Neural criticality from effective latent variables
- Department of Physics, New York University, United States
- Department of Physics, Department of Biology, Initiative in Theory and Modeling of Living Systems, Emory University, United States
- Department of Neuroscience, University of Minnesota Medical School, United States
eLife assessment
This paper provides a simple example of a neural-like system that displays criticality, but not for any deep reason; it's just because a population of neurons are driven (independently!) by a slowly varying latent variable, something that is common in the brain. Moreover, criticality does not imply optimal information transmission (one of its proposed functions). The work is likely to have an important impact on the study of criticality in neural systems and is convincingly supported by the experiments presented.
https://doi.org/10.7554/eLife.89337.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Convincing: Appropriate and validated methodology in line with current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
Observations of power laws in neural activity data have raised the intriguing notion that brains may operate in a critical state. One example of this critical state is ‘avalanche criticality’, which has been observed in various systems, including cultured neurons, zebrafish, rodent cortex, and human EEG. More recently, power laws were also observed in neural populations in the mouse under an activity coarse-graining procedure, and they were explained as a consequence of the neural activity being coupled to multiple latent dynamical variables. An intriguing possibility is that avalanche criticality emerges due to a similar mechanism. Here, we determine the conditions under which latent dynamical variables give rise to avalanche criticality. We find that populations coupled to multiple latent variables produce critical behavior across a broader parameter range than those coupled to a single, quasi-static latent variable, but in both cases, avalanche criticality is observed without fine-tuning of model parameters. We identify two regimes of avalanches, both critical but differing in the amount of information carried about the latent variable. Our results suggest that avalanche criticality arises in neural systems in which activity is effectively modeled as a population driven by a few dynamical variables and these variables can be inferred from the population activity.
Introduction
The neural criticality hypothesis – the idea that neural systems operate close to a phase transition, perhaps for optimal information processing – is both ambitious and banal. Measurements from biological systems are limited in the range of spatial and temporal scales that can be sampled, not only because of the limitations of recording techniques but also due to the fundamentally non-stationary behavior of most, if not all, biological systems. These limitations make proving that an observation indicates critical behavior difficult. At the same time, the idea that brain networks are critical echoes the anthropic principle: tuned another way, a network becomes quiescent or epileptic and in either state, seems unlikely to support perception, thought, or flexible behavior, yet these observations do not explain how such fine-tuning could be achieved. Further muddying the water, researchers have reported multiple kinds of criticality in neural networks, including through analysis of avalanches (Beggs and Plenz, 2003; Plenz et al., 2021; O’Byrne and Jerbi, 2022; Girardi-Schappo, 2021) and of coarse-grained activity (Meshulam et al., 2019), as well as of correlations (Dahmen et al., 2019). How these flavors of critical behavior relate to each other or any functional network mechanism is unknown.
The phenomenon that we will refer to as ‘avalanche criticality’ appears remarkably widespread. It was first observed in cultured neurons (Beggs and Plenz, 2003) and later studied in zebrafish (Ponce-Alvarez et al., 2018), turtles (Shew et al., 2015), rodents (Ma et al., 2019), monkeys (Petermann et al., 2009), and even humans (Poil et al., 2008). The standard analysis, described later, requires extracting power-law exponents from fits to the distributions of avalanche size and of duration and assessing the relationship between exponents. There is debate over whether these observations reflect true power laws, but within the resolution achievable from experiments, neural avalanches exhibit power laws with exponent relationships predicted from theory developed in physical systems (Perkovic et al., 1995).
Avalanche criticality is not the only form of criticality observed in neural systems. Zipf’s law, in which the frequency of a network state is inversely proportional to its rank, appears in systems as diverse as fly motion estimation and the salamander retina (Mora and Bialek, 2011; Schwab et al., 2014; Aitchison et al., 2016). More recently, Meshulam et al., 2019 reported various statistics of population activity in the mouse hippocampus, including the eigenvalue spectrum of the covariance matrix and the activity variance. These were found to scale as populations were ‘coarse-grained’ through a procedure in which neural activities were iteratively combined based on similarity. Similar observations have been reported in spontaneous activity recorded across a wide range of brain areas in the mouse (Morales et al., 2023). Simple neural network models of such data explain neither Zipf’s law nor coarse-grained criticality (Meshulam et al., 2019).
Even though these three forms of criticality are observed through different analyses, they may originate from similar mechanisms. Numerous studies have reported relatively low-dimensional structure in the activity of large populations of neurons (Mazor and Laurent, 2005; Ahrens et al., 2012; Mante et al., 2013; Pandarinath et al., 2018; Stringer et al., 2019; Nieh et al., 2021), which can be modeled by a population of neurons that are broadly and heterogeneously coupled to multiple latent (i.e. unobserved) dynamical variables. Using such a model, we previously reproduced scaling under coarse-graining analysis within experimental uncertainty (Morrell et al., 2021). Zipf’s law has been explained by a similar mechanism (Schwab et al., 2014; Aitchison et al., 2016; Humplik and Tkačik, 2017). A single quasi-static latent variable has been shown to produce avalanche power laws, but not the relationships expected between the critical exponents (Priesemann and Shriki, 2018), while a model including a global modulation of activity can generate avalanche criticality (Mariani et al., 2021), but has not demonstrated coarse-grained criticality (Morrell et al., 2021). It is not known under what conditions the more general latent dynamical variable model generates avalanche criticality.
Here, we examine avalanche criticality in the latent dynamical variable model of neural population activity. We find that avalanche criticality is observed over a wide range of parameters, some of which may be optimal for information representation. These results demonstrate how criticality in neural recordings can arise from latent dynamics in neural activity, without need for fine-tuning of network parameters.
Results
Critical exponents values and crackling noise
We begin by defining the metrics used to quantify avalanche statistics and briefly summarize experimental observations, which have been reviewed in detail elsewhere (Plenz et al., 2021; O’Byrne and Jerbi, 2022; Girardi-Schappo, 2021). Activity is recorded across a set of neurons and binned in time. Avalanches are then defined as contiguous time bins, in which at least one neuron in the population is active. The duration of an avalanche is the number of contiguous time bins and the size is the summed activity during the avalanche. The distributions of avalanche size and duration are fit to power laws ( for size , and for duration ) using standard methods (Clauset et al., 2009).
Power laws can be indicative of criticality, but they can also result from non-critical mechanisms (Touboul and Destexhe, 2017; Priesemann and Shriki, 2018). A more stringent test of criticality is the ‘crackling’ relationship (Perkovic et al., 1995; Touboul and Destexhe, 2017), which involves fitting a third power-law relationship, , and comparing to the predicted exponent , derived from the size and duration exponents, and :
(1)
Previous work demonstrating approximate power laws in size and duration distributions through the mechanism of a slowly changing latent variable did not generate crackling (Touboul and Destexhe, 2017; Priesemann and Shriki, 2018).
Measuring power-laws in empirical data is challenging: it generally requires setting a lower cut-off in the size and duration, and the power-law behavior only has limited range due to the finite size and duration of the recording itself. Nonetheless, there is some consensus (Shew et al., 2015; Fontenele et al., 2019; Ma et al., 2019) that even if and vary over a wide range (1.5 to about 3) across recordings, the values of and stay in a relatively narrow range, from about 1.1 to 1.3.
Avalanche scaling in a latent dynamical variable model
We study a model of a population of neurons that are not coupled to each other directly but are driven by a small number of latent dynamical variables – that is, slowly changing inputs that are not themselves measured (Figure 1A). We are agnostic as to the origin of these inputs: they may be externally driven from other brain areas, or they may arise from large fluctuations in local recurrent dynamics. The model was chosen for its simplicity, and because we have previously shown that this model with at least about five latent variables can produce power laws under the coarse-graining analysis (Morrell et al., 2021). In this paper, we examine avalanche criticality in the same model.
Figure 1
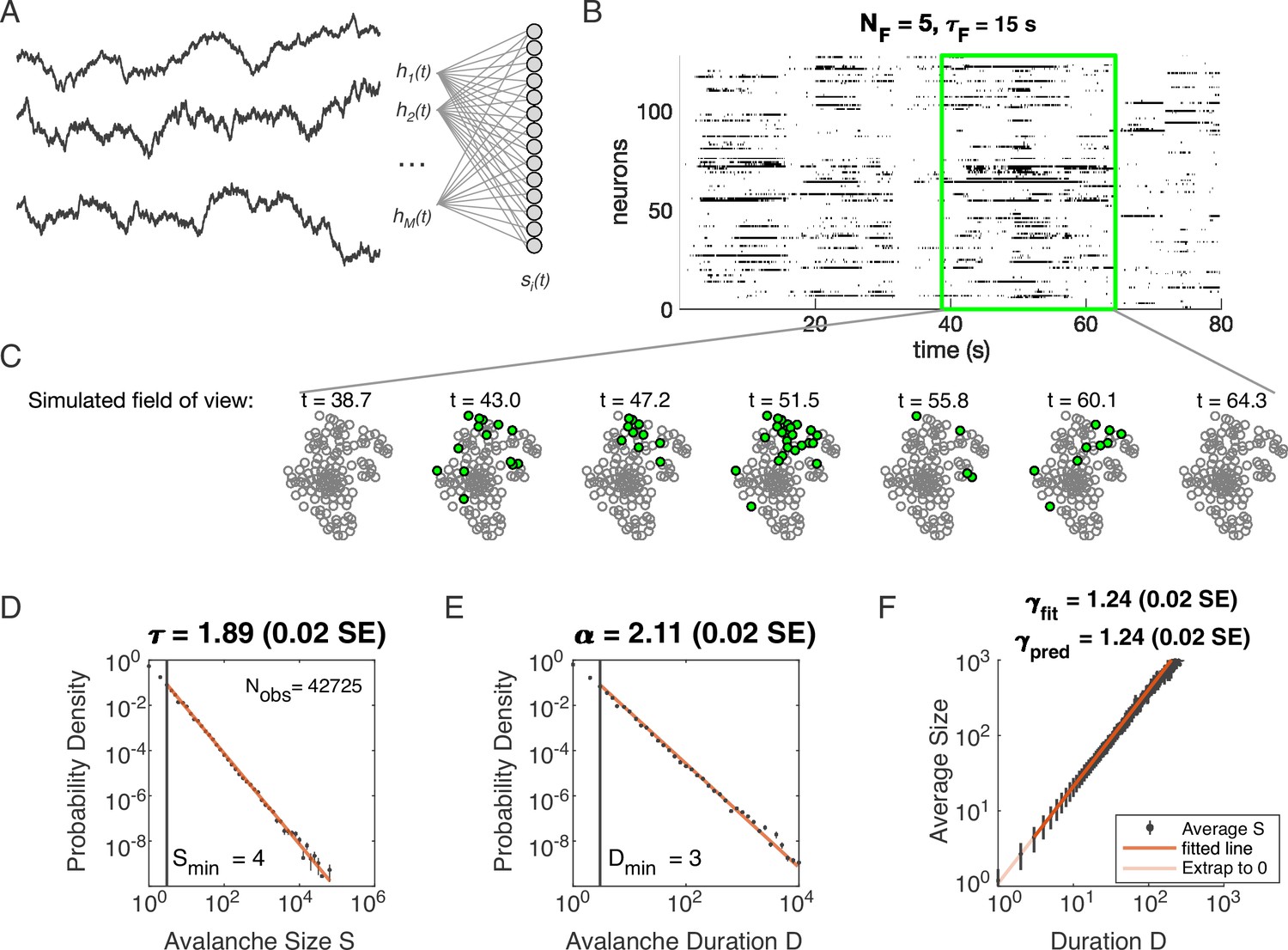
Latent dynamical variable model produces avalanche criticality.
Simulated network is neurons. Other parameters in Table 1. (A) Model structure. Latent dynamical variables are broadly coupled to neurons in the recorded population. (B) Raster plot of a sample of activity binned at 3 ms resolution across 128 neurons with five latent variables, each with correlation timescale . (C) Projection of activity into a simulated field of view for illustration. (D-F) Avalanche analysis in a network (parameters , , and ), showing size distribution (D), duration distribution (E), and size with duration scaling (F). Lower cutoffs used in fitting are shown with vertical lines and their values are indicated in the figures. There are avalanches of size in this simulated dataset. Estimated values of the critical exponents are shown in the titles of the panels.
Specifically, we model the neurons as binary units () that are randomly () coupled to dynamical variables . The probability of any pattern , given the current state of the latent variables, is
(2)
where the parameter controls the scaling of the variables and controls the overall activity level. We modeled each latent variable as an Ornstein-Uhlenbeck process with the time scale (see Materials and methods). Thus our model has four parameters: (input scaling), (activity threshold), (dynamical timescale), and (number of latent variables).
Distributions of avalanche size and avalanche duration within this model followed approximate power laws (Figure 1C; see Materials and methods). In the example shown (, , and ), we found exponents (size) and (duration). Further, the average size of avalanches with fixed duration scaled as , with the fitted , in agreement with the predicted value . Thus, our model could generate avalanche scaling, at least for some parameter choices. In the following sections, we examine how avalanche scaling depends on model parameters (, , and ; see Table 2). We first focus on two sets of simulations: one set with latent variable, which does not generate scaling under coarse-graining (Morrell et al., 2021), and one set with latent variables, which can generate such scaling for some values of parameters , , and (Morrell et al., 2021; Table 1).
Table 1
Simulation parameters for Figure 1.
| Parameter | Description | Value |
|---|---|---|
| bias towards silence | ||
| variance multiplier | ||
| number of latent fields | ||
| latent field time constant | ||
| number of cells |
Avalanche scaling depends on the number of latent variables
We analyzed avalanches from one- and five-variable simulations, each with fixed latent dynamical timescale ( time steps; see Table 2 for parameters). In the following sections, time is measured in simulation time steps, see Materials and methods for converting time steps to seconds. We used established methods for measuring empirical power laws (Clauset et al., 2009). The minimum cutoffs for size () and duration () are indicated by vertical lines in Figure 2. For the population coupled to a single latent variable, the avalanche size distribution was not well fit by a power law (Figure 2A). With a sufficiently high minimum cut-off (), the duration distribution was approximately power-law (Figure 2B).
Table 2
Simulation parameters for Figure 2.
| Parameter | Description | Value |
|---|---|---|
| bias towards silence | (for ) or (for ) | |
| variance multiplier | ||
| number of latent fields | ||
| latent field time constant | ||
| number of cells |
Figure 2 with 4 supplements see all
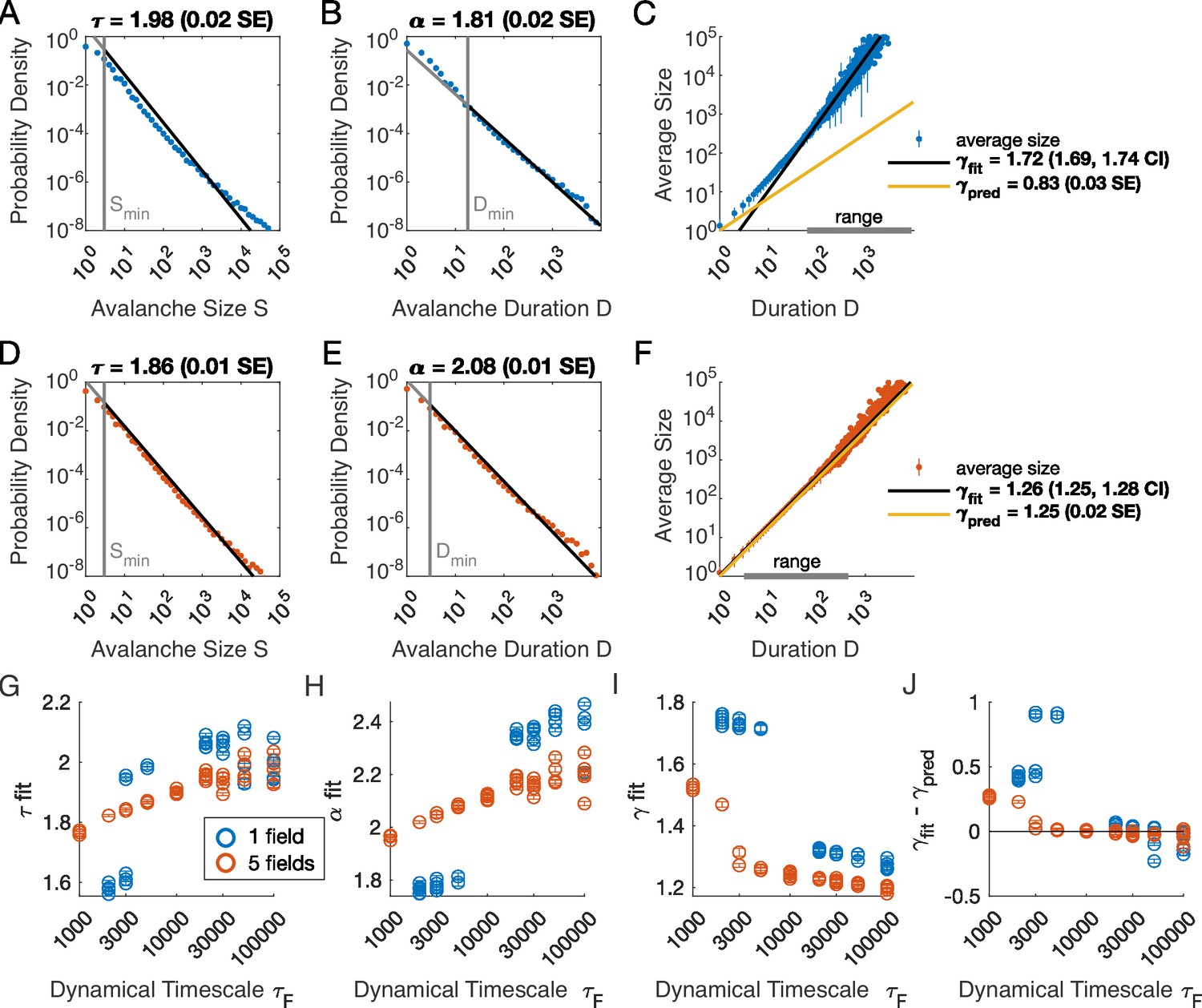
Multiple latent variables generate avalanche scaling at shorter timescales than a single latent variable.
Simulated network is neurons. Other parameters used for simulations for this figure are found in Table 2. (A-C) Scaling analysis for one variable models where the dynamic timescale is equal to 5×103 time steps. (A) Distribution of avalanche sizes. MLE value of exponent for best-fit power law is (0.02 SE), with lower cutoff indicated by the vertical line. (B) Distribution of avalanche duration. MLE value of is 1.81 (0.02 SE). (C) Average size plotted against avalanche duration (blue points), with power-law fit (black line) and predicted relationship (yellow line) from MLE values for exponents in A and B. Gray bar on the horizontal axis indicates range, over which a power law with fits the data (see Materials and methods). (D-F) Analysis of avalanches from a simulation of a population coupled to five independent latent variables where the dynamic timescale is equal to 5×103 time steps. (G) Exponents for avalanche size distributions across timescales for one-variable (blue) and five-variable (red) simulations. Each circle is a simulation with independently drawn coupling parameters. Simulations had to show scaling over at least two decades to be included in panels (G–J). (H) Exponents for avalanche duration distributions for simulations in G. (I) Fitted values of for simulations in G. (J) Difference between fitted and predicted values. Five-variable simulations produce crackling over a wider range of timescales than single-variable simulations.
We next assessed whether the simulation produced crackling. If so, the value obtained by fitting would be similar to . In many cases, such as the one-variable example shown in Figure 2C, the full range of avalanche durations were not fit by a single power law. Therefore, we determined the largest range, over which a power law was a good fit to the simulated observations. In this case, slightly over two decades of apparent scaling were observed starting from avalanches with minimum duration slightly less than 100 time steps (Figure 2C), with a best-fit value of . As we did not find a power-law in the size distribution, calculating is meaningless. If we do it anyway, we obtain (yellow line in Figure 2C), which clearly deviates from the fitted value of . Thus, for the single latent dynamical variable model (), power-law fits are poor, and there is no crackling.
The five-variable model produces a different picture. We now find avalanches, for which size and duration distributions are much better fit by power-law models starting from very low minimum cutoffs (Figure 2D–E, Figure 2—figure supplement 2). Average size scaled with duration, again over more than two decades, with , which was in close agreement with (Figure 2F). Holding other parameters constant, we thus found that scaling relationships and crackling arise in the multi-variable model but not the single-variable model.
Avalanche scaling depends on the time scale of latent variables
Based on simulations in the previous section, we surmised that the five-variable simulation generated scaling more readily due to creating an ‘effective’ latent variable that had slower dynamics than any individual latent variable. We reasoned that at any moment in time, the latent variable state is a vector in the latent space. Because coupling to the latent variables is random throughout the population, only the length () and not the direction of this vector matters, and the timescale of changes in this length would be much slower than , the timescale of each of the components . We therefore speculated that increasing the timescale of dynamics of the latent variables should eventually lead to scaling and crackling in the single-variable model as well as the five-variable one. To examine the dependence of avalanche scaling on this timescale, we simulated one-variable and five-variable networks at fixed and coupled to latent variables with the correlation time of their Ornstein-Uhlenbeck dynamics of time steps, spanning from a factor of 10 faster to a factor of 10 slower than the original in Figure 1. Simulations were replicated five times at each combination of parameters by drawing new latent variable coupling values (), as well as new latent variable dynamics and instances of neural firing. For simulations that passed the criteria to be fitted by power laws, we plot the fitted values of , , , and (Figure 2G–J). Missing points are those for which distributions did not pass the power law fit criteria.
In the single-variable model, best-fit exponents changed abruptly for latent variable timescale around (Figure 2G and H), while in the five-variable model, exponents tended to increase gradually (Figure 2G and H, red). The discontinuity in the single-variable case reflected a change in the lower cutoff values in the power-law fits: size and duration distributions generated with faster latent dynamics could be fit reasonably well to a power law by using a high value of the lower cutoff (Figure 2—figure supplement 3). For time scales greater than ∼104, the minimum cutoffs dropped, and the single-variable model generated power-law distributed avalanches and crackling (Figure 2J), similar to the five-variable model. In summary, in the latent dynamical variable model, introducing multiple variables generated scaling at faster timescales. However, by slowing the timescale of the latent dynamics, the model generated signatures of critical avalanche scaling for both multi- and single-variable simulations.
Avalanche criticality, input scaling, and firing threshold
In the previous section, we found that a very slow single latent dynamical variable generated avalanche criticality in the simulation population. Thus, from now on, we simplify the model in order to characterize avalanche statistics across values of input scaling and firing threshold . Specifically, we modeled a population of neurons coupled to a single quasi-static latent variable. We simulated 103 segments of 104 steps each and drew a new value of the latent variable () for each segment. Ten replicates of the simulation were generated at each of the combinations of and (see Materials and methods).
Almost independent of and , we found quality power law fits and crackling. Figure 3 shows the average (across network realizations) of the exponents extracted from size (, Figure 3A) and duration (, Figure 3C) distributions. At small firing threshold (), we do not observe scaling because the system is always active, and all avalanches merge into one. At large firing threshold and low input scaling , we do not observe scaling because activity is so sparse that all avalanches are small. At intermediate values of the parameters, the simulations generated plausible scaling relationships in size and duration. The difference between and was typically less than 0.1 (Figure 4D–F), which was consistent with previously reported differences between fit and predicted exponents (Ma et al., 2019). Thus, there appears to be no need for fine-tuning to generate apparent scaling in this model, at least in the limit of (near) infinite observation time. Wherever and generate avalanches, there are approximate power-law distributions and crackling.
Figure 3
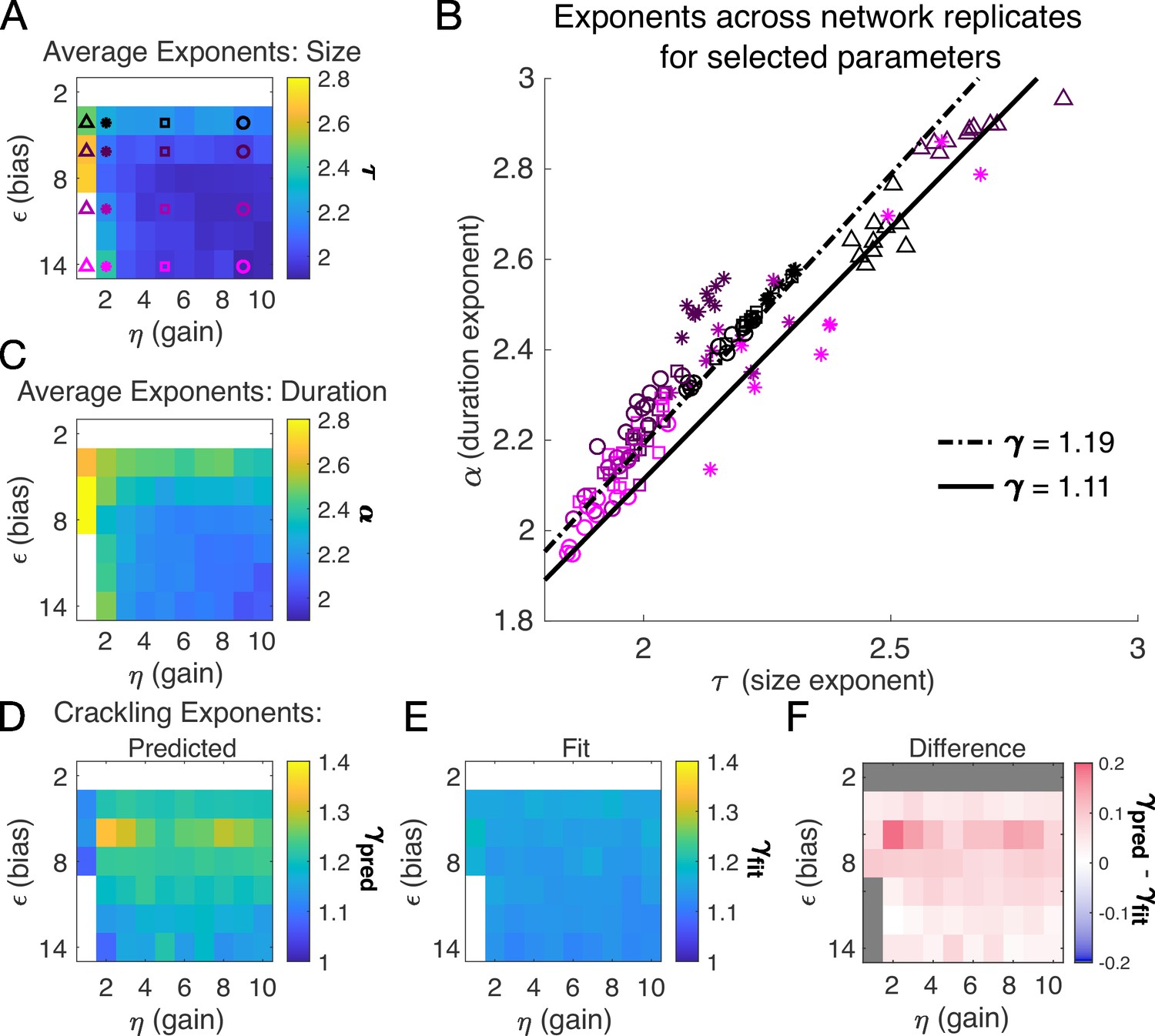
Exponents across network simulations for networks of neurons.
Each parameter combination was simulated for ten replicates, each time drawing randomly the couplings , the latent variable values, and the neural activities. Other parameters in Table 3. (A) Average across replicates for the size exponent . (B) Scatter plot of vs. for each network replicate for parameter combinations indicated in A. Linear relationships between and , corresponding to the minimum and maximum values of from panel E, are shown to guide the eye. (C) Same as A, for duration exponent . (D) Predicted exponent, , derived from A and C. (E) Value of from fit to . (F) Difference between and .
Figure 4 with 1 supplement see all
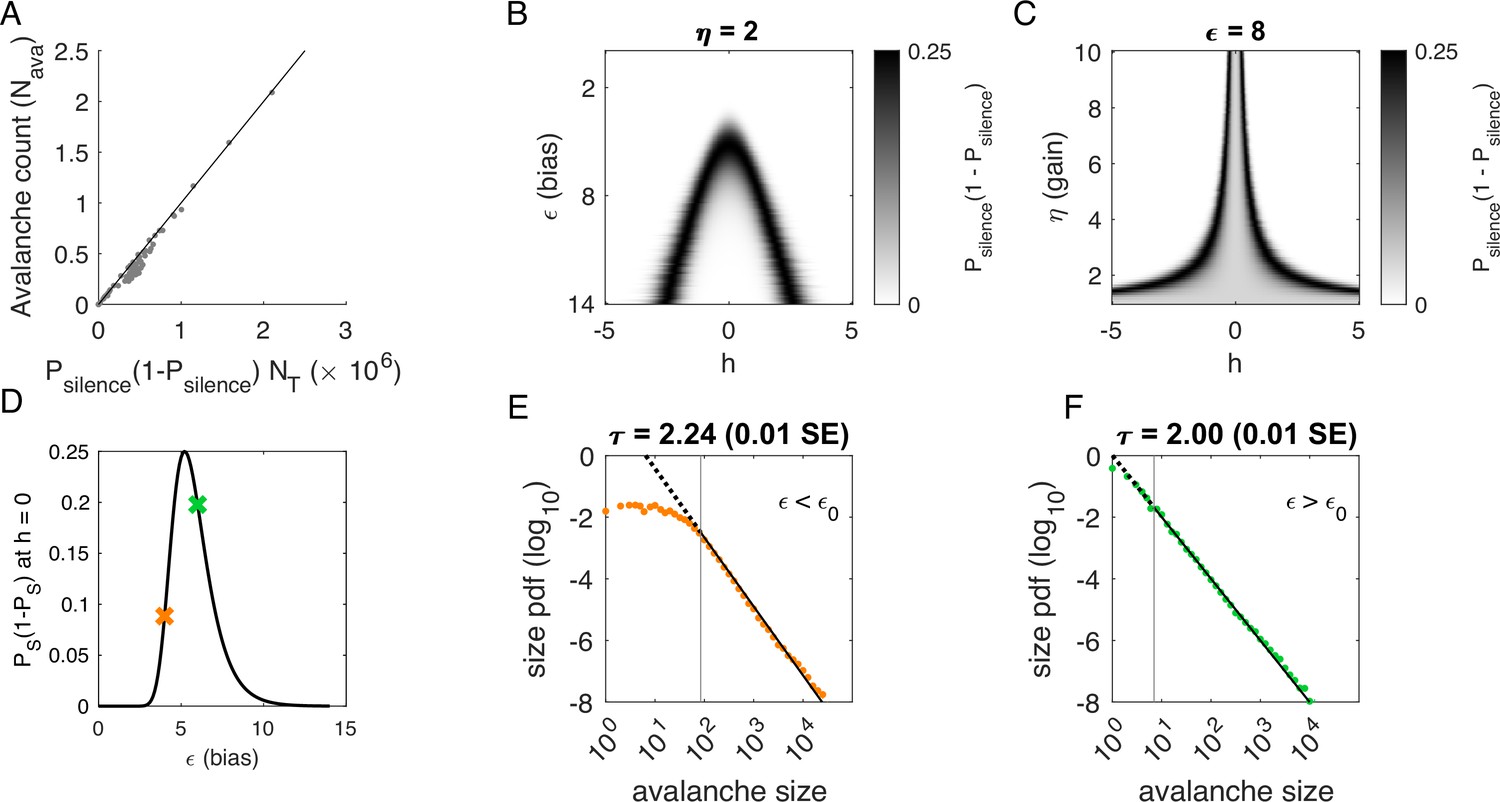
Avalanches in the latent dynamical variable model with a single quasistatic variable.
Parameters in Table 3. (A) Number of avalanches in simulations from Figure 3 as a function of the calculated probability of avalanches at fixed across values of and latent variable . Line indicates equality. (B) Probability of avalanches with across values of and . The latent variable is normally distributed with mean 0 and variance 1. Where the distribution of overlaps with regions of high probability (black), avalanches occur. (C) Probability of avalanches at across values of and . Increasing narrows the range of that generates avalanches. (D) Probability of avalanches at for a populations of 128 neurons (black line) and for a varying . Size distributions corresponding to simulations marked by the green and orange crosses are in E, F. (E) Example of size distribution with (orange marker in D). Size cutoff is close to 100. (F) Example of size distribution with (green marker in D). Size cutoff is < 10.
To determine where avalanches occur, we derive the avalanche rate across values of the latent variable . In the quasi-static model, the probability of an avalanche initiation is the probability of a transition from the quiet to an active state. Because all neurons are conditionally independent, this is . Then the expected number of avalanches is obtained by integrating over at each value of and :
(3)
where is the standard normal distribution. This probability tracks the observed number of avalanches across simulations, Figure 4A.
To gain an intuition for the conditions under which avalanches occur, we show two slices of the avalanche probability, at fixed (Figure 4B) and at fixed (Figure 4C). Black regions indicate where avalanches are likely to occur. If, for a given value of and , there is no overlap between high avalanche probability regions and the distribution of , then there will be no avalanches. For large , avalanches occur because neurons with large coupling to the latent variable (, recall ) are occasionally activated by a value of the latent variable that is sufficient to exceed (Figure 4B). Thus, the scaling parameter controls the value of for which avalanches occur most frequently (Figure 4C). As decreases, avalanches occur for smaller and smaller until avalanches primarily occur when .
To calculate the probability of avalanches, we must integrate over all values of , but we can gain a qualitative understanding of which avalanche regime the system is in by examining the probability of avalanches at . At , the avalanche probability (see Materials and methods) is
(4)
which is maximized at , independent of and . After some algebra, we find that for large . The dependence on reflects that a larger threshold is required for larger networks: large networks () are unlikely to achieve complete network silence, therefore preventing avalanches from occurring. Similarly, small networks () are unlikely to fire consecutively and thus are unlikely to avalanche.
We plot as a function of in Figure 4D. The peak at divides the space into two regions. For , a power-law is only observed in the large-size avalanches, which are rare (Figure 4E, green). By contrast, when , minimum size cutoffs are low (Figure 4F, orange). Both regions, and , exhibit crackling noise scaling. If observation times are not sufficiently long (estimated in Figure 4—figure supplement 1), then scaling will not be observed in the region, whose scaling relations arise from rare events. Insufficient observation times may explain experiments and simulations where avalanche scaling was not found.
Inferring the latent variable
Our analysis of at suggested that there are two types of avalanche regimes: one with high activity and high minimum cutoffs in the power law fit (Type 1), and the other with lower activity and size cutoffs (Type 2). Further, when drops to zero, avalanches disappear because the activity is too high or too low. We now examine how information about the value of the latent variables represented in the network activity relates to the activity type. To delineate these types, we calculated numerically , the value of , for which the probability of avalanches is maximized, and the contours of (Figure 5A). Curves for and and are shown in Figure 5A and B.
Figure 5
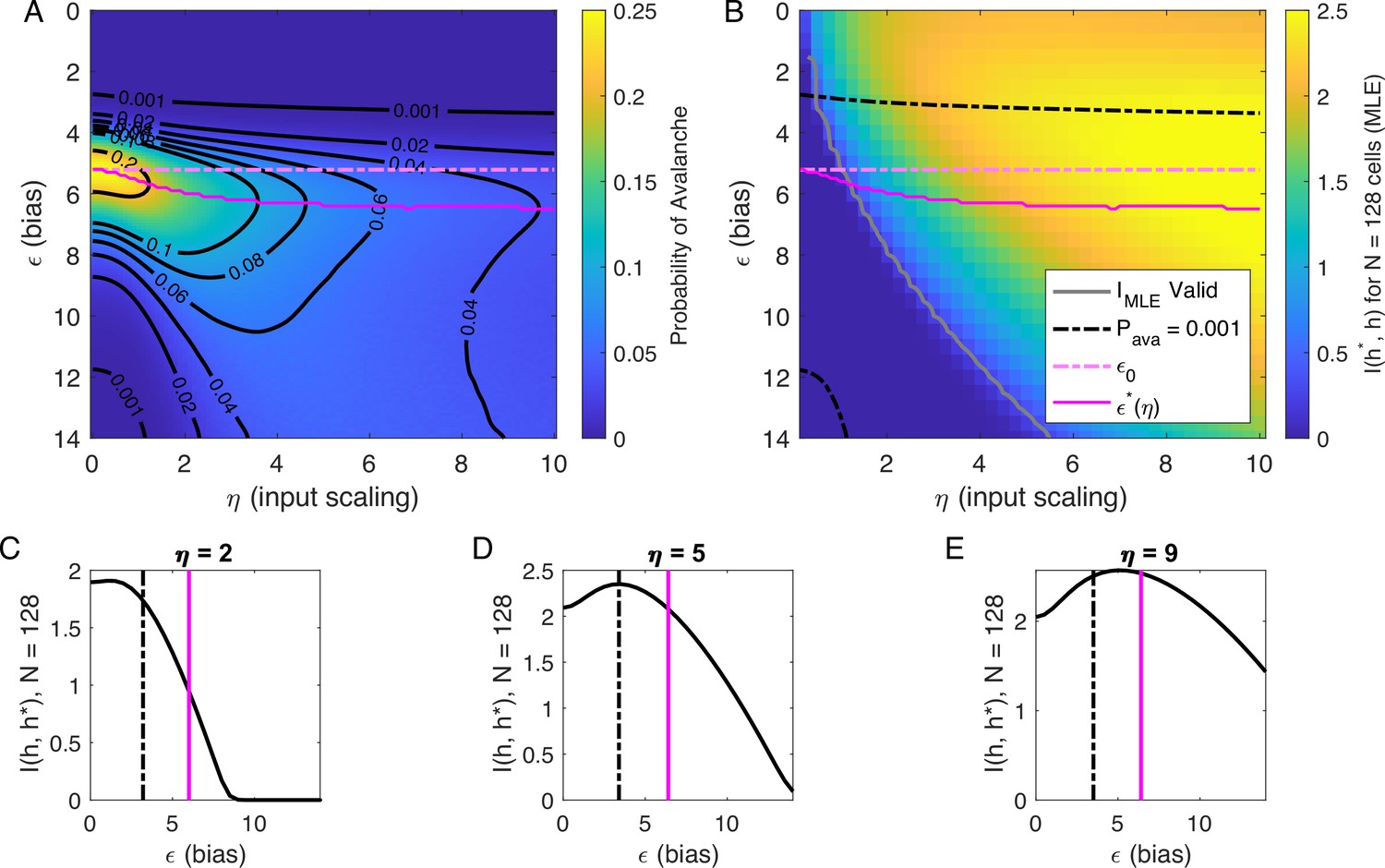
Information in the neural activity about the latent variable is higher in the low- avalanche region, compared to high- avalanche or high-rate avalanche-free activity.
(A) Probability of avalanche per time step across values of and . Solid magenta curve follows , the value of maximizing the probability of avalanches at fixed . Dashed magenta line indicates , calculated analytically, which matches at . (B) Information about latent variable, calculated from maximum likelihood estimate of using population activity. MLE approximation is invalid in the dark-blue region bounded by gray curve. Magenta line marks the maximum values of , reproduced from A. Dashed black curve indicates . The highest information region falls between and the contour for . (C - E) Slices of B, showing for . Magenta and dashed black lines again indicate and , respectively, as in B. Black dashed line marks the approximate boundary between the high-activity/no avalanche and the high-cutoff avalanche, and magenta line marks boundary between high-cutoff and low-cutoff avalanche regions.
We expect that the more cells fire, the more information they would convey, until the firing rate saturates, and inferring the value of the latent variable becomes impossible. Figure 5B supports the prediction: generally, information is higher in regions with more activity (lower , higher ), but only up to a limit: as , information decreases. This decrease begins approximately where the probability of avalanches drops to nearly zero (dashed black lines, Figure 5B–E) because all of the activity merges into a few very large avalanches. In other words, the Type-1 avalanche region coincides with the highest information about the latent variable.
The critical brain hypothesis suggests that the brain operates in a critical state, and its functional role may be in optimizing information processing (Beggs, 2008; Chialvo, 2010). Under this hypothesis, we would expect the information conveyed by the network to be maximized in the regions we observe avalanche criticality. However, we see that critical regions do not always have optimal information transmission. In Figure 5, the region that displays crackling noise is that where avalanches exist (), which corresponds to any value and . This avalanche region encompasses both networks with high information transmission and networks with low information transmission. In summary, observing avalanche criticality in a system does not imply a high-information processing network state. However, the scaling can be seen at smaller cutoffs, and hence with shorter recordings, in the high-information state. This parallels the discussion by Schwab et al., 2014, who noticed that the Zipf’s law always emerges in neural populations driven by quasi-stationary latent fields, but it emerges at smaller system sizes when the information about the latent variable is high.
Discussion
Here, we studied systems with distributed, random coupling to latent dynamical variables and we found that avalanche criticality is nearly always observed, with no fine-tuning required. Avalanche criticality was surprisingly robust to changes in input gain and firing rate threshold. Loss of avalanche criticality could occur if the latent process was not well-sampled, either because the simulation was not long enough or the dynamics of the latent variables were too fast. Finally, while information about the latent variables in the network activity was higher where avalanches were generated compared to when they were not, there was a range of information values across the critical avalanche regime. Thus, avalanche criticality alone was not a predictor of optimal information transmission.
Explaining experimental exponents
A wide range of critical exponents has been found in ex vivo and in vivo recordings from various systems. For instance, the seminal work on avalanche statistics in cultured neuronal networks by Beggs and Plenz, 2003 found size and duration exponents of 1.5 and 2.0 respectively, along with , when time was discretized with a time bin equal to the average inter-event interval in the system. A subset of the in vivo recordings analyzed from anesthetized cat (Hahn et al., 2010) and macaque monkeys (Petermann et al., 2009) also exhibited a size distribution exponent close to 1.5. By contrast, a survey of many in vivo and ex vivo recordings found power-law size distributions with exponents ranging from 1 to 3 depending on the system (Fontenele et al., 2019). Separately, Ma et al., 2019 reported recordings in freely moving rats with size exponents ranging from 1.5 to 2.7. In these recordings, when the crackling relationship held, the reported value of was near 1.2 (Fontenele et al., 2019; Ma et al., 2019).
A model for generating avalanche criticality is a critical branching process (Beggs and Plenz, 2003), which predicts size and duration exponents of 1.5 and 2 and scaling exponent of 2. However, there are alternatives: Lombardi et al., 2023 showed that avalanche criticality may also be produced by an adaptive Ising model in the sub-critical regime, and in this case, the scaling exponent was not 2 but close to 1.6. Our model, across the parameters we tested that produced exponents consistent with the scaling relationship, generated values that ranged from 1.9 to about 2.5. Across those simulations, we found values within a narrow band from 1.1 to 1.3 (see Figure 2I and J and Figure 3H). While the exponent values our model produces are inconsistent with a critical branching process (), they match the ranges of exponents estimated from experiments and reported by Fontenele et al., 2019. In this context, it might be useful to explore if our model and that of Lombardi et al., 2023 might be related, with the adaptive feedback signal of the latter viewed as an effective, latent variable of the former.
A genuine challenge in comparing exponents estimated from different experiments with different recording modalities (spiking activity, calcium imaging, LFP, EEG, or MEG) arises from differences in spatial and temporal scale specific to a particular recording, as well as the myriad decisions made in avalanche analysis, such as defining thresholds or binning in time. Thus, one possible reason for differences in exponents across studies may derive from how the system is sub-sampled in space or coarse-grained in time, both of which systematically change exponents and (Beggs and Plenz, 2003; Shew et al., 2015) and could account for differences in (Capek et al., 2023). The model we presented here could be used as a test bed for examining how specific analysis choices affect exponents estimated from recordings.
A second possible explanation for differences in exponents is that different experiments study similar, but distinct biological phenomena. For instance, networks that were cultured in vitro may differ from those that were not, whether they are in vivo or ex vivo (i.e. brain slices), and sensory-processing networks may have different dynamics from networks with different processing demands. It is possible that certain networks develop connections between neurons such that they truly do produce dynamics that approximate a critical branching process, while other networks have different structure and resulting dynamics and thus can be better understood as coupled neurons receiving feedback (Lombardi et al., 2023) or as a system coupled to latent dynamical variables. This is especially true in sensory systems, where coupling to (latent) external stimuli in a way that the neural activity can be used to infer the stimuli is the reason for the networks’ existence (Schwab et al., 2014).
Relationship to past modeling work
Our model is not the first to produce approximate power-law size and duration distributions for avalanches from a latent variable process (Touboul and Destexhe, 2017; Priesemann and Shriki, 2018). In particular, Priesemann and Shriki, 2018 derived the conditions, under which an inhomogeneous Poisson process could produce such approximate scaling. The basic idea is to generate a weighted sum of exponentially distributed event sizes, each of which are generated from a homogeneous Poisson process. How each process is weighted in this sum determines the approximate power-law exponent, allowing one to tune the system to obtain the critical values of 1.5 and 2. Interestingly, this model did not generate non-trivial scaling of size with duration (). Instead, they found , not the predicted . Our results differ significantly, in that was typically between 1.1 and 1.3 and it was nearly always close to the prediction from and . We speculate that this is due to nonlinearity in the mapping from latent variable to spiking activity, as doubling the latent field does not double the population activity, but doubling the rate of a homogeneous Poisson process does double the expected spike count. As biological networks are likely to have such nonlinearities in their responses to common inputs, this scenario may be more applicable to certain kinds of recordings.
Summary
Latent variables – whether they are emergent from network dynamics (Clark et al., 2023; Sederberg and Nemenman, 2020) or derived from shared inputs – are ubiquitous in large-scale neural population recordings. This fact is reflected most directly in the relatively low-dimensional structure in large-scale population recordings (Stringer et al., 2019; Pandarinath et al., 2018; Nieh et al., 2021). We previously used a model based on this observation to examine signatures of neural criticality under a coarse-graining analysis and found that coarse-grained criticality is generated by systems driven by many latent variables (Morrell et al., 2021). Here, we showed that the same model also generates avalanche criticality, and that when information about the latent variables can be inferred from the network, avalanche criticality is also observed. Crucially, finding signatures of avalanche criticality required long observation times, such that the latent variable was well-sampled. Previous studies showed that Zipf’s law appears generically in systems coupled to a latent variable that changes slowly relative to the sampling time, and that the Zipf’s behavior is easier to observe in the higher information regime (Schwab et al., 2014; Aitchison et al., 2016). However, this also suggests that observation of either scaling at modest data set sizes indeed points to some fine-tuning — namely to the increase of the information in the individual neurons (and, since neurons in these models are conditionally independent, also in the entire network) about the value of the latent variables. In other words, one would expect a sensory part of the brain, if adapted to the statistics of the external stimuli, to exhibit all of these critical signatures at relatively modest data set sizes. In monocular deprivation experiments, when the activity in the visual cortex is transiently not adapted to its inputs, scaling disappears, at least for recordings of a typical duration, and is restored as the system adapts to the new stimulus (Ma et al., 2019). We speculate that the observed recovery of criticality by Ma et al., 2019 could be driven by neurons adapting to the reduced stimuli state, for instance, by adjusting (input scaling) and (firing rate threshold).
Taken together, these results suggest that critical behavior in neural systems – whether based on the Zipf’s law, avalanches, or coarse-graining analysis – is expected whenever neural recordings exhibit some latent structure in population dynamics and this latent structure can be inferred from observations of the population activity.
Materials and methods
Simulation of dynamic latent variable model
Request a detailed protocolWe study a model from Morrell et al., 2021, originally constructed as a model of large populations of neurons in mouse hippocampus. In the original version of the model, neurons are non-interacting, receiving inputs reflective of place-field selectivity as well as input current arising from a random projection from a small number of latent dynamical variables, representing inputs shared across the population of neurons that are not directly measured or controlled. In the current paper, we incorporate only the latent variables (no place variables), and we assume that every cell is coupled to every latent variable with some randomly drawn coupling strength.
The probability of observing a certain population state given latent variables at time is
(5)
where is the normalization, and is the ‘energy’:
(6)
The latent variables are Ornstein-Uhlenbeck processes with zero mean, unit variance, and time constant . Couplings are drawn from the standard normal distribution.
Parameters for each figure are laid out in Tables 1–3. For the infinite time constant simulation, we draw a value and simulate for 10000 time steps, then repeat for 1000 draws of .
Time step units
Request a detailed protocolMost results were presented using arbitrary time units: all times (i.e. and avalanche duration ) are measured in units of an unspecified time step. Specifying a time bin converts the probability of firing into actual firing rates, in spikes per second, and this choice determines which part of the - phase space is most relevant to a given experiment.
The time step is the temporal resolution at which activity is discretized, which varies from several to hundreds of milliseconds across different experimental studies (Beggs and Plenz, 2003; Fontenele et al., 2019; Ma et al., 2019). In physical units and assuming a bin size of 3 ms to 10 ms, our choice of and in Figure 2 would yield physiologically realistic firing rate ranges (Hengen et al., 2016), with high-firing neurons reaching averages rates of 20-50 spikes/second and median firing-rate neurons around 1-2 spikes/second. The timescales of latent variables examined range from about 3 s to 3000 s, assuming 3-ms bins. Inputs with such timescales may arise from external sources, such as sensory stimuli, or from internal sources, such as changes in physiological state.
Simulations were carried out for the same number of time steps (2×106), which would be approximately 1 to 2 ‘hours’, a reasonable duration for in vivo neural recordings. Note that at large values of , the latent variable space is not well sampled during this time period.
Analysis of avalanche statistics
Setting the threshold for observing avalanches
Request a detailed protocolIn our model, we count avalanches as periods of continuous activity (in any subset of neurons) that is book-ended by time bins with no activity in the entire simulated neural network. For real neural populations of modest size, this method fails because there are no periods of quiescence. The typical solution is to set a threshold, and to only count avalanches when the population activity exceeds that threshold, with the hope that results are relatively robust to that choice. In our model, this operation is equivalent to changing , which shifts the probability of firing up or down by a constant amount across all cells independent of inputs. Our results in Figure 3 show that and decrease as the threshold for detection is increased (equivalent to large ), but that the scaling relationship is maintained. The model predicts that would initially increase slightly with the detection threshold before decreasing back to near zero.
Following the algorithm laid out in Clauset et al., 2009, we fit power laws to the size and duration distributions from simulations generating avalanches. We use least-squares fitting to estimate , the scaling exponent for size with duration, assessing the consistency of the fit across decades.
Reading power laws from data
Request a detailed protocolWe want, from each simulation, a quantification of the quality of scaling (how many decades, minimally) and an estimate of the scaling exponents ( for the size distribution, for the duration distribution). We first compile all avalanches observed in the simulation and for each avalanche, calculate its size (total activity across the population during the avalanche) and its duration (number of time bins). Following the steps outlined by Clauset et al., 2009, we use the maximum-likelihood estimator to determine the scaling exponent. This is the solution to the transcendental equation
(7)
where is the Hurwitz zeta function and are observations; that is, either the size or the duration of each avalanche i. For values of , a numerical look-up table based on the built-in Hurwitz zeta function in the symbolic math toolbox was used (MATLAB2019b). For we use an approximation (Clauset et al., 2009),
(8)
To determine , we computed the maximum absolute difference between the empirical cumulative density () function and model’s cumulative density function (the Kolmogorov-Smirnov (KS) statistic; ). The KS statistic was computed between for power-law models with scaling parameter and cutoffs . The value of that minimizes the KS statistic was chosen. Occasionally the KS statistic had two local minima (as in Figure 2—figure supplement 1), indicating two different power-laws. In these cases, the minimum size and duration cutoffs were the smallest values that were within 10% of the absolute minimum of the KS statistic. Note that the statistic is computed for each model only on the power-law portion of the CDF (i.e. ). We do not attempt to determine an upper cut-off value.
To assess the quality of the power-law fit, Clauset et al., 2009 compared the empirical observations to surrogate data generated from a semi-parametric power-law model. The semi-parametric model sets the value of the CDF equal to the empirical CDF values up to and then according to the power-law model for . If the KS statistic for the real data (relative to its fitted model) is within the distribution of the KS statistics for surrogate datasets relative to their respective fitted models, the power-law model was considered a reasonable fit.
Strict application of this methodology could give misleading results. Much of this is due to the loss of statistical power when the minimum cutoff is so high that the number of observations drops. For instance, in the simulations shown in Figure 2, the one-variable duration distribution passed the Clauset et al., 2009 criterion, with a minimum KS statistic of 0.03 when the duration cutoff was 18 time steps. However, for the five-variable simulation in Figure 2, a power-law would be narrowly rejected for both size and duration, despite having much smaller KS statistics: for , the KS statistic was 0.0087 (simulation range: 0.0008 to 0.0082; number of avalanches observed: 58,787) and for it was 0.0084 (simulation range: 0.0011 to 0.0075). Below we discuss this problem in more detail.
Determining range over which avalanche size scales with duration
Request a detailed protocolFor fitting , our aim was to find the longest sampled range, over which we have apparent power-law scaling of size with duration. Because our sampled duration values have linear spacing, error estimates are skewed if a naive goodness of fit criterion is used. We devised the following algorithm. First, the simulation must have at least one avalanche of size 500. We fit over one decade at a time. We chose as the lower duration cutoff the value of minimum duration, for which the largest number of subsequent (longer-duration) fits produced consistent fit parameters (Figure 2—figure supplements 3 and 4, top row). Next, with the minimum duration set, we gradually increased the maximum duration cut-off, and we determined whether there was a significant bias in the residual over the first decade of the fit. We selected the highest duration cutoff, for which there was no bias. Finally, over this range, we re-fit the power law relationship and extracted confidence intervals.
Our analysis focused on finding the apparent power-law relationship that held over the largest log-scale range. A common feature across simulation parameters (, ) was the existence of two distinct power-law regimes. This is apparent in Figure 2I, which shows that when at small , the best-fit (that showing the largest range with power-law-consistent scaling) is much larger ( 1.7), and then above , the best-fit drops to around 1.3.
Statistical power of power-law tests
Request a detailed protocolIn several cases, we found examples of power-law fits that passed the rejection criteria commonly used to determine avalanche scaling relationships because of limited number of observations. A key example is that of the single latent variable simulation shown in Figure 2B, where we could not reject a power law for the duration distribution. Conversely, strict application of the surrogate criteria would reject a power law for distributions that were quantitatively much closer to a power-law (i.e. lower KS statistic), but for which we had many more observations and thus a much stronger surrogate test (Figure 2). This points to the difficulty of applying a single criterion to determining a power-law fit. In this work, we adhere to the criteria set forth in Clauset et al., 2009, with a modification to control for the unreasonably high statistical power of simulated data. Specifically, the number of avalanches used for fitting and for surrogate analysis was capped at 500,000, drawn randomly from the entire pool of avalanches.
Additionally, we found examples, in which a short simulation was rejected, but increasing the simulation time by a factor of five yielded excellent power-law fits. We speculate that this arises due to insufficient sampling of the latent space. These observations raise an important biological point. Simulations provide the luxury of assuming the network is unchanging for as long as the simulator cares to keep drawing samples. In a biological network, this is not the case. Over the course of hours, the effective latent degrees of freedom could change drastically (e.g. due to circadian effects [Aton et al., 2009], changes in behavioral state [Fu et al., 2014], plasticity [Hooks and Chen, 2020], etc.), and the network itself (synaptic scaling, firing thresholds, etc.) could be plastic (Hengen et al., 2016). All these factors can be modeled in our framework by determining appropriate cutoffs (in duration of recording, in time step sizes, for activity distributions) based on specific experimental timescales.
Calculation of avalanche regimes
Request a detailed protocolIn the quasistatic model, we derive the dependence of the avalanche rate on , and number of neurons , finding that there are two distinct regimes, in which avalanches occur. Each time bin is independent, conditioned on the value of . For an avalanche to occur, the probability of silence in the population (i.e. all ) must not be too close to 0 (or there are no breaks in activity) or too close to 1 (or there is no activity). At fixed , the probability of silence is
(9)
An avalanche occurs when a silent time bin is followed by an active bin, which has probability .
Information calculation
Maximum-likelihood decoding
Request a detailed protocolFor large populations coupled to a single latent variable, we estimated the information between population spiking activity and the latent variable as the information between the maximum-likelihood estimator of the latent variable and the latent variable itself. This approximation fails at extremes of network activity levels (low or high).
Specifically, we approximated the log-likelihood of given near by . Thus we assume that is normally distributed about with variance . The variance is then derived from the curvature of the log-likelihood at the maximum. The information between two Gaussian variables, here and , is
(10)
where the average is taken over .
Given a set of observations of the neurons , the likelihood is
(11)
Maximizing the log likelihood gives the following condition:
(12)
(13)
where is the average over observations . The uncertainty in is , which was calculated from the second derivative of the log likelihood:
(14)
(15)
(16)
(17)
This expression depends on the observations only through the maximum-likelihood estimate . When , then the variance is
(18)
To generate Figure 5, we evaluated Equation 10 using Equation 18.
Code availability
Request a detailed protocolSimulation code was adapted from our previous work (Morrell et al., 2021). Code to run simulations and perform analyses presented in this paper is uploaded as Source code 1 and also available from https://github.com/ajsederberg/avalanche (copy archived at Sederberg, 2024).
Data availability
The current manuscript is a computational study, so no data were generated for this manuscript. Modelling code is uploaded as Source code 1.
References
-
Zipf’s law arises naturally when there are underlying, unobserved variablesPLOS Computational Biology 12:e1005110.https://doi.org/10.1371/journal.pcbi.1005110
-
Neuronal avalanches in neocortical circuitsThe Journal of Neuroscience 23:11167–11177.https://doi.org/10.1523/JNEUROSCI.23-35-11167.2003
-
The criticality hypothesis: how local cortical networks might optimize information processingPhilosophical Transactions of the Royal Society A 366:329–343.https://doi.org/10.1098/rsta.2007.2092
-
Dimension of activity in random neural networksPhysical Review Letters 131:118401.https://doi.org/10.1103/PhysRevLett.131.118401
-
Criticality between Cortical StatesPhysical Review Letters 122:208101.https://doi.org/10.1103/PhysRevLett.122.208101
-
Neuronal avalanches in spontaneous activity in vivoJournal of Neurophysiology 104:3312–3322.https://doi.org/10.1152/jn.00953.2009
-
Probabilistic models for neural populations that naturally capture global coupling and criticalityPLOS Computational Biology 13:e1005763.https://doi.org/10.1371/journal.pcbi.1005763
-
Neuronal avalanches across the rat somatosensory barrel cortex and the effect of single whisker stimulationFrontiers in Systems Neuroscience 15:709677.https://doi.org/10.3389/fnsys.2021.709677
-
Coarse graining, fixed points, and scaling in a large population of neuronsPhysical Review Letters 123:178103.https://doi.org/10.1103/PhysRevLett.123.178103
-
Are biological systems poised at criticality?Journal of Statistical Physics 144:268–302.https://doi.org/10.1007/s10955-011-0229-4
-
How critical is brain criticality?Trends in Neurosciences 45:820–837.https://doi.org/10.1016/j.tins.2022.08.007
-
Avalanches, Barkhausen noise, and plain old criticalityPhysical Review Letters 75:4528–4531.https://doi.org/10.1103/PhysRevLett.75.4528
-
Self-organized criticality in the brainFrontiers in Physics 9:639389.https://doi.org/10.3389/fphy.2021.639389
-
Can a time varying external drive give rise to apparent criticality in neural systems?PLOS Computational Biology 14:e1006081.https://doi.org/10.1371/journal.pcbi.1006081
-
Zipf’s law and criticality in multivariate data without fine-tuningPhysical Review Letters 113:068102.https://doi.org/10.1103/PhysRevLett.113.068102
-
Adaptation to sensory input tunes visual cortex to criticalityNature Physics 11:659–663.https://doi.org/10.1038/nphys3370
Article and author information
Author details
Funding
Simons Foundation (Simons-Emory Consortium on Motor Control)
- Ilya Nemenman
National Science Foundation (BCS/1822677)
- Ilya Nemenman
National Institute of Neurological Disorders and Stroke (2R01NS084844)
- Ilya Nemenman
National Institute of Mental Health (1RF1MH130413)
- Audrey Sederberg
Simons Foundation (Investigator Program)
- Ilya Nemenman
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
IN was supported in part by the Simons Foundation Investigator program, the Simons-Emory Consortium on Motor Control, NSF grant BCS/1822677 and NIH grant 2R01NS084844. AS was supported in part by NIH grant 1RF1MH130413-01 and by startup funds from the University of Minnesota Medical School. The authors acknowledge the Minnesota Supercomputing Institute (MSI) at the University of Minnesota for providing resources that contributed to the research results reported within this paper.
Version history
- Sent for peer review:
- Preprint posted:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.89337. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2023, Morrell et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,333
- views
-
- 219
- downloads
-
- 22
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 5
- citations for umbrella DOI https://doi.org/10.7554/eLife.89337
-
- 2
- citations for Reviewed Preprint v1 https://doi.org/10.7554/eLife.89337.1
-
- 1
- citation for Reviewed Preprint v2 https://doi.org/10.7554/eLife.89337.2
-
- 14
- citations for Version of Record https://doi.org/10.7554/eLife.89337.3
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Neural criticality from effective latent variables
eLife 12:RP89337.
https://doi.org/10.7554/eLife.89337.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}