Exploring protein structural ensembles: Integration of sparse experimental data from electron paramagnetic resonance spectroscopy with molecular modeling methods
- Institute for Drug Discovery, Leipzig University Medical School, Germany
- Institute for Medical Physics and Biophysics, Leipzig University Medical School, Germany
- Integrative Center for Bioinformatics, Leipzig University, Germany
Abstract
Under physiological conditions, proteins continuously undergo structural fluctuations on different timescales. Some conformations are only sparsely populated, but still play a key role in protein function. Thus, meaningful structure–function frameworks must include structural ensembles rather than only the most populated protein conformations. To detail protein plasticity, modern structural biology combines complementary experimental and computational approaches. In this review, we survey available computational approaches that integrate sparse experimental data from electron paramagnetic resonance spectroscopy with molecular modeling techniques to derive all-atom structural models of rare protein conformations. We also propose strategies to increase the reliability and improve efficiency using deep learning approaches, thus advancing the field of integrative structural biology.
Introduction
The conformational landscape and its role for protein function
Under physiological conditions, most proteins are highly dynamic, adopting various structures with distinct probabilities. The diversity and thermodynamics of protein structures may be conceptualized as a conformational landscape, which represents a low-dimensional projection of the multidimensional free energy surface of generalized protein coordinates (Figure 1). Following the nomenclature introduced by Frauenfelder et al., a macrostate represents the global thermodynamic state of a protein defined by the physical and (bio)chemical conditions, such as temperature, pressure, chemical potential, type, and concentration of solutes or ligands (Frauenfelder et al., 1991). Within a given macrostate, protein structural rearrangements may occur on different timescales. For example, conformational states (or simply conformations) are separated by barriers of several kT and thus interconvert on the timescale of microseconds to milliseconds. Within each conformational state, fluctuations which occur on the order of nanoseconds separate individual conformational substates, while even faster transitions occur between statistical substates (Frauenfelder et al., 1991; Henzler-Wildman and Kern, 2007). It is conceivable that the macrostate defines the equilibrium distributions of the entire conformational ensemble comprising all timescales (Shi et al., 2015).
Figure 1
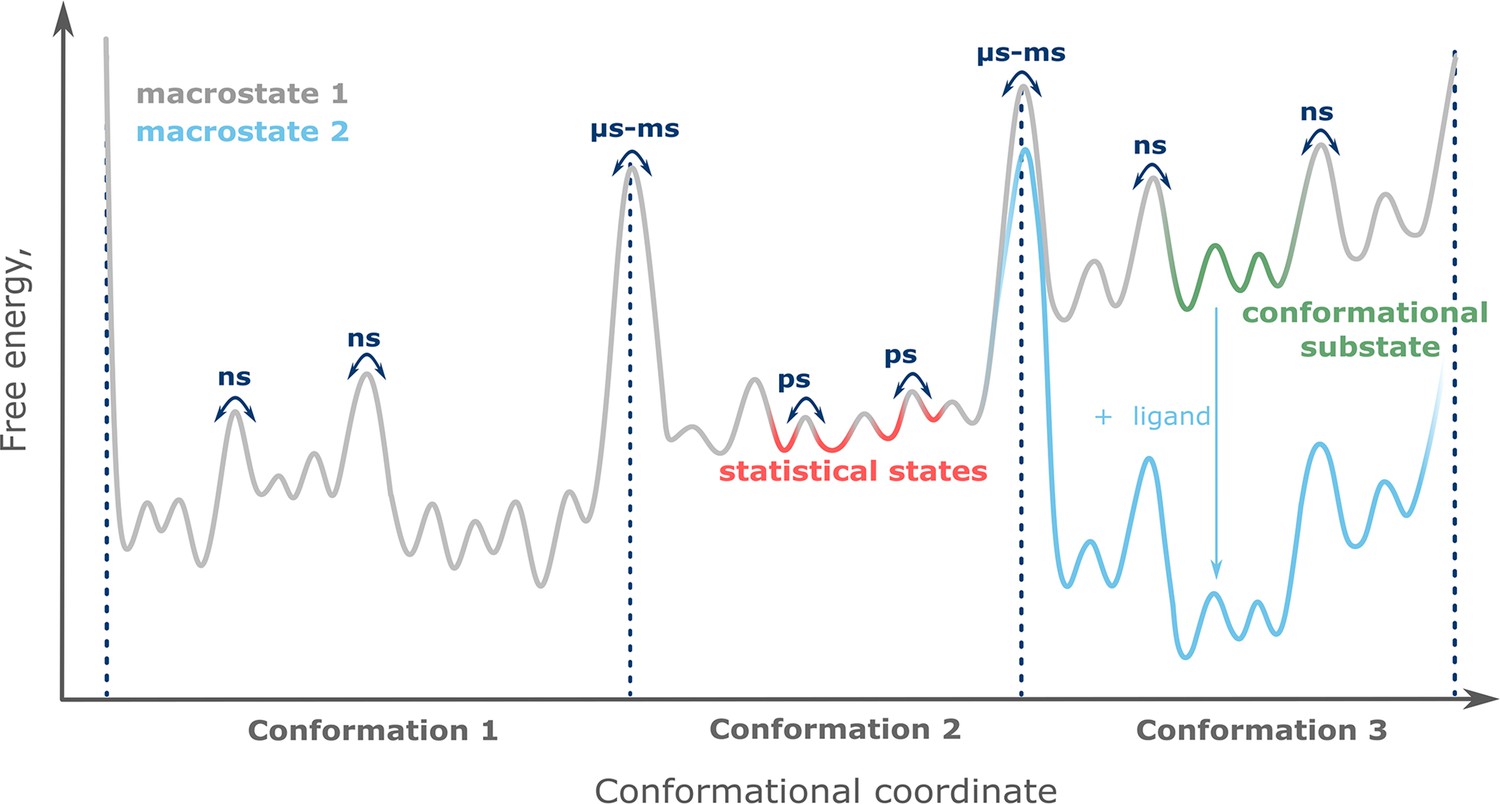
The conformational landscape of proteins.
Each conformational state contributes a specific functional profile. Thus, protein function is defined by the distribution of conformational states, and their redistribution upon interaction with binding partners such as ligands (Figure 1). This functional framework entails that even sparsely populated conformational states can rise to functional relevance and thus should be considered when a protein is targeted pharmacologically. This was recently demonstrated for the most prominent pharmacological targets, G-protein-coupled receptors (GPCRs), where minute amounts of active conformation lead to basal receptor activity (Lerch et al., 2020).
The three tiers of protein states are defined by their timescales of interconversion. Conformational states exchange on the slow, micro- to millisecond timescale (dotted lines), while conformational substates (green) and statistical substates (red) have lifetimes of nanoseconds or picoseconds, respectively. Changing the protein’s macrostate, for example by adding ligand (blue), leads to redistribution of the conformational equilibrium.
While various computational methods have been developed for the characterization of conformational landscapes, slow timescales (milliseconds and beyond) are still challenging to access. These shortcomings can be addressed by using complementary experimental methods, which provide access to slow conformational exchange and can resolve the equilibrium ensemble under (near-) physiological conditions. The integration of these experimental results with molecular modeling culminates in high-resolution structures of rare conformational states and their thermodynamics (Allison, 2017).
Experimental methods for studying conformational landscapes
Currently, the most commonly used approaches to study protein structure include X-ray diffraction, cryo-electron microscopy (EM), nuclear magnetic resonance (NMR) spectroscopy, Förster resonance energy transfer (FRET), and electron paramagnetic resonance (EPR) spectroscopy. Each of these methods has its strengths and limitations. For instance, structures determined by X-ray diffraction provide high resolution, however, the conformational state most stable under crystal conditions may lack physiological relevance (Freed et al., 2010; Dasgupta et al., 1997; Rasmussen et al., 2011). Furthermore, the requirements of crystallization narrow the applicability of X-ray crystallography, because many proteins exhibit flexible regions which prevent crystallization or diminish resolution. This is especially true for membrane proteins, where shortening of dynamics loops or insertion of highly soluble and rigid proteins circumvent this problem (Carpenter et al., 2008; Lacapère et al., 2007; Ding et al., 2021; Thorsen et al., 2014). In order to access conformational dynamics, X-ray structural models commonly serve as a starting point for molecular modeling, for example using molecular dynamics (MD) simulations. However, slow conformational changes (>10−5 s) remain challenging to follow with atomic resolution.
Cryo-EM may in principle directly explore conformational ensembles, and rapid vitrification enables the characterization of macrostates (Glaeser, 2016; Kühlbrandt, 2014; Yip et al., 2020). Though freezing may still introduce bias toward specific conformations, cryo-EM is the most rapidly advancing method for investigating conformational ensembles of proteins (Twomey et al., 2015; Mehra et al., 2020; Bonilla and Kieft, 2022; Noble et al., 2018; Karplus and McCammon, 2002). Pairing individual structural models from cryo-EM with MD simulations has recently given valuable insight into the activation process of G proteins by an activated GPCR (Papasergi-Scott et al., 2023). However, flexible membrane proteins may adopt a vast number of conformational states constituting a great obstacle to current classification approaches.
Most commonly used NMR methods effectively explore structural and dynamic features of small- and medium-sized proteins, typically up to 300 amino acid residues (Clore and Gronenborn, 1991; Opella and Marassi, 2004; Kaptein and Wagner, 2015). Site-specific fluorine NMR extends these capabilities to larger proteins, also enabling observation of dynamic events spanning from nanoseconds to seconds (Prosser and Alonzi, 2023; Danielson and Falke, 1996). Computational integration of NMR data remains challenging due to the added difficulty of assigning resonances to specific residues. Novel, detector-based methods elegantly integrate NMR timescale information with computational modeling (Smith et al., 2023), but access to large amounts of functional sample as well as acquisition and processing times remain limiting factors.
FRET detects conformational changes in the range of 30–80 Å and, in combination with single particle analysis (smFRET), provides access to conformational heterogeneity and exchange dynamics (Ha, 2001; Agam et al., 2023; Gregorio et al., 2017; Zhao et al., 2024). However, fluorophores represent relatively large, flexible, and hydrophobic probes, which limits spatial resolution or may disturb the local structure and dynamics (Sánchez-Rico et al., 2017; Peter et al., 2022).
In this review, we focus on EPR spectroscopy, which allows the investigation of protein dynamics across a broad range of timescales (from picoseconds to seconds or longer) with few restrictions on sample conditions. The application of pulse EPR spectroscopy adds further capabilities in terms of spatial resolution and accurate quantification of individual conformational states. A continuously growing number of computational tools are becoming available assisting with the integration of EPR spectroscopic data and providing a detailed picture of structural dynamics underlying protein function.
Site-directed spin labeling EPR spectroscopy
EPR spectroscopy comprises a large toolbox of methods enabling the exploration of protein systems containing paramagnetic centers. Since unpaired electrons are usually depleted during protein expression, stable radicals need to be introduced for example via site-directed spin labeling in order to obtain an EPR signal (Torricella et al., 2021; Pierro and Drescher, 2023; Jana et al., 2023). Several continuous wave (CW) EPR methods have been developed to study the different timescales of protein dynamics, and gain insight into structure and population of conformational states within an ensemble (Table 1). In the following, we limit our considerations to studies with nitroxides, which are by far the most commonly used spin labels. However, especially for distance measurements several other spin label side chains have been developed, each exhibiting benefits and drawbacks compared to nitroxides that are discussed elsewhere (Fielding et al., 2014). The CW EPR lineshape (first derivative of the absorption spectrum) is highly sensitive to spin label dynamics on the 100 ps to 100 ns timescale which is strongly influenced by structure and dynamics of the protein (Hubbell et al., 1996; Campbell et al., 2022; Mchaourab et al., 1996; Fichou et al., 2019; Pierro et al., 2020). Coexistence of several conformational states leads to superimposed, complex EPR spectra. While a comprehensive theory of spin label motion exists, the interpretation of CW EPR lineshapes remains challenging due to a large number of parameters. In particular cases, when the selection of fitting parameters during lineshape analysis is ambiguous, statistical analysis becomes necessary to assess the likelihood of one parameter set over another (Francis et al., 2012; Etienne et al., 2023; Lindemann et al., 2020).
Table 1
Summarizing information on electron paramagnetic resonance (EPR) spectroscopic techniques.
| Method | Features | References | |||
|---|---|---|---|---|---|
| Dynamics (timescale) | Structure(resolution) | Population | Computational analysis | ||
| CW EPR | Yes (10−10 to 10−7s) | Yes, via scanning (topology) | Yes, ≤3 conformations | Semi-empirical and lineshape analysis | Marsh, 1981; Hubbell and Altenbach, 1994; Columbus and Hubbell, 2002 |
| ST EPR | Yes (10−7 to 10−3 s) | No | No | Heuristic analysis | Hyde and Dalton, 1972 |
| TR EPR | Yes (>10−3 s) | No | Yes | Lineshape analysis | Farahbakhsh et al., 1993 |
| DEER | No | Yes (<10−10 m) | Yes | Parametric and non-parametric fitting models | Jeschke, 2012 |
| ENDOR | No | Yes (>10−11 m) | Yes | Lineshape analysis | Lubitz et al., 2002 |
| SR EPR | Yes, (10−6 to 10−5 s) | No | Yes, ≤2 conformations | Exponential fitting | Bridges et al., 2010 |
Further information on protein topology can be obtained via power saturation CW EPR spectroscopy, which is often combined with spin label scanning. Here, spin labels are introduced to successive sites along a sequence of amino acids and the influence of paramagnetic substances on the saturation behavior is evaluated (Altenbach et al., 1990; Hubbell et al., 2003). In general, full seqeunce coverage with spin labels is desired to uncover even subtle changes in structure and dynamics of the protein segment of interest. However, evaluating or comparing specific secondary structure models with different periodicities, such as α-helix or β-sheet, requires only a strongly reduced set of spin labeling sites. Saturation transfer (ST) EPR and time-resolved (TR) EPR represent two other methods utilizing continuous microwave radiation, extending sensitivity to the timescales of microseconds to milliseconds (Hyde and Dalton, 1972; Hyde and Thomas, 1973; Schwarz et al., 1990; Rayes et al., 2011) and millisecond to hours (Steinhoff et al., 1994; Farahbakhsh et al., 1993; Knierim et al., 2007), respectively. While several approaches for the analysis of ST EPR spectra have been developed (Hustedt and Beth, 2004), these represent purely heuristic methods and will therefore not be discussed in more detail. The dynamic processes picked up by TR EPR are too slow to be modeled using all-atom modeling techniques and are also outside the focus of this review. Notably, all EPR methods mentioned so far exhibit little to no restrictions on the experimental conditions, including a wide range of temperatures or different environments (solution, membranes, living cells, etc.).
The power of EPR spectroscopy is strongly expanded by the application of microwave pulses (pulse EPR spectroscopy). Four-pulse double electron–electron resonance energy transfer (DEER), also known as pulsed electron–electron double resonance (PELDOR), is a pulsed EPR spectroscopic technique usually performed on frozen solutions, in order to resolve distances between two spin labels at sub-Angstrom resolution. This method captures interspin distances ranging from 1.5 to 8.0 nm, and even up to 16.0 nm in fully deuterated samples (Peter et al., 2022; Jeschke, 2012). Moreover, DEER experiments elegantly connect structure and thermodynamics of proteins by resolving the conformational ensemble in probability distance distributions (Elgeti and Hubbell, 2021; Evans et al., 2020; Dawidowski and Cafiso, 2013; Wingler et al., 2019). This makes DEER the prime method for computational integration with structural biology which will be discussed in detail. Electron-nuclear double resonance (ENDOR) assesses hyperfine interactions among magnetic nuclei and paramagnetic centers within solute samples cooled to cryogenic temperatures. It can be implemented as both CW and pulse technique (Lubitz et al., 2002; Weber et al., 2001). ENDOR is effective for revealing the structures of specific parts of protein molecules, achieving atomic-level accuracy in distances below 1.5 nm (Lendzian et al., 1996). Recent work has demonstrated that using fluorinated amino acids (19F-ENDOR), in particular in combination with Gadolinium spin labels, extends the upper distance limit to above 2 nm (Bogdanov et al., 2024). Several computational methods have been developed to simulate ENDOR spectra, however, integration with structural models has not been achieved yet (Meyer et al., 2020; Meyer et al., 2022; Stoll and Schweiger, 2006). Lastly, saturation recovery EPR (SR EPR) represents another pulsed EPR technique used to gain insights into protein dynamics. It enables the resolution of dynamic events on the low to intermediate microsecond timescale which remains difficult to access with other methods (Bridges et al., 2010; Sarewicz et al., 2008; Yang et al., 2015). However, so far no computational approaches for the structural integration of SR EPR have been developed.
Analysis and interpretation of experimental CW EPR data
The sensitivity of CW EPR to molecular motion arises from the incomplete averaging of anisotropic magnetic interactions leading to characteristic lineshapes.
Semi-empirical analysis methods
Derive parameters of molecular motion directly from the lineshape. Columbus and Hubbell showed that the distance between the minimum and maximum of the CW EPR lineshape, the center linewidth δ (Figure 2A), is strongly related with the correlation time and order parameter of the observed motion (Columbus and Hubbell, 2002). Also, the effective hyperfine splitting A’zz, as assessed by the distance between the outer minima can be used to determine the correlation time or the polarity of spin label environment (Freed, 1976; Altenbach and Hubbell, 2015). Axially symmetric systems such as spin-labeled lipids of a membrane bilayer can be analyzed using the parallel (A∥) and perpendicular (A⟂), which significantly simplifies the analysis of the experimental results (Subczynski et al., 2010).
Figure 2

Computational approaches for the analysis and interpretations of continuous wave (CW) electron paramagnetic resonance (EPR) data.
(A) Semi-empirical analysis of the CW EPR lineshape provides insight into the rate of motion (δ), polarity (A’zz) of the spin label environment, parallel (A॥), and perpendicular (A⊥) compounds of CW EPR spectra of spin-labeled membrane bilayer lipids. (B) Lineshape analysis provides access to motional parameters and populations of individual equilibrium conformations. (C) Molecular dynamics (MD) simulations may explore the entire conformational landscape of a protein and provide data to simulate the CW EPR spectrum. The latter is then compared with the experiment. (D) RosettaEPR approach uses results from single and double mutant CW EPR experiments to derive distance constraints for subsequent conformational modeling.
Lineshape analysis
Motional models for analyzing CW EPR lineshapes computationally exist at varying degrees of complexity. Most widely used models for the description of intermediate to slow spin label dynamics solve the stochastic Liouville equation (SLE) and assume microscopic order and macroscopic disorder (MOMD, Figure 2B; Meirovitch et al., 1984; Budil et al., 2006). Such models can include ordering potentials in the lineshape analysis to characterize the amplitude of molecular motions. However, while intricate motional models can be implemented, distinct parameter sets may result in equally good mathematical fits. To this end, strongly correlated fitting parameters indicate that the complexity of the model (i.e., number of parameters) should be reduced to avoid overfitting (Altenbach and Budil, 2024). Motion faster than 1 ns leads to complete averaging of anisotropic magnetic interactions. This simplifies the analysis and an effective Hamiltonian can be used (Hubbell and McConnell, 1971).
Analysis via lineshape simulation includes iterative adjustment of model parameters to fit the experimental spectra. Such methods are implemented in the programs EasySpin, NLSL, MultiComponent, Spinach, Simlabel, and cwepr (Stoll and Schweiger, 2006; Altenbach and Budil, 2024; Budil et al., 1996; Altenbach and Hubbell, 2024; Schröder and Biskup, 2022). These software toolkits require relatively low computational resources and have a user-friendly graphical interface. Lineshape simulations offer valuable insights into the protein local structure, dynamics, topology, conformational changes, and interactions between binding partners. Notably, when a protein conformational change affects spin label dynamics sufficiently leading distinct lineshapes, lineshape analysis can disentangle such multicomponent spectra (Figure 2B) and thus describe conformational equilibria (Altenbach and Budil, 2024). However, CW EPR spectra represent a convolution of spin label and protein dynamics (Mchaourab et al., 1996) and when spin label and protein motions occur on similar timescales, lineshape analysis is reaching its limits. In such cases, integrative analysis approaches incorporating molecular modeling will provide a possible alternative.
MD-based approaches for CW EPR analysis
The majority of integrative methods for the analysis of CW EPR data rely on MD simulations of spin-labeled proteins. MD-SLE (Figure 2C) approach combines short MD simulations with solving the SLE to analyze CW EPR data (Budil et al., 2006; Stoica, 2004). Short MD trajectories corrected for translation and rotation of the protein are assumed to describe only spin label motion. Such trajectories serve as inputs for SLE-solving lineshape analysis. Combining MD-SLE with high-field CW EPR experiments, where protein motions are assumed frozen, further validates the separate treatment of protein and spin label dynamics (Barnes et al., 1999).
Two other approaches construct simplified models of the spin labels dynamics from short MD trajectories, namely hindered Brownian dynamics (MD-HBD, Figure 2C) and hidden Markov models (MD-HMM). These methods generate long-scale stochastic trajectories of spin label dynamics. Stochastic trajectories are then used to compute the trajectory of magnetization, also known as free-induction decay (FID). From the FID, the CW EPR spectrum is reconstructed via Fourier transform (Martin et al., 2019; Steinhoff and Hubbell, 1996; Beier and Steinhoff, 2006; White et al., 2007; Sezer et al., 2008a; Sezer et al., 2009). Besides MD-HBD and MD-HMM, there is also the Direct-MD approach (Figure 2C), which is becoming increasingly popular. It models the magnetization trajectory from longer MD trajectories of spin-labeled proteins without employing stochastic modeling of spin label dynamics (Martin et al., 2019; Oganesyan, 2011; Tyrrell and Oganesyan, 2013).
MD-HBD and MD-HMM have proven effective for calculating the CW EPR spectrum of small- and medium-sized proteins that adopt a single conformational state. However, modeling multiple conformations of large- and medium-sized proteins requires extensive MD simulations lasting several microseconds or longer. While this was still challenging a few years ago, the advent of GPU-based computing made such simulations available to a larger community. We suggest that MD-based approaches, which effectively sample the conformational states of spin labels, should be integrated with deep learning techniques, such as AlphaFold2, RoseTTAFold, or ESMFold (Jumper et al., 2021; Baek et al., 2021; Krishna et al., 2024; Jeliazkov et al., 2023), to enhance conformational sampling of proteins. Structural models of protein conformations produced by such neural networks should be validated and refined through replicas of MD simulations including spin labels and by comparison with experiments (Baek et al., 2021; Sala et al., 2023). To this end, the benefit of combining MD simulations with deep learning is twofold: providing experimentally validated all-atom structural information while assisting with the interpretation of complex CW EPR spectra.
Rosetta is a software toolbox with a wide range of applications, including molecular design, folding, docking, and modeling tools (Leman et al., 2020). Rosetta uses a library of protein fragments and employs Monte-Carlo assembly to construct structural models of protein conformations. These resulting models are then evaluated with a physics-based scoring function. RosettaNMR represents the first algorithms for the de novo prediction of protein structures, which integrated experimental NMR data. This was the basis for the development of the RosettaEPR. RosettaEPR integrates interspin distances into the modeling process, which are derived from exchange broadening via CW EPR of doubly spin-labeled protein (Alexander et al., 2008). The distance range accessible using this approach is limited to <~25 Å. Thus, it should be noted that each line-broadening analysis requires three CW EPR experiments. One experiment with the doubly spin-labeled mutant, and two experiments with each individual single mutant of the spin pair (Farrens et al., 1996; Rabenstein and Shin, 1995; Altenbach et al., 2001). In summary, RosettaEPR represents a computationally efficient approach for conformational modeling, which includes experimental data and does not require a structural template of the protein. However, in contrast to MD approaches, Rosetta does not allow for the observation of time-dependent conformational changes.
Integration of distance information derived from experimental DEER data
Pulsed dipolar spectroscopy (PDS) in combination with site-directed spin labeling (SDSL) gives access to distance distributions between two coupled spins. While several different PDS pulse sequences exist, the most commonly used method is 4-pulse deadtime-free DEER, for which recently application guidelines have been put forward (Pannier et al., 2000; Schiemann et al., 2021). Experimental DEER data consist of time-dependent spin echo intensities (dipolar evolution), which can be translated into interspin distance distributions. In addition to the dipolar interaction of intramolecular spins, DEER signals also contain intermolecular contributions (background), which must either be included in the analysis or subtracted a priori. Several different analysis methods have been developed, which are concisely reviewed in the following. A more detailed introduction including benchmark tests can be found elsewhere (Russell et al., 2022).
Model-free analysis
Model-free analysis of DEER data presents a mathematically ill-posed problem that is typically addressed by Tikhonov regularization which essentially smooths the distance distribution. Adequate smoothness is typically chosen via the L-curve criterion of the regularization parameter, but other methods such as the Akaike information criterion corrected or the Bayesian information criterion exist, and determine the level of detail observed in the analyzed distance distributions (Edwards and Stoll, 2018). While a minimum width of distance peaks makes physical sense, taking into account the conformational entropy of the labels and the protein, the assumption of equal widths for all distance peaks is inconsistent with the heterogeneous picture of a conformational state (Figure 1). The evaluation of populations, one of the main virtues of DEER, is complicated because it requires a posteriori fitting of the distance distribution to a linear combination of parametric distributions with quantifiable area, such as Gaussians.
Model-based analyses
Model-based analyses, such as Gaussian mixture models, assume that DEER distributions represent a superposition of individual distance peaks. Each peak has a specific shape that is described by parameters such as mean position, peak width, and amplitude. This approach dramatically reduces the number of fitting parameters during analysis and provides direct access to populations of individual peaks as well as confidence intervals of each fitting parameter. In addition, simultaneous (global) analysis of multiple DEER datasets of the same spin pair recorded under different conditions further increases the confidence in parameter values such as peak positions, populations, or background parameters (Hustedt et al., 2021; Jeschke et al., 2006; Khan et al., 2023).
Both Tikhonov regularization and parametric models are included in widely used software packages, such as the Python toolbox DEERlab or DeerAnalysis (Fábregas Ibáñez et al., 2020; Stein et al., 2015). More recently, DEER analysis methods using deep learning have been developed. These tools include neural networks trained on a large dataset of synthetic DEER data (Worswick et al., 2018) and show comparable or even improved reliability (Casiraghi et al., 2024). The most prominent example is DeerNet, which is included in the DeerAnalysis2022 and Spinach software packages (ETH Zurich, 2023; Hogben et al., 2011).
One main challenge in interpreting DEER results is peak assignment. In principle, each distance peak is due to a specific protein and label conformation. Thus, if a peak appears shifted, for example under altered ligand conditions, the origin of this shift could be due to a change of the protein or label conformation, or a combination of both. One way to tackle this problem is to select surface-exposed spin labeling sites. This way, when the protein changes conformation, the ensemble of spin label rotamers remains unaffected. Surface exposure can be verified using CW EPR as the lineshape provides a sensitive monitor of spin label dynamics. Once this condition is met, the DEER analysis can be reduced to conformational states and populations of the protein, thus directly linking protein structure and thermodynamics.
PDS methods such as DEER depend on two paramagnetic centers being in proximity, and thus can be used to evaluate and characterize protein oligomerization. Studies evaluating the monomer/dimer equilibrium, the dimer architecture, and functionality have been conducted all of which utilizing distance information and modulation depth parameters obtained from DEER experiments (Hilger et al., 2005; Bergdoll et al., 2018; Pliotas et al., 2012). In cases when more than two spins are present per nano-object, data analysis needs to be amended by power scaling to avoid artificial ‘ghost distances’ (Evans et al., 2020; von Hagens et al., 2013; Khan et al., 2023).
Notably, membrane proteins are commonly investigated in a detergent solubilized form to prevent oligomer formation. Generally, the different properties of detergent and lipid molecules lead to altered spin label dynamics which are easily picked up by CW EPR (Flores Jiménez et al., 2011). Interestingly, the changed label dynamics do not lead to dramatic structural alterations and the DEER distances in different systems are often quite similar. Obviously, this is not necessarily true for the position of conformational equilibria, which are often sensitive to the environmental parameters such as lipid or detergent composition (Van Eps et al., 2017).
Methods for simultaneous modeling of protein and spin label dynamics
Several molecular modeling techniques have been developed to simulate the dynamics of proteins and spin labels. They provide atomistic models of protein conformations that can explain sparse DEER experimental data. Molecular modeling approaches simulate protein and spin labels either simultaneously (combining approaches) or separately (discriminating approaches).
Most combining approaches (Figure 3B), such as restrained-ensemble MD (reMD), ensemble-biased metadynamics (EBMetaD), and bias-resampling ensemble refinement (BRER), steer MD simulations of spin-labeled proteins toward a conformational ensemble that accurately reproduces the experimental interspin distance distributions. This is achieved by introducing a scalable bias potential into the modeling system. The addition of a bias potential by these three approaches is based on the principle of maximum entropy. This principle implies the addition of a minimal bias to the MD simulation that is capable of bringing the modeled ensemble into agreement with the experiment (Pitera and Chodera, 2012). Biased MD simulations can use both full-atom and simplified (dummy) representations of spin labels (Figure 3A). In addition, in certain cases, such as distances between rigid spin labels, it may be feasible to simplify the system by modeling the unlabeled protein and replacing interspin distances with distances between Cβ or C⍺ atoms (Hays et al., 2019).
Figure 3
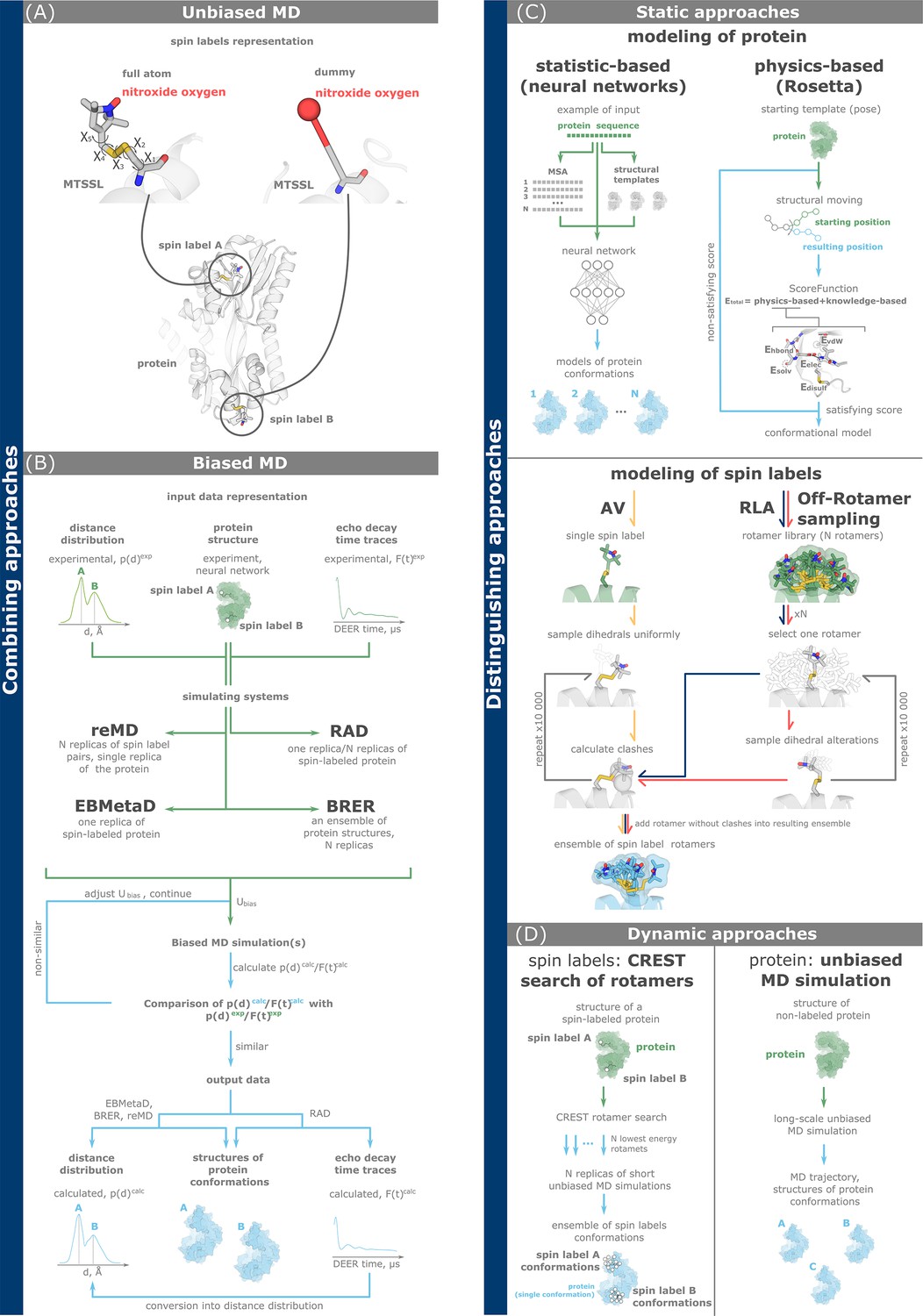
Computational methods for double electron–electron resonance (DEER) data analysis and integration.
(A, B) Combining approaches simultaneously model the dynamics of both a protein and spin labels. Full-atom and dummy representations of spin labels are possible. (C, D) Discriminating approaches investigate conformations of a protein and spin labels separately. (A) Unbiased molecular dynamics (MD) simulations of a spin-labeled protein. (B) Biased MD approaches add biasing potential to the simulating system according to the principle of maximum entropy. The potential is gradually adjusted based on the degree of agreement between simulated and experimental data, including distance distributions (reMD, EBMetaD, and BRER) and echo decay time traces (restrained average dynamics, RAD). (C) Static approaches explore the conformations of either proteins (top) using statistical and physics-based methods, or spin labels (bottom) using accessible volume (AV, yellow arrows), rotamer library approach (RLA, dark blue arrows), and off-rotamer sampling (red arrows). (D) Dynamic discriminating approaches use MD-based techniques to investigate the conformational landscapes of either spin labels (left, CREST/MD) or a protein (right, unbiased MD). In the latter case, both full-atom and coarse-grained representations of the protein are possible.
ReMD (Figure 3B) performs a user-defined number of simulation replicas for the spin labels, while the rest of the system, including protein and solvent, is modeled only once. This method operates with a global bias potential that is distributed across all modeling replicas (Roux and Islam, 2013; Islam et al., 2013; Islam and Roux, 2015). In contrast, EBMetaD is a single-replica metadynamics-based approach designed to bias a user-defined variable, such as an interatomic distance, by incorporating an adjustable bias potential (Marinelli and Faraldo-Gómez, 2015; Hustedt et al., 2018). BRER simulates multiple replicas of the biased MD to adjust the ensemble distribution of a particular geometric property (e.g., interspin distance) to match the experimentally derived data (Hays et al., 2019). The restrained average dynamics (RAD) technique (Figure 3B) also follows the principle of maximum entropy. A key difference between RAD and reMD, EBMetaD or BRER is that MD simulations are directly driven by raw dipolar evolutions rather than distance distributions (Marinelli and Fiorin, 2019). In particular, RAD can model both single and multiple MD simulation replicas.
Choosing a meaningful and effective bias potential, and analyzing biased MD simulations requires experience. Users with less experience in performing MD simulations with non-standard potentials may opt for unbiased MD methods instead (Figure 3A).
In principle, unbiased MD simulations (Figure 3A), can provide a representation of all protein conformations within the ensemble. Quantification of the individual conformations corresponding to the equilibrium populations in an experiment is difficult to access, especially for slow conformational transitions (Grossfield and Zuckerman, 2009; Sawle and Ghosh, 2016). Similar to biased MD simulations, both full-atom and dummy spin label representations are viable options for unbiased MD simulations (Islam et al., 2013). Unbiased MD simulations require more computational time than biased ones to overcome energy barriers between conformations (Figure 1). To enhance conformational sampling in unbiased MD simulations, multiple replicas starting from different geometries of both the protein and spin labels can be used. Another strategy is to implement different initial velocities in multiple MD replicas (Rice and Brünger, 1994).
To set up a molecular model for conducting biased or unbiased MD simulations, including all-atom or dummy description of spin labels, we recommend the Charmm-GUI module called PDB Manipulator (Jo et al., 2014). In addition, the Charmm-GUI offers many options for constructing and parameterizing membrane proteins such as receptors and transporters in various lipid systems. Lipid mono- and bilayers, nanodiscs, micelles and bicelles, lipid hexagonal phase systems, are available. In each case, the lipid composition is customizable (Feng et al., 2023; Qi et al., 2019; Brown et al., 2024).
Methods for separate modeling of protein and spin label dynamics
Discriminating approaches model protein and spin label conformations independently using different methods. We divide discriminating approaches into static (Figure 3C) and dynamic ones (Figure 3D).
Static approaches (Figure 3C) rely on statistical data or physical knowledge to model new variants of molecular geometry and evaluate their reliability (score). Static approaches to modeling spin label conformations work with their full-atom representations during the sampling process. The rotamers of spin labels in the resulting sampled set can be represented by dummy or coarse-grained (CG) models. Static approaches to modeling spin labels include the rotamer library approach (RLA) with its modification called off-rotamer sampling, and the Monte-Carlo accessible volume (AV) sampling (Tessmer et al., 2022). Both RLA and off-rotamer sampling work with a pre-calculated rotamer library, while AV starts with a single spin label structure. In all three approaches, spin label structures are virtually attached to specific labeling sites on the protein structure. The crucial step is the selection of spin label conformations that do not lead to steric clashes (overlapping van der Waals radii) with protein atoms. The main result of all three methods is the ensemble of spin label conformations that can be reliably accommodated at selected label sites. The RLA approach is implemented in the MMM and RosettaEPR programs, and in Python packages such as DEER-PREdict and chiLife (Jeschke, 2018; Alexander et al., 2013; Tesei et al., 2021; Tessmer and Stoll, 2023). AV is implemented in MtsslWizard, mtsslSuite, PRONOX software, and chiLife (Tessmer and Stoll, 2023; Hagelueken et al., 2012; Hagelueken et al., 2013; Hatmal et al., 2012).
Static approaches to modeling protein conformations include statistics-based approaches (neural networks) and a physics-based approach. Neural networks for modeling protein conformations, such as AlphaFold3, AlphaFold2, RoseTTAFold2, ESMFold, OmegaFold, and EquiFold are becoming increasingly popular (Jumper et al., 2021; Jeliazkov et al., 2023; Abramson et al., 2024; Baek et al., 2023; Wu et al., 2022). The main reason is that neural networks allow the rapid generation of multiple and diverse conformational models in a short time. However, currently developed neural networks are not necessarily consistent with the laws of physics (Baek and Baker, 2022). Therefore, the results should be further refined using physics-based approaches, such as MD simulations, a dynamic approach that will be considered further, or the static approach implemented in the Rosetta toolkit (Leman et al., 2020). Rosetta’s scoring function includes physics-based terms that ensure that the modeled conformations would better reproduce the real geometries. Protein conformations obtained by modeling with Rosetta can be integrated with the RLA approach for modeling spin label conformations described above. Note RosettaDEER, which uses a dummy representation of the rotamer library in its pipeline for efficient modeling of spin-labeled protein conformations in agreement with experimental data (Del Alamo et al., 2021).
Dynamic discriminating approaches combine methods that use MD simulations to explore the conformations of either the spin label or the protein (Figure 3D). One such technique for effectively modeling spin label conformations is CREST/MD. In a first step, the CREST software samples low-energy conformations of spin labels attached to the specific sites of the protein (Spicher et al., 2020; Pracht et al., 2020). It then performs multiple replicas of short equilibrating MD simulations of the protein labeled with the previously selected lowest energy spin label conformations. In this way, CREST/MD efficiently explores the conformational space of spin labels. Another group of dynamic discriminating approaches performs long MD simulations of an unlabeled protein. To enhance conformational sampling, simplified CG protein models with appropriate modeling parameters (force fields) can be used. In CG models, only a few particles represent each amino acid residue of the protein, which reduces the computational cost but also reduces the accuracy of the calculations (Monticelli et al., 2008). Modern CG force fields such as Martini 3 and SIRAH do not include parameters for spin labels (Souza et al., 2021; Klein et al., 2023). Thus, the simulation frames of the resulting MD trajectories must be supplemented with, for instance, the RLA approach to attach realistic spin label rotamers. Subsequently, spin–spin distances are calculated, and the resulting distributions are compared with the DEER experiment (Wingler et al., 2019).
Outlook
Distance distributions are the easiest way to integrate sparse EPR data into computational structural biology. Such distributions can be derived from different EPR approaches, in particular CW EPR line-broadening or PDS such as DEER, and compared directly with MD simulations. In this way, MD trajectories can provide us with atomistic structures and dynamics of protein conformations observed in experiment.
There are two major challenges in performing such MD simulations. First, as shown in Figure 1, protein conformations are often separated by high energy barriers, resulting in slow (µs to ms) transitions. This leads to high computational costs and very long simulation times (often weeks or months even on supercomputers), especially for unbiased MD simulations. The second challenge is to obtain reliable simulation parameters (force fields) for the attached spin labels. Force field parameterization is an active area of research with no general solutions yet. Existing tools may not be suitable for a particular task or may be closed source (Jo et al., 2014; Boothroyd et al., 2023). To address the first challenge, we propose to combine MD tools with deep learning approaches. Neural networks can provide a diverse set of protein conformations that serve as starting points for multiple independent and shorter MD replicas. This may improve the efficiency of conformational landscape sampling. The second challenge can be addressed in two ways: either by avoiding the need for parameterization altogether by using discriminating approaches (Figure 3C, D), or by exploring the literature-validated parameters of spin labels. Parameters exist for spin labels such as MTSSL, PROXYL-MTS, BtnRG-TP, Cu2+-nitrilotriacetic, and Cu2+-iminodiacetic acid (Sezer et al., 2008b; Qi et al., 2020; Bogetti et al., 2020). Alternatively, the parameters for the attached spin labels can be determined independently. In this case, special attention should be paid to the calculation of atomic charges (He et al., 2022). We propose the idea of a database of spin label parameters, compatible with commonly used force fields for proteins, and freely available to the research community.
An alternative method for modeling protein conformations uses DEER distances to guide the modeling process. Here, we refer here to rapidly developing deep learning methods, such as AlphaLink and AFEXplorer, which are capable of incorporating experimentally derived geometric constraints directly into the workflow (Stahl et al., 2023; Xie et al., 2023). Although originally developed for photo-crosslinking mass spectrometry data, AlphaLink can be adapted to DEER distance distributions as descriptors. Such neural networks sample the conformational landscape very efficiently, easily generating hundreds or more models. It is imperative to validate such conformational models using physics-based methods such as MD simulations.
Currently, the only method available to integrate CW EPR data with molecular modeling techniques is RosettaEPR (Alexander et al., 2008). It combines the results of EPR experiments performed on two single cysteine mutants and one double cysteine mutant to calculate interspin distance distributions. The main advantage of this approach is its applicability to physiologically relevant temperatures. Computational approaches that integrate the dynamic information encoded in CW EPR lineshapes with structural biology are still lacking. We suggest that data such as the Heisenberg exchange rate or heuristic accessibility (Altenbach et al., 1989; Altenbach et al., 2005) could be converted to accessible surface area, which then can be used as a sparse descriptor to bias deep learning methods such as AlphaFold3, AlphaFold2, RoseTTAFold2, and ESMFold (Jumper et al., 2021; Jeliazkov et al., 2023; Abramson et al., 2024; Baek et al., 2023). Another possible application of experimental CW EPR data is the filtering and validation of structural models predicted by neural networks or observed in MD simulations (Baek and Baker, 2022).
In summary, we highlight the potential applications of using sparse EPR data for atomistic modeling of protein conformations. We hope that this concise and high-level introduction to the field of integrative modeling using EPR constraints will help interested researchers from other research areas to incorporate these methods into their own research and further advance the field.
References
-
Using simulation to interpret experimental data in terms of protein conformational ensemblesCurrent Opinion in Structural Biology 43:79–87.https://doi.org/10.1016/j.sbi.2016.11.018
-
Analyzing CW EPR spectra of nitroxide labeled macromoleculesApplied Magnetic Resonance 55:159–186.https://doi.org/10.1007/s00723-023-01610-2
-
Deep learning and protein structure modelingNature Methods 19:13–14.https://doi.org/10.1038/s41592-021-01360-8
-
A multifrequency electron spin resonance study of T4 lysozyme dynamicsBiophysical Journal 76:3298–3306.https://doi.org/10.1016/S0006-3495(99)77482-5
-
Extending the range of distances accessible by 19F electron-nuclear double resonance in proteins using high-spin Gd(III) labelsJournal of the American Chemical Society 146:6157–6167.https://doi.org/10.1021/jacs.3c13745
-
The promise of cryo-EM to explore RNA structural dynamicsJournal of Molecular Biology 434:167802.https://doi.org/10.1016/j.jmb.2022.167802
-
Development and benchmarking of open force field 2.0.0: The sage small molecule force fieldJournal of Chemical Theory and Computation 19:3251–3275.https://doi.org/10.1021/acs.jctc.3c00039
-
CHARMM GUI membrane builder for oxidized phospholipid membrane modeling and simulationCurrent Opinion in Structural Biology 86:102813.https://doi.org/10.1016/j.sbi.2024.102813
-
Nonlinear-least-squares analysis of slow-motion EPR spectra in one and two dimensions using a modified levenberg–marquardt algorithmJournal of Magnetic Resonance, Series A 120:155–189.https://doi.org/10.1006/jmra.1996.0113
-
Calculating slow-motional electron paramagnetic resonance spectra from molecular dynamics using a diffusion operator approachThe Journal of Physical Chemistry. A 110:3703–3713.https://doi.org/10.1021/jp054738k
-
Comparing the structural dynamics of the human KCNE3 in reconstituted micelle and lipid bilayered vesicle environmentsBiochimica et Biophysica Acta. Biomembranes 1864:183974.https://doi.org/10.1016/j.bbamem.2022.183974
-
Overcoming the challenges of membrane protein crystallographyCurrent Opinion in Structural Biology 18:581–586.https://doi.org/10.1016/j.sbi.2008.07.001
-
A new spin on protein dynamicsTrends in Biochemical Sciences 27:288–295.https://doi.org/10.1016/S0968-0004(02)02095-9
-
Use of 19F NMR to probe protein structure and conformational changesAnnual Review of Biophysics and Biomolecular Structure 25:163–195.https://doi.org/10.1146/annurev.bb.25.060196.001115
-
Integrating an enhanced sampling method and small-angle x-ray scattering to study intrinsically disordered proteinsFrontiers in Molecular Biosciences 8:621128.https://doi.org/10.3389/fmolb.2021.621128
-
Optimal Tikhonov regularization for DEER spectroscopyJournal of Magnetic Resonance 288:58–68.https://doi.org/10.1016/j.jmr.2018.01.021
-
CHARMM-GUI: Past, current, and future developments and applicationsJournal of Chemical Theory and Computation 19:2161–2185.https://doi.org/10.1021/acs.jctc.2c01246
-
Tau-cofactor complexes as building blocks of tau fibrilsFrontiers in Neuroscience 13:1339.https://doi.org/10.3389/fnins.2019.01339
-
New developments in spin labels for pulsed dipolar EPRMolecules 19:16998–17025.https://doi.org/10.3390/molecules191016998
-
Lipid and membrane mimetic environments modulate spin label side chain configuration in the outer membrane protein AThe Journal of Physical Chemistry B 115:14822–14830.https://doi.org/10.1021/jp207420d
-
Probing protein secondary structure using epr: Investigating a dynamic region of visual arrestinApplied Magnetic Resonance 43:405–419.https://doi.org/10.1007/s00723-012-0369-y
-
The energy landscapes and motions of proteinsScience 254:1598–1603.https://doi.org/10.1126/science.1749933
-
BookTheory of slow tumbling ESR spectra for nitroxidesIn: Freed JH, editors. In Spin Labeling Theory and Applications. New York: Academic Press. pp. 53–132.https://doi.org/10.1016/B978-0-12-092350-2.50008-4
-
Conformational exchange in a membrane transport protein is altered in protein crystalsBiophysical Journal 99:1604–1610.https://doi.org/10.1016/j.bpj.2010.06.026
-
Quantifying uncertainty and sampling quality in biomolecular simulationsAnnual Reports in Computational Chemistry 5:23–48.https://doi.org/10.1016/S1574-1400(09)00502-7
-
MtsslWizard: In Silico spin-labeling and generation of distance distributions in PyMOLApplied Magnetic Resonance 42:377–391.https://doi.org/10.1007/s00723-012-0314-0
-
Hybrid refinement of heterogeneous conformational ensembles using spectroscopic dataThe Journal of Physical Chemistry Letters 10:3410–3414.https://doi.org/10.1021/acs.jpclett.9b01407
-
Recent progress in general force fields of small moleculesCurrent Opinion in Structural Biology 72:187–193.https://doi.org/10.1016/j.sbi.2021.11.011
-
Spinach – A software library for simulation of spin dynamics in large spin systemsJournal of Magnetic Resonance 208:179–194.https://doi.org/10.1016/j.jmr.2010.11.008
-
Molecular motion in spin-labeled phospholipids and membranesJournal of the American Chemical Society 93:314–326.https://doi.org/10.1021/ja00731a005
-
BookSite-directed spin labeling of membrane proteinsIn: Hubbell WL, editors. In Membrane Protein Structure. New York: Springer. pp. 224–248.
-
Protein functional dynamics from the rigorous global analysis of DEER data: Conditions, components, and conformationsThe Journal of General Physiology 153:e201711954.https://doi.org/10.1085/jgp.201711954
-
Very slowly tumbling spin labels: Adiabatic rapid passageChemical Physics Letters 16:568–572.https://doi.org/10.1016/0009-2614(72)80426-3
-
New EPR methods for the study of very slow motion: Application to spin-labeled hemoglobinAnnals of the New York Academy of Sciences 222:680–692.https://doi.org/10.1111/j.1749-6632.1973.tb15295.x
-
Structural refinement from restrained-ensemble simulations based on EPR/DEER data: Application to T4 lysozymeThe Journal of Physical Chemistry. B 117:4740–4754.https://doi.org/10.1021/jp311723a
-
Simulating the distance distribution between spin-labels attached to proteinsThe Journal of Physical Chemistry. B 119:3901–3911.https://doi.org/10.1021/jp510745d
-
Ultrafast bioorthogonal spin-labeling and distance measurements in mammalian cells using small, genetically encoded Tetrazine Amino acidsJournal of the American Chemical Society 145:14608–14620.https://doi.org/10.1021/jacs.3c00967
-
DeerAnalysis2006—a comprehensive software package for analyzing pulsed ELDOR dataApplied Magnetic Resonance 30:473–498.https://doi.org/10.1007/BF03166213
-
DEER distance measurements on proteinsAnnual Review of Physical Chemistry 63:419–446.https://doi.org/10.1146/annurev-physchem-032511-143716
-
MMM: A toolbox for integrative structure modelingProtein Science 27:76–85.https://doi.org/10.1002/pro.3269
-
CHARMM-GUI PDB manipulator for advanced modeling and simulations of proteins containing nonstandard residuesAdvances in Protein Chemistry and Structural Biology 96:235–265.https://doi.org/10.1016/bs.apcsb.2014.06.002
-
NMR studies of membrane proteinsJournal of Biomolecular NMR 61:181–184.https://doi.org/10.1007/s10858-015-9918-7
-
Molecular dynamics simulations of biomoleculesNature Structural Biology 9:646–652.https://doi.org/10.1038/nsb0902-646
-
Determining membrane protein structures: Still a challenge!Trends in Biochemical Sciences 32:259–270.https://doi.org/10.1016/j.tibs.2007.04.001
-
Electronic structure of neutral tryptophan radicals in ribonucleotide reductase studied by EPR and ENDOR spectroscopyJournal of the American Chemical Society 118:8111–8120.https://doi.org/10.1021/ja960917r
-
A global minimization toolkit for batch-fitting and χ2 cluster analysis of CW-EPR spectraBiophysical Journal 119:1937–1945.https://doi.org/10.1016/j.bpj.2020.08.042
-
Radicals, radical pairs and triplet states in photosynthesisAccounts of Chemical Research 35:313–320.https://doi.org/10.1021/ar000084g
-
Electron spin resonance: Spin labelsMolecular Biology, Biochemistry, and Biophysics 31:51–142.https://doi.org/10.1007/978-3-642-81537-9_2
-
Trajectory-based simulation of epr spectra: Models of rotational motion for spin labels on proteinsThe Journal of Physical Chemistry. B 123:10131–10141.https://doi.org/10.1021/acs.jpcb.9b02693
-
Motion of spin-labeled side chains in T4 lysozymeCorrelation with Protein Structure and Dynamics. Biochemistry 35:7692–7704.https://doi.org/10.1021/bi960482k
-
Cryo-temperature effects on membrane protein structure and dynamicsPhysical Chemistry Chemical Physics 22:5427–5438.https://doi.org/10.1039/c9cp06723j
-
Analysis of protein-lipid interactions based on model simulations of electron spin resonance spectraThe Journal of Physical Chemistry 88:3454–3465.https://doi.org/10.1021/j150660a018
-
19F electron-nuclear double resonance reveals interaction between redox-active tyrosines across the α/β interface of E. coli ribonucleotide reductaseJournal of the American Chemical Society 144:11270–11282.https://doi.org/10.1021/jacs.2c02906
-
The MARTINI coarse-grained force field: Extension to proteinsJournal of Chemical Theory and Computation 4:819–834.https://doi.org/10.1021/ct700324x
-
A general approach for prediction of motional EPR spectra from Molecular Dynamics (MD) simulations: Application to spin labelled proteinPhysical Chemistry Chemical Physics 13:4724–4737.https://doi.org/10.1039/c0cp01068e
-
Structure determination of membrane proteins by NMR spectroscopyChemical Reviews 104:3587–3606.https://doi.org/10.1021/cr0304121
-
Dead-time free measurement of dipole-dipole interactions between electron spinsJournal of Magnetic Resonance 142:331–340.https://doi.org/10.1006/jmre.1999.1944
-
On the use of experimental observations to bias simulated ensemblesJournal of Chemical Theory and Computation 8:3445–3451.https://doi.org/10.1021/ct300112v
-
Automated exploration of the low-energy chemical space with fast quantum chemical methodsPhysical Chemistry Chemical Physics 22:7169–7192.https://doi.org/10.1039/c9cp06869d
-
Discerning conformational dynamics and binding kinetics of GPCRs by 19F NMRCurrent Opinion in Pharmacology 72:102377.https://doi.org/10.1016/j.coph.2023.102377
-
CHARMM‐GUI Nanodisc Builder for modeling and simulation of various nanodisc systemsJournal of Computational Chemistry 40:893–899.https://doi.org/10.1002/jcc.25773
-
CHARMM-GUI DEER facilitator for spin-pair distance distribution calculations and preparation of restrained-ensemble molecular dynamics simulationsJournal of Computational Chemistry 41:415–420.https://doi.org/10.1002/jcc.26032
-
Restrained-ensemble molecular dynamics simulations based on distance histograms from double electron-electron resonance spectroscopyThe Journal of Physical Chemistry. B 117:4733–4739.https://doi.org/10.1021/jp3110369
-
DEER data analysis software: A comparative guideFrontiers in Molecular Biosciences 9:915167.https://doi.org/10.3389/fmolb.2022.915167
-
Modeling conformational states of proteins with AlphaFoldCurrent Opinion in Structural Biology 81:102645.https://doi.org/10.1016/j.sbi.2023.102645
-
Demonstration of short-lived complexes of cytochrome c with cytochrome bc1 by EPR spectroscopy: implications for the mechanism of interprotein electron transferThe Journal of Biological Chemistry 283:24826–24836.https://doi.org/10.1074/jbc.M802174200
-
Convergence of molecular dynamics simulation of protein native states: Feasibility vs self-consistency ilemmaJournal of Chemical Theory and Computation 12:861–869.https://doi.org/10.1021/acs.jctc.5b00999
-
Benchmark test and guidelines for DEER/PELDOR experiments on nitroxide-labeled biomoleculesJournal of the American Chemical Society 143:17875–17890.https://doi.org/10.1021/jacs.1c07371
-
cwepr - A Python package for analysing cw-EPR data focussing on reproducibility and simple usageJournal of Magnetic Resonance 335:107140.https://doi.org/10.1016/j.jmr.2021.107140
-
Membrane topology of microsomal cytochrome P-450: saturation transfer EPR and freeze-fracture electron microscopy studiesBiochemical and Biophysical Research Communications 171:175–181.https://doi.org/10.1016/0006-291x(90)91373-z
-
Parametrization, molecular dynamics simulation, and calculation of electron spin resonance spectra of a nitroxide spin label on a polyalanine alpha-helixThe Journal of Physical Chemistry. B 112:5755–5767.https://doi.org/10.1021/jp711375x
-
Using Markov models to simulate electron spin resonance spectra from molecular dynamics trajectoriesThe Journal of Physical Chemistry. B 112:11014–11027.https://doi.org/10.1021/jp801608v
-
Multifrequency electron spin resonance spectra of a spin-labeled protein calculated from molecular dynamics simulationsJournal of the American Chemical Society 131:2597–2605.https://doi.org/10.1021/ja8073819
-
Quantifying nucleic acid ensembles with X-ray scattering interferometryMethods in Enzymology 558:75–97.https://doi.org/10.1016/bs.mie.2015.02.001
-
Modeling of spin-spin distance distributions for nitroxide labeled biomacromoleculesPhysical Chemistry Chemical Physics 22:24282–24290.https://doi.org/10.1039/d0cp04920d
-
A straightforward approach to the analysis of double electron-electron resonance dataMethods in Enzymology 563:531–567.https://doi.org/10.1016/bs.mie.2015.07.031
-
Using molecular dynamics to simulate electronic spin resonance spectra of T4 lysozymeThe Journal of Physical Chemistry B 108:1771–1782.https://doi.org/10.1021/jp036121d
-
EasySpin, a comprehensive software package for spectral simulation and analysis in EPRJournal of Magnetic Resonance 178:42–55.https://doi.org/10.1016/j.jmr.2005.08.013
-
Studying lipid organization in biological membranes using liposomes and EPR spin labelingMethods in Molecular Biology 606:247–269.https://doi.org/10.1007/978-1-60761-447-0_18
-
Comparative evaluation of spin-label modeling methods for protein structural studiesBiophysical Journal 121:3508–3519.https://doi.org/10.1016/j.bpj.2022.08.002
-
chiLife: An open-source Python package for in silico spin labeling and integrative protein modelingPLOS Computational Biology 19:e1010834.https://doi.org/10.1371/journal.pcbi.1010834
-
Nitroxide spin labels and EPR spectroscopy: A powerful association for protein dynamics studiesBiochimica et Biophysica Acta (BBA) - Proteins and Proteomics 1869:140653.https://doi.org/10.1016/j.bbapap.2021.140653
-
Microheterogeneity in frozen protein solutionsInternational Journal of Pharmaceutics 487:91–100.https://doi.org/10.1016/j.ijpharm.2015.04.032
-
Simulation of electron paramagnetic resonance spectra of spin-labeled molecules from replica-exchange molecular dynamicsPhysical Review. E, Statistical, Nonlinear, and Soft Matter Physics 88:042701.https://doi.org/10.1103/PhysRevE.88.042701
-
Suppression of ghost distances in multiple-spin double electron-electron resonancePhysical Chemistry Chemical Physics 15:5854–5866.https://doi.org/10.1039/c3cp44462g
-
The electronic structure of the flavin cofactor in DNA photolyaseJournal of the American Chemical Society 123:3790–3798.https://doi.org/10.1021/ja003426m
-
Analysis of nitroxide spin label motion in a protein-protein complex using multiple frequency EPR spectroscopyJournal of Magnetic Resonance 185:191–203.https://doi.org/10.1016/j.jmr.2006.12.009
-
Deep neural network processing of DEER dataScience Advances 4:eaat5218.https://doi.org/10.1126/sciadv.aat5218
Article and author information
Author details
Funding
Deutsche Forschungsgemeinschaft (SFB 1423 #421152132)
- Matthias Elgeti
Bundesministerium für Bildung und Forschung (SECAI 57616814)
- Julia Belyaeva
Deutsche Forschungsgemeinschaft (TRR386 #514664767)
- Matthias Elgeti
The funders had no role in study design, data collection, and interpretation, or the decision to submit the work for publication.
Acknowledgements
The authors thank Dilara Öğütcü, Alexander Zlobin, and Mahdi Bagherpoor Helabad for helpful discussions.
Copyright
© 2024, Belyaeva and Elgeti
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 905
- views
-
- 104
- downloads
-
- 5
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 5
- citations for umbrella DOI https://doi.org/10.7554/eLife.99770
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Exploring protein structural ensembles: Integration of sparse experimental data from electron paramagnetic resonance spectroscopy with molecular modeling methods
eLife 13:e99770.
https://doi.org/10.7554/eLife.99770




{kind=link}
{kind=link}
{kind=link}