Discovering sparse transcription factor codes for cell states and state transitions during development
- Harvard University, United States
- Allen Institute for Brain Science, United States
- Janelia Research Campus, Howard Hughes Medical Institute, United States
Abstract
Computational analysis of gene expression to determine both the sequence of lineage choices made by multipotent cells and to identify the genes influencing these decisions is challenging. Here we discover a pattern in the expression levels of a sparse subset of genes among cell types in B- and T-cell developmental lineages that correlates with developmental topologies. We develop a statistical framework using this pattern to simultaneously infer lineage transitions and the genes that determine these relationships. We use this technique to reconstruct the early hematopoietic and intestinal developmental trees. We extend this framework to analyze single-cell RNA-seq data from early human cortical development, inferring a neocortical-hindbrain split in early progenitor cells and the key genes that could control this lineage decision. Our work allows us to simultaneously infer both the identity and lineage of cell types as well as a small set of key genes whose expression patterns reflect these relationships.
https://doi.org/10.7554/eLife.20488.001Introduction
During development, pluripotent cells make a series of lineage decisions to give rise to the different cell types of the body. These lineage decisions are controlled by intra-cellular molecular networks that include transcription factors and signaling molecules. There are two fundamental challenges associated with understanding the differentiation of individual cells. The first is to identify lineage relationships: how cells and their progeny move from pluripotent through intermediate to terminally differentiated cell states. The second is to identify the key molecular drivers that allow cells to make fate decisions along their developmental trajectory.
Reconstructing cell lineages has traditionally involved prospectively tracking cells and their progeny using a variety of imaging or genetic tools (Buckingham and Meilhac, 2011; Frumkin et al., 2008; Orkin and Zon, 2008; Sulston et al., 1983). Recent progress in single-cell sequencing techniques (Grün et al., 2015; Jaitin et al., 2014; Macosko et al., 2015; Patel et al., 2014; Paul et al., 2015; Treutlein et al., 2014; Zeisel et al., 2015) allows for a complementary view of the transcriptional states of individual cells during the course of development, providing static snapshots of the dynamics of the underlying molecular network. But inferring lineage relationships and the dynamics of the underlying molecular networks has proved difficult using transcriptional data alone, in part because of the high dimensional nature of these data. Overcoming this challenge would be particularly useful for understanding the development of human organs such as the brain where traditional lineage tracing experiments are more difficult.
High dimensional data analysis techniques such as PCA, ICA, or t-SNE, are useful at reducing dimensionality. However, since the resulting axes represent linear combinations of a large number of features (for example, expression levels of each gene), interpreting the analysis or making experimental predictions is sometimes challenging. Meanwhile, traditional statistical methods such as linear multivariate regression have limited applicability for detecting patterns in high dimensional data (Advani and Ganguli, 2016; Donoho and Tanner, 2009). The challenges inherent in high-dimensional data analysis such as identifying discriminatory features are further exacerbated as the fraction of relevant features decreases (Donoho and Tanner, 2009). Computational techniques currently in use to cluster single cell data or to infer relationships among cells are built on these approaches, thereby assuming that all high-variance genes are equally relevant for pattern detection (Marco et al., 2014; Satija et al., 2015; Trapnell et al., 2014). In contrast, decades of work in developmental biology have revealed that combinations of a few transcription factors can be sufficient to experimentally perturb cell fate and developmental decisions (Gilbert, 2014; Graf and Enver, 2009; Takahashi and Yamanaka, 2006) suggesting that the expression patterns of a few genes may be most relevant for making computational inferences. Therefore, there is a need to detect patterns involving a small fraction of all genes. Unfortunately, except in the case of well-studied lineage decisions, we do not know the identity of this fraction.
In statistics, techniques relying on L1 regularization have been successful in contexts where the number of informative variables is known to be small but whose identities are unknown, both for regression problems (Baraniuk, 2007; Candès et al., 2006; Tibshirani, 1996; Wainwright, 2009) and for clustering (Witten and Tibshirani, 2010). Inspired by these successes in statistics, our aim here is to discover generalizable sparse patterns in gene expression data during development (if they exist), and to exploit these patterns to computationally infer the dynamics of cell state transitions from high-dimensional transcriptional data obtained during the course of development.
In this manuscript we analyze expression patterns among cell types with known lineage relationships in late hematopoiesis and discover a pattern in a sparse subset of genes that correlates with these relationships. We develop a Bayesian framework based on this gene expression pattern to simultaneously infer lineage transitions and the key genes that drive them. We apply this method to reconstruct the lineage tree among a different set of cell types in early hematopoietic development, and in this process identify many known drivers of early hematopoiesis, including Gata1, Cebpa and Ebf1. We further extend our method to analyze single-cell gene expression data, using genes exhibiting the discovered pattern to cluster cells from early brain development and to infer lineage relationships between these clusters. Our analysis reveals a split from early progenitors to putative neocortex and mid/hindbrain cell types, as evidenced by the mutually exclusive expression of region-specific genes such as FOXG1, LHX1, and POU3F2 (BRN2). This prediction was validated experimentally in a separate work (Yao et al., 2017). We finally discuss the advantages of using sparse patterns for making inferences and for modeling the underlying gene regulatory networks.
Results
Discovering sparse patterns correlated with lineage transitions
In order to identify gene expression patterns that are robustly predictive of lineage relationships, we analyzed gene expression data from 41 cell types during B- and T- cell development that have an experimentally established developmental lineage (Figure 1A, Heng et al., 2008). We searched for sparse patterns of gene expression amongst groups of three cell types from this collection; subsets of three are the minimal set in which measures of relative similarity can be used infer relative lineage relationships.
Figure 1 with 3 supplements see all

The clear minimum pattern is robustly detected in leaf cell types throughout triplet lineages in B- and T-cell development.
(A) Developmental lineage tree showing relationships among 41 cell types in B- and T-cell development (Heng et al., 2008). Three triplets – the minimal subset of the tree from which relative distances can be studied – are denoted, each including an intermediate root cell type (red) and terminal leaf cell types (blue). 150 triplets among all sets of three cell types within five steps on the lineage tree were extracted for pattern-detection. (B) For each triplet of cell types (left), each gene’s expression level can have the clear minimum pattern in either the root or the leaves (right, top box) where the distribution of gene expression levels in one cell type is well separated from the other two (left, p<0.005 in a two sample t-test); clear maximum pattern (left, bottom) in the root or the leaves: the gene has a clear maximum in one of the cell types (right, p<0.005 in a two sample t-test). (C) A histogram of the number of genes showing the clear minimum pattern among the 150 triplets with known developmental topology. Triplets in which the root has the most genes showing the pattern shown in red; triplets in which one of the leaves has the most genes showing the pattern shown in blue. None of the triplets with more than 10 genes showing the pattern have the most genes with a clear minimum in the root (no red in any histogram bar except for the left most)(D) Principal component analysis of microarray data from the cell types in B- and T- cell development does not reflect known lineage relationships in (A).
-
Figure 1—source data 1
Triplets used for pattern detection.
Sheet 1: The 150 related triplets used for pattern detection are listed, with the root cell type of the triplet in the first column and the two leaves in second and third columns. Cell type names follow (Heng et al., 2008). For each triplet are listed the number of genes with a clear minimum in each cell type and a clear maximum in each cell type (t-test p-value < 0.005). Also listed for each triplet are the length of the triplet, whether the triplet is a lineage progression or a cell fate decision, whether the triplet contains a terminal node, and the entropy in the clear minimum pattern and clear maximum pattern. Sheet 2: The 100 unrelated triplets are listed; cell type names follow (Heng et al., 2008). For each triplet are listed the number of genes with a clear minimum in each cell type and a clear maximum in each cell type (t-test p-value < 0.005) and the entropy in the clear minimum pattern and clear maximum pattern.
- https://doi.org/10.7554/eLife.20488.003
-
Figure 1—source data 2
List of mouse transcription factors.
The list of human transcription factors used to cluster and infer lineages for the hematopoietic and intestinal development trees. The list was adapted from (Thomson et al., 2011).
- https://doi.org/10.7554/eLife.20488.004
We identified 150 triplets of cell types with experimentally verified lineage relationships from B- and T- cell development (Heng et al., 2008) (Figure 1—source data 1). Three such triplets are shown in Figure 1A. These triplets constituted both cell fate decisions (for example, cell type A gives rise to cell type B and C) and lineage progressions (cell type B gives rise to cell type A which then gives rise to cell type C). For each triplet, we noted which cell type was the progenitor or intermediate cell type (‘root’ cell type A) and which cell types were not (‘leaf’ cell types B and C). Note that even in the case in which cell type B gives rise to cell type A which gives rise to cell type C, we will refer to A as the ‘root’ and B and C as ‘leaves’ for that particular triplet. We analyzed transcription factor gene expression data for these triplets from the Immunological Genome Consortium (Heng et al., 2008) since transcription factors are the ultimate drivers of cell fate decisions.
Surprisingly, we found that specific expression patterns involving only single genes correlated well with lineage relationships between three cell types. Genes that are not differentially expressed within a triplet of cell types convey no information about relationships between the cell types. Therefore, we select genes with expression variability among the three cell types. The expression pattern of such genes can belong to one of only two possible patterns: (Figure 1B): the clear minimum pattern: the gene has a clear minimum level in one of the three cell types, with its distribution of gene expression levels being well-separated from the other two (p<0.005 in both two sample t-tests between the minimum cell type and the other two cell types; Figure 1—figure supplement 1A); the clear maximum pattern: the gene has a clear maximum level in one of the cell types (p<0.005 in both sample t-tests; Figure 1—figure supplement 1B). Note that both patterns can be satisfied simultaneously if the distribution of expression levels in the three cell types are all well-separated with a clear maximum and minimum. We tested if either of the two patterns correlated with the lineage topologies between the three cell types with known lineage relationships (Figure 1C, Figure 1—figure supplement 1C).
Triplets of cell types can be separated into categories based on how many genes exhibit the aforementioned patterns. 56% of the triplets contained more than 10 genes exhibiting the clear minimum pattern, and in 100% of these triplets the majority of genes with expression fitting this pattern reached their minimum expression in one of the leaves (Figure 1C) and never in the root of the triplet. The frequency with which the pattern correctly indicated the lineage relationship increased with the number of genes within a triplet exhibiting the pattern, thus suggesting a confidence measure. The genes showing the clear minimum pattern fell into two distinct groups, corresponding to whether the minimum expression level was in one or the other of the two leaves (Figure 1—figure supplement 1A; Figure 1—figure supplement 2C). Thus the expression pattern of the total set of clear minimum genes correlated with the topology. Since genes showing the clear minimum pattern correlated with lineage relationships (Figure 1C) between cell states both in the case of branches and linear sequences of cell state transitions, we refer to them as transition genes.
We further verified that the clear minimum pattern could be observed (a) in the set of all 25,194 genes (Figure 1—figure supplement 2A), (b) using FDR-adjusted p-values (Benjamini and Hochberg, 1995) (Figure 1—figure supplement 2B), (c) in triplets of different lengths along the lineage tree (Figure 1—figure supplement 2D), (d) in triplets both containing only internal nodes and including terminal nodes (Figure 1—figure supplement 2E), (e) and in both lineage progression and cell fate decision triplets (Figure 1—figure supplement 2F).
The clear maximum pattern was a poorer indicator of lineage relationships (Figure 1—figure supplement 1C). 83% of the triplets had more than 10 genes exhibiting this pattern, but 10% of those showed the majority of genes with expression fitting this pattern reaching their maximum in the root while the others did so in the leaves. Crucially, the integrity of the relationship between the clear maximum pattern and lineage topology was not correlated with the number of genes exhibiting the pattern (Figure 1—figure supplement 1C). While the clear maximum pattern did not correlate with lineage relationships, genes exhibiting this pattern identify individual cell types, and therefore we will refer to them as marker genes.
There are many examples of genes known to be functionally important for lineage decisions whose expression patterns fit the clear minimum pattern. In the case of lateral inhibition commonly used during development, progenitor cells express genes together (for example, Notch and Delta) which are differentially expressed in the differentiated states (only Notch or only Delta) (Perrimon et al., 2012) reaching the minimum expression level in one of the leaves. The same pattern is also seen in multiple examples of lineage decisions often involving mutual inhibition, where key genes expressed in the progenitor are differentially regulated in the progeny (Graf and Enver, 2009; Qi et al., 2013; Thomson et al., 2011; Zhang et al., 1999). In each of these cases, key genes reach minimal expression levels in one of the leaves of the triplets.
The observation that genes exhibiting the clear minimum pattern are correlated with the lineage topology of a triplet of cell types further revealed that (i) only this fraction of transcription factors can be useful for inferring lineage relationships, and (ii) the identity of this fraction depends on which group of three cell types were analyzed. As the subset of genes that are informative varies based on the triplet of cell types being considered, establishing lineage relationship between all cell types at once as opposed to three at a time could be challenging. Indeed, our attempt to reconstruct the lineage relationships between all cell types using methods based on PCA failed (Figure 1D).
We further evaluated the clear minimum pattern in 100 triplets in which there was no clear relation between the cell types (Figure 1—source data 1). We found that while there were a substantial number of genes exhibiting a clear minimum in one of the three cell types in unrelated triplets, their minima were evenly distributed amongst the cell types. To quantify that the minima were evenly distributed, we counted the fraction of genes fi which reached a clear minimum in cell type i = A, B, C (for A, B, and C unrelated cell types), and for each triplet, we computed the entropy . We compared the distribution of the entropy and the number of genes showing a minimum in any triplet for unrelated and related triplets (Figure 1—figure supplement 3A). The unrelated triplets have higher entropy and typically more genes with a minimum level. This suggested that unrelated triplets show a distinct pattern from the related triplets.
Using patterns to infer lineages
Together, these observations suggested a strategy for inferring the lineage topology between three cell types: each gene showing the clear minimum pattern with a minimum expression level in a particular cell type increases to the probability that this cell type is not the root of the topology (Figure 2A). We next developed a statistical machinery to systematically detect this pattern in gene expression data and to use the resulting sparse subset of genes to infer lineage relationships between three cell types at a time. We then used the inferred relationships between all sets of three cell types as constraints to determine the full developmental lineage tree.
Figure 2 with 2 supplements see all
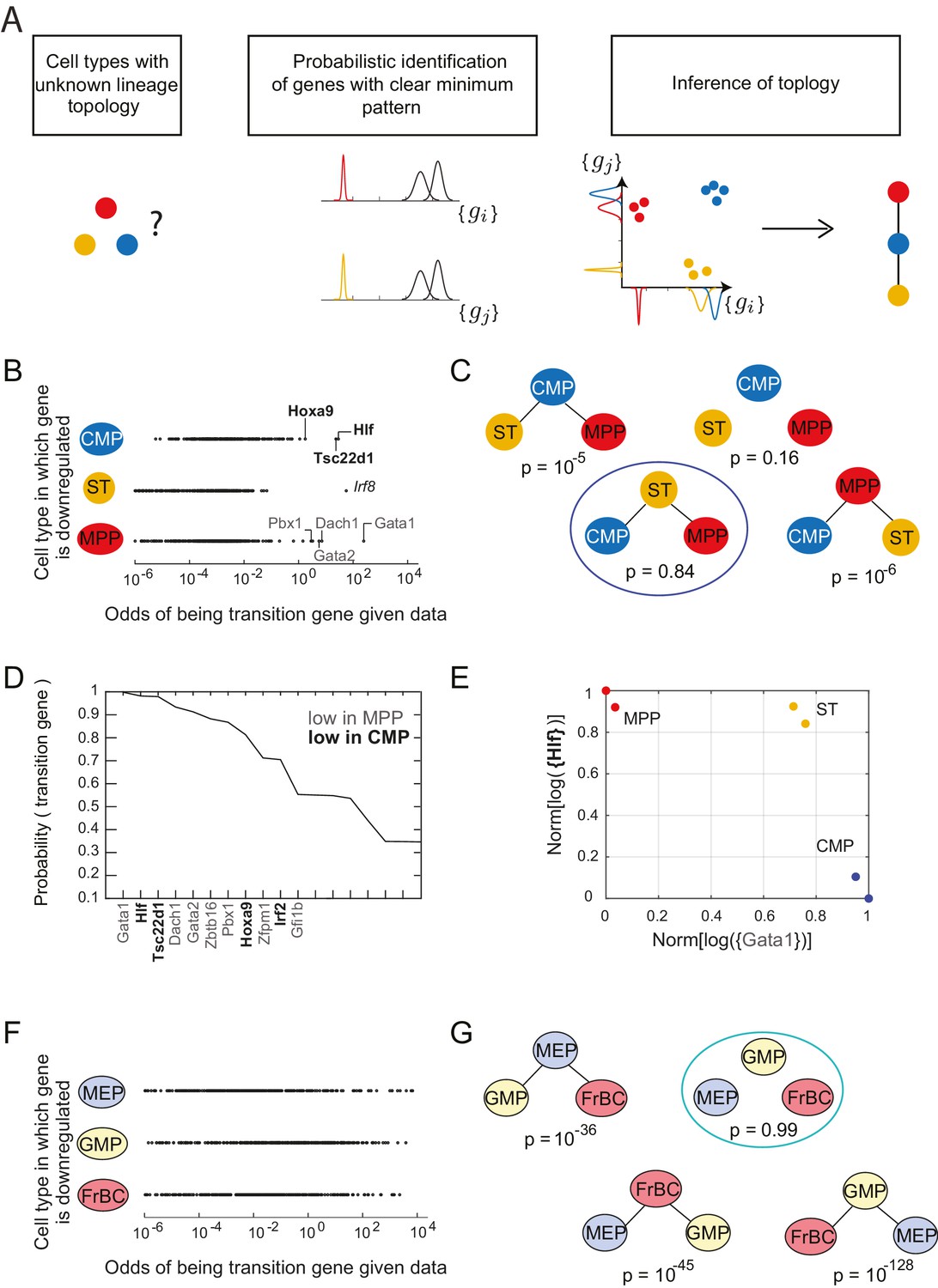
Identification of topology and transition genes (showing clear minimum pattern) for each triplet of cell types.
(A) Schematic for the statistical inference of lineage topology for 3 cell types. Genes with a clear minimum pattern indicate which cell types that are not the root (see Figure 1C) and hence allow inference of the topological relationship. (B) Dot plot (each dot representing a gene) of the cell type that is most likely to have the minimum mean expression of each gene among CMP, ST and MPP as a function of the odds of that gene being a transition gene. Each gene votes against the topology whose root has the minimum mean among the three cell types, and this vote is weighted by the odds that the gene is a transition gene (Equation 1). Two groups of genes, labeled by their names, have high odds of being transition genes and thus cast a strong vote against CMP or MPP being the root.(C) The computed probability of the topology given gene expression data indicates 0.84 probability that ST is the intermediate type.(D) The plot of the probabilities of genes being transition genes for triplet ST/MPP/CMP, given gene expression data and that the topology is MPP – ST – CMP. The names of the 10 genes with the highest probability of being transition genes are shown. Probabilities are calculated assuming the prior odds = 0.05 (see main text). There are two classes of transition genes: one for which gene expression in CMP is greater than expression in MPP (regular font), and another for which gene expression in MPP is greater than expression in CMP (bold font).(E) Plot of the replicates of ST, MPP and CMP in the gene-expression space of the two classes of transition genes (with probability > 0.8). Plotted on each axis is the mean normalized log expression level of the transition genes in the class, each class is denoted in curly brackets by the name of the transition gene with the highest probability.(F) Dot plot for triplet MEP/GMP/FrBC of the cell type that is most likely to have the minimum mean expression as a function of the odds of that gene being a transition gene.(G) The computed probability of the topology given gene expression data is the null hypothesis (p=0.99).
-
Figure 2—source data 1
Early hematopoietic cell types considered.
Listed for each early hematopoietic progenitor whose name is abbreviated in this paper are the Immunological Genome Project descriptor for the cell type, its common name and phenotype, its age and location, and the number of replicates in the data set.
- https://doi.org/10.7554/eLife.20488.009
-
Figure 2—source data 2
Probabilities of topologies for triplets of hematopoietic cell types.
Listed are, for each triplet of cell types, the probabilities of the four topologies for prior odds ; the number of topologies that reach probability for some value of between 10−6 and 102; the non-null topology that has the highest probability over the range of prior odds (if the null topology is the most likely topology for the entire range of prior odds, the topology is marked ‘null’); and the value of highest probability over the range of prior odds; the correct topology and triplet length in the traditional model; and the correct topology and triplet length in the Adolfsson model.
- https://doi.org/10.7554/eLife.20488.010
-
Figure 2—source data 3
Probabilities of transition and marker genes for the hematopoietic lineage tree.
Listed are, for crucial triplets along the lineage tree, the 200 genes with the highest probabilities of belonging to the two transition gene classes and the root marker class, and their associated probabilities.
- https://doi.org/10.7554/eLife.20488.011
The classifications of genes as transition or marker genes in Figure 1 were based on p<0.005 in a two-sample t-test. To implement such classifications probabilistically without arbitrary cutoffs we developed a statistical framework to infer the lineage relationships between each set of three cell types A, B, and C and find the key sets of transition genes (those genes that show the clear minimum pattern), given gene expression data in those cell types. We determined the probability of any possible topological relationship between the cell types referring to cell type A, B, or C being the root of the triplet, or which corresponds to the case where the data does not suggest any lineage relationship between the three cell types because either no significant pattern could be detected, or multiple genes exhibiting the minimum pattern suggested conflicting topologies. Rather than an absolute classification of genes as showing a pattern or not, we calculated the probability of each gene being a marker gene (denoted by ), i.e. gene showing the clear maximum pattern, and the probability of it being a transition gene denoted by , i.e. gene showing the clear minimum pattern (Materials and methods).
We derived the probability of a given topology given the expression data as (Materials and methods):
(1)
where, is the odds of gene being a transition gene and thus having a unique minimum. The term is the probability that the mean of the distribution of the expression levels of gene i in the root cell type is less than the mean in the other two cell types. The odds implicitly contains the only free parameter in our analysis, the prior odds , which defines the number of genes we expect to show the clear minimum pattern a priori, and functions as a sparsity parameter for the inference. Qualitatively, in the above equation, every gene casts a vote against the cell type in which its mean expression is minimal being the root. Further, this vote is weighted by the odds of gene being a transition gene. Thus, genes with a clearer minimum pattern get larger votes in determining which cell type is not the root. In practice, these quantities are computed numerically (Materials and methods).
We note further that if a substantial number of genes cast votes against each of the cell types, then the probability of the null topology increases. We computed the probability of obtaining the null topology among the 150 related triplets and 100 unrelated triplets from our training set. The distribution of the probability of obtaining the null topology was considerably different between the related triplets and the unrelated triplets, with an AUC of 0.96 (Figure 1—figure supplement 3B–C).
Application to hematopoietic gene expression data
We used our statistical framework to recreate the lineage of early hematopoietic differentiation. We considered 11 early hematopoietic progenitors from the ImmGen Consortium microarray data set (Heng et al., 2008) (Figure 2—source data 1). These cell types and their associated relationships were not included in the data set used earlier to study the correlations of the two patterns and lineage topologies. Several features of the early hematopoietic lineage tree are debated (Adolfsson et al., 2005; Iwasaki and Akashi, 2007) (Figure 2—figure supplement 2A). Given only the gene expression data for these different subpopulations of cells, we determined the lineage relationships and the key factors associated with each lineage decision. We calculated the probabilities of topology and marker and transition genes for the possible triplets of cell types using our statistical framework (Figure 2—source data 2). To illustrate our method, we first described the analysis of the expression data from two such triplets of cell types: CMP/ST/MPP and MEP/GMP/FrBC (Figure 2B–G). We then assembled the triplets to form an undirected lineage tree (Figure 3; Video 1).
Figure 3 with 2 supplements see all
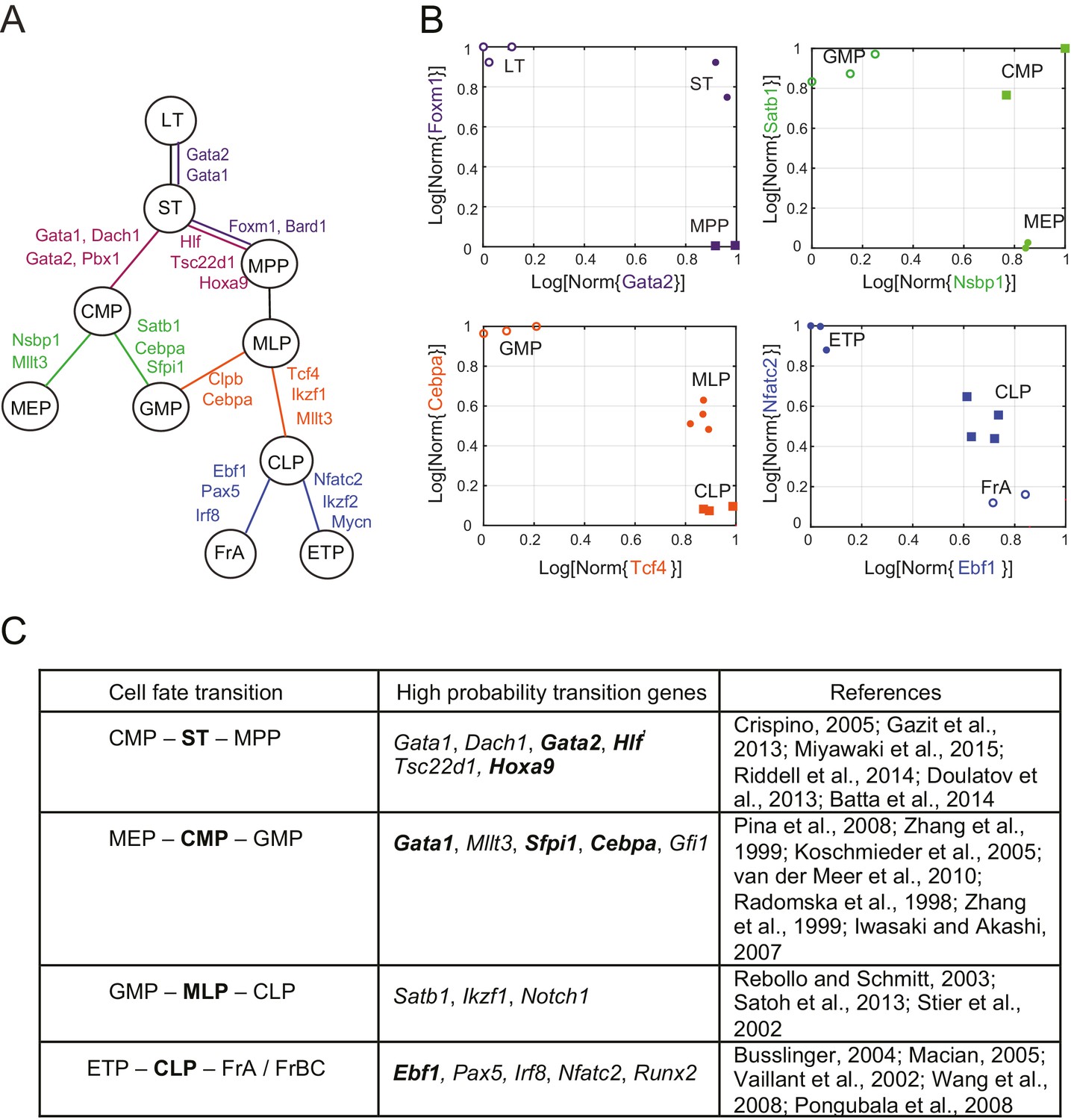
Reconstruction of lineage tree and key transition gene for early hematopoiesis.
(A) Final lineage tree, recapitulating the inferred triplet topologies, with top inferred transition genes indicated along cell fate decisions. (B) Plot of the replicates of different cell types in the gene-expression space of the transition gene classes (probability > 0.8) for 4 cell-fate transitions along the inferred lineage tree in (A). Plotted on each axis is the mean normalized log expression level of the transition genes in the class. The axis labels and data points are color-coded according to the colors in (A). (C) Table with selected transition genes for early hematopoietic cell-fate transitions, along with references to published validations of their functional role. Genes known to be effective for reprogramming are shown in bold.
-
Figure 3—source data 1
Marker genes for early hematopoiesis.
Table with selected marker genes for early hematopoietic cell types, along with references to published validations of their functional role. Genes known to be effective for reprogramming are shown in bold.
- https://doi.org/10.7554/eLife.20488.015
Video 1
Tree-building process for early hematopoietic lineage
Animation of the triplet assembly and pruning process for reconstructing the early hematopoietic lineage. For illustrative purposes, triplets (with p>0.6) are successively selected at random (in practice, the assembly and pruning process was performed on all triplets simultaneously; the resulting tree does not depend on the order in which the triplets are selected). The nodes of the current triplet are highlighted in yellow; if a topology is recognized for the triplet, the root is shown in green and the leaves in yellow, and the triplet edges are shown in magenta. If adding the triplet causes another triplet to be pruned, the soon-to-be-pruned (i.e. offending) edge is highlighted in red. The resulting pruned graph is then shown before adding the next triplet. As more triplets are considered, more edges between nodes are added and then pruned, leading to the final tree.
Following Equation 1, each gene votes against the topology whose central node has the minimum expression of that gene among the three cell types, and this vote is weighted by the odds that the gene is a transition gene. To illustrate this for the triplet of cell types CMP, ST and MPP, we plotted the topology each gene voted most against, i.e. the topology for which is the maximum, versus the odds of that gene being a transition gene (Figure 2B).
We find two groups of genes that are much more likely to be transition genes than any of the other genes, with values of compared to at most for other genes (Figure 2B, regular and bold fonts). These two groups of genes have a large value for either or and thus vote against (cell type CMP is the intermediate) or against (cell type MPP is the intermediate). Together these genes that have a high odds of being transition genes appear to most support topology .
In fact, the intuition in Figure 2B is borne out in the calculation of . Using Equation 1 above and assuming a sparsity parameter of 0.05, we calculate that there is an 84% chance that the topology is (Figure 2C; Figure 2—figure supplement 2B). Although gene Irf8 (Figure 2B, italic font) is strongly downregulated in ST and is expressed at higher levels in CMP and MPP (Figure 2C), we note that its signal is overwhelmed by the large number of genes downregulated in either CMP or MPP, illustrating the statistical nature of the framework.
For each triplet, we evaluated each gene’s probability of being a transition or marker gene (Figure 2—source data 3). Figure 2D shows the names and associated probabilities of the 12 genes most likely to be transition genes for the triplet . The transition genes fall into two groups, corresponding to the two groups in Figure 2B. One group, which includes genes Gata1, Dach1, and Gata2, has higher expression in CMP than in MPP; the other group, which includes Hlf, Tsc22d1, and Hoxa9, has higher expression in MPP. Although the values of the probabilities of the genes being transition genes vary with the value of the sparsity parameter, the relative order of different genes does not change. The genes identified include many genes previously identified as being important for lineage specification (Crispino, 2005; Gazit et al., 2013; Miyawaki et al., 2015). The transition genes we discovered thus not only have gene expression patterns that reflect the lineage decision but also include functionally important genes.
In addition to the transition genes, we identified marker genes () present only in ST (including Mpl and Rai14, consistent with [Solar et al., 1998]) and then symmetrically downregulated in both CMP and MPP (Figure 2—figure supplement 1C). Marker genes for CMP include Srf, Zeb2, Rbpj and Irf8 (consistent with [Goossens et al., 2011; Kurotaki et al., 2013; Ragu et al., 2010; Robert-Moreno et al., 2005; Tamura et al., 2000]); marker genes for MPP include Satb1, consistent with (Satoh et al., 2013). Although these genes were not used to determine the topology, they are good markers for cell types ST, CMP and MPP.
Plotting the cell types using the mean expression levels of the two transition gene class captures the fork in the gene expression space associated with the cell-fate decision (Figure 2E). In contrast with the PCA analysis of the cell types (Figure 2—figure supplement 1E), in which MPP appears to be an intermediate between the hematopoietic stem cell types (LT and ST) and CMP, the projection of the cell types onto the transition-gene subspace shows that ST splits into CMP and MPP.
In contrast to the case of the triplet of cell types CMP/ST/MPP, for triplet MEP/GMP/FrBC, the distributions of genes supporting different topologies are similar (Figure 2F). Thus the most likely topology calculated using Equation 1 is the null hypothesis (99%), which is that transition genes, if they exist, do not have patterns that depend on the cellular topology (Figure 2G, Figure 2—figure supplement 1D), in which case there is insufficient evidence to classify the triplet according to a particular non-null topology. The distribution of the maximal probability of non-null topologies in the different triplets is heavily concentrated near 1, allowing for clear separation between null and non-null triplets (Figure 2—figure supplement 1E). Null topologies were identified by the algorithm for triplets with cells that are from three terminal nodes (for example, the triplet MEP/GMP/FrBC) or from triplets that contain very distantly related triplets (for example, LT/CLP/ETP) (Figure 2—source data 2).
A lineage tree for early hematopoiesis
We next reconstructed the early hematopoietic lineage tree and identified transition genes involved in the different cell state transitions using all the non-null triplet relationships as constraints on the lineage relationships between all cell types. Out of the 165 possible triplets of hematopoietic progenitors, 144 showed one single non-null topology with probability greater than 0.6 over a range of the prior odds from 10−6 to 102. We next determined an undirected graph that recapitulates all of the individual triplet topologies (note that we are only inferring triplet topologies and are not inferring directionality). For example, although triplet CMP/LT/MPP has topology CMP – LT – MPP (Figure 3—figure supplement 1A), we could determine that LT cannot be the direct progenitor of CMP or MPP, because ST is an intermediate between LT and both cell types (Figure 3—figure supplement 1B–C). We could thus 'prune' this triplet when inferring the full graph (Figure 3—figure supplement 1D–E). A visualization of the pruning process is shown in Video 1, where successive triplets are added to the graph, creating new edges and pruning others, leading to the final undirected tree. In practice, though, the pruning process was performed on all triplets simultaneously, not in succession.
The ST/CMP/MPP triplet (Figure 2B–E) immediately distinguishes between two competing models regarding the hierarchy of early hematopoietic progenitors. According to the traditional picture (Iwasaki and Akashi, 2007), MPP is the progenitor of CMP, and ST is the progenitor of MPP – therefore MPP should be an intermediate between ST and CMP and the topology of triplet ST/MPP/CMP should be ST – MPP – CMP (Figure 2—figure supplement 1A, left). According to a model suggested by Adolfsson and colleagues (Adolfsson et al., 2005), ST splits into CMP and MPP (Figure 2—figure supplement 1A, right), and the topology should be CMP – ST – MPP. We identify both CMP – ST – MPP and CMP – LT – MPP as the correct topologies, lending support to the Adolfsson model. The Adolfsson and traditional models differ in the topology of 9 triplets. The inferred expected topologies of 8 out of these nine triplets support the Adolfsson model, which led to the identification of the final tree (Figure 2—figure supplement 2).
The lineage tree that we determined is consistent with the Adolfsson model and contains three additional lineage decisions (Figure 3A–B). First, CMP gives rise to MEP (megakaryocyte/erythroid progenitor) and GMP (granulocyte/macrophage progenitor). Second, MPP gives rise to MLP (multilineage progenitor), which then splits into the GMP and CLP (common lymphoid progenitor) cell types. In the final lineage decision, CLP gives rise to the ETP (pre-T) and FrA (pre-pro-B) cell types.
For each triplet of cell types along the tree, we identified transition and marker classes of genes. Among the 14 triplets that contained only adjacent cell types, we identified on average 24 marker genes per cell type and 25 transition genes (probability threshold of 0.8, prior odds ). Many genes we discovered as belonging with high probability to the transition and marker classes of genes at each lineage decision are known in the literature to be functionally important genes, including classic hematopoietic regulators such as Cebpa, Sfpi1, Gata1, Satb1, Irf8 and Ebf1 (see full tables with references in Figure 3C and Figure 3—source data 1). Additionally, the genes identified include many genes successfully used in hematopoietic reprogramming experiments, including Gata2 and Pbx1 (Figure 3C). Together these observations suggest that the sparse subspace of transition and marker genes identified by our framework not only allows for accurate reconstruction of the lineage hierarchy but also constitutes a set of candidates for relevant biological functions.
As further validation of the inference method, we compared it to the method proposed by Grun et al. on a single-cell intestinal development data set (Grün et al., 2015, 2016). We inferred lineages between each cell type based on their cluster identifications, excluding clusters with fewer than 10 cells, and constructed an undirected lineage tree by taking triplets with probability > 0.6 and applying the pruning rule (Figure 3—figure supplement 2A). The only disagreement between the two methods is the progression from crypt base columnar cells (C2) to different populations of Goblet cells (C4 and C8). Grun et al. hypothesize a C2 – C8 – C4 progression, while we infer the triplet C8 – C2 – C4 with p>0.99, suggesting that the progenitor C2 gives rise to both differentiated Goblet subpopulations. Both lineage trees are supported by the literature (van der Flier and Clevers, 2009). The high probability transition genes included many factors well known for their roles in tissue homeostasis and development (Figure 3—figure supplement 2B), notably Klf4 (Yu et al., 2012), Atoh1 (VanDussen and Samuelson, 2010), Spdef (Noah et al., 2010), Foxa1/Foxa2 (Ye and Kaestner, 2009), and Tcf3 (Merrill et al., 2001).
Inferred lineage tree for human excitatory neuronal progenitors from in vitro single-cell data over 80 days of differentiation
The ease with which single-cell transcriptomic data can be generated (Grün et al., 2015; Jaitin et al., 2014; Macosko et al., 2015; Patel et al., 2014; Paul et al., 2015; Treutlein et al., 2014; Zeisel et al., 2015) presents an opportunity to understand the dynamics of the underlying networks that lead individual cells to their final fate. We studied the differentiation of stem cells both into germ layer progenitors (Jang et al., 2017) and into cortical neurons. To study the latter, we analyzed single-cell gene expression data from 2217 cells from an in vitro differentiation protocol for early human neuronal development (Yao et al., 2017). Briefly, human embryonic stem cells (hESCs) were subjected to a SMAD inhibition-based cortical induction phase, a progenitor expansion phase, and a neural differentiation phase. Single cells were sorted at 12, 26, 54, and 80 days into differentiation, and their gene expression was profiled using the SMART-Seq2 technique (Picelli et al., 2013). In the initial clustering of the single-cell data, dimensionality reduction by PCA (into 15 above-noise components) followed by t-SNE (Van Der Maaten and Hinton, 2008; Satija et al., 2015) showed separation by day and SOX2 expression (Figure 4A). However, the number of predicted clusters varied depending on the perplexity parameter (Figure 4—figure supplement 1A–B). In addition, no clear lineage or distance relationship among the putative types is immediately apparent from this clustering. Analysis of this data with other recent methods such as Monocle and Monocle2 (Trapnell et al., 2014), TSCAN (Ji and Ji, 2016), and StemID (Grün et al., 2016) did not clearly reconstruct lineage or infer key genes regulating transitions (Figure 4A – Bottom, Figure 4—figure supplement 2). Monocle2 (Figure 4—figure supplement 2A) produces a tree with complex branching, but SOX2+ progenitors and DCX+ differentiated neurons do not clearly separate.
Figure 4 with 2 supplements see all

Inference of lineage tree and key transitions genes using single cell expression data from in vitro differentiated developing human brain.
(A) RNA-seq data from single cells collected at days 12, 26, 54, and 80 from a human brain in vitro differentiation protocol (Yao et al., 2017) were analyzed using a variety of existing methods. Partitioning single-cells into cell types through non-linear dimensionality reduction using t-SNE (top) depends on the perplexity parameter (set here to 5, see Figure 4 – Figure Supplement 1A-B) and does not allow for mechanistic understanding. Independent component analysis of all transcription factors with Monocle (bottom) does not show clear structure and could not inform reconstruction of lineage relationships. (B) Maximization algorithm to determine most likely cluster identities , sets of transitions , marker genes () and transition genes (), given single-cell gene expression data . Starting from a seed clustering scheme iterative maximization of the conditional probabilities and converges to most likely set (C) Cell-cell covariance matrix between cells using only the associated high probability marker and transition genes show the final cluster assignments and (right) in contrast to using all transcription factors (left). (D) Selected high probability triplets of clusters plotted in the axes defined by two sets of transition gene classes for each triplet. (top right, ), plotted in transition gene class {CEBPG} also including POU3F1, POU3F2, NR2F1, NR2F2, ARX, LIN28A, TOX3, ZBTB20, PROX1 and SOX15, and class {DMRTA1} also including HES1, HES5, FOXG1, PAX6, HMGA2, SOX2, SOX3, SOX9, SOX6, SP8, OTX2, TGIF, ID4, TCF7L2, and TCFL1. (top left, ), plotted in transition gene class {LHX2} also including FEZF2, FOXG1, HMGA1, SP8, OTX1, SOX11, GLI3, SIX3, ETV5, and class {POU3F2} also including GTF2I, HIF1A, ID1, ID3, PROX1, SALL1, SOX21, TCF12, TRPS1, ZHX2. (bottom left, ), plotted in transition gene class {FOXO1} also including HMGA2, PAX6, and SOX2, and class {LHX2} also including DMRTA2, HMGA1, ARX, LIN28A, OTX2, LITAF, NANOG, POU3F1, SOX15. (bottom right, ), plotted in transition gene class {PAX3} also including CRX, SOX11, EBF2, FOXP4, ASCL1, FOXO3, and SIX3, and class {ARGFX} also including DUXA, HES1, NFIB, PPARA, SOX2, SOX7, and SOX9. (E) Correlations between differentiated cell clusters (Figure 4 – Figure Supplement 4D) and bulk population samples from brain regions (in vivo developmental human data) (Miller et al., 2014). Neuronal cell types can be identified with specific spatial regions of the brain to interpret the topology of the lineage tree. Expression signatures of SOX2+ cell types and were dominated by pluripotency factors, and are not shown. (F) Inferred lineage tree for brain development. Genes associated with neocortical development, and mid-/hind-brain progenitors, and specific neuronal cell types are identified as high probability transition genes and are corroborated by mapping information from in vivo data. Clusters color-coded similarly to (D). D12/26/54/80 labels indicate time of collection of cells within each cell type. Prog refers to SOX2+ cells, Diff refers to SOX2-/DCX+ cells (Figure 4—figure supplement 1C–D).
-
Figure 4—source data 1
Final cluster identities of single cells from in vitro cortical differentiation.
Cells were assigned to a cluster based on an iterative clustering procedure. Their final cluster assignments are shown here. Cell types 8–11 contained bulk brain control cells, and non-neuronal cells which were excluded from the analysis.
- https://doi.org/10.7554/eLife.20488.020
-
Figure 4—source data 2
Probabilities of topologies for triplets of single-cell clusters.
Listed are, for each triplet of clusters, the probability of a given topology and the root of the inferred topology. ‘0’ refers to the null topology. Triplets with p>0.6 were used to construct the lineage tree.
- https://doi.org/10.7554/eLife.20488.021
-
Figure 4—source data 3
Probabilities of Transition and Marker Genes for the Human Brain Developmental Lineage Tree.
Listed are, for crucial triplets along the lineage tree, the genes with the p>0.8 of belonging to the two transition gene classes and the root marker class, and their associated probabilities.
- https://doi.org/10.7554/eLife.20488.022
-
Figure 4—source data 4
Human Brain Development SmartSeq2 Census.
Further detail can be found Materials and methods and in Yao et al. (2017) (Supplemental Information).
- https://doi.org/10.7554/eLife.20488.023
-
Figure 4—source data 5
List of Human Transcription Factors.
List of human transcription factors used to cluster and infer lineages for the cortical differentiation tree. List was adapted from (Ben-Porath et al., 2008).
- https://doi.org/10.7554/eLife.20488.024
Analyzing data from single-cell profiling presents an additional challenge relative to data from population-level profiling because cell types are not previously known and must be inferred from the data. Computationally, it is necessary define a measure of similarity in the gene expression profiles of individual cells so as to be able to cluster them and define cell states. Here again, it is necessary to identify the correct gene subspace to use for clustering. Clustering and determining lineage have typically been performed sequentially and treated as independent problems (Satija et al., 2015; Trapnell, 2015; Trapnell et al., 2014). However, we found that it is informative to solve both these problems simultaneously.
In our framework, the relevant feature set for clustering is the set of marker and transition transcription factors from the triplets with non-null topologies. But determination of these sets of genes and of the transition topologies depends itself on knowledge of the cluster identities. Following previous work on sparse clustering (Witten and Tibshirani, 2010), we simultaneously determined optimal clusters, lineage topology and sets of transition and marker genes by iteratively selecting transition and marker genes and clustering the data using this set of features (Figure 4B).
In order to utilize information about developmental distances in clustering, we iteratively maximized a joint distribution, , over the developmental tree, and the set of clusters of cells, (Figure 4B). Starting with a clustering we first inferred the set of genes and which were identified in high probability triplets, , and we then re-clustered in this new subspace to obtain the clusters for the next iteration .
Initial analysis based on the gap statistic (Tibshirani et al., 2001) suggested that the single-cell gene expression profiles clustered into 20 clusters of cell types. We chose a seed for the iterated clustering procedure by intentionally over-clustering the data into 40 clusters using spectral K-medoids. By being overly discriminative in our initial clustering, we ensured that all genes with differential regulation would be classified as either marker genes or transition genes, and would be preserved in later clustering iterations. We iterated the clustering-inference procedure until the dimension of the re-clustering subspace changed by less than 10% of the total transcription factor space. In this resulting subspace of 469 genes, we finally clustered the cells into the final configuration using K-medoids (Figure 4C, Figure 4—source data 1) where the number of clusters K = 8 was chosen based on the gap statistic (Tibshirani et al., 2001).
We inferred 45 high probability triplets () between the final cell clusters (Figure 4—source data 2). Four such triplets are shown in Figure 4D, plotted in axes defined by transition genes for each triplet (Figure 4—source data 3). Starting with progenitor cell states (SOX2+, Figure 4—figure supplement 1C), we manually appended cell clusters to the tree according to their time information and in agreement with inferred topological restrictions. The first transition involves the production of day 12 neuronal cell type from day 12 progenitor , which is observed in the triplets and . The triplet (, Figure 4D – top left) is mediated by 47 transition genes between and and 87 between and (). Transition genes expressed highly in the branch include CEBPG, POU3F1, POU3F2, NR2F1, NR2F2, ARX, LIN28A, TOX3, ZBTB20, PROX1, and SOX15 which have been previously implicated in proliferation of forebrain progenitors (Au et al., 2013; Borello et al., 2014; Cimadamore et al., 2013; Dominguez et al., 2013; Yang et al., 2015) and the migratory behaviors of ganglionic eminences (Kanatani et al., 2008; Kessaris et al., 2014; Lodato et al., 2014; Olivetti and Noebels, 2012; Reinchisi et al., 2012). The transition genes include DMRTA1, HES1, HES5, FOXG1, PAX6, HMGA2, SOX2, SOX3, SOX9, SOX6, SP8, OTX2, TGIF, ID4, SOX3, TCF7L2, and TCFL1 which are known to be expressed in forebrain progenitors of the developing neocortex, thalamus, and hypothalamus (Abraham et al., 2013; Pozniak et al., 2010; Shimojo et al., 2011; Tzeng and de Vellis, 1998; Wang et al., 2006), and are known to establish dorsal forebrain regional identity; (Azim et al., 2009; Bani-Yaghoub et al., 2006; Borello et al., 2014; Gaston-Massuet et al., 2016; Hagey et al., 2014; Hutton and Pevny, 2011; Johansson et al., 2013; Kikkawa et al., 2013; Kishi et al., 2012; Manuel et al., 2011; Miyoshi and Fishell, 2012; Ohtsuka et al., 2001; Ross et al., 2003; Shen and Walsh, 2005; Sur and Rubenstein, 2005; Yang et al., 2015; Zembrzycki et al., 2007).
The progenitor cell types form the triplet , Figure 4D – top right). The branch is mediated by 39 transition genes including LHX2, FEZF2, FOXG1, HMGA1, SP8, OTX1, SOX11, GLI3, SIX3, and ETV5 which suggest that is comprised of cortical progenitors (Appolloni et al., 2008; Greig et al., 2013; Kishi et al., 2012; Manuel et al., 2011; Raciti et al., 2013). The branch is mediated by 55 transition genes including GTF2I, HIF1A, ID1, ID3, PROX1, POU3F2, SALL1, SOX21 TCF12, TRPS1 and ZHX2, which are associated with mesencephalon and metencephalon regional development, as well as having known involvement with midbrain/hindbrain organizer identity (Buck et al., 2001; Enkhmandakh et al., 2009; Inoue et al., 2012; Jaegle et al., 2003; Kunath et al., 2002; Lavado and Oliver, 2007; Milosevic et al., 2007; Ohba et al., 2004; Uittenbogaard and Chiaramello, 2002; Yao et al., 2017). We additionally inferred the triplet , Figure 4D – bottom left), which suggests a three way split from early progenitor into early differentiated neuron , and progenitors and .
The continuation of the branch is inferred through triplet (). The branch includes transition genes BCL11A, EMX2, FOXP2 and RORB, which are known to be associated with the neocortex and neuronal identity (Cánovas et al., 2015; Ebisu et al., 2016; Greig et al., 2016; Jabaudon et al., 2012; Wiegreffe et al., 2015; Woodworth et al., 2016; Zembrzycki et al., 2007).The triplet () meanwhile is characterized by transition genes in the branch including ASCL1, FOXP2, PAX3, POU3F4, ZIC1, ZIC4, HOXB2, and EN2, which have been shown to regulate fate acquisition in the midbrain/hindbrain (Agoston et al., 2012; Ang, 2006; Di Bonito et al., 2013; Elsen et al., 2008; Hegarty et al., 2013; Miller et al., 2011; Tan et al., 2014).
The cell cluster differentiates into two distinct clusters of post-mitotic neurons -- and (, Figure 4D – bottom right). The branch is inferred from transition genes including PAX3, CRX, SOX11, EBF2, FOXP4, ASCL1, FOXO3, and SIX3 which have strong expression in developing dopaminergic and gabaergic neurons of the midbrain (Agoston et al., 2012; Erickson et al., 2010; Pino et al., 2014; Yang et al., 2015; Yin et al., 2009; Zhang et al., 2002). Transition genes in the branch include ARGFX, DUXA, HES1, NFIB, PPARA, SOX2, SOX7, and SOX9, which are known to be associated with the medulla oblongata region of the hindbrain (Fawcett and Klymkowsky, 2004; Kameda et al., 2011; Kumbasar et al., 2009; Madissoon et al., 2016; Matsui et al., 2000; Stolt et al., 2003).
In addition to interpreting these individual transition genes defining the major branch splits, we correlated the expression over all predicted transition and marker genes in neuronal clusters to in vivo developmental human data (Miller et al., 2014). The in vivo data comprise a representative range of microarray data sampled from different parts of the developing brain at post-conception week 15, including forebrain proliferative regions, midbrain, and hindbrain. The differences in data acquisition methods (RNAseq vs. microarray, single-cell vs heterogeneous populations) resulted in relatively low correlations overall, but there are clear associations between individual clusters and specific brain regions (Figure 4E). Specifically, , maps to the ganglionic eminences, suggesting an interneuron identity, whereas and show better mapping to mid- and hindbrain structures, and appears to be more closely related to neocortex. Overall, this global comparison, combined with the identification of genes with known regional expression, suggests that the inferred clusters from the in vitro data capture the diversity of differentiation into the early stages of the major neuronal lineages (Figure 4F). These lineage predictions based on our analysis techniques were verified experimentally using viral barcoding in a separate work (Yao et al., 2017).
To estimate the sparsity of the underlying network and to find a minimal subset of genes through which lineage could be inferred, we replicated the analysis while only considering a limited set of genes per triplet. We assembled a collection of 20 triplets with maximal leaf-to-leaf distance of 4 nodes, and non-null inferred topology. For each triplet, we ranked genes based on their odds of being a transition gene, agnostic of the true topology of the triplet. We then replicated the inference process using only the N genes with the greatest odds (Figure 4—figure supplement 1E). We found that with as few as 4 genes per triplet, the correct lineage topology could be inferred for all of the triplets. Genes with greatest odds comprise a restricted subset of genes for further experimental investigation. Further, these findings suggest that the dynamics of expression of just four specific genes are sufficient to monitor a particular lineage decision in single cells.
Discussion
Finding an informative subspace of variables for data analysis is a general problem in machine learning, both for regression and clustering (Tibshirani, 1996; Witten and Tibshirani, 2010); the innovation in this paper is to use a statistical pattern learned from known biology to inform this subspace search. The approach we take here is complementary to methods that project expression variability onto coordinates of PCA, ICA or t-SNE maps (Marco et al., 2014; Satija et al., 2015; Trapnell et al., 2014), which are combinations of all variables. Searching for sparse representation of the dynamics has the advantage of providing interpretability and experimental direction (McGibbon and Pande, 2017). Following the dynamics of this small set of high-probability transition genes via fluorescent tagging could allow for the tracking of lineage decisions of individual cells in real time. Further, these genes provide a list of candidates for drivers of fate decisions, and hence a set of experimental hypotheses.
Not all genes give us equal information about the dynamics of differentiation. We discovered that genes showing the clear minimum pattern are most predictive of the sequence of lineage transitions during development. Although our pattern discovery and subsequent lineage reconstruction does not assume any functional role for the clear minimum pattern, we note that this pattern is shown by genes known to be regulators of development during hematopoiesis. The same pattern observed in many differentiating systems (Graf and Enver, 2009; Qi et al., 2013; Thomson et al., 2011; Zhang et al., 1999), and is consistent with mutual inhibition. Mutual inhibition, in turn, is hypothesized to play an important role in maintaining multi-stable systems and in mediating transitions between different stable states of multi-stable systems (Ferrell, 2012).
Discovery of sparse representations of the cell states and variability between them demonstrates the efficacy of low dimensional descriptions of the system. Understanding the dynamics and transitions of complex physical systems composed of a large number of variables has been driven by the discovery of low dimensional order parameters (Anderson, 1978; Landau and Lifshitz, 1951). As opposed to measuring and modeling states as high dimensional objects in their native representation, order parameters provide low dimensional descriptions of the states and dynamics, which has proven crucial in developing both qualitative and quantitative models. Finding small subsets of genes which captures the lineage transitions in cells analogously provides a low dimensional subspace that captures the dynamics in genetic networks and can be useful for modeling (Jang et al., 2017). An accompanying paper allows us to exploit this idea to extract mathematical models for the underlying molecular circuits from single cell gene expression data obtained during germ layer differentiation (Jang et al., 2017).
Materials and methods
In vitro neuronal differentiation
Request a detailed protocolSingle-cell transcriptomic data from the in vitro neural differentiation procedure was obtained as described in Yao et al. (2017) (Supplemental information):
hESCs were dissociated with Accutase and plated on Matrigel-coated 24-well plates at 2.5 × 105 cells/cm2 in DMEM/F12 (#11330–032), 1 × N2, 1 × B27 without vitamin A, 2 mM Glutamax, 100 μM non-essential amino acids, 0.5 mg/mL BSA, 1X Pen-Strep, and 100 μM 2-mercaptoethanol (referred to as basal medium; all from Thermo Fisher, Waltham, MA) with 20 ng/mL FGF2 (Thermo Fisher) and 2 μM thiazovivin. Cortical induction was initiated by changing to the basal medium with 5 μM SB431542 (StemRD, Burlingame, CA), 50 nM LDN193189 (Reagents Direct, Encinitas, CA) and 1 μM cyclopamine (Stemgent, Lexington, MA) (referred to as NIM). NIM was changed daily for 11 days. On day 12, cells were dissociated and seeded on Matrigelcoated 24-well plates at 5 × 105/cm2 in basal medium with 20 ng/mL FGF2 and 2 μM thiazovivin. Progenitor expansion was initiated on D13 by changing to serum-free human neural stem cell culture medium (NSCM, #A10509–01 from Thermo Fisher) containing 20 ng/mL FGF2 and 20 ng/mL EGF. NSCM was changed daily for 6 days. Cultures were passaged once more on D19 with Accutase and replated at 5 × 105 cells/cm2. On D26, cells were dissociated with Accutase and seeded on 24-well plates sequentially coated with poly-D-lysine (Millipore, Billerica, MA) and laminin (Thermo Fisher) at 1 × 105 cells/cm2 in basal medium supplemented with 20 ng/mL FGF2 and 2 μM thiazovivin. On D27, medium was changed to a 1:1 mixture of DMEM/F12 and Neurobasal medium (#21103–049) supplemented with 100 μM cAMP (Sigma-Aldrich, St Louis, MO), 10 ng/mL BDNF (R and D Systems, Minneapolis, MN), 10 ng/mL GDNF (R and D Systems) and 10 ng/mL NT-3 (R and D Systems) (referred to as ND). Cells were maintained in ND medium for four weeks until day 54 with half medium change every other day. Quality of differentiations was routinely assessed by immunostaining at D12 (PAX6 and DCX), at D26 (LHX2, SOX2, EOMES, POU3F2, and TBR1), and at D54 (MAP2 costained with TBR1, CTIP2, SATB2). In addition flow cytometry at D26 (EOMES, SOX2 and PAX6) was performed. Typically, EOMES at day 26 proved the most valuable quality control metric (~10% of cells by both flow cytometry and immunostaining) and predicted failure at D54. Specifically, when EOMES was low (<1% of cells) differentiations failed and were typically dominated by POU3F2+ cell types and/or non-neural ‘other’ cell types. These failed differentiations were eliminated from further analysis, typically ~20% of experiments (5 of 19 experiments in 2016). 50 bp paired-end Smart-Seq2 libraries were prepared from these cells as previously described (Picelli et al., 2013) and mapped as described in Thomsen et al., 2016 and Yao et al. (2017). As each cell was profiled independently (without pooling before amplification, as in methods such as Cel-Seq, STRT, or Drop-Seq), we did not observe the batch effects present in pooling-based methods. Although cells were profiled in plates (batches), there was no significant plate-related variation - this Fixed single-cell transcriptomic characteriza is most likely due to amplification being carried out separately in each well of the plate, thereby precluding cross-talk among barcodes, or plate-related differences in amplification. This is clear from the mixing of cells from different plates in the clustering. A complete census is provided (Figure 4—source data 4).
Gene expression data
Request a detailed protocolHematopoietic gene expression data were downloaded from the Immunological Genome Project (Heng et al., 2008); GEO GSE15907) and log-2 transformed. We restricted the genes considered to 1459 transcription factors. Brain development expression data were log-2 transformed, and 1460 transcription factors were individually normalized by dividing by the 90th-percentile expression value. Lists of mouse and human transcription factors are provided (Figure 1—source data 2, Figure 4—source data 5).
Software
Calculations were performed using custom written MATLAB code (The Mathworks) on the Harvard Research Computing Odyssey cluster. Code is available at https://github.com/furchtgott/sibilant. t-SNE was done using the package provided in (Van Der Maaten, 2009). Monocole was run in R (Core Team, 2015; Trapnell et al., 2014).
Description of algorithm
Request a detailed protocolThe algorithm proceeds according to the following steps:
Find initial seed clustering configuration using K-medoids where K is chosen to be larger than the cluster number inferred from the Gap statistic (Tibshirani et al., 2001)
For all triplets of clusters, find most likely and and given :
Compute by integrating numerically over (Equations 6, 9, and 10).
Compute using Equations 20 and 29.
Identify mostly likely topology and set of and .
Recluster using K-medoids in the space of all and for the triplets with probability > 0.6 of being non-null. Determine new clustering configuration .
Repeat steps 1 and 2 until convergence of
Determine the most likely tree connecting cell clusters, recapitulating high-probability triplet topologies.
Each of these steps is described in the following section.
Bayesian framework for inferring cluster identities, state transitions, and marker and transition genes simultaneously
Notation; Bayes’ rule
Request a detailed protocolGiven gene expression data from single cells , we built a probabilistic framework to simultaneously infer cell cluster identities, , the sequence of transitions between these clusters, the key sets of marker genes that define each cell cluster, and genes that determine the sequence of transitions between clusters. We maximized the joint probability distribution of these variables given the gene expression data, to determine the maximum likelihood estimates of these parameters.
We first consider how to solve this problem in the case in which there are three cell clusters, and we will later build a tree using all possible combinations of three cell clusters. Let the set of three cell clusters be cA, cB and cC with gene expression data for all genes and all cells. The term denotes the expression data for just gene in cells in clusters cA, cB, and cC. The topology of the relationships between cell clusters cA, cB and cC can take on four possible values: : cell cluster cA is in the middle (either cA is the progenitor of cB and cC, or cA is an intermediate cell type between cB and cC); : cell cluster cB is in the middle; : cell cluster cC is in the middle; or : we cannot determine the topology. Complementarily, for each gene we define variables and , where and if the gene is a marker gene, and if the gene is a transition gene, and otherwise. Our task is to determine the probability given gene expression data for all genes .
According to Bayes’ rule, is proportional to the probability of the gene expression data given , and :
(2)
The denominator of the right hand side of Equation 2 is a normalization constant. Expressions , , and are respectively the prior probabilities of and given and the prior probability of given , and the prior probability of . We assume that in the absence of any expression data, the probability that a gene is a transition or marker gene is independent of the topology and clustering configuration: , and .
Conditional independence
Request a detailed protocolIn our model, we assume that knowing the clustering configuration , the topology and whether or not a gene is a marker or transition gene is sufficient to determine the probability distribution for its expression levels in each of the cell clusters. Therefore, the gene expression patterns of different genes are conditionally independent given the topology, clustering and gene type:
(3)
Thus, Equation 2 becomes
(4)
We maximize the evaluated with respect to , and each of the and to obtain the most likely relationships between cell types cA, cB and cC, as well as the genes most likely to be marker and transition genes.
Expression for (transition genes)
Request a detailed protocolTo infer , we need a model to compute the probability of the gene expression data for each gene, , given , and , following Equation 4. Our model for the probability distribution of the expression of a single transition gene in the three cell types is defined solely by the geometry of the arrangement of the cell types in gene expression space, as described in the main text. For example, for and , our model is that the distribution of the expression levels of in the three cell types A, B and C has the smallest mean value in either B or C but not in A (Figure 2A). If the distribution of the expression of gene in cell type A is (we assume a log-normal distribution) with a mean and standard deviation , with analogous expressions for cell types B and C, then our model defining is that either and or and , where , and are the mean values of the expression levels of in cell types A, B and C. Thus,
(5)
The terms in Equation 5 can be calculated by integrating over the prior probability distribution of the means , and and standard deviations , and , with the conditions on the means constraining the domains of integration:
(6)
Probabilities and are defined similarly.
In addition to topologies , and , we consider a null hypothesis in which transition genes have differential expression levels between states, but these levels are not correlated with any particular topology of states. This corresponds to having gene expression levels from cell-types A, B and C coming from three distributions with no restrictions on the relative order of the three means:
(7)
Note that the probability of the data given the null hypothesis is the average of the probabilities of the data given the non-null hypotheses:
(8)
Note that depends on both and .
Expression for (marker genes)
Request a detailed protocolOur model for marker genes assumes that the probability distribution for the expression level of such genes, to be independent of and to be generated from distributions with two cell-types having a low value and the third a high value (for example, for cell-types A and B and for cell-type C, with the constraint :
(9)
Note that does not depend on but does depend on .
Expression for (irrelevant genes)
Request a detailed protocolOur model for genes that are neither marker nor transition genes is that the expression levels of such genes, , is generated from one single distribution :
(10)
Note that does not depend on or .
Numerical integration
Request a detailed protocolEach of the probabilities on the right hand side of Equation 4 is evaluated numerically as above. We assume the distribution of the expression of gene in cluster cA to be log-normal. Given log2-transformed replicate measurements of gene expression of gene in cells belonging to cluster cA, the probability of the data assuming mean and standard deviation is:
(11)
Distributions and are defined analogously.
We take the a priori probability distribution of and , as uniform over a certain range of means and standard deviations estimated from the data. For the log2-transformed hematopoietic gene expression data, we take and .
We take the prior probabilities for the distributions in different cell types to be independent: . The constraints on the order of the means are enforced by the domain of integration, and the prior must be properly normalized over this domain. For example, in Equation 6,
(12)
Integrals were evaluated numerically in MATLAB using trapezoidal integration with step-sizes = 0.05 and = 0.01.
The choice of a log-normal distribution could potentially confound the results, particularly for single-cell RNA-Seq data with significant zero-inflation. This is a potential area for improvement in our algorithm, but the method can easily be adapted to model different distributions of RNA expression, such as gamma distributions (Shahrezaei and Swain, 2008; Wills et al., 2013) or beta-Poisson distributions (Delmans and Hemberg, 2016; Vu et al., 2016). In either case, the probability of the data given different topologies would be computed by numeric integration over the parameters of the distribution, for example, and for the Gamma distribution, by replacing the log-normal distributions in Equations 7, 9 and 10 with ones from the appropriate model.
The choice of the right parametric form for single-cell RNA expression is still an area of active research. Our choice of log-normal distributions assumes that higher order moments of the distributions (beyond standard deviation) ought to have a minimal contribution to the predictions, but we have not tested this extensively.
Although the default prior was the uniform prior, we also implemented an empirical prior by estimating the empirical distribution over all the Immgen cell types, using the kernel density estimation code provided in (Botev et al., 2010). The resulting hematopoietic lineage tree was identical. Using the kernel-density-estimated empirical prior may provide more stability in future analyses.
Probability of topology given gene expression and cluster identities
Request a detailed protocolWe can derive the probability of the topology given the gene expression data and cluster identities by summing over all the and to find the probability of the data given topology :
(13)
(14)
where the probability of gene expression data for gene given topology is obtained by summing over and :
(15)
We consider the odds of a gene being a transition gene as a sparsity parameter, which we vary. We take
The probability of topology given data is proportional to the probability of the data given topology (using Bayes’ rule):
(16)
where
(17)
Therefore, using Equation 14, we obtain the following expression for :
(18)
Equation 18 can be written more explicitly by rewriting Equation 15 as follows:
(19)
Here we have used the fact noted earlier that in our generating model, and do not depend on (Equation 10). The terms cancel out in the numerator and denominator of Equation 18, and we can write Equation 18 in terms of ratios of the probabilities of the data given transition-gene and non-transition-gene status:
(20)
We can rewrite Equation 20 as:
(21)
where is the odds that gene is a transition gene, given clustering:
(22)
and is the probability of given only gene expression data for gene , clustering and that gene is a transition gene:
(23)
Thus each gene’s contribution to the probability of the topology given total gene expression is weighted by the odds that it is transition gene.
Rewriting Equation 21 in terms of negative votes
Request a detailed protocolLet us denote the probability of gene expression data for gene given that cell cluster has the distribution with minimum mean expression as For example, . Then, using and Equations 5 and 8, we can write:
(24)
Therefore, for , we can rewrite Equation 5 as:
(25)
Combining Equations 21 and 25, we derive, for :
(26)
where is the probability that cell cluster (the intermediate cluster in topology ) has the distribution with the minimum mean for gene :
(27)
Every gene can be thought of as casting a vote against cell type being the intermediate, and this vote is weighted by the odds of the gene being a transition gene and having a unique minimum, given the clustering. This corresponds to Equation 1 in the main text.
Expression for
Request a detailed protocolOnce is calculated, it is straightforward to find :
(28)
where is the probability of and given the particular topology , clustering and gene expression. Because we have assumed that gene expression patterns are conditionally independent given , , and (Equation 3), the probabilities of being marker or transition genes or are also conditionally independent given gene expression, clustering and the topology:
(29)
where is the probability that gene is a marker or transition gene given its gene expression, the clustering, and that the topology is .
Choice of prior odds does not affect the most likely topology
Request a detailed protocolThe only free parameter in our calculation above is the prior odds of gene i being a transition gene, . At one extreme, if , then : if we assume that none of the genes are transition genes, then knowing gene expression does not give us any new knowledge of the topology , since only transition genes are informative about . At the other extreme, if then the null hypothesis dominates: if all genes are transition genes, then there will be negative votes against all topologies. We computed the behavior of between these two limits to determine the sensitivity of our answer to .
Figure 2—figure supplement 1 shows the dependence of the probabilities on the prior odds for triplets CMP/ST/MPP and GMP/MEP/FrBC for values of between 10−8 and 102. For triplet CMP/ST/MPP the topology dominates for between 10−2 and 10, whereas for triplet MEP/GMP/FrBC there is no value of the prior odds that strongly favors a non-null topology. For most triplets, the most likely topology does not depend on the choice of prior odds; when building lineage trees, we ignore those triplets where different choices of prior odds lead to different most-likely topologies, i.e. there is more than one non-null topology that reaches probability 0.6 over the range of prior odds.
Determination of lineage tree from triplet topologies
Selection of triplets
Request a detailed protocolIn order to build lineage trees from the topologies we determine for each cell type, we select the triplets for which our determination of the topology is most robust. There is one free parameter in our model: the prior odds for a gene to be a transition gene in the absence of gene expression data, . For each triplet, we vary this parameter between 10−6 and 102 and calculate the probability of the topology given gene expression data as a function of the prior odds.
We want to consider only triplets which showed a single dominant topology. We exclude triplets which show a weak probability for a particular topology or ones which depend on a particular choice of prior odds. We also do not consider triplets which show a strong probability for two different topologies, depending on the choice of prior odds.
There were 14 such triplets among the 165 hematopoietic triplets. Mathematically, these cases come up when the genes that are most likely to show the clear minimum pattern (furthest on the right in a ‘dot plot’) suggest one topology, but if one used a more permissive value of the sparsity parameter, a different topology wins out. One of the cell types might have a small number of genes with very high odds, but then fewer genes with moderately high odds compared to the other cell types. We did not notice a clear pattern in the identity of the triplets exhibiting this behavior, but 9 of the 14 were triplets of length five or greater in the Adolfsson model. One of the triplets with this behavior was the MLP/CMP/GMP triplet, and the dominant topology was either MLP (at low prior odds) or CMP (at higher prior odds). Interestingly, both cell types are progenitors to GMP in the Adolfsson model.
We consider triplets for which only one non-null topology has probability greater than 0.6. The probabilities of the different topologies for each triplet in the hematopoietic tree are shown in Figure 2—source data 1 and for the triplets in the cortical development tree in Figure 4—source data 2.
Pruning rule
Request a detailed protocolWe assemble the triplets with known topology into an undirected graph. Since we determined topologies by considering cell types three at a time, we obtain topological relationships involving both cell types that are nearest neighbors and cell types that are more distantly related. In order to reconstruct the tree, we must determine which cell types are nearest neighbors and which ones are separated by one or more intermediate cell types.
The set of inferred topologies allows us to determine which cell types are separated by intermediates. For every pair of cell types, we ask whether any of the inferred topologies features an intermediate between the two cell types. If such a topology has been inferred, we consider that the two cell types are not nearest neighbors, and that at least one other cell type is an intermediate. For example, we can ignore triplet CMP – LT – MPP because triplet LT – ST – CMP testifies that there exists an intermediate between LT and CMP, and triplet LT – ST – MPP testifies that there exists an intermediate between LT and MPP (Figure 3—figure supplement 1).
Note that this pruning rule does not assume the absence of loops. The lineage tree we infer for the hematopoietic progenitors contains a loop that includes ST to CMP to GMP on one side and ST to MPP to MLP to GMP on the other side. The loop involves triplets CMP – ST – MPP, ST – CMP – GMP, ST – MPP – MLP and MPP – MLP – GMP (we cannot determine the topology of triplet CMP/MLP/GMP). None of the triplets shows a topology that would allow us to break up the loop.
Distinguishing between two models of hematopoiesis
Request a detailed protocolThe topologies we infer support the model from Adolfsson et al. (2005), in which CMP splits from ST-HSC. In particular, there are several triplets that can distinguish the Adolfsson model from the traditional picture, and they support the Adolfsson model. These triplets include CMP – ST – MPP, CMP – ST – MLP, MEP – ST – MLP and CMP – LT – MPP. These triplets show that, unlike in the traditional picture, cell types CMP and MEP split from ST are not descended from MPP or MLP.
On the other hand, triplets LT – MLP – GMP, ST – MLP – GMP and MPP – MLP – GMP show that MLP is an intermediate between the earliest progenitors and GMP. See also Figure 2—figure supplement 2 and Figure 2—source data 2.
Stability analysis
Request a detailed protocolThe inference algorithm depends on several parameters and priors. We performed a stability analysis for both the microarray hematopoietic data and the human brain single cell data to determine the parameter ranges for which the inferred lineage tree was unchanged.
Hematopoiesis
For the prior probability, given that a gene is not a transition gene, that it is an irrelevant gene, our default value was =0.5, but the tree was unchanged for values of between 0.25 and 0.65.
For the prior probabilities of different topologies, our default value was . We varied while keeping the prior probabilities of the non-null topologies equal: . The tree was unchanged for values of between 0.1 and 0.35.
We used a threshold of 0.6 to consider a triplet significant for the tree-building step. The tree was unchanged for thresholds between 0.5 and 0.65.
A key input parameter into the algorithm is the expected prior distribution of means and standard deviations used in the numeric integration. Our default prior was a uniform prior for both means and standard deviations over reasonable ranges of these parameters. We also implemented an empirical prior by estimating the empirical distribution over all the Immgen cell types, using kernel density estimation (Botev et al., 2010). The resulting hematopoietic lineage tree was identical. Using the kernel-density-estimated empirical prior may provide more stability in future analyses.
Brain Development
For the prior probability, given that a gene is not a transition gene, that it is an irrelevant gene, our default value was = 0.5, but the tree was unchanged for values of between 0.02 and 0.97.
For the prior probabilities of different topologies, our default value was . We varied while keeping the prior probabilities of the non-null topologies equal: . The tree was unchanged for values of between 0.06 and 0.96.
We used a threshold of 0.6 to consider a triplet significant for the tree-building step. The tree was unchanged for thresholds between 0.5 and 0.8.
For the single cell data, we also changed the number of initial seed clusters for the iterative algorithm within a range from 30 to 45. In each case, the tree remained the same, and never more than 23% of the cells were clustered into a different cell type.
Data availability
-
Immunological Genome ProjectPublicly available at the NCBI Gene Expression Omnibus (accession no: GSE15907).
-
Single-Cell mRNA Sequencing Reveals Rare Intestinal Cell TypesPublicly available at the NCBI Gene Expression Omnibus (accession no: GSE62270).
-
Region-specific neural stem cell lineages revealed by single-cell rna-seq from human embryonic stem cells [Smart-seq]Publicly available at the NCBI Gene Expression Omnibus (accession no: GSE86982).
References
-
Local moments and localized statesReviews of Modern Physics 50:191–201.https://doi.org/10.1103/RevModPhys.50.191
-
Transcriptional control of midbrain dopaminergic neuron developmentDevelopment 133:3499–3506.https://doi.org/10.1242/dev.02501
-
Six3 controls the neural progenitor status in the murine CNSCerebral Cortex 18:553–562.https://doi.org/10.1093/cercor/bhm092
-
SOX6 controls dorsal progenitor identity and interneuron diversity during neocortical developmentNature Neuroscience 12:1238–1247.https://doi.org/10.1038/nn.2387
-
Role of Sox2 in the development of the mouse neocortexDevelopmental Biology 295:52–66.https://doi.org/10.1016/j.ydbio.2006.03.007
-
Controlling the false discovery rate: a practical and powerful approach to multiple testingJournal of the Royal Statistical Society. Series B 57:289–3000.
-
Kernel density estimation via diffusionThe Annals of Statistics 38:2916–2957.https://doi.org/10.1214/10-AOS799
-
Embryonic expression of the murine homologue of SALL1, the gene mutated in Townes--Brocks syndromeMechanisms of Development 104:143–146.https://doi.org/10.1016/S0925-4773(01)00364-1
-
Tracing cells for tracking cell lineage and clonal behaviorDevelopmental Cell 21:394–409.https://doi.org/10.1016/j.devcel.2011.07.019
-
Stable signal recovery from incomplete and inaccurate measurementsCommunications on Pure and Applied Mathematics 59:1207–1223.https://doi.org/10.1002/cpa.20124
-
SoftwareR: A Language and Environment for Statistical ComputingR: A Language and Environment for Statistical Computing.
-
GATA1 in normal and malignant hematopoiesisSeminars in Cell & Developmental Biology 16:137–147.https://doi.org/10.1016/j.semcdb.2004.11.002
-
Development and differentiation of the intestinal epitheliumCellular and Molecular Life Sciences 60:1322–1332.https://doi.org/10.1007/s00018-003-2289-3
-
Observed universality of phase transitions in high-dimensional geometry, with implications for modern data analysis and signal processingPhilosophical Transactions of the Royal Society A: Mathematical, Physical and Engineering Sciences 367:4273–4293.https://doi.org/10.1098/rsta.2009.0152
-
Embryonic expression of xenopus laevis SOX7Gene Expression Patterns 4:29–33.https://doi.org/10.1016/j.modgep.2003.08.003
-
Bistability, bifurcations, and Waddington's epigenetic landscapeCurrent Biology 22:R458–R466.https://doi.org/10.1016/j.cub.2012.03.045
-
Cell lineage analysis of a mouse tumorCancer Research 68:5924–5931.https://doi.org/10.1158/0008-5472.CAN-07-6216
-
Molecular logic of neocortical projection neuron specification, development and diversityNature Reviews Neuroscience 14:755–769.https://doi.org/10.1038/nrn3586
-
The immunological genome project: networks of gene expression in immune cellsNature Immunology 9:1091–1094.https://doi.org/10.1038/ni1008-1091
-
Gbx2 directly restricts Otx2 expression to forebrain and midbrain, competing with class III POU factorsMolecular and Cellular Biology 32:2618–2627.https://doi.org/10.1128/MCB.00083-12
-
Rorβ induces barrel-like neuronal clusters in the developing neocortexCerebral Cortex 22:996–1006.https://doi.org/10.1093/cercor/bhr182
-
The POU proteins Brn-2 and Oct-6 share important functions in schwann cell developmentGenes & development 17:1380–1391.https://doi.org/10.1101/gad.258203
-
Control of endodermal endocrine development by Hes-1Nature Genetics 24:36–44.https://doi.org/10.1038/71657
-
TSCAN: Pseudo-time reconstruction and evaluation in single-cell RNA-seq analysisNucleic Acids Research 44:e117.https://doi.org/10.1093/nar/gkw430
-
The zinc-finger transcription factor Klf4 is required for terminal differentiation of goblet cells in the colonDevelopment 129:2619–2628.
-
Genetic programs controlling cortical Interneuron fateCurrent Opinion in Neurobiology 26:79–87.https://doi.org/10.1016/j.conb.2013.12.012
-
HMGA regulates the global chromatin state and neurogenic potential in neocortical precursor cellsNature Neuroscience 15:1127–1133.https://doi.org/10.1038/nn.3165
-
Absence of the transcription factor Nfib delays the formation of the basilar pontine and other mossy fiber nucleiThe Journal of Comparative Neurology 513:98–112.https://doi.org/10.1002/cne.21943
-
Expression of Trps1 during mouse embryonic developmentMechanisms of Development 119 Suppl 1:S117–120.https://doi.org/10.1016/S0925-4773(03)00103-5
-
Prox1 expression patterns in the developing and adult murine brainDevelopmental Dynamics 236:518–524.https://doi.org/10.1002/dvdy.21024
-
Dynamic patterning at the pylorus: formation of an epithelial intestine-stomach boundary in late fetal lifeDevelopmental Dynamics 238:3205–3217.https://doi.org/10.1002/dvdy.22134
-
BMP signaling promotes the growth of primary human colon carcinomas in vivoJournal of Molecular Cell Biology 2:318–332.https://doi.org/10.1093/jmcb/mjq035
-
Identification of simple reaction coordinates from complex dynamicsThe Journal of Chemical Physics 146:044109.https://doi.org/10.1063/1.4974306
-
CREB3L1 is a metastasis suppressor that represses expression of genes regulating metastasis, invasion, and angiogenesisMolecular and Cellular Biology 33:4985–4995.https://doi.org/10.1128/MCB.00959-13
-
Tcf3 and Lef1 regulate lineage differentiation of multipotent stem cells in skinGenes & Development 15:1688–1705.https://doi.org/10.1101/gad.891401
-
Rapid loss of intestinal crypts upon conditional deletion of the Wnt/Tcf-4 target gene c-MycMolecular and Cellular Biology 26:8418–8426.https://doi.org/10.1128/MCB.00821-06
-
Sox21 is a repressor of neuronal differentiation and is antagonized by YB-1Neuroscience Letters 358:157–160.https://doi.org/10.1016/j.neulet.2004.01.026
-
Roles of the basic helix-loop-helix genes Hes1 and Hes5 in expansion of neural stem cells of the developing brainJournal of Biological Chemistry 276:30467–30474.https://doi.org/10.1074/jbc.M102420200
-
Interneuron, interrupted: molecular pathogenesis of ARX mutations and X-linked infantile spasmsCurrent Opinion in Neurobiology 22:859–865.https://doi.org/10.1016/j.conb.2012.04.006
-
Signaling mechanisms controlling cell fate and embryonic patterningCold Spring Harbor Perspectives in Biology 4:a005975.https://doi.org/10.1101/cshperspect.a005975
-
Reprogramming fibroblasts to neural-precursor-like cells by structured overexpression of pallial patterning genesMolecular and Cellular Neuroscience 57:42–53.https://doi.org/10.1016/j.mcn.2013.10.004
-
COUP-TFII expressing interneurons in human fetal forebrainCerebral Cortex 22:2820–2830.https://doi.org/10.1093/cercor/bhr359
-
Spatial reconstruction of single-cell gene expression dataNature Biotechnology 33:495–502.https://doi.org/10.1038/nbt.3192
-
Dynamic expression of notch signaling genes in neural stem/progenitor cellsFrontiers in Neuroscience 5:78.https://doi.org/10.3389/fnins.2011.00078
-
CSE1L, DIDO1 and RBM39 in colorectal adenoma to carcinoma progressionCellular Oncology 35:293–300.https://doi.org/10.1007/s13402-012-0088-2
-
Trp53 deficiency protects against acute intestinal inflammationThe Journal of Immunology 191:837–847.https://doi.org/10.4049/jimmunol.1201716
-
The Sox9 transcription factor determines glial fate choice in the developing spinal cordGenes & Development 17:1677–1689.https://doi.org/10.1101/gad.259003
-
The embryonic cell lineage of the nematode caenorhabditis elegansDevelopmental Biology 100:64–119.https://doi.org/10.1016/0012-1606(83)90201-4
-
Estimating the number of clusters in a data set via the gap statisticJournal of the Royal Statistical Society: Series B 63:411–423.https://doi.org/10.1111/1467-9868.00293
-
Regression shrinkage and selection via the lassoJournal of the Royal Statistical Society. Series B 58:267–288.https://doi.org/10.1111/j.1467-9868.2011.00771.x
-
Regulation of mammalian epithelial differentiation and intestine development by class I histone deacetylasesMolecular and Cellular Biology 24:3132–3139.https://doi.org/10.1128/MCB.24.8.3132-3139.2004
-
Defining cell types and states with single-cell genomicsGenome research 25:1491–1498.https://doi.org/10.1101/gr.190595.115
-
Stem cells, self-renewal, and differentiation in the intestinal epitheliumAnnual Review of Physiology 71:241–260.https://doi.org/10.1146/annurev.physiol.010908.163145
-
ConferenceLearning a parametric embedding by preserving local structureTwelfth International Conference on Artificial Intelligence and Statistics (AI-STATS). pp. 384–391.
-
Beta-Poisson model for single-cell RNA-seq data analysesBioinformatics 32:2128–2135.https://doi.org/10.1093/bioinformatics/btw202
-
Sharp thresholds for High-Dimensional and noisy sparsity recovery using $\ell _{1}$ -Constrained Quadratic Programming (Lasso)IEEE Transactions on Information Theory 55:2183–2202.
-
Sox3 expression identifies neural progenitors in persistent neonatal and adult mouse forebrain germinative zonesThe Journal of Comparative Neurology 497:88–100.https://doi.org/10.1002/cne.20984
-
A framework for feature selection in clusteringJournal of the American Statistical Association 105:713–726.https://doi.org/10.1198/jasa.2010.tm09415
-
Ebf2 is required for development of dopamine neurons in the midbrain periaqueductal gray matter of mouseDevelopmental Neurobiology 75:1282–1294.https://doi.org/10.1002/dneu.22284
-
Ventral mesencephalon-enriched genes that regulate the development of dopaminergic neurons in vivoJournal of Neuroscience 29:5170–5182.https://doi.org/10.1523/JNEUROSCI.5569-08.2009
-
Identification, tissue expression, and functional characterization of Otx3, a novel member of the Otx familyJournal of Biological Chemistry 277:28065–28069.https://doi.org/10.1074/jbc.C100767200
Article and author information
Author details
Funding
National Science Foundation
- Leon A. Furchtgott
National Institutes of Health
- Sharad Ramanathan
Allen Foundation
- Vilas Menon
- Sharad Ramanathan
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Sandeep Choubey, Alex Schier, Andrew Murray, David Scadden and Toshihiko Oki for scientific discussions. We also thank Christof Koch, Andrew Murray, KC Huang, Jim Valcourt and Dann Huh for detailed comments and feedback on this work. We are grateful to Simona Lodato for helping us interpret our results and in particular help us write the section on the genes we discover to be important during cortical development. We are particularly grateful to the Senior and Reviewing Editors and to the four peer reviewers, including Nir Yosef, for their very thoughtful comments and suggestions. The study was supported by NSF-GRFP and NDSEG Fellowships (LF), an NIH Pioneer Award (SR), and the Allen Institute for Brain Science (SR).
Copyright
© 2017, Furchtgott et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 6,177
- views
-
- 1,189
- downloads
-
- 32
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 32
- citations for umbrella DOI https://doi.org/10.7554/eLife.20488
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Discovering sparse transcription factor codes for cell states and state transitions during development
eLife 6:e20488.
https://doi.org/10.7554/eLife.20488
Further reading
-
- Computational and Systems Biology
- Developmental Biology
A combination of single-cell techniques and computational analysis enables the simultaneous discovery of cell states, lineage relationships and the genes that control developmental decisions.




{kind=link}
{kind=link}
{kind=link}
{kind=link}