Global mapping of highly pathogenic avian influenza H5N1 and H5Nx clade 2.3.4.4 viruses with spatial cross-validation
- Université Libre de Bruxelles, Belgium
- Government of Haryana, India
- International Livestock Research Institute, Kenya
- Université de Namur, Belgium
- Swiss Institute of Bioinformatics, Switzerland
- University of Lausanne, Switzerland
- University of Oklahoma, United States
- Fudan University, China
- Food and Agriculture Organization of the United Nations, Italy
- FAO Regional Office for Asia and the Pacific, Thailand
- Food and Agriculture Organization of the United Nations, Vietnam
- Fonds National de la Recherche Scientifique, Belgium
Abstract
Global disease suitability models are essential tools to inform surveillance systems and enable early detection. We present the first global suitability model of highly pathogenic avian influenza (HPAI) H5N1 and demonstrate that reliable predictions can be obtained at global scale. Best predictions are obtained using spatial predictor variables describing host distributions, rather than land use or eco-climatic spatial predictor variables, with a strong association with domestic duck and extensively raised chicken densities. Our results also support a more systematic use of spatial cross-validation in large-scale disease suitability modelling compared to standard random cross-validation that can lead to unreliable measure of extrapolation accuracy. A global suitability model of the H5 clade 2.3.4.4 viruses, a group of viruses that recently spread extensively in Asia and the US, shows in comparison a lower spatial extrapolation capacity than the HPAI H5N1 models, with a stronger association with intensively raised chicken densities and anthropogenic factors.
https://doi.org/10.7554/eLife.19571.001Introduction
In 1996, highly pathogenic avian influenza of subtype H5N1 gave rise to the progenitor of the present H5N1 HPAI subtype in Guangdong, China (A/Goose/Guangdong/1/96[H5N1]) (Duan et al., 2007). Initially, restricted to Southern China, the virus started spreading in 2003 and by 2008, it had spread to more than 60 countries (Food and Agriculture Organization of the United Nations, 2016), persisting now in only a few. Transmission of infection from birds to humans was also reported, causing disease in 850 confirmed human cases including 449 deaths, as of May 2016, making this virus a continuing source of human health concerns (WHO/GIP, 2016; Lai et al., 2016). Re-assortment with other influenza viruses led to the replacement of most internal viral genes of the original H5N1 virus. However, the haemagglutinin (HA) gene H5 has remained present in all isolates and was therefore used to develop a standardised ‘clade’ nomenclature, first adopted in 2008, based on the evolution and divergence of H5N1 viruses that evolved from the original HA gene of the 1996 H5N1 virus (WHO/OIE/FAO H5N1 Evolution Working Group, 2008). In the initial years from 1996 to 2008, 10 distinct clades (0–9) had been generated and by 2012, 11 distinct actively circulating clades had been identified (World Health Organization/World Organisation for Animal Health/Food and Agriculture Organization (WHO/OIE/FAO) H5N1 Evolution Working Group, 2014).
Between 2009 and 2013, H5Nx HPAI viruses from the clade 2.3.4 showed an apparent geographical range expansion and were not only of the H5N1 subtype. Continuous live-poultry market surveillance in China identified novel clade 2.3.4 reassortant viruses of different H5N2, H5N5 and H5N8 subtypes, alongside H5N1 (Gu et al., 2011; Zhao et al., 2012, 2013). All these viruses were part of an H5 monophyletic group of viruses that shared the H5 gene of an H5N1 clade 2.3.4 variant with neuraminidase (NA) genes from different viruses (Gu et al., 2013). Consequently, the nomenclature of H5Nx viruses that clustered in this divergent HA group was updated as a new clade 2.3.4.4, in addition to two other new clades (Smith and Donis, 2015). From January 2014 onward, viruses of clade 2.3.4.4 started spreading internationally. The first H5N8 HPAI virus outbreaks outside of China were reported in South Korea and Japan in spring 2014 (Hill et al., 2015). In May 2014, a novel H5N6 clade 2.3.4.4 reassortant caused outbreaks in China and Lao PDR (Wong et al., 2015) and thereafter from Viet Nam and Myanmar. In November 2014, H5N8 HPAI viruses were reported from Germany, Netherlands, UK, Italy and the Russian Federation in rapid succession. In the same autumn and winter 2014/2015, H5N2 HPAI were reported from outbreaks in British Colombia, Canada. This virus contained genes similar to those of the Eurasian clade 2.3.4.4 alongside genes from North American wild bird lineages (World Organisation for Animal Health, 2016 ). In Taiwan, novel (H5N2, H5N3) reassortants also caused several outbreaks in 2014 (Lee et al., 2016). In December 2014, the new H5N8 and H5N2 HPAI viruses were detected in wild birds in Washington USA, before being found in poultry. By February 2015, the H5N2 HPAI virus had triggered a true epidemic in commercial poultry in the US, with nearly 43 million chickens and 7 million turkeys killed or culled across more than 20 different states (Poultry Science Association, 2016). All these HPAI H5N1, H5N2, H5N6 and H5N8 viruses found in Eurasia and North America shared an H5 gene segment belonging to clade 2.3.4.4 (Claes et al., 2014; Food and Agriculture Organization of the United Nations, 2016).
In summary, we can describe two periods and groups of viruses. From 2003 to 2010, the H5 HPAI viruses responsible for international spread and most outbreaks in poultry were of the N1 type, with continuous evolution of the H genes into different sub-lineages and gradual changes in its internal genes yielding clades and sub clades. From 2010 onward, H5Nx clade 2.3.4 viruses reassorted with several other avian influenza viruses leading to generation of a diversity of H5 clade 2.3.4.4 viruses bearing NA other than N1 in Asia. These novel reassortant viruses then began spreading internationally in 2013, in some cases further reassorting with viruses from other geographic lineages to yield new viruses, all bearing an H5 clade 2.3.4.4 haemagglutinin.
Following the spatio-temporal pattern of H5N1 HPAI spread, several spatial analytical studies were conducted to identify risk factors associated with H5N1 HPAI presence. The majority of these have been country-level studies in Thailand (Gilbert et al., 2006), Viet Nam (Minh et al., 2009), China (Martin et al., 2011), Bangladesh (Ahmed et al., 2012), Indonesia (Yupiana et al., 2010) and India (Dhingra et al., 2014). Several studies have also been conducted at regional (Adhikari D, 2009; Gilbert et al., 2008; Williams and Peterson, 2009) and continental levels (Hogerwerf et al., 2010; Peterson and Williams, 2008). Spatial risk factors associated with H5N1 HPAI presence through different studies were reviewed in 2012 (Gilbert and Pfeiffer, 2012) and the study highlighted domestic duck density, indices of water presence (distance to rivers and proportion of land occupied by water) and anthropogenic variables (human population density and distance to roads) to be the most consistent risk factors across studies, countries and scales. However, studies comparing different sets of factors were never carried out at a global scale, and none made a distinction between clades and sub-lineages.
In this analysis, we aimed to produce a first global suitability map for H5N1 HPAI virus sustained transmission, to establish its capacity to provide reliable spatial extrapolations at large spatial scales and to compare different sets of spatial predictor variables in their predictive capacity. Machine learning techniques have become very powerful in reproducing observed distribution patterns with sets of predictor variables, but their skill in spatial extrapolation is rarely quantified and could help better discriminate among sets of important predictor variables. In addition, the very fast recent spread of clade 2.3.4.4 H5Nx viruses (H5N1, H5N2, H5N6 and H5N8), associated with multiple reassortments was unprecedented (De Vries et al., 2015) and warranted further examination. A separate analysis of how 2.3.4.4 H5Nx viruses had spread in the geographical and environmental space was hence carried out in comparison to the HPAI H5N1 viruses.
Results
Boosted Regression Trees (BRT) models were developed to predict the global suitability of H5N1 HPAI and H5Nx clade 2.3.4.4 presence. The predictor variables were categorised into four sets (Table 1) of variables. The Set 1 variables included the host variables of extensive and intensive chicken densities, human population density, and a variable to account for the effect of mass vaccination of poultry in China (IsChina). Set 2 included land cover variables with IsChina. Set 3 included Fourier-transformed climatic variables of land-surface temperature (LST) and Normalised Difference Vegetation Index (NDVI) with IsChina. Finally, Set 4 variables included Set 1 variables in addition to selected variables from the earlier sets that were selected on the basis of prior epidemiological knowledge. The models were subjected to three different types of cross validations to measure their goodness-of-fit (GOF) and transferability: (i) standard cross-validation (CV) with a random and stratified divide between training and validation sets, (ii) a calibrated cross-validation to account for the spatial sorting bias (SSB) sensu Hijmans (2012) i.e. the tendency to have distance between training-presence and testing-presence sites to be smaller than the distance between training-presence and testing-absence sites, and (iii) a spatial cross-validation (Spatial CV) to spatially separate the training and validation sets by large distances and measure the spatial extrapolation capacity of the models.
Table 1
List of predictor variables used for modelling the suitability of HPAI H5N1 and H5Nx clade 2.3.4.4 viruses using BRT models.
Set | Variable full name | Abbreviation | Source |
|---|---|---|---|
Set 1: Host Variables | |||
Duck density | DuDnLg | ||
Extensive Chicken Density | ChDnLgExt | ||
Intensive Chicken Density | ChDnLgInt | ||
Human Population Density | HpDnLg | Linard et al. (2012); Gaughan et al. (2013); Sorichetta et al. (2015); CIESIN's GPW Database | |
Vaccination in China | IsChina | FAO Global Administrative Unit Layers (GAUL) database | |
Set 2 - Land Cover Variables | |||
Evergreen Deciduous Needleleaf Trees | EDNTrees | ||
Evergreen Broadleaf Trees | EBTrees | ||
Deciduous Broadleaf Trees | DBTrees | ||
Mixed/Other Trees | MixedTrees | ||
Shrubs | Shrubs | ||
Herbaceous Vegetation | HerbVeg | ||
Cultivated and Managed Vegetation | CultVeg | ||
Regularly Flooded Vegetation | RegFlVeg | ||
Urban/Built-up | UrbanBltp | ||
Open Water | Owat | ||
Distance to Water | Dwat | - | |
Vaccination in China | IsChina | FAO Global Administrative Unit Layers (GAUL) database | |
Set 3- Eco-climatic Variables | |||
Day LST* Annual mean | Tmp | ||
Day LST Amplitude annual | TmpAmp1an | ||
Day LST Amplitude bi-annual | TmpAmp2an | ||
Day LST Amplitude tri-annual | TmpAmp3an | ||
Day LST Variance annual | TmpVar1an | ||
Day LST Variance bi-annual | TmpVar2an | ||
Day LST Variance annual, bi and tri-annual | TmpVar123an | ||
NDVI† Annual mean | NDVI | ||
NDVI Amplitude annual | NDVIAmp1an | ||
NDVI Amplitude bi-annual | NDVIAmp2an | ||
NDVI Amplitude tri-annual | NDVIAmp3an | ||
NDVI Variance annual | NDVIVar1an | ||
NDVI Variance bi-annual | NDVIVar2an | ||
NDVI Variance tri-annual | NDVIVar3an | ||
NDVI Variance annual, bi and tri-annual | NDVIVar123an | ||
Vaccination in China | IsChina | FAO Global Administrative Unit Layers (GAUL) database | |
Set 4: Risk-based selection of variables | |||
Duck density | DuDnLg | ||
Extensive Chicken Density | ChDnLgExt | ||
Intensive Chicken Density | ChDnLgInt | ||
Human Population Density | HpDnLg | Linard et al. (2012); Gaughan et al. (2013); Sorichetta et al. (2015); CIESIN's GPW Database | |
Cultivated and Managed Vegetation | CultVeg | ||
Open Water | Owat | ||
Distance to Water | Dwat | - | |
Day LST annual mean | Tmp | ||
Vaccination in China | IsChina | FAO Global Administrative Unit Layers (GAUL) database | |
-
*LST = Land Surface Temperature, †NDVI = Normalised Difference Vegetation Index
The bootstrapped goodness of fit values for the H5N1 HPAI and H5Nx HPAI clade 2.3.4.4 models for the different sets of covariates and cross validation methods are shown in Figure 1. For the H5N1 HPAI global model, all overall GOF metrics were good with predictive accuracy Area Under the Curve (AUC) values higher than 0.9 when evaluated through standard CV (Figure 1). The reduction in GOF taking into account the SSB was minor and followed the same pattern. However, when evaluated through spatial CV, the different sets of covariates showed contrasting AUC values. The land-use (Set 2) and eco-climatic (Set 3) based models extrapolated poorly, and the Set 1 and Set 4 performed best. It is also noteworthy, that the combination of Sets 1 and 2 (Set 2.1), or Sets 1 and 3 (Set 3.1) did not result in significantly better models than Set 1 alone (Figure 1—figure supplement 1), and even tended to reduce the average AUC of spatial CV.
Figure 1 with 1 supplement see all

Representation of Area under Receiver Operating Curve (AUC) values for HPAI H5N1 and H5Nx models.
Representation of AUC values for HPAI H5N1 and New Clade H5Nx 2.3.4.4 model for all sets of predictor variables, assessed through standard cross validation (Standard CV), in light grey, and accounting for spatial sorting bias (SSB) in dark grey. On the right, the AUC values for spatial cross validation (Spatial CV) are represented in black. All these metrics represent mean AUC ± standard deviation. Additionally, the AUC values for Set 2.1 and Set 3.1 are represented in Figure 1—figure supplement 1.
The models for the H5Nx clade 2.3.4.4 virus also had high GOF metrics estimated by standard CV (Figure 1). Here too, a significant amount of predictive power was already obtained with the models containing only Set 1 variables, with AUC values close to 0.9. There was a strong impact of spatial CV on the GOF metrics, with a drastic reduction in predictive power when extrapolating over large distances (Figure 1). Throughout the different spatial CV metrics, Set 2, and 4 showed better AUC values than Set 1, and given that Set 4 was more parsimonious, with fewer predictor variables, it was kept as the final model for H5Nx clade 2.3.4.4 suitability. Similar conclusions could be drawn from models using combinations of Set 1 and Set 2 (Set 2.1), or Set 1 and Set 3 (Set 3.1) (Figure 1—figure supplement 1).
The relative contribution (RC) of the predictor variables of Set 1 and Set 4 for H5N1 HPAI and the H5 HPAI clade 2.3.4.4 models are presented in Figure 2. The most noticeable difference concerned the role of domestic duck density, human population density and chicken density. The H5Nx HPAI clade 2.3.4.4 showed much higher RC for human population density and intensively raised chickens than the H5N1 HPAI one. Conversely, a comparatively much higher RC of domestic duck density and extensively raised chicken was observed for the H5N1 HPAI model than for the H5Nx HPAI clade 2.3.4.4 models. Upon the inclusion of additional predictors in Set 4 (Figure 2), the influence of these host-based predictor variables followed a similar pattern. In addition, annual mean temperature made a relatively high contribution in both models, and cultivated vegetation showed a much higher RC in the H5Nx HPAI clade 2.3.4.4 model than in the H5N1 HPAI one.
Figure 2
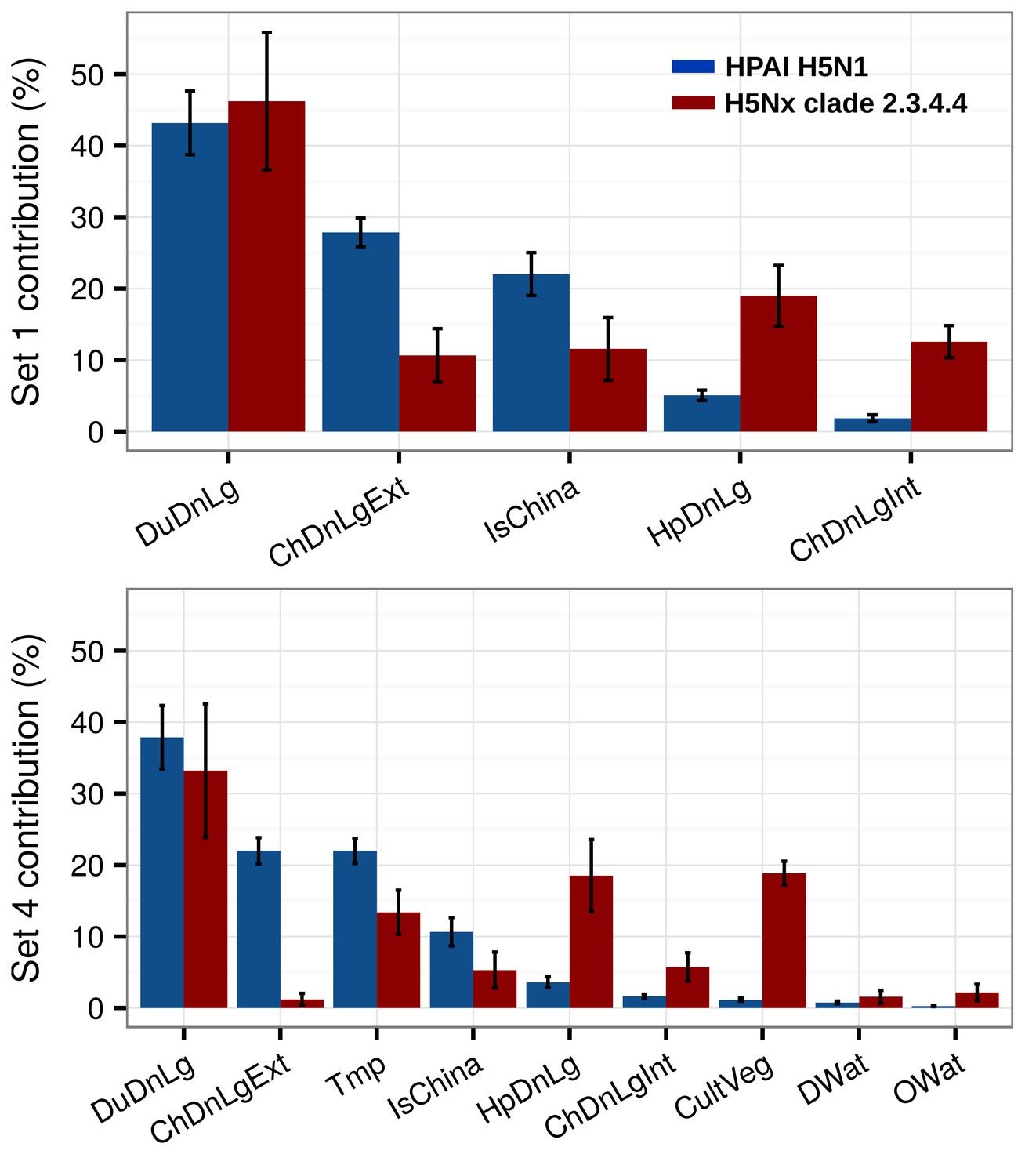
Summary of mean relative contributions for sets of predictor variables.
Summary of the mean relative contributions (%) ± standard deviation of different sets of predictor variables for boosted regression tree models for HPAI H5N1 (in blue) and H5Nx clade 2.3.4.4 (in red). The relative contribution is a measure of the relative importance of each predictor variable included in a BRT model to compute the model prediction. Set 1 predictor variables are represented on top, and Set 4 predictor variables are represented below.
Partial dependence plots of the BRT models allow the contribution of a particular variable to be depicted on the fitted response after taking into account the effect of all the other predictors in the model (Figure 3, and Figure 3—figure supplement 1). The main difference between the partial dependence plots of the different variables was for the density of extensively raised chickens, which showed a positive association with H5N1 HPAI presence contrasting with an absence of association with the H5Nx HPAI clade 2.3.4.4 presence (Figure 3). Other profiles were somewhat comparable for the two groups of viruses and showed a positive association between virus presence and duck density, intensively raised chicken density, human population density, a negative association with the IsChina variable (Figure 3) and an optimum for percentage of cropland and temperature (Figure 3—figure supplement 1). It should be kept in mind that their relative contributions, i.e. their weight in the final prediction strongly differed between the two groups of viruses. It is noteworthy that the models outlined above were built using optimal number of trees estimated through spatial CV instead of standard CV, and this resulted in much lower optimal number of trees compared to standard CV models (Figure 3—figure supplement 2), suggesting that standard CV may be over fitting local clusters of presence points rather than making reliable large-distance predictions. The suitability maps of the models are presented in Figure 4. To interpret the extrapolation capacity of these suitability maps, multivariate environmental similarity surfaces (MESS) (Elith et al., 2010) were computed (Figure 4—figure supplement 3) giving information on where the models extrapolate within the range of predictor variables in the occurrence points. As observed, both models extrapolate prediction in areas with similar environmental conditions, as depicted by positive MESS values. However, the geographical space with high similarity to the occurrence point is comparatively wider for the HPAI H5N1 model, than for the H5Nx clade 2.3.4.4 models.
Figure 3 with 2 supplements see all
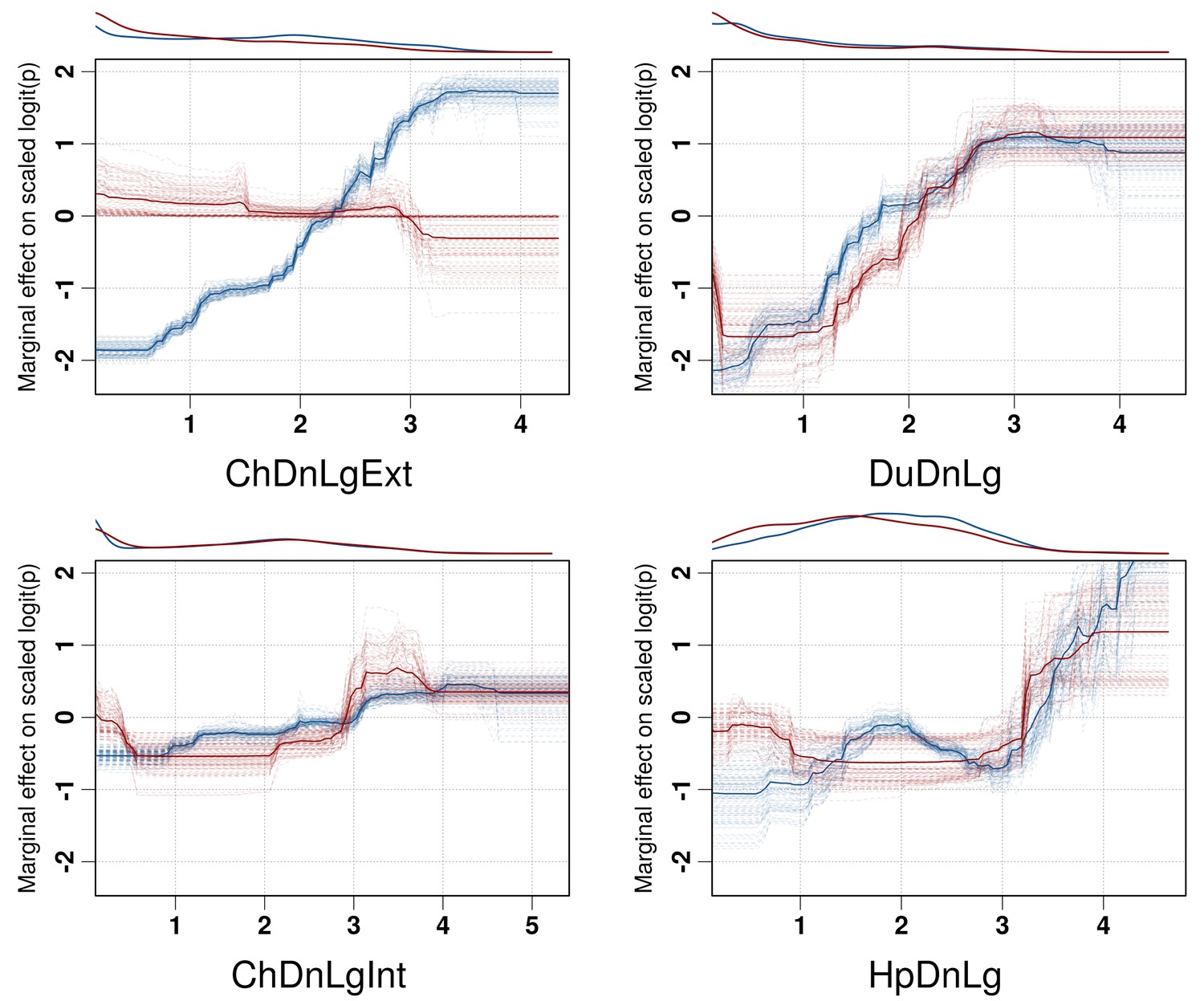
Boosted Regression Tree (BRT) profiles of selected predictor variables.
BRT profiles or partial dependence plots of selected predictor variables for the global HPAI H5N1 (in blue) and H5Nx clade 2.3.4.4 model (in red). The BRT profiles provide a graphical description of the marginal effect of a predictor variable on the response (the probability of virus presence). The solid line represents the mean profile, whilst transparent lines represent each bootstrap. On the top of each plot, the density function of the observed distribution of predictors is displayed for one bootstrap and for the two datasets (HPAI H5N1- in blue and H5Nx clade 2.3.4.4- in red). Four predictor variables were selected for this figure: human population density (HpDnLg), extensive chicken density (ChDnLgExt), intensive chicken density (ChDnLgInt) and duck density (DuDnLg). The BRT profiles of Set 2, Set 3 and Set 4 predictor variables are represented in Figure 3—figure supplement 1. The optimal number of trees at which holdout deviance is minimised in the BRT models for all sets of predictor variables is represented in Figure 3—figure supplement 2.
Figure 4 with 3 supplements see all
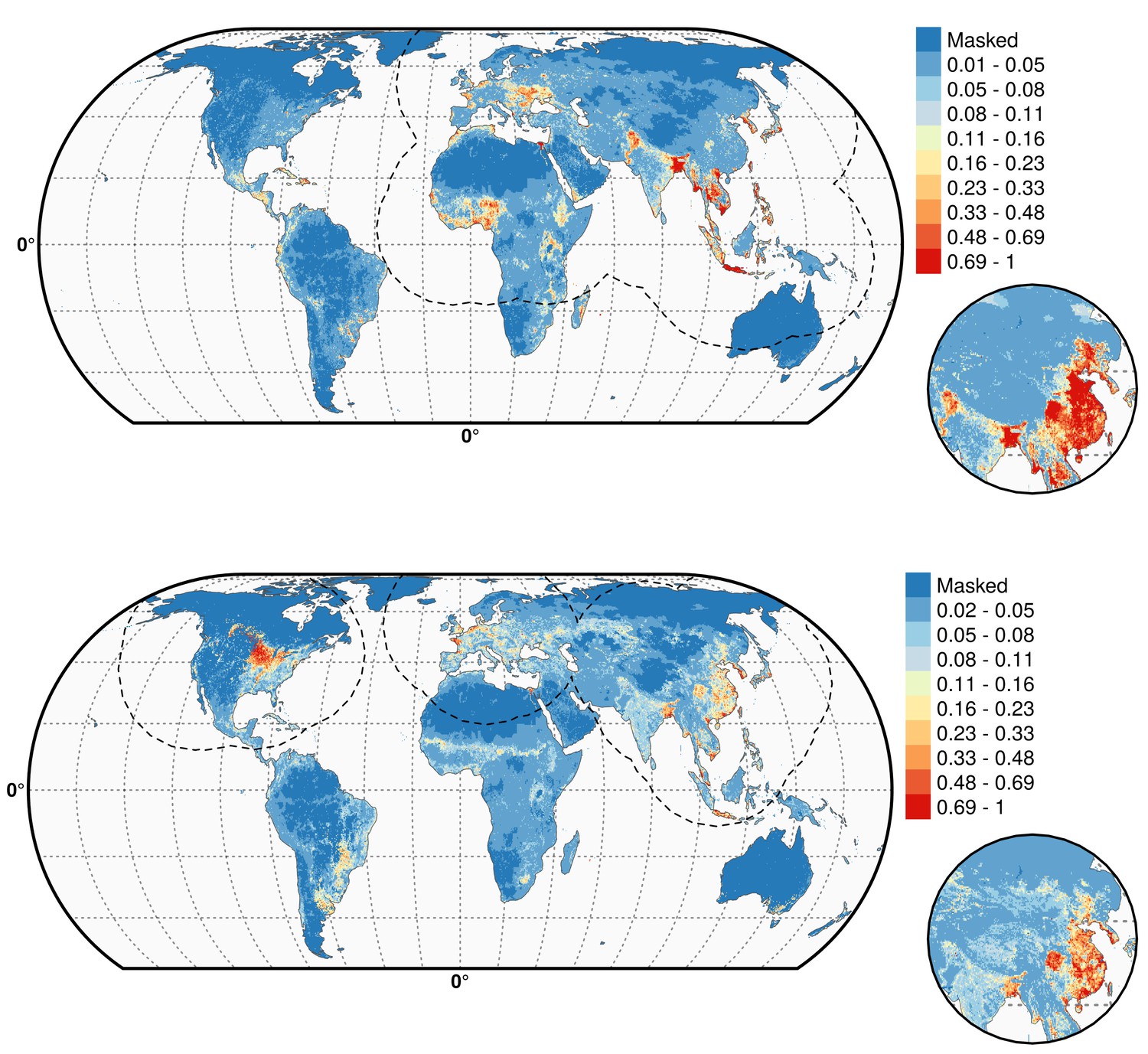
Predicted probability of occurrence of HPAI H5N1 and H5Nx clade 2.3.4.4.
Predicted probability of occurrence of HPAI H5N1 for the Set 1 (top) and of H5Nx clade 2.3.4.4 for the Set 4 (bottom) (Figure 4—source data 1 and 2 respectively). The dashed black line represents a buffer around the occurrence data for the HPAI H5N1 and H5Nx clade 2.3.4.4 predictions, corresponding to an area from which pseudo-absences were selected. The circle inset shows the prediction obtained when the effect of the variable IsChina was removed. The suitability maps HPAI H5N1 and H5Nx clade 2.3.4.4 for Set 2 and Set 3 variables are presented in Figure 4—figure supplement 1 and Figure 4—figure supplement 2 , respectively. The shapefile data used to produce these maps were all from public sources (http://www.naturalearthdata.com/). The graticule is composed of a 20-degree increments and the coordinate system is Eckert IV (EPSG: 54012). This figure was built with the R-3.2.4 software (https://cran.r-project.org/). Additionally, Figure 4—figure supplement 3 depicts the Multivariate environmental similarity surfaces (MESS) maps for HPAI H5N1 and H5Nx clade 2.3.4.4 for the four sets of predictor variables.
-
Figure 4—source data 1
Suitability predictions for the HPAI H5N1 best model (GeoTiff format).
- https://doi.org/10.7554/eLife.19571.010
-
Figure 4—source data 2
Suitability predictions for the H5Nx clade 2.3.4.4 best model (GeoTiff format).
- https://doi.org/10.7554/eLife.19571.011
As expected, high suitability values for the H5N1 HPAI model (Figure 4) are found in several parts of Asia, including China (when the effect of the IsChina variable is removed). Other areas where H5N1 HPAI has spread extensively are highlighted, such as eastern Indo-Gangetic plain, Thailand central plain, south Myanmar and the Red river and Mekong deltas of Vietnam, the island of Java in Indonesia and the Nile Delta in Egypt. The model also highlights areas where H5N1 HPAI was introduced but did not persist over long periods of time, such as in South Korea, Japan, Ukraine and Romania. Areas of western Africa, such as Nigeria, where the H5N1 HPAI outbreaks have been unfolding since late 2014 have been predicted as suitable by the model. Isolated parts in Eastern Europe, North America, Mexico, Dominican Republic and South America, are also deemed suitable for H5N1 establishment.
The suitability map for the H5Nx HPAI clade 2.3.4.4 virus is somewhat different, highlighting more isolated areas (Figure 4). The spatial extrapolation capacity of this model was low, and predictions made at large distances from known points of presence should be interpreted with caution. As this clade is still spreading, there may still be large areas of the landscape where it could potentially become established and where the model predictions may be inaccurate. In areas close to presence points, the predictions are believed to be robust, with several areas within Asia, such as China, South Korea, Japan and Taiwan depicted as suitable. The well-known virus ‘reassortment-sink’ areas of the Indo-Gangetic plains, the river deltas of Vietnam, southern Myanmar and Java, Indonesia, are also highlighted as areas of suitability. In Africa, the Nile delta is depicted as suitable for establishment. In North America, the high suitability areas match the intensive poultry areas of the Midwestern and southern states of USA. The Netherlands, Belgium and northwest France are highlighted with high suitability in Europe. In Australia, the commercial poultry rearing areas of Victoria and New South Wales are predicted as suitable; even though HPAI subtype H5 has never been reported in Australia.
The suitability predictions for the HPAI H5N1 and H5Nx clade 2.3.4.4 best models using Set 1 and Set 4 predictor variables are in Figure 4—source data 1 and 2, respectively. The suitability maps for H5Nx HPAI and H5 clade 2.3.4.4 for Sets 2 and 3 are presented in Figure 4—figure supplement 1 and Figure 4—figure supplement 2, respectively.
Discussion
A first important result of this study is that it was possible to build a global suitability model for HPAI H5N1 virus with a high extrapolation capacity robustly established through spatial cross-validation. Interestingly, H5N1 HPAI outbreaks appeared to be best modelled by predictor variables relating to host distribution. Alternative models based on land use or eco-climatic variables showed marginally better accuracy metrics when evaluated with standard CV, but significantly lower extrapolation capacity than the host-only variable. Even the models combining host variables with other environmental predictors did not produce significantly better results when evaluated through spatial CV. This observation matches earlier observations that association with eco-climatic variables were not consistently reproducible across countries and studies (Gilbert and Pfeiffer, 2012) and that H5N1 HPAI is probably not as strongly environmentally constrained as other authors have suggested (Williams and Peterson, 2009; Zhang et al., 2014). This strongly contrasts with vector-borne diseases, where clear eco-climatic boundaries of vectors can be mapped, and where climate has a strong influence on vector seasonality and population dynamics (McMichael and Lindgren, 2011; Morin and Comrie, 2013). In the case of a directly contagious disease such as avian influenza, successful transmission and clinical outbreaks have been observed over a wide range of temperature and humidity conditions (e.g. Russia, Nigeria, Egypt, Northern China, Indonesia). Our results suggest that the main large-scale constrains to suitability for H5N1 HPAI occurrence are related to the distribution of hosts; densities of chickens and ducks raised in different systems, and to the density of the human population, probably as a surrogate measure for various anthropogenic transmission mechanisms. For the new H5Nx clade 2.3.4.4 viruses, we found a somewhat different result, with a clear improvement of the extrapolation capacity of models using a set of variables combining host distribution and environmental variables. However, these models were of relatively low overall predictive power, most likely because the virus has not yet had a chance to extend fully to its potential range of occurrence as compared to H5N1 HPAI, and false pseudo-absences may have had a strong impact on the construction of models and, therefore, on the accuracy of predictions. For this model, and given its low extrapolation capacity, we emphasise that predictions made at long distances from points of presence should be interpreted with caution, as there may still be large areas where it could potentially become established and where the our model predictions may be inaccurate.
A second important result of this study is to demonstrate the importance of spatial CV in building and validating avian influenza suitability models over large geographical extents. The difference between standard and spatial CV evaluation of GOF was already quite significant for the HPAI H5N1 models. The difference was even more striking for the H5Nx clade 2.3.4.4 models, which all appeared very good when evaluated through standard CV. However, they had poor extrapolation accuracy, sometimes even not much better than a null model when evaluated through spatial CV. Machine-learning techniques used in species distribution modelling have become incredibly powerful at reproducing a pattern from a given set of occurrence data and this is essentially what standard CV measures. However, as our results demonstrate, default cross-validation technique is a very misleading measure of their geographical extrapolation capacity. Spatial CV was found not only to be important for evaluating the extrapolation capacity of a given model, but also to be the only way to truly discriminate our model outputs based on different sets of predictor variables. The focus on extrapolation capacity for selecting predictor variables is driven by the assumption that a model that includes statistical relationships linked to causal mechanisms should spatially extrapolate well, as the cause-consequence statistical associations have a greater chance to apply well in different places than those that are coincidental. Of course, cause-consequence relationships may vary in space too, but the underlying assumption of suitability modelling extrapolation is that these remain constant over the spatial domain within which the model is applied. So, models based on coincidental statistical associations are expected to extrapolate poorly in the geographical domain, and these losses of predictability can hardly be quantified through standard CV because of spatial correlations between training and validation sets.
A third set of important results consisted in the comparison of the H5N1 HPAI and H5Nx clade 2.3.4.4 models, which showed areas of convergences and differences in the geographic and predictor variables spaces. Domestic duck density was the most important variable for both models, though with a lower RC for the H5Nx clade 2.3.4.4 model in Set 4. Ducks have always been strongly associated with areas of persistence and evolution of H5N1 HPAI (Gilbert and Pfeiffer, 2012), which relates to their capacity to act as an intermediate, domestic reservoir between wild Anatidae, the main wild reservoir of avian influenza viruses, and domesticated poultry. Ducks have been referred to as the ‘Trojan horses’ for H5N1 HPAI H5N1 presence (Kim et al., 2014) on account of their role in virus introduction, evolution, transmission and persistence (Hulse-Post et al., 2005), which has been demonstrated in both host pathogenicity (Cornelissen et al., 2013; Smith and Donis, 2015) and geospatial studies (Gilbert and Pfeiffer, 2012). The absence of duck density may in fact explain a lot of the difference in extrapolating capacity found between the host-model (Set 1) and the land-use and eco-climatic models (Set 2 and 3) that cannot discriminate areas with similar land-use and eco-climatic conditions, but that have very different duck densities. For example, India is predicted at relatively high suitability by the land-use model (Set 2, Figure 4) at a very low suitability by the host-based (except around Bangladesh) reflecting the near-absence of significant domestic duck densities in much of the country, in accordance with previous results (Gilbert et al., 2010).
The finding of a strong association between H5Nx clade 2.3.4.4 and ducks was somewhat less expected as the disease was found mostly in chicken farms in more intensive poultry production areas, but results are, however, in line with those of Hill et al. (2015) who found through phylogeographic analysis that the introduction of H5Nx clade 2.3.4.4 to South Korea was associated with areas where domestic ducks and wild waterfowl intermingled. Complex reassortment of multiple subtypes may also occur in areas where domestic ducks and migratory birds have an opportunity to share food, water and habitat, creating opportunities for virus transmission between different species, co-infection of individual animals with different influenza viruses and subsequent gene reassortment (Deng et al., 2013). It would be prudent for countries to put such areas under active surveillance for early detection of HPAI introductions and for monitoring of virus evolution. This would include the countries of the Americas and African continent where duck rearing is not as common as in South East Asia. It is noteworthy that one of the most severe recent H5 HPAI epidemics that started in 2015 in Dordogne region of France, a traditionally important duck rearing area with some of the highest duck densities in the country, even if the outbreaks were apparently caused by distinct H5 viruses from those circulating in Asia. So, the association found with domestic duck densities fits with existing knowledge of H5N1 spatial epidemiology and was a major predictor in both the H5N1 HPAI and H5Nx clade 2.3.4.4 models.
In contrast, the association with extensively and intensively raised chickens provided different results for the H5N1 HPAI and H5Nx clade 2.3.4.4 models, with the latter being more strongly associated with intensified chicken production systems, found in intensive crop production areas with high human population densities. An interesting hypothesis to explain this pattern would be a greater fitness of H5Nx clade 2.3.4.4 viruses to spread through intensive chicken production and poultry trade systems (Claes et al., 2016). We still lack extensive published experimental infection results of the new clade in poultry, but preliminary results are indicative of a lower pathogenicity of the H5Nx clade 2.3.4.4 virus in chickens compared to H5N1 HPAI, with longer survival and shedding period (Kim et al., 2014; Swayne et al., 2015). A lower virulence in chicken was also found for the reassortant H5N2, H5N6 and H5N8 clade 2.3.4.4 viruses compared to previous 2.3.4 HPAI H5N1 viruses (Sun et al., 2016), although they remained highly pathogenic. A lower mortality and longer period of infectivity may assist the virus in circulating longer and within intensified poultry production and trading systems, leading to increased opportunities for onward transmission. Evolution towards reduced pathogenicity would appear an asset in improving farm-to-farm transmission and long-term persistence even in the absence of domestic ducks. This could partly explain the stronger association of H5Nx clade 2.3.4.4 viruses with intensive chicken production areas in eastern Asia and in the US.
Our analyses have focussed on poultry outbreak locations and are therefore of more limited use in identifying the locations of initial introduction of avian influenza viruses, or places where viruses may undergo more frequent reassortment events leading to the local emergence of new viruses. Future work may look more explicitly into those aspects and could lead to better prevention at the sources of virus introduction and emergence.
Material and methods
H5 location data
Request a detailed protocolTwo data sets corresponding to the two groups of viruses were compiled, respectively termed H5N1 HPAI, and H5 HPAI clade 2.3.4.4. The H5N1 HPAI data set was built from the database of the Global Animal Health Information System EMPRES-i of the FAO (Food and Agriculture Organization of the United Nations, 2016) (http://empres-i.fao.org/). A total of 17,068 confirmed outbreaks from January 2004 to March 2015 in poultry were used for this analysis, with the majority of outbreaks located in Asia, and no reports of H5N1 HPAI (not being of clade 2.3.4.4) in the Americas (Figure 5). In the absence of specific clade information on any given H5N1 HPAI outbreaks from 2013 onward, it was assumed to belong to the H5N1 HPAI data set (i.e. not being from clade 2.3.4.4). This may have resulted in some misclassification of some outbreaks in Eurasia, but their number relative to the total number of H5N1 HPAI outbreaks would be very low (<50) given the limited time period.
Figure 5
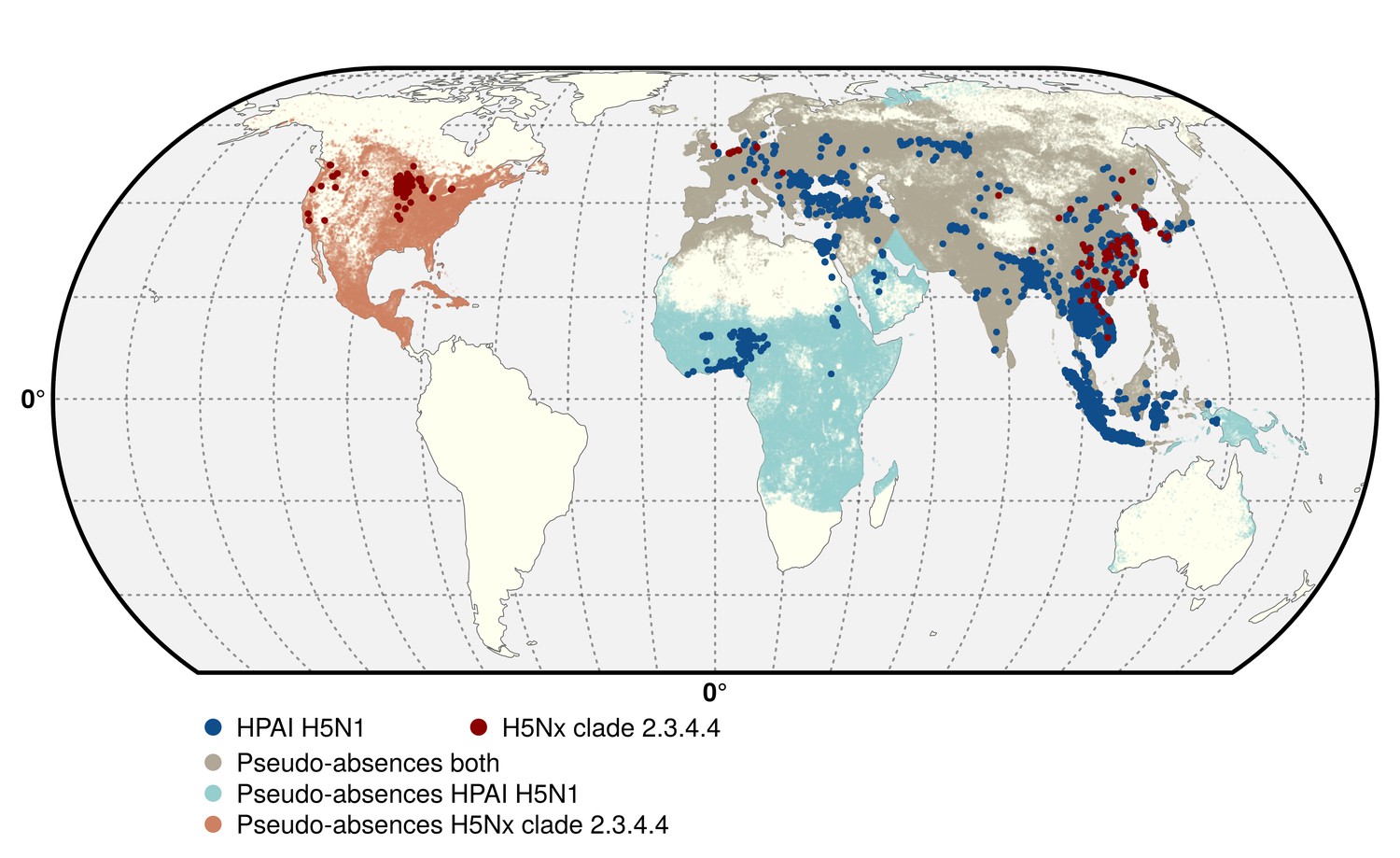
Geographic distribution of presence and pseudo-absences of HPAI H5N1 and HPAI H5Nx clade 2.3.4.4.
Geographic distribution of presence points of HPAI H5N1 (blue) and HPAI H5Nx clade 2.3.4.4 (red). The pseudo-absences are represented in light blue, light red and light brown. This figure was built with the R-3.2.4 software (https://cran.r-project.org/). The shapefile data used to produce these maps were all from public sources (http://www.naturalearthdata.com/). The graticule is composed of a 20-degree increments and the coordinate system is 'EPSG: 54012'.
The H5 HPAI clade 2.3.4.4 data set was built by combining EMPRES-i outbreak location data with clade information from the Swiss Institute of Bioinformatics OpenFlu database (http://openflu.vital-it.ch/) using the procedure detailed in Claes et al. (2014). In addition, searches on ProMed (http://www.promedmail.org/), the United States Department of Agriculture reports (http://www.usda.gov/avian_influenza.html), and other online literature were used for assignation of clade to H5 outbreaks. These included the H5N8, H5N2, H5N6, H5N3 and the recent H5N1 sequences from November 2013 to 15 June 2015. While this procedure was fairly straightforward for the newly emerged H5N8, H5N2, H5N6, H5N3 viruses, it was more challenging to assign a clade to the most recent H5N1 outbreaks. Hence, this H5 HPAI clade 2.3.4.4 data set only included those H5N1 outbreak records occurring after November 2013 that could be classified as clade 2.3.4.4, based upon documented evidence and confirmation from the above sources. This resulted in a dataset with 1309 outbreaks in poultry recorded as belonging to clade 2.3.4.4 from November 2013 to 15th June 2015 (Figure 5), involving 17 affected countries.
Spatial predictor variables
Request a detailed protocolPredictor variables traditionally associated with HPAI occurrence summarised in a recent literature reviews (Gilbert and Pfeiffer, 2012) were selected in addition to a few others. Three categories of variables were included: hosts, land use/land cover and eco-climatic variables. Host variables included log10-transformed extensive and intensive chicken density (Gilbert et al., 2015), duck density (Robinson et al., 2014) and human population density. Whilst the poultry variables were available as global databases (with the exception of ducks, which were computed as detailed below), the human population density layer was built from two different data sources; the Worldpop database (http://www.worldpop.org) in all countries where it was available across Africa (Linard et al., 2012), Asia (Gaughan et al., 2013) and South America (Sorichetta et al., 2015) and the Center for International Earth Science Information Network’s Gridded Population of the World (GPW) database elsewhere (Socioeconomic Data and Applications Center, 2016) (http://sedac.ciesin.columbia.edu/entri). Since both data sets are standardised to match UN national totals, these two databases should be consistent against each other.
The Global Duck Distribution Data were computed using The Gridded Livestock of the World (GLW) version 2 (http://livestock.geo-wiki.org), which only included duck data on Asia, Europe and North America. Using the GLW downscaling method and spatial predictors presented in Robinson et al. (2014), we developed a global-scale model of duck distribution at a spatial resolution of 0.083333 decimal degrees resolution, using all global data available to date on duck distribution in the FAO Global Livestock Information System (GLIS). These new modelled values were used to avail predicted values in Africa and South America, whilst the original GLW version two predictions were maintained for the continents where they were available.
For the land cover data, we used the Global 1 km Consensus Land Cover database (Tuanmu and Jetz, 2014) that distinguishes land use and land cover classes (Table 1) with an index of the prevalence of each class in percentage for a ~1 km pixel (http://www.earthenv.org/landcover.html). These data layers were supplemented by a layer about the distance of each spatial point to the open water. Finally, a third set of spatial predictors (Table 1) describing the seasonality and large-scale pattern of eco-climatic indices such as day-time land surface temperature (day LST) and Normalised Difference Vegetation Index (NDVI) was also used (Scharlemann et al., 2008).
Finally, an additional covariate to account for mass vaccination of poultry against H5N1 in China was also included (IsChina), which could not be captured by any other predictor variable. This term was added only for China because the role played by mass vaccination is believed to be much higher than in any other countries. Post vaccination seropositivity in China ranges between 80% and 95% in China (Martin et al., 2011), whereas papers having looked at post-vaccination seropositivity in Indonesia (Sawitri et al., 2007), Vietnam (Domenech et al., 2009) and Egypt (Rijks and ElMasry, 2009) found it to be insufficient to successfully prevent transmission, often close to 30%. China is also by far the biggest user of vaccines: '125 billion doses of H5N1 vaccine were produced and deployed in total; in China (120 billion), Indonesia (3 billion) and Viet Nam (2 billion) between 2004 and 2012'(Castellan et al., 2014). All the risk factor variables were at a spatial resolution of 0.083333 decimal degrees per pixel, which equals an approximate resolution of 10 by 10 km at the equator.
The predictor variables were categorised into four sets to predict the probability of virus presence (Table 1). Set 1 included the host variables of extensively (ChDnLgExt) and intensively raised chicken density (ChDnLgInt), duck density (DuDnLg), human population density (HpDnLg) and the effect of mass vaccination in China (IsChina). Set 2 included the land use and land cover variables and IsChina, whereas Set 3 included all eco-climatic variables and IsChina. Finally, Set 4 included a selection of variables from the earlier sets that were selected on the basis of prior epidemiological knowledge (Gilbert and Pfeiffer, 2012). These included all variables from Set 1 in addition to (i) the land cover ‘Cultivated and Managed Vegetation’ class accounting for the association between poultry and cropping patterns, (ii) the land cover ‘Open Water’ and ‘Distance to water’ class accounting for the persistence of the virus in landscapes rich in water environment, variables previously found associated with H5N1 HPAI presence in China (Shaman and Kohn, 2009), (iii) the day LST annual mean to account for the persistence of virus in the environment which has been shown to vary with temperature (Liu et al., 2007; Zhang et al., 2014). The combination of variables from Set 1 and Set 2 on one hand (Set 2.1), and of Set 1 and Set 3 (Set 3.1) on the other hand were also investigated.
Modelling procedure
Request a detailed protocolBoosted Regression Tree (BRT) models (Elith et al., 2006) were employed to predict the probability of occurrence of H5N1 HPAI viruses and H5Nx HPAI clade 2.3.4.4, as a function of the sampled predictor variables. We used BRT as it allows for modelling of complex non-linear relationships to be modelled using various types of predictor data and takes into account the interactions between predictor variables (Elith et al., 2008). BRT models generate a large number of regression trees, fitted in a stepwise manner, for optimising the predictive probability of occurrence based on predictor variable values, as compared to several other modelling methods (Elith et al., 2006) and has been shown to produce accurate predictions of H5N1 (Martin et al., 2011) and H7N9 subtypes (Gilbert et al., 2014).
BRT models require data on both presence (provided by two H5 data sets) and absence, and we modelled two separate outcomes using the parameters described further in the section; the presence/absence of H5N1 HPAI and H5Nx HPAI clade 2.3.4.4 viruses. Whilst presence is derived from the two respective H5 data sets, absence data are rarely measured through active surveillance, so need to be approximated by generating pseudo-absences points. The literature yields no consensus on the correct approach to generate pseudo-absence data, so we used an evidence-based probabilistic framework for generating pseudo-absence data points incorporating the main biasing that may have affected the distribution of the presence points (Phillips et al., 2009). We used the bgSample function from the 'seegSDM' package (https://github.com/SEEG-Oxford/seegSDM) (Phillips et al., 2009; Pigott et al., 2014) to generate a pixel level spatial distribution of pseudo-absence based on the human population distribution (Figure 5) to account for differences in surveillance and reporting intensity. This was based on the assumption that under-reporting would be more likely in remote areas with low population density than in highly populated, where the disposal or dead birds and carcasses would more hardly go unnoticed. In addition, the Empres-i database compiles outbreak locations data from very heterogeneous sources and in the absence of explicit GPS location data, the geo-referencing of individual cases is often through the use of place name gazetteers that will tend to force the outbreak location populated place, rather in the exact location of the farm where the disease was found, which would introduce a bias correlated with human population density. Finally, this also allowed to prevent any pseudo-absences in unpopulated regions.
With dynamically spreading pathogens, ‘absences’ may result from a genuine unsuitability for infection, a lack of surveillance or reporting while the pathogen is present, or simply the fact that the pathogen has not been introduced to a region. Minimum and maximum distances to the nearest presence observations were therefore introduced in the selection of pseudo-absence points to limit that effect (Phillips et al., 2009). The minimum distance was set to 10 km in both models, in relation to outbreak surveillance zones for HPAI in most countries. The maximum distance to the nearest positive observation could not be informed by surveillance strategies and was randomly set between 1000 and 3000 km across different bootstrapped runs of the model in order to ensure that the results were not too sensitive to a specific maximum distance. Prior to running the model, the duplicate points falling in the same pixel were summarised, in order to label each pixel as ‘presence’ or ‘pseudo-absence’. This procedure resulted in a reduced data set with 5038 and 403 presence points (pixels) for the H5N1 HPAI and H5Nx HPAI clade 2.3.4.4 models, respectively (Figure 5).
To select the optimal number of trees in the BRT models, the k-fold cross validation procedure described in Elith et al. (2008) was employed, using the R package dismo. Each model was run with four different sets of predictor variables to measure their respective predictive power. In addition, the weight of each predictor variable was also evaluated individually by their relative contribution, a metric was produced that described the proportion of times a particular variable was selected by the model for splitting a decision tree, and the overall improvement it brought to the model (Friedman and Meulman, 2003). In addition to the standard random cross-validation procedure of Elith et al., (2008), a calibrated cross-validation was also computed to account for the SSB (Hijmans, 2012). Clustering of occurrences in species distribution models may lead to inflation of cross-validation metrics because the distance between training-presence and testing-presence sites will tend to be smaller than the distance between training-presence and testing-absence sites (referred to as SSB). To account for SSB, the testing data were sub-sampled using the distance to training data. The first step in this approach is to compute, for each testing-presence site, the distance to the nearest training-presence site. During the sub-sampling procedure, each testing-presence site is paired with the testing-absence site that has the most similar distance to its nearest training-presence site. If the difference between the two distances is more than a specified threshold (33%) the presence site is not used. This procedure ensures that clustering of presence data is accounted for and avoids the inflation of model evaluation metrics.
In addition, we implemented spatial CV, whereby training and testing sets are partitioned on a spatial basis, in order to quantify how model predictions could extrapolate geographically (Gilbert et al., 2014; Randin et al., 2006; Wenger and Olden, 2012). Disease outbreak data are typically clustered, or spatially autocorrelated, and this may bias standard cross validation (CV) procedures because the training and validation data sets are not independent from each other (Randin et al., 2006). A possible consequence is that the goodness of fit metrics provided by the standard CV procedure may overestimate the real capacity of the model to make reliable predictions in areas distant from the training set. The spatial CV procedure was performed by partitioning non randomly the study area into five spatial clusters (Figure 6) by first selecting five reference presence points. A minimum distance was specified between the selected points to obtain a balanced sample size between the clusters. These selected points represent the benchmarks to build the five-folds/clusters of the spatial CV models. Thereafter, the nearest benchmark presence to each observation is identified and labelled with this benchmark point. Finally, the five clusters containing presences and absences are delineated and are used as folds in the spatial cross validation procedure. In the procedure described by Elith et al. (2008), an optimal number of trees for the BRT model is found by finding the minimum deviance to the evaluation set. By replacing the standard CV by the spatial CV, we also allow the optimal number of trees to correspond to the minimum deviance in a geographically distant evaluation set. Both the BRT models were run with the following parameters; a tree complexity of 4, and the initial number of trees set at 100. For the HPAI H5N1 and clade H5Nx 2.3.4.4 model, a learning rate of 0.01 and 0.005, respectively, was used. A step size of 200 and 50 trees was used for the HPAI H5N1 and clade H5Nx 2.3.4.4 models, respectively.
Figure 6
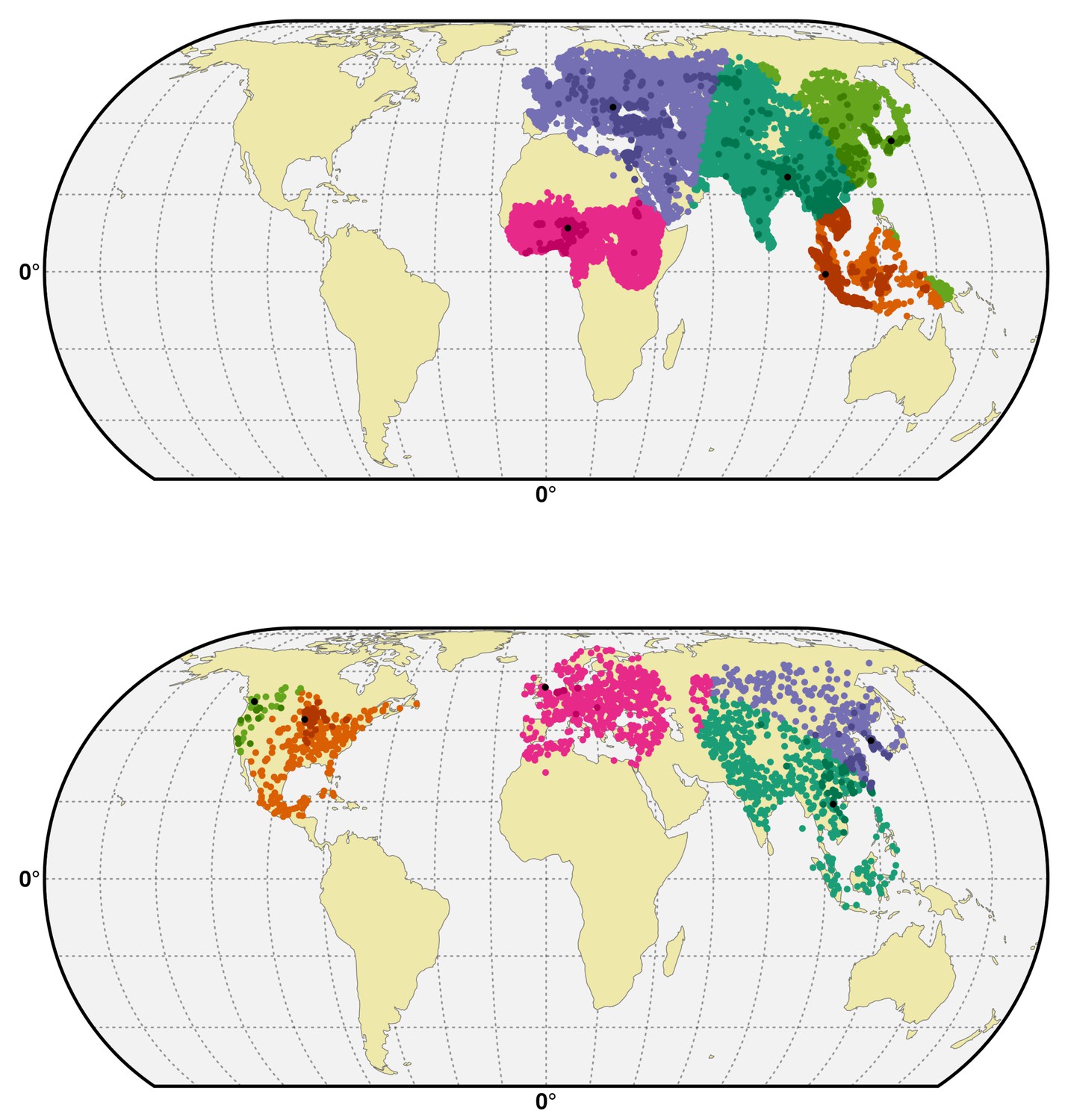
Spatial cross-validation partition for H5N1 HPAI and H5Nx clade 2.3.4.4.
Visualisation of a typical partition used for the spatial cross-validation of the H5N1 HPAI (top) and H5Nx clade 2.3.4.4 (bottom). The presence and pseudo-absences are partitioned into k (five) clusters for training and testing set. One cluster is used for testing data and k-1 clusters are used for sampling training data. The k (five) reference presence points (randomly sampled in each bootstrap) used to build each clusters are represented in black in the map. The code used for implementing the spatial cross validation is detailed in Source code 1. This figure was built with the R-3.2.4 software (https://cran.r-project.org/). The shapefile data used to produce these maps were all from public sources (http://www.naturalearthdata.com/). The graticule is composed of a 20-degree increments and the coordinate system is 'EPSG:54012.
All BRT models were bootstrapped across 20 values of maximum distance to the presence point. For each set of parameters, five splits of training and testing dataset were randomly sampled to compute the CV metrics. All in all, 100 bootstraps were used per group of viruses and per set of predictor variables. The GOF of the models was calculated using Area Under the Receiver Operating Curve (AUC) metrics, and the mean predictions from the bootstrapped models were generated on a continuous scale of 0 to 1 for each pixel, to be mapped over the study area.
We produced the predictions on a global scale to predict the global suitability of H5N1 HPAI and H5Nx clade 2.3.4.4 presence. There are certain uncertainties associated with extrapolating over large geographical domains, and hence, in order to delimit the environments outside of the range of model calibration locations, the multivariate environmental similarity surfaces (MESS) (Elith et al., 2010) was computed on each set of predictors and set of occurrence points.
References
-
Modeling the ecology and distribution of highly pathogenic avian influenza (H5N1) in the indian subcontinentCurrent Science 13:2391–2397.
-
Rapid Emergence of highly pathogenic Avian Influenza Subtypes from a Subtype H5N1 Hemagglutinin variantEmerging Infectious Diseases 21:842–846.https://doi.org/10.3201/eid2105.141927
-
Spatio-temporal epidemiology of highly pathogenic avian influenza (subtype H5N1) in poultry in eastern IndiaSpatial and Spatio-Temporal Epidemiology 11:45–57.https://doi.org/10.1016/j.sste.2014.06.003
-
Experiences with vaccination in countries endemically infected with highly pathogenic avian influenza: the Food and Agriculture Organization perspectiveRevue Scientifique Et Technique De l'OIE 28:293–305.https://doi.org/10.20506/rst.28.1.1865
-
The art of modelling range-shifting speciesMethods in Ecology and Evolution 1:330–342.https://doi.org/10.1111/j.2041-210X.2010.00036.x
-
A working guide to boosted regression treesJournal of Animal Ecology 77:802–813.https://doi.org/10.1111/j.1365-2656.2008.01390.x
-
Multiple additive regression trees with application in epidemiologyStatistics in Medicine 22:1365–1381.https://doi.org/10.1002/sim.1501
-
Free-grazing ducks and highly pathogenic avian influenza, ThailandEmerging Infectious Diseases 12:227–234.https://doi.org/10.3201/eid1202.050640
-
Risk factor modelling of the spatio-temporal patterns of highly pathogenic avian influenza (HPAIV) H5N1: a reviewSpatial and Spatio-Temporal Epidemiology 3:173–183.https://doi.org/10.1016/j.sste.2012.01.002
-
Novel reassortant highly pathogenic avian influenza (H5N5) viruses in domestic ducks, ChinaEmerging Infectious Diseases 17:1060–1063.https://doi.org/10.3201/eid/1706.101406
-
Novel variants of clade 2.3.4 highly pathogenic avian influenza A(H5N1) viruses, ChinaEmerging Infectious Diseases 19:2021–2024.https://doi.org/10.3201/eid1912.130340
-
Wild waterfowl migration and domestic duck density shape the epidemiology of highly pathogenic H5N8 influenza in the Republic of KoreaInfection, Genetics and Evolution 34:267–277.https://doi.org/10.1016/j.meegid.2015.06.014
-
Pathobiological features of a novel, highly pathogenic avian influenza A(H5N8) virusEmerging Microbes & Infections 3:e75.https://doi.org/10.1038/emi.2014.75
-
Global epidemiology of avian influenza A H5N1 virus infection in humans, 1997-2015: a systematic review of individual case dataThe Lancet Infectious Diseases 16:e108–e118.https://doi.org/10.1016/S1473-3099(16)00153-5
-
Highly pathogenic avian influenza viruses H5N2, H5N3, and H5N8 in Taiwan in 2015Veterinary Microbiology 187:50–57.https://doi.org/10.1016/j.vetmic.2016.03.012
-
Climate change: present and future risks to health, and necessary responsesJournal of Internal Medicine 270:401–413.https://doi.org/10.1111/j.1365-2796.2011.02415.x
-
Are niche-based species distribution models transferable in space?Journal of Biogeography 33:1689–1703.https://doi.org/10.1111/j.1365-2699.2006.01466.x
-
Characteristics of poultry production in Egyptian villages and their effect on HPAI vaccination campaign results - Results of a participatory epidemiology studyFood and Agriculture Organisation Report.
-
The vaccination program in Indonesia. In: Vaccination: a tool for the control of avian influenza, Proc. of the Joint OIE/FAO/IZSVe Conference, Verona, Italy March 2007Istituto Zooprofilattico Sperimentale Delle Venezie, Dodet and the Scientific and Technical Department of the O.I.E., Eds 130:151–158.
-
A global 1-km consensus land-cover product for biodiversity and ecosystem modellingGlobal Ecology and Biogeography 23:1031–1045.https://doi.org/10.1111/geb.12182
-
Assessing transferability of ecological models: an underappreciated aspect of statistical validationMethods in Ecology and Evolution 3:260–267.https://doi.org/10.1111/j.2041-210X.2011.00170.x
-
Toward a unified nomenclature system for highly pathogenic avian influenza virus (H5N1)Emerging Infectious Diseases 14:e1.https://doi.org/10.3201/eid1407.071681
-
Ecology and geography of avian influenza (HPAI H5N1) transmission in the Middle East and northeastern AfricaInternational Journal of Health Geographics 8:47.https://doi.org/10.1186/1476-072X-8-47
-
Reassortant highly pathogenic influenza A(H5N6) virus in LaosEmerging Infectious Diseases 21:511–516.https://doi.org/10.3201/eid2103.141488
-
Revised and updated nomenclature for highly pathogenic avian influenza A (H5N1) virusesInfluenza and Other Respiratory Viruses 8:384–388.https://doi.org/10.1111/irv.12230
-
Risk factors of poultry outbreaks and human cases of H5N1 avian influenza virus infection in West Java Province, IndonesiaInternational Journal of Infectious Diseases 14:e800–e805.https://doi.org/10.1016/j.ijid.2010.03.014
-
Evaluating the impact of environmental temperature on global highly pathogenic avian influenza (HPAI) H5N1 outbreaks in domestic poultryInternational Journal of Environmental Research and Public Health 11:6388–6399.https://doi.org/10.3390/ijerph110606388
-
Characterization of three H5N5 and one H5N8 highly pathogenic avian influenza viruses in ChinaVeterinary Microbiology 163:351–357.https://doi.org/10.1016/j.vetmic.2012.12.025
Article and author information
Author details
Timothy P Robinson

Funding
National Institutes of Health (1R01AI101028-02A1)
- Madhur S Dhingra
- Jean Artois
- Xiangming Xiao
- Marius Gilbert
Biotechnology and Biological Sciences Research Council (BB/L019019/1)
- Timothy P Robinson
Medical Research Council (ESEI UrbanZoo (G1100783/1))
- Timothy P Robinson
CGIAR (Research Programs on Agriculture for Nutrition and Health (A4NH) and Livestock)
- Timothy P Robinson
Fonds De La Recherche Scientifique - FNRS (PDR T.0073.13)
- Catherine Linard
- Marius Gilbert
United States Agency for International Development (Emerging Pandemic Threats program)
- Scott H Newman
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
TPR is funded by the ESEI UrbanZoo (G1100783/1), BBSRC-ZELS ZooLinK (BB/L019019/1) programs, and is further supported by the Consultative Group on International Agricultural Research (CGIAR) Research Programs on Agriculture for Nutrition and Health (A4NH) and Livestock. Part of this work was funded by the US National Institutes of Health (1R01AI101028-02A1), United States Agency for International Development (USAID) Emerging Pandemic Threats program, and by the FNRS project ‘Mapping people and livestock’ (PDR T.0073.13)
Copyright
© 2016, Dhingra et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 4,899
- views
-
- 853
- downloads
-
- 57
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 57
- citations for umbrella DOI https://doi.org/10.7554/eLife.19571
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Global mapping of highly pathogenic avian influenza H5N1 and H5Nx clade 2.3.4.4 viruses with spatial cross-validation
eLife 5:e19571.
https://doi.org/10.7554/eLife.19571




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}