The theory of massively repeated evolution and full identifications of cancer-driving nucleotides (CDNs)
- State Key Laboratory of Biocontrol, School of Life Sciences, Sun Yat-sen University, China
- State Key Laboratory of Genetic Resources and Evolution/Yunnan Key Laboratory of Biodiversity Information, Kunming Institute of Zoology, The Chinese Academy of Sciences, China
- GMU-GIBH Joint School of Life Sciences, Guangzhou Medical University, China
- CAS Key Laboratory of Quantitative Engineering Biology, Shenzhen Institute of Synthetic Biology, Institute of Advanced Technology, Chinese Academy of Sciences, China
- Innovation Center for Evolutionary Synthetic Biology, Sun Yat-sen University, China
- Department of Ecology and Evolution, University of Chicago, United States
eLife Assessment
This important paper introduces a theoretical framework and methodology for identifying Cancer Driving Nucleotides (CDNs), primarily based on single nucleotide variant (SNV) frequencies. A variety of solid approaches indicate that a mutation recurring three or more times is more likely to reflect selection rather than being the consequence of a mutation hotspot. The method is rigorously quantitative, though the requirement for larger datasets to fully identify all CDNs remains a noted limitation. The work will be of broad interest to cancer geneticists and evolutionary biologists.
https://doi.org/10.7554/eLife.99340.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Solid: Methods, data and analyses broadly support the claims with only minor weaknesses
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
Tumorigenesis, like most complex genetic traits, is driven by the joint actions of many mutations. At the nucleotide level, such mutations are cancer-driving nucleotides (CDNs). The full sets of CDNs are necessary, and perhaps even sufficient, for the understanding and treatment of each cancer patient. Currently, only a small fraction of CDNs is known as most mutations accrued in tumors are not drivers. We now develop the theory of CDNs on the basis that cancer evolution is massively repeated in millions of individuals. Hence, any advantageous mutation should recur frequently and, conversely, any mutation that does not is either a passenger or deleterious mutation. In the TCGA cancer database (sample size n=300–1000), point mutations may recur in i out of n patients. This study explores a wide range of mutation characteristics to determine the limit of recurrences (i*) driven solely by neutral evolution. Since no neutral mutation can reach i*=3, all mutations recurring at i≥3 are CDNs. The theory shows the feasibility of identifying almost all CDNs if n increases to 100,000 for each cancer type. At present, only <10% of CDNs have been identified. When the full sets of CDNs are identified, the evolutionary mechanism of tumorigenesis in each case can be known and, importantly, gene targeted therapy will be far more effective in treatment and robust against drug resistance.
Introduction
Cancers are complex genetic traits with multiple mutations that interact to yield the ensemble of tumor phenotypes. The ensemble has been characterized as ‘cancer hallmarks’ that include sustaining growth signaling, evading growth suppression, resisting apoptosis, achieving immortality, executing metastasis and so on Hanahan and Weinberg, 2000; Hanahan and Weinberg, 2011; Hanahan, 2022. It seems likely that each of the 6–10 cancer hallmarks is governed by a set of mutations. Most, if not all, of these mutations are jointly needed to drive the tumorigenesis.
In the genetic sense, cancers do not differ fundamentally from other complex traits whereby multiple mutations are simultaneously needed to execute the program. A well-known example is the genetics of speciation whereby interspecific hybrids are either sterile or infertile even though they do not have deleterious genes (Wu and Ting, 2004; Wang et al., 2022; Wu, 2022). A recent example is SARS-CoV-2. The early onset of COVID-19 requires all four mutations of the D614G group and the later Delta strain has 31 mutations accrued in three batches (Ruan et al., 2022b; Ruan et al., 2022a; Cao et al., 2023; Ruan et al., 2023) While cancer research has often proceeded one mutation at a time, each of the mutations has been shown to be insufficient for tumorigenesis until many (Ortmann et al., 2015; Takeda, 2021; Hodis et al., 2022) are co-introduced.
We now aim for the identification of all (or at least most) of the driver mutations in each patient. Both functional tests and treatments demand such identifications. The number of key drivers has been variously estimated to be 6–10 (Martincorena et al., 2017; Anandakrishnan et al., 2019; ICGC/TCGA Pan-Cancer Analysis of Whole Genomes Consortium, 2020). Although cancer driving ‘point mutations’, referred to as Cancer Driving Nucleotides (or CDNs), are not the only drivers, they are indeed abundant (ICGC/TCGA Pan-Cancer Analysis of Whole Genomes Consortium, 2020). Furthermore, CDNs, being easily quantifiable, may be the only type of drivers that can be fully identified (see below). Here, we will focus on the clonal mutations present in all cells of the tumor without considering within-tumor heterogeneity for now (Ling et al., 2015; Turajlic et al., 2019; Black and McGranahan, 2021; Chen et al., 2022a; Zhai et al., 2022; Bian et al., 2023; Zhu et al., 2023).
Since somatic evolution proceeds in parallel in millions of humans, point mutations can recur multiple times as shown in Figure 1. The recurrences should permit the detection of advantageous mutations with unprecedented power. The converse should also be true that mutations that do not recur frequently are unlikely to be advantageous. Figure 1 depicts organismal evolution and cancer evolution. While both panels A and B show 7 mutations, there can be two patterns for cancer evolution - the pattern in (C) where all mutations are at different sites is similar to the results of organismal evolution whereas the pattern in (D) is unique in cancer evolution. The hotspot of recurrences shown in (D) holds the key to finding all CDNs in cancers.
Figure 1
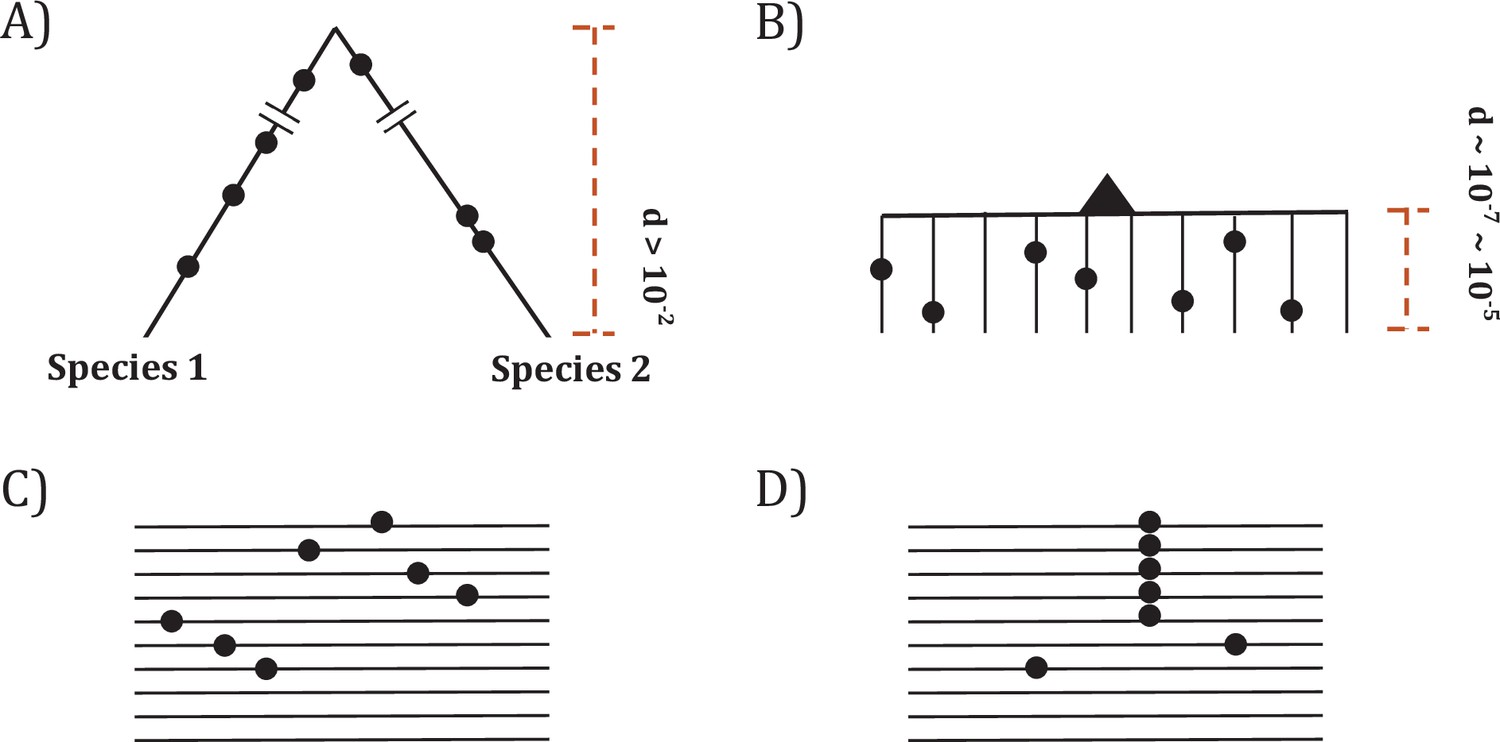
Two modes of DNA sequence evolution.
(A) A hypothetical example of DNA sequences in organismal evolution. (B) Cancer evolution that experiences the same number of mutations as in (A) but with many short branches. (C) A common pattern of sequence variation in cancer evolution. (D) In cancer evolution, the same mutation at the same site may occasionally be seen in multiple sequences. The recurrent sites could be either mutational or functional hotspots, their distinction being the main objective of this study.
In the literature, hotspots of recurrent mutations have been commonly reported (Gartner et al., 2013; Chang et al., 2016; Cannataro et al., 2018; Buisson et al., 2019; Hess et al., 2019; Stobbe et al., 2019; Juul et al., 2021; Nesta et al., 2021; Zhao et al., 2021; Bergstrom et al., 2022; Sherman et al., 2022; Wong et al., 2022; Zeng and Bromberg, 2022). A hotspot, however, could be either a mutational or functional hotspot. Mutational hotspots are the properties of the mutation machinery that would include nucleotide composition, local chromatin structure, timing of replication, etc. (Stamatoyannopoulos et al., 2009; Pleasance et al., 2010; Makova and Hardison, 2015; Polak et al., 2015; Martincorena et al., 2017). In contrast, functional hotspots are CDNs under positive selection. CDN evolution is akin to ‘convergent evolution’ that repeats itself in different taxa (He et al., 2020a; He et al., 2020b; Wu et al., 2020; Pan et al., 2022b; Wu, 2023) and is generally considered the most convincing proof of positive selection.
While many studies conclude that sites of mutation recurrence are largely mutational hotspots (Buisson et al., 2019; Hess et al., 2019; Stobbe et al., 2019; Nesta et al., 2021; Bergstrom et al., 2022), others deem them functional hotspots, driven by positive selection (Gartner et al., 2013; Chang et al., 2016; Bailey et al., 2018; Cannataro et al., 2018; Juul et al., 2021; Zhao et al., 2021; Zeng and Bromberg, 2022). In the attempt to distinguish between these two hypotheses, studies make assumptions, often implicitly, about the relative importance of the two mechanisms in their estimation procedures. The conclusions naturally manifest the assumptions made when extracting information on mutation and selection from the same data (Elliott and Larsson, 2021).
This study consists of three parts. First, the mutational characteristics of sequences surrounding CDNs are analyzed. Second, a rigorous probability model is developed to compute the recurrence level at any sample size. Above a threshold of recurrence, all mutations are CDNs. Third, we determine the necessary sample sizes that will yield most, if not all, CDNs. In the companion study, the current cancer genomic data are analyzed for the characteristics of CDNs that have already been discovered (Zhang et al., 2024). Together, these two studies show how full functional tests and precise target therapy can be done on each cancer patient.
Results
In PART I, we search for the general mutation characteristics at and near high recurrence sites by both machine learning and extensive sequence comparisons. In PART II, we develop the mathematical theory for the maximal level of recurrences of neutral mutations (designated i*). CDNs are thus defined as mutations with ≥i* recurrences in n cancer samples. We then expand in PART III the theory to very large sample sizes (n≥105), thus making it possible to identify all CDNs.
To carry out the analyses, we first compile from the TCGA database the statistics of multiple hit sites (i hits in n samples) in 12 cancer types. This study focuses on the mutational characteristics pertaining to recurrence sites. We often present the three cancer types with the largest sample sizes (lung, breast, and CNS cancers), while many analyses are based on pan-cancer data. Analyses of every of the 12 cancer types individually will be done in the companion paper. The TCGA database is used as it is well established and covers the entire coding region (Cancer Genome Atlas Research Network et al., 2013). Other larger databases (Cerami et al., 2012; Tate et al., 2019; de Bruijn et al., 2023) are employed when the whole exon analyses are not crucial.
The compilation of multi-hit sites across all genes in the genome
Throughout the study, Si denotes the number of synonymous sites where the same nucleotide mutation occurs in i samples among n patients. Ai is the equivalent of Si for non-synonymous (amino acid altering) sites. Table 1 presents the numbers from lung cancer for demonstration. It also shows the Ai and Si numbers with CpG sites filtered out. There are 22.5 million nonsynonymous sites, among which ~0.2 million sites have one hit (A1=195,958) in 1035 patients. The number then decreases sharply as i increases. Thus, A2=2946 (number of 2-hit sites), A3=99, and A4 +A5 +...=79. We also note that the Ai/Si ratio increases from 2.89, 2.82, 3.04–4.71 and so on.
Table 1
An example of Ai and Si (from lung cancer, n=1035).
| All sites | CpG sites removed | |||||
|---|---|---|---|---|---|---|
| i | Ai | Si | Ai / Si | Ai | Si | Ai / Si |
| 0 | 22540623 | 7804281 | 2.89 | 21375384 | 7014012 | 3.04 |
| 1 | 195958 | 69393 | 2.82 | 168371 | 56821 | 2.96 |
| 2 | 2946 | 969 | 3.04 | 2188 | 643 | 3.4 |
| 3 | 99 | 21 | 4.71 | 68 | 16 | 4.25 |
| 4 | 23 | 1 | 23 | 17 | 1 | 17 |
| 5 | 16 | 0 | 16 : 0 | 9 | 0 | 9 : 0 |
| 6 | 10 | 0 | 10 : 0 | 6 | 0 | 6 : 0 |
| 7 | 5 | 0 | 5 : 0 | 5 | 0 | 5 : 0 |
| 8 | 8 | 0 | 8 : 0 | 6 | 0 | 6 : 0 |
| 9 | 4 | 0 | 4 : 0 | 3 | 0 | 3 : 0 |
| ≥3 | 178 | 22 | 8.09 | 122 | 17 | 7.18 |
| ≥4 | 79 | 1 | 79 | 54 | 1 | 54 |
| [10-20] | 7 | 1 | 7 | 4 | 0 | 4 : 0 |
| ≥20 | 6 | 0 | 6 : 0 | 4 | 0 | 4 : 0 |
-
Note –The ratio of Ai/ Si is provided as a measure of selection strength.
Figure 2 shows the average of Ai and Si among the 12 cancer types (see Methods). The salient features are shown by differences between the solid and dotted lines. As will be detailed in PART II, the dotted lines, extending linearly from i=0 to i=1 in logarithmic scale, should be the expected values of Ai and Si, if mutation rate is the sole driving force. In the actual data, (A1) and S1 decrease to ~0.002 of A0 and S0, the step being least affected by selection (see PART II later). For A2 and S2, the decrease is only ~0.01 of A1 and S1. The decrease from i to i+1 becomes smaller and smaller as i increases, suggesting that the process in not entirely neutral. Furthermore, the lower panel of Figure 2 shows that Ai/Si continues to rise as i increases. These patterns again suggest a stronger positive selection at higher i values. The extrapolation lines shown in Figure 2 roughly define i=3 as a cutoff where the expected (A3) falls below 1 (see PART II for details). The precise model of PART II will define high recurrence sites (i≥3) as CDNs.
Figure 2 with 1 supplement see all
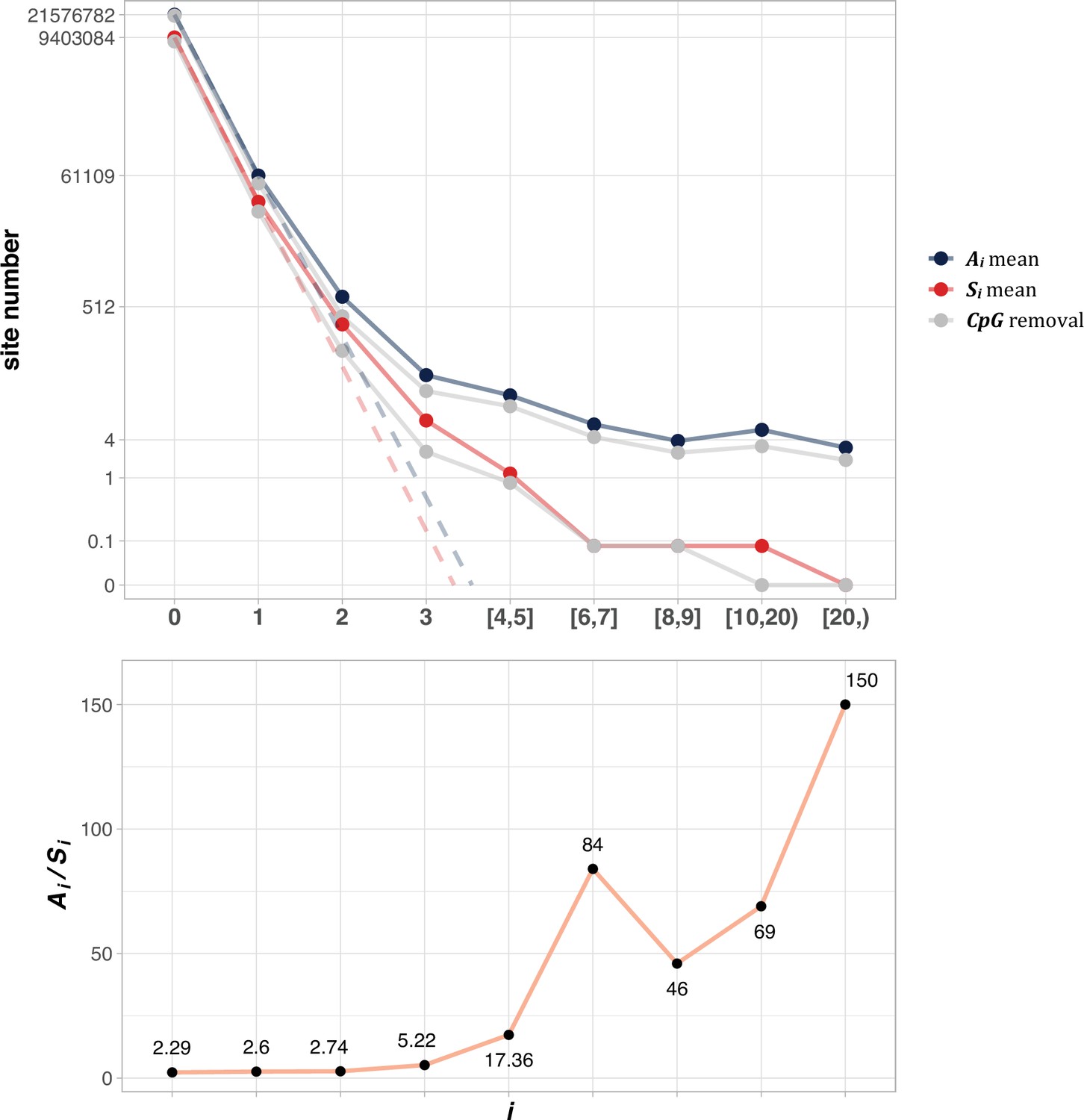
The average Ai and Si values across different i ranges (X-axis).
(Top): The average of Ai and Si in the log scale. Color lines - full data; gray lines - CpG sites removed. The dash lines are linear extrapolations. Bottom: The Ai / Si ratio as a function of i. The drop of Ai / Si ratio at i [8, 9] is due to the potential synonymous CDNs, see Supplementary file 1.
PART I - The mutational characteristic of high recurrence sites
In this part, the analyses are done in two different ways. The sequence-feature approach is to examine the mutation characteristics of sequence features (say, 3 mers, 5 mers, etc.) across patients. The patient-feature approach is to examine patients for their mutation signatures and mutation loads.
The sequence-feature approach
The simplest and best-known sequence feature associated with high mutation rate is CpG sites. In mammals, methylation and de-amination would enhance the mutation rate from CpG to TpG or CpA by five-~tenfold (Hodgkinson and Eyre-Walker, 2011; Ségurel et al., 2014). As the CpG site mutagenesis has been extensively reported, we only present the confirmation in the Supplement (Figure 2—figure supplement 1). Indeed, CpG sites account for ~6.5% of the coding sequences but contributing ~22% among the mutated sites in Figure 2. Hence, the sevenfold increase in the CpG mutation rate should contribute more to Ai and Si as i increases. Table 1 has shown the effects of filtering out CpG sites in the counts of recurrences. Clearly, CpG sites do contribute disproportionately to the recurrences but, even when they are separately analyzed, the conclusion is unchanged. As shown later in PART II, every increment of i should decrease the site number by ~0.002 in the TCGA database. Thus, even with a 10-fold increase in mutation rate, the decrease rate would still be 0.02. In the theory sections, CpG site mutations are incorporated into the model.
In this section, we aim to find out how extreme the mutation mechanisms must be to yield the observed recurrences. If these mechanisms seem implausible, we may reject the mutational-hotspot hypothesis and proceed to test the functional hotspot hypothesis.
The analyses of mutability variation by Artificial Intelligence (AI)
The variation of mutation rate at site level could be shaped by multiple mutational characteristics. Epigenomic features, such as chromatin structure and accessibility, could affect regional mutation rate at kilobase or even megabase scale (Stamatoyannopoulos et al., 2009; Makova and Hardison, 2015), while nucleotide biases by mutational processes typically span only a few base pairs around the mutated site (Roberts et al., 2013; Haradhvala et al., 2018; Herzog et al., 2021). AI-powered multi-modal integration offers a new tool to quantify the joint effect of various factors on mutation rate variability (Luo et al., 2019; Sherman et al., 2022; Song et al., 2023). Here we explore the association between the mutation recurrence (i) and site-level mutation rate predicted by AI.
Figure 3A shows the mutation rate landscape across all recurrence sites in breast, CNS and lung cancer using the deep learning framework Dig (Sherman et al., 2022). In this approach, the mutability of a focus site is calculated based on both local stretch of DNA and broader scale of epigenetic features. The X-axis shows all mutated sites with i>0 scanned by Dig. While the mutation rate fluctuates around the average level, we detect no significant difference in mutation rate as a function of i (Methods). In CNS, two sites exhibited exceptional mutability at i=6, surpassing the average by tenfold. Unsurprisingly, these two are CpG sites and correspond to amino acid change of V774M and R222C in EGFR (Supplementary file 1), which are canonical actionable driver mutations in glioma target therapy. In other words, the two sites called by AI for possible high mutability appear to be selection driven.
Figure 3
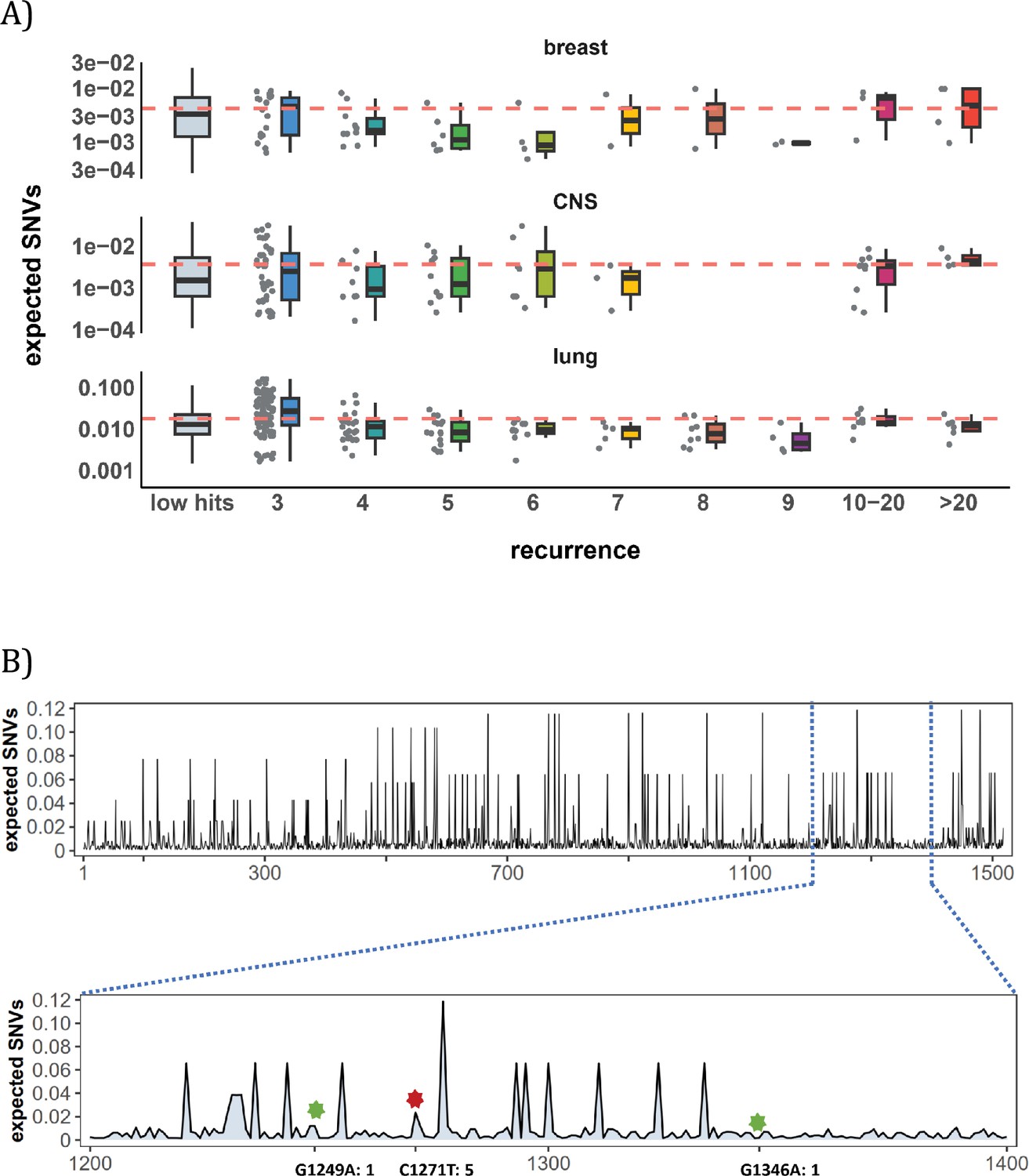
Site-level mutation rate variation obtained from Dig Sherman et al., 2022, a published AI tool.
(A) Each dot represents the expected SNVs (Y-axis) at a site where missense mutations occurred i times in the corresponding cancer population. The boxplot shows the overall distribution of mutability at i, with the red dashed line denoting the average. There is no observable trend that sites of higher i are more mutable (The blank areas are due to the absence of CDNs with mutation recurrence counts of 8 or 9 in CNS cancer mutation data, see Supplementary file 1). (B) A detailed look at the coding region of PAX3 gene in colon cancer. The expected mutability of sites in the 200 bp window is plotted. The three mutated sites in this window, marked by green and red (a CDN site) stars, are not particularly mutable. Overall, the mutation rate varies by about tenfold as is generally known for CpG sites.
In Figure 3B, we take a closer look at how CDN is situated against the background of mutation rate variation, using the example of PAX3 (Paired Box Homeotic Gene 3; Wang et al., 2008; Li et al., 2019). In this typical example, Dig predicts site mutability to vary from site to site. In the lower panel is an expanded look at a stretch of 200 bps. In this stretch, about 8% of sites are five- to tenfold more mutable than the average. But none of them are mutated in the data (i=0). There are indeed three sites with i>0 in this DNA segment including a CDN site C1271T (marked by the red star). This CDN site is estimated to have a twofold elevation in mutability, which is less than 1/50 of the necessary mutability to reach i≥3. The other two mutated sites, marked by the green star, are also indicated.
Other AI methods have also been used in the mutability analysis (Fang et al., 2022), reaching nearly the same conclusion. Overall, while AI often suggests sequence context to influence the local variation in mutation rate, the reported variation does not correspond to the distribution of CDNs. In the next subsection, we further explore the local contexts for potential biases in mutability.
The conventional analyses of local contexts - from 3-mers to 101-mers
Since the AI analyses suggest the dominant role of local sequence context in mutability, we carry out such conventional analyses in depth. Other than the CpG sites, local features such as the TCW (W=A or T) motif recognized by APOBEC family of cytidine deaminases (Burns et al., 2013; Roberts et al., 2013), would have impacts as well. We first calculate the mutation rate for motifs of 3-mer, 5-mer and 7-mer, respectively, with 64, 1024, 16384 in number (see Methods). The pan-cancer analyses across the 12 cancer types are shown in Figure 4A. We use α to designate the fold change between the most mutable motif and the average. Since the number of motifs increases 16-fold between each length class, the α value increases from 4.7 to 8.8 and then to 11.5. Nevertheless, even the most mutable 7-mer¸ TAACGCG, which has a CpG site at the center, is only 11.52-fold higher than the average. This spread is insufficient to account for the high recurrences, which decrease to ~0.002 for each increment of i (see PART II below).
Figure 4 with 1 supplement see all
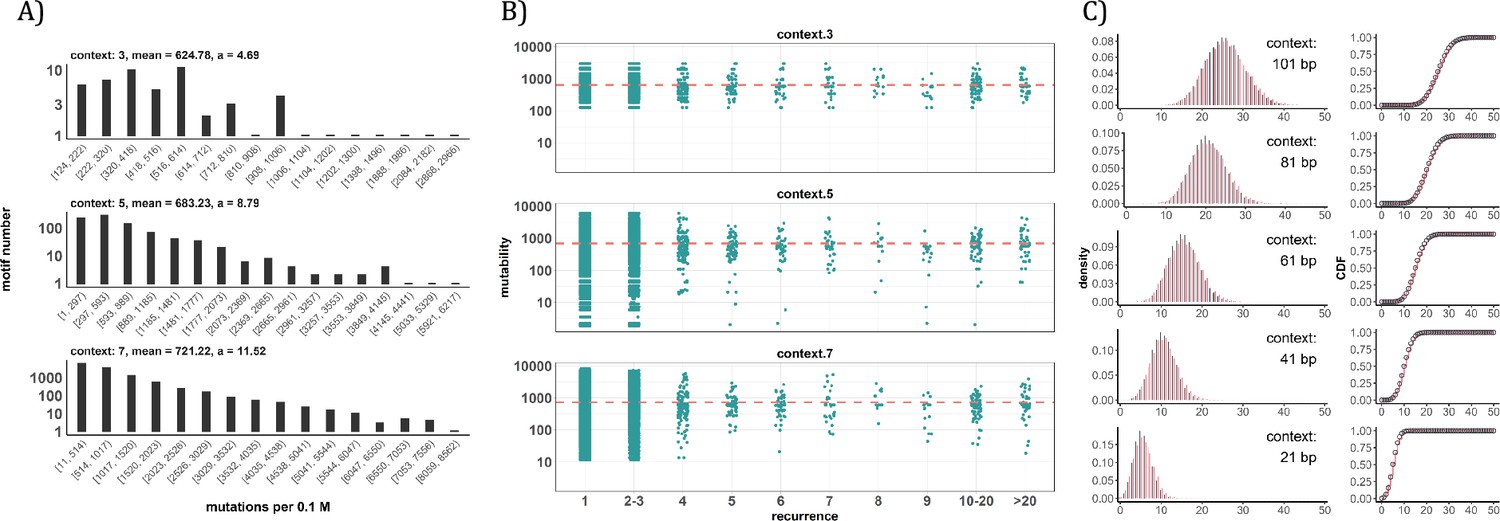
Conventional analyses of local contexts at recurrence sites.
(A) From top panel down - For the 64 (43) 3-mer motifs, their mutational rates are shown on the X-axis. The most mutable motif over the average mutability (α) is 4.69. For the 1024 (=45) 5-mer and 16,384 (47) 7-mer motifs, the α values are, respectively, 8.79 and 11.52. The most mutable motifs, as expected, are dominated by CpG’s. (B) Each dot represents the motif surrounding a high-recurrence site. The recurrence number is shown on the X-axis and the mutability of the associated motif’s mutability (mutations per 0.1 M) is shown on the Y-axis. The average mutation rate across all motifs of given length category is indicated by a red horizontal dashed line. The absence of a trend indicates that the high recurrence sites are not associated with the mutability of the motif. (C) The analysis is extended to longer motifs surrounding each CDN (21, 41, 61, 81, and 101 bp). For each length group, all pairwise comparisons are enumerated. The observed distributions (black bars and points) are compared to the expected Poisson distributions (red bars and curves) and no difference is observed. Thus, local sequences of CDNs do not show higher-than-expected similarity.
A more direct approach is given in Figure 4B explained in the legends. The absence of a trend shows that the high recurrence sites are not associated with the mutability of the motif. In Figure 4C, the analysis extends to longer motifs of 21 bp, 41 bp, 61 bp, 81 bp, and 101 bp surrounding the high-recurrence sites. For example, the motif of 101 bp may be (10, 90), (20, 80) and so on either side of a recurrence site (Figure 4—figure supplement 1). We then compute the pairwise differences in sequences of the motifs among recurrence sites. The logic is that, if certain motifs dictate high mutation rates, we may observe unusually high sequence similarity in the pairwise comparisons. As can be seen in all 5 panels of Figure 4C, there are no outliers in the tail of the distribution. In other words, the sequences surrounding the high-recurrence sites appear rather random. Detailed motif analysis of CDNs within individual cancer types using deep learning models (ResNet, LSTM and GRU) further supports this conclusion.
In conclusion, the analyses by the sequence approach do not find any association between high recurrence sites (i≥3) and the mutability of the local sequences.
The patient-feature approach
In this second approach, we examine the mutation characteristics among patients across sequence features. The first question is whether high recurrence sites tend to happen in patients with higher mutation loads. Figure 5A depicts the distribution of mutation loads among patients harboring a CDN of recurrence i. Hence, a patient’s load may appear several times in the plot, each appearance corresponding to one CDN in the patient’s data. For the comparison across i values, the mutation load is normalized by a z-score within each cancer population to equalize the three cancer types. The overall trend shows consistently that patients with recurrence sites do not bias toward high mutation loads. The presence of recurrence sites in patients with low mutation loads suggests that overall mutation burden is not a determining factor of recurrence.
Figure 5
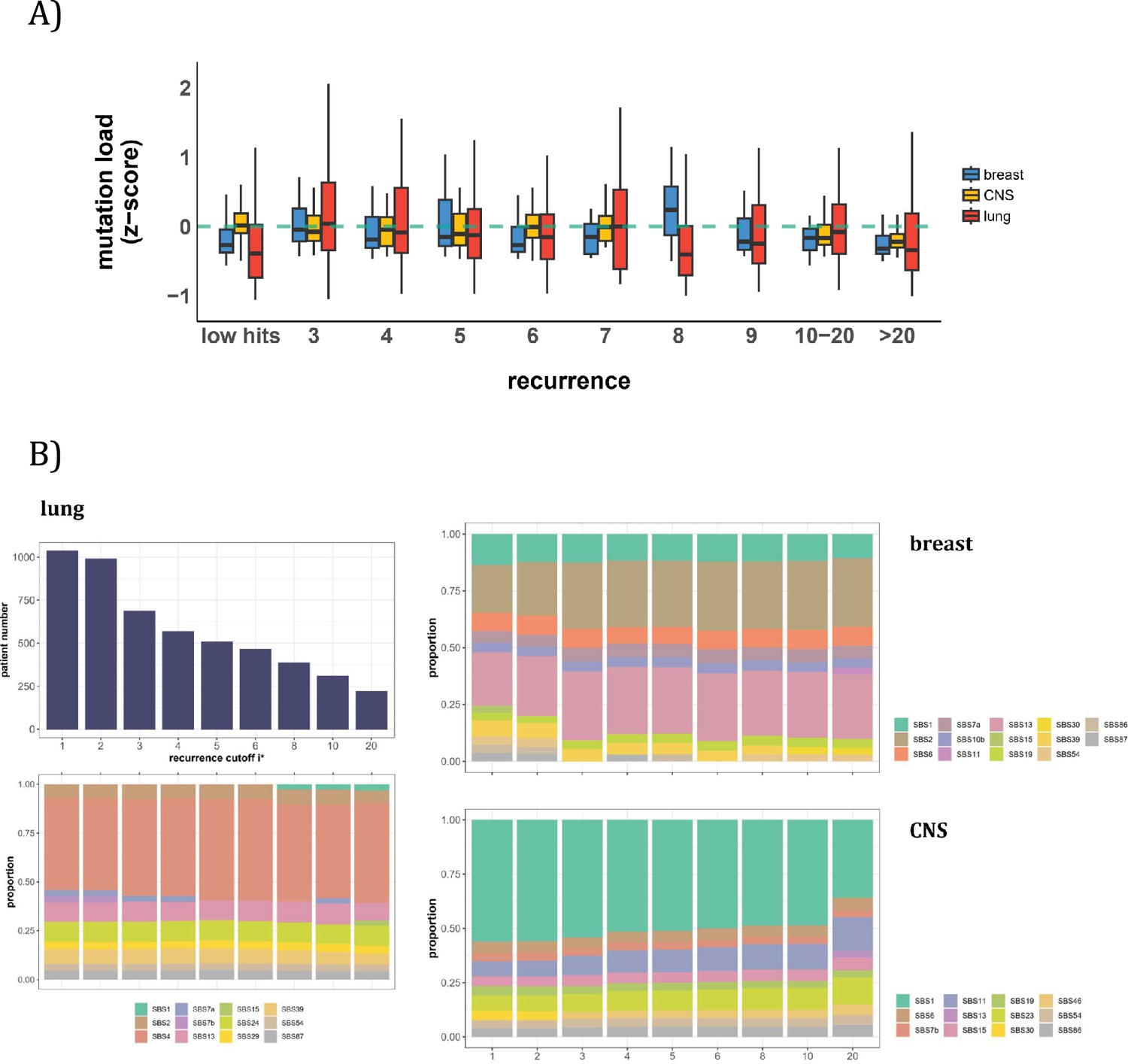
Patient level analysis for mutation load and mutational signatures.
(A) Boxplot depicting the distribution of mutation load among patients with recurrent mutations. The X-axis denotes the count of recurrent mutations, while the Y-axis depicts the normalized z-score of mutation load (see Methods). The green dashed line indicates the mean mutation load. In short, the mutation load does not influence the mutation recurrence among patients. (B) Signature analysis in patients with mutations of recurrences ≥i* (X-axis). For lung cancer (left), the upper panel presents the number of patients for each group, while the lower panel depicts the relative contribution of mutational signatures. For breast cancer, APOBEC-related signatures (SBS2 and SBS13) are notably elevated in all groups of patients with i*≥3, while patients with mutations of recurrence ≥ 20 in CNS cancer exhibit an increased exposure to SBS11 (Blough et al., 2011; Lin et al., 2021; Noeuveglise et al., 2023). Again, patients with higher mutation recurrences do not differ in their mutation signatures.
With the results of Figure 5A, we then ask a related question: whether these high recurrence mutations are driven by factors that affect mutation characteristics. Such influences have been captured by the analyses of ‘mutational signatures’ (Alexandrov et al., 2013; Alexandrov et al., 2020). Each signature represents a distinct mutation pattern (e.g. high rate of TCT ->TAT and other tri-nucleotide changes) associated with a known factor, such as smoking or an aberrant mutator (aristolochic acid, for example). Each patient’s mutation profile can then be summarized by the composite of multiple mutational signatures.
The issue is thus whether a patient’s CDNs can be explained by the patient’s composite mutational signatures. Figure 5B reveals that in lung cancer, the signature compositions among patients with different recurrence cutoffs are statistically indistinguishable (Methods). Smoking (signature SBS4) consistently emerges as the predominant mutational process across all levels of recurrences. In breast cancer, while SBS2 and SBS13 exhibit some differences in the bins of i*=2 and i*=3, the profiles remain rather constant for all bins of i*≥3. The two lowest bins, not unexpectedly, are also different from the rest in the total mutation load (see Figure 5A). In Appendix 1—table 1, we provide a comprehensive review of supporting literature on genes with recurrence sites of i≥3 for breast cancer. In CNS cancer, SBS11 appears significantly different across bins, in particular, i≥20. This is a signature associated with Temozolomide treatment and should be considered a secondary effect. In short, while there are occasional differences in mutational signatures across i* bins, none of such differences can account for the recurrences (see PART II).
To conclude PART I, the high-recurrence sites do not stand out for their mutation characteristics. Therefore, the variation in mutation rate across the whole genome can reasonably be approximated mathematically by a continuous distribution, as will be done below.
PART II - The theory of CDNs
We now develop the theory for Si and Ai under neutrality where i is the recurrence of the mutation at each site. We investigate the maximal level of neutral mutation recurrences (i*), above which the expected values of Si and Ai are both <0. Since no neutral mutations are expected to reach i*, every mutation with the recurrence of i* or larger should be non-neutral. Importantly, given that the expected Si and Ai is a function of Ui where U=nE(u) is in the order of 10–2 and 10–3, i* is insensitive to a wide range of mutation scenarios. For that reason, the conclusion is robust.
The mutation rate of each nucleotide (u) follows a Gamma distribution with a scale parameter θ and a shape parameter k. Gamma distribution is often used for its flexibility and, in this context, models the waiting time required to accumulate k mutations. Its mean (=kθ) and variance (=kθ2) are determined by both parameters but the shape (skewness and kurtosis) is determined only by k. In particular, the Gamma distribution has a long tail suited to modeling a small number of sites with very high mutation rate.
We now use synonymous (Si) mutations as the proxy for neutrality. Hence, in n samples,
(1)
where LS is the total number of synonymous sites and u(l) is the mutation rate of site l. In the equation above, the term is dropped. We note that as u is in the order of 10–6 and n is in the order of 102 from the TCGA data. With the gamma distribution of u whereby the ith moment is given by
we obtain:
here:
In a condensed form,
(2)
where . Similarly, if nonsynonymous mutations are assumed neutral, then,
(3)
The number of 2.3 is roughly the ratio of the total number of nonsynonymous over that of synonymous sites (Hartl and Clark, 1989; Li, 1997; Chen et al., 2019). This number would vary moderately among cancers depending on their nucleotide substitution patterns.
E(u) of Equations 2 and 3 is generally (1~5)×10–6 per site in cancer genomic data and n is generally between 300 and 1000. Hence, nE(u) is the total mutation rate summed over all n patients and is generally between 0.001 and 0.005 in the TCGA data. Given nE(u) is in the order of 10–3, Si and Ai would both decrease by 2~3 orders of magnitude with each increment of i by 1. We note that the total number of synonymous sites, LS, is ~0.9 × 107 and LA is ~2.3 times larger. Therefore, S3 <1 and A3 <1. When i reaches 4, Si ≥4 and Ai ≥4 would both be ≪ 1 when averaged over cancer types.
For each cancer type, the conclusion of S3 <1 and A3 <1 is valid with the actual value of S3 and A3 ranging between 0.01 and 1. In other words, with n<1000,, neutral mutations are unlikely to recur 3 times or more in the TCGA data (i*=3). While Si ≥3 and Ai ≥3 sites are high-confidence CDNs, the value of i* is a function of n. At n≤1,000 for the TCGA data, i* should be 3 but, when n reaches 10,000, i* will be 6. The benefits of large n’s will be explored in PART III.
Possible outliers to the distribution of mutation rate
Although we have explored extensively the sequence contexts, other features beyond DNA sequences could still lead to outliers to mathematically distributions. These features may include DNA stem loops (Buisson et al., 2019) or unusual epigenetic features (Zheng et al., 2014; Makova and Hardison, 2015; Supek and Lehner, 2015). We therefore expand the model by assuming a small fraction of sites (p) to be hyper-mutable that is α fold more mutable than the genomic mean. Most likely, α and p are the inverse of each other. For the bulk of sites (1 p) of the genome, we assume that their mutations follow the Gamma distribution. (Nevertheless, the bulk can be assumed to have a fixed mutation rate of E(u) without affecting the conclusion qualitatively.)
We let p range from 10–2 to 10–5 and α up to 1000. As no stretches of DNA show such unusually high mutation rate (1000-fold higher than the average), such sites are assumed to be scattered across the genome and are rare. With the parameter space of defined above, we choose the (p, α) pairs that agree with the observed values of S1 to S3 which are sufficiently large for estimations. Table 2 presents the value range and standard deviation for p and α across the six cancer types that have >500 patient samples. Among the six cancer types, the lung cancer data do not conform to the constraints and we set p=0. With observed values for S1~3 as constraints, S4 rarely exceeds 1. Hence, even with the purely conjectured existence of outliers in mutation rate, i*=4 is already too high a cutoff.
Table 2
Summary for modeling outlier sites in six cancer types.
| Cancer Type | S3 | p | α | S4 | S5 |
|---|---|---|---|---|---|
| Lung* | -- | 0.0 | -- | -- | -- |
| Breast | 0.12 | 8.75E-04 (8.21E-04) | 88.6 (32.0) | 0.102 (0.068) | 0.004 (0.004) |
| CNS | 0.02 | 2.73E-04 (1.09E-04) | 295.1 (57.0) | 0.448 (0.173) | 0.026 (0.015) |
| Kidney | 0.03 | 3.03E-05 (2.98E-05) | 304.1 (108.0) | 0.067 (0.056) | 0.005 (0.006) |
| Upper-AD tract | 0.47 | 0.002 (0.001) | 48.9 (10.7) | 0.174 (0.078) | 0.005 (0.003) |
| Large intestine | 1.03 | 0.009 (0.001) | 51.6 (1.4) | 0.998 (0.087) | 0.026 (0.003) |
-
Note – For each cancer type, p stands for the proportion of highly mutable sites, with mutation rate being α-fold of the average. S3 gives the expected number without mutable outliers (P=0). S4 and S5 denote the expected number with the best (p, α) pairs with the standard deviation in parentheses. For lung cancer, S2 and S3 do not fit the outlier model (Table 2—source data 1); therefore, we set P=0.
-
Table 2—source data 1
The outlier model parameters and expected Si values for 6 cancer types analyzed.
‘pMinor’ and ‘alpha’ correspond to (‘p, a’) as described in the main text. ‘Eu’ represents the average mutation rate per site per patient for the given cancer type (‘ccType’). ‘s2Expt’ ‘s3Expt’ ‘4’ ‘s5’ and ‘s6’ are the expected Si values for i = 2, 3, 4, 5, 6, respectively. ‘s2Obsv’ and ‘s3Obsv’ represent the observed Si values for S2 and S3.
- https://cdn.elifesciences.org/articles/99340/elife-99340-table2-data1-v1.zip
Table 2 suggests that p has to be smaller than 10–5 and α>1,000 to yield S4 >1. Since the coding region has 3×107 sites, p<10–5 would mean that the outliers are at most in the low hundreds. In other words, the number of high recurrence sites projected by the theory is close to the observed numbers. Therefore, there are really no unknown outlier sites of high mutation rate. Positive selection would be a more straightforward explanation, explained below.
The influence of selection on mutation occurrences
We now show that, although the mutational bias alone cannot account for the high occurrences, selection can easily do so. We assume a fraction, f, of Ai’s to be under positive selection. The fraction should be small, probably ≪ 0.01, and will be labeled . The rest, labeled Ai is considered neutral. Hence, Ai is proportional to and Ai/Si =LA/LS ~2.3. Like Si ≥4, Ai ≥4 ≪ 1. In contrast,
(4)
(5)
where G* is also a constant but its value depends on f. The crucial parameter, w (=2 Ns), is the selective advantage (s) scaled by the population size of progenitor cancer cell (N). Since w can easily be >10, even at i=3, would be >100 as large as . In other words, observed mutation recurrences at i≥3 for advantageous mutation should not be uncommon. Equation 4 also shows that w and E(u) jointly affect the recurrence; therefore, CpG sites (many of which fall in functional sites) are expected to be strongly represented among high recurrence sites.
PART III. The theory of large samples (n > 105) and identification of all CDNs
Using the theory of CDN developed above, the companion paper shows that each sequenced cancer genome in the current databases, on average, harbors only 1~2 CDNs. The number varies in this range depending on the cancer type (Zhang et al., 2024). For comparison, tumorigenesis may require at least 5~10 driver mutations as estimated by various criteria (Armitage and Doll, 1954; Hanahan and Weinberg, 2011; Belikov, 2017; Martincorena et al., 2017; Anandakrishnan et al., 2019; ICGC/TCGA Pan-Cancer Analysis of Whole Genomes Consortium, 2020). The results show that there are many more CDNs that have not been discovered. This is not unexpected since most CDNs are found in <1% of patients. If each CDN is observed in 1% of patients and each patient has 5 CDNs, then there should be at least 500 CDNs for each cancer type.
In the companion study that uses the A/S ratios of Figure 1, the estimated number of CDNs ranges from 500 to 2000, whereas the current estimates based on Ai ≥3 sites is only 50~100 (Zhang et al., 2024). Where, then, are the undiscovered CDNs and how to find them? Since all Ai ≥3 sites are concluded to be CDNs, the bulk of CDNs must be among A1 and A2 sites. The best way to identify the CDNs hidden in A1 and A2 is to increase the sample size, n, dramatically.
We hence extend Equation 1 for Si and Ai to large n’s. Note that Equation 1 drops the term of as it is ~1, when nE(u) ≪ 1. With a large n when is not near 1, the recurrence of mutations would follow a Poisson distribution with the expected value of nE(u). Assuming that u follows a gamma distribution with a shape parameter of k, the probability of observing i mutations would follow the negative binomial distribution as shown below:
(6)
The cumulation density function for Equation 6 is then:
(7)
Then, by definition, Ai ≥i* should be ≪ 1 so that mutations with recurrences i>i* could be defined as CDN. Thus:
(8)
where ε=Ai≥i* denotes the number of sites with mutation recurrence ≥i* under the sole influence of mutational force. could then be regarded as significance of i* since it controls the overall false positive rate of CDNs.
Specifically, with k=1, the probability function of mutation recurrence of a given site would transform to a geometric distribution with P=1 / (1+nE(u)), the cumulative density function (CDF) is then:
(9)
Combined with Equation 5, the mutation recurrence cutoff i* of being a CDN could be expressed as:
(10)
For very large n, 1/nE(u) is small and i*/n can be approximated as
(11)
Equation 11 shows that i*/n would approach asymptotically as n increases. This asymptotic value is attained when n reaches ~106.
Figure 6 shows the range of i* for n up to 106. As expected, i* increases by small increments while n increases in 10-fold jumps. For example, when n increases by 3 orders of magnitude, from 100 to 100,000,, i* only doubles from 3 to 12. The disproportional increment between i* and n explains why we use the actual number of i* for the cutoff, instead of the ratio i*/n. As shown in the inset of Figure 2, the ratio of i*/n would approach the asymptote at n~106, where an advantageous mutation only needs to rise to 0.00006 to be detected. With n reaching this level, we shall be able to separate most CDNs apart from the mutation background.
Figure 6
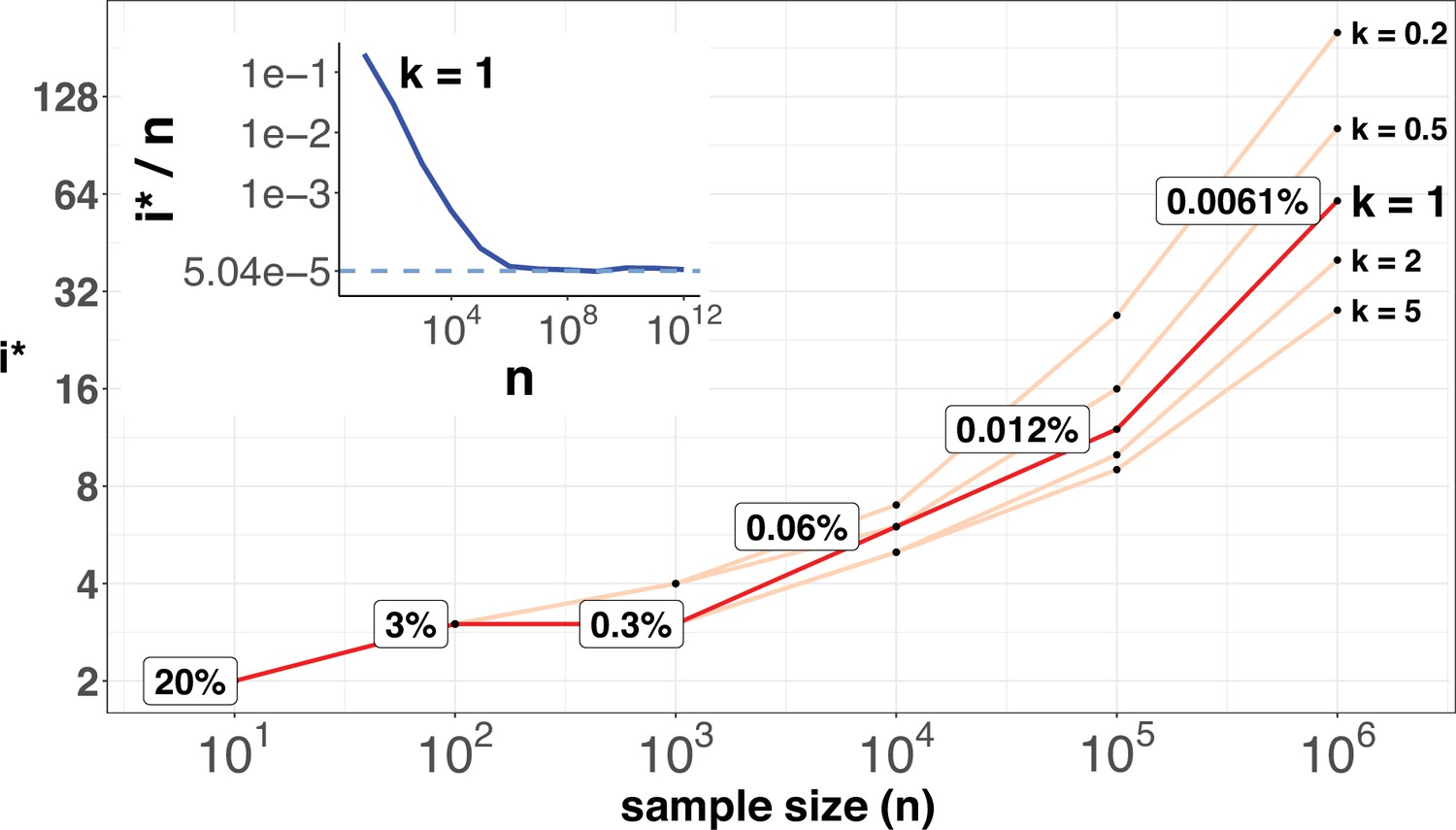
i* values (Y-axis, log scale) against sample sizes (n), X-axis across different shape parameter k’s.
The Y axis presents the i* values under different sample sizes (n) of the X-axis in log scale. Five shape parameters (k) of the gamma-Poisson model are used. In the literatures on the evolution of mutation rate, k is usually greater than 1. The inset figure illustrates how i*/ n (prevalence) would decrease with increasing sample sizes. The prevalence would approach the asymptotic line of [] when n reaches 106. In short, more CDNs (those with lower prevalence) will be discovered as n increases. Beyond n=106, there will be no gain.
When n approaches 105, the number of CDNs will likely increase more than 10-fold as conjectured in Figure 7A. In that case, every patient would have, say, 5 CDNs that can be subjected to gene targeting. (The companion study shows that, at present, an average cancer patient would have fewer than one targetable CDN.) Before the project is realized, it is nevertheless possible to test some aspects of it using the GENIE data of targeted sequencing. Such screening for mutations in the roughly 700 canonical genes serves the purpose of diagnosis with n ranging between 10~17 thousands for the breast, lung and CNS cancers. Clearly, GENIE efforts did not engage in discovering new mutations although they would discover additional CDNs in the canonical genes. In the companion study, we demonstrate that the analysis of CDNs identifies a potential set of 1.6 times more driver genes than those detected by whole gene selection signal calls (Zhang et al., 2024).
Figure 7
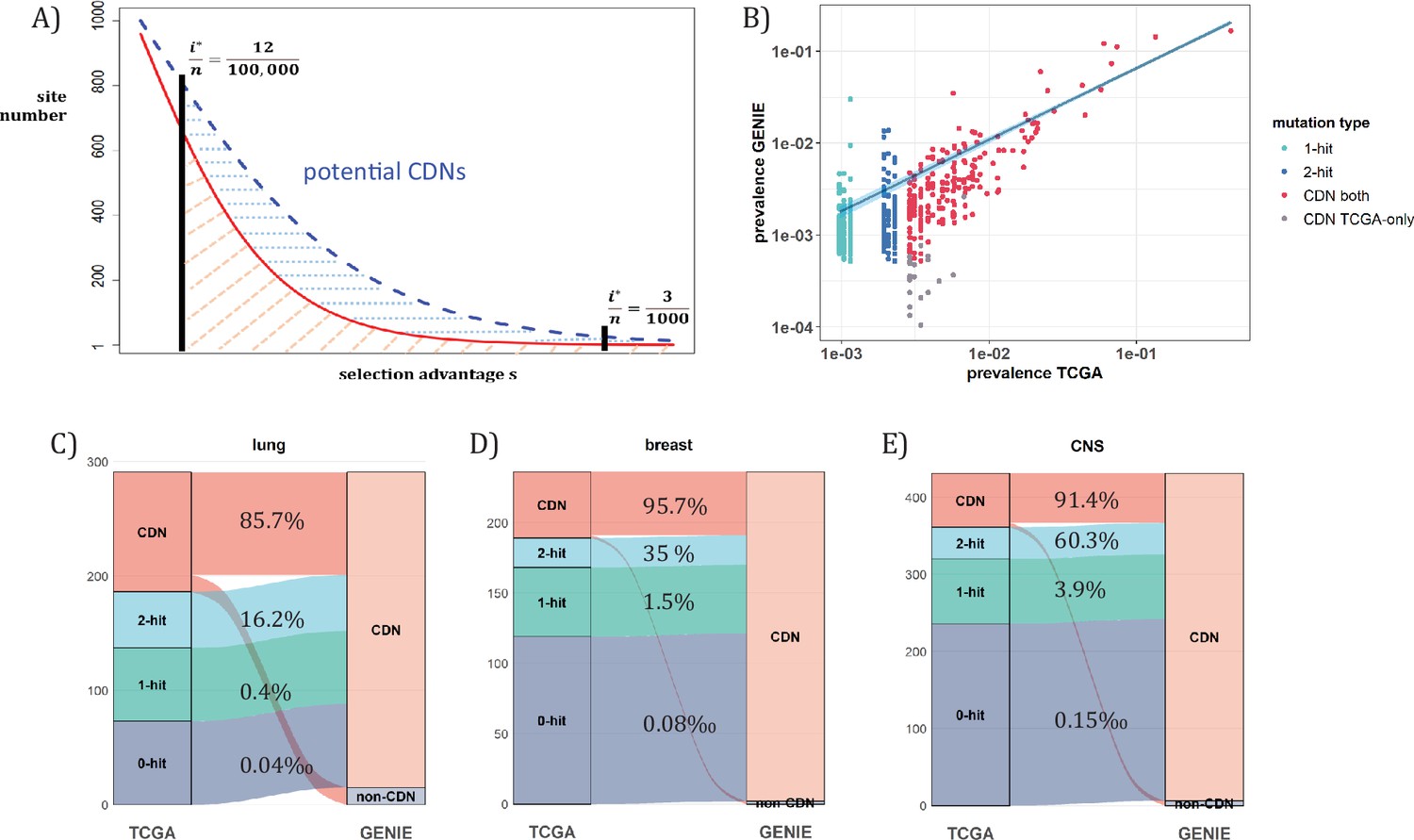
Analysis of CDNs with expanded sample set in GENIE.
(A) Schematic illustrating the impact of sample size expansion on the number of discovered CDNs. The two vertical lines show the cutoffs of i*/n at (3/1000) vs. (12/100,000). The Y axis shows that the potential number of sites would decrease with i*/n, which is a function of selective advantage. The area between the two cutoffs below the line represents the new CDNs to be discovered when n reaches 100,000. The power of n=100,000 is even larger if the distribution follows the blue dashed line. (B) The prevalence (i/n) of sites is well correlated between datasets of different n (TCGA with n<1000 and GENIE with generally tenfold higher), as it should be. Sites are displayed by color. ‘1-hit’: CDNs identified in GENIE but remain in singleton in TCGA, ‘2-hit’: CDNs identified in GENIE but present in doubleton in TCGA. ‘CDN both’: CDNs identified in both databases. (C–E) CDNs discovered in GENIE (n>9000) but absent in TCGA (n<1000). The newly discovered CDNs may fall in TCGA as 0–2 hit sites. The numbers in the middle column show the percentage of lower recurrence (non-CDN) sites in TCGA that are detected as CDNs in the GENIE database, which has much larger n’s.
Figure 7A assumes that the prevalence, i/n, should not be much affected by n, but the cutoff for CDNs, i*/n, would decrease rapidly as n increases. (Figure 7B) shows that the i/n ratios indeed correspond well between TCGA and GENIE, which differ by 10–20-fold in sample size. Importantly, as predicted in Figure 6, the number of CDNs increases by three to fivefold (Figure 7C-E). Many of these newly discovered CDNs from GENIE are found in the A1 and A2 classes of TCGA while many more are found in the A0 class in TCGA. In conclusion, increasing n by one to two orders of magnitude would be the simplest means of finding all CDNs.
Discussion
The nature of high-recurrence mutations has been controversial. Many authors have argued for mutational hotspots (Hess et al., 2019; Stobbe et al., 2019; Nesta et al., 2021; Bergstrom et al., 2022; Wong et al., 2022) but just as many have contended that they are CDNs driven by selection (Gartner et al., 2013; Chang et al., 2016; Bailey et al., 2018; Cannataro et al., 2018; Juul et al., 2021; Zhao et al., 2021; Zeng and Bromberg, 2022). While the two views co-exist, they are in fact incompatible. If the mutational hotspot hypothesis is correct, the selection hypothesis, and the determination of CDNs, would not be needed.
We believe that this study is the first to comprehensively test of the null hypothesis of mutational hotspots. In PART I, the mutational characteristics near all putative CDNs are examined and PART II presents the probability theory based on the analyses. The conclusion is that it is possible to reject the null hypothesis for recurrences as low as 3 in the TCGA data. The main reason for the high sensitivity is shown in Equations 2 and 3 where Ai and Si is proportional to or, roughly 0.002i. We recognized that the conclusion is based on what we currently know about mutation mechanisms. In a sense, the theory developed here can help the search for such unknown mutation mechanisms, if they do exist. Finally, the theory developed would permit the explorations in several new fronts when the sample size, n, expands to 105.
The first front is to identify (nearly) all CDNs. When n reaches 105, any point mutation with a prevalence higher than 12/100,000 would be a CDN, which is 25-fold more sensitive than in the TCGA data (3/1000). The companion analysis suggests that CDNs with lower prevalence, say 12/100,000 may still be highly tumorigenic in patients with the said mutation. If prevalence and potence are indeed poorly correlated, the search for lower prevalence CDNs by increasing n to 105 is equivalent to searching for less common but still potent cancer driving mutations.
The second one is functional tests in patient-derived cell lines. When we have all CDNs identified, a patient can be expected to have multiple (≥5; Zhang et al., 2024) CDNs. These mutations will be the basis of in vitro test, as well as in animal model experiments, by gene editing, as shown recently (Hodis et al., 2022). Targeting multiple mutations simultaneously is necessary and may even be sufficient.
The third front, and arguably the most important one, is cancer treatment by targeted therapy (Dang et al., 2017; Danesi et al., 2021; Waarts et al., 2022; Lin et al., 2023; Zhou et al., 2023). When multiple CDN mutations in the same patient can be simultaneously targeted, the efficacy should be high. No less crucial, resistance to treatment should be diminished since it would be harder on cancer cells to evolve multiple escape routes to evade multiple drugs. Moreover, CDN analysis is crucial for stratifying patients for targeted therapy, as only targeting genes that are positively selected during cancer evolution can truly achieve therapeutic effects.
There will be other fronts to explore with the full set of CDNs. A large database will facilitate the detection of negative selection which has eluded detection (Chen et al., 2022b). Chen et al. have analyzed a curious phenomenon in somatic evolution, which they term ‘quasi-neutral evolution’ (Chen et al., 2019). It will also be possible to study the evolution of mutation mechanisms in cancer cells based on such large samples (Jackson and Loeb, 1998; Ruan et al., 2020). This last topic is addressed in Appendix 1 Note 5 (Appendix 1—figure 2). Finally, at the center of evolutionary genetics is the multi-genic interactions that control complex phenotypes such as human diseases (e.g. diabetes; Vujkovic et al., 2020; Lagou et al., 2023; Xue et al., 2023; Suzuki et al., 2024), genetics of speciation (Chen et al., 2022b; Pan et al., 2022b) and the emergence of viral strains (Deng et al., 2022; Pan et al., 2022a). Cancers may be the first such complex genetic systems that can be unraveled thanks to the massively repeated evolution. As cancer genomics is increasingly adopted in cancer treatment, these benefits should become apparent when n reaches 105 for most cancer types.
Methods
Data collection
Single nucleotide variation (SNV) data for the TCGA cohort was downloaded from the GDC Data Portal (https://portal.gdc.cancer.gov/, data version 2022-02-28). Only mutations identified by at least two pipelines were included in this study. Mutations were further filtered based on their population frequency recorded in the Genome Aggregation Database (gnomAD, version v2.1.1), with an upper threshold of 1‰. We focused on coding region mutations of missense, nonsense, and synonymous types on autosomes. The mutation load for each patient was defined as the sum of these three types of mutations. Patients with a mutation load exceeding 3000 were identified as having a mutator phenotype and were excluded from our analysis. In total, 7369 samples representing 12 cancer types were included for mutation analysis.
Additional mutation data was acquired from the AACR Project GENIE Consortium via cBioPortal. Due to the prevalence of targeted sequencing within the dataset, filtering was implemented to ensure the inclusion of samples with sequencing assays encompassing all exonic regions of target genes. Furthermore, sample-level filtering was performed to guarantee a unique sequencing sample per patient. Germline filtering was applied to the resulting point mutations, removing mutations with SNP frequencies exceeding 0.0005 in any subpopulation annotated by gnomAD. To exclude patients exhibiting hypermutator phenotypes, mutation loads were scaled to the whole exon level with , where and l represent the mutation load and genomic length of target sequencing region, respectively. L denotes the genome-wide whole coding region length. Patients with were subsequently excluded, consistent with the threshold employed for the TCGA dataset.
Calculation of missense and synonymous site number (LA and LS)
The idea of missense or synonymous sites originates from the question that how many missense or synonymous mutations would be expected if each site of the genome were mutated once given background mutation patterns. Here, the background mutation patterns refer to intrinsic biases in the mutational process, such as the over-representation of C>T (or G>A) mutations at CpG sites due to spontaneous deamination of 5-methylcytosine. In coding regions, fourfold degenerate sites are generally considered neutral, as any mutation path would not alter the encoded amino acid sequence. This analysis follows established methods at the single-base level to infer the expected number of missense and synonymous sites across the genome (Gojobori et al., 1982; Wu and Maeda, 1987; Hartl and Clark, 1989; Martincorena et al., 2017).
To illustrate the calculation process, we provide an example of synonymous site estimation. At four-fold degenerate sites throughout the genome, we tally the number of mutations from base m to base v as . The likelihood of observing a mutation from reference base m to variant base v will be , where represents the number of fourfold degenerate site with reference base m. We then normalize all likelihoods by , where represents the sum of likelihoods across 12 possible mutation paths, thus describes the relative probability of an occurred mutation to be at any site. For a given genomic coding region of length L, the synonymous site number will be:
(S1)
with being a Kronecker delta function where:
if is synonymous
otherwise
Similarly, the expected number of missense sites LA, is calculated as follows:
(S2)
Calculation of Ai and Si
For each mutated site, we track its number of recurrent mutations i (i>0) across two mutation categories: missense and synonymous. Subsequently, we aggregate across entire coding region to count the number of sites harboring i missense mutations (Ai) and synonymous mutations (Si). For i=0, we define A0 and S0 as the estimated number of potential missense and synonymous sites that remain unmutated within the current sample size.
AI-based mutation rate analysis
To capture the complex interplay of genomic and epigenomic factors influencing mutation susceptibility, we employed pre-trained artificial intelligence (AI) models from Dig, an aggregated tool combining deep learning and probabilistic models (Sherman et al., 2022). Downloaded from the Dig data portal (http://cb.csail.mit.edu/cb/DIG/downloads/), these models leverage a rich set of features encompassing both kilobase-scale epigenomic context (replicating timing, chromatin accessibility, etc.) and fine-grained base-pair level information (such as sequence context biases) to predict the site level mutation rate. For each cancer type, we re-fitted the pre-trained models with mutations analyzed in our study. The mutation rate for each site, scaled by population size, was obtained via the elementDriver function within Dig, and was represented by EXP_SNV from the final results. For a closer look at mutation rate landscape of PAX3, we re-fitted the AI-model with point mutations from large intestine cancer. The mutation rates were generated site-by-site for the coding regions of PAX3.
Given the scarcity of mutated sites with recurrence i≥3 (comprising only 0.15% of all mutated sites), a rigorous statistical approach was adopted to assess the significance of mutability differences between these high-hit groups and low-hit groups. We implemented the procedure as follows:
(1) Raw significance level: For each recurrence group i (containing Ai sites), a one-sided Kolmogorov-Smirnov (K-S) test was employed to calculate a raw significance level (denoted as ) against the low-hit group.
(2) Resampling for Significance Pool: we resample Ai sites from the entire pool of mutated sites with missense mutations. The significance from one-sided K-S test is calculated against the low hit group. The resampling process was repeated 100,000 times, generating a distribution of resampled significance levels, denoted as .
(3) Adjusted Significance Level: the raw significance was then compared to the resampled significance pool . The proportion of was then calculated as the adjusted significance level that accounted for potential sampling effects.
Motif-based mutability
For a given nucleotide base, we extended the sequence to each side by 1, 2, and 3 base pairs, producing sets of 3-mer, 5-mer, and 7-mer motifs, respectively. We then pooled point mutations from 12 cancer types to create a comprehensive dataset. For 3-mer and 5-mer motifs, we utilized synonymous mutations as the reference for mutation rate calculations. For 7-mer motifs, the vast number of possible sequence combinations (47=16,384) posed a challenge, as synonymous mutations alone might not adequately cover all potential contexts. To address this, we employed all singleton mutations (1-hit mutations) from both missense and synonymous categories for 7-mer motif analysis. This decision was based on the assumption that singleton mutations are less affected by selective pressures, supported by the genome-wide observation that the ratio of missense to synonymous singletons (A1/S1) approximates the ratio of unmutated missense to synonymous sites (A0/S0).
The site number for 3-mer and 5-mer motifs of a given context c was calculated as follows:
Which is an extension of Equation S1, with being a Kronecker delta function where:
if base change of m to v (m > v) is synonymous under sequence context c.
otherwise.
The mutation rate then could be expressed as:
(S3)
for 7-mer motifs, the calculation is:
(S4)
Where for Equations S3 and S4, and represent the mutation numbers with m>v being synonymous and missense under sequence context c, respectively. The mutation rate is then scaled as the expected mutation number per 105 corresponding sequence motifs for better presentation.
Significance for motif enrichment (Figure 4B) mirrored the AI analysis. For each i≥3 site, we calculated raw K-S p-values against motif mutabilities (denoted as ). These were then compared to a resampled significance pool , with the proportion of employed as the final p-value, depicting enrichment significance for highly mutable motifs in recurrence group i against low hits.
Consensus length comparison
To explore potential sequence motifs associated with recurrent mutations (i≥3), we employ a sliding window of 10 bp stride to extract the local context from reference genome (Figure 4—figure supplement 1). We examined diverse window sizes (21, 41, 61, 81, and 101 bp) to capture potential motifs of varying lengths and distances to the mutated site. Consensus length of local contexts was measured by Hamming distance in pairwise comparisons of aligned windows (with same stride) between mutated sites.
To prioritize sequence similarities likely driven by mutational mechanisms rather than functional constraints or gene structure, we restricted consensus comparisons to non-homologous genes. This approach effectively mitigated potential biases arising from homologous genes (e.g., KRAS and NRAS) or repeated domains within a single gene (e.g., FBXW7). The statistical significance of observed consensus lengths was assessed using the K-S test, which compared the empirical distribution of consensus lengths against a Poisson distribution, with mean of λ set to one-quarter of the window size, which reflects the expected distribution under random scenarios.
Mutational signature analysis
The mutation load of each patient could be further decomposed to several known mutational processes, which is represented by mutational signatures. In general, each mutational signature embodies the relative mutabilities across distinct mutational contexts. Leveraging single base substitution (SBS) signatures from COSMIC (v3.3), we employed the SignatureAnalyzer tool to quantify the contribution of each signature to individual mutational loads (Kim et al., 2016). For composition analysis in Figure 5B, we focused on signatures contributing at least 2% to the total mutations within a given cancer type, given that there are 79 mutational signatures in use for deconvolution.
To assess signature contribution changes across recurrence cutoffs (i), we grouped patients with mutations of recurrence i≥i* and scaled signature contributions to 1 to cancel out the population size effect. Pairwise K-S test between different i*s is employed to determine whether signature contributions are significantly different under each i*.
Outlier model
The purpose of the outlier model is to investigate if high-hit sites could be explained by a fraction (p) of highly mutable sites (with mutability α-fold higher). By definition, we have:
(S5)
With n represents the population size and E(u) denotes the average mutation rate per site per patient.
We let p range from 10–5 to 10–2 and α from 1.1 to 1,000. For each (p, α) pair, we solve Equation S5 based on observed S1 (i=1) to obtain E(u). Then, we calculate expectedSi with i=2, 3. The (p, α) pairs are filtered by imposing constraints grounded in observed S2 and S3 values. Specifically, we retained only those pairs whose expected S2 and S3 values resided within the 95% quantile range of a Poisson distribution with λ set to the observed values. This filtering process yielded biologically plausible (p, α) pairs that were then used to derive S4 and S5. Finally, we computed the mean and standard deviation for p, α, S4, and S5 across all filtered pairs to capture their central tendencies and variability.
CDN analysis in GENIE
To circumvent potential biases in E(u) estimation stemming from the varying target gene coverage across sequencing panels within the GENIE dataset, we leveraged E(u) values derived from the corresponding cancer types in the TCGA dataset. Specifically, we focused on 1-hit synonymous mutations within coding regions, as these are generally considered to be the least influenced by selective pressures in coding regions. Based on Equation 1 from the main text, we have:
(S6)
where comes from approximation of from binomial distribution, and n is the population size in TCGA. The calculation for the threshold i*, based on Equation 10 from the main text, is:
(S7)
The only difference in Equation S7 is that we use ne to represent the number of patients sequenced for a target gene in GENIE, considering the overlapping between different assays in use. In essence, we will have for each gene a CDN threshold i*.
The comparison of CDNs between TCGA and GENIE are restricted to genes sequenced by GENIE panels. For CDNs identified in GENIE using Equation S7, we investigated their hit information and CDN identity within TCGA dataset. The CDN flow proportion depicted in Figure 7C–E represents the ratio of sites identified as CDN in GENIE to (i=0, 1, 2) of TCGA. mirrors Ai but specifically considers the coding region sequenced by the GENIE panel. For CDNs identified in TCGA, the flow ratio is just the proportion of sites being identified as CDNs in GENIE. Notably, for CDNs identified in GENIE but lacking mutations in TCGA (i=0), is obtained using Equation S2 with L being the length of coding region sequenced in GENIE.
Appendix 1
1. Literature support for CDNs identified in breast cancer
Verification of site level positive selection in cancer genome has primarily focused on canonical cancer drivers. For non-canonical candidates with experimentally proven tumorigenic activity, CDN sites within these genes emerge as potential key drivers due to their statistically stronger selective advantage. Under this premise, we search for literature evidence for genes harboring CDN sites in breast cancer.
Among the 17 genes with CDN sites in breast cancer, 11 are recognized as canonical drivers by all three major driver gene lists (Appendix 1—table 1). 4 genes (CDC42BPA, ERBB3, KIF1B, NUP93), despite lacking inclusion in canonical breast cancer driver lists, possess explicit experimental support indicating their driving roles in breast tumorigenesis. HIST1H3B has been recognized as a driver gene in breast cancer by IntOGen, corroborated by literatures supporting its association with breast cancer. The four mutation recurrences with R6C alteration in amino acid sequence in RARS2 have been proposed to be linked to defects in mitochondrial transport, the explicit role of RARS2 in breast cancer tumorigenesis remains to be explored.
Appendix 1—table 1
literature support for CDN genes in breast cancer.
| Gene Id | Gene Name | Support |
|---|---|---|
| AKT1 | v-akt murine thymoma viral oncogene homolog 1 | ① ② ③ |
| CDC42BPA | CDC42 binding protein kinase alpha (DMPK-like) | Unbekandt and Olson, 2014; Collins et al., 2018; Kwa et al., 2021; Jiang et al., 2023 |
| CDH1 | cadherin 1, type 1, E-cadherin (epithelial) | ① ② ③ |
| ERBB2 | v-erb-b2 avian erythroblastic leukemia viral oncogene homolog 2 | ① ② ③ |
| ERBB3 | v-erb-b2 avian erythroblastic leukemia viral oncogene homolog 3 | Holbro et al., 2003; Xue et al., 2006; Hamburger, 2008; Sithanandam and Anderson, 2008; Stern, 2008; Huang et al., 2010 |
| FGFR2 | fibroblast growth factor receptor 2 | ① ② ③ |
| FOXA1 | forkhead box A1 | ① ② ③ |
| GATA3 | GATA binding protein 3 | ① ② ③ |
| HIST1H3B | histone cluster 1, H3b | ① ② ③ Xie et al., 2019; Wang et al., 2023* |
| KIF1B | kinesin family member 1B | Munirajan et al., 2008; Yu and Feng, 2010; Liu et al., 2022 |
| KRAS | Kirsten rat sarcoma viral oncogene homolog | ① ② ③ |
| NUP93 | nucleoporin 93 kDa | Bersini et al., 2020; Nataraj et al., 2022 |
| PIK3CA | phosphatidylinositol-4,5-bisphosphate 3-kinase, catalytic subunit alpha | ① ② ③ |
| PTEN | phosphatase and tensin homolog | ① ② ③ |
| RARS2 | arginyl-tRNA synthetase 2, mitochondrial | Wang et al., 2020* |
| SF3B1 | splicing factor 3b, subunit 1, 155 kDa | ① ② ③ |
| TP53 | tumor protein p53 | ① ② ③ |
-
The serial number corresponds to the inclusion of target gene in the following driver gene list: ① CGC Tier-1 list, ② IntOGen, ③ Bailey’s list.
-
The inclusion necessitates that the target gene is annotated as a cancer driver in breast cancer.
-
*
ambiguous, meaning the literature indicates an association between the candidate gene and breast cancer, but lacks explicit experimental evidence.
2. The impact of k for gamma-binomial model
From Equation 2 in the main text, Si is affected by two terms: G and nE(u), where G is:
LS is a constant value given specific cancer type, here we demonstrate how varies with respect to i and k, and elucidate why Si of k=1 indicates the upper bound of CDN cutoff.
Considering the fold change of G from i-1 to i.
(S8)
Appendix 1—figure 1 illustrates how changes with i and k. With k range from 0.1 to 10, the curve of elucidates the extent to which G would impact Si with each increment of i. As detailed in Section 4, k will be >1 for biological significance. In such cases, will always be < 1, meaning G will synergistically collaborate with nE(u) to decrease Si. The diminishing impact of intensifies as k increases. A higher k value would suggest that, for most sites across the genome, mutability falls within a narrow range of >0. In an extreme case, when k=10, = 0.145 at i=20, which is 2 orders weaker than nE(u) for cancer types in TCGA. In practice, k is usually estimated to be between 2–5, depending on the cancer types being investigated (Appendix 1—table 2). Consequently, the reduction of Si with each increase of i is predominantly governed by nE(u), and the Si values with k=1 represent the upper limit driven solely by mutational force.
Appendix 1—figure 1
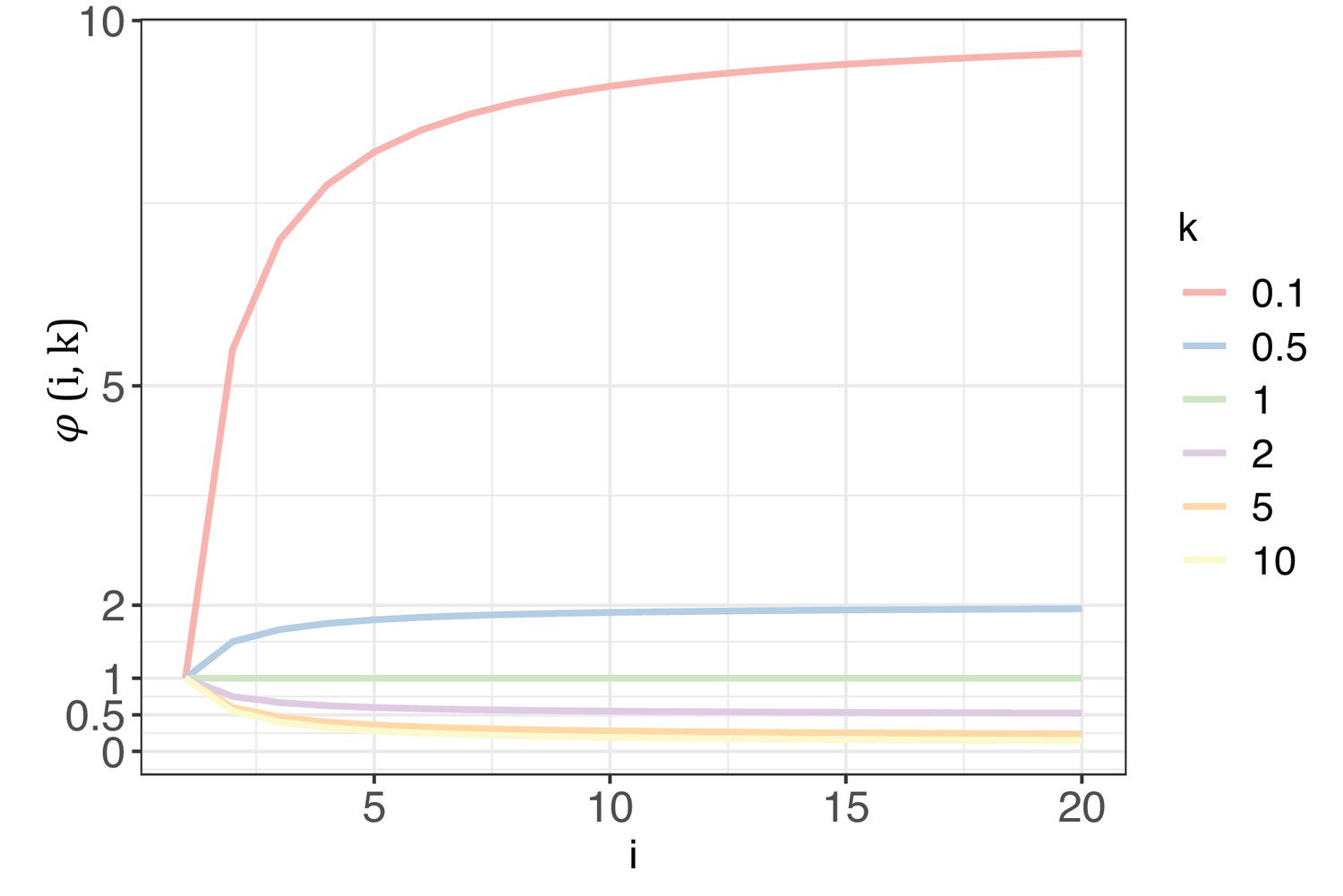
The trend of with each increase of recurrence (i, the x-axis) under different shape parameters of the gamma distribution (k, designated by different colors).
Appendix 1—table 2
k estimated from 12 cancer types.
| Cancer type | k |
|---|---|
| Breast | 5.05 |
| CNS | 2.59 |
| Endometrium | 5.49 |
| Kidney | 7.70 |
| Large intestine | 4.76 |
| Liver | 5.23 |
| Lung | 2.62 |
| Ovary | 4.30 |
| Prostate | 3.60 |
| Stomach | 4.17 |
| Upper-AD tract | 4.14 |
| Urinary tract | 6.14 |
| merged set* | 3.27 |
-
Note:- Estimation of k is derived from negative binomial regression, based on synonymous changes aggregated by the 3 bp local context at mutated sites across all coding genes. The estimation method is implemented in package dndscv.
-
*
The merged set contains mutation information from all 12 cancer types.
3. The impact of negative selection on shape parameter k
Across various studies aiming to depict mutability variation across genome under the gamma distribution, the shape parameter k is always pivotal. Adopting a dichotomous perspective, we inquire into how k compares to 1 under large sample sizes (n≥106). This inquiry is fundamentally linked to the prevalence of negative selection across the cancer genome, as the observed mutation abundance is an amalgamation of mutational and selection forces. In scenarios where purifying selection extensively operates throughout the genome in cancer evolution, even for synonymous sites (Sharp and Li, 1987; Plotkin and Kudla, 2011; Gartner et al., 2013; Chu and Wei, 2019), most genomic sites would not exhibit mutations, resulting in k being ≤1. In attempts to detect negative selection signals in cancer, researchers typically identify only a limited number of genes (Luo et al., 2008; Van den Eynden et al., 2016; Zapata et al., 2018; Bányai et al., 2021). In a CRISPR-Cas9 loss-of-function screen covering 16,540 genes conducted across 558 cancer cell lines, only approximately 6% of genes are under strong negative selection in at least 90% of the cell lines (De Kegel and Ryan, 2019). In an in-house mutation accumulation experiment carried out in HCT116 (a human colorectal carcinoma cell line, data not published), the proportion of mutations under strong negative selection is 0.66% with a selection coefficient (s) of –0.6 (indicating that the survivability of the mutant is 40% of the wildtype). These evidences, in concordance with quasi-neutrality of cancer evolution, suggest that purifying selection is indeed rare in cancer evolution. The mutability for the majority of genomic sites is greater than 0, with shape parameter k>1.
4. Detailed derivation for negative binomial distribution and approximation of i*/n
The derivation of Equation 5 from joint distribution of Gamma-Poisson distribution is well presented in statistically analysis. Here, we assume that the mutation recurrence (i) observed at site level across the genome follows a Poisson distribution of , where the expected number of mutation recurrence follows a Gamma distribution of , with k and being the shape and scale parameters, respectively. Then, the joint probability density function for i can be expressed as:
(S9)
Now, we make use of the probability density function of Gamma distribution,
Which is:
Therefore,
(S10)
Comparing with Equation S10, Equation S9 can be rewrite as:
(S11)
Note that the mean for Gamma distribution is , which leads to . Then, the negative-binomial form of Equation S11 could be further expressed as:
Which is Equation 6 from the main text.
With k=1, , Equation S11 then transforms to:
Which is a geometric distribution with .
For the approximation of i*/n, we let ε=1, then Equation 10 from main text could be rewritten as:
(S12)
For the left side of Equation S12, we use the first-order Tayler expansion,
Substitute this to Equation S12, we have:
Which is Equation 11 from main text.
5. Probing mutation rate variation with large samples
With large sample size sequenced, the data will yield an additional benefit by revealing the evolution of the mutation rate itself. Given that the mutation rate per site is extremely small, the evolution of mutation rate itself has been a most challenging issue (André and Godelle, 2006; Lynch, 2010; Lynch, 2011; Lynch et al., 2016; Ruan et al., 2020; Wei et al., 2022). In particular, without the check of selection, the mutation rate is liable to be trapped in the runaway evolution (Ruan et al., 2020).
Appendix 1—figure 2
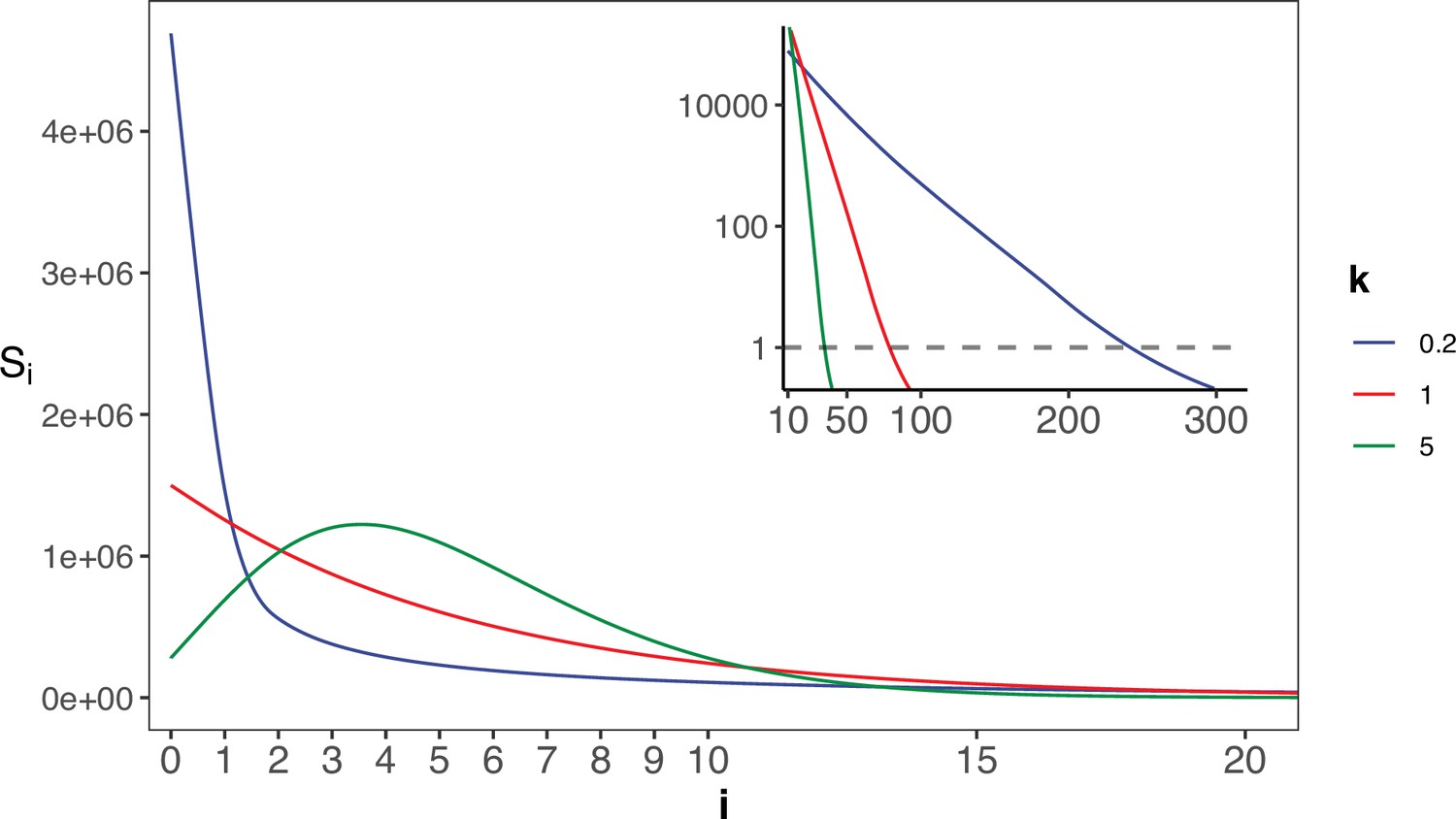
The gamma distribution of recurrences (i) under different shapes.
With E(u)=5 × 10–6, we set the shape parameter k to 0.2, 1 and 5, represented by three distinct colors. The site number of synonymous recurrence i (Si) is indicated on Y-axis. In the context of a large sample size (n=106), the Si distribution clearly distinguishes between different k values, mitigating the overdispersion issue encountered in smaller sample sizes. The inset depicts the distribution on a log10 scale for i≥10, with a horizontal dashed line indicating Si=1, where i* is the CDN cutoff.
The theory of mutation rate of evolution should be based on the distribution of the per-site mutation rate across the genome. However, the empirical data so far only yield the mean. In particular, the spectrum of Si’s for i’s close to 1 would be most informative about the evolution of the mutation mechanism. Appendix 1—figure 2 shows the Si spectrum with k=0.2, 1 or 5 in a Gamma distribution. Note the mode of the distribution (i.e. the peak of the curve) among the 3 curves, which is at 0 or >0 depending on whether k≤1 or>1. Clearly, the observed Si’s can distinguish among the three distributions only when n is very large. The implications of such distributions for the theory of mutation rate evolution are addressed in Discussion.
Data availability
The key scripts used in this study are available at GitLab, copy archived at Zhang, 2024. A subset of key example files for breast cancer analysis can be found in the "/example_data_files" directory. The complete list of CDNs analyzed in this study is provided in Supplementary file 1.
References
-
The age distribution of cancer and a multi-stage theory of carcinogenesisBritish Journal of Cancer 8:1–12.https://doi.org/10.1038/bjc.1954.1
-
Genetic and non-genetic clonal diversity in cancer evolutionNature Reviews. Cancer 21:379–392.https://doi.org/10.1038/s41568-021-00336-2
-
Evidence for APOBEC3B mutagenesis in multiple human cancersNature Genetics 45:977–983.https://doi.org/10.1038/ng.2701
-
The cancer genome atlas pan-cancer analysis projectNature Genetics 45:1113–1120.https://doi.org/10.1038/ng.2764
-
Effect sizes of somatic mutations in cancerJournal of the National Cancer Institute 110:1171–1177.https://doi.org/10.1093/jnci/djy168
-
Was Wuhan the early epicenter of the COVID-19 pandemic?-A critiqueNational Science Review 10:wac287.https://doi.org/10.1093/nsr/nwac287
-
Tumorigenesis as the paradigm of quasi-neutral molecular evolutionMolecular Biology and Evolution 36:1430–1441.https://doi.org/10.1093/molbev/msz075
-
Very large hidden genetic diversity in one single tumor: evidence for tumors-in-tumorNational Science Review 9:wac250.https://doi.org/10.1093/nsr/nwac250
-
Drugging the “undruggable” cancer targetsNature Reviews. Cancer 17:502–508.https://doi.org/10.1038/nrc.2017.36
-
Mutation signatures inform the natural host of SARS-CoV-2National Science Review 9:wab220.https://doi.org/10.1093/nsr/nwab220
-
Non-coding driver mutations in human cancerNature Reviews. Cancer 21:500–509.https://doi.org/10.1038/s41568-021-00371-z
-
A generalizable deep learning framework for inferring fine-scale germline mutation rate mapsNature Machine Intelligence 4:1209–1223.https://doi.org/10.1038/s42256-022-00574-5
-
Patterns of nucleotide substitution in pseudogenes and functional genesJournal of Molecular Evolution 18:360–369.https://doi.org/10.1007/BF01733904
-
The role of ErbB3 and its binding partners in breast cancer progression and resistance to hormone and tyrosine kinase directed therapiesJournal of Mammary Gland Biology and Neoplasia 13:225–233.https://doi.org/10.1007/s10911-008-9077-5
-
Hallmarks of cancer: new dimensionsCancer Discovery 12:31–46.https://doi.org/10.1158/2159-8290.CD-21-1059
-
Adaptive convergence at the genomic level-prevalent, uncommon or very rare?National Science Review 7:947–951.https://doi.org/10.1093/nsr/nwaa076
-
Convergent adaptation of the genomes of woody plants at the land-sea interfaceNational Science Review 7:978–993.https://doi.org/10.1093/nsr/nwaa027
-
Mutagenic mechanisms of cancer-associated DNA polymerase ϵ allelesNucleic Acids Research 49:3919–3931.https://doi.org/10.1093/nar/gkab160
-
Passenger hotspot mutations in cancerCancer Cell 36:288–301.https://doi.org/10.1016/j.ccell.2019.08.002
-
Variation in the mutation rate across mammalian genomesNature Reviews. Genetics 12:756–766.https://doi.org/10.1038/nrg3098
-
Mutant IDH1 enhances temozolomide sensitivity via regulation of the ATM/CHK2 pathway in gliomaCancer Research and Treatment 53:367–377.https://doi.org/10.4143/crt.2020.506
-
YTHDF2-mediated regulations bifurcate BHPF-induced programmed cell deathsNational Science Review 10:wad227.https://doi.org/10.1093/nsr/nwad227
-
Evolution of the mutation rateTrends in Genetics 26:345–352.https://doi.org/10.1016/j.tig.2010.05.003
-
The lower bound to the evolution of mutation ratesGenome Biology and Evolution 3:1107–1118.https://doi.org/10.1093/gbe/evr066
-
Genetic drift, selection and the evolution of the mutation rateNature Reviews. Genetics 17:704–714.https://doi.org/10.1038/nrg.2016.104
-
The effects of chromatin organization on variation in mutation rates in the genomeNature Reviews. Genetics 16:213–223.https://doi.org/10.1038/nrg3890
-
KIF1Bbeta functions as a haploinsufficient tumor suppressor gene mapped to chromosome 1p36.2 by inducing apoptotic cell deathThe Journal of Biological Chemistry 283:24426–24434.https://doi.org/10.1074/jbc.M802316200
-
Effect of mutation order on myeloproliferative neoplasmsThe New England Journal of Medicine 372:601–612.https://doi.org/10.1056/NEJMoa1412098
-
Genomic diversity and post-admixture adaptation in the UyghursNational Science Review 9:wab124.https://doi.org/10.1093/nsr/nwab124
-
Synonymous but not the same: the causes and consequences of codon biasNature Reviews. Genetics 12:32–42.https://doi.org/10.1038/nrg2899
-
Mutations beget more mutations-rapid evolution of mutation rate in response to the risk of runaway accumulationMolecular Biology and Evolution 37:1007–1019.https://doi.org/10.1093/molbev/msz283
-
The runaway evolution of SARS-CoV-2 leading to the highly evolved delta strainMolecular Biology and Evolution 39:msac046.https://doi.org/10.1093/molbev/msac046
-
The twin-beginnings of COVID-19 in Asia and Europe-one prevails quicklyNational Science Review 9:wab223.https://doi.org/10.1093/nsr/nwab223
-
On the epicenter of COVID-19 and the origin of the pandemic strainNational Science Review 10:wac286.https://doi.org/10.1093/nsr/nwac286
-
Determinants of mutation rate variation in the human germlineAnnual Review of Genomics and Human Genetics 15:47–70.https://doi.org/10.1146/annurev-genom-031714-125740
-
Genome-wide mapping of somatic mutation rates uncovers drivers of cancerNature Biotechnology 40:1634–1643.https://doi.org/10.1038/s41587-022-01353-8
-
The ERBB3 receptor in cancer and cancer gene therapyCancer Gene Therapy 15:413–448.https://doi.org/10.1038/cgt.2008.15
-
DeepAlloDriver: a deep learning-based strategy to predict cancer driver mutationsNucleic Acids Research 51:W129–W133.https://doi.org/10.1093/nar/gkad295
-
Human mutation rate associated with DNA replication timingNature Genetics 41:393–395.https://doi.org/10.1038/ng.363
-
ERBB3/HER3 and ERBB2/HER2 duet in mammary development and breast cancerJournal of Mammary Gland Biology and Neoplasia 13:215–223.https://doi.org/10.1007/s10911-008-9083-7
-
Recurrent somatic mutations reveal new insights into consequences of mutagenic processes in cancerPLOS Computational Biology 15:e1007496.https://doi.org/10.1371/journal.pcbi.1007496
-
A platform for validating colorectal cancer driver genes using mouse organoidsFrontiers in Genetics 12:698771.https://doi.org/10.3389/fgene.2021.698771
-
COSMIC: the catalogue of somatic mutations in cancerNucleic Acids Research 47:D941–D947.https://doi.org/10.1093/nar/gky1015
-
Resolving genetic heterogeneity in cancerNature Reviews. Genetics 20:404–416.https://doi.org/10.1038/s41576-019-0114-6
-
The actin-myosin regulatory MRCK kinases: regulation, biological functions and associations with human cancerJournal of Molecular Medicine 92:217–225.https://doi.org/10.1007/s00109-014-1133-6
-
Targeting mutations in cancerThe Journal of Clinical Investigation 132:e154943.https://doi.org/10.1172/JCI154943
-
Pax genes in embryogenesis and oncogenesisJournal of Cellular and Molecular Medicine 12:2281–2294.https://doi.org/10.1111/j.1582-4934.2008.00427.x
-
Extensive gene flow in secondary sympatry after allopatric speciationNational Science Review 9:wac280.https://doi.org/10.1093/nsr/nwac280
-
Convergent adaptive evolution-how common, or how rare?National Science Review 7:945–946.https://doi.org/10.1093/nsr/nwaa081
-
What are species and how are they formed?National Science Review 9:wad017.https://doi.org/10.1093/nsr/nwad017
-
The genetics of race differentiation-should it be studied?National Science Review 10:wad068.https://doi.org/10.1093/nsr/nwad068
-
Expression and potential prognostic value of histone family gene signature in breast cancerExperimental and Therapeutic Medicine 18:4893–4903.https://doi.org/10.3892/etm.2019.8131
-
CanDriS: posterior profiling of cancer-driving sites based on two-component evolutionary modelBriefings in Bioinformatics 22:bbab131.https://doi.org/10.1093/bib/bbab131
-
3 = 1 + 2: how the divide conquered de novo protein structure prediction and what is next?National Science Review 10:wad259.https://doi.org/10.1093/nsr/nwad259
Article and author information
Author details
Funding
National Natural Science Foundation of China (32150006)
- Xuemei Lu
- Chung-I Wu
Guangdong Key R&D Project of China (2022B1111030001)
- Hai-Jun Wen
National Natural Science Foundation of China (32293193)
- Chung-I Wu
National Natural Science Foundation of China (32293190)
- Chung-I Wu
Yunnan Revitalization Talent Support Program Top Team (202405AS350022)
- Xuemei Lu
- Chung-I Wu
National Natural Science Foundation of China (82341092)
- Hai-Jun Wen
National Natural Science Foundation of China (32200493)
- Chung-I Wu
National Key Research and Development Program of China (2021YFC2301300)
- Chung-I Wu
National Key Research and Development Program of China (2021YFC0863400)
- Chung-I Wu
Yunnan Revitalization Talent Support Program Yunling Scholar Project
- Xuemei Lu
National Natural Science Foundation of China (32370659)
- Chung-I Wu
Guangdong Basic and Applied Basic Research Foundation (2023A1515010016)
- Chung-I Wu
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
The authors gratefully acknowledge the following for their support in the initiation of the Cancer Driving Nucleotide (CDN) project: the First Affiliated Hospital, the Seventh Affiliated Hospital of Sun Yat-sen University; Cancer Center of Clifford Hospital, Jinan University; Cancer Hospital Chinese Academy of Medical Sciences, Shenzhen Center; Guangdong Academy of Medical Sciences, Guangdong Provincial People’s Hospital. We thank the Kunming Institute of Zoology for valuable discussions on the CDN concept. We are also grateful to Weiwei Zhai, Qianfei Wang, and Weini Huang for their insightful comments and suggestions. Finally, we acknowledge the American Association for Cancer Research (AACR) and The Cancer Genome Atlas (TCGA) project for providing invaluable datasets and resources that have significantly advanced our understanding of cancer biology and improved patient outcomes. This work was supported by the National Natural Science Foundation of China (32150006 to CIW and XL, 32293193, 32293190, 32200493, and 32370659) to CIW, 82341092 to HJ Wen, the National Key Research and Development Projects of the Ministry of Science and Technology of China (2021YFC2301300, 2021YFC0863400), Guangdong Key Research and Development Program (No. 2022 No. B1111030001), Guangdong Basic and Applied Basic Research Foundation (No. 2023A1515010016), Yunnan Revitalization Talent Support Program Top Team (202405AS350022 to CIW and XL) and Yunnan Revitalization Talent Support Program Yunling Scholar Project (XL).
Version history
- Sent for peer review:
- Preprint posted:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.99340. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2024, Zhang et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,075
- views
-
- 52
- downloads
-
- 6
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 6
- citations for umbrella DOI https://doi.org/10.7554/eLife.99340
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
The theory of massively repeated evolution and full identifications of cancer-driving nucleotides (CDNs)
eLife 13:RP99340.
https://doi.org/10.7554/eLife.99340.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}