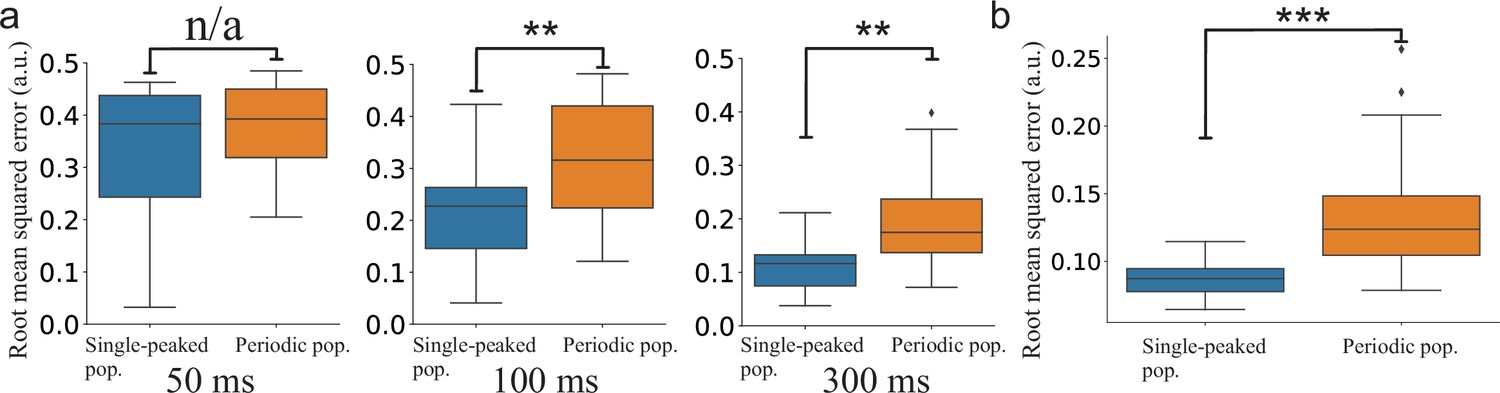
Statistical comparison of the SNN models.
(a) Step-like change: Comparison between the distributions of accumulated RMSEs at different decoding times (, , and , respectively). (b) OU-stimulus: The distributions of RMSE across trials for the two SNNs (). All statistical comparisons in (a) and (b) were based on two-sample Kolmogorov–Smirnov (KS) tests using 30 trials per network.
Discussion
Several studies have suggested that periodic tuning creates an unparalleled precise neural code by minimizing local errors (Sreenivasan and Fiete, 2011; Mathis et al., 2012; Wei et al., 2015; Malerba et al., 2022). Nevertheless, despite this advantage of periodic tuning, single-peaked tuning curves are widespread in early sensory areas and especially in the early visual system. There is a long history of studying information representation using rate-based tuning curves. Still, the effect of spatial periodicity and catastrophic errors on the required decoding time has not been addressed. Here, we showed that the possibility of catastrophic estimation errors (Figure 1a) introduces the possibility that different shapes of tuning curves can have different minimal decoding times.
The emerging question is whether there is a trade-off between the accuracy of a neural code and the minimal required decoding time for single-peaked and periodic tuning. The answer is yes. We found that minimal decoding time increased with decreasing spatial periods of the tuning curves (Figure 4c), suggesting a trade-off between accuracy and speed for populations of tuning curves. The differences in minimal decoding time cannot be explained by the periodicity of the tuning curves not aligning to the stimulus domain, as the same holds comparing populations with integer number of peaks (Figure 4—figure supplement 6). Furthermore, our results remained unchanged when we discarded any decoded stimuli which needed the operation to lie within the stimulus domain , thus ruling out any possible distortion effect of the periodic stimulus and decoding approach. In addition, we show that our results are valid for a range of population sizes (Figure 9a-b), ongoing (Figure 9a-b) and evoked activities (Figure 9c), and stimulus dimensions (Figure 9d). We used the more conservative threshold factor on MSE, , to capture all the nuances w.r.t. the level of ongoing activity even for large population sizes. In simulated networks with spiking neurons, we showed that the use of periodic tuning curves increased the chances of large estimation errors, leading to longer times before switching ‘states’ (Figure 7c) and difficulties tracking a time-varying, one-dimensional stimulus (Figure 7d).
Figure 9
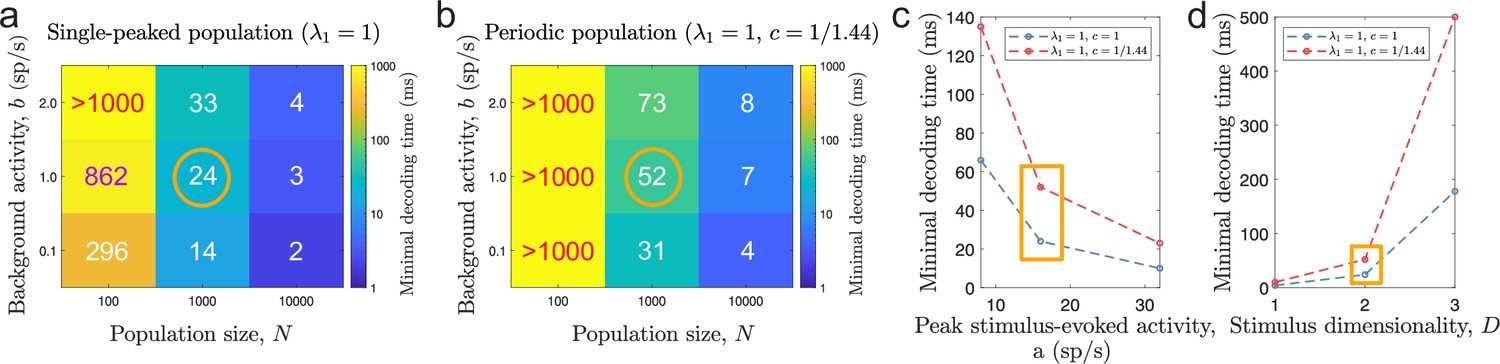
Minimal decoding time for various tuning and stimulus parameters.
(a-b) Minimal decoding time for different combinations of population sizes () and levels of ongoing background activity () for the single-peaked population (a) and the periodic population (b). (c) Minimal decoding time as a function of average stimulus-evoked firing rate (x-axis re-scaled to the corresponding peak amplitude, , for single-peaked tuning curves for easier interpretation). The corresponding amplitudes are and sp/s, respectively. (d) Minimal decoding time as a function of stimulus dimensionality. Unless indicated on the axes, the parameters are set according to the orange circles and rectangles in (a-d). Auxiliary parameters: number of modules , width parameter , and threshold factor .
Experimental data suggest that decoding times can be very short, of the order of tens of milliseconds, reflecting that a considerable part of the information contained in firing rates over long periods is also present in short sample periods (Tovée et al., 1993). Additionally, the first few spikes have been shown to carry significant amounts of task information in both visual (Resulaj et al., 2018), olfactory (Resulaj and Rinberg, 2015), and somatosensory areas (Panzeri et al., 2001; Petersen et al., 2001). As the tuning curves in this study all have equal average firing rates, we can reinterpret the minimal decoding time in terms of the prominence of the first spikes. In our simulations, tens of spikes carry enough information to produce a reliable stimulus estimate free of catastrophic errors (Figure 4—figure supplement 5). As with decoding time, single-peaked tuning curves also need fewer spikes to produce reliable signals. Thus, the speed-accuracy trade-off can be reinterpreted as a trade-off between being accurate and efficient.
The notion of a speed-accuracy trade-off is further strengthened when considering high-dimensional stimuli that demand longer minimal decoding times. Natural stimuli typically have higher dimensionality than those used in animal experiments. Many sensory neurons are tuned to multiple features of the external stimulus, creating mixed selectivity of features (e.g. Garg et al., 2019). For neurons responding to task-related variables, mixed selectivity has been shown to enable linear separability and to improve discriminability (Rigotti et al., 2013; Fusi et al., 2016; Johnston et al., 2020). For continuous stimulus estimations, mixed selectivity has also been proposed to decrease MSE when decoding time is limited (Finkelstein et al., 2018). However, to remove catastrophic errors, which, as we have argued, is not necessarily synonymous with lower MSE, the exponential increase in minimal decoding time could easily lead to very long decoding times. Thus, minimal decoding time should set a bound on the number of features a population can jointly encode reliably. In addition, neurons in sensory areas often exhibit a degree of non-specific activity (Snodderly and Gur, 1995; Barth and Poulet, 2012). Introducing ongoing activity to the populations in our simulations further amplified the differences in minimal decoding times (Figure 6). Thus, for jointly encoded stimuli, especially in areas with high degrees of ongoing activity, a population of single-peaked tuning curves might be the optimal encoding strategy for rapid and reliable communication.
We note that these results might extend beyond the visual areas, too. Although this study focused on tuning curves encoding continuous variables, catastrophic errors can also occur in systems with discrete tuning curves. Sensory stimuli can be fast-varying (or even discontinuous), and large errors can potentially harm the animal. Therefore, constraints on decoding time are likely important for any early sensory area. In addition, hippocampal place cells involved in spatial navigation (O’Keefe and Dostrovsky, 1971; Wilson and McNaughton, 1993) are known for their single-peaked tuning. The interesting observation in this context is that place cells produce reliable signals faster than their input signals from the medial entorhinal cortex with a combination of single- and multi-peaked tuning (Cholvin et al., 2021). On the other hand, for sufficiently slow-varying stimuli, a periodic population can be used together with error correction to remove catastrophic errors (Sreenivasan and Fiete, 2011). Furthermore, for non-periodic stimuli with large domains, the combinatorial nature of periodic tuning curves can create unique stimulus representations far exceeding the spatial periods of the tuning curves (Fiete et al., 2008). Thus, periodic tuning curves are ideal for representing space, where the stimulus domain can be vast, and the change in position is constrained by the speed of movement. Interestingly, when faced with very large arenas, place cells can also exhibit multi-peaked tuning (Eliav et al., 2021).
To summarize, we provide normative arguments for the single-peaked tuning of early visual areas. Rapid decoding of stimulus is crucial for the survival of the animals. Consistent with this, animals and humans can process sensory information at impressive speeds. For example, the human brain can generate differentiating event-related potentials to go/no-go categorization tasks using novel complex visual stimuli in as little as 150 ms (Thorpe et al., 1996). These ‘decoding’ times do not decrease for highly familiar objects, suggesting that the speed of visual processing cannot be reduced by learning (Fabre-Thorpe et al., 2001). Given constraints on low latency communication, it is crucial that each population can quickly produce a reliable signal. In this regard, single-peaked tuning curves are superior to periodic ones. The fact that early visual areas exhibit ongoing activity and encode multi-dimensional stimuli further strengthens the relevance of the differences in minimal decoding time.
To conclude, our work highlights that minimum decoding time is an important attribute and should be considered while evaluating candidate neural codes. Our analysis suggests that decoding of high-dimensional stimuli can be prohibitively slow with rate-based tuning curves. Experimental data on the representation of high-dimensional stimuli is rather scant as relatively low-dimensional stimuli are typically used in experiments (e.g. oriented bars). Our work gives a compelling reason to understand whether and how biological brains can reliably encode high-dimensional stimuli at behaviorally relevant time scales.
Materials and methods
Minimal decoding times - simulation protocols
Request a detailed protocolTo study the dependence of decoding time on MSE for populations with different distributions of spatial frequencies, we simulated populations of synthetic tuning curves (Equation 1). The stimulus was circular with a range. The preferred stimulus conditions were sampled independently from a random uniform distribution over (independently and uniformly for each stimulus dimension). To ensure equal comparison, the preferred locations were shared across all populations. Each neuron’s amplitude, ai, was tuned according to Equation A1.5 to ensure an equal average firing rate across the stimulus domain for all neurons. In each trial, a stimulus was also independently sampled from a uniform distribution over . The spike count for each neuron was then sampled according to Equation 3.
Minimal decoding time was defined as the shortest time for which the neural population approximately reaches the Cramér-Rao bound. To estimate the reaction time in simulations, we incrementally increased the decoding time (using 1 ms increments, starting at ms) until
(10)
As the ML estimator is asymptotically efficient (attaining the Cramér-Rao bound in the limit of infinite data), the threshold factor, , in Equation 10 was added as a relaxation (see figure captions for choices of ). Note that the mean bars on the left- and right-hand sides of Equation 10 refer to the means across stimulus dimensions (for multi-dimensional stimuli) and that refers to taking the diagonal elements from the inverse of the Fisher information matrix, . For a given decoding time , the estimation of MSE was done by repeatedly sampling random stimulus conditions (from a uniform distribution), sampling a noisy response to the stimulus (Poisson distributed spike counts), and then applying maximum likelihood estimation (see next section ’Implementation of maximum likelihood estimator’ for details on implementation). In Figures 3 and 9, 15000 stimulus conditions were drawn for each , and in Figure 4, stimulus conditions were repeatedly drawn until the two first non-zero digits of the MSE were stable for 1000 consecutive trials. However, in controls not presented here, we could not see any significant difference between these two sampling approaches. Because the Fisher information matrix was analytically estimated only in the special case without ongoing activity, it was approximated in simulations by the element-wise average across 10,000 randomly sampled stimulus conditions (also uniformly distributed), where each element was calculated according to Equation A2.12or Equation A2.13 given a random stimulus trial.
Implementation of maximum likelihood estimator
Request a detailed protocolGiven some noisy neural responses, , the maximum likelihood estimator (MLE) chooses the stimulus condition which maximizes the likelihood function, . A common approach is to instead search for the maximum of the log-likelihood function (the logarithm is a monotonic function and therefore preserves any maxima/minima). The stimulus-dependent terms of the log-likelihood can then be expressed as
(11)
Unfortunately, the log-likelihood function is not guaranteed to be concave, and finding the stimulus condition which maximizes the log-likelihood function is not trivial (a non-convex optimization problem). To overcome this difficulty, we combined grid-search with the Nelder–Mead method, an unconstrained non-linear program solver (implemented using MATLAB’s built-in function fminsearch, https://www.mathworks.com/help/matlab/ref/fminsearch.html).
Grid search was used to find a small set of starting points with large log-likelihood values. To do so, we sampled 100 random stimulus conditions within the stimulus interval and selected the four stimulus conditions with the largest log-likelihood values. The true stimulus condition, , was always added to the set of starting points regardless of the log-likelihood value of that condition (yielding a total of 5 starting points).
Then the Nelder–Mead method was used with these starting points to find a set of 5 (possibly local) maxima. The stimulus was decoded as the stimulus, , yielding the largest log-likelihood of the 5 maxima. As we always included the true stimulus condition in the Nelder-Mead search, this approach should not overestimate the amount of threshold distortion but can potentially miss some global estimation errors instead. Finally, as the Nelder–Mead method is unconstrained but the stimulus domain periodic, the output of the maximum likelihood decoder was transformed into the stimulus interval by applying the mod 1 operation on each stimulus dimension,
(12)
Given an estimated stimulus, , the error was then evaluated along each stimulus dimension independently, taking into account the periodic boundary,
(13)
for .
Lastly, to rule out that the estimates before the mod-operation, , outside of the stimulus domain did not influence the results, we also discarded these samples, but this produced similar results.
Spiking network model
Stimuli
Request a detailed protocolAs in the previous simulations, we assumed that the stimulus domain was a circular stimulus defined between . We simulated the responses to two different types of stimuli, (1) a step-like change in stimulus condition from to and (2) a stimulus drawn from a modified Ornstein–Uhlenbeck process
(14)
For parameter values, see Table 1.
Table 1
Parameters and parameter values for O-U stimulus.
| Parameters | Parameter values |
|---|---|
| 0.5 (s) | |
| 0.1 |
Network model
Request a detailed protocolThe spiking networks were implemented as two-layer, feed-forward networks using LIF neurons with (Dirac) delta synapses. The dynamics of the membrane potential for the neurons in the first layer were described by
(15)
where is the voltage of neuron , the membrane time constant, tk the timing of the th input spike to neuron , and the induced EPSP. The neurons in the first layer were constructed to correspond to either single-peaked or periodic tuning curves. Two networks were tested, one network where the first layer corresponds to single-peaked tuning curves and a second network corresponding to periodic tuning curves (with modules). For each neuron in module in the first layer, the input was drawn from independent Poisson point processes with stimulus-dependent rates
(16)
Here, the constants and were chosen such that the baseline firing rate was slightly above zero and the maximal firing rate was slightly below 20 sp/s (see Table 3 for all network-related parameter values). Because of the choice of , the modulation strengths of the inputs were such that the average input to each neuron was equal. For each module in the first layer, the preferred locations were equidistantly placed across .
Similarly, for the second layer, the membrane potential was described by
(17)
where and are synapse-specific EPSPs/IPSPs which depends on the difference in preferred tuning between the pre- and post-synaptic neurons (see Equation 18), the timing of the th spike of pre-synaptic neuron , and the delay (see Table 2, Table 3 for parameter values). The neurons in the second layer were only tuned to a single preferred stimulus location each, equidistantly placed across . Whenever a spike occurred in the first layer, it elicited EPSPs with a delay of 1.5 ms in all neurons in the second layer. The size of the EPSPs depended on the difference in preferred tuning, , between the pre- and post-synaptic neurons
(18)
Here, determines the maximal EPSP (mV), and the constant was chosen such that the full width at half maximum of the EPSP kernels tiled the stimulus domain without overlap. Note that for periodically tuned neurons in the first layer (i.e. with multiple preferred locations), the were determined by the smallest difference in preferred tuning across the multiple preferred locations.
As for the excitatory neurons in the first layer, whenever a spike occurred in the second layer, it elicited IPSPs with a delay of 1.5 ms in all other neurons in the second layer. Again, the size of the IPSPs depended on the difference in preferred tuning, between the two neurons, but this time according to
(19)
Thus, the range of inhibition was much broader compared to the excitation.
Table 2
Parameters and parameter values for LIF neurons.
| Parameters | Parameter values |
|---|---|
| Membrane time constant, (ms) | 20 |
| Threshold memb. potential, (mV) | 20 |
| Reset memb. potential (mV) | 10 |
| Resting potential, V0 (mV) | 0 |
| Refractory period, (ms) | 2 |
Table 3
Spiking network parameters and parameter values.
| Parameters | Parameter values |
|---|---|
| Number of neurons 1st layer, N1 | 500 |
| Number of neurons 2nd layer, N2 | 400 |
| Maximal stimulus-evoked input rate, (sp/s) | 750 |
| Baseline input rate, (sp/s) | 4250 |
| Spatial periods, | [1] or [1,2,3,4] |
| Width parameter, | 0.3 |
| Width parameter (readout layer), | |
| Input EPSP (1st layer), (mV) | 0.2 |
| Maximal EPSP (2nd layer), (mV) | 2 |
| Maximal IPSP (2nd layer), (mV) | 2 |
| Synaptic delays, (ms) | 1.5 |
Evaluating decoding performance
Request a detailed protocolWe assumed that the decoder was instantaneously based on the neuron index of the firing neuron in the readout layer. Let denote a function that provides the index of the neuron firing at time tk. Given the equidistant distribution of preferred locations for the readout neurons, the stimulus is instantaneously decoded by mapping the neuron identity to the interval
(20)
where N2 is the number of neurons in the readout layer. For both stimulus cases, the decoding performance was evaluated using (1) the distribution of RMSE (Figure 7d) or estimated stimulus conditions (Figure 7e) in a sliding window or (2) the distributions of accumulated RMSE (Figure 8).
Parameters
Simulation tools
Request a detailed protocolAll the simulations were done using code written in MATLAB and Python (using Brian2 simulator Stimberg et al., 2019). The simulation code is available at https://github.com/movitzle/Short_Decoding_Time (copy archived at Lenninger, 2023 ).
Approximating minimal decoding time in two-module systems
Request a detailed protocolTo gain an understanding of the interaction between two modules with different spatial periods, consider the likelihood function as a product of the likelihood functions of the two modules individually
(21)
Using the Laplace approximation, each of these functions can be approximated as a periodic sum of Gaussians (Wei et al., 2015). Assuming that each module becomes efficient before the joint likelihood, we only focus on the largest, periodically occurring, peaks
(22)
where denotes the activity pattern of module , the peak closest to the true stimulus condition, s0, and is large enough for to cover the entire stimulus range . The approximation can be seen as ‘rolling out’ the stimulus domain from to . Therefore, to neglect the impact of the stimulus boundary, we assume that the stimulus is in the middle of the stimulus domain and and . Furthermore, assuming that each module is efficient, the width of the Gaussians can be approximated as
(23)
where is the Fisher information of module . The joint likelihood function can thus be approximated as
(24)
As the likelihood functions depend on the particular realization of the spike counts, the distance between the modes of the respective likelihoods closest to the true stimulus condition s0, , is a random variable. Note that in the Results section, is simply referred to as for clarity.
The joint likelihood distribution has its maximal peak close to the true stimulus condition s0 if is the smallest distance between any pairs of peaks of Q1 and Q2 (see Equation A3.7 for details). Assuming that both modules provide efficient estimates, the distance can be approximated as a normally distributed random variable
(25)
where refers to the time-normalized Fisher information of module . Thus, as the decoding time increases, the variance of decreases. Hence, it is necessary for the decoding time to be large enough such that it is rare for not to be the smallest distance between any pair of peaks. Similarly, the distance between the other pair of peaks in Q1 and Q2 within the stimulus range becomes
(26)
where and are indexing the different Gaussians as before. Thus, the threshold for catastrophic error is reached when there is another pair of modes with the same distance between them, that is,
(27)
for some n1 and n2 belonging to the index sets as above. Thus, to avoid catastrophic errors, it is necessary that
(28)
for all and . By solving Equation 28, and taking into account that can be either positive or negative, we get the maximally allowed displacement
(29)
Note that for , all n1 represent the same mode (but one full rotation 1 away). Thus, we limit the search such that and . Assuming that the period of the second module is a scaling of the first module, , the above equation becomes
(30)
Note that stimulus ambiguity can never be resolved if for some pair , which is analogous to the condition in Mathis et al., 2012. To limit the probability of catastrophic estimation errors from the joint distribution to some small error probability , the following should hold
(31)
Because , we have
(32)
where is the error-function and . By rearranging the terms and using Equation A2.8, we can obtain a lower bound on the required decoding time
(33)
where is the time-normalized Fisher information of module . Note that can easily be found using an exhaustive search according to Equation 29 or Equation 30.
Approximating minimal decoding time
Request a detailed protocolTo approximate the order by which the population reaction time scales with the distribution of spatial periods and the stimulus dimensionality, we extended the approximation method introduced by Xie, 2002. The key part of the approximation method is to use a Taylor series to reason about which conditions must hold for the distribution of errors to be normally distributed with a covariance equal to the inverse of the Fisher information matrix. Note that this approximation assumes the existence of a unique solution to the maximum likelihood equations, thus, it does not apply to ambiguous neural codes (e.g. , etc.).
First, let’s recollect the Taylor series with Lagrangian reminder for a general function g
(34)
where is somewhere on the interval . Thus, in the multivariate case, the derivative in the j:th direction of the log-likelihood function for stimulus condition can be rewritten using a Taylor series with Lagrangian reminder as
(35)
for all where is the true stimulus condition and is a stimulus point between and .
If the estimated stimulus is close to the true stimulus, then the quadratic order terms are small. If so, the variance of converges towards (in distribution), where is the Fisher information matrix (Lehmann and Casella, 1998). However, if the estimated stimulus is not close to the true stimulus, then the quadratic terms are not negligible. Therefore, when is sufficiently large, and the variance of the estimation follows the Cramér-Rao bound, the following should hold for all
(36)
In this regime, we make the following term-wise approximations
(37)
and
(38)
which gives
(39)
Because unless (see Equation A4.3, Equation A4.4, Equation A4.5), Equation 39 simplifies to
(40)
Furthermore, because is a diagonal matrix (see Equation A2.18), we have
(41)
Next, by taking the square of the absolute values, we obtain
(42)
Because we assumed that and are sufficiently large to meet the Cramér-Rao bound, we have that
(43)
Inserting Equation 43 into Equation 42 gives
(44)
or, equivalently,
(45)
By approximating the term with an upper bound (see Equation A4.10) and using the expression for Fisher information (Equation A2.8), the expression for population reaction times can be obtained as
(46)
where is a function of . Lastly, by casting Equation 46 in terms of the scale factor , and fitting using (for example) least square regression, we obtain
(47)
where is the number of neurons per module, and K1 and K2 are constants. Note that in the simulations, is fixed and can therefore be incorporated into K1.
Appendix 1
Tuning curves and spike count model
In the paper, we study the representation of a multidimensional stimulus . For simplicity, it is assumed that the range of the stimulus in each dimension is equal, such that for all for some stimulus range (in the main text, we consider for simplicity). Note that these assumption does not qualitatively change the results. Furthermore, we assume that the tuning curves were circular (von Mises) tuning curves
(A1.1)
where ai is the peak amplitude of the stimulus-related tuning curve of neuron , is a width scaling parameter, defines the spatial period of the tuning, determines the location of the firing field(s) in the :th dimension, and determines the amount of background activity. The amplitude parameters ai were tuned such that all tuning curves had the same firing rate when averaged across all stimulus conditions (see Supplementary Equation A1.5).
It is possible to reparametrize the stimuli into a phase variable, . In the article, calculations and numerical simulation are based on phase variables . This only changes the MSE and Fisher information by a constant scaling . As we are interested in comparing the minimal decoding times, not the absolute values of the MSE, we can drop the "unnormalized" stimulus . The tuning curves in Supplementary Equation A1.1 can thus be rewritten using the phase variable as
(A1.2)
Given stimulus condition (or ) and decoding time , the spike count of each neuron was independently sampled from a Poisson distribution with rate . Thus, the probability of observing a particular spike count pattern given is
(A1.3)
Adjusting amplitudes
In order to make a fair comparison of decoding times across populations, we constrain each neuron to have the same average firing rate across the stimulus domain, . The average firing rate over the stimulus domain is
(A1.4)
Thus, given a desired stimulus-evoked firing rate, , over a normalized stimulus range (), the amplitudes will be set to
(A1.5)
Note that the integrals in Equation A1.5 are analytically solvable whenever the relative spatial frequency is a positive integer, in which case we have
(A1.6)
regardless of , here is the modified Bessel function of the first kind. In simulations, was set such that tuning curves with integer spatial frequencies () have amplitudes of 20 sp/s, that is,
(A1.7)
Appendix 2
Fisher information and the Cramér-Rao bound
Assuming a one-dimensional variable, the Cramér-Rao bound gives a lower bound on the MSE of any estimator
(A2.1)
where is the bias of the estimator and is Fisher information, defined as
(A2.2)
where the last equality holds if is twice differentiable and the neural responses are conditionally independent (Lehmann and Casella, 1998). Assuming an unbiased estimator, the bound can be simplified to
(A2.3)
For multi-parameter estimation, let denote the Fisher information matrix, with elements defined analogously to Supplementary Equation A2.2
(A2.4)
then (for unbiased estimators) the Cramér-Rao bound is instead stated as the following matrix inequality (Lehmann and Casella, 1998)
(A2.5)
in the sense that the difference is a positive semi-definite matrix. Thus, this implies the following lower bound for MSE of the k:th term
(A2.6)
where , that is, the estimation of sk using estimator . Note that if is a diagonal matrix, that is, for all , then the following also holds
(A2.7)
For the tuning curves defined in Supplementary Equation A1.1, the diagonal elements of the Fisher information matrix can be analytically solved assuming within each module (see Supplementary Equation A2.19)
(A2.8)
where the bar indicates the sample average across modules and is the stimulus range (note that in the main text, we assume ). The off-diagonal elements, on the other hand, can be shown to be 0 (see below). Thus we have equality in the last inequality of Supplementary Equation A2.6, and the MSE for each stimulus dimension is lower bounded by the inverse of Supplementary Equation A2.8.
Approximating Fisher information
To analytically approximate the Fisher information for a given neural population, we will neglect the impact of ongoing activity . Then, the tuning curves in Supplementary Equation A1.1 factorize as and the log-likelihood for neurons with conditionally independent spike counts becomes
(A2.9)
By taking the second derivatives w.r.t. stimulus dimension, we get for :
(A2.10)
and for
(A2.11)
Consequently, the elements of the Fisher information matrix are given by
(A2.12)
and for
(A2.13)
To simplify calculations, it is possible to reparametrize the stimulus as in Supplementary Equation A1.2 using the formula for Fisher information under reparametrization (Lehmann and Casella, 1998)
(A2.14)
to obtain
(A2.15)
We can approximate the elements of the Fisher information matrix in the limit of large by replacing the sums with integrals, for example,
(A2.16)
where is the number of distinct modules, is the number of neurons in each module, , and the D-dimensional integral is taken over the interval along each dimension. Making the variable substitution for we have
(A2.17)
where the sample average is taken over the population’s distribution of spatial frequencies and is the modified Bessel function of the first kind. Similar calculations for the case yield
(A2.18)
Thus, the stimulus parameters will be asymptotically orthogonal for all of the populations considered in this paper. That is, the covariance matrix will be diagonal. The per-neuron average contribution to each diagonal element of the Fisher information matrix, as reported in the main text, is, therefore
(A2.19)
Appendix 3
Maximum of the joint likelihood function (2 module case)
Assuming that the responses of the two modules are independent, the joint likelihood function can be decomposed into a product of the likelihood functions of the two modules. Using the approximation of each and as Gaussian sums (see Materials and methods), we have the following
(A3.1)
Thus, the contribution of the :th and :th mode of and to the joint likelihood function is
(A3.2)
where we in the last step renamed and to sp and sq, respectively. Unless the width of the tuning curves or the range is very large, all the modes of and , respectively, are well separated (see the end of the section). Thus, it is a reasonable approximation that the maximum of is defined by the maximum of across all combinations of and . Each combination reaches its maximum for some stimulus :
(A3.3)
Taking the derivative w.r.t. on the rightmost terms and solving gives
(A3.4)
Thus, using , the maximal value of each pair is
(A3.5)
Thus, the maximum likelihood choice will approximately be for the :th and :th mode with the smallest , that is, the smallest distance between the modes. Lastly, all modes of and , respectively, need to be sufficiently separated such that no two pairs of and reinforce each other. However, it is well known the full width at half maximum for a Gaussian function is , where for our functions and , and . Thus, given the expression for Fisher information in Equation A2.8, the FWHM can be expressed as
(A3.6)
Thus, for the modes to be separated, it is reasonable to require that the FWHM is no longer than one period length of the module, that is, . Hence, we have that
(A3.7)
Rewriting this into a bound on the time needed for the assumption of separation, we get
(A3.8)
For the parameters used in our simulations, this is satisfied very fast, on the order of tens of microseconds. However, note that the assumption of each module providing efficient estimates, which is a prerequisite for these approximations, requires significantly longer time scales. Thus, the assumption that the individual modes of and are well-separated is, in our case, not likely to be a restrictive assumption.
Appendix 4
Calculate
To approximate the minimal decoding time, we need to calculate (see Equations 38; 39, main text)
(A4.1)
For , using Supplementary Equation A1.1, Equation A1.2, Equation A1.3, we have
(A4.2)
Thus, for becomes
(A4.3)
as odd functions over even intervals integrate to zero. For (note that and follows by symmetry) we have
(A4.4)
and hence,
(A4.5)
Lastly, for we have,
(A4.6)
Thus , becomes
(A4.7)
Each term above have a dependence on , with an odd power. Therefore, when multiplying with and integrating as above, these terms vanish. Hence, we can focus only on the terms including . After some calculus manipulation, it is possible to reduce the expression to include only (for all ).
(A4.8)
Unfortunately, as this integral includes both and , no simple expression can be obtained. Using the variable substitution , we can simplify it slightly to
(A4.9)
Instead, we focus on the difference , which maximizes the above integral for each module. Thus, all integrals can be upper bounded by a constant , yielding the upper bound
(A4.10)
Note that the constant can be incorporated into the regression coefficient K1 in Equation 47 and that the stimulus range, , is assumed to be in the main text.
Appendix 5
Approximating minimal required spike count
Given the approximation of minimal decoding time in Equation 9 (main text), we seek to reformulate the approximation in terms of the required total spike count, instead. The average total spike count for a given population and stimulus condition is
(A5.1)
where is the decoding time. Thus, the average spike count over both stimulus conditions (assuming uniformly distributed stimulus and integer spatial frequencies) and trials for the entire population is
(A5.2)
Consequently, the number of spikes evoked by the stimulus-related tuning of the population is
(A5.3)
Inserting Supplementary Equation A5.3 into Equation 46 (main text) reveals the number of stimulus-evoked spikes, , the population must produce before reaching the predicted lower bound
(A5.4)
Data availability
Code has been made publicly available on Github (https://github.com/movitzle/Short_Decoding_Time, copy archived at Lenninger, 2023).
References
-
Effects of noise correlations on information Encoding and decodingJournal of Neurophysiology 95:3633–3644.https://doi.org/10.1152/jn.00919.2005
-
Experimental evidence for sparse firing in the neocortexTrends in Neurosciences 35:345–355.https://doi.org/10.1016/j.tins.2012.03.008
-
Optimal short-term population coding: When Fisher information failsNeural Computation 14:2317–2351.https://doi.org/10.1162/08997660260293247
-
Mutual information, Fisher information, and population codingNeural Computation 10:1731–1757.https://doi.org/10.1162/089976698300017115
-
Reading population codes: a neural implementation of ideal observersNature Neuroscience 2:740–745.https://doi.org/10.1038/11205
-
A limit to the speed of processing in ultra-rapid visual Categorization of novel natural scenesJournal of Cognitive Neuroscience 13:171–180.https://doi.org/10.1162/089892901564234
-
What grid cells convey about rat locationThe Journal of Neuroscience 28:6858–6871.https://doi.org/10.1523/JNEUROSCI.5684-07.2008
-
Why neurons mix: high Dimensionality for higher cognitionCurrent Opinion in Neurobiology 37:66–74.https://doi.org/10.1016/j.conb.2016.01.010
-
Computing with populations of Monotonically tuned neuronsNeural Computation 15:2115–2127.https://doi.org/10.1162/089976603322297313
-
Receptive fields, Binocular interaction and functional architecture in the cat's visual cortexThe Journal of Physiology 160:106–154.https://doi.org/10.1113/jphysiol.1962.sp006837
-
Nonlinear mixed selectivity supports reliable neural computationPLOS Computational Biology 16:e1007544.https://doi.org/10.1371/journal.pcbi.1007544
-
Correlations and neuronal population informationAnnual Review of Neuroscience 39:237–256.https://doi.org/10.1146/annurev-neuro-070815-013851
-
Performance breakdown in optimal stimulus decodingJournal of Neural Engineering 12:036012.https://doi.org/10.1088/1741-2560/12/3/036012
-
SoftwareShort_Decoding_Time, version swh:1:rev:10086d954d5baaf5bf2c4e5f5b8ec75492e21c19Software Heritage.
-
Bayesian inference with probabilistic population codesNature Neuroscience 9:1432–1438.https://doi.org/10.1038/nn1790
-
Optimal population codes for space: grid cells outperform place cellsNeural Computation 24:2280–2317.https://doi.org/10.1162/NECO_a_00319
-
Novel behavioral paradigm reveals lower temporal limits on mouse olfactory decisionsThe Journal of Neuroscience 35:11667–11673.https://doi.org/10.1523/JNEUROSCI.4693-14.2015
-
Orientation selectivity in Macaque V1: diversity and Laminar dependenceThe Journal of Neuroscience 22:5639–5651.https://doi.org/10.1523/JNEUROSCI.22-13-05639.2002
-
Processing speed in the cerebral cortex and the Neurophysiology of visual maskingProceedings of the Royal Society of London. Series B 257:9–15.https://doi.org/10.1098/rspb.1994.0087
-
Nonlinear population codesNeural Computation 16:1105–1136.https://doi.org/10.1162/089976604773717559
-
Communication in the presence of noiseProceedings of the IRE 37:10–21.https://doi.org/10.1109/JRPROC.1949.232969
-
Grid cells generate an analog error-correcting code for singularly precise neural computationNature Neuroscience 14:1330–1337.https://doi.org/10.1038/nn.2901
-
Information Encoding and the responses of single neurons in the Primate temporal visual cortexJournal of Neurophysiology 70:640–654.https://doi.org/10.1152/jn.1993.70.2.640
Article and author information
Author details
Pawel Andrzej Herman

Funding
Digital Futures
- Movitz Lenninger
- Mikael Skoglund
- Pawel Andrzej Herman
- Arvind Kumar
Vetenskapsrådet
- Arvind Kumar
Institute of Advanced Studies (Fellowship)
- Arvind Kumar
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank the reviewers and editors for their helpful comments on improving the manuscript and Dr. Pascal Helson for proofreading the manuscript.
Copyright
© 2023, Lenninger et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,086
- views
-
- 158
- downloads
-
- 5
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 5
- citations for umbrella DOI https://doi.org/10.7554/eLife.84531
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Are single-peaked tuning curves tuned for speed rather than accuracy?
eLife 12:e84531.
https://doi.org/10.7554/eLife.84531




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}