Interrogating theoretical models of neural computation with emergent property inference
- Department of Neuroscience, Columbia University, United States
- Princeton Neuroscience Institute, United States
- Princeton University, United States
- Allen Institute for Brain Science, United States
- Institute of Neuroscience, Chinese Academy of Sciences, China
- Howard Hughes Medical Institute, United States
- Department of Statistics, Columbia University, United States
Abstract
A cornerstone of theoretical neuroscience is the circuit model: a system of equations that captures a hypothesized neural mechanism. Such models are valuable when they give rise to an experimentally observed phenomenon -- whether behavioral or a pattern of neural activity -- and thus can offer insights into neural computation. The operation of these circuits, like all models, critically depends on the choice of model parameters. A key step is then to identify the model parameters consistent with observed phenomena: to solve the inverse problem. In this work, we present a novel technique, emergent property inference (EPI), that brings the modern probabilistic modeling toolkit to theoretical neuroscience. When theorizing circuit models, theoreticians predominantly focus on reproducing computational properties rather than a particular dataset. Our method uses deep neural networks to learn parameter distributions with these computational properties. This methodology is introduced through a motivational example of parameter inference in the stomatogastric ganglion. EPI is then shown to allow precise control over the behavior of inferred parameters and to scale in parameter dimension better than alternative techniques. In the remainder of this work, we present novel theoretical findings in models of primary visual cortex and superior colliculus, which were gained through the examination of complex parametric structure captured by EPI. Beyond its scientific contribution, this work illustrates the variety of analyses possible once deep learning is harnessed towards solving theoretical inverse problems.
Introduction
The fundamental practice of theoretical neuroscience is to use a mathematical model to understand neural computation, whether that computation enables perception, action, or some intermediate processing. A neural circuit is systematized with a set of equations – the model – and these equations are motivated by biophysics, neurophysiology, and other conceptual considerations (Kopell and Ermentrout, 1988; Marder, 1998; Abbott, 2008; Wang, 2010; O'Leary et al., 2015). The function of this system is governed by the choice of model parameters, which when configured in a particular way, give rise to a measurable signature of a computation. The work of analyzing a model then requires solving the inverse problem: given a computation of interest, how can we reason about the distribution of parameters that give rise to it? The inverse problem is crucial for reasoning about likely parameter values, uniquenesses and degeneracies, and predictions made by the model (Gutenkunst et al., 2007; Erguler and Stumpf, 2011; Mannakee et al., 2016).
Ideally, one carefully designs a model and analytically derives how computational properties determine model parameters. Seminal examples of this gold standard include our field’s understanding of memory capacity in associative neural networks (Hopfield, 1982), chaos and autocorrelation timescales in random neural networks (Sompolinsky et al., 1988), central pattern generation (Olypher and Calabrese, 2007), the paradoxical effect (Tsodyks et al., 1997), and decision making (Wong and Wang, 2006). Unfortunately, as circuit models include more biological realism, theory via analytical derivation becomes intractable. Absent this analysis, statistical inference offers a toolkit by which to solve the inverse problem by identifying, at least approximately, the distribution of parameters that produce computations in a biologically realistic model (Foster et al., 1993; Prinz et al., 2004; Achard and De Schutter, 2006; Fisher et al., 2013; O'Leary et al., 2014; Alonso and Marder, 2019).
Statistical inference, of course, requires quantification of the sometimes vague term computation. In neuroscience, two perspectives are dominant. First, often we directly use an exemplar dataset: a collection of samples that express the computation of interest, this data being gathered either experimentally in the lab or from a computer simulation. Although a natural choice given its connection to experiment (Paninski and Cunningham, 2018), some drawbacks exist: these data are well known to have features irrelevant to the computation of interest (Niell and Stryker, 2010; Saleem et al., 2013; Musall et al., 2019), confounding inferences made on such data. Related to this point, use of a conventional dataset encourages conventional data likelihoods or loss functions, which focus on some global metric like squared error or marginal evidence, rather than the computation itself.
Alternatively, researchers often quantify an emergent property (EP): a statistic of data that directly quantifies the computation of interest, wherein the dataset is implicit. While such a choice may seem esoteric, it is not: the above ‘gold standard’ examples (Hopfield, 1982; Sompolinsky et al., 1988; Olypher and Calabrese, 2007; Tsodyks et al., 1997; Wong and Wang, 2006) all quantify and focus on some derived feature of the data, rather than the data drawn from the model. An emergent property is of course a dataset by another name, but it suggests different approach to solving the same inverse problem: here, we directly specify the desired emergent property – a statistic of data drawn from the model – and the value we wish that property to have, and we set up an optimization program to find the distribution of parameters that produce this computation. This statistical framework is not new: it is intimately connected to the literature on approximate bayesian computation (Beaumont et al., 2002; Marjoram et al., 2003; Sisson et al., 2007), parameter sensitivity analyses (Raue et al., 2009; Karlsson et al., 2012; Hines et al., 2014; Raman et al., 2017), maximum entropy modeling (Elsayed and Cunningham, 2017; Savin and Tkačik, 2017; Młynarski et al., 2020), and approximate bayesian inference (Tran et al., 2017; Gonçalves et al., 2019); we detail these connections in Section 'Related approaches'.
The parameter distributions producing a computation may be curved or multimodal along various parameter axes and combinations. It is by quantifying this complex structure that emergent property inference offers scientific insight. Traditional approximation families (e.g. mean-field or mixture of gaussians) are limited in the distributional structure they may learn. To address such restrictions on expressivity, advances in machine learning have used deep probability distributions as flexible approximating families for such complicated distributions (Rezende and Mohamed, 2015; Papamakarios et al., 2019a) (see Section 'Deep probability distributions and normalizing flows'). However, the adaptation of deep probability distributions to the problem of theoretical circuit analysis requires recent developments in deep learning for constrained optimization (Loaiza-Ganem et al., 2017), and architectural choices for efficient and expressive deep generative modeling (Dinh et al., 2017; Kingma and Dhariwal, 2018). We detail our method, which we call emergent property inference (EPI) in Section 'Emergent property inference via deep generative models'.
Equipped with this method, we demonstrate the capabilities of EPI and present novel theoretical findings from its analysis. First, we show EPI’s ability to handle biologically realistic circuit models using a five-neuron model of the stomatogastric ganglion (Gutierrez et al., 2013): a neural circuit whose parametric degeneracy is closely studied (Goldman et al., 2001). Then, we show EPI’s scalability to high dimensional parameter distributions by inferring connectivities of recurrent neural networks that exhibit stable, yet amplified responses – a hallmark of neural responses throughout the brain (Murphy and Miller, 2009; Hennequin et al., 2014; Bondanelli et al., 2019). In a model of primary visual cortex (Litwin-Kumar et al., 2016; Palmigiano et al., 2020), EPI reveals how the recurrent processing across different neuron-type populations shapes excitatory variability: a finding that we show is analytically intractable. Finally, we investigated the possible connectivities of a superior colliculus model that allow execution of different tasks on interleaved trials (Duan et al., 2021). EPI discovered a rich distribution containing two connectivity regimes with different solution classes. We queried the deep probability distribution learned by EPI to produce a mechanistic understanding of neural responses in each regime. Intriguingly, the inferred connectivities of each regime reproduced results from optogenetic inactivation experiments in markedly different ways. These theoretical insights afforded by EPI illustrate the value of deep inference for the interrogation of neural circuit models.
Results
Motivating emergent property inference of theoretical models
Consideration of the typical workflow of theoretical modeling clarifies the need for emergent property inference. First, one designs or chooses an existing circuit model that, it is hypothesized, captures the computation of interest. To ground this process in a well-known example, consider the stomatogastric ganglion (STG) of crustaceans, a small neural circuit which generates multiple rhythmic muscle activation patterns for digestion (Marder and Thirumalai, 2002). Despite full knowledge of STG connectivity and a precise characterization of its rhythmic pattern generation, biophysical models of the STG have complicated relationships between circuit parameters and computation (Goldman et al., 2001; Prinz et al., 2004).
A subcircuit model of the STG (Gutierrez et al., 2013) is shown schematically in Figure 1A. The fast population (f1 and f2) represents the subnetwork generating the pyloric rhythm and the slow population (s1 and s2) represents the subnetwork of the gastric mill rhythm. The two fast neurons mutually inhibit one another, and spike at a greater frequency than the mutually inhibiting slow neurons. The hub neuron couples with either the fast or slow population, or both depending on modulatory conditions. The jagged connections indicate electrical coupling having electrical conductance , smooth connections in the diagram are inhibitory synaptic projections having strength onto the hub neuron, and nS for mutual inhibitory connections. Note that the behavior of this model will be critically dependent on its parameterization – the choices of conductance parameters .
Figure 1 with 4 supplements see all
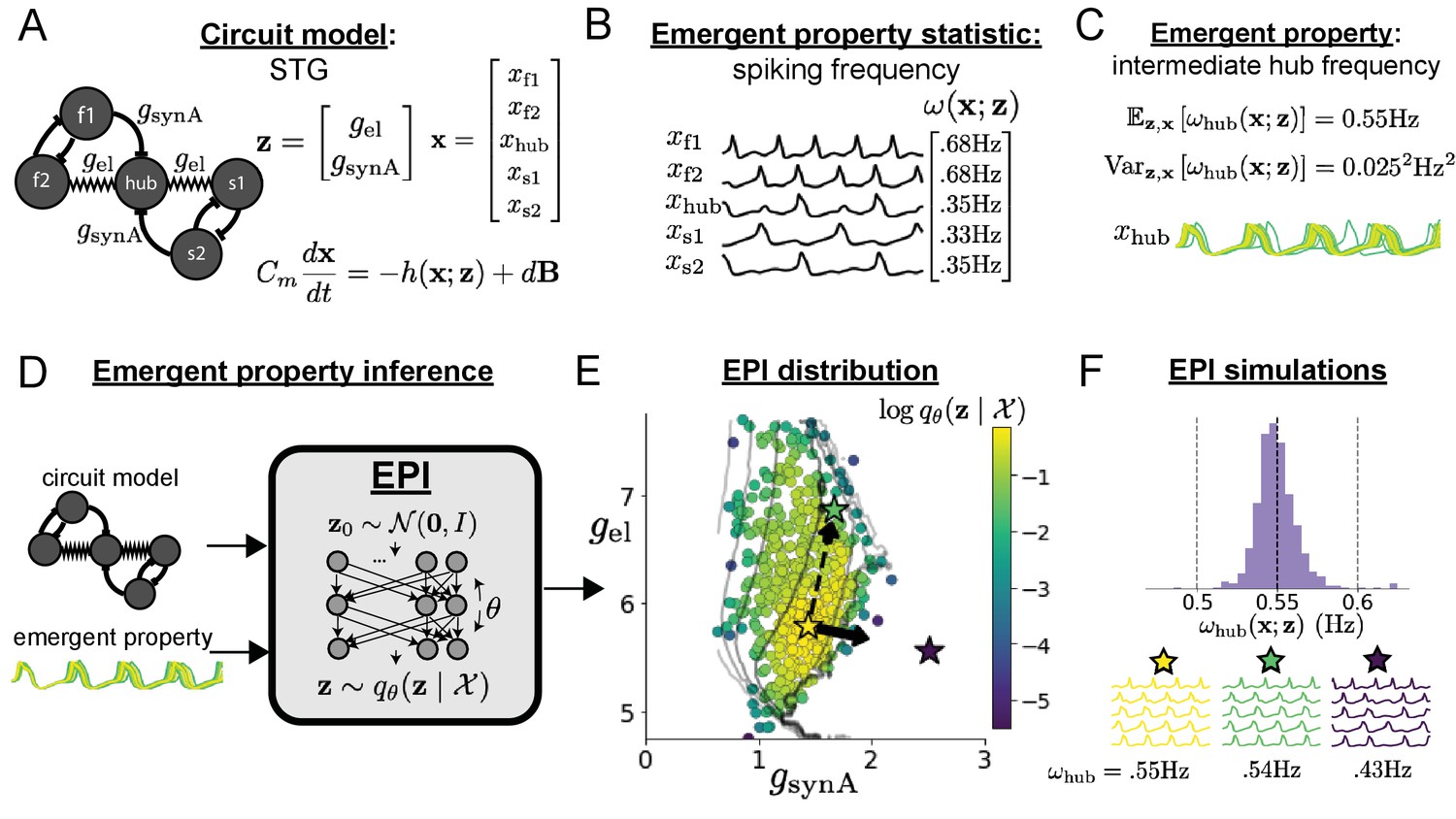
Emergent property inference in the stomatogastric ganglion.
(A) Conductance-based subcircuit model of the STG. (B) Spiking frequency is an emergent property statistic. Simulated at nS and nS. (C) The emergent property of intermediate hub frequency. Simulated activity traces are colored by log probability of generating parameters in the EPI distribution (Panel E). (D) For a choice of circuit model and emergent property, EPI learns a deep probability distribution of parameters . (E) The EPI distribution producing intermediate hub frequency. Samples are colored by log probability density. Contours of hub neuron frequency error are shown at levels of 0.525, 0.53, … 0.575 Hz (dark to light gray away from mean). Dimension of sensitivity (solid arrow) and robustness (dashed arrow). (F) (Top) The predictions of the EPI distribution. The black and gray dashed lines show the mean and two standard deviations according the emergent property. (Bottom) Simulations at the starred parameter values.
Second, once the model is selected, one must specify what the model should produce. In this STG model, we are concerned with neural spiking frequency, which emerges from the dynamics of the circuit model (Figure 1B). An emergent property studied by Gutierrez et al. is the hub neuron firing at an intermediate frequency between the intrinsic spiking rates of the fast and slow populations. This emergent property (EP) is shown in Figure 1C at an average frequency of 0.55 Hz. To be precise, we define intermediate hub frequency not strictly as 0.55 Hz, but frequencies of moderate deviation from 0.55 Hz between the fast (.35Hz) and slow (.68Hz) frequencies.
Third, the model parameters producing the emergent property are inferred. By precisely quantifying the emergent property of interest as a statistical feature of the model, we use emergent property inference (EPI) to condition directly on this emergent property. Before presenting technical details (in the following section), let us understand emergent property inference schematically. EPI (Figure 1D) takes, as input, the model and the specified emergent property, and as its output, returns the parameter distribution (Figure 1E). This distribution – represented for clarity as samples from the distribution – is a parameter distribution constrained such that the circuit model produces the emergent property. Once EPI is run, the returned distribution can be used to efficiently generate additional parameter samples. Most importantly, the inferred distribution can be efficiently queried to quantify the parametric structure that it captures. By quantifying the parametric structure governing the emergent property, EPI informs the central question of this inverse problem: what aspects or combinations of model parameters have the desired emergent property?
Emergent property inference via deep generative models
EPI formalizes the three-step procedure of the previous section with deep probability distributions (Rezende and Mohamed, 2015; Papamakarios et al., 2019a). First, as is typical, we consider the model as a coupled set of noisy differential equations. In this STG example, the model activity (or state) is the membrane potential for each neuron, which evolves according to the biophysical conductance-based equation:
(1)
where = 1nF, and is a sum of the leak, calcium, potassium, hyperpolarization, electrical, and synaptic currents, all of which have their own complicated dependence on activity and parameters , and is white gaussian noise (Gutierrez et al., 2013; see Section 'STG model' for more detail).
Second, we determine that our model should produce the emergent property of ‘intermediate hub frequency’ (Figure 1C). We stipulate that the hub neuron’s spiking frequency – denoted by statistic – is close to a frequency of 0.55 Hz, between that of the slow and fast frequencies. Mathematically, we define this emergent property with two constraints: that the mean hub frequency is 0.55 Hz,
(2)
and that the variance of the hub frequency is moderate
(3)
In the emergent property of intermediate hub frequency, the statistic of hub neuron frequency is an expectation over the distribution of parameters and the distribution of the data that those parameters produce. We define the emergent property as the collection of these two constraints. In general, an emergent property is a collection of constraints on statistical moments that together define the computation of interest.
Third, we perform emergent property inference: we find a distribution over parameter configurations of models that produce the emergent property; in other words, they satisfy the constraints introduced in Equations 2 and 3. This distribution will be chosen from a family of probability distributions , defined by a deep neural network (Rezende and Mohamed, 2015; Papamakarios et al., 2019a; Figure 1D, EPI box). Deep probability distributions map a simple random variable (e.g. an isotropic gaussian) through a deep neural network with weights and biases to parameters of a suitably complicated distribution (see Section 'Deep probability distributions and normalizing flows' for more details). Many distributions in will respect the emergent property constraints, so we select the most random (highest entropy) distribution, which also means this approach is equivalent to bayesian variational inference (see Section 'EPI as variational inference'). In EPI optimization, stochastic gradient steps in are taken such that entropy is maximized, and the emergent property is produced (see Section 'Emergent property inference (EPI)'). We then denote the inferred EPI distribution as , since the structure of the learned parameter distribution is determined by weights and biases , and this distribution is conditioned upon emergent property .
The structure of the inferred parameter distributions of EPI can be analyzed to reveal key information about how the circuit model produces the emergent property. As probability in the EPI distribution decreases away from the mode of (Figure 1E yellow star), the emergent property deteriorates. Perturbing along a dimension in which changes little will not disturb the emergent property, making this parameter combination robust with respect to the emergent property. In contrast, if is perturbed along a dimension with strongly decreasing , that parameter combination is deemed sensitive (Raue et al., 2009; Raman et al., 2017). By querying the second-order derivative (Hessian) of at a mode, we can quantitatively identify how sensitive (or robust) each eigenvector is by its eigenvalue; the more negative, the more sensitive and the closer to zero, the more robust (see Section 'Hessian sensitivity vectors'). Indeed, samples equidistant from the mode along these dimensions of sensitivity (, smaller eigenvalue) and robustness (, greater eigenvalue) (Figure 1E, arrows) agree with error contours (Figure 1E contours) and have diminished or preserved hub frequency, respectively (Figure 1F activity traces). The directionality of suggests that changes in conductance along this parameter combination will most preserve hub neuron firing between the intrinsic rates of the pyloric and gastric mill rhythms. Importantly and unlike alternative techniques, once an EPI distribution has been learned, the modes and Hessians of the distribution can be measured with trivial computation (see Section 'Deep probability distributions and normalizing flows').
In the following sections, we demonstrate EPI on three neural circuit models across ranges of biological realism, neural system function, and network scale. First, we demonstrate the superior scalability of EPI compared to alternative techniques by inferring high-dimensional distributions of recurrent neural network connectivities that exhibit amplified, yet stable responses. Next, in a model of primary visual cortex (Litwin-Kumar et al., 2016; Palmigiano et al., 2020), we show how EPI discovers parametric degeneracy, revealing how input variability across neuron types affects the excitatory population. Finally, in a model of superior colliculus (Duan et al., 2021), we used EPI to capture multiple parametric regimes of task switching, and queried the dimensions of parameter sensitivity to characterize each regime.
Scaling inference of recurrent neural network connectivity with EPI
To understand how EPI scales in comparison to existing techniques, we consider recurrent neural networks (RNNs). Transient amplification is a hallmark of neural activity throughout cortex and is often thought to be intrinsically generated by recurrent connectivity in the responding cortical area (Murphy and Miller, 2009; Hennequin et al., 2014; Bondanelli et al., 2019). It has been shown that to generate such amplified, yet stabilized responses, the connectivity of RNNs must be non-normal (Goldman, 2009; Murphy and Miller, 2009), and satisfy additional constraints (Bondanelli and Ostojic, 2020). In theoretical neuroscience, RNNs are optimized and then examined to show how dynamical systems could execute a given computation (Sussillo, 2014; Barak, 2017), but such biologically realistic constraints on connectivity (Goldman, 2009; Murphy and Miller, 2009; Bondanelli and Ostojic, 2020) are ignored for simplicity or because constrained optimization is difficult. In general, access to distributions of connectivity that produce theoretical criteria like stable amplification, chaotic fluctuations (Sompolinsky et al., 1988), or low tangling (Russo et al., 2018) would add scientific value to existing research with RNNs. Here, we use EPI to learn RNN connectivities producing stable amplification, and demonstrate the superior scalability and efficiency of EPI to alternative approaches.
We consider a rank-2 RNN with neurons having connectivity and dynamics
(4)
where , , , and . We infer connectivity parameters that produce stable amplification. Two conditions are necessary and sufficient for RNNs to exhibit stable amplification (Bondanelli and Ostojic, 2020): and , where is the eigenvalue of with greatest real part and is the maximum eigenvalue of . RNNs with and will be stable with modest decay rate ( close to its upper bound of 1) and exhibit modest amplification ( close to its lower bound of 1). EPI can naturally condition on this emergent property
(5)
Variance constraints predicate that the majority of the distribution (within two standard deviations) are within the specified ranges.
For comparison, we infer the parameters likely to produce stable amplification using two alternative simulation-based inference approaches. Sequential Monte Carlo approximate bayesian computation (SMC-ABC) (Sisson et al., 2007) is a rejection sampling approach that uses SMC techniques to improve efficiency, and sequential neural posterior estimation (SNPE) (Gonçalves et al., 2019) approximates posteriors with deep probability distributions (see Section 'Related approaches'). Unlike EPI, these statistical inference techniques do not constrain the predictions of the inferred distribution, so they were run by conditioning on an exemplar dataset , following standard practice with these methods (Sisson et al., 2007; Gonçalves et al., 2019). To compare the efficiency of these different techniques, we measured the time and number of simulations necessary for the distance of the predictive mean to be less than 0.5 from (see Section 'Scaling EPI for stable amplification in RNNs').
As the number of neurons in the RNN, and thus the dimension of the parameter space , is scaled, we see that EPI converges at greater speed and at greater dimension than SMC-ABC and SNPE (Figure 2A). It also becomes most efficient to use EPI in terms of simulation count at (Figure 2B). It is well known that ABC techniques struggle in parameter spaces of modest dimension (Sisson et al., 2018), yet we were careful to assess the scalability of SNPE, which is a more closely related methodology to EPI. Between EPI and SNPE, we closely controlled the number of parameters in deep probability distributions by dimensionality (Figure 2—figure supplement 1), and tested more aggressive SNPE hyperparameter choices when SNPE failed to converge (Figure 2—figure supplement 2). In this analysis, we see that deep inference techniques EPI and SNPE are far more amenable to inference of high dimensional RNN connectivities than rejection sampling techniques like SMC-ABC, and that EPI outperforms SNPE in both wall time (elapsed real time) and simulation count.
Figure 2 with 3 supplements see all
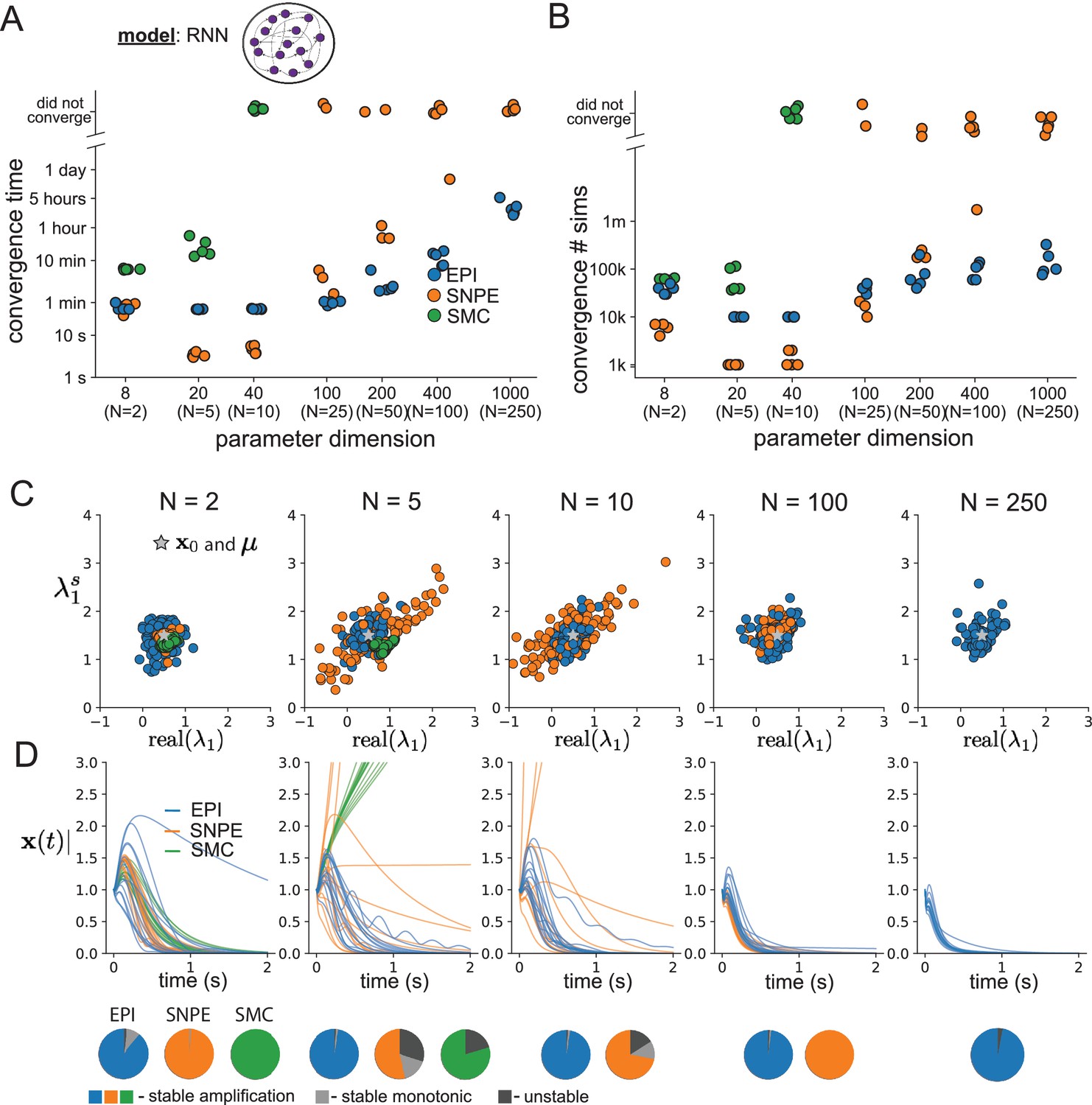
Inferring recurrent neural networks with stable amplification.
(A) Wall time of EPI (blue), SNPE (orange), and SMC-ABC (green) to converge on RNN connectivities producing stable amplification. Each dot shows convergence time for an individual random seed. For reference, the mean wall time for EPI to achieve its full constraint convergence (means and variances) is shown (blue line). (B) Simulation count of each algorithm to achieve convergence. Same conventions as A. (C) The predictive distributions of connectivities inferred by EPI (blue), SNPE (orange), and SMC-ABC (green), with reference to (gray star). (D) Simulations of networks inferred by each method (). Each trace (15 per algorithm) corresponds to simulation of one . (Below) Ratio of obtained samples producing stable amplification, stable monotonic decay, and instability.
No matter the number of neurons, EPI always produces connectivity distributions with mean and variance of and according to (Figure 2C, blue). For the dimensionalities in which SMC-ABC is tractable, the inferred parameters are concentrated and offset from the exemplar dataset (Figure 2C, green). When using SNPE, the predictions of the inferred parameters are highly concentrated at some RNN sizes and widely varied in others (Figure 2C, orange). We see these properties reflected in simulations from the inferred distributions: EPI produces a consistent variety of stable, amplified activity norms , SMC-ABC produces a limited variety of responses, and the changing variety of responses from SNPE emphasizes the control of EPI on parameter predictions (Figure 2D). Even for moderate neuron counts, the predictions of the inferred distribution of SNPE are highly dependent on and , while EPI maintains the emergent property across choices of RNN (see Section 'Effect of RNN parameters on EPI and SNPE inferred distributions').
To understand these differences, note that EPI outperforms SNPE in high dimensions by using gradient information (from ). This choice agrees with recent speculation that such gradient information could improve the efficiency of simulation-based inference techniques (Cranmer et al., 2020), as well as reflecting the classic tradeoff between gradient-based and sampling-based estimators (scaling and speed versus generality). Since gradients of the emergent property are necessary in EPI optimization, gradient tractability is a key criteria when determining the suitability of a simulation-based inference technique. If the emergent property gradient is efficiently calculated, EPI is a clear choice for inferring high dimensional parameter distributions. In the next two sections, we use EPI for novel scientific insight by examining the structure of inferred distributions.
EPI reveals how recurrence with multiple inhibitory subtypes governs excitatory variability in a V1 model
Dynamical models of excitatory (E) and inhibitory (I) populations with supralinear input-output function have succeeded in explaining a host of experimentally documented phenomena in primary visual cortex (V1). In a regime characterized by inhibitory stabilization of strong recurrent excitation, these models give rise to paradoxical responses (Tsodyks et al., 1997), selective amplification (Goldman, 2009; Murphy and Miller, 2009), surround suppression (Ozeki et al., 2009), and normalization (Rubin et al., 2015). Recent theoretical work (Hennequin et al., 2018) shows that stabilized E-I models reproduce the effect of variability suppression (Churchland et al., 2010). Furthermore, experimental evidence shows that inhibition is composed of distinct elements – parvalbumin (P), somatostatin (S), VIP (V) – composing 80% of GABAergic interneurons in V1 (Markram et al., 2004; Rudy et al., 2011; Tremblay et al., 2016), and that these inhibitory cell types follow specific connectivity patterns (Figure 3A; Pfeffer et al., 2013). Here, we use EPI on a model of V1 with biologically realistic connectivity to show how the structure of input across neuron types affects the variability of the excitatory population – the population largely responsible for projecting to other brain areas (Felleman and Van Essen, 1991).
Figure 3 with 4 supplements see all
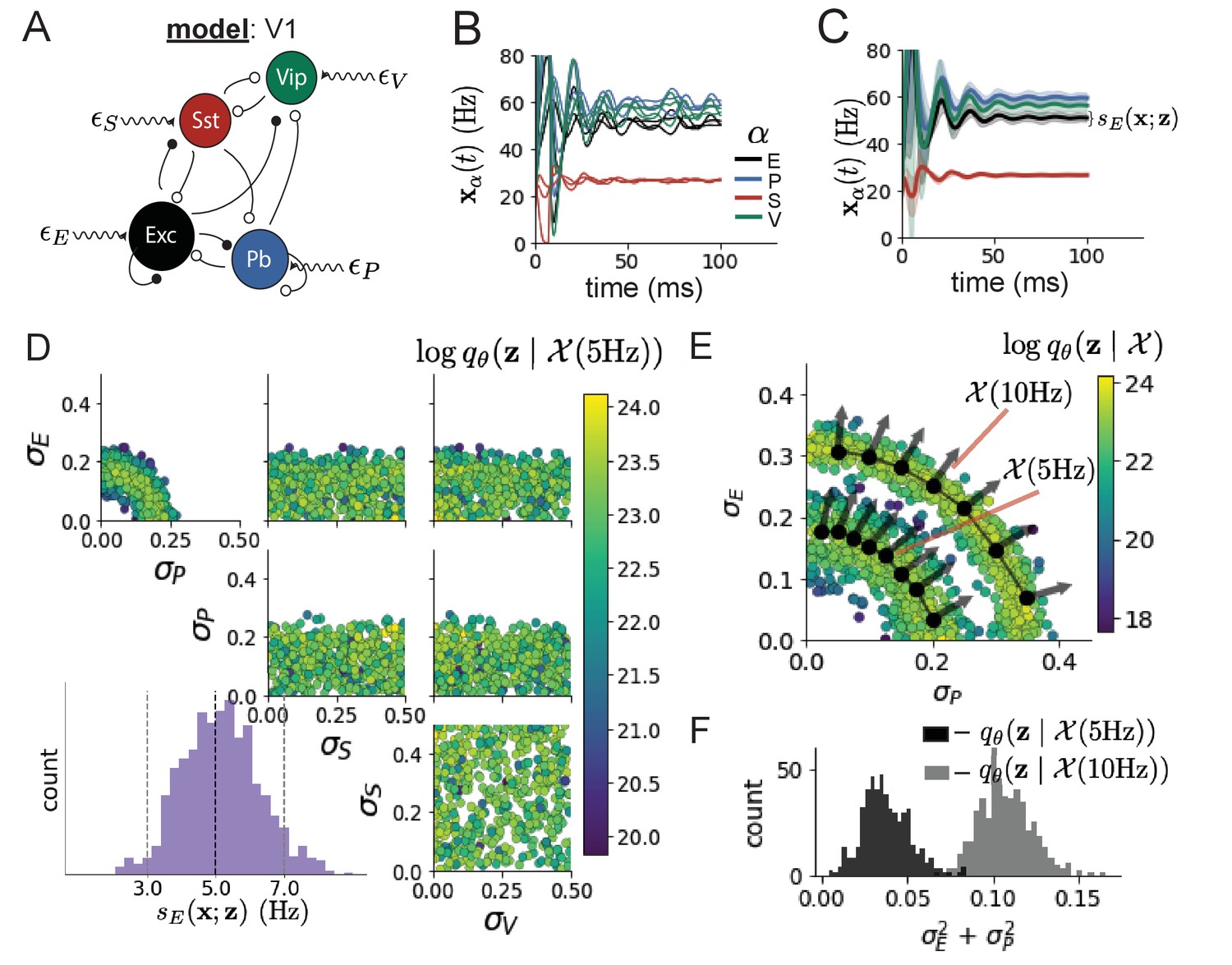
Emergent property inference in the stochastic stabilized supralinear network (SSSN).
(A) Four-population model of primary visual cortex with excitatory (black), parvalbumin (blue), somatostatin (red), and VIP (green) neurons (excitatory and inhibitory projections filled and unfilled, respectively). Some neuron-types largely do not form synaptic projections to others (). Each neural population receives a baseline input , and the E- and P-populations also receive a contrast-dependent input . Additionally, each neural population receives a slow noisy input . (B) Transient network responses of the SSSN model. Traces are independent trials with varying initialization and noise . (C) Mean (solid line) and standard deviation (shading) across 100 trials. (D) EPI distribution of noise parameters conditioned on E-population variability. The EPI predictive distribution of is show on the bottom-left. (E) (Top) Enlarged visualization of the - marginal distribution of EPI and . Each black dot shows the mode at each . The arrows show the most sensitive dimensions of the Hessian evaluated at these modes. (F) The predictive distributions of of each inferred distribution and .
We considered response variability of a nonlinear dynamical V1 circuit model (Figure 3A) with a state comprised of each neuron-type population’s rate . Each population receives recurrent input , where is the effective connectivity matrix (see Section 'Primary visual cortex') and an external input with mean , which determines population rate via supralinear nonlinearity . The external input has an additive noisy component with variance . This noise has a slower dynamical timescale than the population rate, allowing fluctuations around a stimulus-dependent steady-state (Figure 3B). This model is the stochastic stabilized supralinear network (SSSN) (Hennequin et al., 2018)
(6)
generalized to have multiple inhibitory neuron types. It introduces stochasticity to four neuron-type models of V1 (Litwin-Kumar et al., 2016). Stochasticity and inhibitory multiplicity introduce substantial complexity to the mathematical treatment of this problem (see Section 'Primary visual cortex: Mathematical intuition and challenges') motivating the analysis of this model with EPI. Here, we consider fixed weights and input (Palmigiano et al., 2020), and study the effect of input variability on excitatory variability.
We quantify levels of E-population variability by studying two emergent properties
(7)
where is the standard deviation of the stochastic -population response about its steady state (Figure 3C). In the following analyses, we select 1 Hz2 variance such that the two emergent properties do not overlap in .
First, we ran EPI to obtain parameter distribution producing E-population variability around 5 Hz (Figure 3D). From the marginal distribution of and (Figure 3D, top-left), we can see that is sensitive to various combinations of and . Alternatively, both and are degenerate with respect to evidenced by the unexpectedly high variability in those dimensions (Figure 3D, bottom-right). Together, these observations imply a curved path with respect to of 5 Hz, which is indicated by the modes along (Figure 3E).
Figure 3E suggests a quadratic relationship in E-population fluctuations and the standard deviation of E- and P-population input; as the square of either or increases, the other compensates by decreasing to preserve the level of . This quadratic relationship is preserved at greater level of E-population variability (Figure 3E and Figure 3—figure supplement 1). Indeed, the sum of squares of and is larger in than (Figure 3F, ), while the sum of squares of and are not significantly different in the two EPI distributions (Figure 3—figure supplement 3, ), in which parameters were bounded from 0 to 0.5. The strong interaction between E- and P-population input variability on excitatory variability is intriguing, since this circuit exhibits a paradoxical effect in the P-population (and no other inhibitory types) (Figure 3—figure supplement 4), meaning that the E-population is P-stabilized. Future research may uncover a link between the population of network stabilization and compensatory interactions governing excitatory variability.
EPI revealed the quadratic dependence of excitatory variability on input variability to the E- and P-populations, as well as its independence to input from the other two inhibitory populations. In a simplified model (), it can be shown that surfaces of equal variance are ellipsoids as a function of (see Section 'Primary visual cortex: Mathematical intuition and challenges'). Nevertheless, the sensitive and degenerate parameters are intractable to predict mathematically, since the covariance matrix depends on the steady-state solution of the network (Hennequin et al., 2018; Gardiner, 2009), and terms in the covariance expression increase quadratically with each additional neuron-type population (see also Section 'Primary visual cortex: Mathematical intuition and challenges'). By pointing out this mathematical complexity, we emphasize the value of EPI for gaining understanding about theoretical models when mathematical analysis becomes onerous or impractical.
EPI identifies two regimes of rapid task switching
It has been shown that rats can learn to switch from one behavioral task to the next on randomly interleaved trials (Duan et al., 2015), and an important question is what neural mechanisms produce this computation. In this experimental setup, rats were given an explicit task cue on each trial, either Pro or Anti. After a delay period, rats were shown a stimulus, and made a context (task) dependent response (Figure 4A). In the Pro task, rats were required to orient toward the stimulus, while in the Anti task, rats were required to orient away from the stimulus. Pharmacological inactivation of the SC impaired rat performance, and time-specific optogenetic inactivation revealed a crucial role for the SC on the cognitively demanding Anti trials (Duan et al., 2021). These results motivated a nonlinear dynamical model of the SC containing four functionally defined neuron-type populations. In Duan et al., 2021, a computationally intensive procedure was used to obtain a set of 373 connectivity parameters that qualitatively reproduced these optogenetic inactivation results. To build upon the insights of this previous work, we use the probabilistic tools afforded by EPI to identify and characterize two linked, yet distinct regimes of rapid task switching connectivity.
Figure 4 with 5 supplements see all
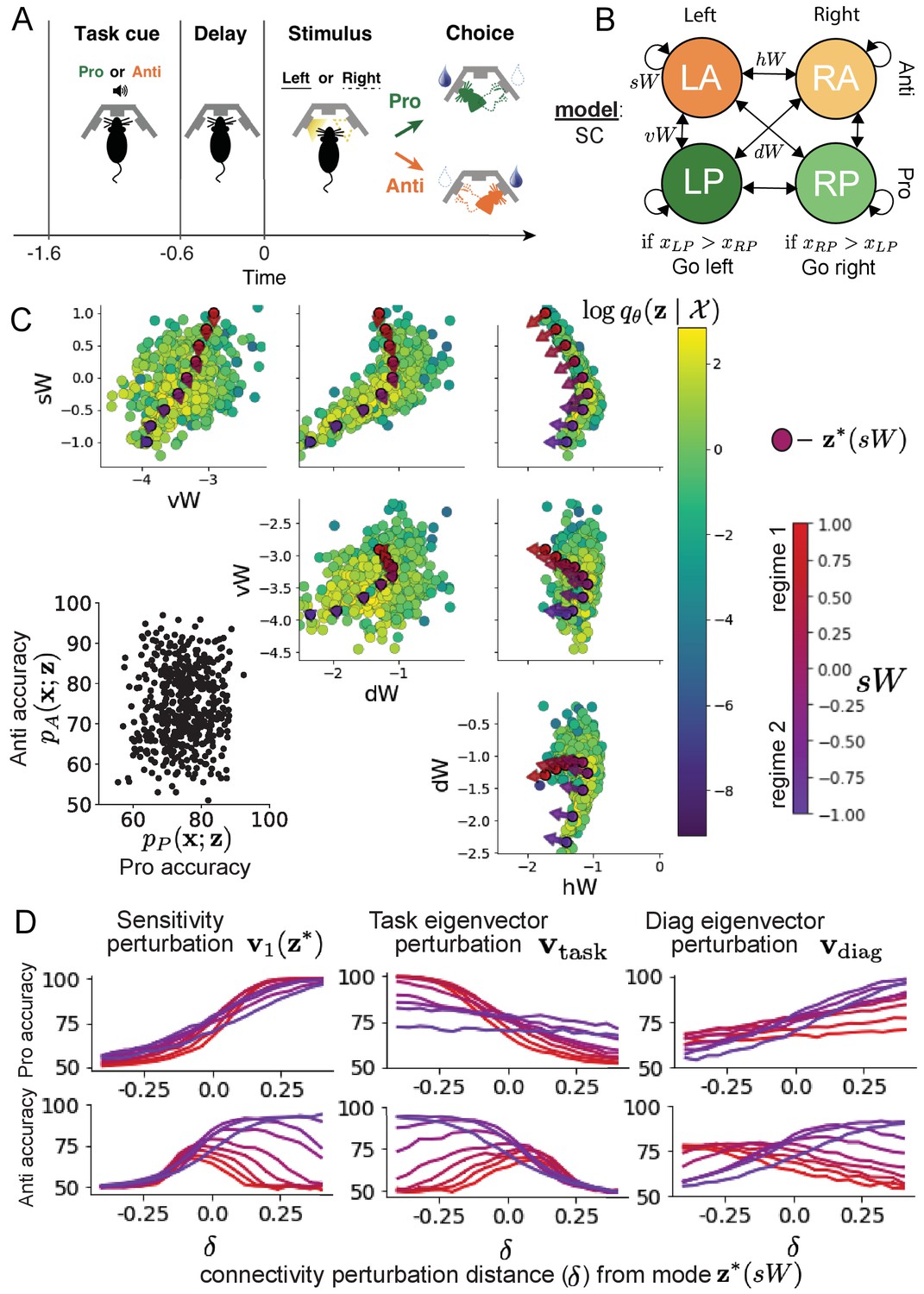
Inferring rapid task switching networks in superior colliculus.
(A) Rapid task switching behavioral paradigm (see text). (B) Model of superior colliculus (SC). Neurons: LP - Left Pro, RP - Right Pro, LA - Left Anti, RA - Right Anti. Parameters: - self, - horizontal, -vertical, - diagonal weights. (C) The EPI inferred distribution of rapid task switching networks. Red/purple parameters indicate modes colored by . Sensitivity vectors are shown by arrows. (Bottom-left) EPI predictive distribution of task accuracies. (D) Mean and standard error ( = 25, bars not visible) of accuracy in Pro (top) and Anti (bottom) tasks after perturbing connectivity away from mode along (left), (middle), and (right).
In this SC model, there are Pro- and Anti-populations in each hemisphere (left (L) and right (R)) with activity variables (Duan et al., 2021). The connectivity of these populations is parameterized by self , vertical , diagonal and horizontal connections (Figure 4B). The input is comprised of a positive cue-dependent signal to the Pro- or Anti-populations, a positive stimulus-dependent input to either the Left or Right populations, and a choice-period input to the entire network (see Section 'SC model'). Model responses are bounded from 0 to 1 as a function of an internal variable
(8)
The model responds to the side with greater Pro neuron activation; for example the response is left if at the end of the trial. Here, we use EPI to determine the network connectivity that produces rapid task switching.
Rapid task switching is formalized mathematically as an emergent property with two statistics: accuracy in the Pro task and Anti task . We stipulate that accuracy be on average 0.75 in each task with variance
(9)
Seventy-five percent accuracy is a realistic level of performance in each task, and with the chosen variance, inferred models will not exhibit fully random responses (50%), nor perfect performance (100%).
The EPI inferred distribution (Figure 4C) produces Pro- and Anti-task accuracies (Figure 4C, bottom-left) consistent with rapid task switching (Equation 9). This parameter distribution has rich structure that is not captured well by simple linear correlations (Figure 4—figure supplement 1). Specifically, the shape of the EPI distribution is sharply bent, matching ground truth structure indicated by brute-force sampling (Figure 4—figure supplement 5). This is most saliently observed in the marginal distribution of - (Figure 4C top-right), where anticorrelation between and switches to correlation with decreasing . By identifying the modes of the EPI distribution at different values of (Figure 4C red/purple dots), we can quantify this change in distributional structure with the sensitivity dimension (Figure 4C red/purple arrows). Note that the directionality of these sensitivity dimensions at changes distinctly with , and are perpendicular to the robust dimensions of the EPI distribution that preserve rapid task switching. These two directionalities of sensitivity motivate the distinction of connectivity into two regimes, which produce different types of responses in the Pro and Anti tasks (Figure 4—figure supplement 2).
When perturbing connectivity along the sensitivity dimension away from the modes
(10)
Pro-accuracy monotonically increases in both regimes (Figure 4D, top-left). However, there is a stark difference between regimes in Anti-accuracy. Anti-accuracy falls in either direction of in regime 1, yet monotonically increases along with Pro accuracy in regime 2 (Figure 4D, bottom-left). The sharp change in local structure of the EPI distribution is therefore explained by distinct sensitivities: Anti-accuracy diminishes in only one or both directions of the sensitivity perturbation.
To understand the mechanisms differentiating the two regimes, we can make connectivity perturbations along dimensions that only modify a single eigenvalue of the connectivity matrix. These eigenvalues , , , and correspond to connectivity eigenmodes with intuitive roles in processing in this task (Figure 4—figure supplement 3A). For example, greater will strengthen internal representations of task, while greater will amplify dominance of Pro and Anti pairs in opposite hemispheres (Section 'Connectivity eigendecomposition and processing modes'). Unlike the sensitivity dimension, the dimensions that perturb isolated connectivity eigenvalues for are independent of (see Section 'Connectivity eigendecomposition and processing modes'), e.g.
(11)
Connectivity perturbation analyses reveal that decreasing has a very similar effect on Anti accuracy as perturbations along the sensitivity dimension (Figure 4D, middle). The similar effects of perturbations along the sensitivity dimension and reduction of task eigenvalue (via perturbations along ) suggest that there is a carefully tuned strength of task representation in connectivity regime 1, which if disturbed results in random Anti-trial responses. Finally, we recognize that increasing has opposite effects on Anti-accuracy in each regime (Figure 4D, right). In the next section, we build on these mechanistic characterizations of each regime by examining their resilience to optogenetic inactivation.
EPI inferred SC connectivities reproduce results from optogenetic inactivation experiments
During the delay period of this task, the circuit must prepare to execute the correct task according to the presented cue. The circuit must then maintain a representation of task throughout the delay period, which is important for correct execution of the Anti-task. Duan et al. found that bilateral optogenetic inactivation of SC during the delay period consistently decreased performance in the Anti-task, but had no effect on the Pro-task (Figure 5A; Duan et al., 2021). The distribution of connectivities inferred by EPI exhibited this same effect in simulation at high optogenetic strengths γ, which reduce the network activities by a factor (Figure 5B) (see Section 'Modeling optogenetic silencing').
Figure 5 with 2 supplements see all
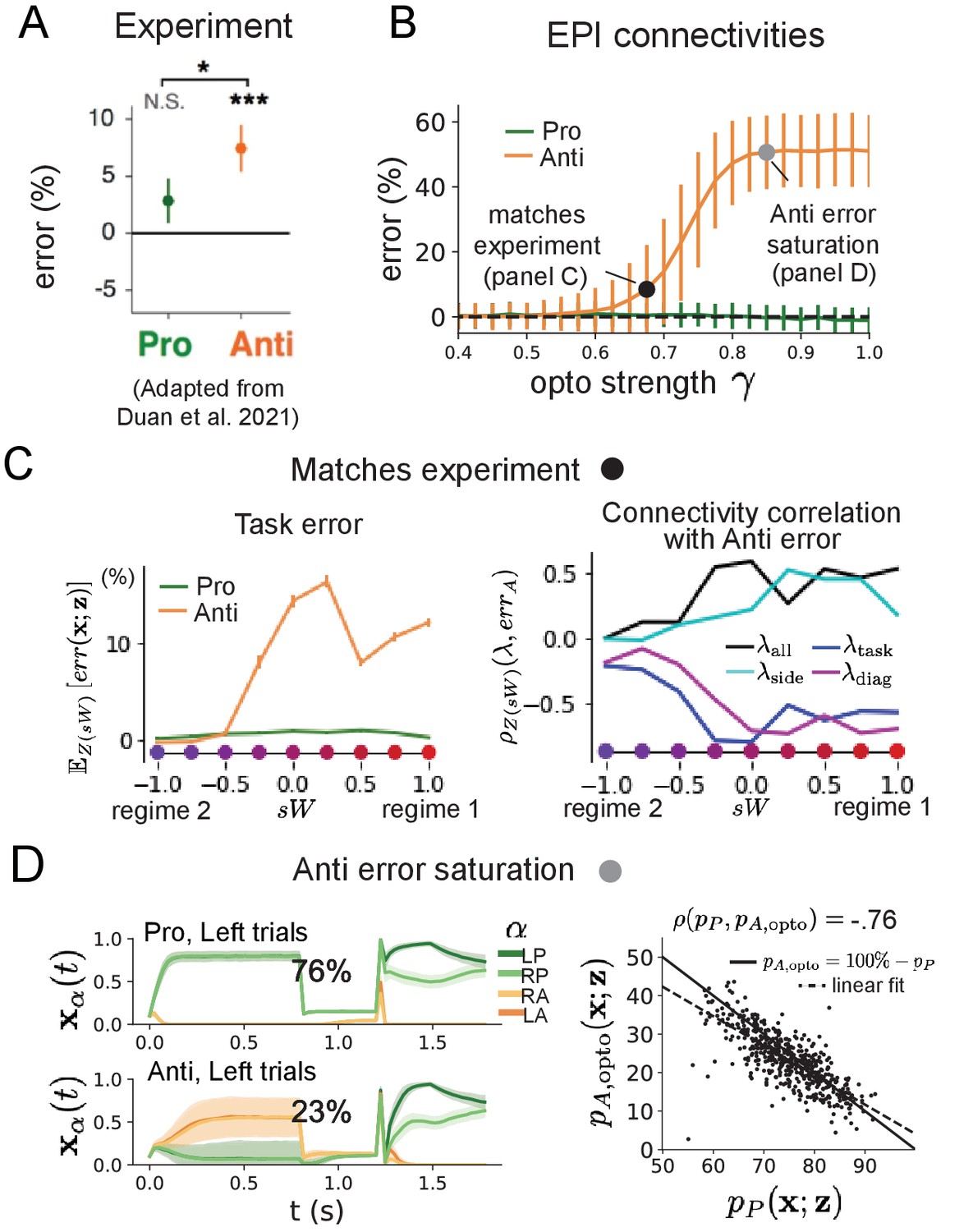
Responses to optogenetic perturbation by connectivity regime.
(A) Mean and standard error (bars) across recording sessions of task error following delay period optogenetic inactivation in rats. (B) Mean and standard deviation (bars) of task error induced by delay period inactivation of varying optogenetic strength γ across the EPI distribution. (C) (Left) Mean and standard error of Pro and Anti error from regime 1 to regime 2 at . (Right) Correlations of connectivity eigenvalues with Anti error from regime 1 to regime 2 at . (D) (Left) Mean and standard deviation (shading) of responses of the SC model at the mode of the EPI distribution to delay period inactivation at . Accuracy in Pro (top) and Anti (bottom) task is shown as a percentage. (Right) Anti-accuracy following delay period inactivation at versus accuracy in the Pro-task across connectivities in the EPI distribution.
To examine how connectivity affects response to delay period inactivation, we grouped connectivities of the EPI distribution along the continuum linking regimes 1 and 2 of Section 'EPI identifies two regimes of rapid task switching'. is the set of EPI samples for which the closest mode was (see Section 'Mode identification with EPI'). In the following analyses, we examine how error, and the influence of connectivity eigenvalue on Anti-error change along this continuum of connectivities. Obtaining the parameter samples for these analysis with the learned EPI distribution was more than 20,000 times faster than a brute force approach (see Section 'Sample grouping by mode').
The mean increase in Anti-error of the EPI distribution is closest to the experimentally measured value of 7% at (Figure 5B, black dot). At this level of optogenetic strength, regime 1 exhibits an increase in Anti-error with delay period silencing (Figure 5C, left), while regime 2 does not. In regime 1, greater and decrease Anti-error (Figure 5C, right). In other words, stronger task representations and diagonal amplification make the SC model more resilient to delay period silencing in the Anti-task. This complements the finding from Duan et al., 2021 (Duan et al., 2021) that and improve Anti accuracy.
At roughly (Figure 5B, gray dot), the Anti-error saturates, while Pro-error remains at zero. Following delay period inactivation at this optogenetic strength, there are strong similarities in the responses of Pro- and Anti-trials during the choice period (Figure 5D, left). We interpreted these similarities to suggest that delay period inactivation at this saturated level flips the internal representation of task (from Anti to Pro) in the circuit model. A flipped task representation would explain why the Anti-error saturates at 50%: the average Anti-accuracy in EPI inferred connectivities is 75%, but average Anti accuracy would be 25% (100% - ) if the internal representation of task is flipped during the delay period.This hypothesis prescribes a model of Anti-accuracy during delay period silencing of , which is fit closely across both regimes of the EPI inferred connectivities (Figure 5D, right). Similarities between Pro- and Anti-trial responses were not present at the experiment-matching level of (Figure 5—figure supplement 2 left) and neither was anticorrelation in and (Figure 5—figure supplement 2 right).
In summary, the connectivity inferred by EPI to perform rapid task switching replicated results from optogenetic silencing experiments. We found that at levels of optogenetic strength matching experimental levels of Anti-error, only one regime actually exhibited the effect. This connectivity regime is less resilient to optogenetic perturbation, and perhaps more biologically realistic. Finally, we characterized the pathology in Anti-error that occurs in both regimes when optogenetic strength is increased to high levels, leading to a mechanistic hypothesis that is experimentally testable. The probabilistic tools afforded by EPI yielded this insight: we identified two regimes and the continuum of connectivities between them by taking gradients of parameter probabilities in the EPI distribution, we identified sensitivity dimensions by measuring the Hessian of the EPI distribution, and we obtained many parameter samples at each step along the continuum at an efficient rate.
Discussion
In neuroscience, machine learning has primarily been used to reveal structure in neural datasets (Paninski and Cunningham, 2018). Careful inference procedures are developed for these statistical models allowing precise, quantitative reasoning, which clarifies the way data informs beliefs about the model parameters. However, these statistical models often lack resemblance to the underlying biology, making it unclear how to go from the structure revealed by these methods, to the neural mechanisms giving rise to it. In contrast, theoretical neuroscience has primarily focused on careful models of neural circuits and the production of emergent properties of computation, rather than measuring structure in neural datasets. In this work, we improve upon parameter inference techniques in theoretical neuroscience with emergent property inference, harnessing deep learning towards parameter inference in neural circuit models (see Section 'Related approaches').
Methodology for statistical inference in circuit models has evolved considerably in recent years. Early work used rejection sampling techniques (Beaumont et al., 2002; Marjoram et al., 2003; Sisson et al., 2007), but EPI and another recently developed methodology (Gonçalves et al., 2019) employ deep learning to improve efficiency and provide flexible approximations. SNPE has been used for posterior inference of parameters in circuit models conditioned upon exemplar data used to represent computation, but it does not infer parameter distributions that only produce the computation of interest like EPI (see Section 'Scaling inference of recurrent neural network connectivity with EPI'). When strict control over the predictions of the inferred parameters is necessary, EPI uses a constrained optimization technique (Loaiza-Ganem et al., 2017) (see Section 'Augmented lagrangian optimization') to make inference conditioned on the emergent property possible.
A key difference between EPI and SNPE, is that EPI uses gradients of the emergent property throughout optimization. In Section 'Scaling inference of recurrent neural network connectivity with EPI', we showed that such gradients confer beneficial scaling properties, but a concern remains that emergent property gradients may be too computationally intensive. Even in a case of close biophysical realism with an expensive emergent property gradient, EPI was run successfully on intermediate hub frequency in a five-neuron subcircuit model of the STG (Section 'Motivating emergent property inference of theoretical models'). However, conditioning on the pyloric rhythm (Marder and Selverston, 1992) in a model of the pyloric subnetwork model (Prinz et al., 2004) proved to be prohibitive with EPI. The pyloric subnetwork requires many time steps for simulation and many key emergent property statistics (e.g. burst duration and phase gap) are not calculable or easily approximated with differentiable functions. In such cases, SNPE, which does not require differentiability of the emergent property, has proven useful (Gonçalves et al., 2019). In summary, choice of deep inference technique should consider emergent property complexity and differentiability, dimensionality of parameter space, and the importance of constraining the model behavior predicted by the inferred parameter distribution.
In this paper, we demonstrate the value of deep inference for parameter sensitivity analyses at both the local and global level. With these techniques, flexible deep probability distributions are optimized to capture global structure by approximating the full distribution of suitable parameters. Importantly, the local structure of this deep probability distribution can be quantified at any parameter choice, offering instant sensitivity measurements after fitting. For example, the global structure captured by EPI revealed two distinct parameter regimes, which had different local structure quantified by the deep probability distribution (see Section 'Superior colliculus'). In comparison, bayesian MCMC is considered a popular approach for capturing global parameter structure (Girolami and Calderhead, 2011), but there is no variational approximation (the deep probability distribution in EPI), so sensitivity information is not queryable and sampling remains slow after convergence. Local sensitivity analyses (e.g. Raue et al., 2009) may be performed independently at individual parameter samples, but these methods alone do not capture the full picture in nonlinear, complex distributions. In contrast, deep inference yields a probability distribution that produces a wholistic assessment of parameter sensitivity at the local and global level, which we used in this study to make novel insights into a range of theoretical models. Together, the abilities to condition upon emergent properties, the efficient inference algorithm, and the capacity for parameter sensitivity analyses make EPI a useful method for addressing inverse problems in theoretical neuroscience.
Code availability statement
All software written for this study is available at https://github.com/cunningham-lab/epi (copy archived at swh:1:rev:38febae7035ca921334a616b0f396b3767bf18d4), Bittner, 2021.
Materials and methods
Emergent property inference (EPI)
Solving inverse problems is an important part of theoretical neuroscience, since we must understand how neural circuit models and their parameter choices produce computations. Recently, research on machine learning methodology for neuroscience has focused on finding latent structure in large-scale neural datasets, while research in theoretical neuroscience generally focuses on developing precise neural circuit models that can produce computations of interest. By quantifying computation into an emergent property through statistics of the emergent activity of neural circuit models, we can adapt the modern technique of deep probabilistic inference towards solving inverse problems in theoretical neuroscience. Here, we introduce a novel method for statistical inference, which uses deep networks to learn parameter distributions constrained to produce emergent properties of computation.
Consider model parameterization , which is a collection of scientifically meaningful variables that govern the complex simulation of data . For example (see Section 'Motivating emergent property inference of theoretical models'), may be the electrical conductance parameters of an STG subcircuit, and the evolving membrane potentials of the five neurons. In terms of statistical modeling, this circuit model has an intractable likelihood , which is predicated by the stochastic differential equations that define the model. From a theoretical perspective, we are less concerned about the likelihood of an exemplar dataset , but rather the emergent property of intermediate hub frequency (which implies a consistent dataset ).
In this work, emergent properties are defined through the choice of emergent property statistic (which is a vector of one or more statistics), and its means , and variances :
(12)
In general, an emergent property may be a collection of first-, second-, or higher-order moments of a group of statistics, but this study focuses on the case written in Equation 12. In the STG example, intermediate hub frequency is defined by mean and variance constraints on the statistic of hub neuron frequency (Equations 2 and 3). Precisely, the emergent property statistics must have means and variances over the EPI distribution of parameters () and the data produced by those parameters (), where the inferred parameter distribution itself is parameterized by deep network weights and biases .
In EPI, a deep probability distribution is optimized to approximate the parameter distribution producing the emergent property . In contrast to simpler classes of distributions like the gaussian or mixture of gaussians, deep probability distributions are far more flexible and capable of fitting rich structure (Rezende and Mohamed, 2015; Papamakarios et al., 2019a). In deep probability distributions, a simple random variable (we choose an isotropic gaussian) is mapped deterministically via a sequence of deep neural network layers (g1, . gl) parameterized by weights and biases to the support of the distribution of interest:
(13)
Such deep probability distributions embed the inferred distribution in a deep network. Once optimized, this deep network representation of a distribution has remarkably useful properties: fast sampling and probability evaluations. Importantly, fast probability evaluations confer fast gradient and Hessian calculations as well.
Given this choice of circuit model and emergent property , is optimized via the neural network parameters to find a maximally entropic distribution within the deep variational family that produces the emergent property :
(14)
where is entropy. By maximizing the entropy of the inferred distribution , we select the most random distribution in family that satisfies the constraints of the emergent property. Since entropy is maximized in Equation 14, EPI is equivalent to bayesian variational inference (see Section 'EPI as variational inference'), which is why we specify the inferred distribution of EPI as conditioned upon emergent property with the notation . To run this constrained optimization, we use an augmented lagrangian objective, which is the standard approach for constrained optimization (Bertsekas, 2014), and the approach taken to fit Maximum Entropy Flow Networks (MEFNs) (Loaiza-Ganem et al., 2017). This procedure is detailed in Section 'Augmented lagrangian optimization' and the pseudocode in Algorithm 'Augmented lagrangian optimization'.
In the remainder of Section 'Emergent property inference (EPI)', we will explain the finer details and motivation of the EPI method. First, we explain related approaches and what EPI introduces to this domain (Section 'Related approaches'). Second, we describe the special class of deep probability distributions used in EPI called normalizing flows (Section 'Deep probability distributions and normalizing flows'). Then, we establish the known relationship between maximum entropy distributions and exponential families (Section 'Maximum entropy distributions and exponential families'). Next, we explain the constrained optimization technique used to solve Equation 14 (Section 'Augmented lagrangian optimization'). Then, we demonstrate the details of this optimization in a toy example (Section 'Example: 2D LDS'). Finally, we explain how EPI is equivalent to variational inference (Section 'EPI as variational inference').
Related approaches
Request a detailed protocolWhen bayesian inference problems lack conjugacy, scientists use approximate inference methods like variational inference (VI) (Saul and Jordan, 1998) and Markov chain Monte Carlo (MCMC) (Metropolis et al., 1953; Hastings, 1970). After optimization, variational methods return a parameterized posterior distribution, which we can analyze. Also, the variational approximation is often chosen such that it permits fast sampling. In contrast MCMC methods only produce samples from the approximated posterior distribution. No parameterized distribution is estimated, and additional samples are always generated with the same sampling complexity. Inference in models defined by systems of differential has been demonstrated with MCMC (Girolami and Calderhead, 2011), although this approach requires tractable likelihoods. Advancements have introduced sampling (Calderhead and Girolami, 2011), likelihood approximation (Golightly and Wilkinson, 2011), and uncertainty quantification techniques (Chkrebtii et al., 2016) to make MCMC approaches more efficient and expand the class of applicable models.
Simulation-based inference (Cranmer et al., 2020) is model parameter inference in the absence of a tractable likelihood function. The most prevalent approach to simulation-based inference is approximate bayesian computation (ABC) (Beaumont et al., 2002), in which satisfactory parameter samples are kept from random prior sampling according to a rejection heuristic. The obtained set of parameters do not have a probabilities, and further insight about the model must be gained from examination of the parameter set and their generated activity. Methodological advances to ABC methods have come through the use of Markov chain Monte Carlo (MCMC-ABC) (Marjoram et al., 2003) and sequential Monte Carlo (SMC-ABC) (Sisson et al., 2007) sampling techniques. SMC-ABC is considered state-of-the-art ABC, yet this approach still struggles to scale in dimensionality (Sisson et al., 2018; Figure 2). Still, this method has enjoyed much success in systems biology (Liepe et al., 2014). Furthermore, once a parameter set has been obtained by SMC-ABC from a finite set of particles, the SMC-ABC algorithm must be run again from scratch with a new population of initialized particles to obtain additional samples.
For scientific model analysis, we seek a parameter distribution represented by an approximating distribution as in variational inference (Saul and Jordan, 1998): a variational approximation that once optimized yields fast analytic calculations and samples. For the reasons described above, ABC and MCMC techniques are not suitable, because they only produce a set of parameter samples lacking probabilities and have unchanging sampling rate. EPI infers parameters in circuit models using the MEFN (Loaiza-Ganem et al., 2017) algorithm with a deep variational approximation. The deep neural network of EPI (Figure 1E) defines the parametric form (with weights and biases as variational parameters ) of the variational approximation of the inferred parameter distribution . The EPI optimization is enabled using stochastic gradient techniques in the spirit of likelihood-free variational inference (Tran et al., 2017). The analytic relationship between EPI and variational inference is explained in Section 'EPI as variational inference'.
We note that, during our preparation and early presentation of this work (Bittner et al., 2019a; Bittner et al., 2019b), another work has arisen with broadly similar goals: bringing statistical inference to mechanistic models of neural circuits (Nonnenmacher et al., 2018; Michael et al., 2019; Gonçalves et al., 2019). We are encouraged by this general problem being recognized by others in the community, and we emphasize that these works offer complementary neuroscientific contributions (different theoretical models of focus) and use different technical methodologies (ours is built on our prior work [Loaiza-Ganem et al., 2017], theirs similarly [Lueckmann et al., 2017]).
The method EPI differs from SNPE in some key ways. SNPE belongs to a ‘sequential’ class of recently developed simulation-based inference methods in which two neural networks are used for posterior inference. This first neural network is a deep probability distribution (normalizing flow) used to estimate the posterior (SNPE) or the likelihood (sequential neural likelihood (SNL) [Papamakarios et al., 2019b]). A recent approach uses an unconstrained neural network to estimate the likelihood ratio (sequential neural ratio estimation (SNRE) [Hermans et al., 2020]). In SNL and SNRE, MCMC sampling techniques are used to obtain samples from the approximated posterior. This contrasts with EPI and SNPE, which use deep probability distributions to model parameters, which facilitates immediate measurements of sample probability, gradient, or Hessian for system analysis. The second neural network in this sequential class of methods is the amortizer. This unconstrained deep network maps data (or statistics or model parameters ) to the weights and biases of the first neural network. These methods are optimized on a conditional density (or ratio) estimation objective. The data used to optimize this objective are generated via an adaptive procedure, in which training data pairs (, ) become sequentially closer to the true data and posterior.
The approximating fidelity of the deep probability distribution in sequential approaches is optimized to generalize across the training distribution of the conditioning variable. This generalization property of the sequential methods can reduce the accuracy at the singular posterior of interest. Whereas in EPI, the entire expressivity of the deep probability distribution is dedicated to learning a single distribution as well as possible. The well-known inverse mapping problem of exponential families (Wainwright and Jordan, 2008) prohibits an amortization-based approach in EPI, since EPI learns an exponential family distribution parameterized by its mean (in contrast to its natural parameter, see Section 'Maximum entropy distributions and exponential families'). However, we have shown that the same two-network architecture of the sequential simulation-based inference methods can be used for amortized inference in intractable exponential family posteriors when using their natural parameterization (Bittner and Cunningham, 2019).
Finally, one important differentiating factor between EPI and sequential simulation-based inference methods is that EPI leverages gradients during optimization. These gradients can improve convergence time and scalability, as we have shown on an example conditioning low-rank RNN connectivity on the property of stable amplification (see Section 'Scaling inference of recurrent neural network connectivity with EPI'). With EPI, we prove out the suggestion that a deep inference technique can improve efficiency by leveraging these emergent property gradients when they are tractable. Sequential simulation-based inference techniques may be better suited for scientific problems where is intractable or unavailable, like when there is a nondifferentiable emergent property. However, the sequential simulation-based inference techniques cannot constrain the predictions of the inferred distribution in the manner of EPI.
Structural identifiability analysis involves the measurement of sensitivity and unidentifiabilities in scientific models. Around a single parameter choice, one can measure the Jacobian. One approach for this calculation that scales well is EAR (Karlsson et al., 2012). A popular efficient approach for systems of ODEs has been neural ODE adjoint (Chen et al., 2018) and its stochastic adaptation (Li et al., 2020). Casting identifiability as a statistical estimation problem, the profile likelihood works via iterated optimization while holding parameters fixed (Raue et al., 2009). An exciting recent method is capable of recovering the functional form of such unidentifiabilities away from a point by following degenerate dimensions of the fisher information matrix (Raman et al., 2017). Global structural non-identifiabilities can be found for models with polynomial or rational dynamics equations using DAISY (Pia Saccomani et al., 2003), or through mean optimal transformations (Hengl et al., 2007). With EPI, we have all the benefits given by a statistical inference method plus the ability to query the first- or second-order gradient of the probability of the inferred distribution at any chosen parameter value. The second-order gradient of the log probability (the Hessian), which is directly afforded by EPI distributions, produces quantified information about parametric sensitivity of the emergent property in parameter space (see Section 'Emergent property inference via deep generative models').
Deep probability distributions and normalizing flows
Request a detailed protocolDeep probability distributions are comprised of multiple layers of fully connected neural networks (Equation 13). When each neural network layer is restricted to be a bijective function, the sample density can be calculated using the change of variables formula at each layer of the network. For ,
(15)
However, this computation has cubic complexity in dimensionality for fully connected layers. By restricting our layers to normalizing flows (Rezende and Mohamed, 2015; Papamakarios et al., 2019a) – bijective functions with fast log determinant Jacobian computations, which confer a fast calculation of the sample log probability. Fast log probability calculation confers efficient optimization of the maximum entropy objective (see Section 'Augmented lagrangian optimization').
We use the real NVP (Dinh et al., 2017) normalizing flow class, because its coupling architecture confers both fast sampling (forward) and fast log probability evaluation (backward). Fast probability evaluation facilitates fast gradient and Hessian evaluation of log probability throughout parameter space. Glow permutations were used in between coupling stages (Kingma and Dhariwal, 2018). This is in contrast to autoregressive architectures (Papamakarios et al., 2017; Kingma et al., 2016), in which only one of the forward or backward passes can be efficient. In this work, normalizing flows are used as flexible parameter distribution approximations having weights and biases . We specify the architecture used in each application by the number of real NVP affine coupling stages, and the number of neural network layers and units per layer of the conditioning functions.
When calculating Hessians of log probabilities in deep probability distributions, it is important to consider the normalizing flow architecture. With autoregressive architectures (Kingma et al., 2016; Papamakarios et al., 2017), fast sampling and fast log probability evaluations are mutually exclusive. That makes these architectures undesirable for EPI, where efficient sampling is important for optimization, and log probability evaluation speed predicates the efficiency of gradient and Hessian calculations. With real NVP coupling architectures, we get both fast sampling and fast Hessians making both optimization and scientific analysis efficient.
Maximum entropy distributions and exponential families
Request a detailed protocolThe inferred distribution of EPI is a maximum entropy distribution, which have fundamental links to exponential family distributions. A maximum entropy distribution of form:
(16)
where is the sufficient statistics vector and a vector of their mean values, will have probability density in the exponential family:
(17)
The mappings between the mean parameterization and the natural parameterization are formally hard to identify except in special cases (Wainwright and Jordan, 2008).
In this manuscript, emergent properties are defined by statistics having a fixed mean and variance as in Equation 12. The variance constraint is a second moment constraint on :
(18)
As a general maximum entropy distribution (Equation 16), the sufficient statistics vector contains both first and second order moments of
(19)
which are constrained to the chosen means and variances
(20)
Thus, is used to denote the mean parameter of the maximum entropy distribution defined by the emergent property (all constraints), while is only the mean of . The subscript ‘opt’ of is chosen since it contains all the constraint values to which the EPI optimization algorithm must adhere.
Augmented lagrangian optimization
Request a detailed protocolTo optimize in Equation 14, the constrained maximum entropy optimization is executed using the augmented lagrangian method. The following objective is minimized:
(21)
where there are average constraint violations
(22)
are the lagrange multipliers where is the number of total constraints
(23)
and is the penalty coefficient. The mean parameter and sufficient statistics are determined by the means and variances of the emergent property statistics defined in Equation 14. Specifically, is a concatenation of the first and second moments (Equation 19) and is a concatenation of their constraints and (Equation 20). (Although, note that this algorithm is written for general and to satisfy the more general class of emergent properties.) The lagrange multipliers are closely related to the natural parameters of exponential families (see Section 'EPI as variational inference'). Weights and biases of the deep probability distribution are optimized according to Equation 21 using the Adam optimizer with learning rate 10−3 (Kingma and Ba, 2015).
The gradient with respect to entropy can be expressed using the reparameterization trick as an expectation of the negative log density of parameter samples over the randomness in the parameterless initial distribution ):
(24)
Thus, the gradient of the entropy of the deep probability distribution can be estimated as an average of gradients with respect to the base distribution :
(25)
The gradients of the log density of the deep probability distribution are tractable through the use of normalizing flows (see Section 'Deep probability distributions and normalizing flows').
The full EPI optimization algorithm is detailed in Algorithm 1. The lagrangian parameters are initialized to zero and adapted following each augmented lagrangian epoch, which is a period of optimization with fixed (, ) for a given number of stochastic gradient descent (SGD) iterations. A low value of is used initially, and conditionally increased after each epoch based on constraint error reduction. The penalty coefficient is updated based on the result of a hypothesis test regarding the reduction in constraint violation. The p-value of is computed, and is updated to with probability . The other update rule is given a batch size and . Throughout the study, , while β was chosen to be either 2 or 4. The batch size of EPI also varied according to application.
| Algorithm 1. Emergent property inference |
|---|
| 1 initialize by fitting to an isotropic gaussian of mean and variance 2 initialize and . 3 for Augmented lagrangian epoch do 4 for SGD iteration do 5 Sample , get transformed variable , 6 Update by descending its stochastic gradient (using ADAM optimizer [Kingma and Ba, 2015]). 7 end 8 Sample , get transformed variable , 9 Update . 10 Update (see text for detail). 11 end |
In general, and should start at values encouraging entropic growth early in optimization. With each training epoch in which the update rule for is invoked, the constraint satisfaction terms are increasingly weighted, which generally results in decreased entropy (e.g. see Figure 1—figure supplement 1C). This encourages the discovery of suitable regions of parameter space, and the subsequent refinement of the distribution to produce the emergent property. The momentum parameters of the Adam optimizer are reset at the end of each augmented lagrangian epoch, which proceeds for iterations. In this work, we used a maximum number of augmented lagrangian epochs .
Rather than starting optimization from some drawn from a randomized distribution, we found that initializing to approximate an isotropic gaussian distribution conferred more stable, consistent optimization. The parameters of the gaussian initialization were chosen on an application-specific basis. Throughout the study, we chose isotropic Gaussian initializations with mean at the center of the support of the distribution and some variance , except for one case, where an initialization informed by random search was used (see Section 'Stomatogastric ganglion'). Deep probability distributions were fit to these gaussian initializations using 10,000 iterations of stochastic gradient descent on the evidence lower bound (as in Bittner and Cunningham, 2019) with Adam optimizer and a learning rate of .
To assess whether the EPI distribution produces the emergent property, we assess whether each individual constraint on the means and variances of is satisfied. We consider the EPI to have converged when a null hypothesis test of constraint violations being zero is accepted for all constraints at a significance threshold . This significance threshold is adjusted through Bonferroni correction according to the number of constraints . The p-values for each constraint are calculated according to a two-tailed nonparametric test, where 200 estimations of the sample mean are made using samples of at the end of the augmented lagrangian epoch. Of all augmented lagrangian epochs, we select the EPI inferred distribution as that which satisfies the convergence criteria and has greatest entropy.
When assessing the suitability of EPI for a particular modeling question, there are some important technical considerations. First and foremost, as in any optimization problem, the defined emergent property should always be appropriately conditioned (constraints should not have wildly different units). Furthermore, if the program is underconstrained (not enough constraints), the distribution grows (in entropy) unstably unless mapped to a finite support. If overconstrained, there is no parameter set producing the emergent property, and EPI optimization will fail (appropriately).
Example: 2D LDS
Request a detailed protocolTo gain intuition for EPI, consider a two-dimensional linear dynamical system (2D LDS) model (Figure 1—figure supplement 1A):
(26)
with
(27)
To run EPI with the dynamics matrix elements as the free parameters (fixing s), the emergent property statistics were chosen to contain parts of the primary eigenvalue of , which predicate frequency, , and the growth/decay, , of the system
(28)
is the eigenvalue of greatest real part when the imaginary component is zero, and alternatively that of positive imaginary component when the eigenvalues are complex conjugate pairs. To learn the distribution of real entries of that produce a band of oscillating systems around 1 Hz, we formalized this emergent property as having mean zero with variance , and the oscillation frequency having mean 1 Hz with variance 0.1 Hz2:
(29)
To write the emergent property in the form required for the augmented lagrangian optimization (Section 'Augmented lagrangian optimization'), we concatenate these first and second moment constraints into a vector of sufficient statistics and constraint values .
(30)
From now on in all scientific applications (Sections 'Stomatogastric ganglion', 'Scaling EPI for stable amplification in RNNs', 'Primary visual cortex', 'Superior colliculus'), we specify how the EPI optimization was setup by specifying , , and .
Unlike the models we presented in the main text, this model admits an analytical form for the mean emergent property statistics given parameter , since the eigenvalues can be calculated using the quadratic formula:
(31)
We study this example, because the inferred distribution is curved and multimodal, and we can compare the result of EPI to analytically derived contours of the emergent property statistics.
Despite the simple analytic form of the emergent property statistics, the EPI distribution in this example is not simply determined. Although is calculable directly via a closed form function, the distribution cannot be derived directly. This fact is due to the formally hard problem of the backward mapping: finding the natural parameters from the mean parameters of an exponential family distribution (Wainwright and Jordan, 2008). Instead, we used EPI to approximate this distribution (Figure 1—figure supplement 1B). We used a real NVP normalizing flow architecture three coupling layers and two-layer neural networks of 50 units per layer, mapped onto a support of . (see Section 'Deep probability distributions and normalizing flows').
Even this relatively simple system has nontrivial (although intuitively sensible) structure in the parameter distribution. To validate our method, we analytically derived the contours of the probability density from the emergent property statistics and values. In the - plane, the black line at , dashed black line at the standard deviation , and the dashed gray line at twice the standard deviation follow the contour of probability density of the samples (Figure 1—figure supplement 2A). The distribution precisely reflects the desired statistical constraints and model degeneracy in the sum of and . Intuitively, the parameters equivalent with respect to emergent property statistic have similar log densities.
To explain the bimodality of the EPI distribution, we examined the imaginary component of . When (which is the case on average in ), we have
(32)
In Figure 1—figure supplement 2B, we plot the contours of where is fixed to 0 at one standard deviation (, black dashed) and two standard deviations (, gray dashed) from the mean of . This validates the curved multimodal structure of the inferred distribution learned through EPI. Subtler combinations of model and emergent property will have more complexity, further motivating the use of EPI for understanding these systems. As we expect, the distribution results in samples of two-dimensional linear systems oscillating near 1 Hz (Figure 1—figure supplement 3).
EPI as variational inference
Request a detailed protocolIn variational inference, a posterior approximation is chosen from within some variational family to be as close as possible to the posterior under the KL divergence criteria
(33)
This KL divergence can be written in terms of entropy of the variational approximation:
(34)
(35)
Since the marginal distribution of the data (or ‘evidence’) is independent of , variational inference is executed by optimizing the remaining expression. This is usually framed as maximizing the evidence lower bound (ELBO)
(36)
Now, we will show how the maximum entropy problem of EPI is equivalent to variational inference. In general, a maximum entropy problem (as in Equation 16) has an equivalent lagrange dual form:
(37)
with lagrange multipliers . By moving the lagrange multipliers within the expectation
(38)
inserting a within the expectation,
(39)
and finally choosing to be likelihood averaged statistics as in EPI
(40)
we can compare directly to the objective used in variational inference (Equation 36). We see that EPI is exactly variational inference with an exponential family likelihood defined by sufficient statistics , and where the natural parameter is predicated by the mean parameter . Equation 40 implies that EPI uses an improper (or uniform) prior, which is easily changed.
This derivation of the equivalence between EPI and variational inference emphasizes why defining a statistical inference program by its mean parameterization is so useful. With EPI, one can clearly define the emergent property that the model of interest should produce through intuitive selection of for a given . Alternatively, figuring out the correct natural parameters for the same that produces is a formally hard problem.
Stomatogastric ganglion
In Section 'Motivating emergent property inference of theoretical models' and 'Emergent property inference via deep generative models', we used EPI to infer conductance parameters in a model of the stomatogastric ganglion (STG) (Gutierrez et al., 2013). This five-neuron circuit model represents two subcircuits: that generating the pyloric rhythm (fast population) and that generating the gastric mill rhythm (slow population). The additional neuron (the IC neuron of the STG) receives inhibitory synaptic input from both subcircuits, and can couple to either rhythm dependent on modulatory conditions. There is also a parametric regime in which this neuron fires at an intermediate frequency between that of the fast and slow populations (Gutierrez et al., 2013), which we infer with EPI as a motivational example. This model is not to be confused with an STG subcircuit model of the pyloric rhythm (Marder and Selverston, 1992), which has been statistically inferred in other studies (Prinz et al., 2004; Gonçalves et al., 2019).
STG model
Request a detailed protocolWe analyze how the parameters govern the emergent phenomena of intermediate hub frequency in a model of the stomatogastric ganglion (STG) (Gutierrez et al., 2013) shown in Figure 1A with activity , using the same hyperparameter choices as Gutierrez et al. Each neuron’s membrane potential for is the solution of the following stochastic differential equation:
(41)
The input current of each neuron is the sum of the leak, calcium, potassium, hyperpolarization, electrical and synaptic currents. Each current component is a function of all membrane potentials and the conductance parameters . Finally, we include gaussian noise to the model of Gutierrez et al. so that the model stochastic, although this is not required by EPI.
The capacitance of the cell membrane was set to . Specifically, the currents are the difference in the neuron’s membrane potential and that current type’s reversal potential multiplied by a conductance:
(42)
(43)
(44)
(45)
(46)
(47)
The reversal potentials were set to , , , , and . The other conductance parameters were fixed to . , , and had different values based on fast, intermediate (hub) or slow neuron. The fast conductances had values , , and . The intermediate conductances had values , , and . Finally, the slow conductances had values , , and .
Furthermore, the Calcium, Potassium, and hyperpolarization channels have time-dependent gating dynamics dependent on steady-state gating variables , and , respectively:
(48)
(49)
(50)
(51)
(52)
(53)
(54)
where we set , , , , , , , , , and .
Finally, there is a synaptic gating variable as well:
(55)
When the dynamic gating variables are considered, this is actually a 15-dimensional nonlinear dynamical system. The gaussian noise has variance A2, and introduces variability in frequency at each parameterization .
Hub frequency calculation
Request a detailed protocolIn order to measure the frequency of the hub neuron during EPI, the STG model was simulated for time steps of . The chosen and were the most computationally convenient choices yielding accurate frequency measurement. We used a basis of complex exponentials with frequencies from 0.0 to 1.0 Hz at 0.01 Hz resolution to measure frequency from simulated time series
(56)
To measure spiking frequency, we processed simulated membrane potentials with a relu (spike extraction) and low-pass filter with averaging window of size 20, then took the frequency with the maximum absolute value of the complex exponential basis coefficients of the processed time-series. The first 20 temporal samples of the simulation are ignored to account for initial transients.
To differentiate through the maximum frequency identification, we used a soft-argmax Let be the complex exponential filter bank dot products with the signal , where . The soft-argmax is then calculated using temperature parameter
(57)
where . The frequency is then calculated as
(58)
Intermediate hub frequency, like all other emergent properties in this work, is defined by the mean and variance of the emergent property statistics. In this case, we have one statistic, hub neuron frequency, where the mean was chosen to be 0.55 Hz,(Equation 2) and variance was chosen to be 0.0252 Hz2 (Equation 3).
EPI details for the STG model
Request a detailed protocolEPI was run for the STG model using
(59)
(60)
and
(61)
(see Sections 'Maximum entropy distributions and exponential families', 'Augmented lagrangian optimization', and example in Section 'Example: 2D LDS'). Throughout optimization, the augmented lagrangian parameters η and , were updated after each epoch of iterations (see Section 'Augmented lagrangian optimization'). The optimization converged after five epochs (Figure 1—figure supplement 4).
For EPI in Figure 1E, we used a real NVP architecture with three coupling layers and two-layer neural networks of 25 units per layer. The normalizing flow architecture mapped to a support of , initialized to a gaussian approximation of samples returned by a preliminary ABC search. We did not include , for numerical stability. EPI optimization was run with an augmented lagrangian coefficient of , hyperparameter , a batch size , and we simulated one per . The architecture converged with criteria .
Hessian sensitivity vectors
Request a detailed protocolTo quantify the second-order structure of the EPI distribution, we evaluated the Hessian of the log probability . The eigenvector of this Hessian with most negative eigenvalue is defined as the sensitivity dimension , and all subsequent eigenvectors are ordered by increasing eigenvalue. These eigenvalues are quantifications of how fast the emergent property deteriorates via the parameter combination of their associated eigenvector. In Figure 1D, the sensitivity dimension v1 (solid) and the second eigenvector of the Hessian v2 (dashed) are shown evaluated at the mode of the distribution. Since the Hessian eigenvectors have sign degeneracy, the visualized directions in 2-D parameter space were chosen to have positive . The length of the arrows is inversely proportional to the square root of the absolute value of their eigenvalues and . For the same magnitude perturbation away from the mode, intermediate hub frequency only diminishes along the sensitivity dimension (Figure 1E–F).
Scaling EPI for stable amplification in RNNs
Rank-2 RNN model
Request a detailed protocolWe examined the scaling properties of EPI by learning connectivities of RNNs of increasing size that exhibit stable amplification. Rank-2 RNN connectivity was modeled as , where , , and . This RNN model has dynamics
(62)
In this analysis, we inferred connectivity parameterizations that produced stable amplification using EPI, SMC-ABC (Sisson et al., 2007), and SNPE (Gonçalves et al., 2019) (see Section Related methods).
Stable amplification
Request a detailed protocolFor this RNN model to be stable, all real eigenvalues of must be less than 1: , where denotes the greatest real eigenvalue of . For a stable RNN to amplify at least one input pattern, the symmetric connectivity must have an eigenvalue greater than 1: , where is the maximum eigenvalue of . These two conditions are necessary and sufficient for stable amplification in RNNs (Bondanelli and Ostojic, 2020).
EPI details for RNNs
Request a detailed protocolWe defined the emergent property of stable amplification with means of these eigenvalues (0.5 and 1.5, respectively) that satisfy these conditions. To complete the emergent property definition, we chose variances () about those means such that samples rarely violate the eigenvalue constraints. To write the emergent property of Equation 5 in terms of the EPI optimization, we have
(63)
(64)
and
(65)
(see Sections 'Maximum entropy distributions and exponential families', 'Augmented lagrangian optimization', and example in Section 'Example: 2D LDS'). Gradients of maximum eigenvalues of Hermitian matrices like are available with modern automatic differentiation tools. To differentiate through the , we solved the following equation for eigenvalues of rank-2 matrices using the rank reduced matrix
(66)
For EPI in Figure 2, we used a real NVP architecture with three coupling layers of affine transformations parameterized by two-layer neural networks of 100 units per layer. The initial distribution was a standard isotropic gaussian mapped to the support of . We used an augmented lagrangian coefficient of , a batch size , , and we simulated one per . We chose to use iterations per augmented lagrangian epoch and emergent property constraint convergence was evaluated at (Figure 2B blue line, and Figure 2C–D blue). It was fastest to initialize the EPI distribution on a Tesla V100 GPU, and then subsequently optimize it on a CPU with 32 cores. EPI timing measurements accounted for this initialization period.
Methodological comparison
Request a detailed protocolWe compared EPI to two alternative simulation-based inference techniques, since the likelihood of these eigenvalues given is not available. Approximate bayesian computation (ABC) (Beaumont et al., 2002) is a rejection sampling technique for obtaining sets of parameters that produce activity close to some observed data . Sequential Monte Carlo approximate bayesian computation (SMC-ABC) is the state-of-the-art ABC method, which leverages SMC techniques to improve sampling speed. We ran SMC-ABC with the pyABC package (Klinger et al., 2018) to infer RNNs with stable amplification: connectivities having eigenvalues within an -defined −2 distance of
(67)
SMC-ABC was run with a uniform prior over , a population size of 1000 particles with simulations parallelized over 32 cores, and a multivariate normal transition model.
SNPE, the next approach in our comparison, is far more similar to EPI. Like EPI, SNPE treats parameters in mechanistic models with deep probability distributions, yet the two learning algorithms are categorically different. SNPE uses a two-network architecture to approximate the posterior distribution of the model conditioned on observed data . The amortizing network maps observations to the parameters of the deep probability distribution. The weights and biases of the parameter network are optimized by sequentially augmenting the training data with additional pairs (, ) based on the most recent posterior approximation. This sequential procedure is important to get training data to be closer to the true posterior, and to be closer to the observed data. For the deep probability distribution architecture, we chose a masked autoregressive flow with affine couplings (the default choice), three transforms, 50 hidden units, and a normalizing flow mapping to the support as in EPI. This architectural choice closely tracked the size of the architecture used by EPI (Figure 2—figure supplement 1). As in SMC-ABC, we ran SNPE with . All SNPE optimizations were run for a limit of 1.5 days, or until two consecutive rounds resulted in a validation log probability lower than the maximum observed for that random seed. It was always faster to run SNPE on a CPU with 32 cores rather than on a Tesla V100 GPU.
To compare the efficiency of these algorithms for inferring RNN connectivity distributions producing stable amplification, we develop a convergence criteria that can be used across methods. While EPI has its own hypothesis testing convergence criteria for the emergent property, it would not make sense to use this criteria on SNPE and SMC-ABC which do not constrain the means and variances of their predictions. Instead, we consider EPI and SNPE to have converged after completing its most recent optimization epoch (EPI) or round (SNPE) in which the distance is less than 0.5. We consider SMC-ABC to have converged once the population produces samples within the ball ensuring stable amplification.
When assessing the scalability of SNPE, it is important to check that alternative hyperparamterizations could not yield better performance. Key hyperparameters of the SNPE optimization are the number of simulations per round , the number of atoms used in the atomic proposals of the SNPE-C algorithm (Greenberg, 2019), and the batch size . To match EPI, we used a batch size of for , however we found to be helpful for SNPE in higher dimensions. While yielded SNPE convergence for , we found that a substantial increase to yielded more consistent convergence at (Figure 2—figure supplement 2A). By increasing , we also necessarily increase the duration of each round. At , we tried two hyperparameter modifications. As suggested in Greenberg, 2019, we increased by an order of magnitude to improve gradient quality, but this had little effect on the optimization (much overlap between same random seeds) (Figure 2—figure supplement 2B). Finally, we increased by an order of magnitude, which yielded convergence in one case, but no others. We found no way to improve the convergence rate of SNPE without making more aggressive hyperparameter choices requiring high numbers of simulations. In Figure 2C–D, we show samples from the random seed resulting in emergent property convergence at greatest entropy (EPI), the random seed resulting in greatest validation log probability (SNPE), and the result of all converged random seeds (SMC).
Effect of RNN parameters on EPI and SNPE inferred distributions
Request a detailed protocolTo clarify the difference in objectives of EPI and SNPE, we show their results on RNN models with different numbers of neurons and random strength . The parameters inferred by EPI consistently produces the same mean and variance of and , while those inferred by SNPE change according to the model definition (Figure 2—figure supplement 3A). For and , the SNPE posterior has greater concentration in eigenvalues around than at , where the model has greater randomness (Figure 2—figure supplement 3B top, orange). At both levels of when , the posterior of SNPE has lower entropy than EPI at convergence (Figure 2—figure supplement 3B top). However at , SNPE results in a predictive distribution of more widely dispersed eigenvalues (Figure 2—figure supplement 3A bottom), and an inferred posterior with greater entropy than EPI (Figure 2—figure supplement 3B bottom). We highlight these differences not to focus on an insightful trend, but to emphasize that these methods optimize different objectives with different implications.
Note that SNPE converges when it’s validation log probability has saturated after several rounds of optimization (Figure 2—figure supplement 3C), and that EPI converges after several epochs of its own optimization to enforce the emergent property constraints (Figure 2—figure supplement 3D blue). Importantly, as SNPE optimizes its posterior approximation, the predictive means change, and at convergence may be different than (Figure 2—figure supplement 3D orange, left). It is sensible to assume that predictions of a well-approximated SNPE posterior should closely reflect the data on average (especially given a uniform prior and a low degree of stochasticity); however, this is not a given. Furthermore, no aspect of the SNPE optimization controls the variance of the predictions (Figure 2—figure supplement 3D orange, right).
Primary visual cortex
V1 model
Request a detailed protocolE-I circuit models, rely on the assumption that inhibition can be studied as an indivisible unit, despite ample experimental evidence showing that inhibition is instead composed of distinct elements (Tremblay et al., 2016). In particular three types of genetically identified inhibitory cell-types – parvalbumin (P), somatostatin (S), VIP (V) – compose 80% of GABAergic interneurons in V1 (Markram et al., 2004; Rudy et al., 2011; Tremblay et al., 2016), and follow specific connectivity patterns (Figure 3A; Pfeffer et al., 2013), which lead to cell-type-specific computations (Mossing et al., 2021; Palmigiano et al., 2020). Currently, how the subdivision of inhibitory cell-types, shapes correlated variability by reconfiguring recurrent network dynamics is not understood.
In the stochastic stabilized supralinear network (Hennequin et al., 2018), population rate responses to mean input , recurrent input and slow noise are governed by
(68)
where , and the noise is an Ornstein-Uhlenbeck process
(69)
with . The noisy process is parameterized as
(70)
so that parameterizes the variance of the noisy input in the absence of recurrent connectivity (). As contrast increases, input to the E- and P-populations increases relative to a baseline input . Connectivity () and input ( and ) parameters were fit using the deterministic V1 circuit model (Palmigiano et al., 2020)
(71)
(72)
and
(73)
To obtain rates on a realistic scale (100-fold greater), we map these fitted parameters to an equivalence class
(74)
(75)
and
(76)
Circuit responses are simulated using time steps at from an initial condition drawn from . Standard deviation of the E-population is calculated as the square root of the temporal variance from to
(77)
EPI details for the V1 model
Request a detailed protocolTo write the emergent properties of Equation 7 in terms of the EPI optimization, we have
(78)
(79)
(or ), and
(80)
(see Sections 'Maximum entropy distributions and exponential families', 'Augmented lagrangian optimization', and example in Section 'Example: 2D LDS').
For EPI in Figure 3D–E and Figure 3—figure supplement 1, we used a real NVP architecture with three coupling layers and two-layer neural networks of 50 units per layer. The normalizing flow architecture mapped to a support of . EPI optimization was run using three different random seeds for architecture initialization with an augmented lagrangian coefficient of , , a batch size , and simulated 100 trials to calculate average for each . We used iterations per epoch. The distributions shown are those of the architectures converging with criteria at greatest entropy across three random seeds. Optimization details are shown in Figure 3—figure supplement 2. The sums of squares of each pair of parameters are shown for each EPI distribution in Figure 3—figure supplement 3. The plots are histograms of 500 samples from each EPI distribution from which the significance p-values of Section 'EPI reveals how recurrence with multiple inhibitory subtypes governs excitatory variability in a V1 model' are determined.
Sensitivity analyses
Request a detailed protocolIn Figure 3E, we visualize the modes of throughout the - marginal. At each local mode , where is fixed, we calculated the Hessian and visualized the sensitivity dimension in the direction of positive .
Testing for the paradoxical effect
Request a detailed protocolThe paradoxical effect occurs when a populations steady state rate is decreased (or increased) when an increase (decrease) in current is applied to that population (Tsodyks et al., 1997). To see which, if any, populations exhibited a paradoxical effect, we examined responses to changes in input to individual neuron-type populations, where the initial condition was the steady state response to (Figure 3—figure supplement 4). Input magnitudes were chosen so that the effect is salient (0.002 for E and P, but 0.02 for S and V). Only the P-population exhibited the paradoxical effect at this connectivity and input .
Primary visual cortex: Mathematical intuition and challenges
Request a detailed protocolWe write the original Equations 68 and 69 in the following way:
(81)
where in this paper we chose , the covariance of the noise to be
(82)
where is the reparameterized standard deviation of the noise for population α from Equation 70.
We are interested in computing the covariance of the activity. For that, first we define , the total input to each cell type, and the matrix , the negative Jacobian . Then, Equation 81 can be written as an 8-dimensional system. Linearizing around the fixed point of the system without fluctuations, we find the equations that describe the fluctuations of the input to each cell type:
(83)
where is a vector with the private noise of each variable. The term is multiplied by a non-diagonal matrix, because the noise that the voltage receives is the exact same as the one that comes from the OU process and not another process. The covariance of the inputs can be found as the solution the following Lyapunov equation (Hennequin et al., 2018; Gardiner, 2009):
(84)
Where can be eliminated by solving this block matrix multiplication:
(85)
The equation above is another Lyapunov Equation, now in 4 dimensions. In the simplest case in which , the voltage is directly driven by white noise, and can be expressed in powers of and . Because satisfies its own polynomial equation (Cayley Hamilton theorem), there will be four coefficients for the expansion of and four for , resulting in 16 coefficients that define for a given . Due to symmetry arguments (Gardiner, 2009), in this case the diagonal elements of the covariance matrix of the voltage will have the form:
(86)
These coefficients are complicated functions of the Jacobian of the system. Although expressions for these coefficients can be found explicitly, only numerical evaluation of those expressions determine which components of the noisy input are going to strongly influence the variability of excitatory population. Showing the generality of this dependence in more complicated noise scenarios (e.g. as in Section 'EPI reveals how recurrence with multiple inhibitory subtypes governs excitatory variability in a V1 model'), is the focus of current research.
Superior colliculus
SC model
Request a detailed protocolThe ability to switch between two separate tasks throughout randomly interleaved trials, or ‘rapid task switching,’ has been studied in rats, and midbrain superior colliculus (SC) has been show to play an important in this computation (Duan et al., 2015). Neural recordings in SC exhibited two populations of neurons that simultaneously represented both task context (Pro or Anti) and motor response (contralateral or ipsilateral to the recorded side), which led to the distinction of two functional classes: the Pro/Contra and Anti/Ipsi neurons (Duan et al., 2021). Given this evidence, Duan et al. proposed a model with four functionally-defined neuron-type populations: two in each hemisphere corresponding to the Pro/Contra and Anti/Ipsi populations. We study how the connectivity of this neural circuit governs rapid task switching ability.
The four populations of this model are denoted as left Pro (LP), left Anti (LA), right Pro (RP) and right Anti (RA). Each unit has an activity () and internal variable () related by
(87)
where , and control the position and shape of the nonlinearity. We order the neural populations of and in the following manner
(88)
which evolve according to
(89)
with time constant , step size 24 ms and Gaussian noise of variance . These hyperparameter values are motivated by modeling choices and results from Duan et al., 2021.
The weight matrix has four parameters for self , vertical , horizontal , and diagonal connections:
(90)
We study the role of parameters in rapid task switching.
The circuit receives four different inputs throughout each trial, which has a total length of 1.8 s.
(91)
There is a constant input to every population,
(92)
a bias to the Pro populations
(93)
rule-based input depending on the condition
(94)
(95)
a choice-period input
(96)
and an input to the right or left-side depending on where the light stimulus is delivered
(97)
The input parameterization was fixed to , , , , , and .
Task accuracy calculation
Request a detailed protocolThe accuracies of the Pro- and Anti-tasks are calculated as
(98)
and
(99)
where and calculate the decision made in each trial (approximately 1 for correct and 0 for incorrect choices). Specifically,
(100)
in Pro-trials where the stimulus is on the left side, and Θ approximates the Heaviside step function. Similarly,
(101)
in Anti-trials where the stimulus was on the left side. Our accuracy calculation only considers one stimulus presentation (Left), since the model is left-right symmetric. The accuracy is averaged over 200 independent trials, and the Heaviside step function is approximated as
(102)
where .
EPI details for the SC model
Request a detailed protocolTo write the emergent properties of Equation 9 in terms of the EPI optimization, we have
(103)
(104)
and
(105)
(see Sections 'Maximum entropy distributions and exponential families', 'Augmented lagrangian optimization', and example in Section 'Example: 2D LDS').
Throughout optimization, the augmented lagrangian parameters η and , were updated after each epoch of iterations (see Section 'Augmented lagrangian optimization'). The optimization converged after ten epochs (Figure 4—figure supplement 4).
For EPI in Figure 4C, we used a real NVP architecture with three coupling layers of affine transformations parameterized by two-layer neural networks of 50 units per layer. The initial distribution was a standard isotropic gaussian mapped to a support of . We used an augmented lagrangian coefficient of , a batch size , and . The distribution was the greatest EPI distribution to converge across five random seeds with criteria .
The bend in the EPI distribution is not a spurious result of the EPI optimization. The structure discovered by EPI matches the shape of the set of points returned from brute-force random sampling (Figure 4—figure supplement 5A) These connectivities were sampled from a uniform distribution over the range of each connectivity parameter, and all parameters producing accuracy in each task within the range of 60% to 90% were kept. This set of connectivities will not match the distribution of EPI exactly, since it is not conditioned on the emergent property. For example, the parameter set returned by the brute-force search is biased toward lower accuracies (Figure 4—figure supplement 5B).
Mode identification with EPI
Request a detailed protocolWe found one mode of the EPI distribution for fixed values of from 1 to −1 in steps of 0.25. To begin, we chose an initial parameter value from 500 parameter samples that had closest value to 1. We then optimized this estimate of the mode (for fixed ) using probability gradients of the deep probability distribution for 500 steps of gradient ascent with a learning rate of . The next mode (at ) was found using the previous mode as the initialization. This and all subsequent optimizations used 200 steps of gradient ascent with a learning rate of , except at where a learning rate of was used. During all mode identification optimizations, the learning rate was reduced by half (decay = 0.5) after every 100 iterations.
Sample grouping by mode
Request a detailed protocolFor the analyses in Figure 5C and Figure 5—figure supplement 1, we obtained parameters for each step along the continuum between regimes 1 and 2 by sampling from the EPI distribution. Each sample was assigned to the closest mode . Sampling continued until 500 samples were assigned to each mode, which took 2.67 s (5.34 ms/sample-per-mode). It took 9.59 min to obtain just five samples for each mode with brute force sampling requiring accuracies between 60% and 90% in each task (115 s/sample-per-mode). This corresponds to a sampling speed increase of roughly 21,500 once the EPI distribution has been learned.
Sensitivity analysis
Request a detailed protocolAt each mode, we measure the sensitivity dimension (that of most negative eigenvalue in the Hessian of the EPI distribution) . To resolve sign degeneracy in eigenvectors, we chose to have negative element in . This tells us what parameter combination rapid task switching is most sensitive to at this parameter choice in the regime.
Connectivity eigendecomposition and processing modes
Request a detailed protocolTo understand the connectivity mechanisms governing task accuracy, we took the eigendecomposition of the connectivity matrices , which results in the same eigenmodes for all parameterized by (Figure 4—figure supplement 3A). These eigenvectors are always the same, because the connectivity matrix is symmetric and the model also assumes symmetry across hemispheres, but the eigenvalues of connectivity (or degree of eigenmode amplification) change with . These basis vectors have intuitive roles in processing for this task, and are accordingly named the all eigenmode - all neurons co-fluctuate, side eigenmode - one side dominates the other, task eigenmode - the Pro or Anti-populations dominate the other, and diag mode - Pro- and Anti-populations of opposite hemispheres dominate the opposite pair. Due to the parametric structure of the connectivity matrix, the parameters are a linear function of the eigenvalues associated with these eigenmodes.
(106)
(107)
We are interested in the effect of raising or lowering the amplification of each eigenmode in the connectivity matrix by perturbing individual eigenvalues λ. To test this, we calculate the unit vector of changes in the connectivity that result from a change in the associated eigenvalues
(108)
where
(109)
and for example . So is the normalized column of A corresponding to eigenmode . The parameter dimension () that increases the eigenvalue of connectivity is -invariant (Equation 109) and . By perturbing along , we can examine how model function changes by directly modulating the connectivity amplification of specific eigenmodes, which have interpretable roles in processing in each task.
Modeling optogenetic silencing
Request a detailed protocolWe tested whether the inferred SC model connectivities could reproduce experimental effects of optogenetic inactivation in rats (Duan et al., 2021). During periods of simulated optogenetic inactivation, activity was decreased proportional to the optogenetic strength
(110)
Delay period inactivation was from .
Data availability
All software and scripts for emergent property inference and the analyses in this manuscript can be found on the Cunningham Lab github at this link: https://github.com/cunningham-lab/epi (copy archived at https://archive.softwareheritage.org/swh:1:rev:38febae7035ca921334a616b0f396b3767bf18d4).
References
-
Complex parameter landscape for a complex neuron modelPLOS Computational Biology 2:e94.https://doi.org/10.1371/journal.pcbi.0020094
-
Recurrent neural networks as versatile tools of neuroscience researchCurrent Opinion in Neurobiology 46:1–6.https://doi.org/10.1016/j.conb.2017.06.003
-
ConferenceDegenerate solution networks for theoretical neuroscienceComputational and Systems Neuroscience Meeting (COSYNE), Lisbon, Portugal.
-
ConferenceExamining models in theoretical neuroscience with degenerate solution networksBernstein Conference 2019 Germany.
-
Softwareepi, version swh:1:rev:38febae7035ca921334a616b0f396b3767bf18d4 https://archive.softwareheritage.org/swh:1:rev:38febae7035ca921334a616b0f396b3767bf18d4Software Heritage.
-
Coding with transient trajectories in recurrent neural networksPLOS Computational Biology 16:e1007655.https://doi.org/10.1371/journal.pcbi.1007655
-
ConferenceNeural ordinary differential equationsAdvances in Neural Information Processing Systems. pp. 6571–6583.
-
Bayesian solution uncertainty quantification for differential equationsBayesian Analysis 11:1239–1267.https://doi.org/10.1214/16-BA1017
-
Stimulus onset quenches neural variability: a widespread cortical phenomenonNature Neuroscience 13:369–378.https://doi.org/10.1038/nn.2501
-
ConferenceDensity estimation using real nvpProceedings of the 5th International Conference on Learning Representations.
-
Collicular circuits for flexible sensorimotor routingNature Neuroscience 1:1–11.https://doi.org/10.1038/s41593-021-00865-x
-
Structure in neural population recordings: an expected byproduct of simpler phenomena?Nature Neuroscience 20:1310–1318.https://doi.org/10.1038/nn.4617
-
Significance of conductances in Hodgkin-Huxley modelsJournal of Neurophysiology 70:2502–2518.https://doi.org/10.1152/jn.1993.70.6.2502
-
Riemann manifold Langevin and hamiltonian monte carlo methodsJournal of the Royal Statistical Society: Series B 73:123–214.https://doi.org/10.1111/j.1467-9868.2010.00765.x
-
Global structure, robustness, and modulation of neuronal modelsThe Journal of Neuroscience 21:5229–5238.https://doi.org/10.1523/JNEUROSCI.21-14-05229.2001
-
ConferenceMarcel Nonnenmacher, and Jakob H Macke. automatic posterior transformation for likelihood-free inferenceInternational Conference On Machine Learning.
-
Universally sloppy parameter sensitivities in systems biology modelsPLOS Computational Biology 3:e189.https://doi.org/10.1371/journal.pcbi.0030189
-
ConferenceLikelihood-free mcmc with amortized approximate ratio estimatorsInternational Conference on Machine Learning PMLR. pp. 4239–4248.
-
Determination of parameter identifiability in nonlinear biophysical models: a bayesian approachJournal of General Physiology 143:401–416.https://doi.org/10.1085/jgp.201311116
-
An efficient method for structural identifiability analysis of large dynamic systems*IFAC Proceedings Volumes 45:941–946.https://doi.org/10.3182/20120711-3-BE-2027.00381
-
ConferenceImproved variational inference with inverse autoregressive flowAdvances in Neural Information Processing Systems. pp. 4743–4751.
-
ConferenceAdam: a method for stochastic optimizationInternational Conference On Learning Representations.
-
ConferenceGlow: generative flow with invertible 1x1 convolutionsAdvances in Neural Information Processing Systems. pp. 10215–10224.
-
pyABC: distributed, likelihood-free inferenceBioinformatics 34:3591–3593.https://doi.org/10.1093/bioinformatics/bty361
-
Coupled oscillators and the design of central pattern generatorsMathematical Biosciences 90:87–109.https://doi.org/10.1016/0025-5564(88)90059-4
-
Inhibitory stabilization and visual coding in cortical circuits with multiple interneuron subtypesJournal of Neurophysiology 115:1399–1409.https://doi.org/10.1152/jn.00732.2015
-
ConferenceMaximum entropy flow networksInternational Conference On Learning Representations.
-
ConferenceFlexible statistical inference for mechanistic models of neural dynamicsAdvances in Neural Information Processing Systems. pp. 1289–1299.
-
BookSloppiness and the geometry of parameter spaceIn: Mannakee B. K, editors. Uncertainty in Biology. Springer. pp. 271–299.https://doi.org/10.1007/978-3-319-21296-8_11
-
From biophysics to models of network functionAnnual Review of Neuroscience 21:25–45.https://doi.org/10.1146/annurev.neuro.21.1.25
-
Cellular, synaptic and network effects of neuromodulationNeural Networks 15:479–493.https://doi.org/10.1016/S0893-6080(02)00043-6
-
Interneurons of the neocortical inhibitory systemNature Reviews Neuroscience 5:793–807.https://doi.org/10.1038/nrn1519
-
Equation of state calculations by fast computing machinesThe Journal of Chemical Physics 21:1087–1092.https://doi.org/10.1063/1.1699114
-
ConferenceStatistical inference for analyzing sloppiness in neuroscience modelsBernstein Conference 2019 Germany.
-
Single-trial neural dynamics are dominated by richly varied movementsNature Neuroscience 22:1677–1686.https://doi.org/10.1038/s41593-019-0502-4
-
ConferenceRobust statistical inference for simulation-based models in neuroscienceBernstein Conference 2018 Germany.
-
Computational models in the age of large datasetsCurrent Opinion in Neurobiology 32:87–94.https://doi.org/10.1016/j.conb.2015.01.006
-
Using constraints on neuronal activity to reveal compensatory changes in neuronal parametersJournal of Neurophysiology 98:3749–3758.https://doi.org/10.1152/jn.00842.2007
-
Neural data science: accelerating the experiment-analysis-theory cycle in large-scale neuroscienceCurrent Opinion in Neurobiology 50:232–241.https://doi.org/10.1016/j.conb.2018.04.007
-
ConferenceMasked autoregressive flow for density estimationAdvances in Neural Information Processing Systems. pp. 2338–2347.
-
ConferenceSequential neural likelihood: fast likelihood-free inference with autoregressive flowsThe 22nd International Conference on Artificial Intelligence and Statistics. pp. 837–848.
-
Similar network activity from disparate circuit parametersNature Neuroscience 7:1345–1352.https://doi.org/10.1038/nn1352
-
Delineating parameter unidentifiabilities in complex modelsPhysical Review E 95:032314.https://doi.org/10.1103/PhysRevE.95.032314
-
ConferenceVariational inference with normalizing flowsInternational Conference on Machine Learning.
-
Three groups of interneurons account for nearly 100% of neocortical GABAergic neuronsDevelopmental Neurobiology 71:45–61.https://doi.org/10.1002/dneu.20853
-
Integration of visual motion and locomotion in mouse visual cortexNature Neuroscience 16:1864–1869.https://doi.org/10.1038/nn.3567
-
BookA mean field learning algorithm for unsupervised neural networksIn: Jordan M. I, editors. Learning in Graphical Models. Springer. pp. 541–554.https://doi.org/10.1007/978-94-011-5014-9_20
-
Maximum entropy models as a tool for building precise neural controlsCurrent Opinion in Neurobiology 46:120–126.https://doi.org/10.1016/j.conb.2017.08.001
-
Chaos in random neural networksPhysical Review Letters 61:259–262.https://doi.org/10.1103/PhysRevLett.61.259
-
Neural circuits as computational dynamical systemsCurrent Opinion in Neurobiology 25:156–163.https://doi.org/10.1016/j.conb.2014.01.008
-
ConferenceHierarchical implicit models and likelihood-free variational inferenceAdvances in Neural Information Processing Systems. pp. 5523–5533.
-
Paradoxical effects of external modulation of inhibitory interneuronsThe Journal of Neuroscience 17:4382–4388.https://doi.org/10.1523/JNEUROSCI.17-11-04382.1997
-
Graphical models, exponential families, and variational inferenceFoundations and Trends in Machine Learning 1:1–305.https://doi.org/10.1561/2200000001
-
Neurophysiological and computational principles of cortical rhythms in cognitionPhysiological Reviews 90:1195–1268.https://doi.org/10.1152/physrev.00035.2008
-
A recurrent network mechanism of time integration in perceptual decisionsJournal of Neuroscience 26:1314–1328.https://doi.org/10.1523/JNEUROSCI.3733-05.2006
Article and author information
Author details
Funding
National Science Foundation (DGE-1644869)
- Sean R Bittner
NINDS (5R01NS100066)
- Sean R Bittner
- John Cunningham
McKnight Endowment Fund for Neuroscience (Faculty Award)
- John Cunningham
Gatsby Charitable Foundation (GAT3708)
- Sean R Bittner
- Agostina Palmigiano
- Kenneth D Miller
- John Cunningham
Simons Foundation (542963)
- Sean R Bittner
- John Cunningham
National Science Foundation (1707398)
- Sean R Bittner
- Agostina Palmigiano
- Kenneth D Miller
- John Cunningham
NIH (5U19NS107613)
- Agostina Palmigiano
- Kenneth D Miller
Simons Foundation (Postdoctoral Fellowship)
- Chunyu A Duan
NIH (U01-NS108683)
- Agostina Palmigiano
- Kenneth D Miller
NIH (R01-EY029999)
- Agostina Palmigiano
Grossman Charitable Foundation
- Sean R Bittner
- John Cunningham
Simons Foundation (553017)
- Kenneth D Miller
Howard Hughes Medical Institute
- Carlos D Brody
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work was funded by NSF Graduate Research Fellowship, DGE-1644869, McKnight Endowment Fund, NIH NINDS 5R01NS100066, Simons Foundation 542963, NSF NeuroNex Award, DBI-1707398, The Gatsby Charitable Foundation, Simons Collaboration on the Global Brain Postdoctoral Fellowship, Chinese Postdoctoral Science Foundation, and International Exchange Program Fellowship. We also acknowledge the Marine Biological Laboratory Methods in Computational Neuroscience Course, where this work was discussed and explored in its early stages. Helpful conversations were had with Larry Abbott, Stephen Baccus, James Fitzgerald, Gabrielle Gutierrez, Francesca Mastrogiuseppe, Srdjan Ostojic, Liam Paninski, and Dhruva Raman.
Copyright
© 2021, Bittner et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,473
- views
-
- 352
- downloads
-
- 19
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 19
- citations for umbrella DOI https://doi.org/10.7554/eLife.56265
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Interrogating theoretical models of neural computation with emergent property inference
eLife 10:e56265.
https://doi.org/10.7554/eLife.56265
Further reading
-
- Computational and Systems Biology
- Neuroscience
Mechanistic modeling in neuroscience aims to explain observed phenomena in terms of underlying causes. However, determining which model parameters agree with complex and stochastic neural data presents a significant challenge. We address this challenge with a machine learning tool which uses deep neural density estimators—trained using model simulations—to carry out Bayesian inference and retrieve the full space of parameters compatible with raw data or selected data features. Our method is scalable in parameters and data features and can rapidly analyze new data after initial training. We demonstrate the power and flexibility of our approach on receptive fields, ion channels, and Hodgkin–Huxley models. We also characterize the space of circuit configurations giving rise to rhythmic activity in the crustacean stomatogastric ganglion, and use these results to derive hypotheses for underlying compensation mechanisms. Our approach will help close the gap between data-driven and theory-driven models of neural dynamics.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}