OpenNucleome for high-resolution nuclear structural and dynamical modeling
- Department of Chemistry, Massachusetts Institute of Technology, United States
eLife assessment
This important work significantly advances the field of computational modeling of genome organization through the development of OpenNucleome. The evidence supporting the tool's effectiveness is compelling as the authors compare their predictions with experimental data. It is anticipated that OpenNucleome will attract significant interest from the biophysics and genomics communities.
https://doi.org/10.7554/eLife.93223.3.sa0Significance of the findings:
Important: Findings that have theoretical or practical implications beyond a single subfield
- Landmark
- Fundamental
- Important
- Valuable
- Useful
Strength of evidence:
Compelling: Evidence that features methods, data and analyses more rigorous than the current state-of-the-art
- Exceptional
- Compelling
- Convincing
- Solid
- Incomplete
- Inadequate
During the peer-review process the editor and reviewers write an eLife Assessment that summarises the significance of the findings reported in the article (on a scale ranging from landmark to useful) and the strength of the evidence (on a scale ranging from exceptional to inadequate). Learn more about eLife Assessments
Abstract
The intricate structural organization of the human nucleus is fundamental to cellular function and gene regulation. Recent advancements in experimental techniques, including high-throughput sequencing and microscopy, have provided valuable insights into nuclear organization. Computational modeling has played significant roles in interpreting experimental observations by reconstructing high-resolution structural ensembles and uncovering organization principles. However, the absence of standardized modeling tools poses challenges for furthering nuclear investigations. We present OpenNucleome—an open-source software designed for conducting GPU-accelerated molecular dynamics simulations of the human nucleus. OpenNucleome offers particle-based representations of chromosomes at a resolution of 100 KB, encompassing nuclear lamina, nucleoli, and speckles. This software furnishes highly accurate structural models of nuclear architecture, affording the means for dynamic simulations of condensate formation, fusion, and exploration of non-equilibrium effects. We applied OpenNucleome to uncover the mechanisms driving the emergence of ‘fixed points’ within the nucleus—signifying genomic loci robustly anchored in proximity to specific nuclear bodies for functional purposes. This anchoring remains resilient even amidst significant fluctuations in chromosome radial positions and nuclear shapes within individual cells. Our findings lend support to a nuclear zoning model that elucidates genome functionality. We anticipate OpenNucleome to serve as a valuable tool for nuclear investigations, streamlining mechanistic explorations and enhancing the interpretation of experimental observations.
Introduction
The highly complex structural organization of the human nucleus plays a crucial role in the functioning and regulation of our cells (Dekker et al., 2017; Hübner et al., 2013; Bickmore, 2013; Gorkin et al., 2014; Dekker and Mirny, 2016; Furlong and Levine, 2018; Finn and Misteli, 2019; Chen and Belmont, 2019; Lin et al., 2021; Liu et al., 2024). The complexity arises from the diverse range of nuclear landmarks, such as nucleoli (Lafontaine et al., 2021), nuclear speckles (Chen and Belmont, 2019; Lamond and Spector, 2003), and the nuclear lamina (van Steensel and Belmont, 2017), each serving distinct functions. These landmarks provide specialized environments for various nuclear processes, allowing for efficient coordination and regulation of gene expression. Moreover, the spatial arrangement of chromosomes within the nucleus, intertwined with the nuclear landmarks, is critical for proper gene regulation and communication between different genome regions. Disruptions or abnormalities in the nuclear organization can have profound consequences on cellular function and can contribute to the development of diseases, including cancer and genetic disorders (Seruga et al., 2008; Schuster-Böckler and Lehner, 2012).
Recent advancements in experimental techniques have significantly enhanced our understanding of nuclear organization (Bickmore, 2013; Schmitt et al., 2016; McCord et al., 2020; Parmar et al., 2019; Jerkovic and Cavalli, 2021; Chen et al., 2016). The advent of high-throughput sequencing-based methods, such as genome-wide chromosome-conformation capture (Hi-C), has unveiled crucial structural elements of the genome (Dekker et al., 2002; Lieberman-Aiden et al., 2009), including chromatin loops (Rao et al., 2014), topologically associating domains (Dixon et al., 2016; Dekker and Heard, 2015), and compartments (Lieberman-Aiden et al., 2009). Additionally, sequencing-based techniques such as DamID (Greil et al., 2006), Chip-Seq (Park, 2009), and TSA-Seq (Chen et al., 2018) have revealed valuable information regarding interactions between chromosomes and nuclear landmarks. However, it is worth noting that these sequencing methods often offer averaged contacts, which can mask the heterogeneity present across populations, although single-cell techniques are also emerging (Wen et al., 2020; Ramani et al., 2017; Nagano et al., 2013). Moreover, translating contact data into spatial positions can be challenging, adding complexity to interpreting experimental findings.
To complement these sequencing approaches, microscopic imaging techniques directly probe the spatial positions within individual nuclei (Bickmore, 2013; van Steensel and Belmont, 2017; Chen et al., 2015; Boettiger et al., 2016; Shachar et al., 2015). Recent advancements in DNA FISH (fluorescence in situ hybridization) have enabled high-throughput imaging of thousands of loci simultaneously (Su et al., 2020; Takei et al., 2021). These imaging studies have not only confirmed the structural features observed through sequencing techniques but have also provided valuable insights into the heterogeneity present at the single-cell level.
The abundance of available experimental data in the field of nuclear organization provides a fertile ground for structural modeling (Qi et al., 2020; Qi and Zhang, 2019; Boninsegna et al., 2022; Fujishiro and Sasai, 2022; Shi and Thirumalai, 2021; Dekker et al., 2013; Jost et al., 2014; Giorgetti et al., 2014; Di Pierro et al., 2017; Buckle et al., 2018; Nuebler et al., 2018; Bianco et al., 2018; Shi et al., 2018; MacPherson et al., 2018; Shin et al., 2023; Amiad-Pavlov et al., 2021; Brahmachari et al., 2022; Jiang et al., 2022; Ganai et al., 2014; Liu et al., 2018; Laghmach et al., 2020; Chu and Wang, 2021; Lappala et al., 2021; Chu and Wang, 2022; Goychuk et al., 2023; Sun et al., 2021; Kadam et al., 2023). To make sense of this wealth of information, various computational approaches have been introduced, with polymer simulation approaches being extensively utilized. These simulation techniques aid in reconstructing structural ensembles that closely replicate experimental data, offering valuable insights into the mechanisms underlying chromosome folding. In recent studies, these approaches have also been employed to investigate the interplay between the genome and the nuclear lamina (Bajpai et al., 2021; Kamat et al., 2023; Laghmach et al., 2021; Stephens et al., 2018), as well as nucleoli (Qi and Zhang, 2021), shedding light on their dynamic relationships.
Despite the progress made in computational modeling, the absence of well-documented software with easy-to-follow tutorials pose a challenge. Many research groups develop their own independent software, which complicates cross-validation and hinders the establishment of best practices for genome modeling (Fujishiro and Sasai, 2022; Yildirim et al., 2023; Oliveira Junior et al., 2021). Moreover, comprehensive models of the entire nucleus, especially at high resolution, remain scarce. Addressing these limitations and fostering collaboration in the scientific community can be achieved through the development of open-source tools. By promoting transparency and accessibility, such tools have the potential to greatly facilitate nuclear modeling and contribute to a more unified and collaborative research environment.
We present OpenNucleome, an open-source software designed for conducting molecular dynamics (MD) simulations of the human nucleus. This software streamlines the process of setting up whole nucleus simulations through just a few lines of Python scripting. OpenNucleome can unveil intricate, high-resolution structural and dynamic chromosome arrangements at a 100KB resolution. It empowers researchers to track the kinetics of condensate formation and fusion while also exploring the influence of chemical modifications on condensate stability. Furthermore, it facilitates the examination of nuclear envelope deformation’s impact on genome organization. The software’s modular architecture enhances its adaptability and extensibility. Leveraging the power of OpenMM (Eastman et al., 2017), a GPU-accelerated MD engine, OpenNucleome ensures efficient simulations.
Our work demonstrates the fidelity of the simulated nuclear organizations by faithfully reproducing Hi-C, Lamin B DamID, TSA-Seq, and DNA-MERFISH data. The dynamic insights extracted from this model are pivotal in advancing our understanding of nuclear organization mechanisms. Our findings reveal that inherent heterogeneity in chromosome contacts naturally emerges within single cells. Interestingly, robust contacts between chromosomes and nuclear bodies can also be established due to a coupled self-assembly mechanism. Notably, the resilience of contacts involving nuclear bodies supports a nuclear zoning model for genome function. In the realm of nuclear investigations, we anticipate OpenNucleome to serve as an invaluable tool, seamlessly complementing experimental techniques.
Results
Non-equilibrium nucleus model at 100 KB resolution
We present an open-source implementation of a computational framework that facilitates the structural and dynamical characterization of the human nucleus. This framework builds upon a previous investigation but incorporates several significant modifications. Firstly, we enhance the model resolution by a factor of 10, enabling the precise determination of the spatial positioning of each chromatin segment measuring 100KB in length. Secondly, we present a kinetic scheme for speckles that accounts for the phosphorylation of protein molecules. This inclusion captures the influence of chemical reactions on the stability and dynamics of nuclear bodies. Thirdly, we incorporate explicit nuclear envelope dynamics to explore the impact of large-scale deformations on genome organization. Finally, our implementation into OpenMM offers the advantages of Python Scripting and GPU acceleration, facilitating easy extension and customization. These features will facilitate the broad applicability and adoption of the proposed model.
The nucleus model provides particle-based representations for chromosomes, nucleoli, speckles, and the nuclear envelope. As shown in Figure 1A and B, each of the 46 chromosomes is represented as a beads-on-a-string polymer, where each bead represents a 100-KB-long genomic segment. Based on Hi-C data, we further assign each bead as compartment A, B, or C to signify euchromatin, heterochromatin, or pericentromeric regions. The lamina was modeled as a spherical enclosure with 10 µm diameter, using discrete particles arranged to represent a mesh grid with covalent bonds linking together nearest neighbors (Strom et al., 2021). We modeled nucleoli and speckles as liquid droplets that emerge through the spontaneous phase separation of coarse-grained particles, representing protein and RNA molecule aggregates (Chen and Belmont, 2019; Lafontaine et al., 2021). These particles exhibited attractive interactions within the same type to promote condensation. More details about the various components of the system can be found in the Appendix 1, section ‘Components of the whole nucleus model’.
Figure 1
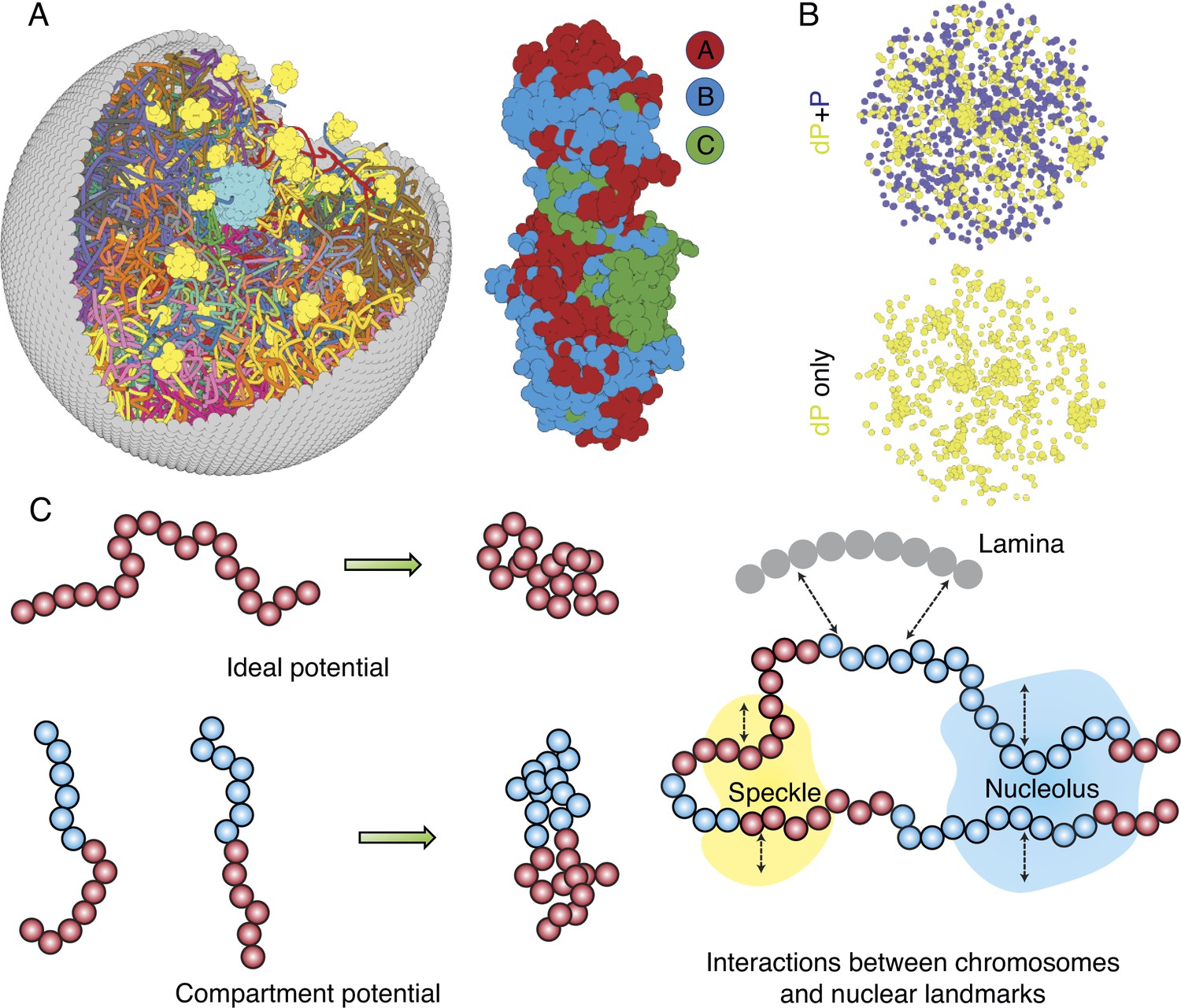
Computer model of the human nucleus for structural and dynamical characterizations.
(A) 3D rendering of the nucleus model with particle-based representations for the 46 chromosomes shown as ribbons, the nuclear lamina (gray), nucleoli (cyan), and speckles (yellow). As shown on the right, chromosomes are modeled as beads-on-a-string polymers at a 100 KB resolution, with the beads further categorized into compartment A (red), compartment B (light blue), or centromeric regions (green). (B) Speckle particles undergo chemical modifications concurrent to their spatial dynamics, and the de-phosphorylated (dP) particles contribute to droplet formation. (C) Illustration of the ideal and compartment potential that promotes chromosome compaction and microphase separation. Specific interactions between chromosomes and nuclear landmarks are shown on the right.
The energy function of the nucleus model includes three components that account for the self-assembly of chromosomes, the assembly of nuclear bodies, and the coupling between chromosomes and nuclear landmarks. Therefore, the model approximates nuclear organization as a coupled self-assembly process. The chromosome energy function (see Equation 7 in Appendix 1, section ‘Hi-C inspired interactions for the diploid human genome’) includes terms that account for the polymer connectivity and excluded volume effect, an ideal potential, compartment-specific interactions, and specific interchromosomal interactions. As shown in Figure 1C, the ideal potential is only applied for beads from the same chromosome to approximate the effect of loop extrusion by Cohesin molecules (Sanborn et al., 2015; Fudenberg et al., 2016) for chromosome compaction and territory formation (Di Pierro et al., 2016; Zhang and Wolynes, 2017). Compartment-specific interactions, on the other hand, promote microphase separation and compartmentalization of euchromatin and heterochromatin. Finally, interchromosomal interactions account for sequence-specific effects that compartment-dependent potentials cannot capture.
Interactions among coarse-grained particles that form nuclear bodies were designed to promote and stabilize the formation of liquid droplets, as has been revealed by many experiments (Handwerger et al., 2005; Caragine et al., 2018; Caragine et al., 2019). We adopted the Lennard–Jones potential for nucleolar particles to mimic the weak, multivalent interactions that arise from protein and RNA molecules that make up the nucleoli. As a first attempt to approximate their complex dynamics, we considered two types of particles that form speckles: phosphorylated (P) and de-phosphorylated (dP). The two types can interconvert via chemical reactions (Brackley et al., 2017; Söding et al., 2020; Carrero et al., 2006) and dP particles share attractive interactions modeled with the Lennard–Jones potential.
As shown in Figure 1C, to recognize specific interactions between chromosomes and nuclear landmarks, we introduced contact potentials between them. These potentials are inspired by the experimental techniques that probe the corresponding contacts. Appendix 1, sections ‘Chromosome–nuclear landmark interactions’ and ‘Nuclear landmark–nuclear landmark interactions’ contain more details about all the nuclear landmark-related energy functions.
Optimization of model parameters with experimental data
The nucleus model was designed to be interpretable such that energy terms represent physical processes. Furthermore, the expressions of the interaction potentials were also designed such that their parameters can be determined from experimental data via the maximum entropy optimization algorithm (Lin et al., 2021; Xie and Zhang, 2019; Schuette et al., 2023). Below, we briefly outline the procedure used for parameter optimization and further details can be found in Appendix 1, section ‘Optimization of the whole nucleus model parameters.
As illustrated in Figure 2, starting from a given set of parameters, we first perform MD simulations to produce a collection of 3D structures for the diploid genome and various nuclear bodies. These structures are then transformed into a contact map or contact probabilities between chromatin beads and nuclear landmarks by averaging over homologous chromosomes. Constraints corresponding to different energy terms could be obtained from the simulated results and compared with those estimated from Hi-C, SON TSA-Seq, and Lamin B DamID profiles. Finally, the model parameters were updated based on the difference between simulated and experimental constraints using the adaptive moment estimation (Adam) optimization algorithm (Kingma and Ba, 2014). The three steps can be repeated with updated parameters to improve the simulation-experiment agreement further.
Figure 2 with 1 supplement see all
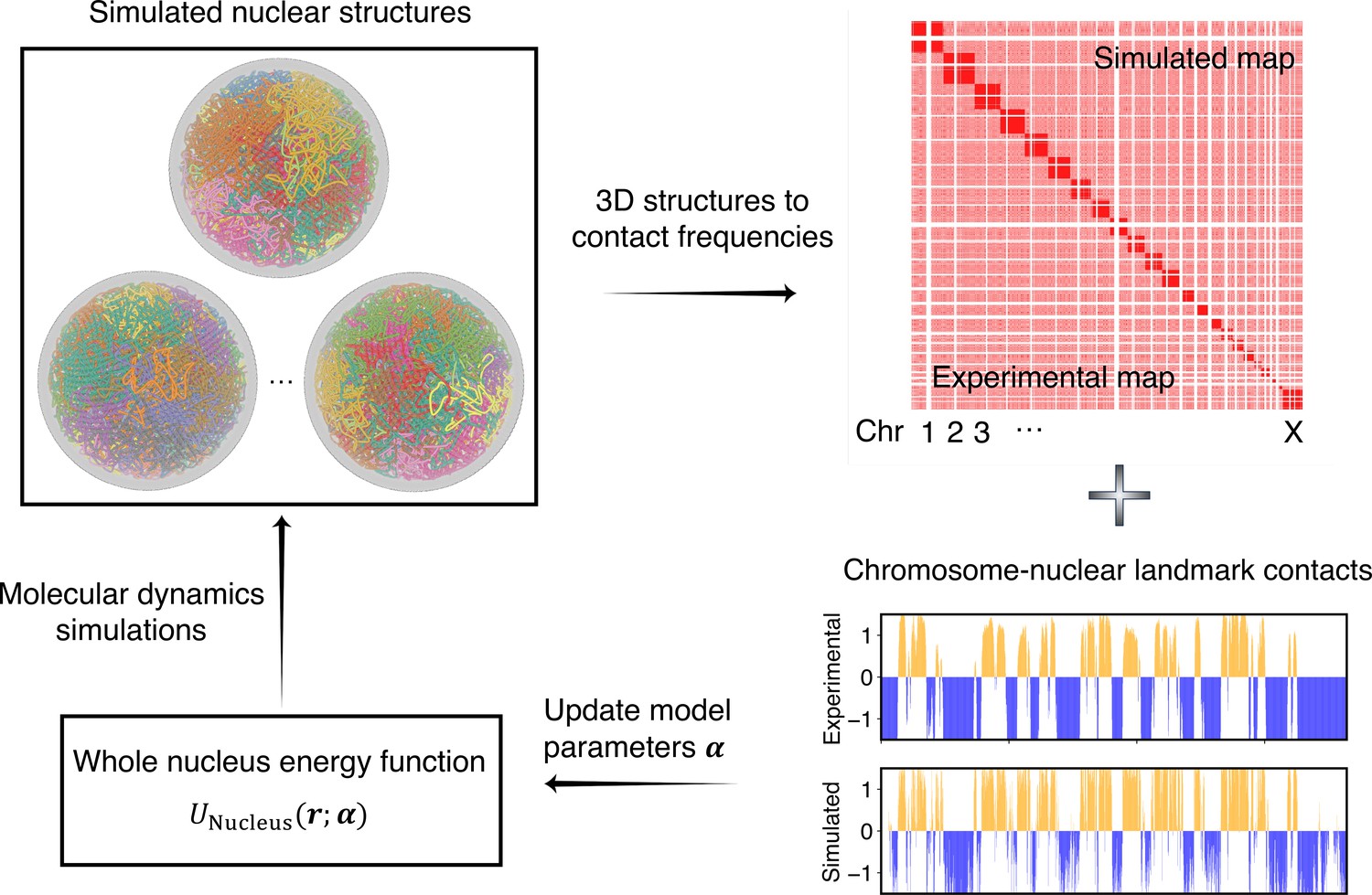
Overview of the iterative algorithm for parameterizing the nucleus model with experimental data.
Starting from an initial set of parameters, we perform molecular dynamics (MD) simulations to produce an ensemble of nuclear structures. These structures can be transformed into contacts between chromosomes or between chromosomes and nuclear landmarks for direct comparison with experimental data. Differences between simulated and experiment contacts are used to update parameters for additional rounds of optimization if needed.
No quantitative experimental data exists for interactions among nuclear body particles to serve as constraints. We varied the strength of the interaction potential to produce 2–3 nucleoli and ∼30 speckle clusters during the simulations (Figure 2—figure supplement 1) while ensuring the fluidity of the resulting droplets.
Molecular dynamics simulations with GPU acceleration
We implemented the nucleus model into the MD engine OpenMM (Eastman et al., 2017). OpenMM offers an excellent interface with Python scripting, significantly improving the readability and customizability of the model. The code was designed into functional modules, with different components, such as chromosomes and nuclear landmarks, written as separate classes. This design further facilitates the introduction of additional nuclear components, if desired, with minimal changes to existing code. We provide examples of simulation set up, trajectory analysis, parameter optimization, and introducing new features in the GitHub repository.
Figure 3A illustrates the workflow for setting up and executing whole nucleus simulations. A configuration file that provides the position of individual particles in the PDB file format is needed to initialize the simulations. This file also contains topological information regarding whether a particle represents chromosomes or nuclear landmarks and the identity of specific chromosomes. The input file can be generated with provided Python scripts by randomly distributing the positions of chromosomes, speckles, and nucleoli, though optimized configurations are also included in the GitHub repository. By default, the lamina particles will be uniformly placed on a sphere of 10 μm in diameter. Upon parsing the configuration file, interactions among various components can be set up with optimized parameters. This step will produce an object that can be used for MD simulations. As shown in Figure 3B, the workflow only requires a few lines of code. The package also includes analysis scripts to compute contact maps, monitor conformational dynamics, and track nuclear bodies.
Figure 3
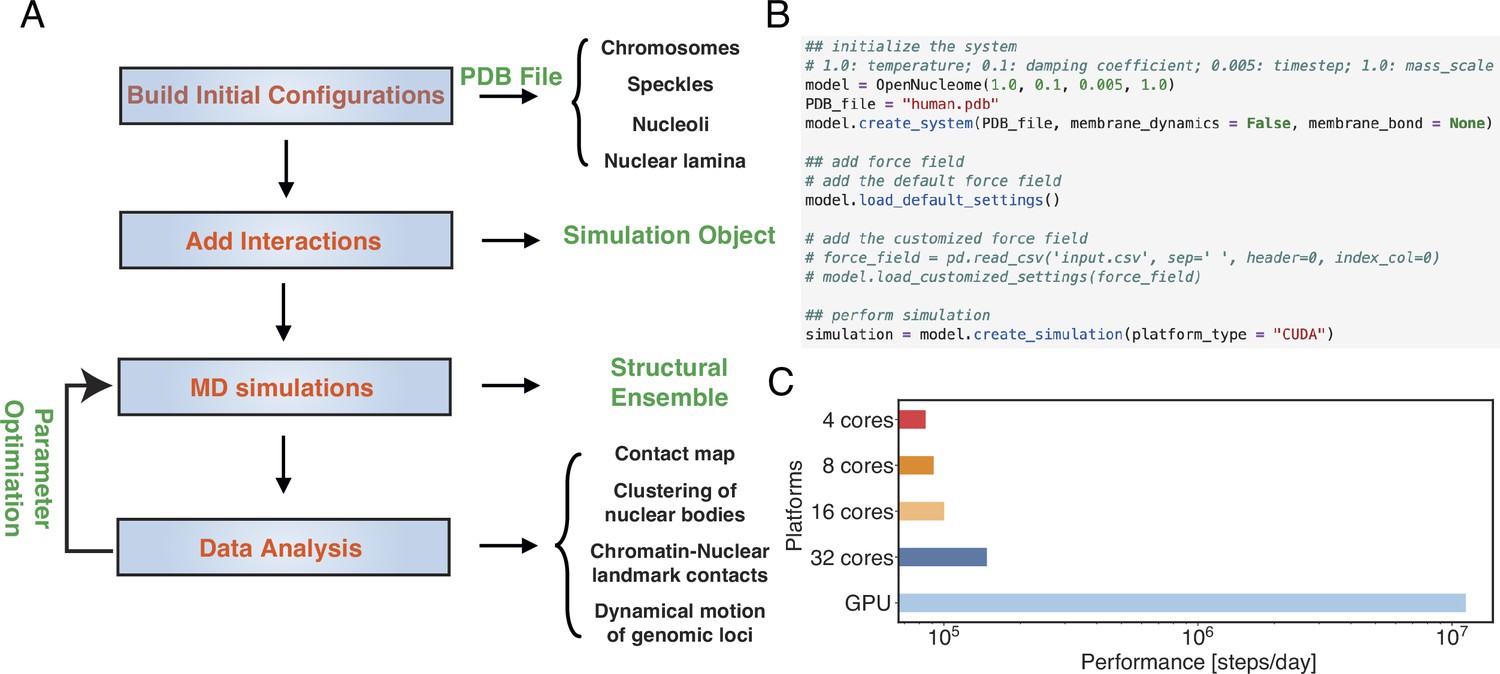
OpenNucleome facilitates GPU-accelerated simulations of the human nucleus.
(A) Illustration of workflow for setting up, performing, and analyzing molecular dynamics (MD) simulations. (B) Python scripts setting up whole nucleus simulations. (C) Performance of MD simulations on different number of CPU cores and a single GPU.
A significant benefit of OpenMM is its native support of GPU acceleration. As shown in Figure 3C, the simulation speed with one Nvidia Volta V100 GPU is 150 times faster than that of the four Intel Xeon Platinum 8260 CPU cores. Notably, this performance enhancement cannot be achieved by simply increasing the CPU core numbers. For example, the simulation speed with 32 CPU cores is less than twice that of 4 CPU cores, potentially due to the system’s heterogeneous distribution of particles.
Simulations reproduce and predict diverse experimental data
We extensively validated the parameterized nucleus model to examine its biological relevance. MD simulations initialized from 50 different initial configurations were performed to build an ensemble of structures. As mentioned in the following section, a diverse set of initial configurations is essential for reproducing interchromosomal contacts probed in Hi-C. From the simulated structures, we computed various quantities for direct comparison with experimental measurements. Given that the majority of experimental data were analyzed for the haploid genome, we adopted a similar approach by averaging over paternal and maternal chromosomes to facilitate direct comparison. More details on data analysis can be found in Appendix 1, section ‘Details of simulation data analysis’.
We compared the simulated contact probabilities among chromosomes with Hi-C data. As shown in Figure 4A and Figure 4—figure supplement 1, the simulated and experimental contact maps are highly correlated. The squares along the diagonal support the formation of chromosome territories that promote intrachromosomal contacts, and the apparent checkboard patterns follow the compartmentalization of various chromatin types. We further examined the decay of intrachromosomal contacts as a function of the sequence separation, which is known to deviate from that of an equilibrium globule (Lieberman-Aiden et al., 2009). As shown in Figure 4B, the simulated results overlap well with the Hi-C data (orange curve). In addition, the simulated average contact probabilities between various compartment types match values estimated from Hi-C data. Moreover, the simulated and experimental average contact probabilities between pairs of chromosomes agree well, and the Pearson correlation coefficient between the two datasets reaches 0.89.
Figure 4 with 1 supplement see all
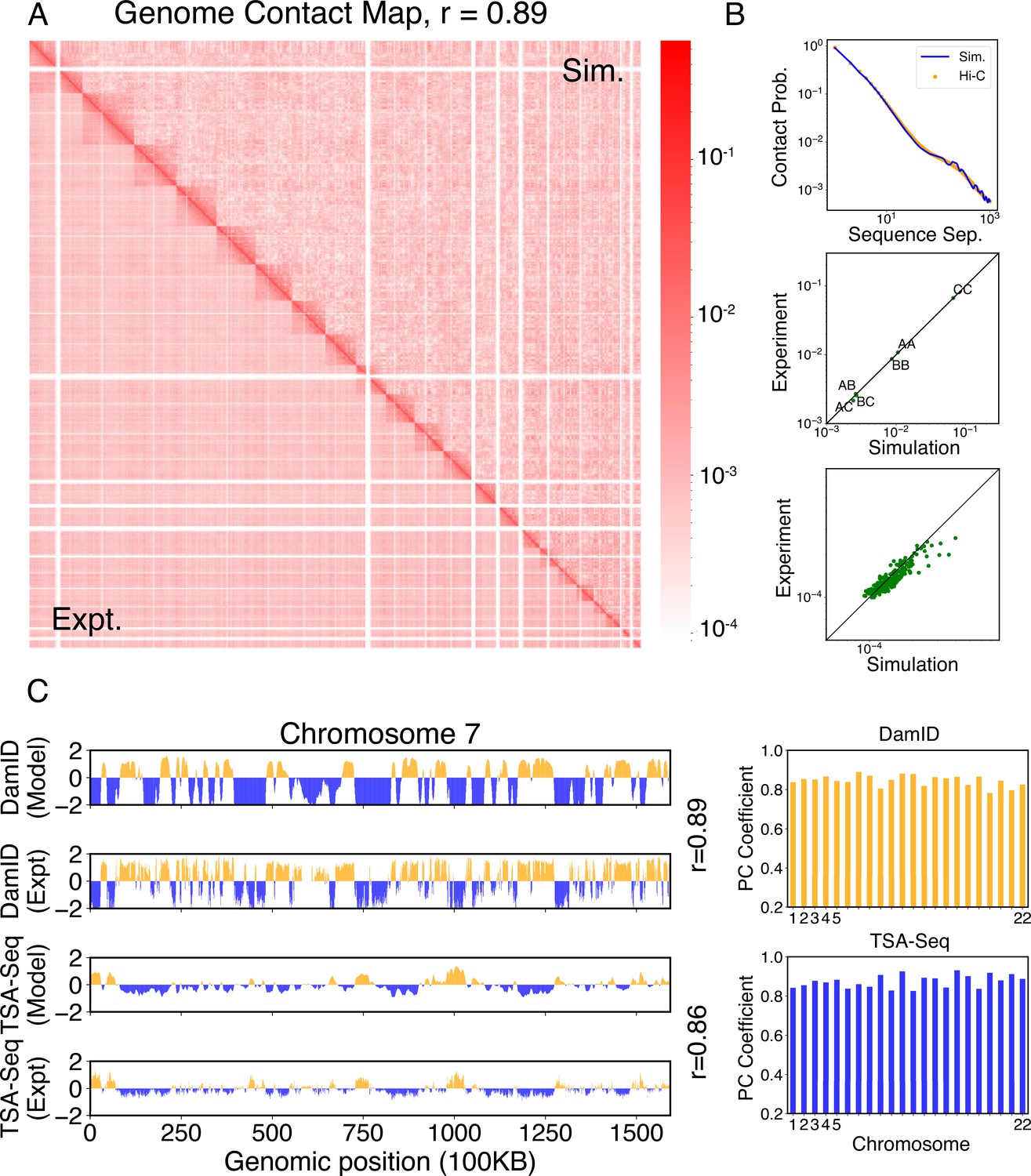
Simulated structures reproduce contact frequencies between chromosomes and between chromosomes and nuclear landmarks.
(A) Comparison between simulated (top right) and experimental (bottom left) whole-genome contact probability maps with Pearson correlation coefficient r = 0.89. Zoom-ins of various regions are provided in Figure 4—figure supplement 1. (B) Comparison between simulated and experimental average contact frequencies, including average contacts between genomic loci from the same chromosomes at a given separation (top), average contacts between genomic loci classified into different compartment types (middle), and average contacts between various chromosome pairs (bottom). (C) Comparison between simulated and experimental Lamin-B DamID (top) and SON TSA-Seq signals (bottom), with Pearson correlation coefficients of haploid chromosomes shown on the right.
We further examined the contacts between chromosomes and nuclear landmarks. As illustrated in Figure 4C, the simulated Lamin-B DamID signals for chromosome 7 match well with the experimental results, capturing the complex contact pattern that weaves chromatin toward and away from the nuclear envelope. Similarly, SON TSA-Seq data that quantify the contact between chromosomes and speckles are well captured by simulated structures. The anti-correlation between DamID and TSA-Seq is clearly visible. The observed agreement between simulation and experimental results is not limited to any particular chromosome. Good agreements are achieved for all chromosomes.
The simulations also provide 3D representations of the nucleus that can be compared with DNA-MERFISH data (Su et al., 2020). We found that the simulated radius of gyration of individual chromosomes matches well with experimental values (Figure 4A). The simulated and experimental average normalized chromosome radial positions also correlate strongly, as shown in Figure 5B. We note that while the sequencing results presented in Figure 4 were used for model parameterization, the MERFISH data were not. Therefore, the simulation results here are de novo predictions, and their agreement with experimental data strongly supports the coupled assembly mechanism used for designing the energy function.
Figure 5
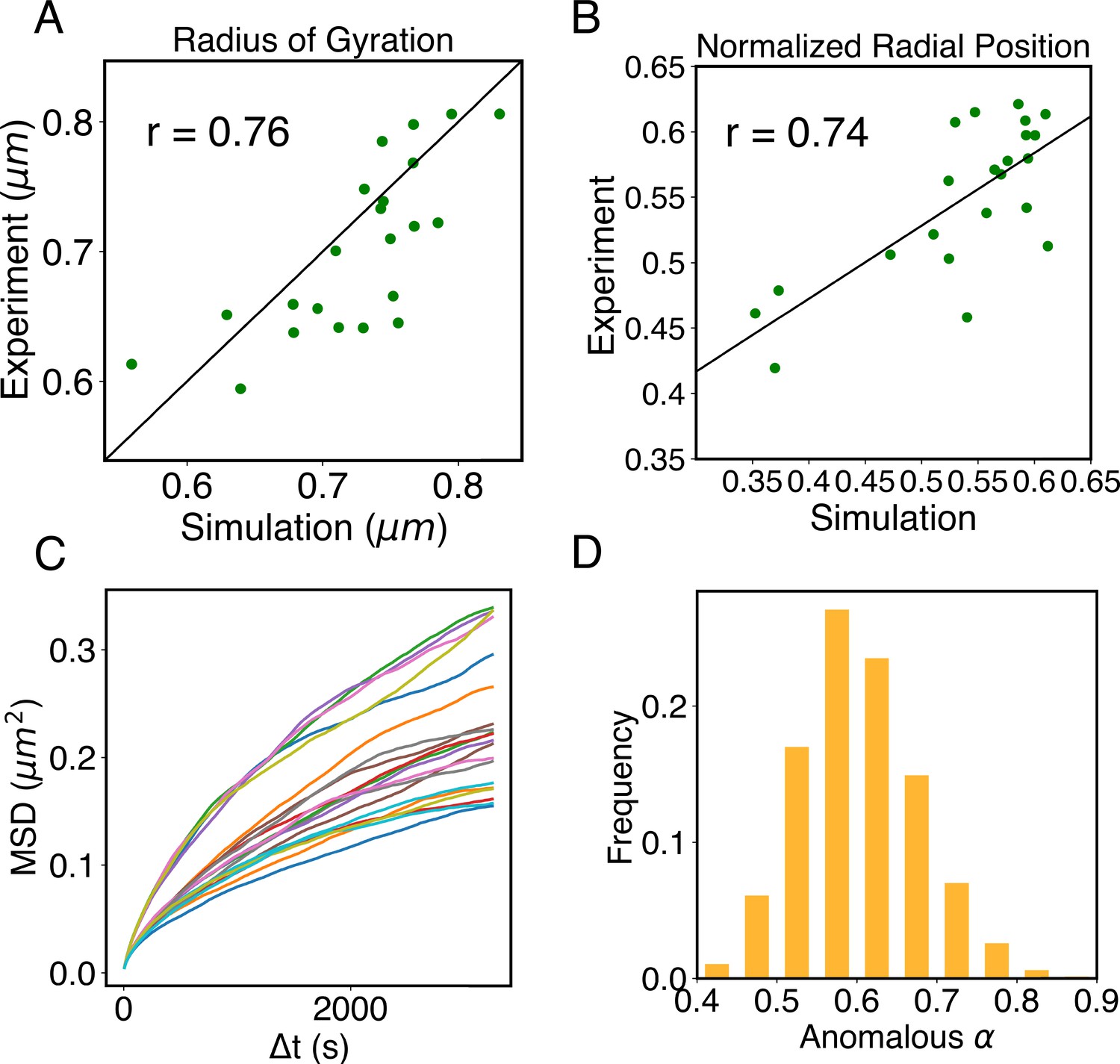
Structural and dynamical predictions of the nucleus model match results from microscopy imaging.
(A) Comparison between the simulated and experimental radius of gyration, , for haploid chromosomes. The Pearson correlation coefficient between the two, r, is shown in the legend. (B) Comparison between the simulated and experimental normalized radial positions for haploid chromosomes, with their Pearson correlation coefficient shown in the legend. Detailed definition of the normalized radial positions is provided in Appendix 1, section ‘Computing simulated normalized chromosome radial positions’. (C) Mean-squared displacements (MSDs) as a function of time are shown for selected telomeres. (D) The probability distribution of the anomalous exponent, α, obtained from fitting the MSDs curves for all telomeres with the expression, .
A significant advantage of MD simulation-based models is the dynamical information they naturally produce. We measured the dynamics of telomeres by tracking the mean-square displacements (MSDs), , as a function of time. In Figure 5C, we plot representative MSD trajectories over a 1-hr timescale. In line with previous research (Di Pierro et al., 2018; Bronstein et al., 2009; Lee et al., 2021), telomeres display anomalous subdiffusive motion. When fitted with the equation , these trajectories yield a spectrum of α values, with a peak around 0.59. The exponent and the diffusion coefficient both match well with the experimental values (Bronshtein et al., 2015; Jack et al., 2022), upon setting the nucleoplasmic viscosity as (see Appendix 1, section ‘Mapping the reduced time unit to real time’ for more details).
The good agreement in the dynamics of individual loci further inspired us to examine the diffusion of whole chromosomes. In particular, we plotted the normalized chromosome radial positions as a function of time in Figure 6A. Remarkably, we found that chromosomes appear arrested and no significant changes in their positions are observed over timescales comparable to the cell cycle (see also Figure 6—figure supplement 1). Therefore, our simulations predict that large-scale movements of chromosomes are unlikely during the G1 phase.
Figure 6 with 2 supplements see all
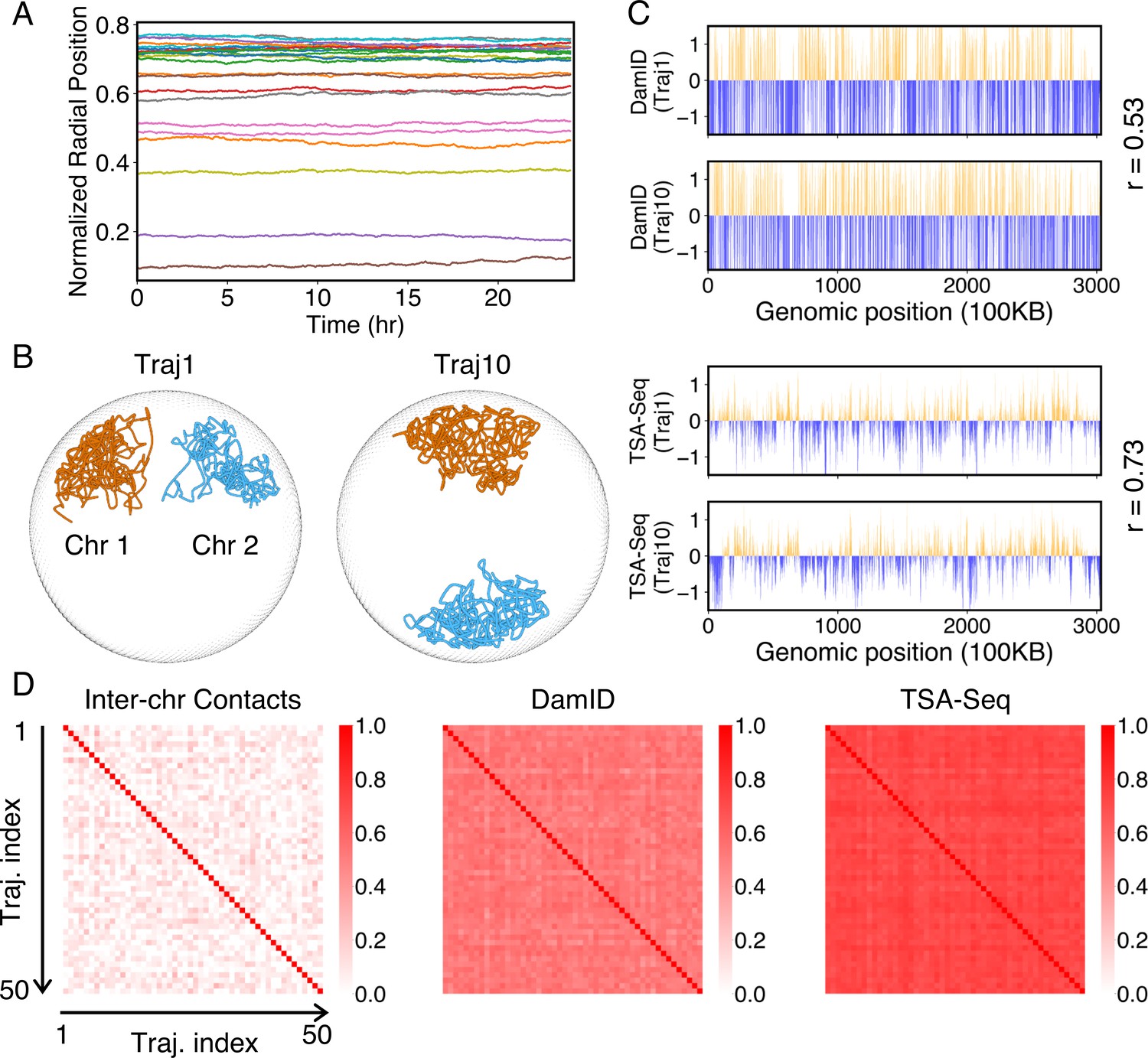
Heterogeneity and conserved features of nuclear organizations.
(A) Normalized chromosome radial positions as a function of simulation time. (B) Contacts between chromosomes 1 and 2 from two independent simulation trajectories show significant variations. (C) Genome-wide in silico Lamin B DamID (top) and SON TSA-Seq (bottom) profiles computed from two independent trajectories. Pearson correlation coefficients, r, are provided on each plot. (D) Pairwise Person correlation coefficients between interchromosomal contact matrices (left), genome-wide Lamin B DamID profiles (middle), and genome-wide SON TSA-Seq profiles (right) determined from independent trajectories. The averages excluding the diagonals of the three datasets are 0.06, 0.53, and 0.72.
Heterogeneity and robustness of the simulated conformational ensemble
The lack of relaxation of chromosome radial positions suggests the importance of starting configurations used to initialize the simulations. Statistical averages of the resulting ensemble of nuclear structures depend crucially on these starting configurations. Using an optimization procedure, we selected them from 1000 configurations to maximize the agreement with experimental lamin-B DamID and interchromosomal contact probabilities. Appendix 1, section ‘Initial configurations for simulations’ provides more details on preparing the 1000 initial configurations.
We selected a total of 50 starting configurations to initiate independent simulations. Smaller sets of starting configurations are not sufficient to reproduce the interchromosomal contact probabilities, as shown in Figure 6—figure supplement 2B. Notably, different sets of 50 configurations selected from independent trials show significant overlap (Figure 6—figure supplement 2D), supporting the robustness of the selection protocol in detecting conserved features of genome organization.
While the ensemble as a whole is relatively robust, individual configurations with the ensemble exhibit significant differences. For example, the Lamin B DamID profiles produced from different trajectories are only weakly correlated (Figure 6C), with an average correlation coefficient of 0.53. These weak correlations result from significant differences in the normalized radial positions of chromosomes, as can be seen in representative configurations from two simulation trajectories (Figure 6B). The fluctuations of normalized radial positions cause changes in contacts between chromosomes as well, resulting in little correlation between interchromosomal contact matrices (Figure 6D).
We examined genome organizations reported by Su et al. and found a similar variation of interchromosomal contact probabilities across individual cells (Figure 6—figure supplement 2A and D). Notably, the simulated configurations capture the fluctuations of interchromosomal contacts observed in DNA-MERFISH data, further supporting the biological relevance of the reported in silico structures.
Despite the differences in interchromosomal contacts across trajectories, high conservation of connections between chromosomes and speckles can be observed in individual simulations. For example, the average correlation coefficient between in silico SON TSA-Seq profiles produced from different trajectories is 0.72, much higher than the corresponding value for Lamin B DamID profiles. Conservation of contacts between chromosomes and nuclear bodies (zones) across individual cells has indeed been reported in a previous study that simultaneously images chromatin and various subnuclear structures (Takei et al., 2021).
Nuclear deformation preserves chromosome–nuclear body contacts
Numerous studies have highlighted the remarkable influence of nuclear shape on the positioning of chromosomes and the regulation of gene expression (Brahmachari et al., 2022; Contessoto et al., 2023). The nucleus, once regarded as a mere compartment for DNA storage, is increasingly recognized as a dynamic and intricately structured organelle. To better understand the interplay between nuclear shape and genome organization as a fundamental mechanism that shapes the transcriptional landscape, we performed additional simulations in which the nuclear lamina was altered from a sphere into more ellipsoidal shapes by applying a force along the z-axis (Figure 7A). More details about these simulations can be found in Appendix 1, section ‘Nuclear envelope deformation simulations’.
Figure 7 with 1 supplement see all
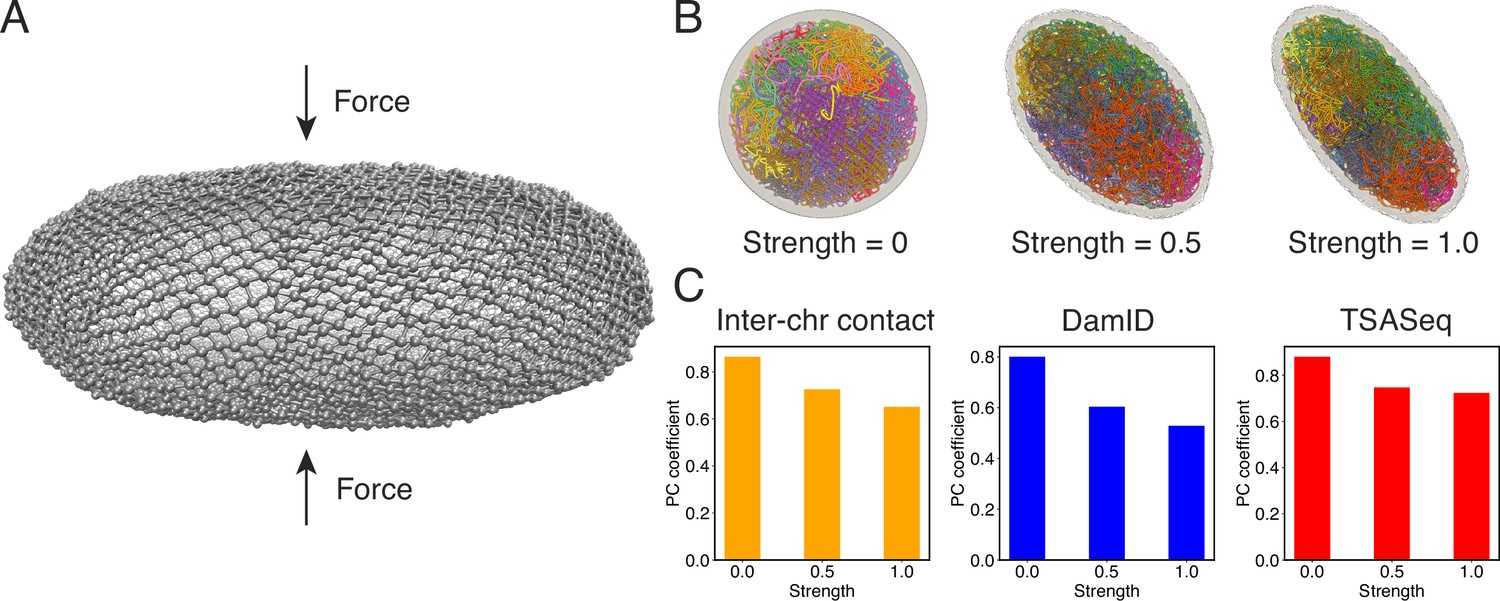
Nuclear deformations influence genome organization while preserving chromatin-speckle contacts.
(A) Illustration of force-induced nuclear envelope deformation. The nuclear lamina is modeled as a particle mesh where neighboring lamina particles are covalently bonded together. (B) Example nucleus conformations at different strengths of applied force. (C) Pearson correlation coefficients between results from simulations of deformed nuclei and those from a spherical nucleus for interchromosomal contacts (left), DamID profiles (middle), and TSA-Seq (right). The values at zero force were computed from two independent simulations starting from the same initial configurations.
As illustrated in Figure 7B, the presence of external forces resulted in significant alterations in nuclear shape. We conducted two independent simulations with different force strengths, leading to varying degrees of deformation in the nuclear lamina. This deformation, in turn, caused a reorganization of chromosomes, affecting their normalized radial positions and pairwise contacts (see Figure 7—figure supplement 1 and Figure 7C). We observed that more deformed nuclei exhibited lower correlation coefficients for interchromosomal contacts compared to results obtained from simulations in a spherical nucleus. Similarly, the DamID profiles exhibited significant variations upon nucleus deformation, whereas TSA-Seq signals were much less affected and remained highly correlated with the results from the spherical nucleus simulations.
Therefore, it appears that speckles, and potentially other nuclear condensates, can dynamically reorganize in response to changes in chromosome conformations to maintain contacts with genomic loci. This robustness in nuclear body contacts may be essential for ensuring the robust functioning of the genome in a population of cells with significant variability in nuclear shape.
Discussion
We introduced a computational model, OpenNucleome, to facilitate simulations for the human nucleus at high structural and temporal resolution. We conducted extensive cross-validation with experimental data to support the biological relevance of simulated 3D structures. Implementing the model into the MD package, OpenMM enables GPU acceleration for long-timescale simulations. Tutorials in the format of Python Scripts with extensive documentation are provided to facilitate the adoption of the model by the community.
Our software enhances the capabilities of existing genome simulation tools Fujishiro and Sasai, 2022; Yildirim et al., 2023; Oliveira Junior et al., 2021. Specifically, OpenNucleome aligns with the design principles of Open-MiChroM (Oliveira Junior et al., 2021), prioritizing open-source accessibility while expanding simulation capabilities to the entire nucleus. Similar to software from the Alber lab (Yildirim et al., 2023), OpenNucleome offers high-resolution genome organization that faithfully reproduces a diverse range of experimental data. Furthermore, beyond static structures, OpenNucleome facilitates dynamic simulations with explicit representations of various nuclear condensates, akin to the model developed by Fujishiro and Sasai, 2022.
A significant advantage of OpenNucleome lies in its predictive power for dynamical information. For example, the model succeeded in reproducing the subdiffusive behavior of telomeres. We further showed that the dynamics of individual chromosomes are slow and their radial positions do not relax over the time course of a cell cycle. This is consistent with previous theoretical estimations on chromosome dynamics (Rosa and Everaers, 2008) and recent observations of solid behavior of chromatin in vivo (Strickfaden et al., 2020). Live cell experiments that directly track the positions of multiple chromosomes could further validate/falsify this prediction. We anticipate the model will greatly facilitate the investigation of the dynamics of genomic loci and nuclear bodies and the interpreting of live cell imaging results.
Slow chromosome dynamics and a lack of conformational relaxation naturally result in the heterogeneity of chromosome radial positions across individual cells. This heterogeneity raises doubts about the notion that chromosome radial positions provide robust and reliable mechanisms for gene regulation (Hübner et al., 2013; Maeshima et al., 2010; Fraser and Bickmore, 2007; Takizawa et al., 2008). Instead, our results support the nuclear zoning model for gene regulation (Takei et al., 2021), where specific loci function as ‘fixed points’ anchored to certain nuclear bodies in all cells. This anchoring mechanism robustly creates the desired molecular environment surrounding these genomic segments. Unlike chromosome radial positions, contacts between genomic loci and speckles can be robustly established in individual cells, as shown in our simulations. It was achieved through a nucleation process that attracts speckle particles toward specific loci due to specific interactions. Nucleation occurs much more rapidly than chromosome rearrangement due to the smaller size of speckle particles. The coupled self-assembly mechanism for chromosomes and nuclear bodies can similarly facilitate the formation of other nuclear zones for different kinds of fixed points.
Despite the heterogeneity in chromosome positions and interchromosomal contacts, the ensemble of nuclear structures as a whole is not random and exhibits conserved features. For example, on average, certain chromosomes remain closer to the nuclear envelope than others (see Figure 5B). Similarly, the average contact frequency between certain chromosome pairs is higher than others, though this trend can be frequently violated in individual cells. How such conserved features arise as cells exit from the mitotic phase remains unclear and would be interesting for further explorations.
Methods
Molecular dynamics simulation details
We used the software package OpenMM Eastman et al., 2017 to perform MD simulations in reduced units at constant temperature (T = 1.0). Unless otherwise specified, we froze the lamina particles and only propagated the dynamics of chromatin, nucleoli, and speckles.
Two integration schemes were used with a time step of dt = 0.005to efficiently generate structural ensembles and produce realistic dynamical information, respectively. For simulations used in parameter optimization and building structural ensembles, we employed the Langevin integrator with a damping coefficient of . In the case of MSD calculations shown in Figure 6, we utilized Brownian dynamics with a damping coefficient of . The higher damping coefficient provides a better approximation to the viscous nucleus environment, while the smaller value in the Langevin integrator facilitates conformational sampling with faster diffusion rates.
We employed the semi-grand Monte Carlo technique (Sadigh et al., 2012) to simulate chemical transitions between two types of speckle particles. At every 4000 simulation steps, we attempt a total of chemical reactions that converts one type of speckle particles to the other type with a probability of 0.2. corresponds to the total number of speckle particles, and the switching probability was chosen to be comparable to the experimental phosphorylation rate. More details on the speckle dynamics are provided in Appendix 1, section ‘Speckles as phase-separated droplets undergoing chemical modifications’.
When deforming the nuclear envelope, we unfroze the lamina particles and evolved them dynamically as the rest of the nucleus. Bonded interactions among lamina particles held the nuclear envelope together as a particle mesh. A harmonic force along the z-axis was introduced to compress the particle mesh. More details are provided in Appendix 1, section ‘Nuclear envelope deformation simulations’.
For simulations used to optimize parameters, a total of 50 independent 3-million-step-long trajectories were performed. Configurations were recorded at every 2000 simulation steps for analysis. The first 500,000 steps of each trajectory were discarded as equilibration. For production simulations, we performed 50 independent 10-million-step long trajectories starting from different initial configurations. Nuclear structures were again recorded at every 2000 steps to determine statistical averages presented in the article. An additional eight simulations of 30million steps in length were performed to compute telomere MSDs.
We mapped the reduced units to real units with the conversion of length scale σ = 385nm and the timescale in Brownian dynamics simulations . These conversions were determined as detailed in Appendix 1, section ‘Unit conversion’.
Experimental data processing and analysis
We obtained the in situ Hi-C data, SON TSA-seq data, and Lamin-B DamID data of HFF cell lines from the 4DN data portal. The intra and interchromosomal interactions were calculated at 100KB resolution with VC_SQRT normalization applied to the interaction matrices. Hi-C data extraction and normalization were performed using Juicer tools (Durand et al., 2016). We followed the same processing and normalization method described in Zhang et al., 2021 to analyze TSA-seq data. Two biological replicates of Lamin-B DamID data were merged and the normalized counts over Dam-only control were used for analysis. The SON TSA-Seq and Lamin-B DamID data were processed at the 25KB resolution and the average values at the 100KB resolution were used in Figure 4 for model validation.
Appendix 1
Components of the whole nucleus model
As outlined in the main text, the whole nucleus model consists of chromosomes, nucleoli, speckles, and the nuclear lamina. Below, we provide details on the particle-based representations of the various components, totaling 70542 coarse-grained beads. Abbreviations are frequently used for clarity in notation, with N for nucleus, La for lamina, No for nucleoli, and Sp for speckles.
Chromosomes as beads on the string polymers
We explicitly modeled the 46 human chromosomes as beads-on-a-string polymers. Each coarse-grained bead represents a 100 KB genomic segment, totaling 60642 beads for the genome. We assigned each bead as either compartment type A, B, C, or N. The compartment assignments for types A and B were extracted from the Hi-C contact matrix for HFF cells (Krietenstein et al., 2020) using the cooltools software (Venev et al., 2020), and compartment C were identified as centromeric regions based on the DNA sequence. Compartment N denotes genomic regions that cannot be assigned as A, B, or C due to a lack of Hi-C data.
The nuclear lamina as a particle-based mesh
The nuclear envelope provides an enclosure to confine DNA and a repressive environment to organize chromatin with specific interactions (Hetzer, 2010). To account for the role of the nuclear lamina while keeping our model simple, we approximate it with discrete particles uniformly placed on a sphere.
Following our previous work (Kamat et al., 2023), we used the Fibonacci grid to initialize the lamina particles, which form a uniform and almost equidistant network of lamina particles on the surface of the nucleus (Swinbank and James Purser, 2006; Li et al., 2007). The Cartesian coordinates associated with the ith lamina particles are defined as
(1)
where represents the number of lamina particles, , and is the golden angle. We set as the radius of the human foreskin fibroblasts (HFF) cell nucleus.
Nucleoli as phase-separated droplets
Nucleoli have been shown to behave as liquid droplets that form through phase separation (Lafontaine et al., 2021; Pederson, 2011; Shin and Brangwynne, 2017). We modeled the droplets with coarse-grained beads. While the composition of nucleoli is rather complex, we only used one type of particle for simplicity. In our simulations, we fixed the number of nucleolus particles, , based on the experimental concentration of nuclear protein NPM1, (Qi and Zhang, 2021; Kamat et al., 2023; Zhu et al., 2019). For example,
(2)
where is the Avogadro constant and is the average nucleolous size (Caragine et al., 2018; Caragine et al., 2019).
Speckles as phase-separated droplets undergoing chemical modifications
Similar to nucleoli, speckles have also been shown to behave as liquid droplets (Chen and Belmont, 2019). However, one crucial unique feature of speckles is the constant chemical modifications of protein molecules comprising them, such as splicing factors (Spector and Lamond, 2011). The phosphorylation of these molecules has been argued to be essential for the dynamics and the number of speckles. Therefore, we implemented a kinetic scheme introduced by de Vries and coworkers to account for the chemical reactions. In this scheme, we consider two types of speckle molecules: phosphorylated (Sp-P) and de-phosphorylated (Sp-dP). Only Sp-dP particles share attractive interactions.
The two protein types can inter-convert via chemical reactions with a transition probability matrix T defined as
(3)
For simplicity, we assume the forward transition rate from Sp-P to Sp-dP particles is identical to the reverse rate. Because of the symmetry in transition rates, the average number of dP particles , where is the total number of speckle particles.
We chose the transition probability as 0.2 to be consistent with the phosphorylation rate. In particular, we estimate the rate as
(4)
where τ is the time interval between consecutive attempts of chemical reactions. As detailed in section ‘Molecular dynamics simulation details’, the reactions were attempted every 4000 simulation steps, with a time step of 0.005. The time unit in our simulations is 0.65 s (see section ‘Mapping the reduced time unit to real time’). The estimated value for k12 is in the same order as the experimental phosphorylation rate (Velazquez-Dones et al., 2005).
We estimated the total number of speckle particles as follows. Assuming that there is a total of 30 speckles (Galganski et al., 2017), we have , where is the number of Sp-dP particles in each cluster. This estimation assumes that only Sp-dP particles share attractive interactions and contribute to cluster formation. From the experimentally estimated relative mass densities of the protein concentrations in the speckle and nucleolus droplet as (Handwerger et al., 2005), we have
(5)
We assumed that speckle and nucleolus particles have identical mass and each nucleolus has 100 particles. The radius for speckle and nucleolus was approximated as 0.3 and , yielding and . Because of the kinetic scheme defined in Equation 3, only parts of Sp-dP particles will participate in droplet formation during the simulations. Therefore, we increase the particle number and set , which yields .
Energy function of the whole nucleus model
As detailed below, the energy function of the whole nucleus, , consists of interactions among chromosomes, among nuclear landmarks, and cross interactions between the two. Therefore,
(6)
Hi-C inspired interactions for the diploid human genome
The energy function of the genome model is defined as
(7)
determines a generic polymeric topology of chromosomes with excluded volume effect:
(8)
where the subscripts , and i+2 represent the index of , and beads, respectively, and and denote the bonding and angular potential applied for neighboring beads to ensure the connectivity of the chromatin chain and follow:
(9)
where, as discussed in Equation 32, represents the size of the chromatin bead. The soft-core potential provides excluded volume effects for pairs of beads from the same or different chromosomes and follows:
(10)
where denotes a soft-core potential added to each pair formed by beads index i and j to account for the excluded volume effect while allowing the finite probability of cross-over of polymer chains.
(11)
which corresponds to the Lennard–Jones potential capped off at a finite volume within a repulsive core to allow for chain crossing at a finite energy cost. and is chosen as the distance at which .
is the intra-chromosomal potential applied to genomic loci within the same chromosome, while is the compartment-specific interaction potential. The ideal potential, which can be rigorously derived following the maximum entropy principle (Roux and Weare, 2013; Zhang and Wolynes, 2015), adopts the following form:
(12)
where I indexes over each chromosome and i and j index over pair of beads on that chromosome. depends only on the sequence separation between two beads i and j. measures the probability of contact formation for two loci separated by a distance of rij, and its ensemble average corresponds to the contact probability measured in Hi-C experiments. adopts the form
(13)
The numerical value of rc was determined from the Hi-C contact map, as detailed in the next section. This contact probability function depicts that when but when . The power-law decay with an exponent of 4 is consistent with the relationship between contact probability and spatial distances revealed in imaging studies (Qi and Zhang, 2019; Wang et al., 2017). The tanh function ensures the continuity of the function and its derivative around rc (Appendix 1—figure 1). Additionally, we truncated the ideal potential to be applicable for a sequence separation less than or equal to 100 MB and set the parameters for larger sequence separations to be zero. As shown in Figure 4 of the main text, our parameterized ideal potential produced chromosomes with sizes comparable to imaging results. Incorporating longer-range interactions to improve the model further is straightforward but would also significantly increase the number of parameters.
Similar to the ideal potential discussed above, we have
(14)
where Ti and Tj denote the compartment types of beads i and j which can be A, B, or C. Therefore, CG beads of the same compartment types will share the same interaction parameter , which will be derived from average Hi-C contact frequencies as detailed in the following sections.
To account for specific interactions between chromosomes, we introduced the interchromosomal potential as
(15)
index the haploid chromosomes, and parental and maternal chromosomes share identical parameters. This potential allows the model to capture interactions beyond those arising purely from compartmentalization as defined in Equation 14.
All parameters in the energy function are summarized in Appendix 1—table 1. The procedure used for parameter optimization is detailed in the following sections.
Appendix 1—table 1
Summary of the various terms of the chromosome energy function and the algorithms used for parameter optimization.
See also Appendix 1, section ‘Hi-C inspired interactions for the diploid human genome’ for detailed expression of the energy function and ‘Adam optimizer for chromosome interaction parameters’ for details on the optimization algorithm.
| Potentials | Functional forms | Parameter values |
|---|---|---|
| Bonding potential | in Equation 9 | Standard values in coarse-grained polymer models |
| Angular Potential | in Equation 9 | Standard values in coarse-grained polymer models |
| Soft-core potential | in Equation 11 | Standard values in coarse-grained polymer models |
| Ideal potential | in Equation 12 | Values for were obtained from optimizations against Hi-C data (see Appendix 1—figure 3). |
| Compartment potential | in Equation 14 | Values for were obtained from optimizations against Hi-C data (see Appendix 1—table 2) |
| Inter potential | in Equation 15 | Values for were obtained from optimizations against Hi-C data (see Appendix 1—figure 4) |
Appendix 1—table 2
Summary of interaction parameters between various compartment types, that is, defined in Equation 14.
| αAA | –0.074185 |
| αAB | 0.112285 |
| αAC | 0.009947 |
| αBB | 0.059981 |
| αBC | 0.072481 |
| αCC | 0.088825 |
Nuclear landmark–nuclear landmark interactions
The general energy function for interactions among nuclear landmark particles is defined as
(16)
The nuclear lamina was modeled as a particle mesh, and bonded potentials were introduced for nearest neighbor particles defined as
(17)
with . i indices all the lamina particles, and j represents the nearest four neighbors around i determined from the initial configuration for which the particles were placed on a Fibonacci grid. To avoid pairs (i, j) being counted twice or more, we set j always larger than i.
Short-ranged, non-bonded interactions were introduced among nuclear landmark particles to account for attractions that promote phase separation and the excluded volume effect. These interactions were modeled with a cut and shifted Lennard–Jones (LJ) potential defined as
(18)
with . We note that when was set as , the potential has no attractive regime and only serves to prevent the overlap among particles, that is, the excluded volume effect.
For attractive interactions between nucleolus particles, and between type dP speckle particles, we set the parameters as , and . Therefore,
(19)
where the sums iterate over pairs of nucleolus particles and speckle dP particles.
For the excluded volume effect between nucleolus and speckle particles, between dP and P particles, and between P particles, we set the parameters as , and . These potentials are consistent with the estimated size of 0.5 σ for speckle and nucleolus particles.
The excluded volume effect was also introduced between lamina and nucleolus particles and between the lamina and speckle particles to confine the nuclear bodies inside the nuclear envelope. We set the parameters as , and . The value for was chosen based on a linear combination of the lamina particle size (1.0 σ) and the speckle/nucleolus particle size (0.5 σ).
Therefore, the excluded volume potential can be written as
(20)
We used abbreviations to denote various nuclear landmarks, with La for the nuclear lamina, Sp-P for P-type speckle particles, Sp-dP for dP-type speckle particles, and No for nucleolus particles. All the interaction parameters for the nuclear landmarks are listed in Appendix 1—table 3 for convenient reference.
Appendix 1—table 3
Summary of the interaction potentials among particles that make up the nuclear landmarks and their corresponding parameter values.
See also Appendix 1, section ‘Nuclear landmark–nuclear landmark interactions’ for further discussion and ‘Unit conversion’ for choosing the size of various particles, from which the were derived with a linear combination rule.
| Potentials | Function forms | Parameter values |
|---|---|---|
| Nucleolus/nucleolus | in Equation 18 | and were chosen to mimic short-range attractions that produce an average of two nucleoli per cell. . |
| Sp-dP/Sp-dP (speckles) | in Equation 18 | and were chosen to mimic short-range attractions that produce around 30 speckle droplets. . |
| Sp-dP/Sp-P (speckles) | in Equation 18 | and were chosen as standard values to provide the excluded volume effect. . |
| Sp-P/Sp-P (speckles) | in Equation 18 | and were chosen as standard values to provide the excluded volume effect. . |
| Nucleolus/speckle | in Equation 18 | and were chosen as standard values to provide the excluded volume effect. . |
| Nucleolus/lamina | in Equation 18 | and were chosen as standard values to provide the excluded volume effect. . |
| Speckle/lamina | in Equation 18 | and were chosen as standard values to provide the excluded volume effect. . |
| Lamina/lamina | in Equation 18 | and were chosen as standard values to provide the excluded volume effect. . |
-
* As mentioned in Appendix 1, section ‘Mapping lamina bead size to real unit’, a larger value for was used here to provide a stronger excluded volume effect that prevents these particles from crossing the nucleus boundary or getting stuck in the space of the lamina particle mesh grid.
Chromosome–nuclear landmark interactions
The energy function for interactions between chromosome and nuclear landmark particles is defined as
(21)
The functional form of the potential used to describe interactions between chromosomes and nuclear landmarks is inspired by experimental techniques that probe their contacts, such as Lamin B DamID and SON TSA-Seq. For example, the average contact probability between a chromatin bead i and the nuclear lamina can be estimated as
(22)
where j indexes over the lamina particles. is defined as
(23)
It is a switching function that approaches one for , a threshold distance at which we set chromatin and the lamina as in contact. We chose to obtain a reasonable decay of contact probability between chromosomes and nuclear landmarks. was selected as the average size of the lamina (1.0 σ) and chromatin (0.5 σ) particles.
For the computational model to reproduce the experimental contact probability, following the maximum entropy argument (Roux and Weare, 2013; Zhang and Wolynes, 2015), the interaction potential between chromosomes and the nuclear lamina adopts the following form:
(24)
A similar argument to the one outlined above was used to derive the interactions among chromosomes from Hi-C data, that is, Equations 12, 14, and 15 (Hetzer, 2010). The individual parameters were optimized to ensure a match between simulated and experimental Lamin B DamID data. The second term was included to account for the excluded volume effect and prevent chromatin from moving outside the envelope.
The interaction potential between chromosomes and the speckles adopts a similar form defined as
(25)
The second sum for j only includes dP-type speckle particles. The individual parameters were optimized to ensure a match between simulated and experimental SON TSA-seq data.
Finally, the interaction potential between chromosomes and nucleoli is defined as
(26)
Because of the low data quality for the ChIP-Seq experiments for detecting chromatin-nucleoli contacts, we did not perform systematic optimizations for . Instead, we simply set them as , with . is the probability for the chromatin bead i to contact nucleoli as quantified by the software SPIN (Wang et al., 2021).
We list all the interaction parameters between chromosomes and the nuclear landmarks in Appendix 1—table 4.
Appendix 1—table 4
Summary of the interaction potentials between chromatin particles and nuclear landmarks and their corresponding parameter values.
See also Appendix 1, section ‘Chromosome–nuclear landmark interactions’ for further discussion and ‘Adam optimizer for chromosome–nuclear body interaction parameters’ for details on the optimization algorithm.
| Potentials | Functional forms | Parameter values |
|---|---|---|
| Chromatin-nucleolus | in Equation 26 | provides a smooth transition in the tanh function for contacts. reflects the minimal distances between chromatin and nucleolus beads as reflected in the excluded volume potential defined in Appendix 1—table 3. The interaction strength of the ith chromatin bead , where is the probability for the chromatin bead i to contact nucleoli as quantified by the software SPIN (Wang et al., 2021). |
| Chromatin-speckle | in Equation 25 | and were similarly determined as in . Value for the interaction strength of the ith chromatin bead was obtained from optimizations against SON TSA-Seq data. |
| Chromatin-lamina | in Equation 24 | and were similarly determined as in . Value for the interaction strength of the ith chromatin bead was obtained from optimizations against Lamin B DamID data. The extra Lennard Jones potential was included to provide the excluded volume effect, with and as standard values. . |
-
* As mentioned in Appendix 1, section ‘Mapping lamina bead size to real unit’, a larger value for was used here to provide a stronger excluded volume effect that prevents these particles from crossing the nucleus boundary or getting stuck in the space of the lamina particle mesh grid.
Optimization of the whole nucleus model parameters
Below, we describe the procedures used to derive model parameters.
Connecting imaging and Hi-C data with the contact function
The function f(r) defined in Equation 13 was used to determine the chromatin contact probabilities. The availability of spatial positions and Hi-C data makes possible the definition of a contact function, f(r), that converts distances into contact probabilities. In particular, we determined rc as the value at which the simulated average interchromosomal contact probability matches the experimental value, that is,
(27)
The angular brackets represent ensemble averaging, performed using the structures at 100 KB resolution reported in our previous work (Kamat et al., 2023). Matching simulation and experimental values produced nm. We note that this estimation for rc is comparable to the average bond length (0.5 σ), thus ensuring that nearest neighbor genomic regions with contact probability close to 1, that is, .
Adam optimizer for chromosome interaction parameters
Mathematical expressions for the various energy terms in were designed such that their ensemble averages can be mapped onto combinations of contact frequencies measured in Hi-C. The correspondence between the energy functions and Hi-C measurements allows model parameterization with an efficient adaptive moment (Adam) algorithm (Kingma and Ba, 2014). Specifically, , and were tuned to satisfy the following constraints:
(28)
where is the Kronecker delta function with the following definition:
(29)
The angular bracket represents the ensemble average, and is the corresponding experimental contact frequency.
During the optimization process, our aim was to minimize the disparity between experimental findings and simulated data. To achieve this, we defined the cost function as follows:
(30)
where the index i iterates over all the constraints defined in Equation 28.
The details of the algorithm for parameter optimization are as follows:
Starting with a set of values for , and , we performed 50 independent 3-million-step long MD simulations to obtain an ensemble of nuclear configurations. The 500K steps of each trajectory are discarded as equilibration. We collected the configurations at every 2000 simulation steps from the rest of the simulation trajectories to compute the ensemble averages defined on the left-hand side of Equationi 13.
Check the convergence of the optimization by calculating the percentage of error defined as . The summation over i includes all the average contact probabilities defined in Equation 28.
If the error is less than a tolerance value , the optimization has converged, and we stop the simulations. Otherwise, we update the parameters, α, using the Adam optimizer (Kingma and Ba, 2014). With the new parameter values, we return to step one and restart the iteration.
Adam optimizer for chromosome–nuclear body interaction parameters
Similar to those among chromatin particles, the interaction parameters between chromatin and nuclear landmarks were optimized with Adam’s algorithm to reproduce experimental constraints.
The constraints that we aimed to reproduce were defined as follows:
(31)
where and measure the contacts between chromatin bead i and nuclear lamina and speckles, respectively, as defined in Equations 42 and 45. and denote the lamina and speckle association frequency for chromatin bead i as measured in Lamin B DamID and SON TSA-Seq experiments. N denotes the number of chromatin beads. We combined the constraints defined in Equation 31 with those in Equation 28 to simultaneously optimize the parameters using the iterative algorithm outlined in the previous section. We note that the interaction potential between chromatin and speckles defined in Equation 25 did not use precisely the same function as in . We chose to sum over all speckle dP particles, rather than identifying the droplets, which is difficult to do during the simulations.
Parameter optimization for nuclear body–nuclear body interactions
As much remains to be known about the organization of nuclear bodies, we designed the interaction potentials and parameters based on qualitative observations without extensive fine-tuning. For example, we used the standard Lennard–Jones potential (Equation 18) to mimic short-range interactions. The lengthscales, , in these potentials, were chosen based on a linear combination of the size of interacting particles, as discussed in section ‘Unit conversion’.
The interaction strength, , was set as 1.0 to be on the same order as thermal energy (), when the potential was used to account for the excluded volume effect.
For attractive interactions that promote phase separation and nuclear body formation, we set . Smaller values failed to produce clustered nucleoli, while much larger values significantly decreased the fluidity of the resulting droplets. The same value was used for speckle dP particles and produced droplet numbers comparable to experimental observations (Figure 2—figure supplement 1).
Unit conversion
The reduced unit for length scale is noted as σ. We set the nucleus radii as 13σ. Assuming a nucleus with an average size of 5 μm, we have σ = 385 nm.
Mapping chromatin bead size to real unit
We estimated the size of the chromosome bead as 192.5 nm based on super-resolution imaging data as follows. The median radius of gyration has been shown to follow a power-law scaling as a function of domain length with an exponent of 0.3 (Boettiger et al., 2016). Assuming that the radius of a domain is proportional to the radius of gyration, we have
(32)
We previously estimated the size of 1 MB bead as nm, and Equation 32 yields the size of 100 KB as .
Mapping lamina bead size to real unit
We chose the number and the diameter of lamina beads by estimating the distance between nearest neighbor lamina beads. We found that at , when the lamina particles were placed on the Fibonacci grid over the spherical surface, the average nearest neighbor distance was 0.52. Therefore, we set when considering the excluded volume effect between lamina particles. However, when modeling the excluded volume effect between lamina and chromatin, nucleolus, or speckle particles, we used (see Equation 20). A larger value provides a stronger excluded volume effect that prevents these particles from crossing the nucleus boundary or getting stuck in the space of the lamina particle mesh grid.
Mapping nucleoli bead size to real unit
The size of nucleolus particles () was estimated as follows. Since the average number of nucleoli inside a cell nucleus ranges from 2 to 5, we approximate the number of particles comprising individual droplets as , assuming a total of three nucleoli. corresponds to the total number of nucleolus particles. With a space-filling model, the ratio of the volume between one nucleolus and the cell nucleus can be estimated as
(33)
where denotes the effective radius of a nucleolus particle, and is the nucleus size. Using experimental values for the nucleolus and nucleus size (Caragine et al., 2018; Caragine et al., 2019) as and , we have .
Mapping speckle bead size to real unit
A similar procedure as in the previous section was used to estimate the size of speckle particles . Since approximately 600 dP-type speckle particles form speckle clusters, each speckle cluster consists of around 20 particles. This estimation assumes a total of 30 speckle droplets in the system, consistent with the experimentally reported range of 20–50 speckles.
With a space-filling model, the ratio of the volume between one speckle and the cell nucleus can be estimated as
(34)
where . Using experimental values for the speckle and nucleus size
(Handwerger et al., 2005) as and , we have .
Mapping the reduced time unit to real time
We determined the timescale mapping by matching the simulated diffusion coefficient of chromatin particles with experimental values. The diffusion coefficient in our simulations can be estimated from the fluctuation-dissipation theorem (Kubo, 1966) as , where the friction coefficient . Using the conversion from , we have
(35)
We used the simulation setup when deriving the last equation.
In the meantime, from the Stokes–Einstein (SE) equation, we have , where η is the viscosity and is the radius of chromatin beads. Therefore,
(36)
and
(37)
Setting the nucleoplasmic viscosity as produces . This mapping produced diffusion coefficients and MSD curves that match well with experimental measurements presented in Bronshtein et al., 2015, as discussed in the main text. We note that the chosen value for the nucleoplasmic viscosity indeed falls into the range of reported experimental values from to (Platani et al., 2002; Tseng et al., 2004).
Molecular dynamics simulation details
Initial configurations for simulations
Due to the slow relaxation dynamics of whole chromosomes relative to the simulation timescale, the reported results are sensitive to the configurations used to initialize the simulations. Therefore, we designed the following protocol to prepare the initial configurations and ensure the biological relevance of simulation results.
We first created a total of 1000 configurations for the genome by sequentially generating the conformation of each one of the 46 chromosomes as follows. For a given chromosome, we start by placing the first bead at the center (origin) of the nucleus. The positions of the following beads, i, were determined from the -th bead as . v is a normalized random vector, and 0.5 was selected as the bond length between neighboring beads. To produce globular chromosome conformations, we rejected vectors, v, that led to bead positions with distance from the center larger than . Upon creating the conformation of a chromosome i, we shift its center of mass to a value determined as follows. We first compute a mean radial distance, with the following equation:
(38)
where Di is the average value of Lamin B DamID profile for chromosome i. and represent the highest and lowest average DamID values of all chromosomes, and and represent the upper and lower bound in radial positions for chromosomes. As shown in Appendix 1—figure 2, the average Lamin B DamID profiles are highly correlated with normalized chromosome radial positions as reported by DNA MERFISH (Su et al., 2020), supporting their use as a proxy for estimating normalized chromosome radial positions. We then select as a uniformly distributed random variable within the range . Without loss of generality, we randomly chose the directions for shifting all 46 chromosomes.
We further relaxed the 1000 configurations to build more realistic genome structures. Following an energy minimization process, 1-million-step MD simulations were performed starting from each configuration. Simulations were performed with the following energy function:
(39)
where is defined as in Equation 7. is the excluded volume potential between chromosomes and lamina, that is, only the second term in Equation 24. Parameters in were from a preliminary optimization. The end configurations of the MD simulations were collected to build the final configuration ensemble (FCE).
We further computed the Pearson correlation coefficient of pairwise interchromosomal contacts between different structures in FCE (see section ‘Computing pairwise interchromosomal contact probabilities’). As shown in Figure 6—figure supplement 2A, the probability distribution of these correlation coefficients is comparable with that determined from DNA-MERFISH structures, supporting the biological relevance of the structural diversity in the constructed ensemble.
From 1000 relaxed configurations, we selected a subset of structures to initialize simulations presented in the main text. An optimization procedure was introduced for structure selection. We start this procedure by randomly select N structures to build the initial configuration ensemble (ICE). We then iteratively go through every configuration in ICE and replace with a structure from FCE that’s not already included in ICE. We then compute the Pearson correlation coefficient between new average ICE interchromosomal contact probabilities and experimental values. If the Pearson correlation coefficient is higher than the value determined from the original ICE, the new structure is accepted and the ICE is updated. Otherwise, the new structure is rejected. We stop the selection process for when the Pearson correlation coefficient stops improving.
We found that as N increases, the agreement between ICE interchromosomal contact probabilities and experimental values continue to increase (Figure 6—figure supplement 2B). We set N = 50, which produces a Pearson correlation coefficient between ICE and experimental interchromosomal contact probabilities of 0.9. Further increasing N does not significantly improve the agreement but incurs more computational cost.
It is worth noting that the outcomes of the selection procedure depend on the initial set of configurations included in ICE at the beginning. However, we found that the ICEs produced from 20 independent trials are highly correlated (Figure 6—figure supplement 2C) and all reproduce the heterogeneity in interchromosomal contacts seen in DNA MERFISH data (Figure 6—figure supplement 2D). Therefore, the selection procedure is robust and can produce biologically meaningful configurations to initialize simulations.
With the chromosome positions prepared, we randomly placed 300 nucleoli and 1600 speckle particles inside the nucleus to complete the set up of initial configurations.
Langevin dynamics simulations
We used the Langevin integrator with the damping coefficient to control the temperature at T = 1.0 for simulations used for parameter optimization and for producing an ensemble of nucleus structures. Langevin dynamics simulations allow faster chromosome movements, compared to Brownian dynamics simulations, facilitating the conformational sampling. In these simulations, the lamina particles were frozen and no explicit dynamics were considered for the nuclear envelope.
Brownian dynamics simulations
We also performed Brownian dynamics simulations with damping coefficient to control the temperature at T = 1.0. These simulations provide better approximations of the overdamped dynamics of chromatin for direct comparison with live cell imaging studies. As detailed in section ‘Unit conversion’, upon mapping the coarse-grained timescale to the physical unit, Brownian dynamics simulations produce diffusion coefficients for telomeres comparable to experimental values (see Figure 5).
Nuclear envelope deformation simulations
We performed Langevin dynamics simulations to investigate the impact of nuclear envelope deformation on genome organization. To induce a compressing force along the z-axis, we introduced a harmonic potential in the form of
(40)
where zi is the z coordinate of the ith lamina bead, and represents the total number of lamina beads. The particles in the system evolve under the combined effect of and defined in Equation 6.
Details of simulation data analysis
The computer simulations yield 3D coordinates of the diploid genome. However, when comparing directly with experimental data processed for the haploid genome, unless stated otherwise, we computed averages across paternal and maternal chromosomes to ascertain various genome-wide properties as listed below.
Computing simulated contact probabilities
Simulated contact probability maps were computed by averaging over chromosome configurations collected from all trajectories. For a given configuration, the contact probability between two chromatin segments (i and j) was evaluated using the contact function defined in Equation 13.
Computing the Pearson correlation coefficients between experimental and simulated contact maps
We computed the Pearson correlation coefficients (PCCs) between experimental and simulated contact maps in Figure 4A and Figure 4—figure supplement 1 as
(41)
where xi and yi represent the experimental and simulated contact probabilities, and n is the total number of data points. Only non-redundant data points, that is, half of the pairwise contacts, are used in the PCC calculation.
Computing pairwise interchromosomal contact probabilities
For a given genome structure, we computed the pairwise interchromosomal contacts as follows. For every pair of chromosomes, we determined their contact probability by averaging all genomic pairs from two chromosomes using Equation 13. We then averaged over all four pairs of diploid chromosomes to compute the haploid average contacts. In total, there are contact pairs between haploid chromosomes excluding the sex chromosomes.
Distances from nuclear bodies and association frequencies
The contacts of a chromatin bead i with the nuclear lamina were evaluated as
(42)
with . We average over the ensemble of nuclear configurations and homologs to compute the in silico Lamin B DamID signal as
(43)
where the angular brackets indicate ensemble averaging. is defined as the genome wide average of .
For chromatin-speckle contacts, we first identified the speckles formed at any given structure using the density-based spatial clustering algorithm DBSCAN (Ester et al., 1996) as implemented in the scikit library for Python (Pedregosa et al., 2011). For the identified droplets, we computed their center of mass coordinates, and the radius of gyration, R. With the identified clusters, we then determined the distance from the ith chromatin bead to the sth speckle as
(44)
where represents the L2 norm. We subtract the radius of the speckle cluster in the above equation to determine the distance to the droplet surface. From the list of distances to different speckles, the contact between chromatin bead i and speckles is computed as
(45)
where we sum over all the Ns speckle clusters. A similar expression was used for determining the contacts between chromatin and nucleoli.
Finally, we average over the ensemble of nuclear configurations and homologs to compute the in silico SON TSA-Seq signal as
(46)
where the angular brackets indicate ensemble averaging. is defined as the genome wide average of .
Computing simulated normalized chromosome radial positions
For a given chromosome i, we first determined its center of mass position denoted as Ci. Starting from the center of the nucleus, O, we extend the vector to identify the intersection point with the nuclear lamina as Pi. The normalized radial position of chromosome i is then defined as , where represents the L2 norm.
Computing simulated chromosome radii of gyration
The radius of gyration for a chromosome is computed as
(47)
where and n are the center of mass and the number of beads of the chromosome. i indices over all the chromosome beads and correspond to the Cartesian coordinates of bead i. represents the L2 norm.
Computing simulated mean-square displacement
MSD for telomeres were computed as
(48)
where , and represent the time interval, the time step, and the total number of steps, respectively. The summation over t corresponds to averaging over eight independent trajectories. MSDs telomeres from paternal and maternal chromosomes are separately computed and analyzed.
Details of experimental data analysis
Interchromosomal contacts from DNA MERFISH data
We collected the DNA MERFISH data reported in Su et al., 2020 to construct the experimental ensemble of 5455 genome structures. For each structure, we computed the pairwise interchromosomal contacts following the procedure outlined in section ‘Computing pairwise interchromosomal contact probabilities’.
To better visualize and analyze interchromosomal contacts, we applied the Uniform Manifold Approximation and Projection (UMAP) technique as implemented in software package umap-learn (McInnes et al., 2018; Moshtagh, 2005), with default parameters to reduce the 231 haploid contacts into two dimensions. All 5455 DNA MERFISH structures were included in this analysis.
The same transformations produced from the UMAP analysis of experimental structures were applied to in silico configurations to produce results shown in Figure 6—figure supplement 2C and D .
Computing experimental normalized chromosome radial positions
We followed the same procedure outlined in section ‘Computing simulated normalized chromosome radial positions’ to compute the experimental values. To determine the center of the nucleus using DNA MERFISH data, we used the algorithm, minimum volume enclosing ellipsoid (MVEE) (Moshtagh, 2005), to fit an ellipsoid for each genome structure. The optimal ellipsoid defined as is obtained by optimizing subjecting to the constraint that . correspond to the list of chromatin positions determined experimentally.
Computing experimental radii of gyration
We computed the experimental radii of gyration with using the same expression as that for analyzing simulated structures (Equation 47).
Appendix 1—figure 1
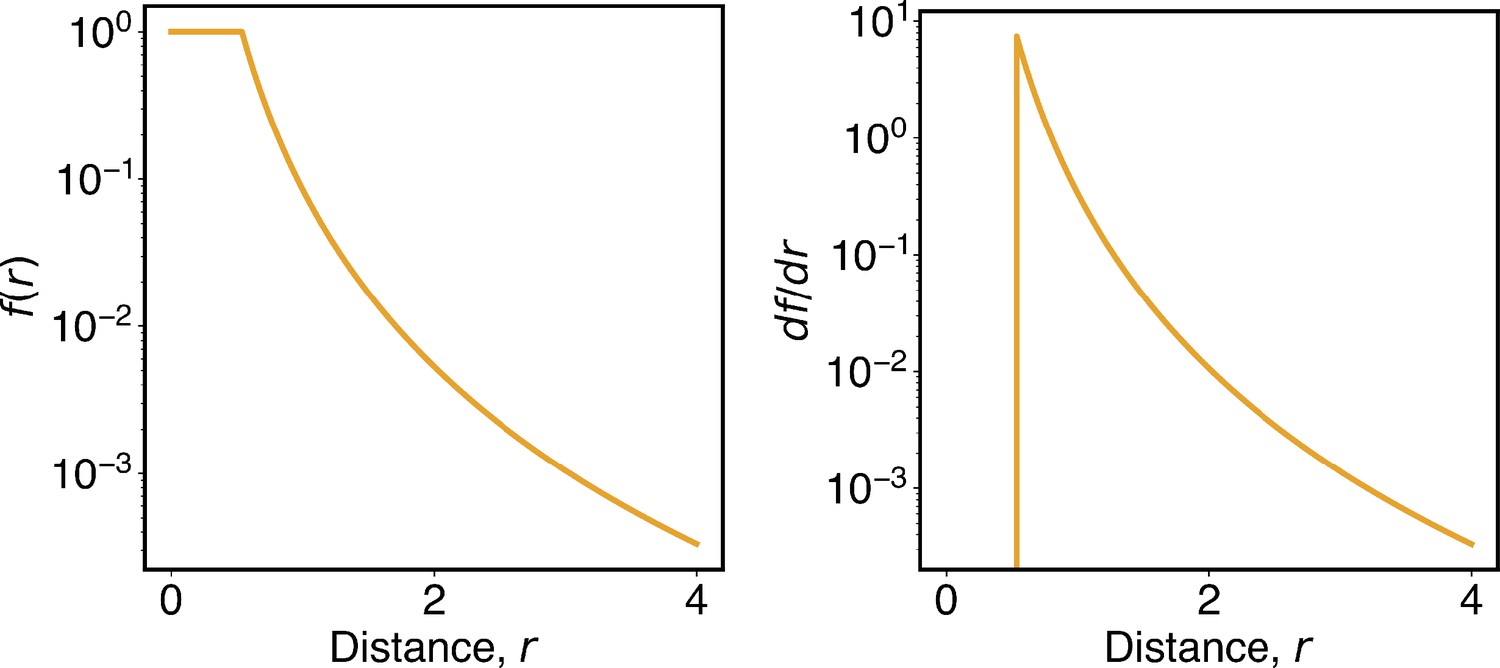
The function defined in Equation 13 smoothly switches from high to low contact probabilities.
The left and right panels plot the function and its derivative as a function of the distance, r.
Appendix 1—figure 2
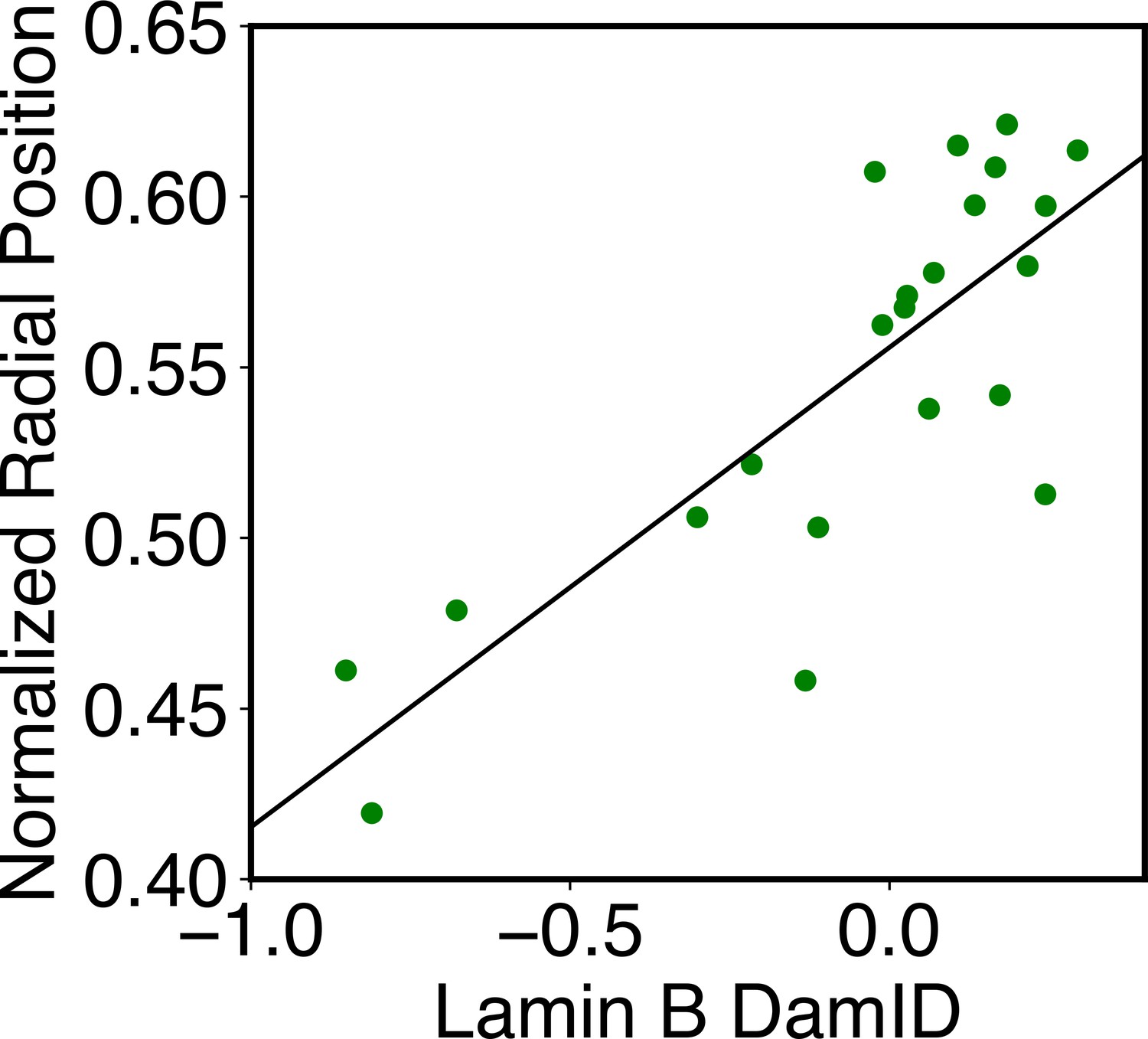
Correlation between average DamID profiles of individual chromosomes with their normalized radial positions.
The normalized radial positions were determined using the average value of all cells reported from DNA MERFISH data (Su et al., 2020). The correlation coefficient between the two datasets is 0.8.
Appendix 1—figure 3
Parameters of the ideal potential, , as defined in Equation 12.
Numerical values for are included in the software’s GitHub repository.
Appendix 1—figure 4
Parameters of the inter potential, , as defined in Equation 15.
Numerical values for are included in the software’s GitHub repository.
Appendix 1—figure 5
Parameters of the chromosome-lamina potential, , as defined in Equation 24.
Numerical values for are included in the software’s GitHub repository.
Appendix 1—figure 6
Parameters of the chromosome-lamina potential, , as defined in Equation 25.
Numerical values for are included in the software’s GitHub repository.
Appendix 1—figure 7
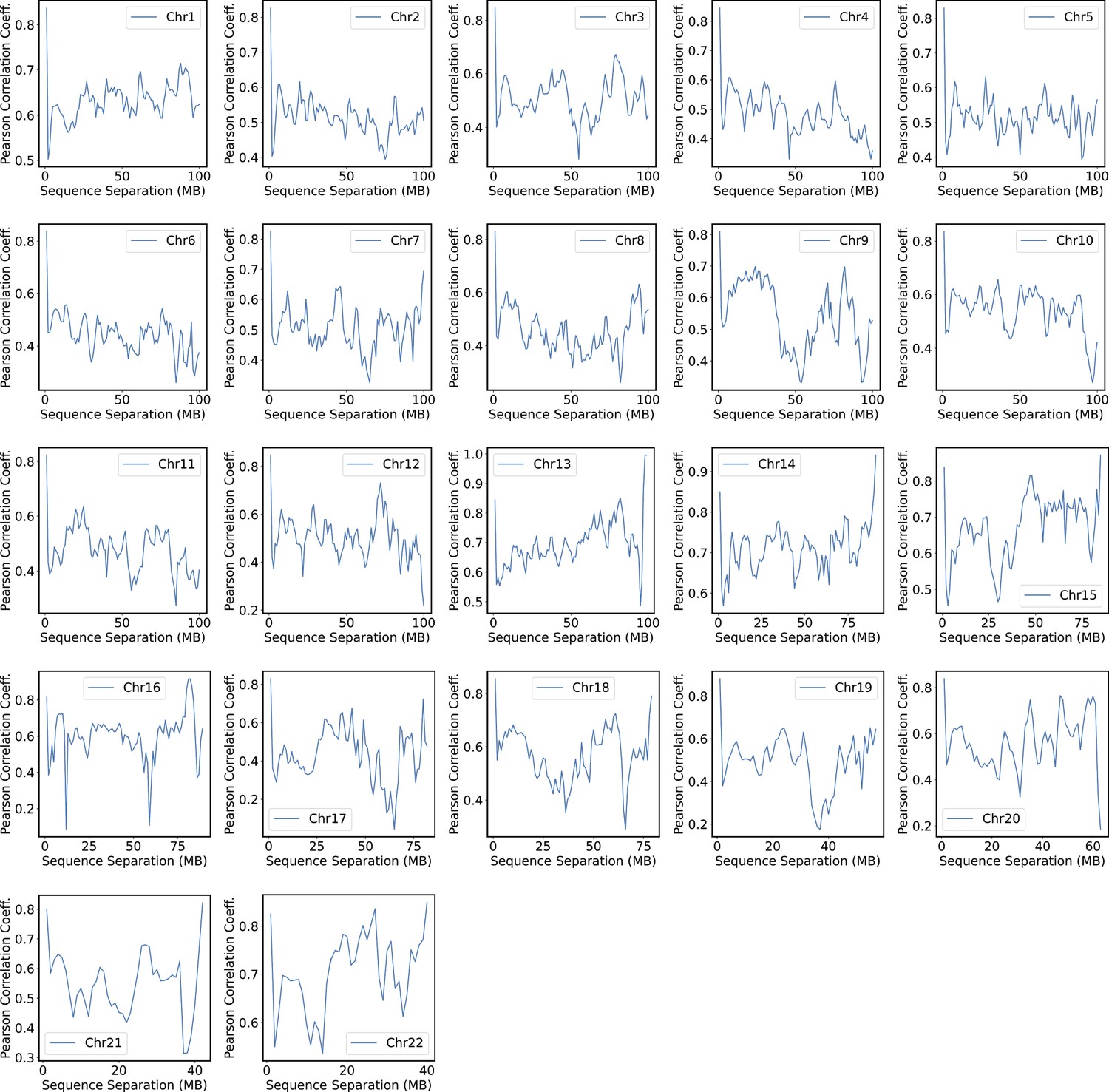
Pearson correlation coefficients between experimental and simulated contact probabilities at various sequence separations within specific chromosomes.
For each chromosome, we first gathered a set of experimental contacts alongside a matching set of simulated ones for genomic pairs within a particular separation range. The Pearson correlation coefficient at the corresponding sequence separation was then determined using Equation 41. We limited the calculations to half of the chromosome length to ensure the availability of sufficient data.
Data availability
Hi-C data (https://data.4dnucleome.org, accession number: 4DNFIB59T7NN). SON TSA-seq data (https://data.4dnucleome.org, accession number: pulldown data 4DNEX6U8TS3Y, control data 4DNEXI7XUWFK). LaminB DamID data (https://data.4dnucleome.org, accession number 4DNESXZ4FW4T). The software is available at https://github.com/ZhangGroup-MITChemistry/OpenNucleome (copy archived at ZhangGroup-MITChemistry, 2024).
-
4DN Data PortalID 4DNESXZ4FW4T. LaminB1 DamID of HFFc6 Tier 1 cells – cells were transduced with virus expressing Dam-LaminB1, gDNA was harvested after 4 days and processed for DamID-seq.
-
4DN Data PortalID 4DNEXI7XUWFK. Set of Input for SON Ab2 TSA-seq version 2 Reaction Condition 2 (PBS 50% Sucrose) Enhancement Condition E (1:300 tyramide-biotin, 30 minute reaction) on HFFc6 cells.
-
4DN Data PortalID 4DNEX6U8TS3Y. TSA-seq against SON protein on HFFc6 (Tier 1).
-
4DN Data PortalID 4DNFIB59T7NN. Ultrastructural Details of Mammalian Chromosome Architecture.
-
4DN Data PortalID 4DNEXFUGLVQA. DamID-seq with DAM-LMNB1 on HFFc6 (Tier 1).
References
-
The spatial organization of the human genomeAnnual Review of Genomics and Human Genetics 14:67–84.https://doi.org/10.1146/annurev-genom-091212-153515
-
Ephemeral protein binding to DNA shapes stable nuclear bodies and chromatin domainsBiophysical Journal 112:1085–1093.https://doi.org/10.1016/j.bpj.2017.01.025
-
Shaping the genome via lengthwise compaction, phase separation, and lamina adhesionNucleic Acids Research 50:4258–4271.https://doi.org/10.1093/nar/gkac231
-
Loss of lamin A function increases chromatin dynamics in the nuclear interiorNature Communications 6:8044.https://doi.org/10.1038/ncomms9044
-
Transient anomalous diffusion of telomeres in the nucleus of mammalian cellsPhysical Review Letters 103:018102.https://doi.org/10.1103/PhysRevLett.103.018102
-
Surface fluctuations and coalescence of nucleolar droplets in the human cell nucleusPhysical Review Letters 121:148101.https://doi.org/10.1103/PhysRevLett.121.148101
-
Modelling the compartmentalization of splicing factorsJournal of Theoretical Biology 239:298–312.https://doi.org/10.1016/j.jtbi.2005.07.019
-
Imaging specific genomic DNA in living cellsAnnual Review of Biophysics 45:1–23.https://doi.org/10.1146/annurev-biophys-062215-010830
-
Mapping 3D genome organization relative to nuclear compartments using TSA-Seq as a cytological rulerThe Journal of Cell Biology 217:4025–4048.https://doi.org/10.1083/jcb.201807108
-
Genome organization around nuclear specklesCurrent Opinion in Genetics & Development 55:91–99.https://doi.org/10.1016/j.gde.2019.06.008
-
Deciphering the molecular mechanism of the cancer formation by chromosome structural dynamicsPLOS Computational Biology 17:e1009596.https://doi.org/10.1371/journal.pcbi.1009596
-
Exploring the three-dimensional organization of genomes: interpreting chromatin interaction dataNature Reviews. Genetics 14:390–403.https://doi.org/10.1038/nrg3454
-
Chromatin domains: The unit of chromosome organizationMolecular Cell 62:668–680.https://doi.org/10.1016/j.molcel.2016.05.018
-
OpenMM 7: Rapid development of high performance algorithms for molecular dynamicsPLOS Computational Biology 13:e1005659.https://doi.org/10.1371/journal.pcbi.1005659
-
ConferenceA density-based algorithm for discovering clusters in large spatial databases with noiseKDD-96 Proceedings. pp. 226–231.
-
Formation of chromosomal domains by loop extrusionCell Reports 15:2038–2049.https://doi.org/10.1016/j.celrep.2016.04.085
-
Nuclear speckles: molecular organization, biological function and role in diseaseNucleic Acids Research 45:10350–10368.https://doi.org/10.1093/nar/gkx759
-
Chromosome positioning from activity-based segregationNucleic Acids Research 42:4145–4159.https://doi.org/10.1093/nar/gkt1417
-
Cajal bodies, nucleoli, and speckles in the Xenopus oocyte nucleus have a low-density, sponge-like structureMolecular Biology of the Cell 16:202–211.https://doi.org/10.1091/mbc.e04-08-0742
-
The nuclear envelopeCold Spring Harbor Perspectives in Biology 2:a000539.https://doi.org/10.1101/cshperspect.a000539
-
Chromatin organization and transcriptional regulationCurrent Opinion in Genetics & Development 23:89–95.https://doi.org/10.1016/j.gde.2012.11.006
-
Understanding 3D genome organization by multidisciplinary methodsNature Reviews. Molecular Cell Biology 22:511–528.https://doi.org/10.1038/s41580-021-00362-w
-
Phase separation and correlated motions in motorized genomeThe Journal of Physical Chemistry. B 126:5619–5628.https://doi.org/10.1021/acs.jpcb.2c03238
-
Modeling epigenome folding: formation and dynamics of topologically associated chromatin domainsNucleic Acids Research 42:9553–9561.https://doi.org/10.1093/nar/gku698
-
Compartmentalization with nuclear landmarks yields random, yet precise, genome organizationBiophysical Journal 122:1376–1389.https://doi.org/10.1016/j.bpj.2023.03.003
-
The fluctuation-dissipation theoremReports on Progress in Physics 29:255–284.https://doi.org/10.1088/0034-4885/29/1/306
-
The nucleolus as a multiphase liquid condensateNature Reviews. Molecular Cell Biology 22:165–182.https://doi.org/10.1038/s41580-020-0272-6
-
Mesoscale liquid model of chromatin recapitulates nuclear order of eukaryotesBiophysical Journal 118:2130–2140.https://doi.org/10.1016/j.bpj.2019.09.013
-
The interplay of chromatin phase separation and lamina interactions in nuclear organizationBiophysical Journal 120:5005–5017.https://doi.org/10.1016/j.bpj.2021.10.012
-
Nuclear speckles: a model for nuclear organellesNature Reviews. Molecular Cell Biology 4:605–612.https://doi.org/10.1038/nrm1172
-
Stressed Fibonacci spiral patterns of definite chiralityApplied Physics Letters 90:164102.https://doi.org/10.1063/1.2728578
-
Multiscale modeling of genome organization with maximum entropy optimizationThe Journal of Chemical Physics 155:010901.https://doi.org/10.1063/5.0044150
-
From 1D sequence to 3D chromatin dynamics and cellular functions: a phase separation perspectiveNucleic Acids Research 46:9367–9383.https://doi.org/10.1093/nar/gky633
-
Chromatin structure: does the 30-nm fibre exist in vivo?Current Opinion in Cell Biology 22:291–297.https://doi.org/10.1016/j.ceb.2010.03.001
-
UMAP: uniform manifold approximation and projectionJournal of Open Source Software 3:861.https://doi.org/10.21105/joss.00861
-
A scalable computational approach for simulating complexes of multiple chromosomesJournal of Molecular Biology 433:166700.https://doi.org/10.1016/j.jmb.2020.10.034
-
ChIP-seq: advantages and challenges of a maturing technologyNature Reviews. Genetics 10:669–680.https://doi.org/10.1038/nrg2641
-
How the genome folds: the biophysics of four-dimensional chromatin organizationAnnual Review of Biophysics 48:231–253.https://doi.org/10.1146/annurev-biophys-052118-115638
-
The nucleolusCold Spring Harbor Perspectives in Biology 3:a000638.https://doi.org/10.1101/cshperspect.a000638
-
Scikit-learn: machine learning in pythonThe Journal of Machine Learning Research 12:2825–2830.
-
Cajal Body dynamics and association with chromatin are ATP-dependentNature Cell Biology 4:502–508.https://doi.org/10.1038/ncb809
-
Predicting three-dimensional genome organization with chromatin statesPLOS Computational Biology 15:e1007024.https://doi.org/10.1371/journal.pcbi.1007024
-
Data-driven polymer model for mechanistic exploration of diploid genome organizationBiophysical Journal 119:1905–1916.https://doi.org/10.1016/j.bpj.2020.09.009
-
Chromatin network retards nucleoli coalescenceNature Communications 12:6824.https://doi.org/10.1038/s41467-021-27123-9
-
Structure and dynamics of interphase chromosomesPLOS Computational Biology 4:e1000153.https://doi.org/10.1371/journal.pcbi.1000153
-
On the statistical equivalence of restrained-ensemble simulations with the maximum entropy methodThe Journal of Chemical Physics 138:084107.https://doi.org/10.1063/1.4792208
-
Genome-wide mapping and analysis of chromosome architectureNature Reviews. Molecular Cell Biology 17:743–755.https://doi.org/10.1038/nrm.2016.104
-
Cytokines and their relationship to the symptoms and outcome of cancerNature Reviews. Cancer 8:887–899.https://doi.org/10.1038/nrc2507
-
Mechanisms for active regulation of biomolecular condensatesTrends in Cell Biology 30:4–14.https://doi.org/10.1016/j.tcb.2019.10.006
-
Nuclear specklesCold Spring Harbor Perspectives in Biology 3:a000646.https://doi.org/10.1101/cshperspect.a000646
-
Fibonacci grids: a novel approach to global modellingQuarterly Journal of the Royal Meteorological Society 132:1769–1793.https://doi.org/10.1256/qj.05.227
-
Micro-organization and visco-elasticity of the interphase nucleus revealed by particle nanotrackingJournal of Cell Science 117:2159–2167.https://doi.org/10.1242/jcs.01073
-
Mass spectrometric and kinetic analysis of ASF/SF2 phosphorylation by SRPK1 and Clk/StyThe Journal of Biological Chemistry 280:41761–41768.https://doi.org/10.1074/jbc.M504156200
-
Learning the formation mechanism of domain-level chromatin states with epigenomics dataBiophysical Journal 116:2047–2056.https://doi.org/10.1016/j.bpj.2019.04.006
-
Evaluating the role of the nuclear microenvironment in gene function by population-based modelingNature Structural & Molecular Biology 30:1193–1206.https://doi.org/10.1038/s41594-023-01036-1
-
Genomic energy landscapesBiophysical Journal 112:427–433.https://doi.org/10.1016/j.bpj.2016.08.046
-
SoftwareOpenNucleome, version swh:1:rev:380e3b5a65446081d6d4007362e121da18d8b1e9Software Heritage.
Article and author information
Author details
Funding
National Institute of General Medical Sciences (R35GM133580)
- Bin Zhang
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work was supported by the National Institutes of Health (grant R35GM133580).
Version history
- Sent for peer review:
- Preprint posted:
- Reviewed Preprint version 1:
- Reviewed Preprint version 2:
- Version of Record published:
Cite all versions
You can cite all versions using the DOI https://doi.org/10.7554/eLife.93223. This DOI represents all versions, and will always resolve to the latest one.
Copyright
© 2024, Lao et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,087
- views
-
- 140
- downloads
-
- 8
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 4
- citations for umbrella DOI https://doi.org/10.7554/eLife.93223
-
- 2
- citations for Reviewed Preprint v1 https://doi.org/10.7554/eLife.93223.1
-
- 2
- citations for Version of Record https://doi.org/10.7554/eLife.93223.3
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
OpenNucleome for high-resolution nuclear structural and dynamical modeling
eLife 13:RP93223.
https://doi.org/10.7554/eLife.93223.3




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}