Structure in the variability of the basic reproductive number (R0) for Zika epidemics in the Pacific islands
- IBENS, UMR 8197 CNRS-ENS Ecole Normale Supérieure, France
- CREST, ENSAE, Université Paris Saclay, France
- Institut Pasteur, Unité de Génétique Fonctionnelle des Maladies Infectieuses, France
- URA 3012, France
- Institut Louis Malardé, France
- UPMC/IRD, France
Abstract
Before the outbreak that reached the Americas in 2015, Zika virus (ZIKV) circulated in Asia and the Pacific: these past epidemics can be highly informative on the key parameters driving virus transmission, such as the basic reproduction number (). We compare two compartmental models with different mosquito representations, using surveillance and seroprevalence data for several ZIKV outbreaks in Pacific islands (Yap, Micronesia 2007, Tahiti and Moorea, French Polynesia 2013-2014, New Caledonia 2014). Models are estimated in a stochastic framework with recent Bayesian techniques. for the Pacific ZIKV epidemics is estimated between 1.5 and 4.1, the smallest islands displaying higher and more variable values. This relatively low range of suggests that intervention strategies developed for other flaviviruses should enable as, if not more effective control of ZIKV. Our study also highlights the importance of seroprevalence data for precise quantitative analysis of pathogen propagation, to design prevention and control strategies.
https://doi.org/10.7554/eLife.19874.001eLife digest
Zika virus is an infectious disease primarily transmitted between people by mosquitoes. While most people develop mild flu-like symptoms, infection during pregnancy can interfere with how the baby’s head and brain develop. Until recently, the virus had only been seen sporadically in Africa and Asia, but since 2007, outbreaks have been recorded on several Pacific islands. In 2015, the Zika virus reached the Americas, and within six months over 1.5 million cases had been reported in Brazil alone.
There is an urgent need to understand how the Zika virus moves within a population in order to help policymakers, and public health professionals, plan treatment and control of outbreaks of the disease. Researchers often use predictive models to estimate how a disease will spread. A parameter commonly calculated by these models is the “basic reproductive number”, or R0, which represents the average number of additional cases of the disease caused by one infected individual.
Using models that incorporated data from Zika virus outbreaks that occurred on several Pacific islands, Champagne et al. have produced estimates of R0 that range from 1.5-4.1.
The R0 values are greater than one, indicating that infection will spread within a population, but in the same range as those obtained for dengue fever, another closely related mosquito-borne disease. This suggests that by taking appropriate measures, the spread of Zika and dengue can be controlled to similar extents.
A closer look at the relationship between the population size and the predicted R0 value for each Pacific island revealed an unexpected inverse relationship: the smaller the population, the larger the value of R0. Since other regional factors may also explain these large differences between settings, further work is needed to disentangle context-specific from disease-specific factors. In this respect, data about seroprevalence (the number of people whose blood shows evidence of a past infection) in different populations is crucial for precisely analyzing the spread of Zika virus.
https://doi.org/10.7554/eLife.19874.002Introduction
In May 2015, the first local cases of Zika were recorded in Brazil and by December of the same year the number of cases had surpassed 1.5 million. On February 2016, the World Health Organization declared Zika as a public health emergency of international concern (Who, 2016) and in March 2016, local transmission of Zika was recognized in 34 countries. Previously the Zika virus had circulated in Africa and Asia but only sporadic human cases had been reported. In 2007 the outbreak on Yap (Micronesia) was the first Zika outbreak outside Africa and Asia (Duffy et al., 2009). Since, Zika outbreaks have been also reported in French Polynesia and in New Caledonia (Cao-Lormeau et al., 2014; Dupont-Rouzeyrol et al., 2015) between 2013 and 2014 and subsequently, there have been cases of Zika disease in the Cook Islands, the Solomon Islands, Samoa, Vanuatu, and Easter Island (Chile) (see Figure 1 in Petersen et al. [2016]).
Zika virus (ZIKV) is a flavivirus, mostly transmitted via the bites of infected Aedes mosquitoes, although non-vector-borne transmission has been documented (sexual and maternofoetal transmission, laboratory contamination, transmission through transfusion) (Musso and Gubler, 2016). The most common clinical manifestations include rash, fever, arthralgia, and conjunctivitis (Musso and Gubler, 2016) but a large proportion of infections are asymptomatic or trigger mild symptoms that can remain unnoticed. Nevertheless, the virus may be involved in many severe neurological complications, including Guillain-Barre syndrome (Cao-Lormeau et al., 2016) and microcephaly in newborns (Schuler-Faccini et al., 2015). These complications and the impressive speed of its geographically propagation make the Zika pandemic a public health threat (Who, 2016). This reinforces the urgent need to characterize the different facets of virus transmission and to evaluate its dispersal capacity. We address this here by estimating the key parameters of ZIKV transmission, including the basic reproduction number (), based on previous epidemics in the Pacific islands.
Defined as the average number of secondary cases caused by one typical infected individual in an entirely susceptible population, the basic reproduction number () is a central parameter in epidemiology used to quantify the magnitude of ongoing outbreaks and it provides insight when designing control interventions (Diekmann et al., 2010). It is nevertheless complex to estimate (Diekmann et al., 2010; van den Driessche and Watmough, 2002), and therefore, care must be taken when extrapolating the results obtained in a specific setting, using a specific mathematical model. In the present study, we explore the variability of using two models in several settings that had Zika epidemics in different years and that vary in population size (Yap, Micronesia 2007, Tahiti and Moorea, French Polynesia 2013–2014, and New Caledonia 2014). These three countries were successively affected by the virus, resulting in the first significant human outbreaks and they differ in several ways, including population size and location specific features. Hence, the comparison of their parameter estimates can be highly informative on the intrinsic variability of . For each setting, we compare two compartmental models using different parameters defining the mosquito populations. Both models are considered in a stochastic framework, a necessary layer of complexity given the small population size and recent Bayesian inference techniques (Andrieu et al., 2010) are used for parameter estimation.
Results
We use mathematical transmission models and data from surveillance systems and seroprevalence surveys for several ZIKV outbreaks in Pacific islands (Yap, Micronesia 2007 (Duffy et al., 2009), Tahiti and Moorea, French Polynesia 2013–2014 (CHSP, 2014; Mallet et al., 2015; Aubry et al., 2015b), New Caledonia 2014 [DASS, 2014]) to quantify the ZIKV transmission variability.
Two compartmental models with vector-borne transmission are compared (cf. Figure 1). Both models use a Susceptible-Exposed-Infected-Resistant (SEIR) framework to describe the virus transmission in the human population, but differ in their representation of the mosquito population. Figure 1a is a schematic representation derived from Pandey et al. (2013) and formulates explicitly the mosquito population, with a Susceptible-Exposed-Infected (SEI) dynamic to account for the extrinsic incubation period (time taken for viral dissemination within the mosquito).
Figure 1
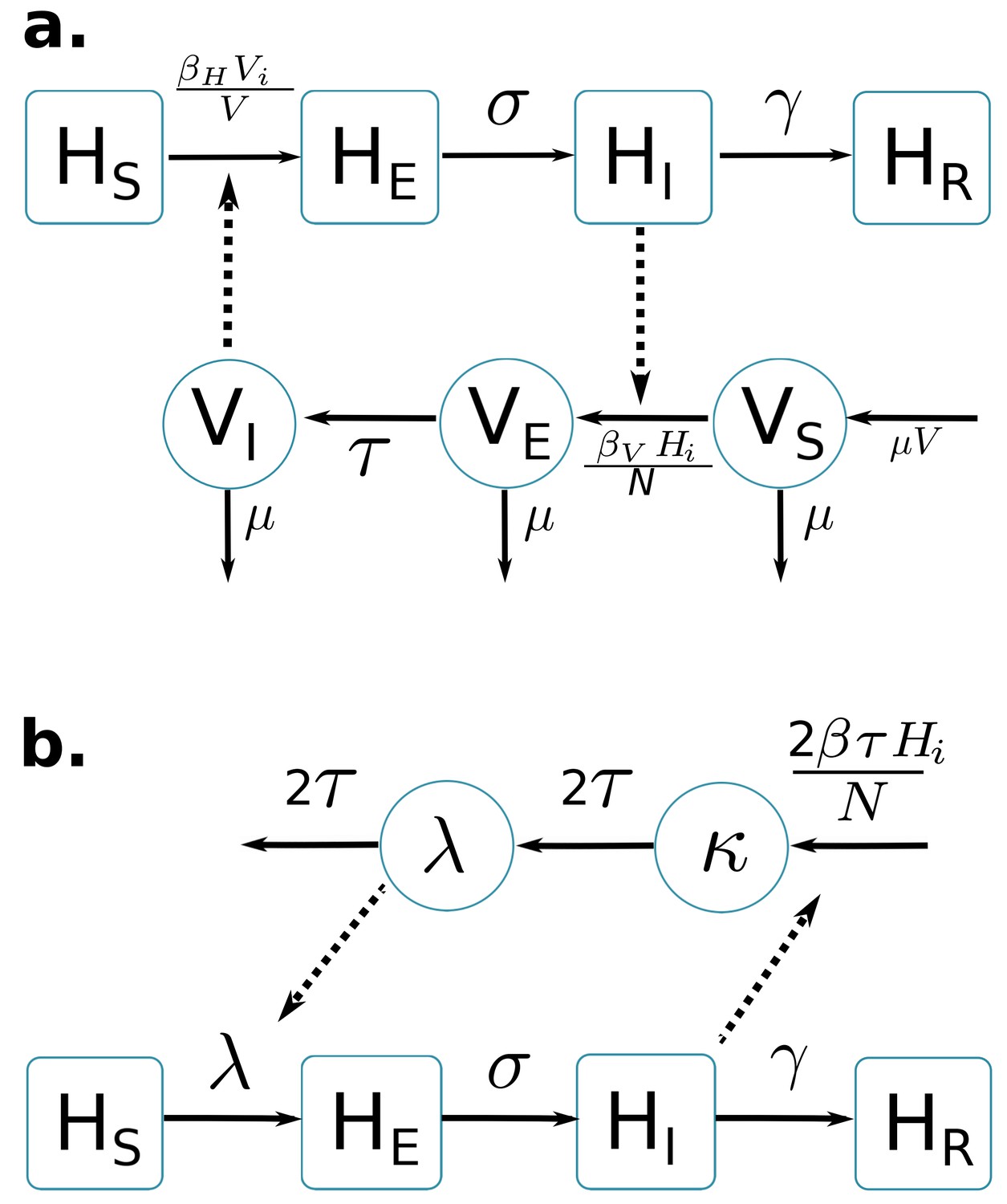
Graphical representation of compartmental models.
Squared boxes and circles correspond respectively to human and vector compartments. Plain arrows represent transitions from one state to the next. Dashed arrows indicate interactions between humans and vectors. (a) Pandey model (Pandey et al., 2013). susceptible individuals; infected (not yet infectious) individuals; infectious individuals; recovered individuals; is the rate at which -individuals move to infectious class ; infectious individuals () then recover at rate ; susceptible vectors; infected (not yet infectious) vectors; infectious vectors; constant size of total mosquito population; is the rate at which -vectors move to infectious class ; vectors die at rate . (b) Laneri model (Laneri et al., 2010). susceptible individuals; infected (not yet infectious) individuals; infectious individuals; recovered individuals; is the rate at which -individuals move to infectious class ; infectious individuals () then recover at rate ; implicit vector-borne transmission is modeled with the compartments and ; current force of infection; latent force of infection reflecting the exposed state for mosquitoes during the extrinsic incubation period; is the transition rate associated to the extrinsic incubation period.
By contrast, in the second model (Figure 1b) based on Laneri et al. (2010) the vector is modeled implicitly: the two compartments and do not represent the mosquito population but the force of infection for vector to human transmission. This force of infection passes through two successive stages in order to include the delay associated with the extrinsic incubation period: stands for this latent phase of the force of infection whereas corresponds directly to the rate at which susceptible humans become infected.
The basic reproduction number of the models () is calculated using the next Generation Matrix method (Diekmann et al., 2010):
In addition, we consider that only a fraction of the total population is involved in the epidemic, due to spatial heterogeneity, immuno-resistance, or cross-immunity. For both models we define with H the total size of the population reported by census.
The dynamics of ZIKV transmission in these islands is highly influenced by several sources of uncertainties. In particular, the small population size (less than 7000 inhabitants in Yap) leads to high variability in transmission rates. Therefore all these models are simulated in a discrete stochastic framework (Poisson with stochastic rates [Bretó et al., 2009]), to take this phenomenon into account. Stochasticity requires specific inference techniques: thus estimations are performed with PMCMC algorithm (particle Markov Chain Monte Carlo [Andrieu et al., 2010]).
Using declared Zika cases from different settings, the two stochastic models (Figure 1) were fitted (Figures 2–3). These models allow us to describe the course of the observed number of cases and estimate the number of secondary cases generated, . Our estimates of lie between 1.6 (1.5–1.7) and 3.2 (2.4–4.1) and vary notably with respect to settings and models (Figures 2–3 and Tables 1–2). Strikingly, Yap displays consistently higher values of in both models and in general, there is an inverse relationship between island size and both the value and variability of . This phenomenon may be explained by the higher stochasticity and extinction probability associated with smaller populations and can also reflect the information contained in the available data. However, the two highly connected islands in French Polynesia, Tahiti and Moorea, display similar values despite their differing sizes.
Figure 2

Results using the Pandey model.
Posterior median number of observed Zika cases (solid line), 95% credible intervals (shaded blue area) and data points (black dots). First column: particle filter fit. Second column: Simulations from the posterior density. Third column: posterior distribution. (a) Yap. (b) Moorea. (c) Tahiti. (d) New Caledonia. The estimated seroprevalences at the end of the epidemic (with 95% credibility intervals) are: (a) 73% (CI95: 68–77, observed 73%); (b) 49% (CI95: 45–53, observed 49%); (c) 49% (CI95: 45–53, observed 49%); (d) 39% (CI95: 8–92). See Figure 4.
Figure 3

Results using the Laneri model.
Posterior median number of observed Zika cases (solid line), 95% credible intervals (shaded blue area) and data points (black dots). First column: particle filter fit. Second column: Simulations from the posterior density. Third column: posterior distribution. (a) Yap. (b) Moorea. (c) Tahiti. (d) New Caledonia. The estimated seroprevalences at the end of the epidemic (with 95% credibility intervals) are: (a) 72% (CI95: 68–77, observed 73%); (b) 49% (CI95: 45–53, observed 49%); c) 49% (CI95: 45–53, observed 49%); d) 65% (CI95: 24–91). See Figure 5.
Table 1
Parameter estimations for the Pandey model. Posterior median (95% credible intervals). All the posterior parameter distributions are presented in Figures 6–9 .
| Pandey model | Yap | Moorea | Tahiti | New Caledonia | |
|---|---|---|---|---|---|
| Population size | H | 6892 | 16,200 | 178,100 | 268,767 |
| Basic reproduction number | 3.2 (2.4–4.1) | 2.6 (2.2–3.3) | 2.4 (2.0–3.2) | 2.0 (1.8–2.2) | |
| Observation rate | 0.024 (0.019-0.032) | 0.058 (0.048-0.073) | 0.060 (0.050-0.073) | 0.024 (0.010-0.111) | |
| Fraction of population involved | 74% (69–81) | 50% (48–54) | 50% (46–54) | 40% (9–96) | |
| Initial number of infected individuals | 2 (1–8) | 5 (0–21) | 329 (16–1047) | 37 (1–386) | |
| Infectious period in human (days) | 5.2 (4.1–6.7) | 5.2 (4.1–6.8) | 5.2 (4.1–6.7) | 5.5 (4.2–6.8) | |
| Extrinsic incubation period in mosquito (days) | 10.6 (8.7–12.5) | 10.5 (8.6–12.4) | 10.5 (8.6–12.6) | 10.7 (8.9–12.5) | |
| Mosquito lifespan (days) | 15.6 (11.7–19.3) | 15.3 (11.4–19.1) | 15.1 (11.2–19.0) | 15.4 (11.6–19.4) |
Table 2
Parameter estimations for the Laneri model. Posterior median (95% credible intervals). All the posterior parameter distributions are presented in Figures 10–13.
| Laneri model | Yap | Moorea | Tahiti | New Caledonia | |
|---|---|---|---|---|---|
| Population size | H | 6892 | 16,200 | 178,100 | 268,767 |
| Basic reproduction number | 2.2 (1.9–2.6) | 1.8 (1.6–2.0) | 1.6 (1.5–1.7) | 1.6 (1.5–1.7) | |
| Observation rate | 0.024 (0.019–0.033) | 0.057 (0.047–0.07) | 0.057 (0.049–0.069) | 0.014 (0.010–0.037) | |
| Fraction of population involved | 73% (69–78) | 51% (47–55) | 54% (49–59) | 71% (27–98) | |
| Initial number of infected individuals | 2 (1–10) | 9 (1–28) | 667 (22–1570) | 82 (2–336) | |
| Infectious period in human (days) | 5.3 (4.1–6.6) | 5.3 (4.1–6.7) | 5.2 (4.1–6.7) | 5.4 (4.1–6.8) | |
| Extrinsic incubation period in mosquito (days) | 10.7 (8.8–12.7) | 10.6 (8.6–12.6) | 10.5 (8.5–12.5) | 10.8 (8.9–12.8) |
Regarding model variability, estimates are always higher and coarser with the Pandey model than with the Laneri model (cf. Tables 1–2). The Pandey model has two additional estimated parameters (in particular, the mosquito lifespan), which can explain the higher variability of the output. It is worth noting that these parameters are very sensitive (see Materials and methods). The difference in may also be linked to the difference in the estimated initial number of infected individuals (), which is higher in the Laneri model than in the Pandey model. Because of the high proportion of asymptomatic cases (the ratio of asymptomatic:symptomatic is estimated to be 1:1.3, V.-M Cao-Lormeau personal communication), it is hard to determine which scenario is more realistic, the time between introduction of the disease into the island and the first reported symptomatic case being unknown in most settings.
For the durations of infectious and intrinsic incubation (in human) and extrinsic incubation (in mosquito) periods, the posterior density ressembles the informative prior (cf. Figures 6–13), indicating the models’ incapacity to identify properly these parameters without more informative data. Moreover, these parameters have a clear sensitivity (see Materials and methods) and precise field measures are therefore crucial for reliable model predictions.
The fraction of the population involved in the epidemic is well estimated when the seroprevalence is known (in Yap and French Polynesia). In these cases, the proportion of the population involved is slightly greater than the seroprevalence rate, indicating a very high infection rate among involved individuals. In New Caledonia, as no information on seroprevalence was available, the fraction of population involved displays very large confidence intervals (cf. Tables 1 and 2), indicating that the model did not manage to identify properly this parameter with the available data. In this case, this parameter is highly correlated to the observation rate (cf Figures 17 and 21): and seem unidentifiable without precise information on seroprevalence.
Discussion
The reproduction number is a key parameter in epidemiology that characterizes the epidemic dynamics and the initial spread of the pathogen at the start of an outbreak in a susceptible population. can be used to inform public health authorities on the level of risk posed by an infectious disease, vaccination strategy, and the potential effects of control interventions (Anderson and May, 1982). In the light of the potential public health crisis generated by the international propagation of ZIKV, characterization of the potential transmissibility of this pathogen is crucial for predicting epidemic size, rate of spread and efficacy of intervention.
Using data from both surveillance systems and seroprevalence surveys in four different geographical settings across the Pacific (Duffy et al., 2009; CHSP, 2014; Mallet et al., 2015; DASS, 2014; Aubry et al., 2015b), we have estimated the basic reproductive number (see Figures 2–3 and Tables 1–2). Our estimate of obtained by inference based on Particle MCMC (Andrieu et al., 2010) has values in the range 1.6 (1.5–1.7) – 3.2 (2.4–4.1). Our estimates vary notably across settings. Lower and finer values are found in larger islands. This phenomenon can at least in part be explained by large spatial heterogeneities and higher demographic stochasticity for islands with smaller populations, as well as the influence of stochasticity on biological and epidemiological processes linked to virus transmission. This phenomenon can also be specific to the selection of the studied islands or can reflect a highly clustered geographical pattern, the global incidence curve being the smoothed overview of a collection of more explosive small size outbreaks. However, it is notable that the two French Polynesian islands yield similar estimates of despite differing population sizes. Indeed, other important factors differ among French Polynesia, New Caledonia and Yap, such as the human genetic background and their immunological history linked to the circulation of others arboviruses. Moreover, whilst both New Caledonia and French Polynesia populations were infected by the same ZIKV lineage and transmitted by the same principle vector species, Aedes aegypti, the epidemic in Yap occurred much earlier with a different ZIKV lineage (Wang et al., 2016) and vectored by a different mosquito species Aedes hensilli (Ledermann et al., 2014). In French Polynesia, the vector Aedes polynesiensis is also present and dominates in Moorea with higher densities than in Tahiti. Finally, different vector control measures have been conducted in the three countries.
To date, studies investigating Zika outbreaks in the Pacific have always estimated using a deterministic framework. Using a similar version of the Pandey model in French Polynesia, Kucharski et al. (Kucharski et al., 2016) estimated between 1.6 and 2.3 (after scaling to square root for comparison) for Tahiti and between 1.8 and 2.9 in Moorea. These estimates are slightly lower and less variable than ours. This difference can be explained firstly by the chosen priors on mosquito parameters and secondly because our model includes demographic stochasticity. Moreover, they predicted a seroprevalence rate at the end of the epidemic of 95–97%, far from the 49% measured. In Yap island, a study (Funk et al., 2016) used a very detailed deterministic mosquito model, and estimated an for Zika between 2.9 and 8. In this case, our lower and less variable estimates may come from the fact that our model is more parsimonious in the number of uncertain parameters, especially concerning the mosquito population. Finally, a third study (Nishiura et al., 2016a) relied on another method for calculation (based on the early exponential growth rate of the epidemic) in French Polynesia as a whole and in Yap. Again, the obtained parameters are lower than ours in French Polynesia and higher in Yap. The first estimations for South America using a similar methodology (Nishiura et al., 2016b; Towers et al., 2016; Gao et al., 2016) lead to similar values. In all these studies a deterministic framework is used excluding the possibility of accounting for the high variability of biological and epidemiological processes exacerbated by the small size of the population. In these three studies, like in ours, it is worth noting that little insight is obtained regarding mosquito parameters. Posterior distribution mimics the chosen prior (cf. Figures 6–13). Both the simulation of the epidemics and the estimated are highly sensitive to the choice of priors on mosquito parameters, for which precise field measures are rare.
In the absence of sufficient data, the modeling of mosquito-borne pathogen transmission is a difficult task due to non-linearity and non-stationarity of the involved processes (Cazelles and Hales, 2006). This work has then several limitations. First, our study is limited by the completeness and quality of the data, with regard to both incidence and seroprevalence, but, above all, by the scarcity of information available on mosquitoes. Incidence data is aggregated at the island scale and cannot disentangle the effects of geography and observation noise to explain bimodal curves observed in Yap and New Caledonia. Moreover, although all data came from national surveillance systems, we had very little information about the potential degree of under-reporting, especially due to the high proportion of mildly symptomatic cases, at a time when the dangerous complications associated with the virus were unknown. Moreover, some cases might have been misdiagnosed as other flaviviruses, due to similarity in clinical manifestations or cross-reactivity in assays. Seroprevalence data were gathered from small sample sizes and were also sensitive to cross reactivity in populations non naive to dengue. In addition, they were missing in New Caledonia, which leads to strong correlation between our estimation of the observation rate and the fraction of the population involved in the epidemic. Because of the high proportion of asymptomatic or mildly symptomatic cases, the magnitude of the outbreaks is difficult to evaluate without precise seroprevalence data (Metcalf et al., 2016) or detection of mild, asymptomatic or pre-symptomatic infections (Thompson et al., 2016). Considering vectors, no demographic data were available and this partly explains the large variability of our estimations. Secondly, incidence and seroprevalence data were difficult to reconcile; the use of incidence data led to higher infection rates than those observed in the seroprevalence data. This difficulty has been overcome by considering that only a fraction of the population () is involved in the epidemic and then our model manages to reproduce the observed seroprevalence rate. This exposed fraction could be the result of spatial heterogeneity and high clustering of cases and transmission, as observed for dengue. The small dispersal of the mosquito and the limited population inter-mingling likely leads to considerable spatial variation in the extent of exposure to the virus and pockets of refugia in Tahiti as elsewhere (Telle et al., 2016). For instance, previous dengue infection rates in French Polynesia display large spatial variations even within islands (Daudens et al., 2009). Finer scale incidence and seroprevalence data would be useful to explore this. Another explanation for higher predicted than observed infection rates could be due to interaction with other flaviviruses. The Zika outbreak was concomitant with dengue outbreaks in French Polynesia (CHSP, 2014; Mallet et al., 2015) and New Caledonia (DASS, 2014). Examples of coinfection have been reported (Dupont-Rouzeyrol et al., 2015) but competition between these close pathogens may also have occurred. Finally, mathematical models with vectorial transmission may tend to estimate high attack rates, sometimes leading to a contradiction between observed incidence and observed seroprevalence. Assumptions on the proportionality between infected mosquitoes and the force of infection, as well as the density-dependence assumption in these models could be questioned. Indeed even if these assumptions are at the heart of the mathematical models of mosquito-borne pathogen transmission (Reiner et al., 2013; Smith et al., 2014), a recent review (Halstead, 2008) and recent experimental results (Bowman et al., 2014; Harrington et al., 2014) question these important points.
On a final note, the estimates of for ZIKV are similar to but generally on the lower side of estimates made for two other flaviviruses of medical importance, dengue and Yellow Fever viruses (Favier et al., 2006; Imai et al., 2015; Massad et al., 2003), even though caution is needed in the comparison of studies with differing models, methods and data sources. Interventions strategies developed for dengue should thus enable as, if not more effective control of ZIKV, with the caveat that ZIKV remains principally a mosquito-borne pathogen with little epidemiological significance of the sexual transmission route. Even though further work and data are needed to support this hypothesis (Brauer et al., 2016), two recent studies indicated that sexual transmission alone is not sufficient to sustain an epidemic (Gao et al., 2016; Towers et al., 2016).
In conclusion, using recent stochastic modeling methods, we have been able to determine estimates of for ZIKV with an unexpected relationship with population size. Further data from the current Zika epidemic in South America that is caused by the same lineage as French Polynesia lead to estimates in the same range of values (Nishiura et al., 2016b; Towers et al., 2016; Gao et al., 2016). Our study highlights the importance of gathering seroprevalence data, especially for a virus that often leads to an asymptomatic outcome and it would provide a key component for precise quantitative analysis of pathogen propagation to enable improved planning and implementation of prevention and control strategies.
Materials and methods
Data
During the 2007 outbreak that struck Yap, 108 suspected or confirmed Zika cases (16 per 1000 inhabitants) were reported by reviewing medical records and conducting prospective surveillance between April 1st and July 29th 2007 (Duffy et al., 2009). In French Polynesia, sentinel surveillance recorded more than 8700 suspected cases (32 per 1000 inhabitants) across the whole territory between October 2013 and April 2014 (CHSP, 2014; Mallet et al., 2015). In New Caledonia, the first Zika case was imported from French Polynesia on 2013 November 12th. Approximately 2500 cases (9 per 1000 inhabitants) were reported through surveillance between January (first autochtonous case) and August 2014 (DASS, 2014).
For Yap and French Polynesia, the post-epidemic seroprevalence was assessed. In Yap, a household survey was conducted after the epidemic, yielding an infection rate in the island of 73% (Duffy et al., 2009). In French Polynesia, three seroprevalence studies were conducted. The first one took place before the Zika outbreak, and concluded that most of the population was naive for Zika virus (Aubry et al., 2015a). The second seroprevalence survey was conducted between February and March 2014, at the end of the outbreak, and reported a seroprevalence rate around 49% (Aubry et al., 2015b). The third one concerned only schoolchildren in Tahiti and was therefore not included in the present study.
Demographic data on population size were based on censuses from Yap (Duffy et al., 2009), French Polynesia (Insee, 2012), and New Caledonia (Insee, 2014).
Models and inference
Model equations
View detailed protocolAlthough the models are simulated in a stochastic framework, we present them with ordinary differential equations for clarity. The reactions involved in the stochastic models are the same as those governed by the deterministic equations, but the simulation process differs through the use of discrete compartments. It is described in the next section.
The equations describing Pandey model are:
where is the proportion of susceptible mosquitoes, the proportion of exposed mosquitoes, and the proportion of infected mosquitoes. Since we are using a discrete model, we cannot use directly the proportions , and whose values are smaller than one. Therefore, we rescale using , which leads to , , and . In this model, the force of infection for humans is , and the force of infection for mosquitoes is
The equations describing Laneri model are:
In this model, the role of mosquitoes in transmission is represented only through the delay they introduce during the extrinsic incubation period (EIP, incubation period in the mosquito). For modeling reasons, this delay is included by representing the force of infection from infected humans to susceptible humans with two compartments and : in this formalism, the duration between the moment when an exposed individual becomes infectious and the moment when another susceptible individual acquires the infection has a gamma distribution of mean (Laneri et al., 2010; Roy et al., 2013; Lloyd, 2001). Therefore, represents the current force of infection for humans . The compartment represents the same force of infection but at a previous stage, reflecting the exposed phase for mosquitoes during the extrinsic incubation period. As an analogy to Pandey model, the force of infection for mosquitoes is , and therefore, the parameter can be interpreted as the product of a transmission parameter by the proportion of susceptible mosquitoes: . The force of infection for mosquitoes is then similar to Pandey’s : .
Again, since we are using a discrete model, we cannot use directly the proportions and whose values are smaller than one. Therefore, we rescale up to a factor , which leads to and .
In both models, following the dominant paradigm that diseases transmitted by Aedes mosquitoes are highly clustered, we restricted the total population measured by census to a fraction , in which the parameter is estimated. This formulation makes the hypothesis that a fraction of the total population is not at risk from the epidemic, because of individual factors or because the individuals remain in areas where the virus is not present. Moreover as the vector’s flying range is small, the clustering of ZIKV infection may be reinforced. This may result in escapees from infection within the population, even at a single island scale. The available data does not allow further exploration of the mechanisms underlying these phenomena, which seem fundamental to understand ZIKV propagation. At the very least, the restriction to a fraction enables the model to reproduce the observed seroprevalence rates, and to provide coherent results with respect to both data sources (seroprevalence and surveillance data).
Stochastic framework
Request a detailed protocolBoth models are simulated in a stochastic and discrete framework, the Poisson with stochastic rates formulation (Bretó et al., 2009), to include the uncertainties related to small population size. In this framework, the number of reactions occurring in a time interval is approximated by a multinomial distribution. In a model with possible reactions and compartments, being the state of the system at time and the model parameters, the probability that each reaction with rate occurs times in is calculated as follows (Dureau et al., 2013):
with, being the number of individual in compartment at time ,
(the number of individuals staying in compartment in )
(multinomial coefficient)
Observation models
Request a detailed protocolThe only observed compartments are the infected humans (incidence measured every week) and the recovered humans (seroprevalence at the end of the outbreak when data is available). In order to link the model to the data, two observation models, for both incidence and seroprevalence data, are needed.
Observation model on incidence data
Request a detailed protocolThe observed weekly incidence is assumed to follow a negative binomial distribution (Bretó et al., 2009) whose mean equals the number of new cases predicted by the model times an estimated observation rate .
The observation rate accounts for non observed cases, due to non reporting from medical centers, mild symptoms unseen by health system, and asymptomatic infections. Without additional data, it is not possible to make a distinction between these three categories of cases. We also implicitely make the assumption that these cases transmit the disease as much as reported symptomatic cases.
The observation model for incidence data is therefore :
being the observed incidence, and the incidence predicted by the model. The dispersion parameter (Bretó et al., 2009) is fixed at 0.1.
Observation model on seroprevalence data
Request a detailed protocolSeroprevalence data is fitted for Tahiti, Moorea, and Yap settings. It is assumed that the observed seroprevalence at the end of the epidemic follows a normal distribution with fixed standard deviation, whose mean equals the number of individuals in the compartment predicted by the model.
The observation model for seroprevalence data is therefore :
at the last time step, with notations detailed for each model in Table 3.
Table 3
Details of the observation models for seroprevalence
| Island | Date | Standard deviation | Observed seroprevalence |
|---|---|---|---|
| Yap | 2007-07-29 | 150 | 5005 (Duffy et al., 2009) |
| Moorea | 2014-03-28 | 325 | 0.49 × 16200 = 7938 (Aubry et al., 2015b) |
| Tahiti | 2014-03-28 | 3562 | 0.49 × 178100 = 87269 (Aubry et al., 2015b) |
Prior distributions
Request a detailed protocolInformative prior distributions are assumed for the mosquito lifespan, the duration of infectious period, and both intrinsic and extrinsic incubation periods. The initial numbers of infected mosquitoes and humans are estimated, and the initial number of exposed individuals is set to the initial number of infected to reduce parameter space. We assume that involved populations are naive to Zika virus prior to the epidemic and set the initial number of recovered humans to zero. The other priors and associated references are listed in Table 4.
Table 4
Prior distributions of parameters. 'Uniform[0,20]' indicates a uniform distribution in the range [0,20]. 'Normal(5,1) in [4,7]' indicates a normal distribution with mean five and standard deviation 1, restricted to the range [4,7].
| Parameters | Pandey model | Laneri model | References | |||
|---|---|---|---|---|---|---|
| squared basic reproduction number | Uniform[0, 20] | Uniform[0, 20] | assumed | |||
| transmission from human to mosquito | Uniform[0,10] | . | assumed | |||
| infectious period (days) | Normal(5,1) in [4,7] | Normal(5,1) in [4,7] | (Mallet et al., 2015) | |||
| intrinsic incubation period (days) | Normal(4,1) in [2,7] | Normal(4,1) in [2,7] | (Nishiura et al., 2016b; Bearcroft, 1956; Lessler et al., 2016) | |||
| extrinsic incubation period (days) | Normal(10.5,1) in [4,20] | Normal(10.5,1) in [4,20] | (Hayes, 2009; Chouin-Carneiro et al., 2016) | |||
| mosquito lifespan (days) | Normal(15,2) in [4,30] | . | (Brady et al., 2013; Liu-Helmersson et al., 2014) | |||
| fraction of population involved | Uniform[0,1] | Uniform[0,1] | ||||
| Initial conditions (t=0) | Pandey model | Laneri model | ||||
|---|---|---|---|---|---|---|
| HI(0) | infected humans | Uniform[10-6,1]N | Uniform[10-6,1]N | |||
| HE(0) | exposed humans | HI(0) | HI(0) | |||
| HR(0) | recovered humans | 0 | 0 | |||
| infected vectors | VI(0)=Uniform[10-6,1]H | L(0)=Uniform[10-6,1]N | ||||
| exposed vectors | VE(0) = VI(0) | K(0)=L(0) | ||||
| Local conditions | Yap | Moorea | Tahiti | New Caledonia | References | |
|---|---|---|---|---|---|---|
| r | observation rate | Uniform[0,1] | Uniform[0,1] | Uniform[0,0.3] | Uniform[0,0.23] | (Mallet et al., 2015; DASS, 2014) |
| H | population size | 6,892 | 16,200 | 178,100 | 268,767 | (Duffy et al., 2009; Insee, 2012, 2014) |
The range for the prior on observation rate is reduced for Tahiti and New Caledonia, in order to reduce the parameter space and facilitate convergence. In both cases, we use the information provided with the data source. In French Polynesia, 8750 cases we reported, but according to local health authorities, more than 32,000 people would have attended health facilities for Zika (Mallet et al., 2015) (8750/32000 ≤ 0.3). In New Caledonia, approximately 2500 cases were reported but more than 11,000 cases were estimated by heath authorities (DASS, 2014) (2500/11000 ≤ 0.23). In both cases, these extrapolations are lower bounds on the real number of cases (in particular, they do not estimate the number of asymptomatic infections), and therefore can be used as upper bounds on the observation rate.
Estimations
Inference with PMCMC
Request a detailed protocolThe complete model is represented using the state space framework, with two equation systems: the transition equations refer to the transmission models, and the measurement equations are given by the observation models.
In a deterministic framework, this model could be directly estimated using MCMC, with a Metropolis-Hastings algorithm targeting the posterior distribution of the parameters. This algorithm would require the calculation of the model likelihood at each iteration.
In our stochastic framework, the model output is given only through simulations and the likelihood is intractable. In consequence, estimations are performed with the PMCMC algorithm (particle Markov Chain Monte Carlo (Andrieu et al., 2010)), in the PMMH version (particle marginal Metropolis-Hastings). This algorithm uses the Metropolis-Hastings structure, but replaces the real likelihood by its estimation with Sequential Monte Carlo (SMC).
Algorithm 1 PMCMC (Andrieu et al., 2010) (PMMH version, as in SSM (Dureau et al., 2013)) |
|---|
| In a model with observations and particles. is the transition kernel. |
| 1: Initialize . 2: Using SMC algorithm, compute and sample from . 3: for do 4: Sample from 5: Using SMC algorithm, compute and sample from 6: Accept (et ) with probability 7: If accepted, and . Otherwise and . 8: end for |
SMC (Doucet et al., 2001) is a filtering method that enables to recover the latent variables and estimate the likelihood for a given set of parameters. The data is treated sequentially, by adding one more data point at each iteration. The initial distribution of the state variables is approximated by a sample a particles, and from one iteration to the next, all the particles are projected according to the dynamic given by the model. The particles receive a weight according to the quality of their prediction regarding the observations. Before the next iteration, all the particles are resampled using these weights, in order to eliminate low weight particles and concentrate the computational effort in high probability regions. Model likelihood is also computed sequentially at each iteration (Dureau et al., 2013; Doucet and Johansen, 2011).
Algorithm 2 SMC (Sequential Monte Carlo, as implemented in SSM [Dureau et al., 2013]) |
|---|
In a model with observations and particles. |
| is the model likelihood . is the weight and is the state associated to particle at iteration . |
| 1: Set , . 2: Sample from . 3: for do 4: for do 5: Sample from 6: Set 7: end for 8: Set and 9: Resample from 10: end for |
A gaussian kernel is used in the PMCMC algorithm, with mean and fixed variance (random walk Metropolis Hastings).
Initialization
Request a detailed protocolPMCMC algorithm is very sensitive to initialization of both the parameter values and the covariance matrix . Several steps of initialization are therefore used.
Firstly, parameter values are initialized by maximum likelihood through simplex algorithm on a deterministic version of the model. We apply the simplex algorithm to a set of 1000 points sampled in the prior distributions and we select the parameter set with the highest likelihood.
Secondly, in order to initialise the covariance matrix, an adaptative MCMC (Metropolis Hastings) framework is used (Roberts and Rosenthal, 2009; Dureau et al., 2013). It uses the empirical covariance of the chain , and aims to calibrate the acceptance rate of the algorithm to an optimal value. The transition kernel is also mixed (with a probability ) with another gaussian using the identity matrix to improve mixing properties.
The parameter is approximated by successive iterations using the empirical acceptance rate of the chain.
The adaptative PMCMC algorithm itself may have poor mixing properties without initialization. A first estimation of the covariance matrix is computed using KMCMC algorithm (Dureau et al., 2013). In the KMCMC algorithm, the model is simulated with stochastic differential equations (intermediate between deterministic and Poisson with stochastic rates frameworks) and the SMC part of the adaptative PMCMC is replaced by the extended Kalman filter. When convergence is reached with KMCMC, then, adaptative PMCMC is used.
The PMCMC algorithm is finally applied on the output of the adaptative PMCMC, using 50,000 iterations and 10,000 particles. Calculations are performed with SSM software (Dureau et al., 2013) and R version 3.2.2.
Calculation
is calculated using the Next Generation Matrix approach (NGM) (19).
Calculation in Pandey model
Request a detailed protocolThen we have,
and
We calculate the eigen values of :
Then or and the highest eigenvalue is .
This formula defines as "the number of secondary cases per generation" (Dietz, 1993): i.e can be written as the geometric mean , where is the number of infected mosquitoes after the introduction of one infected human in a naive population, and is the number of infected humans after the introduction of one infected mosquito in a naive population. With this definition, herd immunity is reached when of the population is vaccinated (Dietz, 1993).
Calculation in Laneri model
Request a detailed protocolFollowing the analogy with Pandey model, we compute the spectral radius of the NGM for the Laneri model.
Then we have,
and
We calculate the eigen values of :
Then or and the highest eigenvalue is .
Because and can be seen as parameters rather than state variables, the interpretation of the spectral radius as the of the model is not straightforward. Therefore, we computed the of the model through simulations, by counting the number of secondary infections after the introduction of a single infected individual in a naive population. Since Laneri model is considered here as a vector model, the number of infected humans after the introduction of a single infected is considered as . We simulated 1000 deterministic trajectories, using parameter values sampled in the posterior distributions for all parameters except initial conditions. With this method, the confidence intervals for number of infected humans () are similar to the ones of estimated by the model. As a consequence, was approximated by the spectral radius of the NGM in our results with our stochastic framework (cf. Table 5).
Table 5
Square root of the number of secondary cases after the introduction of a single infected individual in a naive population. Median and 95% credible intervals of 1000 deterministic simulations using parameters from the posterior distribution.
| Pandey model | Laneri model | |
|---|---|---|
| Yap | 3.1 (2.5–4.3) | 2.2 (1.9–2.6) |
| Moorea | 2.6 (2.2–3.3) | 1.8 (1.6–2.0) |
| Tahiti | 2.4 (2.0–3.2) | 1.6 (1.5–1.7) |
| New Caledonia | 2.0 (1.8–2.2) | 1.6 (1.5–1.7) |
As a robustness check, the same method was applied to Pandey model : the confidence intervals for the number of secondary cases in simulations are very similar to the ones of (cf. Table 5).
Sensitivity analysis
Request a detailed protocolIn order to analyse the influence of parameter values on the model’s outputs, a sensitivity analysis was performed, using LHS/PRCC technique (Blower and Dowlatabadi, 1994), on Tahiti example. Similar results were obtained for the other settings. Three criteria were retained as outputs for the analysis: the seroprevalence at the last time point, the intensity of the peak of the outbreak and the date of the peak. We used uniform distributions for all parameters, which are listed in Tables 6 and 7. For model parameters, we used the same range as for the prior distribution. For initial conditions, the observation rate and the fraction involved in the epidemic , we used the 95% confidence interval obtained by PMCMC, in order to avoid unrealistic scenarios.
Table 6
Sensitivity analysis in Pandey model. Tahiti island. 1000 parameter sets were sampled with latin hypercube sampling (LHS), using 'lhs' R package (Carnell, 2016). On each parameter set, the model was simulated deterministically in order to explore variability in parameters without interference with variations due to stochasticity. PRCC were computed using the 'sensitivity' R package (Pujol et al., 2016).
| Parameters | Distribution | Seroprevalence | Peak intensity | Peak date |
|---|---|---|---|---|
| Model parameters | ||||
| Uniform[0,20] | 0.87 | 0.90 | −0.55 | |
| Uniform[0,10] | −0.66 | −0.73 | 0.35 | |
| Uniform[4,7] | −0.25 | 0.10 | 0.20 | |
| Uniform[2,7] | −0.03 | −0.10 | 0.15 | |
| Uniform[4,20] | −0.05 | −0.07 | 0.06 | |
| Uniform[4,30] | −0.56 | −0.70 | 0.49 | |
| Initial conditions | ||||
| HI(0) | Uniform[2.10-5,0.011] | 0.05 | −0.02 | 0.02 |
| VI(0) | Uniform[10-4,0.034] | 0.11 | −0.00 | −0.26 |
| Fraction involved and observation model | ||||
| Uniform[0.46,0.54] | 0.47 | 0.15 | −0.03 | |
| Uniform[0.048,0.072] | −0.04 | 0.03 | 0.05 |
Table 7
Sensitivity analysis in Laneri model. Tahiti island. 1000 parameter sets were sampled with latin hypercube sampling (LHS), using 'lhs' R package (Carnell, 2016). On each parameter set, the model was simulated deterministically in order to explore variability in parameters without interference with variations due to stochasticity. PRCC were computed using the 'sensitivity' R package (Pujol et al., 2016).
| Parameters | Distribution | Seroprevalence | Peak intensity | Peak date |
|---|---|---|---|---|
| Model parameters | ||||
| Uniform[0,20] | 0.62 | 0.93 | −0.50 | |
| Uniform[4,7] | 0.01 | 0.62 | 0.15 | |
| Uniform[2,7] | −0.03 | −0.54 | 0.21 | |
| Uniform[4,20] | −0.03 | −0.70 | 0.47 | |
| Initial conditions | ||||
| HI(0) | Uniform[10-5,0.015] | 0.05 | 0.02 | −0.32 |
| L(0) | Uniform[2.10-5,0.004] | 0.05 | 0.00 | −0.16 |
| Fraction involved and observation model | ||||
| Uniform[0.49,0.59] | 0.80 | 0.34 | 0.02 | |
| Uniform[0.048,0.068] | −0.01 | 0.01 | −0.02 |
For all criteria, the key parameters in both models are transmission parameters ( and ). High values for are positively correlated with a large seroprevalence and a high and early peak. On the contrary, high values for the parameters introducing a delay in the model, the incubation periods in human () and in mosquito (), are associated with a lower and later peak, and have no significant effect on seroprevalence. Moreover, the simulations are clearly sensitive to the other model parameters, in particular the mosquito lifespan () in Pandey model.
Concerning other parameters, the initial conditions have a noticeable effect on the date of the peak only. As expected, the fraction involved in the epidemic () influences the magnitude of the outbreak, by calibrating the proportion of people than can be infected, but it has no significant effect on the timing of the peak.
Complementary results
These complementary results include PMCMC results for both models in the four settings: the epidemic trajectories regarding the human compartments for infected and recovered individuals (Figures 4,5), the detailed posterior distributions for all parameters (Figures 6–13) and correlation plots for all models (Figures 14–21).
Figure 4
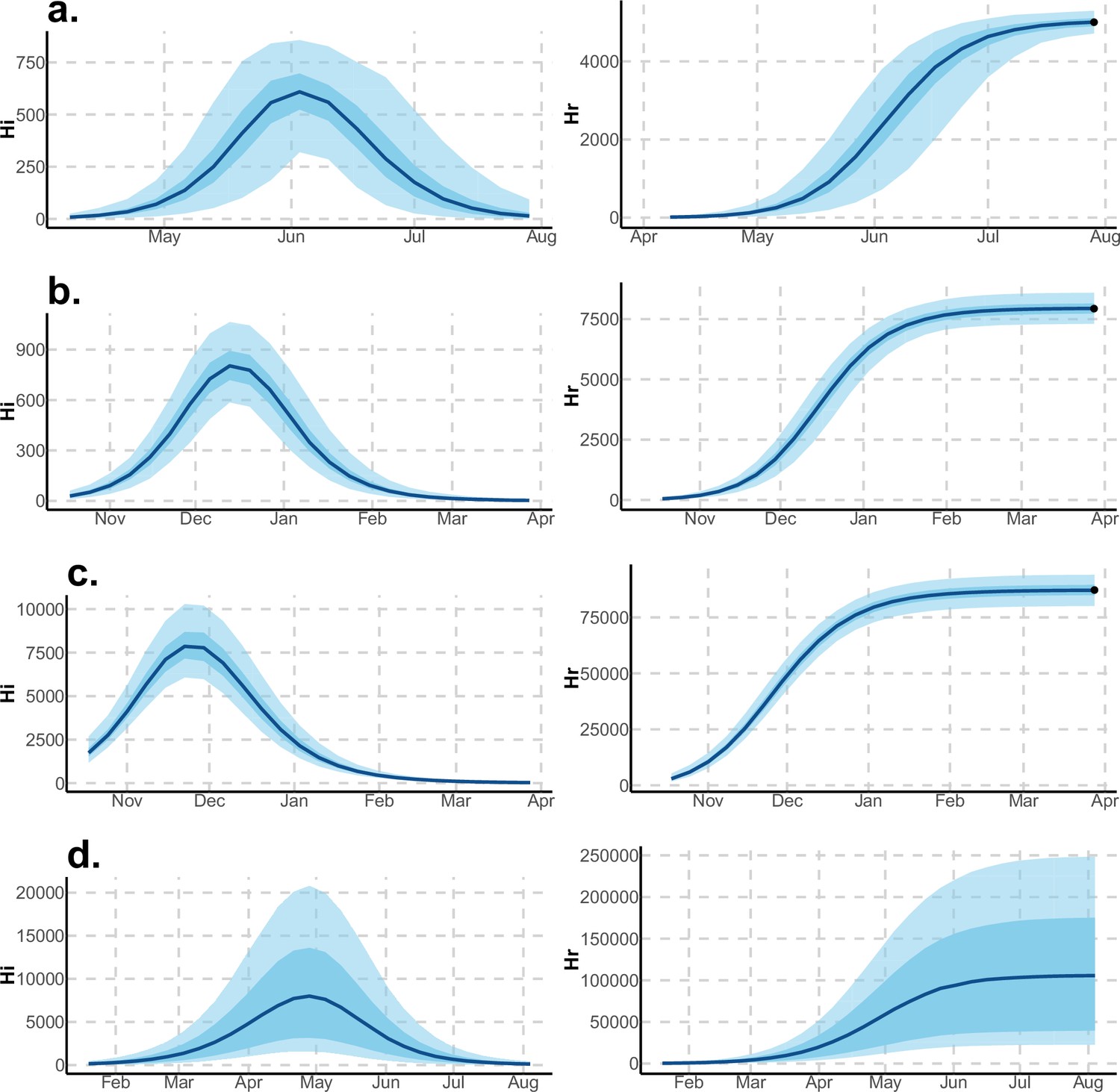
Infected and recovered humans evolution during the outbreak with Pandey model.
Simulations from the posterior density: posterior median (solid line), 95% and 50% credible intervals (shaded blue areas) and observed seroprevalence (black dots). First column: Infected humans (). Second column: Recovered humans (). (a) Yap. (b) Moorea. (c) Tahiti. (d) New Caledonia.
Figure 5
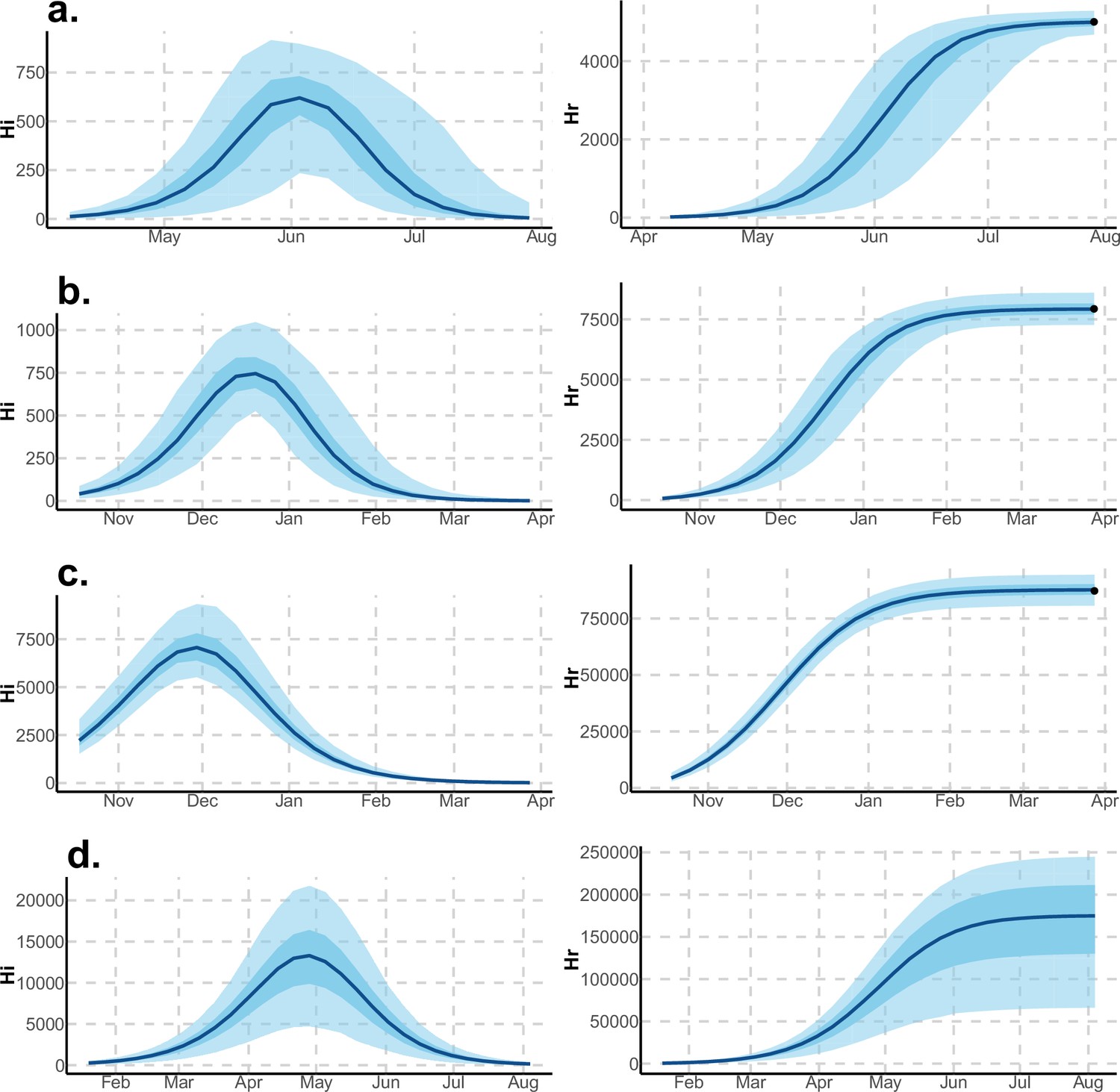
Infected and recovered humans evolution during the outbreak with Laneri model.
Simulations from the posterior density: posterior median (solid line), 95% and 50% credible intervals (shaded blue areas) and observed seroprevalence (black dots). First column: Infected humans (). Second column: Recovered humans (). (a) Yap. (b) Moorea. (c) Tahiti. (d) New Caledonia.
Figure 6
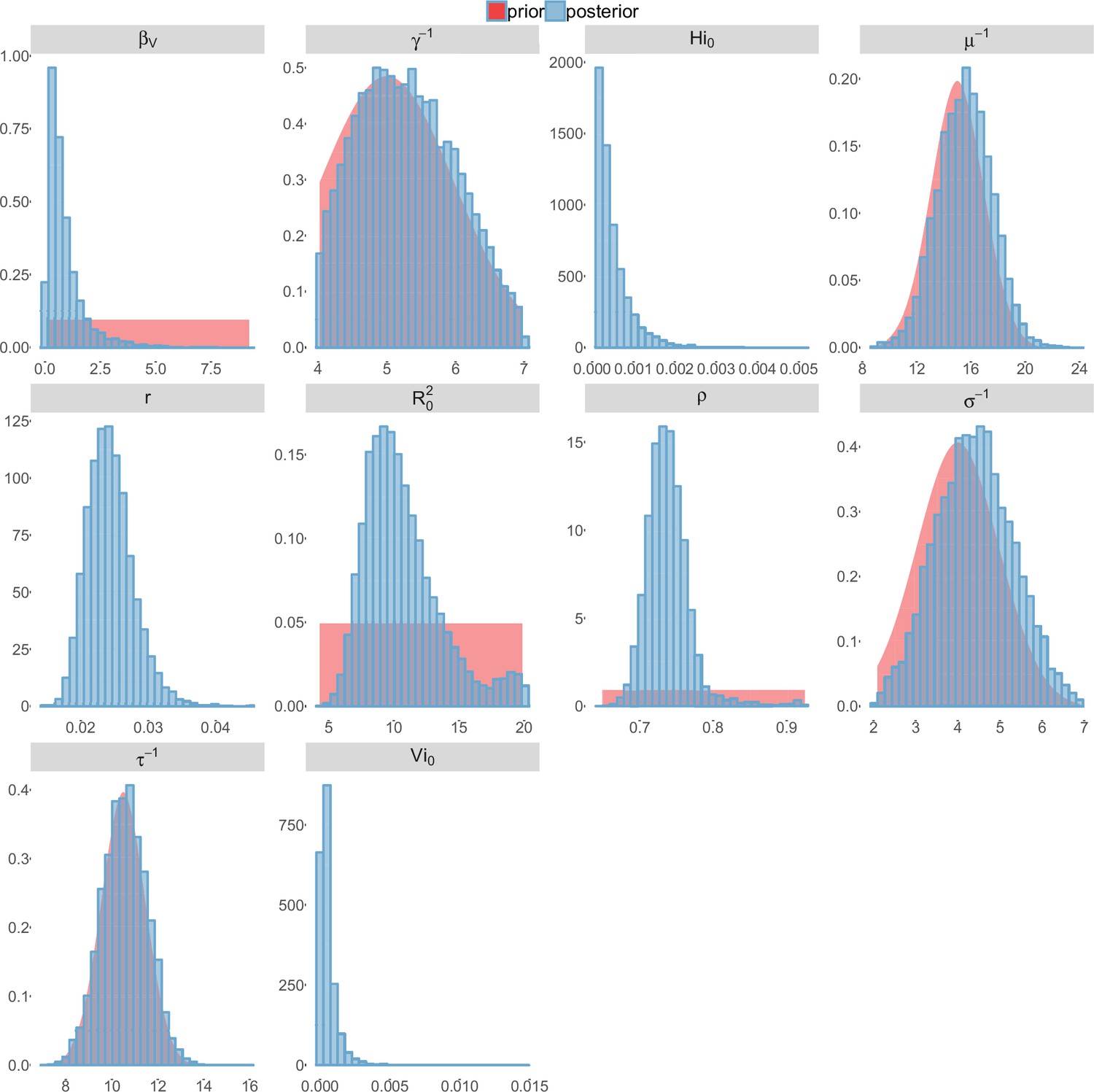
Posterior distributions.
Pandey model, Yap island.
Figure 7
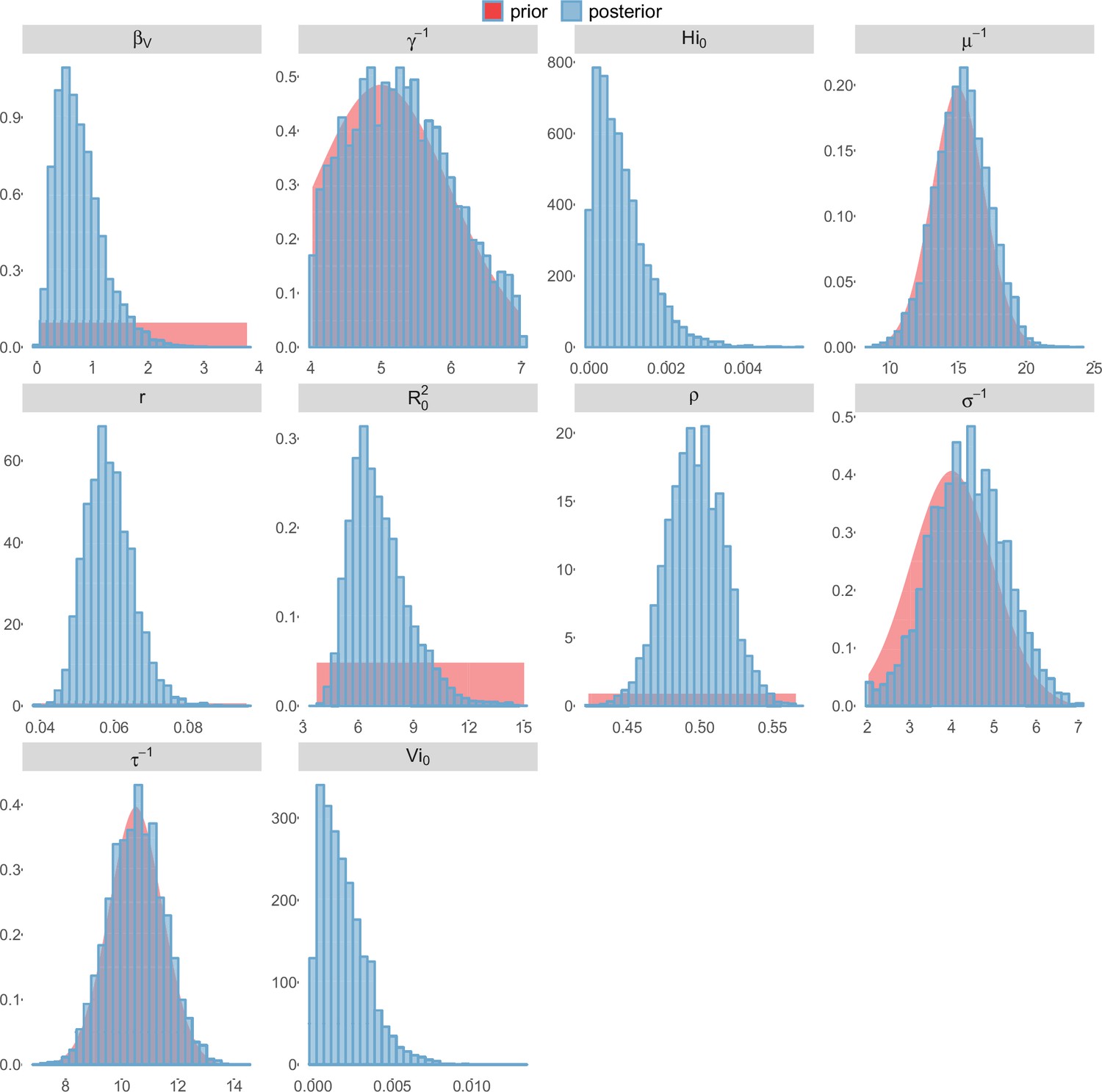
Posterior distributions.
Pandey model, Moorea island.
Figure 8
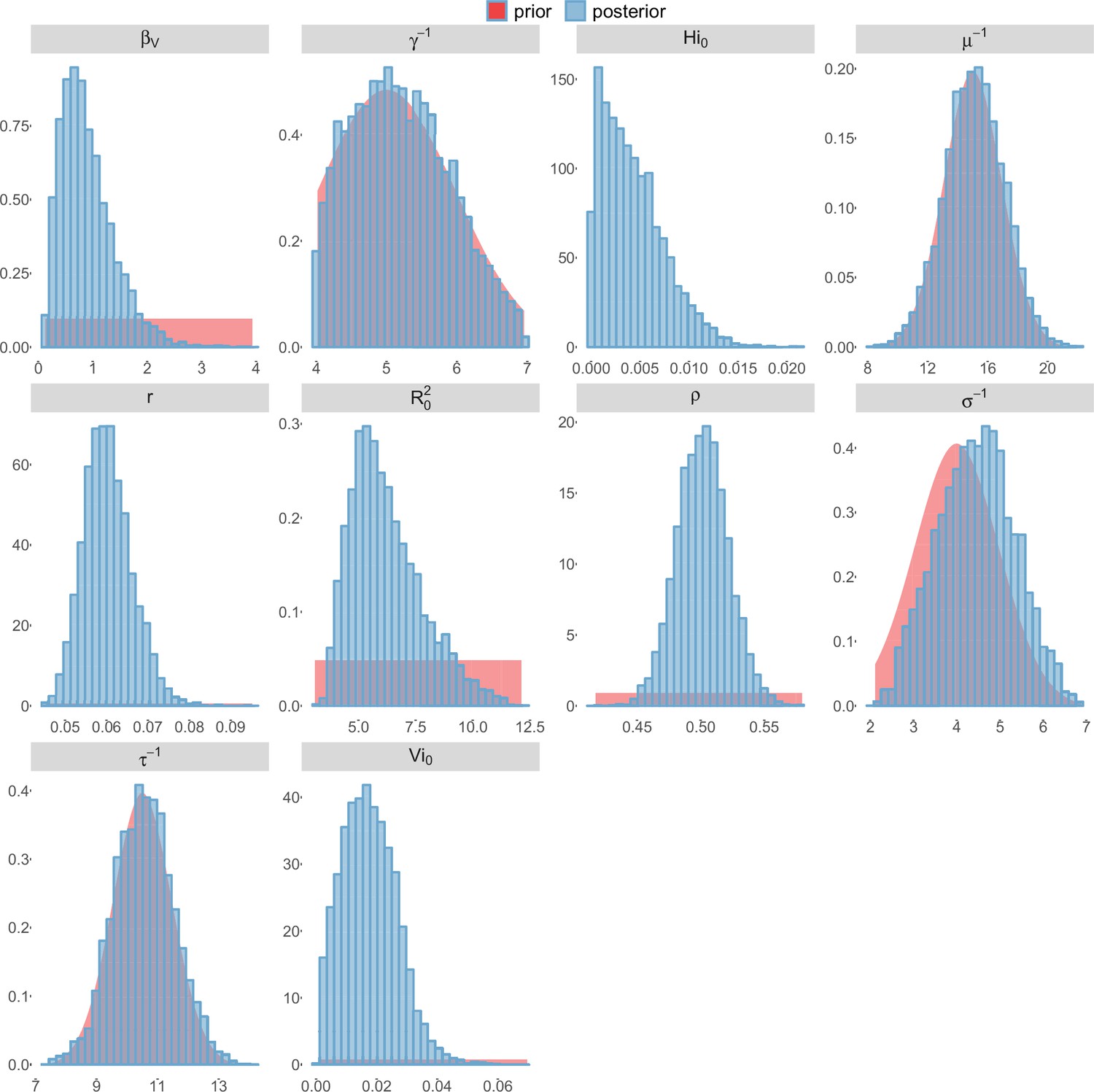
Posterior distributions.
Pandey model, Tahiti island.
Figure 9
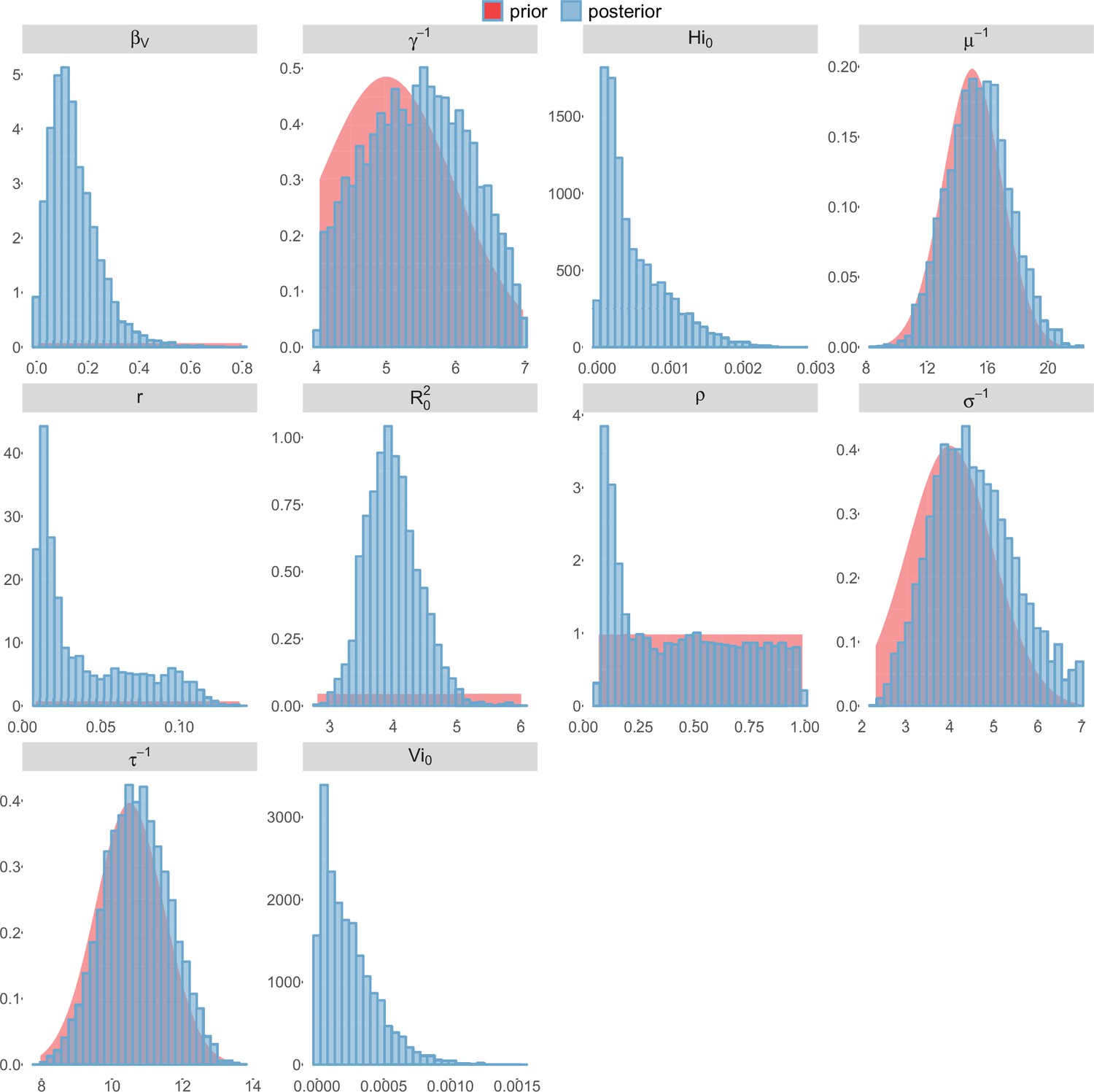
Posterior distributions.
Pandey model, New Caledonia.
Figure 10
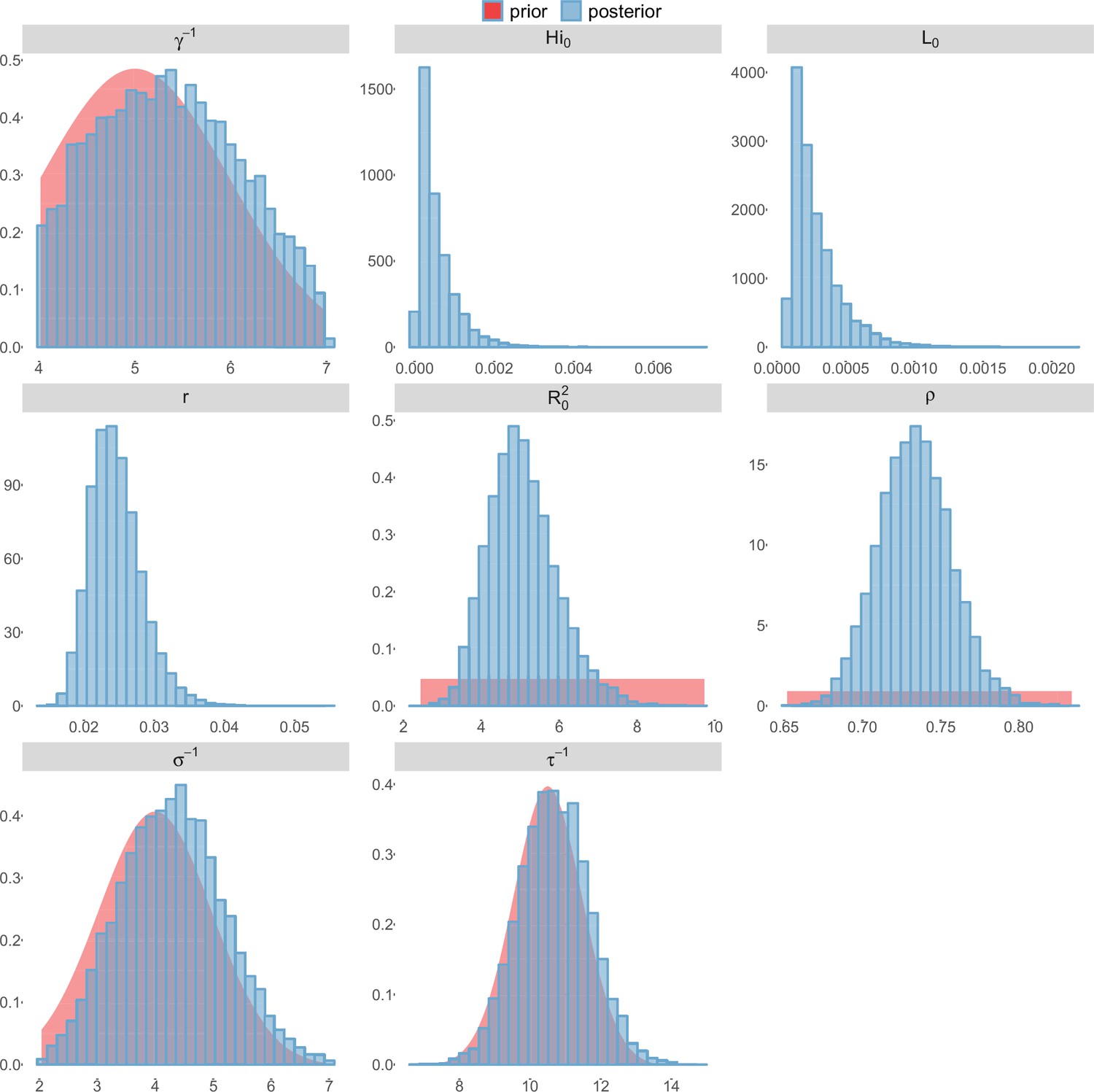
Posterior distributions.
Laneri model, Yap island.
Figure 11
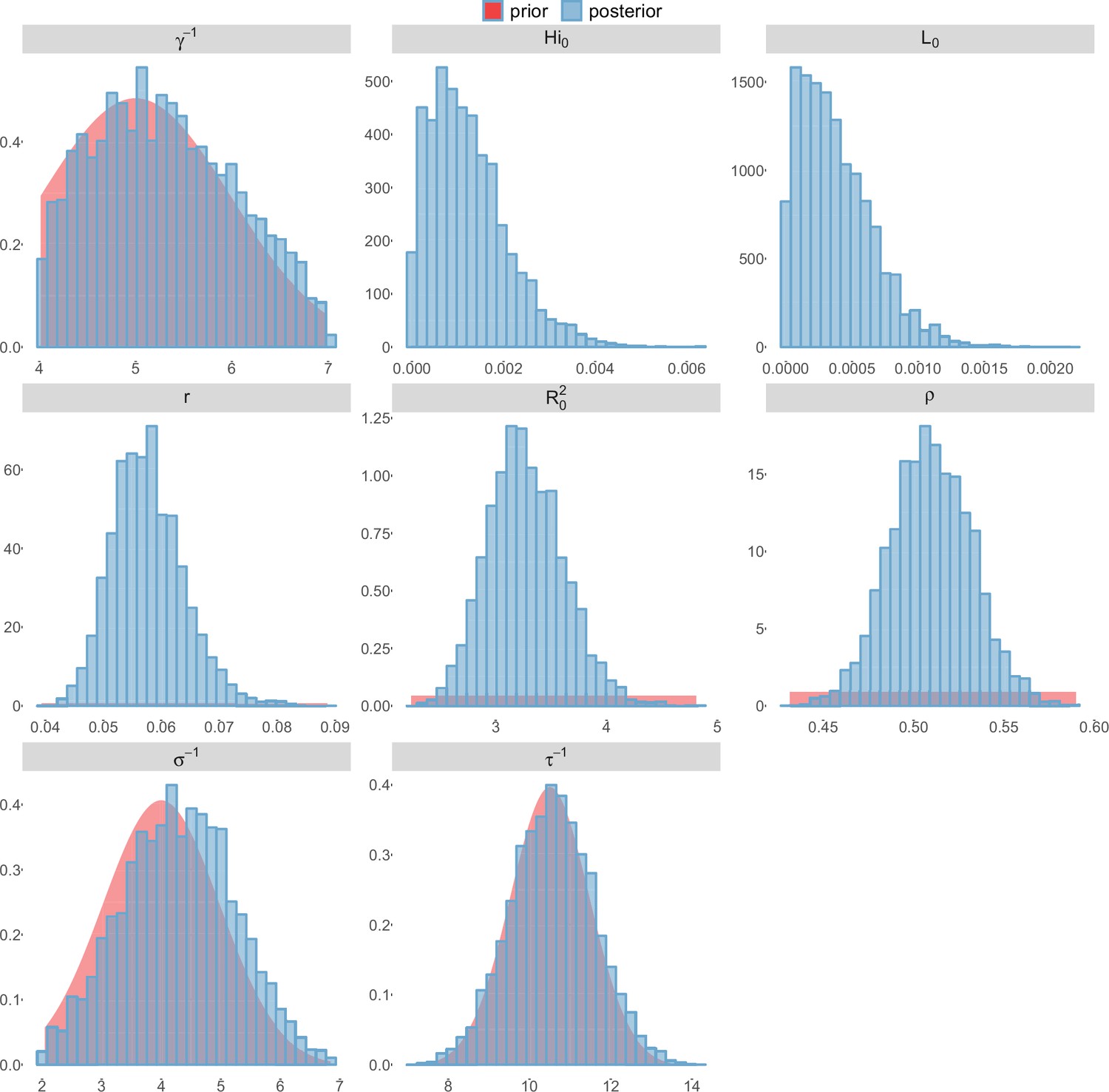
Posterior distributions.
Laneri model, Moorea island.
Figure 12
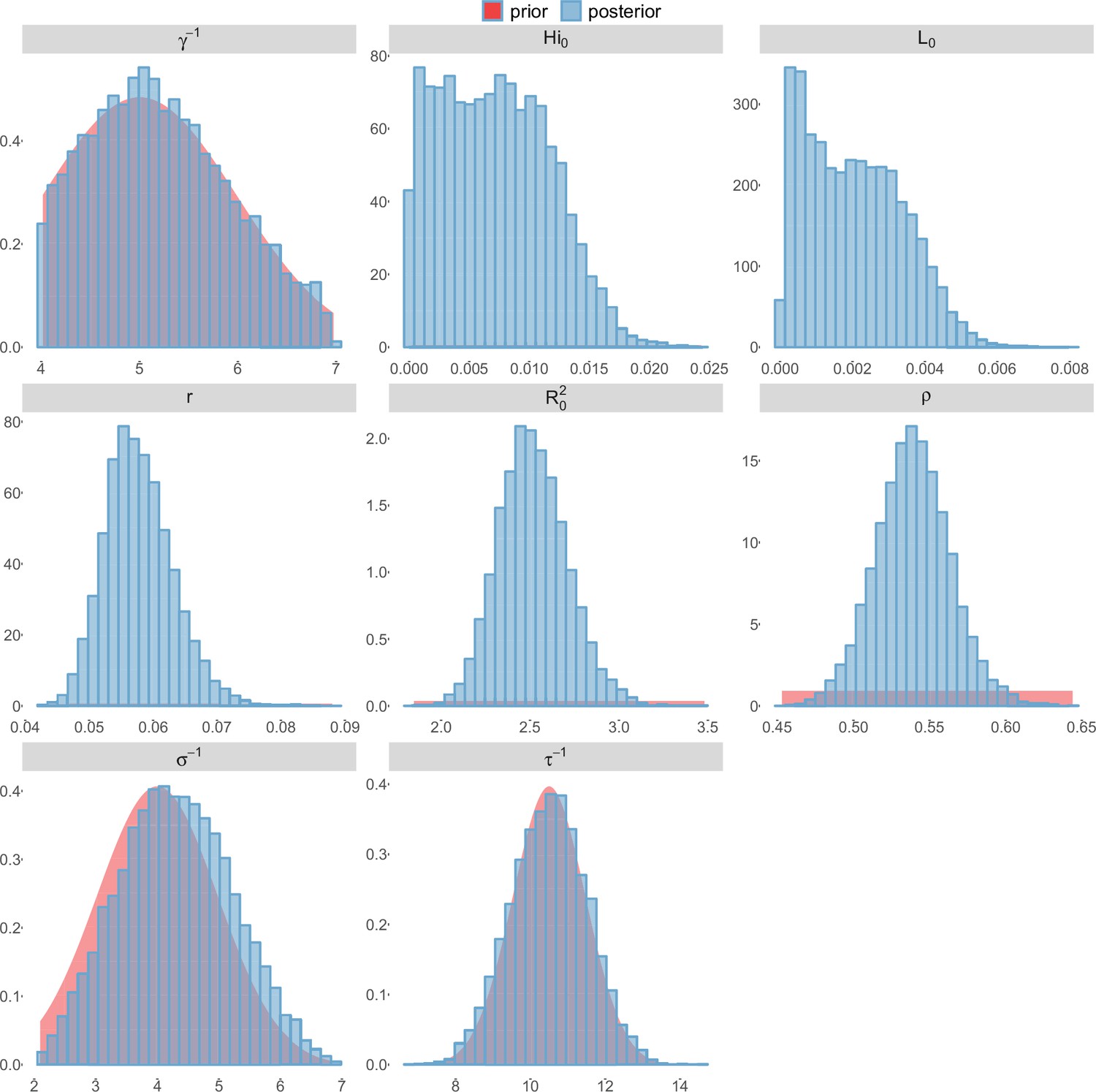
Posterior distributions.
Laneri model, Tahiti island.
Figure 13

Posterior distributions.
Laneri model, New Caledonia.
Figure 14
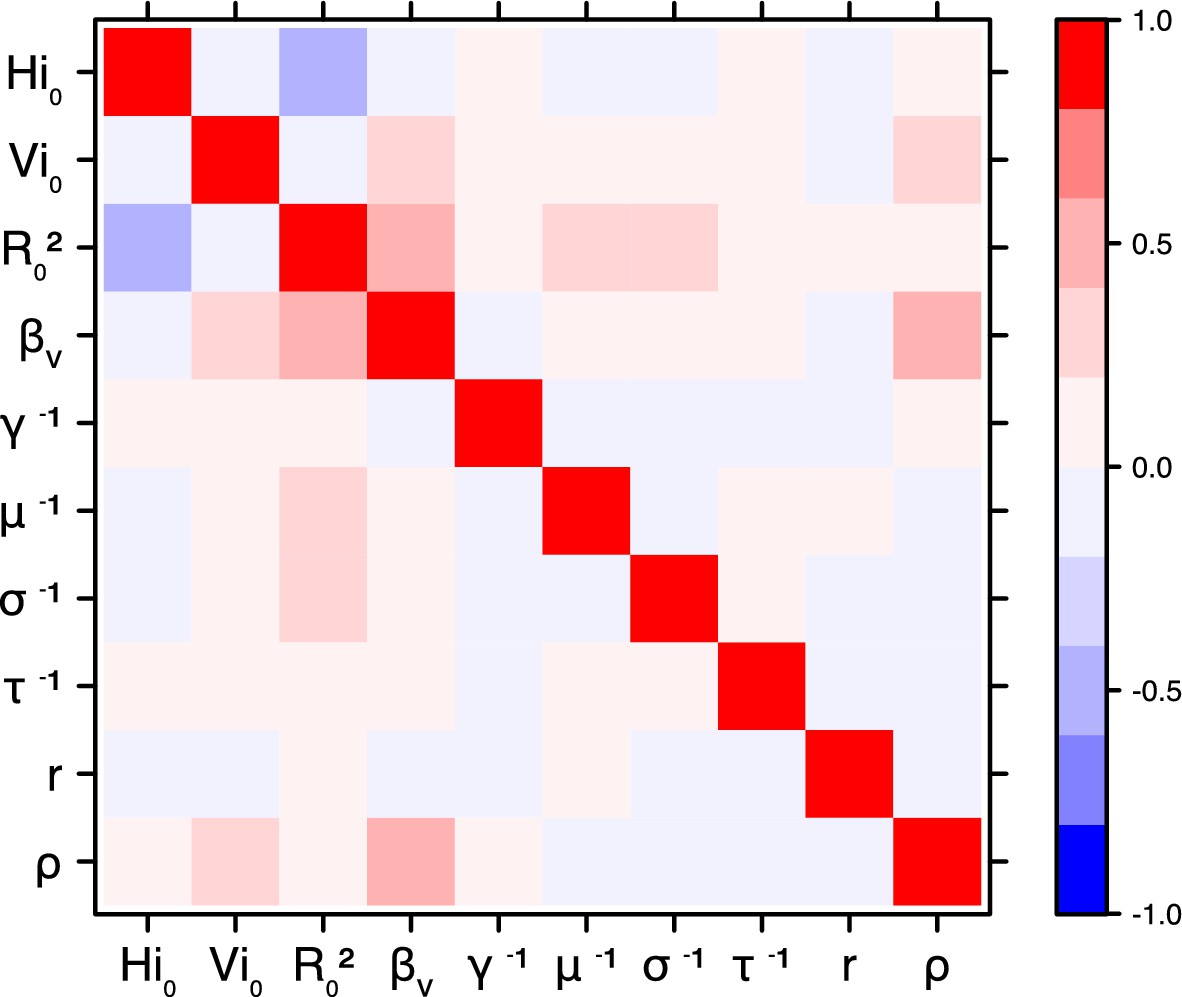
Correlation plot of MCMC output.
Pandey model, Yap island.
Figure 15
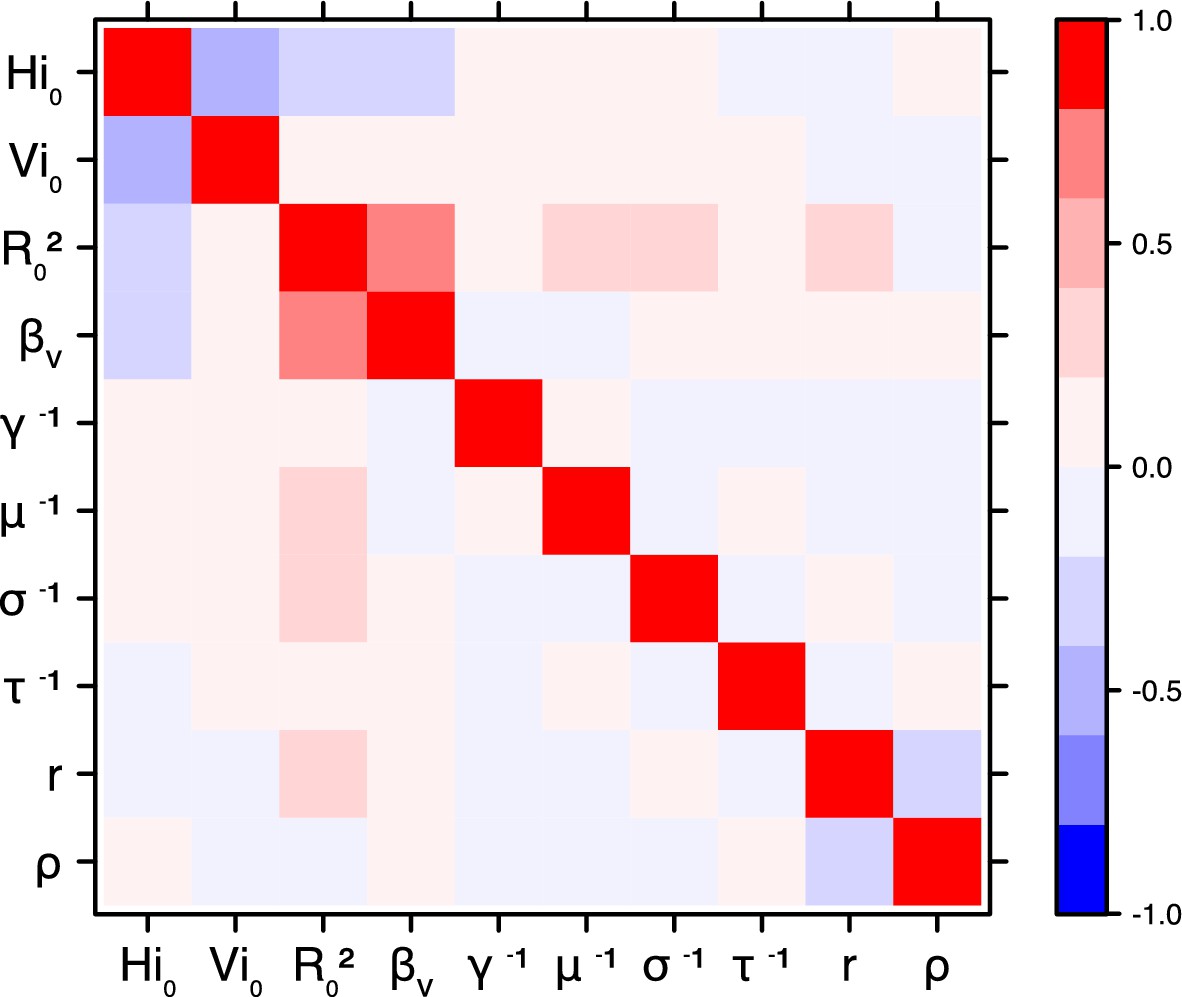
Correlation plot of MCMC output.
Pandey model, Moorea island.
Figure 16

Correlation plot of MCMC output.
Pandey model, Tahiti island.
Figure 17
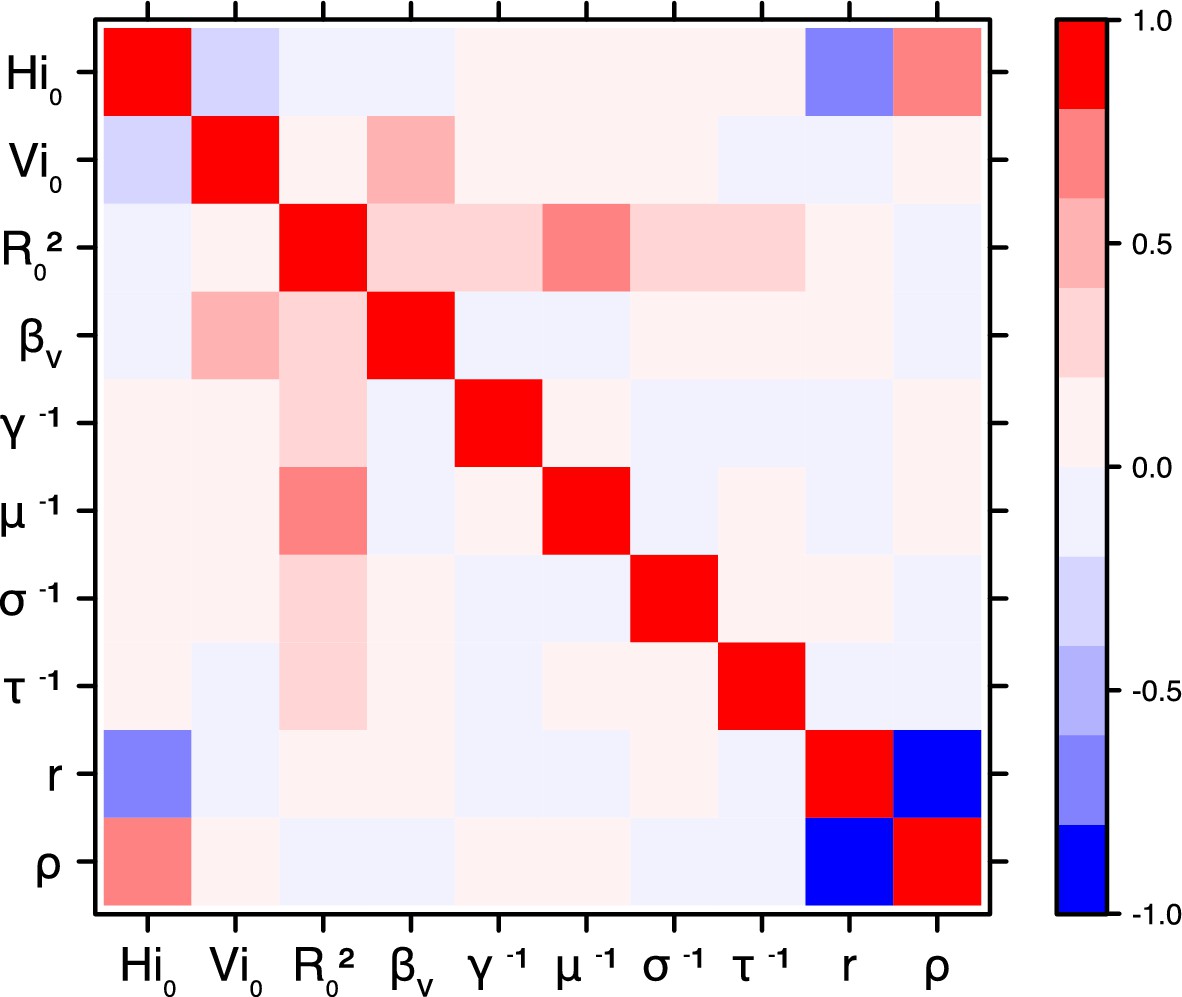
Correlation plot of MCMC output.
Pandey model, New Caledonia.
Figure 18
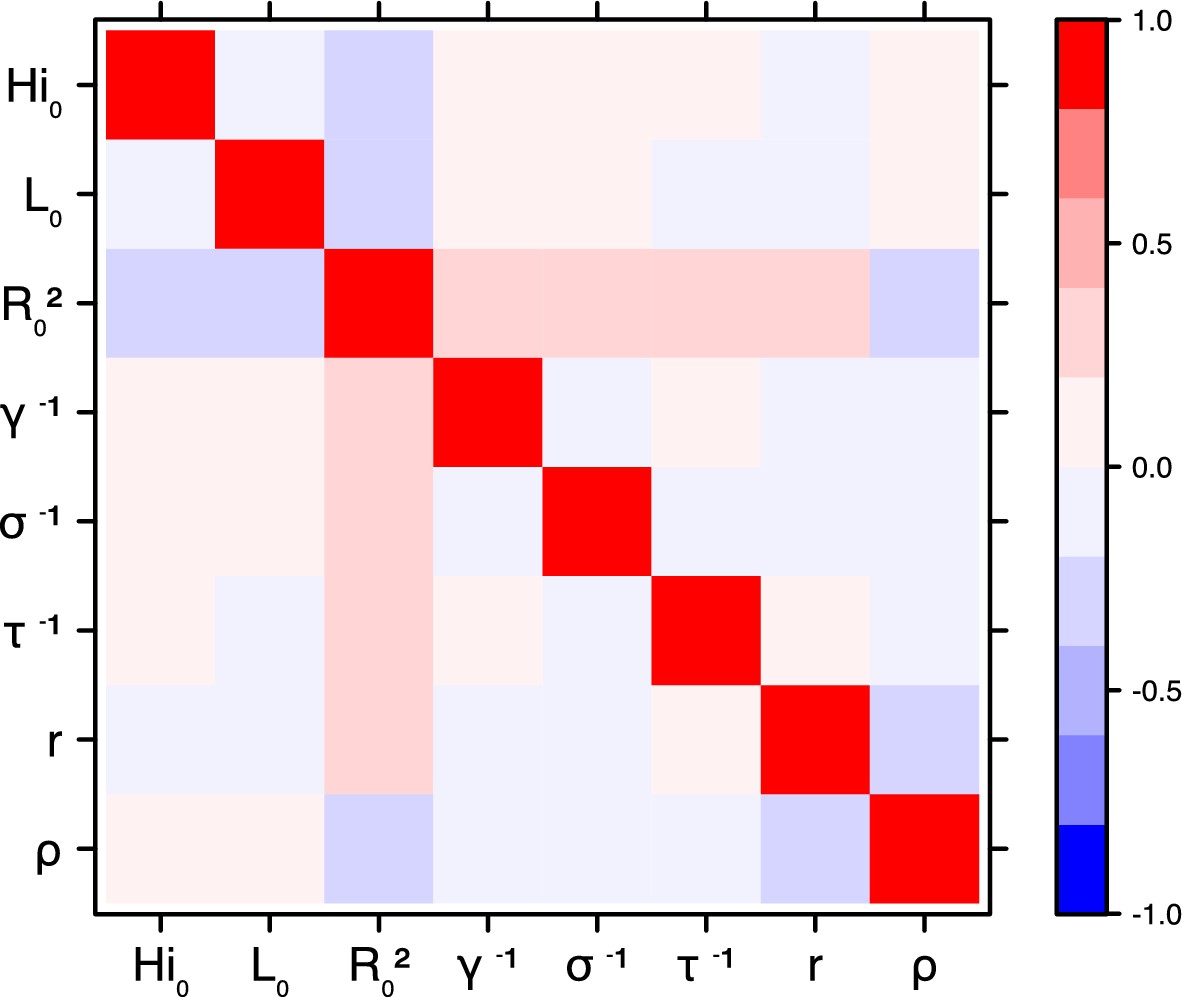
Correlation plot of MCMC output.
Laneri model, Yap island.
Figure 19
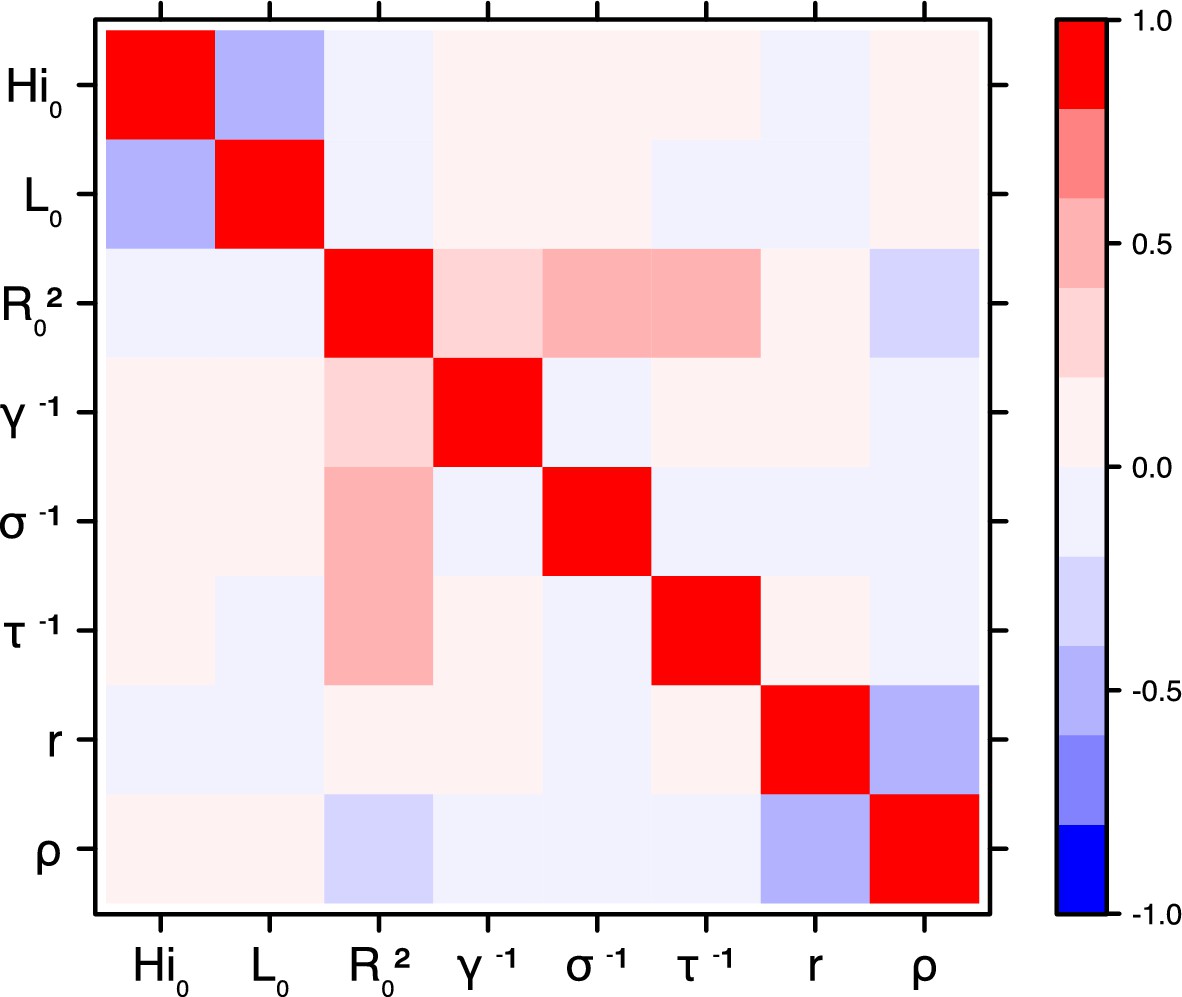
Correlation plot of MCMC output.
Laneri model, Moorea island.
Figure 20
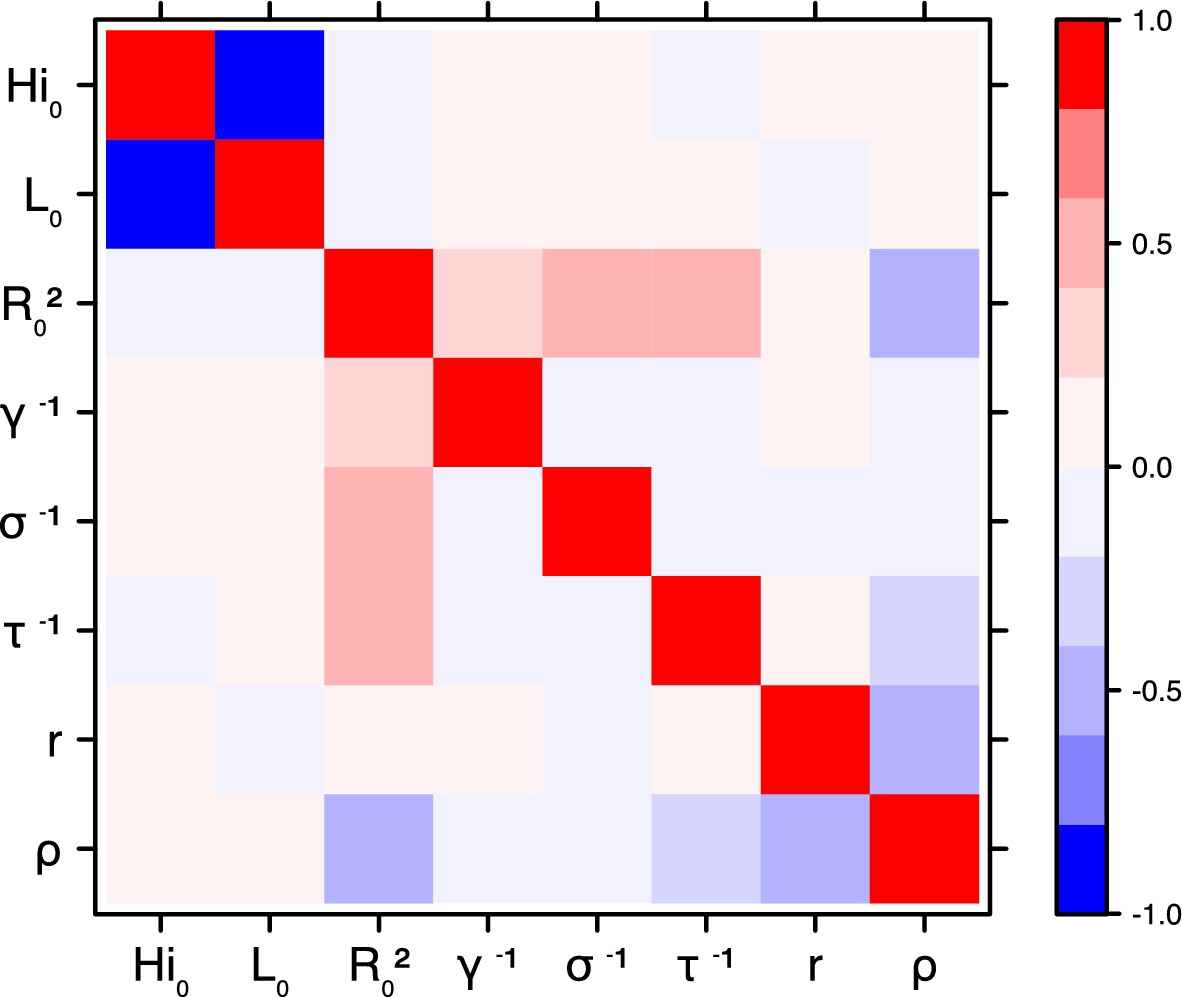
Correlation plot of MCMC output.
Laneri model, Tahiti island.
Figure 21
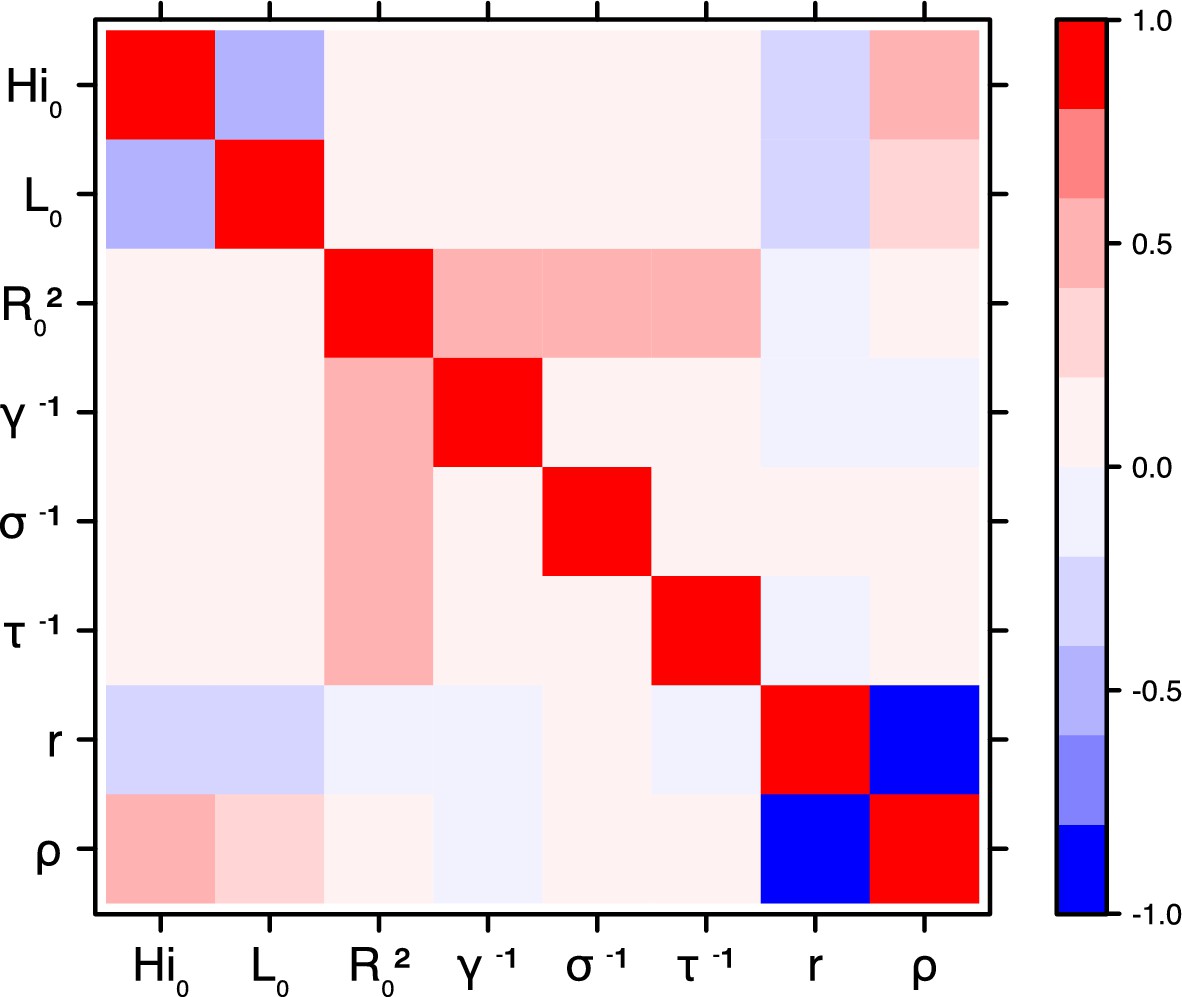
Correlation plot of MCMC output.
Laneri model, New Caledonia.
Correlation between estimated parameters
Request a detailed protocolThe inference technique may fail to estimate some parameters due to identifiability issues. In particular, when two parameters are highly correlated to one another, the model manages to estimate the pair of parameters but not each one separately. The analysis of correlation between parameters’ posterior distributions can reveal such cases. The following graphics display for each model the correlation coefficients between all pairs of parameters across the MCMC chain. For example, in models for New Caledonia, the observation rate and the fraction of the population involved in the epidemic are strongly negatively correlated (Figures 17,21): the inference technique does not manage to estimate properly these two parameters, due to the lack of information on seroprevalence.
Code and source data files
Request a detailed protocolThe estimation tools are provided by the open source software SSM (Dureau et al., 2013) (State Space Models, RRID:SCR_014647), available at https://github.com/JDureau/ssm and https://github.com/sballesteros/ssm-predict. The codes for the implementation of each model are provided as supplementary file.
References
-
Particle Markov chain Monte Carlo methodsJournal of the Royal Statistical Society: Series B 72:269–342.https://doi.org/10.1111/j.1467-9868.2009.00736.x
-
Seroprevalence of arboviruses among blood donors in French Polynesia, 2011-2013International Journal of Infectious Diseases 41:11–12.https://doi.org/10.1016/j.ijid.2015.10.005
-
ConferenceSerosurvey of Dengue, Zika and Other Mosquito-Borne Viruses in French Polynesia64th Annual Meeting of the American Society of Tropical Medicine and Hygiene.
-
Zika virus infection experimentally induced in a human volunteerTransactions of the Royal Society of Tropical Medicine and Hygiene 50:442–448.https://doi.org/10.1016/0035-9203(56)90090-6
-
Sensitivity and uncertainty analysis of complex models of disease transmission: An HIV Model, as an ExampleInternational Statistical Review / Revue Internationale de Statistique 62:229–243.https://doi.org/10.2307/1403510
-
Assessing the relationship between vector indices and dengue transmission: a systematic review of the evidencePLoS Neglected Tropical Diseases 8:e2848.https://doi.org/10.1371/journal.pntd.0002848
-
Some models for epidemics of vector-transmitted diseasesInfectious Disease Modelling.https://doi.org/10.1016/j.idm.2016.08.001
-
Time series analysis via mechanistic modelsThe Annals of Applied Statistics 3:319–348.https://doi.org/10.1214/08-AOAS201
-
Zika Virus, French Polynesia, South Pacific, 2013Emerging Infectious Diseases 20:1084–1086.https://doi.org/10.3201/eid2006.140138
-
Package ‘lhs’Package ‘lhs’, 0.14, http://cran.stat.auckland.ac.nz/web/packages/lhs/lhs.pdf.
-
Differential Susceptibilities of Aedes aegypti and Aedes albopictus from the Americas to Zika VirusPLoS Neglected Tropical Diseases 10:e0004543.https://doi.org/10.1371/journal.pntd.0004543
-
WebsiteSurveillance de la dengue et du zika en Polynésie française, données actualisées au 28 mars 2014Centre d’hygiène et de salubrité publique.
-
WebsiteSituation sanitaire en Nouvelle Calédonie. Les arboviroses : Dengue, Chikungunya, ZikaDirection des Affaires Sanitaires et Sociales de Nouvelle Calédonie.
-
Épidémiologie de la dengue et stratégies de lutte en Polynésie française, 2006-2008. Numéro thématique. Polynésie française : une situation particulièreBulletin Epidémiologique Hebdomadaire, N°48-49-50 pp. 499–503.
-
The construction of next-generation matrices for compartmental epidemic modelsJournal of the Royal Society Interface 7:873–885.https://doi.org/10.1098/rsif.2009.0386
-
The estimation of the basic reproduction number for infectious diseasesStatistical Methods in Medical Research 2:23–41.https://doi.org/10.1177/096228029300200103
-
BookSequential Monte Carlo Methods in PracticeNew York: Springer.https://doi.org/10.1007/978-1-4757-3437-9
-
A tutorial on particle filtering and smoothing: fifteen years laterA tutorial on particle filtering and smoothing: fifteen years later.
-
Zika virus outbreak on yap island, Federated States of MicronesiaNew England Journal of Medicine 360:2536–2543.https://doi.org/10.1056/NEJMoa0805715
-
Co-infection with Zika and dengue viruses in 2 patients, New Caledonia, 2014Emerging Infectious Diseases 21:381–382.https://doi.org/10.3201/eid2102.141553
-
Early determination of the reproductive number for vector-borne diseases: the case of dengue in BrazilTropical Medicine and International Health 11:332–340.https://doi.org/10.1111/j.1365-3156.2006.01560.x
-
Dengue virus-mosquito interactionsAnnual Review of Entomology 53:273–291.https://doi.org/10.1146/annurev.ento.53.103106.093326
-
Heterogeneous feeding patterns of the dengue vector, Aedes aegypti, on individual human hosts in rural ThailandPLoS Neglected Tropical Diseases 8:e3048.https://doi.org/10.1371/journal.pntd.0003048
-
Zika Virus outside AfricaEmerging Infectious Diseases 15:1347–1350.https://doi.org/10.3201/eid1509.090442
-
Estimating dengue transmission intensity from sero-prevalence surveys in multiple countriesPLoS Neglected Tropical Diseases 9:e0003719.https://doi.org/10.1371/journal.pntd.0003719
-
ReportPopulations légales au recensement de la population 2012 De Polynésie françaiseInstitut National de la Statistique et des Etudes Economiques.
-
ReportPopulations légales au recensement de la population 2014 de Nouvelle-CalédonieInstitut National de la Statistique et des Etudes Economiques.
-
Transmission Dynamics of Zika Virus in Island Populations: A Modelling Analysis of the 2013-14 French Polynesia OutbreakPLoS Neglected Tropical Diseases 10:e0004726.https://doi.org/10.1371/journal.pntd.0004726
-
Forcing versus feedback: epidemic malaria and monsoon rains in northwest IndiaPLoS Computational Biology 6:e1000898.https://doi.org/10.1371/journal.pcbi.1000898
-
Aedes hensilli as a potential vector of Chikungunya and Zika VirusesPLoS Neglected Tropical Diseases 8:e3188.https://doi.org/10.1371/journal.pntd.0003188
-
Times to key events in Zika Virus infection and implications for blood donation: a systematic reviewBulletin of the World Health Organization 94:841–849.https://doi.org/10.2471/BLT.16.174540
-
Destabilization of epidemic models with the inclusion of realistic distributions of infectious periodsProceedings of the Royal Society B: Biological Sciences 268:985–993.https://doi.org/10.1098/rspb.2001.1599
-
Bilan de l’épidémie à virus Zika en Polynésie françaiseBulletin d’Informations Sanitaires Epidemiologiques Et Statistiques 13:.
-
Dengue and the risk of urban yellow fever reintroduction in São Paulo State, BrazilRevista de Saúde Pública 37:477–484.https://doi.org/10.1590/S0034-89102003000400013
-
Transmission potential of Zika Virus infection in the South PacificInternational Journal of Infectious Diseases 45:95–97.https://doi.org/10.1016/j.ijid.2016.02.017
-
Preliminary estimation of the basic reproduction number of zika virus infection during Colombia epidemic, 2015-2016Travel Medicine and Infectious Disease 14:274–276.https://doi.org/10.1016/j.tmaid.2016.03.016
-
Comparing vector–host and SIR models for dengue transmissionMathematical Biosciences 246:252–259.https://doi.org/10.1016/j.mbs.2013.10.007
-
Package 'sensitivity'Package 'sensitivity', https://cran.r-project.org/web/packages/sensitivity/sensitivity.pdf.
-
A systematic review of mathematical models of mosquito-borne pathogen transmission: 1970-2010Journal of The Royal Society Interface 10:20120921.https://doi.org/10.1098/rsif.2012.0921
-
Examples of adaptive MCMCJournal of Computational and Graphical Statistics 18:349–367.https://doi.org/10.1198/jcgs.2009.06134
-
Possible Association Between Zika Virus Infection and Microcephaly — Brazil, 2015MMWR. Morbidity and Mortality Weekly Report 65:59–62.https://doi.org/10.15585/mmwr.mm6503e2
-
Recasting the theory of mosquito-borne pathogen transmission dynamics and controlTransactions of the Royal Society of Tropical Medicine and Hygiene 108:185–197.https://doi.org/10.1093/trstmh/tru026
-
From mosquitos to humans: Genetic Evolution of Zika VirusCell Host & Microbe 19:561–565.https://doi.org/10.1016/j.chom.2016.04.006
Article and author information
Author details
Funding
Centre National de la Recherche Scientifique (Pepiniere interdisciplinaire Eco-Evo-Devo)
- Clara Champagne
- David Georges Salthouse
- Bernard Cazelles
European Commission (Seventh Framework Program [FP7 2007-2013] for the DENFREE project under Grant Agreement 282 348)
- Clara Champagne
- David Georges Salthouse
- Richard Paul
- Van-Mai Cao-Lormeau
- Bernard Cazelles
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
CC, DGS and BC are partially supported by the "Pépiniere interdisciplinaire Eco-Evo-Devo" from the Centre National de la Recherche Scientifique (CNRS). The research leading to these results has also received funding from the European Commission Seventh Framework Program [FP7/2007–2013] for the DENFREE project under Grant Agreement 282 378. The funders played no role in the study design, data collection, analysis, or preparation of the manuscript.
Copyright
© 2016, Champagne et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,636
- views
-
- 383
- downloads
-
- 34
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 34
- citations for umbrella DOI https://doi.org/10.7554/eLife.19874
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Structure in the variability of the basic reproductive number (R0) for Zika epidemics in the Pacific islands
eLife 5:e19874.
https://doi.org/10.7554/eLife.19874




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}