Mathematical Modeling: Telomeres open a window on stem cell division
- University of California Irvine, United States
Stem cells are undifferentiated cells that can develop into more specialized cells. There are two kinds of stem cells: embryonic stem cells and adult stem cells. Embryonic stem cells are active during early development and give rise to all the different cell types in the body. Adult stem cells are specific to each tissue and give rise to all the specialized cells in a particular tissue or organ. When a stem cell divides, each new cell has the potential to either remain a stem cell or differentiate into a more specialized type of cell (Figure 1A). However, it can be difficult to analyze these division patterns in humans. Now, in eLife, Benjamin Werner, Fabian Beier, Arne Traulsen and colleagues have used a mathematical model to reconstruct the dynamics of blood stem cells from measurements of telomere length (Werner et al., 2015).
Figure 1
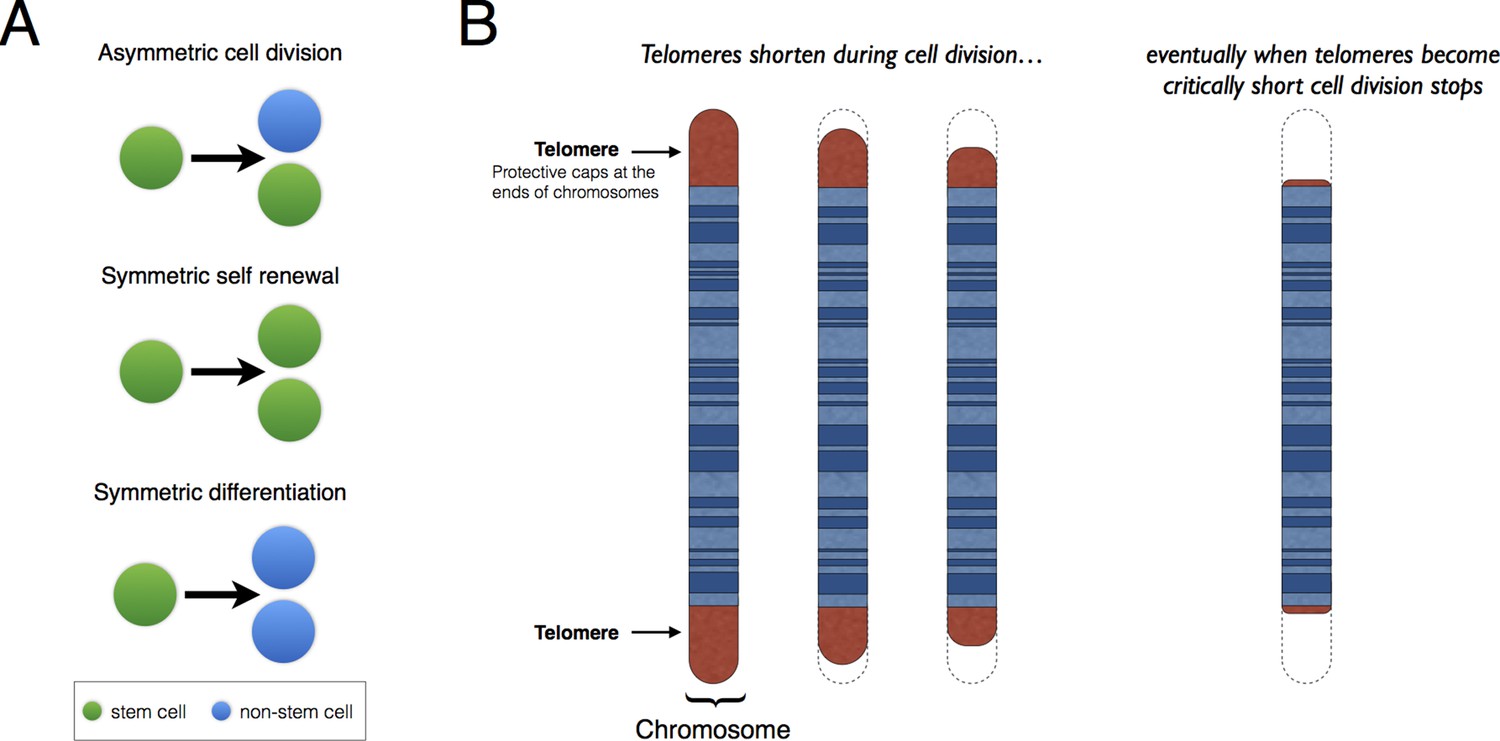
Patterns of stem cell division and the protective role of telomeres.
(A) Stem cells can divide asymmetrically to produce a new stem cell and a non-stem cell that can differentiate to replace other types of cells that are lost from the tissue because of cell death (top). Stem cells can also divide symmetrically, producing two daughter stem cells (symmetric self-renewal, middle) or two non-stem cells (symmetric differentiation, bottom). (B) Telomeres are the regions of DNA that cap and protect the ends of linear chromosomes. Each time a cell divides the telomeres get shorter. When telomeres become too short, cell division stops.
Telomeres are lengths of DNA that cap both ends of linear chromosomes (Figure 1B), and they protect the chromosomes by preventing their natural ends from being interpreted as breaks in the DNA. During cell division, the enzymes that duplicate DNA cannot copy the very ends of chromosomes; this ‘end-replication problem’ is part of the reason why the telomeres get shorter each time a cell divides (Martinez and Blasco, 2015). When telomeres become very short, they lose their protective properties and cell division stops. This process is known as ‘replicative senescence’ and is correlated with aging: put simply, telomeres get shorter as people get older.
Replicative senescence is believed to have evolved as a means to curb excessive cell division, which is a hallmark of cancer. However, human cancers find ways to bypass this process, typically by expressing an enzyme called telomerase that acts to lengthen the telomeres. Telomerase is highly active in embryonic stem cells, but it is not expressed in most normal cells.
Werner, Beier, Traulsen and colleagues – who are based at the Max Planck Institute for Evolutionary Biology, RWTH Aachen University Hospital, University Hospital Zürich and the Mayo Clinic – measured the average telomere lengths from blood samples taken from 356 individuals aged between 0 and 85 years old. Two alternative models of stem cell dynamics were then analyzed. The first model considered that the stem cells only divide asymmetrically, producing one stem cell and one non-stem cell. The second model included both asymmetric cell division and symmetric self-renewal (where a stem cell divides to form two daughter stem cells; Figure 1A). Werner, Beier et al. found that the first model predicted a linear relationship between average telomere length and the donor’s age, whereas the second model predicted a nonlinear decrease in telomere length. The data strongly favored the second model.
The findings suggest that symmetric self-renewal is more frequent during adolescence. Since symmetric self-renewal could promote the accumulation of mutations (Tomasetti and Vogelstein, 2015), this has implications for understanding how cancer emerges. A previous theoretical study argued that the high number of cell divisions that occur during fetal development puts us at risk of acquiring mutations even before birth (Frank and Nowak, 2003). The new results extend this argument into childhood and adolescence. That is, before adulthood is reached, there is possibly a relatively high risk of acquiring mutations that may predispose an individual to cancer – even if the onset of cancer typically occurs much later in life.
An important question that arises from this study concerns the exact nature of the cell divisions that ensure tissue maintenance in adulthood. In the model of Werner, Beier et al., tissues are maintained in adulthood through asymmetric cell divisions. However, as they point out, this model cannot be mathematically distinguished from an alternative mechanism that relies on a mixture of symmetric self-renewal and symmetric differentiation (i.e., when the stem cell divides to produce two non-stem cells). This is because tissues can also be maintained if the probabilities of symmetric self-renewal and differentiation are balanced and controlled through feedback loops (Lander et al., 2009); this latter model is supported by stem cell data from both humans and other animals (see Shahryiari and Komarova, 2013 for references). Some mathematical models suggest that the prevalence of mutations depends on the division patterns, so it may be possible to distinguish between them mathematically (Shahryiari and Komarova, 2013).
Using telomere length as an indicator of biological processes is not a new idea. Telomere length has previously been singled out as a marker to identify adult stem cells and their location in the body (Flores et al., 2008). From a modeling perspective, the length of telomeres has also been proposed as a signal to assess the risk posed by pre-cancerous mutations in healthy individuals (Rodriguez-Brenes et al., 2014). Telomere length might also help predict the success rate of cancer therapies, and studies of telomerase inhibitors predict better outcomes for patients with short telomere length (Chiappori et al., 2015). The work by Werner, Beier et al. adds an important contribution in this context, allowing us to use telomere lengths to gain insights into cell division patterns that occur in vivo.
References
-
The longest telomeres: a general signature of adult stem cell compartmentsGenes & Development 22:654–667.https://doi.org/10.1101/gad.451008
-
Replicating through telomeres: a means to an endTrends in Biochemical Sciences 40:504–515.https://doi.org/10.1016/j.tibs.2015.06.003
Article and author information
Author details
Ignacio A Rodriguez-Brenes

Publication history
Copyright
© 2016, Rodriguez-Brenes et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,787
- views
-
- 296
- downloads
-
- 3
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Mathematical Modeling: Telomeres open a window on stem cell division
eLife 5:e12481.
https://doi.org/10.7554/eLife.12481
Further reading
-
- Computational and Systems Biology
To help maximize the impact of scientific journal articles, authors must ensure that article figures are accessible to people with color-vision deficiencies (CVDs), which affect up to 8% of males and 0.5% of females. We evaluated images published in biology- and medicine-oriented research articles between 2012 and 2022. Most included at least one color contrast that could be problematic for people with deuteranopia (‘deuteranopes’), the most common form of CVD. However, spatial distances and within-image labels frequently mitigated potential problems. Initially, we reviewed 4964 images from eLife, comparing each against a simulated version that approximated how it might appear to deuteranopes. We identified 636 (12.8%) images that we determined would be difficult for deuteranopes to interpret. Our findings suggest that the frequency of this problem has decreased over time and that articles from cell-oriented disciplines were most often problematic. We used machine learning to automate the identification of problematic images. For a hold-out test set from eLife (n=879), a convolutional neural network classified the images with an area under the precision-recall curve of 0.75. The same network classified images from PubMed Central (n=1191) with an area under the precision-recall curve of 0.39. We created a Web application (https://bioapps.byu.edu/colorblind_image_tester); users can upload images, view simulated versions, and obtain predictions. Our findings shed new light on the frequency and nature of scientific images that may be problematic for deuteranopes and motivate additional efforts to increase accessibility.
-
- Computational and Systems Biology
The force developed by actively lengthened muscle depends on different structures across different scales of lengthening. For small perturbations, the active response of muscle is well captured by a linear-time-invariant (LTI) system: a stiff spring in parallel with a light damper. The force response of muscle to longer stretches is better represented by a compliant spring that can fix its end when activated. Experimental work has shown that the stiffness and damping (impedance) of muscle in response to small perturbations is of fundamental importance to motor learning and mechanical stability, while the huge forces developed during long active stretches are critical for simulating and predicting injury. Outside of motor learning and injury, muscle is actively lengthened as a part of nearly all terrestrial locomotion. Despite the functional importance of impedance and active lengthening, no single muscle model has all these mechanical properties. In this work, we present the viscoelastic-crossbridge active-titin (VEXAT) model that can replicate the response of muscle to length changes great and small. To evaluate the VEXAT model, we compare its response to biological muscle by simulating experiments that measure the impedance of muscle, and the forces developed during long active stretches. In addition, we have also compared the responses of the VEXAT model to a popular Hill-type muscle model. The VEXAT model more accurately captures the impedance of biological muscle and its responses to long active stretches than a Hill-type model and can still reproduce the force-velocity and force-length relations of muscle. While the comparison between the VEXAT model and biological muscle is favorable, there are some phenomena that can be improved: the low frequency phase response of the model, and a mechanism to support passive force enhancement.




{kind=link}