A billion years arms-race between viruses, virophages, and eukaryotes
- Department of Biology, University of Oxford, United Kingdom
eLife assessment
The important study by Barreat and Katzourakis examines the evolutionary history of eukaryotic viruses (and related mobile elements) in the Bamfordvirae kingdom, and evaluates potential alternative scenarios regarding the origin of different lineages in this highly diverse kingdom. Through convincing phylogenetic analyses, the authors propose a new evolutionary model for the origin of this kingdom where their last common ancestor is inferred to have been an exogenous, non-virophage DNA virus with a small genome. This work advances our understanding of the deep evolutionary history of viruses, the interaction between viruses and the first eukaryotes, and the diversification of viral lineages.
https://doi.org/10.7554/eLife.86617.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Convincing: Appropriate and validated methodology in line with current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
Bamfordviruses are arguably the most diverse group of viruses infecting eukaryotes. They include the Nucleocytoplasmic Large DNA viruses (NCLDVs), virophages, adenoviruses, Mavericks and Polinton-like viruses. Two main hypotheses for their origins have been proposed: the ‘nuclear-escape’ and ‘virophage-first’ hypotheses. The nuclear-escape hypothesis proposes an endogenous, Maverick-like ancestor which escaped from the nucleus and gave rise to adenoviruses and NCLDVs. In contrast, the virophage-first hypothesis proposes that NCLDVs coevolved with protovirophages; Mavericks then evolved from virophages that became endogenous, with adenoviruses escaping from the nucleus at a later stage. Here, we test the predictions made by both models and consider alternative evolutionary scenarios. We use a data set of the four core virion proteins sampled across the diversity of the lineage, together with Bayesian and maximum-likelihood hypothesis-testing methods, and estimate rooted phylogenies. We find strong evidence that adenoviruses and NCLDVs are not sister groups, and that Mavericks and Mavirus acquired the rve-integrase independently. We also found strong support for a monophyletic group of virophages (family Lavidaviridae) and a most likely root placed between virophages and the other lineages. Our observations support alternatives to the nuclear-escape scenario and a billion years evolutionary arms-race between virophages and NCLDVs.
Introduction
Viruses in the kingdom Bamfordvirae comprise one of the most diverse groups in terms of their genome complexity, ecology and morphology. These dsDNA viruses include the largest viruses characterised to date (Legendre et al., 2014; Scheid, 2016), virophages which are virus parasites of other viruses (Fischer and Suttle, 2011; La Scola et al., 2008), endogenous viruses that colonise the genomes of eukaryotes (Kapitonov and Jurka, 2006; Pritham et al., 2007), and a diverse set of viruses that have been identified from metagenomic data (Bellas and Sommaruga, 2021; Moniruzzaman et al., 2020; Paez-Espino et al., 2019; Roux et al., 2017; Schulz et al., 2020; Yutin et al., 2015). More formally, these viruses are classified into the Nucleocytoplasmic Large DNA Viruses (NCLDVs) which comprise families in the phylum Nucleocytoviricota (Aylward et al., 2021), the virophage parasites of NCLDVs (family Lavidaviridae; Fischer, 2021), adenoviruses (family Adenoviridae) which infect vertebrates (Harrach et al., 2019), the Maverick/Polinton endogenous viruses that colonise the genomes of eukaryotes (Kapitonov and Jurka, 2006; Pritham et al., 2007), Polinton-like viruses (PLVs) which are abundant in aquatic metagenomes (Bellas and Sommaruga, 2021; Yutin et al., 2015), and capsidless elements such as transpovirons (Desnues et al., 2012), mitochondrial and cytoplasmic linear plasmids (Krupovic and Koonin, 2015; Meinhardt et al., 1997). The wide taxonomic distribution of NCLDV and Maverick hosts, which comprise all major eukaryotic lineages (Kapitonov and Jurka, 2006; Pritham et al., 2007; Schulz et al., 2020), seem to point to an ancient origin of these viral groups.
Despite their diversity, the elements share an ancestral gene module used for capsid morphogenesis, which is the feature that distinguishes viruses from other mobile genetic elements (Koonin et al., 2021). The ancestral module is formed by double and single jelly-roll capsid proteins, a family C5 (adenoviral-like) protease and a family FtsK/HerA DNA packaging ATPase (Krupovic et al., 2016c; Yutin et al., 2015). In fact, the jelly-roll capsid proteins and DNA packaging ATPase, also occur in phages from the families Turriviridae, Tectiviridae, Corticoviridae, and Autolykiviridae, which suggests a common viral ancestor for eukaryotic bamfordviruses and their prokaryotic virus relatives (Koonin et al., 2020; Woo et al., 2021). These observations are at odds with the suggestion that NCLDVs originated by reductive evolution, possibly from a fourth domain of cellular life (Colson et al., 2018; Legendre et al., 2012; Patil and Kondabagil, 2021).
Currently, two hypotheses have been proposed for the origin of the eukaryotic Bamfordvirae: the ‘nuclear-escape’ and ‘virophage-first’ scenarios (Figure 1). According to the nuclear-escape scenario, the elements in this lineage evolved from an endogenous virus in the nucleus of an early eukaryote, a Maverick-like ancestor (Koonin and Krupovic, 2017; Krupovic and Koonin, 2015; Krupovic and Koonin, 2016a). Adenoviruses, cytoplasmic linear plasmids and NCLDVs evolved after their ancestor escaped from the nucleus (Koonin et al., 2015a; Krupovic and Koonin, 2015). Therefore, the nuclear-escape hypothesis predicts that adenoviruses form a clade with NCLDVs and cytoplasmic linear plasmids, and that the proteins shared by cytoplasmic linear plasmids and NCLDVs have a single common origin (Koonin and Krupovic, 2017; Krupovic and Koonin, 2015). The nuclear-escape hypothesis is based on phylogenetic trees of the protein-primed DNA polymerase B, which show a paraphyletic group of Mavericks at the base of the other lineages (Koonin and Krupovic, 2017; Krupovic et al., 2016c; Krupovic and Koonin, 2015). However, the trees are missing NCLDVs which encode a non-homologous nucleotide-primed DNA polymerase, and could therefore not be included in the analyses, and only show the position for Mavirus-like virophages which encode the protein-primed DNA polymerase.
Figure 1

The two main hypotheses for the origin of virophages and NCLDVs.
In the virophage first hypothesis, NCLDVs diverge early with its sister lineage evolving into protovirophages. In the nuclear escape hypothesis, NCLDVs descend from endogenous elements (encoding an integrase) that became exogenous; virophages then evolved to become their parasites.
The virophage-first scenario is based on the close similarity in gene content between the Mavirus virophage and Mavericks, and the ability of Mavirus to integrate into eukaryotic genomes (Fischer and Hackl, 2016; Fischer and Suttle, 2011). Integrated Mavirus virophages reactivate upon giant virus infection and confer protection against Cafeteria roenbergensis virus in the flagellate Cafeteria burkhardae (Fischer and Hackl, 2016). The virophage-first scenario therefore suggests that an ancestral virophage evolved shortly after the origin of NCLDVs, and was able to parasitise NCLDVs by virtue of their shared promoter and poly-A sequences (Campbell et al., 2017; Fischer and Suttle, 2011). One of these lineages of ancestral virophages would have gained an integrase and endogenised into eukaryotic hosts providing an immune defence system, which gave rise to Mavericks and other elements (Fischer and Suttle, 2011; Katzourakis and Aswad, 2014). A nuclear-escape would have still occurred for adenoviruses and cytoplasmic linear plasmids, but not NCLDVs, which would belong to a different clade suggesting the immediate ancestor of NCLDVs was an exogenous virus.
Phylogenetics can be used to test competing evolutionary models of virus origins in a rigorous statistical framework. Each tree represents an evolutionary hypothesis which is inferred from matrices of aligned homologous characters with different states (the data). In molecular phylogenetics, nucleotide or amino acid alignments are used as the data to obtain the topology of a tree (and also rates or branch lengths). In statistical terms, the data matrices are used to calculate the tree likelihood (probability of the data given the parameters) in both maximum-likelihood and Bayesian frameworks (Schmidt and von Haeseler, 2009; Nascimento et al., 2017). In maximum likelihood, the preferred tree is the one with the parameter values that maximise the tree likelihood (Schmidt and von Haeseler, 2009). In Bayesian inference, a posterior probability distribution for the parameters is estimated from their prior distributions and the tree likelihood (probability of the parameters given the data) (Nascimento et al., 2017). Together, these approaches can be used to assess the plausibility of competing evolutionary models that make different predictions about tree topologies and the position of the root.
Understanding the diversification of these viruses remains a major open question in virus evolution. To address this problem, we have analysed a data set of virus representatives sampled across the diversity of the eukaryotic bamfordvirus lineage and focused on the 4 core virion proteins: major and minor capsid proteins, protease and ATPase. We use explicit hypothesis-testing methods and estimate the position of the root in our phylogenies, which allowed us to infer the direction of evolution followed by the proteins in the morphogenetic module. Our results suggest a new model for the evolutionary origins of these viruses, which is consistent with an exogenous, non-virophage ancestor.
Results
The rooted Bayesian and maximum-likelihood trees estimated from the concatenated data had the best overall support and shared important topological similarities (Figures 2 and 3). In the Bayesian tree, adenoviruses were placed in a clade with Mavericks and most PLVs with a high posterior probability (0.94, Figure 2), and to the exclusion of NCLDVs. This arrangement was also observed in the maximum likelihood tree topology shown in Figure 3, although with a low bootstrap support (34%). The virophages (family Lavidaviridae) emerged as a strongly supported monophyletic group on both trees (posterior probability = 1 in the Bayesian analysis, 95% bootstrap support in the maximum-likelihood analysis), while Polinton-like viruses were clearly polyphyletic.
Figure 2 with 6 supplements see all
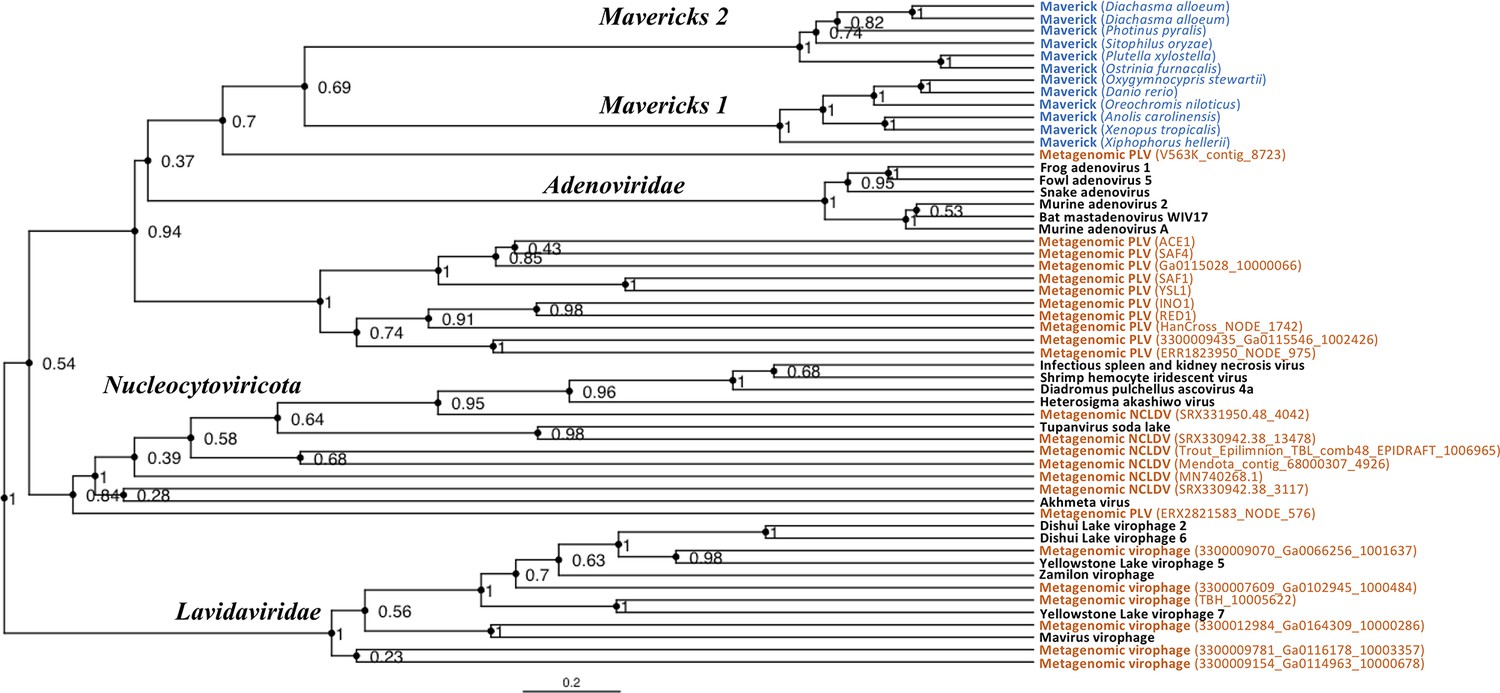
Rooted Bayesian maximum clade credibility tree of the major lineages of eukaryotic viruses in the kingdom Bamfordvirae.
The tree is based on the concatenated alignment of 4 core proteins involved in virion morphogenesis (major and minor capsid proteins, ATPase and protease). Tree computed in BEAST 2 (Bouckaert et al., 2019) using a relaxed molecular clock and 140 million generations (relative burn-in of 25%). Black: reference viral genomes, Blue: endogenous elements, Orange: metagenomic sequences.
Figure 3 with 1 supplement see all
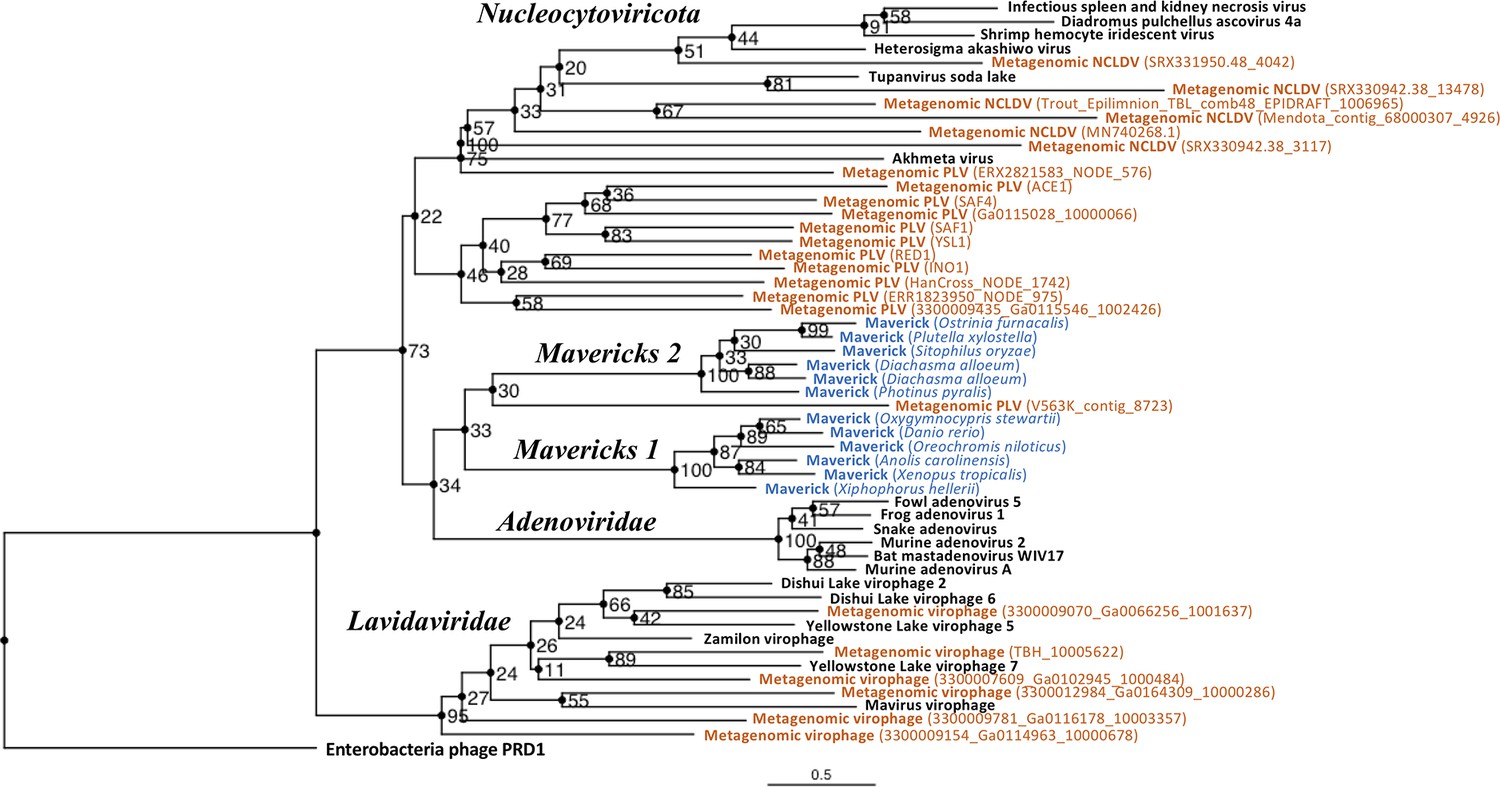
Outgroup-rooted maximum likelihood tree of the major lineages of eukaryotic viruses in the kingdom Bamfordvirae.
The tree is based on the concatenated alignment of 4 core proteins involved in virion morphogenesis (major and minor capsid proteins, ATPase and protease). Enterobacteria phage PRD1 (Tectiviridae) was used as the outgroup for rooting. Tree computed in RAxML-NG with 200 random starting trees and 2200 bootstraps (Kozlov et al., 2019). Black: reference viral genomes, Blue: endogenous elements, Orange: metagenomic sequences.
The position of the root inferred both through the Bayesian relaxed-clock analysis and by outgroup rooting with the Enterobacteria phage PRD1 (Tectiviridae), was between virophages and all the other viral lineages. In the Bayesian analysis, the root was placed on this position in 54% of trees (Figure 2), while in the maximum-likelihood analysis the clade of (Adenoviruses + Mavericks + PLVs+NCLDVs), that is to the exclusion of virophages, received a bootstrap support of 73% (Figure 3). We also examined alternative placements of the root sampled during the Bayesian Markov-chain Monte Carlo (MCMC) to assess the frequency of other hypotheses (Supplementary file 2). Rooting on the clade formed by NCLDVs + PLV BS_539 (ERX2821583_NODE_576) was observed in 27.4% of trees. The root positions at the next highest frequencies were on the branch of PLV BS_539 (5.6%), NCLDVs (5.3%) and PLV BS_539 + NCLDVs + virophages (5%). Roots on other branches were observed at frequencies lower than 1% (Supplementary file 2).
The monophyly of virophages and the root on this branch were also observed in the single-protein trees. The major and minor capsid single-protein trees recovered a monophyletic Lavidaviridae (0.97 and 0.52 posterior probability), and also inferred the root to be placed between virophages and the other viruses (29% and 28%, Figure 2—figure supplement 1, Figure 2—figure supplement 2). Although the root was observed at a different position for the ATPase and protease trees; these analyses also failed to recover a monophyletic family of virophages (Figure 2—figure supplement 3, Figure 2—figure supplement 4). However, when virophages were constrained to be monophyletic the root was placed again between virophages and the other lineages, and thus in agreement with our findings using the concatenated data, major and minor capsid proteins (Figure 2—figure supplement 5, Figure 2—figure supplement 6).
The Bayesian and maximum-likelihood tests of topology were also consistent with each other. We used the Akaike information criterion (AIC) to compare the plausibility of the maximum-likelihood topologies consistent with the nuclear-escape and alternative scenarios. All the comparisons preferred a non-sister grouping of adenoviruses and NCLDVs (Table 1). Indeed, the Akaike weights, which can be interpreted as the normalised relative likelihood of the models given the data (Posada and Buckley, 2004), strongly favoured the alternative scenario over the nuclear-escape hypothesis (Concatenated data = 99.7%, Protease = 99.7%, Major capsid protein = 72%, Minor capsid protein = 94.3%). The approach using the posterior model odds, calculated following the method of Bergsten et al., 2013, also favoured the alternative scenarios in all of the data sets: concatenated and single-protein (Table 2). This was strongest for the concatenated data (posterior model odds, H0/H1=0.000536), but the same pattern held for the single-protein analyses (posterior model odds = {Protease: 0.00166, Major capsid: 0.11485, Minor capsid: 0.000639}). The Bayesian stepping-stone analysis on the concatenated data also strongly supported the alternative scenario (NCLDVs and adenoviruses are not sister groups), over the nuclear-escape hypothesis (NCLDVs and adenoviruses are sister groups; Table 3).
Table 1
Comparison between the nuclear-escape and alternative maximum-likelihood models based on the Akaike information criterion (AIC).
The log-likelihoods for the models were obtained from the best maximum-likelihood tree consistent with each hypothesis found in RAxML-NG (Kozlov et al., 2019). Results are shown for the concatenated data set of four core proteins (ATPase, protease, major capsid, and minor capsid) and for the protease, major and minor capsid proteins, respectively. The AIC was size-corrected given that the alignment (sample) size was small relative to the number of free parameters, that is n/k<40 (Posada and Buckley, 2004; Symonds and Moussalli, 2011). The best model is highlighted in boldface. The ‘alternatives’ refer to non ‘nuclear-escape’ scenarios, that is, models which are not consistent with the predictions made by the nuclear-escape.
| Model | Characters | Log-likelihood | AIC* | AICc† | ΔAICc‡ | Weight§ |
|---|---|---|---|---|---|---|
| Nuclear-escape (M0) | Concatenated | –41,618.19 | 83,616.37 | 83,864.09 | 11.41 | 0.003 |
| Alternatives (M1) | Concatenated | –41,612.48 | 83,604.96 | 83,852.68 | 0.00 | 0.997 |
| Nuclear-escape (M0) | Protease | –6,323.233 | 12,898.47 | 10,898.22 | 11.37 | 0.003 |
| Alternatives (M1) | Protease | –6,317.550 | 12,887.10 | 10,886.85 | 0.00 | 0.997 |
| Nuclear-escape (M0) | Major capsid | –16,305.52 | 32,861.04 | 34,173.54 | 1.90 | 0.279 |
| Alternatives (M1) | Major capsid | –16,304.57 | 32,859.14 | 34,171.64 | 0.00 | 0.721 |
| Nuclear-escape (M0) | Minor capsid | –10,234.56 | 20,719.11 | 17,855.48 | 5.62 | 0.057 |
| Alternatives (M1) | Minor capsid | –10,231.75 | 20,713.50 | 17,849.86 | 0.00 | 0.943 |
-
*
.
-
†
.
-
‡
.
-
§
.
Table 2
Posterior model odds of the nuclear-escape and alternative hypotheses using concatenated and single-protein data sets.
Tree topologies consistent with each hypothesis were filtered and counted from a Bayesian MCMC following the method of Bergsten et al., 2013. All ratios favour the alternative scenarios to the nuclear-escape hypothesis. The best model is highlighted in boldface. The ‘alternatives’ refer to non-’nuclear-escape’ scenarios, that is, models which are not consistent with the predictions made by the nuclear-escape.
| Model | Characters | MCMC tree frequency | Posterior model oddsP(M0 | X)/P(M1 | X) |
|---|---|---|---|
| Nuclear-escape (M0) | Concatenated | 15/28,001 (0.0536%) | 5.36 ⋅ 10–4 < 1 |
| Alternatives (M1) | Concatenated | 27,986/28,001 (99.946%) | |
| Nuclear-escape (M0) | Protease | 333/200,001 (0.166%) | 1.66 ⋅ 10–3 < 1 |
| Alternatives (M1) | Protease | 199,668/200,001 (99.998%) | |
| Nuclear-escape (M0) | Major capsid | 20,605/200,001 (10.302%) | 1.15 ⋅ 10–1 < 1 |
| Alternatives (M1) | Major capsid | 179,396/200,001 (89.697%) | |
| Nuclear-escape (M0) | Minor capsid | 128/200,001 (0.0639%) | 6.39 ⋅ 10–4 < 1 |
| Alternatives (M1) | Minor capsid | 199,873/200,001 (99.936%) |
Table 3
Bayesian stepping-stone analysis of the nuclear-escape and alternative hypotheses.
Each scenario was run on the concatenated data set in MrBayes 3 (Ronquist and Huelsenbeck, 2003) for 20 million generations (average standard deviation of split frequencies <0.01). The Bayes factor strongly rejects a sister relationship between adenoviruses and NCLDVs (nuclear-escape hypothesis). The best model is highlighted in boldface. The ‘alternatives’ refer to non ‘nuclear-escape’ scenarios, that is, models which are not consistent with the predictions made by the nuclear-escape.
| Model | Likelihood of best state (cold chain) | Log-Marginal-likelihood (ln) | Mean Log-marginal-likelihood (ln) | Bayes factorP(X | M0)/P(X | M1) |
|---|---|---|---|---|
| Nuclear-escape (M0) | Run 1: –36,318.81 | Run 1: –36,376.42 | –36,353.44 | 3.5×10–94 << 1* |
| Run 2: –36,318.81 | Run 2: –36,352.75 | |||
| Alternatives (M1) | Run 1: –35,965.90 | Run 1: –36,137.56 | –36,138.25 | |
| Run 2: –35,981.46 | Run 2: –36,450.19 |
-
*
Strong support against M0.
As an independent test of the predictions made by the nuclear-escape hypothesis, we analysed the origin of the transcriptional proteins shared between NCLDVs and cytoplasmic linear plasmids. According to the nuclear-escape hypothesis, these genes were acquired by the most recent common ancestor of cytoplasmic linear plasmids and NCLDVs, and should thus have a single origin. However, our analyses indicate that these proteins were acquired independently by cytoplasmic linear plasmids and NCLDVs. The maximum-likelihood trees for the Rbp2 subunit of the DNA-directed RNA polymerase, helicase and mRNA-capping proteins all suggest they have independent origins in NCLDVs and cytoplasmic linear plasmids (Figure 3—figure supplement 1). The homologues specific to cytoplasmic linear plasmids clustered with those of eukaryotes and their distribution agrees with a monophyletic origin in this group. Interestingly, the phylogenetic patterns for NCLDVs were consistent with a single-capture (monophyletic origin) for the mRNA-capping enzyme and the helicase, while the distribution of the Rpb2 was consistent with multiple-captures/exchanges (polyphyletic origin).
Discussion
To gain a better understanding of the evolutionary history of the bamfordviruses of eukaryotes, we analysed a set of four core virion morphogenesis proteins (major and minor capsids, DNA-packaging ATPase and protease) sampled across the diversity of the lineage and using an explicit hypothesis-testing framework. In addition, we analysed the origins of three proteins shared by cytoplasmic linear plasmids and NCLDVs. We found strong evidence against the nuclear-escape hypothesis. We also found support for a position of the root between virophages (family Lavidaviridae) and the other viral lineages. This position of the root suggests a new evolutionary model for the origin of these viral lineages. However, we recognise that some alternative root positions were also observed at lower frequencies in the Bayesian analyses, which could be interpreted as ‘virophage-first’-like scenarios.
We have shown that adenoviruses and NCLDVs are not sister groups as proposed by the nuclear-escape hypothesis (Koonin and Krupovic, 2017; Krupovic and Koonin, 2015). Instead, adenoviruses belong to a clade with Mavericks, to the exclusion of NCLDVs. The phylogenies of the proteins shared by cytoplasmic linear plasmids and NCLDVs also disagree with a nuclear escape. Indeed, phylogenies of the protein-primed DNA polymerase place cytoplasmic linear plasmids as the sister-group to adenoviruses (Krupovic et al., 2016c), implying that adenoviruses, cytoplasmic linear plasmids and NCLDVs form a clade. If a single nuclear-escape had occurred we would expect the Rbp2, helicase and mRNA capping enzymes shared by cytoplasmic linear plasmids and NCLDVs to have a monophyletic origin (since they descend from the same ‘escaped’ ancestor). However, their distribution agrees with a more recent origin in cytoplasmic linear plasmids. These observations agree with the more restricted taxonomic distribution of cytoplasmic linear plasmids, which are known only to infect fungi in the Order Saccharomycetales (Division Ascomycota; Meinhardt et al., 1997), in contrast to the taxonomically diverse eukaryotic hosts of NCLDVs.
Virophages emerged as a highly supported monophyletic group in our analyses. This supports the validity of the family Lavidaviridae which has been based on shared gene contents of virophages and their parasitic (or commensal) lifestyles (Fischer, 2021; Krupovic et al., 2016b). By using two independent rooting methods, relaxed-molecular clocks and outgroup rooting, we found that the root was placed most confidently between virophages and the other lineages; making them the most basal lineage of eukaryotic bamfordviruses. The basal position of virophages has also been found in an independent work that looked at phylogenies based on the ATPase and a concatenation of the ATPase and the major capsid protein (Woo et al., 2021). This basal position of virophages and their divergence prior to the origin of NCLDVs, suggests that the protovirophages were not parasites of other viruses. Instead, they would have become parasites of other viruses at a later point once the most recent common ancestor of NCLDVs had evolved (see Ideas and speculation).
The tree topologies that we estimated (Figure 2 and Figure 3), also suggest that the most recent common ancestor of Mavericks, adenoviruses and PLVs was not a virophage, which is at odds with a virophage-first scenario. Indeed, the basal position of virophages is inconsistent with the virophage-first hypothesis which proposes that protovirophages coevolved with NCLDVs, acquired an integrase and then gave rise to Mavericks and other elements in the lineage (Campbell et al., 2017; Fischer and Suttle, 2011). However, we found that the second-highest frequency root sampled in the Bayesian MCMC was on the branch of PLV BS_539 + NCLDVs (frequency = 27.4%). Rooting on this branch would be consistent with a ‘virophage-first’-like scenario, where the lineage of NCLDVs and associated viruses evolved early and in parallel with protovirophages. Therefore, we cannot definitely rule out a ‘virophage-first’-like scenario. In contrast, root placements on the branch leading to Mavericks and consistent with nuclear-escape were observed in 0% of the trees, which seems to rule out this possibility (Supplementary file 2).
The relative timing of events suggests that the most recent common ancestor of eukaryotic bamfordviruses existed more than a billion years ago. There is general agreement based on paleontological and molecular evidence that the Last Eukaryotic Common Ancestor (LECA) existed at least 1 billion years ago (Porter, 2020). Analyses of genetic exchanges between the DNA-dependent RNA polymerases of NCLDVs and eukaryotes have determined that the two super-clades of NCLDVs (PAM and MAPI) already existed before the origin of LECA (Guglielmini et al., 2019). Moreover, discovery and phylogenetic analysis of actin and actin-related proteins encoded in NCLDVs, also suggest that early gene transfers occurred between these viruses and proto-eukaryotes before the emergence of LECA (Da Cunha et al., 2022). The basal placement that we observed for virophages, or alternatively, their early origin after the divergence of the NCLDV lineage (‘virophage-first’-like scenario), suggest that virophages evolved after the origin of the first NCLDVs during the diversification of the early eukaryotes. These observations, together with the existence of various phage relatives that infect bacteria and archaea, point to a very early origin of the kingdom Bamfordvirae, perhaps extending to the initial stages of cellular life. Studies that consider the time-dependent rate phenomenon in reconstructing viral evolution may be able to shed light on these issues (Aiewsakun and Katzourakis, 2016; Ghafari et al., 2021).
Ideas and speculation
Our analyses favour a new model for the evolution of the major lineages of eukaryotic bamfordviruses; we call this model the ‘exogenous, non-virophage scenario’. The model is presented in Figure 4, where we have mapped shared character states onto a diagram of the concatenated Bayesian phylogeny (which has the best overall support). According to this idea, the most recent common ancestor of the eukaryotic bamfordviruses was a small exogenous dsDNA virus with a linear genome, flanked by inverted repeats. The virus had an autonomous (i.e. non-virophage) lifestyle. It used a protein-primed DNA polymerase B for replication and its morphogenetic module was formed by the major and minor jelly-roll capsid proteins, an adenoviral-like protease and the FtsK/HerA family DNA-packaging ATPase. The gain of the adenoviral-like protease differentiated this eukaryotic lineage from their phage relatives (Krupovic and Koonin, 2015). The first divergence from this ancestor led to the emergence of the protovirophages, and another lineage that would give rise to Mavericks, adenoviruses, PLVs, and NCLDVs (Figure 4).
Figure 4

Evolutionary model for the origin of the major lineages of eukaryotic viruses in the kingdom Bamfordvirae.
The viral ancestor is inferred to have been an exogenous virus, while the rve-integrase was captured independently by the clade of Mavericks + Polinton like virus BS_13 and Mavirus, possibly by horizontal gene transfer. Virophages evolved from an autonomous virus that became specialised to parasitise the ancestor of NCLDVs. The vertical cross-hatching indicates that the trait is found in some but not all members of the group. Acronyms refer to genes and genomic features present in the viral genomes: (pPOLB) (protein-primed DNA polymerase B) , (MCP) (major capsid protein), (mCP) (minor capsid protein), (int) (rve-type integrase), (pro) (adenoviral-like protease), (atp) (FtsK/HerA DNA packaging ATPase), (TIRs) (terminal inverted repeats).
The second divergence would have given rise to the lineage from which NCLDVs evolved. The most recent common ancestor of NCLDVs is believed to have already had a complex genome (~40 genes), which involved the gain of numerous genes from their eukaryotic hosts, other viruses and bacteria (Iyer et al., 2006; Koonin and Yutin, 2010; Yutin and Koonin, 2012). Once this virus evolved the capacity to exploit significant cell resources, there would have been a window of opportunity for protovirophages to evolve into specialised parasites of NCLDVs, occupying this new ecological niche. The close match between virophage and NCLDV regulatory sequences, which underlie the capacity of virophages to parasitise NCLDVs, may have evolved by parallel evolutionary changes on the sequences of their shared virus ancestor. It is plausible that functional regulatory sequences in virophages could evolve de novo by a few changes in the ancestral promoters/terminators. For example, functional lac operon promoters have been evolved successfully even from random sequences in the presence of lactose in E. coli (Yona et al., 2018). A deletion mutant in the ORF 8 gene of the Guarani virophage expanded its host range to previously non-permissive giant viruses, so the acquisition and mutation of proteins involved in virus-virophage interactions may also be critical for virophage adaptation (Mougari et al., 2020). Interestingly, the exchange of the protein-primed DNA polymerase B by a nucleotide-primed DNA polymerase B (Mönttinen et al., 2021; Yutin and Koonin, 2012), may have been an early counter-measure of NCLDVs to decrease the parasitic burden imposed by virophages. The acquisition of this new polymerase, may be in part responsible for the considerable increases in genome size that we see in NCLDVs relative to other eukaryotic bamfordviruses. Therefore, we can hypothesise that the large genomes of NCLDVs, which is one of their most distinctive features, could have evolved as a result of their ancient interaction with virophages.
The distribution of the rve-integrase on the phylogeny suggests it was acquired independently on two separate occasions. Indeed, the rve-integrase is a universal feature of Mavericks + PLV BS_13, while it does not seem to be present in any of their closest relatives. Therefore, the rve-integrase seems to be a unique derived feature of the clade of Mavericks + PLV BS_13. Mavirus also encodes a rve-integrase but it appears to be the only virophage with this gene (no other hits found in a blastp search of the nr database using the labels ‘Lavidaviridae’ + ‘unclassified Lavidaviridae’). Since Mavirus is firmly nested within the phylogenies for the morphogenetic module, it seems likely that this is a unique derived feature of Mavirus. The most parsimonious explanation for these observations is that the integrase gene was acquired on two separate occasions and that the common ancestor of Mavirus and Mavericks was an exogenous virus without an integrase (# character state changes = 2 gains). This is in line with a previous proposal that Mavirus evolved by recombination of an ancestral virophage with a Maverick (Yutin et al., 2013).
Concluding remarks
Our findings strengthen the view of a viral origin for NCLDVs and other eukaryotic elements in the kingdom Bamfordvirae. We have decisively shown that adenoviruses and NCLDVs are not sister groups, and that adenoviruses, virophages, PLVs and NCLDVs did not escape from the nucleus. The rve-integrase appears to have been captured independently by Mavericks +PLV BS_13 on the one hand, and by Mavirus on the other. These observations support a new evolutionary model that is different from the nuclear-escape and virophage-first scenarios. This new model proposes that the ancestor of the eukaryotic viruses in the kingdom Bamfordvirae was an exogenous, non-virophage DNA virus with a small genome. The lifestyle of virophages would have evolved at a later stage as these became specialised parasites of the ancestral NCLDVs. Darwin’s closing words in the Origin of Species are well-suited for this group of viruses: ‘from so simple a beginning endless forms most beautiful and most wonderful have been, and are being, evolved’ (Darwin, 1859).
Materials and methods
We used maximum-likelihood and Bayesian hypothesis-testing methods to compare the plausibility of the nuclear-escape versus alternative evolutionary scenarios. We focused on the 4 core virion proteins shared by viruses in this lineage: major and minor capsid proteins, ATPase and protease. Rooted phylogenies were inferred from the data using a relaxed molecular-clock or an outgroup rooting method. We then assessed whether adenoviruses and NCLDVs formed a monophyletic group as predicted by the nuclear-escape scenario. Finally, we studied the origin of the proteins shared by cytoplasmic linear plasmids and NCLDVs. A more detailed description of methods is presented below.
Selection of viral sequences
Request a detailed protocolWe first compiled a data set of viruses belonging to the families Phycodnaviridae, Mimiviridae, Ascoviridae, Iridoviridae, Marseilleviridae, Asfarviridae, Poxviridae, Adenoviridae, and Lavidaviridae that were obtained from the NCBI using accession numbers listed in the International Committee for the Taxonomy of Viruses (ICTV) master species list 2020 .v1. Previous analyses have shown that Mavericks/Polintons fall into two major groups based on the protein-primed DNA polymerase: the group I Mavericks (that include elements from vertebrates) and the group II Mavericks (which include elements present in insects) (Kapitonov and Jurka, 2006). Group I Mavericks can be distinguished from group II elements by the presence of a ~140 aa insertion similar to a bacterial ‘very-short-patch’ (VSR) repair endonuclease (Kapitonov and Jurka, 2006). To make sure both groups were represented in our analyses, we included the vertebrate Mavericks reported in Barreat and Katzourakis, 2021, and added 12 new intact Maverick elements that we discovered in the genomes of insects and which lack the VSR insertion (Supplementary file 1).
We also included the sequences for Polinton-like viruses, virophages and NCLDVs that have been reported in the metagenomic works of Bellas and Sommaruga, 2021, Moniruzzaman et al., 2020, Schulz et al., 2020, Paez-Espino et al., 2019, Roux et al., 2017 and Yutin et al., 2015. Additional genomes for medusavirus (Yoshikawa et al., 2019), cedratvirus (Jeudy et al., 2020), tupanviruses (Abrahão et al., 2018), pandoraviruses (Antwerpen et al., 2015; Philippe et al., 2013; Legendre et al., 2018), pithovirus (Legendre et al., 2014), mollivirus (Legendre et al., 2015), insectomime virus (Boughalmi et al., 2013), tokyovirus (Takemura, 2016), kaumoebavirus (Bajrai et al., 2016), faustoviruses (Benamar et al., 2016), pacmanvirus, orpheovirus and the Dishui lake virophages (Sayers et al., 2021), were also included. In total, the data set consisted of 9,222 virus genomes.
Protein prediction and subsampling approach
Request a detailed protocolWe devised a subsampling approach to arrive at a representative subset of sequences to carry out the phylogenetic analyses and tests of topology. First, open-reading frames for all sequences were predicted with getorf in EMBOSS (Rice et al., 2000). Next, we used a set of Hidden Markov Models (hmmbuild/hmmsearch, HMMER version 3.3.2 using the default parameters) for each of the 4 core proteins involved in virion morphogenesis (major and minor capsid proteins, ATPase and protease) to extract homologous proteins in 9 groups: genomic/metagenomic virophages, genomic/metagenomic NCLDVs, metagenomic PLVs, PLVs described in Yutin et al., 2015, adenoviruses, and Mavericks 1 and 2 lineages. We used the major capsid protein to make multiple sequence alignments in MAFFT (Katoh et al., 2002) and construct approximate phylogenies for each group in FastTree 2 (Price et al., 2010). A total of 2803 major capsid proteins could be identified in the genome data, which comprised: adenoviruses (71 sequences), Mavericks 1/2 (28 sequences), NCLDVs NCBI/metagenomic (2,031 sequences), PLVs Yutin/metagenomic (327 sequences), and virophages NCBI/metagenomic (346 sequences). The trees were used to subsample 6 representatives from each of the 9 groups maintaining the maximal diversity in Treemmer (Menardo et al., 2018). The final data set contained representatives of 54 taxa (Supplementary file 1).
Protein multiple sequence alignment
Request a detailed protocolUsing the list of representative taxa for the major capsid proteins, we retrieved the corresponding sequences for the ATPase, protease and minor capsid proteins in each genome. We confirmed that each prediction corresponded to its homology group using HHpred (Soding et al., 2005). Sequences were aligned in MAFFT (Katoh et al., 2002) and trimmed using trimAl (Capella-Gutiérrez et al., 2009). We then built a concatenated alignment using a custom script written in Python (van Rossum et al., 2009).
Bayesian phylogenetic inference
Request a detailed protocolWe constructed single-protein and concatenated rooted trees in BEAST 2 (Bouckaert et al., 2019). Best models for amino acid substitution were selected for each partition in ModelTest-NG (Darriba et al., 2020). The model LG +G + I (with 4 categories for the gamma rate heterogeneity) was used for the major capsid, protease and ATPase, while the model LG +G (with 4 categories for the gamma rate heterogeneity) was used for the minor capsid protein. We imposed monophyletic constraints at the level of well-established viral clades/families: NCLDVs, Adenoviridae, vertebrate Mavericks and invertebrate Mavericks (however, the monophyly between both groups of Mavericks was not constrained). The monophyly of virophages and Polinton-like virophages were not constrained. We conducted a Bayesian MCMC with a chain length of 140 million generations for the concatenated data set and 200 million generations for the single proteins (sampling every 5,000th generation and using relaxed molecular clocks). Convergence was assessed by inspecting the runs for good-mixing and stationarity, and ensuring that Effective Sample Sizes were >200 for all parameters in Tracer (Rambaut et al., 2018).
Maximum-likelihood phylogenetic inference
Request a detailed protocolWe estimated a maximum-likelihood tree in RAxML-NG (Kozlov et al., 2019) using the concatenated data set and the same monophyletic constraints on well-established groups as described above. Proteins of the Enterobacteria phage PRD1 (ATPase, major, and minor capsid) were included in the alignment for outgroup rooting. We chose the best substitution models in ModelTest-NG (Darriba et al., 2020). For the protease and ATPase, we used model LG +G + I+F (with 4 categories for the gamma rate heterogeneity), and for the major and minor capsid proteins we used model LG +G + F (with four categories for the gamma rate heterogeneity). The analysis was started from 200 random starting trees and run with 2200 bootstrap replicates.
Akaike information criterion
Request a detailed protocolTo compare the plausibility of the maximum-likelihood trees consistent with each hypothesis, we inferred the best supported phylogenies in RAxML-NG and then performed model-selection based on the Akaike information criterion (Kozlov et al., 2019; Posada and Buckley, 2004). Specifically, we compared a constrained model consistent with nuclear-escape where adenoviruses and NCLDVs are sister groups, to a model where the sister relationship between adenoviruses and NCLDVs was not constrained (alternative model). We included a partitioned analysis of the concatenated data set and three core proteins individually (protease, major and minor capsid), using the amino acid substitution models described in the previous section. The analyses were run with 200 random starting trees and we kept the estimate for the log-likelihood of the best tree model for the calculation of the AICs. The AIC for each model was size-corrected given that the alignment (sample) sizes were small compared to the number of free parameters in each model, or n/k<40 (Posada and Buckley, 2004; Symonds and Moussalli, 2011). For the comparison, we calculated the Akaike weights which can be interpreted as the normalised relative likelihood of the model given the data (Posada and Buckley, 2004), or as an analogue of the probability that a model is the best approximating model given the data within a set of candidates (Symonds and Moussalli, 2011). The ATPase was not included in the single-protein analyses since adenoviruses encode a non-homologous ABC family ATPase (Burroughs et al., 2007), and therefore it cannot be used to test their evolutionary relationships to other bamfordviruses.
Posterior model odds
Request a detailed protocolThe tree topologies obtained in the Bayesian MCMCs for the single proteins and the concatenated data set, were loaded and filtered in PAUP (Swofford, 1998). Following the posterior model odds method of Bergsten et al., 2013, we counted the number of trees which contained a sister grouping of adenoviruses and NCLDVs (nuclear-escape hypothesis) and compared them to the number of trees inconsistent with this grouping (alternative hypotheses). The posterior model odds were calculated as the ratio of these two quantities (Bergsten et al., 2013). The ATPase was again excluded from the single-protein analysis given that adenoviruses could not be included.
Marginal likelihood and Bayes factors
Request a detailed protocolWe estimated the marginal likelihood of each hypothesis using stepping-stone sampling. We ran the analysis on the concatenated data set, for 20 million generations in MrBayes 3 (Ronquist and Huelsenbeck, 2003). For both analyses, we used the monophyletic constraints described above. In the marginal calculation for the nuclear-escape hypothesis, we used a topological constraint on the sister grouping of adenoviruses and NCLDVs, while we imposed a negative topological constraint on the monophyly of adenoviruses and NCLDVs for the alternatives (adenoviruses and NCLDVs cannot be sister groups). We calculated the Bayes factors as the number e to the power of the difference in log-marginal likelihoods, and compared the resulting value to the table of Kass and Raftery, 1995.
Cytoplasmic linear plasmids
Request a detailed protocolCytoplasmic linear plasmids have lost the ancestral module of genes involved in formation of the capsid, but they have gained three genes encoding a mRNA capping-enzyme, a helicase and the Rpb2 subunit of the DNA-dependent RNA-polymerase II (Koonin et al., 2015b; Krupovic and Koonin, 2015). We used the proteins in cytoplasmic linear plasmids (Supplementary file 3), to search for homologous sequences in the non-redundant protein database using blastp (Altschul et al., 1990) and restricting searches to ‘Eukaryota (taxid:2759)’ and ‘Viruses (taxid:10239)’. The identity of significant matches (evalue <1e-10) was confirmed with HHpred (Soding et al., 2005), and in the case of eukaryotes, only sequences mapping to chromosome assemblies were used. Virus, eukaryotic and plasmid homologues were aligned in MAFFT (Katoh et al., 2002) and conserved blocks recovered from trimAl (Capella-Gutiérrez et al., 2009). We chose the best models for protein evolution in ModelTest-NG (Darriba et al., 2020) and ran a maximum-likelihood tree search in RAxML-NG (Kozlov et al., 2019) with 1000 non-parametric bootstrap replicates for each protein separately.
Data availability
The Hidden Markov Models used to find homologues of the four core proteins (n = 38), and concatenated and single-protein alignments used for phylogenetic inference have been deposited in Figshare. The scripts used for sequence concatenation and for the AIC analyses are available on GitHub (copy archived at Barreat, 2023).
-
figshareMultiple sequence alignments and HMMs of the four core virion proteins of eukaryotic bamfordviruses.https://doi.org/10.6084/m9.figshare.19576117
References
-
Time-dependent rate phenomenon in virusesJournal of Virology 90:7184–7195.https://doi.org/10.1128/JVI.00593-16
-
Basic local alignment search toolJournal of Molecular Biology 215:403–410.https://doi.org/10.1016/S0022-2836(05)80360-2
-
Whole-genome sequencing of a Pandoravirus isolated from Keratitis-inducing AcanthamoebaGenome Announcements 3:e00136-15.https://doi.org/10.1128/genomeA.00136-15
-
Phylogenomics of the maverick virus-like mobile genetic elements of vertebratesMolecular Biology and Evolution 38:1731–1743.https://doi.org/10.1093/molbev/msaa291
-
Softwarejosegabrielnb/virophage-origins, version swh:1:rev:3ec29e4e06cec8b957a4939858e4e96984c051adSoftware Heritage.
-
Faustoviruses: comparative Genomics of new Megavirales family membersFrontiers in Microbiology 7:3.https://doi.org/10.3389/fmicb.2016.00003
-
Bayesian tests of Topology hypotheses with an example from diving beetlesSystematic Biology 62:660–673.https://doi.org/10.1093/sysbio/syt029
-
BEAST 2.5: an advanced software platform for Bayesian evolutionary analysisPLOS Computational Biology 15:e1006650.https://doi.org/10.1371/journal.pcbi.1006650
-
Disentangling the origins of Virophages and PolintonsCurrent Opinion in Virology 25:59–65.https://doi.org/10.1016/j.coviro.2017.07.011
-
Giant viruses Encode actin-related proteinsMolecular Biology and Evolution 39:msac022.https://doi.org/10.1093/molbev/msac022
-
Modeltest-NG: a new and Scalable tool for the selection of DNA and protein evolutionary modelsMolecular Biology and Evolution 37:291–294.https://doi.org/10.1093/molbev/msz189
-
The Virophage family LavidaviridaeCurrent Issues in Molecular Biology 40:1–24.https://doi.org/10.21775/cimb.040.001
-
Adenoviruses across the animal Kingdom: a walk in the zooFEBS Letters 593:3660–3673.https://doi.org/10.1002/1873-3468.13687
-
The DNA methylation landscape of giant virusesNature Communications 11:2657.https://doi.org/10.1038/s41467-020-16414-2
-
Bayes factorsJournal of the American Statistical Association 90:773–795.https://doi.org/10.1080/01621459.1995.10476572
-
MAFFT: a novel method for rapid multiple sequence alignment based on fast Fourier transformNucleic Acids Research 30:3059–3066.https://doi.org/10.1093/nar/gkf436
-
Evolution of double-stranded DNA viruses of Eukaryotes: from Bacteriophages to Transposons to giant virusesAnnals of the New York Academy of Sciences 1341:10–24.https://doi.org/10.1111/nyas.12728
-
Polintons, Virophages and Transpovirons: a tangled web linking viruses, Transposons and immunityCurrent Opinion in Virology 25:7–15.https://doi.org/10.1016/j.coviro.2017.06.008
-
Global organization and proposed Megataxonomy of the virus worldMicrobiology and Molecular Biology Reviews 84:e00061-19.https://doi.org/10.1128/MMBR.00061-19
-
Viruses defined by the position of the Virosphere within the Replicator spaceMicrobiology and Molecular Biology Reviews 85:e0019320.https://doi.org/10.1128/MMBR.00193-20
-
Polintons: A hotbed of Eukaryotic virus, Transposon and Plasmid evolutionNature Reviews. Microbiology 13:105–115.https://doi.org/10.1038/nrmicro3389
-
Self-Synthesizing Transposons: unexpected key players in the evolution of viruses and defense systemsCurrent Opinion in Microbiology 31:25–33.https://doi.org/10.1016/j.mib.2016.01.006
-
A classification system for Virophages and satellite virusesArchives of Virology 161:233–247.https://doi.org/10.1007/s00705-015-2622-9
-
Genomics of Megavirus and the elusive fourth domain of lifeCommunicative & Integrative Biology 5:102–106.https://doi.org/10.4161/cib.18624
-
Diversity and evolution of the emerging Pandoraviridae familyNature Communications 9:2285.https://doi.org/10.1038/s41467-018-04698-4
-
Microbial linear PlasmidsApplied Microbiology and Biotechnology 47:329–336.https://doi.org/10.1007/s002530050936
-
A biologist’s guide to Bayesian Phylogenetic analysisNature Ecology & Evolution 1:1446–1454.https://doi.org/10.1038/s41559-017-0280-x
-
Coevolutionary and Phylogenetic analysis of Mimiviral replication machinery suggest the cellular origin of MimivirusesMolecular Biology and Evolution 38:2014–2029.https://doi.org/10.1093/molbev/msab003
-
Insights into Eukaryogenesis from the fossil recordInterface Focus 10:20190105.https://doi.org/10.1098/rsfs.2019.0105
-
Posterior summarization in Bayesian phylogenetics using Tracer 1.7Systematic Biology 67:901–904.https://doi.org/10.1093/sysbio/syy032
-
EMBOSS: the European molecular biology open software suiteTrends in Genetics 16:276–277.https://doi.org/10.1016/s0168-9525(00)02024-2
-
Mrbayes 3: Bayesian Phylogenetic inference under mixed modelsBioinformatics 19:1572–1574.https://doi.org/10.1093/bioinformatics/btg180
-
Database resources of the National center for biotechnology informationNucleic Acids Research 49:D10–D17.https://doi.org/10.1093/nar/gkaa892
-
A strange Endocytobiont revealed as largest virusCurrent Opinion in Microbiology 31:58–62.https://doi.org/10.1016/j.mib.2016.02.005
-
BookPhylogenetic inference using maximum likelihood methodsIn: Lemey P, Salemi M, Vandamme AM, editors. The Phylogenetic Handbook: A Practical Approach to Phylogenetic Analysis and Hypothesis Testing. Cambridge: Cambridge University Press. pp. 181–209.https://doi.org/10.1017/CBO9780511819049
-
The Hhpred interactive server for protein Homology detection and structure predictionNucleic Acids Research 33:W244–W248.https://doi.org/10.1093/nar/gki408
-
BookPAUP*. Phylogenetic Analysis Using Parsimony (*and Other Methods)Sinauer Associates.
-
A brief guide to model selection, Multimodel inference and model averaging in behavioural Ecology using Akaike’s information criterionBehavioral Ecology and Sociobiology 65:13–21.https://doi.org/10.1007/s00265-010-1037-6
-
SoftwarePython 3 reference manualPython.
-
Random sequences rapidly evolve into de novo promotersNature Communications 9:1530.https://doi.org/10.1038/s41467-018-04026-w
-
Medusavirus, a novel large DNA virus discovered from hot spring waterJournal of Virology 93:e02130-18.https://doi.org/10.1128/JVI.02130-18
Article and author information
Author details
Jose Gabriel Nino Barreat

Funding
National Academy of Medicine of Venezuela (Dr. Jose Gregorio Hernandez Award)
- Jose Gabriel Nino Barreat
Pembroke College Oxford (Dr. Jose Gregorio Hernandez Award)
- Jose Gabriel Nino Barreat
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We wish to thank Peter Simmonds and Alexander Suh for their critical reading and comments on the manuscript which served to improve this work. We also thank the reviewers for their recommendations and feedback. This work was supported by a doctoral scholarship (Dr. Jose Gregorio Hernandez Award) to JGNB made by the National Academy of Medicine of Venezuela and Pembroke College, Oxford.
Version history
- Preprint posted:
- Sent for peer review:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
- Version of Record updated:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.86617. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2023, Barreat and Katzourakis
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 3,591
- views
-
- 242
- downloads
-
- 21
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 15
- citations for umbrella DOI https://doi.org/10.7554/eLife.86617
-
- 1
- citation for Reviewed Preprint v1 https://doi.org/10.7554/eLife.86617.1
-
- 1
- citation for Reviewed Preprint v2 https://doi.org/10.7554/eLife.86617.2
-
- 4
- citations for Version of Record https://doi.org/10.7554/eLife.86617.3
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
A billion years arms-race between viruses, virophages, and eukaryotes
eLife 12:RP86617.
https://doi.org/10.7554/eLife.86617.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}