Research: The readability of scientific texts is decreasing over time
- Karolinska Institutet, Sweden
Abstract
Clarity and accuracy of reporting are fundamental to the scientific process. Readability formulas can estimate how difficult a text is to read. Here, in a corpus consisting of 709,577 abstracts published between 1881 and 2015 from 123 scientific journals, we show that the readability of science is steadily decreasing. Our analyses show that this trend is indicative of a growing use of general scientific jargon. These results are concerning for scientists and for the wider public, as they impact both the reproducibility and accessibility of research findings.
https://doi.org/10.7554/eLife.27725.001Introduction
Reporting science clearly and accurately is a fundamental part of the scientific process, facilitating both the dissemination of knowledge and the reproducibility of results. The clarity of written language can be quantified using readability formulas, which estimate how understandable written texts are (Flesch, 1948; Kincaid et al., 1975; Chall and Dale, 1995; Danielson, 1987; DuBay, 2004; Štajner et al., 2012). Texts written at different times can vary in their readability: trends towards simpler language have been observed in US presidential speeches (Lim, 2008), novels (Danielson et al., 1992; Jatowt and Tanaka, 2012) and news articles (Stevenson, 1964). There are studies that have investigated linguistic trends within the scientific literature. One study showed an increase in positive sentiment (Vinkers et al., 2015), finding that positive words such as 'novel' have increased dramatically in scientific texts since the 1970s. A tentative increase in complexity has been reported in scientific texts in a limited dataset (Hayes, 1992), but the extent of this phenomenon and any underlying reasons for such a trend remain unknown.
To investigate trends in scientific readability over time, we downloaded 709,577 article abstracts from PubMed, from 123 highly cited journals selected from 12 fields of research (Figure 1A–C). These journals cover general, biomedical and life sciences. This journal list included, among others, Nature, Science, NEJM, The Lancet, PNAS and JAMA (see Materials and methods and Supplementary file 1) and the publication dates ranged from 1881 to 2015. We quantified the reading level of each abstract using two established measures of readability: the Flesch Reading Ease (FRE; Flesch, 1948; Kincaid et al., 1975) and the New Dale-Chall Readability Formula (NDC; Chall and Dale, 1995). The FRE is calculated using the number of syllables per word and the number of words in each sentence. The NDC is calculated using the number of words in each sentence and the percentage of 'difficult words'. Difficult words are defined as those words which do not belong to a predefined list of common words (see Materials and methods). Lower readability is indicated by a low FRE score or a high NDC score (Figure 1A).
Figure 1

Data and readability analysis pipeline.
(A) Schematic depicting the major steps in the abstract extraction and analysis pipeline. Readability formulas are provided in full in Materials and methods. (B) Number of articles in the corpus published in each year. The color scale is logarithmic. (C) Starting year of each journal within the corpus. This corresponds to the first article in PubMed with an abstract. The color scale is linear. Source data for this figure is available in Figure 2—source data 1.
Results
The primary research question was to examine how the readability of an article's abstract relates to its year of publication. We observed a strong decreasing trend of the average yearly FRE (r = -0.93, 95% CI [-0.95,-0.90], p <10-15) and a strong increasing trend of average yearly NDC (r = 0.93, 95% CI [0.91,0.95], p <10 -15) (Figure 2A–E). Next, we examined the relationship between the components of the readability metrics and year of publication. The average number of syllables in each word (FRE component) and the percentage of difficult words (NDC component) showed pronounced increases over years (Figure 2F,G). Sentence length (FRE and NDC component) showed a steady increase with year after 1960 (Figure 2H), the period in which the majority of abstracts were published (Figure 1B). FRE and NDC were correlated with one another (r = -0.72, 95% CI [-0.72,-0.72], p <10-15) (Figure 2E).
Figure 2 with 1 supplement see all
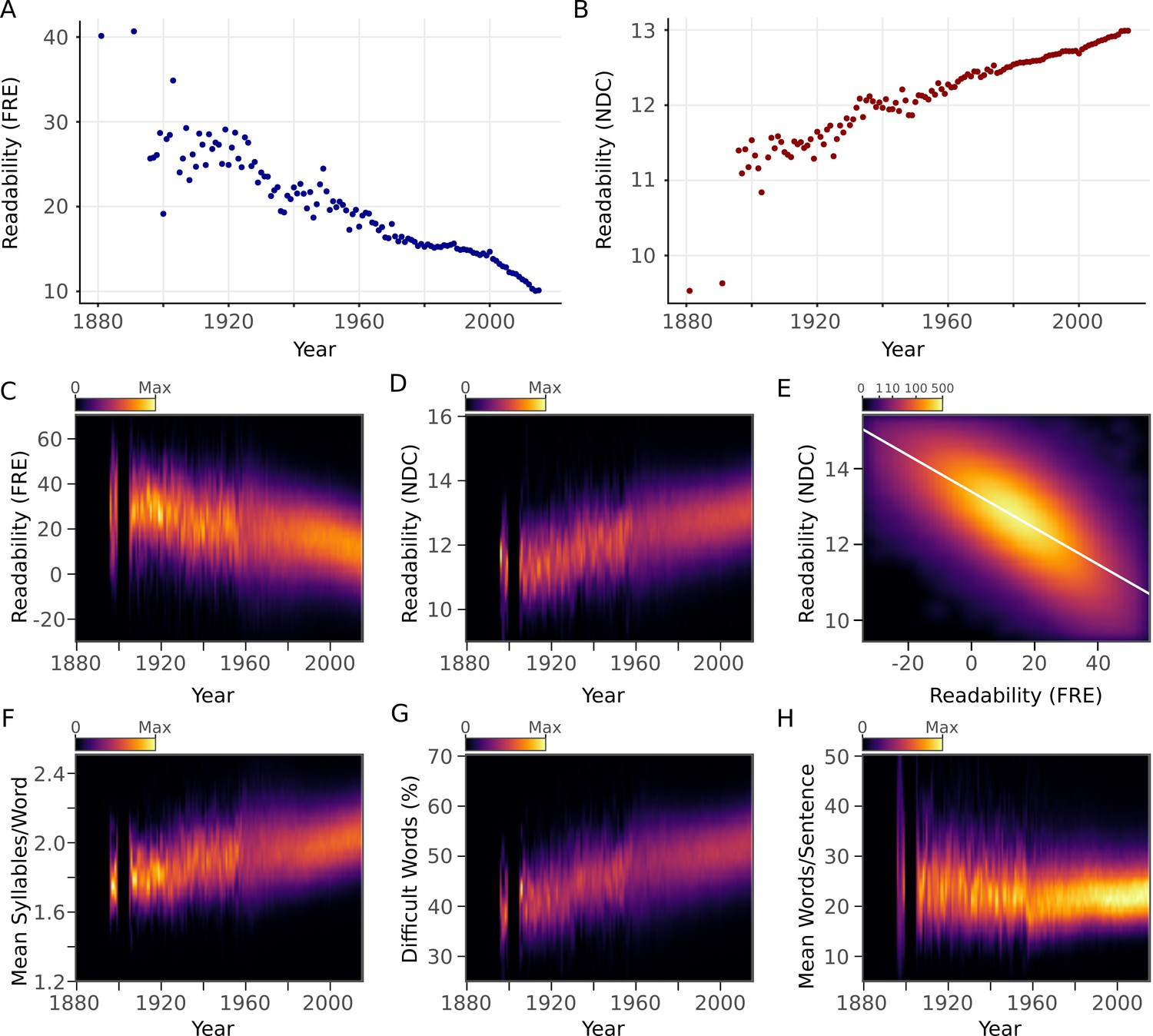
Scientific abstracts have become harder to read over time.
(A) Mean Flesch Reading Ease (FRE) readability for each year. Lower scores indicate less readability. (B) Mean New Dale-Chall (NDC) readability for each year. Higher scores indicate less readability. (C,D) Kernel density estimates displaying the readability (C: FRE, D: NDC) distribution of all abstracts for each year. Color scales are linear and represent relative density of scores within each year. (E) Relationship between FRE and NDC scores across all abstracts, depicted by a two-dimensional kernel density estimate. Axis limits are set to include at least 99% of the data. The color scale is exponential and represents the number of articles at each pixel. (F-H) Kernel density estimates displaying the components of the readability measures (F: syllable to word ratio; G: percentage of difficult words; H: word to sentence ratio) distribution of all abstracts for each year. Color scales are linear and represent relative density of values within each year. For kernel density plots over time (C,D,F,G,H), years with fewer than 10 abstracts are excluded to obtain accurate density estimates.
-
Figure 2—source data 1
Readability data of abstracts and number of authors per article.
- https://doi.org/10.7554/eLife.27725.005
-
Figure 2—source data 2
Readability data when no preprocessing is done.
- https://doi.org/10.7554/eLife.27725.006
The readability of individual abstracts was formally evaluated in relation to year of publication using a linear mixed effects model with journal as a random effect for both measures. The fixed effect of year was significantly related to FRE and NDC scores (Table 1). The average yearly trends combined with this statistical model reveal that the complexity of scientific writing is increasing with time. In order to explore whether this trend was consistent across all 12 selected fields, we extracted the slopes (random effects) from the mixed effects models for each journal. This showed that the trend of decreasing readability over time is not specific to any particular field, although there are differences in magnitude between fields (Figure 3). Further, only two journals out of 123 showed clear increases in FRE across time (Figure 3—figure supplement 1).
Figure 3 with 1 supplement see all
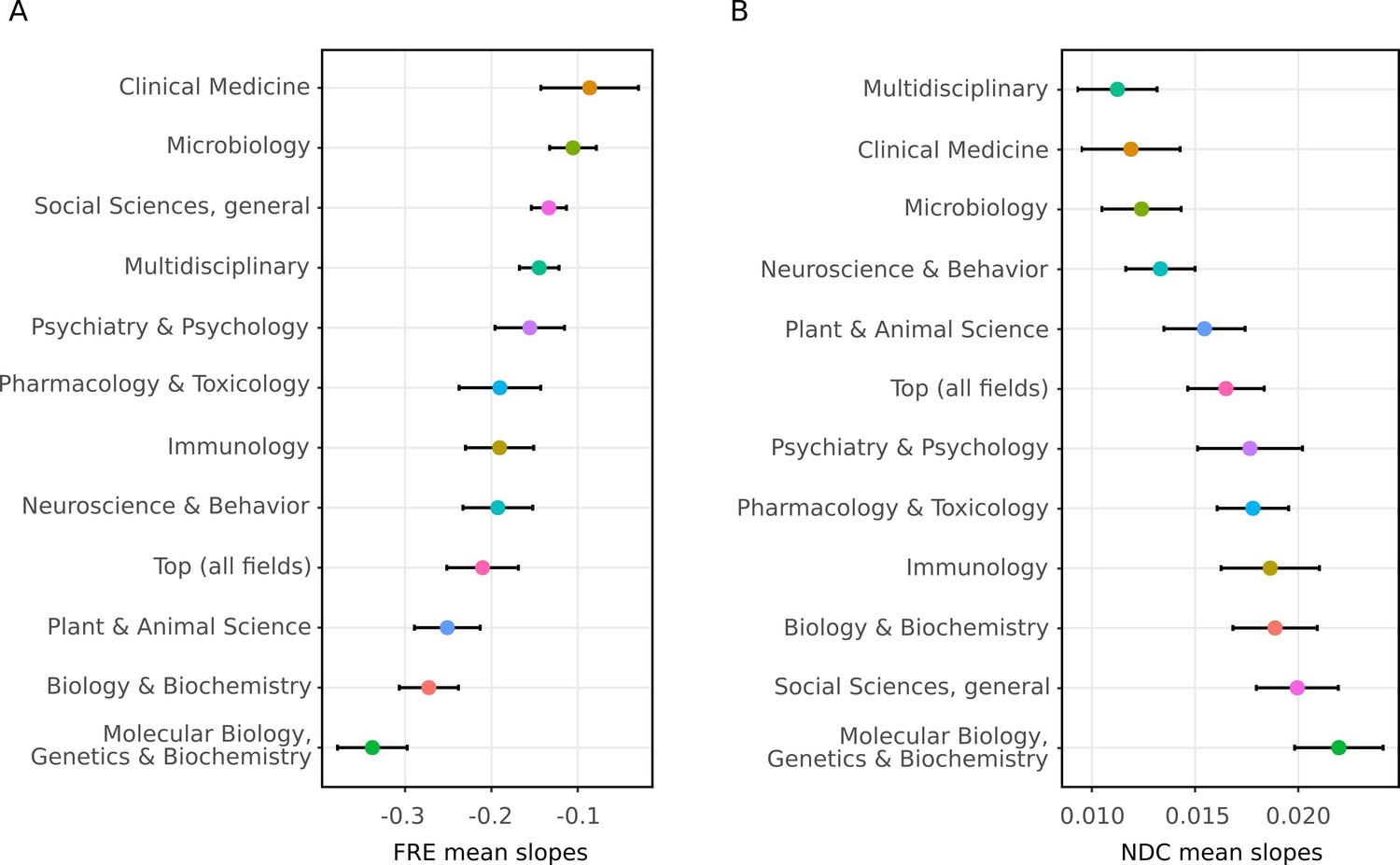
The decline in readability differs between scientific fields.
The random slopes for each journal were extracted from the best fitting linear mixed effect model (M2) and summarized according to which field they belong to (The error bars represent SE of the mean slope). Since some journals belong to more than one field, some random slopes appear in more than one summary. The trend of decreasing readability is not specific to any one field. (A) Summaries of random slopes for Flesch Reading Ease. (B) Summaries of random slopes for New Dale-Chall.
-
Figure 3—source data 1
Summary of FRE and NDC journal random slopes for each field extracted from the linear mixed model (M2).
- https://doi.org/10.7554/eLife.27725.010
-
Figure 3—source data 2
FRE and NDC random slopes for each journal extracted from the linear mixed model (M2).
- https://doi.org/10.7554/eLife.27725.011
Table 1
Model fits for two different linear mixed effect models examining the relationship between readability scores and year.
A null model (M0) without year as a predictor is included as a baseline comparison. Lower dAIC and dBIC values indicate better model fit. FRE = Flesch Reading Ease; NDC = New Dale-Chall Readability Formula; M0 = Journal as random effect with varying intercepts; M1 = M0 with an added fixed effect of time; M2 = M1 with varying slopes for the random effect of journal; dAIC = difference in Akaike Information Criterion from the best fitting model (M2); dBIC = difference in Bayesian Information Criterion from the best fitting model (M2); df = Degrees of Freedom calculated using Satterthwaite approximation.
| Metric | Model | dAIC | dBIC | beta | CI 95% | t | df | p |
|---|---|---|---|---|---|---|---|---|
| FRE | M0 | 16008 | 15974 | - | - | - | - | - |
| M1 | 5240 | 5217 | -0.14 | [-0.15, -0.14] | -104.2 | 709543 | p <10-15 | |
| M2 | 0 | 0 | -0.19 | [-0.22, -0.16] | -12.7 | 123 | p <10-15 | |
| NDC | M0 | 28593 | 28559 | - | - | - | - | - |
| M1 | 4077 | 4054 | 0.014 | [0.014, 0.014] | 158.0 | 709559 | p <10-15 | |
| M2 | 0 | 0 | 0.016 | [0.015, 0.018] | 20.5 | 117 | p <10-15 |
To verify that the readability of abstracts was representative of the readability of the entire articles, we downloaded full text articles from six additional independent journals from which all articles were available in the PubMed Central Open Access Subset (Figure 4A). Although, as has previously been reported (Dronberger and Kowitz, 1975), abstracts are less readable than the full articles, there was a strong positive relationship between readability of the abstracts and the full texts (FRE: r = 0.60, 95% CI [0.60, 0.60], p <10-15; NDC: r = 0.63, 95% CI [0.63, 0.63], p <10-15, Figure 4B, Figure 4—figure supplements 1 and 2). This implies that the increasing complexity of scientific writing generalizes to the full texts.
Figure 4 with 2 supplements see all
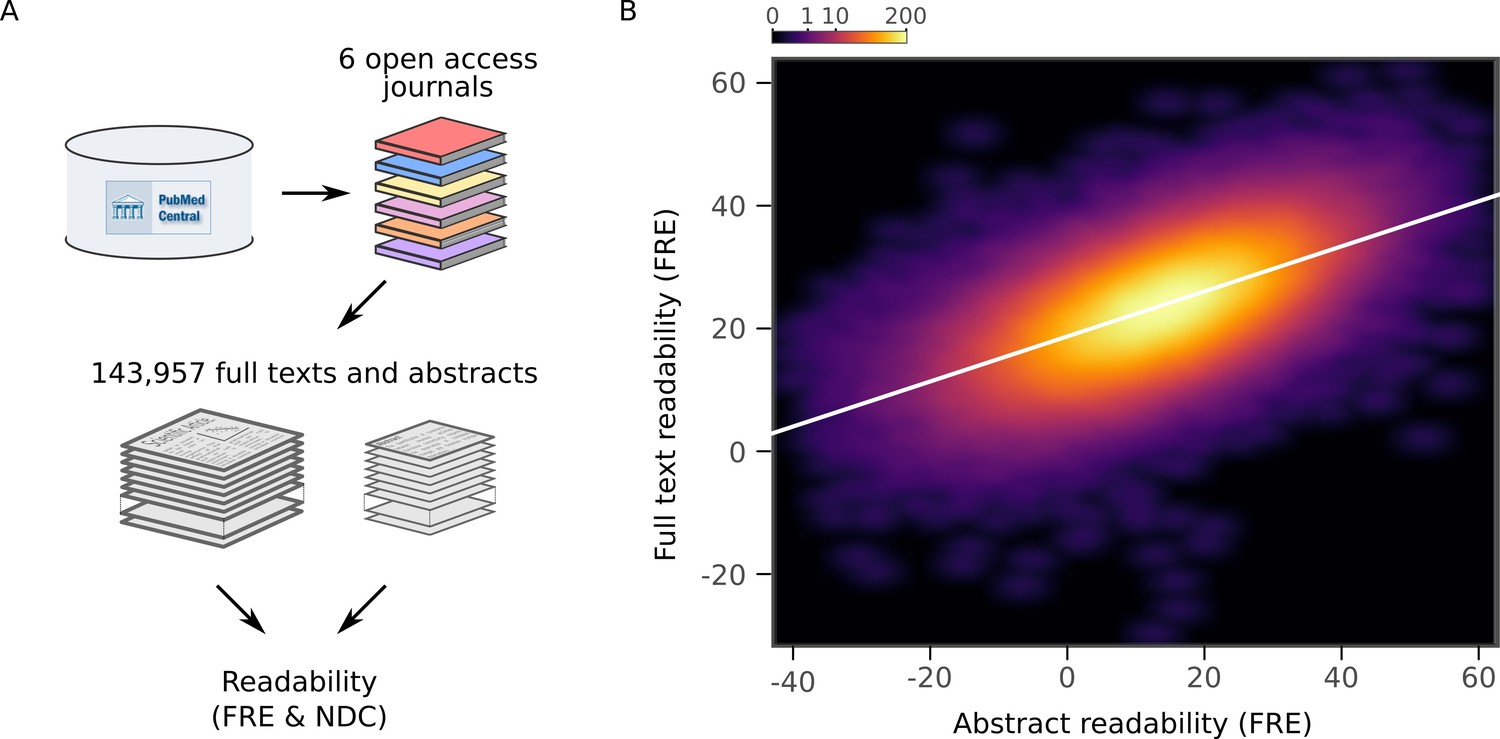
Readability of scientific abstracts correlates with readability of full texts.
(A) Schematic depicting the major steps in the full text extraction and analysis pipeline. (B) Relationship between Flesch Reading Ease (FRE) scores of abstracts and full texts across the full text corpus, depicted by a two-dimensional kernel density estimate. The color scale is exponential and represents the number of articles at each pixel. Axis limits are set to include at least 99% of the data. For New Dale-Chall (NDC) scores, see Figure 4—figure supplement 1. For each journal separately, see Figure 4—figure supplement 2.
-
Figure 4—source data 1
Readability data used in full text analysis.
- https://doi.org/10.7554/eLife.27725.015
There could be a number of explanations for the observed trend in scientific readability. We formulated two plausible and testable hypotheses: (1) There is an increase in the number of co-authors over time (Figure 5A) (see also (Epstein, 1993; Drenth, 1998). If the number of co-authors correlates with readability, this underlies the observed effect (i.e. a case of 'too many cooks spoil the broth'). (2) An increase in a general scientific jargon is leading to a vocabulary which is almost exclusively used by scientists and less readable in general (i.e. a 'science-ese').
Figure 5 with 1 supplement see all
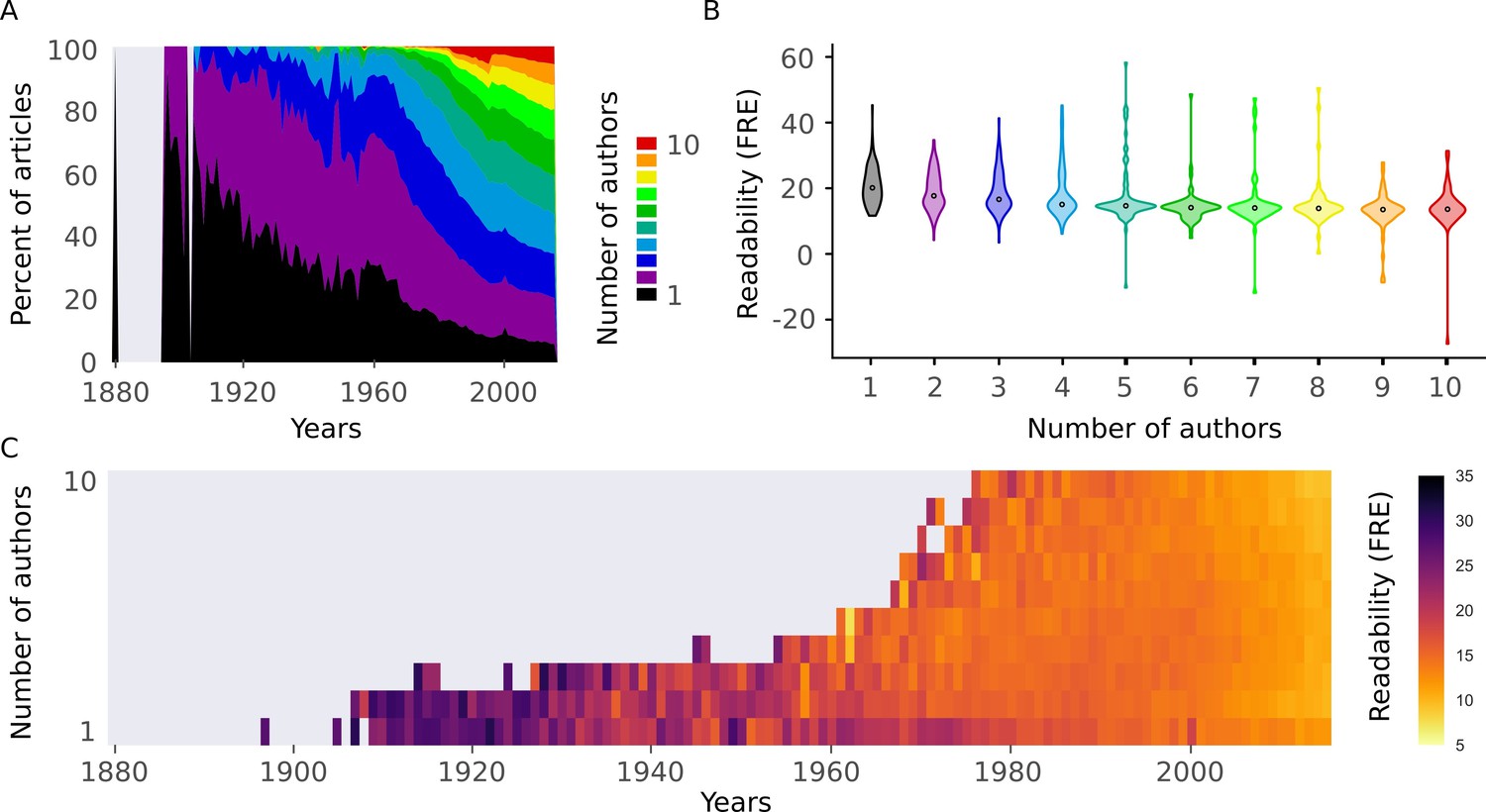
Readability is affected by the number of authors.
(A) Proportion of number of authors per year for all articles in the abstract corpus. (B) Distributions of Flesch Reading Ease (FRE) scores for different numbers of authors (1-10). For New Dale-Chall (NDC), see Figure 5—figure supplement 1A (C) Mean FRE score for each year for different numbers of authors (1-10). For visualization purposes, bins with fewer than 10 abstracts are excluded. For NDC, see Figure 5—figure supplement 1B. Source data for this figure is available in Figure 2—source data 1.
To test the first hypothesis, we divided the data by the number of authors. More authors were associated with decreased readability (Figure 5B, Figure 5—figure supplement 1A). However, we observed the same trend of decreasing readability across years regardless of the number of authors (Figure 5C, Figure 5—figure supplement 1B). When we included the number of authors as a predictor in the linear mixed effects model, it was significantly related to readability, while the fixed effect of year remained significant (Table 2). We can therefore reject the hypothesis that the increase in the number of authors on scientific articles is responsible for the observed trend, although abstract readability does decrease with more authors.
Table 2
Linear mixed effect models predicting readability scores by year and number of authors with journals as random effect.
FRE = Flesch Reading Ease; NDC = New Dale-Chall Readability Formula; df = Degrees of Freedom calculated using Satterthwaite approximation. signifies that abstracts with only 1 to 10 authors are included in the model.
| Metric | Subset | n | Random Effect | beta | CI 95% | t | df | p |
|---|---|---|---|---|---|---|---|---|
| FRE | Yes* | 652357 | Year | -0.17 | [-0.19, -0.14] | -11.3 | 122 | p<10-15 |
| Authors | -0.24 | [-0.26, -0.23] | -30.0 | 651832 | p <10-15 | |||
| No | 707250 | Year | -0.18 | [-0.21, -0.15] | -12.3 | 123 | p <10-15 | |
| Authors | -0.07 | [-0.08, -0.06] | -23.5 | 704922 | p<10-15 | |||
| NDC | Yes* | 652357 | Year | 0.014 | [0.012, 0.015] | 16.5 | 119 | p<10-15 |
| Authors | 0.033 | [0.032, 0.034] | 63.6 | 651516 | p <10-15 | |||
| No | 707250 | Year | 0.016 | [0.014, 0.017] | 19.6 | 118 | p <10-15 | |
| Authors | 0.008 | [0.007, 0.008] | 40.3 | 701014 | p <10-15 |
To test the second hypothesis, we constructed a measure for in-group scientific vocabulary. We selected the 2,949 most common words which were not included in the NDC common word list from 12,000 abstracts sampled at random (see Materials and methods for procedure). This is analogous to a 'science-specific common word list'. This list also includes topics which have increased over time (e.g. 'gene') and subject-specific words (e.g. 'tumor'), which are not indicative of an in-group scientific vocabulary. We removed such words to create a general scientific jargon list (2,138 words; see Materials and methods and Supplementary file 2). While the percentage of common words from the NDC common word list decreased with year (r = −0.93, 95% CI [-0.93, -0.93], p <10-15, Figure 6A), there was an increase in the percentage of science-specific common words (r = 0.90, 95% CI [0.90, 0.91], p <10-15) and general scientific jargon (r = 0.96, 95% CI [0.95, 0.96], p <10-15) (Figure 6A). Twelve general science jargon words are presented in Figure 6B. While one word ('appears') decreased with time, all the remaining examples show sharp increases over time. Taken together, this provides evidence in favor of the hypothesis that there is an increase in general scientific jargon which partially accounts for the decreasing readability.
Figure 6
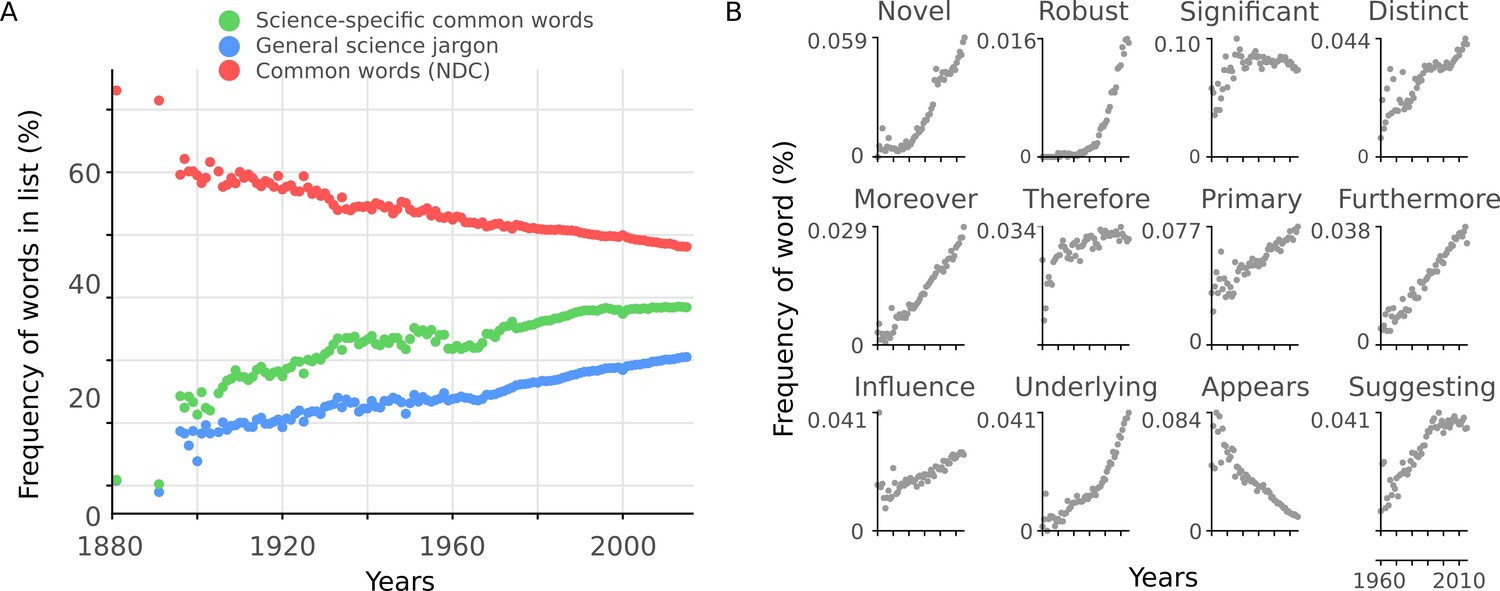
Readability is affected by general scientific jargon.
(A) Mean percentage of words in abstracts per year included in three different lists: science-specific common words (green, 2,949 words), general scientific jargon (blue, 2,138 words) and NDC common words (red, 2,949 words). (B) Example general science jargon words taken from the general scientific jargon list. Mean percentage of each word’s frequency in abstracts per year is shown.
-
Figure 6—source data 1
Frequency of words in lists and example word use per article.
- https://doi.org/10.7554/eLife.27725.020
-
Figure 6—source data 2
PubMed ID for files used in training and verification lists of science common word list.
- https://doi.org/10.7554/eLife.27725.021
Discussion
From analyzing over 700,000 abstracts in 123 journals from the biomedical and life sciences, as well as general science journals, we have shown a steady decrease of readability over time in the scientific literature. It is important to put the magnitude of these results in context. A FRE score of 100 is designed to reflect the reading level of a 10- to 11-year old. A score between 0 and 30 is considered understandable by college graduates (Flesch, 1948; Kincaid et al., 1975). In 1960, 14% of the texts in our corpus had a FRE below 0. In 2015, this number had risen to 22%. In other words, more than a fifth of scientific abstracts now have a readability considered beyond college graduate level English. However, the absolute readability scores should be interpreted with some caution: scores can vary due to different media (e.g. comics versus news articles; Štajner et al., 2012) and education level thresholds can be imprecise (Stokes, 1978). We then validated abstract readability against full text readability, demonstrating that it is a suitable approximation for comparing main texts.
We investigated two possible reasons why this trend has occurred. First, we found that readability of abstracts correlates with the number of co-authors, but this failed to fully account for the trend through time. Second, we showed that there is an increase in general scientific jargon over years. These general science jargon words should be interpreted as words which scientists frequently use in scientific texts, and not as subject specific jargon. This finding is indicative of a progressively increasing in-group scientific language ('science-ese').
An alternative explanation for the main finding is that the cumulative growth of scientific knowledge makes an increasingly complex language necessary. This cannot be directly tested, but if this were to fully explain the trend, we would expect a greater diversity of vocabulary as science grows more specialized. While accounting for the original finding of the increase in difficult words and of syllable count, this would not explain the increase of general scientific jargon words (e.g. 'furthermore' or 'novel', Figure 6B). Thus, this possible explanation cannot fully account for our findings.
Lower readability implies less accessibility, particularly for non-specialists, such as journalists, policy-makers and the wider public. Scientific journalism offers a key role in communicating science to the wider public (Bubela et al., 2009) and scientific credibility can sometimes suffer when reported by journalists (Hinnant and Len-Ríos, 2009). Considering this, decreasing readability cannot be a positive development for efforts to accurately communicate science to non-specialists. Further, amidst concerns that modern societies are becoming less stringent with actual truths, replaced with true-sounding 'post-facts' (Manjoo, 2011; Nordenstedt and Rosling, 2016) science should be advancing our most accurate knowledge. One way to achieve this is for science to maximize its accessibility to non-specialists.
Lower readability is also a problem for specialists (Hartley, 1994; Hartley and Benjamin, 1998; Hartley, 2003). This was explicitly shown by Hartley (1994) who demonstrated that rewriting scientific abstracts, to improve their readability, increased academics’ ability to comprehend them. While science is complex, and some jargon is unavoidable (Knight, 2003), this does not justify the continuing trend that we have shown. It is also worth considering the importance of comprehensibility of scientific texts in light of the recent controversy regarding the reproducibility of science (Prinz et al., 2011; McNutt, 2014; Begley and Ioannidis, 2015; Nosek et al., 2015; Camerer et al., 2016). Reproducibility requires that findings can be verified independently. To achieve this, reporting of methods and results must be sufficiently understandable.
Readability formulas are not without their limitations. They provide an estimate of a text’s readability and should not be interpreted as a categorical measure of how well a text will be understood. For example, readability can be affected by text size, line spacing, the use of headers, as well as by the use of visual aids such as tables or graphs, none of which are captured by readability formulas (Hartley, 2013; Badarudeen and Sabharwal, 2010). Many semantic properties of texts are overlooked, including the complexity of ideas, the rhetorical structure and the overall coherence of the text (Bruce et al., 1981; Danielson, 1987; Zamanian and Heydari, 2012). Changing a text solely to improve readability scores does not automatically make a text more understandable (Duffy and Kabance, 1982; Redish, 2000).
Despite the limitations of readability formulas, our study shows that recent scientific texts are, on average, less readable than older scientific texts. This trend was not specific to any one field, even though the size of this association varied across fields. Some fields also had a steeper decline in NDC scores, while less of a decline in FRE scores, and vice versa (Figure 3). Further research should explore possible reasons for these differences, as it may give clues on how to improve readability. For example, the adoption of structured abstracts which are known to assist readability (Hartley and Benjamin, 1998; Hartley, 2003) might lead to a less steep decline for some fields.
What more can be done to reverse this trend? The emerging field of science communication deals with ways science can effectively communicate ideas to a wider audience (Treise and Weigold, 2002; Nielsen, 2013; Fischhoff, 2013). One suggestion from this field is to create accessible 'lay summaries', which have been implemented by some journals (Kuehne and Olden, 2015). Others have noted that scientists are increasing their direct communication with the general public through social media (Peters et al., 2014), and this trend could be encouraged. However, while these two suggestions may increase accessibility of scientific results, neither will reverse the readability trend of scientific texts. Another proposal is to make scientific communication a necessary part of undergraduate and graduate education (Brownell et al., 2013).
Scientists themselves can estimate their own readability in most word processing software. Further, while some journals aim for high readability, perhaps a more thorough review of article readability should be carried out by journals in the review process. Finally, in an era of data metrics, it is possible to assess a scientist’s average readability, analogous to the h-index for citations (Hirsch, 2005). Such an 'r-index' could be considered an asset for those scientists who emphasize clarity in their writing.
Materials and methods
Journal selection
Request a detailed protocolWe aimed to obtain journals from which articles are highly cited from a representative selection of the biomedical and life sciences, as well as from journals which cover all fields of science, which were indexed on PubMed. Using the Thomson Reuters Research Front Maps (http://archive.sciencewatch.com/dr/rfm/) and the Thomson Reuters Journal Citation Reports, we selected 12 fields:
Top (all fields)
Biology & Biochemistry
Clinical Medicine
Immunology
Microbiology
Molecular Biology, Genetics & Biochemistry
Multidisciplinary
Neuroscience & Behavior
Pharmacology & Toxicology
Plant & Animal Science
Psychiatry & Psychology
Social Sciences, general
'Multidisciplinary' accounts for journals which publish work from multiple fields, but which did not fit into any one category. 'Top (all fields)' refers to the journals which are most highly cited across all fields, i.e. which have the highest impact factor from the 2014 Thomson Reuters Journal Citation Reports. The 'Social Sciences, general' field within the biomedical and life sciences includes journals from the subfields of 'Health Care Sciences & Services' and 'Primary Health Care'. Journals were semi-automatically selected by querying the PubMed API using the R package RISmed (Kovalchik, 2016) according to the following criteria:
There should be more than 15 years between the years of the first five and most recent five PubMed entries.
There should not be fewer than 100 articles returned for the journal.
The impact factor of the journal should not be below 1 according to the 2014 Thomson Reuters Journal Citation Report.
The articles within the journal should be in English.
The number of selected journals should provide as equal representation as possible of subfields within the broader research fields.
From each of 11 of the fields, the 12 most highly cited journals were selected. The final field (Multidisciplinary) only contained six journals, as no more journals could be identified which met all inclusion criteria. Some journals exist in multiple fields, thus the number of journals (123) is below the possible maximum of 138 journals. See Supplementary file 1 for the journals and their field mappings.
Articles were downloaded from PubMed between April 22, 2016 and May 15, 2016, and on June 12, 2017. The later download date was to correct for originally having only included 11 journals in one of the fields (when the data was first downloaded). The text of the abstract, journal name, title of article, PubMed IDs and publication year were extracted. Throughout the article, we only used data up to and including the year 2015.
Language preprocessing
Request a detailed protocolAbstracts downloaded from PubMed were preprocessed so that the words and syllables could be counted. TreeTagger (version 3.2 (Linux); (Schmid, 1994) was used to identify sentence endings and to remove non-words (e.g. numbers) and any remaining punctuation from the abstracts. Scientific texts contain numerous phrasings which TreeTagger did not parse adequately. We did three rounds of quality control where at least 200 preprocessed articles, sampled at random, were compared with their original texts. After identifying irregularities with the TreeTagger performance, regular expression heuristics were created to prepare the abstracts prior to using the TreeTagger algorithm. After the three rounds of quality control, the stripped abstracts contained only words with at least one syllable and periods to end sentences. Sentences containing only one word were ignored.
The heuristic rules after quality control rounds included: removing all abbreviations, adding spaces after periods when missing, adding a final period at the end of the abstract when missing, removing numbers that ended sentences, identifying sentences that end with 'etc.' and keeping the period, removing all single letter words except 'a', 'A' and 'I', removing nucleic acid sequences, replacing hyphens with a space, removing periods arising from the use of binomial nomenclature, and removing copyright and funding information. All preprocessing scripts are available at https://github.com/wiheto/readabilityinscience (Plavén-Sigray et al., 2017; copy archived at https://github.com/elifesciences-publications/readabilityinscience). Examples of texts before and after preprocessing are presented in Supplementary file 3. We confirmed that the observed trends were not induced by the preprocessing steps by running the readability analysis presented in Figure 1D,E using the raw data (Figure 2—figure supplement 1).
Language and readability metrics
Request a detailed protocolTwo well-established readability measures were used throughout the article: the Flesch Reading Ease (FRE) (Flesch, 1948; Kincaid et al., 1975) and the New Dale-Chall Readability Formula (NDC) (Chall and Dale, 1995). These measures use different language metrics: syllable count, sentence count, word count and percentage of difficult words. Two different readability metrics were chosen to ensure that the results were not induced by a single method. FRE was chosen due to its popularity and consistency with other readability metrics (Didegah and Thelwall, 2013), and because it has previously been applied to trends over time (Lim, 2008; Danielson et al., 1992; Jatowt and Tanaka, 2012; Stevenson, 1964). NDC was chosen since it is both well established and compares well with more recent methods for analyzing readability (Benjamin, 2012).
Counting the syllables of a word was performed in a three step fashion. First, the word was required to have a vowel or a 'y' in it. Second, the word was queried against a dictionary that contained specified syllable counts using the natural language toolkit (NLTK) (version 3.2.2; Bird et al., 2009). If there were multiple possible syllable counts for a given word, the longer alternative was chosen. Third, if the word was not in the dictionary, the number of vowels (excluding diphthongs) was counted. If a word ended in a 'y', this was counted as an additional syllable in this third step.
Word count was calculated by counting all the words in the abstract that had at least one syllable. The number of sentences was calculated by counting the number of periods in the preprocessed abstracts.
The percentage of difficult words originated from (Chall and Dale, 1995), defined as words which do not belong to a list of common words. The 'NDC common word' list used here was taken from the NDC implementation in the textstat python package (https://github.com/shivam5992/textstat) which included 2,949 words (Supplementary file 2). This list excludes some words from the original NDC common word list (such as abbreviations, e.g. 'A.M.'; and double words, e.g. 'all right').
FRE uses both the average number of syllables per word and the average number of words per sentence to estimate the reading level.
where 'words', 'sentences' and 'syllables' entail the number of each in the text, respectively.
NDC scores are calculated by using the percentage of difficult words and the average sentence length of abstracts. While the NDC was originally calculated on 100 words due to computational limitations, we used the entire text.
where 'words', and 'sentences' entail the number of each in the text, respectively. 'Difficult' is the number of words that are not present in the NDC common word list.
We have used two well-established readability formulas in our analysis. The application of readability formulas has previously been questioned (Duffy and Kabance, 1982; Redish and Selzer, 1985; Zamanian and Heydari, 2012) and modern alternatives have been proposed (see (Benjamin, 2012). However, NDC has been shown to perform comparably with these more modern methods (Benjamin, 2012).
Science-specific common word and general science jargon lists
Request a detailed protocolWe created two common word lists using the abstracts in our dataset:
Science-specific common words: Words frequently used by scientists which are not part of the NDC common word list. This contains units of measurement (e.g. 'mol'), subject-specific words (e.g. 'electrophoresis'), general science jargon words (e.g. 'moreover') and some proper nouns (e.g. 'european').
General science jargon: A subset of science-specific common words. These are non-subject-specific words that are frequently used by scientists. This list contains words with a variety of different linguistic functions (e.g. 'endogenous', 'contribute' and 'moreover'). General science jargon can be considered the basic vocabulary of a 'science-ese'. Science-ese is analogous to legalese, which is the general technical language used by legal professionals.
To construct the science-specific common word list, 12,000 articles were selected to identify words frequently used in the scientific literature. In order to avoid any recency bias, 2,000 articles were randomly selected from six different decades (starting at the 1960s). From these articles, the frequency of all words was calculated. After excluding words in the NDC common word list, the 2,949 most frequent words were selected. The number 2,949 was selected to be the same length as the NDC common word list.
To validate that this list is identifying a general scientific terminology, we created a verification list by performing the same steps as above on an additional independent set of 12,000 articles. Of the 2,949 words in the science-specific common word list, 90.95% of the words were present in the verification list (see Supplementary file 2 for both word lists). The 24,000 articles used in the derivation and verification of the lists were excluded from all further analysis.
The general scientific jargon list contained 2,138 words. It was created by manually filtering the science-specific common word list. All four co-authors went through the science-specific common word list and rated each word. The following guidelines were formulated to exclude words from being classed as general science jargon: (1) abbreviations, roman numerals, or units that survived preprocessing (e.g. 'mol'). (2) Field-specific words (e.g. 'hepatitis'). (3) Words whose frequency may be changing through time due to major discoveries (e.g. 'gene'). (4) Nouns and adjectives that refer to non-science objects and could be placed in a general easy word list (e.g. 'mouse', 'green', 'September'). Remaining words were classed as possible general science jargon word. After comparing each co-authors’ ratings, the final list was created. The co-authors performed the ratings to identify jargon words independently. However, half way through the ratings there was a meeting to control that the guidelines were being performed in a similar way. In this meeting, the authors discussed examples from their ratings. Due to this, the ratings can not be classed as completely independent.
Comparison of full texts vs abstracts
Request a detailed protocolTo compare the readability of full texts and abstracts, we chose six journals from the PubMed Central Open Access Subset for which all full texts of articles were available under a Creative Commons or similar license. The journals were BMC Biology, eLife, Genome Biology, PLoS Biology, PLoS Medicine and PLoS ONE. None of them were a part of the original journal list which was used in the main analysis. They were selected as they all cover biomedicine and life sciences and as open access journals, we were legally allowed to bulk-download both abstracts and full texts. However, none of the included journals have existed for a long period of time (Supplementary file 4). As such, they cannot be said to represent the same time range covered by the 123 journals used in the main analysis. Custom scripts were written to extract the full text in the textfiles downloaded from each respective journal. In total, 143,957 articles were included in the full text analysis. Both article abstracts and full texts were preprocessed according to the procedure outlined above and readability measures were calculated.
Statistics
All statistical modeling was performed in R version 3.3.2.
We evaluated the relationship between the readability of single abstracts and year of publication separately for FRE and NDC scores. The data can be viewed as hierarchically structured since abstracts belonging to different journals may differ in key aspects. In addition, journals span over different ranges of years (Figure 1C and Supplementary file 1). In order to account for this structure, we performed linear mixed effect modeling using the R-packages lme4 version 1.1-12 (Bates et al., 2014), and lmerTest version 2.0-33 (Kuznetsova et al., 2015) with maximum likelihood estimation. We compared different models of increasing complexity. The included models were as following: (M0) a null model in which readability score was predicted only by journal as random effect with varying intercepts; (M1) the same as M0, but with an added fixed effect of time; and (M2) the same as M1, but with varying slopes for the random effect of journal (Table 1). We selected the best fitting model as determined by the Akaike Information Criterion and the Bayesian Information Criterion.
In order to test that the trend was not explained by the increasing number of authors with year, we specified an additional model. It was identical to M2 above, but also included the number of authors as a second fixed effect. Some articles (n = 2,327) lacked author information, and were excluded from the analysis. This model was performed using two sets of the data: i) a subset including only articles with one to ten authors (n = 652,357), ii) a full dataset consisting of all articles with complete author information (n = 707,250) (Table 2). The motivation for (i) was that abstracts with many authors may bias the results.
Data availability
-
PMC Open Access SubsetPublicly available at the NCBI ftp site for oa_bulk.
References
-
Assessing readability of patient education materials: current role in orthopaedicsClinical Orthopaedics and Related Research 468:2572–2580.https://doi.org/10.1007/s11999-010-1380-y
-
Fitting Linear Mixed-Effects Models using lme4Journal of Statistical Software 67:51.
-
Reconstructing readability: recent developments and recommendations in the analysis of text difficultyEducational Psychology Review 24:63–88.https://doi.org/10.1007/s10648-011-9181-8
-
Science communication to the general public: Why we need to teach undergraduate and graduate students this skill as part of their formal scientific trainingJournal of Undergraduate Neuroscience Education 12:E6–E10.
-
Why readability formulas failIEEE Transactions on Professional Communication 24:50–52.https://doi.org/10.1109/TPC.1981.6447826
-
Science communication reconsideredNature Biotechnology 27:514–518.https://doi.org/10.1038/nbt0609-514
-
Journalists and Novelists: A Study of Diverging StylesJournalism Quarterly 69:436–446.https://doi.org/10.1177/107769909206900217
-
Abstract readability as a factor in information systemsJournal of the American Society for Information Science 26:108–111.https://doi.org/10.1002/asi.4630260206
-
Testing a readable writing approach to text revisionJournal of Educational Psychology 74:733–748.https://doi.org/10.1037/0022-0663.74.5.733
-
The sciences of science communicationPNAS 110 Suppl 3:14033–14039.https://doi.org/10.1073/pnas.1213273110
-
A new readability yardstickJournal of Applied Psychology 32:221–233.https://doi.org/10.1037/h0057532
-
Three ways to improve the clarity of journal abstractsBritish Journal of Educational Psychology 64:331–343.https://doi.org/10.1111/j.2044-8279.1994.tb01106.x
-
An evaluation of structured abstracts in journals published by the British Psychological SocietyBritish Journal of Educational Psychology 68:443–456.https://doi.org/10.1111/j.2044-8279.1998.tb01303.x
-
Improving the clarity of journal abstracts in psychology: the case for structureScience Communication 24:366–379.https://doi.org/10.1177/1075547002250301
-
Tacit understandings of health literacyScience Communication 31:84–115.https://doi.org/10.1177/1075547009335345
-
Longitudinal analysis of historical texts’ readabilityProceedings of the 12th ACM/IEEE-CS Joint Conference on Digital Libraries pp. 353–354.
-
Derivation of New Readability Formulas (Automated Readability Index, Fog Count and Flesch Reading Ease Formula) for Navy Enlisted PersonnelNaval Technical Training Command Millington TN Research Branch. RBR-8-75.
-
SoftwareRISmed: Download Content from NCBI Databases, version 2.1.6R Package Version.
-
Scientific communication and the nature of scienceScience & Education 22:2067–2086.https://doi.org/10.1007/s11191-012-9475-3
-
Chasing 60{%} of maternal deaths in the post-fact eraThe Lancet 388:1864–1865.https://doi.org/10.1016/S0140-6736(16)31793-7
-
Believe it or not: how much can we rely on published data on potential drug targets?Nature Reviews Drug Discovery 10:712.https://doi.org/10.1038/nrd3439-c1
-
The place of readability formulas in technical communicationJournal of Reading Behavior 32:46–52.
-
Readability formulas have even more limitations than Klare discussesACM Journal of Computer Documentation 24:132–137.https://doi.org/10.1145/344599.344637
-
Proceedings of the International Conference on New Methods in Language Processing44–49, Probabilistic part-of-speech tagging using decision trees, Proceedings of the International Conference on New Methods in Language Processing.
-
Workshop on Natural Language Processing for Improving Textual Accessibility14–21, What can readability measures really tell us about text complexity?, Workshop on Natural Language Processing for Improving Textual Accessibility.
-
Readability of conservative and sensational papers since 1872Journalism Quarterly 41:201–206.https://doi.org/10.1177/107769906404100206
-
The reliability of readability formulaeJournal of Research in Reading 1:21–34.https://doi.org/10.1111/j.1467-9817.1978.tb00170.x
-
Advancing science communicationScience Communication 23:310–322.https://doi.org/10.1177/107554700202300306
-
Readability of texts: state of the artTheory and Practice in Language Studies 2:43–53.https://doi.org/10.4304/tpls.2.1.43-53
Decision letter
-
Stuart KingReviewing Editor; eLife, United Kingdom
In the interests of transparency, eLife includes the editorial decision letter and accompanying author responses. A lightly edited version of the letter sent to the authors after peer review is shown, indicating the most substantive concerns; minor comments are not usually included.
Thank you for submitting your article "The readability of scientific texts is decreasing over time" for consideration as a Feature Article by eLife. Your article has been reviewed by two peer reviewers, Ralf Barkemeyer (Reviewer #1) and Christiaan Vinkers (Reviewer #2), and an Associate Features Editor, Stuart King.
The reviewers have discussed the reviews with one another and the Associate Features Editor has drafted this decision to help you prepare a revised submission. We hope you will be able to submit the revised version within two months.
Summary
This manuscript – which first appeared as a preprint on bioRxiv – reports a decline in the readability of scientific texts meaning that, on average, papers published in recent decades are harder to read than those from over a century ago. Two possible explanations are tested: an increase in the number of authors per manuscript, and the wider use of uncommon language (referred to as "general scientific jargon"). All three reviewers agree that the manuscript is timely and relevant, and that it has the potential to make a clear contribution to the existing literature. The research design looks sound, and mainly builds on two well-established measures of readability. The analyses appear to be executed in a rigorous and transparent manner, and the authors generate a set of straightforward and intuitive but highly relevant findings. The reviewers hope that this manuscript will raise awareness, and encourage scientists and publishers to take readability into account when authoring or reviewing scientific papers.
Nevertheless, there are some issues that need to be addressed, and several revisions that would strengthen the manuscript. Most can be handled by editing the text to provide more details or clarity, or by improving the presentation of the figures. One will require a more fine-grained analysis of the data that is already available.
Essential Revisions:
1. Both of the readability formulas reported in the Materials and methods section contain mistakes. The constant in the Flesch Reading Ease (FRE) formula is incorrectly given as "206.385" instead of "206.835". The New Dale-Chall (NDC) Readability Formula is repeatedly missing the "× 100" that converts the fraction of "difficult words" to a percentage. The inequality symbols (i.e. > and {less than or equal to}) have also been transposed in the NDC formula meaning that, if followed as written, the scores would not be adjusted properly. From the data provided, it is clear that the correct NDC formula was used for the analyses. But we cannot check the FRE calculations because the "syllable counts" are missing from the data provided (see point 4). Please confirm that the correct FRE formula was used and fix the mistakes described above.
2. The readability measures chosen appear plausible and test two complementary dimensions of readability. However, please provide some more justification as to why these two measures were chosen and not others.
3. Please elaborate on the limitations of readability metrics in general, and those linked to text pre-processing. For example, visual aids are not captured even though they might improve comprehension; or the fact that FRE does not take into account parentheses and other ways of structuring text (which might also aid readability).
4. The authors have agreed to make the data and scripts openly accessible, which is applaudable. However, the data provided with the full submission is missing the syllable counts. Please provide all the data needed to recreate the figures in this version of the manuscript. This also includes the analyses related to the full texts, number of authors, and "general scientific jargon". Please see the section on "Source Data Files" in eLife's author guide for more details.
5. The current Figures 1 and 3are packed with data and somewhat difficult to follow. Please divide them each into two separate figures. For Figure 1, separate the summary graphics from the panels showing the main trends. For Figure 3, the data related to number of authors should be separated from that related to "general scientific jargon".
6. The phrase "high-impact journals" is used without explanation. The specific meaning of the word "impact" in this context is unclear and could arguably be considered jargon. Please explain this phrase in the text or replace with a more accurate description like "highly cited journals".
7. Please elaborate on the criteria used to select the "six representative" open-access journals for the full-text analysis. Please also provide information equivalent to that provided for the journals in the abstract-only analysis.
8. As it stands now, the analysis remains at a very high level. Digging deeper into the existing data might reveal avenues to pursue to address the poor readability of scientific texts. Please report and discuss the trends in readability (or the average values) for the different journals and/or fields of research. For example, showing that articles in some journals are more readable than others might encourage someone to trace these differences back to specific editorial policies (word limits etc.) that could then be adopted more widely.
9. The literature on science communication is extensive, covering both the underlying communication process as well as its implications. Please strengthen the manuscript's links to this literature; for example, by discussing to what extent is it necessary that non-specialists can read and understand scientific articles, given that mainstream media and other new outlets have been created to specifically focus on non-specialist audiences in this context. While the reviewers likely agree with the authors' line of argument, some more contextualization and justification would be helpful here.
10. Please integrate the "Supplementary methods" into the "Materials and methods" section, to avoid the need to jump back and forth in the text. The sections on selecting journal fields and identifying "candidate jargon" would also benefit from being critically edited to improve clarity.
11. On a related point, please define classifications like "science-specific common words" and "candidate general science jargon" more clearly, and then consistently use them throughout the text. As currently written, some readers would not recognize uncommon/formal words - such as "novel", "robust", "moreover" and "therefore" - as scientific jargon. It would also be helpful if the discussion on this topic were expanded.
12. The FRE score of 48.2 for the submitted manuscript is respectable. However, please look for further opportunities to make the article easier to read, including ways that would not necessarily get picked up by the readability formulas referenced in the article. For example, while most English speakers are likely to know the verb "understand", fewer will be familiar with the adjective "understandable", and fewer still the noun "understandability" (which is used in the manuscript's abstract). Please consider using fewer nouns and more verbs throughout the abstract, main text and figure captions (e.g. "Scientific abstracts have become harder to read over time" rather than "Readability of scientific abstracts decreases over time".)
https://doi.org/10.7554/eLife.27725.028Author response
Essential Revisions:
1. Both of the readability formulas reported in the Materials and methods section contain mistakes. The constant in the Flesch Reading Ease (FRE) formula is incorrectly given as "206.385" instead of "206.835". The New Dale-Chall (NDC) Readability Formula is repeatedly missing the "× 100" that converts the fraction of "difficult words" to a percentage. The inequality symbols (i.e. > and {less than or equal to}) have also been transposed in the NDC formula meaning that, if followed as written, the scores would not be adjusted properly. From the data provided, it is clear that the correct NDC formula was used for the analyses. But we cannot check the FRE calculations because the "syllable counts" are missing from the data provided (see point 4). Please confirm that the correct FRE formula was used and fix the mistakes described above.
We thank the reviewers for noting the typos in the readability formulas.
These mistakes were not present in the analysis code and have now been corrected in the text. We further apologise for the syllable count being omitted from the source data we included. This has been fixed and included as source data (see the response to point 4 for a further details regarding the source data).
2. The readability measures chosen appear plausible and test two complementary dimensions of readability. However, please provide some more justification as to why these two measures were chosen and not others.
Our reason for using two measures was to make sure the result was not merely induced by the measure itself. The reasons for using FRE were because of its popularity and because it has been used in looking at temporal trends in other studies. The reason for using NDC was because it includes something different to FRE in how it is calculated (the common word lists). Further it performs comparatively compared to recently proposed readability measures. We have added some sentences to justify the choice of two readability metrics in the first paragraph of the “Language and Readability metrics” subsection of the Material and methods section.
3. Please elaborate on the limitations of readability metrics in general, and those linked to text pre-processing. For example, visual aids are not captured even though they might improve comprehension; or the fact that FRE does not take into account parentheses and other ways of structuring text (which might also aid readability).
We agree that it is important to emphasize the limitations of readability formulas. We have therefore amended the limitations paragraph with examples for text elements which contribute to understanding but which are often removed during pre-processing or not captured by readability formulas.
4. The authors have agreed to make the data and scripts openly accessible, which is applaudable. However, the data provided with the full submission is missing the syllable counts. Please provide all the data needed to recreate the figures in this version of the manuscript. This also includes the analyses related to the full texts, number of authors, and "general scientific jargon". Please see the section on "Source Data Files" in eLife's author guide for more details.
Source data is now provided for Figures 2, 3, 4 and 6.
We have now added the summed syllable-count to the “Figure 2—source data 1”, which provides all the information for FRE and NDC to be calculated per article.
We have further added “number of authors” to the same file. We have added a similar file: “Figure 2—source data 2” for the analysis on the unpreprocessed data. This allows for full recreation of the relevant figures (Figure 2 and its supplement).
“Figure 3—source data 1” and “Figure 3—source data 2” is now included and will allow reproduction of Figure 3 and its supplement.
“Figure 4—source data 1” is now included and allows reproduction of Figure 4 and its supplements.
“Figure 6—source data 1” contains all the information needed to reproduce Figure 6.
“Figure 6—source data 2” is also included which allows for the analysis to be reproduced regarding the derivation of the science easy words.
Figure 5 and Figure 1 both use “Figure 2—source data 1” as their source data.
It is associated with Figure 2 as most of the data in the file belongs to Figure 2. In the figure captions of both Figure 1 and Figure 5 it is noted that “Figure 2—source data 1” is where the source data can be found.
In sum all figures with data now have relevant source data that can be used to recreate the figures. Finally, we have placed all the scripts on a public repository on GitHub: https://github.com/wiheto/readabilityinscience and these are now available.
5. The current Figures 1 and 3 are packed with data and somewhat difficult to follow. Please divide them each into two separate figures. For Figure 1, separate the summary graphics from the panels showing the main trends. For Figure 3, the data related to number of authors should be separated from that related to "general scientific jargon".
We have divided up the figures as requested. There are now six figures in total: the summary graphic (Figure 1); the main readability result (Figure 2); the random effects per field (Figure 3; and per journal in the figure supplement); the full text data (Figure 4); the number of authors (Figure 5); the “jargon” analysis (Figure 6).
6. The phrase "high-impact journals" is used without explanation. The specific meaning of the word "impact" in this context is unclear and could arguably be considered jargon. Please explain this phrase in the text or replace with a more accurate description like "highly cited journals".
The reviewers are correct that this term is unclear, and this term is certainly a form of science-ese. The text has been amended to say “highly cited” both in the introduction and methods.
7. Please elaborate on the criteria used to select the "six representative" open-access journals for the full-text analysis. Please also provide information equivalent to that provided for the journals in the abstract-only analysis.
We have expanded upon the reasons for why these particular six journals have been included in the abstract-full text analysis. Importantly, one of the main reasons to choose these journals was because they were Open Access - and Open Access journals are the only ones that allow us to download full texts en masse without violating the terms and conditions of services like Pubmed. We have added a supplementary file to the manuscript (Supplementary file 4), which displays information about the journals included in this analysis. Further, we have also now provided additional supplementary figures (Figure 4—figure supplement 2), demonstrating that the observed correlation between readability for abstracts and full texts is present in each of the journals included in the analysis.
8. As it stands now, the analysis remains at a very high level. Digging deeper into the existing data might reveal avenues to pursue to address the poor readability of scientific texts. Please report and discuss the trends in readability (or the average values) for the different journals and/or fields of research. For example, showing that articles in some journals are more readable than others might encourage someone to trace these differences back to specific editorial policies (word limits etc.) that could then be adopted more widely.
We agree with the reviewers that a deeper analysis can yield ideas and hypotheses for future research on how to improve readability. We have therefore extracted the random effect (i.e. slope) of each journal from the mixed models and plotted them both by themselves, and as field-summaries, in Figure 3 and its supplement. This shows that the trend is present in all fields, although some journals do not show a decline in readability. We have amended the results section accordingly, and added a discussion about the possibility of future research to examine why there are differences between fields and journals, and how this could yield clues on how to address the problem.
9. The literature on science communication is extensive, covering both the underlying communication process as well as its implications. Please strengthen the manuscript's links to this literature; for example, by discussing to what extent is it necessary that non-specialists can read and understand scientific articles, given that mainstream media and other new outlets have been created to specifically focus on non-specialist audiences in this context. While the reviewers likely agree with the authors' line of argument, some more contextualization and justification would be helpful here.
In answer to this point we have rewritten two paragraphs. The paragraph that begins “Lower readability implies less accessibility, particularly for non-specialists, such as journalists, policy-makers and the wider public” (Discussion, fourth paragraph) now clarifies that “non-specialists” also applies to journalists within the mainstream media. This should clarify that this even affects those that use science journalism as a news source. We have also changed the focus of this paragraph from previously talking about scientific literacy and now focus more on scientific journalism. This is because it is hard to see that scientific literacy is causally affected by our results here, and it was a speculative link of troubling trends.
Additionally the paragraph that begins “What more can be done to reverse this trend?” (Discussion, penultimate paragraph) makes greater links with the literature in scientific communication. We state some of the more prominent proposals that have been made to make scientific texts more accessible.
10. Please integrate the "Supplementary methods" into the "Materials and methods" section, to avoid the need to jump back and forth in the text. The sections on selecting journal fields and identifying "candidate jargon" would also benefit from being critically edited to improve clarity.
The two sections that were previously in the Supplementary Methods, namely the selection of journal fields and identifying candidate jargon have both been moved to the Materials and methods section. Both sections have been made shorter and clearer.
11. On a related point, please define classifications like "science-specific common words" and "candidate general science jargon" more clearly, and then consistently use them throughout the text. As currently written, some readers would not recognize uncommon/formal words - such as "novel", "robust", "moreover" and "therefore" - as scientific jargon. It would also be helpful if the discussion on this topic were expanded.
The Material and methods subsection “Science-specific common word and general science jargon lists” has been completely rewritten where we give clear definitions of what these two terms mean. We have also dropped the term “candidate” from the entire text as it could be considered confusing. The initial reason for including it was to not definitively declare these terms as jargon, since they have been defined only by excluding certain categories of words. An additional sentence has been added to the discussion paragraph to clarify how to interpret general scientific jargon.
12. The FRE score of 48.2 for the submitted manuscript is respectable. However, please look for further opportunities to make the article easier to read, including ways that would not necessarily get picked up by the readability formulas referenced in the article. For example, while most English speakers are likely to know the verb "understand", fewer will be familiar with the adjective "understandable", and fewer still the noun "understandability" (which is used in the manuscript's abstract). Please consider using fewer nouns and more verbs throughout the abstract, main text and figure captions (e.g. "Scientific abstracts have become harder to read over time" rather than "Readability of scientific abstracts decreases over time".)
We have now gone through the manuscript and, to the best of our ability, tried to improve the readability further. For example, sentences have been shortened, nouns have been replaced by verbs when suitable, and complicated words have been replaced by simpler synonyms when this could be done without losing meaning. Further, some parts of the text have been completely rewritten to make them easier to understand, such as the entire journal selection procedure paragraph in the Material and methods section. Please see the track-changed document for all readability improvements in the manuscript.
In addition to the revisions detailed above requested by the reviewers, we identified three additional issues with the article:
There was a typo in the FRE calculation of a scalar in the analysis code. The part “1.015 * words/sentences” was incorrectly set to 1.1015. This has led to a very slight increase in all FRE scores when fixed. This change has had no effect on the observed trend. However, the sentence “In other words, more than a quarter of scientific abstracts now have a readability considered beyond college graduate level English.” (Discussion, first paragraph) has been changed to “In other words, more than a fifth of scientific abstracts now have a readability considered beyond college graduate level English.”
The selection criteria state that 12 journals from each field were included. However, for the field Immunology, only 11 journals had been included by mistake. The Journal “Brain Behav Immun” has now been added. This has increased the number of abstracts from 707,452 to 709,577 and all values reported in the article have been updated accordingly. This includes a new training and verification set for the “general science jargon” analysis, for which there are now 2,138 general jargon words instead of 2,140 previous ones. These changes have not led to any difference in the interpretation of the results.
We noticed that the language parameters for the TreeTagger software used for preprocessing differed slightly between Linux and Windows versions. Previously the full text analysis had been run on Windows and the abstract analysis on Linux. The full text analysis has now also been run on Linux. This has led to minor differences in readability scores for the full text analysis. These minor differences have no impact on the interpretation of the results. We have also noted relevant package version numbers and the operating system used in the Material and methods section.
In sum these three changes have no impact on the conclusions drawn from the overall analysis. They however ensure that the analysis is more correct and easier to reproduce.
https://doi.org/10.7554/eLife.27725.029Article and author information
Author details
Björn Christian Schiffler

William Hedley Thompson
Acknowledgements
This article has a FRE score of 49. The abstract has a FRE score of 40.
Publication history
- Received:
- Accepted:
- Version of Record published:
- Version of Record updated:
Copyright
© 2017, Plavén-Sigray et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 39,538
- views
-
- 2,576
- downloads
-
- 206
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 206
- citations for umbrella DOI https://doi.org/10.7554/eLife.27725
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Research: The readability of scientific texts is decreasing over time
eLife 6:e27725.
https://doi.org/10.7554/eLife.27725

Further reading
-
The increasing use of scientific jargon is making scientific texts harder to read.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}