Structural insights into hormone recognition by the human glucose-dependent insulinotropic polypeptide receptor
- School of Pharmacy, Fudan University, China
- The CAS Key Laboratory of Receptor Research, Shanghai Institute of Materia Medica, Chinese Academy of Sciences, China
- School of Life Science and Technology, ShanghaiTech University, China
- University of Chinese Academy of Sciences, China
- Department of Pharmacology, School of Basic Medical Sciences, Fudan University, China
- School of Artificial Intelligence and Automation, Huazhong University of Science and Technology, China
- The National Center for Drug Screening, Shanghai Institute of Materia Medica, Chinese Academy of Sciences, China
- Department of Biophysics and Department of Pathology of Sir Run Run Shaw Hospital, Zhejiang University School of Medicine, China
Abstract
Glucose-dependent insulinotropic polypeptide (GIP) is a peptide hormone that exerts crucial metabolic functions by binding and activating its cognate receptor, GIPR. As an important therapeutic target, GIPR has been subjected to intensive structural studies without success. Here, we report the cryo-EM structure of the human GIPR in complex with GIP and a Gs heterotrimer at a global resolution of 2.9 Å. GIP adopts a single straight helix with its N terminus dipped into the receptor transmembrane domain (TMD), while the C terminus is closely associated with the extracellular domain and extracellular loop 1. GIPR employs conserved residues in the lower half of the TMD pocket to recognize the common segments shared by GIP homologous peptides, while uses non-conserved residues in the upper half of the TMD pocket to interact with residues specific for GIP. These results provide a structural framework of hormone recognition and GIPR activation.
Introduction
Glucose-dependent insulinotropic polypeptide (GIP) is a 42-amino acid peptide hormone that plays crucial role in glucose regulation and fatty acid metabolism. In response to food intake, GIP is secreted by intestinal K cells to enhance insulin secretion and peripheral fatty acid uptake (Kim et al., 2007), as well as a number of neuronal effects (Faivre and Hölscher, 2013). The pleiotropic functions of GIP is mediated by its cognate receptor (GIPR), a member of class B1 G protein-coupled receptors (GPCRs) that also include glucagon receptor (GCGR) and glucagon-like peptide-1 receptor (GLP-1R). GIPR, together with GCGR and GLP-1R, forms the central endocrine network in regulating insulin sensitivity and energy homeostasis, and they are validated drug targets (Lagerström and Schiöth, 2008; Finan et al., 2016; Longuet et al., 2008). Intensive efforts were made in drug discovery targeting these receptors (Yang et al., 2021). A number of GLP-1R selective ligands have been developed successfully to treat type 2 diabetes and obesity. Encouragingly, peptide ligands that bind both GIPR and GLP-1R show better clinical efficacy than the GLP-1R agonist alone. As such, GIPR has emerged as a hot target pursued by pharmaceutical research community.
GIPR contains a large extracellular domain (ECD) and a 7-transmembrane domain (TMD). Both are involved in ligand recognition and receptor activation (Parthier et al., 2009; Koth et al., 2012; Yang et al., 2015). Cryo-electron microscopy (cryo-EM) structures of GCGR and GLP-1R, as well as several other class B1 GPCRs have been solved, providing a general mechanism of two-domain model for peptide recognition and receptor activation. However, GIP displays an exquisite sequence specificity towards GIPR as it does not bind to other class B1 GPCRs. However, the efforts to understand the ligand selectivity by GIPR have been hampered by technical difficulties in expression and stabilization of the ligand-GIPR complexes for structural studies. We have overcome such challenges and determined a high-resolution (2.9 Å) structure of the human GIPR in complex with the stimulatory G protein (Gs) using single-particle cryo-EM approach in conjunction with NanoBiT strategy (Duan et al., 2020). Together with functional studies, our results demonstrate several unique structural features that distinguish GIPR from other members of the glucagon subfamily of class B1 GPCRs and provide an important template for rational design of GIPR agonists for therapeutic development.
Results
Structure determination
To prepare a high-quality human GIPR–Gs complex, we overcame several technical obstacles to enhance the expression level and protein stability by adding a double tag of maltose binding protein at the C terminus and a BRIL fusion protein at the N terminus (Figure 1—figure supplement 1A), as well as employing the NanoBiT tethering strategy (Duan et al., 2020; Zhou et al., 2020; Sun et al., 2020; Figure 1—figure supplement 1A,B). To solve the GIP1-42–GIPR–Gs structure, we further introduced one mutation (T345F) to stabilize the assembly of complex (Figure 1—figure supplement 1C,D). This mutation does not affect the ligand binding or potency of GIP1-42 in cAMP accumulation assay (Figure 1—figure supplement 1G,H). Large-scale purification was followed and the GIP1-42–GIPR–Gs complexes were collected by size-exclusion chromatography (SEC) for cryo-EM studies (Figure 1—figure supplement 1E,F). The activity of the modified GIPR construct was confirmed by cAMP accumulation assay showing a response similar to that of the wild-type (WT; Figure 1—figure supplement 1G).
The GIP1-42–GIPR–Gs complexes were imaged using a Titan Krios equipped with a Gatan K3 Summit direct electron detector (Figure 1—figure supplement 2). 2D classification showed a clear secondary structure feature and random distribution of the particles. Different directions of the particles enabled a high-resolution cryo-EM map reconstruction (Figure 1—figure supplement 2B). A total of 295,021 particles were selected after 3D refinement and polishing, leading to an overall resolution of 2.9 Å (Figure 1—figure supplement 2C,D and Table 1).
Table 1
Cryo-EM data collection, refinement, and validation statistics.
| GIP–GIPR–Gs–Nb35 complex | |
|---|---|
| Data collection and processing | |
| Magnification | 46,685 |
| Voltage (kV) | 300 |
| Electron exposure (e–/Å2) | 80 |
| Defocus range (μm) | −1.2 to −2.2 |
| Pixel size (Å) | 1.071 |
| Symmetry imposed | C1 |
| Initial particle images (no.) | 4,895,399 |
| Final particle images (no.) | 295,021 |
| Map resolution (Å) FSC threshold | 2.9 0.143 |
| Map resolution range (Å) | 2.7–5.0 |
| Refinement | |
| Initial model used (PDB code) | PDB codes 6WPW and 2QKH |
| Model resolution (Å) FSC threshold | 2.9 0.5 |
| Model resolution range (Å) | 2.7–5.0 |
| Map sharpening B factor (Å2) | −86.3 |
| Model composition Non-hydrogen atoms Protein residues Lipids | 9409 1156 6 |
| B factors (Å2) Protein Ligand Lipids | 133 143 121 |
| R.m.s. deviations Bond lengths (Å) Bond angles (Å) | 0.005 1.036 |
| Validation MolProbity score Clash score Poor rotamers (%) | 1.21 4.23 0.00 |
| Ramachandran plot Favored (%) Allowed (%) Disallowed (%) | 98.15 1.85 0.00 |
Overall structure
Apart from the α-helical domain (AHD) of Gαs which is flexible in most cryo-EM GPCR–G protein complex structures, the bound GIP1-42, GIPR, and Gs were well defined in the EM density maps (Figure 1, Figure 1—figure supplement 3). Except for the ECD, side chains of the majority of amino acid residues are well resolved in all protein components. The final model contains 30 GIP1-42 residues, the Gαβγ subunits of Gs, and the GIPR residues from Q30ECD to S4158.66b (class B GPCR numbering in superscript) (Wootten et al., 2013), with six amino acid residues missing at helix 8. As a general feature in most reported class B1 GPCR–Gs complex structures (Qiao et al., 2020; Zhang et al., 2017a; Zhao et al., 2019; Ma et al., 2020), the density of ECD is relatively poor owning to its intrinsic flexibility, which limited the accuracy in model building for the GIPR ECD region compared to other regions of the complex structure. Given a low resolution of the density map, the ECD structure is model based on the crystal structure of GIPR ECD (PDB code: 2QKH). Notable conformation difference from GCGR (Qiao et al., 2020) or GLP-1R (Zhang et al., 2017a) was observed in the extracellular loop 1 (ECL1).
Figure 1 with 3 supplements see all

Cryo-EM structure of the GIP1-42–GIPR–Gs complex.
(A) Cut-through view of the cryo-EM density map that illustrates the GIP1-42–GIPR–Gs complex and the disc-shaped micelle. The unsharpened cryo-EM density map at the 0.07 threshold shown as light gray surface indicates a micelle diameter of 11 nm. The colored cryo-EM density map is shown at the 0.16 threshold. (B) Model of the complex as a cartoon, with GIP1-42 as helix in orange. The receptor is shown in light sky blue, Gαs in yellow, Gβ subunit in cyan, Gγ subunit in navy blue, and Nb35 in gray.
-
Figure 1—source data 1
Effects of GIP1-42-mediated cAMP accumulation and binding affinity.
- https://cdn.elifesciences.org/articles/68719/elife-68719-fig1-data1-v2.xlsx
Similar to other class B1 GPCR–Gs complexes, the TM6 of GIPR shows a sharp kink in the middle and TM7 displays an outward movement. Like parathyroid hormone receptor-1 (PTH1R)–Gs and corticotropin-releasing factor receptor type 1 (CRF1R)–Gs cryo-EM structures (Zhao et al., 2019; Ma et al., 2020), the TMD of GIPR is surrounded by annular detergent micelle, with a diameter of 12 nm thereby mimicking the lipid bilayer morphology (Figure 1). In addition, we also observed several cholesterols molecules in the cryo-EM map.
Ligand recognition
In the complex, GIP adopts a single continuous helix that penetrates into the TMD core through its N-terminal half (residues 1–15), while the C-terminal half (residues 16–30) is recognized by the ECD and ECL1 (Figure 2A–C). Y1P (P indicates that the residue belongs to the peptide ligand) of GIP points to TMs 2–3, forms hydrogen bonds with R1902.67b and Q2243.37b, and makes hydrophobic contacts with V2273.40b and W2965.36b. This observation received support of the mutagenesis study, where mutant W296A decreased the potency of GIP-induced cAMP signaling by 50-fold (Figure 2D), and the reductions in mutants R190A and Q224A were 71- and 5-fold, respectively, as reported in a previous report (Yaqub et al., 2010). N-terminal truncation of either Y1P or both Y1P and A2P led to reduced efficacy or loss of activity (Kerr et al., 2011; Gabe et al., 2020), highlighting a crucial role of Y1P. E3P, D9P, and D15P are three negatively charged residues in the N-terminal half of GIP and form salt bridges with R1832.60b, R3707.35b, and R289ECL2, respectively. Removal of these salt bridges by alanine substitution at either R1832.60b (Yaqub et al., 2010) or R3707.35b (Figure 2D) greatly reduced GIP potency (by 76- and 55-fold, respectively), whereas the effect on mutant R289A was mild (6-fold, Figure 2D). Polar interactions also occurred between S8P and N290ECL2 as well as Y10P and Q1381.40b. The GIP–TMD interface was further stabilized by a complementary nonpolar network involving TM1 (L1341.36b, L1371.39b, and Y1411.43b) and TM7 (L3747.39b and I3787.43b) via A2P, F6P, and Y10P of GIP (Figure 2C), in line with decreased ligand potencies observed in Y141A (by 103-fold), L374A (by 41-fold), and I378A (by 8-fold) mutants (Figure 2D). These mutants also caused significant potency decreases in GIP1-42-induced β-arrestin2 recruitment (Figure 2—figure supplement 1).
Figure 2 with 2 supplements see all
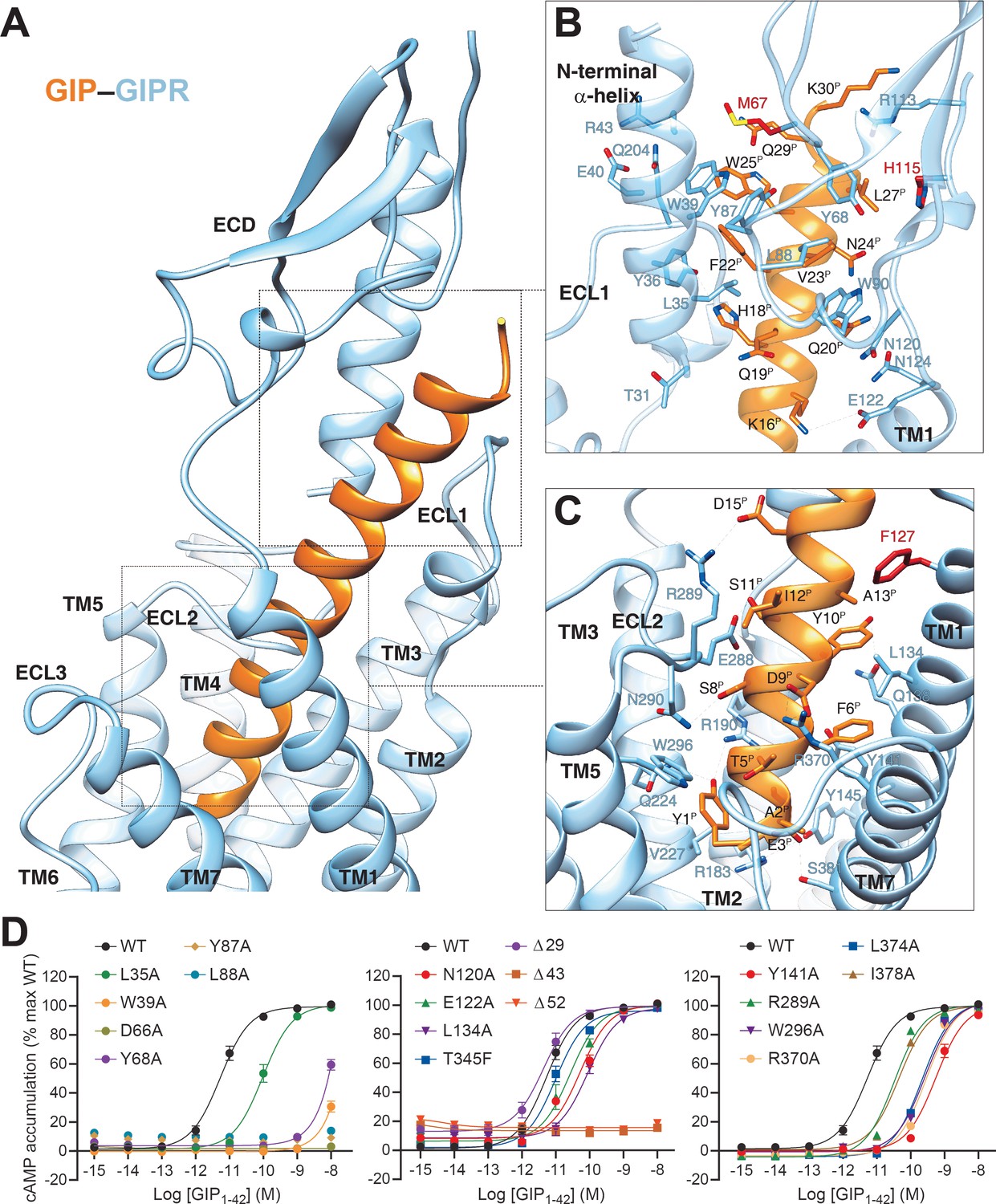
Molecular recognition of GIP by GIPR.
(A) The binding mode of GIP (orange) with GIPR (light sky blue), showing that the N-terminal half of GIP penetrates into a pocket formed by all TM helices except TM4, ECL2, and ECL3, whereas the C-terminal half is recognized by ECD, ECL1, and TM1. (B, C) Close-up views of the interactions between GIP and GIPR. The residues and side chains that could not be modelled in the ECD are colored in red. (D) Signaling profiles of GIPR mutants. cAMP accumulation in wild-type (WT) and single-point mutated GIPR expressing in HEK 293T cells. Signals were normalized to the maximum response of the WT and dose–response curves were analyzed using a three-parameter logistic equation. All data were generated and graphed as means ± S.E.M. of at least three independent experiments, conducted in quadruplicate. Δ, truncated residues.
-
Figure 2—source data 1
Effects of residue mutation in the ligand-binding pocket on GIP1-42-induced cAMP accumulation, cell surface expression, and binding affinity.
- https://cdn.elifesciences.org/articles/68719/elife-68719-fig2-data1-v2.xlsx
The C-terminal half of GIP was clasped by the GIPR ECD, closely resembling the crystal structure of GIP–GIPR ECD (PDB code: 2QKH) (Parthier et al., 2007). Consistent with the interaction patterns observed in other class B1 GPCRs (Parthier et al., 2007), the hydrophobic residues (F22P, V23P, L26P, and L27P) in the C-terminal half of GIP occupy a complementary binding groove of the GIPR ECD, consisting of a series of hydrophobic residues (L35, Y36, W39, M67, Y68, Y87, L88, P89, and W90). Alanine substitutions in W39, D66, and Y68 significantly reduced the potency of GIP (Figure 2D). Besides, several polar contacts including H18P-Y36 and Q20P-N124 were observed. Notably, the cryo-EM map suggests that the ECL1 stands upwards to approach the N-terminal α-helix of ECD and forms hydrogen bonds with the side chain of Y36 (Figure 2A,B), resulting in a close contact between TMD and ECD for GIP-bound GIPR (interface area = 571 Å2), significantly larger than that of GLP-1-bound GLP-1R (362 Å2), reinforcing the importance of ECD in GIP recognition.
Receptor activation
GIPR shares ~50% sequence similarity with GCGR, especially in the TMD region (75%); thus, GCGR structures published previously provide a good template for the present study (Figure 2—figure supplement 2; Qiao et al., 2020; Hilger et al., 2020; Jazayeri et al., 2016; Zhang et al., 2018; Chang et al., 2020). It was found the TMD of activated GIPR exhibits a conformation similar to that of GCGR activated by glucagon or ZP3780 (Cα RMSD = 1.2 and 0.7 Å, respectively) (Qiao et al., 2020; Hilger et al., 2020) and distinct from that of GCGR bound by the negative allosteric modulator NNC0640 or partial agonist NNC1702 (Cα RMSD = 4.0 and 3.9 Å, respectively) (Zhang et al., 2017b). Facilitated by Gly7.50b located in the middle of TM7, the extracellular half of TM7 bends towards TM6 by 8.0 Å (measured by Cα atom of Gly7.32b) (Figure 2—figure supplement 2). This feature and the outward movement of ECL3 expanded the ligand binding pocket. Meanwhile, the extracellular tip of TM1 was extended by one turn and moved inward by 8.0 Å (measured by Cα atom of the residues at 1.30b) (Figure 2—figure supplement 2). Together with the raised ECL1, these conformational changes stabilized ligand binding.
In the intracellular side, the sharp kink in the middle of TM6 led to an outward movement of its intracellular portion measured by Cα atom of R3366.35b (18.9 Å, similar to that of other Gs-coupled class B1 receptors). This was accompanied by the movement of the intracellular tip of TM5 toward TM6 by 7.6 Å (measured by Cα atom of the residues at 5.67b), thereby creating an intracellular cavity for G protein coupling (Figure 2—figure supplement 2).
G protein coupling
In our model, Gs protein is anchored by the α5 helix of Gαs (GαH5), thereby fitting to the cytoplasmic cavity formed by TMs 3, 5, and 6, intracellular loops (ICLs) 1–2 and H8 (Figure 3). In general, the GIPR–Gs complex shows a similar receptor–G protein interface as other reported class B1 receptor structures such as GLP-1R (Zhang et al., 2020), GLP-2R (glucagon-like peptide-2 receptor) (Sun et al., 2020), GCGR (Qiao et al., 2020), PTH1R (Zhao et al., 2019), SCTR (secretin receptor) (Dong et al., 2020), and GHRHR (growth hormone-releasing hormone receptor) (Zhou et al., 2020), suggesting a common G protein signaling mechanism (Figure 3A). The hydrophobic residues at the C-terminal of GαH5 (L388GαH5, Y391GαH5, L393GαH5, and L394GαH5) insert into a small hydrophobic pocket formed by Y2403.53b, L2413.54b, L2443.57b, L2453.58b, I3175.58b, I3205.60b, L3215.61b, and L3255.65b (Figure 3B). The side chain of R3386.37b points to Gαs and makes one hydrogen bond with L394GαH5. Of note is that the interaction between R380GαH5 and ICL2 results in five hydrogen bonds with the backbone atoms of L2453.58b, V2463.59b, L2473.60b, and V248ICL2, significantly more than that observed in GLP-1R, SCTR, or GCGR (Figure 3C). The polar residues in ICL2 (S251ICL2 and E253ICL2) produce two hydrogen bonds with K34 and Q35 of Gαs, while H8 forms several hydrogen bonds with ICL1, then contacts with Gβ (E3988.49b-R164ICL1-D312Gβ, E4028.53b-R164ICL1-D312Gβ) (Figure 3D). Together, these specific interactions contribute to the Gs coupling specificity of GIPR.
Figure 3
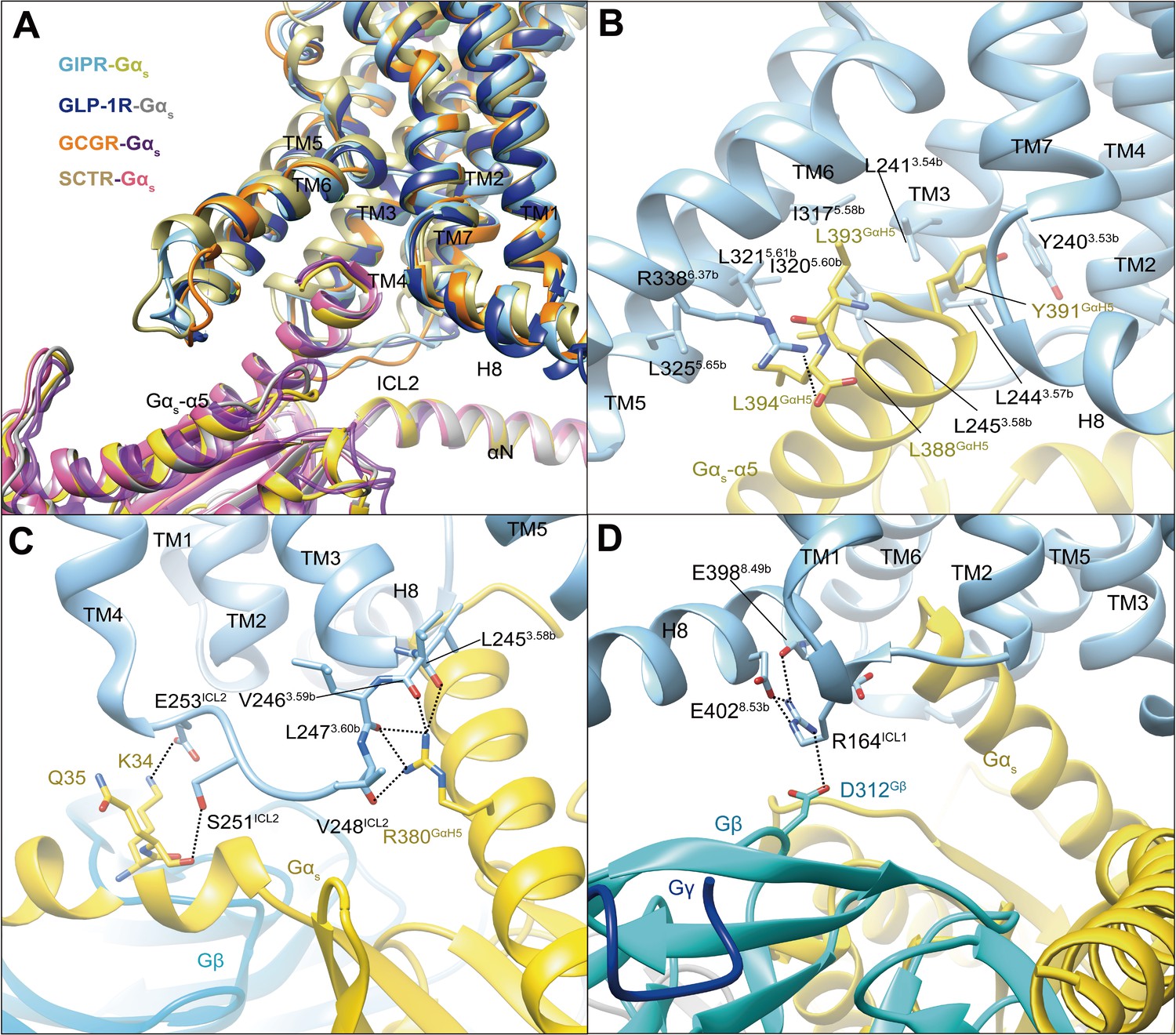
G protein coupling of GIPR.
(A) Comparison of G protein coupling among GIPR, GLP-1R (Zhang et al., 2020), GCGR (Qiao et al., 2020), and SCTR (Dong et al., 2020). The Gαs α5-helix of the Gαs Ras-like domain inserts into an intracellular crevice of GIPR TMD. (B) Interaction between GIPR and the C terminus of Gαs. (C) Polar interactions between ICL2 and Gαs. (D) Polar interactions between H8 and ICL1 of the GIPR and Gβ. The GIP1-42–GIPR–Gαs structure is colored light sky blue (GIPR), gold (Gαs), and cyan (Gβ). Residues involved in interactions are shown as sticks. Polar interactions are shown as black dashed lines.
Ligand specificity
GIP, GLP-1, and glucagon are three important metabolic hormones exerting distinct functions in glucose homeostasis, in spite of high degrees of sequence similarity. Superimposing the TMD of GIP-bound GIPR with that of GLP-1-bound GLP-1R (Zhang et al., 2020) or glucagon-bound GCGR (Qiao et al., 2020) displays a similar ligand-binding pocket and the three peptides all adopt a single continuous helix, with the N terminus penetrating to the TMD core to the same depth, while the C terminus anchors the ECD and ECL1 in a receptor-specific manner (Figure 4). Notably, the ECL1 of GIPR stands upwards in line with TMs 2 and 3 and moves towards the TMD core by 5~7 Å. Such a movement, together with a α-helical extension in TM1 by six residues, allows GIP to shift to TM1 by 2.7 and 3.3 Å (measured by Cα atom of L27P) relative to GLP-1 (Zhang et al., 2020) and glucagon (Qiao et al., 2020), respectively (Figure 4—figure supplement 1).
Figure 4 with 4 supplements see all
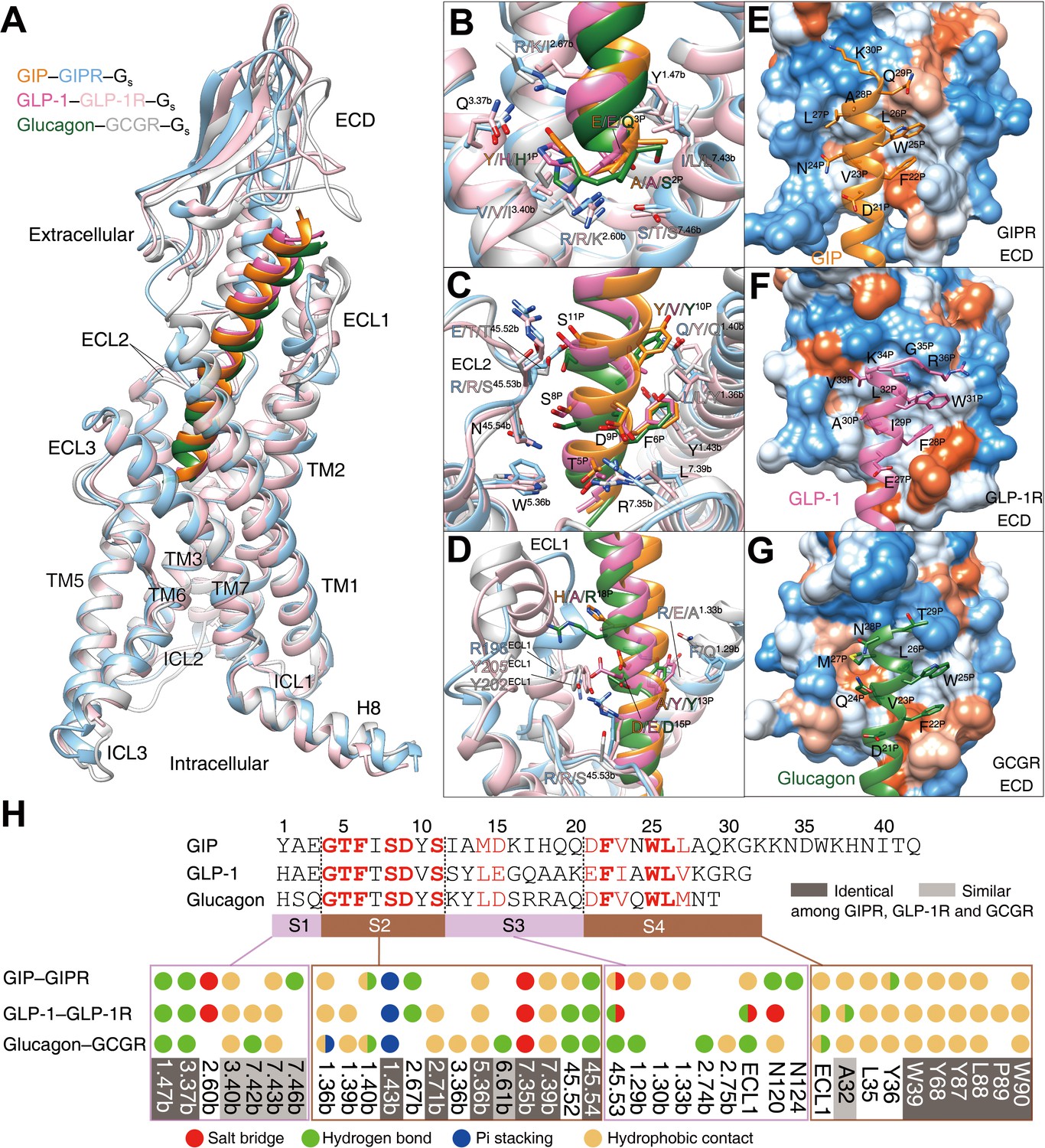
Ligand specificity among GIPR, GLP-1R, and GCGR.
(A) Comparison of the overall structures of GIP1-42–GIPR–Gs, GLP-1–GLP-1R–Gs (Zhang et al., 2020) and glucagon–GCGR–Gs complexes (Qiao et al., 2020). G proteins are omitted for clarity. (B–D) Close-up views of the interaction between TMD and peptide. Based on sequence similarity, the peptides are divided into four segments: N terminus (residues 1–3, B), segment 2 (residues 4–11, C), segment 3 (residues 12–20, D), and the C terminus (residues 21 to the end, E–G), where segments 2 and 4 are highly conserved among GIP, GLP-1, and glucagon. Residues are numbered based on GIP for peptides, and labeled with class B GPCR numbering in superscript for receptors (Wootten et al., 2013). (E–G) Close-up views of the interface between GIPR ECD and GIP C terminus (E), between GLP-1R and GLP-1 C terminus (F), and between GCGR and glucagon C terminus (G). The ECD is shown in surface representation and colored from dodger blue for the most hydrophilic region, to white, to orange red for the most hydrophobic region. (H) Comparison of peptide recognition modes for three receptors, described by fingerprint strings encoding different interaction types of the surrounding residues in each receptor. Peptide residue numbers on the top are shown based on GIP. The ligand-binding pocket residues that are identical or similar across three receptors are highlighted in dark gray and light gray, respectively. Color codes are listed on the bottom.
Based on the sequence similarity, the three peptides can be divided into four segments: two common segments (residues 4–11 and 21–30 in GIP) and two unique segments (residues 1–3 and 12–20 in GIP) (Figure 4H). The N terminus (residues 1–3) makes massive contacts with the conserved central polar network of class B1 GPCRs including one hydrogen bond with Q3.37b stabilized by the hydrophobic residue at 3.40b; one hydrogen bond with Y1.47b made by the third peptide residue (Figure 4B,H); residues 4–11 interact with salt bridges of R7.35b, pi-stacking of Y1.43b, hydrophobic L2.71b, W5.36b, and L7.39b, as well as several hydrogen bonds in ECL2 (Figure 4C,H); residues 12–20 are divergent and mainly interact with ECLs 1–2 and TMs 1–2 (Figure 4D,H).
To accommodate varying lengths of side chains at A13P/Y/Y, I17P/Q/R, Q19P/A/A, and Q20P/K/Q, both TM1 and ECL1 adjusted their conformations to avoid clashes (Figure 4D, Figure 4—figure supplement 1). For example, ECL1 of GLP-1R is more distant from GLP-1 than that of GIPR from GIP, whereas repulsion of the side chain of R18P was seen between GCGR and glucagon. Therefore, receptor-specific interaction may reside in this region, which precludes the binding of GLP-1 or glucagon to GIPR revealed by MD simulations (Figure 4—figure supplement 2). As far as C terminus is concerned, all three peptides form extensive hydrophobic contacts with the ECD, resulting from the hydrophobic composition of amino acids in both sides (Figure 4E–H). It appears that GIPR, GLP-1R, and GCGR employ conserved residues to recognize the common segments of their endogenous peptides and use non-conserved residues to make specific interaction that govern the ligand selectivity.
Discussion
As one of the incretin hormones, GIP modulates glucose metabolism by stimulating the β-cells to release insulin (Seino et al., 2010). Unlike GLP-1, it does not suppress gastric emptying and appetite, while exerting opposite actions on pancreatic α-cells as well as adipocytes leading to glucagon secretion and lipogenesis (Seino et al., 2010). Coupled with reduced sensitivity in type 2 diabetic patients, development of GIPR-based therapeutics met little success (Coskun et al., 2018).
Comparison of the full-length structures of six glucagon subfamily of GPCRs demonstrates that bound peptides (GLP-1, exendin-P5, glucagon, ZP3780, secretin, GHRH, GLP-2, and GIP) all adopt a single straight helix with their N terminus inserted into the TMD core, while the C-terminal is recognized by the ECD (Zhou et al., 2020; Sun et al., 2020; Qiao et al., 2020; Zhang et al., 2017a; Dong et al., 2020). For parathyroid hormone subfamily of GPCRs, the long-acting PTH analog (LA-PTH) predominantly exhibits an extended helix with its N terminus inserted deeply into the TMD, where the peptide C terminus may bend occasionally (Zhao et al., 2019). In the case of CRF subfamily of GPCRs, the N terminus (first seven residues) of urocortin 1 (UCN1) and CRF1 present an extended loop conformation, and its C-terminal residues (8–40) adopt a single extended helix (Ma et al., 2020; Liang et al., 2020). As far as calcitonin subfamily of GPCRs is concerned, calcitonin gene-related peptide (CGRP) has an unstructured loop in both N- and C-terminal regions (Liang et al., 2018a). Looking at pituitary adenylate-cyclase-activating peptide (PACAP) and vasoactive intestinal polypeptide (VIP) receptor subfamily, PACAP displays an extended α-helix, while maxadilan, a natural PAC1R agonist (61-amino acid long), forms the N- and C-terminal helices that are linked as a loop (Duan et al., 2020; Liang et al., 2020; Wang et al., 2020). These observations highlight diversified peptide binding modes among class B1 GPCRs (Figure 4—figure supplement 3).
Species differences in class B1 receptor responsiveness are diversified and receptor specific, which is tolerable for some receptors such as GLP-1R and GCGR, but leads to concerns for others like GIPR and parathyroid hormone receptor-2 (PTH2R) (Sparre-Ulrich et al., 2016; Hoare et al., 1999). Interestingly, the sequence identities between human and mouse at both ligand and receptor levels are more conserved between GLP-1 and GLP-1R (100% and 93%) than that between GIP and GIPR (92% and 81%) (Sparre-Ulrich et al., 2016). Such a divergence is not caused by changes in peptide potency, but resides in the biological property of either GIP or the receptor (Sparre-Ulrich et al., 2016; Bailey, 2020). However, it may affect GIP-related pharmacology markedly (Sparre-Ulrich et al., 2016). Indeed, a previous study found that human GIP is a comparatively weak partial agonist in rodent models (Sparre-Ulrich et al., 2016). Human (Pro3)GIP is a full agonist with identical maximum response as human GIP, whereas both rat and mouse (Pro3)GIPs are partial agonists (Sparre-Ulrich et al., 2016; Bailey, 2020). Of note is that among rat, mouse, and human GIPs, the only residue change (from His to Arg) occurs at the 18th position (Sparre-Ulrich et al., 2016). From a structural biology perspective, the variation in the sequences of both GIP (H18P/R/R for human, rat, and mouse) and GIPR, and the consequent alterations in either peptide-binding or G protein-coupling may offer an explanation. Nonetheless, it may also complicate knowledge transfer from rodents to humans for clinical development of GIPR-based therapeutics.
The interactions between the three receptors (GIPR, GLP-1R, and GCGR) and their endogenous peptides transduce precise cellular signals responsible for glucose control. While GIP1-42, GLP-1, and glucagon each binds to the cognate receptor with high affinity (pIC50 = 8.07, 8.25 and 7.31, respectively), glucagon also cross-reacts with GLP-1R with a pIC50 value of 6.19 (Yuliantie et al., 2020; Darbalaei et al., 2020). This property is consistent with their behavior in inducing cAMP responses: GIP1-42 and GLP-1 specifically activate GIPR and GLP-1R, respectively, whereas glucagon can elicit cAMP accumulation mediated by both GCGR and GLP-1R (EC50 = 1.14 nM; Figure 4—figure supplement 4), highlighting the complexity of their interactive functionalities. Our studies show that the recognition pattern among these three peptide–receptor pairs is instituted by a common and closely related mechanism where the extracellular portion of the receptor mainly binds to a cognate ligand, while the TMD activates a cascade of signaling events. The upper half of the TMD pocket composed of the top parts of ECL1, TM1, and TM2 interacts with unique residues in the peptide through flexible movement of ECL1 and complementary shape formation by TM1 and TM2, thereby conferring selectively and discriminating unrelated ligands. The lower half of the TMD pocket composed of TMs 3, 6, and 7 displays conserved sequences for recognition of common residues in the peptide. Its key function is to converge external signal into the cytoplasm and executes transduction with high efficiency. This mechanistic design reflects evolutionary advantages because multiple polypeptides could be accurately recognized via different sequences in the upper half of the TMD pocket.
Finally, GIPR, combined with GLP-1R and GCGR, have been intensively studied as targets of dual- or tri- agonists (Skow et al., 2016; Alexiadou et al., 2019). Combined activation of GLP-1R and GIPR by dual agonists would provide synergistic and improved effects in glycemic and body weight control (Bastin and Andreelli, 2019). The GLP-1R/GIPR dual-agonists LY3298176 (developed by Eli Lilly) and NN9709 (developed by Novo Nordisk/Marcadia) as well as GLP-1R/GCGR/GIPR tri-agonist HM15211 (developed by Hamni Pharmaceuticals) are undergoing phase II or III clinical trials (Yang et al., 2021). The detailed structural information on GIPR reported here will certainly be of value to better understand the mode of actions of these therapeutic peptides.
Materials and methods
Key resources table
| Reagent type (species) or resource | Designation | Source or reference | Identifiers | Additional information |
|---|---|---|---|---|
| Gene | GIPR_human | NCBI | NM_000164.4 | |
| Strain, strain background(Escherichia coli) | BL21 (DE3) | TIANGEN | Cat # CB105 | |
| Cell line (Homo sapiens) | HEK 293T | ATCC | Cat # CRL-3216 | |
| Cell line (hamster) | CHO-K1 | ATCC | Cat # CCL-61 | |
| Cell line (insect) | Sf9 | Invitrogen | N/A | |
| Cell line (insect) | High-Five insect cells | ThermoFisher Scientific | Cat # B85502 | |
| Recombinant DNA reagent | pFastBac-HA-BRIL-TEV-2GSA-GIPR(22-421)T345F-15AA-LgBiT-TEV-OMBP-MBP | This paper | N/A | |
| Recombinant DNA reagent | pFastBac-HA-BRIL-TEV-2GSA-GIPR(22-421)−15AA-LgBiT-TEV-OMBP-MBP | This paper | N/A | |
| Recombinant DNA reagent | pFastBac-DNGαs | This paper | N/A | |
| Recombinant DNA reagent | pFastBac-Gβ1-peptide 86 | https://doi.org/10.1038/s41422-020-00442-0 | N/A | |
| Recombinant DNA reagent | pFastBac-Gγ2 | https://doi.org/10.1038/s41422-020-00442-0 | N/A | |
| Recombinant DNA reagent | PMESy4-Nb35 | https://doi.org/10.1016/j.molcel.2020.01.013 | N/A | |
| Recombinant DNA reagent | pcDNA3.1-GIPR (WT and mutants)−3Flag | This paper | N/A | |
| Peptide, recombinant protein | GIP1-42 | GenScript | N/A | |
| Chemical compound, drug | Protease Inhibitor Cocktail, EDTA-Free | TragetMol | Cat # C0001 | |
| Chemical compound, drug | Apyrase | Sigma-Aldrich (Merck) | Cat # A6132 | |
| Chemical compound, drug | TCEP | Sigma-Aldrich (Merck) | Cat # C4706 | |
| Chemical compound, drug | Lauryl maltose neopentylglycol (LMNG) | Anatrace | Cat # NG310 | |
| Chemical compound, drug | Cholesterol hemisuccinate (CHS) | Anatrace | Cat # CH210 | |
| Chemical compound, drug | Glyco-diosgenin (GDN) | Anatrace | Cat # GDN101 | |
| Chemical compound, drug | Amylose resin | NEB | Cat # E8021L | |
| Chemical compound, drug | ESF 921 culture medium | Expression Systems | Cat # 96-00-01 | |
| Chemical compound, drug | Fetal bovine serum (FBS) | Gibco | Cat # 10099–141 | |
| Chemical compound, drug | DMEM | Gibco | Cat # 12430–054 | |
| Chemical compound, drug | X-tremeGHNE HP DNA Transfection Reagent | Sigma-Aldrich (Roche) | Cat # 6366236001 | |
| Chemical compound, drug | Digitonin | Biosynth | Cat # D-3203 | |
| Chemical compound, drug | Salt active nuclease | Sigma-Aldrich | Cat # SRE0015-5KU | |
| Chemical compound, drug | Sodium pyruvate | Gibco | Cat # 11360–0’70 | |
| Chemical compound, drug | Lipofectamine 2000 transfection reagent | Invitrogen | Cat # 11668–019 | |
| Chemical compound, drug | 125I-GIP | PerkinElmer | Cat # NEX402010UC | |
| Chemical compound, drug | BSA | ABCONE | Cat # A23088-100G | |
| Antibody | Anti-Flag primary antibody | Sigma-Aldrich | Cat # F3165 | |
| Antibody | Anti-mouse Alexa Fluor 488 conjugated secondary antibody | Invitrogen | Cat # A-21202 | |
| Commercial assay, kit | LANCE Ultra cAMP kit | PerkinElmer | Cat # 2675984 | |
| Software, algorithm | MotionCor2.1 | doi:10.1126/science.aav7942 | N/A | https://msg.ucsf.edu/em/software/motioncor2.html |
| Software, algorithm | Gctf v1.06 | https://doi.org/10.1016/j.jsb.2015.11.003 | N/A | https://www2.mrc-lmb.cam.ac.uk/research/locally-developed-software/zhang-software/ |
| Software, algorithm | RELION-3.0-beta2 | https://doi.org/10.1016/j.jsb.2012.09.006 | N/A | https://www3.mrc-lmb.cam.ac.uk/relion/index.php/Download_%26_install |
| Software, algorithm | COOT | https://doi.org/10.1107/S0907444904019158 | N/A | https://www2.mrc-lmb.cam.ac.uk/personal/pemsley/coot/ |
| Software, algorithm | Phenix | https://doi.org/10.1107/S0907444909052925 | N/A | http://www.phenix-online.org/ |
| Software, algorithm | Chimera | https://doi.org/10.1002/jcc.20084 | N/A | https://www.cgl.ucsf.edu/chimera/ |
| Software, algorithm | PyMOL | Schrödinger | N/A | https://pymol.org/2/ |
| Software, algorithm | GraphPad Prism v7.0 | GraphPad Software | N/A | https://www.graphpad.com/ |
| Software, algorithm | FreeSASA | doi:10.12688/f1000research.7931.1 | N/A | http://freesasa.github.io/ |
| Software, algorithm | Gromacs 2018.5 | doi:10.1016/j.softx.2015.06.001 | N/A | https://manual.gromacs.org/2018.5/download.html |
| Software, algorithm | Protein Preparation Wizard | Schrödinger | N/A | https://www.schrodinger.com/products/protein-preparation-wizard |
| Software, algorithm | CHARMM-GUI Membrane Builder | https://doi.org/10.1002/jcc.23702 | N/A | https://charmm-gui.org/ |
| Software, algorithm | CHARMM36-CAMP | https://doi.org/10.1021/ct200328p | N/A | |
| Software, algorithm | LINCS algorithm | https://doi.org/10.1021/ct700200b | N/A | |
| Software, algorithm | Semi-isotropic Parrinello-Rahman barostat | https://doi.org/10.1016/0022-3093(93)90111-A | N/A |
Cell culture
Request a detailed protocolSpodoptera frugiperda (Sf9) (Invitrogen) and High-Five insect cells (ThermoFisher Scientific) were cultured in ESF 921 serum-free medium (Expression Systems) at 27°C and 120 rpm.
Constructs
Request a detailed protocolThe human GIPR DNA (Genewiz) with one mutation (T345F) was cloned into a modified pFastBac vector (Invitrogen). The native signal peptide was replaced by the hemagglutinin signal peptide (HA) to enhance receptor expression. A BRIL fusion protein was added at the N-terminal of the ECD with a TEV protease site and 2GSA linker between them. Forty-five amino acids (Q422-C466) were truncated at the C terminus where LgBiT was added with a 15-amino acid (15AA) polypeptide linker in between, followed by a TEV protease cleavage site and an optimized maltose binding protein–maltose binding protein tag (OMBP-MBP). A dominant-negative bovine Gαs (DNGαs) (S54N, G226A, E268A, N271K, K274D, R280K, T284D, and I285T) construct was used to stabilize the complex (Zhou et al., 2020; Liang et al., 2018b). SmBiT34 (peptide 86, Promega) subunit was added to the C terminus of rat Gβ1 with a 15AA polypeptide linker between them. The modified rat Gβ1 and bovine Gγ2 were both cloned into a pFastBac vector.
Protein expression
Request a detailed protocolBaculoviruses containing the above complex construct were prepared by the Bac-to-Bac system (Invitrogen). GIPR and Gs heterotrimer were co-expressed in High-Five cells. Briefly, insect cells were grown in ESF 921 culture medium (Expression Systems) to a density of 3.2 × 106 cells/mL, and then cells were infected with four kinds of viral preparations: BRIL-TEV-2GSA-GIPR(22-421)T345F-15AA-LgBiT-TEV-OMBP-MBP, Gαs, Gβ1-peptide 86, and Gγ2 at a ratio of 1:3:3:3. After 48 hr incubation at 27°C, the cells were collected by centrifugation and stored at −80°C until use.
Nb35 expression and purification
Request a detailed protocolNanobody-35 (Nb35) with a 6× his tag at the C terminus was expressed in the periplasm of E. coli BL21 (DE3) cells. Briefly, Nb35 target gene was transformed in the bacterium and amplified in TB culture medium with 100 μg/mL ampicillin, 2 mM MgCl2, 0.1% (w/v) glucose at 37°C, 180 rpm. When OD600 reached 0.7–1.2, 1 mM IPTG was added to induce expression followed by overnight incubation at 28°C. The cell pellet was then collected at 3000 rpm under 4°C and stored at −80°C. Nb35 was purified as by size-exclusion chromatography using a HiLoad 16/600 Superdex 75 column (GE Healthcare) with running buffer containing 20 mM HEPES, 100 mM NaCl, pH 7.4. Fractions of Nb35 were concentrated to ~3 mg/mL and quickly frozen in the liquid nitrogen with 10% glycerol and stored in −80°C.
Complex formation and purification
View detailed protocolCell pellets were lysed in a buffer consisting of 20 mM HEPES, 100 mM NaCl, pH 7.4, 10 mM MgCl2, 1 mM MnCl2, and 10% glycerol supplemented with protease inhibitor cocktail, EDTA-free (TragetMol). Subsequently, cell membranes were collected by ultracentrifugation at 4°C, 90,000 g for 35 min. The membranes were resuspended with a buffer containing 20 mM HEPES, 100 mM NaCl, pH 7.4, 10 mM MgCl2, 1 mM MnCl2, and 10% glycerol. The complex of GIPR-Gs was assembled by adding 15 μM GIP1-42 (GenScript), 100 μM TCEP, 25 mU/mL Apyrase (Sigma-Aldrich), 15 μg/mL Nb35, and 100 U salt active nuclease (Sigma-Aldrich) supplemented with protease inhibitor cocktail for 1.5 hr incubation at room temperature (RT). The preparation was then solubilized with 0.5% (w/v) lauryl maltose neopentylglycol (LMNG, Anatrace) and 0.1% (w/v) cholesterol hemisuccinate (CHS, Anatrace) with additional 1 μM GIP1-42 for 3 hr at 4°C. The supernatant was isolated by centrifugation at 90,000 g for 35 min, and the solubilized complex was incubated with amylose resin (NEB) for 2.5 hr at 4°C. After batch binding, the resin was collected by centrifugation at 550 g and loaded onto a gravity flow column. The resin in column was firstly washed with five column volumes of buffer containing 20 mM HEPES, pH 7.4, 100 mM NaCl, 10% (v/v) glycerol, 5 mM MgCl2, 1 mM MnCl2, 25 μM TCEP, 3 μM GIP1-42, 0.1% (w/v) LMNG, and 0.02% (w/v) CHS. Subsequently, the resin was washed with 25 column volumes of buffer containing 20 mM HEPES, pH 7.4, 100 mM NaCl, 10% (v/v) glycerol, 5 mM MgCl2, 1 mM MnCl2, 25 μM TCEP, 3 μM GIP1-42, 0.03% (w/v) LMNG, 0.01% (w/v) glyco-diosgenin (GDN, Anatrace), and 0.008% (w/v) CHS. The protein was then incubated with a buffer containing 20 mM HEPES, pH 7.4, 100 mM NaCl, 10% (v/v) glycerol, 5 mM MgCl2, 1 mM MnCl2, 25 μM TCEP, 50 μM GIP1-42, 10 μg/mL Nb35, 0.03% (w/v) LMNG, 0.01% (w/v) glyco-diosgenin, 0.008% (w/v) CHS, and 30 μg/mL His-tagged TEV protease on the column overnight at 4°C. The flow through was collected and concentrated to 500 μL using a 100 kDa filter (Merck Millipore). Size-exclusion chromatography was performed by loading the protein onto Superose 6 Increase 10/300 GL (GE Healthcare) column with running buffer containing 20 mM HEPES, pH 7.4, 100 mM NaCl, 10 mM MgCl2, 100 μM TCEP, 5 μM GIP1-42, 0.00075% (w/v) LMNG, 0.00025% (w/v) glyco-diosgenin, 0.0002% (w/v) CHS, and 0.00025% digitonin (Anatrace). Monomeric GIPR-Gs complexes were collected and concentrated for cryo-EM analysis.
Data acquisition and image processing
Request a detailed protocolThe purified GIP1-42–GIPR–Gs–Nb35 complex at a concentration of 6–7 mg/mL was mixed with 100 μM GIP1-42 at 4°C and applied to glow-discharged holey carbon grids (Quantifoil R1.2/1.3, Au 300 mesh) that were subsequently vitrified by plunging into liquid ethane using a Vitrobot Mark IV (ThermoFisher Scientific). A Titan Krios equipped with a Gatan K3 Summit direct electron detector was used to acquire Cryo-EM images. The microscope was operated at 300 kV accelerating voltage, at a nominal magnification of 46,685× in counting mode, corresponding to a pixel size of 1.071 Å. Totally, 8023 movies were obtained with a defocus range of −1.2 to −2.2 μm. An accumulated dose of 80 electrons per Å2 was fractionated into a movie stack of 36 frames.
Dose-fractionated image stacks were subjected to beam-induced motion correction using MotionCor2.1. A sum of all frames, filtered according to the exposure dose, in each image stack was used for further processing. Contrast transfer function parameters for each micrograph were determined by Gctf v1.06. Particle selection, 2D and 3D classifications were performed on a binned dataset with a pixel size of 2.142 Å using RELION-3.0-beta2. Auto-picking yielded 4,895,399 particle projections that were subjected to reference-free 2D classification to discard false-positive particles or particles categorized in poorly defined classes, producing 2,754,623 particle projections for further processing. This subset of particle projections was subjected to a round of maximum-likelihood-based three dimensional classifications with a pixel size of 2.142 Å, resulting in one well-defined subset with 1,395,031 projections. Further 3D classifications with mask on the receptor produced one good subset accounting for 565,239 particles, which were subjected to another round of 3D classifications with mask on the ECD. A selected subset containing 295,021 projections was then subjected to 3D refinement and Bayesian polishing with a pixel size of 1.071 Å. After the last round of refinement, the final map has an indicated global resolution of 2.94 Å at a Fourier shell correlation (FSC) of 0.143. Local resolution was determined using the Bsoft package with half maps as input maps.
Model building and refinement
Request a detailed protocolThe cryo-EM structure of GCGR–Gs–Nb35 complex (PDB code 6WPW) (Qiao et al., 2020) and the crystal structure of GIPR ECD (PDB code 2QKH) (Parthier et al., 2007) were used as the start for model building and refinement against the EM map. The model was docked into the EM density map using Chimera (Pettersen et al., 2004), followed by iterative manual adjustment and rebuilding in COOT (Emsley and Cowtan, 2004). Real space refinement was performed using Phenix (Adams et al., 2010). The model statistics were validated using MolProbity (Chen et al., 2010). Structural figures were prepared in Chimera and PyMOL (https://pymol.org/2/). The final refinement statistics are provided in Table 1.
cAMP accumulation assay
Request a detailed protocolGIP1-42-stimulated cAMP accumulation was measured by a LANCE Ultra cAMP kit (PerkinElmer). Briefly, HEK 293T cells were cultured in DMEM (Gibco) supplemented with 10% (v/v) fetal bovine serum (FBS, Gibco) and 1% (v/v) sodium pyruvate (Gibco) at 37°C, 5% CO2. Cells were seeded onto six-well cell culture plates and transiently transfected with different GIPR constructs using Lipofectamine 2000 transfection reagent (Invitrogen). All the mutant constructs were modified by single-point mutation in the setting of the WT construct (HA-Flag-3GSA-GIPR(22-466)). After 24 hr culture, the transfected cells were seeded onto 384-well microtiter plates at a density of 3000 cells per well in HBSS supplemented with 5 mM HEPES, 0.1% (w/v) bovine serum albumin (BSA), and 0.5 mM 3-isobutyl-1- methylxanthine. The cells were stimulated with different concentrations of GIP1-42 for 40 min at RT. Eu and Ulight were then diluted by cAMP detection buffer and added to the plates separately to terminate the reaction. Plates were incubated at RT for 40 min and the fluorescence intensity measured at 620 nm and 650 nm by an EnVision multilabel plate reader (PerkinElmer).
Whole-cell binding assay
Request a detailed protocolCHO-K1 cells were cultured in F12 medium with 10% FBS and seeded at a density of 30,000 cells/well in Isoplate-96 plates (PerkinElmer). The WT (HA-Flag-3GSA-GIPR(22-466)) or mutant GIPR were transiently transfected using Lipofectamine 2000 transfection reagent. The mutant construct was modified by single-point mutation in the setting of the WT construct. Twenty-four hours after transfection, cells were washed twice, and incubated with blocking buffer (F12 supplemented with 33 mM HEPES and 0.1% BSA, pH 7.4) for 2 hr at 37°C. For homogeneous binding, cells were incubated in binding buffer with a constant concentration of 125I-GIP (40 pM, PerkinElmer) and increasing concentrations of unlabeled GIP1-42 (3.57 pM–1 μM) at RT for 3 hr. Following incubation, cells were washed three times with ice-cold PBS and lysed by addition of 50 μL lysis buffer (PBS supplemented with 20 mM Tris–HCl, 1% Triton X-100, pH 7.4). Fifty microliters of scintillation cocktail (OptiPhase SuperMix, PerkinElmer) was added, and the plates were subsequently counted for radioactivity (counts per minute, CPM) in a scintillation counter (MicroBeta2 Plate Counter, PerkinElmer).
β-Arrestin2 recruitment
Request a detailed protocolHEK 293T cells (3 × 106 cells/10 cm plate) were grown for 24 hr before transfection with 10.6 μg plasmid containing GIPR tagged with Rluc8 and β-arrestin with a Venus-tag in the N terminus at a ratio of 1:9. Transiently transfected cells were then seeded onto poly-d-lysine coated 96-well culture plates (50,000 cells/well) in DMEM with 10% FBS. Cells were grown overnight before incubation in assay buffer (HBSS supplemented with 10 mM HEPES and 0.1% BSA, pH 7.4) for 30 min at 37°C. Coelentrazine-h (Yeasen Biotech) was added to a final concentration of 5 μM for 5 min before bioluminescence resonance energy transfer (BRET) readings were made using an EnVision plate reader (PerkinElmer). BRET baseline measurements were collected for 10 cycles prior to ligand addition. Following peptide addition, BRET was measured for 50 cycles. The BRET signal (ratio of 535 nm over 470 nm emission) was corrected to the baseline and then vehicle-treated condition to determine ligand-induced changes in BRET response. Concentration–response values were obtained from the area-under-the-curve (AUC) of the responses elicited by GIP1-42.
Receptor surface expression
Request a detailed protocolCell surface expression was determined by flow cytometry to the N-terminal Flag tag on the WT GIPR (HA-Flag-3GSA-GIPR(22-466)) and its mutants transiently expressed in HEK 293T cells. All the mutant constructs were modified by single-point mutation in the setting of the WT construct. Briefly, approximately 2 × 105 cells were blocked with PBS containing 5% BSA (w/v) at RT for 15 min and then incubated with 1:300 anti-Flag primary antibody (diluted with PBS containing 5% BSA, Sigma-Aldrich) at RT for 1 hr. The cells were then washed three times with PBS containing 1% BSA (w/v) followed by 1 hr incubation with 1:1000 anti-mouse Alexa Fluor 488 conjugated secondary antibody (diluted with PBS containing 5% BSA, Invitrogen) at RT in the dark. After washing three times, cells were re-suspended in 200 μL PBS containing 1% BSA for detection by NovoCyte (Agilent) utilizing laser excitation and emission wavelengths of 488 nm and 530 nm, respectively. For each sample, 20,000 cellular events were collected, and the total fluorescence intensity of positive expression cell population was calculated. Data were normalized to the WT receptor.
Molecular dynamics simulations
Request a detailed protocolMolecular dynamic simulations were performed by Gromacs 2018.5. The peptide–GIPR complexes were built based on the cryo-EM GIP–GIPR–Gs complex and prepared by the Protein Preparation Wizard (Schrodinger 2017–4) with the G protein and Nb35 nanobody removed. The receptor chain termini were capped with acetyl and methylamide, and the titratable residues were left in their dominant state at pH 7.0. The complexes were embedded in a bilayer composed of 200 POPC lipids and solvated with 0.15 M NaCl in explicitly TIP3P waters using CHARMM-GUI Membrane Builder (Wu et al., 2014). The CHARMM36-CAMP force filed (Guvench et al., 2011) was adopted for protein, peptides, lipids, and salt ions. The Particle Mesh Ewald (PME) method was used to treat all electrostatic interactions beyond a cut-off of 10 Å, and the bonds involving hydrogen atoms were constrained using LINCS algorithm (Hess, 2008). The complex system was firstly relaxed using the steepest descent energy minimization, followed by slow heating of the system to 310 K with restraints. The restraints were reduced gradually over 50 ns. Finally, restrain-free production run was carried out for each simulation, with a time step of 2 fs in the NPT ensemble at 310 K and 1 bar using the Nose–Hoover thermostat and the semi-isotropic Parrinello–Rahman barostat (Aoki and Yonezawa, 1992), respectively. The buried interface areas were calculated with FreeSASA (Mitternacht, 2016) using the Sharke–Rupley algorithm with a probe radius of 1.2 Å. The last 700 ns trajectory of each simulation was used to root mean square fluctuation (RMSF) calculation.
Statistical analysis
Request a detailed protocolAll functional data were presented as means ± standard error of the mean (S.E.M.). Statistical analysis was performed using GraphPad Prism 7 (GraphPad Software). Concentration–response curves were evaluated with a three-parameter logistic equation. The significance was determined with either two-tailed Student’s t-test or one-way ANOVA. Significant difference is accepted at p<0.001.
Data availability
Atomic coordinates of the GIP-GIPR-Gs complex have been deposited in the Protein Data Bank under accession code 7DTY and Electron Microscopy Data Bank (EMDB) accession code EMD-30860. All data generated or analysed during this study are included in the manuscript and supporting files. Source data files have been provided for Figure 2, Figure 1—figure supplement 1 and Figure 4—figure supplement 4.
-
Electron Microscopy Data BankID EMD-30860. Structural basis of ligand selectivity conferred by the human glucose-dependent insulinotropic polypeptide receptor.
References
-
PHENIX: a comprehensive Python-based system for macromolecular structure solutionActa Crystallographica Section D Biological Crystallography 66:213–221.https://doi.org/10.1107/S0907444909052925
-
Cracking the combination: Gut hormones for the treatment of obesity and diabetesJournal of Neuroendocrinology 31:e12664.https://doi.org/10.1111/jne.12664
-
Dual GIP-GLP1-Receptor agonists in the treatment of type 2 diabetes: a short review on emerging data and therapeutic potentialDiabetes, Metabolic Syndrome and Obesity : Targets and Therapy 12:1973–1985.https://doi.org/10.2147/DMSO.S191438
-
Cryo-electron microscopy structure of the glucagon receptor with a dual-agonist peptideJournal of Biological Chemistry 295:9313–9325.https://doi.org/10.1074/jbc.RA120.013793
-
MolProbity: all-atom structure validation for macromolecular crystallographyActa Crystallographica Section D Biological Crystallography 66:12–21.https://doi.org/10.1107/S0907444909042073
-
Evaluation of biased agonism mediated by dual agonists of the GLP-1 and glucagon receptorsBiochemical Pharmacology 180:114150.https://doi.org/10.1016/j.bcp.2020.114150
-
Structure and dynamics of the active Gs-coupled human secretin receptorNature Communications 11:4137.https://doi.org/10.1038/s41467-020-17791-4
-
Coot: model-building tools for molecular graphicsActa Crystallographica Section D Biological Crystallography 60:2126–2132.https://doi.org/10.1107/S0907444904019158
-
Neuroprotective effects of D-Ala(2)GIP on Alzheimer's disease biomarkers in an APP/PS1 mouse modelAlzheimer's Research & Therapy 5:20.https://doi.org/10.1186/alzrt174
-
CHARMM additive all-atom force field for carbohydrate derivatives and its utility in polysaccharide and carbohydrate-protein modelingJournal of Chemical Theory and Computation 7:3162–3180.https://doi.org/10.1021/ct200328p
-
P-LINCS: A Parallel Linear Constraint Solver for Molecular SimulationJournal of Chemical Theory and Computation 4:116–122.https://doi.org/10.1021/ct700200b
-
Characterization and biological actions of N-terminal truncated forms of glucose-dependent insulinotropic polypeptideBiochemical and Biophysical Research Communications 404:870–876.https://doi.org/10.1016/j.bbrc.2010.12.077
-
Structural diversity of G protein-coupled receptors and significance for drug discoveryNature Reviews Drug Discovery 7:339–357.https://doi.org/10.1038/nrd2518
-
Dominant Negative G Proteins Enhance Formation and Purification of Agonist-GPCR-G Protein Complexes for Structure DeterminationACS Pharmacology & Translational Science 1:12–20.https://doi.org/10.1021/acsptsci.8b00017
-
Passing the baton in class B GPCRs: peptide hormone activation via helix induction?Trends in Biochemical Sciences 34:303–310.https://doi.org/10.1016/j.tibs.2009.02.004
-
UCSF Chimera--a visualization system for exploratory research and analysisJournal of Computational Chemistry 25:1605–1612.https://doi.org/10.1002/jcc.20084
-
GIP and GLP-1, the two incretin hormones: Similarities and differencesJournal of Diabetes Investigation 1:8–23.https://doi.org/10.1111/j.2040-1124.2010.00022.x
-
Diabetes and obesity treatment based on dual incretin receptor activation: 'twincretins'Diabetes, Obesity and Metabolism 18:847–854.https://doi.org/10.1111/dom.12685
-
CHARMM-GUI Membrane Builder toward realistic biological membrane simulationsJournal of Computational Chemistry 35:1997–2004.https://doi.org/10.1002/jcc.23702
-
Conformational states of the full-length glucagon receptorNature Communications 6:7859.https://doi.org/10.1038/ncomms8859
-
G protein-coupled receptors: structure- and function-based drug discoverySignal Transduction and Targeted Therapy 6:7.https://doi.org/10.1038/s41392-020-00435-w
Article and author information
Author details
Funding
National Natural Science Foundation of China (81872915)
- Ming-Wei Wang
National Natural Science Foundation of China (32071203)
- Lihua Zhao
National Natural Science Foundation of China (81773792)
- Dehua Yang
National Natural Science Foundation of China (81973373)
- Dehua Yang
National Natural Science Foundation of China (21704064)
- Qingtong Zhou
National Science and Technology Major Project of China (2018ZX09735-001)
- Ming-Wei Wang
National Science and Technology Major Project of China (2018ZX09711002-002-005)
- Dehua Yang
National Key Basic Research Program of China (2018YFA0507000)
- Ming-Wei Wang
Ministry of Science and Technology of China (2018YFA0507002)
- H Eric Xu
Shanghai Municipal Science and Technology Commission (2019SHZDZX02)
- H Eric Xu
Chinese Academy of Sciences (XDB37030103)
- H Eric Xu
Shanghai Science and Technology Development Fund (18430711500)
- Ming-Wei Wang
Novo Nordisk (NNCAS-2017-1-CC)
- Dehua Yang
Shanghai Science and Technology Development Fund (18ZR1447800)
- Lihua Zhao
Youth Innovation Promotion Association of the Chinese Academy of Sciences (2018325)
- Lihua Zhao
Shanghai Institutes for Biological Sciences, Chinese Academy of Sciences
- Dehua Yang
- Lihua Zhao
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Elita Yuliantie, Wen Sun, Zhaotong Cong, Fulai Zhou, Yuqi Ping, X Edward Zhou, Karsten Melcher, Jinhuan Chen, and Xijiang Pan for technical advice. The cryo-EM data were collected at Cryo-Electron Microscopy Research Center, Shanghai Institute of Materia Medica. This work was partially supported by National Natural Science Foundation of China 81872915 (M-WW), 32071203 (LHZ), 81773792 (DHY), 81973373 (DHY), and 21704064 (QTZ); National Science and Technology Major Project of China – Key New Drug Creation and Manufacturing Program 2018ZX09735–001 (M-WW) and 2018ZX09711002–002–005 (DHY); National Key Basic Research Program of China 2018YFA0507000 (M-WW); Ministry of Science and Technology of China 2018YFA0507002 (HEX); Shanghai Municipal Science and Technology Major Project 2019SHZDZX02 (HEX); Strategic Priority Research Program of Chinese Academy of Sciences XDB37030103 (HEX); Shanghai Municipality Science and Technology Development Fund 18430711500 (M-WW) and 18ZR1447800 (LHZ); Novo Nordisk-CAS Research Fund grant NNCAS-2017–1-CC (DHY); The Young Innovator Association of CAS 2018325 (LHZ); and SA-SIBS Scholarship Program (LHZ and DHY).
Copyright
© 2021, Zhao et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 5,193
- views
-
- 940
- downloads
-
- 43
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 43
- citations for umbrella DOI https://doi.org/10.7554/eLife.68719
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Structural insights into hormone recognition by the human glucose-dependent insulinotropic polypeptide receptor
eLife 10:e68719.
https://doi.org/10.7554/eLife.68719




{kind=link}
{kind=link}
{kind=link}
{kind=link}