Extensive cargo identification reveals distinct biological roles of the 12 importin pathways
- RIKEN, Japan
- National Institute of Advanced Industrial Science and Technology, Japan
Abstract
Vast numbers of proteins are transported into and out of the nuclei by approximately 20 species of importin-β family nucleocytoplasmic transport receptors. However, the significance of the multiple parallel transport pathways that the receptors constitute is poorly understood because only limited numbers of cargo proteins have been reported. Here, we identified cargo proteins specific to the 12 species of human import receptors with a high-throughput method that employs stable isotope labeling with amino acids in cell culture, an in vitro reconstituted transport system, and quantitative mass spectrometry. The identified cargoes illuminated the manner of cargo allocation to the receptors. The redundancies of the receptors vary widely depending on the cargo protein. Cargoes of the same receptor are functionally related to one another, and the predominant protein groups in the cargo cohorts differ among the receptors. Thus, the receptors are linked to distinct biological processes by the nature of their cargoes.
https://doi.org/10.7554/eLife.21184.001Introduction
In interphase cells, proteins and RNAs migrate into and out of the nuclei through the central channels of the nuclear pore complexes (NPC) embedded in the nuclear envelope. These nuclear pores are lined with FG-repeat domains that constitute a permeability barrier, and only macromolecules that reversibly interact with the FG-repeats can permeate this barrier (Schmidt and Görlich, 2016). One such group of proteins, the importin (Imp)-β family proteins, are nucleocytoplasmic transport receptors (NTRs) that primarily carry nuclear proteins and small RNAs as their cargoes through the nuclear pores, although non-importin family NTRs also act depending on the cargo and physiological conditions (Kose et al., 2012; Lu et al., 2014; Weberruss et al., 2013). The human genome encodes 20 species of Imp-β family NTRs, of which 10 [Imp-β, transportin (Trn)-1, -2, -SR (-3), Imp-4, -5 (RanBP5), -7, -8, -9, and -11] are nuclear import receptors, 7 [exportin (Exp)-1 (CRM1), -2 (CAS/CSE1L), -5, -6, -7, -t, and RanBP17] are export receptors, 2 (Imp-13 and Exp-4) are bi-directional receptors, and the function of RanBP6 is undetermined (Kimura and Imamoto, 2014). These NTRs constitute multiple parallel transport pathways. The basic mechanism of directional transport was elucidated in the early years (Görlich and Kutay, 1999), but even today, the number of NTR-specific cargoes that has been reported is surprisingly small, hindering a biological understanding of the nucleocytoplasmic transport system.
NTRs are thought to transport specific cohorts of cargoes by binding to specific sites on those cargoes (Chook and Süel, 2011), but the consensus structures of the NTR-binding sites have been established for only a few NTRs (Soniat and Chook, 2015) as follows: the classical nuclear localization signal (cNLS) for the Imp-α family adapters, which connects Imp-β and cargoes (Lange et al., 2007); PY-NLS for Trn-1 and -2 (Lee et al., 2006; Süel et al., 2008); the nuclear export signal (NES) for Exp-1 (Hutten and Kehlenbach, 2007); the SR-rich domain that binds to Trn-SR (Kataoka et al., 1999; Maertens et al., 2014); and Lys-rich NLS (IK-NLS) for yeast Kap121p (Imp-5 homolog; Kobayashi and Matsuura, 2013; Kobayashi et al., 2015). The β-like importin-binding (BIB) domain is another NTR-binding site (Jäkel and Görlich, 1998), but its consensus sequence and NTR specificity remain obscure. Among the NTRs, Imp-β exclusively uses one of the seven species of the Imp-α family of proteins as an adapter for cargo binding, and many Imp-α/β cargoes have been reported, although Imp-β also directly binds to cargoes (Goldfarb et al., 2004). Among the import receptors, Trn-1 and its closest homolog Trn-2 have the second-highest number of cargoes reported thus far, and the PY-NLS motif has been defined, although in some cases the motif is difficult to recognize because of sequence diversity and structural disorder is another requisite (Soniat and Chook, 2015, 2016). For the cargoes of other NTRs, the consensus structures of NTR-binding sites have hardly been derived because only limited numbers of cargoes have been reported, including Imp-β-direct cargoes.
There are many reports on the differential spatiotemporal expression of Imp-β family NTRs, including tissue specificities in humans (Quan et al., 2008), developmental or spermatogenic stage specificities in mice (Major et al., 2011; Quan et al., 2008), and tissue or response specificities in plants (Huang et al., 2010). Expression regulation is not only transcriptional but also miRNA-mediated (Li et al., 2013; Szczyrba et al., 2013) or locally translationally mediated (Perry and Fainzilber, 2009). Additionally, the NTRs are functionally regulated by protein modifications (Wang et al., 2009), inhibitory factors (Lieu et al., 2014), and specific anchorings (Makhnevych et al., 2003). These nucleocytoplasmic transport regulations must significantly influence cellular physiology, and their significance may be elucidated if the affected cargoes can be specified. Indeed, in previous studies, NTR regulations have been linked to cellular responses through the functions of specific cargoes. For example, in prostate cancer cells treated with a cinnamaldehyde derivative, the expression of Imp-7 and the transcription factor Egr1 are induced, and the Egr1 imported by Imp-7 activates apoptotic gene transcription (Kang et al., 2013). In another example, when the nuclear import of some ribosomal proteins (RPs) is inhibited by the repression of Imp-7 expression, other unassembled RPs restrain the negative regulator of p53 Mdm2 and thereby activate p53 to inhibit cell growth (Golomb et al., 2012). Additionally, the inhibition of Trn-2 by the caspase-generated HuR (ELAVL1) fragment is crucial for the cytoplasmic retention of full-length HuR, which induces myogenesis (Beauchamp et al., 2010) or staurosporine-induced apoptosis (von Roretz et al., 2011). In many other studies, mutations of particular NTR genes in model organisms, including yeast, flies, and plants, have resulted in defects in specific biological processes (Kimura and Imamoto, 2014). Thus, each NTR has its own inherent biological significance. However, the details of the molecular processes are largely uncharacterized because the responsible cargoes have not been identified. If we could identify more cargoes, further studies of cellular regulation by nucleocytoplasmic transport would be possible.
We previously established a method for identifying the cargoes of a nuclear import receptor called SILAC-Tp (Kimura et al., 2013a, 2013b, 2014). SILAC-Tp employs stable isotope labeling with amino acids in cell culture (SILAC) (Ong et al., 2002), an in vitro reconstituted nuclear transport system (Adam et al., 1990), and quantitative mass spectrometry. A recent advancement of the Orbitrap mass spectrometer drastically increased the identified and quantified protein numbers, and this advancement has been successfully applied to other cargo identification methods (Kırlı et al., 2015; Thakar et al., 2013). Here, we utilized this advancement for the SILAC-Tp method and identified import cargoes of all 12 NTRs, of which 10 are import and two are bi-directional receptors. Our results illustrate the basic framework and the biological significance of the nucleocytoplasmic transport pathways.
Results and discussion
SILAC-Tp effectively identifies cargoes
SILAC-Tp employs an in vitro nuclear transport system, and all 12 NTRs import their reported specific cargoes in this system (Figure 1—figure supplement 1C). The transport system consists of permeabilized HeLa cells labeled with ‘heavy’ amino acids by SILAC, unlabeled HeLa nuclear extract depleted of Imp-β family NTRs and RCC1, unlabeled HeLa cytosolic extract depleted of Imp-β family NTRs, one species of recombinant NTR, p10/NTF2, and an ATP regeneration system. Unlabeled ‘light’ proteins in the nuclear extract are imported into the nuclei of the permeabilized cells. Simultaneously, a control reaction without the NTR is performed. Next, the proteins are extracted from the nuclei and identified and quantified by LC-MS/MS. The recipient nuclei contain both the imported and endogenous proteins, and the ratio of the imported to the endogenous fraction of a protein is calculated as the unlabeled/labeled or light/heavy (L/H) ratio. The quotient of the L/H ratios with the NTR (+NTR) and without it (control), that is, (L/H+NTR)/(L/HCtl), of a protein is defined as the +NTR/Ctl value and is used as the index for cargo potentiality.
In one run of SILAC-Tp (control or +NTR), approximately 2500 to 4000 proteins were identified, and the L/H ratios of 1700 to 3100 proteins were quantified. To calculate the +NTR/Ctl value, one protein has to be quantified in both the control and +NTR reactions, and we discarded L/H+NTR values that lacked the counterpart L/HCtl values. We performed three replicates of SILAC-Tp for each of the 12 NTRs. In the three replicates, 1235 to 1671 proteins were assigned with +NTR/Ctl values three times, and 364 to 502 proteins were assigned only twice (Supplementary file 1). We did not consider proteins with single +NTR/Ctl values, although a protein with only a single but high +NTR/Ctl value may still be a cargo (see below). To normalize the index values of the three replicates, the Z-scores of the log2(+NTR/Ctl) were calculated within each replicate (Figure 1—figure supplement 2A and B). Ranking the proteins that have three +NTR/Ctl values by the median of the three Z-scores may reasonably sort the candidate cargoes. However, if the lower Z-score of a protein with only two +NTR/Ctl values is higher than the median Z-scores of those candidate cargoes, the protein may also be a candidate cargo. Thus, we ranked the proteins by the second (the lower of the two or the middle of the three) Z-scores, and termed the result the 2nd-Z-ranking (Supplementary file 1).
To define the border that separates candidate cargoes from other proteins in the 2nd-Z-ranking, we first reviewed the distribution of reported Trn-1 cargoes in the Trn-1 2nd-Z-ranking because many Trn-1 cargoes have been reported. For an unbiased evaluation, we employed the lists of cargoes consolidated by other researchers (Chook and Süel, 2011). Twenty-seven reported cargoes were included in the 2nd-Z-ranking (totaling 1649 proteins; Supplementary file 1, Trn-1 ‘Report and feature’). We calculated the reported cargo rates (to serve as a proxy for precision), recall, and Fisher’s exact test p-values for rank cutoffs in increments of 1%. Computing reported cargo rate requires deciding which candidate cargoes should be considered as false positives. Since a gold standard set of definitely non-cargo proteins is not available, it is not clear which previously unreported cargoes should be counted as false positives, and which, if any, should be discarded as unclear. Therefore, we estimated reported cargo rates in two ways: (i) treating all the 1622 proteins not reported as cargoes as negative examples (Figure 1—figure supplement 3A and Figure 1—source data 1A); and (ii) discarding proteins with undetermined or nuclear subcellular localization according to Uniprot annotation, and treating the remaining 259 non-nuclear proteins as negative examples (Figure 1—figure supplement 3A and Figure 1—source data 1B). In the former case, the reported cargo rate corresponds to a lower bound on the precision, and even in the latter case, the reported cargo rates are expected to underestimate precision, because almost certainly some of the proteins that we exclude as unclear are in fact true cargoes.
To select cargoes with high sensitivity, we employed the cutoff of 15% that yields a high recall of 0.741 (Figure 1—figure supplement 3B and Figure 1—source data 1A and 1B; recall is not affected by the assumptions of negative examples). Among the 27 reported cargoes, 20 cargoes were ranked in the top 15% (247 proteins; p=5.39 × 10−12 by Fisher’s exact test), and the others were dispersed in the lower ranks (Figures 1A and 2A; Figure 1—figure supplement 2C and E).
Figure 1 with 3 supplements see all
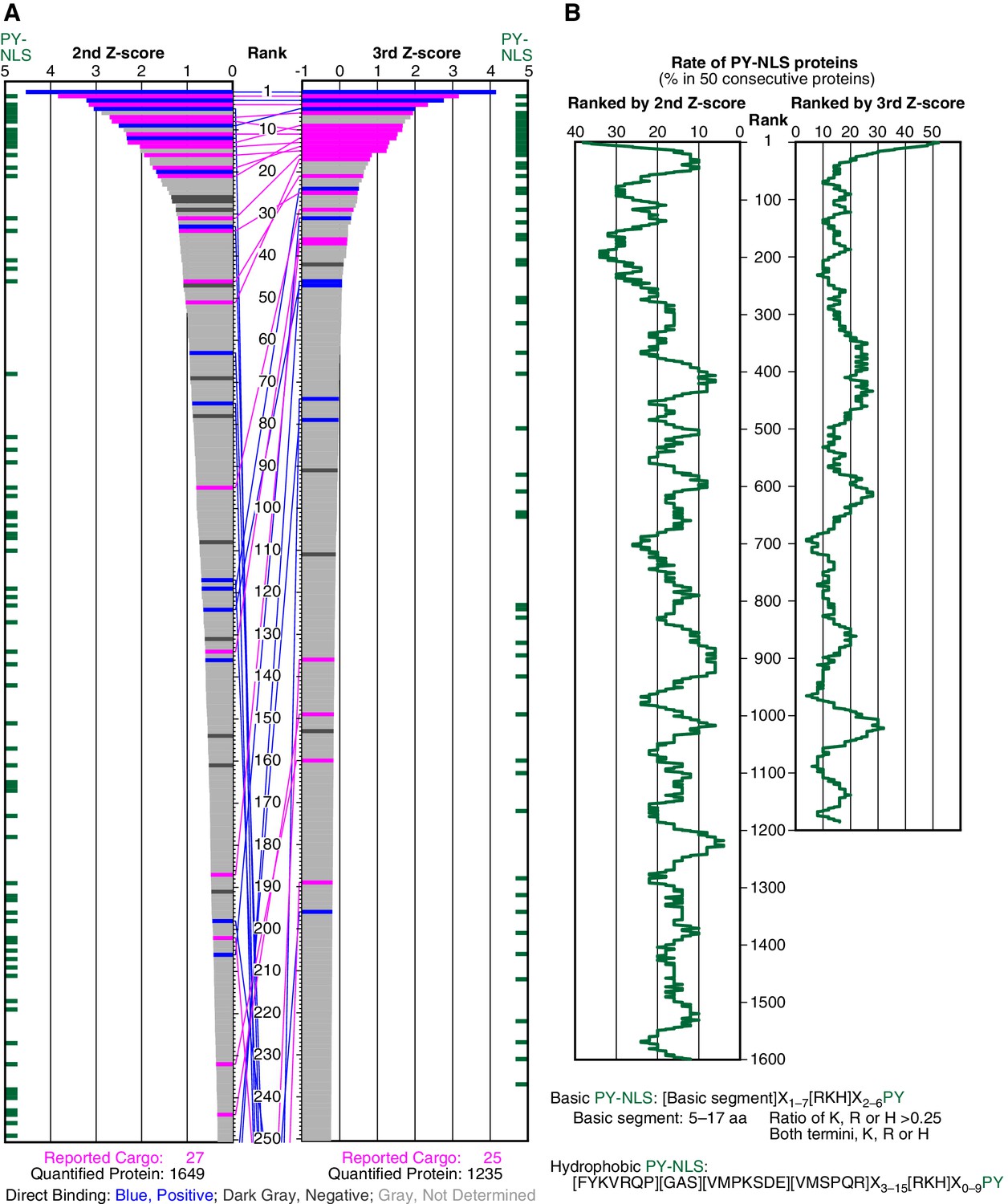
SILAC-Tp effectively sorts Trn-1 cargoes.
(A) Z-scores in the Trn-1 2nd- and 3rd-Z-rankings. The second (left) and third (right) Z-scores are presented for the top 250 proteins in the Trn-1 2nd- and 3rd-Z-rankings, respectively. The total number of ranked (quantified) proteins and the number of previously reported cargoes included in the ranking are indicated at the bottom. The magenta bars represent previously reported cargoes. The blue and dark gray bars represent the proteins that did and did not bind directly to Trn-1, respectively, in the bead halo assays (Supplementary file 2). Identical proteins marked by the colors are connected by lines. Proteins that carry PY-NLS motifs are indicated by green bars. (B) Distribution of PY-NLS motif-containing proteins in the rankings. The percentage of the proteins carrying PY-NLS motifs in 50 consecutively aligned proteins is presented along with the 2nd- and 3rd-Z-rankings (left and right, respectively). For example, the top 50 proteins in the 2nd-Z-ranking include 19 (38%) PY-NLS motif-containing proteins, and thus the value at position 1 is 38%. Two types of PY-NLS motifs, basic and hydrophobic, are defined as presented at the bottom.
-
Figure 1—source data 1
Statistical analysis of reported cargoes in the Trn-1 2nd- and 3rd-Z-ranking.
(A, B) Reported cargo rates, recall, and p-values of the Trn-1 2nd-Z-percentile ranking. Reported cargoes and proteins that have not been reported as cargoes (unreported candidate cargoes) in the top 1% to 20% ranks were counted in 1% rank increments, and the reported cargo rates (a lower bound on precision), recall (sensitivity), and p-values were calculated using two definitions of negative examples: (i) assuming any protein not reported as a cargo is negative (A), or (ii) assuming only those annotated to have non-nuclear localization in Uniprot to be negative (B). p-values were calculated by Fisher's exact test. The row marked in cyan corresponds to the 2nd-Z-15% cargoes. (C, D) Reported cargo rates, recall, and p-values of the Trn-1 3rd-Z-percentile ranking. Reported cargo rates, recall, and p-values of the top 1% to 20% ranks were calculated similarly using two definitions of negative examples. The row marked in magenta corresponds to the 3rd-Z-4% cargoes. See also Figure 1—figure supplement 3.
- https://doi.org/10.7554/eLife.21184.003
Figure 2 with 3 supplements see all

Trn-1, Imp-13, and Trn-SR cargo rankings.
(A–C) The top 100 proteins in the Trn-1 (A), Imp-13 (B), and Trn-SR (C) 2nd- and 3rd-Z-rankings (left and right, respectively). Magenta, reported cargoes; blue, proteins bound directly to the NTR in the bead halo assays (Supplementary file 2); orange in (C), SR-rich SFs that have not been reported; and green in (C), other RS (SR)-domain proteins. Identical proteins marked by the colors are connected by lines.
We examined the direct binding of Trn-1 to a subset of proteins in the 2nd-Z-ranking using a bead halo assay (Patel and Rexach, 2008) (Supplementary file 2) in which the binding of GFP-fusion proteins to GST-Trn-1 on glutathione-Sepharose beads was observed by fluorescence microscopy. If RanGTP (a Q69L GTP-fixed mutant) (Bischoff and Ponstingl, 1995) inhibits the protein–Trn-1 binding, the functionality of the binding is verified. For all the bead halo assays in this work, we principally selected well-characterized proteins that have not been reported as cargoes from (i) proteins ranked high (within the top 15% in the 2nd-Z-ranking or 4% in the 3rd-Z-ranking, see below), around presumptive cutoffs (within about top 15–25% in the 2nd-Z-ranking), or lower and (ii) highly ranked proteins that are suspected as indirect cargoes or false positives based on their well-known features, for example, S100A6 or EEF1A2 (see the legend of Supplementary file 2). The negative rate of the bead halo assays should be higher than the true overall false-positive rate of the SILAC-Tp, because proteins in (ii) are selected preferentially. Seventeen novel candidate cargoes in the top 266 (top 16%) bound to Trn-1, and RanGTP inhibited the binding (Figure 1A; Supplementary file 1, Trn-1 ‘Direct binding’; Supplementary file 2). Although the assays were not comprehensive, many of the highly ranked proteins are bona fide Trn-1 cargoes. The highly ranked proteins that did not bind to Trn-1 in the assays are still candidate indirect cargoes that may form complexes with other proteins that directly bind to Trn-1 (see the case of POLE3 for Imp-13 below). As an example of a protein with only a single but high Z-score (+NTR/Ctl value), DIMT1 bound to Trn-1 (DHRS4 with Imp-β is another example), but we did not consider such proteins.
Because many reported Trn-1 cargoes carry PY-NLSs, we examined the distribution of PY-NLS motif-containing proteins in the 2nd-Z-ranking (Figure 1B). The percentages of PY-NLS motif-containing proteins within a window width of 50 positions were higher in the range of the top 200, indicating a higher rate of PY-NLS motif-containing proteins within the top 250 (top 15%). The reported Trn-1 cargoes were similarly distributed in the Trn-2 2nd-Z-ranking (Supplementary file 1, Trn-2 ‘Report or feature’). Because Trn-1 and -2 share nearly the same reported cargoes (Twyffels et al., 2014), this result demonstrates the reproducibility of the SILAC-Tp method. Based on these evaluations, we assumed that the proteins in the top 15% (247 proteins) of the 2nd-Z-ranking are candidate cargoes with high sensitivity (0.741) and termed them the 2nd-Z-15% cargoes.
Next, we examined whether the cutoff employed for Trn-1 is applicable to Imp-13 and Trn-SR whose 2nd-Z-rankings include several reported cargoes. The Imp-13 2nd-Z-ranking (totaling 2060 proteins) includes eight reported cargoes (Supplementary file 1, Imp-13), and seven of these are ranked in the top 244 (top 12%; p=2.83 × 10−7; Figure 2B; Figure 2—figure supplements 1A and 2A). In bead halo assays for a subset of the ranked proteins, 24 novel candidate cargoes in the top 326 (top 16%) bound directly to Imp-13, and RanGTP inhibited the binding (Figure 2—figure supplement 2A; Supplementary file 1, Imp-13; Supplementary file 2). One component of a reported cargo complex, that is, POLE3, did not bind to Imp-13, but its binding partner CHRAC1 (Walker et al., 2009) did. Thus, the binding partners of the direct cargoes are also ranked high. Many reported Trn-SR cargoes are SR-domain proteins (Chook and Süel, 2011), and they can be grouped into either SR-rich splicing factors (SFs) or other SR-domain proteins. The Trn-SR 2nd-Z-ranking (totaling 2021 proteins) contains three reported cargoes (Supplementary file 1, Trn-SR), and they are ranked in the top 55 (top 3%; p=1.91 × 10−5; Figure 2C; Figure 2—figure supplement 2B). The 2nd-Z-ranking contains seven SR-rich SFs other than the reported SFs, and five of these are ranked in the top 90 (top 4%; p=7.61 × 10−18). The 2nd-Z-ranking also contains another four proteins that are annotated with ‘RS-domain’ in UniProt, and three of these are ranked in the top 202 (top 10%; p=3.65 × 10−3). Finally, in bead halo assays for a subset, 11 novel candidate cargoes in the top 237 (top 12%) bound directly to Trn-SR, and RanGTP inhibited the binding (Figure 2—figure supplement 2B; Supplementary file 1, Trn-SR; Supplementary file 2). Hence, the 2nd-Z-15% cargoes could also be defined for Imp-13 (309 proteins) and Trn-SR (302 proteins), and we applied this cutoff to the other NTRs that have few reported cargoes. The 2nd-Z-15% cargoes of the 12 NTRs are presented in Supplementary file 3. Some of the 2nd-Z-15% cargoes with low numbers of L/H counts showed deviation in Z-scores or L/H ratios in the three replicates of SILAC-Tp (Supplementary file 1), and an example of their quantitation qualities is presented in Supplementary file 4.
Exceptionally, Imp-β uses Imp-α as an adaptor for cargo binding, and the cytosolic extract used for the transport system contained endogenous Imp-α. Four Imp-αs were found in the Imp-β 2nd-Z-ranking (totaling 2027 proteins), and three of these are in the 2nd-Z-15% cargoes (p=1.19 × 10−2; Supplementary file 1, Imp-β; Supplementary file 3). Thus, the Imp-β candidate cargoes must include both Imp-β-direct and Imp-α-dependent cargoes. Indeed, 31 proteins in the top 276 (top 14%) bound directly to Imp-α, -β, or both in the bead halo assays (Supplementary file 1, Imp-β; Figure 2—figure supplement 3; Supplementary file 2). The border for the Imp-β candidate cargoes can be relaxed because Imp-β imports more cargoes than other NTRs with the help of Imp-α. Indeed, in the bead halo assays, many proteins in the top 35% of the 2nd-Z-ranking bound to Imp-α, although most of the proteins that bound directly to Imp-β were ranked in the top 259 (13%). Here, we employed the Imp-β 2nd-Z-15% cargoes (303 proteins) to enable equal comparisons with the cargoes of other NTRs.
Cargo selection with higher specificity
Deviation of the LC-MS/MS quantification within the three replicates complicates cargo selection. However, the Z-scores of the highly ranked reported cargoes were reasonably high in all the three replicates possibly because many of the reported cargoes are abundant proteins that seldom produce outliers in quantification (Figure 1—figure supplement 2; Figure 2—figure supplement 1). To select proteins that have high Z-scores in all the three replicates, we next ranked the proteins that had three +NTR/Ctl values by the third (lowest) Z-scores (3rd-Z-ranking). The reported cargo rates, recall, and p-values were calculated in 1% rank increments under two assumptions similarly to the case of 2nd-Z-ranking (Figure 1—figure supplement 3A and B and Figure 1—source data 1C and 1D). The reported cargo rate calculated under the assumption that proteins annotated with non-nuclear localization (178 proteins) are negative examples is as high as 0.85 at the cutoff of top 4% (Figure 1—figure supplement 3A and Figure 1—source data 1D). The Trn-1 3rd-Z-ranking (totaling 1235 proteins) included 25 reported cargoes, and 17 of these were ranked in the top 37 (top 3%; p=1.67 × 10−22; Figures 1A and 2A; Figure 1—figure supplement 2D and F; Supplementary file 1). Seven proteins in the top 47 (top 4%) were novel Trn-1-direct cargoes that were verified in the bead halo assays (Figures 1A and 2A; Supplementary files 1 and 2). The percentage of PY-NLS motif-containing proteins within a window width of 50 positions was highest at the first position (Figure 1B), indicating that PY-NLS motif-containing proteins are concentrated in the top 50 (top 4%). Thus, most of the proteins that ranked in the top 4% (49 proteins) of the 3rd-Z-ranking are highly reliable cargoes, and we termed these proteins the 3rd-Z-4% cargoes. In a comparison between the Trn-1 2nd-Z-15% and 3rd-Z-4% cargoes, most of the 3rd-Z-4% cargoes were also 2nd-Z-15% cargoes (Figure 1A). Some reported or newly identified cargoes in the 2nd-Z-15% cargoes were ranked lower in the 3rd-Z-ranking due to the deviations in the third Z-scores.
In the Imp-13 3rd-Z-ranking (totaling 1671 proteins), seven proteins were reported cargoes, and six of these were ranked in the top 58 (top 3%; p=9.20 × 10−9; Figure 2B; Figure 2—figure supplements 1B and 2A; Supplementary file 1). Additionally, the 3rd-Z-4% cargoes (66 proteins) included eight novel cargoes that directly bound to Imp-13 (Figure 2B; Figure 2—figure supplement 2A; Supplementary files 1 and 2). In the Trn-SR 3rd-Z-ranking (totaling 1591 proteins), both of the two reported cargoes were ranked in the top 18 (top 1%; p=1.21 × 10−4), four of the five other SR-rich SFs were in the top 45 (top 3%; p=2.74 × 10−6), one of the three SR-domain proteins (other than the SR-rich SFs) was ranked 63rd (top 4%; p=0.11), and six novel cargoes within the top 4% (63 proteins) bound directly to Trn-SR (Figure 2C; Figure 2—figure supplement 2B; Supplementary files 1 and 2). In cases of both Imp-13 and Trn-SR, the proteins were replaced between the 2nd- and 3rd-Z-rankings in a manner similar to the case for Trn-1. We concluded that the 3rd-Z-4% criteria is highly specific including few false positives, albeit at the cost of losing many genuine cargoes. Hence, we employed the 3rd-Z-4% cargoes mainly for the characterization of the identified cargoes, whereas the 2nd-Z-ranking was used for the evaluation of the import efficiencies of the expected cargoes. The 3rd-Z-4% cargoes of the 12 NTRs are presented in Figure 3.
Figure 3
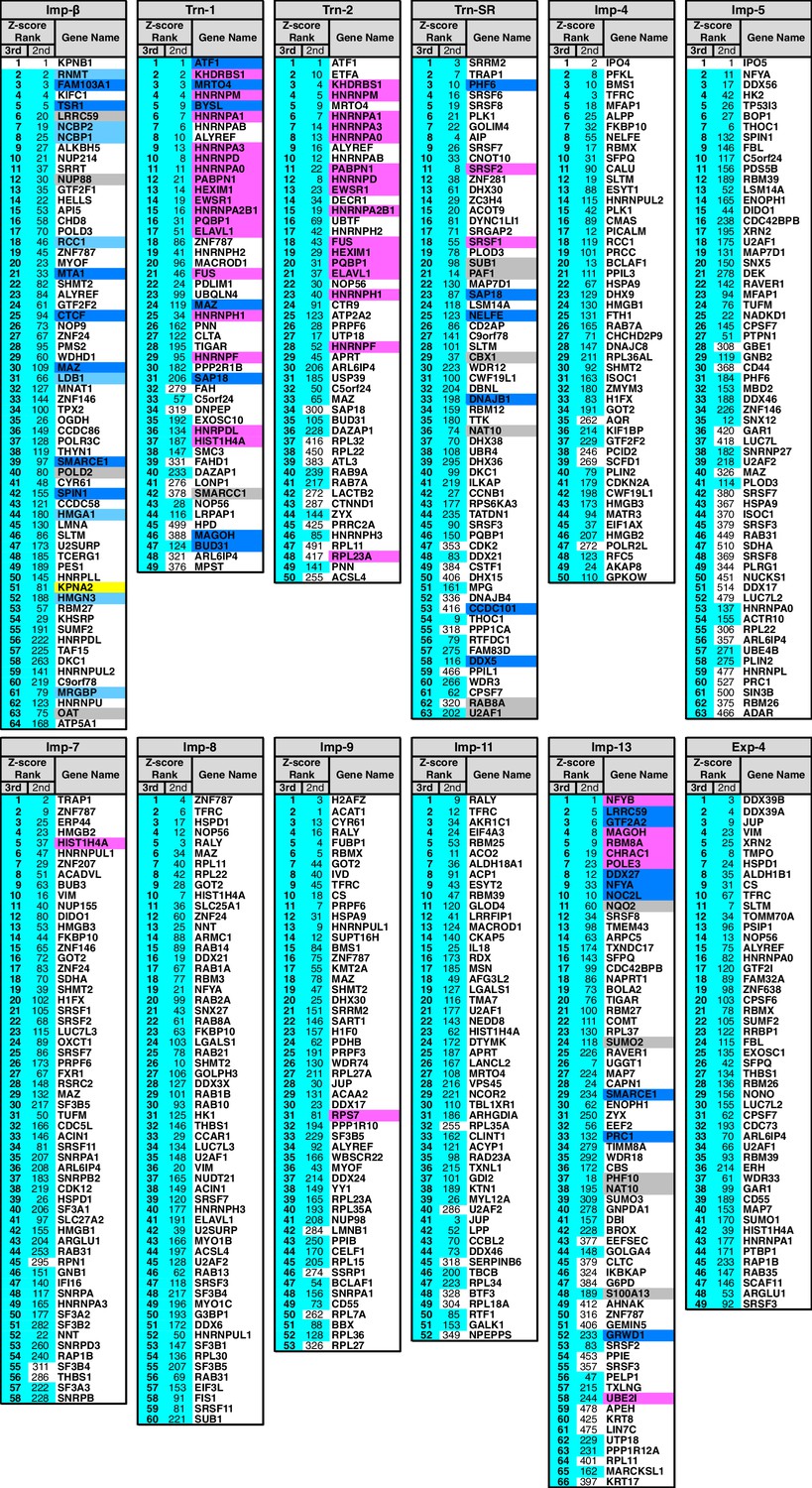
3rd-Z-4% cargoes of the 12 NTRs.
The 3rd-Z-4% cargoes of each NTR are listed by the gene names in the 3rd-Z-rank orders. The ranks by the second Z-scores are also shown. The 3rd-Z-4% and 2nd-Z-15% cargoes are indicated by cyan in the rank columns. Colors in the gene name columns: magenta, reported cargoes; blue, cargoes bound directly to the NTR in the bead halo assays (Supplementary file 2); light blue, cargoes bond directly to Imp-α but not to Imp-β; gray, proteins that did not bind to the NTRs; and yellow, Imp-α. For the 2nd-Z-15% cargoes, see Supplementary file 3.
Redundancy in the import pathways
A total of 468 proteins were identified as 3rd-Z-4% cargoes of the 12 NTRs, and 332 of these are unique to one NTR, which clearly reflects the division of roles among the NTRs (Supplementary file 5B). Another 136 proteins were shared by two to seven NTRs, and the mean number of shared cargoes between two NTRs was 4.8. In the maximum-likelihood phylogenetic tree of the 12 NTRs (Figure 4A), Trn-1 and -2 (84% sequence identity) are paired most closely, and Imp-7 and -8 (65% identity) are the second-most closely paired. These paired NTRs share 28 and 19 cargoes, respectively, and they are paired similarly in a hierarchical clustering based on the cargo profiles (Figure 4B and C). The other NTRs that were paired weakly in the phylogenetic tree, namely, Imp-13 and Trn-SR (23% identity), Imp-4 and -5 (22% identity), and Imp-9 and -11 (19% identity), did not form the same pairs when clustering by their cargoes. Thus, the NTR–cargo interactions are conserved only within the highly homologous NTRs. The 2nd-Z-15% cargoes included as many as 1416 proteins in total, 827 of which are shared by two to 12 NTRs, and 589 are unique to one NTR (Supplementary file 5A and 5D). Imp-7 and -8 share the largest number (162) among the 2nd-Z-15% cargoes, but Trn-1 and -2 share no more than the other pairs. Of the 247 Trn-1 and 246 Trn-2 2nd-Z-15% cargoes, 69 are shared, and 36 of these are ranked within the top 50 in either ranking. Thus, Trn-1 and -2 still share many highly ranked cargoes but few lower ranked cargoes within the top 15%. The import efficiency of a cargo may differ between Trn-1 and -2, and only one of Trn-1 or -2 may import inefficient cargoes that are ranked lower.
Figure 4
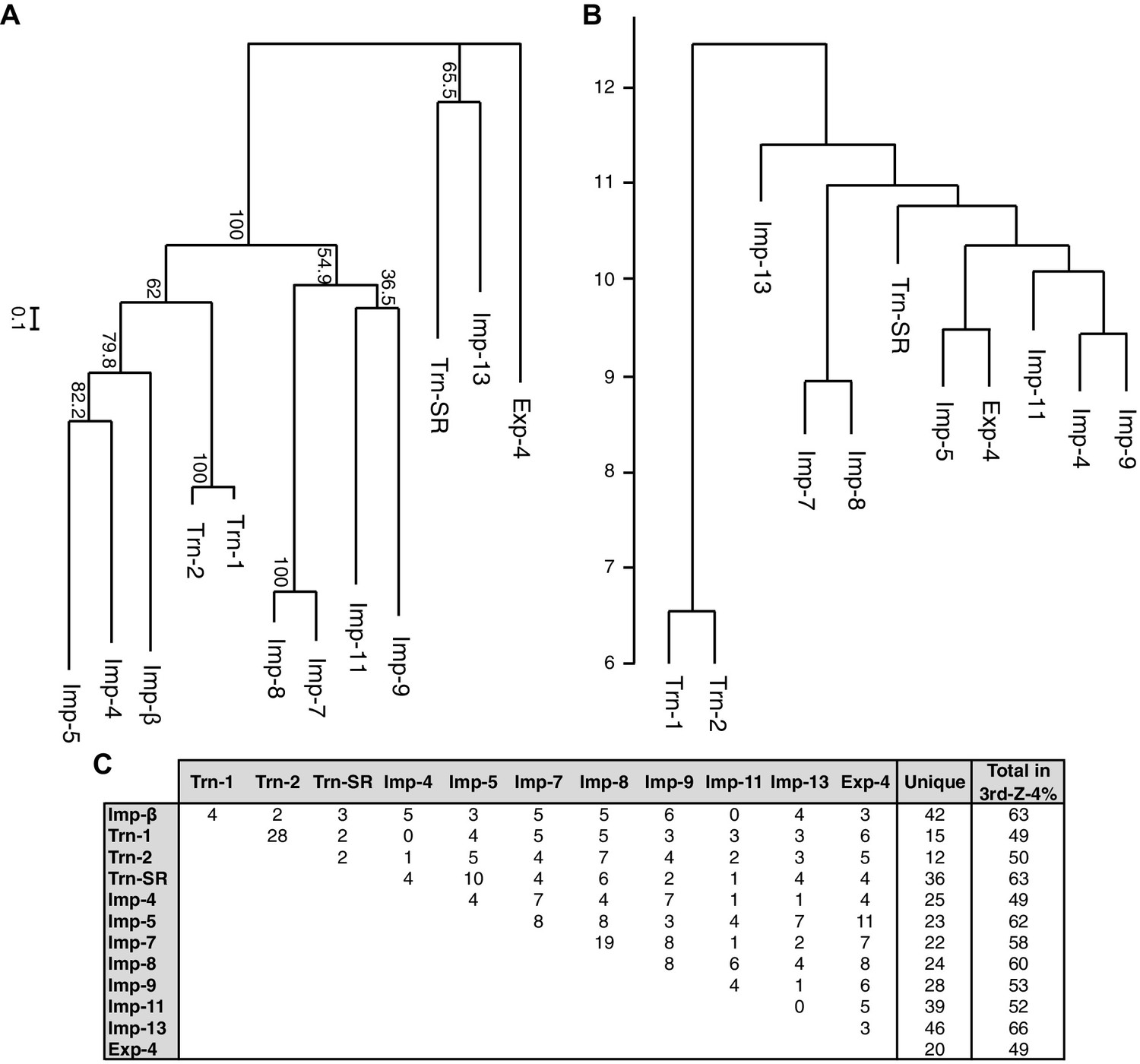
Phylogenetic tree and cargo profile hierarchical clustering of the Imp-β family import receptors.
(A) Phylogenetic tree of the 12 Imp-β family import receptors with the bootstrap values. Scale bar indicates substitutions per site. (B) A hierarchical clustering dendrogram of the same NTRs (except Imp-β) based on the similarities of their 3rd-Z-4% cargo profiles. Imp-β was excluded because Imp-α connects to Imp-β and many of the identified cargoes. The scale indicates the intercluster distance. (C) The numbers of 3rd-Z-4% cargoes shared by two NTRs. For the 2nd-Z-15% cargoes, see Supplementary file 5A.
Division of roles among the NTRs
Because NTR-dependent transport is regulated, a cargo cohort of an NTR must be imported simultaneously and act cooperatively. To explore the roles of the NTR cargoes, the 3rd-Z-4% and 2nd-Z-15% cargoes of each NTR were analyzed for enrichment of Gene Ontology (GO) terms (Gene Ontology Consortium, 2015) using g:Profiler (Reimand et al., 2016). For all the combinations of a GO term and an NTR, the number of cargoes annotated with the term and the significance (p-values according to g:SCS) of the term enrichment are listed (Supplementary files 6B, 6C, 7, and 8). Depending on the hierarchy of the GO terms, the terms are significantly annotated (p<0.05) to the cargo cohorts of none to 12 of the NTRs. Broader terms with smaller term depths are linked to more NTRs, whereas more defined terms with larger term depths are linked to fewer NTRs. Indeed, all 12 of the NTRs are linked to many broad terms, although the cargo numbers and the significances vary widely. Because similar terms were listed redundantly, we selected representative GO terms from those enriched significantly (p<0.05) for the 3rd-Z-4% cargoes of the 12 NTRs and tabulated the correspondences between the cargoes and the annotated terms (Supplementary file 9). To compare the GO terms that are specifically linked to each NTR, we listed the terms that are enriched significantly for the cargoes of four or fewer NTRs (Figures 5 and 6). Here, again we extracted the representative terms to decrease the size of the list. The selected terms for the 3rd-Z-4% cargoes plainly exhibit the roles of the cargo cohorts. For example, significant numbers of Imp-4, -7 and Exp-4 cargoes are annotated with DNA recombination or DNA conformation (geometric) change (Figure 5; Supplementary file 9), which are terms for biological processes (BPs). These cargoes are also annotated with chromatin, which is a term for cellular component (CC; Figure 6A; Supplementary file 9), and DNA binding, which is for molecular function (MF; Figure 6B; Supplementary file 9), all related to DNA recombination and DNA conformation change. For another example, the Trn-SR cargoes are significantly annotated with a range of terms for BPs that are related to cell division or nuclear division and terms for CCs that include condensed chromosome, kinetochore, spindle, and centrosome. Similarly, most of the examined NTRs are linked to terms for BPs via the 3rd-Z-4% cargoes (Figure 5) as follows: Imp-β, -4, -7, and Trn-SR are linked to chromatin or chromosome organization; Imp-β, -4, and -13 are linked to DNA repair; Imp-β is linked to mRNA capping; Trn-SR and Exp-4 are linked to mRNA polyadenylation; Trn-1 and -2 are linked to mRNA stabilization; Trn-2, -SR, Imp-5, -9, and Exp-4 are linked to ribosome biogenesis or rRNA processing; Trn-SR is linked to protein folding, modification, ubiquitination, and catabolic process; and Imp-4 and -7 are linked to apoptosis. The NTRs are also consistently linked to the terms for CCs and MFs (Figure 6) as follows: Trn-SR, Imp-5, -9, and Exp-4 are linked to Cajal body; Imp-β is linked to cap-binding complex; and Trn-SR is linked to pre-mRNA binding, snoRNA binding, and RNA helicase activity.
Figure 5
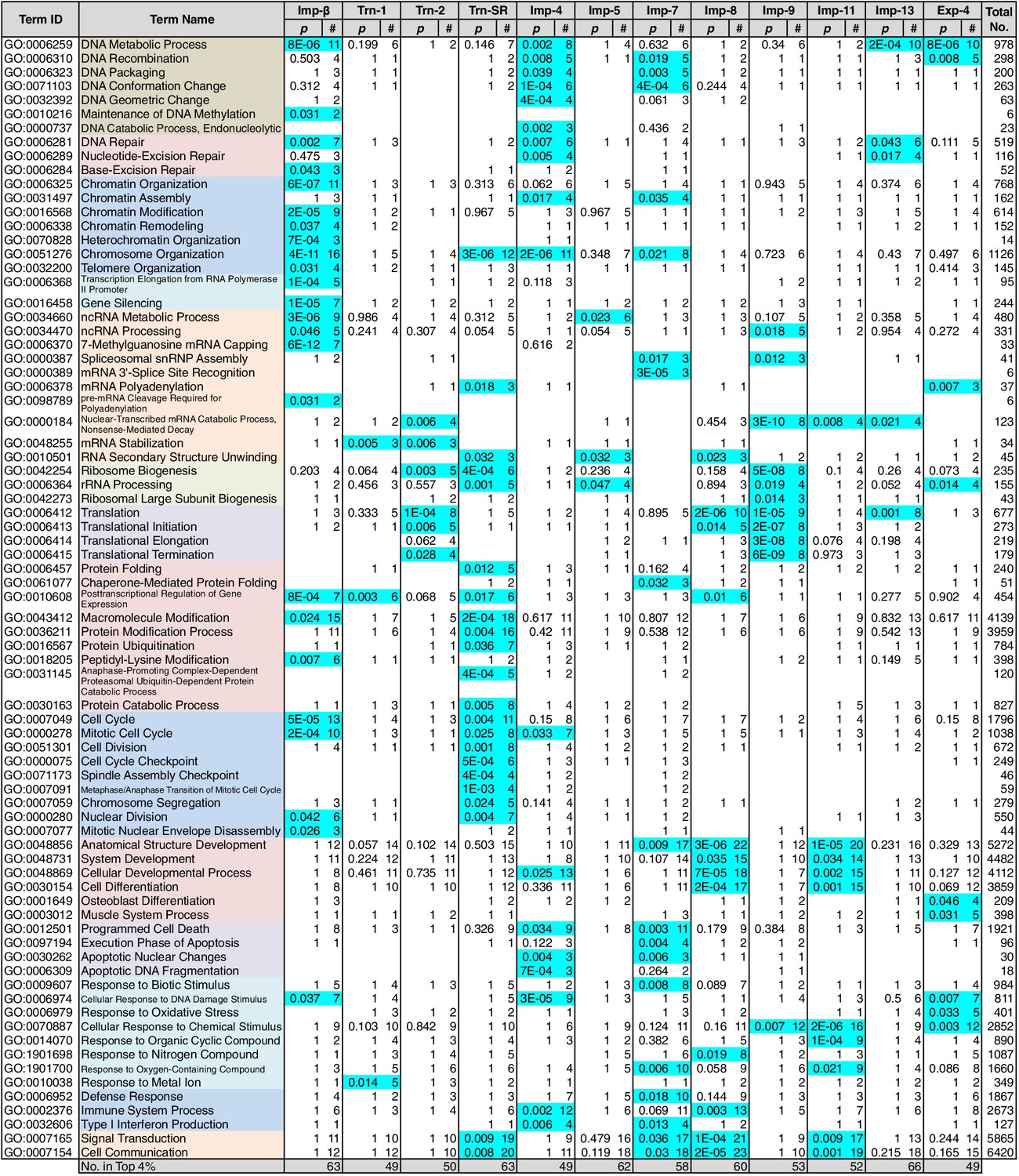
GO term (Biological Process) enrichments of the 3rd-Z-4% cargoes.
The 3rd-Z-4% cargoes were analyzed for GO term (term type, Biological Process) enrichment. The significantly enriched terms (p<0.05, cyan) in the 3rd-Z-4% cargoes of four or fewer NTRs were selected, and a representative term for each group of highly similar is presented with their p-values and the numbers (#) of cargoes annotated with them. Total No. denotes the number of proteins annotated with each term in the database. Related terms are bundled in the same color. This table was extracted from Supplementary file 6B. All the GO terms annotated to the 3rd-Z-4% cargoes are listed in Supplementary file 7. The correspondence between each 3rd-Z-4% cargo and GO term is summarized in Supplementary file 9. For the 2nd-Z-15% cargoes, see Supplementary files 6A, 8, and 10.
Figure 6

GO term (Cellular Component and Molecular Function) enrichments of the 3rd-Z-4% cargoes.
The 3rd-Z-4% cargoes were analyzed, and the results are presented in a format similar to that of Figure 5. (A) Term type, Cellular Component. (B) Term type, Molecular Function. These tables were extracted from Supplementary file 6B. All the GO terms annotated to the 3rd-Z-4% cargoes are listed in Supplementary file 7. The correspondence between each 3rd-Z-4% cargo and GO term is summarized in Supplementary file 9. For the 2nd-Z-15% cargoes, see Supplementary file 6A, 8, and 10.
Nearly twice as many GO terms were annotated to the 2nd-Z-15% cargoes. The correspondences between the 2nd-Z-15% cargoes of the 12 NTRs and selected representative GO terms enriched significantly for them are tabulated in Supplementary file 10. The excerpted list of terms enriched significantly for the cargoes of four or fewer NTRs contains terms partially different from those in Figures 5 and 6 (Supplementary file 6A), but many of the NTRs are still linked to terms similar to those of the 3rd-Z-4% cargoes. For example, Imp-β and Trn-SR are linked to terms related to cell or nuclear division by the 3rd-Z-4% cargoes (Figure 5) and to partially different terms that are still related to cell or nuclear division by the 2nd-Z-15% cargoes (Supplementary file 6A). Additionally, Imp-4 is linked to terms related to DNA structure regulation, DNA repair, and apoptosis in both lists. Similarly, most of the examined NTRs are linked in both lists to similar terms that are related to any of the following: chromatin organization, chromosome organization, DNA repair, ribosome biogenesis, protein modification, cell division, nuclear division, and apoptosis. Thus, we regard the 3rd-Z-4% list as a core table of the cargo roles. Naturally, the 2nd-Z-15% cargoes linked the NTRs to additional terms (Supplementary file 6A) as follows: Imp-β, -4, and Trn-SR are linked to DNA-dependent DNA replication; Trn-1 and Imp-7 are linked to gene silencing by RNA; Imp-β, -7, and -13 are linked to rRNA transcription; Imp-β and Trn-SR are linked to protein methylation; Trn-SR is linked to protein peptidyl-prolyl isomerization; Trn-2, Imp-4, and -8 are linked to circadian rhythm; Imp-β, -4, -13, and Trn-SR are linked to terms for CCs and MFs that are related to RNA polymerase (RNAP) II transcription; and subsets of the NTRs are linked to varying terms that are related to differentiation, development, and response. As an important result, we have illustrated the general framework of the division of roles among the NTRs for the first time, in which one NTR is linked to many BPs and conversely each broadly defined BP is supported by many NTRs, but each closely defined BP is supported by a restricted number of NTRs. One typical example is the allocation of mRNA processing factors (see below).
Allocation of mRNA processing factors to the NTRs
Some of the GO terms related to mRNA processing were specifically linked to four or fewer NTRs by the 3rd-Z-4% and 2nd-Z-15% cargoes (Figure 5; Supplementary file 6A). However, many other terms related to mRNA processing were linked to more NTRs, and conversely, all the NTRs were implicated in mRNA processing. The 2nd- and 3rd-Z-rankings for the 12 NTRs included 275 and 242 proteins, respectively, that were annotated with mRNA processing (Supplementary file 6B and 6C). To see the allocation of these proteins to the NTRs, the ranks of these proteins are arranged in a table (Supplementary file 11A). The 2nd- and 3rd-Z-rankings revealed similar results. As summarized for the 2nd-Z-ranking (Figure 7), particular groups of the mRNA-processing factors are allocated to specific NTRs, showing that each NTR is linked to distinct reactions in mRNA processing: the proteins related to mRNA capping are allocated to Imp-β almost exclusively; hnRNP A0 is allocated to Trn-1, -2, Imp-4, -11, and others; hnRNP A1, A2B1, A3, D, F, H1–3, and M are allocated to Trn-1 and -2, and additionally Imp-9 and Exp-4; hnRNP U-like 1 are allocated to Imp-7, -8, and -9; SR-rich SFs are primarily allocated to Trn-SR and secondarily to Imp-7, -8, and -9; SFs 3A and B are allocated to Imp-4, -7, -8, -9, -11, and Exp-4; PQ-rich SF is allocated to Imp-4, -7, -8, and Exp-4; snRNP A–C is allocated to Imp-4, -7, -8, and Exp-4; exon junction complex (EJC) components are exclusively allocated to Imp-11 and -13; cleavage and polyadenylation specificity factor (CPSF) 1 is allocated to Imp-7 and -9; CPSF5 (NUDT21), 6, and 7 are less specifically allocated to other NTRs; general transcription factor IIF is allocated to Imp-β, -4, and Trn-SR; and RNAP II associating factors are allocated to Trn-SR and separately to other NTRs. Thus, the NTRs import distinctive subsets of mRNA processing factors. In the 2nd-Z-ranking, the SR-rich SFs were not allocated to Imp-5, but they were identified as the Imp-5 3rd-Z-4% cargoes. Thus, subsets of proteins involved in a broadly defined BP, for example, mRNA processing, are allocated to different NTRs, in a manner representative of role division among the NTRs.
Figure 7
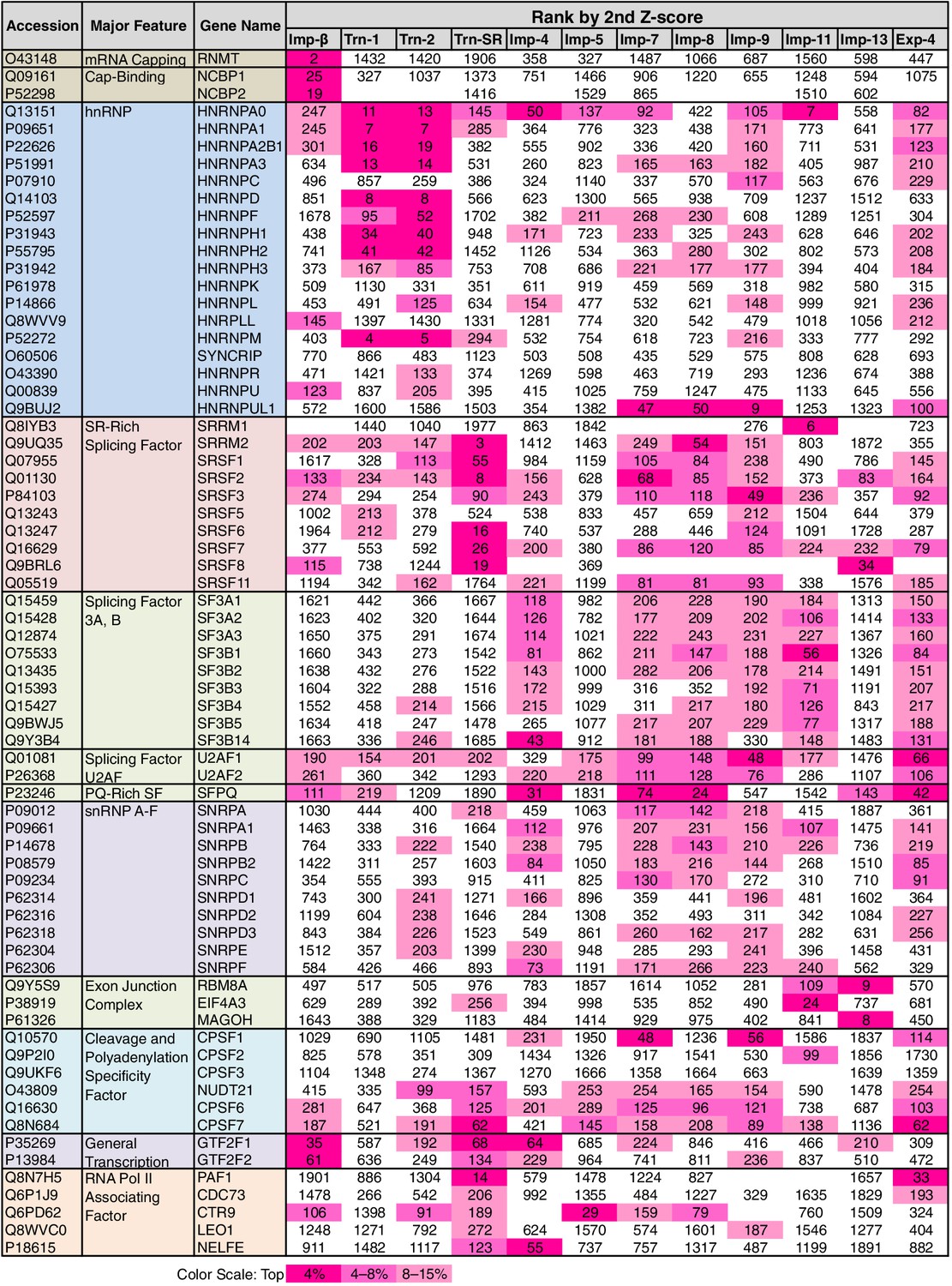
mRNA processing factors in the 2nd-Z-rankings.
The ranks of the mRNA processing factors in the 2nd-Z-rankings of the 12 NTRs are presented. The color scale is set by percentile rank as indicated. The 2nd-Z-rankings of the 12 NTRs include 275 proteins in total that are annotated with mRNA processing in GO. Of these, 69 were selected and are presented. For other factors and the 3rd-Z-rankings, see Supplementary file 11A.
Allocation of RPs to the NTRs
RPs migrate into the nuclei for ribosome assembly, but the NTRs responsible for import have been determined for only a few of RPs (Chook and Süel, 2011). The 3rd-Z-4% cargoes include 15 RPs (Supplementary files 1, 5C, and 11B). To see the allocations of all the RPs to the NTRs, the ranks of the RPs in the 2nd-Z-rankings are arranged in a table (Figure 8). Because the +NTR/Ctl values were obtained for most of the RPs in the three SILAC-Tp replicates, the second Z-scores are the median Z-scores in most cases, and they should fairly reflect the import efficiencies. Half of the RPs are included in the 2nd-Z-15% cargoes of one to five NTRs, and most of the RPs are ranked in the top 30% in the 2nd-Z-rankings of additional NTRs. Surprisingly, most RPs, especially the 60S subunit proteins, are ranked in the top 50% of most of the 2nd-Z-rankings, and few RPs are ranked lower. These findings imply that most of the RPs are allocated to multiple NTRs, but the import efficiencies vary depending on the NTR. Indeed, several RPs are reported cargoes of multiple NTRs (Jäkel and Görlich, 1998; Jäkel et al., 2002). Imp-7, -8, and -9 primarily import RPs, Imp-11 and Exp-4 secondarily import RPs, and all other NTRs also contribute to the import of RPs to some extent. Among the highly homologous NTR pairs, Trn-2 and Imp-8 import RPs more efficiently than Trn-1 and Imp-7, respectively, which indicates that RP import is one of the roles shared unequally by similar NTRs. This differentiation is clearer in the 3rd-Z-rankings (Supplementary file 11B).
Figure 8
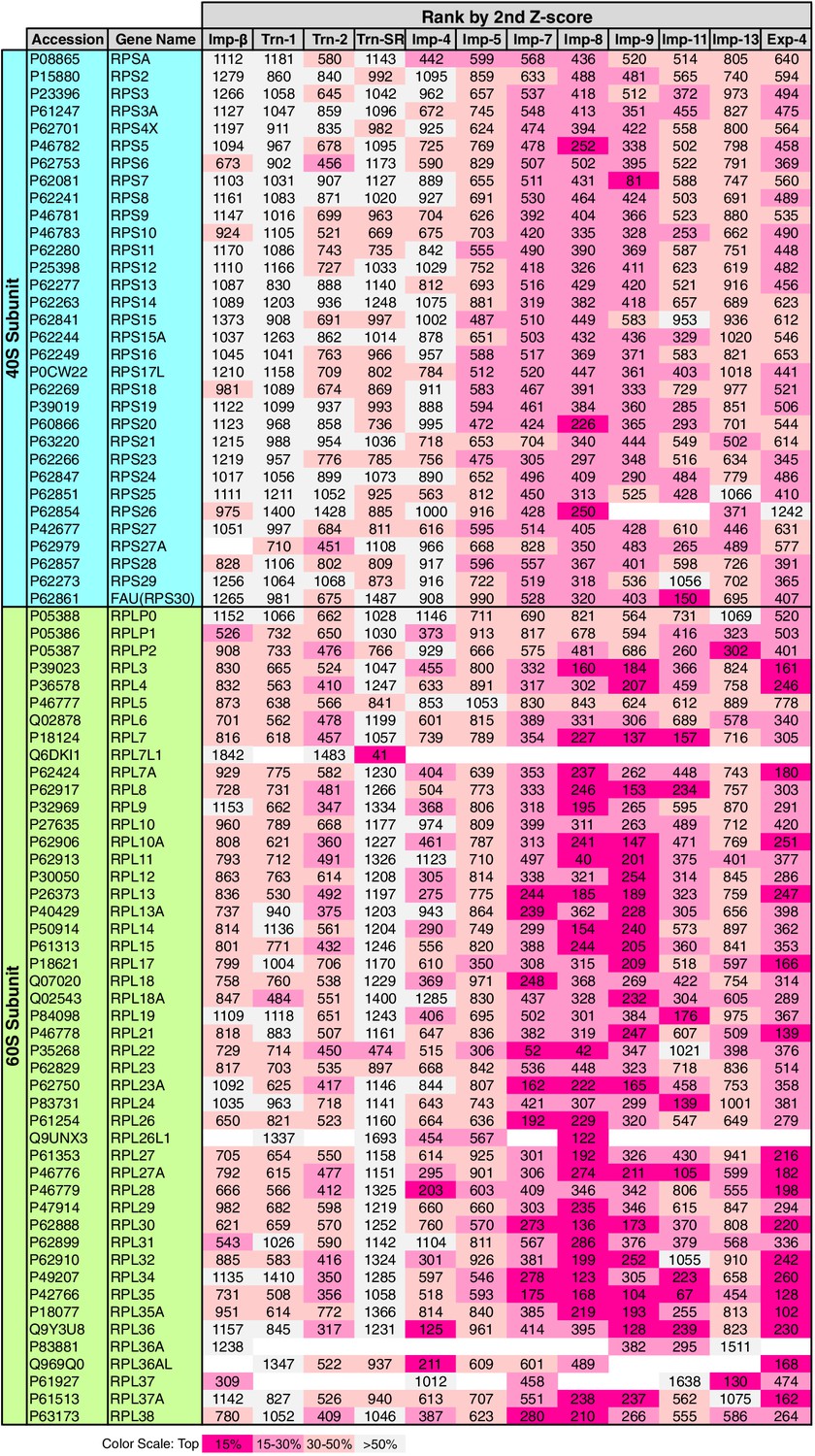
Ribosomal proteins in the 2nd-Z-rankings.
The ranks of the ribosomal proteins in the 2nd-Z-rankings of the 12 NTRs are presented. The color scale is set by the percentile rank as indicated. For the 3rd-Z-rankings, see Supplementary file 11B.
Allocation of transcription factors to the NTRs
Sequence-specific DNA-binding transcription factors (annotated with ‘transcription factor activity, sequence specific DNA binding’ in GO) play pivotal roles in many cellular processes, but they are not significantly enriched in the 3rd-Z-4% cargoes of any NTR (Supplementary file 6B). Transcription cofactors (annotated with ‘transcription factor activity, protein binding’), which may engage in gene-specific transcription, are significantly enriched in the 3rd-Z-4% cargoes of only three NTRs (Figure 6B; Supplementary file 6B). Nonetheless, transcription factors (sequence-specific DNA binding) are enriched in the Imp-β 2nd-Z-15% cargoes, and cofactors (protein binding) are enriched in the 2nd-Z-15% cargoes of 10 NTRs (Supplementary file 6C). Additionally, some transcription factors and cofactors are included in the 2nd-Z-15% cargoes, albeit not enriched. Thus, the 2nd-Z-15% cargoes of each NTR include 17 to 36 transcription factors or cofactors as listed at the bottom of Supplementary file 11D. We performed GO analyses (term type, BP) for these transcription factors and cofactors (Supplementary file 11C and 11D). The annotated terms may reflect both direct transcription regulation activities and indirect effects via transcription. The proteins annotated with histone modification are enriched in the Imp-β and -13 cargoes, and the term may reflect their direct functions. The cargoes of several NTRs annotated with varying types of nuclear receptor signaling may act as cofactors in receptor-regulated transcription. In contrast, many of the transcription factors and cofactors identified as cargoes are annotated differently with various terms related to cell proliferation, development, rhythmic processes, or apoptosis and may act on these processes via transcriptional regulation. Thus, the NTRs import transcription factors and cofactors that work in distinct cellular processes.
Characterizations of the cargoes of individual NTRs
The GO analyses elucidated the characteristics of the NTR-specific cargoes, but the terms are annotated to not only the central players but also many indirect participants in BPs. Here, we primarily discuss the roles of the notable 3rd-Z-4% cargoes of each NTR and supplement this information with references to the 2nd-Z-15% cargoes. To make our points clear, we classified the 3rd-Z-4% and 2nd-Z-15% cargoes by their characteristics and their allocations to each NTR are presented in Supplementary file 5C and 5E. We describe the features of the Imp-13 and Trn-SR cargoes first, because it includes the discussion on an export cargo or SR-domains. Biological functions linked to NTRs by the natures of their cargoes need to be verified by further experiments.
Imp-13 cargoes
Several Imp-13 cargoes have previously been reported, and our SILAC-Tp clearly reproduced the reported import specificities. Nuclear transcription factor Y subunits β (NFYB) and γ (NFYC) have been reported to be Imp-13 specific cargoes, whereas subunit α (NFYA), which has a BIB-like sequence, has been reported to bind to multiple NTRs (Kahle et al., 2005). NFYB is ranked first in both the Imp-13 2nd- and 3rd-Z-rankings, and NFYC is a 2nd-Z-15% cargo (Figure 3; Supplementary files 1 and 3). Additionally, we identified NFYA as a cargo of multiple NTRs. Interestingly, a subunit of the general transcription factor TFIIA (GTF2A2) that interacts with NFYA (Rolland et al., 2014) is also a highly ranked Imp-13 3rd-Z-4% cargo. We could not identify the Imp-13 reported cargo glucocorticoid receptor (Tao et al., 2006) in our MS, but proteins that may interact with nuclear receptors, e.g., thyroid hormone receptor-associated protein 3 (THRAP3) (Ito et al., 1999), RNA-binding protein 14 (RBM14) (Iwasaki et al., 2001), and transcription activator BRG1 (SMARCA4) (Dai et al., 2008), were identified as Imp-13 2nd-Z-15% cargoes. THRAP3 interacts with EJC (Lee et al., 2010), whose subunits, RNA-binding protein RBM8A and mago nashi homolog MAGOH, are well-characterized Imp-13 cargoes (Mingot et al., 2001). RBM8A and MAGOH are highly ranked Imp-13 3rd-Z-4% cargoes, which were not identified as cargoes of the other NTRs with the exception of Trn-1. However, another EJC subunit, that is, translation initiation factor 4A-III (EIF4A3) (Shibuya et al., 2004), was identified as an Imp-11 3rd-Z-4% cargo. Thus, the EJC subunits are imported through different pathways. A well-characterized Imp-13 cargo, SUMO-conjugating enzyme UBC9 (UBE2I) (Mingot et al., 2001), was identified as a 3rd-Z-4% cargo, and SUMO2 and SUMO3 were also identified as 3rd-Z-4% cargoes. Components of the chromatin accessibility complex CHRAC15 (CHRAC1) and DNA polymerase ε subunit 3 (POLE3) are also Imp-13 reported cargoes (Walker et al., 2009), and they are highly ranked 3rd-Z-4% cargoes. In the GO analysis, Imp-13 was linked to chromatin modification by the 2nd-Z-15% cargoes (Supplementary file 6A). Nucleolar complex protein 2 homolog (NOC2L) is ranked 10th in both the second and third Z-scores, and lysine-specific demethylase 2A (KDM2A) is ranked second in the second Z-score. The Imp-13 2nd-Z-15% cargoes include many actin-related proteins that are involved in chromatin remodeling and transcription (Oma and Harata, 2011; Yoo et al., 2007).
Surprisingly, a reported Imp-13 export cargo eIF1A (EIF1AX; Mingot et al., 2001) was identified as a 2nd-Z-15% cargo (ranked 84th and 164th by the second and third Z-score, respectively; Supplementary files 1 and 3). If a protein endogenous to the permeabilized cell nuclei is exported preferentially in the +NTR in vitro transport reaction, the (L/H+NTR)/(L/HCtl) value will be raised and the protein will be ranked high. However, it cannot be generalized because we have only one example. Most of the highly ranked Imp-13 cargoes must be import cargoes, because in all the bead halo assays where the cargoes bound to Imp-13 RanGTP inhibited the binding (Supplementary file 2).
Trn-SR cargoes
The reported Trn-SR cargoes include SR-rich splicing factors (SFs) that coordinate transcription elongation, mRNA splicing, and mRNA export (Zhong et al., 2009). Here, we found that proteins engaging in these processes are also Trn-SR cargoes. The Trn-SR 3rd-Z-4% cargoes include the RNA polymerase (RNAP) II elongation factors NELFE and PAF1 (a subunit of the Paf1 complex, PAF1C), DDX and DHX family RNA helicases, and the THO complex subunit THOC1 as well as SR-rich SFs. The 2nd-Z-15% cargoes additionally include PAF1C subunits CTR9, CDC73, and LEO, FACT complex subunits SSRP1 and SPT16, additional DDX and DHX family helicases, and THOC6 and THOC3 (Supplementary file 5C and 5E). Trn-SR bound to NELFE, CDC73, DDX5, and DDX27 in the bead halo assays (Figure 3, Supplementary files 1, 2, and 3). Peptidyl-prolyl cis-trans isomerases, which are contained in human spliceosomes (Wahl et al., 2009), were also identified as 3rd-Z-4% and 2nd-Z-15% cargoes. DnaJ homologs were also identified as 3rd-Z-4% and 2nd-Z-15% cargoes, although the spliceosome component DNAJC8 (Zhou et al., 2002) was not. The 3rd-Z-4% cargoes also include proteins related to nuclear division or chromosome segregation, the Ser/Thr protein kinase PLK1, dual specificity protein kinase TTK, G2/M-specific cyclin-B1 (CCNB1), cyclin-dependent kinase (CDK) 2, protein FAM83D, and dynein 1 light intermediate chain 1 (DYNC1LI1) in addition to proteins related to histone acetylation or deacetylation including histone deacetylase complex subunit SAP18 and SAGA-associated factor 29 homolog CCDC101. Indeed, in the bead halo assays, Trn-SR bound to SAP18 and CCDC101 (Figure 3; Supplementary files 1, 2, and 3). Additionally, the 2nd-Z-15% cargoes include many proteins that are related to nucleosome or chromatin regulation. Thus, the Trn-SR cargoes are involved in chromosome regulation in addition to the coordination of transcription elongation, mRNA splicing, and mRNA export.
Surprisingly, SR-rich SFs, which have been assumed to be Trn-SR-specific cargoes, were also identified as cargoes of other NTRs (Figure 7). To determine the allocation of the other SR-domain proteins to the NTRs, we here analyzed the distribution of SRSRSR hexa-peptide sequences in the 3rd-Z-4% cargoes (Supplementary file 11E). Imp-5, -7, -8, and Exp-4 as well as Trn-SR may be the specific NTRs for proteins with the hexa-peptide, most of which are nuclear proteins. The hexa-peptide-containing proteins other than the SR-rich SFs are primarily included in the Imp-5 and Exp-4 cargoes.
Imp-β cargoes
The Imp-β cargoes play roles in DNA synthesis and repair and chromatin regulation. The Imp-β 3rd-Z-4% cargoes include DNA polymerase δ subunits (POLD2 and 3) and mismatch repair endonuclease PMS2 (Supplementary file 5C). Additionally, the Imp-β 2nd-Z-15% cargoes include PCNA-associated factor KIAA0101 and DNA-(apurinic or apyrimidinic site) lyase (APEX1) (Supplementary file 5E). These proteins act in DNA synthesis or repair. The notable 3rd-Z-4% cargoes related to chromatin regulation include high-mobility group (HMG) proteins, histone acetyltransferase complex NuA4 subunit MRGBP, SWI/SNF-related regulator of chromatin SMARCE1, Spindlin-1 (SPIN1), chromodomain-helicase CHD8, and lymphoid-specific helicase HELLS. Additionally, the 2nd-Z-15% cargoes include the NuA4 subunit MORF4L2, SWI/SNF complex subunit SMARCC2, chromatin assembly factor 1 subunit CHAF1B, polycomb protein EED, and sister chromatid cohesion protein PDS5B. Chromatin remodeling by some of these factors is closely related to transcription. The 3rd-Z-4% cargoes include general transcription factor TFIIF (GTF2F1 and 2), TFIIH subunit MAT1, and TBP-associating factor TAF15, and the 2nd-Z-15% cargoes include TFIIH subunit cyclin-H (CCNH) and mediator complex subunit MED15. The sequence-specific transcription factors and cofactors are described above. mRNA capping factors are Imp-β cargoes as described. Thus, many Imp-β cargoes are related to the initial stage of gene expression.
Trn-1 and -2 cargoes
The transcription factor ATF1 was ranked first in both the 2nd- and 3rd-Z-rankings of the Trn-1 and -2 but was ranked low for the other NTRs (Figure 3; Supplementary files 3 and 5). As described, many of the cargoes that ranked higher in the Trn-1 and -2 2nd- and 3rd-Z-rankings (e.g. hnRNPs) are shared by Trn-1 and -2, but RPs are included only in the Trn-2 3rd-Z-4% cargoes. Additional divergences can be observed between their 2nd-Z-15% cargoes. As expected, their cargoes include many mRNA processing factors, but among them snRNPs are preferentially included in the Trn-2 2nd-Z-15% cargoes (Figure 7). Actin and actin-related proteins (ARPs), which play roles in chromatin remodeling and transcription (Visa and Percipalle, 2010; Yoo et al., 2007), proteins related to nuclear division, and tRNA ligases are preferentially Trn-1 cargoes, whereas proteins related to DNA repair and HMG proteins are preferentially Trn-2 cargoes (Supplementary file 5E).
Imp-4 cargoes
In the GO analysis, Imp-4 was linked to DNA metabolic processes, chromosome organization, and related terms (Figures 5 and 6). Consistently, replication factor C subunit 5 (RFC5) and HMG proteins are Imp-4 3rd-Z-4% cargoes, and the 2nd-Z-15% cargoes include DNA polymerase α subunit POLA1, DNA ligase I (LIG1), DNA topoisomerase I (TOP1), SWI/SNF complex subunit SMARCC2, the SWI/SNF-related chromatin regulator SMARCA5, nucleosome remodeling factor subunit BPTF, and FACT complex subunit SPT16 (Supplementary file 5C and 5E). The participation of the Imp-4 cargoes in chromatin organization is supported by a report that Imp-4 binds to the histone chaperon complex (Tagami et al., 2004), although the subunits were not identified in our MS. Imp-4 was also linked to cell cycle in the GO analysis. The Imp-4 3rd-Z-4% cargoes include the regulator of chromosome condensation RCC1 and the Ser/Thr protein kinase PLK1, and the 2nd-Z-15% cargoes include the sister chromatid cohesion protein PDS5 homolog PDS5B. Imp-4 was also linked to programed cell death or apoptosis in the GO analysis. The representative related 3rd-Z-4% cargoes are the death-promoting transcriptional repressor BCLAF1 and the tumor suppressor ARF (CDKN2A), and the 2nd-Z-15% cargoes are ribosomal L1 domain-containing protein 1 (RSL1D1) and apoptosis-inducing factor 1 (AIFM1).
Imp-5 cargoes
Few characteristics are unique to the Imp-5 3rd-Z-4% cargo cohort. However, this cohort includes proteins related to ribosome biogenesis, such as rRNA 2'-O-methyltransferase fibrillarin (FBL), H/ACA ribonucleoprotein complex subunit 1 (GAR1), and the ribosome biogenesis protein BOP1. This group also includes proteins related to nucleosome or chromatin organization, including spindlin-1 (SPIN1), protein DEK, the methyl-CpG-binding domain protein MBD2, and the paired amphipathic helix protein SIN3B (Supplementary file 5C). SR-rich SFs are also included as described. The Imp-5 2nd-Z-15% cargoes include many ARPs, proteins related to spindle organization or microtubule-based processes, and several CDKs (Supplementary file 5E). Thus, a portion of the Imp-5 cargoes may be involved in cytokinesis. A number of translation initiation factors (eIFs) and elongation factors, many of which are annotated with nuclear localization (Supplementary file 1), are also among the Imp-5 2nd-Z-15% cargoes.
Imp-7 and -8 cargoes
The cognate NTRs Imp-7 and -8 share many 3rd-Z-4% and 2nd-Z-15% cargoes (Figure 4; Supplementary file 5A). The major cargoes of these NTRs are a range of mRNA SFs, but by the third Z-scores, snRNPs were identified only as Imp-7 and not Im-8 cargoes (Supplementary file 5C). Additional divergences can be observed between the Imp-7 and -8 cargoes (Supplementary file 5C and 5E). HMG proteins were identified only as Imp-7 3rd-Z-4% and 2nd-Z-15% cargoes, whereas more RPs were identified as Imp-8 cargoes. Proteins related to cell cycle regulation, the mitotic checkpoint protein BUB3, cell division cycle 5-like protein (CDC5L), and CDK12, are included in the Imp-7 3rd-Z-4% cargoes, and the Ser/Thr protein kinase PLK1 is a 2nd-Z-15% cargo, but these proteins are not Imp-8 cargoes. Many eIFs are Imp-8 but not Imp-7 2nd-Z-15% cargoes.
Imp-9 cargoes
The Imp-9 cargoes include many RPs and mRNA SFs. Proteins that are important for DNA packaging or nucleosome organization were also identified as Imp-9 cargoes (Supplementary file 5C and 5E). Histone H2A.Z, which is located in specific regions on chromosome (Weber and Henikoff, 2014), is ranked first and third in the third and second Z-scores, respectively. Additionally, the linker histone H1 (H1F0), histone-lysine N-methyltransferase 2A (KMT2A), and the SPT16 and SSRP1 subunits of the FACT complex, which regulates histone H2A.Z (Jeronimo et al., 2015), were also identified as 3rd-Z-4% cargoes. Among the Imp-9 2nd-Z-15% cargoes, other histones, DNA topoisomerase I (TOP1) and IIα (TOP2A), HMG proteins, SWI/SNF-related matrix-associated actin-dependent regulator of chromatin subfamily E member 1 (SMARCE1), and scaffold attachment factor B1 (SAFB) are included.
Imp-11 cargoes
Imp-11 was linked to developmental processes in the GO analysis (Figure 5; Supplementary file 6A), and few proteins with typical nuclear functions, such as DNA replication, nucleosome organization, and transcription, were found among the Imp-11 3rd-Z-4% cargoes (Supplementary file 5C). The Imp-11 2nd-Z-15% cargoes include several proteins related to nuclear division, such as Pogo transposable element with ZNF domain (POGZ), α-endosulfine (ENSA), CDK regulatory subunit 2 (CKS2), and the Ser/Thr protein kinase NEK7 (Supplementary file 5E). Many ARPs, tubulins and their related factors, tRNA ligases, and mRNA SFs are also in the Imp-11 2nd-Z-15% cargoes.
Exp-4 cargoes
The subunits of RNAP II elongation factors and mRNA processing factors are the representative Exp-4 cargoes, although they are also cargoes of several other NTRs (Supplementary file 5C and 5E). PAF1C subunit parafibromin (CDC73) is an Exp-4 3rd-Z-4% cargo, and other PAF1C subunits, that is, PAF1 and RTF1, FACT complex subunits, i.e., SSRP1 and SPT16 (SUPT16H), and elongation complex protein 2 (ELP2) are 2nd-Z-15% cargoes. A variety of mRNA processing factors, including 3’-end processing factors and THO complex subunits, are also Exp-4 3rd-Z-4% and 2nd-Z-15% cargoes. Thus, the factors that act in processes from transcription elongation to mRNA export are included in the Exp-4 cargoes. As discussed for another bi-directional NTR Imp-13, the possibility cannot be denied that the identified Exp-4 candidate cargoes include export cargoes.
Seemingly non-nuclear proteins
A number of nucleoporins (NUPs), which are the components of the NPC, were identified as cargoes. Increasing evidence demonstrates that the import of NUPs through NPCs is important for gene expression (Burns and Wente, 2014). Moreover, many mitochondrial proteins are highly ranked. These proteins preferentially localize to the mitochondria due to chaperon-regulated or cotranslational mechanisms in vivo and might interact with NTRs in the in vitro transport system. The transport system contains cytosolic extract and unlabeled (light) mitochondrial proteins in it could be imported if they interact with NTRs. The (L/H+NTR)/(L/HCtl) values of them can be calculated, because LC-MS/MS can quantify low levels of labeled (heavy) proteins whether they are endogenous to the recipient nuclei or residual after washing. Thus, mitochondrial proteins with high (L/H+NTR)/(L/HCtl) values are imported proteins even if the import is fortuitous. Nuclear localization is annotated to many mitochondrial proteins (Supplementary file 1), and actual nuclear localization is possible as in the cases of AIFM1 and ATFS-1 (Nargund et al., 2012; Susin et al., 1999). As was the case with the high-throughput cargo identification of the export receptor Exp-1 (CRM1) (Kırlı et al., 2015), our method identified other seemingly cytoplasmic proteins as cargoes. We did not detect direct binding between the NTRs and some of these cytoplasmic proteins, for example, Ras-related Rab family proteins and S100 proteins, in the bead halo assays (Supplementary file 2), but nuclear import by indirect binding is still possible.
Additional remarks
Here, we have presented the first complete picture of nuclear import via the 12 importin pathways. The 12 pathways must serve distinct roles because the NTRs are linked to different cellular processes by their cargoes. However, the cargoes are intricately allocated to the NTRs, and each NTR is linked to multiple cellular processes. The biological functions of NTRs designated in this work should be further clarified in future experiments.
We used HeLa nuclear extract as the cargo source, but it might not reconstitute all NTR–cargo interactions precisely because proteins in the nuclear extract might have different modifications or binding partners from those in cytoplasm where NTRs bind to cargoes in vivo. Some reported cargoes were ranked lower in the 2nd- and 3rd-Z-ranking, and it might be attributable to these differences of protein states. Alternatively, the transport capacity of our in vitro transport system might not be enough to identify all the cargoes, especially those with low transport efficiency. To reach a definitive conclusion, experiments in vivo might be needed.
We could not find any novel motifs that may serve as NTR-binding sites on the identified cargoes using the ungapped motif search method of MEME (Bailey and Elkan, 1994). A more extensive search for such motifs and higher order structures using alternative methods is currently underway.
Materials and methods
SILAC-Tp
Request a detailed protocolSILAC-Tp has previously been described in detail (Kimura et al., 2014), but we provide a brief description here. HeLa-S3 cytosolic and nuclear extracts were depleted of Imp-β family NTRs with phenyl-Sepharose (GE healthcare), and the nuclear extract was subsequently depleted of RCC1 with a Ran-affinity method and concentrated. The extracts were dialyzed against transport buffer (TB, 20 mM HEPES–KOH (pH 7.3), 110 mM KOAc, 2 mM MgOAc, 5 mM NaOAc, 0.5 mM EGTA, 2 mM DTT, and 1 μg/mL each of aprotinin, pepstatin A, and leupeptin). Adherent HeLa-S3 cells were labeled with u-13C6 Lys and u-13C6 Arg by SILAC (Ong et al., 2002) and seeded onto a glass plate. After rinsing in ice cold TB, the cells were permeabilized with 40 μg/mL digitonin in TB for 5 min on ice and then rinsed again. The permeabilized cells were pretreated with 4 μM RanGDP and an ATP regeneration system in TB for 20 min at 30°C to remove the residual Imp-β family NTRs and then rinsed. The cells were incubated in transport mixture (50% cytosolic extract, 10% nuclear extract, 1 μM p10/NTF2, and ATP regeneration system in TB) with (+NTR) or without (Ctl) 0.3–0.7 μM of one NTR for 20 min at 30°C for the import reaction. (The NTR concentrations were optimized using the recombinant cargoes presented in Figure 1—figure supplement 1C.) After rinsing, the cells were incubated in extract mixture (50% cytosolic extract and ATP regeneration system in TB) for 20 min at 30°C and rinsed with NaCl-TB (TB containing 110 mM NaCl instead of KOAc) to remove the nonspecifically binding proteins. To extract the proteins, the cells were suspended in nuclear buffer (20 mM Tris–HCl, pH 8.0, 420 mM NaCl, 1.5 mM MgCl2, 0.2 mM EDTA, 2 mM DTT, and 1 μg/mL each of aprotinin, pepstatin A, and leupeptin), sonicated, and centrifuged.
Actually, the transport reactions for two NTRs were simultaneously performed with one control reaction and triplicated. The simultaneously processed NTRs were Imp-β and Imp-13, Trn-1 and -2, Imp-7 and -8, Imp-9 and -11, and Imp-5 and Trn-SR, and the reactions for Imp-4 and Exp-4 were performed individually with controls.
Peptide analysis by LC-MS/MS
Request a detailed protocolAfter the in vitro transport reaction, 25 μg each of the extracted proteins was concentrated by acetone precipitation, reduced with DTT, and alkylated with iodoacetamide. The proteins were digested with trypsin and Lys-C endopeptidase (enzyme/substrate ≈ 1/50) for 16 hr at 37°C. The peptides were evaporated to dryness, dissolved in Solvent-1 (0.1% TFA and 15% CH3CN), and fractionated on Empore Cation Exchange-SR (3M, Maplewood, Minnesota). For the fractionation, the support was stacked manually inside the tapered end of a micropipette tip, the tip was fixed into the punched lid of a microtube, and the liquids were run by centrifugation (Wiśniewski et al., 2009). The resin was sequentially washed by ethanol and Solvent-1 containing 500 mM ammonium acetate and equilibrated with Solvent-1, and the peptides were then applied. After washing in Solvent-1, the peptides were eluted stepwise by Solvent-1 containing 125, 250, and 500 mM ammonium acetate and Solvent-2 (5% NH4OH, 30% methanol, and 15% CH3CN). The eluates were evaporated to dryness, and the peptides were dissolved in 0.1% TFA and 2% CH3CN.
The peptides were applied to a liquid chromatograph (LC) (EASY-nLC 1000; Thermo Fisher Scientific, Waltham, Massachusetts) coupled to a Q Exactive hybrid quadrupole-Orbitrap mass spectrometer (Thermo Fisher Scientific) with a nanospray ion source in positive mode. The LC was performed on a NANO-HPLC capillary column C18 (75 μm x 150 mm, 3 μm particle size, Nikkyo Technos, Tokyo) at 45°C. The peptides were eluted with a 100-min 0–30% CH3CN gradient and a subsequent 20-min 30–65% gradient in the presence of 0.1% formic acid at a flow rate of 300 nL/min. The Q Exactive-MS was operated in the top-10 data-dependent scan mode. The parameters for the Q Exactive operation were as follows: spray voltage, 2.3 kV; capillary temperature, 275°C; mass range (m/z), 350–1800; and normalized collision energy, 28%. The raw data were acquired with Xcalibur (RRID:SCR_014593; ver. 2.2 SP1).
Protein identification and quantitation
Request a detailed protocolThe MS and MS/MS data were searched against the Swiss-Prot database (2014_07–2016_01) using Proteome Discoverer (RRID:SCR_014477; ver. 1.4, Thermo Fisher Scientific) with the MASCOT search engine software (RRID:SCR_014322; ver. 2.4.1, Matrix Science, London). The search parameters were as follows: taxonomy, Homo sapiens; enzyme, trypsin; static modifications, carbamidomethyl (Cys); dynamic modifications, oxidation (Met); precursor mass tolerance, ±6 ppm; fragment mass tolerance, ±20 mDa; maximum missed cleavages, 1; and quantitation, SILAC (R6, K6). The proteins were considered identified when their false discovery rates were less than 5%. The SILAC L/H ratios were also calculated by Proteome Discoverer (ver. 1.4) with the default setting: show the raw quan values, false; minimum quan value threshold, 0; replace missing quan values with minimum intensity, false; use single-peak quan channels, false; apply quan value corrections, true; reject all quan values if not all quan channels are present, false; fold change threshold for up-/down-regulation, 1.5; maximum allowed fold change, 100; use ratios above maximum allowed fold change for quantification, false; percent co-isolation excluding peptides from quantification, 100; protein quantification, use only unique peptides; experimental bias, none. Proteins with L/H count ≥1 were included in further analysis. The L/H counts are shown in Supplementary file 1. To access the mass spectrometry data, see below.
From the SILAC quantitation values of the control and +NTR reactions, the +NTR/Ctl = (L/H+NTR)/(L/HCtl) ratio of each protein was calculated, and the Z-score of the log2(+NTR/Ctl) of each protein was calculated within each replicate.
where is of each protein, is the mean of , and is the standard deviation of .
Reported cargo rate and recall
Request a detailed protocolTo calculate reported cargo rate (a lower bound on precision) and recall (sensitivity), we used the 27 and 25 reported cargoes of Trn-1 as the positive examples of the 2nd- and 3rd-Z-rankings, respectively. We do not have explicit labeling of negative examples. Most likely some portion of the proteins not reported as cargoes are genuine cargoes, but it is difficult to estimate that portion. Therefore, as a rough guide we tallied statistics under two simple assumptions: (i) that all proteins not reported as cargoes should be treated as negative examples and (ii) that in the proteins not reported as cargoes, proteins annotated in Uniprot (RRID:SCR_002380) as having non-nuclear subcellular localization should be treated as negative examples and the other proteins excluded from the analysis (treated as neither positive nor negative). The first definition yielded 1622 and 1210 negative examples in the 2nd- and 3rd-Z-ranking, respectively, and the second definition 259 and 178 in the 2nd- and 3rd-Z-ranking, respectively. Since the first definition is maximally pessimistic, it allows estimation of an upper bound on the rate of false positives, while the second definition is more optimistic.
where denotes the number of previously reported cargoes (a lower bound on the number of positive examples) and denotes the number of negative examples in the top i%; while denotes the total number of previously reported cargoes.
Gene ontology analysis
Request a detailed protocolGO (RRID:SCR_002811) analyses were performed using g:Profiler (RRID:SCR_006809; r1488-1536_e83_eg30) (Reimand et al., 2016). The search parameters were the following: organism, Homo sapiens; significance threshold, g:SCS; statistical domain size, all known genes; GO version, GO direct 2015-12-09 to 2016-01-21, releases/2015-12-08.
Phylogenetic analysis of the 12 Imp-β family NTRs
Request a detailed protocolThe phylogeny was inferred by maximum likelihood using RAxML (RRID:SCR_006086; ver. 8.1.17) (Stamatakis, 2006) with 1000 bootstrap replicates and the LG model with gamma-distributed rate variation. The amino acid sequences were aligned using Clustal Omega (RRID:SCR_001591; ver. 1.2.0) (Sievers et al., 2011) with the default parameters, and the resulting multiple alignments were trimmed using trimAl (ver. 1.2) (Capella-Gutiérrez et al., 2009) in gappyout mode.
Hierarchical clustering of the 11 Imp-β family NTRs based on the degree of overlap of the 3rd-Z-4% cargoes
Request a detailed protocolWe performed a hierarchical clustering of the Imp-β family NTRs based on their cargo profile similarities using Ward's method with Euclidean distance as implemented in the software R (RRID:SCR_001905; R Development Core Team, 2012). Here, we omitted Imp-β because its cargoes include many Imp-α-dependent indirect cargoes. To define a cargo profile for each NTR, we first defined a set of cargoes by merging the 3rd-Z-4% cargoes of the 11 NTRs other than Imp-β, which yielded a total of 426 cargoes. We then defined length 426 binary vectors for each NTR with a 1 for each cargo in the top 4% list and a 0 otherwise and input these 11 vectors into R to perform the clustering.
Bead halo assay
Request a detailed protocolThe proteins and Escherichia coli extracts were prepared as described (Kimura et al., 2013a). The bead halo assays (Supplementary file 2) were performed as described (Patel and Rexach, 2008). Briefly, GST or GST-NTR was immobilized on glutathione-Sepharose (GE healthcare), and mixed with an extract of E. coli expressing a GFP-fusion protein in EHBN buffer (10 mM EDTA, 0.5% 1,6-hexanediol, 10 mg/mL bovine serum albumin, and 125 mM NaCl), and the binding was observed by fluorescent microscopy. The GTP-fixed mutant of Ran Q69L-Ran, which inhibits specific NTR–cargo interactions, was added to determine the specificity of the binding. The expression and degradation levels of the GFP-fusion proteins were analyzed, and the concentrations of GFP-moieties were quantified by triplicate quantitative Western blotting of the extracts with an anti-GFP antibody. Because the GFP-moiety weakly bound to GST-Trn-1, GST-Trn-2, and GST-Trn-SR in the bead halo assay, the concentrations of the GFP-fusion proteins and GFP (control) were equalized, and images were acquired and processed under identical condition. In contrast, because the GFP-moiety does not bind to GST-Imp-13, GST-Imp-β, or GST-Imp-α, the control reaction mixture for these NTRs contained higher concentration of GFP than any other GFP-fusion proteins. Three images (GST, GST-NTR, and GST-NTR + Q69L-Ran) for each GFP-fusion protein were acquired under identical conditions, and the background intensities and dynamic ranges were equalized.
Cell line
Request a detailed protocolHeLa-S3 (RRID:CVCL_0058; mycoplasma, not detected) was obtained from Dr. Fumio Hanaoka (RIKEN).
Antibodies
GFP-fusion proteins used for in vitro transport
Request a detailed protocolThe GFP-fusion proteins used in Figure 1—figure supplement 1C were prepared as described (Kimura et al., 2013a). For accessions and references, see Supplementary file 12B. The SOX2 cDNA (pF1KB9652) was from Kazusa DNA Res. Inst. (Kisarazu, Japan), and the others were cloned from a HeLa cDNA library (SuperScript, Life Technology) by PCR.
Database deposition
Request a detailed protocolThe mass spectrometry proteomics data have been deposited to the ProteomeXchange Consortium (RRID:SCR_004055; http://www.proteomexchange.org/) via the PRIDE (RRID:SCR_003411; Vizcaíno et al., 2016) partner repository with the dataset identifier PXD004655.
The .msf and .raw data files of each experiment summarized in Supplementary file 1 are listed in Supplementary file 12A. The protein and peptide quantitation results can be seen by opening .msf files by Proteome Discoverer software. To see spectra and chromatograms, .msf files and corresponding .raw files must be in the same local directory. A demo version of Proteome Discoverer can be downloaded at the Thermo Scientific omics software portal site (https://portal.thermo-brims.com/).
Data availability
-
SILAC-Tp (12 importins)Publicly available at the Pride Archive (accession no: PXD004655).
References
-
Nuclear protein import in permeabilized mammalian cells requires soluble cytoplasmic factorsThe Journal of Cell Biology 111:807–816.https://doi.org/10.1083/jcb.111.3.807
-
ConferenceFitting a mixture model by expectation maximization to discover motifs in biopolymersProceedings of the Second International Conference on Intelligent Systems for Molecular Biology. pp. 28–36.
-
The cleavage of HuR interferes with its transportin-2-mediated nuclear import and promotes muscle fiber formationCell Death and Differentiation 17:1588–1599.https://doi.org/10.1038/cdd.2010.34
-
From hypothesis to mechanism: uncovering nuclear pore complex links to gene expressionMolecular and Cellular Biology 34:2114–2120.https://doi.org/10.1128/MCB.01730-13
-
Nuclear import by karyopherin-βs: recognition and inhibitionBiochimica et Biophysica Acta (BBA) - Molecular Cell Research 1813:1593–1606.https://doi.org/10.1016/j.bbamcr.2010.10.014
-
Gene Ontology Consortium: going forwardNucleic acids research 43:D1049–1056.https://doi.org/10.1093/nar/gku1179
-
Importin alpha: a multipurpose nuclear-transport receptorTrends in Cell Biology 14:505–514.https://doi.org/10.1016/j.tcb.2004.07.016
-
Transport between the cell nucleus and the cytoplasmAnnual Review of Cell and Developmental Biology 15:607–660.https://doi.org/10.1146/annurev.cellbio.15.1.607
-
CRM1-mediated nuclear export: to the pore and beyondTrends in Cell Biology 17:193–201.https://doi.org/10.1016/j.tcb.2007.02.003
-
Transportin-SR, a nuclear import receptor for SR proteinsThe Journal of Cell Biology 145:1145–1152.https://doi.org/10.1083/jcb.145.6.1145
-
Identification of cargo proteins specific for the nucleocytoplasmic transport carrier transportin by combination of an in vitro transport system and stable isotope labeling by amino acids in cell culture (SILAC)-based quantitative proteomicsMolecular & Cellular Proteomics 12:145–157.https://doi.org/10.1074/mcp.M112.019414
-
Novel approaches for the identification of nuclear transport receptor substratesMethods in Cell Biology 122:353–378.https://doi.org/10.1016/B978-0-12-417160-2.00016-3
-
Crystal structure of the karyopherin Kap121p bound to the extreme C-terminus of the protein phosphatase Cdc14pBiochemical and Biophysical Research Communications 463:309–314.https://doi.org/10.1016/j.bbrc.2015.05.060
-
Structural basis for cell-cycle-dependent nuclear import mediated by the karyopherin Kap121pJournal of Molecular Biology 425:1852–1868.https://doi.org/10.1016/j.jmb.2013.02.035
-
Classical nuclear localization signals: definition, function, and interaction with importin alphaJournal of Biological Chemistry 282:5101–5105.https://doi.org/10.1074/jbc.R600026200
-
TRAP150 activates pre-mRNA splicing and promotes nuclear mRNA degradationNucleic Acids Research 38:3340–3350.https://doi.org/10.1093/nar/gkq017
-
The p53-induced factor Ei24 inhibits nuclear import through an importin β-binding-like domainThe Journal of Cell Biology 205:301–312.https://doi.org/10.1083/jcb.201304055
-
Expression of nucleocytoplasmic transport machinery: clues to regulation of spermatogenic developmentBiochimica et Biophysica Acta (BBA) - Molecular Cell Research 1813:1668–1688.https://doi.org/10.1016/j.bbamcr.2011.03.008
-
Importin 13: a novel mediator of nuclear import and exportThe EMBO Journal 20:3685–3694.https://doi.org/10.1093/emboj/20.14.3685
-
Stable isotope labeling by amino acids in cell culture, SILAC, as a simple and accurate approach to expression proteomicsMolecular & Cellular Proteomics 1:376–386.https://doi.org/10.1074/mcp.M200025-MCP200
-
Nuclear transport factors in neuronal functionSeminars in Cell & Developmental Biology 20:600–606.https://doi.org/10.1016/j.semcdb.2009.04.014
-
Evolutionary and transcriptional analysis of karyopherin beta superfamily proteinsMolecular & Cellular Proteomics 7:1254–1269.https://doi.org/10.1074/mcp.M700511-MCP200
-
SoftwareR: A Language and environment for statistical computingR Foundation for Statistical Computing, Vienna, Austria.
-
G:Profiler-a web server for functional interpretation of gene lists (2016 update)Nucleic Acids Research 44:W83–W89.https://doi.org/10.1093/nar/gkw199
-
Transport Selectivity of nuclear pores, Phase Separation, and Membraneless OrganellesTrends in Biochemical Sciences 41:46–61.https://doi.org/10.1016/j.tibs.2015.11.001
-
eIF4AIII binds spliced mRNA in the exon junction complex and is essential for nonsense-mediated decayNature Structural & Molecular Biology 11:346–351.https://doi.org/10.1038/nsmb750
-
Nuclear localization signals for four distinct karyopherin-β nuclear import systemsBiochemical Journal 468:353–362.https://doi.org/10.1042/BJ20150368
-
Identification of ZNF217, hnRNP-K, VEGF-A and IPO7 as targets for microRNAs that are downregulated in prostate carcinomaInternational Journal of Cancer 132:775–784.https://doi.org/10.1002/ijc.27731
-
Importin 13 regulates nuclear import of the glucocorticoid receptor in airway epithelial cellsAmerican Journal of Respiratory Cell and Molecular Biology 35:668–680.https://doi.org/10.1165/rcmb.2006-0073OC
-
Identification of CRM1-dependent nuclear export cargos using quantitative mass spectrometryMolecular & Cellular Proteomics 12:664–678.https://doi.org/10.1074/mcp.M112.024877
-
Nuclear functions of actinCold Spring Harbor Perspectives in Biology 2:a000620.https://doi.org/10.1101/cshperspect.a000620
-
2016 update of the PRIDE database and its related toolsNucleic Acids Research 44:D447–D456.https://doi.org/10.1093/nar/gkv1145
-
Transportin 2 regulates apoptosis through the RNA-binding protein HuRJournal of Biological Chemistry 286:25983–25991.https://doi.org/10.1074/jbc.M110.216184
-
Importin 13 mediates nuclear import of histone fold-containing chromatin accessibility complex heterodimersJournal of Biological Chemistry 284:11652–11662.https://doi.org/10.1074/jbc.M806820200
-
Repression of classical nuclear export by S-nitrosylation of CRM1Journal of Cell Science 122:3772–3779.https://doi.org/10.1242/jcs.057026
-
Histone variants: dynamic punctuation in transcriptionGenes & Development 28:672–682.https://doi.org/10.1101/gad.238873.114
-
Blm10 facilitates nuclear import of proteasome core particlesThe EMBO Journal 32:2697–2707.https://doi.org/10.1038/emboj.2013.192
-
Combination of FASP and StageTip-based fractionation allows in-depth analysis of the hippocampal membrane proteomeJournal of Proteome Research 8:5674–5678.https://doi.org/10.1021/pr900748n
-
A novel role of the actin-nucleating Arp2/3 complex in the regulation of RNA polymerase II-dependent transcriptionJournal of Biological Chemistry 282:7616–7623.https://doi.org/10.1074/jbc.M607596200
Article and author information
Author details
Funding
Japan Society for the Promotion of Science (KAKENHI,15K07064)
- Makoto Kimura
RIKEN (FY2014 Incentive Research Project)
- Makoto Kimura
Japan Agency for Medical Research and Development (Platform Project for Supporting in Drug Discovery and Life Science Research)
- Kenichiro Imai
Japan Society for the Promotion of Science (KAKENHI,26251021)
- Naoko Imamoto
Japan Society for the Promotion of Science (KAKENHI,26116526)
- Naoko Imamoto
Japan Society for the Promotion of Science (KAKENHI,15H05929)
- Naoko Imamoto
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Martin Beck, Alessandro Ori, and Kentaro Tomii for helpful discussion, Masahiro Oka for a supporting experiment, Shoko Motohashi and Ai Watanabe for technical assistance, and Hiroshi Mamada for a plasmid. We also thank the Support Unit for Bio-Material Analysis, RIKEN BSI Research Resource Center, especially Kaori Otsuki, Masaya Usui, and Aya Abe for MS analysis. This work was supported by JSPS KAKENHI Grant Number 15K07064 and a RIKEN FY2014 Incentive Research Project to MK, KAKENHI Grant Numbers 26251021, 26116526, and 15H05929 to NI, and the Platform Project for Supporting in Drug Discovery and Life Science Research (Platform for Drug Discovery, Informatics, and Structural Life Science) from the Japan Agency for Medical Research and Development (AMED) to KI.
Copyright
© 2017, Kimura et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 5,132
- views
-
- 1,024
- downloads
-
- 112
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 112
- citations for umbrella DOI https://doi.org/10.7554/eLife.21184
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Extensive cargo identification reveals distinct biological roles of the 12 importin pathways
eLife 6:e21184.
https://doi.org/10.7554/eLife.21184




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}