Glycan processing in the Golgi as optimal information coding that constrains cisternal number and enzyme specificity
- Raman Research Institute, India
- Laboratoire Physico Chimie Curie, Institut Curie, CNRS UMR168, France
- Industrial Engineering and Operations Research, Columbia University, United States
- Simons Centre for the Study of Living Machines, National Centre for Biological Sciences, India
Abstract
Many proteins that undergo sequential enzymatic modification in the Golgi cisternae are displayed at the plasma membrane as cell identity markers. The modified proteins, called glycans, represent a molecular code. The fidelity of this glycan code is measured by how accurately the glycan synthesis machinery realizes the desired target glycan distribution for a particular cell type and niche. In this article, we construct a simplified chemical synthesis model to quantitatively analyse the trade-offs between the number of cisternae, and the number and specificity of enzymes, required to synthesize a prescribed target glycan distribution of a certain complexity to within a given fidelity. We find that to synthesize complex distributions, such as those observed in real cells, one needs to have multiple cisternae and precise enzyme partitioning in the Golgi. Additionally, for a fixed number of enzymes and cisternae, there is an optimal level of specificity (promiscuity) of enzymes that achieves the target distribution with high fidelity. The geometry of the fidelity landscape in the multidimensional space of the number and specificity of enzymes, inter-cisternal transfer rates, and number of cisternae provides a measure for robustness and identifies stiff and sloppy directions. Our results show how the complexity of the target glycan distribution and number of glycosylation enzymes places functional constraints on the Golgi cisternal number and enzyme specificity.
Editor's evaluation
This article contributes to an important and largely unexplored topic in cell biology: the understanding of glycosylation. The authors introduce a mathematical model of glycosylation in the Golgi apparatus and use the model to investigate how the complexity (diversity) and fidelity of the plasma membrane glycan distribution depend on parameters such as the number of Golgi cisternae or enzyme specificity. The article is well written and makes the effort to present a rather complex topic in an accessible way by leaving some of the details in the appendices.
https://doi.org/10.7554/eLife.76757.sa0Introduction
A majority of the proteins synthesized in the endoplasmic reticulum (ER) are transferred to the Golgi cisternae for further chemical modification by glycosylation (Alberts, 2002), a process that sequentially and covalently attaches sugar moieties to proteins, catalyzed by a set of enzymatic reactions within the ER and the Golgi cisternae. These enzymes, called glycosyltransferases, are localized in the ER and cis-medial and trans-Golgi cisternae in a specific manner (Varki, 2009; Cummings and Pierce, 2014). Glycans, the final products of this glycosylation assembly line, are delivered to the plasma membrane (PM) conjugated with proteins, whereupon they engage in multiple cellular functions, including immune recognition, cell identity markers, cell-cell adhesion, and cell signalling (Varki, 2009; Cummings and Pierce, 2014; Varki, 2017; Drickamer and Taylor, 1998; Gagneux and Varki, 1999). This glycan code (Gabius, 2018; Dwek, 1996), representing information (Winterburn and Phelps, 1972) about the cell, is generated dynamically, following the biochemistry of sequential enzymatic reactions and the biophysics of secretory transport (Varki, 2017; Varki, 1998; Pothukuchi et al., 2019).
In this article, we will focus on the role of glycans as markers of cell identity. For the glycans to play this role, they must inevitably represent a molecular code (Gabius, 2018; Varki, 2017; Pothukuchi et al., 2019). While the functional consequences of glycan alterations have been well studied, the glycan code has remained an enigma (Gabius, 2018; Pothukuchi et al., 2019; Bard and Chia, 2016; D’Angelo et al., 2013). We study the fidelity of molecular code generation, that is, the precision and reliability with which the glycan distribution is created. While it has been recognized that fidelity of the glycan code is necessary for reliable cellular recognition (Demetriou et al., 2001), a quantitative measure of fidelity of the mechanism and the constraints that fidelity requirements put on cellular structure and organization are lacking.
There are two aspects of the cell-type-specific glycan code and the code generation mechanism that have an important bearing on quantifying fidelity. The first is that extant glycan distributions have high complexity (section ‘Complexity of glycan code’), owing to evolutionary pressures arising from (a) reliable cell-type identification amongst a large set of different cell types in a complex organism, the preservation and diversification of ‘self-recognition’ (Drickamer and Taylor, 1998), (b) pathogen-mediated selection pressures (Varki, 2009; Varki, 2017; Gagneux and Varki, 1999), and (c) herd immunity within a heterogenous population of cells of a community (Wills and Green, 1995) or within a single organism (Drickamer and Taylor, 1998). We interpret this to mean that the target distribution of glycans for a given cell type is complex; in section ‘Complexity of glycan code’, we define a quantitative measure for complexity and demonstrate its implications. The second is that the cellular machinery for the synthesis of glycans, which involves sequential chemical processing via cisternal resident enzymes and cisternal transport, is subject to variation and noise (Varki, 2017; Varki, 1998; Pothukuchi et al., 2019); the synthesized glycan distribution is, therefore, a function of cellular parameters such as the number and specificity of enzymes, inter-cisternal transfer rates, and number of cisternae. We will discuss an explicit model of the cellular synthesis machinery in section ‘Synthesis of glycans in the Golgi cisternae’.
Here, we define fidelity as the minimum achievable Kullback-Leibler (KL) divergence (Cover and Thomas, 2012; MacKay, 2003) between the synthesized distribution of glycans and the target glycan distribution as a function of given cellular parameters, such as the number and specificity of enzymes, inter-cisternal transfer rates, and number of cisternae (section ‘Optimization problem’). Using a simplified chemical synthesis model, we analyse the trade-offs between the number of cisternae and the number and specificity of enzymes in order to achieve a prescribed target glycan distribution with high fidelity (section ‘Results of optimization’). Our analysis leads to a number of interesting results, a few of which we list here:
First, since an important function of the glycan spectrum is cell type/niche identification, it seems natural to relate glycan complexity to organismal complexity taken to be associated with the number of cell types in the organism (Carroll, 2001; Bonner, 1998). Here, we provide a measure of the complexity of the glycan distribution of a given cell type using mass spectrometry coupled with determination of molecular structure (MSMS) data. Using this we have analysed the MSMS data from hydra, planaria, and mammalian cells. We find that the complexity of the glycan distribution indeed correlates with the organism complexity.
Constructing a high-fidelity representation of a complex target distribution, such as those observed in real cells, requires a complex Golgi machinery with multiple cisternae, precise enzyme partitioning, and control on enzyme specificity. This definition of fidelity of the glycan code allows us to provide a quantitative argument for the evolutionary requirement of multiple compartments. While it is possible to produce complex glycan distributions in one compartment using a large number of enzymes, such a design would inevitably require a more elaborate genetic cost.
Within our synthesis model, an increase in the number of Golgi cisternae drives an increase in the glycan complexity, keeping everything else fixed.
We explore the geometry of the fidelity landscape in the multidimensional space of the number and specificity of enzymes, inter-cisternal transfer rates, and number of cisternae. This allows us to discuss issues such as robustness to noise, and stiff and sloppy directions in this multidimensional space.
For fixed number of enzymes and cisternae, there is an optimal level of specificity of enzymes that achieves the complex target distribution with high fidelity. Keeping the number of enzymes fixed, having low specificity or sloppy enzymes and larger cisternal number could give rise to a diverse repertoire of functional glycans, a strategy used in organisms such as plants and algae. Promiscuous enzymes bring in the potential for evolvability (Kirschner and Gerhart, 2008); promiscuity allows the system to be stable to random mutations in proteins or variations in the target distribution.
Thus, our results imply that the pressure to produce the target glycan code for a given cell type with high fidelity places strong constraints on the cisternal number and enzyme specificity (Sengupta and Linstedt, 2011). Taken together, our quantitative analysis of the trade-offs has deep implications for the non-equilibrium self-assembly of Golgi cisternae and suggests that the control of cisternal number must involve a coupling of non-equilibrium self-assembly of cisternae with enzymatic chemical reaction kinetics (Glick and Malhotra, 1998). This combined dynamics of chemical processing with non-equilibrium membrane dynamics involving fission, fusion, and transport (Sachdeva et al., 2016; Sens and Rao, 2013) opens up a new direction for future research.
Complexity of glycan code
Since each cell type (in a niche) is identified with a distinct glycan profile (Gabius, 2018; Varki, 2017; Pothukuchi et al., 2019), and this glycan profile is noisy because of the stochastic noise associated with the synthesis and transport (Pothukuchi et al., 2019; Bard and Chia, 2016; D’Angelo et al., 2013), a large number of different cell types can be differentiated only if the cells are able to produce a large set of glycan profiles that are distinguishable in the presence of this noise. Our task is to identify a quantitative measure for the complexity of a glycan profile such that a set of more complex glycan profiles is able to support a larger number of well-separated profiles, and therefore, a larger number of cell types, or equivalently, a more complex organism (a rigorous definition of complexity can be given in terms of the KL metric [Cover and Thomas, 2012; MacKay, 2003] between two glycan profiles. We declare that two profiles are distinguishable only if the KL distance between the profiles is more than a given tolerance. This tolerance is an increasing function of the noise. We define the complexity of a set of possible glycan profiles as the size of the largest subset such that the KL distance of any pair of profiles is larger than the tolerance). Furthermore, we would like to be able to estimate the complexity of a glycan profile from molecular structure (MSMS) measurements (Cummings and Crocker, 2020; Subramanian et al., 2018; Sahadevan et al., 2014).
In order to identify such a quantitative measure of complexity, we first need a consistent way of smoothening or coarse-graining the raw glycan profiles obtained from MSMS measurements to remove measurement and synthesis noise. Here, we denoise the glycan profile by approximating it by a Gaussian mixture model (GMM) with a specified number of components that are supported on a finite set of indices (Bacharoglou, 2010). Since the size of the set of all possible -component Gaussian densities is an increasing function of , we define the complexity of a mixture of Gaussians as the number of components . Figure 1 demonstrates that the value of at which the -component GMM approximation of the target profile saturates is a good measure of complexity. Using this definition we see that the complexity of the glycan profiles of various organisms correlates well with the number of cell types in an organism (details of the procedure are given in Appendix 1). We will now describe a general model of the cellular machinery that is capable of synthesizing glycans of any complexity. We expect that cells need a more elaborate mechanism to produce profiles from a more complex set.
Figure 1
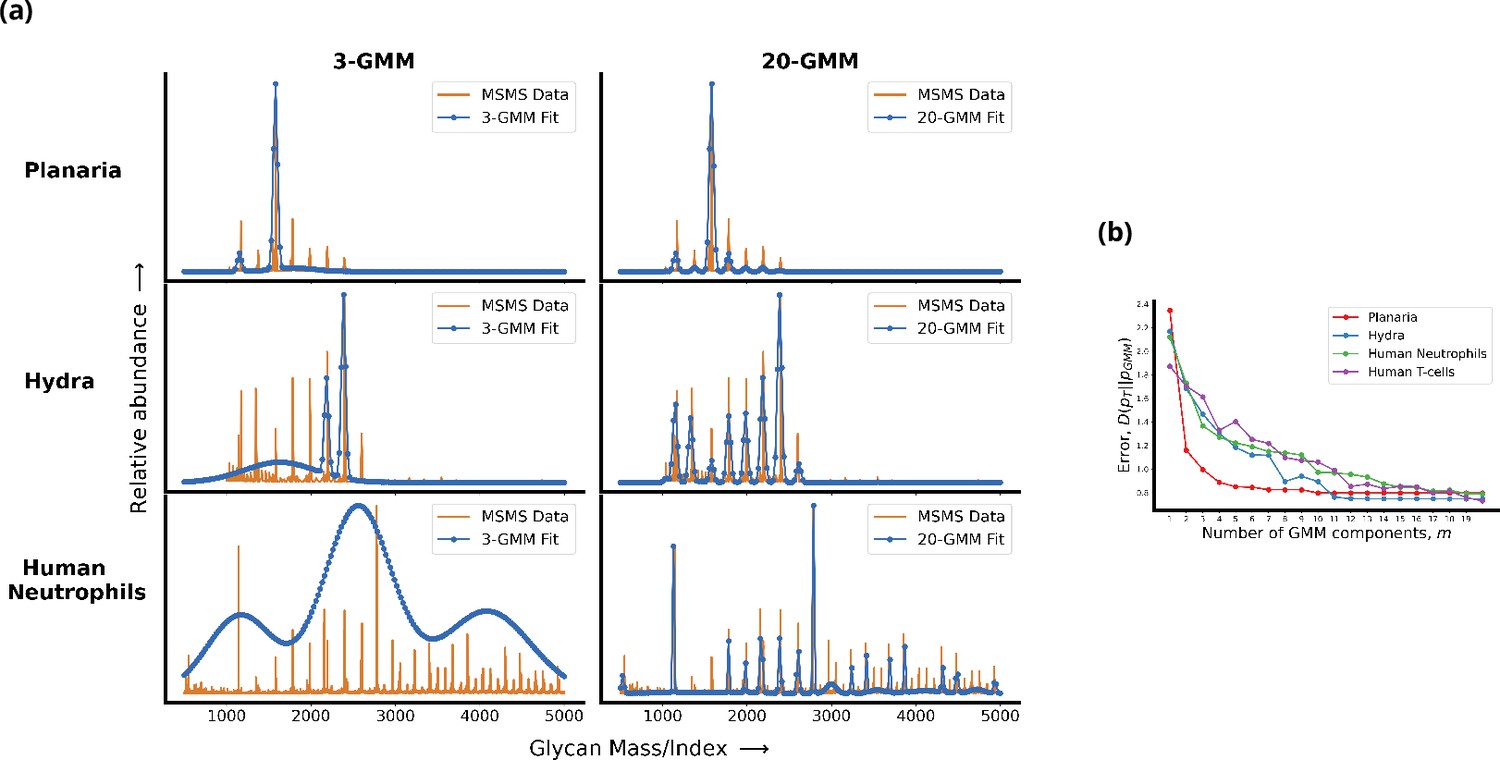
Living cells display a complex glycan distribution.
(a) 3-Gaussian mixture model (GMM) and 20-GMM approximation for the relative abundance of glycans taken from mass spectrometry coupled with determination of molecular structure (MSMS) data of planaria Schmidtea mediterranea, Hydra magnipapillata, and human neutrophils. (b) The change in the Kullback–Leibler (KL) divergence as a function of the number of GMM components . The KL divergence for planaria saturates at , for hydra at , and for human cells at . Thus, the number of components required to approximate the glycan profile correlates well with the complexity of the organism. Details are given in Appendix 1.
Synthesis of glycans in the Golgi cisternae
The glycan display at the cell surface is a result of proteins that flux through and undergo sequential chemical modification in the secretory pathway, comprising an array of Golgi cisternae situated between the ER and PM, as depicted in Figure 2. Glycan-binding proteins (GBPs) are delivered from the ER to the first cisterna, whereupon they are processed by the resident enzymes in a sequence of steps that constitute the N-glycosylation process (Varki, 2009). A generic enzymatic reaction in the cisterna involves the catalysis of a group transfer reaction in which the monosaccharide moiety of a simple sugar donor substrate, for example, UDP-Gal, is transferred to the acceptor substrate, by a Michaelis–Menten (MM)-type reaction (Varki, 2009)
(1)
Figure 2

Enzymatic reaction and transport network in the secretory pathway.
Represented here is the array of Golgi cisternae (blue) indexed by situated between the endoplasmic reticulum (ER) and plasma membrane (PM). Glycan-binding proteins are injected from the ER to cisterna-1 at rate . Superimposed on the Golgi cisternae is the transition network of chemical reactions (column) – inter-cisternal transfer (rows), the latter with rates . denotes the acceptor substrate in compartment and the glycosyl donor is chemostated in each cisterna. This results in a distribution (relative abundance) of glycans displayed at the PM (red curve), which is representative of the cell type.
From the first cisterna, the proteins with attached sugars are delivered to the second cisterna at a given inter-cisternal transfer rate, where further chemical processing catalyzed by the enzymes resident in the second cisterna occurs. This chemical processing and inter-cisternal transfer continue until the last cisterna, thereupon the fully processed glycans are displayed at the PM (Varki, 2009). The network of chemical processing and inter-cisternal transfer forms the basis of the physical model that we will describe next.
Any physical model of such a network of enzymatic reactions and cisternal transfer needs to be augmented by reaction and transfer rates and chemical abundances. To obtain the range of allowed values for the reaction rates and chemical abundances, we use the elaborate enzymatic reaction models, such as the KB2005 model (Umaña and Bailey, 1997; Krambeck et al., 2009; Krambeck and Betenbaugh, 2005) (with a network of 22,871 chemical reactions and 7565 oligosaccharide structures) that predict the N-glycan distribution based on the activities and levels of processing enzymes distributed in the Golgi cisternae of mammalian cells. For the allowed rates of cisternal transfer, we rely on the recent study by Ungar and coworkers (Fisher et al., 2019; Fisher and Ungar, 2016), whose study shows how the overall Golgi transit time and cisternal number can be tuned to engineer a homogeneous glycan distribution.
Model
Chemical reaction and transport network in cisternae
We consider an array of Golgi cisternae, labelled by , between the ER and PM (Figure 2). GBPs, denoted as , are delivered from the ER to cisterna-1 at an injection rate . It is well established that the concentration of the glycosyl donor in the jth cisterna is chemostated (Varki, 2009; Hirschberg et al., 1998; Caffaro and Hirschberg, 2006; Berninsone and Hirschberg, 2000), thus in our model we hold its concentration constant in time for the jth cisterna. The acceptor reacts with to form the glycosylated acceptor , following an MM reaction (1) catalyzed by the appropriate enzyme. The acceptor has the potential of being transformed into , and so on, provided the requisite enzymes are present in that cisterna. This leads to the sequence of enzymatic reactions , where enumerates the sequence of glycosylated acceptors using a consistent scheme (such as in Umaña and Bailey, 1997). The glycosylated GBPs are transported from cisterna-1 to cisterna-2 at an inter-cisternal transfer rate , whereupon similar enzymatic reactions proceed. The processes of intra-cisternal chemical reactions and inter-cisternal transfer continue to the other cisternae and form a network as depicted in Figure 2. Although, in this article, we focus on a sequence of reactions that form a line graph, the methodology we propose extends to tree-like reaction sequences, and more generally to reaction sequences that form a directed acyclic graph.
Let denote the maximum number of possible glycosylation reactions in each cisterna , catalyzed by enzymes labelled as , with , where is the total number of enzyme species in each cisterna. Since many substrates can compete for the substrate-binding site on each enzyme, one expects in general that . The configuration space of the network in Figure 2 is . For the N-glycosylation pathway in a typical mammalian cell, , = 10–20, and = 4–8 (Umaña and Bailey, 1997; Krambeck and Betenbaugh, 2005; Krambeck et al., 2009; Fisher and Ungar, 2016). We account for the fact that the enzymes have specific cisternal localization by setting their concentrations to zero in those cisternae where they are not present.
The action of enzyme on the substrate in cisterna is given by
(2)
where . In general, the forward, backward, and catalytic rates , , and , respectively, depend on the cisternal label , the reaction label , and the enzyme label , which parametrize the MM reactions (Price and Stevens, 1999). For instance, structural studies on glycosyltransferase-mediated synthesis of glycans (Moremen and Haltiwanger, 2019) would suggest that the forward rate depends on the binding energy of the enzyme to acceptor substrate and a physical variable that characterizes the cisternae.
A potential candidate for such a cisternal variable is pH (Kellokumpu, 2019), whose value is maintained homeostatically in each cisterna (Casey et al., 2010); changes in pH can affect the shape of an enzyme (substrate) or its charge properties, and in general the reaction efficiency of an enzyme has a pH optimum (Price and Stevens, 1999). Another possible candidate for a cisternal variable is membrane bilayer thickness (Dmitrieff et al., 2013); indeed, both pH (Llopis et al., 1998) and membrane thickness are known to have a gradient across the Golgi cisternae. We take , where is the binding probability of enzyme with substrate , and define the binding probability using a biophysical model, similar in spirit to the Monod-Wyman-Changeux model of enzyme kinetics (Monod et al., 1965; Changeux and Edelstein, 2005) that depends on enzyme-substrate-induced fit.
Let and denote, respectively, the optimal ‘shape’ for enzyme and the substrate . We assume that the mismatch (or distortion) energy between the substrate and enzyme is , with a binding probability given by
(3)
where is a distance metric defined on the space of (e.g. the square of the -norm would be related to an elastic distortion model [Savir and Tlusty, 2007]) and the vector parametrizes enzyme specificity. This distortion model captures the above idea that the reaction between the flexible enzyme and fixed substrate is facilitated by an induced fit. A large value of indicates a highly specific enzyme, a small value of indicates a promiscuous enzyme. It is recognized that the degree of enzyme specificity or sloppiness is an important determinant of glycan distribution (Varki, 2009; Roseman, 2001; Hossler et al., 2007; Yang et al., 2018).
Our synthesis model is mean field, in that we ignore stochasticity in glycan synthesis that may arise from low copy numbers of substrates and enzymes, multiple substrates competing for the same enzymes, and kinetics of inter-cisternal transfer (Umaña and Bailey, 1997; Krambeck et al., 2009; Krambeck and Betenbaugh, 2005). Then the usual MM steady-state conditions for (2), which assumes that the concentration of the intermediate enzyme-substrate complex does not change with time, imply that
where is the concentration of the acceptor substrate in compartment .
Together with the constancy of the total enzyme concentration, , this immediately fixes the kinetics of product formation (not including inter-cisternal transport),
(4)
where
and
This reparametrization of the reaction rates in terms of is convenient since it relates to experimentally measurable parameters and MM constant , for each , which can be easily read out (see Appendix 2). As is the usual case, the maximum velocity is not an intrinsic property of the enzyme because it is dependent on the enzyme concentration ; while is an intrinsic parameter of the enzyme and the enzyme-substrate interaction. The enzyme catalytic efficiency, the so-called “” , is high for perfect enzymes (Bar-Even et al., 2015) with minimum mismatch.
We now add to this chemical reaction kinetics the rates of injection () and inter-cisternal transport from the cisterna to ; in Appendix 3, we display the complete set of equations that describe the changes in the substrate concentrations with time. These kinetic equations automatically obey the conservation law for the protein concentration (). At steady state, these kinetic equations lead to a set of nonlinear recursion equations (15)-(16) that are displayed in Appendix 3, which can be solved numerically to obtain the steady-state glycan concentrations, , as a function of the independent vectors , , and , the transport rates and specificity, .
Optimization problem
Let denote the ‘target’ concentration distribution, normalized to the distribution so that , for a particular cell type, that is, the goal of the sequential synthesis mechanism described in the section ‘Chemical reaction and transport network in cisternae’ is to approximate . Let denote the normalized steady-state glycan concentration distribution displayed on the PM. Then Equation 16 implies that , . We measure the fidelity between the and by the ratio of the KL divergence (Cover and Thomas, 2012; MacKay, 2003) to the entropy
(5)
The reason why we divide the KL divergence by the entropy of the target distribution is to enable comparison of the fidelity of the mechanism across target distributions of different complexity. Note that high fidelity corresponds to low values of , vice versa.
Thus, the problem of designing a sequential synthesis mechanism that approximates for a given enzyme specificity , transport rate , number of enzymes , and number of cisternae is given by
(6)
where we emphasize that the optimum fidelity is a function of . Note that there is a separation of time scales implicit in Optimization A – the chemical kinetics of the production of glycans and their display on the PM happens over cellular time scales, while the issues of trade-offs and changes of parameters are related to evolutionary timescales.
Optimization A, though well-defined, is a hard problem since the steady-state concentrations (16) are not explicitly known in terms of the parameters . In Appendix 4, we formulate an alternative problem Optimization B in which the steady-state concentrations are defined explicitly in terms of new parameters , and , and prove that Optimization A and Optimization B are exactly equivalent. This is a crucial insight that allows us to obtain all the results that follow. In Appendix 5, we describe the variant of the sequential quadratic programming (SQP) (Boyd and Vandenberghe, 2004), which we use to numerically solve the optimization problem.
Results
The dimension of the optimization search space is extremely large . To make the optimization search more manageable, we make the following simplifying assumptions:
We ignore the -dependence of the vectors , or alternatively of – see Appendix 4 for details.
The enzyme-substrate-binding probability is still dependent on the substrate . We assume that the shape function is a scalar (a length), that is, . It further simplifies the algebra to assume that the lengths of the substrates are integer multiples of a basic unit (which we take to be 1), that is, . The norm that appears in (3) is taken to be the absolute value difference . Other metrics, such as , corresponding to the elastic distortion model (Savir and Tlusty, 2007), do not pose any computational difficulties, and we see that the results of our optimization remain qualitatively unchanged.
We drop the dependence of the specificity on and , and take it to be a scalar .
These restrictions significantly reduce the dimension of the optimization search, so much so that in certain limits we can solve the problem analytically (in Appendix 6, we show that Equation 21 can be solved analytically in the limit since the glycan index can be approximated by a continuous variable, and the recursion relations for the steady-state glycan concentrations Equations 15–16 can be cast as a matrix differential equation. This allows us to obtain an explicit expression for the steady-state concentration in terms of the parameters ). This helps us obtain some useful heuristics (Appendix 6) on how to tune the parameters, for example, , , , and others, in order to generate glycan distributions of a given complexity. These heuristics inform our more detailed optimization using ‘realistic’ target distributions.
The calculations in Appendix 6 imply, as one might expect, that the synthesis model needs to be more elaborate, that is, needs a larger number of cisternae or a larger number of enzymes , in order to produce a more complex glycan distribution. For a real cell type in a niche, the specific elaboration of the synthesis machinery would depend on a variety of control costs associated with increasing and . While an increase in the number of enzymes would involve genetic and transcriptional costs, the costs involved in increasing the number of cisternae could be rather subtle.
Notwithstanding the relative control costs of increasing and , it is clear from the special case that increasing the number of cisternae achieves the goal of obtaining an accurate representation of the target distribution. Suppose the target distribution for a fixed , that is, when , and 0 otherwise, and that the enzymes that catalyze the reactions are highly specific. In this limit, Optimization A reduces to a simple enumeration exercise (Jaiman and Thattai, 2018): clearly, one needs enzymes, one for each reactions, in order to generate . For a single Golgi cisterna with a finite cisternal residence time (finite ), the chemical synthesis network will generate a significant steady-state concentration of lower index glycans with , contributing to a low fidelity. To obtain high fidelity, one needs multiple Golgi cisternae with a specific enzyme partitioning with enzymes in cisterna . This argument can be generalized to the case where the target distribution is a finite sum of delta functions. The more general case, where the enzymes are allowed to have variable specificity, needs a more detailed study, to which we turn to next.
Target distribution from coarse-grained MSMS
As discussed in the section ‘Complexity of glycan code’, we obtain the target glycan distribution from glycan profiles for real cells using MSMS measurements (Cummings and Crocker, 2020). The raw MSMS data, however, is not suitable as a target distribution. This is because it is very noisy, with chemical noise in the sample and Poisson noise associated with detecting discrete events being the most relevant (Du et al., 2008). This means that many of the small peaks in the raw data are not part of the signal, and one has to ‘smoothen’ the distribution to remove the impact of noise.
We use MSMS data from human T-cells (Cummings and Crocker, 2020) for our analysis. As discussed in the section ‘Complexity of glycan code’, the GMMs are often used to approximate distributions with a mixed number of modes or peaks (MacKay, 2003), or in our setting, a given fixed complexity. Here, we use a variation of the GMMs (see Appendix 1 for details) to create a hierarchy of increasingly complex distributions to approximate the MSMS raw data. Thus, the 3-GMM and 20-GMM approximations represent the low- and high-complexity benchmarks, respectively. In Appendix 1, we show that the likelihood for the glycan distribution of the human T-cell saturates at 20 peaks. Thus, statistically the human T-cell glycan distribution is accurately approximated by 20 peaks.
This hierarchy allows us to study the trade-off between the complexity of the target distribution and the complexity of the synthesis model needed to generate the distribution as follows. Let denote the -component GMM approximation for the human T-cell MSMS data. We sample this target distribution at indices , that represent the glycan indices, and then renormalize to obtain the discrete distribution . To highlight the role of target distribution complexity, we focus on the 3-GMM (low complexity) and 20-GMM approximation (high complexity) in describing our results.
Trade-offs between number of enzymes, number of cisternae, and enzyme specificity to achieve given complexity
We summarize the main results that follow from an optimization of the parameters of the glycan synthesis machinery to a given target distribution in Figure 3 and Figure 4.
Figure 3
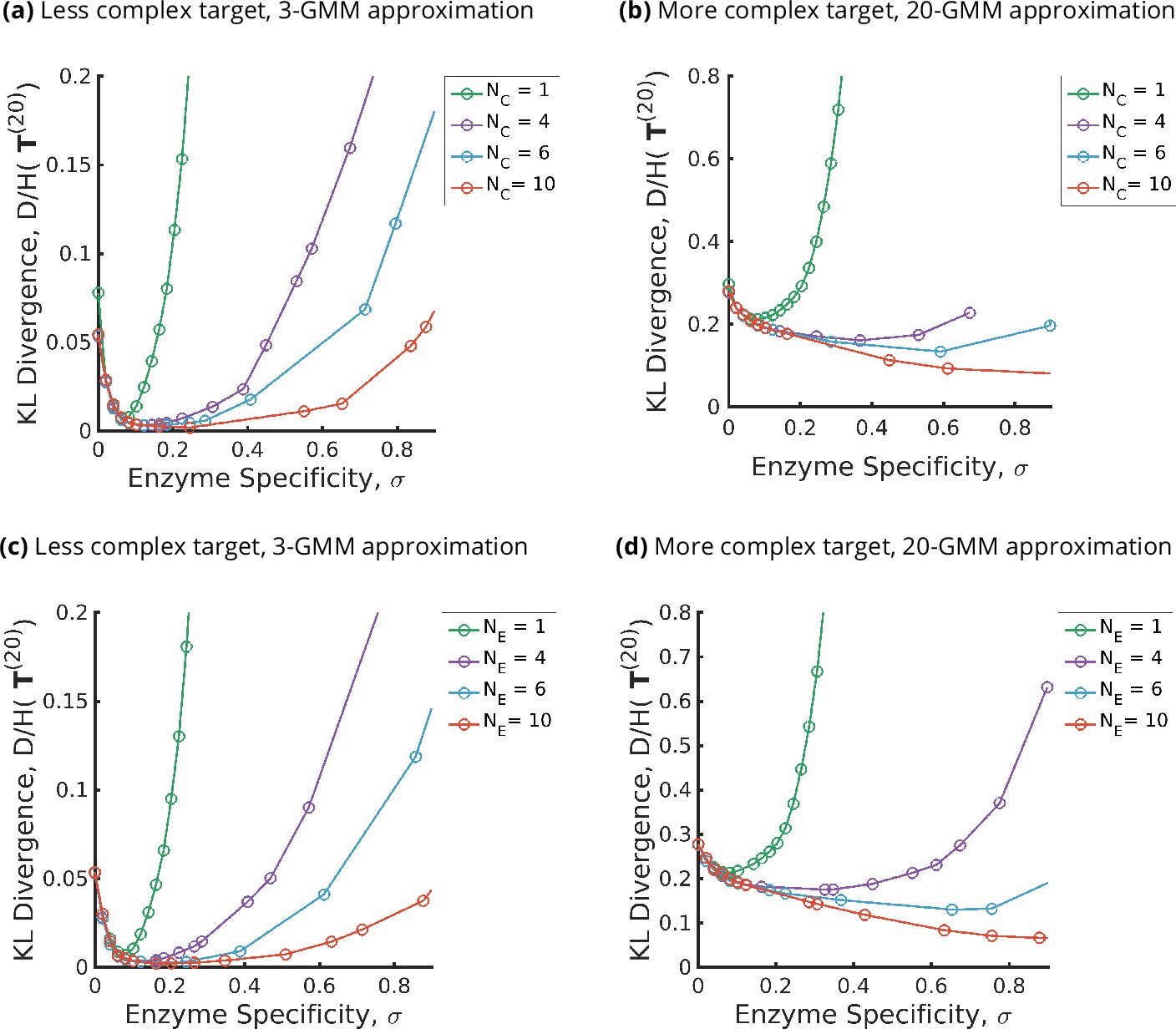
Trade-offs amongst the glycan synthesis parameters, enzyme specificity , cisternal number , and enzyme number to achieve a complex target distribution .
(a, b) Normalised Kullback–Leibler distance as a function of and (for fixed ), (c, d) as a function of and (for fixed ), with the target distribution set to the 3-Gaussian mixture model (GMM) (less complex) and 20-GMM (more complex) approximations for the human T-cell mass spectrometry coupled with determination of molecular structure (MSMS) data. is a convex function of for each , decreasing in for each , increasing in the complexity of for fixed . The specificity that minimizes the error for given is an increasing function of and the complexity of the target distribution .
Figure 4
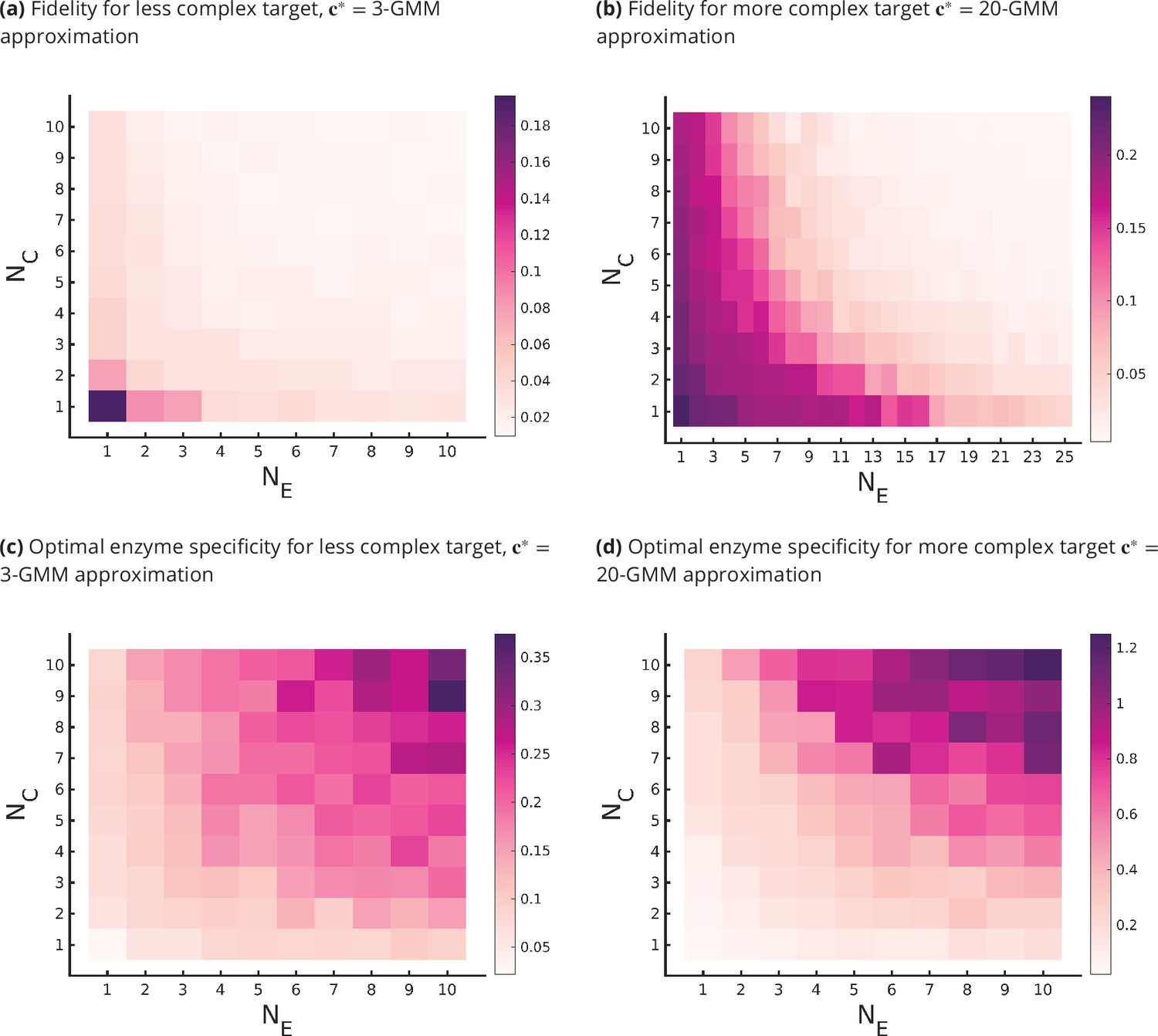
Fidelity of glycan distribution and optimal enzyme properties to achieve a complex target distribution.
The target is taken from 3-Gaussian mixture model (GMM) (less complex) and 20-GMM (more complex) approximations of the human T-cell mass spectrometry coupled with determination of molecular structure (MSMS) data. (a, b) Optimum fidelity as a function of . More complex distributions require either a larger or . The marginal impact of increasing and on the fidelity is approximately equal. (c, d) Enzyme specificity that achieves as a function of . increases with increasing or . To synthesize the more complex 20-GMM approximation with high fidelity requires enzymes with higher specificity compared to those needed to synthesize the broader, less complex 3-GMM approximation.
The optimal fidelity is a convex function of for fixed values for other parameters (see Figure 3), that is, it first decreases with and then increases beyond a critical value of .
The lower complexity distributions can be synthesized with high fidelity with small , whereas higher complexity distributions require significantly larger (see Figure 4a and b). For a typical mammalian cell, the number of enzymes in the N-glycosylation pathway is in the range (Umaña and Bailey, 1997; Krambeck and Betenbaugh, 2005; Krambeck et al., 2009; Fisher and Ungar, 2016), Figure 4b would then suggest that the optimal cisternal number would range from (Sengupta and Linstedt, 2011).
The fidelity is decreasing in and for fixed values of the other parameters, and increasing in the complexity of for fixed . The marginal contribution of and in improving fidelity is approximately equal (see Figure 4a and b). We discuss the origin of this symmetry later in this section.
The optimal enzyme specificity , which minimizes the error as function of with fixed at , is an increasing function of and the complexity of the target distribution (Figure 3a and b and Figure 4c and d). This is consistent with the results in Appendix 6 where we established that the width of the synthesized distribution is inversely dependent on the specificity : since a GMM approximation with fewer peaks has wider peaks, is low, and vice versa. Similar results hold when is fixed at , and is varied (see Figure 3c and d and Figure 4c and d).
Our results are consistent with those in Fisher et al., 2019. They optimize incoming glycan ratio, transport rate, and effective reaction rates in order to synthesize a narrow target distribution centred around the desired glycan. The ability to produce specific glycans without much heterogeneity is an important goal in the pharmaceutical industry. They define heterogeneity as the total number of glycans synthesized and show that increasing the number of compartments decreases heterogeneity and increases the concentration of the specific glycan. They also show that the effect of compartments in reducing heterogeneity cannot be compensated by changing the transport rate. Our results are entirely consistent with theirs – we have shown that decreases as we increase . Thus, if the target distribution has a single sharp peak, increasing will reduce the heterogeneity in the distribution.
We insert an important cautionary note here. It would seem that the results in Figure 4 imply that there is an approximate symmetry in the model, that is, increasing either or affects the fidelity, optimal enzyme specificity, and the sensitivity in approximately the same way. This would be an erroneous inference, and is a consequence of the distortion model we have used for calculating the binding probabilities of substrates with enzymes. The root cause for this apparent symmetry is that we have allowed for all enzymes to catalyze reactions in all cisternae (albeit with different efficiencies). This symmetry is violated by simply restricting the activity of the enzymes to be dependent on the cisternae. A simple realization of this in terms of the distortion model is given in Appendix 7.
Optimal partitioning of enzymes in cisternae
Having studied the optimum to attain a given target distribution with high fidelity, we ask what is the optimal partitioning of the enzymes in these cisternae? Answering this within the context of our chemical reaction model (section ‘Chemical reaction and transport network in cisternae’) requires some care since it incorporates the following enzymatic features: (a) enzymes with a finite specificity can catalyze several reactions, although with an efficiency that varies with both the substrate index and cisternal index , and (b) every enzyme appears in each cisternae; however, their reaction efficiencies depend on the enzyme levels, the enzymatic reaction rates, and the enzyme matching function , all of which depend on the cisternal index .
Therefore, instead of focusing on the cisternal partitioning of enzymes, we identify the chemical reactions that occur with high propensity in each cisternae. For this we define an effective reaction rate for in the jth cisterna as
(7)
According to our model presented in the section ‘Chemical reaction and transport network in cisternae’, the list of reactions with high effective reaction rates in each cisterna corresponds to a cisternal partitioning of the perfect enzymes. In a future study, we will consider a Boolean version of a more complex chemical model to address more clearly the optimal enzyme partitioning amongst cisternae.
Figure 5ai shows the heat map of the effective reaction rates in each cisterna for the optimal that minimizes the normalized KL distance to the 20-GMM target distribution (see Figure 5aii). The optimized glycan profile displayed in Figure 5aiii is very close to the target. An interesting observation from Figure 5ai is that the same reaction can occur in multiple cisternae.
Figure 5
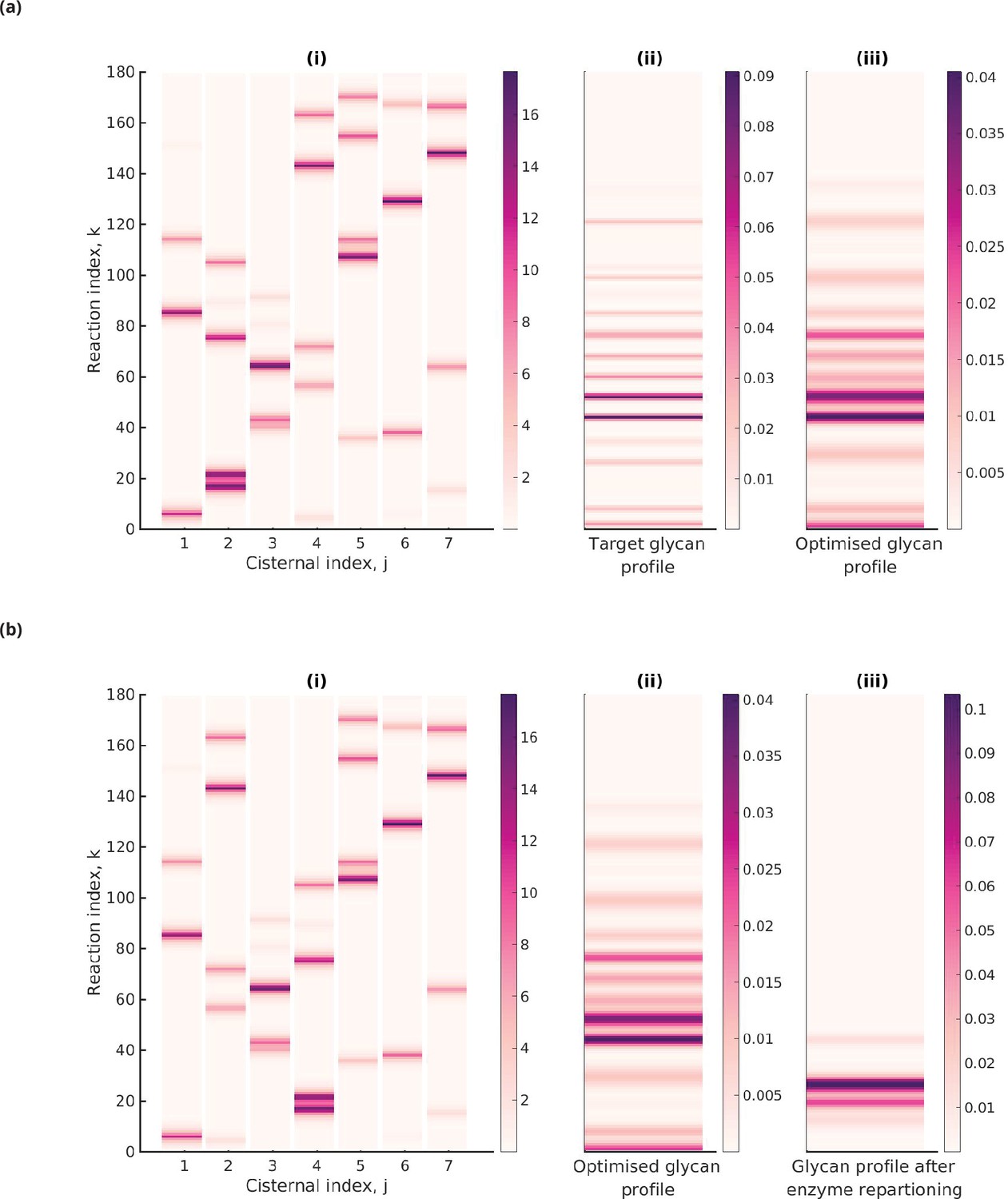
Optimal enzyme partitioning in cisternae.
(a) Heat map of the effective reaction rates in each cisterna (representing the optimal enzyme partitioning) and the steady-state concentration in the last compartment () for the 20-Gaussian mixture model (GMM) target distribution. Here, , , normalized . (b) Effective reaction rates after swapping the optimal enzymes of the fourth and second cisternae. The displayed glycan profile is considerably altered from the original profile.
Keeping everything else fixed at the optimal value, we ask whether simply repartitioning the optimal enzymes amongst the cisternae alters the displayed glycan distribution. In Figure 5bi, we have exchanged the enzymes of the fourth and second cisterna. The glycan profile after enzyme partitioning (see Figure 5biii) is now completely altered (compare Figure 5bii with Figure 5biii). Thus, one can generate different glycan profiles by repartitioning enzymes amongst the same number of cisternae (Jaiman and Thattai, 2018).
Geometry of the fidelity landscape
Here we show that the optimum solution is not unique, rather it is highly degenerate, with several equally good optimum solutions. Thus the multidimensional fidelity landscape in , , , and is typically rugged. We analyse the geometry of this fitness landscape by doing a local Hessian analysis about the optimal solutions.
Degeneracies in the synthesis model
The synthesis model is highly degenerate, in the sense that many combinations of parameters give rise to the same glycan profile. This makes the optimization non-convex as there are many equally good minima. These degeneracies are both discrete and continuous. The continuous degeneracies correspond to regions in reaction rate ()-transport rate () space moving along which does not change the concentration profile. The discrete degeneracies are disconnected regions in the parameter space which correspond to the same glycan profile. The number of discrete degeneracies increases exponentially with increase in (). We also find that the fraction of initial conditions converging to a solution close to the global minima increases on increasing (). Technical details of these issues are discussed in Appendix 8.
Stiff and sloppy directions
We analyse the change in fidelity on small perturbations in , , , and around the optimal solution. This allows us to determine where the cell needs to develop a tighter control mechanism (stiff directions) and where it has more leeway around the optimal values (sloppy directions). We do this by analysing the eigenvalues and eigenvectors of the Hessian around the optimal point (details in Appendix 9). We find that small perturbations around the optimal values in change the glycan profile a lot more compared to perturbations in the other parameters and this stiffness in generally decreases on increasing (Figure 6a–c). Small perturbations in and some directions around the optimum also significantly alter the glycan profile and the stiffness increases on increasing , eventually becoming comparable to . The glycan profile is robust to perturbations in most and some directions (Figure 6b). The total average stiffness of the optimization parameters, defined by the mean of all eigenvalues of the hessian, decreases on increasing (Figure 6c).
Figure 6

Stiff and sloppy directions in the optimization parameters.
(a) Eigenvectors of the Hessian matrix for . The x-axis indexes the eigenvectors, the y-axis indexes the components of the eigenvectors, and the greyscale denotes the absolute value of the component in the range . The components are grouped according to (), and the eigenvectors are ordered according to the most dominant component in the eigenvector (, orange; , blue; , green; , purple). There is some mixing of the different components ( and or and ) but this is usually small. (b) The distribution of eigenvalues of the Hessian matrix . Each stripe represents an eigenvalue, and the location of the stripe on the x-axis represents whether the dominant component of the associated eigenvector belongs to , , , or direction. (c) The average stiffness along , , , or directions, defined by the log of the average of eigenvalues corresponding to the eigenvectors in the respective group, as a function of for fixed . (d) Total average stiffness as a function of .
Implications for robustness to parametric noise
Since the synthesized glycan distribution displayed by the cell marks its identity, it must be robust to noise intrinsic to the synthesis machinery. The degeneracy of solutions and sloppy directions in the fidelity landscape makes the glycan distribution robust to intrinsic noise in the synthesis and cell-to-cell variations in the kinetic parameters. We find that the number of degeneracies increases on increasing (), and the average stiffness of the optimized parameters decreases on increasing (), making the synthesis more robust to parameter fluctuations. Further, while the parameter space is high dimensional, the dimension of controllable parameters (measured by the stiff directions) is low dimensional. We find this dimensional reduction a compelling idea which we will take up later.
Strategies to achieve high glycan diversity
So far we have studied how the complexity of the target glycan distribution places constraints on the evolution of Golgi cisternal number and enzyme specificity. We now take up another issue, namely, how the physical properties of the Golgi cisternae, namely, cisternal number and inter-cisternal transport rate, may drive the diversity of glycans (Varki, 2011; Dennis et al., 2009). There is substantial correlative evidence to support the idea that cell types that carry out extensive glycan processing employ larger numbers of Golgi cisternae. For example, the salivary Brunner’s gland cells secrete mucous that contains heavily O-glycosylated mucin as its major component (Van Halbeek et al., 1983). The Golgi complex in these specialized cells contain 9–11 cisternae per stack. Additionally, several organisms such as plants and algae secrete a rather diverse repertoire of large, complex glycosylated proteins, for a variety of functions (McFarlane et al., 2014; Koch et al., 2015; O’Neill et al., 2004; Hayashi and Kaida, 2011; Kumar et al., 2011; Gow and Hube, 2012; Atmodjo et al., 2013; Free, 2013; Pauly et al., 2013; Burton and Fincher, 2014). These organisms possess enlarged Golgi complexes with multiple cisternae per stack (Becker and Melkonian, 1996; Mironov et al., 2017; Donohoe et al., 2007; Mogelsvang et al., 2003; Ladinsky et al., 2002).
We define diversity as the total number of glycan species produced above a specified threshold abundance . This last condition is necessary because very small peaks will not be distinguishable in the presence of noise. In computing the diversity from our chemical synthesis model, we have chosen the threshold to be , where is the total number of glycan species. We have checked that the qualitative results do not depend on this choice (see Appendix 10—figure 1).
We use the sigmoid function as a differentiable approximation to the Heaviside function and define the following optimization to maximize diversity for a given set of parameter values, :
where, as before, /min, and /min, and is the threshold. See Appendix 2 for details on the parameter estimation.
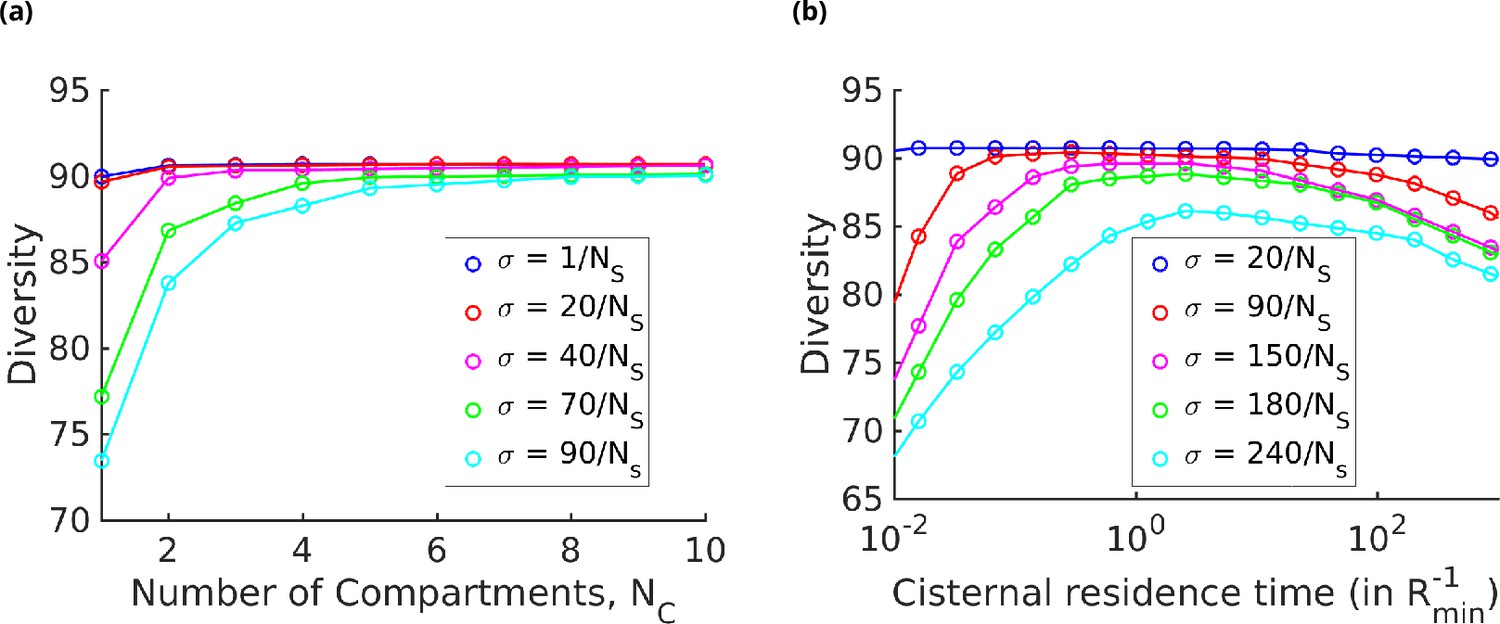
The results displayed in Figure 7a show that for a fixed specificity the diversity at first increases with the number of cisternae , and then saturates at a value that depends on . For very-high-specificity enzymes, one can achieve very high diversity by appropriately increasing . This establishes the link between glycan diversity and cisternal number. However, this link is correlational at best since there are many ways to achieve high glycan diversity – notably by increasing the number of enzymes.
Figure 7
Strategies for achieving high glycan diversity.
Diversity versus and transport rate at various values of specificity for fixed . (a) Diversity vs. at optimal transport rate . Diversity initially increases with , but eventually levels off. The levelling off starts at a higher when is increased. These curves are bounded by the curve. (b) Diversity vs. cisternal residence time () in units of the reaction time () at various value of , for fixed and .
On the other hand, one of the goals of glycoengineering is to produce a particular glycan profile with low heterogeneity (Fisher et al., 2019; Jaiman and Thattai, 2018). For low-specificity enzymes, the diversity remains unchanged upon increasing the cisternal residence time. For enzymes with high specificity, the diversity typically shows a non-monotonic variation with the cisternal residence time. At small cisternal residence time, the diversity decreases from the peak because of the early exit of incomplete oligomers. At large cisternal residence time, the diversity again decreases as more reactions are taken to completion. Note that the peak is generally very flat, which is consistent with the results in Fisher et al., 2019. To get a sharper peak, as advocated for instance by Jaiman and Thattai, 2018, one might need to increase the number of high-specificity enzymes further.
Discussion
The precision of the stereochemistry and enzymatic kinetics of these N-glycosylation reactions (Varki, 2009) has inspired a number of mathematical models (Umaña and Bailey, 1997; Krambeck et al., 2009; Krambeck and Betenbaugh, 2005) that predict the N-glycan distribution based on the activities and levels of processing enzymes distributed in the Golgi cisternae of mammalian cells and compare these predictions with N-glycan mass spectrum data. Models such as the KB2005 model (Umaña and Bailey, 1997; Krambeck and Betenbaugh, 2005; Krambeck et al., 2009) are extremely elaborate (with a network of 22,871 chemical reactions and 7565 oligosaccharide structures) and require many chemical input parameters. These models have an important practical role to play, that of being able to predict the impact of the various chemical parameters on the glycan distribution, and to evaluate appropriate metabolic strategies to recover the original glycoprofile. Additionally, a recent study by Ungar and coworkers (Fisher et al., 2019; Fisher and Ungar, 2016) shows how physical parameters, such as overall Golgi transit time and cisternal number, can be tuned to engineer a homogeneous glycan distribution. Overall, such models can help predict glycosylation patterns and direct glycoengineering projects to optimize glycoform distributions.
Our focus is different. We are interested in the role of glycans as a marker or molecular code of cell identity (Gabius, 2018; Varki, 2017; Pothukuchi et al., 2019), and in particular, understanding enzymatic and transport processes located in the secretory apparatus of the cell that ensure that this code is generated with high fidelity. To do this, we have had to develop a new formal apparatus that allows us to address these questions and discuss trade-offs between competing drives. Since our analysis draws on many diverse fields, we provide a short summary of the assumptions, methods, and results of the article before discussing the implications of our work.
The glycan profile on the cell surface is a marker of cell-type identity (Varki, 2009; Gabius, 2018; Varki, 2017; Pothukuchi et al., 2019). We define the complexity of a glycan profile to be the minimum number of GMM components required to approximate the profile to within the noise floor. We show that with this definition of complexity more complex organisms correlate with higher complexity glycan profiles. We use this to analyse the complexity of the glycan profiles of planaria, hydra, and mammalian cells (Drickamer and Taylor, 1998).
The glycans at the cell surface are the end product of a sequential chemical processing via a set of enzymes resident in the Golgi cisternae and transport across cisternae (Varki, 2017; Varki, 1998; Pothukuchi et al., 2019). We have proposed a general model for chemical synthesis and transport that, in principle, allows us to compute the synthesized glycan distribution at the cell surface as a function of the enzymes , reaction rates , enzyme configurations , specificity of enzymes , number of cisternae , and transport rates . However the large dimension of the search space makes this optimization intractable. We thus use a simplified synthesis model with fewer parameters; while our quantitative results are based on this simplified model, we believe that at a qualitative level our results have more general validity.
We define the fidelity of a synthesis mechanism as the minimum normalized KL divergence (Cover and Thomas, 2012; MacKay, 2003) between synthesized glycan distribution on the cell surface and a ‘target’ profile.
The results of the optimization over rates and enzyme configurations for a given value of and a target distribution of given complexity are given in Figure 3 and Figure 4. Here, we highlight some qualitative consequences of the model:
Keeping the number of enzymes fixed, a more elaborate transport mechanism (via control of and ) is essential for synthesizing high-complexity target distributions to within a high fidelity, or equivalently, low error (Figure 4a and b). Fewer cisternae cannot be compensated for by optimizing the enzymatic synthesis via control of parameters , , and . An empirical verification of this would involve a coordinated analysis of the glycan profiles, ultrastructure of Golgi, and the number of glycosylation enzymes across many species.
Thus, our study suggests that the requirement that a glycan code of a given complexity be synthesized with sufficiently high fidelity imposes functional control on the Golgi cisternal number. It also provides an argument for the evolutionary requirement of multiple compartments by demonstrating that the fidelity and robustness of the glycan code arising from a chemical synthesis that involves multiple cisternae are higher than the one that involves a single cisterna (keeping everything else fixed) (see Figure 4a and b and Figure 6) This feature, that with multiple cisternae and precise enzyme partitioning one may generically achieve a highly accurate representation of the target distribution, has been highlighted in an algorithmic model of glycan synthesis Jaiman and Thattai, 2018.
Combining (a) and (b), our study quantitatively shows that constructing a high-fidelity representation of a complex target distribution, such as those observed in real cells, requires a complex Golgi machinery with multiple cisternae, precise enzyme partitioning, and control on enzyme specificity. This definition of fidelity of the glycan code allows us to provide a quantitative argument for the evolutionary requirement of multiple compartments. While it is possible to produce complex glycan distributions in one compartment using a large number of enzymes, such a design would inevitably require a more elaborate genetic cost.
Organisms such as plants and algae have a diverse repertoire of glycans that are utilized in a variety of functions (McFarlane et al., 2014; Koch et al., 2015; O’Neill et al., 2004; Hayashi and Kaida, 2011; Kumar et al., 2011; Gow and Hube, 2012; Atmodjo et al., 2013; Free, 2013; Pauly et al., 2013; Burton and Fincher, 2014). Our study shows that it is optimal to use low-specificity enzymes to synthesize target distributions with high diversity (Figure 7). However, this compromises on the complexity of the glycan distribution, revealing a tension between complexity and diversity. One way of relieving this tension is to have larger and .
Our study shows that for a fixed and , there is an optimal enzyme specificity that achieves the lowest distance from a given target distribution. As we see in Figure 4d, this optimal enzyme specificity can be very high for highly complex target distributions. Such high specificity can lower fitness when the environment, and hence the target glycan distribution, fluctuates rapidly, and the synthesis parameters cannot change rapidly enough to track the environment (Nam et al., 2012; Peracchi, 2018). This compromise, between robustness to a changing environment and high fidelity in synthesizing high-complexity glycan profiles, is achievable by sloppy enzymes coupled with error-correcting mechanisms (Nam et al., 2012; Peracchi, 2018). However, sloppy enzymes create ‘wrong’ glycans, and therefore, ex-post error-correcting mechanisms must be in place to correct synthesis errors to ensure high fidelity of the glycan code. A task for the future is to understand the role of intracellular transport in providing non-equilibrium proofreading mechanisms to reduce such coding errors, and its optimal adaptive strategies and plasticity in a time-varying environment.
Combining (c) and (d), we find that keeping the number of enzymes fixed, having low specificity or sloppy enzymes, and larger cisternal number could give rise to a diverse repertoire of functional glycans. Sloppy or promiscuous enzymes bring in the potential for evolvability (Kirschner and Gerhart, 2008), and sloppiness allows the system to be stable to random mutations in proteins or variations in the target distribution.
The model solution is degenerate, in the sense that there are many equally good global minimas. These degeneracies are both continuous and discrete. The continuous degeneracies correspond to regions in the reaction rate – transport rate space, moving along which will not change the concentration profile, thus ensuring robustness to internal noise. This suggests that the distribution is robust to slight cell-to-cell variations in these kinetic parameters.
Our model implies that close to a local minima the inter-cisternal transport rate and the specificity of the enzymes are stiff directions, that is, the cell should exercise tighter control on and as compared to the other parameters. The reaction rates close to the local minima are sloppy directions, and moving along these directions does not change the glycan profile much.
Taken together, our quantitative analysis of the trade-offs has deep implications for non-equilibrium self-assembly of the Golgi cisternae, and suggests that the non-equilibrium control of cisternal number must involve a coupling of non-equilibrium self-assembly of cisternae with enzymatic chemical reaction kinetics (Glick and Malhotra, 1998).
Admittedly the chemical network that we have considered here is much simpler than the chemical network associated with the possible protein modifications in the secretory pathway. For instance, typical N-glycosylation pathways would involve the glycosylation of a variety of GBPs. Further, apart from N-glycosylation, there are other glycoprotein, proteoglycan, and glycolipid synthesis pathways (Alberts, 2002; Varki, 2009; Pothukuchi et al., 2019). Our task has been to get at a qualitative understanding using quantitative methods and thereby to arrive at general principles. We believe our analysis is generalizable and that the qualitative results we have arrived at would still hold. To conclude, our work establishes the link between the cisternal machinery (chemical and transport) and high-fidelity synthesis of a complex glycan code. We find that the pressure to achieve the target glycan code for a given cell type places strong constraints on the cisternal number and enzyme specificity (Sengupta and Linstedt, 2011). An important implication is that a description of the non-equilibrium self-assembly of a fixed number of Golgi cisternae must combine the dynamics of chemical processing and membrane dynamics involving fission, fusion, and transport (Sengupta and Linstedt, 2011; Sachdeva et al., 2016; Sens and Rao, 2013). We believe that this is a promising direction for future research.
Appendix 1
Constructing target distributions for glycans of a given cell type
The distribution of the glycans on the cell surface is obtained via mass spectrometry. The x-axis of mass spectroscopy (MS) graphs is mass/charge of the ionized sample molecules, and the y-axis is relative intensity corresponding to each mass/charge value, taking the highest intensity as 100%. This relative intensity roughly correlates with the relative abundances of the molecules in the sample.
The raw MS data is noisy and cannot be directly used as the target distribution in our optimization problem. There are three major sources of noise in the MS data (Du et al., 2008): chemical noise in the sample, the Poisson noise associated with detecting discrete events, and the Nyquist–Johnson noise associated with any charge system. We propose a simple model that accounts for the chemical noise and the Poisson sampling noise. Using this noise model and the available MS data, we generate parametric bootstrap samples of glycan measurements and fit a GMM on this sample to approximate the glycan distribution. This GMM probability distribution is used as the target distribution in our numerical experiments.
The MS data obtained from Cummings and Crocker, 2020; Subramanian et al., 2018; Sahadevan et al., 2014 had mass ranging between 500 and 5000 Da with intensity reported at every 0.0153 Da. We first bin this MS data into 180 bins and take the maximum value within each bin as the value of intensity for that bin. Appendix 1—figure 1 plots the raw MS data and the binned distribution. Next, we describe the parametric bootstrap model that we used to generate the glycan data. Let represent the relative intensity of the kth bin in the binned MS graph. We generate a sample population of glycans using the MS data in the following way:
Poisson sampling noise: The MS data does not have absolute count information. We assume an arbitrary maximum count and define the intensity . The plots in Appendix 1—figure 2a show that the results are not sensitive to the specific value of .
Chemical noise: The sample used for MS analysis also contains small amounts of molecules that are not glycans. These appear as very small peaks in the MS data. We assume that the probability pk that the peak at index corresponds to a glycan is given by
which adequately suppresses this chemical noise.
Bootstrapped glycan data: The count nk at the glycan index is distributed according to the following distribution:
We assume that the MS data was generated from N different cells. Thus, the total count at glycan index k is given by the sum of N i.i.d. samples distributed according to the distribution above. In Appendix 1—figure 2b, we show that results are insensitive to N. We normalize the count distribution by the total number of counts across all the bins to obtain the bootstrapped probability mass function PT.
Appendix 1—figure 1
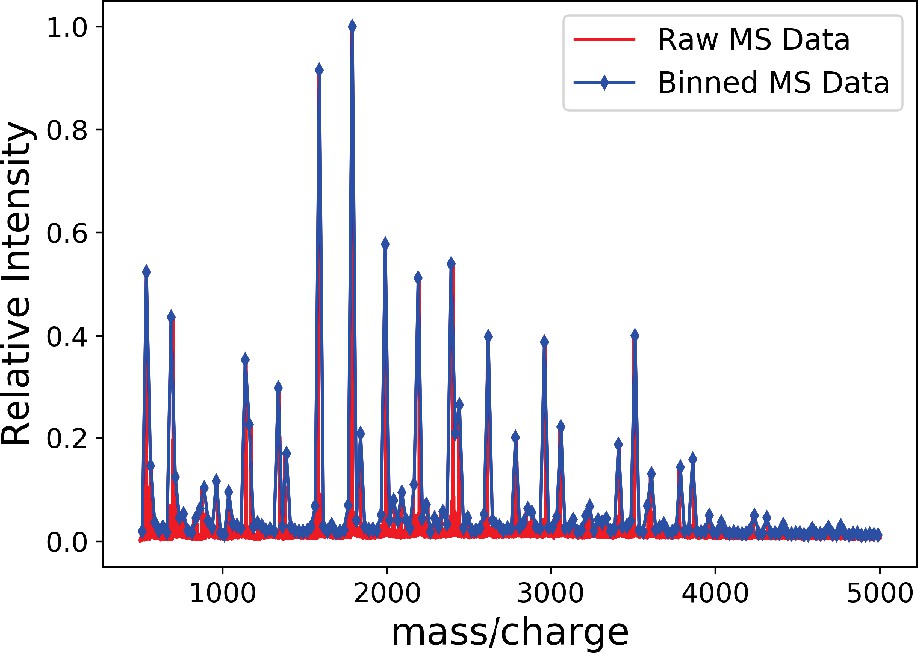
The binned mass spectroscopy (MS) data (blue) approximates the raw MS data (red) very well.
We use this binned data for Gaussian mixture model (GMM) approximation of the MS data.
Appendix 1—figure 2
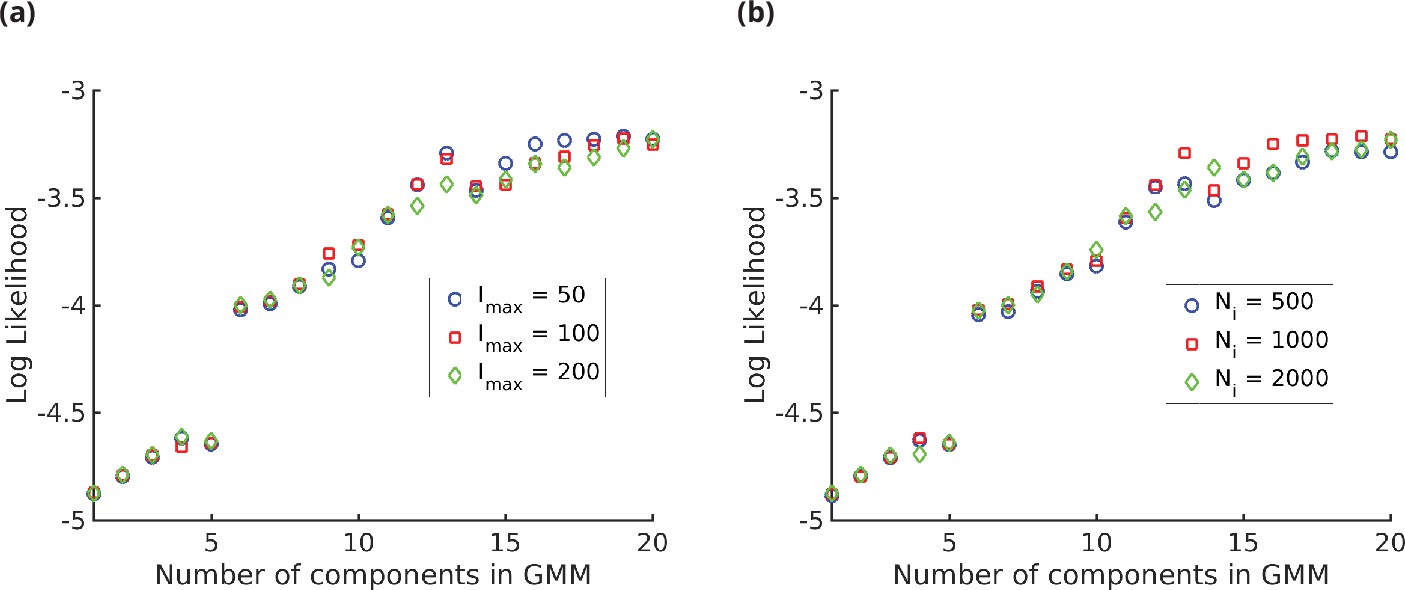
Log likelihood vs. number of components () in the Gaussian mixture model (GMM).
We see that the log likelihood saturates at around,, thus 20-GMM is a very good representation of the mass spectroscopy (MS) data from human T-cells. The different symbols are for (a) different values of the maximum intensity and (b) different values of the number of i.i.d. samples, showing the insensitivity of the log likelihood to the value of and.
The bootstrapped distribution is noisy, and hence cannot be used directly as the target distribution. We use a GMM-based approach to denoise the raw data. The advantage of using a GMM-based approach is that it creates an easily interpretable hierarchy of increasingly more detailed distributions to approximate the mass spectrometry profile. We define the complexity of a mass spectrometry profile as the minimum number of components (individual Gaussians) in the GMM model required to approximate it. The details of the GMM calculations are as follows. We fix the number of components . We want to approximate the bootstrapped probability by the -component mixture of Gaussian distributions , where denotes the Gaussian distribution with mean and variance , and , the parameter vector . We compute the optimal -component GMM approximation by minimizing the KL divergence as a function of parameter vector . Since
the optimization problem is equivalent to
This is a non-convex optimization. We use an expectation-maximization (EM)-based iterative heuristic to compute a local maximum. Let denote the current value of the parameters. For each component , and index , define
Then , and . We interpret as the probability that the count in bin came from component . Define
Then, we have that
and
Define
(8)
Then, we have that
Therefore, the iterative algorithm in (Equation 11) generates a sequence with non-decreasing values of , and the sequence converges to a local maximum. Next, we show that the optimization in (8) can be computed efficiently.
-update
(9)-update
(10)-update
(11)
where is the minimum allowed width of the Gaussians, in our case since glycan index, , takes integer values with spacing 1.
Since this is a heuristic algorithm for a non-convex optimization, we performed several initializations of the algorithm to identify the best local maximum.
The number of components in a GMM is a free parameter. The KL divergence between the true and GMM approximated (), shown in Figure 1, saturates at some value of the number of components, and adding components beyond this only increases model complexity without increasing the quality of approximation. We define the complexity of a mass spectrometry data by the number of components at which saturation is reached. We compare the complexity of glycan profiles of hydra, planaria, and humans. The numbers of cell types in hydra, planaria, and humans are around 41 (Siebert et al., 2019), 44 (Fincher et al., 2018), and 103 (Han et al., 2020), respectively, based on transcriptome analysis (these are lower bounds based on the main cell types, and especially for planaria and hydra, are subject to constant revision). Our analysis of the MSMS data of these organisms suggests that organisms with fewer cell types have less complex glycan distribution.
Appendix 2
Parameter estimation
The typical transport time of glycoproteins across the Golgi complex is estimated to be in the range 15–20 mins (Umaña and Bailey, 1997), which corresponds to the transport rate /min. We bound the transport rate for our optimization between 0.01/min and 1/min.
Next, we estimate the range of values for the chemical reaction rates. The injection rate is in the range 100–1500 pmol/106 cell 24 hr (Umaña and Bailey, 1997; Krambeck et al., 2009). For our calculation, we set pmol/106 cells 24 hr = 0.27 pmol/106 cells min, where 387.30 is the geometric mean of 100 and 1500. We set the range for the enzymatic rate to be
where and denote the Michaelis constants and of the αth enzyme. The conversion from 1 pmol/106 cells to concentration can be obtained by taking cisternal volume () to be 2.5 µm3 (Umaña and Bailey, 1997; Krambeck et al., 2009). This gives
(12)
In Appendix 2—table 1, we report the parameters for the eight enzymes taken from Table 3 in Umaña and Bailey, 1997. From these parameters, it follows that
Appendix 2—table 1
Enzyme parameters taken from Table 3 in Umaña and Bailey, 1997 that we use to calculate the bounds on the reaction rate .
Here, and denote the Michaelis constant and of the αth enzyme.
| (µmol) | (pmol/106 cell-min) | |
|---|---|---|
| 1 | 100 | 5 |
| 2 | 260 | 7.5 |
| 3 | 200 | 5 |
| 4 | 100 | 5 |
| 5 | 190 | 2.33 |
| 6 | 130 | .16 |
| 7 | 3400 | .16 |
| 8 | 4000 | 9.66 |
Appendix 3
Kinetics of sequential chemical reactions and transport
On including the rates of injection () and inter-cisternal transport from the cisterna to into the chemical reaction kinetics, the change in substrate concentrations with time is given by
(13)
for cisterna-1, and
(14)
for cisternae . These set of dynamical equations (13)-(14), with initial conditions, can be solved to obtain the concentration for . Equations (13)-(14) automatically obey the conservation law for the protein concentration (), that is, the total protein concentration in the jth cisterna automatically satisfies
for .
At steady state, the left-hand side of equations (13)-(14) is set to zero, which, after rescaling the kinetic parameters in terms of the injection rate , that is, and , gives the following recursion relations for the steady-state concentrations of the glycans in each cisterna. In the first cisterna,
(15)
and in cisternae ,
(16)
Equations (15)-(16) automatically imply that the total steady-state glycan concentration in each cisterna is given by
Appendix 4
Reformulation of Optimization A
Define a new set of parameters,
(17)
where denotes the steady-state glycan concentration corresponding to a specific . Define by the following set of linear equations:
(18)
for , and
(19)
for . Then, by the definition of in (17), it trivially follows that the steady-state concentration corresponding to is a solution for (18)–(19).
Next, we show that for obtained from (18)–(19) for any parameter , there exists parameter such that (15)–(16) are automatically satisfied when we set , that is, is the steady-state concentration for , and vice versa. Let
and let
Then, our task is to show that . Suppose . Let , , and be the corresponding parameters. Define
Then .
Next, suppose . Let , denote the corresponding parameters. Since , it follows that . Thus, there exist parameters , , and such that
(20)
Therefore, satisfy (15) and (16), that is, .
Thus, the set of all concentration profiles defined by (18)–(19) as a function of all possible values of the parameters is identical to the set defined by (15)–(16) as a function of . This is a crucial insight since it allows us to search the entire parameter space using (18)–(19), where the concentration is known explicitly in terms of .
To pose the new optimization problem, it is convenient to define , for , and . Furthermore, the glycan distribution of the surface is given by . Thus, it follows that Optimization B
(21)
is equivalent to (6). Since is explicitly known as a function of , Optimization B (21) is a more tractable optimization problem than (6). Note that in this setting the function in (21) is independent of the rates . See Appendix 4—figure 1 for a flow chart of the two optimization schemes.
Appendix 4—figure 1
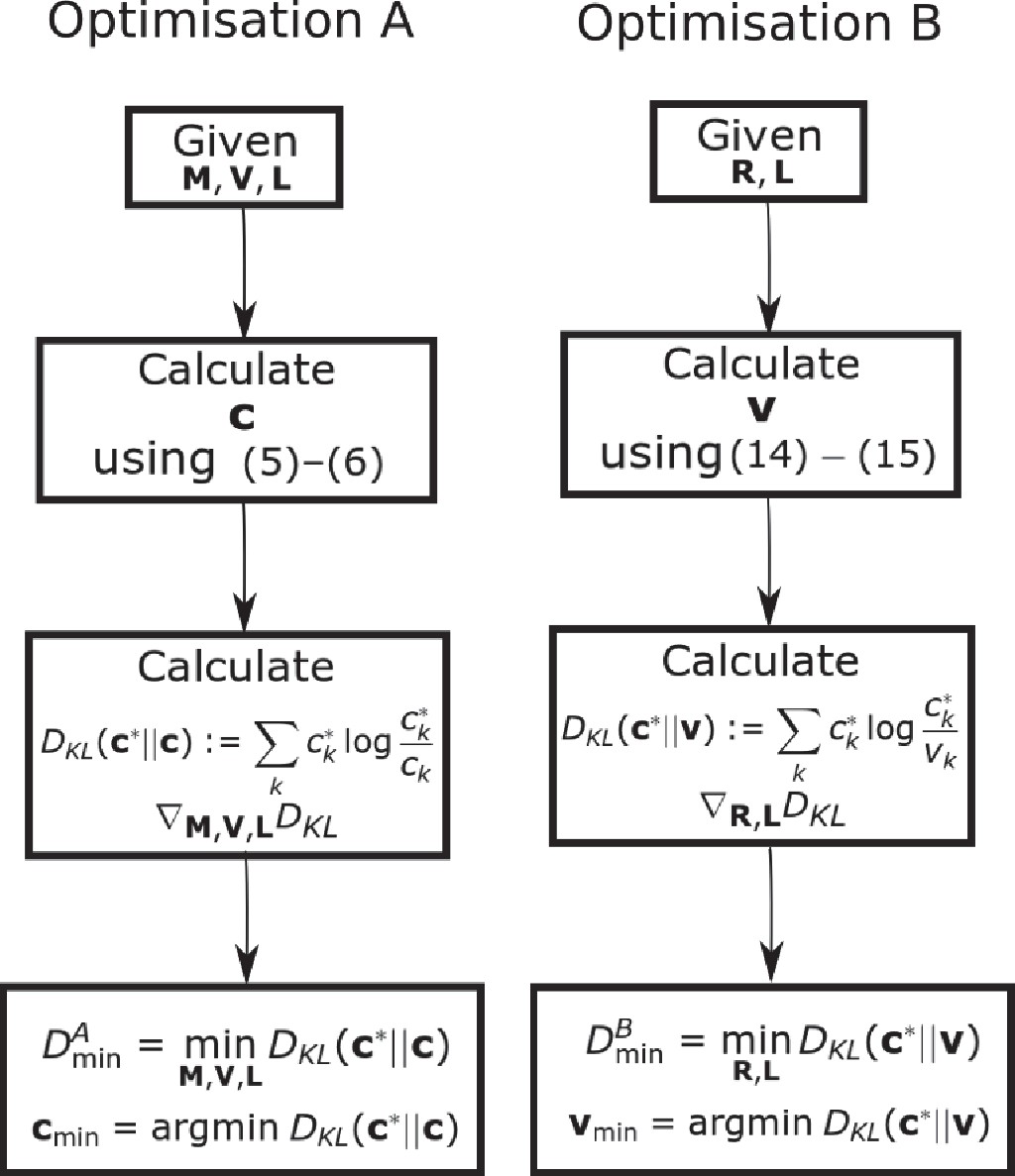
Flow chart showing the optimization schemes for Optimization A and B.
We prove that by showing the set of all is equal to the set of all . We additionally establish that the optimum .
While 21 is easy to implement, we note that the parameters (e.g. reaction rates, specificity) are not constrained to take only physically relevant values; a legitimate concern is that the absence of such physicochemical constraints might drive this optimization to physically unrealistic solutions.
There are two possible ways to impose these parameter constraints. One is to impose constraints on the ‘microscopic’ chemical parameters, such as the rate of individual reactions and the inter-cisternal transport rate . These take into consideration constraints arising from molecular enzymatic processes. The other is to impose constraints on ‘global’ physical parameters, such as the total transport time across the Golgi cisternae and the average enzymatic reaction time. Here, we impose constraints on the microscopic reaction and transport parameters to define constrained Optimization B:
The upper and lower bounds on the rates and are estimated in Appendix 2: /min (resp. /min) and /min (resp. /min).
Appendix 5
Numerical scheme for performing the non-convex optimization
We solve Optimization C using the numerical scheme detailed below. The optimization problem consists of minimizing a non-convex objective with linear box constraints. We use the MATLAB FMINCON function to solve this optimization. We use SQP, a gradient-based iterative optimization scheme for solving optimizations with non-linear differentiable objective and constraints. Since our problem is non-convex and SQP only gives local minima, we initialize the algorithm with many random initial points. We use SOBOLSET function of MATLAB to generate space filling pseudo-random numbers. We have taken 1000 initializations for each , and value. We have taken 50 equally spaced points between 0 and 1 to explore the -space for Figure 3. Some minor fluctuations in due to non-convexity of the objective function in the final results were smoothed out by taking the convex hull of the vs. graph. The results for and (Figure 4) were obtained by adding to the optimization vector and then performing the optimization.
A similar numerical scheme was used to optimize diversity.
Appendix 6
Analytical solution when
It is possible to obtain analytical expressions for the steady-state glycan distribution in the limit when the glycan index can be approximated by a continuous variable. In this case, (15)–(16) can be cast as differential equations,
(22)
and
(23)
for . In equation 22 and equation 23,
(24)
where the indicator function is equal to 1 if the argument is true, and 0 otherwise and is the derivative of with respect to .
Define a vector function of the continuous variable by . Then, (equation 22) and (equation 23) can be written as
(25)
where the matrix is given by
(26)
with
The functions and involve absolute value and indicator functions; therefore, the differential equation has to be solved in a piecewise manner assuming continuity of solution .
The general solution of (25)
(27)
is written in terms of the Magnus function , obtained from the Baker–Campbell–Hausdorff formula (Blanes et al., 2009),
where is the commutator, and the higher order terms in … contain higher order nested commutators.
Here, we establish conditions under which the series that defines solution to the differential equation (25) converges. We also solve (25) for some special cases.
The commutator
where
The general form of is given by Blanes et al., 2009
(28)
where is a permutation of , , and .
Let . Define
We can bound all the matrix elements of in the following way:
(29)
The matrix
where for appropriately defined polynomials . Thus, it follows that and . Consequently, the series will converge if , that is, . Assuming , we can bound as
(30)
Since the parameters , and are finite and positive, and is finite, has a finite upper bound, implying that is always greater than zero, and the series has a finite radius of convergence.
While in principle we can obtain the glycan profile for any and with arbitrary accuracy, assuming , we provide explicit formulae for a few representative cases: (i) and (ii) .
i. : The solution of the differential equation is given by
(31)
A representative concentration profile is plotted in Appendix 6—figure 1. The concentration profile consists of two distinct components: an initial exponential decay, and then an exponential rise and fall concentrated around . The relative weight of these two components is controlled by the sensitivity and the rate . Such explicit formulae can be obtained for any , as long as .
Appendix 6—figure 1
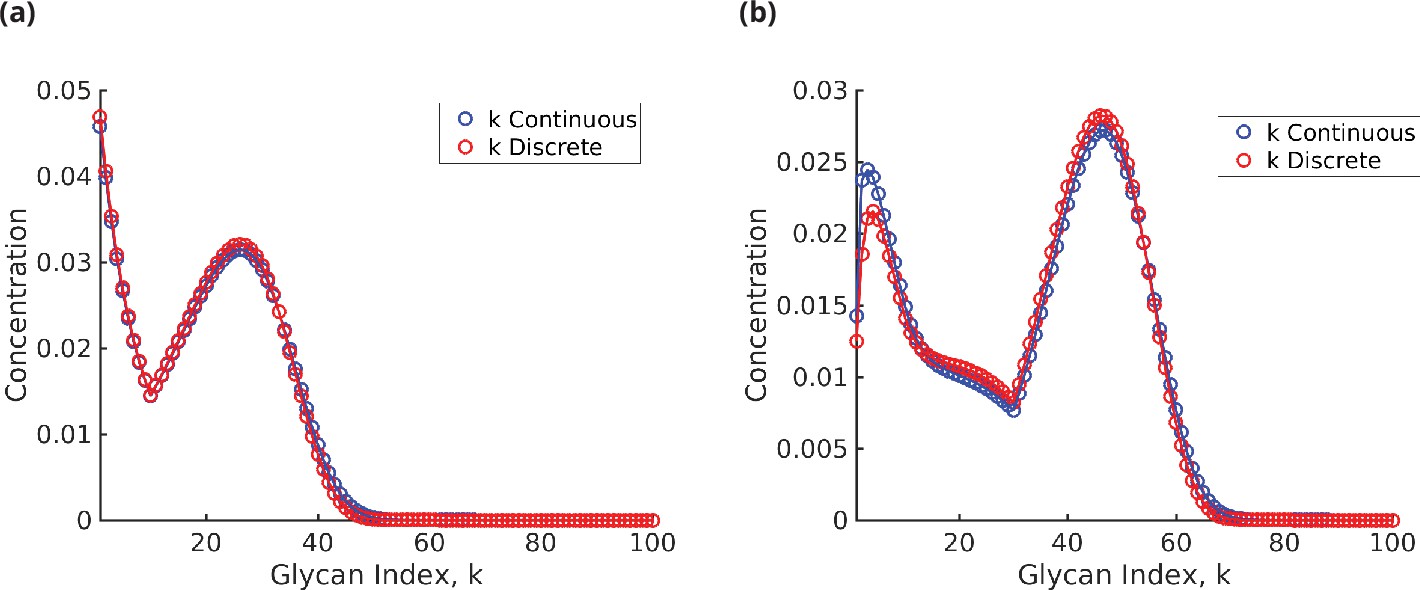
Glycan concentration profile calculated from the model using (a) formula (31) for and (b) formulae (32)–(36) for .
ii. : The concentration profile in cisterna-2 can be obtained from the following calculation. Let denote the ‘length’ of the enzyme in cisterna . For ,
(32)
Next, consider the case where . Then, for
(33)
and for ,
(34)
Next, the case where . For ,
(35)
For ,
(36)
The integrals in (32)–(36) can be evaluated numerically. The result of the numerical computation is shown in Appendix 6—figure 1.
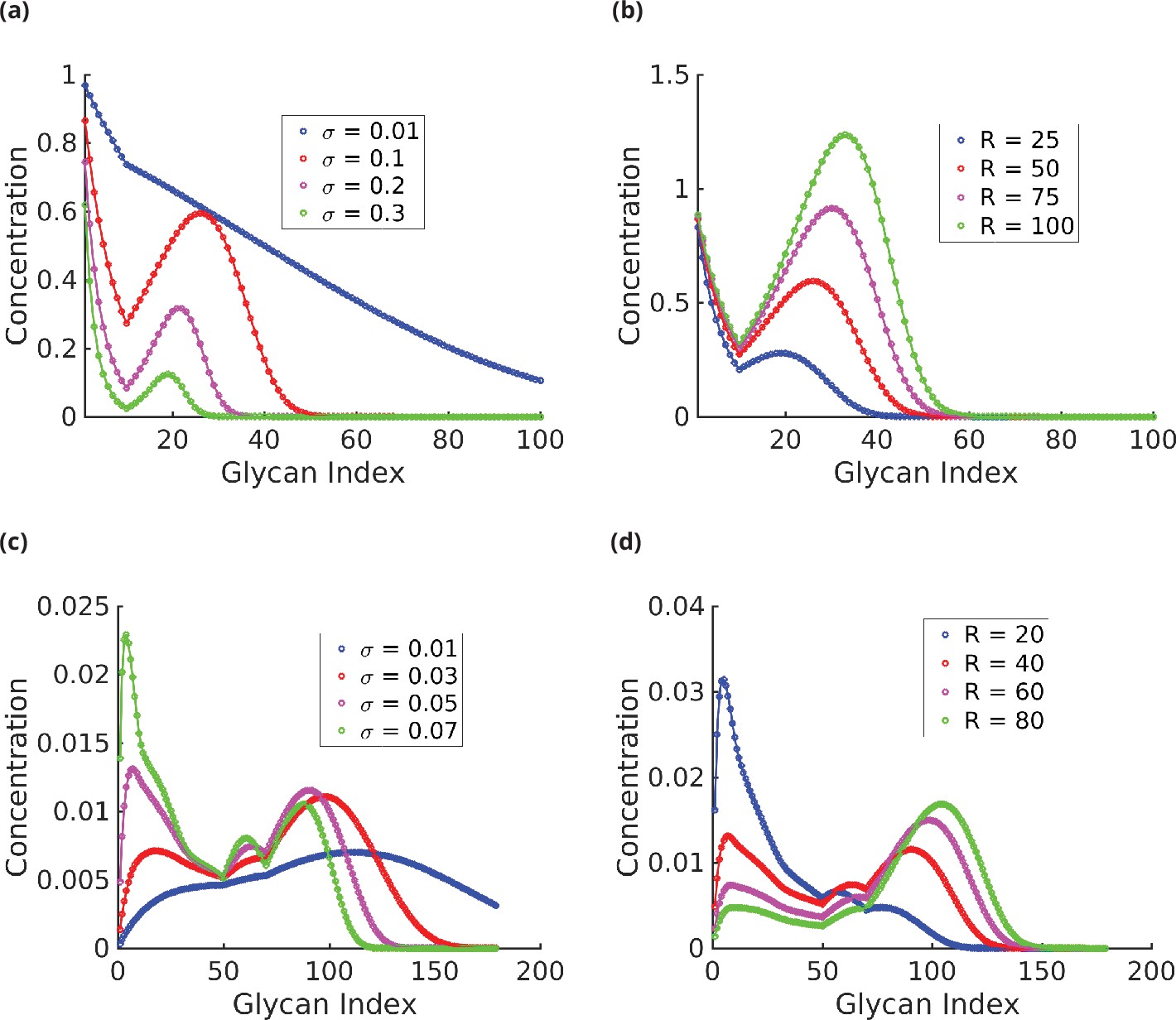
Appendix 6—figure 2a–d plots the glycan profile as one varies the enzyme specificity , the reaction rates , and transport rates , for two different values of and . The results in the plots lead us to the following general observations:
Very-low-specificity enzymes cannot generate complex glycan distributions. Keeping everything else fixed, intermediate or high-specificity enzymes can generate glycan distributions of higher complexity by increasing or (Appendix 6—figure 2a and c).
Decreasing the specificity or increasing the rates increases the proportion of higher index glycans. Keeping everything else fixed, changes in the rate have a stronger impact on the relative weights of the higher index glycans to lower index glycans. The relative weight of the higher index glycans increases with increasing and (Appendix 6—figure 2b–d).
Keeping everything else fixed, decreasing enzyme specificity increases the spread of the distribution around the peaks (Appendix 6—figure 2a and c).
Appendix 6—figure 2
Glycan profile as a function of specificity (a, c) and reaction rates (b, d).
(a) . ck decreases exponentially with for very low and very high ; however, the decay rate is lower at low . For intermediate values of , the distribution has exactly two peaks, one of which is at , and eventually decays exponentially. The width of the distribution is a decreasing function of . (b) . At low , ck is concentrated at low . The proportion of higher index glycans in an increasing function of . (c) . As increases, the distribution becomes more complex – from a single-peaked distribution at low to a maximum of four-peaked distribution at high . The peaks gets sharper, and more well defined as increases. (d) . As in the plots in (b), increasing shifts the peaks towards higher index glycans and the proportion of higher index glycan increases.
Appendix 7
Extended distortion model shows lack of apparent symmetry
The results in Figure 4 seem to imply that there is an approximate symmetry in the model, that is, increasing either or affects the fidelity, optimal enzyme specificity, and the sensitivity in approximately the same way. This is a consequence of the distortion model we are using for calculating the binding probabilities of substrates with enzymes, which allows every enzyme to in principle catalyze any reaction in any cisterna. This allowed for the ideal enzyme length in Equation 3 to vary across the cisternae in an unconstrained manner, leading to simplification in the calculation. We now find that by changing this aspect of the model the apparent symmetry between is lifted. A more reasonable model for the ideal enzyme length is given by
that is, the nominal length can be distorted in a cisterna by a correction but within a specified bound that is not subject to optimization. One can render some enzymes inactive in certain cisternae by choosing appropriate values of and . For small values for the bound , for example, (here, is the number of enzymatic reactions), the decrease in on increasing is small compared to increasing (see Appendix 7—figure 1). On the other hand, for large , for example, , there is an approximate symmetry between and (see Appendix 7—figure 1). Here, we have taken the bounds to be compartment independent, that is, .
Appendix 7—figure 1
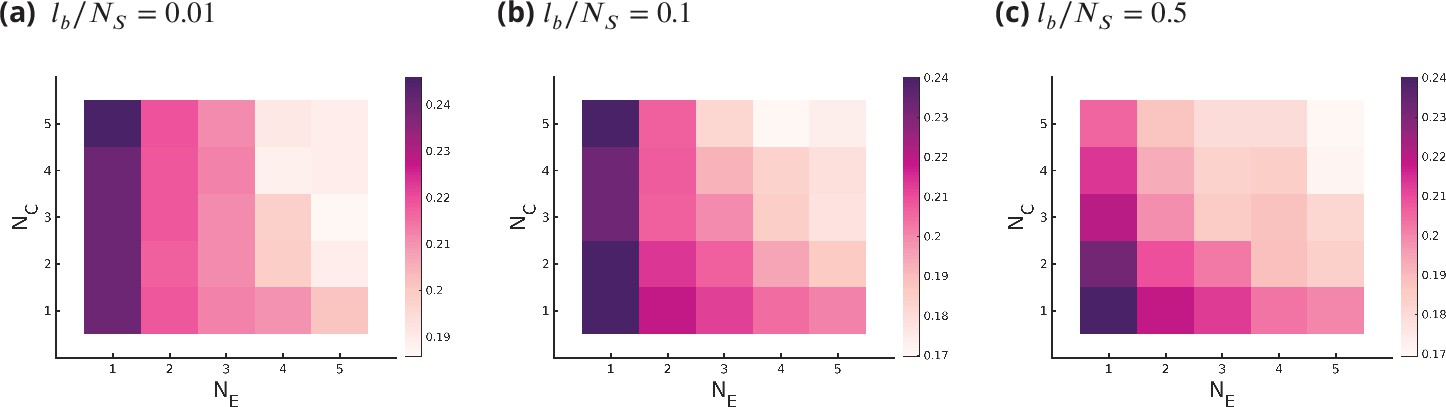
Optimum fidelity as a function of for different values of , where bounds the deformation in the ideal length of an enzyme .
Small values of restrict all enzymes from working in all cisternae and all substrates, where large value of removes this constraint.
Appendix 8
Redundancies and non-convexity of the optimization
Validation of the numerical optimization scheme
In order to test whether our numerical optimization procedure is able to converge to the global minimum, we run the following test. We generate 100 random values of within their respective ranges for a problem instance with . The sampled value for is used to generate concentration profiles that are then used as the target distribution for the optimization. Since the target distribution is achievable, the optimal value of the constrained Optimization B for these sampled targets is . We solve the constrained Optimization B using our numerical scheme. The average optimal value across all sampled values was 9.1835e-07, 30 out of 100 values were exactly zero, and the highest was 1.1761e-05. Therefore, the optimization scheme was able to recover the concentration profiles almost exactly. Next, we ask whether the optimization problem recovers the value of that was used to create the particular target distribution. We were able to recover exactly, except in cases where the concentration profile was almost a delta function at the first glycan (see Appendix 8—figure 1). This is because decides the typical width of the empirical distribution, and hence the optimal is determined by the typical width of the target distribution, except in the pathological case of a concentration profile that is almost a delta function at the first glycan – such a concentration profile can be made produced for any value by simply making transport very fast as compared to the reaction rates.
Appendix 8—figure 1
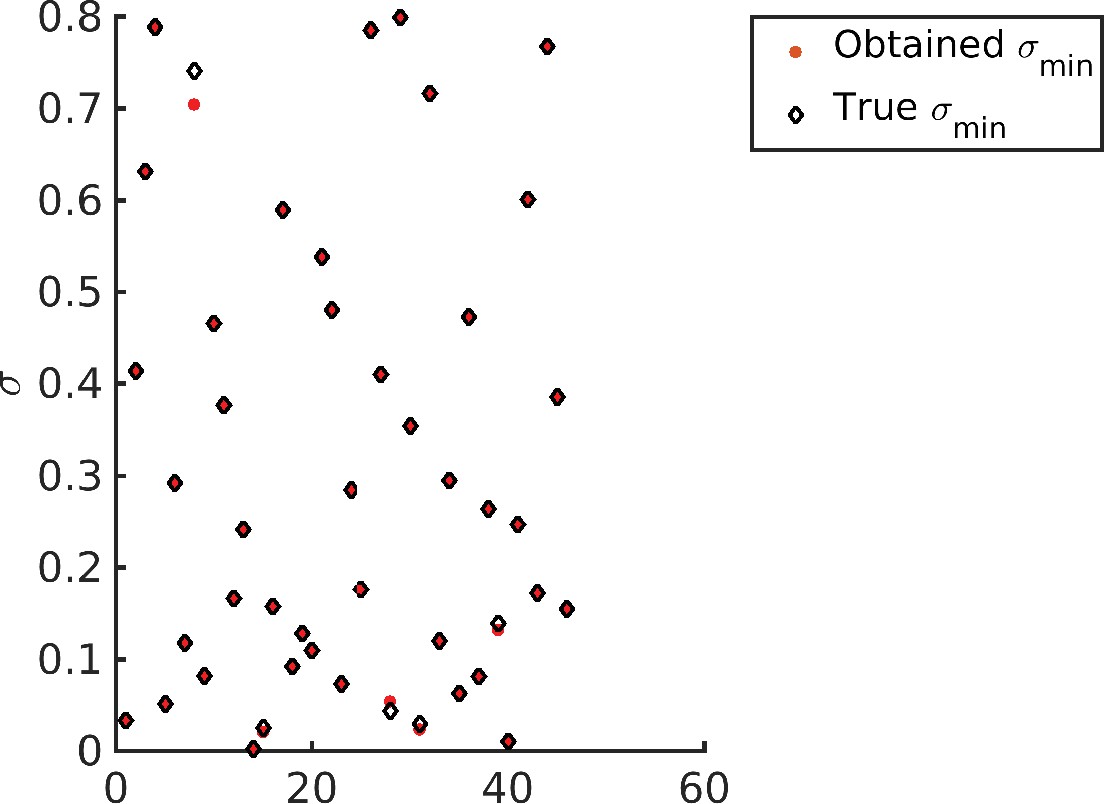
Recovering the values for different target distribution.
Note that barring four data points all other optimized values (red dots) exactly overlap with the corresponding target (diamonds).
We note that the optimization in is not convex and leads to many equally good minimas corresponding to different values of . The resulting redundancies in the model and their importance are discussed next.
Degeneracy in the model
Recall that in equation 7, we defined
In terms of these renormalized rates, the steady-state glycan concentration can be written as
(37)
that is, the concentration is only a function of . Thus, any combination of that maps to the same value of will result in the same concentration profile and will be indistinguishable from the perspective of the objective function. Additionally, the mapping from to the concentration profile also has degeneracy. We show these redundancies in the schematic below, which shows a systematic reduction in dimension to 1 (scalar), which is the quantity we optimize,
Since if and only if , it follows that the last mapping does not have redundancy. Some of the sources of degeneracies in the mapping from to are as follows:
For fixed , setting and leaves invariant.
Permutations in the index leave invariant. Thus, there are at least distinct minima that map to the same value of , and therefore, the same concentration .
Additionally, there are degeneracies coming from the optimization which depend on the target distribution . Having discussed the sources of degeneracies of the optimized solution, we now discuss the distribution of the optimized solutions.
Distribution of minima
To study the behaviour of the optimization algorithm for different initial points, we numerically investigate the distribution of function values at different local minima. Since the dimension of the optimization problem is , which is large, we divide the optimization space into a grid of points. We did this numerical experiment for . The value of for and for the rest. The target distribution for all the cases is a single Gaussian with mean 20, standard deviation 5, with support on . The results of this numerical experiment are summarized in Appendix 8—figure 2 and Appendix 8—table 1, from which we deduce the following:
A large fraction of the initial starting points converge to a set of degenerate minima with objective function value exactly equal to the global minimum. These minima are a result of the degeneracies of the optimization problem.
There are other local minima with objective value very close to (but not equal) the global minimum. Most initial points converge to one of these two sets of minima.
Finally, there are a small set of local minima with significantly higher objective values. These correspond to minima with . The fraction of initial points that converge to such minima reduces as the dimension of the optimization space increases.
Appendix 8—table 1
Distribution of local minima.
| Fraction of initial conditions within | ||||
|---|---|---|---|---|
| 1 | 1 | 0.0228 | 0.44 | 0.56 |
| 2 | 1 | 0.0081 | 0.44 | 0.73 |
| 1 | 2 | 0.0051 | 0.29 | 0.70 |
| 2 | 2 | 1.17e-4 | 0.29 | 0.84 |
Appendix 8—figure 2

for various initial conditions, sorted in increasing order for clarity.
This clearly shows the fraction of initial conditions for which the optimized is small (see Appendix 8—table 1).
Appendix 9
Robustness of optimization to small perturbations
We analyse the sensitivity to small perturbations around the optimal point by calculating the Hessian of the KL divergence,
(38)
Here, denotes the entire set of optimization variables (note that the entries in are normalized by their respective range and do not carry physical dimensions). We calculated the eigenvalues, denoted by , and eigenvectors, denoted by , of the Hessian matrix to identify the stiff and sloppy directions (Gutenkunst et al., 2007; Machta et al., 2013) in the optimization space. The eigenvectors of the Hessian matrix can be grouped in , and directions by looking for the most dominant component in the eigenvector. We find that most of the eigenvectors have significant entries along the direction of only one of the optimization variables , for example, in Figure 6a, the eigenvectors 21–36 have significant entries only in the directions. There is, however, a small number of eigenvectors that have entries over more than one optimization direction, for example, the eigenvector with dominant direction has some component as well (Figure 6a).
Stiff and sloppy directions
We find that the eigenvalues of the eigenvectors dominated by and some , directions are orders of magnitude higher than for those dominated by the directions (see Figure 6b). This suggests that has a valley-like structure around the optimal, with and some being the flat or sloppy directions.
The fact that enzyme specificity and some of the directions are stiff should not be surprising since the typical width and position of peaks in the synthesized distribution are primarily controlled by and . We have already shown that is a sharp convex function of for low values of (see Figure 3), which gradually flattens out as we increase .
The fact that transport rate is a stiff direction is surprising! The stiffness in is due to the fact that the optimal is always at the lower bound, and with even slight increase in , the transport becomes too fast for the reactions to be able to produce the intermediate products. For the -dominated eigenvectors, there are bands of sloppy direction and stiff directions. We define the average stiffness in , and by a weighted average of eigenvalues, where the weight is given by the strength of the corresponding components of the eigenvector.
Here, , , and .
Figure 6c shows , , , and as a function of for fixed . The average stiffness in directions, , is considerably lower than the average stiffness in , and directions. is the stiffest direction but the stiffness decreases on increasing the . Interestingly, the stiffness along directions increases on increasing .
We now define the total average stiffness , that is, log of the sum of the eigenvalues divided by the dimension of the optimization problem, in the space of . We find that the average stiffness is higher for low values of as compared to higher values of , with a few exceptions; and eventually, the average stiffness settles to a fixed low value (Figure 6d).
Appendix 10
Insensitivity of diversity to threshold cth
Since the threshold used to count the number of glycan species in the definition of diversity is arbitrary (see section ‘Strategies to achieve high glycan diversity’), we here show that the qualitative results we obtain are independent of this choice (Appendix 10—figure 1).
Appendix 10—figure 1
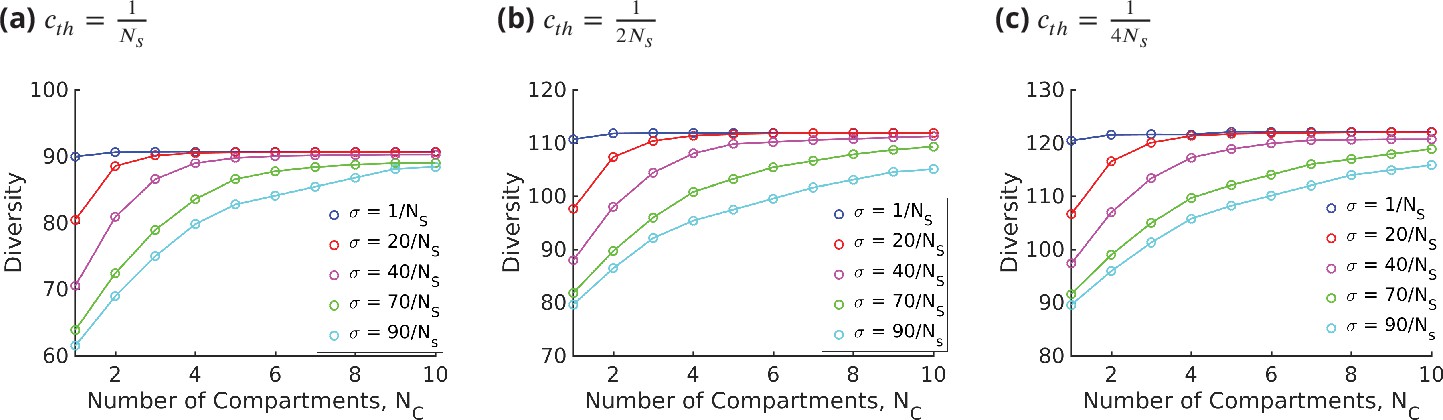
Diversity vs. for different values of keeping fixed, for three different values of the threshold, .
Changing the value of the threshold only changes the saturation value of the diversity curve.
Appendix 11
Table of symbols used in the article (Appendix 11—table 1)
Appendix 11—table 1
Table of symbols and their definitions.
| Symbol | Definition |
|---|---|
| Concentration of th glycan in th compartment | |
| Transport rate from th to compartment | |
| Specificity of the enzymes | |
| Ideal substrate length for αth enzyme in th compartment | |
| Enzyme parameter related to the Michaelis constant | |
| Enzyme parameter related to | |
| Reaction parameter for Optimization B | |
| KL divergence between and | |
| Fidelity, KL divergence normalized by the entropy of the target | |
| Effective reaction rate of th reaction in th compartment |
Data availability
The current manuscript is a computational study, so no data have been generated for this manuscript. The following repository on github contains the code and the data (numerical data + Mass Spec data) that are used in the paper: https://github.com/alkeshyadav/Glycosylation, (copy archived at URL swh:1:rev:a46c6eb76c5f07458d07e44267f48bbaaff6fc5a).
-
GitHubID Glycosylation. Glycan processing in the Golgi: optimal information coding and constraints on cisternal number and enzyme specificity.
References
-
Evolving views of pectin biosynthesisAnnual Review of Plant Biology 64:747–779.https://doi.org/10.1146/annurev-arplant-042811-105534
-
Approximation of probability distributions by convex mixtures of Gaussian measuresProceedings of the American Mathematical Society 138:2619–2628.https://doi.org/10.1090/S0002-9939-10-10340-2
-
Cracking the Glycome Encoder: Signaling, Trafficking, and GlycosylationTrends in Cell Biology 26:379–388.https://doi.org/10.1016/j.tcb.2015.12.004
-
The secretory pathway of protists: spatial and functional organization and evolutionMicrobiological Reviews 60:697–721.https://doi.org/10.1128/mr.60.4.697-721.1996
-
Nucleotide sugar transporters of the Golgi apparatusCurrent Opinion in Structural Biology 10:542–547.https://doi.org/10.1016/s0959-440x(00)00128-7
-
The Magnus expansion and some of its applicationsPhysics Reports 470:151–238.https://doi.org/10.1016/j.physrep.2008.11.001
-
The origins of multicellularityIntegrative Biology 1:27–36.https://doi.org/10.1002/(SICI)1520-6602(1998)1:1<27::AID-INBI4>3.0.CO;2-6
-
Evolution and development of cell walls in cereal grainsFrontiers in Plant Science 5:456.https://doi.org/10.3389/fpls.2014.00456
-
Nucleotide sugar transporters of the Golgi apparatus: from basic science to diseasesAccounts of Chemical Research 39:805–812.https://doi.org/10.1021/ar0400239
-
Sensors and regulators of intracellular pHNature Reviews. Molecular Cell Biology 11:50–61.https://doi.org/10.1038/nrm2820
-
Allosteric mechanisms of signal transductionScience (New York, N.Y.) 308:1424–1428.https://doi.org/10.1126/science.1108595
-
The challenge and promise of glycomicsChemistry & Biology 21:1–15.https://doi.org/10.1016/j.chembiol.2013.12.010
-
Evolving views of protein glycosylationTrends in Biochemical Sciences 23:321–324.https://doi.org/10.1016/s0968-0004(98)01246-8
-
A noise model for mass spectrometry based proteomicsBioinformatics (Oxford, England) 24:1070–1077.https://doi.org/10.1093/bioinformatics/btn078
-
Glycobiology: Toward Understanding the Function of SugarsChemical Reviews 96:683–720.https://doi.org/10.1021/cr940283b
-
Glycosphingolipids: synthesis and functionsThe FEBS Journal 280:6338–6353.https://doi.org/10.1111/febs.12559
-
Cell type transcriptome atlas for the planarian Schmidtea mediterraneaScience (New York, N.Y.) 360:eaaq1736.https://doi.org/10.1126/science.aaq1736
-
Bridging the Gap between Glycosylation and Vesicle TrafficFrontiers in Cell and Developmental Biology 4:15.https://doi.org/10.3389/fcell.2016.00015
-
Fungal cell wall organization and biosynthesisAdvances in Genetics 81:33–82.https://doi.org/10.1016/B978-0-12-407677-8.00002-6
-
The sugar code: Why glycans are so importantBio Systems 164:102–111.https://doi.org/10.1016/j.biosystems.2017.07.003
-
Importance of the Candida albicans cell wall during commensalism and infectionCurrent Opinion in Microbiology 15:406–412.https://doi.org/10.1016/j.mib.2012.04.005
-
Universally sloppy parameter sensitivities in systems biology modelsPLOS Computational Biology 3:0030189.https://doi.org/10.1371/journal.pcbi.0030189
-
Golgi pH, Ion and Redox Homeostasis: How Much Do They Really Matter?Frontiers in Cell and Developmental Biology 7:93.https://doi.org/10.3389/fcell.2019.00093
-
A mathematical model of N-linked glycosylationBiotechnology and Bioengineering 92:711–728.https://doi.org/10.1002/bit.20645
-
Emerging themes in cryptococcal capsule synthesisCurrent Opinion in Structural Biology 21:597–602.https://doi.org/10.1016/j.sbi.2011.08.006
-
Structure of the Golgi and distribution of reporter molecules at 20 degrees C reveals the complexity of the exit compartmentsMolecular Biology of the Cell 13:2810–2825.https://doi.org/10.1091/mbc.01-12-0593
-
Parameter space compression underlies emergent theories and predictive modelsScience (New York, N.Y.) 342:604–607.https://doi.org/10.1126/science.1238723
-
BookInformation Theory, Inference and Learning AlgorithmsCambridge University Press.
-
The Cell Biology of Cellulose SynthesisAnnual Review of Plant Biology 65:69–94.https://doi.org/10.1146/annurev-arplant-050213-040240
-
Tomographic evidence for continuous turnover of Golgi cisternae in Pichia pastorisMolecular Biology of the Cell 14:2277–2291.https://doi.org/10.1091/mbc.e02-10-0697
-
On the nature of allosteric transitions: a plausible modelJournal of Molecular Biology 12:88–118.https://doi.org/10.1016/s0022-2836(65)80285-6
-
Emerging structural insights into glycosyltransferase-mediated synthesis of glycansNature Chemical Biology 15:853–864.https://doi.org/10.1038/s41589-019-0350-2
-
Network context and selection in the evolution to enzyme specificityScience (New York, N.Y.) 337:1101–1104.https://doi.org/10.1126/science.1216861
-
Rhamnogalacturonan II: structure and function of a borate cross-linked cell wall pectic polysaccharideAnnual Review of Plant Biology 55:109–139.https://doi.org/10.1146/annurev.arplant.55.031903.141750
-
The Limits of Enzyme Specificity and the Evolution of MetabolismTrends in Biochemical Sciences 43:984–996.https://doi.org/10.1016/j.tibs.2018.09.015
-
Translation of genome to glycome: role of the Golgi apparatusFEBS Letters 593:2390–2411.https://doi.org/10.1002/1873-3468.13541
-
BookFundamentals of Enzymology: The cell and molecular biology of catalytic proteinsOxford University Press.
-
Reflections on glycobiologyThe Journal of Biological Chemistry 276:41527–41542.https://doi.org/10.1074/jbc.R100053200
-
Control of organelle size: the Golgi complexAnnual Review of Cell and Developmental Biology 27:57–77.https://doi.org/10.1146/annurev-cellbio-100109-104003
-
(Re)modeling the GolgiMethods in Cell Biology 118:299–310.https://doi.org/10.1016/B978-0-12-417164-0.00018-5
-
Stem cell differentiation trajectories in Hydra resolved at single-cell resolutionScience (New York, N.Y.) 365:eaav9314.https://doi.org/10.1126/science.aav9314
-
Identification of multiple isomeric core chitobiose-modified high-mannose and paucimannose N-glycans in the planarian Schmidtea mediterraneaThe Journal of Biological Chemistry 293:6707–6720.https://doi.org/10.1074/jbc.RA117.000782
-
A mathematical model of N-linked glycoform biosynthesisBiotechnology and Bioengineering 55:890–908.https://doi.org/10.1002/(SICI)1097-0290(19970920)55:6<890::AID-BIT7>3.0.CO;2-B
-
Factors controlling the glycosylation potential of the Golgi apparatusTrends in Cell Biology 8:34–40.https://doi.org/10.1016/s0962-8924(97)01198-7
-
Evolutionary forces shaping the Golgi glycosylation machinery: why cell surface glycans are universal to living cellsCold Spring Harbor Perspectives in Biology 3:a005462.https://doi.org/10.1101/cshperspect.a005462
-
A genetic herd-immunity model for the maintenance of MHC polymorphismImmunological Reviews 143:263–292.https://doi.org/10.1111/j.1600-065x.1995.tb00679.x
-
Functional and informatics analysis enables glycosyltransferase activity predictionNature Chemical Biology 14:1109–1117.https://doi.org/10.1038/s41589-018-0154-9
Article and author information
Author details
Funding
Department of Atomic Energy, Government of India (RTI4006)
- Madan Rao
Simons Foundation (287975)
- Madan Rao
JC Bose Fellowship (DST-SERB)
- Madan Rao
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank M Thattai, A Jaiman, S Ramaswamy, and A Varki for discussions, and S Krishna and R Bhat for very useful suggestions on the manuscript. We thank our group members at the Simons Centre for many incisive inputs. We are very grateful to P Babu and PS Sabarinath for consultations on the MSMS data and literature. MR acknowledges support from the Department of Atomic Energy (India), under project no. RTI4006, the Simons Foundation (grant no. 287975), and a JC Bose Fellowship from DST-SERB (India). We acknowledge the computational facilities at NCBS. This work has received support under the program Investissements d’Avenir launched by the French Government and implemented by ANR with the references ANR-10-LABX-0038 and ANR-10-IDEX-0001-02 PSL. MR thanks Institut Curie for hosting a visit under the Labex program, and QV thanks the Simons Centre (NCBS) for hosting his visit.
Copyright
© 2022, Yadav et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,217
- views
-
- 274
- downloads
-
- 8
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 8
- citations for umbrella DOI https://doi.org/10.7554/eLife.76757
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Glycan processing in the Golgi as optimal information coding that constrains cisternal number and enzyme specificity
eLife 11:e76757.
https://doi.org/10.7554/eLife.76757




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}