Learning: Neural networks subtract and conquer
Two theoretical studies reveal how networks of neurons may behave during reward-based learning.
- University of Cambridge, United Kingdom
To thrive in their environments, animals must learn how to process lots of inputs and take appropriate actions (Figure 1A). This sort of learning is thought to involve changes in the ability of synapses (the junctions between neurons) to transmit signals, with these changes being facilitated by rewards such as food. However, reward-based learning is difficult because reward signals do not provide specific instructions for individual synapses on how they should change. Moreover, while the latest algorithms for reinforcement learning achieve human-level performance on many problems (see, for example, Mnih et al., 2015), we still do not fully understand how brains learn from rewards. Now, in eLife, two independent theoretical studies shed new light on the neural mechanisms of learning.
The studies address two complementary aspects of reward-based learning in recurrent neuronal networks – artificial networks of neurons that exhibit dynamic, temporally-varying activity. In both studies, actions are generated by a recurrent network (the “decision network”) that is composed of hundreds of interconnected neurons that continuously influence each others’ activity (Figure 1). The decision network integrates sensory information about the state of the environment and responds with an action that may or may not result in a reward. The network can also change the ability of individual synapses to transmit signals, referred to as synapse strength. Over a period of time, increasing the strength of synapses that promote an action associated with a reward leads to the network choosing actions that receive rewards more often, which results in learning.
Figure 1
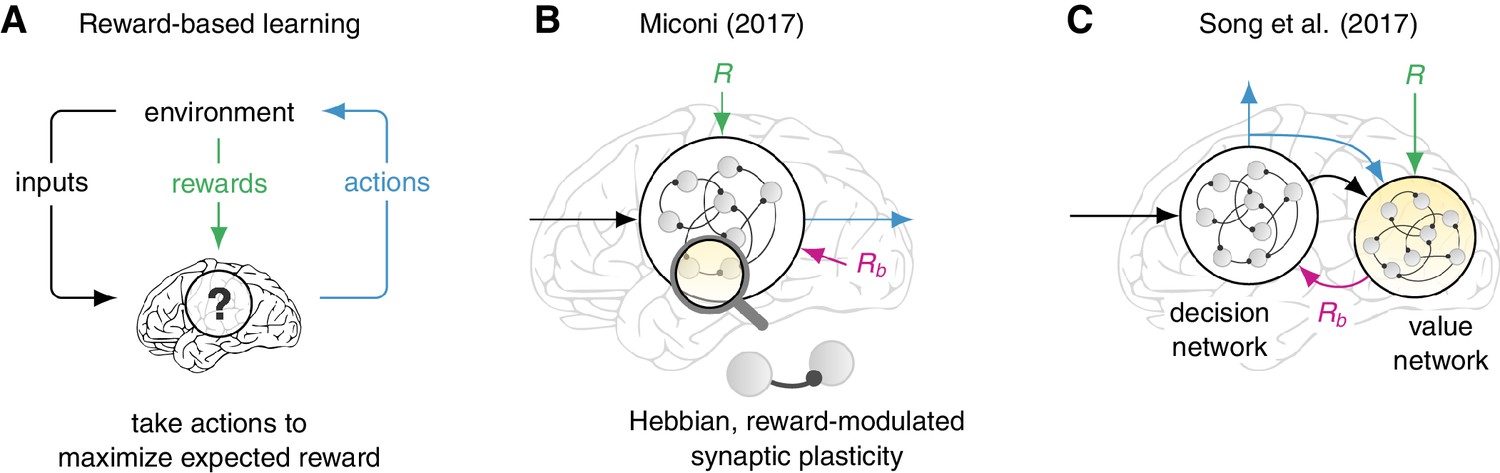
Models for reward-based learning in neural networks.
(A) Many behavioral tasks can be formulated as reward-based (or reinforcement) learning problems: the animal learns to use sensory inputs to perform actions that maximize the expected reward. Miconi and, independently, Song et al. addressed two complementary aspects of how brain circuits might solve such problems. (B) Miconi studied a biologically plausible form of a synaptic plasticity rule (ability of a synapse to strengthen or weaken), which is modulated by reward and is capable of learning complex tasks by adjusting the connectivity of a “decision network” (Miconi, 2017). The strengths of synapses are modified according to a function of the electrical activities on each side of the synapse and a delayed reward signal (R) delivered at the end of each trial. Critically, successful learning requires an appropriate reward baseline (Rb) to be subtracted from the actual reward, but exactly how this baseline can be estimated by another circuit is not addressed. (C) Song et al. show that the total future reward can be estimated dynamically by a separate “value network” that integrates the rewards received from the environment as well as the activity (and outputs) of the decision network (Song et al., 2017). The output of the value network then serves as a reward baseline used to modulate a mathematically optimal, but biologically infeasible, rule that governs the synaptic plasticity in the decision network. Neurons are shown as gray circles, and synapses as black lines with a circle at one end.
At the core of both studies lies a classic algorithm for reinforcement learning known as REINFORCE, which aims to maximize the expected reward in such scenarios (Figure 1A; Williams, 1992). In this algorithm, the strength of a synapse that connects neuron j to neuron i, Wij, changes to Wij + αEij(t) x (R(t) − Rb), where α is a constant, Eij is a quantity called the eligibility, t is time, R is the reward and Rb is a quantity called the reward baseline. The eligibility Eij(t) expresses how much a small change of Wij affects the action taken by the decision network at time t.
The conceptual simplicity of REINFORCE and the fact that it can be applied to the tasks commonly studied in neuroscience labs make it an attractive starting point to study the neural mechanisms of reward-based learning. Yet, this algorithm raises two fundamental questions. Firstly, how can a synapse estimate its own eligibility, using only locally-available information? Indeed, in a recurrent network, a change in synapse strength can influence a third neuron, implying that the eligibility depends on the activity of that third neuron, which the synapse will have never seen. Perhaps more importantly, in scenarios where the reward arrives after the network has produced long sequences of actions, the synapse must search the stream of recently experienced electrical signals for those that significantly influenced the action choice, so that the corresponding synapses can be reinforced. Secondly, how can the network com- pute an adequate reward baseline Rb?
In one of the papers Thomas Miconi of the Neurosciences Institute in La Jolla reports, somewhat surprisingly, that simply accumulating over time a superlinear function (such as f(x) = x3) of the product of the electrical signals on both sides of the synapse, returns a substitute for the optimal synapse eligibility that works well in practice (Miconi, 2017). This form of eligibility turns REINFORCE into a rule for the ability of synapses to strengthen or weaken (a property known as synaptic plasticity) that is more biologically realistic than the original optimal REINFORCE algorithm (Figure 1B) and is similar in spirit to models of synaptic plasticity involving neuromodulators such as dopamine or acetylcholine (Frémaux and Gerstner, 2016).
Miconi’s practical use of a superlinear function seems key to successful learning in the presence of delayed rewards. This nonlinearity tends to discard small (and likely inconsequential) co-fluctuations in electrical activity on both sides of the synapse, while amplifying the larger ones. While a full understanding of the success of this rule will require more analysis, Miconi convincingly demonstrates successful training of recurrent networks on a variety of tasks known to rely on complex internal dynamics. Learning also promotes the emergence of collective dynamics similar to those observed in real neural circuits (for example, Stokes et al., 2013; Mante et al., 2013).
As predicted by the theory of REINFORCE (Peters and Schaal, 2008), Miconi found it essential to subtract a baseline reward (Rb) from the actual reward (R) obtained at the end of the trial. While Miconi simply assumes that such predictions are available, Francis Song, Guangyu Yang and Xiao-Jing Wang of New York University and NYU Shanghai wondered how the brain could explicitly learn such detailed, dynamic reward predictions (Song et al., 2017). Alongside the main decision network, they trained a second recurrent network, called the “value network”, to continuously predict the total future reward on the basis of past activity in the decision network (including past actions; Figure 1C). These reward predictions were then subtracted from the true reward to guide learning in the decision network. Song et al. were also able to train networks on an impressive array of diverse cognitive tasks, and found compelling similarities between the dynamics of their decision networks and neural recordings.
Importantly, although Song et al. used synapse eligibilities (with a few other machine learning tricks) that are not biologically plausible to train both networks optimally, their setup now makes it possible to ask other questions related to how neurons represent uncertainty and value. For example, when it is only possible to observe part of the surrounding environment, optimal behavior often requires individuals to take their own internal uncertainty about the state of the world into account (e.g. allowing an animal to opt for lower, but more certain rewards). Networks trained in such contexts are indeed found to select actions on the basis of an internal sense of uncertainty on each trial. Song et al. tested their model in a simple economic decision-making task where in each trial the network is offered a choice of two alternatives carrying different amounts of rewards. They found that there are neurons in the value network that exhibit selectivity to offer value, choice and value, or choice alone. This is in agreement with recordings from the brains of monkeys performing the same task.
The complementary findings of these two studies could be combined into a unified model of reward-based learning in recurrent networks. To be able to build networks that not only behave, but also learn, like animals promises to bring us closer to understanding the neural basis of behavior. However, progress from there will rely critically on our ability to analyze the time-dependent strategies used by trained networks (Sussillo and Barak, 2013), and to identify neural signatures of such strategies.
References
-
Neuromodulated spike-timing-dependent plasticity, and theory of three-factor learning rulesFrontiers in Neural Circuits 9:1–19.https://doi.org/10.3389/fncir.2015.00085
-
Reinforcement learning of motor skills with policy gradientsNeural Networks 21:682–697.https://doi.org/10.1016/j.neunet.2008.02.003
Article and author information
Author details
Guillaume Hennequin

Acknowledgements
GH would like to thank Virginia Rutten for helpful comments.
Publication history
Copyright
© 2017, Hennequin
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,494
- views
-
- 300
- downloads
-
- 0
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Learning: Neural networks subtract and conquer
eLife 6:e26157.
https://doi.org/10.7554/eLife.26157
Further reading
-
- Neuroscience
Trained neural network models, which exhibit features of neural activity recorded from behaving animals, may provide insights into the circuit mechanisms of cognitive functions through systematic analysis of network activity and connectivity. However, in contrast to the graded error signals commonly used to train networks through supervised learning, animals learn from reward feedback on definite actions through reinforcement learning. Reward maximization is particularly relevant when optimal behavior depends on an animal’s internal judgment of confidence or subjective preferences. Here, we implement reward-based training of recurrent neural networks in which a value network guides learning by using the activity of the decision network to predict future reward. We show that such models capture behavioral and electrophysiological findings from well-known experimental paradigms. Our work provides a unified framework for investigating diverse cognitive and value-based computations, and predicts a role for value representation that is essential for learning, but not executing, a task.




{kind=link}