Research: Publication bias and the canonization of false facts
- University of Copenhagen, Denmark
- University of Washington, United States
- North Carolina State University, United States
Abstract
Science is facing a “replication crisis” in which many experimental findings cannot be replicated and are likely to be false. Does this imply that many scientific facts are false as well? To find out, we explore the process by which a claim becomes fact. We model the community’s confidence in a claim as a Markov process with successive published results shifting the degree of belief. Publication bias in favor of positive findings influences the distribution of published results. We find that unless a sufficient fraction of negative results are published, false claims frequently can become canonized as fact. Data-dredging, p-hacking, and similar behaviors exacerbate the problem. Should negative results become easier to publish as a claim approaches acceptance as a fact, however, true and false claims would be more readily distinguished. To the degree that the model reflects the real world, there may be serious concerns about the validity of purported facts in some disciplines.
https://doi.org/10.7554/eLife.21451.001Introduction
Science is a process of collective knowledge creation in which researchers use experimental, theoretical and observational approaches to develop a naturalistic understanding of the world. In the development of a scientific field, certain claims stand out as both significant and stable in the face of further experimentation (Ravetz, 1971). Once a claim reaches this stage of widespread acceptance as true, it has transitioned from claim to fact. This transition, which we call canonization, is often indicated by some or all of the following: a canonized fact can be taken for granted rather than treated as an open hypothesis in the subsequent primary literature; tests that do no more than to confirm previously canonized facts are seldom considered publication-worthy; and canonized facts begin to appear in review papers and textbooks without the company of alternative hypotheses. Of course the veracity of so-called facts may be called back into question (Arbesman, 2012; Latour, 1987), but for time being the issue is considered to be settled. Note that we consider facts to be epistemological rather than ontological: a claim is a fact because it is accepted by the relevant community, not because it accurately reflects or represents underlying physical reality (Ravetz, 1971; Latour, 1987).
But what is the status of these facts in light of the widely reported replication crisis in science? Large scale analyses have revealed that many published papers in fields ranging from cancer biology to psychology to economics cannot be replicated in subsequent experiments (Begley and Ellis, 2012; Open Science Collaboration, 2015; Errington et al., 2014; Ebrahim et al., 2014; Chang and Li, 2015; Camerer et al., 2016; Baker, 2016). One possible explanation is that many published experiments are not replicable because many of their conclusions are ontologically false (Ioannidis, 2005; Higginson and Munafò, 2016).
If many experimental findings are ontologically false, does it follow that many scientific facts are ontologically untrue? Not necessarily. Claims of the sort that become facts are rarely if ever tested directly in their entirety. Instead, such claims typically comprise multiple subsidiary hypotheses which must be individually verified. Thus multiple experiments are usually required to establish a claim. Some of these may include direct replications, but more typically an ensemble of distinct experiments will produce multiple lines of evidence before a claim is accepted by the community.
For example, as molecular biologists worked to unravel the details of the eukaryotic RNA interference (RNAi) pathway in the early 2000s, they wanted to understand how the RNAi pathway was initiated. Based on work with Drosophila cell lines and embryo extracts, one group of researchers made the claim that the RNAi pathway is initiated by the Dicer enzyme which slices double-stranded RNA into short fragments of 20–22 amino acids in length (Bernstein et al., 2001). Like many scientific facts, this claim was too broad to be validated directly in a single experiment. Rather, it comprised a number of subsidiary assertions: an enzyme called Dicer exists in eukaryotic cells; it is essential to initiate the RNAi pathway; it binds dsRNA and slices it into pieces; it is distinct from the enzyme or enzyme complex that destroys targeted messenger RNA; it is ubiquitous across eukaryotes that exhibit RNAi pathway. Researchers from numerous labs tested these subsidiary hypotheses or aspects thereof to derive numerous lines of convergent evidence in support of the original claim. While the initial breakthrough came from work in Drosophila melanogaster cell lines ((Bernstein et al., (2001), subsequent research involved in establishing this fact drew upon in vitro and in vivo studies, genomic analyses, and even mathematical modeling efforts, and spanned species including the fission yeast Schizosaccharomyces pombe, the protozoan Giardia intestinalis, the nemotode Caenorhabditis elegans, the flowering plant Arabidopsis thaliana, mice, and humans (Jaskiewicz and Filipowicz, 2008). Ultimately, sufficient supporting evidence accumulated to establish as fact the original claim about Dicer’s function.
Requiring multiple studies to establish a fact is no panacea, however. The same processes that allow publication of a single incorrect result can also lead to the accumulation of sufficiently many incorrect findings to establish a false claim as fact (McElreath and Smaldino, 2015).
This risk is exacerbated by publication bias (Sterling, 1959; Rosenthal, 1979; Newcombe, 1987; Begg and Berlin, 1988; Dickersin, 1990; Easterbrook et al., 1991; Song et al., 2000; Olson et al., 2002; Chan and Altman, 2005; Franco et al., 2014). Publication bias arises when the probability that a scientific study is published is not independent of its results (Sterling, 1959). As a consequence, the findings from published tests of a claim will differ in a systematic way from the findings of all tests of the same claim (Song et al., 2000; Turner et al., 2008).
Publication bias is pervasive. Authors have systematic biases regarding which results they consider worth writing up; this is known as the “file drawer problem” or “outcome reporting bias” (Rosenthal, 1979; Chan and Altman, 2005). Journals similarly have biases about which results are worth publishing. These two sources of publication bias act equivalently in the model developed here, and thus we will not attempt to separate them. Nor would separating them be simple; even if authors’ behavior is the larger contributor to publication bias (Olson et al., 2002; Franco et al., 2014), they may simply be responding appropriately to incentives imposed by editorial preferences for positive results.
What kinds of results are most valued? Findings of statistically significant differences between groups or treatments tend to be viewed as more worthy of submission and publication than those of non-significant differences. Correlations between variables are often considered more interesting than the absence of correlations. Tests that reject null hypotheses are commonly seen as more noteworthy than tests that fail to do so. Results that are interesting in any of these ways can be described as “positive”.
A substantial majority of the scientific results published appear to be positive ones (Csada et al., 1996). It is relatively straightforward to measure the fraction of published results that are negative. One extensive study found that in 2007, more than 80% of papers reported positive findings, and this number exceeded 90% in disciplines such as psychology and ecology (Fanelli, 2012). Moreover, the fraction of publications reporting positive results has increased over the past few decades. While this high prevalence of positive results could in principle result in part from experimental designs with increasing statistical power and a growing preference for testing claims that are believed likely to be true, publication bias doubtless contributes as well (Fanelli, 2012).
How sizable is this publication bias? To answer that, we need to estimate the fraction of negative results that are published, and doing so can be difficult because we rarely have access to the set of findings that go unpublished. The best available evidence of this sort comes from registered clinical trials. For example, a 2008 meta-analysis examined 74 FDA-registered studies of antidepressants (Turner et al., 2008). In that analysis, 37 of 38 positive studies were published as positive results, but only 3 of 24 negative studies were published as negative results. An additional 5 negative studies were re-framed as positive for the purposes of publication. Thus, negative studies were published at scarcely more than 10% the rate of positive studies.
We would like to understand how the possibility of misleading experimental results and the prevalence of publication bias shape the creation of scientific facts. Mathematical models of the scientific process can help us understand the dynamics by which scientific knowledge is produced and, consequently, the likelihood that elements of this knowledge are actually correct. In this paper, we look at the way in which repeated efforts to test a scientific claim establish this claim as fact or cause it to be rejected as false.
We develop a mathematical model in which successive publications influence the community’s perceptions around the likelihood of a given scientific claim. Positive results impel the claim toward fact, whereas negative results lead in the opposite direction. Describing this process, Latour, (1987) compared the fate of a scientific claim to that of a rugby ball, pushed alternatively toward fact or falsehood by the efforts of competing teams, its fate determined by the balance of their collective actions. Put in these terms, our aim in the present paper is to develop a formal model of how the ball is driven up and down the epistemological pitch until one of the goal lines is reached. In the subsequent sections, we outline the model, explain how it can be analyzed, present the results that we obtain, and consider its implications for the functioning of scientific activity.
Model
In this section, we will develop a simplified model of scientific activity, designed to capture the important qualitative features of fact-creation as a dynamic process.
Model description
We explore a simple model in which researchers sequentially test a single claim until the scientific community becomes sufficiently certain of its truth or falsehood that no further experimentation is needed. Our model is conceptually related to those developed in refs. (Rzhetsky et al., 2006; McElreath and Smaldino, 2015), though it is considerably simpler than either since we only consider a single claim at a time.
Figure 1 provides a schematic illustration of the experimentation and publication process. We begin with a claim which is ontologically either true or false. Researchers sequentially conduct experiments to test the claim; these experiments are typically not direct replications of one another, but rather distinct approaches that lend broader support to the claim. Each experiment returns either a positive outcome supporting the claim, or a negative outcome contravening it. For mathematical simplicity, we assume all tests to have the same error rates, in the sense that if the claim under scrutiny is false, then investigators obtain false positives with probability . Conversely, when the claim is true, investigators obtain false negatives with probability . We take these error rates to be the ones that are conventionally associated with statistical hypothesis testing, so that is equivalent to the significance level (technically, the size) of a statistical test and is the test’s power. We assume that, as in any reasonable test, a true claim is more likely to generate a positive result than a negative one: . A broader interpretation of and beyond statistical error does not change the interpretation of our results.
Figure 1

Conducting and reporting the test of a claim.
In our model, a scientific claim is either true or false. Researchers conduct an experiment which either supports or fails to the support the claim. True claims are correctly supported with probability while false claims are incorrectly supported with probability . Next, the researchers may attempt to publish their results. Positive results that support the claim are published with probability whereas negative results that fail to support the claim are published with probability . This process then repeats, with additional experiments conducted until the claim is canonized as fact or rejected as false.
After completing a study, the investigators may attempt to publish their experimental results. However, publication bias occurs in that the result of the experiment influences the chance that a study is written up as a paper and accepted for publication. Positive results are eventually published somewhere with probability whereas negative results are eventually published somewhere with probability . Given the reluctance of authors to submit negative results and of journals to publish them, we expect that in general .
Finally, readers attempt to judge whether a claim is true by consulting the published literature only. For modeling purposes, we will consider a best-case scenario, in which the false positive and false negative rates and are established by disciplinary custom or accepted benchmarks, and readers perform Bayesian updating of their beliefs based upon these known values. In practice, these values may not be as well standardized or widely reported as would be desirable. Moreover, readers are unlikely to be this sophisticated in drawing their inferences. Instead readers are likely to form subjective beliefs in an informal fashion based on a general assessment of the accumulated positive and negative results and the strength of each. But the Bayesian updating case provides a well-defined model under which to explore the distortion of belief by publication bias.
The problem is that the results described in the published literature are now biased by the selection of which articles are drafted and accepted for publication. We assume that readers are unaware of the degree of this bias, and that they fail to correct for publication bias in drawing inferences from the published data. It may seem pessimistic that researchers would fail to make this correction, but much of the current concern over the replication crisis in science is predicated on exactly this. Moreover, it is usually impossible for a researcher to accurately estimate the degree of publication bias in a given domain.
Model dynamics
Consider a claim that the community initially considers to have probability of being true. Researchers iteratively test hypotheses that bear upon the claim until it accumulates either sufficient support to be canonized as fact, or sufficient counter-evidence to be discarded as false. If the claim is true, the probability that a single test leads to a positive publication is , and the corresponding probability of a negative publication is . The remaining probability corresponds to results of the test not being published. If the claim is false, these probabilities are and for positive and negative published outcomes, respectively. Given that a claim is true, the probability that a published test of that claim reports a positive outcome is therefore
(1)
For a false claim, the probability that a published test is positive is
(2)
Because only the ratio of to matters for the purposes of our model, we set to 1 for the remainder of the paper. We initially assume that is constant, but will relax this assumption later.
To formalize ideas, consider a sequence of published outcomes , and let be the number of positive published outcomes in the first terms of . When the probability of publishing a negative result is constant, the outcomes of published experiments are exchangeable random variables. Thus after published tests, the distribution of for a true claim is the binomial distribution and for a false claim is . Moreover, the sequence is a Markov chain. When the extent of publication bias is known, we can compute the conditional probability that a claim is true, given , as
(3)
We now consider the consequences of drawing inferences based on the published data alone, without correcting for publication bias. For model readers who do not condition on publication bias, let be the perceived, conditional probability that a claim is true given . We say “perceived” because these readers use Bayes’ Law to update , but do so under the incorrect assumption that there is no publication bias, i.e., that . To ease the narrative, we refer to the perceived conditional probability that a claim is true as the “belief” that the claim is true. Expressing this formally,
(4)
Note that without publication bias, we have and , and thus Equation 3 coincides with Equation 4.
From the perspective of an observer who is unaware of any publication bias, the pair is a sufficient statistic for the random variable representing the truth value of the claim in question. This follows from the definition of statistical sufficiency and the fact that
By analogous logic, the pair is also a sufficient statistic for an observer aware of the degree of publication bias provided that the publication probabilities and are constant.
We envision science as proceeding iteratively until the belief that a claim is true is sufficiently close to 1 that the claim is canonized as fact, or until belief is sufficiently close to 0 that the claim is discarded as false. We let and be the belief thresholds at which a claim is rejected or canonized as fact, respectively (), and refer to these as evidentiary standards. In our analysis, we make the simplifying assumption that the evidentiary standards are symmetric, i.e., . We describe the consequences of relaxing this assumption in the Discussion.
Thus, mathematically, we model belief in the truth of a claim as a discrete-time Markov chain with absorbing boundaries at the evidentiary standards for canonization or rejection (Figure 2A). When the Markov chain represents belief, its possible values lie in the interval from 0 to 1. For mathematical convenience, however, it is often helpful to convert belief to the log odds scale, that is, . Some algebra shows that the log odds of belief can be written as
(5)
Figure 2
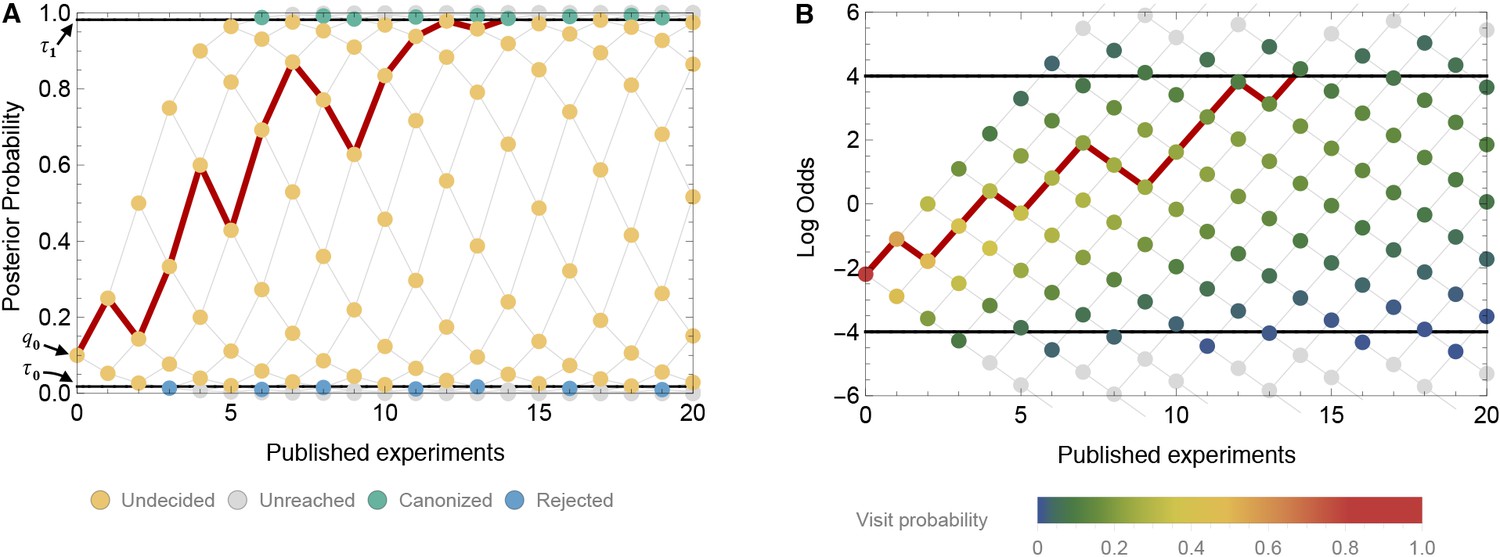
A time-directed graph represents the evolution of belief over time.
In panel A, the horizontal axis indicates the number of experiments published and the vertical axis reflects the observer’s belief, quantified as the probability that the claim is true. The process begins at the single point at far left with an initial belief . Each subsequent experiment either supports the claim, moving to the next node up and right, or contradicts the claim, moving to the next node down and right. At yellow nodes, the status of the claim is as yet undecided. At green nodes, it is canonized as fact, and at blue nodes, it is rejected as false. The black horizontal lines show the evidentiary standards ( and ). The red path shows one possible trajectory, in which a positive experiment is followed by a negative, then two positives, then a negative, etc., ultimately becoming canonized as fact when it reaches the upper boundary. Panel B shows the same network, but with the vertical axis representing log odds and using color to indicate the probability that the process visits each node. In log-odds space, each published positive result shifts belief by the constant distance and each negative result by a different distance . Shown here (in both panel A and B) is a false claim with false positive rate , false negative rate , publication probabilities and , and initial belief . In this case, the claim is likely to be canonized as fact, despite being false.
The log odds scale is convenient because, as Equation. 5 shows, each published positive outcome increases the log odds of belief by a constant increment
(Figure 2B). Each published negative outcome decreases the log odds of belief by
Below, we will see that much of the behavior of our model can be understood in terms of the expected change in the log odds of belief for each published outcome. For a true claim, the expected change in the log odds of belief is
(6)
whereas for a false claim, the expected change in the log odds of belief is
(7)
Computing canonization and rejection probabilities
In general, we cannot obtain a closed-form expression for the probability that a claim is canonized as fact or for the probability that it is rejected as false. We can, however, derive recursive expressions for the probabilities that after published experiments a claim has been canonized as fact, has been discarded as false, or remains undecided. From these, it is straightforward to compute the canonization and rejection probabilities numerically to any desired level of precision.
For each number of published experiments , the state space for is simply . Partition this state space as follows:
That is, is the set of outcomes corresponding to a belief greater than the evidentiary standard for canonization, is the set of outcomes corresponding to a belief less than the evidentiary standard for rejection, and is the set of outcomes corresponding to belief in between these two standards (the “interior”). Let be the number of publications until a claim is either canonized or rejected. Formally,
For a true claim, we calculate the probability of canonization as follows. (A parallel set of equations gives the probability of canonization for a false claim.) For each , define . That is, is the probability that there are exactly positive outcomes in the first publications, and the claim has yet to be canonized or rejected by publication . Suppose these probabilities are known for each . Then for each , these probabilities can be found recursively by
For computational purposes, in the recursion above we define whenever . The probability that the claim has yet to be canonized or rejected by publication is simply
Let be the probability that a claim is first canonized at publication . Formally,
Let be the smallest value of for which . To calculate the probability of canonization, we calculate for all . The probability of canonization is then . For the analyses in this paper, we have set .
Results
We focus throughout the paper on the dynamic processes by which false claims are canonized as facts, and explore how the probability of this happening depends on properties of the system such as the publication rate of negative results, the initial beliefs of researchers, the rates of experimental error, and the degree of evidence required to canonize a claim. In principle, the converse could be a problem as well: true claims could be discarded as false. However, this is rare in our model. Publication bias favors the publication of positive results and therefore will not tend to cause true claims to be discarded as false, irrespective of other parameters. We first establish this, and then proceed to a detailed examination of how scientific experimentation and publication influences the rate at which false claims are canonized as fact.
True claims tend to be canonized as facts
In our model, true claims are almost always canonized as facts. Figure 3 illustrates this result in the form of a receiver operating characteristic (ROC) curve. Holding the other parameters constant, the curve varies the negative publication rate , and uses the vertical and horizontal axes to indicate the probabilities that true and false claims respectively are canonized as fact.
Figure 3

ROC curves reveal that true claims are almost always canonized as fact.
In the receiver operating characteristic (ROC) curves shown here, the vertical axis represents the probability that a true claim is correctly canonized as fact, and the horizontal axis represents the probability that a false one is incorrectly canonized as fact. Panel A: lax evidentiary standards and . Panel B: strict evidentiary standards and . Error rates and initial belief are , , and . Each point along the ROC curve corresponds to a different value of the negative publication rate, , as indicated by color. Grey regions of the curve correspond to the unlikely situations in which , i.e., negative results are more likely to be published than positive ones. The figures reveal two important points. First, when negative results are published at any rate , the vast majority of true claims are canonized as fact. Second, when negative results are published at a low rate ( less than 0.3 or 0.2 depending on evidentiary standards), many false claims will also be canonized as true.
One might fear that as the probability of publishing negative results climbs toward unity, the risk of rejecting a true claim would increase dramatically as well. This is not the case. Even as the probability of publishing negative results approaches 1, the risk of rejecting a true claim is low when evidentiary standards are lax (Figure 3A), and negligible when evidentiary standards are strict (Figure 3B).
This result turns out to be general across a broad range of parameters. Assuming the mild requirements that (i) tests of a true claim are more likely to result in positive publications than negative publications (i.e., , or equivalently ), and (ii) positive published outcomes increase belief that the claim is true (, or equivalently ), true claims are highly likely to be canonized as facts. The exceptions occur only when minimal evidence is needed to discard a claim, i.e., when initial belief is small (). In such cases a bit of bad luck—the first one or two published experiments report false negatives, for example—can cause a true claim to be rejected. But otherwise, truth is sufficient for canonization.
Unfortunately, truth is not required for canonization. The risk of canonizing a false claim—shown on the horizontal axis in Figure 3—is highly sensitive to the rate at which negative results are published. When negative results are published with high probability, false claims are seldom canonized. But when negative results are published with lower probability, many false claims are canonized.
Thus we see that the predominant risk associated with publication bias is the canonization of false claims. In the remainder of this analysis, we focus on this risk of incorrectly establishing a false claim as a fact.
Publication of negative results is essential
As we discussed in the introduction, authors and journals alike tend to be reluctant to publish negative results, and as we found in the previous subsection, when most negative results go unpublished, science performs poorly. Here, we explore this relationship in further detail.
Figure 4 shows how the probability of erroneously canonizing a false claim as fact depends on the probability that a negative result is published. False claims are likely to be canonized below a threshold rate of negative publication, and unlikely to be canonized above this threshold. For example, when the false positive rate is 0.05, the false negative rate is 0.4, and the evidentiary requirements are strong (yellow points in Panel 4D), a false claim is likely to be canonized as fact unless negative results are at least 20% as likely as positive results to be published.
Figure 4
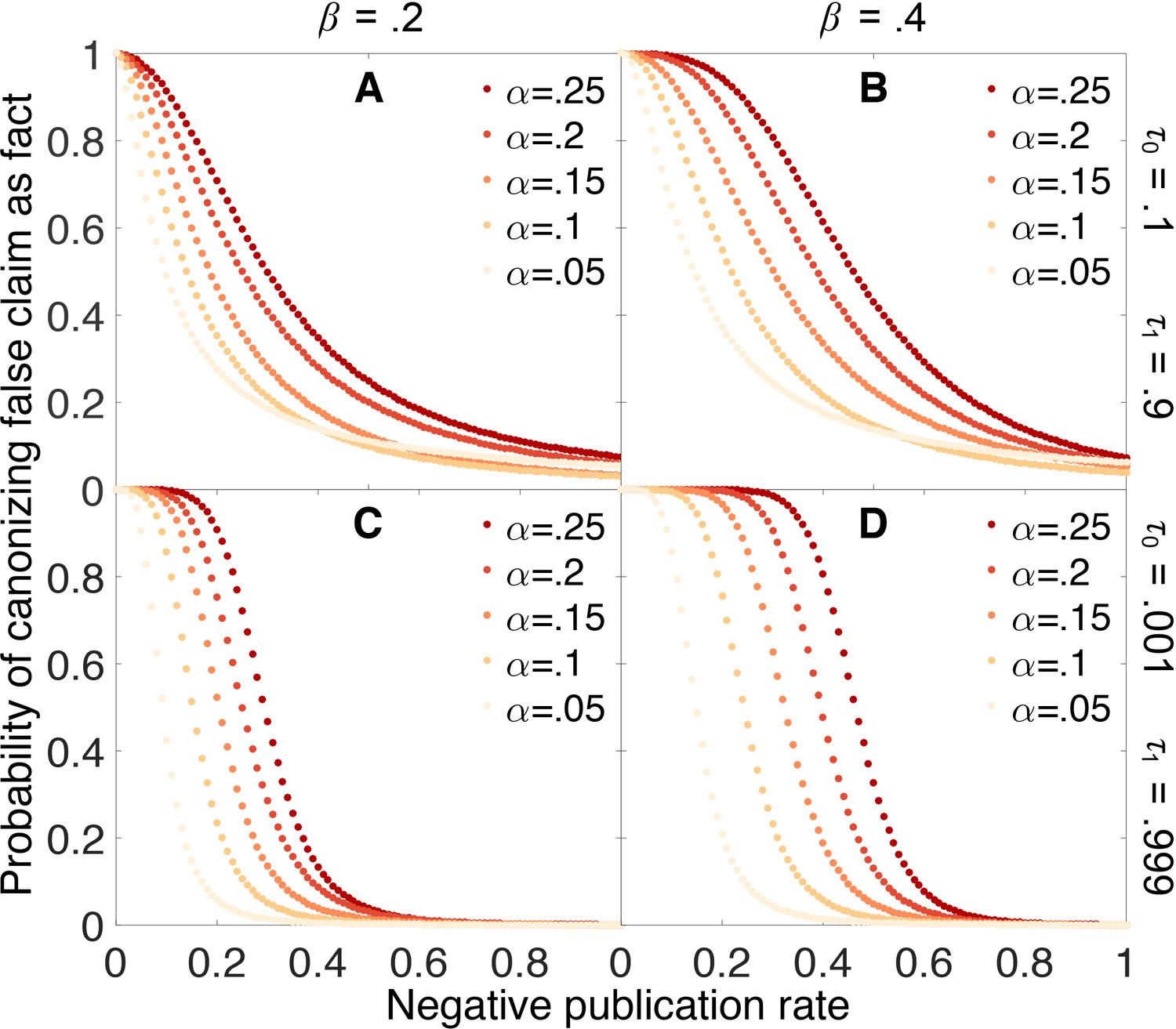
Publishing negative outcomes is essential for rejecting false claims.
Probability that a false claim is incorrectly canonized, as a function of the negative publication rate. Throughout, initial belief is , and individual data series show false positive rates (yellow), (red). Top row: weak evidentiary standards and . Panel A: false negative rate . Panel B: . Panels C–D: similar to panels A–B, with more demanding evidentiary standards and .
Figure 4 also reveals that the probability of canonizing false claims as facts depends strongly on both the false positive rate and the false negative rate of the experimental tests. As these error rates increase, an increasingly large fraction of negative results must be published to preserve the ability to discriminate between true and false claims.
Initial beliefs usually do not matter much
If the scientific process is working properly, it should not automatically confirm what we already believe, but rather it should lead us to change our beliefs based on evidence. Our model indicates that in general, this is the case.
Figure 5 shows how the probability that a false claim is canonized as true depends on the initial belief that the claim is true. Under most circumstances, the probability of canonization is relatively insensitive to initial belief. False canonization rates depend strongly on initial belief only when evidentiary standards are weak and experiments are highly prone to error (Figure 5B). In this case, belief is a random walk without a systematic tendency to increase or decrease with each published outcome, and thus the odds of canonization or rejection depend most strongly on the initial belief.
Figure 5
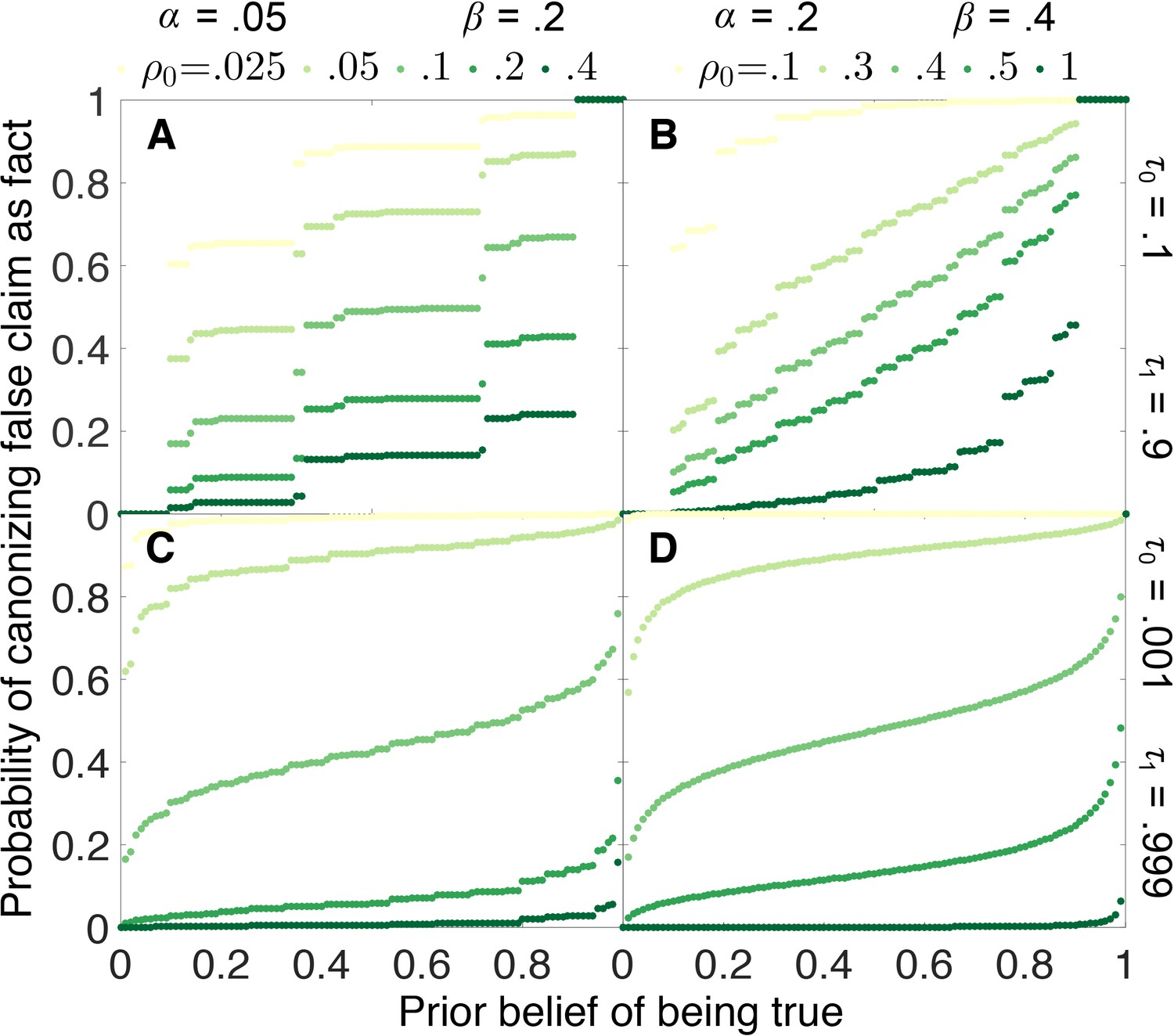
False canonization rates are relatively insensitive to initial belief, unless experimental tests are inaccurate and evidentiary standards are weak.
Probability that a false claim is mistakenly canonized as a true fact vs. prior belief for various negative publication rates. Top row: weak evidentiary standards and . Panel A: false positive rate , false negative rate , and publication rate of negative results (light green), (dark green). Panel B: , , and (light green), (dark green). Panels C–D: similar to panels A–B, with more demanding evidentiary standards and .
The step-function-like appearance of some of the results in Figure 5, particularly Figure 5A, is a real property of the curves in question and not a numerical artifact. The “steps” arise because, when evidentiary standards are weak, canonization or rejection often happens after a small number of experiments. Because the number of experiments must be integral, probabilities of false canonization can change abruptly when a small change in initial belief increases or decreases the number of experiments in the most likely path to canonization or rejection.
Stronger evidentiary standards do not reduce the need to publish negative outcomes
We have seen in the previous sections that the scientific process struggles to distinguish true from false claims when the rate of publishing negative results is low. We might hope that we could remedy this problem simply by demanding more evidence before accepting a claim as fact. Unfortunately, this is not only expensive in terms of time and effort—sometimes it will not even help.
Figure 6 illustrates the problem. In this figure, we see the probability of canonizing a false claim as a function of negative publication rate for three different evidentiary standards: , , and . When the false positive rate is relatively low (Figure 6A), increasing the evidentiary requirements reduces the chance of canonizing a false claim for negative publication rates above 0.1 or so, but below this threshold there is no advantage to requiring stronger evidence. When the false positive rate is higher (Figure 6B), the situation is even worse: for negative publication rates below 0.3 or so, increasing evidentiary requirements actually increases the chance of canonizing a false fact.
Figure 6

Strengthening evidentiary requirements does not necessarily decrease canonization of false facts.
In panel A, the false positive rate is , the false negative rate is , the original belief in the claim is , and the evidentiary standards are symmetric . In panel B, the false positive rate is increased to while the other parameters remain unchanged. Particularly in this latter case, increasing evidentiary standards does not necessarily decrease the rate at which false claims are canonized as facts.
The limited benefits of strengthening evidentiary standards can be understood through the mathematical theory of random walks (Norris, 1998). In short, the thresholds of belief for canonizing or rejecting a claim are absorbing boundaries such that once belief attains either boundary, the walk terminates and beliefs will not change further. Increasing the evidentiary standards for canonization or rejection is tantamount to increasing the distance between these boundaries and the initial belief state. Basic results from the theory of random walks suggest that, as the distance between the initial state and the boundaries increases, the probability of encountering one boundary before the other depends increasingly strongly on the average change in the log odds of belief at each step (experiment), and less on the random fluctuations in belief that arise from the stochasticity of the walk. Thus, for exacting evidentiary standards, the probability of eventual canonization or rejection depends critically on the average change in the log odds of belief for each experiment. These are given by Equation 6 for a true claim and Equation 7 for a false one.
Figure 7 shows how the expected change in log odds of belief varies in response to changes in the publication rate of negative outcomes, for both false and true claims. Critically, for false claims, if too few negative outcomes are published, then on average each new publication will increase the belief that the claim is true, because there is a high probability this publication will report a positive result. Thus, paradoxically, scientific activity does not help sort true claims from false ones in this case, but instead promotes the erroneous canonization of false claims. The only remedy for this state of affairs is to publish enough negative outcomes that, on average, each published result moves belief in the “correct” direction, that is, towards canonization of true claims (a positive average change per experiment in log odds of belief) and rejection of false ones (a negative average change per experiment in log odds of belief).
Figure 7
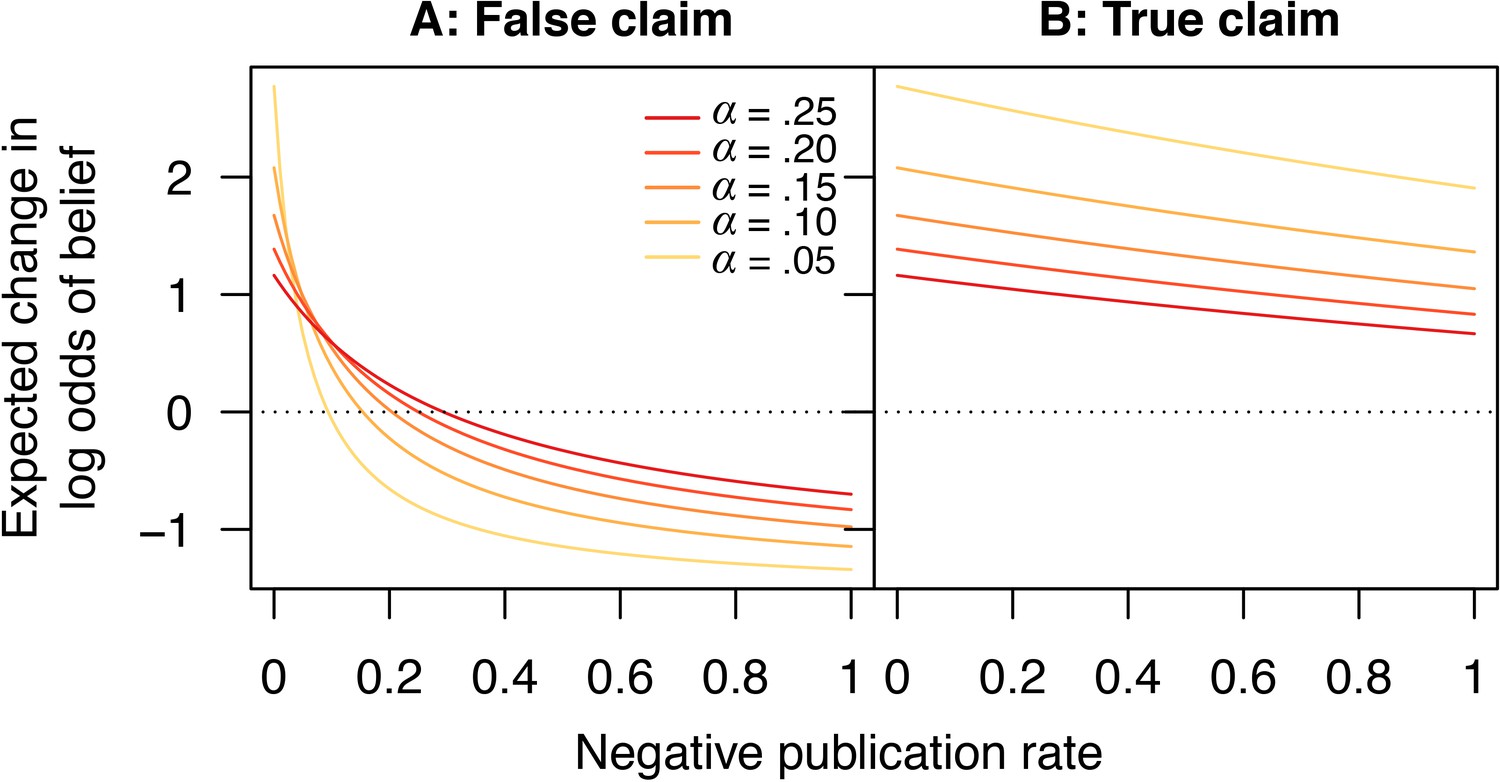
Scientific activity will tend to increase belief in false claims if too few negative outcomes are published.
Expected change in log odds of belief vs. negative publication rate for (A) false and (B) true claims. Lines show false positive rates (yellow), (red). Other parameter values are false negative rate and positive publication rate .
Two additional points are in order here. First, for true claims, under most circumstances the expected change in the log odds of belief is positive (Figure 7B). That is, on average, scientific activity properly increases belief in true claims, and thus the risk of incorrectly rejecting a true claim is small (under reasonable evidentiary standards). Second, the observation that more exacting evidentiary standards can occasionally increase the chance of incorrectly canonizing a false claim is not much of an argument in favor of weaker evidentiary standards. In short, weaker standards cause canonization or rejection to depend more strongly on the happenstance of the first several published experiments. When scientific activity tends to increase belief in a false claim, weaker evidentiary standards appear beneficial because they increase the chance that a few initial published negatives will lead to rejection and bring a halt to further investigation. While this is a logical result of the model, it is somewhat tantamount to stating that, if scientific activity tends to increase belief in false claims, then the best option is to weaken the dependence on scientific evidence. More robust practices for rejecting false claims seem desirable.
-hacking dramatically increases the probability of canonizing false claims
Our model has been based on the optimistic premise that the significance levels reported in each study accurately reflect the actual false positive rates. This means that there is only a 5% chance that a false claim will yield a positive result at the level.
In practice, reported significance levels can be misleading. Questionable research practices of all sorts can result in higher-than-reported false positive rates; these include p-hacking (Head et al., 2015), outcome switching (Le Noury et al., 2015), unreported multiple comparisons (Tannock, 1996), data dredging (Smith and Ebrahim, 2002), HARKing—hypothesizing after the results are known (Kerr, 1998), data-dependent analysis (Gelman and Loken, 2014), and opportunistic stopping or continuation (Pocock, 1987). Insufficient validation of new technologies, or even software problems can also drive realized error rates far above what is expected given stated levels of statistical confidence (see e.g. ref. Eklund et al., 2016). Research groups may be positively disposed toward their prior hypotheses or reluctant to contradict the work of closely allied labs. Finally, industry-sponsored clinical trials often allow the sponsors some degree of control over whether results are published (Kasenda et al., 2016), resulting in an additional source of publication bias separate from the journal acceptance process.
To understand the consequences of these problems and practices, we can extend our model to distinguish the actual false positive rate from the nominal false positive rate which is reported in the paper and used by readers to draw their inferences. We assume the actual false positive rate is always at least as large as the nominal rate, that is, . In this scenario, the probability that a false claim leads to a positive published outcome depends on the actual false positive rate, i.e.,
However, the change in belief following a positive or negative published outcome respectively depends on the nominal false positive rate:
An inflated false positive rate makes it much more likely that false claims will be canonized as true facts (Figure 8). For example, suppose the false negative rate is and the nominal false positive rate is , but the actual false positive rate is . Even eliminating publication bias against negative outcomes (i.e., ) and using strong evidentiary standards does not eliminate the possibility that false claims will be canonized as facts under these circumstances (Figure 8). Less dramatic inflation of the false positive rate leaves open the possibility that true vs. false claims can be distinguished, but only if a higher percentage of negative outcomes is published.
Figure 8
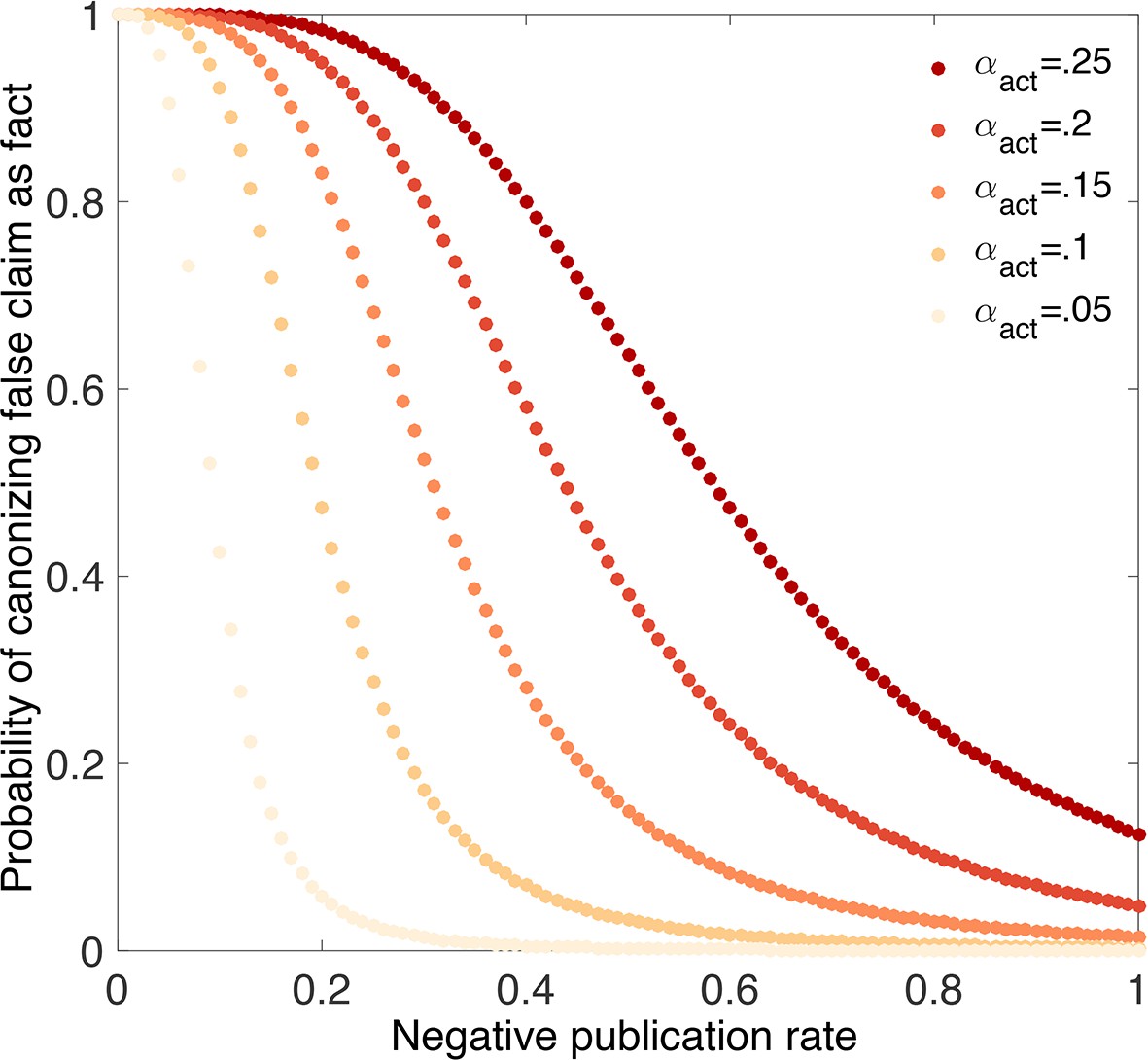
-hacking dramatically increases the chances of canonizing false claims.
Probability that a false claim is canonized as fact vs. fraction of negative outcomes. Throughout, all positive outcomes are published (), and the nominal false positive rate is , the false negative rate is , and evidentiary standards are strong ( and ). Curves show actual false positive rates (yellow), (red). Compared with Figure 4C, in which the nominal rates are equal to the actual rates, the probability of canonizing a false claim as fact is substantially higher.
Increasing negative publication rates as a claim approaches canonization greatly increases accuracy
Thus far we have told a troubling story. Without high probabilities of publication for negative results, the scientific process may perform poorly at distinguishing true claims from false ones. And there are plenty of reasons to suspect that negative results are not always be likely to be published.
However, authors, reviewers, and editors are all drawn to unexpected results that challenge or modify prevalent views—and for a claim widely believed to be true, a negative result from a well-designed study is surprising. As a consequence, the probability of publishing a negative result may be higher for claims that are already considered likely to be true (Silvertown and McConway, 1997; Ioannidis, 2005)
In a simulation of point estimation by successive experimentation, de Winter and Happee considered an even more extreme situation in which it is only possible to publish results that contradict the prevailing wisdom (de Winter and Happee, 2013). They argue that this has efficiency benefits, but their results have been challenged persuasively by van Assen and colleagues (van Assen et al., 2014). In any event, such a publication strategy would not work in the framework we consider here, because a claim could neither be canonized nor rejected if each new published result were required to contradict the current beliefs of the community.
Some meta-analyses have revealed patterns consistent with this model (Poulin, 2000). For example, when the fluctuating asymmetry hypothesis was proposed in evolutionary ecology, the initial publications exclusively reported strong associations between symmetry and attractiveness or mating success. As time passed, however, an increasing fraction of the papers on this hypothesis reported negative findings with no association between these variables (Simmons et al., 1999). A likely interpretation is that initially journals were reluctant to publish results inconsistent with the hypothesis, but as it became better established, negative results came to be viewed as interesting and worthy of publication (Simmons et al., 1999; Palmer, 2000; Jennions and Møller, 2002).
To explore the consequences of this effect, we consider a model in which the probability of publishing a negative outcome increases linearly from a baseline value when belief in the claim is weak, to a maximum value of when belief in the claim is strong. We assume that the probability of publishing a negative outcome is , where is the baseline probability for publishing negative outcomes, and is the current belief. As before, our agents are unaware of any publication bias in updating their own beliefs.
Figure 9 indicates that dynamic publication rates can markedly reduce (though not eliminate) the false canonization rate under many scenarios. In particular, Figure 9 suggests that even if it is difficult to publish negative outcomes for claims already suspected to be false, we can still accurately sort true claims from false ones provided that negative outcomes are more readily published for claims nearing canonization. In practice, this mechanism may play an important role in preventing false results from becoming canonized more frequently.
Figure 9
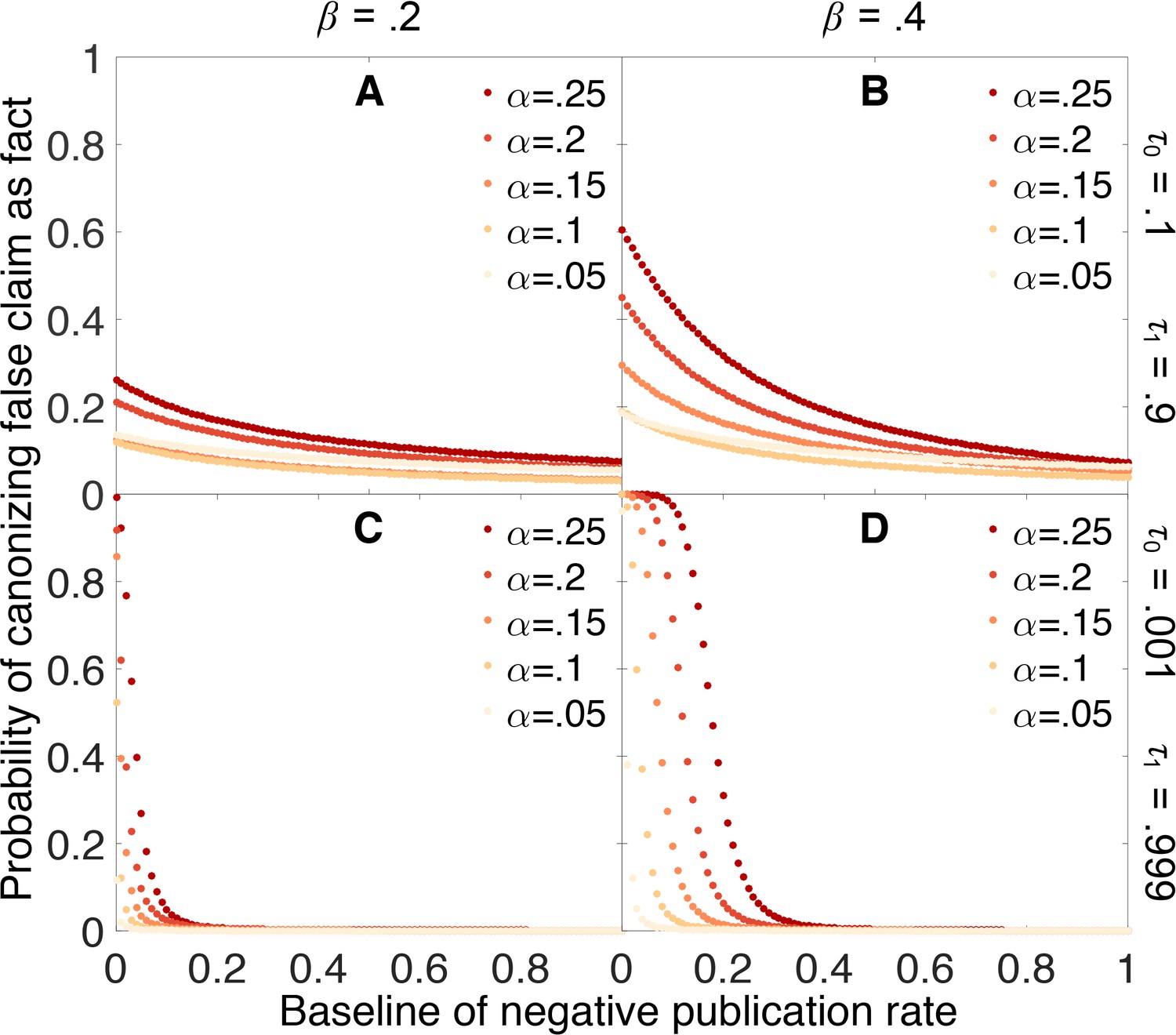
Publishing a larger fraction of negative outcomes as belief increases lessens the chances of canonizing false claims.
Probability that a false claim is mistakenly canonized as a true fact vs. baseline probability of publishing a negative outcome. The baseline probability of publishing a negative outcome is the probability that prevails when belief in the claim is weak. The actual probability of publishing a negative outcome increases linearly from the baseline rate when belief is 0 to a value of 1 when belief is 1. All other parameters are the same as in Figure 4.
Discussion
In the model of scientific inquiry that we have developed here, publication bias creates serious problems. While true claims will seldom be rejected, publication bias has the potential to cause many false claims to be mistakenly canonized as facts. This can be avoided only if a substantial fraction of negative results are published. But at present, publication bias appears to be strong, given that only a small fraction of the published scientific literature presents negative results. Presumably many negative results are going unreported. While this problem has been noted before (Knight, 2003), we do not know of any previous formal analysis of its consequences regarding the establishment of scientific facts.
Should scientists publish all of their results?
There is an active debate over whether science functions most effectively when researchers publish all of their results, or when they publish only a select subset of their findings Nelson et al,, 2012; de Winter and Happee, 2013; van Assen et al., 2014; McElreath and Smaldino, 2015). In our model, we observe no advantage to selective publication; in all cases treated we find that false canonization decreases monotonically with increasing publication of negative results. This seems logical enough. Decision theory affirms that in the absence of information costs, withholding information cannot on average improve performance in a decision problem such as the classification task we treat here (Savage, 1954; Good, 1967; Ramsey, 1990). As Good (1967) notes, a decision-maker “should use all the evidence already available, provided that the cost of doing so is negligible.”
Nonetheless, several research groups have argued that selective publishing can be more efficient than publishing the results of all studies. Clearly they must be implicitly or explicitly imposing costs of some sort on the acts of publishing papers or reading them, and it can be instructive to see where these costs lie. One source of such costs comes simply from the increased volume of scientific literature that ensues when all results are published; this is sometimes known as the “cluttered office” effect (Nelson et al., 2012). If we envision that search costs increase with the volume of literature, for example, it may be beneficial not to publish everything.
Another possible cost is that of actually writing a paper and going through the publication process. If preparing a paper for publication is costly relative to doing the experiments which would be reported, it may be advantageous to publish only a subset of all experimental results. This is the argument that de Winter and Happee make when, in a mathematical model of point estimation, they find that selective publication minimizes the variance given the number of publications (as opposed to the number of experiments conducted). Note, however, that they assume a model of science in which experiments are only published when they contradict the prevailing wisdom—and that their results have been roundly challenged in a followup analysis ( van Assen et al., 2014).
McElreath and Smaldino (2015) analyzed a model that is more similar to ours in structure. As we do, they consider repeated tests of binary-valued hypotheses. But rather than focusing on a single claim at a time, they model the progress of a group of scientists testing a suite of hypotheses. Based on this model, McElreath and Smaldino conclude that there can be advantages to selective publication under certain conditions.
While selective publication certainly can ameliorate the cluttered office problem—observed in their model as the flocking of researchers to questions already shown likely to be false—we are skeptical about the other advantages to selective publication. McElreath and Smaldino’s model and results appear to rely in part on their assumption that “the only information relevant for judging the truth of a hypothesis is its tally, the difference between the number of published positive and the number of published negative findings” (p. 3).
As a mathematical claim, this is incorrect. Presumably the claim is instead intended to be a tactical assumption that serves to simplify the analysis. But this assumption is severely limiting. The tally is often an inadequate summary of the evidence in favor of a hypothesis. One can see the problem with looking only at the tally by considering a simple example in which false positive rates are very low, false negative rates are high, and all studies are published. There is mild evidence that a hypothesis is false if no positive studies and one negative study have been published, but there is strong evidence that the hypothesis is true if three positive and four negative studies have been published. Yet both situations share the same tally: . The same problem arises when publication bias causes positive and negative findings to be published at different rates.
If one is forced to use only the tally to make decisions, an agent can sometimes make better inferences by throwing away some of the data (i.e., under selective publication). For example, when false negatives are common it may be beneficial to suppress some fraction of the negative results lest they swamp any signal from true positive findings. This is not the case when the agent has access to complete information about the number of positive and the number of negative results published. As a result, it is unclear whether most of McElreath and Smaldino’s arguments in favor of selective publication are relevant to optimal scientific inference, or whether they are consequences of the assumption that agents draw their inferences based on the tally alone.
What do we do about the problem of publication bias?
Several studies have indicated that much of the publication bias observed in science can be attributed to authors not writing up null results, rather than journals rejecting null results (Dickersin et al., 1992; Olson et al., 2002; Franco et al., 2014). This does not necessarily exonerate the journals; authors may be responding to incentives that the journals have put in place (Song et al., 2000). Authors may be motivated by other reputational factors as well. It would be a very unusual job talk, promotion seminar, or grant application that was based primarily upon negative findings.
So what can we as a scientific community do? How can we avoid canonizing too many false claims, so that we can be confident in the veracity of most scientific facts? In this paper, we have shown that strengthening evidentiary standards does not necessarily help. In the presence of strong publication bias, false claims become canonized as fact not so much because of a few misleading chance results, but rather because on average, misleading results are more likely to be published than correct ones.
Fortunately, this problem may be ameliorated by several current aspects of the publication process. In this paper, we have modeled claims that have only one way of generating “positive” results. For many scientific claims, e.g. those like our Dicer example that propose particular mechanisms, this may be appropriate. In other cases, however, results may be continuous: not only do we care whether variables and are correlated, but also we want to know about the strength of the correlation, for example. This does not make the problem go away, if stronger or highly significant correlations are seen as more worthy of publication than weaker or non-significant correlations. However, one advantage of framing experimental results as continuous-valued instead of binary is that there may be multiple opposing directions in which a result could be considered positive. For example, the expression of two genes could be correlated, uncorrelated, or anticorrelated. Both correlation and anticorrelation might be seen as positive results, whereas the null result of no correlation could be subject to publication bias. But suppose there is truly no effect: what does publication bias do in this case? We would expect to see false positives in both directions. Meta-analysis would readily pick up the lack of a consistent direction of the effect, and (if the authors avoid mistakenly inferring population heterogeneity) it is unlikely that correlations in either direction would be falsely canonized as fact.
Our model assumes that research continues until each claim is either rejected or canonized as fact. In practice, researchers can and do lose interest in certain claims. False claims might generate more conflicting results, or take longer to reach one of the evidentiary thresholds; either mechanism could lead researchers to move on to other problems and leave the claim as unresolved. If this is the case, we might expect that instead of being rejected or canonized as fact, many false claims might simply be abandoned.
Another possible difference between the model and the real world is that we model the evidentiary standards as symmetric, but in practice it may require less certainty to discard a claim as false than it requires to accept the same claim as fact. In this case, the probability of rejecting false claims would be higher than predicted in our model—possibly with only a very small increase in the probability of rejecting true claims.
The scientific community could also actively respond to the problem of canonizing false claims. One of the most direct ways would be to invest more heavily in the publication of negative results. A number of new journals or collections within journals have been established to specialize in publishing negative results. These include Elsevier’s New Negatives in Plant Science, PLOS One’s Positively Negative collection, Biomed Central’s Journal of Negative Results in Biomedicine, and many others (Editors, 2016). Alternatively, peer reviewed publication may be unnecessary; simply publishing negative results on preprint archives such as the arXiv, bioRxiv, and SocArXiv may make these results sufficiently visible. In either case, we face an incentive problem: if researchers accrue scant credit or reward for their negative findings, there is little reason for them to invest the substantial time needed in taking a negative result from a bench-top disappointment to a formal publication.
Another possibility—which may already be in play—involves shifting probabilities of publishing negative results. We have shown that if negative results become easier to publish as a claim becomes better established, this can greatly reduce the probability of canonizing false claims. One possibility is that negative results may become easier to publish as they become more surprising to the community, i.e., as researchers become increasingly convinced that a claim is true. Referees and journal editors could make an active effort to value papers of this sort. At present, however, our experience suggests that negative results or even corrections of blatant errors in previous publications rarely land in journals of equal prestige to those that published the original positive studies (Matosin et al., 2014).
A final saving grace is that even after false claims are established as facts, science can still self-correct. In this paper, we have assumed for simplicity that claims are independent propositions, but in practice claims are entangled in a web of logical interrelations. When a false claim is canonized as fact, inconsistencies between it and other facts soon begin to accumulate until the field is forced to reevaluate the conflicting facts. Results that resolve these conflicts by disproving accepted facts then take on a special significance and suffer little of the stigma placed upon negative results. Until the scientific community finds more ways to deal with publication bias, this may be an essential corrective to a process that sometimes loses its way.
We conclude with a note on what this work tells us about the value of science as a means of comprehending the natural world. Science denialists on both ends of the ideological spectrum might be tempted to invoke our findings as justification for their world-views. This would be a mistake. The facts that science denialists target are almost always very different from the types of facts we are modeling. We are modeling small-scale facts of modest import, the kind that would be established based on one or two dozen studies and then considered settled. The reality of anthropogenic climate change, the lack of connection between vaccination and autism, or the causative role of smoking in cancer are very different. Facts of this sort have enormous practical importance; they are supported by massive volumes of research; and they have been established despite well-funded groups with powerful incentives to expose any evidence that might give cause for skepticism. The process by which false claims can become canonized as fact in our model simply would not operate under these circumstances.
Of all the institutions and methods that humankind have developed to make sense of our universe, science has proven unparalleled in its power to generate useful models of physical phenomena. Nothing that we have written here changes this. The point of asking questions such as those in the present paper is not to de-legitimize science, but rather to improve the accuracy and efficiency of scientific inquiry.
References
-
Publication bias: a problem in interpreting medical dataJournal of the Royal Statistical Society. Series A 151:419–463.https://doi.org/10.2307/2982993
-
Is economics research replicable? sixty published papers from thirteen journals say “usually NotFinance and Economics Discussion Series 083:1–26.https://doi.org/10.17016/feds.2015.083
-
Publication bias in clinical researchThe Lancet 337:867–872.https://doi.org/10.1016/0140-6736(91)90201-Y
-
The statistical crisis in scienceAmerican Scientist 102:460–465.https://doi.org/10.1511/2014.111.460
-
On the principle of total evidenceThe British Journal for the Philosophy of Science 17:319–321.https://doi.org/10.1093/bjps/17.4.319
-
Role of dicer in posttranscriptional RNA silencingCurrent Topics in Microbiology and Immunology 320:77–97.https://doi.org/10.1007/978-3-540-75157-1_4
-
Relationships fade with time: a meta-analysis of temporal trends in publication in ecology and evolutionProceedings of the Royal Society B: Biological Sciences 269:43–48.https://doi.org/10.1098/rspb.2001.1832
-
HARKing: hypothesizing after the results are knownPersonality and Social Psychology Review 2:196–217.https://doi.org/10.1207/s15327957pspr0203_4
-
BookScience in Action: How to Follow Scientists and Engineers Through SocietyHarvard University Press.
-
The extent and consequences of p-hacking in sciencePLoS Biology 13:e1002106.https://doi.org/10.1371/journal.pbio.1002106
-
let’s publish fewer papersPsychological Inquiry 233:291–293.https://doi.org/10.1080/1047840x.2012.705245
-
Quasi-replication and the contract of error: lessons from sex ratios, heritabilities and fluctuating asymmetryAnnual Review of Ecology and Systematics 31:441–480.https://doi.org/10.1146/annurev.ecolsys.31.1.441
-
Statistical problems in the reporting of clinical trialsNew England Journal of Medicine 317:426–432.https://doi.org/10.1056/NEJM198708133170706
-
Manipulation of host behaviour by parasites: a weakening paradigm?Proceedings of the Royal Society B: Biological Sciences 267:787–792.https://doi.org/10.1098/rspb.2000.1072
-
Weight or the value of knowledgeThe British Journal for the Philosophy of Science 41:1–4.https://doi.org/10.1093/bjps/41.1.1
-
Scientific knowledge and its social problemsBritish Society for the Philosophy of Science 7:72.https://doi.org/10.1017/s0007087400012875
-
The file drawer problem and tolerance for null resultsPsychological Bulletin 86:638–641.https://doi.org/10.1037/0033-2909.86.3.638
-
Fluctuating paradigmProceedings of the Royal Society B: Biological Sciences 266:593–595.https://doi.org/10.1098/rspb.1999.0677
-
Publication decisions and their possible effects on inferences drawn from tests of significance –Or vice versaJournal of the American Statistical Association 54:30–34.https://doi.org/10.1080/01621459.1959.10501497
-
False-positive results in clinical trials: Multiple significance tests and the problem of unreported comparisonsJournal of the National Cancer Institute 88:206–207.https://doi.org/10.1093/jnci/88.3-4.206
-
Selective publication of antidepressant trials and its influence on apparent efficacyNew England Journal of Medicine 358:252–260.https://doi.org/10.1056/NEJMsa065779
Article and author information
Author details
Funding
John Templeton Foundation
- Carl T Bergstrom
Danish National Research Foundation
- Silas Boye Nissen
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
The authors thank Jacob G Foster, Frazer Meacham and Kevin Zollman for helpful comments and suggestions on the manuscript. This work was supported by the Danish National Research Foundation and by a generous grant to the Metaknowledge Network from the John Templeton Foundation. KG thanks the University of Washington Department of Biology for sabbatical support.
Reviewing Editor
- Peter Rodgers, eLife, United Kingdom
Publication history
- Received:
- Accepted:
- Version of Record published:
Copyright
© 2016, Nissen et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 29,920
- views
-
- 2,909
- downloads
-
- 181
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 181
- citations for umbrella DOI https://doi.org/10.7554/eLife.21451
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Research: Publication bias and the canonization of false facts
eLife 5:e21451.
https://doi.org/10.7554/eLife.21451

Further reading
-
A bias towards publishing positive results is making it harder to distinguish between true and false claims in science.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}