Early analysis of the Australian COVID-19 epidemic
- Centre for Epidemiology and Biostatistics, Melbourne School of Population and Global Health, The University of Melbourne, Australia
- Victorian Infectious Diseases Reference Laboratory Epidemiology Unit at The Peter Doherty Institute for Infection and Immunity, The University of Melbourne and Royal Melbourne Hospital, Australia
- Australian Institute of Tropical Health and Medicine, James Cook University, Australia
- Telethon Kids Institute and Curtin University, Australia
- Defence Science and Technology, Department of Defence, Australia
- Kirby Institute for Infection and Immunity, University of New South Wales, Australia
- School of Mathematics and Statistics, University of New South Wales, Australia
- School of Public Health and Community Medicine, University of New South Wales, Australia
- Centre for the Mathematical Modelling of Infectious Diseases, Department of Infectious Disease Epidemiology, London School of Hygiene and Tropical Medicine, United Kingdom
- Infection and Immunity Theme, Murdoch Children’s Research Institute, The Royal Children’s Hospital, Australia
- School of Mathematics and Statistics, The University of Melbourne, Australia
Abstract
As of 1 May 2020, there had been 6808 confirmed cases of COVID-19 in Australia. Of these, 98 had died from the disease. The epidemic had been in decline since mid-March, with 308 cases confirmed nationally since 14 April. This suggests that the collective actions of the Australian public and government authorities in response to COVID-19 were sufficiently early and assiduous to avert a public health crisis – for now. Analysing factors that contribute to individual country experiences of COVID-19, such as the intensity and timing of public health interventions, will assist in the next stage of response planning globally. We describe how the epidemic and public health response unfolded in Australia up to 13 April. We estimate that the effective reproduction number was likely below one in each Australian state since mid-March and forecast that clinical demand would remain below capacity thresholds over the forecast period (from mid-to-late April).
Introduction
A small cluster of cases of the disease now known as COVID-19 was first reported on December 29, 2019, in the Chinese city of Wuhan (World Health Organization, 2020a). By early May 2020, the disease had spread to all global regions, and overwhelmed some the world’s most developed health systems. More than 2.8 million cases and 260,000 deaths had been confirmed globally, and the vast majority of countries with confirmed cases were reporting escalating transmission (World Health Organization, 2020b).
As of 1 May 2020, there were 6808 confirmed cases of COVID-19 in Australia. Of these, 98 had died from the disease. Encouragingly, the daily count of new confirmed cases had been declining since late March 2020, with 308 cases reported nationally since 14 April (Australian Government Department of Health, 2020a). This suggests that Australia has (to date) avoided a “worst-case” scenario — one where planning models estimated a peak daily demand for 35,000 ICU beds by around May 2020, far exceeding the health system’s capacity of around 2,200 ICU beds (Moss et al., 2020).
The first wave of COVID-19 epidemics, and the government and public responses to them, have varied vastly across the globe. For example, many European countries and the United States are in the midst of explosive outbreaks with overwhelmed health systems (Remuzzi and Remuzzi, 2020; The Lancet, 2020). Meanwhile, countries such as Singapore and South Korea had early success in containing the spread, partly attributed to their extensive surveillance efforts and case targeted interventions (Ng et al., 2020; COVID-19 National Emergency Response Center, Epidemiology and Case Management Team, Korea Centers for Disease Control and Prevention, 2020). However, despite those early successes, Singapore has recently taken additional steps to further limit transmission in the face of increasing importations and community spread (Government of Singapore, 2020). Other locations in the region, including Taiwan, Hong Kong and New Zealand, have had similar epidemic experiences, achieving control through a combination of border, case targeted and social distancing measures.
Analysing key epidemiological and response factors — such as the intensity and timing of public health interventions — that contribute to individual country experiences of COVID-19 will assist in the next stage of response planning globally.
Here we describe the course of the COVID-19 epidemic and public health response in Australia from 22 January up to mid-April 2020 (summarised in Figure 1). We then quantify the impact of the public health response on disease transmission (Figure 2) and forecast the short-term health system demand from COVID-19 patients (Figure 3).
Figure 1 with 2 supplements see all
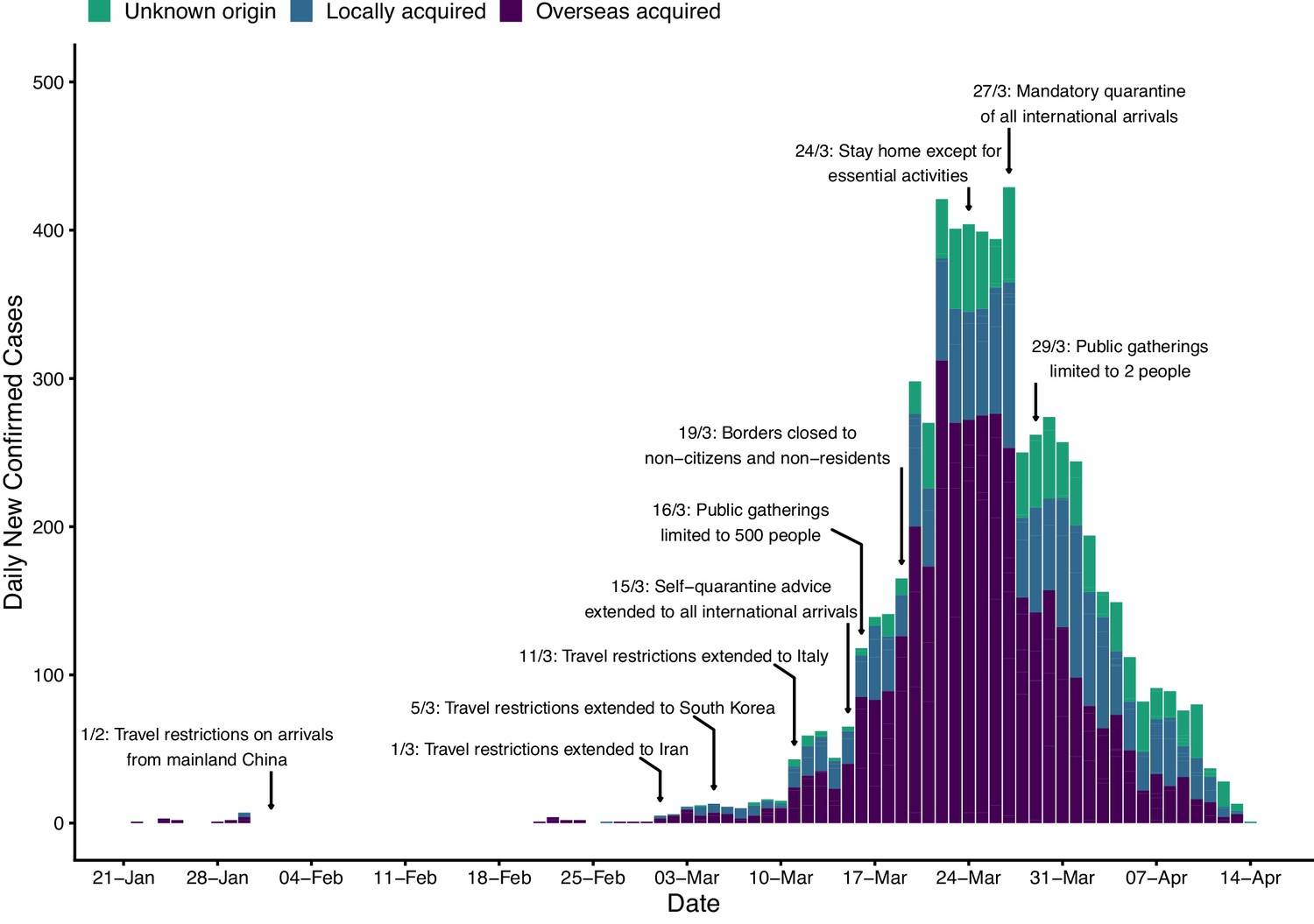
Time series of new daily confirmed cases of COVID-19 in Australia by import status (purple = overseas acquired, blue = locally acquired, green = unknown origin) from 22 January 2020 (first case detected) to 13 April 2020.
Dates of selected key border and social distancing measures implemented by Australian authorities are indicated by annotations above the plotted case counts. These measures were in addition to case targeted interventions (case isolation and contact quarantine) and further border measures, including enhanced testing and provision of advice, on arrivals from other selected countries, based on a risk-assessment tool developed in early February (Shearer et al., 2020). Note that Australian citizens and residents (and their dependants) were exempt from travel restrictions, but upon returning to Australia were required to quarantine for 14 days from the date of arrival. A full timeline of social distancing and border measures is provided in Figure 1—figure supplement 2.
Figure 2 with 3 supplements see all
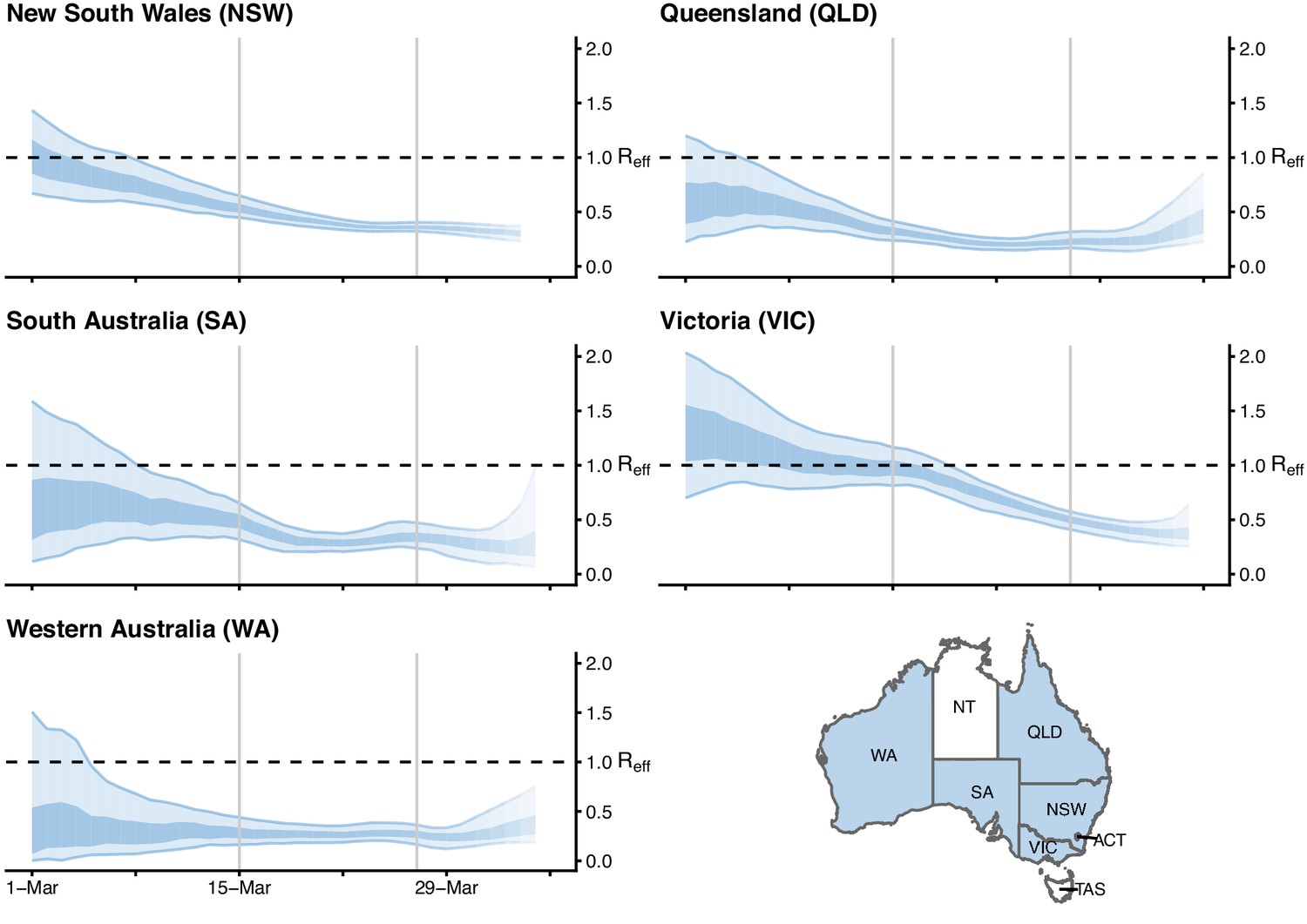
Time-varying estimate of the effective reproduction number () of COVID-19 by Australian state (light blue ribbon = 90% credible interval; dark blue ribbon = 50% credible interval) from 1 March to 5 April 2020, based on data up to and including 13 April 2020.
Confidence in the estimated values is indicated by shading with reduced shading corresponding to reduced confidence. The horizontal dashed line indicates the target value of 1 for the effective reproduction number required for control. Not presented are the Australian Capital Territory (ACT), Northern Territory (NT) and Tasmania (TAS), as these states/territories had insufficient local transmission. The uncertainty in the estimates represent variability in a population-level average as a result of imperfect data, rather than individual-level heterogeneity in transmission (i.e., the variation in the number of secondary cases generated by each case).
Figure 3 with 1 supplement see all
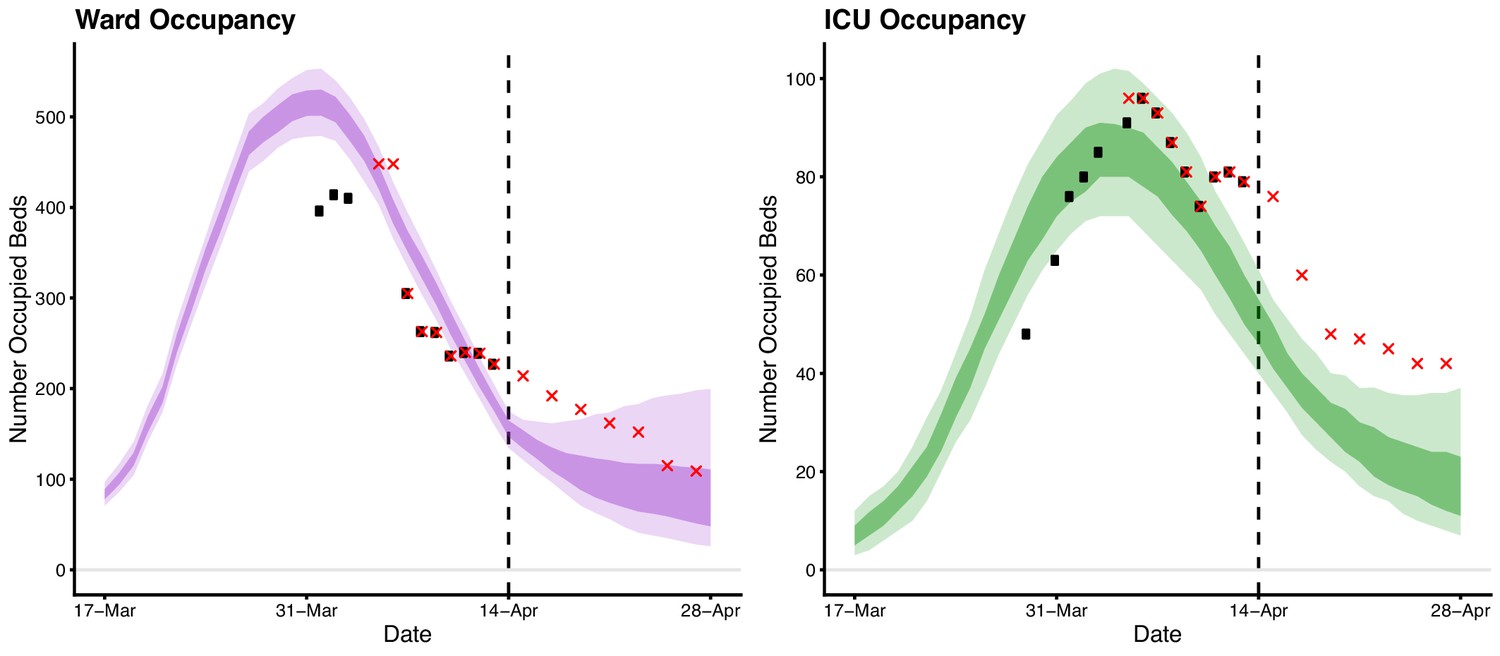
Forecasted daily hospital ward (left) and intensive care unit (right) occupancy (dark ribbons = 50% confidence intervals; light ribbons = 95% confidence intervals) from 17 March to 28 April.
Occupancy = the number of beds occupied by COVID-19 patients on a given day. Black dots indicate the reported ward and ICU occupancy available from the Australian national COVID-19 database at the time. These data were retrospectively updated where complete data were available (red crosses). Australian health system ward and ICU bed capacities are estimated to be over 25,000 and 1,100, respectively, under the assumption that 50% of total capacity could possibly be dedicated to COVID-19 patients (Australian Institute of Health and Welfare, 2019). The forecasted daily case counts are shown in Figure 3—figure supplement 1.
Timeline of the Australian epidemic
Australia took an early and precautionary approach to COVID-19. On 1 February, when China was the only country reporting uncontained transmission, Australian authorities restricted all travel from mainland China to Australia, in order to reduce the risk of importation of the virus. Only Australian citizens and residents (and their dependants) were permitted to travel from China to Australia. These individuals were advised to self-quarantine for 14 days from their date of arrival. Further border measures, including enhanced testing and provision of additional advice, were placed on arrivals from other countries, based on a risk-assessment tool developed in early February (Shearer et al., 2020).
The day before Australia imposed these restrictions (January 31), 9720 cases of COVID-19 had been reported in mainland China (World Health Organization, 2020c). Australia had so far detected and managed nine imported cases, all with recent travel history from or a direct epidemiological link to Wuhan (Australian Government Department of Health, 2020b). Before the restrictions, Australia was expecting to receive approximately 200,000 air passengers from mainland China during February 2020 (Australian Bureau of Statistics, 2019). Travel numbers fell dramatically following the imposed travel restrictions.
These restrictions were not intended (and highly unlikely [Errett et al., 2020]) to prevent the ultimate importation of COVID-19 into Australia. Their purpose was to delay the establishment of an epidemic, buying valuable time for health authorities to plan and prepare.
During the month of February, with extensive testing and case targeted interventions (case isolation and contact quarantine) initiated from 29 January (Australian Government Department of Health, 2020d), Australia detected and managed only 12 cases. Meanwhile, globally, the geographic extent of transmission and daily counts of confirmed cases and deaths continued to increase drastically (World Health Organization, 2020d). In early March, Australia extended travel restrictions to a number of countries with large uncontained outbreaks, namely Iran (as of 1 March) (Commonwealth Government of Australia, 2020a), South Korea (as of 5 March) (Commonwealth Government of Australia, 2020b) and Italy (as of 11 March) (Commonwealth Government of Australia, 2020c).
Despite these measures, the daily case counts rose sharply in Australia during the first half of March. While the vast majority of these cases were connected to travellers returning to Australia from overseas, localised community transmission had been reported in areas of Sydney (NSW) and Melbourne (VIC) (Australian Government Department of Health, 2020c). Crude plots of the cumulative number of cases by country showed Australia on an early trajectory similar to the outbreaks experienced in China, Europe and the United States, where health systems had become or were becoming overwhelmed (Australian Government Department of Health, 2020f).
From 16 March, the Australian Government progressively implemented a range of social distancing measures in order to reduce and prevent further community transmission (Commonwealth Government of Australia, 2020d). The day before, authorities had imposed a self-quarantine requirement on all international arrivals (Commonwealth Government of Australia, 2020e). On 19 March, Australia closed its borders to all non-citizens and non-residents (Commonwealth Government of Australia, 2020f), and on March 27, moved to a policy of mandatory quarantine for any returning citizens and residents (Commonwealth Government of Australia, 2020g). By 29 March, social distancing measures had been escalated to the extent that all Australians were strongly advised to leave their homes only for limited essential activities and public gatherings were limited to two people (Commonwealth Government of Australia, 2020h).
By late March, daily counts of new cases appeared to be declining, suggesting that these measures had successfully reduced transmission.
Quantifying the impact of the response
Quantifying changes in the rate of spread of infection over the course of an epidemic is critical for monitoring the collective impact of public health interventions and forecasting the short-term clinical burden. A key indicator of transmission in context is the effective reproduction number () — the average number of secondary infections caused by an infected individual in the presence of public health interventions and for which no assumption of 100% susceptibility is made. If control efforts are able to bring below 1, then on average there will be a decline in the number of new cases reported. The decline will become apparent after a delay of approximately one incubation period plus time to case detection and reporting following implementation of the control measure (i.e., at least two weeks).
Using case counts from the Australian national COVID-19 database, we estimated over time for each Australian state from 24 February to 5 April 2020 (Figure 2). We used a statistical method that estimates time-varying by using an optimally selected moving average window (according to the continuous ranked probability score) to smooth the curve and reduce the impact of localised clusters and outbreaks that may cause large fluctuations (London School of Hygiene & Tropical Medicine Mathematical Modelling of Infectious Diseases nCoV working group, 2020). Importantly, the method accounts for time delays between illness onset and case notification. Incorporation of this lag is critical for accurate interpretation of the most recent data in the analysis, to be sure that an observed drop in the number of reported cases reflects an actual drop in case numbers.
Results show that has likely been below one in each Australian state since early-to-mid March. These estimates are geographically averaged results over large areas and it is possible that was much higher than one in a number of localised settings (see Figure 2). The estimated time-varying value is based on cases that have been identified as a result of local transmission, whereas imported cases only contribute to the force of infection. Imported and locally acquired cases were assumed to be equally infectious. The method for estimating is sensitive to this assumption. Hence, we performed a sensitivity analysis to assess the impact of stepwise reductions in the infectiousness of imported cases on as a result of quarantine measures implemented over time (see Figure 2—figure supplement 1, Figure 2—figure supplement 2, and Figure 2—figure supplement 3). The sensitivity analyses suggest that may well have dropped below one later than shown in Figure 2.
In Victoria and New South Wales, the two Australian states with a substantial number of local cases, the effective reproduction number likely dropped from marginally above one to well below one within a two week period (considering both our main result and those from the sensitivity analyses) coinciding with the implementation of social distancing measures. A comparable trend was observed in New Zealand and many Western European countries, including France, Spain and Germany (London School of Hygiene & Tropical Medicine Mathematical Modelling of Infectious Diseases nCoV working group, 2020), where similar national, stage-wise social distancing policies were enacted (Flaxman et al., 2020). However, most of these European countries experienced widespread community transmission prior to the implementation of social distancing measures, with estimates reaching between 1.5 and 2 in early March and declining over a longer period (three to four weeks) relative to Australia.
Forecasting the clinical burden
Next we used our estimates of time-varying to forecast the short-term clinical burden in Australia. Estimates were input into a mathematical model of disease dynamics that was extended to account for imported cases. A sequential Monte Carlo method was used to infer the model parameters and appropriately capture the uncertainty (Moss et al., 2019a), conditional on each of a number of sampled trajectories up to 5 April, from which point they were assumed to be constant. The model was subsequently projected forward from April 14 to April 28, to forecast the number of reported cases, assuming a symptomatic detection probability of 80%.
The number of new daily hospitalisations and ICU admissions were estimated from recently observed and forecast case counts. Specifically, the age distribution of projected cases, and age-specific probabilities of hospitalisation and ICU admission, were extracted from Australian age-specific data on confirmed cases, assuming that this distribution would remain unchanged (see Table 1). In order to calculate the number of occupied ward/ICU beds per day, length-of-stay in a ward bed and ICU bed were assumed to be Gamma distributed with means (SD) of 11 (3.42) days and 14 (5.22) days, respectively. Our results indicated that with the public health interventions in place as of 13 April, Australia’s hospital ward and ICU occupancy would remain well below capacity thresholds over the period from 14 to 28 April.
Table 1
Age-specific proportions of confirmed cases extracted from the Australian national COVID-19 database and age-specific estimates of the probability of hospitalisation and ICU admission for confirmed cases.
| Age | Proportion of cases | Pr(hospitalisation | confirmed case) | Pr(ICU admission | confirmed case) |
|---|---|---|---|
| 0-9 | 0.0102 | 0.1475 | 0.0000 |
| 10-18 | 0.0186 | 0.1081 | 0.0090 |
| 19-29 | 0.2258 | 0.0504 | 0.0007 |
| 30-39 | 0.1587 | 0.0865 | 0.0074 |
| 40-49 | 0.1291 | 0.0947 | 0.0208 |
| 50-59 | 0.1550 | 0.1112 | 0.0173 |
| 60-69 | 0.1686 | 0.1529 | 0.0318 |
| 70-79 | 0.1050 | 0.2440 | 0.0558 |
| 80+ | 0.0290 | 0.3815 | 0.0462 |
Conclusions
Our analysis suggests that Australia’s combined strategy of early, targeted management of the risk of importation, case targeted interventions, and broad-scale social distancing measures applied prior to the onset of (detected) widespread community transmission has substantially mitigated the first wave of COVID-19. More detailed analyses are required to assess the relative impact of specific response measures, and this information will be crucial for the next phase of response planning. Other factors, such as temperature, humidity and population density may influence transmission of SARS-CoV-2 (Kissler et al., 2020). Whether these factors have played a role in the relative control of SARS-CoV-2 in some countries, remains an open question. Noting that epidemics are established in both the northern and southern hemispheres, it may be possible to gain insight into such factors over the next six months, via for example a comparative analysis of transmission in Australia and Europe.
We further anticipated that the Australian health care system was well positioned to manage the projected COVID-19 case loads over the forecast period (up to 28 April). Ongoing situational assessment and monitoring of forecast hospital and ICU demand will be essential for managing possible future relaxation of broad-scale community interventions. Vigilance for localised increases in epidemic activity and in particular for outbreaks in vulnerable populations such as residential aged care facilities, where a high proportion of cases are likely to be severe, must be maintained.
One largely unknown factor at present is the proportion of SARS-CoV-2 infections that are asymptomatic, mild or undiagnosed. Even if this number is high, the Australian population would still be largely susceptible to infection. Accordingly, complete relaxation of the measures currently in place would see a rapid resurgence in epidemic activity. This problem is not unique to Australia. Many countries with intensive social distancing measures in place are starting to grapple with their options and time frames for a gradual return to relative normalcy (Gottlieb et al., 2020).
There are difficult decisions ahead for governments, and for now Australia is one of the few countries fortunate enough to be able to plan the next steps from a position of relative calm as opposed to crisis.
Materials and methods
Estimating the time-varying effective reproduction number
Overview
The method used to estimate is described in Cori et al., 2013, as implemented in the R package, EpiNow (Abbott et al., 2020). This method is currently in development by the Centre for the Mathematical Modelling of Infectious Diseases at the London School of Hygiene and Tropical Medicine (London School of Hygiene & Tropical Medicine Mathematical Modelling of Infectious Diseases nCoV working group, 2020). Full details of their statistical analysis and code base is available via their website (https://epiforecasts.io/covid/).
The uncertainty in the estimates (shown in Figure 2; Figure 2—figure supplements 1, 2 and 3) represents variability in a population-level average as a result of imperfect data, rather than individual-level heterogeneity in transmission (i.e., the variation in the number of secondary cases generated by each case). This is akin to the variation represented by a confidence interval (i.e., variation in the estimate resulting from a finite sample), rather than a prediction interval (i.e., variation in individual observations).
We provide a brief overview of the method and sources of imperfect data below, focusing on how the analysis was adapted to the Australian context.
Data
We used line-lists of reported cases for each Australian state/territory extracted from the national COVID-19 database. The line-lists contain the date when the individual first exhibited symptoms, date when the case notification was received by the jurisdictional health department and where the infection was acquired (i.e., overseas or locally).
Reporting delays and under-reporting
Request a detailed protocolA pre-hoc statistical analysis was conducted in order to estimate a distribution of the reporting delays from the line-lists of cases, using the code base provided by London School of Hygiene & Tropical Medicine Mathematical Modelling of Infectious Diseases nCoV working group, 2020. The estimated reporting delay is assumed to remain constant over time. These reporting delays are used to: (i) infer the time of symptom onset for those without this information, and; (ii) infer how many cases in recent days are yet to be recorded. Adjusting for reporting delays is critical for inferring when a drop in observed cases reflects a true drop in cases.
Trends identified using this approach are robust to under-reporting, assuming that it is constant. However, absolute values of may be biased by reporting rates. Pronounced changes in reporting rates may also impact the trends identified.
The delay from symptom onset to reporting is likely to decrease over the course of the epidemic, due to improved surveillance and reporting. We used a delay distribution estimated from observed reporting delays from the analysis period, which is therefore likely to underestimate reporting delays early in the epidemic, and overestimate them as the epidemic progressed. Underestimating the delay would result in an overestimate of , as the inferred onset dates (for those that were unknown) and adjustment for right-truncation, would result in more concentrated inferred daily cases (i.e., the inferred cases would be more clustered in time than in reality). The converse would be true when overestimating the delay. The impact of this misspecified distribution will be greatest on the most recent estimates of , where inference for both right-truncation and missing symptom onset dates is required.
Estimating the effective reproduction number over time
Request a detailed protocolBriefly, the was estimated for each day from 24 February 2020 up to 5 April 2020 using line list data – date of symptom onset, date of report, and import status – for each state. The method assumes that the serial interval (i.e., time between symptom onset for an index and secondary case) is uncertain, with a mean of 4.7 days (95% CrI: 3.7, 6.0) and a standard deviation of 2.9 days (95% CrI: 1.9, 4.9), as estimated from early outbreak data in Wuhan, China (Nishiura et al., 2020). Combining the incidence over time with the uncertain distribution of serial intervals allows us to estimate over time.
A different choice of serial interval distribution would affect the estimated time varying . This sensitivity is explored in detail in Flaxman et al., 2020, though we provide a brief description of the impact here. For the same daily case data, a longer average serial interval would correspond to an increased estimate of when , and a decreased estimate when . This effect can be understood intuitively by considering the epidemic dynamics in these two situations. When , daily case counts are increasing on average. The weighted average case counts (weighted by the serial interval distribution), decrease as the mean of the serial interval increases (i.e., as the support is shifted to older/lower daily case data). In order to generate the same number of observed cases in the present, must increase. A similar observation can be made for .
In the context of our analyses (Figure 2), when the estimated is above 1, assuming a longer mean serial interval would further increase the estimates in each jurisdiction (i.e., the upper 75% of the Victorian posterior distribution for approximately the first 7–10 days, while stretching the upper tails in the other jurisdictions). When the estimated is below 1, a higher mean serial interval would further decrease those estimates. Qualitatively, this does not impact on the time series of in each Australian jurisdiction.
A prior distribution was specified for , with mean 2.6 (informed by Imai et al., 2020) and a broad standard deviation of 2 so as to allow for a range of values. Finally, is estimated with a moving average window, selected to optimise the continuous ranked probability score, in order to smooth the curve and reduce the impact of localised events (i.e., cases clustered in time) causing large variations.
Note that up to 20% of reported cases in the Australian national COVID-19 database do not have a reported import status (see Figure 1). Conservatively, we assumed that all cases with an unknown or unconfirmed source of acquisition were locally acquired.
Accounting for imported cases
Request a detailed protocolA large proportion of cases reported in Australia from January until now were imported from overseas. It is critical to account for two distinct populations in the case notification data – imported and locally acquired – in order to perform robust analyses of transmission in the early stages of this outbreak. The estimated time-varying value is based on cases that have been identified as a result of local transmission, whereas imported cases contribute to transmission only (Thompson et al., 2019).
Specifically, the method assumes that local and imported cases contribute equally to transmission. The results under this assumption are presented in Figure 2. However, it is likely that imported cases contributed relatively less to transmission than locally acquired cases, as a result of quarantine and other border measures which targeted these individuals (Figure 1—figure supplement 2). In the absence of data on whether the infector of local cases was themselves an imported or local case (from which we could robustly estimate the contribution of imported cases to transmission), we explored this via a sensitivity analysis. We aimed to explore the impact of a number of plausible scenarios, based on our knowledge of the timing, extent and level of enforcement of different quarantine policies enacted over time.
Prior to 15 March, returning Australian residents and citizens (and their dependents) from mainland China were advised to self-quarantine. Note that further border measures were implemented during this period, including enhanced testing and provision of advice on arrivals from selected countries based on a risk assessment tool developed in early February (Shearer et al., 2020). On 15 March, Australian authorities imposed a self-quarantine requirement on all international arrivals, and from 27 March, moved to a mandatory quarantine policy for all international arrivals.
Hence for the sensitivity analysis, we assumed two step changes in the effectiveness of quarantine of overseas arrivals (timed to coincide with the two key policy changes), resulting in three intervention phases: prior to 15 March (self-quarantine of arrivals from selected countries); 15–27 March inclusive (self-quarantine of arrivals from all countries); and 27 March onward (mandatory quarantine of overseas arrivals from all countries). We further assumed that the relative infectiousness of imported cases decreased with each intervention phase. The first two intervention phases correspond to self-quarantine policies, so we assume that they resulted in a relatively small reduction in the relative infectiousness of imported cases (the first smaller than the second, since the pre-15 March policy only applied to arrivals from selected countries). The third intervention phase corresponds to mandatory quarantine of overseas arrivals in hotels which we assume is highly effective at reducing onward transmission from imported cases, but allows for the occasional transmission event. We then varied the percentage of imported cases contributing to transmission over the three intervention phases, as detailed in Table 2.
Table 2
Percentage of imported cases assumed to be contributing to transmission over three intervention phases for each sensitivity analysis.
We assume two step changes in the effectiveness of quarantine of overseas arrivals, resulting in three intervention phases: prior to 15 March (self-quarantine of arrivals from selected countries); 15–27 March inclusive (self-quarantine of arrivals from all countries); and 27 March onward (mandatory quarantine of overseas arrivals from all countries).
| Imported cases contributing to transmission | |||
|---|---|---|---|
| Sensitivity analysis | Prior to 15 March | 15–27 March | 27 March– |
| 1 | 90% | 50% | 1% |
| 2 | 80% | 50% | 1% |
| 3 | 50% | 20% | 1% |
-
The results of these three analyses are shown in Figure 2—figure supplements 1, 2 and 3, respectively.
Forecasting short-term ward and ICU bed occupancy
We used the estimates of time-varying to forecast the national short-term ward/ICU occupancy due to COVID-19 patients.
Forecasting case counts
Request a detailed protocolThe forecasting method combines an SEEIIR (susceptible-exposed-infectious-recovered) population model of infection with daily COVID-19 case notification counts, through the use of a bootstrap particle filter (Arulampalam et al., 2002). This approach is similar to that implemented and described in Moss et al., 2019b, in the context of seasonal influenza forecasts for several major Australian cities. Briefly, the particle filter method uses post-regularisation (Doucet et al., 2001), with a deterministic resampling stage (Kitagawa, 1996). Code and documentation are available at https://epifx.readthedocs.io/en/latest/. The daily case counts by date of diagnosis were modelled using a negative binomial distribution with a fixed dispersion parameter k, and the expected number of cases was proportional to the daily incidence of symptomatic infections in the SEEIIR model; this proportion was characterised by the observation probability. Natural disease history parameters were sampled from narrow uniform priors, based on values reported in the literature for COVID-19 (Table 3), and each particle was associated with an trajectory that was drawn from the state/territory trajectories in Figure 2 up to 5 April, from which point they are assumed to be constant. The model was subsequently projected forward from April 14 to April 28, to forecast the number of reported cases, assuming a detection probability of 80%.
Table 3
SEEIIR forecasting model parameters.
| Parameter | Definition | Value/Prior distribution |
|---|---|---|
| σ | Inverse of the mean incubation period | |
| γ | Inverse of the mean infectious period | |
| τ | Time of first exposure (days since 2020-01-01) | |
| Probability of observing a case | 0.8 | |
| k | Dispersion parameter on Negative-Binomial | 100 |
| observation model |
In order to account for imported cases, we used daily counts of imported cases to construct a time-series of the expected daily importation rate and, assuming that such cases were identified one week after initial exposure, introduced exposure events into each particle trajectory by adding an extra term to the force of infection equation.
Model equations below describe the flow of individuals in the population from the susceptible class (S), through two exposed classes (E1, E2), two infectious classes (I1, I2) and finally into a removed class (R). The state variables correspond to the proportion of individuals in the population (of size N) in each compartment. Given the closed population and unidirectional flow of individuals through the compartments, we evaluate the daily incidence of symptomatic individuals (at time t) as the change in cumulative incidence (the bracketed term in the expression for below). Two exposed and infectious classes are chosen such that the duration of time in the exposed or infectious period has an Erlang distribution. The corresponding parameters are given in Table 2.
Model equations:
With initial conditions:
Observation model:
With time-varying transmission rate corresponding to trajectory i:
Forecasting ward and ICU bed occupancy from observed and projected case counts
Request a detailed protocolThe number of new daily hospitalisations and ICU admissions were estimated from recently observed and forecasted case counts by:
Estimating the age distribution of projected case counts using data from the national COVID-19 database on the age-specific proportion of confirmed cases;
Estimating the age-specific hospitalisation and ICU admission rates using data from the national COVID-19 database. We assumed that all hospitalisations and ICU admissions were either recorded or were missing at random (31% and 58% of cases had no information recorded under hospitalisation or ICU status, respectively);
Randomly drawing the number of hospitalisations/ICU admissions in each age-group (for both the observed and projected case counts) from a binomial distribution with number of trials given by the expected number of cases in each age group (from 1), and probability given by the observed proportion of hospitalisations/ICU admissions by age group (from 2).
Finally, in order to calculate the number of occupied ward/ICU beds per day, length-of-stay in a ward bed and ICU bed were assumed to be Gamma distributed with means (SD) of 11 (3.42) days and 14 (5.22) days, respectively. We assumed ICU admissions required a ward bed prior to, and following, ICU stay for a Poisson distributed number of days with mean 2.5. Relevant Australian data were not available to parameterise a model that captures the dynamics of patient flow within the hospital system in more detail. Instead, these distributions were informed by a large study of clinical characteristics of 1099 COVID-19 patients in China (Guan et al., 2020). This model provides a useful indication of hospital bed occupancy based on limited available data and may be updated as more specific data (e.g., on COVID-19 patient length-of-stay) becomes available.
Data availability
Analysis code is included in the supplementary materials. Datasets analysed and generated during this study are included in the supplementary materials. For estimates of the time-varying effective reproduction number (Figure 2), the complete line listed data within the Australian national COVID-19 database are not publicly available. However, we provide the cases per day by notification date and state (as shown in Figure 1 and Figure 1–figure supplement 1) which, when supplemented with the estimated distribution of the delay from symptom onset to notification (samples from this distribution are provided as a data file), analyses of the time-varying effective reproduction number can be performed.
References
-
A tutorial on particle filters for online nonlinear/non-Gaussian bayesian trackingIEEE Transactions on Signal Processing 50:174–188.https://doi.org/10.1109/78.978374
-
WebsiteCoronavirus (COVID-19) current situation and case numbersAustralian Government Department of Health. Accessed May 1, 2020.
-
2019-nCoV acute respiratory disease, Australia: epidemiology report 1Communicable Diseases Intelligence 44:13.https://doi.org/10.33321/cdi.2020.44.13
-
COVID-19, Australia: epidemiology report 12Communicable Diseases Intelligence 44:36.https://doi.org/10.33321/cdi.2020.44.36
-
WebsiteUpdate on novel coronavirus (COVID-19) in Australia media release 29 FebruaryAccessed February 29, 2020.
-
A new framework and software to estimate time-varying reproduction numbers during epidemicsAmerican Journal of Epidemiology 178:1505–1512.https://doi.org/10.1093/aje/kwt133
-
Coronavirus Disease-19: summary of 2,370 contact investigations of the first 30 cases in the republic of koreaOsong Public Health and Research Perspectives 11:81–84.https://doi.org/10.24171/j.phrp.2020.11.2.04
-
An integrative review of the limited evidence on international travel bans as an emerging infectious disease disaster control measureJournal of Emergency Management : JEM 1:7–14.https://doi.org/10.5055/jem.2020.0446
-
Clinical characteristics of coronavirus disease 2019 in ChinaNew England Journal of Medicine 382:1708–1720.https://doi.org/10.1056/NEJMoa2002032
-
ReportReport 3: Transmissibility of 2019-nCoVImperial College London COVID-19 Response Team.
-
Monte carlo filter and smoother for Non-Gaussian nonlinear state space modelsJournal of Computational and Graphical Statistics 5:1–25.https://doi.org/10.2307/1390750
-
Anatomy of a seasonal influenza epidemic forecastCommunicable Diseases Intelligence 43:1–14.https://doi.org/10.33321/cdi.2019.43.7
-
Accounting for Healthcare-Seeking behaviours and testing practices in Real-Time influenza forecastsTropical Medicine and Infectious Disease 4:12.https://doi.org/10.3390/tropicalmed4010012
-
Evaluation of the effectiveness of surveillance and containment measures for the first 100 patients with COVID-19 in Singapore - January 2-February 29, 2020MMWR. Morbidity and Mortality Weekly Report 69:307–311.https://doi.org/10.15585/mmwr.mm6911e1
-
Serial interval of novel coronavirus (COVID-19) infectionsInternational Journal of Infectious Diseases 93:284–286.https://doi.org/10.1016/j.ijid.2020.02.060
-
COVID-19 and Italy: what next?The Lancet 395:1225–1228.https://doi.org/10.1016/S0140-6736(20)30627-9
Article and author information
Author details
Funding
Department of Health, Australian Government
- James M McCaw
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This study represents surveillance data reported through the Communicable Diseases Network Australia (CDNA) as part of the nationally coordinated response to COVID-19. We thank public health staff from incident emergency operations centres in state and territory health departments, and the Australian Government Department of Health, along with state and territory public health laboratories. We thank members of CDNA for their feedback and perspectives on the study results. We thank Dr Jonathan Tuke for helping to assemble Australian national and state announcements of COVID-19 response measures.
Copyright
© 2020, Price et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 6,997
- views
-
- 533
- downloads
-
- 76
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 76
- citations for umbrella DOI https://doi.org/10.7554/eLife.58785
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Early analysis of the Australian COVID-19 epidemic
eLife 9:e58785.
https://doi.org/10.7554/eLife.58785




{kind=link}
{kind=link}
{kind=link}