Peer review process
Revised: This Reviewed Preprint has been revised by the authors in response to the previous round of peer review; the eLife assessment and the public reviews have been updated where necessary by the editors and peer reviewers.
Read more about eLife’s peer review process.Editors
- Reviewing EditorPhilip BoonstraUniversity of Michigan, Ann Arbor, United States of America
- Senior EditorEduardo FrancoMcGill University, Montreal, Canada
Reviewer #1 (Public review):
Summary:
This manuscript addresses an important methodological issue-the fragility of meta-analytic findings-by extending fragility concepts beyond trial-level analysis. The proposed EOIMETA framework provides a generalizable and analytically tractable approach that complements existing methods such as the traditional Fragility Index and Atal et al.'s algorithm. The findings are significant in showing that even large meta-analyses can be highly fragile, with results overturned by very small numbers of event recodings or additions. The evidence is clearly presented, supported by applications to vitamin D supplementation trials, and contributes meaningfully to ongoing debates about the robustness of meta-analytic evidence. Overall, the strength of evidence is moderate to strong.
Strengths:
(1) The manuscript tackles a highly relevant methodological question on the robustness of meta-analytic evidence.
(2) EOIMETA represents an innovative extension of fragility concepts from single trials to meta-analyses.
(3) The applications are clearly presented and highlight the potential importance of fragility considerations for evidence synthesis.
Reviewer #3 (Public review):
Summary and strengths:
In this manuscript, Grimes presents an extension of Ellipse of Insignificant (EOI) and Region of Attainable Redaction (ROAR) metrics to meta-analysis setting as metrics for fragility and robustness evaluation of meta-analysis. The author applies these metrics to three meta-analyses of Vitamin D and cancer mortality, finding substantial fragility in their conclusions. Overall, I think extension/adaption is a conceptually valuable addition to meta-analysis evaluation, and the manuscript is generally well-written.
Specific comments:
(1) The manuscript would benefit from a clearer explanation of in what sense EOIMETA is generalizable. The author mentions this several times, but without a clear explanation of what they mean here.
(2) The authors mentioned the proposed tools assume low between-study heterogeneity. Could the author illustrate mathematically in the paper how the between-study heterogeneity would influence the proposed measures? Moreover, the between-study heterogeneity is high in Zhang et al's 2022 study. It would be a good place to comment on the influence of such high heterogeneity on the results, and specifying a practical heterogeneity cutoff would better guide future users.
(3) I think clarifying the concepts of "small effect", "fragile result", and "unreliable result" would be helpful for preventing misinterpretation by future users. I am concerned that the audience may be confusing these concepts. A small effect may be related to a fragile meta-analysis result. A fragile meta-analysis doesn't necessarily mean wrong/untrustworthy results. A fragile but precise estimate can still reflect a true effect, but whether that size of true effect is clinically meaningful is another question. Clarifying the effect magnitude, fragility, and reliability in the discussion would be helpful.
Comments on revisions:
I am unable to find the author's responses to my previous round comments (Reviewer #3) in the revision package, though replies to the other reviewers are present. I will provide my updated feedback once these responses are available for review.
Author response:
The following is the authors’ response to the original reviews
Public Reviews:
Reviewer #1 (Public review):
Summary:
This manuscript addresses an important methodological issue - the fragility of meta-analytic findings - by extending fragility concepts beyond trial-level analysis. The proposed EOIMETA framework provides a generalizable and analytically tractable approach that complements existing methods such as the traditional Fragility Index and Atal et al.'s algorithm. The findings are significant in showing that even large meta-analyses can be highly fragile, with results overturned by very small numbers of event recodings or additions. The evidence is clearly presented, supported by applications to vitamin D supplementation trials, and contributes meaningfully to ongoing debates about the robustness of meta-analytic evidence. Overall, the strength of evidence is moderate to strong, though some clarifications would further enhance interpretability.
Strengths:
(1) The manuscript tackles a highly relevant methodological question on the robustness of meta-analytic evidence.
(2) EOIMETA represents an innovative extension of fragility concepts from single trials to meta-analyses.
(3) The applications are clearly presented and highlight the potential importance of fragility considerations for evidence synthesis.
Weaknesses:
(1) The rationale and mathematical details behind the proposed EOI and ROAR methods are insufficiently explained. Readers are asked to rely on external sources (Grimes, 2022; 2024b) without adequate exposition here. At a minimum, the definitions, intuition, and key formulas should be summarized in the manuscript to ensure comprehensibility.
(2) EOIMETA is described as being applicable when heterogeneity is low, but guidance is missing on how to interpret results when heterogeneity is high (e.g., large I²). Clarification in the Results/Discussion is needed, and ideally, a simulation or illustrative example could be added.
(3) The manuscript would benefit from side-by-side comparisons between the traditional FI at the trial level and EOIMETA at the meta-analytic level. This would contextualize the proposed approach and underscore the added value of EOIMETA.
(4) Scope of FI: The statement that FI applies only to binary outcomes is inaccurate. While originally developed for dichotomous endpoints, extensions exist (e.g., Continuous Fragility Index, CFI). The manuscript should clarify that EOIMETA focuses on binary outcomes, but FI, as a concept, has been generalized.
Reviewer #2 (Public review):
Summary:
The study expands existing analytical tools originally developed for randomized controlled trials with dichotomous outcomes to assess the potential impact of missing data, adapting them for meta-analytical contexts. These tools evaluate how missing data may influence meta-analyses where p-value distributions cluster around significance thresholds, often leading to conflicting meta-analyses addressing the same research question. The approach quantifies the number of recodings (adding events to the experimental group and/or removing events from the control group) required for a meta-analysis to lose or gain statistical significance. The author developed an R package to perform fragility and redaction analyses and to compare these methods with a previously established approach by Atal et al. (2019), also integrated into the package. Overall, the study provides valuable insights by applying existing analytical tools from randomized controlled trials to meta-analytical contexts.
Strengths:
The author's results support his claims. Analyzing the fragility of a given meta-analysis could be a valuable approach for identifying early signs of fragility within a specific topic or body of evidence. If fragility is detected alongside results that hover around the significance threshold, adjusting the significance cutoff as a function of sample size should be considered before making any binary decision regarding statistical significance for that body of evidence. Although the primary goal of meta-analysis is effect estimation, conclusions often still rely on threshold-based interpretations, which is understandable. In some of the examples presented by Atal et al. (2019), the event recoding required to shift a meta-analysis from significant to non-significant (or vice versa) produced only minimal changes in the effect size estimation. Therefore, in bodies of evidence where meta-analyses are fragile or where results cluster near the null, it may be appropriate to adjust the cutoff. Conducting such analyses-identifying fragility early and adapting thresholds accordingly-could help flag fragile bodies of evidence and prevent future conflicting meta-analyses on the same question, thereby reducing research waste and improving reproducibility.
Weaknesses:
It would be valuable to include additional bodies of conflicting literature in which meta-analyses have demonstrated fragility. This would allow for a more thorough assessment of the consistency of these analytical tools, their differences, and whether this particular body of literature favored one methodology over another. The method proposed by Atal et al. was applied to numerous meta-analyses and demonstrated consistent performance. I believe there is room for improvement, as both the EOI and ROAR appear to be very promising tools for identifying fragility in meta-analytical contexts.
I believe the manuscript should be improved in terms of reporting, with clearer statements of the study's and methods' limitations, and by incorporating additional bodies of evidence to strengthen its claims.
Reviewer #3 (Public review):
Summary and strengths:
In this manuscript, Grimes presents an extension of the Ellipse of Insignificant (EOI) and Region of Attainable Redaction (ROAR) metrics to the meta-analysis setting as metrics for fragility and robustness evaluation of meta-analysis. The author applies these metrics to three meta-analyses of Vitamin D and cancer mortality, finding substantial fragility in their conclusions. Overall, I think extension/adaptation is a conceptually valuable addition to meta-analysis evaluation, and the manuscript is generally well-written.
Specific comments:
(1) The manuscript would benefit from a clearer explanation of in what sense EOIMETA is generalizable. The author mentions this several times, but without a clear explanation of what they mean here.
(2) The authors mentioned the proposed tools assume low between-study heterogeneity. Could the author illustrate mathematically in the paper how the between-study heterogeneity would influence the proposed measures? Moreover, the between-study heterogeneity is high in Zhang et al's 2022 study. It would be a good place to comment on the influence of such high heterogeneity on the results, and specifying a practical heterogeneity cutoff would better guide future users.
(3) I think clarifying the concepts of "small effect", "fragile result", and "unreliable result" would be helpful for preventing misinterpretation by future users. I am concerned that the audience may be confusing these concepts. A small effect may be related to a fragile meta-analysis result. A fragile meta-analysis doesn't necessarily mean wrong/untrustworthy results. A fragile but precise estimate can still reflect a true effect, but whether that size of true effect is clinically meaningful is another question. Clarifying the effect magnitude, fragility, and reliability in the discussion would be helpful.
I am very appreciative of the insightful comments you all shared, and in light of them have made several clarifications and revisions. Thank you again, I am grateful to have received such considered feedback and I hope I’ve addressed any outstanding issues. I have replied to each reviewer’s recommendations in this document sequentially for ease of scanning, and am most grateful for the summary strengths and weaknesses, which I am also incorporated into these replies. Thank you again!
Recommendations for the authors:
Reviewer #1 (Recommendations for the authors):
(1) The manuscript makes the important argument that many meta-analyses are inherently fragile, which aligns with prior work (e.g., PMID: 40999337). Please add the reference to the statements.
Excellent point, thank you – I’ve expanded the discussion of fragility analysis, and its application to meta-analysis, including this reference.
(2) The rationale and mathematical underpinnings of the proposed EOI and ROAR methods are not sufficiently explained. While the authors cite Grimes (2022, 2024b), readers are expected to rely heavily on these external sources without adequate exposition in the current paper. This limits the ability to fully evaluate the reasonableness of the methods or to reproduce the approach. I strongly recommend expanding the description of EOI and ROAR within the manuscript.
I agree fully – I was a little remiss in this scope, as I was worried about overwhelming the reader. However, I was too sparse with detail and have now extended the text this way to describe the methods intuitively as possible (see Discussion, subsection “Ellipse of Insignificance and Region of Attainable Redaction”
(3) In the Methods, the authors note that EOIMETA is applicable when between-study heterogeneity is low. However, the manuscript provides little guidance on how to interpret results when heterogeneity is high (e.g., larger I² values). I recommend clarifying this issue in the Results or Discussion sections, emphasizing the limitations of EOIMETA under high heterogeneity. Ideally, the authors could include either a small simulation study or an illustrative example to demonstrate the performance of the method in such settings.
This is an excellent question, and I was remiss for not considering it better in the manuscript. Originally, the simple idea was to just pool the results for EOI, in which case heterogeneity would be an issue. But I then subsequently added weighed-inverse variance methods to account for situations with increased heterogeneity, so my initial comment was not strictly correct. I’ve changed the text in several places, notably in the methods and in the discussion (see reply point 5).
(4) While EOIMETA is introduced as a generalizable fragility metric for meta-analyses, the illustrative examples would benefit from clearer comparisons with the traditional Fragility Index (FI). Because FI is well established in the RCT literature and familiar to many readers, presenting side-by-side results (e.g., FI at the trial level versus EOIMETA at the meta-analytic level) would provide important context. Such comparisons would also highlight the added value of EOIMETA, underscoring that even when individual trials appear robust under FI, the pooled meta-analysis may remain fragile.
This is an excellent idea! The new table is given below. Note that traditional FI are not defined for non-significant results, and EOI is ambiguous for counts <2.
(5) In the Discussion currently states that the Fragility Index (FI) applies only to binary outcomes. This is not entirely accurate. While the original FI was indeed developed for dichotomous endpoints, subsequent methodological work has extended the concept to other data types, including continuous outcomes (continuous fragility index, CFI). The manuscript should acknowledge this distinction: EOIMETA presently focuses on binary outcomes at the meta-analytic level, but FI more broadly is not restricted to binary data. Adding this clarification, with appropriate citations, would improve accuracy and place EOIMETA more clearly within the broader fragility literature.
Thank you for this catch – clarified now in the discussion:
Reviewer #2 (Recommendations for the authors):
(1) Typos/inconsistencies/writing clarifications: All table and figure legends and titles are missing a period at the end of each sentence. In the sentence "to be estimated by bootstrap methods. Initially, we ran...", there should be a space between "methods" and "Initially" (line 113).
Apologies, these are now remedied.
(2) In Table 2, the total number of patients in the meta-analysis of all 12 studies is reported as 133,262, whereas the text states 133,475 patients. Based on my calculations from Figure 2, the total appears to be 133,262. Could you please clarify this discrepancy?
Certainly – your calculations are correct. The text figure was a typo based on a very early draft where the summation function was not correctly run, and doubled counted some cases. This was fixed for the figure but not the text. The text should now match, thank you for spotting this. There are some issues with figure 2, which I will address in next few points.
(3) Regarding this point, the meta-analysis by Zhang et al. (2019) shows some inconsistencies in the reported number of patients in the paper. According to the data provided on GitHub the total number of patients is 37671. However, Table 1 of the paper lists 38538 patients, and the main text states "5 RCTs involving 39168 patients." Similarly, for Guo et al. (2023), the main text reports that the meta-analysis included 11 RCTs with 112165 patients, whereas the table lists 111952, which appears consistent with the data available on GitHub. There is also a discrepancy in Zhang et al. (2022), which cites 61853 patients in the introduction but 61223 patients in Table 1. These inconsistencies should be clarified, as even small discrepancies in reported sample sizes can undermine the credibility of the analyses presented.
Well-spotted – the incorrect figures are artefacts of an early draft with a double-counting summation function, and I should have spotted them and removed them prior to submission. To clarify, the correct figures from each study (which agree with github data) are given in the corrected table 1.
Thus, there are 38,538 subjects in the Zhang et al 2019 analysis, which matches the first sheet of the github listing. The confusion comes from sheet 2 which was included only with this, which breaks these events down into events / non-events (hence the total non-events being 37,671) but keeps the old labels. This is needlessly confusing, and accordingly I have re-uploaded the data with correct headers for sheet 2. This summation problem was also apparent in the total of figure 2, which has been replaced with a correct version now. Thank you for spotting this!
(4) In line 158, who does "He" refer to? Please clarify this in more detail.
Apologies, this was a typo and should have read “the” – now corrected.
(5) The discrepant results of the RCT by Scragg et al. (2018) between the meta-analysis by Zhang et al. and that by Guo et al. could be presented in a table. This could be included as supplementary material or, preferably, in the main text (Results section).
To avoid confusion, I will add a version of this to the github files for interested users to explore.
(6) In the legend of Figure 2, a period is missing at the end of the sentence. Additionally, although it is generally understood, it would be helpful to specify that the numbers in parentheses represent the confidence intervals. Please confirm whether these are 95%, 89%, or 99% confidence intervals.
Apologies, these are 95% CIs. Clarified now in updated legends.
(7) The statement of "The more recent and robust methods for fragility analysis (EOI) and redaction (ROAR) have potential applications beyond fragile-by-design RCTs, extending to cohort studies, preclinical work, and even ecological studies, as stated by the author" in line 163. Could you please provide references supporting these claims? I believe the relevant references may be included in the EOI paper, but it would be helpful to cite them here as well.
This has recently been used in new analysis now cited in the introduction with fuller description of method for context. Please see response to reviewer 1, points 2
(8) Since the study was previously published as a preprint (https://www.medrxiv.org/content/10.1101/2025.08.15.25333793v1.full-text), this should be mentioned in the manuscript.
Added as a note now.
(9) It would also be valuable to include a figure illustrating ROAR for the same meta-analyses presented in Figure 1 for EOI, possibly as supplementary material.
See reply to point 10.
(10) Finally, it would be interesting to provide plots of both EOI and ROAR for the meta-analyses of all 12 included studies. These graphs could be replicated using the code examples provided by the author in the original EOI and ROAR publications.
These have now been added to the github repository as supplementary material.
(11a) Replications of EOI fragility: eoicfunc.R (github): - In the code provided on GitHub, an error occurred in the "EllipseFromEquation" function within eoifunc. This was due to the PlaneGeometry package not being available for the latest version of R. I attempted several installation methods (using devtools, remotes, and GitHub, as well as direct installation from a URL). However, after adjusting the code, I was able to run the analyses. For the full cohort, including all 12 studies using the EOI approach, I obtained a Minimal Experimental Arm only recoding (xi) = 14 and a Minimal Control Arm only recoding (yi) = 15, whereas the authors reported that 5 recodings were sufficient. It appears that differences in code versions or functions might have slightly affected the results. After downgrading R and running the eoic function with PlaneGeometry successfully installed, the fragility index for the EOI approach was 15 rather than 5.
Apologies for the issue with PlaneGeometry, I will try to fix this for future iterations. The difference you see is an artefact of running EOIFUNC on pooled data, rather than the dedicated EOIMETA function, with the chief difference being that EOIFUNC doesn’t apply WIV correction. If we simply pool events, this is the output:
Author response image 1.
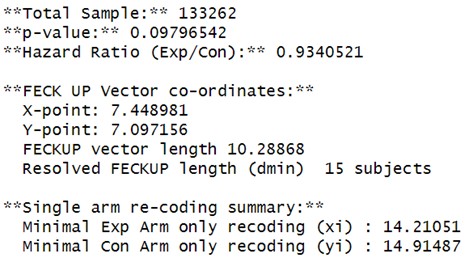
If the reviewer uses the EOIMETA function which employs inverse weighing, then to define each trial we use a vector of events and non-events in each arm. For all the 12 studies, this would be (in R code syntax, or import from github file)
Author response image 2.
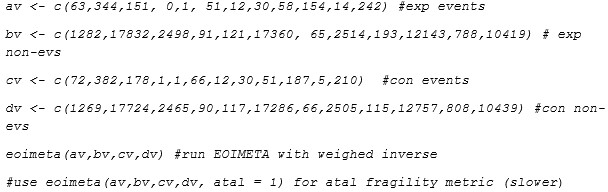
Then they will obtain:
Author response image 3.
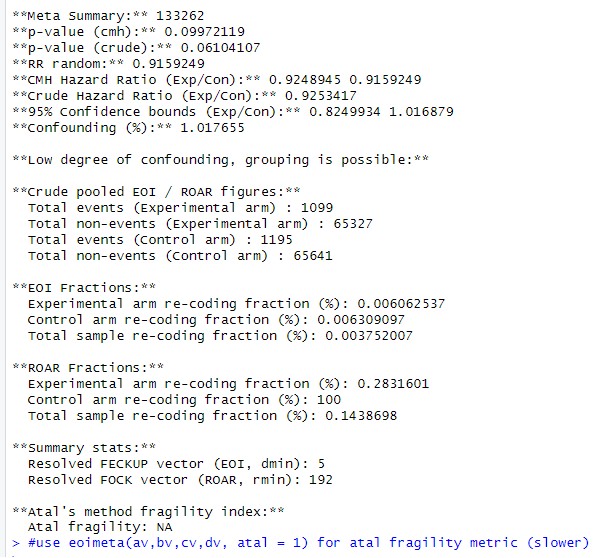
If the reviewer runs a simple pooler analysis with weighed inverse correction turned off, they should return a similar answer as a simple eoifunc call, save the zero count correction difference. But EOIMETA weighs the sample, and is reported in main paper.
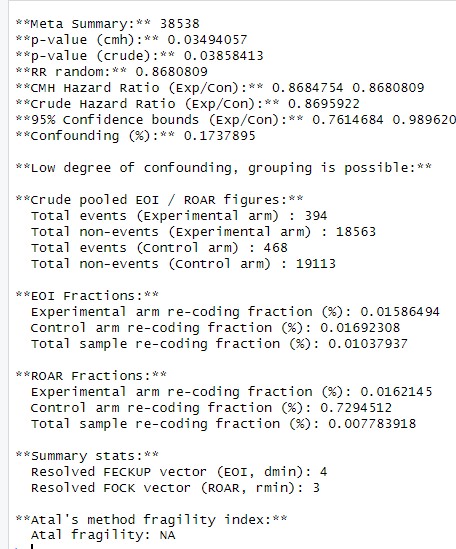
(12) I recalculated the eoic function for Zhang et al. (2019) and found a fragility index (dmin) of 1. FECKUP Vector Length: 0.5722. Minimal Experimental Arm Recoding (xi): 0.7738. Minimal Control Arm Recoding (yi): 0.8499.
This again appears to be an artefact of using eoifunc rather than eoimeta; with eoimeta, which uses WIV to adjust the studies for heterogeneity effects, this is the reported output:
Author response image 4.
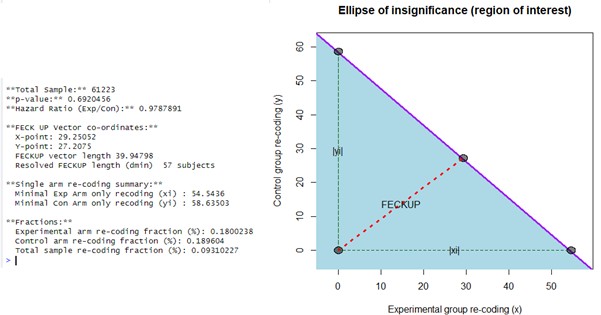
(13) Using the previous code (before downgrading R and loading PlaneGeometry), I recalculated the EOI for Zhang et al. (2022) and found Minimal Experimental Arm only recoding (xi) = 55 and Minimal Control Arm only recoding (yi) = 59-results slightly closer to those reported by the authors. After properly loading PlaneGeometry, I recalculated and obtained for Zhang et al. (2022): Fragility index (dmin) = 57; FECKUP Vector Length = 39.948; Minimal Experimental Arm Recoding (xi) = 54.5436; Minimal Control Arm Recoding (yi) = 58.635.
Again this appears to be a difference in using eoifunc or eoimeta as a call - I can replicate this result using EOIFUNC:
Author response image 5:
But adjusting for study weighing with eoimeta:
Author response image 6.

(14) For Guo et al. (2022), the EOI fragility index was 17 [dmin = 17]. FECKUP Vector Length: 11.3721. Minimal Experimental Arm Recoding (xi): -15.6825. Minimal Control Arm Recoding (yi): -16.5167. However, the authors report an EOI fragility of 38. Since I was able to load PlaneGeometry properly and run eoicfunc.R (from GitHub) without errors, the discrepancies likely reflect minor coding or version inconsistencies rather than software limitations.
These again stem from using eoifunc on simple pooled data versus eoimeta, which adjusts by study.
(15) Replications of ROAR fragility: roarfunc.R (github): - For Guo et al. (2022), the ROAR fragility calculated using roarfunc.R was 16 [rmin (Redaction Fragility Index) = 16]. FOCK Vector Length: 15.942. Minimal Experimental Arm Redaction (xc): 15.9442. Minimal Control Arm Redaction (yc): 978.8906. In the main text, the author reports a redaction fragility of 37. What might explain these discrepancies?
Again, this stems from EOIMETA versus EOIFUNC (and roarfunc calls without weighed adjustment). As the reviewer has observed, the fragility increases when there is no study level adjustment, which we have now added to the discussion text.
(16) In generic_run.R, line 6 contains a bug - it is missing a forward slash (/) between the directory path and the filename. The correct line of code should be: pathload = paste0(pathname, "/", filename, exname). The same issue occurs in generalcode.R.
Apologies, I will correct this in the upload!
(17) Theoretical framework: Is there any other method available for comparison besides the one proposed by Atal et al.? Could you include a brief literature review describing alternative approaches?
To my knowledge, there is not – Xing et al (now referenced) covered this earlier in the year, and I have included an expanded background for this purpose. Please see reply to reviewer 1, point 1.
(18a) There appears to be no heterogeneity in the meta-analysis in terms of effect sizes and I², likely because most values are quite large, yet the included studies address very different populations (e.g., patients with COPD, NSCLC survivors, older adults, women, and GI cancer survivors). This could have been explained more clearly, including how such diverse literature might influence fragility indices or whether there is a logical rationale for combining these studies. Could you perform a sensitivity analysis or provide a conceptual explanation of how the heterogeneity - or lack thereof - across these trials may affect the fragility indices? Although I² values are small, the conceptual heterogeneity among studies suggests that the pooled results may be comparing fundamentally different clinical contexts, which requires clarification.
I think this is a very pertinent point, I am unsure as to why these authors combined such diverse populations without any consideration of whether they were comparable, but this is a common problem in meta-analysis. I have added the following to the discussion to address this problem:
“The use of vitamin D meta-analyses in this work was chosen as illustrative rather than specific, but it is worth noting that there are methodological concerns with much vitamin D research. (Grimes aet al., 2024). The three studies cited in this work report relatively low heterogeneity in their meta-analysis in both effect sizes and I2 values, but it is worth noting that the included studies addressed very different populations, including patients with Chronic Obstructive Pulmonary Disease, Non small cell lung cancer survivors, women only cohorts, older adults, and gastrological cancer survivors. These groups have presumably different risk factors for cancer deaths, and why the authors of these studies combined the cohorts with fundamentally different clinical contexts is unclear. Why the heterogeneity appeared so relatively low in different groups is also a curious feature. This goes beyond the scope of the current work, but serves as an example of the reality that meta-analysis is only as strong as its underlying data and methodological rigor in comparing like-with-like, and the conclusions drawn from them must always be seen in context.”
Reviewer #3 (Recommendations for the authors):
(1) Line 156, acronym FI not defined.
Apologies, I this is now defined at the outset as “fragility index”.
(2) Line 158, typo "He"?
Apologies again, this was a typo and was supposed to read “the”, fixed now.
(3) Across the manuscript, I think the "re-coding" phrasing may confuse clinical readers. Maybe rephrasing to "flipping event classification" or "flipping group" would be better.
Excellent point – this has now been modified at the outset.



