A critical re-evaluation of fMRI signatures of motor sequence learning
- The Brain and Mind Institute, University of Western Ontario, Canada
- Department of Computer Science, University of Western Ontario, Canada
- Department of Statistical and Actuarial Sciences, University of Western Ontario, Canada
Abstract
Despite numerous studies, there is little agreement about what brain changes accompany motor sequence learning, partly because of a general publication bias that favors novel results. We therefore decided to systematically reinvestigate proposed functional magnetic resonance imaging correlates of motor learning in a preregistered longitudinal study with four scanning sessions over 5 weeks of training. Activation decreased more for trained than untrained sequences in premotor and parietal areas, without any evidence of learning-related activation increases. Premotor and parietal regions also exhibited changes in the fine-grained, sequence-specific activation patterns early in learning, which stabilized later. No changes were observed in the primary motor cortex (M1). Overall, our study provides evidence that human motor sequence learning occurs outside of M1. Furthermore, it shows that we cannot expect to find activity increases as an indicator for learning, making subtle changes in activity patterns across weeks the most promising fMRI correlate of training-induced plasticity.
eLife digest
It has famously been claimed that it takes 10,000 hours to become an expert at something. But while most of us will never become concert pianists, we can all learn new motor skills and improve existing ones – from touch-typing to tennis – by practicing. What happens in the brain to produce these improvements in performance?
Researchers have tried to answer this question by scanning the brains of people as they practice motor skills, but the results have proved inconsistent. Some studies find that specific brain areas become more active as people practice. This could indicate that these areas are ‘storing’ new skills. But others report that brain activity decreases with practice. This might indicate that practice instead makes certain brain areas work more efficiently. It is also unclear where in the brain these learning-related changes occur. Some studies suggest that most occur in the primary motor cortex, or M1 – the area that sends commands to muscles. Others suggest that most changes take place outside of M1, in areas that plan movements.
Berlot et al. set out to resolve these inconsistencies by scanning the brains of healthy volunteers as they learned to play six 9-digit sequences on a keyboard. Each volunteer completed about 4,000 training trials over 5 weeks, and had their brain scanned four times. As the weeks passed, the volunteers became faster and more accurate at playing the sequences. However, the activity of their primary motor cortex did not change. By contrast, the activity of areas involved in planning movements decreased throughout training. The patterns of activity for each individual sequence reorganized throughout learning in the areas outside of the M1. This happened most quickly during the early stages of training when the volunteers showed the fastest improvements in performance.
Overall, these findings suggest that when we learn a new skill, activity in the brain areas supporting that skill decrease as the brain becomes more efficient. Increases in brain activity are thus unlikely to reflect the acquired skill. Instead, more subtle changes, in which the brain uses more specific patterns of activity to encode the skill, may underlie improved performance. This may also be true for other types of learning, such as acquiring a new language.
Introduction
Humans have the remarkable ability to learn complex sequences of movements. While behavioural improvements in sequence learning tasks are easily observable, the underlying neural processes remain elusive. Understanding the neural underpinnings of motor sequence learning could provide clues about more general mechanisms of plasticity in the brain. This motivation has led numerous functional magnetic resonance imaging (fMRI) studies to investigate the brain changes related to motor sequence learning. However, there is little agreement about how and where in the brain learning-related changes are observable. Previous studies include reports of signal increases across various brain regions (Floyer-Lea and Matthews, 2005; Grafton et al., 1995; Hazeltine et al., 1997; Karni et al., 1995; Lehéricy et al., 2005; Penhune and Doyon, 2002), as well as signal decreases (Jenkins et al., 1994; Peters et al., 2017; Toni et al., 1998; Ungerleider et al., 2002; Wiestler and Diedrichsen, 2013), nonlinear changes in activation (Ma et al., 2010; Xiong et al., 2009), spatial shifts in activity (Lehéricy et al., 2006; Steele and Penhune, 2010), changes in multivariate patterns (Wiestler and Diedrichsen, 2013; Wymbs and Grafton, 2015), and changes in inter-regional functional connectivity (Bassett et al., 2015; Bassett et al., 2011; Doyon et al., 2002; Mattar et al., 2016). Additionally, some experiments have matched the speed of performance (Karni et al., 1995; Penhune and Doyon, 2002; Steele and Penhune, 2010; Lehéricy et al., 2005; Seidler et al., 2002; Seidler et al., 2005), while others have not (Bassett et al., 2015; Lutz et al., 2004; Wiestler and Diedrichsen, 2013; Wymbs and Grafton, 2015). Given that fMRI analysis has many degrees of freedom, these inconsistencies may not be too surprising. However, the implicit pressure in the publication system to report findings may also have contributed to a lack of coherency. To address this issue, we designed a comprehensive longitudinal study of motor sequence learning that allowed us to systematically reinvestigate previous findings. In order to increase transparency, we pre-registered the design, as well as all tested hypotheses on the Open Science Framework (Berlot et al., 2017; https://osf.io/etnqc), and make the full dataset available to the research community (Berlot, 2020; OpenNeuro accession number ds002776).
The main aim of our study was to systematically evaluate different ideas of how learning-related changes are reflected in the fMRI signal. In the context of motor sequence learning, the most commonly examined brain region is the primary motor cortex (M1). Previous reports of increased M1 activation after long-term learning have been interpreted as additional recruitment of neuronal resources for trained behavior, taken to suggest the skill is represented in M1 (Floyer-Lea and Matthews, 2005; Karni et al., 1995; Karni et al., 1998; Lehéricy et al., 2005; Penhune and Doyon, 2002; for a review see Dayan and Cohen, 2011; Figure 1a). Since then, several pieces of evidence have suggested that sequence-specific memory may not reside in M1 (Beukema et al., 2019; Wiestler and Diedrichsen, 2013; Yokoi and Diedrichsen, 2019). However, some of these reports studied skill acquisition over a course of a few days, while human skill typically evolves over weeks (and months) of practice. Therefore, including several weeks of practice might be more suitable to test whether, and at what time point, M1 develops skill-specific representations.
Figure 1
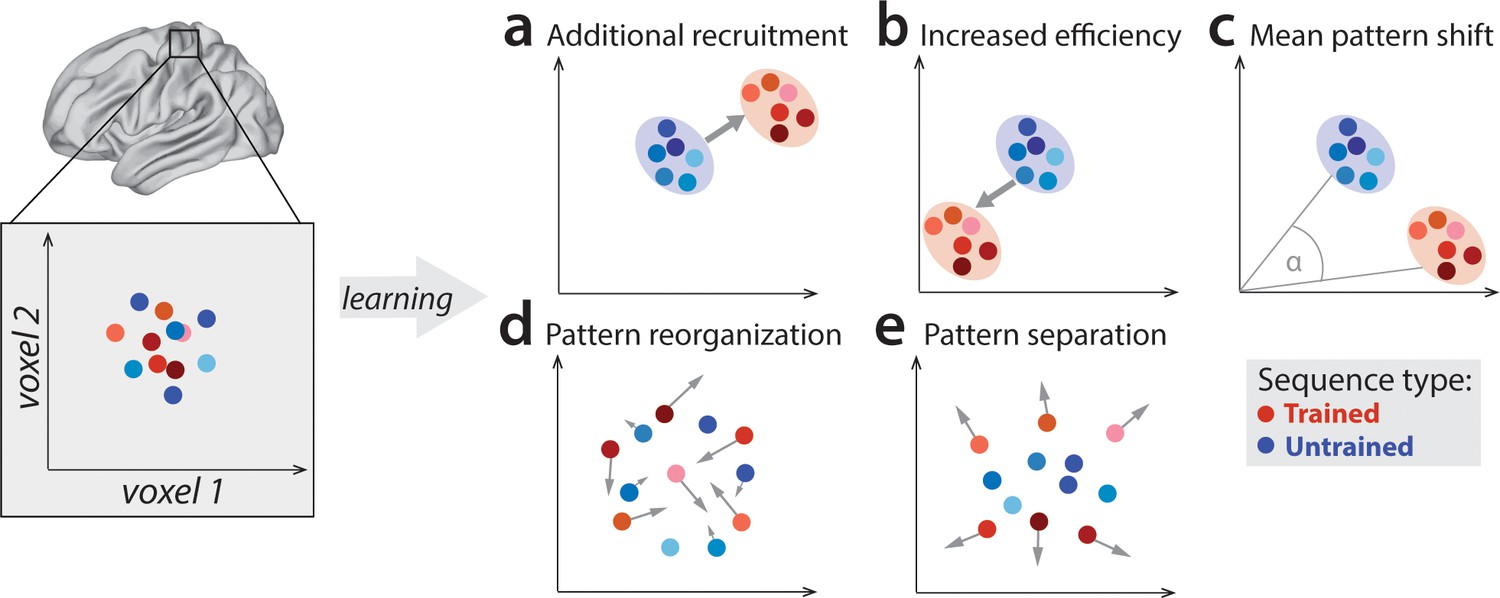
Potential fMRI signatures of learning in a specific brain area.
Each panel shows hypothetical activation for the six trained sequences (red) and the six untrained sequences (blue) in the space of two hypothetical voxels. (a) Activation could increase during learning across voxels, indicating additional recruitment of resources involved in skilled behavior. (b) Activation could decrease across voxels, implying that the region performs its function more efficiently. (c) Some voxels (x-axis) could increase activation with training, while others (y-axis) could decrease. This would lead to a shift of the overall activity pattern in the region without an overall net change in activation. (d) Activation patterns specific to each trained sequence could undergo more change than untrained sequences, reflective of plastic reorganization of the sequence representation. Arrow length in the figure indicates the amount of reorganization. (e) One specific form of such reorganization would be increasing dissimilarities (pattern separation) between activity patterns for individual trained sequences.
Outside of M1, learning-related activation changes have been reported in premotor and parietal areas (Grafton et al., 2002; Hardwick et al., 2013; Honda et al., 1998; Penhune and Doyon, 2002; Tamás Kincses et al., 2008; Vahdat et al., 2015), with activation increases commonly interpreted as increased involvement of these areas in the skilled behavior. Yet, recent studies have mostly found that, as the motor skill develops, activation in these areas predominantly decreases (Penhune and Steele, 2012; Wiestler and Diedrichsen, 2013; Wu et al., 2004). Such reductions are harder to interpret as they could reflect a reduced areal involvement in skilled performance or, alternatively, more energy efficient implementation of the same function (Figure 1b; Picard et al., 2013; Poldrack et al., 2005). To complicate things further, regional activity increases and decreases could occur simultaneously in the same area (Figure 1c; Steele and Penhune, 2010). In such a scenario, the net activation in the region would not change, yet, the trained sequences would engage slightly different subpopulations of the region than untrained sequences.
A variant of this idea is that each specific sequence becomes associated with dedicated neuronal subpopulation (and hence fMRI activity pattern). Such a representation would form the neural correlate of sequence-specific learning – the part of the skill that does not generalize to novel, untrained motor sequences (Karni et al., 1995). Sequence-specific activation patterns should change early in learning (Figure 1d), when behavior improves most rapidly, and stabilize later, once the skill has consolidated and an optimal pattern is established (Peters et al., 2017). One possible way in which sequence-specific patterns could reorganize is by becoming more distinct from one another (Figure 1e; Wiestler and Diedrichsen, 2013). Having a distinctive code for each sequence might be of particular importance to the system in a trained state, allowing it to produce different dynamical sequences, while avoiding confusion or ‘tangling’ of the different neural trajectories (Russo et al., 2018).
To systematically examine the cortical changes associated with motor sequence learning, we carried out a longitudinal study over 5 weeks of training with 4 sessions of high-field (7 Tesla) fMRI scans. Behavioural performance in the first three scanning sessions was imposed to the same speed of performance. This allowed us to inspect whether examined fMRI metrics reflect brain reorganization, independent of behavioral change. However, controlling for speed incurs the danger of not tapping into neural resources that are necessary for skilled performance (Orban et al., 2010; Poldrack, 2000). We therefore compared the fMRI session with paced performance at the end of behavioural training with one acquired with full speed performance (Figure 2). This manipulation allowed us to systematically assess the role of speed on the fMRI metrics of learning, thereby addressing an important methodological problem faced by virtually every study on motor learning.
Figure 2 with 1 supplement see all

Experimental design and paradigm.
(a) Apparatus and task. Participants were trained to perform six 9-item sequences on a keyboard device. For each finger press, the corresponding digit on the screen turned green (correct) or red (incorrect). During fMRI scans 1–3, an expanding pink line under the numbers indicated the pace at which participants had to press the keys. See Figure 2—figure supplement 1 for trial structure during scanning sessions. (b) Training protocol lasted for 5 weeks, and included four behavioral test sessions (yellow underlay) and four scans (grey underlay). Scans 1–3 were performed at a paced speed, while scan 4 performance was full speed (fs). (c) Average group performance executing trained sequences across the training sessions, measured in seconds. The average movement time (MT) decreased with learning. Shaded area denotes between-subject standard error. (d) Performance during scanning sessions and behavioral tests, measured in seconds. Performance of trained sequences improved across all subsequent behavioral test sessions. Performance improved also for untrained sequences from week 2 onwards, suggesting some transfer in learning, but performance was still faster for trained sequences, indicating sequence-specific learning. Error bars indicate between-subject standard error. Stars denote significance levels lower than p<0.001.
Results
Speed of sequence execution increases with learning
We trained 26 participants to perform six 9-digit sequences with their right hand on a keyboard device (Figure 2a). During training, they received visual feedback (green for correct and red for incorrect presses) and were rewarded for both accuracy and speed (see Materials and methods). Over the course of 5 weeks, participants practiced ~4000 trials (Figure 2b). This led to substantial performance improvement, with the average movement time (MT) to complete a sequence decreasing from an initial 3.2 s to 1.2 s at the end of the training (Figure 2c). The training regime was complemented with behavioral assessments on four occasions designed to specifically assess participants’ performance on trained sequences relative to untrained sequences (Figure 2d, yellow underlay). Prior to training (test day 1), the speed of sequence execution did not differ between trained and untrained sequences. For all subsequent sessions, MTs were significantly faster for trained than untrained sequences (p<0.001), implying sequence-specific learning. Additionally, performance of trained sequences improved between all subsequent sessions, even after week 3 (week 3–5: t(25)=5.49, p=1.1e−5). Thus, participants’ performance of trained sequences improved across the five weeks.
To assess fMRI changes with learning, participants underwent four fMRI scans (1st scan: before the main training; 2nd scan: week 2; 3rd and 4th scan: week 5), performing both trained and untrained sequences (Figure 2d – grey underlay). The first session served as a baseline, where all of the presented sequences (trained and untrained) were novel to participants. Both trained and untrained sequences were always cued by presenting the corresponding digits on the screen (Figure 2a). During the first three sessions, participants were paced with a metronome so that all sequences, trained and untrained, were performed at the same speed as in the first scan. Performance in the fourth session was at maximum speed, resulting in significantly lower MTs for trained compared to untrained sequences (Figure 2d). To assess different neural signatures of observed behavioral learning, we first examined how the overall evoked activation changed over weeks of training for the same speed of movement.
Overall activation does not change in M1
First, we re-investigated the classical finding that activity, measured as the percent BOLD signal change relative to rest, increased in M1 for matched performance after long-term training (Karni et al., 1995; Figure 1a). Our task elicited activation in a range of cortical areas (Figure 3a for session 1 – that is, prior to learning). A region of interest (ROI) analysis of the hand area of M1, contralateral to the performing hand, however, showed no significant change across weeks (F(2,50)=0.44, p=0.85). There was a significant main effect of sequence type (F(1,25)=6.32, p=0.019), but none of the post-hoc t-tests revealed a significant difference. Additionally, the interaction between the two factors was also not significant (F(2,50)=0.17, p=0.84).
Figure 3 with 1 supplement see all
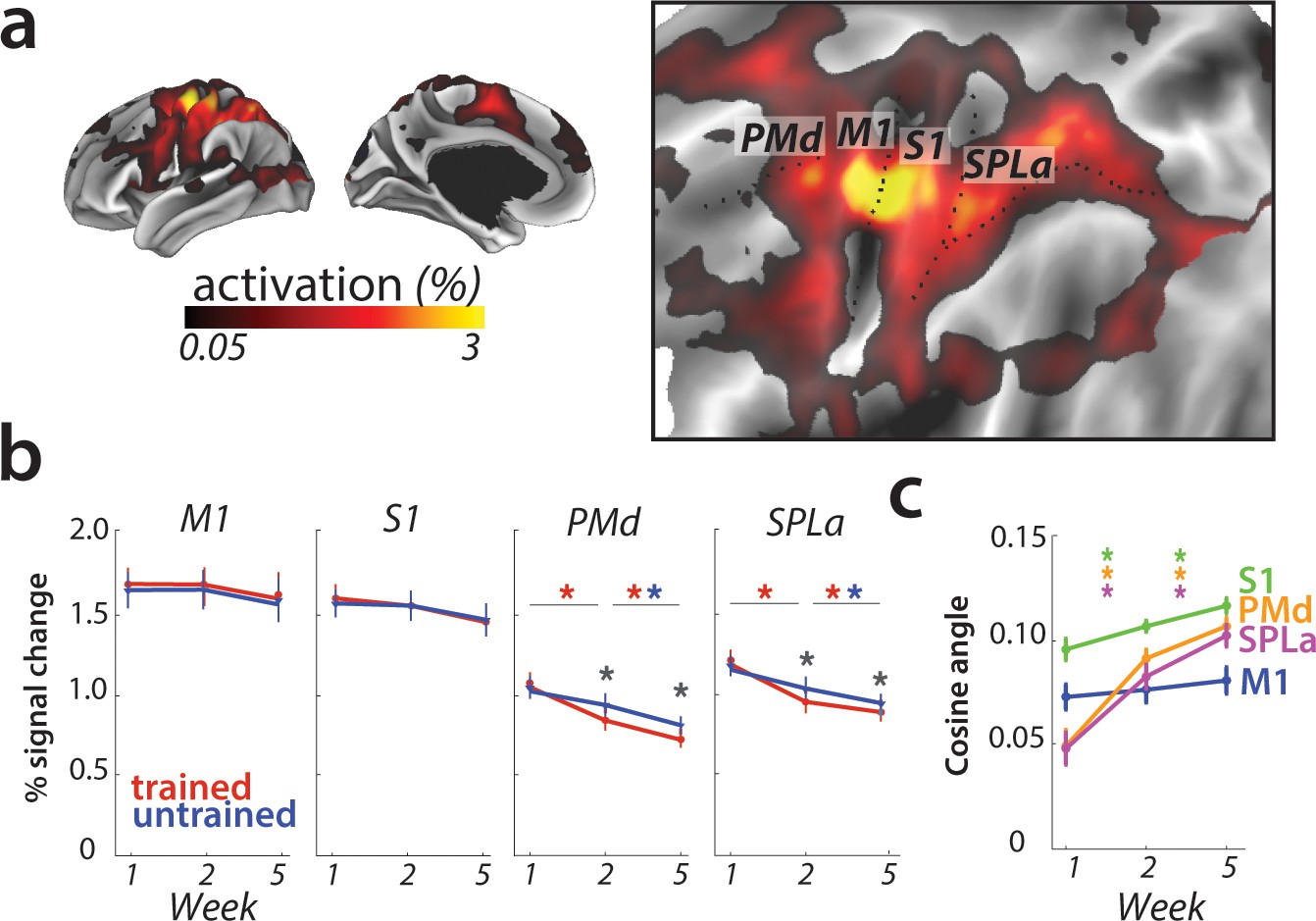
Overall activation and changes with learning in defined regions of interest.
(a) Average activation during production of any sequence in scanning session 1 (prior to learning) in the hemisphere contralateral to the performing hand. Activation was contrasted against resting baseline. On the right, activation map is presented on a flattened surface, corresponding to surface maps in other figures. (b) Changes in activation across predefined areas – primary motor cortex (M1), primary somatosensory cortex (S1), premotor dorsal area (PMd) and superior parietal lobule – anterior (SPLa). No significant changes in activation were observed in M1 or S1 across weeks or between trained and untrained sequences (* indicates p<0.01). Error bars indicate between-subject standard error. See Figure 3—figure supplement 1a for results with error trials excluded. (c) The cosine angle dissimilarity between average trained and untrained sequence across scanning weeks. The cosine angle increased significantly across weeks in PMd, SPLa and S1, but not M1 (* indicates p<0.05). Error bars indicate between-subject standard error. See Figure 3—figure supplement 1b for results with error trials excluded.
The absence of overall activity changes, however, should not be taken as evidence for an absence of plasticity in the region. It is possible that some subregions of M1 increased in activation for learned sequences, while other decreased, as suggested by Steele and Penhune, 2010. Such mixed changes would result in a shift of the overall pattern, which would lead to an increase in the angle between the mean activity pattern for trained and untrained sequences (Figure 1c). Because we calculated the angle between activity patterns for each participant separately, this criterion does not assume that the observed shift is spatially consistent across individuals – any idiosyncratic shift could be detected. Therefore it serves as a sensitive statistical criterion to detect shifts in spatial location of activation, which were previously reported only descriptively (Steele and Penhune, 2010).
However, in M1, the averaged cosine angle (Figure 3c) remained unchanged across the weeks (F(2,50)=1.71, p=0.19), indicating that the average activity pattern remained comparable across trained and untrained sequences. In sum, we found no evidence for activation increases (Karni et al., 1995), decreases, or relative shifts in activation patterns (Steele and Penhune, 2010) in M1.
Learning-related activation changes in premotor and parietal areas
To investigate activation changes in areas outside of M1, we calculated changes in activity between the weeks in a map-wise approach (Figure 4a). Over the three measurement time points, we found no reliable activation increases in any cortical area that was activated by the task in week 1. Instead, we observed widespread learning-related reductions in activity in premotor and parietal areas (Figure 4a), in line with our pre-registered prediction. These activation reductions were observed across both subsequent sessions (i.e. weeks 1–2, weeks 2–5) for trained and untrained sequences, with bigger reductions for trained sequences. In weeks 2 and 5, trained sequences elicited overall lower activity than untrained sequences (Figure 4b; see Figure 4—figure supplement 1 for statistical maps). These learning-related reductions in activity were also statistically significant in our predefined ROIs in premotor (dorsal premotor cortex – PMd) and parietal cortices (anterior superior parietal lobule – SPLa) (Figure 3b): In a 3 (week) x 2 (sequence type) ANOVA on observed activation both main effects and interaction were highly significant in PMd (week: F(2,50)=17.47, p=1.77e−6; sequence type: F(1,25)=11.86, p=2.03e−3; interaction: F(2,50)=13.22, p=2.46e−5) as well as in SPLa (week: F(2,50)=19.14, p=6.73e-7; sequence type: F(1,25)=19.36, p=1.77e−4; interaction: F(2,50)=21.59, p=1.74e−7). In contrast, no main effect of week was observed in S1 (F(2,50)=1.82, p=0.17). Neither was there a significant effect of sequence type (F(1,25)=0.19, p=0.66), or interaction between the two factors (F(2,50)=2.01, p=0.14). This pattern of results on changes in overall activation remained unchanged after excluding error trials from the analyses (see Figure 3—figure supplement 1a). Thus, we observed widespread activation decreases with learning across secondary and association cortical areas.
Figure 4 with 1 supplement see all

Changes in average activation across the cortical surface.
(a) Average change in activation across subsequent sessions. Activation was measured as difference in percent signal change relative to the resting baseline. Activation decreased (blue shades) in motor-related regions across sessions during sequence execution. (b) Contrast of activation for trained vs. untrained sequences per scanning session. In weeks 2 and 5, trained sequences elicited lower activation in motor-related regions than untrained sequences (blue shades; see Figure 4—figure supplement 1 for t-maps and statistical quantification of activation clusters). Areas with observed increases in activation for trained sequences (red shades) lie in the default mode network that showed on average lower activity during task than rest.
In a few smaller areas, activation increased with learning (red patches in Figure 4a–b). This was observed uniformly in areas with activity at or below baseline – thus these changes reflect decreased suppression of activity rather than increases. It is likely that these activity increases are not task relevant, but instead reflect the increasing automaticity and lower need for central attentional resources with learning (see Discussion).
We also examined whether there were, in addition to the overall activity decreases, shifts in the average activity patterns in the predefined regions of interest (Figure 1c). As for M1, we calculated the cosine angle dissimilarity (see Materials and methods) between the average activity patterns for trained and untrained sequences, separately for each scanning session. Figure 5a shows cosine angle dissimilarities between trained and untrained sequences in PMd, displayed using multidimensional scaling (MDS). Patterns for trained sequences moved away from the starting point over weeks, and became more different from untrained patterns. Both in parietal and premotor areas there was clear evidence for a shift – cosine angular dissimilarity between the average trained and untrained sequence activation increased significantly across weeks (PMd: F(2,50)=23.63, p=5.98e−8; SPLa: F(2,50)=23.19, p=7.49e−8) (Figure 3c). S1 also showed a significant increase in cosine dissimilarity between trained and untrained patterns with learning (F(2,50)=8.68, p=5.79e−4). These changes, however, were much less pronounced than those observed in premotor and parietal areas. This observed increase in dissimilarity between average trained and untrained pattern in PMd and SPLa, and to a lesser extent in S1, was also observed when analyzing only trials with correct performance (see Figure 3—figure supplement 1b).
Figure 5
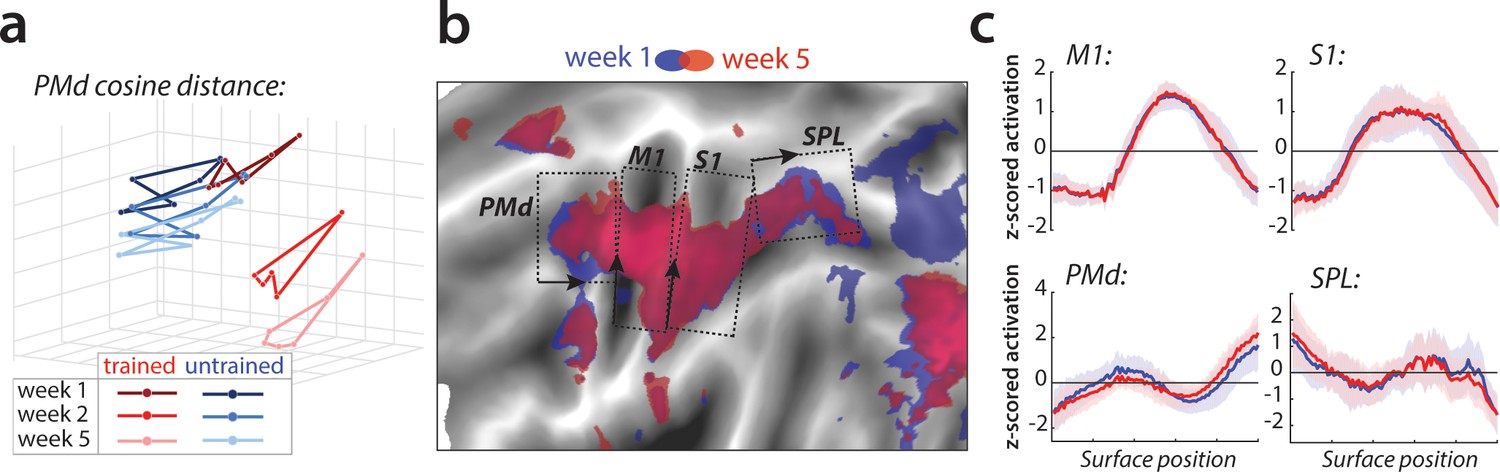
Relative change in evoked activation.
(a) Multidimensional scaling plot of cosine angle dissimilarities for trained and untrained sequences in premotor dorsal area (PMd) across weeks 1–5. Each dot represents a single sequence, and dots are connected for each session and sequence type separately. Trained sequences on average become more distant from untrained sequences with learning. Untrained sequences on average also progress across weeks, but less than trained sequences. (b) Normalized activation plots for trained sequences in week 1 (blue) and 5 (red). The arrows and brackets indicate the direction and range of activation cross-sections presented in c). Areas: dorsal premotor cortex (PMd), primary motor cortex (M1), primary somatosensory cortex (S1), superior parietal lobule (SPL). (c) Cross-section of elicited activation for trained sequences in defined areas, in weeks 1 (blue) and 5 (red).
To investigate whether the observed changes in the overall activity patterns in premotor and parietal areas were spatially consistent across individuals, we normalized (z-scored) activation maps in each region and assessed the relative contribution of subregions to overall activation in weeks 1 and 5 (Figure 5b). Comparing the pattern of activation revealed that before training (week 1, blue) sequences elicit relatively more activation in rostral parts of the premotor and supplementary motor areas, and that activity was more caudal after training (week 5, red; Figure 5c displays the cross-section of relative activation changes). Some differences were also observed in the posterior parietal cortex, with activation shifting from more posterior to anterior subregions after learning (Figure 5c). Altogether, these results show that with learning, the execution of sequences relies on slightly different subareas within premotor and parietal regions.
Sequence-specific activity patterns reorganize early in learning
Our analyses so far have been concerned with changes in the overall pattern of trained vs. untrained sequences, and showed widespread reductions in activation and some more subtle changes in relative location. The sequence-specific performance advantage, however, indicates that the brain must represent specific sequences – i.e., there should be activity patterns that are unique to each individual sequence. Sequence-specific learning should then be reflected in changes of these sequence-specific activity patterns with learning (Figure 1d). Consistent with previous results (Wiestler and Diedrichsen, 2013; Yokoi and Diedrichsen, 2019), we detected sequence-specific activity patterns, i.e. activity patterns that differentiate between the tested motor sequences, in various cortical regions, even in session 1 (Figure 6a). This allowed us to assess their reorganization across sessions.
Figure 6 with 1 supplement see all
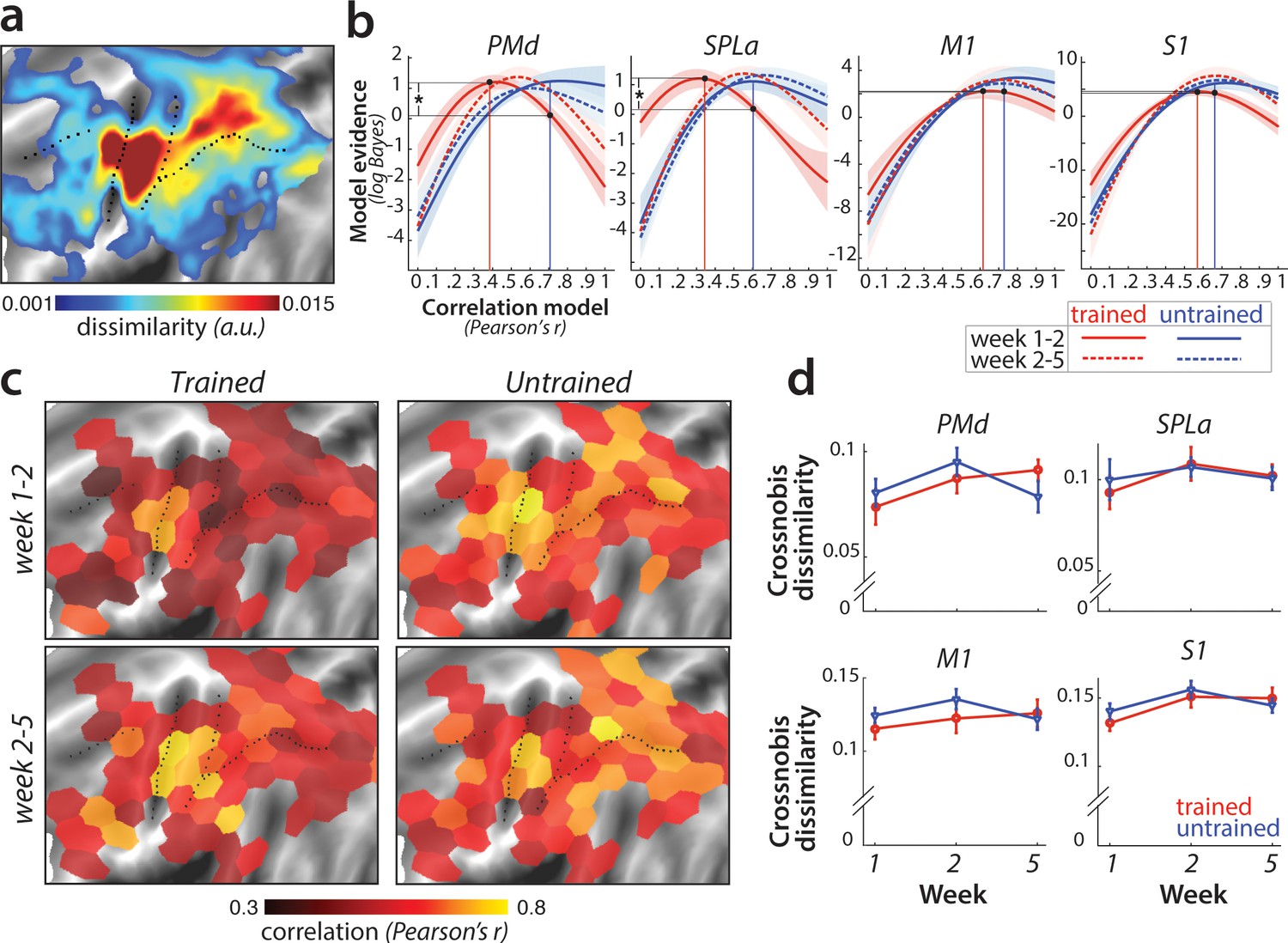
Sequence-specific activity patterns reorganize across sessions.
(a) Cortical surface map of crossnobis dissimilarities between activity patterns for different sequences in session 1. These regions encode which sequence is executed by the participant. (b) Evidence of models of correlation values between r = 0 and r = 1 for sequence-specific patterns across weeks 1–2 (solid) and 2–5 (dashed), separately for trained (red) and untrained (blue) sequences. Evidence was assessed with a type-II log-likelihood, relative to the average log-likelihood across models. Shaded areas indicate standard error across participants. Difference between log-likelihoods can be interpreted as a log-Bayes factor, with a difference of 1 indicating positive evidence. Vertical lines indicate the winning correlation model for trained (red) and untrained (blue) patterns across weeks 1–2. Black dots are projections of the two winning models onto the correlation function of trained sequences across weeks 1–2. The horizontal lines from the two black dots indicate the likelihood of the trained data under the two models, which was tested in a crossvalidated t-test. See Figure 6—figure supplement 1a for the same analysis with error trials excluded. (c) Map displaying the correlation of the winning model for trained and untrained sequences across weeks 1–2 and 2–5. The correlation of the winning correlation model is shown in all tessels where the difference between evidence for winning model vs. worst-fitting model exceeds log-Bayes factor of 1 (averaged across participants). See Figure 6—figure supplement 1b for the difference in best model correlation between trained and untrained sequences, and an indication of tessels where the difference is significant, as based on the crossvalidated t-test. (d) Crossnobis dissimilarities between trained and untrained sequence pairs across weeks. No significant effect of week, sequence type or their interaction was observed in any of the regions. Error bars indicate standard error across participants.
Our pre-registered hypothesis (https://osf.io/etnqc) was that earlier in learning sequence-specific activity patterns would change more for trained than untrained sequences, and would stabilize later in learning. In contrast to the other ideas tested in this paper, this was a novel hypothesis and not based on previous reports. Specifically, we predicted that the correlation of each sequence-specific pattern between weeks 1 and 2 should be lower for trained as compared to untrained sequences. The problem with performing a simple correlation analysis on the patterns, however, is that the estimated correlation will be biased by noise – that is, more within-session variability for one set of sequences will result in a lower correlation (Diedrichsen et al., 2018). To address this problem, we used the pattern component modelling (PCM) framework which explicitly models and estimates the signal and noise for each session explicitly. Using this approach, we estimated the likelihood of participants’ data under a series of models, each assuming a true correlation in the range between 0 (uncorrelated patterns) and 1 (perfect positive correlation; see Materials and methods for details). Figure 6b shows the log-likelihood for each specific correlation model relative to the mean across all models. In SPLa, the most likely correlation of the activity patterns for the trained sequences between weeks 1 and 2 was r = 0.37. For week 2–5, the likelihood peaked at r = 0.6. In contrast, the likelihood functions for untrained sequences indicated that the most likely model was between r = 0.6–0.7 for both week 1–2 and 2–5. The advantage of this analysis is that we can be sure that the observed low correlation in week 1–2 for trained sequence was not due to increased noise. In fact, if the noise in one or both sessions was too high, then the model would be unable to distinguish between any of the correlation models – i.e., the likelihood curve would be a flat line.
To statistically assess the difference in correlations across trained and untrained sequences, we compared the likelihood of the data of trained sequences between two models: the best-fitting model for the trained sequences (r = 0.37 in SPLa) and the correlation model best fitting the data of untrained sequences (r = 0.6) (black dots and projections onto y-axis in Figure 6b). To avoid double-dipping, the ‘best-fitting’ model was chosen on 25 participants (n-1) and the likelihood assessed on the left-out subject (see Materials and methods). The difference in model evidence was significant for correlation between weeks 1–2 in SPLa (t(25)=2.88, p=4.0e−3). In contrast, no difference in correlation was observed later in learning, between weeks 2 and 5 (t(25)=1.21, p=0.24). A similar pattern of results was observed in PMd, with correlation of trained sequences significantly lower than that of untrained sequences between weeks 1 and 2 (t(25)=2.93, p=3.6e−3), but not between weeks 2 and 5 (t(25)=0.88, p=0.39). No such change in correlation across weeks 1–2 was observed in M1 (t(25)=0.43, p=0.34). In S1, the effect was just significant (t(25)=1.72, p=0.049). To ensure that the observed lower correlation for trained patterns was not due to larger difference in error rate between weeks 1 and 2 for trained than for untrained sequences, we repeated the analysis excluding error trials. The pattern of results remained unchanged in PMd and SPLa (see Figure 6—figure supplement 1a), with lower correlation for trained than untrained patterns across weeks 1–2. In S1, after accounting for error trials, the correlation across weeks 1–2 did no longer differ between trained and untrained patterns. Overall, we found significant evidence that sequence-specific trained patterns in SPLa and PMd reorganize more in weeks 1–2 as compared to the untrained sequences, and stabilize later on with learning, in line with our new pre-registered prediction.
To determine more generally where in the neocortex sequence-specific plasticity could be detected, we fit PCM correlation models to regularly tessellated regions spanning the cortical surface. Figure 6c displays the correlation with the highest evidence for activity patterns across weeks 1–2 and 2–5; separately for trained and untrained sequences. In general, the highest correlations were found in core sensorimotor areas. Across weeks 1–2 for trained sequences, correlations were significantly lower in a number of dorsal premotor, inferior frontal, and parietal regions (Figure 6c). Across the cortex, correlation for trained patterns increased for weeks 2–5, resulting in similar values which did not differ significantly between trained and untrained sequences for most tessels (see Figure 6—figure supplement 1b). Together, these results confirmed that sequence-specific activation patterns in secondary association areas show less stability early in learning, but stabilize later on.
Can we obtain further insight into how the sequence-specific patterns change in these areas? One specific preregistered prediction was that there would be an increase in distinctiveness (dissimilarity) between fMRI patterns underlying each trained sequence (Wiestler and Diedrichsen, 2013; Figure 1e). To test this hypothesis, we calculated crossnobis dissimilarities (Walther et al., 2016) between sequence-specific activations, separately for trained and untrained sequences. In contrast to our prediction, no significant change in dissimilarity across weeks was observed in any of the predefined regions (Figure 6d). This suggests that the reorganization observed for trained sequences early in learning did not increase the average distinctiveness of the sequence-specific patterns.
Trained sequences elicit distinct patterns during full speed performance
In the last part of the experiment, we asked whether some of the negative findings (e.g. no changes in M1, no increase in dissimilarities for trained sequences) might have been due to the fact that participants were paced at a relatively slow speed. Matching the speed across sessions allows for the comparisons of changes in neural activity for exactly the same behavioral output (Karni et al., 1995; Lehéricy et al., 2005). However, it could be that controlling for speed impairs our ability to study brain representations of motor skill; simply because after learning, the system is not challenged enough to activate the neuronal representations supporting skilled performance. Consequently, several studies have not (Bassett et al., 2011; Wymbs and Grafton, 2015), or not strictly (Wiestler and Diedrichsen, 2013), matched performance across sessions or levels of training. To examine the effect of performance speed, we added a fourth scanning session (full speed - fs), just a day after from the third session in week 5, in which participants were instructed to perform the sequence as fast as possible.
Performance during the 4th scan was 1010 ms faster than in the first session (t(25)=15.7, p=1.82e−14) and also 338 ms (t(25)=9.92, p=4.58e−10) faster for trained than for untrained sequences. Averaged over trained and untrained sequences, we found that the faster performance in this session led to an increase in activity across premotor and parietal areas (Figure 7a,b). Although trained sequences were executed faster than untrained sequences, activation was still lower for trained compared to untrained sequences, similar to what we observed for paced performance (Figure 7c; see Figure 7—figure supplement 1a for statistical maps). In M1 and S1, we found no difference in activation between trained and untrained sequences (Figure 7a; M1: t(25)=1.78, p=0.09; S1: t(25)=1.69, p=0.10). Overall, the pattern of results for evoked activation did not change qualitatively when participants performed at full speed.
Figure 7 with 1 supplement see all

Speed-related changes in activation and dissimilarities.
(a) Overall activation in week 5 in paced and full speed sessions for trained (red) and untrained (blue) sequences. Activation was measured as percent signal change over resting baseline (* indicates p<0.05). Error bars indicate standard error across participants. (b) Increase in activation for full speed compared to paced speed in percent signal change, averaged across trained and untrained sequences. Red colors indicate an increase in activity during full speed performance compared to paced performance. Blue colors indicate higher activation during paced compared to full speed performance. (c) Difference in activation elicited for trained relative to untrained sequences, during the paced and full speed sessions (see Figure 7—figure supplement 1a for statistical maps). Trained > untrained is shown in red, untrained > trained in blue. (d) Average crossnobis dissimilarity between sequence-specific patterns in paced and full speed sessions for trained (red) and untrained (blue) sequences. Dissimilarities are significantly larger for trained, as compared to untrained patterns in PMd during the full-speed session (* indicates p<0.05). Error bars indicate standard error across participants. (e) Difference between crossnobis dissimilarities across full speed and paced sessions, averaged across trained and untrained sequences. Higher dissimilarities for full speed than paced session are shown in red, whereas blue/green hues indicate higher dissimilarities during paced than full speed session. (f) Difference in dissimilarities for trained relative to untrained sequences, during the paced and full speed sessions. Trained > untrained is shown in red, untrained > trained in blue/green. Trained sequences elicited higher dissimilarities than untrained in full speed, but not paced session (see Figure 7—figure supplement 1b for statistical t-maps).
Next, we examined whether the brain representations of individual sequences are similarly engaged at slow and fast speeds. The correlation between sequence-specific patterns was relatively high (r = 0.62) across our regions of interest. We found no differences between the different regions (F(3,75)=1.47, p=0.23), or sequence types (trained vs. untrained: F(1,25)=0.25, p=0.62). Thus, the sequence-specific representations activated during performance at high skill level (full speed) are at least partly activated even when performance slowed down.
Having established that the mean activation results are replicated across paced and full-speed performance, and that similar sequence-specific representations are activated in both cases, we tested whether activation patterns for different trained sequences are more distinct during full speed performance, as reported in Wiestler and Diedrichsen, 2013. Overall, crossnobis dissimilarities increased at full speed for trained sequences in PMd and SPLa (Figure 7e). No such changes were found in M1 or S1. Moreover, trained sequences showed larger dissimilarities than untrained at full-speed performance across premotor and parietal cortices (Figure 7f), which was not the case for the last paced session. In our predefined ROIs, this difference was significant for PMd (Figure 7d), but also parietal areas showed significantly higher dissimilarities between trained sequences at full speed (Figure 7—figure supplement 1b). This suggests that while activity patterns at full speed are correlated to those during paced performance, they are more distinguishable for trained sequences.
Could this effect be driven by behavioral performance, with trained sequences performed more differently at full speed (i.e. different speeds across trained sequences), while untrained sequences were performed at a more equal speed? To test for this, we calculated crossnobis dissimilarities between movement times associated with different trained and untrained sequences. The dissimilarities based on speed of performance did not differ significantly across trained and untrained sequences (t(25)=0.57, p=0.57). Therefore, increased dissimilarity of trained compared to untrained patterns in premotor and parietal areas could not be explained by a difference in execution speed. Instead, this effect likely reflects changes in activity patterns underlying full speed skilled performance.
Striatal activity patterns for trained sequences manifest at full speed performance
We observed learning-related changes in cortical association areas, but not in the primary motor cortex. Of course, learning could also be driven by neuronal changes in subcortical brain regions (Ashby et al., 2010; Graybiel, 2000; Graybiel and Grafton, 2015; Hikosaka et al., 1999; Yin et al., 2009). The striatum in particular has been proposed as a structure where motor skills are stored (Kawai et al., 2015; Lehéricy et al., 2006). Inspecting changes in overall activity across sessions, we observed no difference in activity between trained and untrained sequences in either putamen or caudate nucleus (Figure 8a).
Figure 8
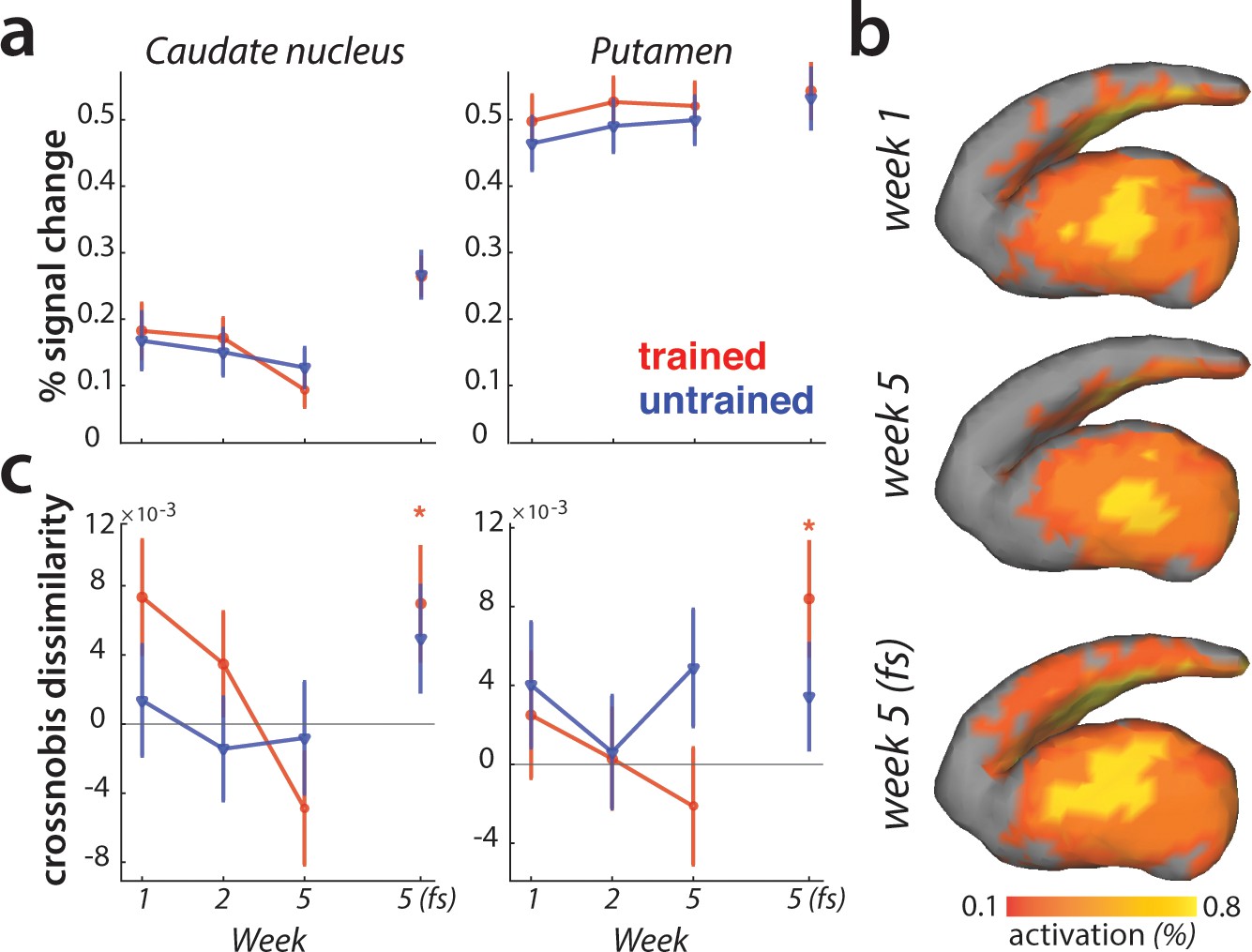
Striatal changes in activation and dissimilarities with learning.
(a) Overall activation (percent signal change over resting baseline), for trained (red) and untrained (blue) sequences. Activation did not differ across sessions, or sequence types in the striatum. Error bars indicate the standard error across participants. (b) Activation during performance of trained sequences in the striatum across weeks 1, 5 (paced speed) and 5 (full speed – fs), averaged across sequences and participants. (c) Crossnobis dissimilarities between activation patterns of sequence pairs, calculated separately for trained and untrained patterns. Dissimilarities were not significantly different for trained or untrained sequences during paced performance. At full speed, sequence-specific activity patterns amongst trained sequences differed significantly in both caudate nucleus and pallidum (* indicates p<0.05). Error bars indicate the standard error across participants.
Previous experiments have reported that with learning, activation moves from more ‘cognitive’ areas of the striatum (i.e. caudate nucleus) to more ‘motor’ areas (i.e. putamen) (Coynel et al., 2010; Lehéricy et al., 2005; Reithler et al., 2010). Our data fail to replicate this result: Both the visual inspection (Figure 8b), and statistical quantification of the mean pattern difference for trained and untrained sequences across sessions revealed no such learning-specific shift of mean striatal activation pattern with learning.
Lastly, we examined if the striatum represents individual sequences. During the paced sessions, activity patterns for different sequences were not distinguishable in either caudate nucleus or putamen (Figure 8c). However, during full speed performance trained sequences elicited distinct activity patterns in both regions (i.e. crossnobis dissimilarity >0: caudate nucleus: t(25)=2.27, p=0.032; putamen: t(25)=2.44, p=0.022; Figure 8c). This effect was specific to the trained sequences, with untrained sequences still exhibiting undistinguishable patterns of activity at full speed. Thus, we found some evidence that trained motor sequences are represented in the form of distinct activity patterns in the striatum during full speed skilled performance.
To examine whether the speed purely pulls the signal out of the noise better, or qualitatively changes the representation, we, similarly to the analyses in the cortical regions, performed the PCM correlation model across the paced and full speed sessions in week 5. The correlation between sequence-specific patterns in both regions was higher than 0 (putamen: t(25)=9.56, p=8.0e−10; caudate: t(25)=6.37, p=1.1e−6), but lower than 1 (putamen: t(25)=8.85, p=3.6e−9; caudate: t(25)=5.86, p=4.1e−6). Similarly as for the cortical regions, we found no differences between the caudate nucleus and putamen (F(3,75)=0.19, p=0.66), or sequence types (trained vs. untrained: F(1,25)=0.05, p=0.83). Thus, the sequence-specific representations activated during performance at high skill level (full speed) are at least partly activated even when performance slowed down. This suggests that moving faster engages similar representations as moving slower, but helps to increase the signal-to-noise ratio.
Discussion
Here we present a large longitudinal motor sequence learning study that allowed us to systematically investigate several previously proposed fMRI signatures of motor learning, including one new hypothesis concerning the change in multivariate activity patterns with learning. The existing literature, with its diversity of experimental protocols and analysis approaches, does currently not provide a consistent picture of learning-related changes. This inconsistency is exacerbated by the fact that most papers prioritize making new claims over re-examining previously established findings. Consequently, it is very hard to assess the replicability of most past findings. We address this issue here by a) producing a well-powered, longitudinal data set that tackles some of the methodological inconsistencies (i.e. speed matching), b) pre-registering both design and hypotheses, and c) making data and analysis pipelines openly available, such that other hypotheses and analyses techniques can be freely tested.
Our findings reveal that parietal and premotor areas show widespread decreases in overall activation, as well as reorganization of sequence-specific patterns early in learning. Additionally, we observed that sequence specific patterns in these areas (as well as the striatum) were more distinct during full speed performance. In contrast to this set of results, none of these learning-specific metrics were detected in M1, even after 5 weeks of training.
On the one hand, our lack of any observable change in M1 activation contradicts some prior results, where increased activation in M1 was observed for matched performance after learning (Karni et al., 1995; Matsuzaka et al., 2007; Penhune and Doyon, 2002; Steele and Penhune, 2010; Vahdat et al., 2015), and does not align with reports of M1 stimulations influencing consolidation or storage of motor skills (in motor sequence tasks: Kang and Paik, 2011; Nitsche et al., 2003; Reis et al., 2009; Waters-Metenier et al., 2014; in other motor tasks: Classen et al., 1998; Galea et al., 2011; Hadipour-Niktarash et al., 2007). We also found no support for a combination of increases and decreases of activation with training, which would lead to an overall change of the mean activity pattern (Steele and Penhune, 2010).
Instead, our results suggest that the pattern of neural activity in M1 does not change as participants become more skilled at producing motor sequences. This is consistent with a recent line of evidence demonstrating that M1 does not change activation with learning (Huang et al., 2013), and primarily encodes single movement elements, rather than sequences (Yokoi et al., 2018; Russo et al., 2019). Somewhat more surprisingly, we also observed no difference in overall M1 activation during full speed performance, when performance was considerably faster for trained sequences. This suggests that the activity increases related to faster movement speeds are compensated for by the shorter duration spent on the task.
Primary somatosensory cortex in many ways paralleled the results observed in M1. We observed no overall activation change, or change in the sequence-specific pattern correlation across sessions. The only exception was the observed shift in the mean activation pattern across sessions. One possible explanation is that feedback-related sensory activity in S1 undergoes some plastic changes with learning. This is consistent with a recent study demonstrating that S1, but not M1, is involved during consolidation of motor skills (Kumar et al., 2019; for a review on somatosensory plasticity in motor learning see Ostry and Gribble, 2016).
In contrast to the limited evidence of learning-related changes in primary somatosensory and primary motor areas, higher order association areas (e.g. parietal and premotor cortices) displayed an array of learning-related changes. First, activation decreased in areas involved in sequence execution, with larger decreases for trained as compared to untrained sequences. This result contrasts with other previous studies reporting increases in activation in premotor areas with learning (Grafton et al., 2002; Honda et al., 1998; Penhune and Doyon, 2002; Vahdat et al., 2015). Partially responsible for these inconsistencies may be a publication bias, favoring reports of signal increases over signal decreases with learning. For example, a recent metanalysis reanalyzed evidence for signal increases in the main text, while moving the (matched) evidence for signal decreases into the supplementary materials (Hardwick et al., 2013). Our data corroborate a number of recent studies reporting reduced activation in task-evoked premotor and parietal areas (Steele and Penhune, 2010; Wiestler and Diedrichsen, 2013; Wu et al., 2004).
The only activation increases for trained relative to untrained sequences were observed in areas that were suppressed below baseline during sequence execution. This has also been previously reported in a motor sequence learning study (Tamás Kincses et al., 2008), where deactivation was larger during performance of trained than random sequences. These areas include the precuneous, temporal parietal junction and the cingulate, regions commonly assigned to the default mode network (Raichle et al., 2001; Shulman et al., 1997). This group of regions is more activated during rest than during task performance, and has been associated with functions such as episodic memory retrieval and attention to internal states (Andrews-Hanna et al., 2010; Gusnard et al., 2001). Our observation of decreased inhibition of the default mode network likely reflects central attentional resources being freed up, allowing participants to engage in other mental processes (e.g., daydreaming) while performing the task. Thus, this release from initial deactivation is possibly task-irrelevant, reflecting increased automaticity with learning (Shamloo and Helie, 2016).
Overall, changes in average activation are relatively hard to interpret, as they could reflect a combination of numerous factors. As a more direct fMRI metric of plasticity, we suggest to inspect changes in the sequence-specific activity patterns, since these constitute a more likely fMRI correlate of the sequence-specific performance advantage observed after training. In this project, this provided us with two key insights of how activation patterns reorganize in association areas with learning. First, activity patterns associated with each of individual trained sequences, changed to a greater extent earlier in learning, and stabilized later. This finding resonates with several animal studies suggesting that the emergence of skilled behavior is associated with early plasticity and later stabilization of neuronal activity patterns (Makino et al., 2017; Peters et al., 2017). Here we report a similar effect in humans, and advance these findings by demonstrating that this reorganization occurs at the level of sequence-specific patterns. In past studies using rodent models, sequence-specific patterns could not be dissociated from the overall activity pattern, as the animals were only trained on production of a single sequence. Additionally, by pacing participants’ speed, we were able to cleanly dissociate changes in the organization of activity patterns from changes in the behavioral performance or variability. Second, activation patterns became more distinct for trained sequences at full speed. This indicates that the engagement of specific neuronal subpopulations for different sequences is particularly important when pushing the limit of performance.
While our study focused on the role of cortical areas in motor sequence learning, we also examined activation in the striatum, which has been suggested to play a critical role in skilled performance (Graybiel and Grafton, 2015; Kawai et al., 2015; Otchy et al., 2015). In contrast to previous fMRI studies (Coynel et al., 2010; Lehéricy et al., 2006; Reithler et al., 2010), we did not find clear evidence for differences in overall activity, or shifts of the overall activity pattern with learning. Nonetheless, we observed distinguishable striatal activation patterns for different trained sequences at full speed, in line with a recent report showing distinguishable striatal patterns for performance of consolidated motor sequences (Pinsard et al., 2018). While by itself the finding of differential sequence-specific activity patterns is not evidence for a causal role of the striatum in the production of skilled behaviors, it is a necessary condition for such a functional role. Therefore, our results here are in line with the proposed involvement of the striatum in motor sequence learning. Additionally, our results suggest that full speed performance might be particularly important for further studies of striatal multivariate activation to counteract the generally lower signal-to-noise ratio in this region.
An important feature of our design was that we collected imaging data in the trained state, both when performance was clamped to the initial speed, and when participants performed as fast as possible. Previous studies have usually included only one of these two options, making direct comparisons difficult (see Lutz et al., 2004 for an examination of various execution speeds on BOLD activity and Orban et al., 2010 in a motor learning context). Our results provide two important insights: first, in terms of the overall fMRI activation, the pattern of results remained the same for paced vs. full speed performance. This indicates that, in this specific case, the increased motor demands and the decreased time on task averaged out. In general, however, these two factors may not balance perfectly – therefore paced performance may be a better choice when comparing overall activation across sessions. Second, even though slow and paced performance in the trained state activated sequence-specific activation patterns, these were much stronger when performing at maximal speeds. Thus, for questions regarding the fine-grained patterns, it might be more suitable to challenge the system fully.
Of course, our list of inspected fMRI metrics of learning was not exhaustive. For instance, we did not investigate whether various fMRI correlates of learning predict behavioral outcomes, or how functional connectivity and network metrics change with learning, partly because of the absence of specific predictions. Pre-registration of hypothesis are especially important for these analyses, since the search space of possible tests becomes exponentially larger (e.g. correlating all possible brain metrics with all possible behavioral metrics; or using various metrics to assess inter-regional relationships). However, we hope that our dataset can serve as a resource for other researchers to (re-)test novel predictions about learning related changes.
Conclusion
The search for neural substrates of learning is a daunting task: the acquisition of longitudinal data sets is work intensive, and the large dimensionality of possible brain metrics makes the search difficult (Poldrack, 2000). Historically, the question was simplified by studying activation increases in single areas as proxies for motor ‘engram’ localization (Lashley, 1950; Berlot et al., 2018). Here we found no evidence for such activation increases; instead we observed widespread and distributed decreases in activation across cortical areas. In contrast, subtler changes in the distributed patterns of fMRI activity have the potential to provide more direct metrics of plasticity. Increased pattern reorganization (across weeks), and larger pattern separation for trained sequences was found across prefrontal, parietal, and striatal regions. These metrics may be useful as general fMRI correlates of neural reorganization beyond the domain of motor learning.
Materials and methods
Participants
Twenty-seven volunteers participated in the experiment. One of them was excluded because field map acquisition was distorted in one of the four scans. The average age of the remaining 26 participants was 22.2 years (SD = 3.3 years), and the sample included 17 women and 9 men. All participants were right-handed and had no prior history of psychiatric or neurological disorders. They provided written informed consent to all procedures and data usage before the study started. The experimental procedures were approved by the Ethics Committee at Western University.
Apparatus
Participants performed finger sequences with their right hand on an MRI-compatible keyboard (Figure 2a), with keys numbered 1–5 for thumb-little finger. The keys had a groove for each fingertip and were not depressible. The force of isometric finger presses was measured by the force transducers (FSG-15N1A, Sensing and Control, Honeywell; dynamic range 0–25 N) mounted underneath each key with an update rate of 2 ms. A key press was recognized when the sensor force exceeded 1 N. The measured signal was amplified and sampled at 200 Hz.
Learning paradigm
Request a detailed protocolParticipants were trained to execute six 9-digit finger sequences over a period of five weeks (Figure 2a). They were randomly split into two groups, with trained sequences of one group constituting the untrained sequences for the other group and vice versa. Finger sequences of both groups were matched as closely as possible in terms of the starting finger, number of finger repetitions in a sequence and first-order finger transitions. This counterbalancing between the groups ensured that any of the observed results were not specific to a set of chosen trained sequences.
In the pre-training session prior to the first scan (Figure 2b), participants were acquainted with the apparatus and task performed during scanning. Sequences executed during this pre-training session were not encountered later on in the experiment.
During the training sessions, participants were trained to perform the six sequences as fast as possible. They received visual feedback for the correctness of their presses with digits turning green for a correct finger press and red for an incorrect one. After each trial, participants received points based on the accuracy and their movement time (MT – time from the first press until the last finger release in the sequence; Figure 2c). Trials executed correctly and faster than participant’s median MT from the previous blocks were rewarded with 1 point. If participants performed correctly and 20% faster than the median MT from previous blocks, they received 3 points. If they made a mistake or performed below their median MT, they received 0 points. Participants performed each sequence twice in a row: digits were written on the screen for the first execution, but removed for the second execution so that participants had to perform the finger sequence from memory. Training sessions were broken into several blocks, each consisting of 24 trials (4 trials per trained sequence), with time between blocks to rest. At the end of each block, participants received feedback on their error rate, median MT and points obtained during the block. If participants performed with an error of <15% and faster than the previous median MT, the MT threshold was updated. This design feature was chosen to maintain participants’ motivation to execute the sequences as fast as possible, within the allowed error range.
During the behavioral test sessions (Figure 2d), participants executed both the trained sequences they were trained on, as well as matched untrained sequences, with all sequences randomly interspersed. As in training, each sequence was performed twice in a row – however, the 9-digit sequence numbers were presented on the screen present on both executions. Therefore, the requirement to remember the sequences from the first to second execution, which was present in training sessions, was omitted for test sessions. For this reason, performance in training and test sessions (Figure 2c–d) cannot be directly compared.
As an additional feature of the four behavioral test sessions, we examined participants’ performance with their left hand. Specifically, we tested them on execution of intrinsically-matched trained sequences (i.e. producing the same finger combinations), extrinsically-matched trained sequences (i.e. producing the same external consequences using mirrored fingers) and random sequences. This was added to probe to what extent learning generalized to the other effector in intrinsic or extrinsic coordinate frames, at different stages of learning. Per session, participants performed 4 repetitions of each trained sequence in intrinsically-matched space and 4 repetitions in extrinsically-matched space.
Experimental design during scanning
Request a detailed protocolParticipants underwent four scanning sessions (Figure 2d) – with the first one before learning regime started, the second after a week and two more scans after completion of the 5 training weeks. Each scanning session consisted of eight functional runs. We employed an event-related design, randomly intermixing execution of trained and untrained sequences. Each sequence was repeated twice in a row with digits present on the screen during both executions. Thus, there was no need to memorize either trained or untrained sequences from first to second execution in the scanner. Each sequence was repeated for a total of six times in every run. Each trial started with 1 s preparation time, during which the sequence was presented on the screen. After that time, a ‘go’ signal was displayed as short pink line underneath the sequence numbers. In scanning sessions 1–3, this line started expanding below the written numbers, indicating the speed at which participants were required to press along. In scanning session 4, only a short line was presented in front and underneath the sequences. When the line disappeared, this signaled a ‘go’ cue for participants to execute the presented sequence as fast as possible. The execution phase including the feedback on overall performance lasted for 3.5 s, and the inter-trial interval was 0.5 s (see Figure 2—figure supplement 1). Each trial lasted for 5 s. Participants always received 3 points upon correct execution of the sequence, and 0 points otherwise. Five periods of rest, each 10 s long, were added randomly between trials in each run to provide a better estimate of baseline activation. Participants performed the task inside the scanner for approximately 75 min. After each scanning session, they filled out a recall and recognition questionnaires on trained and untrained sequences performed inside the scanner.
Image acquisition
Request a detailed protocolData was acquired on a 7-Tesla Siemens Magnetom scanner with a 32-receive channel head coil (8-channel parallel transmit). Anatomical T1-weighted scan was acquired at the beginning of the first scanning session, using a magnetization-prepared rapid gradient echo sequence (MPRAGE) with voxel size of 0.75 × 0.75×0.75 mm isotropic (field of view = 208×157 x 110 mm [A-P; R-L; F-H], encoding direction coronal). Functional data were acquired using a sequence (GRAPPA 3, multi-band acceleration factor 2, repetition time [TR]=1.0 s, echo time [TE]=20 ms, flip angle [FA]=30 deg). We acquired 44 slices with isotropic voxel size of 2 × 2 × 2 mm. For estimating magnetic field inhomogeneities, we additionally acquired a gradient echo field map. Acquisition was in the transversal orientation with field of view 210 × 210 × 160 mm and 64 slices with 2.5 mm thickness (TR = 475 ms, TE = 4.08 ms, FA = 35 deg). To monitor the use of 7T for human research, participants filled out a questionnaire rating their levels of dizziness, wellbeing, alertness and focus after each imaging session.
First-level analysis
Request a detailed protocolFunctional data were analyzed using SPM12 and custom written MATLAB code. Functional runs were corrected for geometric distortions using fieldmap data (Hutton et al., 2002), and head movements during the scan (3 translations: x, y, z; 3 rotations: pitch, roll, yaw), and aligned across sessions to the first run of the first session. The functional data were then co-registered to the anatomical scan. No smoothing or normalization to an atlas template was performed.
Preprocessed data were analyzed using a general linear model (GLM; Friston et al., 1994). Each of the performed sequences was defined as a separate regressor per imaging run, resulting in 12 regressors per run (6 trained, 6 untrained sequences), together with intercept for each of the functional runs. All instances of sequence execution were included into estimating regressors, regardless of whether the execution was correct or erroneous (see section Treatment of error trials below). The regressor was a boxcar function starting at the beginning of the trial and lasting for trial duration. The boxcar function was convolved with a hemodynamic response function, with a time to peak of 5.5 s, and time to undershoot of 12.5 s. We adjusted the hrf onset individually per participant. For that, we defined a combined region of interest between PMd and M1, and averaged the response across all voxels in the combined ROI for all performed sequences (i.e. trained and untrained sequences together) in session 1. We then performed a grid-search with delay values of 0, 0.5 and 1 s, and chose the one that maximally fit the evoked response for each subject. The same delay was used across all sessions. Ultimately, this analysis resulted in one activation estimate (beta image) for each of the 12 conditions per run, in each scanning session.
Surface reconstruction and regions of interest
Request a detailed protocolWe reconstructed individual subjects’ cortical surfaces using FreeSurfer (Dale et al., 1999). All individual surfaces were aligned to the FreeSurfer’s Left-Right symmetric template (Workbench, 164 k nodes) via spherical registration. To detect sequence representation across the cortical surface, we used a surface-based searchlight approach (Oosterhof et al., 2011), where for each node we selected a circular region of 120 voxels in the grey matter. The resulting analyses (dissimilarities between sequence-specific activity patterns, see below) was assigned to the center node. As a slightly coarser alternative to searchlights, we performed regular tessellation of cortical surface into 162 tessels per hemisphere. This allowed us to fit correlation models (see below) across the cortical surface, while not being as computationally intensive as searchlight analyses.
We defined four regions of interest to cover primary somato-motor regions as well as secondary associative regions. M1 was defined using probabilistic cytoarchitectonic map (Fischl et al., 2008) by including nodes with the highest probability of belonging to Brodmann area (BA) 4, while excluding nodes more than 2.5 cm from the hand knob (Yousry et al., 1997). Similarly, S1 was defined as nodes related to hand representation in BA 1, 2 and 3. Additionally, we included dorsal premotor cortex (PMd) as the lateral part of the middle frontal gyrus. The anterior part of the superior parietal lobule (SPLa) was defined to include anterior, medial and ventral intraparietal sulcus. We also defined caudate nucleus and putamen as striatal regions of interest. The definition was carried out in each subject using FSL’s (Jenkinson et al., 2012) subcortical segmentation.
Changes in overall activation
Request a detailed protocolWe calculated the average percent signal change for trained and untrained sequences (averaged across the 6 trained and 6 untrained sequences) relative to the baseline for each voxel. The resulting volume map was projected to the surface for each subject, and a group statistical t-map was generated across subjects. Statistical maps were thresholded at p<0.01, uncorrected, and the family-wise error corrected p-value for the size of the peak activation and activation cluster size was determined using a permutation test. Specifically, we ran 1000 simulations where we randomly flipped the sign of the contrast for subjects (chosen at random out of 226 possible permutations). The rationale behind this is that under the null hypothesis, there should be no difference between the two conditions, and the sign of each contrast should be interchangeable. As for the data, we thresholded the statistical map from each permutation, and recorded the peak t-value (across the map) and the size of the largest cluster. The real data was then compared against this distribution to assess the probability of the observed t-value and cluster-size under the null hypothesis.
Additionally, we assessed changes in percent signal in predefined regions of interest (M1, S1, PMd, SPLa). This was performed in the native volume space of each subject. To do so, we averaged the percent signal change of voxels belonged to a defined region per subject and quantified activation changes across subjects using ANOVAs and t-tests across subjects.
Besides overall activation, we also examined relative changes in elicited activation for trained sequences across sessions. This was done by normalizing (z-scoring) the percent signal change surface maps across voxels, separately for each subject. Normalization was applied both map-wise (for Figure 5b), as well as for each of the pre-defined ROIs separately (for cross-sections in Figure 5c). Statistical assessment of the difference between relative evoked activation pattern for trained vs. untrained sequence was carried out by calculating cosine angle dissimilarities between the mean evoked patterns. Cosine angle dissimilarity was chosen because it is not sensitive to overall magnitude in activation, and therefore assesses the difference in the relative activation distribution.
Dissimilarities between sequence-specific activity patterns
Request a detailed protocolTo evaluate which cortical areas display sequence-specific encoding, we performed a searchlight analysis calculating the dissimilarities between evoked beta patterns of individual sequences. Beta patterns were first multivariately prewhitened (standardized by voxels’ residuals and weighted by the voxel covariance matrix), which has been found to increase the reliability of dissimilarity estimates (Walther et al., 2016). We then calculated the cross-validated squared Mahalanobis dissimilarities (i.e. crossnobis dissimilarities) between evoked sequence patterns (66 dissimilarity pairs for 6 trained and 6 untrained sequences). These dissimilarities were then averaged overall, as well as separately for pairs within trained sequences, and within untrained sequences. This metric was used both for searchlight analysis and calculation of metric within predefined regions (cortical and striatal). The cortex surface maps contrasting dissimilarities between trained and untrained sequences were corrected for multiple comparisons using permutations, as described above for percent signal change surface maps.
Pattern component analyses: modelling sequence-specific correlation across sessions
Request a detailed protocolCorrespondence of sequence-specific patterns across sessions was quantified using pattern component modelling (PCM; Diedrichsen et al., 2018). This framework is superior at estimating correlations than simply performing Pearson’s correlation on raw activity patterns, or even in a crossvalidated fashion. The main problem with estimating correlations on data is that activation patterns are biased by noise, which varies across scanning sessions, and would therefore underestimate the true correlation. PCM separately models the noise and signal component, and can in this way combat the issue more than by simply performing crossvalidation. We designed 30 correlation models with correlations between 0 and 1 in equal step sizes and assessed the group likelihood of the observed data under each model.
Subsequent group inferences were performed using crossvalidated approach on assessing individual log-Bayes factors (model evidence). A crossvalidated approach was used to ensure that our choice of ‘best-fitting models’ and the evidence associated was independent and did not involve double-dipping. Specifically, we used n-1 subjects to determine the best-fitting models for trained and untrained patterns and recorded the log-Bayes factors for those two correlation models on the left-out subject. This was repeated across all subjects and a t-test was performed on the recorded log-Bayes factors (i.e. out-of-sample model evidences). The same evaluation was performed for pre-defined regions of interest (Figure 6b), as well as a regular tessellation across the cortical surface (Figure 6c).
Treatment of error trials
Request a detailed protocolAs in behavioral sessions, participants were instructed to keep their error rate below 15% also inside the scanner. This was on average achieved, with the following error rate for trained vs. untrained sequences across the 4 scanning sessions: Week 1: 0.14 ± 0.02 vs. 0.15 ± 0.02, week 2: 0.08 ± 0.01 vs. 0.14 ± 0.02, week 5: 0.06 ± 0.01 vs. 0.09 ± 0.01, speeded scan week 5: 0.14 ± 0.01 vs. 0.13 ± 0.01. The number of errors varied significantly across sessions, and between sequence types. A session x sequence type ANOVA was significant for week (F(3,75)=9.19, p=2.97e−5), sequence type (F(1,25)=11.16, p=2.63e−3), as well as for their interaction (F(3,75)=8.39, p=7.00e−5). Post-hoc t-tests revealed that the error rate differed between trained and untrained sequences in week 2 (t(25)=4.20, p=2.95e−4) and 5 (t(25)=4.81, p=6.1e−5), but not in week 1 and for the speeded session of week 5. To control for difference in error rate, we performed an additional first-level analysis with error trials excluded to ensure that our results were not due to inclusion of errors. Indeed, our results did not differ qualitatively when excluding errors, therefore we here report only the analyses with all trials included.
Code availability
Request a detailed protocolThe code is available at https://github.com/eberlot/motor_sequence_learning.git (Berlot, 2020; copy archived at https://github.com/elifesciences-publications/motor_sequence_learning/).
Data availability
fMRI data and analysis pipelines have been deposited to OpenNeuro, under the accession number ds002776. Analysis code is available on GitHub at https://github.com/eberlot/motor_sequence_learning.git (copy archived at https://github.com/elifesciences-publications/motor_sequence_learning).
References
-
Cortical and basal ganglia contributions to habit learning and automaticityTrends in Cognitive Sciences 14:208–215.https://doi.org/10.1016/j.tics.2010.02.001
-
Learning-induced autonomy of sensorimotor systemsNature Neuroscience 18:744–751.https://doi.org/10.1038/nn.3993
-
In search of the engram, 2017Current Opinion in Behavioral Sciences 20:56–60.https://doi.org/10.1016/j.cobeha.2017.11.003
-
Binding during sequence learning does not alter cortical representations of individual actionsThe Journal of Neuroscience 39:6968–6977.https://doi.org/10.1523/JNEUROSCI.2669-18.2019
-
Rapid plasticity of human cortical movement representation induced by practiceJournal of Neurophysiology 79:1117–1123.https://doi.org/10.1152/jn.1998.79.2.1117
-
Cortical folding patterns and predicting cytoarchitectureCerebral Cortex 18:1973–1980.https://doi.org/10.1093/cercor/bhm225
-
Distinguishable brain activation networks for short- and long-term motor skill learningJournal of Neurophysiology 94:512–518.https://doi.org/10.1152/jn.00717.2004
-
Statistical parametric maps in functional imaging: a general linear approachHuman Brain Mapping 2:189–210.https://doi.org/10.1002/hbm.460020402
-
Functional mapping of sequence learning in normal humansJournal of Cognitive Neuroscience 7:497–510.https://doi.org/10.1162/jocn.1995.7.4.497
-
Motor sequence learning with the nondominant left hand a PET functional imaging studyExperimental Brain Research 146:369–378.https://doi.org/10.1007/s00221-002-1181-y
-
The striatum: where skills and habits meetCold Spring Harbor Perspectives in Biology 7:a021691.https://doi.org/10.1101/cshperspect.a021691
-
Parallel neural networks for learning sequential proceduresTrends in Neurosciences 22:464–471.https://doi.org/10.1016/S0166-2236(99)01439-3
-
Motor sequence learning: a study with positron emission tomographyThe Journal of Neuroscience 14:3775–3790.https://doi.org/10.1523/JNEUROSCI.14-06-03775.1994
-
Effect of a tDCS electrode montage on implicit motor sequence learning in healthy subjectsExperimental & Translational Stroke Medicine 3:2–7.https://doi.org/10.1186/2040-7378-3-4
-
Society for Experimental Biology, Physiological Mechanisms in Animal Behavior454–482, Insearch of the engram, Society for Experimental Biology, Physiological Mechanisms in Animal Behavior, Academic Press.
-
Asymmetry of cortical activation during maximum and convenient tapping speedNeuroscience Letters 373:61–66.https://doi.org/10.1016/j.neulet.2004.09.058
-
Skill Representation in the Primary Motor Cortex After Long-Term PracticeJournal of Neurophysiology 97:1819–1832.https://doi.org/10.1152/jn.00784.2006
-
Facilitation of implicit motor learning by weak transcranial direct current stimulation of the primary motor cortex in the humanJournal of Cognitive Neuroscience 15:619–626.https://doi.org/10.1162/089892903321662994
-
Sensory plasticity in human motor learningTrends in Neurosciences 39:114–123.https://doi.org/10.1016/j.tins.2015.12.006
-
Dynamic cortical and subcortical networks in learning and delayed recall of timed motor sequencesThe Journal of Neuroscience 22:1397–1406.https://doi.org/10.1523/JNEUROSCI.22-04-01397.2002
-
Parallel contributions of cerebellar, striatal and M1 mechanisms to motor sequence learningBehavioural Brain Research 226:579–591.https://doi.org/10.1016/j.bbr.2011.09.044
-
Reorganization of corticospinal output during motor learningNature Neuroscience 20:1133–1141.https://doi.org/10.1038/nn.4596
-
Extended practice of a motor skill is associated with reduced metabolic activity in M1Nature Neuroscience 16:1340–1347.https://doi.org/10.1038/nn.3477
-
The neural correlates of motor skill automaticityJournal of Neuroscience 25:5356–5364.https://doi.org/10.1523/JNEUROSCI.3880-04.2005
-
Neural correlates of encoding and expression in implicit sequence learningExperimental Brain Research 165:114–124.https://doi.org/10.1007/s00221-005-2284-z
-
Changes in default mode network as automaticity develops in a categorization taskBehavioural Brain Research 313:324–333.https://doi.org/10.1016/j.bbr.2016.07.029
-
Common blood flow changes across visual tasks: ii. decreases in cerebral cortexJournal of Cognitive Neuroscience 9:648–663.https://doi.org/10.1162/jocn.1997.9.5.648
-
Imaging brain plasticity during motor skill learningNeurobiology of Learning and Memory 78:553–564.https://doi.org/10.1006/nlme.2002.4091
-
How self-initiated memorized movements become automatic: a functional MRI studyJournal of Neurophysiology 91:1690–1698.https://doi.org/10.1152/jn.01052.2003
-
The role of human primary motor cortex in the production of skilled finger sequencesThe Journal of Neuroscience 38:1430–1442.https://doi.org/10.1523/JNEUROSCI.2798-17.2017
Article and author information
Author details
Funding
Natural Sciences and Engineering Research Council of Canada (NSERC Discovery Grant (RGPIN-2016-04890))
- Jörn Diedrichsen
Canada First Research Excellence Fund (BrainsCAN)
- Jörn Diedrichsen
Ontario Trillium Foundation (Graduate Student Scholarship)
- Eva Berlot
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
The work was supported by an Ontario Trillium Scholarship to EB, an NSERC Discovery Grant (RGPIN-2016–04890) to JD, and the Canada First Research Excellence Fund (BrainsCAN). We thank Giacomo Ariani, Tamar Makin, Andrew Pruszynski, and Atsushi Yokoi for helpful comments on an earlier version of the manuscript.
Ethics
Human subjects: Informed consent and data usage agreement was obtained from participants prior to the onset of the study. It was emphasized that participants could withdraw from the study at any timepoint. The experimental procedures were approved by the Ethics Committee at Western University (HSREB File Number: 107061).
Copyright
© 2020, Berlot et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 4,829
- views
-
- 608
- downloads
-
- 102
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 102
- citations for umbrella DOI https://doi.org/10.7554/eLife.55241
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
A critical re-evaluation of fMRI signatures of motor sequence learning
eLife 9:e55241.
https://doi.org/10.7554/eLife.55241




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}