Population codes enable learning from few examples by shaping inductive bias
- John A Paulson School of Engineering and Applied Sciences, Harvard University, United States
- Center for Brain Science, Harvard University, United States
Abstract
Learning from a limited number of experiences requires suitable inductive biases. To identify how inductive biases are implemented in and shaped by neural codes, we analyze sample-efficient learning of arbitrary stimulus-response maps from arbitrary neural codes with biologically-plausible readouts. We develop an analytical theory that predicts the generalization error of the readout as a function of the number of observed examples. Our theory illustrates in a mathematically precise way how the structure of population codes shapes inductive bias, and how a match between the code and the task is crucial for sample-efficient learning. It elucidates a bias to explain observed data with simple stimulus-response maps. Using recordings from the mouse primary visual cortex, we demonstrate the existence of an efficiency bias towards low-frequency orientation discrimination tasks for grating stimuli and low spatial frequency reconstruction tasks for natural images. We reproduce the discrimination bias in a simple model of primary visual cortex, and further show how invariances in the code to certain stimulus variations alter learning performance. We extend our methods to time-dependent neural codes and predict the sample efficiency of readouts from recurrent networks. We observe that many different codes can support the same inductive bias. By analyzing recordings from the mouse primary visual cortex, we demonstrate that biological codes have lower total activity than other codes with identical bias. Finally, we discuss implications of our theory in the context of recent developments in neuroscience and artificial intelligence. Overall, our study provides a concrete method for elucidating inductive biases of the brain and promotes sample-efficient learning as a general normative coding principle.
Editor's evaluation
This important study presents a theory of generalization in neural population codes and proposes sample efficiency as a new normative principle. The theory can be used to identify the set of 'easily learnable' stimulus-response mappings from neural data and makes strong behavioral predictions that can be evaluated experimentally. Overall, the new method for elucidating inductive biases of the brain is highly compelling and will be of interest to theoretical and experimental neuroscientists working towards understanding how the cortex works.
https://doi.org/10.7554/eLife.78606.sa0Introduction
The ability to learn quickly is crucial for survival in a complex and an everchanging environment, and the brain effectively supports this capability. Often, only a few experiences are sufficient to learn a task, whether acquiring a new word (Carey and Bartlett, 1978) or recognizing a new face (Peterson et al., 2009). Despite the importance and ubiquity of sample efficient learning, our understanding of the brain’s information encoding strategies that support this faculty remains poor (Tenenbaum et al., 2011; Lake et al., 2017; Sinz et al., 2019).
In particular, when learning and generalizing from past experiences, and especially from few experiences, the brain relies on implicit assumptions it carries about the world, or its inductive biases (Wolpert, 1996; Sinz et al., 2019). Reliance on inductive bias is not a choice: inferring a general rule from finite observations is an ill-posed problem which requires prior assumptions since many hypotheses can explain the same observed experiences (Hume, 1998). Consider learning a rule that maps photoreceptor responses to a prediction of whether an observed object is a threat or is neutral. Given a limited number of visual experiences of objects and their threat status, many threat-detection rules are consistent with these experiences. By choosing one of these threat-detection rules, the nervous system reveals an inductive bias. Without the right biases that suit the task at hand, successful generalization is impossible (Wolpert, 1996; Sinz et al., 2019). In order to understand why we can quickly learn to perform certain tasks accurately but not others, we must understand the brain’s inductive biases (Tenenbaum et al., 2011; Lake et al., 2017; Sinz et al., 2019).
In this paper, we study sample efficient learning and inductive biases in a general neural circuit model which comprises of a population of sensory neurons and a readout neuron learning a stimulus-response map with a biologically-plausible learning rule (Figure 1A). For this circuit and learning rule, inductive bias arises from the nature of the neural code for sensory stimuli, specifically its similarity structure. While different population codes can encode the same stimulus variables and allow learning of the same output with perfect performance given infinitely many samples, learning performance can depend dramatically on the code when restricted to a small number of samples, where the reliance on and the effect of inductive bias are strong (Figure 1B, C and D). Given the same sensory examples and their associated response values, the readout neuron may make drastically different predictions depending on the inductive bias set by the nature of the code, leading to successful or failing generalizations (Figure 1C and D). We say that a code and a learning rule, together, have a good inductive bias for a task if the task can be learned from a small number of examples.
Figure 1
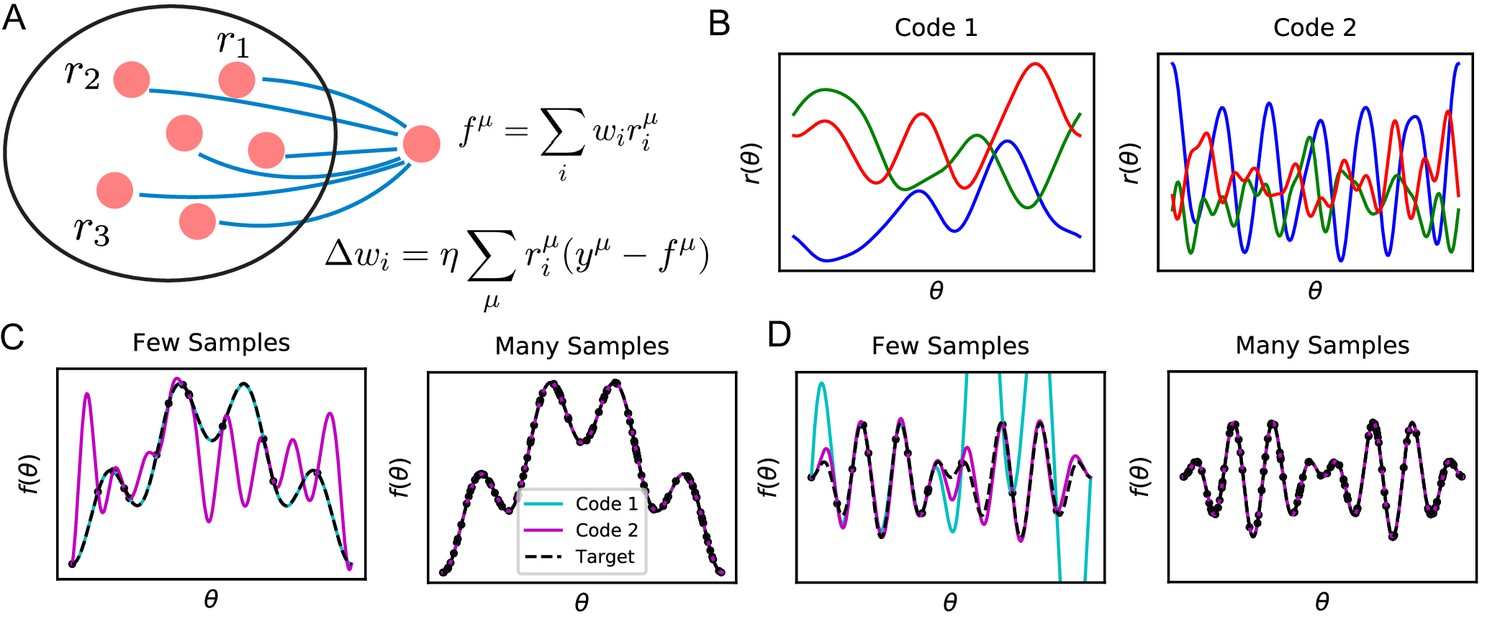
Learning tasks through linear readouts exploit representations of the population code to approximate a target response.
(A) The readout weights from the population to a downstream neuron, shown in blue, are updated to fit target values , using the local, biologically plausible delta rule. (B) Examples of tuning curves for two different population codes: Smooth tuning curves (Code 1) and rapidly varying tuning curves (Code 2). (C) (Left) A target function with low frequency content is approximated through the learning rule shown in A using these two codes. The readout from Code 1 (turquoise) fits the target function (black) almost perfectly with only training examples, while readout from Code 2 (purple) does not accurately approximate the target function. (Right) However, when the number of training examples is sufficiently large (), the target function is estimated perfectly by both codes, indicating that both codes are equally expressive. (D) The same experiment is performed on a task with higher frequency content. (Left) Code 1 fails to perform well with samples indicating mismatch between inductive bias and the task can prevent sample efficient learning while Code 2 accurately fits the target. (Right) Again, provided enough data , both models can accurately estimate the target function. Details of these simulations are given in Methods Generating example codes (Figure 1).
In order to understand how population codes shape inductive bias and allow fast learning of certain tasks over others with a biologically plausible learning rule, we develop an analytical theory of the readout neuron’s learning performance as a function of the number of sampled examples, or sample size. We find that the readout’s performance is completely determined by the code’s kernel, a function which takes in pairs of population response vectors and outputs a representational similarity defined by the inner product of these vectors. We demonstrate that the spectral properties of the kernel introduce an inductive bias toward explaining sampled data with simple stimulus-response maps and determine compatibility of the population code with the learning task, and hence the sample-efficiency of learning. We apply this theory to data from the mouse primary visual cortex (V1) (Stringer et al., 2021; Pachitariu et al., 2019; Stringer et al., 2018a; Stringer et al., 2018b), and show that mouse V1 responses support sample-efficient learning of low frequency orientation discrimination and low spatial frequency reconstruction tasks over high frequency ones. We demonstrate the discrimination bias in a simple model of V1 and show how response nonlinearity, sparsity, and relative proportion of simple and complex cells influence the code’s bias and performance on learning tasks, including ones that involve invariances. We extend our theory to temporal population codes, including codes generated by recurrent neural networks learning a delayed response task. We observe that many codes could support the same kernel function, however, by analyzing data from mouse primary visual cortex (V1) (Stringer et al., 2021; Pachitariu et al., 2019; Stringer et al., 2018a; Stringer et al., 2018b), we find that the biological code is metabolically more efficient than others.
Overall, our results demonstrate that for a fixed learning rule, the neural sensory representation imposes an inductive bias over the space of learning tasks, allowing some tasks to be learned by a downstream neuron more sample-efficiently than others. Our work provides a concrete method for elucidating inductive biases of populations of neurons and suggest sample-efficient learning as a novel functional role for population codes.
Results
Problem setup
We denote vectors with bold lower-case symbols and matrices with bold upper-case symbols. We denote an average of a function over random variable as . Euclidean inner products between vectors are denoted either as or and real Euclidean -space is denoted . Sets of variables are represented with .
We consider a population of neurons whose responses, , vary with the input stimuli, which is parameterized by a vector variable , such as the orientation and the phase of a grating (Figure 1A). These responses define the population code. Throughout this work, we will mostly assume that this population code is deterministic: that identical stimuli generate identical neural responses.
From the population responses, a readout neuron learns its weights to approximate a stimulus-response map, or a target function , such as one that classifies stimuli as apetitive () or aversive (), or a more smooth one that attaches intermediate values of valence. We emphasize that in our model only the readout neuron performs learning, and the population code is assumed to be static through learning. Our theory is general in its assumptions about the structure of the population code and the stimulus-response map considered (Methods Theory of generalization), and can apply to many scenarios.
The readout neuron learns from stimulus-response examples with the goal of generalizing to previously unseen ones. Example stimuli , () are sampled from a probability distribution describing stimulus statistics . This distribution can be natural or artificially created, for example, for a laboratory experiment (Appendix Discrete stimulus spaces: finding eigenfunctions with matrix eigendecomposition). From the set of learning examples, , the readout weights are learned with the local, biologically-plausible delta-rule, ,where is a learning rate (Figure 1A). Learning with weight decay, which privileges readouts with smaller norm, can also be accommodated in our theory as we discuss in (Appendix Weight decay and ridge regression). With or without weight decay, the learning rule converges to a unique set of weights (Appendix Convergence of the delta-rule without weight decay). Generalization error with these weights is given by
(1)
which quantifies the expected error of the trained readout over the entire stimulus distribution . This quantity will depend on the population code , the target function and the set of training examples . Our theoretical analysis of this model provides insights into how populations of neurons encode information and allow sample-efficient learning.
Kernel structure of population codes controls learning performance
First, we note that the generalization performance of the learned readout on a given task depends entirely on the inner product kernel, defined by , which quantifies the similarity of population responses to two different stimuli and . The kernel, or similarity matrix, encodes the geometry of the neural responses. Concretely, distances (in neural space) between population vectors for stimuli can be computed from the kernel (Edelman, 1998; Kriegeskorte et al., 2008; Laakso and Cottrell, 2000; Kornblith et al., 2019; Cadieu et al., 2014; Pehlevan et al., 2018). The fact that the solution to the learning problem only depends on the kernel is due to the convergence of the learning rule to a unique solution for the training set (Neal, 1994; Girosi et al., 1995). The dataset-dependent fixed point of the learning rule is a linear combination of the population vectors on the dataset . Thus, the learned function computed by the readout neuron is
(2)
where the coefficient vector satisfies (Appendix Convergence of the delta-rule without weight decay), and the matrix has entries and . The matrix K+ is the pseudo-inverse of . In these expressions the population code only appears through the kernel , showing that the kernel alone controls the learned response pattern. This result applies also to nonlinear readouts (Appendix Convergence of Delta-rule for nonlinear readouts), showing that the kernel can control the learned solution in a variety of cases.
Since predictions only depend on the kernel, a large set of codes achieve identical desired performance on learning tasks. This is because the kernel is invariant with respect to rotation of the population code. An orthogonal transformation applied to a population code generates a new code with an identical kernel (Appendix Alternative neural codes with same kernel) since . Codes and will have identical readout performance on all possible learning tasks. We illustrate this degeneracy in Figure 2 using a publicly available dataset which consists of activity recorded from ∼20,000 neurons from the primary visual cortex of a mouse while shown static gratings (Stringer et al., 2021; Pachitariu et al., 2019). An original code is rotated to generate (Figure 2A) which have the same kernels (Figure 2B) and the same performance on a learning task (Figure 2C).
Figure 2
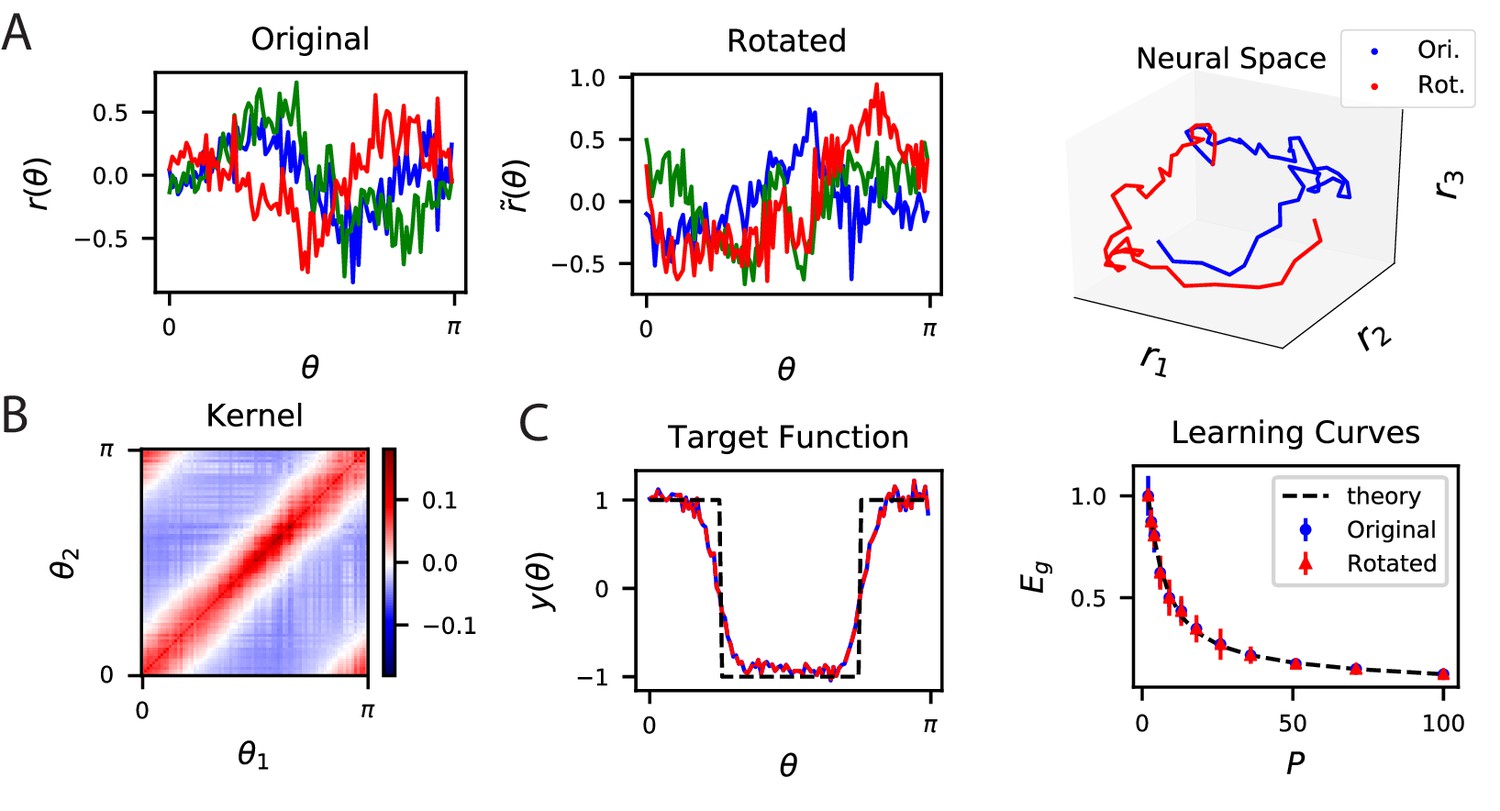
The inner product kernel controls the generalization performance of readouts.
(A) Tuning curves for three example recorded Mouse V1 neurons to varying static grating stimuli oriented at angle (Stringer et al., 2021; Pachitariu et al., 2019) (Left) are compared with a randomly rotated version (Middle) of the same population code. (Right) These two codes, original (Ori.) and rotated (Rot.) can be visualized as parametric trajectories in neural space. (B) The inner product kernel matrix has elements . The original V1 code and its rotated counterpart have identical kernels. (C) In a learning task involving uniformly sampled angles, readouts from the two codes perform identically, resulting in identical approximations of the target function (shown on the left as blue and red curves) and consequently identical generalization performance as a function of training set size (shown on right with blue and red points). The theory curve will be described in the main text.
Code-task alignment governs generalization
We next examine how the population code affects generalization performance of the readout. We calculated analytical expressions of the average generalization error in a task defined by the target response after observing stimuli using methods from statistical physics (Methods Theory of generalization). Because the relevant quantity in learning performance is the kernel, we leveraged results from our previous work studying generalization in kernel regression (Bordelon et al., 2020; Canatar et al., 2021), and approximated the generalization error averaged over all possible realizations of the training dataset composed of stimuli, . As increases, the variance in due to the composition of the dataset decreases, and our expressions become descriptive of the typical case. Our final analytical result is given in Equation (11) in Methods Theory of generalization. We provide details of our calculations in Methods Theory of generalization and Appendix Theory of generalization, and focus on their implications here.
One of our main observations is that given a population code , the singular value decomposition of the code gives the appropriate basis to analyze the inductive biases of the readouts (Figure 3A). The tuning curves for individual neurons form an -by- matrix , where , possibly infinite, is the number of all possible stimuli. We discuss the SVD for continuous stimulus spaces in Appendix Singular value decomposition of continuous population responses. The left-singular vectors (or principal axes) and singular values of this matrix have been used in neuroscience for describing lower dimensional structure in the neural activity and estimating its dimensionality, see e.g. (Stopfer et al., 2003; Kato et al., 2015; Bathellier et al., 2008; Gallego et al., 2017; Sadtler et al., 2014; Stringer et al., 2018b, Stringer et al., 2021; Litwin-Kumar et al., 2017; Gao et al., 2017; Gao and Ganguli, 2015). We found that the function approximation properties of the code are controlled by the singular values, or rather their squares which give variances along principal axes, indexed in decreasing order, and the corresponding right singular vectors , which are also the kernel eigenfunctions (Methods Theory of generalization and Appendix Singular value decomposition of continuous population responses). This follows from the fact that learned response (Equation (2)) is only a function of the kernel , and the eigenvalues and orthonormal (uncorrelated) eigenfunctions collectively define the code’s inner-product kernel through an eigendecomposition (Mercer, 1909) (Methods Theory of generalization and Appendix Theory of generalization).
Figure 3 with 1 supplement see all
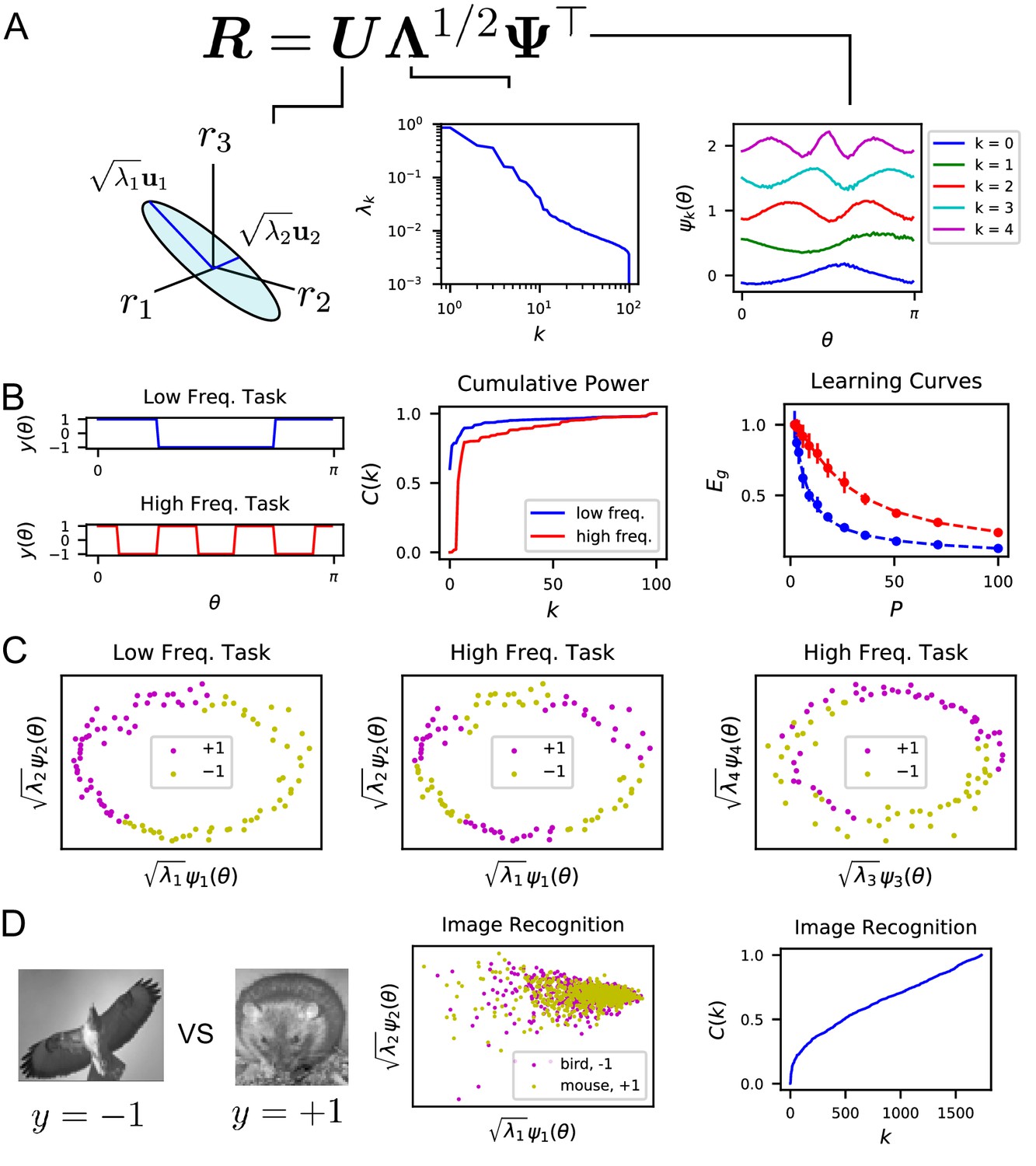
The singular value decomposition (SVD) of the population code reveals the structure and inductive bias of the code.
(A) SVD of the response matrix gives left singular vectors (principal axes), kernel eigenvalues , and kernel eigenfunctions . The ordering of eigenvalues provides an ordering of which modes can be learned by the code from few training examples. The eigenfunctions were offset by 0.5 for visibility. (B) (Left) Two different learning tasks , a low frequency (blue) and high frequency (red) function, are shown. (Middle) The cumulative power distribution rises more rapidly for the low frequency task than the high frequency, indicating better alignment with top kernel eigenfunctions and consequently more sample-efficient learning as shown in the learning curves (right). Dashed lines show theoretical generalization error while dots and solid vertical lines are experimental average and standard deviation over 30 repeats. (C) The feature space representations of the low (left) and high (middle and right) frequency tasks. Each point represents the embedding of a stimulus response vector along the -th principal axis . The binary target value is indicated with the color of the point. The easy (left), low frequency task is well separated along the top two dimensions, while the hard, high frequency task is not linearly separable in two (middle) or even with four feature dimensions (right). (D) On an image discrimination task (recognizing birds vs mice), V1 has an entangled representation which does not allow good performance of linear readouts. This is evidenced by the top principal components (middle) and the slowly rising curve (right).
Our analysis shows the existence of a bias in the readout towards learning certain target responses faster than others. The target response and the learned readout response can be expressed in terms of these eigenfunctions . Our theory shows that the readout’s generalization is better if the target function is aligned with the top eigenfunctions , equivalent to decaying rapidly with (Appendix Spectral bias and code-task alignment). We formalize this notion by the following metric. Mathematically, generalization error can be decomposed into normalized estimation errors for the coefficients of these eigenfunctions , , where . We found that the ordering of the eigenvalues controls the rates at which these mode errors decrease as increases (Methods Theory of generalization, Appendix Spectral bias and code-task alignment), (Bordelon et al., 2020): . Hence, larger eigenvalues mean lower generalization error for those normalized mode errors . We term this phenomenon the spectral bias of the readout. Based on this observation, we propose code-task alignment as a principle for good generalization. To quantify code-task alignment, we use a metric which was introduced in Canatar et al., 2021 to measure the compatibility of a kernel with a learning task. This is the cumulative power distribution which measures the total power of the target function in the top eigenmodes, normalized by the total power (Canatar et al., 2021):
(3)
Stimulus-response maps that have high alignment with the population code’s kernel will have quickly rising cumulative power distributions , since a large proportion of power is placed in the top modes. Target responses with high can be learned with fewer training samples than target responses with low since the mode errors are ordered for all (Appendix Spectral bias and code-task alignment).
Probing learning biases in neural data
Our theory can be used to probe the learning biases of neural populations. Here, we provide various examples of this using publicly available calcium imaging recordings from mouse primary visual cortex (V1). Our examples illustrate how our theory can be used to analyze neural data.
We first analyzed population responses to static grating stimuli oriented at an angle (Stringer et al., 2021; Pachitariu et al., 2019). We found that the kernel eigenfunctions have sinusoidal shape with differing frequency. The ordering of the eigenvalues and eigenfunctions in Figure 3A (and Figure 3—figure supplement 1) indicates a frequency bias: lower frequency functions of are easier to estimate at small sample sizes.
We tested this idea by constructing two different orientation discrimination tasks shown in Figure 3B and C, where we assign static grating orientations to positive or negative valence with different frequency square-wave functions of . We trained the readout using a subset of the experimentally measured neural responses, and measured the readout’s generalization performance. We found that the cumulative power distribution for the low frequency task has a more rapidly rising (Figure 3B). Using our theory of generalization, we predicted learning curves for these two tasks, which express the generalization error as a function of the number of sampled stimuli . The error for the low frequency task is lower at all sample sizes than the hard, high-frequency task. The theoretical predictions and numerical experiments show perfect agreement (Figure 3B). More intuition can be gained by visualizing the projection of the neural response along the top principal axes (Figure 3C). For the low-frequency task, the two target values are well separated along the top two axes. However, the high-frequency task is not well separated along even the top four axes (Figure 3C).
Using the same ideas, we can use our theory to get insight into tasks which the V1 population code is ill-suited to learn. For the task of identifying mice and birds (Stringer et al., 2018b, Stringer et al., 2018a) the linear rise in cumulative power indicates that there is roughly equal power along all kernel eigenfunctions, indicating that the representation is poorly aligned to this task (Figure 3D).
To illustrate how our approach can be used for different learning problems, we evaluate the ability of linear readouts to reconstruct natural images from neural responses to those images (Figure 4). The ability to reconstruct sensory stimuli from a neural code is an influential normative principle for primary visual cortex (Olshausen and Field, 1997). Here, we ask which aspects of the presented natural scene stimuli are easiest to learn to reconstruct. Since mouse V1 neurons tend to be selective towards low spatial frequency bands (Niell and Stryker, 2008Bonin et al., 2011; Vreysen et al., 2012), we consider reconstruction of band-pass filtered images with spatial frequency wave-vector constrained to an annulus for (in units of ) and plot the cumulative power associated with each choice of the upper limit (Figure 4C and D). The frequency cutoffs were chosen in this way to preserve the volume in Fourier space to for , which quantifies the dimension of the function space. We see that the lower frequency band-limited images are easier to reconstruct, as evidenced by their cumulative power and learning curves (Figure 4D and E). This reflects the fact that the population preferentially encodes low spatial frequency content in the image (Figure 4F). Experiments with additional values of are provided in the Figure 4—figure supplement 1 with additional details found in the Appendix Visual scene reconstruction task.
Figure 4 with 1 supplement see all
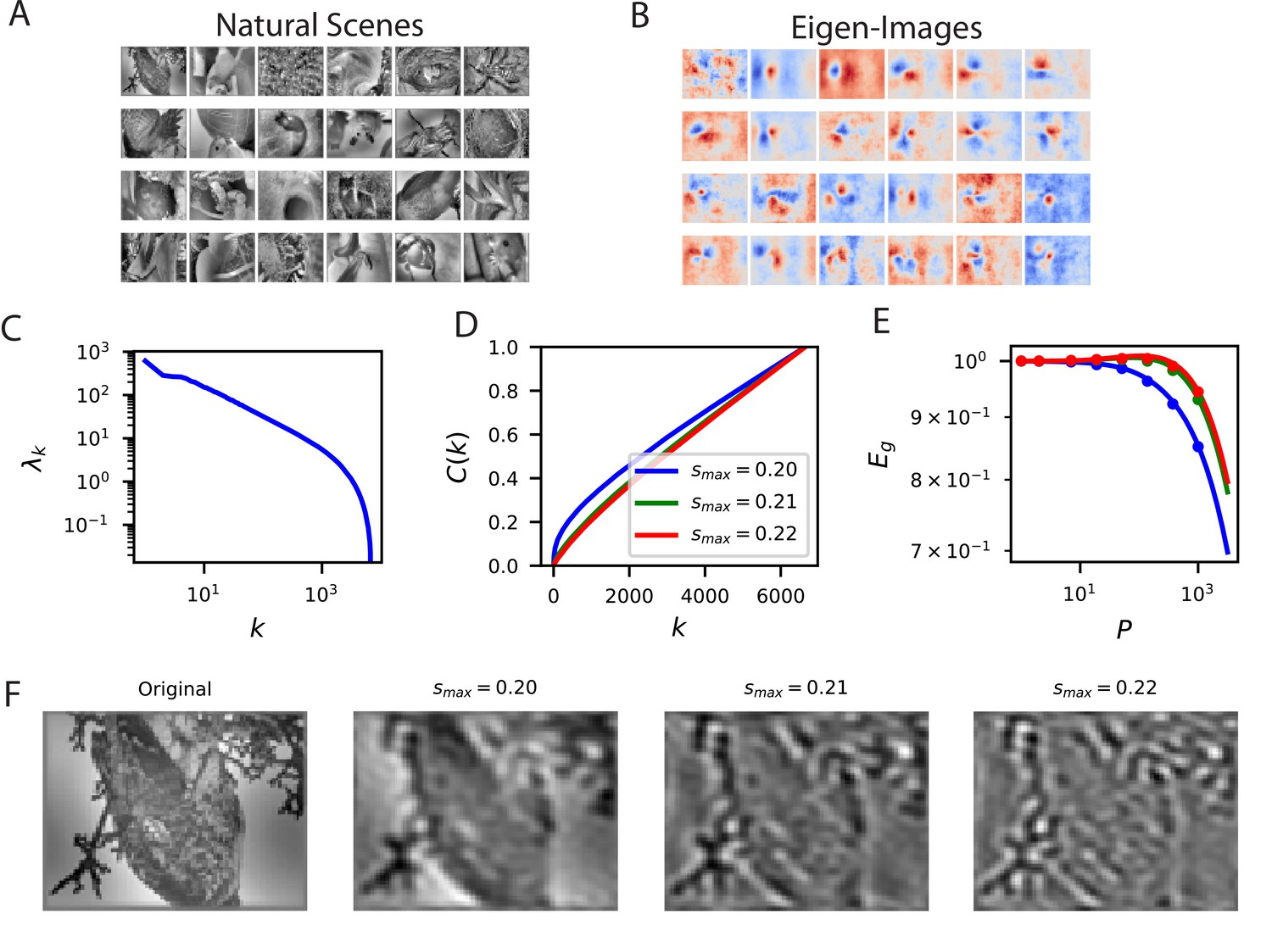
Reconstructing filtered natural images from V1 responses reveals preference for low spatial frequencies.
(A) Natural scene stimuli were presented to mice and V1 cells were recorded. (B) The images weighted by the top eigenfunctions . These “eigenimages" collectively define the difficulty of reconstructing images through readout. (C) The kernel spectrum of the V1 code for natural images. (D) The cumulative power curves for reconstruction of band-pass filtered images. Filters preserve spatial frequencies in the range , chosen to preserve volume in Fourier space as is varied. (E) The learning curves obey the ordering of the cumulative power curves. The images filtered with the lowest band-pass cutoff are easiest to reconstruct from the neural responses. (F) Examples of a band-pass filtered image with different preserved frequency bands.
Mechanisms of spectral bias and code-task alignment in a simple model of V1
How do population level inductive biases arise from properties of single neurons? To illustrate that a variety of mechanisms may be involved in a complex manner, we study a simple model of V1 to elucidate neural mechanisms that lead to the low frequency bias at the population level. In particular, we focus on neural nonlinearities and selectivity profiles.
We model responses of V1 neurons as photoreceptor inputs passed through Gabor filters and a subsequent experimentally motivated power-law nonlinearity (Adelson and Bergen, 1985; Olshausen and Field, 1997; Rumyantsev et al., 2020), modeling a population of orientation selective simple cells (Figure 5A) (see Appendix A simple feedforward model of V1). In this model, the kernel for static gratings with orientation is of the form , and, as a consequence, the eigenfunctions of the kernel in this setting are Fourier modes. The eigenvalues, and hence the strength of the spectral bias, are determined by the nonlinearity as we discuss in Appendix Gabor model spectral bias and fit to V1 data. We numerically fit the parameters of the nonlinearity to the V1 responses and use these parameters our investigations in Figure 5—figure supplement 1.
Figure 5 with 3 supplements see all
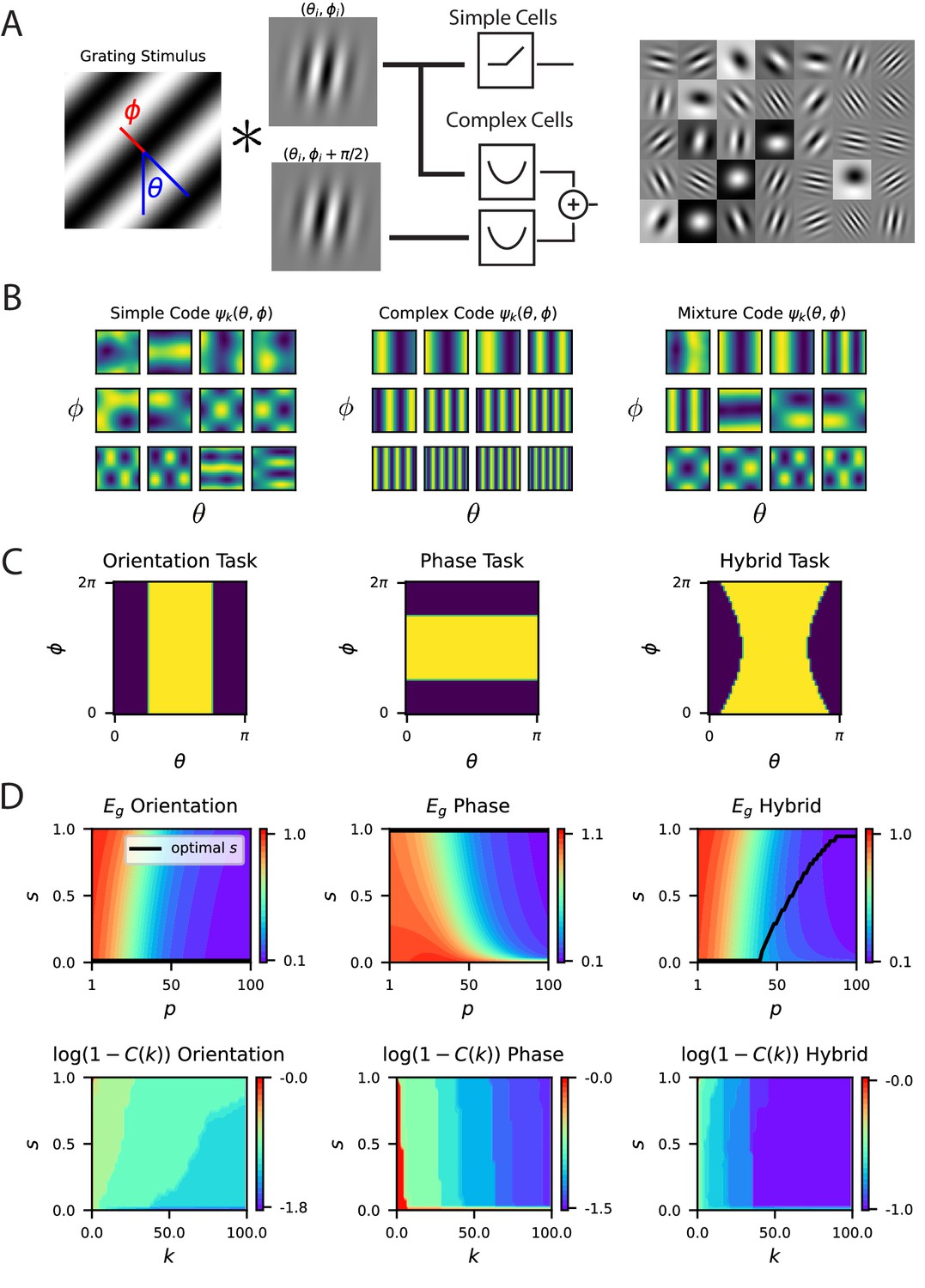
A model of V1 as a bank of Gabor filters recapitulates experimental inductive bias.
(A) Gabor filtered inputs are mapped through nonlinearity. A grating stimulus (left) with orientation and phase is mapped through a circuit of simple and complex cells (middle). Some examples of randomly sampled Gabor filters (right) generate preferred orientation tuning of neurons in the population. (B) We plot the top 12 eigenfunctions (modes) for pure simple cell population, pure complex cell population and a mixture population with half simple and half complex cells. The pure complex cell population has all eigenfunctions independent of phase . A pure simple cell population or mixture codes depend on both orientation phase in a nontrivial way. (C) Three tasks are visualized, where color indicates the binary target value ± 1. The left task only depends on orientation stimulus variable , the middle only depends on phase , the hybrid task (right) depends on both. (D) (top) Generalization error and cumulative power distributions for the three tasks as a function of the simple-complex cell mixture parameter .
Next, to further illustrate the importance of code-task alignment, we study how invariances in the code to stimulus variations may affect the learning performance. We introduce complex cells in addition to simple cells in our model with proportion of simple cells (Appendix Gabor model spectral bias and fit to V1 data; Figure 5A), and allow phase, , variations in static gratings. We use the energy model (Adelson and Bergen, 1985; Simoncelli and Heeger, 1998) to capture the phase invariant complex cell responses (Appendix Phase variation, complex cells and invariance, complex cell populations are phase invariant). We reason that in tasks that do not depend on phase information, complex cells should improve sample efficiency.
In this model, the kernel for the V1 population is a convex combination of the kernels for the simple and complex cell populations where is the kernel for a pure simple cell population that depends on both orientation and phase, and is the kernel of a pure complex cell population that is invariant to phase (Appendix Complex cell populations are phase invariant). Figure 5C shows top kernel eigenfunctions for various values of elucidating inductive bias of the readout.
Figure 5D and E show generalization performance on tasks with varying levels of dependence on phase and orientation. On pure orientation discrimination tasks, increasing the proportion of complex cells by decreasing improves generalization. Increasing the sensitivity to the nuisance phase variable, , only degrades performance. The cumulative power curve is also maximized at . However, on a task which only depends on the phase, a pure complex cell population cannot generalize, since variation in the target function due to changes in phase cannot be explained in the codes’ responses. In this setting, a pure simple cell population attains optimal performance. The cumulative power curve is maximized at . Lastly, in a nontrivial hybrid task which requires utilization of both variables , an optimal mixture exists for each sample budget which minimizes the generalization error. The cumulative power curve is maximized at different values depending on , the component of the target function. This is consistent with an optimal heterogenous mix, because components of the target are learned successively with increasing sample size. V1 must code for a variety of possible tasks and we can expect a nontrivial optimal simple cell fraction . We conclude that the degree of invariance required for the set of natural tasks, and the number of samples determine the optimal simple cell, complex cell mix. We also considered a more realistic model where the relative selectivity of each visual cortex neuron to phase , measured with the F1/F0 ratio takes on a continuum of possible values with some cells more invariant to phase and some less invariant. In (Appendix Energy model with partially phase-selective cells, Figure 5—figure supplement 3) we discuss a simple adaptation of the energy model which can interpolate between a population of entirely simple cells and a population of entirely complex cells, giving diverse selectivity for the intermediate regime. We show that this model reproduces the inductive bias of Figure 5.
Small and large sample size behaviors of generalization
Recently, Stringer et al., 2018b argued that the input-output differentiability of the code, governed by the asymptotic rate of spectral decay, may be enabling better generalization. Our results provide a more nuanced view of the relation between generalization and kernel spectra. First, generalization with low sample sizes crucially depend on the top eigenvalues and eigenfunctions of the code’s kernel, not the tail. Second, generalization requires alignment of the code with the task of interest. Non-differentiable codes can generalize well if there is such an alignment. To illustrate these points, here, we provide examples where asymptotic conditions on the kernel spectrum are insufficient to describe generalization performance for small sample sizes (Figure 6, Figure 6—figure supplement 1 and Appendix Asymptotic power law scaling of learning curves), and where non-differentiable kernels generalize better than differentiable kernels (Figure 6—figure supplement 2).
Figure 6 with 2 supplements see all

The top eigensystem of a code determines its low- generalization error.
(A) A periodic variable is coded by a population of neurons with tuning curves of different widths (top). Narrow, wide and optimal refers to the example in C. These codes are all smooth (infinitely differentiable) but have very different feature space representations of the stimulus variable , as random projections reveal (below). (B) (left) The population codes in the above figure induce von Mises kernels with different bandwidths . (right) Eigenvalues of the three kernels. (C) (left) As an example learning task, we consider estimating a ‘bump’ target function. The optimal kernel (red, chosen as optimal bandwidth for ) achieves a better generalization error than either the wide (green) or narrow (blue) kernels. (middle) A contour plot shows generalization error for varying bandwidth and sample size . (right) The large generalization error scales in a power law. Solid lines are theory, dots are simulations averaged over 15 repeats, dashed lines are asymptotic power law scalings described in main text. Same color code as B and C-left.
Our example demonstrates how a code allowing good generalization for large sample sizes can be disadvantageous for small sizes. In Figure 6A, we plot three different populations of neurons with smooth (infinitely differentiable) tuning curves that tile a periodic stimulus variable, such as the direction of a moving grating. The tuning width, , of the tuning curves strongly influences the structure of these codes: narrower widths have more high frequency content as we illustrate in a random 3D projection of the population code for (Figure 6A). Visualization of the corresponding (von Mises) kernels and their spectra are provided in Figure 6B. The width of the tuning curves control bandwidths of the kernel spectra Figure 6B, with narrower curves having an later decay in the spectrum and higher high frequency eigenvalues. These codes can have dramatically different generalization performance, which we illustrate with a simple “bump" target response (Figure 6C). In this example, for illustration purposes, we let the network learn with a delta-rule with a weight decay, leading to a regularized kernel regression solution (Appendix Weight decay and ridge regression). For a sample size of , we observe that codes with too wide or too narrow tuning curves (and kernels) do not perform well, and there is a well-performing code with an optimal tuning curve width , which is compatible with the width of the target bump, . We found that optimal is different for each (Figure 6C). In the large- regime, the ordering of the performance of the three codes are reversed (Figure 6C). In this regime generalization error scales in a power law (Appendix Asymptotic power law scaling of learning curves) and the narrow code, which performed worst for , performs the best. This example demonstrates that asymptotic conditions on the tail of the spectra are insufficient to understand generalization in the small sample size limit. The bulk of the kernel’s spectrum needs to match the spectral structure of the task to generalize efficiently in the low-sample size regime. However, for large sample sizes, the tail of the eigenvalue spectrum becomes important. We repeat the same exercise and draw the same conclusions for a non-differentiable kernel (Laplace) (Figure 6—figure supplement 1) showing that these results are not an artifact of the infinite differentiability of von Mises kernels. We further provide examples where non-differentiable kernels generalizing better than differentiable kernels in Figure 6—figure supplement 2.
Time-dependent neural codes
Our framework can directly be extended to learning of arbitrary time-varying functions of time-varying inputs from an arbitrary spatiotemporal population code (Methods RNN experiment, Appendix Time dependent neural codes). In this setting, the population code is a function of an input stimulus sequence and possibly its entire history, and time . A downstream linear readout learns a target sequence from a total of examples that can come at any time during any sequence.
As a concrete example, we focus on readout from a temporal population code generated by a recurrent neural network in a task motivated by a delayed reach task (Ames et al., 2019; Figure 7A and B). In this task, the network is presented for a short time an input cue sequence coding an angular variable which is drawn randomly from a distribution (Figure 7C). The recurrent neural network must remember this angle and reproduce an output sequence which is a simple step function whose height depends on the angle which begins after a time delay from the cessation of input stimulus and lasts for a short time (Figure 7D).
Figure 7
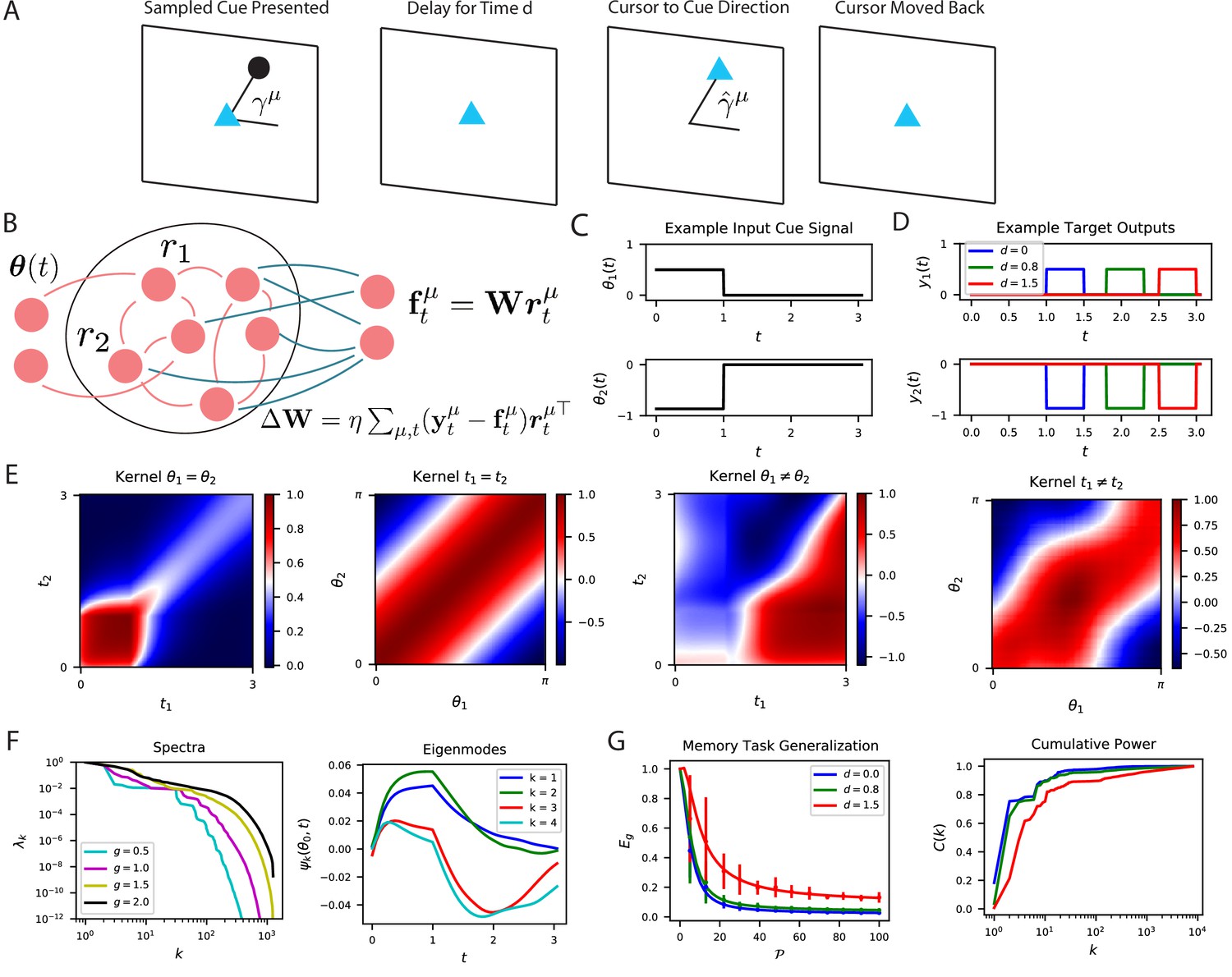
The performance of time-dependent codes when learning dynamical systems can be understood through spectral bias.
(A) We study the performance of time dependent codes on a delayed response task which requires memory retrieval. A cue (black dot) is presented at an angle . After a delay time , the cursor position (blue triangle) must be moved to the remembered cue position and then subsequently moved back to the origin after a short time. (B) The readout weights (blue) of a time dependent code can be learned through a modified delta rule. (C) Input is presented to the network as a time series which terminates at . The sequences are generated by drawing an angle and using two step functions as input time-series that code for the cosine and the sine of the angle (Methods RNN experiment, Appendix Time dependent neural codes). We show an example of the one of the variables in a input sequence. (D) The target functions for the memory retrieval task are step functions delayed by a time . (E) The kernel compares the code for two sequences at two distinct time points. We show the time dependent kernel for identical sequences (left) and the stimulus dependent kernel for equal time points (middle left) as well as for non-equal stimuli (middle right) and non-equal time (right). (F) The kernel can be diagonalized, and the eigenvalues determine the spectral bias of the reservoir computer (left). We see that higher gain networks have higher dimensional representations. The ‘eigensystems’ are functions of time and cue angle. We plot only components of top systems (right). (G) The readout is trained to approximate a target function , which requires memory of the presented cue angle. (left) The theoretical (solid) and experimental (vertical errorbar, 100 trials) generalization error are plotted for the three delays against training sample size . (right) The ordering of matches the ordering of the curves as expected.
The kernel induced by the spatiotemporal code is shown in Figure 7E. The high dimensional nature of the activity in the recurrent network introduces complex and rich spatiotemporal similarity structure. Figure 7F shows the kernel’s eigensystem, which consists of stimulus dependent time-series for each eigenvalue . An interesting link can be made with this eigensystem and linear low-dimensional manifold dynamics observed in several cortical areas (Stopfer et al., 2003; Kato et al., 2015; Gallego et al., 2017; Cunningham and Yu, 2014; Sadtler et al., 2014; Gao and Ganguli, 2015; Gallego et al., 2018; Chapin and Nicolelis, 1999; Bathellier et al., 2008). The kernel eigenfunctions also define the latent variables obtained through a singular value decomposition of the neural activity (Gallego et al., 2017). With enough samples, the readout neuron can learn to output the desired angle with high fidelity (Figure 7G). Unsurprisingly, tasks involving long time delays are more difficult and exhibit lower cumulative power curves. Consequently, the generalization error for small delay tasks drops much more quickly with increasing samples .
Biological codes are metabolically more efficient and more selective than other codes with identical kernels
Although, the performance of linear readouts may be invariant to rotations that preserve kernels (Figure 2), metabolic efficiency may favor certain codes over others (Barlow, 1961; Atick and Redlich, 1992; Attneave, 1954; Olshausen and Field, 1997; Simoncelli and Olshausen, 2001), reducing degeneracy in the space of codes with identical kernels. To formalize this idea, we define to be the vector of spontaneous firing rates of a population of neurons, and be the spiking rate vector in response to a stimulus . The vector ensures that neural responses are non-negative. The modulation with respect to the spontaneous activity, , gives the population code and defines the kernel, . To avoid confusion with , we will refer to as total spiking activity. We propose that population codes prefer smaller spiking activity subject to a fixed kernel. In other words, because the kernel is invariant to any change of the spontaneous firing rates and left rotations of , the orientation and shift of the population code should be chosen such that the resulting total spike count is small.
We tested whether biological codes exhibit lower total spiking activity than others exhibiting the same kernel on mouse V1 recordings, using deconvolved calcium activity as a proxy for spiking events (Stringer et al., 2021; Pachitariu et al., 2019; Pachitariu et al., 2018) (Methods Data analysis; Figure 8). To compare the experimental total spiking activity to other codes with identical kernels, we computed random rotations of the neural responses around spontaneous activity, , and added the that minimizes total spiking activity and maintains its nonnegativity (Methods Generating RROS codes). We refer to such an operation as RROS (random rotation and optimal shift), and a code generated by an RROS operation as an RROS code. The matrix is a randomly sampled orthogonal matrix (Anderson et al., 1987). In other words, we compare the true code to the most metabolically efficient realizations of its random rotations. This procedure may result in an increased or decreased total spike count in the code, and is illustrated in a synthetic dataset in Figure 8A. We conducted this procedure on subsets of various sizes of mouse V1 neuron populations, as our proposal should hold for any subset of neurons (Methods Generating RROS codes), and found that the true V1 code is much more metabolically efficient than randomly rotated versions of the code (Figure 8B and C). This finding holds for both responses to static gratings and to natural images as we show in Figure 8B and C respectively.
Figure 8 with 2 supplements see all

The biological code is more metabolically efficient than random codes with same inductive biases.
(A) We illustrate our procedure in a synthetic example. A non-negative population code (left) can be randomly rotated about its spontaneous firing rate (middle), illustrated as a purple dot, and optimally shifted to a new non-negative population code (right). If the kernel is measured about the spontaneous firing rate, these transformations leave the inductive bias of the code invariant but can change the total spiking activity of the neural responses. We refer to such an operation as random rotation + optimal shift (RROS). We also perform gradient descent over rotations and shifts, generating an optimized code (opt). (B) Performing RROS on neuron subsamples of experimental Mouse V1 recordings (Stringer et al., 2021; Pachitariu et al., 2019), shows that the true code has much lower average cost compared to random rotations of the code. The set of possible RROS transformations (Methods Generating RROS codes, and Methods Comparing sparsity of population codes) generates a distribution over average cost, which has higher mean than the true code. We also optimize metabolic cost over the space of RROS transformations, which resulted in the red dashed lines. We plot the distance (in units of standard deviations) between the cost of the true and optimal codes and the cost of randomly rotated codes for different neuron subsample sizes . (C) The same experiment performed on Mouse V1 responses to ImageNet images from 10 relevant classes (Stringer et al., 2018a; Stringer et al., 2018b). (D) The lifetime (LS) and population sparseness (PS) levels (Methods Lifetime and population sparseness) are higher for the Mouse V1 code than for a RROS code. The distance between average LS and PS of true code and RROS codes increases with .
To further explore metabolic efficiency, we posed an optimization problem which identifies the most efficient code with the same kernel as the biological V1 code. This problem searches over rotation matrices and finds the matrix and off-set vector which gives the lowest cost (Methods Comparing sparsity of population codes) (Figure 8). Although the local optimum identified with the algorithm is lower in cost than the biological code, both the optimal and biological codes are significantly displaced from the distribution of random codes with same kernel. Our findings do not change when data is preprocessed with an alternative strategy, an upper bound on neural responses is imposed on rotated codes, or subsets of stimuli are considered (Figure 8—figure supplement 1). We further verified these results on electrophysiological recordings of mouse visual cortex from the Allen Institute Brain Observatory (de Vries et al., 2020), (Figure 8—figure supplement 2). Overall, the large disparity in total spiking activity between the true and randomly generated codes with identical kernels suggests that metabolic constraints may favor the biological code over others that realize the same kernel.
The disparity between the true biological code and the RROS code is not only manifested in terms of total activity level, but also in terms of single neuron and single stimulus sparseness measures, specifically lifetime and population sparseness distributions (Methods Lifetime and population sparseness) (Willmore and Tolhurst, 2001; Lehky et al., 2005; Treves and Rolls, 1991; Pehlevan and Sompolinsky, 2014). In Figure 8D, we compare the lifetime and population sparseness distributions of the true biological code with a RROS version of the same code, revealing biological neurons have significantly higher lifetime sparseness. In Appendix Necessary conditions for optimally sparse codes, we provide analytical arguments which suggest that tuning curves of optimally sparse non-negative codes with full-rank kernels will have selective tuning.
Discussion
Elucidating inductive biases of the brain is fundamentally important for understanding natural intelligence (Tenenbaum et al., 2011; Lake et al., 2017; Sinz et al., 2019; Zador, 2019). These biases are coded into the brain by the dynamics of its neurons, the architecture of its networks, its representations and plasticity rules. Finding ways to extract the inductive biases from neuroscience datasets requires a deeper theoretical understanding of how all these factors shape the biases, and is an open problem. In this work, we attempted to take a step towards filling this gap by focusing on how the structure of static neural population codes shape inductive biases for learning of a linear readout neuron under a biologically plausible learning rule. If the readout neuron’s output is correlated with behavior, and that correlation is known, then our theory could possibly be modified to predict what behavioral tasks can be learned faster.
Under the delta rule, the generalization performance of the readout is entirely dependent on the code’s inner product kernel; the kernel is a determinant of inductive bias. In its finite dimensional form, the kernel is an example of a representational similarity matrix and is a commonly used tool to study neural representations (Edelman, 1998; Kriegeskorte et al., 2008; Laakso and Cottrell, 2000; Kornblith et al., 2019; Cadieu et al., 2014; Pehlevan et al., 2018). Our work elucidates a concrete link between this experimentally measurable mathematical object, and sample-efficient learning.
We derived an analytical expression for the generalization error as a function of sample-size under very general conditions, for an arbitrary stimulus distribution, arbitrary population code and an arbitrary target stimulus-response map. We used our findings in both theoretical and experimental analysis of primary visual cortex, and temporal codes in a delayed reach task. This generality of our theory is a particular strength.
Our analysis elucidated two principles that define the inductive bias. The first one is spectral bias: kernel eigenfunctions with large eigenvalues can be estimated using a smaller number of samples. The second principle is the code-task alignment: target functions with most of their power in top kernel eigenfunctions can be estimated efficiently and are compatible with the code. The cumulative power distribution, (Canatar et al., 2021), provides a measure of this alignment. These findings define a notion of ‘simplicity’ bias in learning from examples, and provides a solution to the question of what stimulus-response maps are easier to learn. A similar simplicity bias has been also observed in training deep neural networks (Rahaman et al., 2019; Xu et al., 2019; Kalimeris et al., 2019). Due to a correspondence between gradient-descent trained neural networks in the infinite-width limit and kernel machines (Jacot et al., 2018), results on the spectral bias of kernel machines may shed light onto these findings (Bordelon et al., 2020; Canatar et al., 2021). Though our present analysis focused on learning a single layer weight vector with the biologically plausible delta-rule, future work could explore the learning curves of other learning rules for deep networks (Bordelon and Pehlevan, 2022a), such as feedback alignment (Lillicrap et al., 2016) or perturbation methods (Jabri and Flower, 1992). Such analysis could explore how inductive bias is also shaped by choice of learning rule, as well as the structure of the initial population code.
We applied our findings in both theoretical and experimental analysis of mouse primary visual cortex. We demonstrated a bias of neural populations towards low frequency orientation discrimination and low spatial frequency reconstruction tasks. The latter finding is consistent with the finding that mouse visual cortex neurons are selective for low spatial frequency (Niell and Stryker, 2008; Vreysen et al., 2012). The toy model of the visual cortex as a mixture of simple and complex cells demonstrated how invariances, specifically the phase invariance of the complex cells, in the population code can facilitate learning some tasks involving phase invariant responses at the expense of performance on others. The role of invariances in learning with kernel methods and deep networks have recently been investigated in machine learning literature, showing that invariant representations can improve capacity (Farrell et al., 2021) and sample efficiency for invariant learning problems (Mei et al., 2021; Li et al., 2019; Xiao and Pennington, 2022).
A recent proposal considered the possibility that the brain acts as an overparameterized interpolator (Hasson et al., 2020). Suitable inductive biases are crucial to prevent overfitting and generalize well in such a regime (Belkin et al., 2019). Our theory can explain these inductive biases since, when the kernel is full-rank, which typically is the case when there are more neurons in the population than the number of learning examples, the delta rule without weight decay converges to an interpolator of the learning examples. Modern deep learning architectures also operate in an overparameterized regime, but generalize well (Zhang et al., 2016; Belkin et al., 2019), and an inductive bias towards simple functions has been proposed as an explanation (Bordelon et al., 2020; Canatar et al., 2021; Kalimeris et al., 2019; Valle-Perez et al., 2018). However, we also showed that interpolation can be harmful to prediction accuracy when the target function has some variance unexplained by the neural code or if the neural responses are significantly noisy, motivating use of explicit regularization.
Our work promotes sample efficiency as a general coding principle for neural populations, relating neural representations to the kinds of problems they are well suited to solve. These codes may be shaped through evolution or themselves be learned through prior experience (Zador, 2019). Prior related work in this area demonstrated the dependence of sample-efficient learning of a two-angle estimation task on the width of the individual neural tuning curves (Meier et al., 2020) and on additive function approximation properties of sparsely connected random networks (Harris, 2019).
A sample efficiency approach to population coding differs from the classical efficient coding theories (Attneave, 1954; Barlow, 1961; Atick and Redlich, 1992; Srinivasan et al., 1982; van Hateren, 1992; Rao and Ballard, 1999; Olshausen and Field, 1997; Chalk et al., 2018), which postulate that populations of neurons optimize information content of their code subject to metabolic constraints or noise. While these theories emphasize different aspects of the code’s information content (such as reduced redundancy, predictive power, or sparsity), they do not address sample efficiency demands on learning. Further, recent studies demonstrated hallmarks of redundancy and correlation in population responses (Chapin and Nicolelis, 1999; Bathellier et al., 2008; Pitkow and Meister, 2012; Gao and Ganguli, 2015; Abbasi-Asl et al., 2016; Gallego et al., 2018; Stringer et al., 2018b), violating a generic prediction of efficient coding theories that responses of different neurons should be uncorrelated across input stimuli in high signal-to-noise regimes to reduce redundancy in the code and maximize information content (Barlow, 1961; Atick and Redlich, 1992; Srinivasan et al., 1982; van Hateren, 1992; Haft and van Hemmen, 1998; Huang and Rao, 2011). In our theory, the structured correlations of neural responses correspond to the decay in the spectrum of the kernel, and play a key role in biasing learned readouts towards simple functions.
In recent related studies, the asymptotic decay rate of the kernel’s eigenspectrum was argued to be important for generalization (Stringer et al., 2018b) and robustness (Nassar et al., 2020). The spectral decay rate in the mouse V1 was found to be consistent with a high dimensional (power law) but smooth (differentiable) code, and smoothness was argued to be an enabler of generalization (Stringer et al., 2018b). While we also identify power law spectral decays, we show that sample-efficient learning requires more than smoothness conditions in the form of asymptotic decay rates on the kernel’s spectrum. The interplay between the stimulus distribution, target response and the code gives rise to sample efficient learning. Because of spectral bias, the top eigenvalues govern the small sample size behavior. The tail of the spectrum becomes important at large sample sizes.
Though the kernel is degenerate with respect to rotations of the code in the neural activity space, we demonstrated that the true V1 code has much lower average activity than random codes with the same kernel, suggesting that evolution and learning may be selecting neural codes with low average spike rates which preserve sample-efficiency demands for downstream learning tasks. We predict that metabolic efficiency may be a determinant in the orientation and placement of the ubiquitously observed low-dimensional coding manifolds in neural activity space in other parts of the brain (Gallego et al., 2018). The demand of metabolic efficiency is consistent with prior sparse coding theories (Niven and Laughlin, 2008; Olshausen and Field, 1997; Simoncelli and Olshausen, 2001; Hromádka et al., 2008), however, our theory emphasizes sample-efficient learning as the primary normative objective for the code. As a note of caution, while our analysis holds under the assumption that the neural code is deterministic, real neurons exhibit variability in their responses to repeated stimuli. Such noisy population codes do not generally achieve identical generalization performance under RROS transformations. For example, if each neuron is constrained to produce i.i.d. Poisson noise, then simple shifts of the baseline firing rate reduce the information content of the code. However, if the neural noise is Gaussian (even with stimulus dependent noise covariance), then the generalization error is conserved under RROS operations (Appendix Effect of noise on RROS symmetry). Further studies could focus on revealing the space of codes with equivalent inductive biases under realistic noise models.
Our work constitutes a first step towards understanding inductive biases in neuronal circuits. To achieve this, we focused on a linear, delta-rule readout of a static population code. More work is need to study other factors that affect inductive bias. Importantly, sensory neuron tuning curves can adapt during perceptual learning tasks (Gilbert, 1994; Goltstein et al., 2021; Ghose et al., 2002; Schoups et al., 2001) with the strength of adaptation dependent on brain area (Yang and Maunsell, 2004; Adab et al., 2014; Op de Beeck et al., 2007). In many experiments, these changes to tuning in sensory areas are small (Schoups et al., 2001; Ghose et al., 2002), satisfying the assumptions of our theory. For example monkeys trained on noisy visual motion detection exhibit changes in sensory-motor (LIP) but not sensory areas (MT), consistent with a model of readout from a static sensory population code (Law and Gold, 2008; Shadlen and Newsome, 2001). However, other perceptual learning tasks and other brain areas can exhibit significant changes in neural tuning (Recanzone et al., 1993; Pleger et al., 2003; Furmanski et al., 2004). This diversity of results motivates more general analysis of learning in multi-layer networks, where representations in each layer can adapt flexibly to task structure (Shan and Sompolinsky, 2021; Mastrogiuseppe et al., 2022; Bordelon and Pehlevan, 2022b; Ahissar and Hochstein, 2004). Alternatively, our current analysis of inductive bias can still be consistent with multi-layer learning if the network is sufficiently overparameterized and tuning curves change very little (Jacot et al., 2018; Lee et al., 2018; Shan and Sompolinsky, 2021). In this case, network training is equivalent to kernel learning with a kernel that depends on the learning rule and architecture (Bordelon and Pehlevan, 2022a). However, in the regime of neural network training where tuning curves change significantly, more sophisticated analytical tools are needed to predict generalization (Flesch et al., 2021; Yang and Hu, 2021; Bordelon and Pehlevan, 2022b). Although our work focused on linear readouts, arbitrary nonlinear readouts which generate convex learning objectives have been recently studied in the high dimensional limit, giving qualitatively similar learning curves which depend on kernel eigenvalues and task model alignment (Loureiro et al., 2021b; Cui et al., 2022) (see Appendix Typical case analysis of nonlinear readouts).
Our work focused on how signal correlations influence inductive bias (Averbeck et al., 2006; Cohen and Kohn, 2011). However, since real neurons do exhibit variability in their responses to identical stimuli, one should consider the effect of neural noise and noise correlations in learning. We provide a preliminary analysis of learning with neural noise in Appendix Impact of neural noise and unlearnable targets on learning, where we show that neural noise can lead to irreducible asymptotic error which depends on the geometry of the signal and noise correlations. Further, if the target function is not fully expressible as linear combinations of neural responses, overfitting peaks in the learning curves are possible, but can be mitigated with regularization implemented by a weight decay in the learning rule (see Appendix 1—figure 1). Future work could extend our analysis to study how signal and noise correlations interact to shape inductive bias and generalization performance in the case where the noise correlation matrices are non-isotropic, including the role of differential correlations (Moreno-Bote et al., 2014). Overall, future work could build on the present analysis to incorporate a greater degree of realism in a theory of inductive bias.
Finally, we discuss possible applications of our work to experimental neuroscience. Our theory has potential implications for experimental studies of task learning. First, in cases where the population selective to stimuli can be measured directly, an experimenter could design easy or difficult tasks for an animal to learn from few examples, under a hypothesis that the behavioral output is a linear function of the observed neurons. Second, in cases where it is unclear which neural population contributes to learning, one could utilize our theory to solve the inverse problem of inferring the relevant kernel from observed learning curves on different tasks (Wilson et al., 2015). From these tasks, the experimenter could compare the inferred kernel to those of different recorded populations. For instance, one could compare the kernels from separate populations to the inferred kernel obtained from learning curves on certain visual learning tasks. This could provide new ways to test theories of perceptual learning (Gilbert, 1994). Lastly, extensions of our framework could quantify the role of neural variability on task learning and the limitation it imposes on accuracy and sample efficiency.
Methods
Generating example codes (Figure 1)
The two codes in Figure 1 were constructed to produce two different kernels for :
(4)
An infinite number of codes could generate either of these kernels. After diagonalizing the kernel into its eigenfunctions on a grid of 120 points, , we used a random rotation matrix (which satisfies ) to generate a valid code
(5)
This construction guarantees that and . We plot the tuning curves for the first three neurons. The target function in the first experiment is , while the second experiment used .
Theory of generalization
Recent work has established analytic results that predict the average case generalization error for kernel regression
(6)
where is the generalization error for a certain sample of size and is the kernel regression solution for (Appendix Convergence of the delta-rule without weight decay) (Bordelon et al., 2020; Canatar et al., 2021). The typical or average case error is obtained by averaging over all possible datasets of size . This average case generalization error is determined solely by the decomposition of the target function along the eigenbasis of the kernel and the eigenspectrum of the kernel. This continuous diagonalization again takes the form (Appendix Singular value decomposition of continuous population responses) (Rasmussen and Williams, 2005)
(7)
Our theory is also applicable to discrete stimuli if is a Dirac measure as we describe in (Appendix Discrete stimulus spaces: finding eigenfunctions with matrix eigendecomposition). Since the eigenfunctions form a complete set of square integrable functions (Rasmussen and Williams, 2005), we expand both the target function and the learned function in this basis , where are understood to be functions of the dataset . The eigenfunctions are orthonormal , which implies that the generalization error for any set of coefficients is
(8)
We now introduce the equivalent training error, or empirical loss, written directly in terms of eigenfunction coefficients , which depends on the random dataset
(9)
This loss function is minimized by delta rule updates with weight decay constant . It is straightforward to verify that the -minimizing coefficients are , giving the learned function where the vectors and have entries and for each training stimulus . The kernel gram matrix has entries . The limit of the minimizer of coincides with kernel interpolation. This allows us to characterize generalization without reference to learned readout weights . The generalization error for this optimal function is
(10)
We note that the dependence on the randomly sampled dataset only appears through the matrix . Thus to compute the typical generalization error we need to average this matrix over realizations of datasets, i.e.. There are multiple strategies to perform such an average and we will study one here based on a partial differential equation which was introduced in Sollich, 1998; Sollich, 2002 and studied further in Bordelon et al., 2020. We describe in detail one method for performing such an average in Appendix Computation of learning curves. After this computation, we find that the generalization error can be approximated at large as
(11)
where , giving the desired result. We note that (11) defines the function implicitly in terms of the sample size . Taking gives the generalization error of the minimum norm interpolant, which desribes the generalization error of the solution. This result was recently reproduced using the replica method from statistical mechanics in an asymptotic limit where the number of neurons and samples are large (Bordelon et al., 2020; Canatar et al., 2021). Other recent works have verified our theoretical expressions on a variety of kernels and datasets (Loureiro et al., 2021b; Simon et al., 2021).
Additional intuition for the spectral bias phenomenon can be gained from the expected learned function , which is the average readout prediction over possible datasets . The function is defined implicitly as and decreases with from to its asymptotic value . The coefficient for the -th eigenfunction approaches the true coefficient vk as . The -th eigenfunction is effectively learned when . For large eigenvalues , fewer samples are needed to satisfy this condition, while small eigenvalue modes will require more samples.
RNN experiment
For the simulations in Figure 7, we integrated a rate-based recurrent network model with neurons, time constant and gain . Each of the randomly chosen angles generates a trajectory over equally spaced points in . The two dimensional input sequence is simply . Target function for a delay is which is nonzero for times . In each simulation, the activity in the network is initialized to . The kernel gram matrix is computed by taking inner products of the time varying code at for different inputs and at different times. Learning curves represent the generalization error obtained by randomly sampling time points from the total time points generated in the simulation process and training readout weights to convergence with gradient descent.
Data analysis
Data source and processing
Mouse V1 neuron responses to orientation gratings were obtained from a publicly available dataset (Stringer et al., 2021; Pachitariu et al., 2019). Two-photon calcium microscopy fluorescence traces were deconvolved into spike trains and spikes were counted for each stimulus, as described in Stringer et al., 2021. The presented grating angles were distributed uniformly over radians. Data pre-processing, which included z-scoring against the mean and standard deviation of null stimulus responses, utilized the provided code for this experiment, which also publicly available at https://github.com/MouseLand/stringer-et-al-2019 (Stringer, 2019). This preprocessing technique was used in all Figures in the paper. To reduce corruption of the estimated kernel from neural noise (trial-to-trial variability), we first trial average responses, binning the grating stimuli oriented at different angles into a collection of 100 bins over the interval from and averaging over all of the available responses from each bin. Since grating angles were sampled uniformly, there is a roughly even distribution of about 45 responses in each bin. After trial averaging, SVD was performed on the response matrix , generating the eigenspectrum and kernel eigenfunctions as illustrated in Figure 3. Figures 2, 3 and 8, all used this data anytime responses to grating stimuli were mentioned.
In Figures 3D, 4 and 8C, the responses of mouse V1 neurons to ImageNet images (Deng et al., 2009) were obtained from a different publicly available dataset (Stringer et al., 2018a). The images were taken from 15 different classes from the Imagenet dataset with ethological relevance to mice (birds, cats, flowers, hamsters, holes, insects, mice, mushrooms, nests, pellets, snakes, wildcats, other animals, other natural, other man made). In the experiment in Figure 3D we use all images from the mice and birds category for which responses were recorded. The preprocessing code and image category information were obtained from the publicly available code base at https://github.com/MouseLand/stringer-pachitariu-et-al-2018b (Stringer, 2018c). Again, spike counts were obtained from deconvolved and z-scored calcium fluorescence traces. In the reconstruction experiment shown in Figure 4 we use the entire set of images for which neural responses were recorded.
Generating RROS codes
In Figure 8, the randomly rotated codes are generated by sampling a matrix from the Haar measure on the set of -by- orthogonal matrices (Anderson et al., 1987), and chosing a by solving the following optimization problem:
(12)
which minimizes the total spike count subject to the kernel and nonnegativity of firing rates. The solution to this problem is given by .
Comparing sparsity of population codes
To explore the metabolic cost among the set of codes with the same inductive biases, we estimate the distribution of average spike counts of codes with the same inner product kernel as the biological code. These codes are generated in the form where solves the optimization problem
(13)
To quantify the distribution of such codes, we randomly sample from the invariant (Haar) measure for orthogonal matrices and compute the optimal as described above. This generates the aqua colored distribution in Figure 8B and C.
We also attempt to characterize the most efficient code with the same inner product kernel
(14)
Since this optimization problem is non-convex in , there is no theoretical guarantee that minima are unique. Nonetheless, we attempt to optimize the code by starting at the identity matrix and conduct gradient descent over orthogonal matrices (Plumbley, 2004). Such updates take the form
(15)
where is the matrix exponential. To make the loss function differentiable, we incorporate the non-negativity constraint with a soft-minimum:
(16)
where is a normalizing constant and . In the limit, this cost function converges to the exact optimization problem with non-negativity constraint. Finite , however, allows learning with gradient descent. Gradients are computed with automatic differentiation in JAX (Bradbury et al., 2018). This optimization routine is run until convergence and the optimal value is plotted as dashed red lines labeled ‘opt’. in Figure 8.
We show that our result is robust to different pre-processing techniques and to imposing bounds on neural firing rates in the Figure 8—figure supplement 1. To demonstrate that our result is not an artifact of z-scoring the deconvolved signals against the spontaneous baseline activity level, we also conduct the random rotation experiment on the raw deconvolved signals. In addition, we show that imposing realistic constraints on the upper bound of the each neuron’s responses does not change our findings. We used a subset of neurons and computed random rotations. However, we only accepted a code as valid if it’s maximum value was less than some upper bound ub. Subsets of neurons in the biological code achieve maxima in the range between 3.2 and 4.7. We performed this experiment for so that the artificial codes would have maxima that lie in the same range as the biological code.
Lifetime and population sparseness
We compute two more refined measures of sparseness in a population code. For each neuron we compute the lifetime sparseness (also known as selectivity) and for each stimulus we compute the population sparseness which are defined as the following two ratios (Willmore and Tolhurst, 2001; Lehky et al., 2005; Treves and Rolls, 1991; Pehlevan and Sompolinsky, 2014)
(17)
The normalization factors ensure that these quantities lie in the interval between . Intuitively, lifetime sparseness quantifies the variability of each neuron’s responses over the full set of stimuli, whereas population sparseness quantifies the variability of responses in the code for a given stimulus .
Fitting a Gabor model to mouse V1 kernel
Under the assumption of translation symmetry in the kernel , we averaged the elements of the over rows of the empirical mouse V1 kernel (Pachitariu et al., 2019)
(18)
where angular addition is taken mod . This generates the black dots in Figure 5B. We aimed to fit a threshold-power law nonlinearity of the form to the kernel. Based on the Gabor model discussed above, we parameterized tuning curves as
(19)
where is the preferred angle of the -th neuron’s tuning curve. Rather than attempting to perform a fit of of this form to the responses of each of the -k neurons, we instead simply attempt to fit to the population kernel by optimizing over under the assumption of uniform tiling of . However, we noticed that two of these variables are constrained by the sparsity level of the code. If each neuron, on average, fires for only a fraction of the uniformly sampled angles , then the following relationship holds between and
(20)
Calculation of the coding level for the recorded responses allowed us to infer from during optimization. This reduced the free parameter set to . We then solve the following optimization problem
(21)
where integration over is performed numerically. Using the Scipy Trust-Region constrained optimizer, we found which we use as the fit parameters in Figure 5.
Lead contact
Requests for information should be directed to the lead contact, Cengiz Pehlevan (cpehlevan@seas.harvard.edu).
Data and code availability
Mouse V1 neuron responses to orientation gratings and preprocessing code were obtained from a publicly available dataset: https://github.com/MouseLand/stringer-et-al-2019, (Stringer et al., 2021; Pachitariu et al., 2019).
Responses to ImageNet images and preprocessing code were obtained from another publicly available dataset, https://github.com/MouseLand/stringer-pachitariu-et-al-2018b (Stringer et al., 2018a).
The code generated by the authors for this paper is also available https://github.com/Pehlevan-Group/sample_efficient_pop_codes (Pehlevan-Group, 2022).
Appendix 1
Singular value decomposition of continuous population responses
SVD of population responses is usually evaluated with respect to a discrete and finite set of stimuli. In the main paper, we implicitly assumed that a generalization of SVD to a continuum of stimuli. In this section we provide an explicit construction of this generalized SVD using techniques from functional analysis. Our construction is an example of the quasimatrix SVD defined in Townsend and Trefethen, 2015 and justifies our use of SVD in the main text.
For our construction, we note that Mercer’s theorem guarantees the existence of an eigendecomposition of any inner product kernel in terms of a complete orthonormal set of functions (Rasmussen and Williams, 2005). In particular, there exist a non-negative (but possibly zero) summable eigenvalues and a corresponding set of orthonormal eigenfunctions such that
(22)
For a stimulus distribution , the set of functions are orthonormal and form a complete basis for square integrable functions L2 which means
(23)
Next, we use this basis to construct the SVD. Each of the tuning curves (assumed to be square integrable) can be expressed in this basis with the top of the functions in the set
(24)
where we introduced a matrix of expansion coefficients. Note that . We compute the singular value decomposition of the finite matrix
(25)
We note that the signal correlation matrix for this population code can be computed in closed form
(26)
due to the orthonormality of . Thus the principal axes of the neural correlations are the left singular vectors of . We may similarly express the inner product kernel in terms of the eigenfunctions
(27)
The kernel eigenvalue problem demands (Rasmussen and Williams, 2005)
(28)
The vectors must be identical to , the Cartesian unit vectors, if the eigenvalues are non-degenerate. From this exercise, we find that the SVD for has the form . With this choice, the population code admits a singular value decomposition
(29)
This singular value decomposition demonstrates the connection between neural manifold structure (principal axes ) and function approximation (kernel eigenfunctions ). This singular value decomposition can be verified by computing the inner product kernel and the correlation matrix, utilizing the orthonormality of and . This exercise has important consequences for the space of learnable functions, which is at most dimensional since linear readouts lie in .
Discrete stimulus spaces: finding eigenfunctions with matrix eigendecomposition
In our discussion so far, our notation suggested that take a continuum of values. Here we want to point that our theory still applies if take a discrete set of values. In this case, we can think of a Dirac measure , where indexes all the values can take. With this choice
(30)
Demanding this equality for generates a matrix eigenvalue problem
(31)
where . The eigenfunctions over the stimuli are identified as the columns of while the eigenvalues are the diagonal elements of .
Experimental considerations
In an experimental setting, a finite number of stimuli are presented and the SVD is calculated over this finite set regardless of the support of . This raises the question of the interpretation of this SVD and its relation to the inductive bias theory we presented. Here we provide two interpretations.
In the first interpretation, we think of the empirical SVD as providing an estimate of the SVD over the full distribution . To formalize this notion, we can introduce a Monte-Carlo estimate of the integral eigenvalue problem
(32)
For this interpretation to work, the experimenter must sample the stimuli from , which could be the natural stimulus distribution. Measuring responses to a larger number of stimuli gives a more accurate approximation of the integral above, which will provide a better estimate of generalization performance on the true distribution .
In the second interpretation, we construct an empirical measure on experimental stimulus values , and consider learning and generalization over this distribution. This allows the application of our theory to an experimental setting where is designed by an experimenter. For example, the experimenter could procure a complicated set of videos, to which an associated function must be learned. After showing these videos to the animal and measuring neural responses, the experimenter could compute, with our theory, generalization error for a uniform distribution over this full set of videos. Our theory would predict generalization over this distribution after providing supervisory feedback for only a strict subset of videos. Under this interpretation, the relationship between the integral eigenvalue problem and matrix eigenvalue problem is exact rather than approximate
(33)
Demanding either of (32) or (33) equalities for generates a matrix eigenvalue problem
(34)
The eigenfunctions restricted to are identified as the columns of while the eigenvalues are the diagonal elements of . For the case where and are finite, the spectrum obtained through eigendecomposition of the kernel is the same as would be obtained through the finite signal correlation matrix , since they are inner and outer products of trial averaged population response matrices .
Translation invariant kernels
For the special case where the data distribution is uniform over volume and the kernel is translation invariant , the kernel can be diagonalized in the basis of plane waves
(35)
The eigenvalues are the Fourier components of the Kernel while the eigenfunctions are plane waves . The set of admissible momenta are determined by the boundary conditions. The diagonalized representation of the kernel is therefore
(36)
For example, if the space is the torus , then the space of admissable momenta are the points on the integer lattice . Reality and symmetry of the kernel demand that and . Most of the models in this paper consider , where the kernel has the following Fourier/Mercer decomposition
(37)
where we invoked the simple trigonometric identity . By recognizing that form a complete orthonormal set of functions with respect to , we have identified this as the collection of kernel eigenfunctions.
Invariant kernels possess invariant eigenfunctions
Suppose the kernel is invariant to some set of transformations , by which we mean that
(38)
We will now show that any eigenfunction of such a kernel with nonzero eigenvalue must be an invariant function. Let be an eigenfunction with eigenvalue , then
(39)
This establishes that all functions which depend on transformations must necessarily lie in the null-space of .
Theory of generalization
Convergence of the delta-rule without weight decay
In this section, we discuss the delta-rule convergence when weight decay parameter is set to . The next section considers the simpler case where . Gradient descent training of readout weights on a finite sample of size converges to the kernel regression solution (Bartlett et al., 2020; Hastie et al., 2020). Let be the dataset with samples and target values . We introduce a shorthand for convenience. The empirical loss we aim to minimize is a sum of the squared losses of each data point in the training set
(40)
Performing gradient descent updates
(41)
recovers the delta rule that we discussed in the main text (Widrow and Hoff, 1960; Hertz et al., 1991). Letting the empirical response matrix have a SVD , and expanding the weights and labels in their respective SVD bases, we find
(42)
For all directions with , the dynamics converge to the unique fixed point , while for all modes with , the weights remain at . Thus
(43)
where K+ is the Moore-Penrose inverse of the kernel matrix . The predictions of the learned function are given by which can be expressed as
(44)
The fact that the solution can be written in terms of a linear combination of is known as the representer theorem (Schölkopf et al., 2001; Rasmussen and Williams, 2005). A similar analysis for nonlinear readouts where is provided in Appendix Convergence of delta-rule for nonlinear readouts.
Weight decay and ridge regression
We can introduce a regularization term in our learning problem which penalizes the size of the readout weights. This leads to a modified learning objective of the form
(45)
Inclusion of this regularization alters the learning rule through weight decay, which multiplies the existing weight value by a factor of before adding the data dependent update. The fixed point of these dynamics is . This learning problem and gradient descent dynamics have a closed form solution
(46)
The generalization benefits of explicit regularization through weight decay is known to be related to the noise statistics in the learning problem (Canatar et al., 2021). This is visible in the Appendix 1—figure 1 , where unlearnable target functions demand nonzero optimal regularization. We simulate weight decay only in Figure 6C, where we use to improve numerical stability at large .
Computation of learning curves
Recent work has established analytic results that predict the average case generalization error for kernel regression
(47)
where is the generalization error for a certain sample of size and is the kernel regression solution for (Bordelon et al., 2020; Canatar et al., 2021). The typical or average case error is obtained by averaging over all possible datasets of size . This average case generalization error is determined solely by the decomposition of the target function along the eigenbasis of the kernel and the eigenspectrum of the kernel. This diagonalization takes the form
(48)
Since the eigenfunctions form a complete set of square integrable functions, we expand both the target function and the learned function in this basis
(49)
Due to the orthonormality of the kernel eigenfunctions , the generalization error for any set of coefficients is
(50)
We now introduce training error, or empirical loss, which depends on the disorder in the dataset
(51)
It is straightforward to verify that the optimal which minimizes is the kernel regression solution for kernel with eigenvalues when . The optimal weights can be identified through the first order condition which gives
(52)
where are the eigenfunctions evaluated on the training data and is a a diagonal matrix containing the kernel eigenvalues. The generalization error for this optimal solution is
(53)
We note that the dependence on the randomly sampled dataset only appears through the matrix . Thus to compute the typical generalization error we need to average over this matrix . There are multiple strategies to perform such an average and we will study one here based on a partial differential equation which was introduced in Sollich, 1998; Sollich, 2002 and studied further in Bordelon et al., 2020; Canatar et al., 2021. In this setting, we denote the average matrix for a dataset of size . We first will derive a recursion relationship using the Sherman Morrison formula for a rank-1 update to an inverse matrix. We imagine adding a new sampled feature vector to a dataset with size . The average matrix at samples can be related to through the Sherman Morrison rule
(54)
where in the last step we approximated the average of the ratio with the ratio of averages. This operation, is of course, unjustified theoretically, but has been shown to produce accurate learning curves (Sollich, 2002; Bordelon et al., 2020). Since the chosen basis of kernel eigenfunctions are orthonormal, the average over the new sample is trivial . We thus arrive at the following recursion relationship for
(55)
By introducing an additional source so that , we can relate ’s first and second moments through differentiation
(56)
Thus the recursion relation simplifies to
(57)
where we approximated the finite difference in as a derivative, treating as a continuous variable. Taking the trace of both sides and defining we arrive at the following quasilinear PDE
(58)
with the initial condition . Using the method of characteristics, we arrive at the solution . Using this solution to , we can identify the solution to
(59)
The generalization error, therefore can be written as
(60)
(61)
where , giving the desired result. Note that depends on implicitly, which is the source of the factor. This result was recently reproduced using techniques from statistical mechanics (Bordelon et al., 2020; Canatar et al., 2021).
Spectral bias and code-task alignment
Through implicit differentiation it is straightforward to verify that the ordering of the mode errors matches the ordering of the eigenvalues (Canatar et al., 2021). Let , then we have
(62)
Since , the first bracket must be negative and the second bracket must be positive. Further, it is straightforward to compute that . Therefore implies for all . Since at we therefore have that for all and consequently . Modes with larger eigenvalues have lower normalized mode errors . This observation can be used to prove that target functions acting on the same data distribution with higher cumulative power distributions for all will have lower generalization error normalized by total target power, , for all . Proof can be found in Canatar et al., 2021.
Asymptotic power law scaling of learning curves
Exponential spectral decays:
First, we will study the setting relevant to the von-Mises kernel where and where . This exponential behavior accounts for differences in bandwidth between kernels which modulates the base of the exponential scaling of with . We will approximate the sum over all mode errors with an integral
(63)
If we include a regularization parameter , then as . Making the change of variables , we transform the above integral into
The remaining integral over is either dominated near if and behaves as a -independent constant or else is dominated near , in which case the integral scales as . Multiplying these resulting functions with the prefactor, we find the following scaling laws for generalization.
(64)
Thus, we obtain a power law scaling of the learning curve which is dominated at large by . For the von-Mises kernel we can approximate the spectra with and giving rise to a generalization scaling scaling .
Power law spectral decays
The same arguments can be applied for power law kernels and power law targets , which is of interest due to its connection to nonlinear rectified neural populations. In this setting, the generalization error is
(65)
We see that there are two possible power law scalings for with the exponents and 2. At large this formula will be dominated by the term with minimum exponent so .
Laplace kernel generalization
We calculate similar learning curves as we did for the von-Mises kernel but with Laplace kernels to show that our results is not an artifact of the infinite differentiability of the Von Mises kernel. Each of these Laplace kernels has the same asymptotic power law spectrum , exhibiting a discontinuous first derivative (Figure 6A). Despite having the same spectral scaling at large , these kernels can give dramatically different performance in learning tasks, again indicating the influence of the top eigenvalues on generalization at small (Figure 6). Again, the trend for which kernels perform best at low can be reversed at large . In this case, all generalization errors scale with (Figure 6B). More generally, our theory shows that if the task power spectrum and kernel eigenspectrum are both falling as power laws with exponents and respectively, then the generalization error asymptotically falls with a power law, (Methods) (Bordelon et al., 2020). This decay is fastest when for which . Therefore, the tail of the kernel’s eigenvalue spectrum determines the large sample size behavior of the generalization error for power law kernels. Small sample size limit is still governed by the bulk of the spectrum.
Learning with multiple output channels
Our theory is not limited to scalar target functions but rather can be easily extended to multiple output functions from the same data, if for example the task requires computing class membership for categories. In this setting, each data point has the form with . For these classes, the generalization error takes the form
(66)
We therefore find that the generalization error in the multi-class setting is the same as the obtained for a single scalar target function with power spectrum (Bordelon et al., 2020; Canatar et al., 2021). The relevant cumulative power distribution measures the fraction of total output variance captured by the first eigenfunctions of the population code
(67)
Convergence of Delta-rule for nonlinear readouts
In this section, we consider gradient descent dynamics of an arbitrary convex loss function. For instance, we can consider a binary classification problem where by outputting a prediction of . We could, for example, train a model using the hinge loss so that the classifier will converge to a kernel support vector machine (SVM) (Schölkopf et al., 2002). The generalization of the classifier would be the error rate of compared to the ground truth .
Let be the dataset with samples and target values . We introduce a shorthand for convenience. The loss we aim to minimize is the sum of the losses of each data point in the training set with an additional weight decay parameter
(68)
For convex and nonzero , the above objective is strongly convex, indicating the existence of a unique minimizer which can be found from simple first order learning rules. For the initial condition for does not influence the final result.
We will now show that the dynamics will converge to a function which only depends on the code through the kernel . To simplify the argument, we consider starting from an initial condition of and performing gradient descent updates. Under such an assumption, the weights will always be in the span of the population vectors on the training set since
(69)
The derivative in the final term is taken with respect to the first argument . This update is still local and recovers the delta rule that we discussed in the main text for (Widrow and Hoff, 1960; Hertz et al., 1991). We can express in terms of the population vectors so that defines the linear weighting of each sample. The dynamics of these coefficients are
(70)
where is the kernel Gram matrix evaluated on the training points. We multiply both sides of this equation by , and define , which satisfy the following simplified dynamics
(71)
where K+ is the pseudo-inverse of . The nonlinear fixed point condition is , which transparently only depends on the kernel rather than the full code . The above equation recovers the correct linear equation for square loss. For an arbitrary test point , the model makes prediction using , which also only depends on the kernel on test point and train points , as well as the kernel gram matrix .
To illustrate a specific case with a square error and nonlinear readout, consider output neurons which produce activity for invertible nonlinear function with non-vanishing gradient, and gradient based learning on . This gives , which is still a local learning rule. Thus the weights at convergence can be written as and the learned function can be written as is given by . To see this, first note that for all so that . The interpolation condition can be expressed as , giving the desired result . The predictions of the model on a test stimulus are given by . We see that this solution only depends on the kernel (directly and indirectly through ), rather than the full code.
Typical case analysis of nonlinear readouts
The analysis of typical case generalization can be extended to nonlinear predictors and loss functions described by (68) which depend on the scalar prediction variable (Loureiro et al., 2021a). Thanks Further, if is well approximated as a Gaussian process, then the generalization performance can still be characterized using statistical mechanics methods (Loureiro et al., 2021a). Many qualitative features of our results continue to hold, including that the kernel’s diagonalization governs training and generalization and that improvements in code task alignment lead to improvements in generalization.
In a later work by Cui et al., 2022, SVM and ridge classifiers trained on codes and tasks with power law spectra were analyzed asymptotically, showing power law generalization error decay rates . These classification learning curves for power law spectra were shown to follow power laws with exponents which are qualitatively similar to the exponents obtained with the square loss which we describe in our section titled Small and Large Sample Size Behaviors of Generalization. Just as in our theory, decay rate exponents are larger for codes which are well aligned to the task and are smaller for codes which are non-aligned.
Visual scene reconstruction task
Reconstruction of natural scenes from neural responses
Using the mouse V1 responses to natural scenes, we attempt to reconstruct original images from the neural codes using different numbers of images. The presented natural scenes are taken from ten classes of imagenet which can be downloaded from https://github.com/MouseLand/stringer-pachitariu-et-al-2018b. Let be a -dimensional flattened vector containing the pixel values of the μ-th image and let represent the neural response to the μ-th image. The goal in the problem is to learn a collection of weights which map neural responses to images
(72)
The generalization error again measures the average error on all points, averaged over all possible datasets of size . If the optimal weights for dataset is then the generalization error is
(73)
After identifying eigenfunctions , we expand the images in this basis where . The generalization error is therefore and the cumulative power is . We perform this reconstruction task on many filtered versions of the natural scenes. To construct a filter, we first compute the Fourier transform of the image. Let represent the non-flattened image and let represent the Fourier transform of the image, computed explicitly as
(74)
To develop the band-pass filter, we calculate for each of the indices in the matrix. For a band-pass filter with parameters we simply zero out the entries in which correspond to states with frequencies outside the appropriate band: for any with then . We then perform the inverse Fourier transform on to obtain a filtered version of the original image.
A simple feedforward model of V1
Linear neurons
We consider a simplified but instructive model of the V1 population code as a linear-nonlinear map from photoreceptor responses through Gabor filters and then nonlinearity (Adelson and Bergen, 1985; Olshausen and Field, 1997; Rumyantsev et al., 2020). Let represent the two-dimensional retinotopic position of photoreceptors. The firing rates of the photoreceptor at position to a static grating stimulus oriented at angle is
(75)
We model each V1 neuron’s receptive field as a Gabor filter of the receptor responses . The -th V1 neuron has preferred wavevector , generating the following set of weights between photoreceptors and the -th V1 neuron
(76)
The V1 population code is obtained by filtering the photoreceptor responses. By approximating the resulting sum over all retinal photoreceptors with an integral, we find the response of neuron to grating stimulus with wavenumber is
(77)
The response of neuron is computed through nonlinear rectification of this input current . For a linear neuron , the kernel has the following form
(78)
where the kernel is normalized to have maximum value of 1. Note that this normalization of the kernel is completely legitimate since it merely rescales each eigenvalue by a constant and does not change the learning curves.
Since the kernel only depends on the difference between angles , it is said to posess translation invariance. Such translation invariant kernels admit a Mercer decomposition in terms of Fourier modes since the Fourier modes diagonalize shift invariant integral operators on . For the linear neuron, the kernel eigenvalues scale like , indicating infinite differentiability of the tuning curves. Since decays rapidly with , we find that this Gabor code has an inductive bias that favors low frequency functions of orientation .
Nonlinear simple cells
Introducing nonlinear functions that map input currents into the V1 population into firing rates, we can obtain a non-linear kernel which has the following definition
(79)
In this setting, it is convenient to restrict and assume that the preferred wavevectors are uniformly distributed over the circle. In this case, it suffices to identify a decomposition of the composed function in the basis of Chebyshev polynomials which satisfy
(80)
which can be computed efficiently with an appropriate quadrature scheme. Once the coefficients an are determined, we can compute the kernel by first letting to be the angle between and and letting be the angle between and
(81)
Thus the kernel eigenvalues are .
Asymptotic scaling of spectra
Activation functions that encourage sparsity have slower eigenvalue decays. If the nonlinear activation function has the form , then the spectrum decays like . A simple argument justifies this scaling: if the function is only times differentiable then since must diverge. Therefore . Note that this scaling is independent of the threshold. Examples of these scalings can be found in Figure 5—figure supplements 1 and 2.
Phase variation, complex cells and invariance
We can consider a slightly more complicated model where Gabors and stimuli have phase shifts
(82)
The simple cells are generated by nonlinearity
(83)
The input currents into the simple V1 cells can be computed exactly
(84)
When , the simple cell tuning curves only depend on and , allowing a Fourier decomposition
(85)
The simple cell kernel , therefore decomposes into Fourier modes over
(86)
where . It therefore suffices to solve the infinite sequence of integral eigenvalue problems over
(87)
With this choice it is straightforward to verify that the kernel eigenfunctions are with corresponding eigenvalue . Since bn is not translation invariant in , the eigenfunctions are not necessarily Fourier modes. These eigenvalue problems for bn must be solved numerically when using arbitrary nonlinearity . The top eigenfunctions of the simple cell kernel depend heavily on the phase of the two grating stimuli . Thus, a pure orientation discrimination task which is independent of phase requires a large number of samples to learn with the simple cell population.
Complex cell populations are phase invariant
V1 also contains complex cells which possess invariance to the phase of the stimulus.
(88)
Again using Gabor filters we model the complex cell responses with a quadratic nonlinearity and sum over two squared filters which are phase shifted by
(89)
which we see is independent of the phase of the grating stimulus. Integrating over the set of possible Gabor filters with again gives the following kernel for the complex cells
(90)
Remarkably, this kernel is independent of the phase of the grating stimulus. Thus, complex cell populations possess good inductive bias for vision tasks where the target function only depends on the orientation of the stimulus rather than it’s phase. In reality, V1 is a mixture of simple and complex cells. Let represent the relative proportion of neurons which are simple cells and the relative proportion of complex cells. The kernel for the mixed V1 population is given by a simple convex combination of the simple and complex cell kernels
(91)
where denotes neuron type (simple vs complex, tuning etc) and are probability distributions over the V1 neuron identities, the simple cell identities and the complex cell identities respectively. Increasing increases the phase dependence of the code by giving greater weight to the simple cell population. Decreasing gives weight to the complex cell population, encouraging phase invariance of readouts.
Visualization of feedforward Gabor V1 model and induced kernels
Examples of the induced kernels for the Gabor-bank V1 model are provided in Figure 5. We show how choice of rectifying nonlinearity and sparsifying threshold influence the kernel and their spectra. Learning curves for simple orientation tasks are provided.
Gabor model spectral bias and fit to V1 data
Motivated by findings in the primary visual cortex (Hansel and van Vreeswijk, 2002; Miller and Troyer, 2002; Priebe et al., 2004; Priebe and Ferster, 2008), we studied the spectral bias induced by rectified power-law nonlinearities of the form . From theory, such a power-law activation function arises in a spiking neuron when firing is driven by input fluctuations (Hansel and van Vreeswijk, 2002; Miller and Troyer, 2002). Further, this activation is observed in intracellular recordings over the dynamic range of neurons in primary visual cortex (Priebe and Ferster, 2008). For example, in cats, the power, , ranges from 2.7 to 3.9 (Priebe et al., 2004). We fit parameters of our model to the Mouse V1 kernel and compared to other parameter sets in Figure 5—figure supplement 1. Our best fit value of is lower but on par with the estimates from the cat and reproduces the observed kernel. Computation of the kernel and its eigenvalues (Appendix Nonlinear simple cells) indicates a low frequency bias: the eigenvalues for low frequency modes are higher than those for high frequency modes, indicating a strong inductive bias to learn functions of low frequency in the orientation. Decreasing sparsity (lower ) leads to a faster decay in the spectrum (but similar asymptotic scaling at the tail, see Figure 5—figure supplements 1 and 2) and a stronger bias towards lower frequency functions (Figure 5). The effect of the power of nonlinearity is more nuanced: increasing power may increase spectra at lower frequencies, but may also lead to a faster decay at the tail (Figure 5—figure supplements 1 and 2 ). In general, an exponent implies a power-law asymptotic spectral decay as (Appendix Nonlinear simple cells). The behavior at low frequencies may have significant impact for learning with few samples. Overall, our findings show that the spectral bias of a population code can be determined in non-trivial ways by its biophysical parameters, including neural thresholds and nonlinearities.
Energy model with partially phase-selective cells
The model of the V1 population as a mixture of purely simple and purely complex cells is an idealization which fails to capture the variability in phase selectivity of cells observed in experiment. In this section, we describe a simple model which can interpolate between an invariant code and a code which has high alignment with phase-dependent eigenfunctions. Further, a single scalar parameter will control how strongly the population is biased towards invariance. We define for nonlinear function and scalar which is constructed as follows
(92)
This linear combination is inspired by the construction of simple cells in Dayan & Abbot Chapter 2 (Dayan and Abbott, 2001). If all are equal, then this tuning curve is invariant to phase . To generate variability in selectivity to phase , we will draw from a Dirichlet distrbution on the simplex with concentration parameter so that with . In the limit, the probability density concentrates on , leading to a code comprised entirely of complex cells which are invariant to phase . In the limit, the density is concentrated around the “edges” of the simplex such as , where only one preferred phase is present per neuron. For intermediate values, neurons are partially selective to phase. As before, the selectivity or invariance to phase is manifested in the kernel decomposition and leads to similar learning curves for the three tasks of the main paper (Orientation, Phase, Hybrid). We provide an illustration of tuning curves, F1/F0 distributions, eigenfunctions, and learning curves in Figure 5—figure supplement 3.
Time dependent neural codes
RNN model and decomposition
In this setting, the population code is a function of an input stimulus sequence and time . In general the neural code at time can depend on the entire history of the stimulus input for , as is the case for recurrent neural networks. We denote dependence of a function on in this causal manner with the notation . In a learning task, a set of readout weights are chosen so that a downstream linear readout approximates a target sequence which maps input stimulus sequences to output scalar sequences. The quantity of interest is the generalization , which in this case is an average over both input sequences and time, . The average is computed over a distribution of input stimulus sequences . To train the readout, , the network is given a sample of stimulus sequences . For the μ-th training input sequence, the target system is evaluated at a set of discrete time points giving a collection of target values and a total dataset of size . The average case generalization computes a further average of the generalization error over randomly sampled datasets of size .
Learning is again achieved through iterated weight updates with delta-rule form, but now have contributions from both sequence index and time . As before, optimization of the readout weights is equivalent to kernel regression with a kernel that computes inner products of neural population vectors at different times for different input sequences . This kernel depends on details of the time varying population code including its recurrent intrinsic dynamics as well as its encoding of the time-varying input stimuli. The optimization problem and delta rule described above converge to the kernel regression solution for kernel gram matrix (Dong et al., 2020; Yang, 2019; Yang, 2020). The learned function has the form , where for kernel gram matrix which is computed for the entire set of training sequences, and the vector is the vector containing the desired target outputs for each sequence. Assuming a probability distribution over sequences , the kernel can be diagonalized with orthonormal eigenfunctions . Our theory carries over from the static case: kernels whose top eigenfunctions have high alignment with the target dynamical system will achieve the best average case generalization performance.
Alternative neural codes with same kernel
Orthogonal transformations are sufficient for linear kernel-preserving transformations
We will now show that for any linear transformation which preserves the inner product kernel , there exists an orthogonal matrix such that .
Proof.
Let for all stimuli . To preserve the kernel, we must have
(93)
Taking projections against each of the orthonormal eigenfunctions (see Appendix Singular value decomposition of continuous population responses), we define vectors as , allowing us to express the SVD of the population code . These vectors are orthonormal since, by the definition of the kernel eigenfunctions ,
(94)
Since and have the same inner product kernel, they must posess the same kernel eigenfunctions and kernel eigenvalues , which are identified through the eigenvalue problem
(95)
We therefore have the following two singular value decompositions for and
(96)
where and are both complete sets of orthonormal vectors (the sums above run over possible zero eigenvalues). Taking the equation , we multiply both sides of the equation by and average over giving
(97)
For an eigenmode with positive eigenvalue , this implies , while there is no corresponding constraint for the null modes with . However, the action of on the nullspace of the code has no influence on so there is no loss in generality to restrict consideration to transformations which satisfy for all (rather than just the modes). This choice gives . Thus, the space of codes with equivalent kernels to generated through linear transformations is equivalent to all possible orthogonal transformations of the original code . ∎
Effect of noise on RROS symmetry
The random rotation and optimal shift (RROS) operations introduced in the main text preserve generalization performance under the assumption of a deterministic neural code. However, for noisy codes, the presence of RROS symmetry is dependent on the noise distribution. Below we discuss two commonly analyzed distributions: the Gaussian distribution and the Poisson distribution. For Gaussian noise, the RROS operations preserve the generalization performance and the local Fisher information. However, if noise is constrained to be Poisson then RROS operations do not preserve generalization or Fisher information.
First, we will analyze stimulus dependent Gaussian noise, where generalization performance is preserved under rotations and baseline shifts. Note that if the code at obeyed , then the rotated and shifted code follows . This rotated and shifted code , when centered, will exhibit identical generalization performance as the original code. This is true both for learning from a trial averaged or non-trial averaged code. In the case of Gaussian noise on a centered code, the dataset transforms under a rotation as . The optimal weights for a linear model similarly transform as . Under these transformations the predictor on test point is unchanged since
(98)
Further, the local Fisher information matrix is is unchanged under the transformation . Under this transformation, the covariance simply transforms linearly and the matrices will annihilate under the trace. This shows that, for some noise models, our assumption that rotations and baseline shifts preserve generalization performance will be valid.
However, for Poisson noise, where the variance is tied to the mean firing rate, the RROS operations will not preserve noise structure or information content. The Fisher information at scalar stimulus for a Poisson neuron is . A baseline shift to the tuning curve will not change the numerator since the derivative of the tuning curve is invariant to this transformation, but it will increase the denominator.
Necessary conditions for optimally sparse codes
Next we argue why optimally sparse codes should be lifetime and population selective. We consider the following optimization problem: find a non-negative neural responses and baseline vector so that baseline subtracted responses realize a desired inner product kernel and have minimal total firing. This is equivalent to finding the most metabolically efficient code among the space of codes with equivalent inductive bias. Mathematically, we formulate this problem as
(99)
To enforce the constraints for the definition of the kernel and the non-negativity of the responses, we introduce the following Lagrangian
(100)
where 1 is the vector containing all ones, the Lagrange multiplier matrix enforces the definition of the kernel and the KKT multiplier matrix enforces the non-negativity constraints for each element of . The KKT conditions require that any local optimum of the objective would have to satisfy the following equations (Kuhn and Tucker, 2014)
(101)
where denotes the element-wise Hadamard product. Using the complementary slackness condition , and the first optimality condition , we have
(102)
Therefore, for any neuron-stimulus pair , either or . Further, under the condition that K is full rank, we conclude that for any stimulus μ, from the equation . Let represent the set of stimuli for which neuron fires. We will call this the receptive field set for neuron . Let have entries
(103)
where the matrix is the minor of obtained by taking all rows and columns with indices , and denotes pseudo-inverse of . Then the -th neuron’s tuning curve is a function of the index set the baseline and the neuron-independent matrix . The non-negativity constraint for neuron ’s tuning curve implies that for all . To satisfy the definition of the kernel, we have the following constraint on the matrix , the index sets and baselines
(104)
This equation implictly defines the index sets the baselines and the KKT matrix . We see that, in order to fit an arbitrary kernel, the receptive field sets and baselines for each neuron must be sufficiently diverse since otherwise only a low rank kernel matrix can be achieved from the optimally sparse code. As a concrete example, suppose that so that and for all . For example, this could occur if each neuron fired for every possible stimulus. In this case, the kernel would be rank one: . In order to achieve a higher rank code there must be sufficient diversity of the receptive fields . Thus the only way for optimally sparse codes to realize high rank kernels is to have neurons to have different receptive field sets . The necessary optimality conditions thus reveal a preference for sparse neural tuning curves to have high lifetime sparseness; to achieve diverse index sets , any given neuron will fire only for a unique subset of the possible stimuli.
Impact of neural noise and unlearnable targets on learning
While our analysis so far has focused on deterministic population codes, our theory can be extended to neural populations which exhibit variability in responses to identical stimuli. For each stimulus , we let the population response be a random vector with mean and covariance .
The (deterministic) target function can be decomposed in terms of the mean response as (the usual decomposition gives an unphysical target function which fluctuates with the variability in neural responses). For a given configuration of weights , the generalization error (which is an average over the joint distribution of ) is determined only by the signal and noise correlation matrices:
(105)
where we utilized the fact that to eliminate the cross-term. The two terms in the final expression can be thought of as a bias-variance decomposition over the noise in neural responses. The minimum achievable loss can be obtained by differentiation of the generalization error expression with respect to , giving . We note that any noise correlation matrix with noise orthogonal to coding direction will give the minimal (zero) asymptotic error. Alignment of the noise with gives higher asymptotic error.
In addition to the irreducible error, the presence of neural noise can alter the learning curve at finite . An analytical study of this is difficult, which we leave for future work. We numerically study the effect of neural variability on generalization performance in the orientation discrimination tasks for non-trial-averaged Mouse V1 code in Appendix 1—figure 1 . We note that the generalization error is worse at each finite value of when compared to trial averaged (noise free) learning curves. We varied the regularization parameter and did not find an obvious non-zero optimal weight decay , consistent with small noise levels.
Neural noise is not the only phenomenon that can degrade task learning. Codes which are incapable of expressing the target function through linear readouts are also susceptible to overfitting. As explained in Canatar et al., 2021, the components of the target function that are inexpressible act as a source of noise on the learning process which can overfit this noise. Such a scenario can occur, for example, when the readout neuron only gets input from a sparse subset of the coding neural population (Seeman et al., 2018). We show in Appendix 1—figure 1C-D that using subsampled populations of size can indeed lead to a regime where more data can hurt performance leading to an overfitting error peak, a subsequent non-vanishing asymptotic error, and an optimal weight decay parameter . This phenomenon is known as double descent in machine learning literature (Belkin et al., 2019; Mei and Montanari, 2020; Canatar et al., 2021). At small , these codes are not sufficiently expressive to learn the target function through linear readout. The overfitting peak occurs near the interpolation threshold, the largest value of where all training sets could be perfectly fit in the limit (Canatar et al., 2021). At infinite , generalization error asymptotes to the amount of unexplained variance in the target function.
Appendix 1—figure 1
Neural noise and subsampled neural codes can lead to overfitting.
(A) The learning curves without trial averaging (solid) and with trial averaging (dashed) for the high and low frequency orientation discrimination task. In principle, neural noise could limit asymptotic performance and lead to the existence of an optimal weight decay parameter . (B) Performance at vs ridge shows that there is not an optimal weight decay parameter. (C) Generalization of readouts trained on subsets of V1 neurons exhibit non-monotonic learning curves with an overfitting peak around . (D) The performance of subsamples of neurons as a function of the weight decay parameter at samples show that, for sufficiently small , there is a non-zero optimal .
Data availability
Mouse V1 neuron responses to orientation gratings and preprocessing code were obtained from a publicly available dataset: https://github.com/MouseLand/stringer-et-al-2019. Responses to ImageNet images and preprocessing code were obtained from another publicly available dataset, https://github.com/MouseLand/stringer-pachitariu-et-al-2018b. The code generated by the authors for this paper is also available https://github.com/Pehlevan-Group/sample_efficient_pop_codes, (copy archived at swh:1:rev:6cd4f0fe7043ae214dd682a9dc035a497ffa2d61).
-
FigshareRecordings of ten thousand neurons in visual cortex in response to 2,800 natural images.https://doi.org/10.25378/janelia.6845348.v4
-
FigshareRecordings of ~20,000 neurons from V1 in response to oriented stimuli.https://doi.org/10.25378/janelia.8279387.v3
References
-
ConferenceDo retinal ganglion cells project natural scenes to their principal subspace and whiten them?2016 50th Asilomar Conference on Signals, Systems and Computers.https://doi.org/10.1109/ACSSC.2016.7869658
-
Perceptual learning of simple stimuli modifies stimulus representations in posterior inferior temporal cortexJournal of Cognitive Neuroscience 26:2187–2200.https://doi.org/10.1162/jocn_a_00641
-
Spatiotemporal energy models for the perception of motionJournal of the Optical Society of America. A, Optics and Image Science 2:284–299.https://doi.org/10.1364/josaa.2.000284
-
The reverse hierarchy theory of visual perceptual learningTrends in Cognitive Sciences 8:457–464.https://doi.org/10.1016/j.tics.2004.08.011
-
Generation of random orthogonal matricesSIAM Journal on Scientific and Statistical Computing 8:625–629.https://doi.org/10.1137/0908055
-
What does the retina know about natural scenes?Neural Computation 4:196–210.https://doi.org/10.1162/neco.1992.4.2.196
-
Some informational aspects of visual perceptionPsychological Review 61:183–193.https://doi.org/10.1037/h0054663
-
Neural correlations, population coding and computationNature Reviews. Neuroscience 7:358–366.https://doi.org/10.1038/nrn1888
-
BookPossible Principles Underlying the Transformation of Sensory MessagesCambridge University.
-
Benign overfitting in linear regressionPNAS 117:30063–30070.https://doi.org/10.1073/pnas.1907378117
-
Local diversity and fine-scale organization of receptive fields in mouse visual cortexThe Journal of Neuroscience 31:18506–18521.https://doi.org/10.1523/JNEUROSCI.2974-11.2011
-
ConferenceSpectrum dependent learning curves in kernel regression and wide neural networksProceedings of the 37th International Conference on Machine Learning of Proceedings of Machine Learning Research. pp. 1024–1034.
-
ConferenceSelf-Consistent Dynamical Field Theory of Kernel Evolution in Wide Neural NetworksAdvances In Neural Information Processing Systems.
-
Deep neural networks rival the representation of primate it cortex for core visual object recognitionPLOS Computational Biology 10:e1003963.https://doi.org/10.1371/journal.pcbi.1003963
-
Principal component analysis of neuronal ensemble activity reveals multidimensional somatosensory representationsJournal of Neuroscience Methods 94:121–140.https://doi.org/10.1016/s0165-0270(99)00130-2
-
Measuring and interpreting neuronal correlationsNature Neuroscience 14:811–819.https://doi.org/10.1038/nn.2842
-
Dimensionality reduction for large-scale neural recordingsNature Neuroscience 17:1500–1509.https://doi.org/10.1038/nn.3776
-
BookTheoretical Neuroscience: Computational and Mathematical Modeling of Neural SystemsThe MIT Press.
-
ConferenceImagenet: A large-scale hierarchical image databaseIn 2009 IEEE conference on computer vision and pattern recognition.
-
ConferenceReservoir computing meets recurrent kernels and structured transformsNeurIPS Proceedings.
-
Representation is representation of similaritiesThe Behavioral and Brain Sciences 21:449–467.https://doi.org/10.1017/s0140525x98001253
-
On simplicity and complexity in the brave new world of large-scale neuroscienceCurrent Opinion in Neurobiology 32:148–155.https://doi.org/10.1016/j.conb.2015.04.003
-
Physiological correlates of perceptual learning in monkey V1 and V2Journal of Neurophysiology 87:1867–1888.https://doi.org/10.1152/jn.00690.2001
-
Regularization theory and neural networks architecturesNeural Computation 7:219–269.https://doi.org/10.1162/neco.1995.7.2.219
-
How noise contributes to contrast invariance of orientation tuning in cat visual cortexThe Journal of Neuroscience 22:5118–5128.https://doi.org/10.1523/JNEUROSCI.22-12-05118.2002
-
Predictive codingWiley Interdisciplinary Reviews. Cognitive Science 2:580–593.https://doi.org/10.1002/wcs.142
-
Weight perturbation: an optimal architecture and learning technique for analog vlsi feedforward and recurrent multilayer networksIEEE Transactions on Neural Networks 3:154–157.https://doi.org/10.1109/72.105429
-
Advances in Neural Information Processing SystemsNeural tangent kernel: convergence and generalization in neural networks, Advances in Neural Information Processing Systems, Curran Associates, Inc.
-
ConferenceSGD on neural networks learns functions of increasing complexityIn Advances in Neural Information Processing Systems 32: Annual Conference on Neural Information Processing Systems 2019.
-
Representational similarity analysis-connecting the branches of systems neuroscienceFrontiers in Systems Neuroscience 2:4.https://doi.org/10.3389/neuro.06.004.2008
-
BookNonlinear programmingIn: Kuhn HW, editors. Traces and Emergence of Nonlinear Programming. Springer. pp. 1–4.https://doi.org/10.1007/978-3-0348-0439-4
-
Content and cluster analysis: assessing representational similarity in neural systemsPhilosophical Psychology 13:47–76.https://doi.org/10.1080/09515080050002726
-
Building machines that learn and think like peopleThe Behavioral and Brain Sciences 40:e253.https://doi.org/10.1017/S0140525X16001837
-
ConferenceDeep neural networks as gaussian processesIn International Conference on Learning Representations.
-
Random synaptic feedback weights support error backpropagation for deep learningNature Communications 7:13276.https://doi.org/10.1038/ncomms13276
-
Learning curves of generic features maps for realistic datasets with a teacher-student modelAdvances in Neural Information Processing Systems 34:18137–18151.https://doi.org/10.1088/1742-5468/ac9825
-
The generalization error of random features regression: precise asymptotics and the double descent curveCommunications on Pure and Applied Mathematics 75:667–766.https://doi.org/10.1002/cpa.22008
-
Adaptive tuning curve widths improve sample efficient learningFrontiers in Computational Neuroscience 14:12.https://doi.org/10.3389/fncom.2020.00012
-
XVI. Functions of positive and negative type, and their connection the theory of integral equationsPhilosophical Transactions of the Royal Society of London. Series A, Containing Papers of A Mathematical or Physical Character 209:415–446.https://doi.org/10.1098/rsta.1909.0016
-
Neural noise can explain expansive, power-law nonlinearities in neural response functionsJournal of Neurophysiology 87:653–659.https://doi.org/10.1152/jn.00425.2001
-
ConferenceOn 1/n neural representation and robustnessAdvances in Neural Information Processing Systems 33.
-
Highly selective receptive fields in mouse visual cortexThe Journal of Neuroscience 28:7520–7536.https://doi.org/10.1523/JNEUROSCI.0623-08.2008
-
Energy limitation as a selective pressure on the evolution of sensory systemsThe Journal of Experimental Biology 211:1792–1804.https://doi.org/10.1242/jeb.017574
-
Robustness of spike deconvolution for neuronal calcium imagingThe Journal of Neuroscience 38:7976–7985.https://doi.org/10.1523/JNEUROSCI.3339-17.2018
-
BookRecordings of 20,000 Neurons from V1 in Response to Oriented StimuliAmerican Physiological Society.
-
Why do similarity matching objectives lead to hebbian/anti-hebbian networks?Neural Computation 30:84–124.https://doi.org/10.1162/neco_a_01018
-
Decorrelation and efficient coding by retinal ganglion cellsNature Neuroscience 15:628–635.https://doi.org/10.1038/nn.3064
-
ConferenceLie group methods for optimization with orthogonality constraintsIn International Conference on Independent Component Analysis and Signal Separation.
-
The contribution of spike threshold to the dichotomy of cortical simple and complex cellsNature Neuroscience 7:1113–1122.https://doi.org/10.1038/nn1310
-
ConferenceOn the spectral bias of neural networksIn International Conference on Machine Learning.
-
ConferenceA generalized representer theoremIn Proceedings of the 14th Annual Conference on Computational Learning Theory and 5th European Conference on Computational Learning Theory, COLT ’01/EuroCOLT ’01.
-
BookLearning with Kernels: Support Vector Machines, Regularization, Optimization, and BeyondMIT press.
-
Neural basis of a perceptual decision in the parietal cortex (area lip) of the rhesus monkeyJournal of Neurophysiology 86:1916–1936.https://doi.org/10.1152/jn.2001.86.4.1916
-
ConferenceNeural tangent kernel eigenvalues accurately predict generalizationICLR 2022 Conference.
-
A model of neuronal responses in visual area MTVision Research 38:743–761.https://doi.org/10.1016/s0042-6989(97)00183-1
-
Natural image statistics and neural representationAnnual Review of Neuroscience 24:1193–1216.https://doi.org/10.1146/annurev.neuro.24.1.1193
-
ConferenceApproximate learning curves for Gaussian processes9th International Conference on Artificial Neural Networks.https://doi.org/10.1049/cp:19991148
-
BookGaussian process regression with mismatched modelsIn: Dietterich T, Becker S, Ghahramani Z, editors. Advances in Neural Information Processing Systems. MIT Press. pp. 1–2.
-
Predictive coding: a fresh view of inhibition in the retinaProceedings of the Royal Society of London. Series B, Biological Sciences 216:427–459.https://doi.org/10.1098/rspb.1982.0085
-
Continuous analogues of matrix factorizationsProceedings of the Royal Society A 471:20140585.https://doi.org/10.1098/rspa.2014.0585
-
ConferenceDeep learning generalizes because the parameter-function map is biased towards simple functionsIn International Conference on Learning Representations.
-
Dynamics of spatial frequency tuning in mouse visual cortexJournal of Neurophysiology 107:2937–2949.https://doi.org/10.1152/jn.00022.2012
-
Characterizing the sparseness of neural codesNetwork: Computation in Neural Systems 12:255.https://doi.org/10.1080/net.12.3.255.270
-
The lack of a priori distinctions between learning algorithmsNeural Computation 8:1341–1390.https://doi.org/10.1162/neco.1996.8.7.1341
-
The effect of perceptual learning on neuronal responses in monkey visual area v4The Journal of Neuroscience 24:1617–1626.https://doi.org/10.1523/JNEUROSCI.4442-03.2004
-
ConferenceTensor programs iv: Feature learning in infinite-width neural networksIn International Conference on Machine Learning.
-
ConferenceUnderstanding deep learning requires rethinking generalizationIn 5th Int. Conf. on Learning Representations (ICLR 2017).
Article and author information
Author details
Funding
National Science Foundation (DMS-2134157)
- Blake Bordelon
- Cengiz Pehlevan
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Jacob Zavatone-Veth and Abdulkadir Canatar for useful comments and discussions about this manuscript. BB acknowledges the support of the NSF-Simons Center for Mathematical and Statistical Analysis of Biology at Harvard (award #1764269) and the Harvard Q-Bio Initiative. CP and BB were also supported by NSF grant DMS-2134157.
Copyright
© 2022, Bordelon and Pehlevan
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,565
- views
-
- 416
- downloads
-
- 18
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 18
- citations for umbrella DOI https://doi.org/10.7554/eLife.78606
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Population codes enable learning from few examples by shaping inductive bias
eLife 11:e78606.
https://doi.org/10.7554/eLife.78606




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}