A functional model of adult dentate gyrus neurogenesis
- School of Life Sciences and School of Computer and Communication Sciences, Ecole Polytechnique Fédérale de Lausanne, Switzerland
- Departments of Neurobiology and Statistics, University of Chicago, United States
- Grossman Center for Quantitative Biology and Human Behavior, University of Chicago, United States
Abstract
In adult dentate gyrus neurogenesis, the link between maturation of newborn neurons and their function, such as behavioral pattern separation, has remained puzzling. By analyzing a theoretical model, we show that the switch from excitation to inhibition of the GABAergic input onto maturing newborn cells is crucial for their proper functional integration. When the GABAergic input is excitatory, cooperativity drives the growth of synapses such that newborn cells become sensitive to stimuli similar to those that activate mature cells. When GABAergic input switches to inhibitory, competition pushes the configuration of synapses onto newborn cells toward stimuli that are different from previously stored ones. This enables the maturing newborn cells to code for concepts that are novel, yet similar to familiar ones. Our theory of newborn cell maturation explains both how adult-born dentate granule cells integrate into the preexisting network and why they promote separation of similar but not distinct patterns.
Introduction
In the adult mammalian brain, neurogenesis, the production of new neurons, is restricted to a few brain areas, such as the olfactory bulb and the dentate gyrus (Deng et al., 2010). The dentate gyrus is a major entry point of input from cortex, primarily entorhinal cortex (EC), to the hippocampus (Amaral et al., 2007), which is believed to be a substrate of learning and memory (Jarrard, 1993). Adult-born cells in dentate gyrus mostly develop into dentate granule cells (DGCs), the main excitatory cells that project to area CA3 of hippocampus (Deng et al., 2010).
The properties of rodent adult-born DGCs change as a function of their maturation stage, until they become indistinguishable from other mature DGCs at approximately 8 weeks (Deng et al., 2010; Johnston et al., 2016; Figure 1a). Many of them die before they fully mature (Dayer et al., 2003). Their survival is experience dependent and relies on NMDA receptor activation (Tashiro et al., 2006). Initially, newborn DGCs have enhanced excitability (Schmidt-Hieber et al., 2004; Li et al., 2017) and stronger synaptic plasticity than mature DGCs, reflected by a larger long-term potentiation (LTP) amplitude and a lower threshold for induction of LTP (Wang et al., 2000; Schmidt-Hieber et al., 2004; Ge et al., 2007). Furthermore, after 4 weeks of maturation adult-born DGCs have only weak connections to interneurons, while at 7 weeks of age, their activity causes indirect inhibition of mature DGCs (Temprana et al., 2015).
Figure 1 with 1 supplement see all
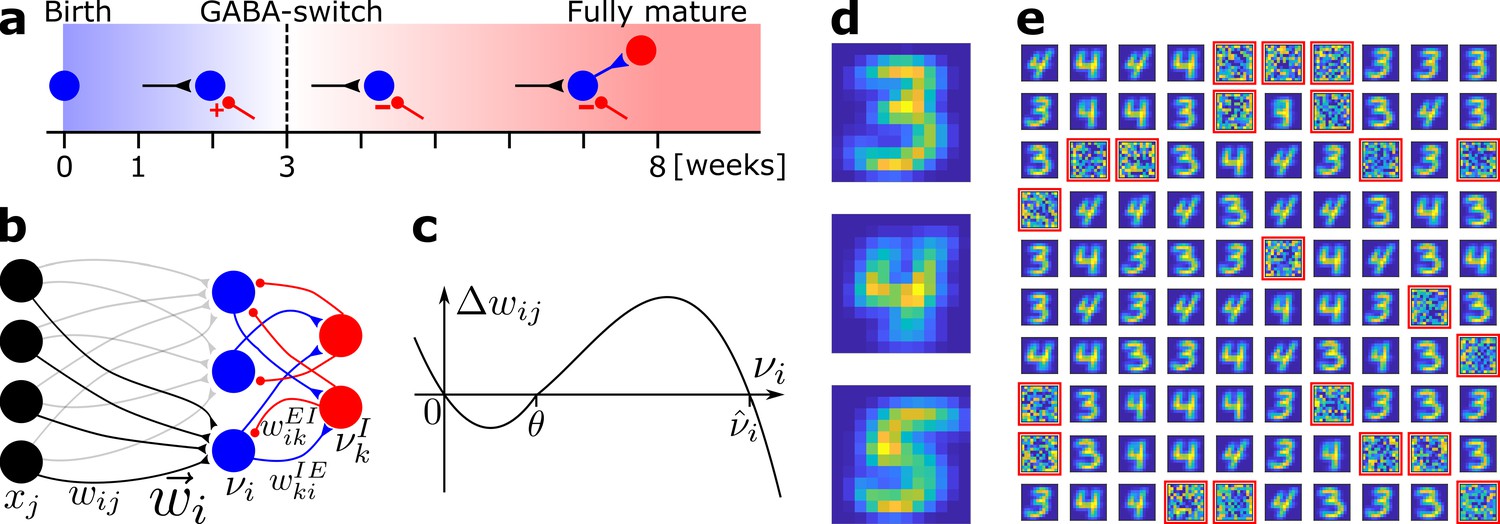
Network model and pretraining.
(a) Integration of an adult-born DGC (blue) as a function of time: GABAergic synaptic input (red) switches from excitatory (+) to inhibitory (−); strong connections to interneurons develop only later; glutamatergic synaptic input (black), interneuron (red). (b) Network structure. EC neurons (black, rate xj) are fully connected with weights to DGCs (blue, rate ). The feedforward weight vector onto neuron is depicted in black. DGCs and interneurons (red, rate ) are mutually connected with probability and and weights and , respectively. Connections with a triangular (round) end are glutamatergic (GABAergic). (c) Given presynaptic activity , the weight update is shown as a function of the firing rate of the postsynaptic DGC with LTD for and LTP for . (d) Center of mass for three ensembles of patterns from the MNIST data set, visualized as 12 × 12 pixel patterns. The two-dimensional arrangements and colors are for visualization only. (e) One hundred receptive fields, each defined as the set of feedforward weights, are represented in a two-dimensional organization. After pretraining with patterns from MNIST digits 3 and 4, 79 DGCs have receptive fields corresponding to threes and fours of different writing styles, while 21 remain unselective (highlighted by red frames).
Newborn DGCs receive no direct connections from mature DGCs (Deshpande et al., 2013; Alvarez et al., 2016) (yet see Vivar et al., 2012), but are indirectly activated via interneurons (Alvarez et al., 2016; Heigele et al., 2016). At about 3 weeks after birth, the γ-aminobutyric acid (GABAergic) input from interneurons to adult-born DGCs switches from excitatory in the early phase to inhibitory in the late phase of maturation (Ge et al., 2006; Deng et al., 2010) (‘GABA-switch’, Figure 1a). Analogous to a similar transition during embryonic and early postnatal stages (Wang and Kriegstein, 2011), the GABA-switch is caused by a change in the expression profile of chloride cotransporters. In the early phase of maturation, newborn cells express the cotransporter NKCC1, which leads to a high intracellular chloride concentration. Hence, the GABA reversal potential is higher than the resting potential (Ge et al., 2006; Heigele et al., 2016), and GABAergic inputs lead to Cl− ions outflow through the ionic receptors, which results in depolarization of the newborn cell (Ben-Ari, 2002; Owens and Kriegstein, 2002). In the late phase of maturation, expression of the -coupled cotransporter KCC2 kicks in, which lowers the intracellular chloride concentration of the newborn cell to levels similar to those of mature cells, leading to a hyperpolarization of the cell membrane due to Cl− inflow upon GABAergic stimulation (Ben-Ari, 2002; Owens and Kriegstein, 2002). The transition from depolarizing (excitatory) to hyperpolarizing (inhibitory) effects of GABA is referred to as the ‘GABA-switch’. It has been shown that GABAergic inputs are crucial for the integration of newborn DGCs into the preexisting circuit (Ge et al., 2006; Chancey et al., 2013; Alvarez et al., 2016; Heigele et al., 2016).
The mammalian dentate gyrus contains – just like hippocampus in general – a myriad of inhibitory cell types (Freund and Buzsáki, 1996; Somogyi and Klausberger, 2005; Klausberger and Somogyi, 2008), including basket cells, chandelier cells, and hilar cells (Figure 1—figure supplement 1). Basket cells can be subdivided in two categories: some express cholecystokinin (CCK) and vasoactive intestinal polypeptide (VIP), while the others express parvalbumin (PV) and are fast-spiking (Freund and Buzsáki, 1996; Amaral et al., 2007). Chandelier cells also express PV (Freund and Buzsáki, 1996). Overall, it has been estimated that PV is expressed in 15–21% of all dentate GABAergic cells (Freund and Buzsáki, 1996) and in 20–25% of the GABAergic neurons in the granule cell layer (Houser, 2007). Amongst the GABAergic hilar cells, 55% express somatostatin (SST) (Houser, 2007) and somatostatin-positive interneurons (SST-INs) represent about 16% of the GABAergic neurons in the dentate gyrus as a whole (Freund and Buzsáki, 1996). While axons of hilar interneurons stay in the hilus and provide perisomatic inhibition onto dentate GABAergic cells, axons of hilar-perforant-path-associated interneurons (HIPP) extend to the molecular layer and provide dendritic inhibition onto both DGCs and interneurons (Yuan et al., 2017). HIPP axons generate lots of synaptic terminals and extend as far as 3.5 mm along the septotemporal axis of the dentate gyrus (Amaral et al., 2007). PV-expressing interneurons (PV-INs) and SST-INs both target adult-born DGCs early (after 2–3 weeks) in their maturation (Groisman et al., 2020). PV-INs provide both feedforward inhibition and feedback inhibition (also called lateral inhibition) to the DGCs (Groisman et al., 2020). In general, SST-INs provide lateral, but not feedforward, inhibition onto DGCs (Stefanelli et al., 2016; Groisman et al., 2020; Figure 1—figure supplement 1).
Adult-born DGCs are preferentially reactivated by stimuli similar to the ones they experienced during their early phase of maturation, up to 3 weeks after cell birth (Tashiro et al., 2007). Even though the amount of newly generated cells per month is rather low (3–6% of the total DGCs population [van Praag et al., 1999; Cameron and McKay, 2001]), adult-born DGCs are critical for behavioral pattern separation (Clelland et al., 2009; Sahay et al., 2011a; Jessberger et al., 2009), in particular in tasks where similar stimuli or contexts have to be discriminated (Clelland et al., 2009; Sahay et al., 2011a). However, the functional role of adult-born DGCs is controversial (Sahay et al., 2011b; Aimone et al., 2011). One view is that newborn DGCs contribute to pattern separation through a modulatory role (Sahay et al., 2011b). Another view suggests that newborn DGCs act as encoding units that become sensitive to features of the environment which they encounter during a critical window of maturation (Kee et al., 2007; Tashiro et al., 2007). Some authors have even challenged the role of newborn DGCs in pattern separation in the classical sense and have proposed a pattern integration effect instead (Aimone et al., 2011), while others suggest a dynamical (Aljadeff et al., 2015; Shani-Narkiss et al., 2020) or forgetting (Akers et al., 2014) role for newborn DGCs. Within that broader controversy, we ask two specific questions: First, why are GABAergic inputs crucial for the integration of newborn DGCs into the preexisting circuit? And second, why are newborn DGCs particularly important in tasks where similar stimuli or contexts have to be discriminated?
To address these questions, we present a model of how newborn DGCs integrate into the preexisting circuit. In contrast to earlier models where synaptic input connections onto newborn cells were assumed to be strong enough to drive them (Chambers et al., 2004; Becker, 2005; Crick and Miranker, 2006; Wiskott et al., 2006; Chambers and Conroy, 2007; Aimone et al., 2009; Appleby and Wiskott, 2009; Weisz and Argibay, 2009; Temprana et al., 2015; Finnegan and Becker, 2015; DeCostanzo et al., 2018), our model uses an unsupervised biologically plausible Hebbian learning rule that makes synaptic connections between EC and newborn DGCs either disappear or grow from small values at birth to values that eventually enable feedforward input from EC to drive DGCs. Contrary to previous modeling studies, our plasticity model does not require an artificial renormalization of synaptic connection weights since model weights are naturally bounded by the synaptic plasticity rule. We show that learning with a biologically plausible plasticity rule is possible thanks to the GABA-switch, which has been overlooked in previous modeling studies. Specifically, the growth of synaptic weights from small values is supported in our model by the excitatory action of GABA, whereas, after the switch, specialization of newborn cells arises from competition between DGCs, triggered by the inhibitory action of GABA. Furthermore, our theory of adult-born DGCs integration yields a transparent explanation of why newborn cells favor pattern separation of similar stimuli, but do not impact pattern separation of distinct stimuli.
Results
We model a small patch of cells within dentate gyrus as a recurrent network of 100 DGCs and 25 GABAergic interneurons, omitting the Mossy cells for the sake of simplicity (Figure 1b). The modeled interneurons correspond to SST-INs from the HIPP category, as they are the providers of feedback inhibition to DGCs through dendritic projections (Stefanelli et al., 2016; Yuan et al., 2017; Groisman et al., 2020; Figure 1—figure supplement 1). The activity of a DGC with index and an interneuron with index is described by their continuous firing rates and , respectively. Firing rates are modeled by neuronal frequency–current curves that vanish for weak input and increase if the total input into a neuron is larger than a firing threshold. Since newborn DGCs exhibit enhanced excitability early in maturation (Schmidt-Hieber et al., 2004; Li et al., 2017), the firing threshold of model neurons increases during maturation from a lower to a higher value (Materials and methods). Connectivity in a localized patch of dentate neurons is high: DGCs densely project to GABAergic interneurons (Acsády et al., 1998), and SST-INs heavily project to cells in their neighborhood (Amaral et al., 2007). Hence, in the recurrent network model, each model DGC projects to, and receives input from, a given interneuron with probability 0.9. The exact percentage of GABAergic neurons (or SST-INs) in the dentate gyrus as a whole is not known, but has been estimated at about 10% and only a fraction of these are SST-INs (Freund and Buzsáki, 1996). The number of inhibitory neurons in our model network might therefore seem too high. However, our results are robust to substantial changes in the number of inhibitory neurons (Supplementary file 2).
Each of the 100 model DGCs receives input from a set of 144 model EC cells (Figure 1b). In the rat, the number of DGCs has been estimated to be about 106, while the number of EC input cells is estimated to be about 2 · 105 (Andersen et al., 2007), yielding an expansion factor from EC to dentate gyrus of about 5. Theoretical analysis suggests that the expansion of the number of neurons enhances decorrelation of the representation of input patterns (Marr, 1969; Albus, 1971; Marr, 1971; Rolls and Treves, 1998) and promotes pattern separation (Babadi and Sompolinsky, 2014). Our standard network model does not reflect this expansion because we want to highlight the particular ability of adult neurogenesis in combination with the GABA-switch to decorrelate input patterns independently of specific choices of the network architecture. However, we show later that an enlarged network with an expansion from 144 model EC cells to 700 model DGCs (similar to the anatomical expansion factor) yields similar results.
At birth, a DGC with index does not receive synaptic glutamatergic input yet. Hence, the connection from any model EC cell with index is initialized at . The growth or decay of the synaptic strength of the connection from to is controlled by a Hebbian plasticity rule (Figure 1c):
(1)
where xj is the firing rate of the presynaptic EC neuron, η (‘learning rate’) is the susceptibility of a cell to synaptic plasticity, and are positive parameters (Materials and methods, Table 1). The first term on the right-hand side of Equation (1) describes LTP whenever the presynaptic neuron is active ( and the postsynaptic firing is above a threshold θ; the second term on the right-hand side of Equation (1) describes long-term depression (LTD) whenever the presynaptic neuron is active and the postsynaptic firing rate is positive but below the threshold θ; LTD stops if the synaptic weight is zero. Such a combination of LTP and LTD is consistent with experimental data (Artola et al., 1990; Sjöström et al., 2001) as shown in earlier rate-based (Bienenstock et al., 1982) or spike-based (Pfister and Gerstner, 2006) plasticity models. The third term on the right-hand side of Equation (1) implements heterosynaptic plasticity (Chistiakova et al., 2014; Zenke and Gerstner, 2017): whenever strong presynaptic input arriving at synapses drives the firing of postsynaptic neuron at a rate above θ, the weight of a synapse is downregulated if synapse does not receive any input, while the weights of synapses are simultaneously increased due to the first term (Lynch et al., 1977). Importantly, the threshold condition for the third term (postsynaptic rate above θ) is the same as that for induction of LTP in the first term so that if some synapses are potentiated, silent synapses are depressed. In the model, heterosynaptic interaction between synapses is induced since information about postsynaptic activity is shared across synapses. This could be achieved in biological neurons via backpropagating action potentials or similar depolarization of the postsynaptic membrane potential at several synaptic locations; alternatively, heterosynaptic crosstalk could be implemented by signaling molecules. Note that since our neuron model is a point neuron, all synapses are neighbors of each other. In our model, the ‘heterosynaptic’ term has a negative sign which ensures that the weights cannot grow without bounds (Materials and methods). In this sense, the third term has a ‘homeostatic’ function (Zenke and Gerstner, 2017), yet acts on a time scale faster than experimentally observed homeostatic synaptic plasticity (Turrigiano et al., 1998).
Table 1
Parameters for the simulations.
| Biologically plausible network | Simplified network | |||
|---|---|---|---|---|
| Network | ||||
| (Figures 1–4) | ||||
| (Figure 4—figure supplement 1–2) | ||||
| Connectivity | ||||
| Dynamics | ms | ms | ms | |
| Plasticity | ||||
| Numerical simulations | ms | ms | ||
We ask whether such a biologically plausible plasticity rule enables adult-born DGCs to be integrated in an existing network of mature cells. To address this question, we exploit two observations (Figure 1a): first, the effect of interneurons onto newborn DGCs exhibits a GABA-switch from excitatory to inhibitory after about three weeks of maturation (Ge et al., 2006; Deng et al., 2010) and, second, newborn DGCs receive input from interneurons early in their maturation (before the third week), but project back to interneurons only later (Temprana et al., 2015). For simplicity, no plasticity rule was implemented within the dentate gyrus: connections between newborn DGCs and inhibitory cells are either absent or present with a fixed value (see below). However, before integration of adult-born DGCs can be addressed, an adult-stage network where mature cells already store some memories has to be constructed.
Mature neurons represent prototypical input patterns
In an adult-stage network, some mature cells already have a functional role. Hence, we start with a network that already has strong random EC-to-DGC connection weights (Materials and methods). We then pretrain our network of 100 DGCs using the same learning rule (Equation (1), with identical learning rate η for all DGCs) that we will use later for the integration of newborn cells. For the stimulation of EC cells, we apply patterns representing thousands of handwritten digits in different writing styles from MNIST, a standard data set in artificial intelligence (Lecun et al., 1998). Even though we do not expect EC neurons to show a two-dimensional arrangement, the use of two-dimensional patterns provides a simple way to visualize the activity of all 144 EC neurons in our model (Figure 1d). We implicitly model feedforward inhibition from PV-INs (Groisman et al., 2020; Figure 1—figure supplement 1) by normalizing input patterns so that all inputs have the same amplitude (Materials and methods). Below, we present results for a representative combination of three digits (digits 3, 4, and 5), but other combinations of digits have also been tested (Supplementary file 1).
After pretraining with patterns from digits 3 and 4 in a variety of writing styles, we examine the receptive field of each DGC. Each receptive field, consisting of the connections from all 144 EC neurons onto one DGC, is characterized by its spatial structure (i.e. the pattern of connection weights) and its total strength (i.e. the efficiency of the optimal stimulus to drive the cell). We observe that out of the 100 DGCs, some have developed spatial receptive fields that correspond to different writing styles of digit 3, others receptive fields that correspond to variants of digit 4 (Figure 1e).
Behavioral discrimination has been shown to be correlated with classification accuracy based on DGC population activity (Woods et al., 2020). Hence, to quantify the representation quality, we compute classification performance by a linear classifier that is driven by the activity of our 100 DGC model cells (Materials and methods). At the end of pretraining, the classification performance for patterns of digits 3 and 4 from a distinct test set not used during pretraining is high: 99.25% (classification performance on digit 3: 98.71%; digit 4: 99.80%), indicating that nearly all input patterns of the two digits are well represented by the network of mature DGCs. The median classification performance for 10 random combinations of two groups of pretrained digits is 98.54%, the 25th percentile 97.26%, and the 75th percentile 99.5% (Supplementary file 1).
A detailed mathematical analysis (Materials and methods) shows that heterosynaptic plasticity in Equation (1) ensures that the total strength of the receptive field of each selective DGC converges to a stable value which is similar for selective DGCs confirming the homeostatic function of heterosynaptic plasticity (Zenke and Gerstner, 2017). As a consequence, synaptic weights are intrinsically bounded without the need to impose hard bounds on the weight dynamics. Moreover, we find that the spatial structure of the receptive field represents the weighted average of all those input patterns for which that DGC is responsive. The mathematical analysis also shows that those DGCs that do not develop selectivity have weak synaptic connections and a very low total strength of the receptive field.
After convergence of synaptic weights during pretraining, selective DGCs are considered mature cells. Mature cells are less plastic than newborn cells (Schmidt-Hieber et al., 2004; Ge et al., 2007). So in the following, unless specified otherwise, we set in Equation (1) for mature cells (feedforward connection weights from EC to mature cells remain therefore fixed). A scenario where mature cells retain synaptic plasticity is also investigated (see Robustness of the model and Supplementary file 4). Some DGCs did not develop any strong weight patterns during pretraining and exhibit unselective receptive fields (highlighted in red in Figure 1e). We classify these as unresponsive units.
Newborn neurons become selective for novel patterns during maturation
In our main neurogenesis model, we replace unresponsive model units by plastic newborn DGCs ( in Equation (1)), which receive lateral GABAergic input but do not receive feedforward input yet (all weights from EC are set to zero). The replacement of unresponsive neurons reflects the fact that unresponsive units have weak synaptic connections and, experimentally, a lack of NMDA receptor activation has been shown to be deleterious for the survival of newborn DGCs (Tashiro et al., 2006). To mimic exposure of an animal to a novel set of stimuli, we now add input patterns from digit 5 to the set of presented stimuli, which was previously limited to patterns of digits 3 and 4. The novel patterns from digit 5 are randomly interspersed into the sequence of patterns from digits 3 and 4; in other words, the presentation sequence was not optimized with a specific goal in mind.
We postulate that functional integration of newborn DGCs requires the two-step maturation process caused by the GABA-switch from excitation to inhibition. Since excitatory GABAergic input potentially increases correlated activity within the dentate gyrus network, we predict that newborn DGCs respond to familiar stimuli during the early phase of maturation, but not during the late phase, when inhibitory GABAergic input leads to competition.
To test this hypothesis, our model newborn DGCs go through two maturation phases (Materials and methods). The early phase of maturation is cooperative because, for each pattern presentation, activated mature DGCs indirectly excite the newborn DGCs via GABAergic interneurons. We assume that in natural settings, the activation of receptors is low enough that the mean membrane potential remains below the chloride reversal potential at which shunting inhibition would be induced (Heigele et al., 2016). In this regime, the net effect of synaptic activity is hence excitatory. This lateral activation of newborn DGCs drives the growth of their receptive fields in a direction similar to those of the currently active mature DGCs. Consistent with our hypothesis we find that, at the end of the early phase of maturation, newborn DGCs show a receptive field corresponding to a mixture of several input patterns (Figure 2a).
Figure 2 with 2 supplements see all
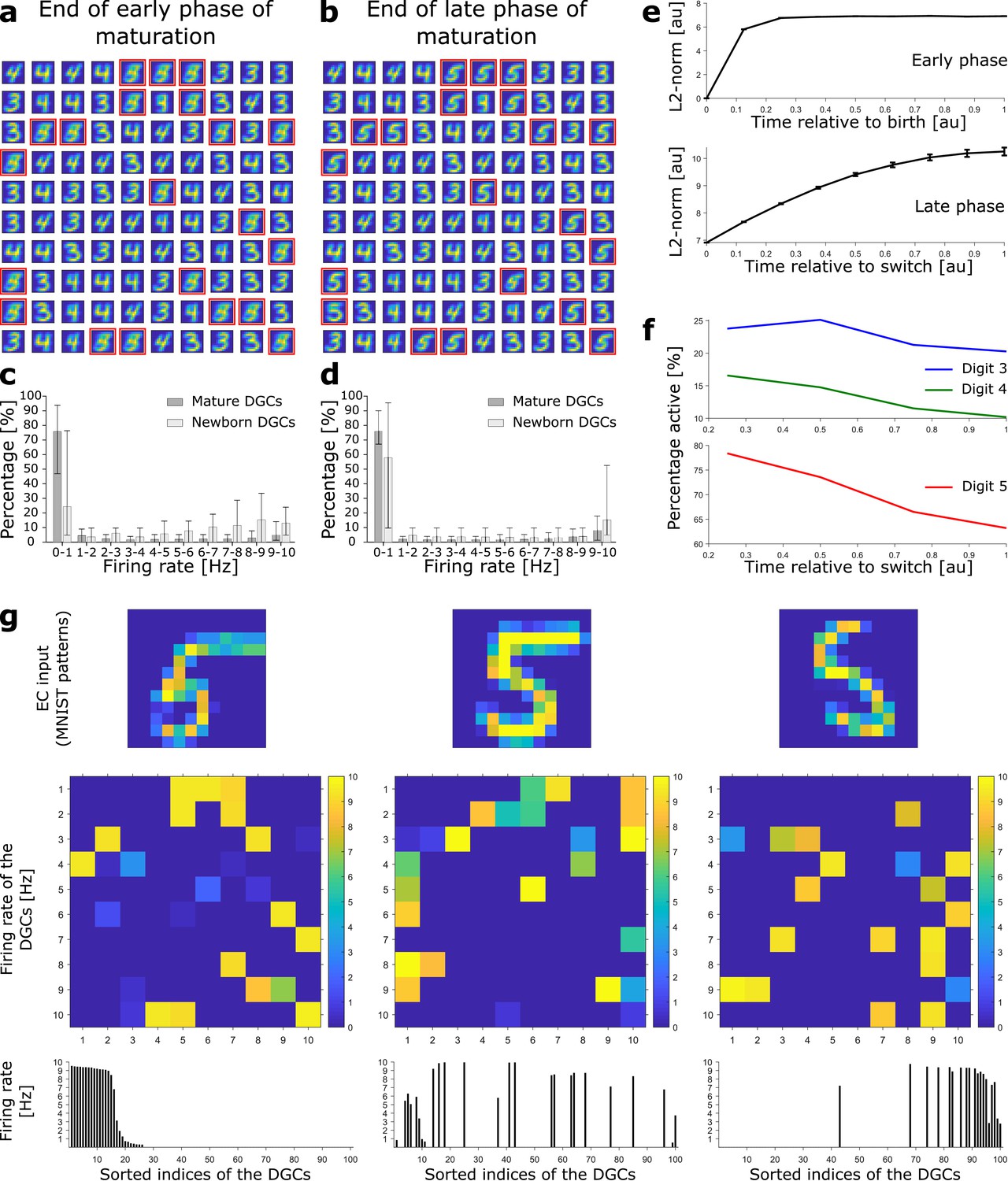
Newborn DGCs become selective for novel patterns during maturation.
(a) Unselective neurons are replaced by newborn DGCs, which learn their feedforward weights while patterns from digits 3, 4, and 5 are presented. At the end of the early phase of maturation, the receptive fields of all newborn DGCs (red frames) show mixed selectivity. (b) At the end of the late phase of maturation, newborn DGCs are selective for patterns from the novel digit 5, with different writing styles. (c, d) Distribution of the percentage of model DGCs (mean with 10th and 90th percentiles) in each firing rate bin at the end of the early (c) and late (d) phase of maturation. Statistics calculated across MNIST patterns (‘3’s, ‘4’s, ‘5’s). Percentages are per subpopulation (mature and newborn). Note that neurons with firing rate < 1 Hz for one pattern may fire at medium or high rate for another pattern. (e) The L2-norm of the feedforward weight vector onto newborn DGCs (mean ± SEM) increases as a function of maturation indicating growth of synapses and receptive field strength. Horizontal axis: time = 1 indicates end of early (top) or late (bottom) phase (two epochs per phase, ). (f) Percentage of newborn DGCs activated (firing rate > 1 Hz) by a stimulus averaged over test patterns of digits 3, 4, and 5 as a function of maturation. (g) At the end of the late phase of maturation, three different patterns of digit 5 applied to EC neurons (top) cause different firing rate patterns of the 100 DGCs arranged in a matrix of 10-by-10 cells (middle). DGCs with a receptive field (see b) similar to a presented EC activation pattern respond more strongly than the others. Bottom: Firing rates of the DGCs with indices sorted from highest to lowest firing rate in response to the first pattern. All three patterns shown come from the testing set, and are correctly classified using our readout network.
In the late phase of maturation, model newborn DGCs receive inhibitory GABAergic input from interneurons, similar to the input received by mature DGCs. Given that at the end of the early phase, newborn DGCs have receptive fields similar to those of mature DGCs, lateral inhibition induces competition with mature DGCs for activation during presentation of patterns from the novel digit. Because model newborn DGCs start their late phase of maturation with a higher excitability (lower threshold) compared to mature DGCs, consistent with observed enhanced excitability of newborn cells (Schmidt-Hieber et al., 2004; Li et al., 2017), the activation of newborn DGCs is facilitated for those input patterns for which no mature DGC has preexisting selectivity. Therefore, in the late phase of maturation, competition drives the synaptic weights of most newborn DGCs toward receptive fields corresponding to different subcategories of the ensemble of input patterns of the novel digit 5 (Figure 2b).
The total strength of the receptive field of a given DGC can be characterized by the sum of the squared synaptic weights of all feedfoward projections onto the cell (i.e. the square of the L2-norm). During maturation, the L2-norm of the feedforward weights onto newborn DGCs increases (Figure 2e) indicating an increase in total glutamatergic innervation, e.g., through an increase in the number and size of spines (Zhao et al., 2006). Nevertheless, the distribution of firing rates of newborn DGCs is shifted to lower values at the end of the late phase compared to the end of the early phase of maturation (Figure 2c,d), consistent with in vivo calcium imaging recordings showing that newborn DGCs are more active than mature DGCs (Danielson et al., 2016).
We emphasize that upon presentation of a pattern of a given digit, only those DGCs with a receptive field similar to the specific writing style of the presented pattern become strongly active, others fire at a medium firing rate, yet others at a low rate (Figure 2g). As a consequence, the firing rate of a particular newborn DGC at the end of its maturation to a pattern from digit 5 is strongly modulated by the specific choice of stimulation pattern within the class of ‘5’s. Analogous results are obtained for patterns from pretrained digits 3 and 4 (Figure 2—figure supplement 1). Hence, the ensemble of DGCs is effectively performing pattern separation within each digit class as opposed to a simple ternary classification task. The selectivity of newborn DGCs develops during maturation. Indeed, during the late, competitive, phase, the percentage of active newborn DGCs decreases, both upon presentation of familiar patterns (digits 3 and 4), as well as upon presentation of novel patterns (digit 5) (Figure 2f). This reflects the development of the selectivity of our model newborn DGCs from broad to narrow tuning, consistent with experimental observations (Marín-Burgin et al., 2012; Danielson et al., 2016).
If two novel ensembles of digits (instead of a single one) are introduced during maturation of newborn DGCs, we observe that some newborn DGCs become selective for one of the novel digits, while others become selective for the other novel digit (Figure 2—figure supplement 2). This was expected, since we have found earlier that DGCs are becoming selective for different prototype writing styles even within a digit category; hence introducing several additional digit categories of novel patterns simply increases the prototype diversity. Therefore, newborn DGCs can ultimately promote separation of several novel overarching categories of patterns, no matter if they are learned simultaneously or sequentially (Figure 2—figure supplement 2).
Adult-born neurons promote better discrimination
As above, we compute classification performance of our model network as a surrogate for behavioral discrimination (Woods et al., 2020). At the end of the late phase of maturation of newborn DGCs, we obtain an overall classification performance of 94.56% for the three ensembles of digits (classification performance for digit 3: 90.50%; digit 4: 98.17%; digit 5: 95.18%). Confusion matrices show that although novel patterns are not well classified at the end of the early phase of maturation (Figure 3e), they are as well classified as pretrained patterns at the end of the late phase of maturation (Figure 3f).
Figure 3
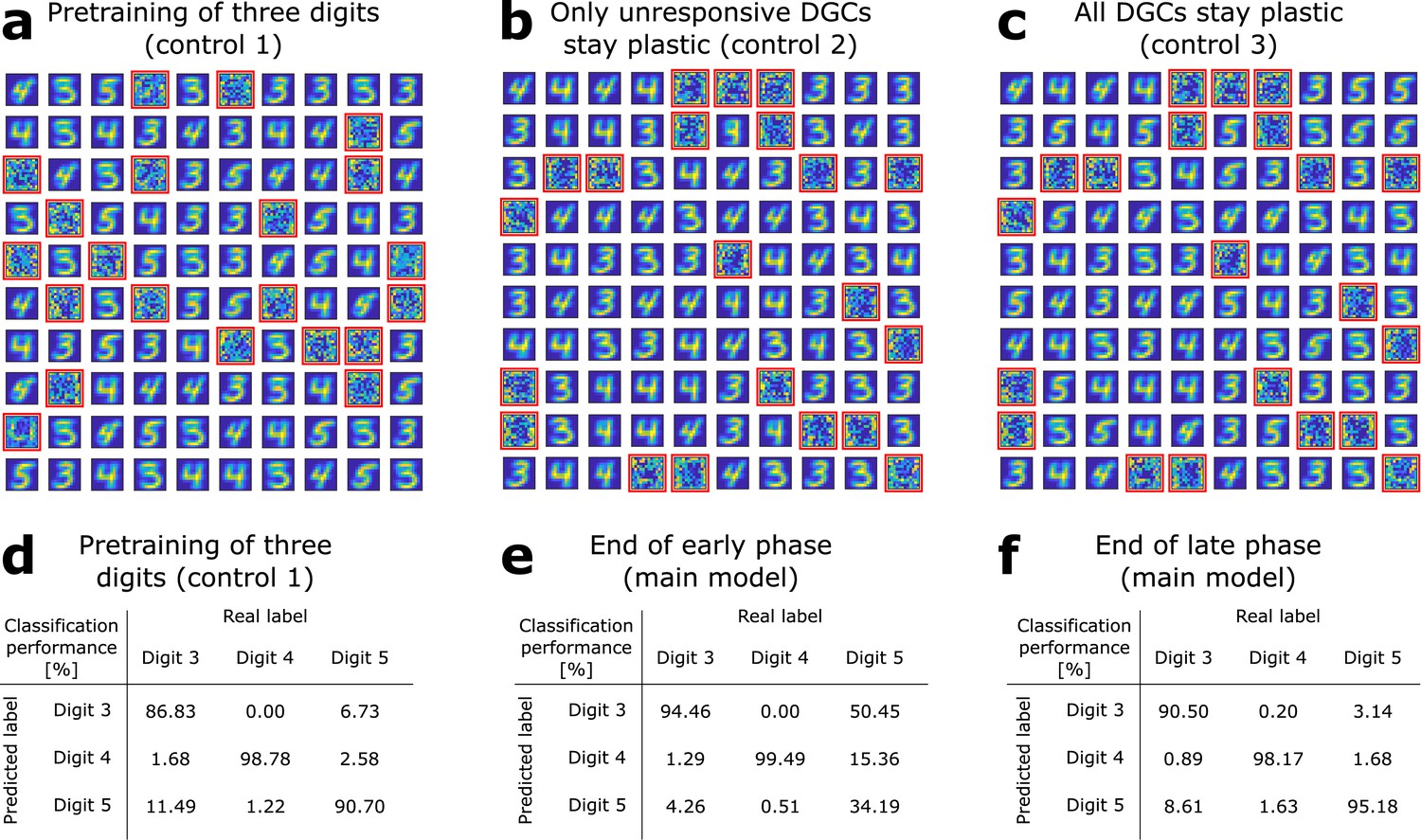
The GABA-switch guides learning of novel representations.
(a) Pretraining on digits 3, 4, and 5 simultaneously without neurogenesis (control 1). Patterns from digits 3, 4, and 5 are presented to the network while all DGCs learn their feedforward weights. After pretraining, 79 DGCs have receptive fields corresponding to the three learned digits, while 21 remain unselective (as in Figure 1e). (b) Sequential training without neurogenesis (control 2). After pretraining as in Figure 1e, the unresponsive neurons stay plastic, but they fail to become selective for digit 5 when patterns from digits 3, 4, and 5 are presented in random order. (c) Sequential training without neurogenesis but all DGCs stay plastic (control 3). Some of the DGCs previously responding to patterns from digits 3 or 4 become selective for digit 5. (d–f) Confusion matrices. Classification performance in percent (using a linear classifier as readout network) for control 1 (d) and for the main model at the end of the early (e) and late (f) phase; Figure 2a,b.
We compare this performance with that of a network where all three digit ensembles are directly simultaneously pretrained starting from random weights (Figure 3a, control 1). In this case, the overall classification performance is 92.09% (classification performance for digit 3: 86.83%; digit 4: 98.78%; digit 5: 90.70%). The confusion matrix shows that all three digits are decently classified, but with an overall lower performance (Figure 3d). Across 10 simulation experiments, classification performance is significantly higher when a novel ensemble of patterns is learned sequentially by newborn DGCs (P2; Supplementary file 1), than if all patterns are learned simultaneously (P1; Supplementary file 1). Indeed, the distribution of for the 10 simulation experiments has a mean which is significantly different from zero (Wilcoxon signed rank test: p-val = 0.0020, Wilcoxon signed rank = 55; one-way t-test: p-val = 0.0269, t-stat = 2.6401, df = 9; Supplementary file 1).
The GABA-switch guides learning of novel representations
To assess whether maturation of newborn DGCs promotes learning of a novel ensemble of digit patterns, we compare our results with two control models without neurogenesis (controls 2 and 3).
In control 2, similar to the neurogenesis case, the feedforward weights and thresholds of mature DGCs are fixed (learning rate ) after pretraining with patterns from digits 3 and 4, while the thresholds and weights of all unresponsive neurons remain plastic () upon introduction of patterns from the novel digit 5. The only differences to the model with neurogenesis are that unresponsive neurons: (1) keep their feedforward weights (i.e. no reinitialization to zero values) and (2) keep the same connections from and to inhibitory neurons. In this case, we find that the previously unresponsive DGCs do not become selective for the novel digit 5, no matter during how many epochs patterns are presented (we went up to 100 epochs) (Figure 3b, control 2). Therefore, if patterns from digit 5 are presented to the network, the model fails to discriminate them from the previously learned digits 3 and 4: the overall classification performance is 81.69% (classification performance for digit 3: 85.94%; digit 4: 97.56%; digit 5: 59.42%). This result suggests that integration of newborn DGCs is beneficial for sequential learning of novel patterns.
In control 3, all DGCs keep plastic feedforward weights (learning rate ) after pretraining and introduction of the novel digit 5, no matter if they became selective or not for the pretrained digits 3 and 4. We observe that in the case where all neurons are plastic, learning of the novel digit induces a change in selectivity of mature neurons. Several DGCs switch their selectivity to become sensitive to the novel digit (Figure 3c), while none of the previously unresponsive units becomes selective for presented patterns (compare with Figure 1e). In contrast to the model with neurogenesis, we observe a drop in classification performance to 90.92% (classification performance for digit 3: 85.45%; digit 4: 98.37%; digit 5: 88.90%). We find that the classification performance for digit 3 is the one which decreases the most. This is due to the fact that many DGCs previously selective for digit 3 modified their weights to become selective for digit 5. Importantly, the more novel patterns are introduced, the more overwriting of previously stored memories occurs. Hence, if all DGCs remain plastic, discrimination between a novel pattern and a familiar pattern stored long ago is impaired.
Maturation of newborn neurons shapes the representation of novel patterns
Since each input pattern stimulates slightly different, yet overlapping, subsets of the 100 model DGCs in a sparse code such that about 20 DGCs respond to each pattern (Figure 2g), there is no simple one-to-one assignment between neurons and patterns. In order to visualize the activity patterns of the ensemble of DGCs, we perform dimensionality reduction. We construct a two-dimensional space using the activity patterns of the network at the end of the late phase of maturation of newborn DGCs trained with ‘3’s, ‘4’s and ‘5’s. One axis connects the center of mass (in the 100-dimensional activity space) of all DGC responses to ‘3’s with all responses to ‘5’s (arbitrarily called ‘axis 1’) and the other axis those from ‘4’s to ‘5’s (arbitrarily called ‘axis 2’). We then project the activity of the 100 model DGCs upon presentation of MNIST testing patterns onto those two axes, both at the end of the early and late phase of maturation of newborn DGCs (Materials and methods). Each two-dimensional projection is illustrated by a dot whose color corresponds to the digit class of the presented input pattern (blue for digit 3, green for digit 4, red for digit 5). Different input patterns within the same digit class cause different activation patterns of the DGCs, as depicted by extended clouds of dots of the same color (Figure 4a,b). Interestingly, an example pattern of a ‘5’ that is visually similar to a ‘4’ (characterized by the green cross) yields a DGC representation that lies closer to other ‘4’s (green cloud of dots) than to typical ‘5’s (red cloud of dots) (Figure 4b). Noteworthy the separation of the representation of ‘5’s from ‘3’s and ‘4’s is better at end of the late phase (Figure 4b) when compared to the end of the early phase of maturation (Figure 4a). For instance, even though the pattern ‘5’ corresponding to the orange cross is represented close to representations of ‘4’s at the end of the early phase of maturation (green cloud of dots, Figure 4a), it is represented far from any ‘3’s and ‘4’s at the end of maturation (Figure 4b). The expansion of the representation of ‘5’s into a previously empty subspace evolves as a function of time during the late phase of maturation (Figure 4d).
Figure 4 with 2 supplements see all
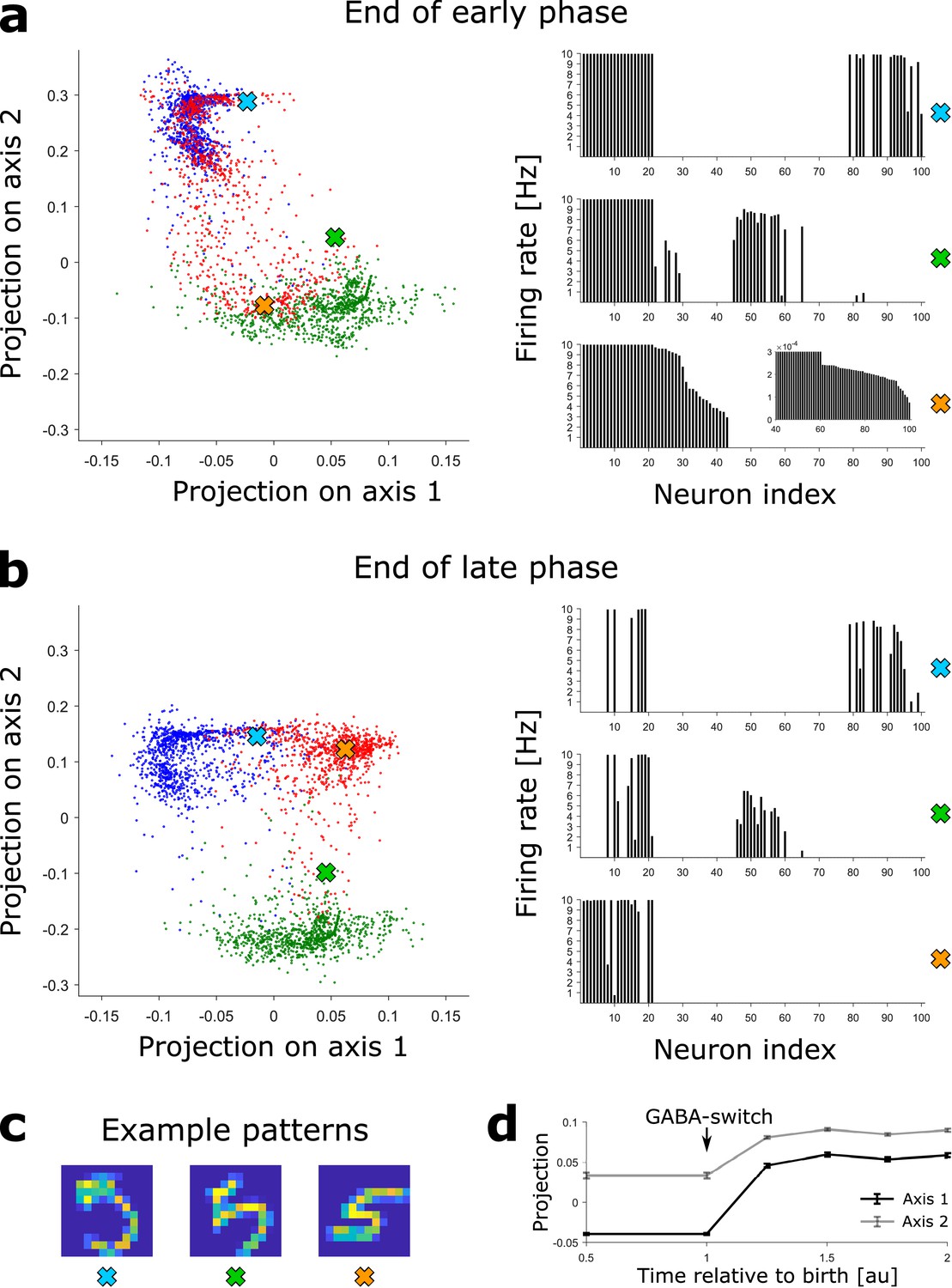
Novel patterns expand the representation into a previously empty subspace.
(a) Left: The DGC activity responses at the end of the early phase of maturation of newborn DGCs are projected on discriminatory axes. Each point corresponds to the representation of one input pattern. Color indicates digit 3 (blue), 4 (green), and 5 (red). Right: Firing rate profiles of three example patterns (highlighted by crosses on the left) are sorted from high to low for the pattern represented by the orange cross (inset: zoom of firing rates of DGCs with low activity). (b) Same as (a), but at the end of the late phase of maturation of newborn DGCs. Note that the red dots around the orange cross have moved into a different subspace. (c) Example patterns of digit 5 corresponding to the symbols in (a) and (b). All three are accurately classified by our readout network. (d) Evolution of the mean (± SEM) of the projection of the activity upon presentation of all test patterns of digit 5.
Robustness of the model
Our results are robust to changes in network architecture. As mentioned earlier, neither the exact number of GABAergic neurons (Supplementary file 2), nor that of DGCs is critical. Indeed, a larger network with 700 DGCs, thus mimicking the anatomically observed expansion factor of about 5 between EC and dentate gyrus (all other parameters unchanged), yields similar results (Supplementary file 3).
In the network with 700 DGCs, 275 cells remain unresponsive after pretraining with digits 3 and 4. In line with our earlier approach in the network with 100 DGCs, we can algoritmically replace all unresponsive neurons with newborn DGCs before patterns of digit 5 are added. Upon maturation, newborn DGC receptive fields provide a detailed representation of the prototypes of the novel digit 5 (Figure 4—figure supplement 1) and good classification performance is obtained (Supplementary file 3). Interestingly, due to the randomness of the recurrent connections, some newborn DGCs become selective for particular prototypes of the familiar (pretrained) digits 3 and 4 that are not already extensively represented by the network (see newborn DGCs selective for digit 4 highlighted by magenta squares in Figure 4—figure supplement 1).
As an alternative to replacing all unresponsive cells simultaneously, we can also replace only a fraction of them by newborn cells so as to simulate a continuous turn-over of cells. For example, if 119 of the 275 unresponsive cells are replaced by newborn DGCs before the start of presentations of digit 5, then these 119 cells become selective for different writing styles and generic features of the novel digit 5 (Figure 4—figure supplement 2) and allow a good classification performance of all three digits. On the other hand, replacing only 35 of the 275 unresponsive cells is not sufficient (Supplementary file 3). In an even bigger network with more than 144 EC cells and more than 700 DGCs, we could choose to replace 1% of the total DGC population per week by newborn cells, consistent with biology (van Praag et al., 1999; Cameron and McKay, 2001). Importantly, if only a small fraction of unresponsive cells are replaced at a given moment, other unresponsive cells remain available to be replaced later by newborn DGCs that are then ready to learn new stimuli.
Interestingly, the timing of the introduction of the novel stimulus is important. In our main neurogenesis model with 100 DGCs, we introduce the novel digit 5 at the beginning of the early phase of maturation, which consists of one epoch of MNIST training patterns (all patterns are presented once). If the novel digit is only introduced in the middle of the early phase (half epoch), it cannot be properly learned (classification performance for digit 5: 46.52%). However, if introduced after three-eights or one-quarter of the early phase, the novel digit can be picked out (classification performance for digit 5: 93.61% and 94.17%, respectively). We thus observe an increase in performance the earlier the novel digit is introduced after cell birth (classification performance for digit 5 was 95.18% when introduced at the beginning of the early phase of maturation). Therefore, our model predicts that a novel stimulus has to be introduced early enough with respect to newborn DGC maturation to be well discriminated and that the accuracy of discrimination is better the earlier it is introduced.
This could lead to an online scenario of our model, where adult-born DGCs are produced every day and different classes of novel patterns are introduced at different timepoints. To understand whether newborn DGCs in their early and late phase of maturation would interfere, two aspects should be kept in mind. First, since model newborn DGCs in the early phase of maturation do not project to other neurons yet, they do not influence the circuit and thus do not affect maturation of other newborn DGCs. Second, since model newborn DGCs in the late phase of maturation project to GABAergic neurons in the dentate gyrus, they will, just like mature cells, indirectly activate newborn DGCs that are in their early phase of maturation. As a result, early phase newborn DGCs will develop receptive fields that represent an average of all the stimuli that excite the mature and late phase newborn DGCs, which indirectly activate them. The ultimate selectivity of newborn DGCs is determined after the GABA-switch, when competition sets in, which makes those cells that have recently switched most sensitive to aspects of the input patterns that are not yet well represented by other cells. Therefore, in an online scenario, different model newborn DGCs would become selective for different novel patterns according to both their maturation stage with respect to presentation of the novel patterns, and the selectivity of mature and late phase newborn DGCs which indirectly activate them.
Finally, in our neurogenesis model, we have set the learning rate of mature DGCs to zero despite the observation that mature DGCs retain some plasticity (Schmidt-Hieber et al., 2004; Ge et al., 2007). We therefore studied a variant of the model in which mature DGCs also exhibit plasticity. First, we used our main model with 100 DGCs and 21 newborn DGCs. The implementation was identical, except that the learning rate of the mature DGCs was kept at a nonzero value during the maturation of the 21 newborn DGCs. We do not observe a large change in classification performance, even if the learning rate of the mature cells is the same as that of newborn cells (Supplementary file 4). Second, we used our extended network with 700 DGCs to be able to investigate the effect of plastic mature DGCs while having a proportion of newborn cells matching experiments. We find that with 35 newborn DGCs (corresponding to the experimentally reported fraction of about 5%), plastic mature DGCs (with a learning rate half of that of newborn cells) improve classification performance (Supplementary file 4). This is due to the fact that several of the mature DGCs (that were previously selective for ‘3’s or ‘4’s) become selective for prototypes of the novel digit 5. Consequently, more than the 35 newborn DGCs specialize for digit 5, so that digit 5 is eventually represented better by the network with mature cell plasticity than the standard network where plasticity is limited to newborn cells. Note that those mature DGCs that had earlier specialized on writing styles of digit 3 or 4 similar to a digit 5 are most likely to retune their selectivity. If the novel inputs were very distinct from the pretrained familiar inputs, mature DGCs would be unlikely to develop selectivity for the novel inputs.
Newborn DGCs become selective for similar novel patterns
To investigate whether our theory for integration of newborn DGCs can explain why adult dentate gyrus neurogenesis promotes discrimination of similar stimuli, but does not affect discrimination of distinct patterns (Clelland et al., 2009; Sahay et al., 2011a), we use a simplified competitive winner-take-all network (Materials and methods). It contains only as many DGCs as trained clusters, and the GABAergic inhibitory neurons are implicitly modeled through direct DGC-to-DGC inhibitory connections. DGCs are either silent or active (binary activity state, while in the detailed network DGCs had continuous firing rates). The synaptic plasticity rule is however the same as for the detailed network, with different parameter values (Materials and methods). We also construct an artificial data set (Figure 5a,b) that allows us to control the similarity of pairs of clusters (Materials and methods). The MNIST data set is not appropriate to distinguish similar from dissimilar patterns, because all digit clusters are similar and highly overlapping, reflected by a high within cluster dispersion (e.g. across the set of all ‘3’) compared to the separation between clusters (e.g. typical ‘3’ versus typical ‘5’).
Figure 5

A newborn DGC becomes selective for similar but not distinct novel stimuli.
(a) Center of mass of clusters and of an artificial data set ( and , respectively, separated by angle Ω) are represented by arrows that point to the surface of a hypersphere. Dots represent individual patterns. (b) Center of mass of three clusters of the artificial data set, visualized as 16 × 8 pixel patterns. The two-dimensional arrangements and colors are for visualization only. (c, d) Example input patterns (activity of 16 × 8 input neurons) from clusters 1 and 2 for similar clusters (c, ), and distinct clusters (d, ). Below: dots correspond to patterns, crosses indicate the input patterns shown (schematic). (e, f) After pretraining with patterns from two clusters, the receptive fields (set of synaptic weights onto neurons 1 and 2) exhibit the center of mass of each cluster of input patterns (blue and green crosses). (g, h) Novel stimuli from cluster 3 (orange dots) are added. If the clusters are similar, the receptive field of the newborn DGC (red cross) moves toward the center of mass of the three clusters during its early phase of maturation (g), and if the clusters are distinct toward the center of mass of the two pretrained clusters (h). (i, j) Receptive field after the late phase of maturation for the case of similar (i) or distinct (j) clusters. (k, l) For comparison, the center of mass of all patterns of the blue and green clusters (left column) and of the blue, green, and orange clusters (right column) for the case of similar (k) or distinct (l) clusters. Color scale: input firing rate or weight normalized to .
After a pretraining period, a first mature DGC responds to patterns of cluster 1 and a second mature DGC to those of cluster 2 (Figure 5e,f). We then fix the feedforward weights of those two DGCs and introduce a newborn DGC in the network. Thereafter, we present patterns from three clusters (the two pretrained ones, as well as a novel one), while the plastic feedforward weights of the newborn DGC are the only ones that are updated. We observe that the newborn DGC ultimately becomes selective for the novel cluster if it is similar () to the two pretrained clusters (Figure 5i), but not if it is distinct (, Figure 5j). The selectivity develops in two phases. In the early phase of maturation of the newborn model cell, a pattern from the novel cluster that is similar to one of the pretrained clusters activates the mature DGC that has a receptive field closest to the novel pattern. The activated mature DGC drives the newborn DGC via lateral excitatory GABAergic connections to a firing rate where LTP is triggered at active synapses onto the newborn DGC. LTP also happens when a pattern from one of the pretrained clusters is presented. Thus, synaptic plasticity leads to a receptive field that reflects the average of all stimuli from all three clusters (Figure 5g).
To summarize our findings in a more mathematical language, we characterize the receptive field of the newborn cell by the vector of its feedforward weights. Analogous to the notion of a firing rate vector that represents the set of firing rates of an ensemble of neurons, the feedforward weight vector represents the set of weights of all synapses projecting onto a given neuron (Figure 1b). In the early phase of maturation, for similar clusters, the feedforward weight vector onto the newborn DGC grows in the direction of the center of mass of all three clusters (the two pretrained ones and the novel one), because for each pattern presentation, be it a novel pattern or a familiar one, one of the mature DGCs becomes active and stimulates the newborn cell (compare Figure 5g and Figure 5k). However, if the novel cluster has a low similarity to pretrained clusters, patterns from the novel cluster do not activate any of the mature DGCs. Therefore, the receptive field of the newborn cell reflects the average of stimuli from the two pretrained clusters only (compare Figure 5h and Figure 5l).
As a result of the different orientation of the feedforward weight vector onto the newborn DGC at the end of the early phase of maturation, two different situations arise in the late phase of maturation, when lateral GABAergic connections are inhibitory. If the novel cluster is similar to the pretrained clusters, the weight vector onto the newborn DGC at the end of the early phase of maturation lies at the center of mass of all the patterns across the three clusters. Thus, it is closer to the novel cluster than the weight vector onto either of the mature DGCs (Figure 5g). So if a novel pattern is presented, the newborn DGC wins the competition between the three DGCs, and its feedforward weight vector moves toward the center of mass of the novel cluster (Figure 5i). By contrast, if the novel cluster is distinct, the weight vector onto the newborn DGC at the end of the early phase of maturation is located at the center of mass of the two pretrained clusters (Figure 5h). If a novel pattern is presented, no output unit is activated since their receptive fields are not similar enough to the input pattern. Therefore, the newborn DGC always stays silent and does not update its feedforward weights (Figure 5j). These results are consistent with studies that have suggested that dentate gyrus is only involved in the discrimination of similar stimuli, but not distinct stimuli (Gilbert et al., 2001; Hunsaker and Kesner, 2008). For discrimination of distinct stimuli, another pathway might be used, such as the direct EC to CA3 connection (Yeckel and Berger, 1990; Fyhn et al., 2007).
In conclusion, our model suggests that adult dentate gyrus neurogenesis promotes discrimination of similar patterns because newborn DGCs can ultimately become selective for novel stimuli, which are similar to already learned stimuli. On the other hand, newborn DGCs fail to represent novel distinct stimuli, precisely because they are too distinct from other stimuli already represented by the network. Presentation of novel distinct stimuli in the late phase of maturation therefore does not induce synaptic plasticity of the newborn DGC feedforward weight vector toward the novel stimuli. In the simplified network, the transition between similar and distinct can be determined analytically (Materials and methods). This analysis clarifies the importance of the switch from cooperative dynamics (excitatory interactions) in the early phase to competitive dynamics (inhibitory interactions) in the late phase of maturation.
Upon successful integration the receptive field of a newborn DGC represents an average of novel stimuli
With the simplified model network, it is possible to analytically compute the maximal strength of the DGC receptive field via the L2-norm of the feedforward weight vector onto the newborn DGC (Materials and methods). In addition, the angle between the center of mass of the novel patterns and the feedforward weight vector onto the adult-born DGC can also be analytically computed (Materials and methods). To illustrate the analytical results and characterize the evolution of the receptive field of the newborn DGC, we thus examine the angle φ of the feedforward weight vector with the center of mass of the novel cluster (i.e. the average of the novel stimuli), as a function of maturation time (Figure 6b,c, Figure 6—figure supplement 1).
Figure 6 with 1 supplement see all
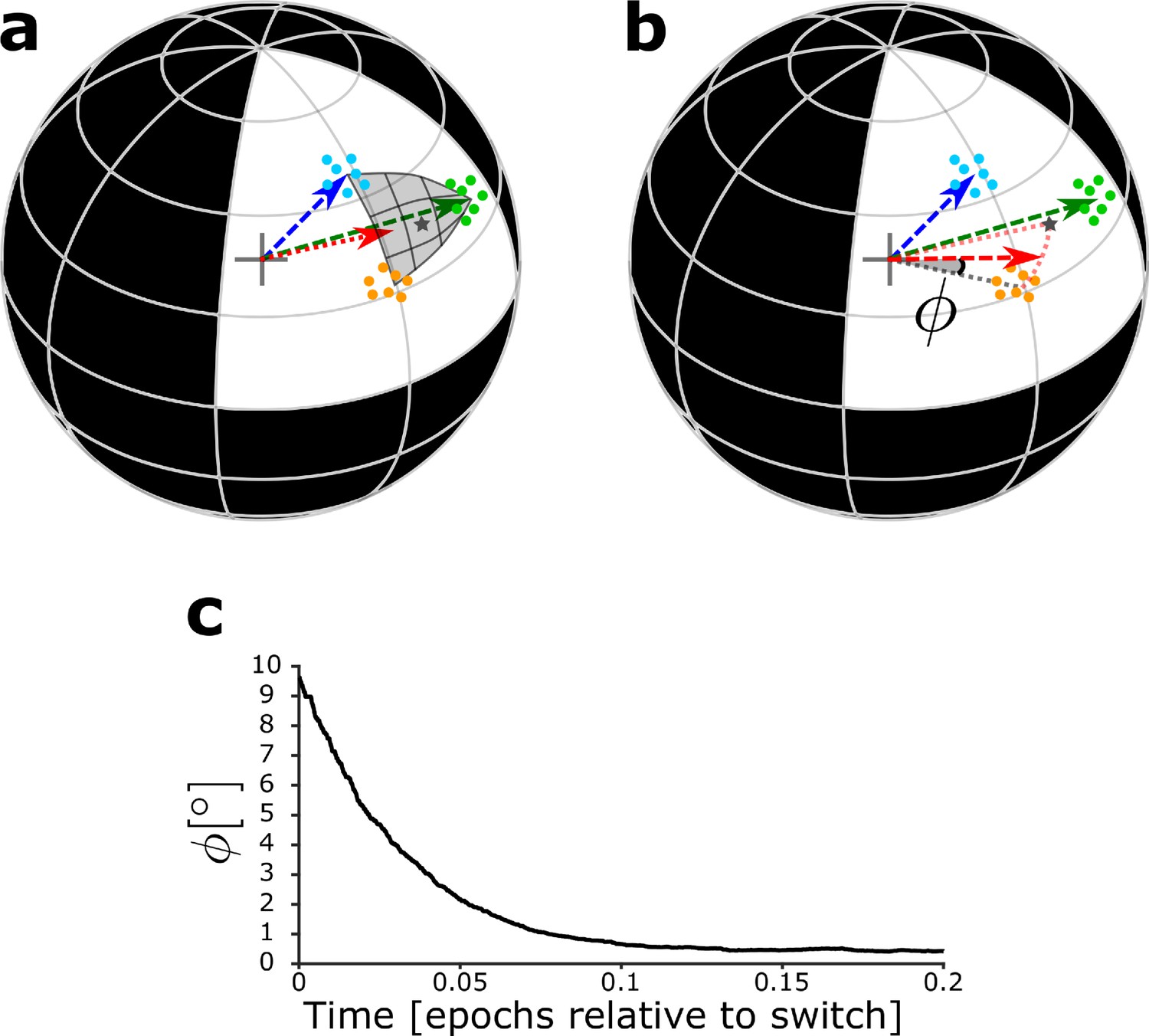
Maturation dynamics for similar patterns.
(a) Schematics of the unit hypersphere with three clusters of patterns (colored dots) and three scaled feedforward weight vectors (colored arrows). After pretraining, the blue and green weight vectors point to the center of mass of the corresponding clusters. Patterns from the novel cluster (orange points) are presented only later to the network. During the early phase of maturation, the newborn DGC grows its vector of feedforward weights (red arrow) in the direction of the subspace of patterns which indirectly activate the newborn cell (dark grey star: center of mass of the presented patterns, located below the part of the sphere surface highlighted in grey). (b) During the late phase of maturation, the red vector turns toward the novel cluster. The symbol φ indicates the angle between the center of mass of the novel cluster and the feedforward weight vector onto the newborn cell. (c) The angle φ decreases in the late phase of maturation of the newborn DGC if the novel cluster is similar to the previously stored clusters. Its final average value of is caused by the jitter of the weight vector around the center of mass of the novel cluster.
In the early phase of maturation, the feedforward weight vector onto the newborn DGC grows, while its angle with the center of mass of the novel cluster stays constant (Figure 6—figure supplement 1). In the late phase of maturation, the angle φ between the center of mass of the novel cluster and the feedforward weight vector onto the newborn DGC decreases in the case of similar patterns (Figure 6c, Figure 6—figure supplement 1), but not in the case of distinct patterns (Figure 6—figure supplement 1), indicating that the newborn DGC becomes selective for the novel cluster for similar but not for distinct patterns.
The analysis of the simplified model thus leads to a geometric picture that helps us to understand how the similarity of patterns influences the evolution of the receptive field of the newborn DGC before and after the switch from excitation to inhibition of the GABAergic input. For novel patterns that are similar to known patterns, the receptive field of a newborn DGC at the end of maturation represents the average of novel stimuli.
The cooperative phase of maturation promotes pattern separation for any dimensionality of input data
Despite the fact that input patterns in our model represent the activity of 144 or 128 model EC cells, the effective dimensionality of the input data was significantly below 100 because the clusters for different input classes were rather concentrated around their respective center of mass. We define the effective input dimensionality as the participation ratio (Mazzucato et al., 2016; Litwin-Kumar et al., 2017) (Materials and methods). Using this definition, the input data of both the MNIST 12 × 12 patterns from digits 3, 4, and 5 and the seven clusters of the handmade dataset for similar patterns () are relatively low-dimensional ( of a maximum of 144, and of a maximum of 128, respectively). We emphasize that in both cases the spread of the input data around the cluster center implies that the effective dimensionality is larger than the number of clusters. In natural settings, we expect the input data to have even higher dimension. Therefore, here we investigate the effect of dimensionality of the input data on our neurogenesis model by increasing the spread around the cluster centers.
We use our simplified network model and create similar artificial datasets () with different values for the concentration parameter κ (Materials and methods). The smaller the κ, the broader the distributions around their center of mass; hence, the larger the overlap of patterns generated from different cluster distributions. Therefore, we can increase the effective dimensionality of the input by decreasing the concentration parameter κ. First, as expected from our analytical analysis (Materials and methods), we find that the broader the cluster distributions the smaller the length of the feedforward weight vector onto newborn DGCs (from just below 1.5 with to about 1.35 with ). Second, we examine the ability of the simplified network to discriminate input patterns coming from input spaces with different dimensionalities. To do so, we compare our neurogenesis model (Neuro.) with a random initialization model (RandInitL.). In both cases, two DGCs are pretrained with patterns from two clusters, as above. Then we fix the weights of the two mature DGCs and introduce patterns from a third cluster as well as a newborn DGC. For the neurogenesis case, after maturation of the newborn DGC we fix its weights (while for the random initialization model we keep them plastic) upon introduction of patterns from a fourth cluster as well as another newborn DGC, and so on until the network contains seven DGCs and patterns from the full dataset of seven clusters have been presented. We compare our neurogenesis model, where each newborn DGC starts with zero weights and undergo a two-phase maturation (one epoch per phase), with a random initialization model where each newborn DGC is directly fully integrated into the circuit and whose feedforward weight vector is randomly initialized with a length of 0.1 (RandInitL.) and is then learned for two epochs.
Since clusters can be highly overlapping, we assess discrimination performance by computing the reconstruction error at the end of training. Reconstruction error is evaluated analogously to classification error, except that the readout layer has the task of an autoencoder: it contains as many readout units as there are input units. Reconstruction error is the mean squared distance between the input vector and the reconstructed output vector based on testing patterns. We observe that for any dimensionality of the input space, even as high as 97-dimensional, the neurogenesis model performs better (has a lower total reconstruction error) than the random initialization model (Supplementary file 5). Indeed, in the neurogenesis case newborn DGCs grow their feedforward weights (from zero) in the direction of presented input patterns in their early cooperative phase of maturation and can later become selective for novel patterns during the competitive phase. In contrast, since the random initialization model has no early cooperative phase, the newborn DGC weight vector does not grow unless an input pattern is by chance well aligned with its randomly initialized weight vector (which is unlikely in a high-dimensional input space). We get similar results for a larger initialization of the synaptic weights (e.g. the length of the weight vector at birth is set to 1, results not shown). Importantly, in high input dimensions, the advantage of a larger weight vector length at birth in the random initialization model is overridden by the capability of newborn DGCs to grow their weight vector in the appropriate direction during their early cooperative phase of maturation. Finally, we note that even if the length of the feedforward weight vector onto newborn DGCs is set to 1.5 (RandInitH., Supplementary file 5), which is the upper bound according to our analytical results (Materials and methods), the random initialization model performs worse than the neurogenesis model for low up to relatively high-dimensional input spaces (, Supplementary file 5) despite its advantage in the competition conferred by the longer weight vector. It is only when input clusters are extremely broad and overlapping that the random initialization model performs similarly to the neurogenesis model (, Supplementary file 5). In other words, a random initialization at full length of weight vectors works well if input data is homogeneously distributed on the positive quadrant of the unit sphere but fails if the input data is clustered in a few directions. Moreover, random initialization requires that synaptic weights are large from the start which is biologically not plausible. In summary, the two-phase neurogenesis model is advantageous because the feedforward weights onto newborn cells can start at arbitrarily small values; their growth is, during the cooperative phase, guided to occur in a direction that is relevant for the task at hand; the final competitive phase eventually enables specialization onto novel inputs.
Discussion
While experimental studies, such as manipulating the ratio of NKCC1 to KCC2, suggest that the switch from excitation to inhibition of the GABAergic input onto adult-born DGCs is crucial for their integration into the preexisting circuit (Ge et al., 2006; Alvarez et al., 2016) and that adult dentate gyrus neurogenesis promotes pattern separation (Clelland et al., 2009; Sahay et al., 2011a; Jessberger et al., 2009), the link between channel properties and behavior has remained puzzling (Sahay et al., 2011b; Aimone et al., 2011). Our modeling work shows that the GABA-switch enables newborn DGCs to become selective for novel stimuli, which are similar to familiar, already-stored, representations, consistent with the experimentally observed function of pattern separation (Clelland et al., 2009; Sahay et al., 2011a; Jessberger et al., 2009).
Previous modeling studies already suggested that newborn DGCs integrate novel inputs into the representation in dentate gyrus (Chambers et al., 2004; Becker, 2005; Crick and Miranker, 2006; Wiskott et al., 2006; Chambers and Conroy, 2007; Appleby and Wiskott, 2009; Aimone et al., 2009; Weisz and Argibay, 2009; Temprana et al., 2015; Finnegan and Becker, 2015; DeCostanzo et al., 2018). However, our work differs from them in four important aspects. First of all, we implement an unsupervised biologically plausible plasticity rule, while many studies used supervised algorithmic learning rules (Chambers et al., 2004; Becker, 2005; Chambers and Conroy, 2007; Weisz and Argibay, 2009; Finnegan and Becker, 2015; DeCostanzo et al., 2018). Second, as we model the formerly neglected GABA-switch, the connection weights from EC to newborn DGCs are grown from small values through cooperativity in the early phase of maturation. This integration step was mostly bypassed in earlier models by initialization of the connectivity weights toward newborn DGCs to random, yet fully grown values (Crick and Miranker, 2006; Aimone et al., 2009; Weisz and Argibay, 2009; Finnegan and Becker, 2015). Third, as the dentate gyrus network is commonly modeled as a competitive network, weight normalization is crucial. In our framework, competition occurs during the late phase of maturation. Previous modeling works either applied algorithmic weight normalization or hard bounds on the weights at each iteration step (Crick and Miranker, 2006; Aimone et al., 2009; Weisz and Argibay, 2009; Temprana et al., 2015; Finnegan and Becker, 2015). Instead, our plasticity rule includes heterosynaptic plasticity, which intrinsically softly bounds connectivity weights by a homeostatic effect. Finally, although some earlier computational models of adult dentate gyrus neurogenesis could explain the pattern separation abilities of newborn cells, separation was obtained independently of the similarity between the stimuli. Contrarily to experimental data, no distinction was made between similar and distinct patterns (Chambers et al., 2004; Becker, 2005; Crick and Miranker, 2006; Wiskott et al., 2006; Chambers and Conroy, 2007; Aimone et al., 2009; Appleby and Wiskott, 2009; Weisz and Argibay, 2012; Temprana et al., 2015; Finnegan and Becker, 2015; DeCostanzo et al., 2018). To our knowledge, we present the first model that can explain both (1) how adult-born DGCs integrate into the preexisting network and (2) why they promote pattern separation of similar stimuli and not distinct stimuli.
Our work emphasizes why a two-phase maturation of newborn DGCs is beneficial for proper integration in the preexisting network. From a computational perspective, the early phase of maturation, when GABAergic inputs onto newborn DGCs are excitatory, corresponds to cooperative unsupervised learning. Therefore, the synapses grow in the direction of patterns that indirectly activate the newborn DGCs via GABAergic interneurons (Figure 6a). At the end of the early phase of maturation, the receptive field of a newborn DGC represents the center of mass of all input patterns that led to its (indirect) activation. In the late phase of maturation, GABAergic inputs onto newborn DGCs become inhibitory, so that lateral interactions change from cooperation to competition, causing a shift of the receptive fields of the newborn DGCs toward novel features (Figure 6b). At the end of maturation, newborn DGCs are thus selective for novel inputs. This integration mechanism is in agreement with the experimental observation that newborn DGCs are broadly tuned early in maturation, yet highly selective at the end of maturation (Marín-Burgin et al., 2012; Danielson et al., 2016). Loosely speaking, the cooperative phase of excitatory GABAergic input promotes the growth of the synaptic weights coarsely in the relevant direction, whereas the competitive phase of inhibitory GABAergic input helps to specialize on detailed, but potentially important differences between patterns.
In the context of theories of unsupervised learning, the switch of lateral GABAergic input to newborn DGCs from excitatory to inhibitory provides a biological solution to the ‘problem of unresponsive units’ (Hertz et al., 1991). Unsupervised competitive learning has been used to perform clustering of input patterns into a few categories (Rumelhart and Zipser, 1985; Grossberg, 1987; Kohonen, 1989; Hertz et al., 1991; Du, 2010). Ideally, after learning of the feedforward weights between an input layer and a competitive network, input patterns that are distinct from each other activate different neuron assemblies of the competitive network. After convergence of competitive Hebbian learning, the vector of feedforward weights onto a given neuron points to the center of mass of the cluster of input patterns for which it is selective (Kohonen, 1989; Hertz et al., 1991). Yet, if the synaptic weights are randomly initialized, it is possible that the set of feedforward weights onto some neurons of the competitive network point in a direction ‘quasi-orthogonal’ (Materials and methods) to the subspace of the presented input patterns. Therefore, those neurons, called ‘unresponsive units’, will never get active during pattern presentation. Different learning strategies have been developed in the field of artificial neural networks to avoid this problem (Grossberg, 1976; Bienenstock et al., 1982; Rumelhart and Zipser, 1985; Grossberg, 1987; DeSieno, 1988; Kohonen, 1989; Hertz et al., 1991; Du, 2010). However, most of these algorithmic approaches lack a biological interpretation. In our model, weak synapses onto newborn DGCs form spontaneously after neuronal birth. The excitatory GABAergic input in the early phase of maturation drives the growth of the synaptic weights in the direction of the subspace of presented patterns that succeed in activating some of the mature DGCs. Hence, the early cooperative phase of maturation can be seen as a smart initialization of the synaptic weights onto newborn DGCs, close enough to novel patterns so as to become selective for them in the late competitive phase of maturation. However, the cooperative phase is helpful only if the novel patterns are similar to the input statistics defined by the set of known (familiar) patterns.
Our results are in line with the classic view that dentate gyrus is responsible for decorrelation of inputs (Marr, 1969; Albus, 1971; Marr, 1971; Rolls and Treves, 1998), a necessary step for differential storage of similar memories in CA3, and with the observation that dentate gyrus lesions impair discrimination of similar but not distinct stimuli (Gilbert et al., 2001; Hunsaker and Kesner, 2008). To discriminate distinct stimuli, another pathway might be involved, such as the direct EC to CA3 connection (Yeckel and Berger, 1990; Fyhn et al., 2007).
The parallel of neurogenesis in dentate gyrus and olfactory bulb suggests that similar mechanisms could be at work in both areas. Yet, even though adult olfactory bulb neurogenesis seems to have a similar functional role to adult dentate gyrus neurogenesis (Sahay et al., 2011b), follow a similar integration sequence and undergo a GABA-switch from excitatory to inhibitory, the circuits are different in several aspects. First, while newborn neurons in dentate gyrus are excitatory, newborn cells in the olfactory bulb are inhibitory. Second, the newborn olfactory cells start firing action potentials only once they are well integrated (Carleton et al., 2003). Therefore, in view of a transfer of results to the olfactory bulb, it would be interesting to adjust our model of adult dentate gyrus neurogenesis accordingly. For example, a voltage-based synaptic plasticity rule could be used to account for subthreshold plasticity mechanisms (Clopath et al., 2010).
Our model of transition from an early cooperative phase to a late competitive phase makes specific predictions, at the behavioral and cellular level. In our model, the early cooperative phase of maturation can only drive the growth of synaptic weights onto newborn cells if they are indirectly activated by mature DGCs through GABAergic input, which has an excitatory effect due to the high NKCC1/KCC2 ratio early in maturation. Therefore, our model predicts that NKCC1-knockout mice would be impaired in discriminating similar contexts or objects because newborn cells stay silent due to lack of indirect activation. The feedforward weight vector onto newborn DGCs could not grow in the early phase and newborn DGCs could not become selective for novel inputs. Therefore, our model predicts that since newborn DGCs are poorly integrated into the preexisting circuit, they are unlikely to survive. If, however, in the same paradigm newborn cells are activated by light-induced or electrical stimulation, we predict that they become selective to novel patterns. Thus discrimination abilities would be restored and newborn DGCs are likely to survive. Analogously, we predict that using inducible NKCC1-knockout mice, animals would gradually be impaired in discrimination tasks after induced knockout and reach a stable maximum impairment about 3 weeks after the start of induced knockout.
Experimental observations support the importance of the switch from early excitation to late inhibition of the GABAergic input onto newborn DGCs. An absence of early excitation using NKCC1-knockout mice has been shown to strongly affect synapse formation and dendritic development in vivo (Ge et al., 2006). Conversely, a reduction in inhibition in the dentate gyrus through decrease in KCC2 expression has been associated with epileptic activity (Pathak et al., 2007; Barmashenko et al., 2011). An analogous switch of the GABAergic input has been observed during development, and its proper timing has been shown to be crucial for sensorimotor gating and cognition (Wang and Kriegstein, 2011; Furukawa et al., 2017). In addition to early excitation and late inhibition, our theory also critically depends on the time scale of the switching process. In our model, the switch makes an instantaneous transition between early and late phase of maturation. Several experimental results have suggested that the switch is indeed sharp and occurs within a single day, both during development (Khazipov et al., 2004; Tyzio et al., 2007; Leonzino et al., 2016) and adult dentate gyrus neurogenesis (Heigele et al., 2016). Furthermore, in hippocampal cell cultures, expression of KCC2 is upregulated by GABAergic activity but not affected by glutamatergic activity (Ganguly et al., 2001). A similar process during adult dentate gyrus neurogenesis would increase the number of newborn DGCs available for representing novel features by advancing the timing of their switch. In this way, instead of a few thousands of newborn DGCs ready to switch (3–6% of the whole population [van Praag et al., 1999; Cameron and McKay, 2001], divided by 30 days), a larger fraction of newborn DGCs would be made available for coding, if appropriate stimulation occurs. Finally, while neurotransmitter switching has been observed following sustained stimulation for hours to days (Li et al., 2020), it is still unclear if it has the same functional role as the GABA-switch in our model. In particular, it remains an open question if neurotransmitter switching promotes the integration of neurons in the same way as our model GABA-switch does in the context of adult dentate gyrus neurogenesis.
To conclude, our theory for integration of adult-born DGCs suggests that newborn cells have a coding – rather than a modulatory – role during dentate gyrus pattern separation function. Our theory highlights the importance of GABAergic input in adult dentate gyrus neurogenesis and links the switch from excitation to inhibition to the integration of newborn DGCs into the preexisting circuit. Finally, it illustrates how Hebbian plasticity of EC to DGC synapses along with the switch make newborn cells suitable to promote pattern separation of similar but not distinct stimuli, a long-standing mystery in the field of adult dentate gyrus neurogenesis (Sahay et al., 2011b; Aimone et al., 2011).
Materials and methods
Network architecture and neuronal dynamics
Request a detailed protocolDGCs are the principal cells of the dentate gyrus. They mainly receive excitatory projections from the EC through the perforant path and GABAergic inputs from local interneurons, as well as excitatory input from Mossy cells. They project to CA3 pyramidal cells and inhibitory neurons, as well as local Mossy cells (Acsády et al., 1998; Henze et al., 2002; Amaral et al., 2007; Temprana et al., 2015; Figure 1—figure supplement 1). In our model, we omit Mossy cells for simplicity and describe the dentate gyrus as a competitive circuit consisting of DGCs and GABAergic interneurons (Figure 1b). The activity of neurons in EC represents an input pattern . Because the perforant path also induces strong feedforward inhibition in the dentate gyrus (Li et al., 2013), we assume that the effective EC activity is normalized, such that for any input pattern (Figure 1—figure supplement 1). We use different input patterns , in the simulations of the model.
In our network, model EC neurons have excitatory all-to-all connections to the DGCs. In rodent hippocampus, spiking mature DGCs activate interneurons in dentate gyrus, which in turn inhibit other mature DGCs (Temprana et al., 2015; Alvarez et al., 2016). In our model, the DGCs are thus recurrently connected with inhibitory neurons (Figure 1b). Connections from DGCs to interneurons exist in our model with probability and have a weight . Similarly, connections from interneurons to DGCs occur with probability and have a weight . All parameters are reported in Table 1 (Biologically plausible network).
Before an input pattern is presented, all rates of model DGCs are initialized to zero. We assume that the DGCs have a frequency–current curve that is given by a rectified hyperbolic tangent (Dayan and Abbott, 2001), which is similar to the frequency–current curve of spiking neuron models with refractoriness (Gerstner et al., 2014). Moreover, we exploit the equivalence of two common firing rate equations (Miller and Fumarola, 2012) and let the firing rate of DGC upon stimulation with input pattern evolve according to:
(2)
where denotes rectification: for and zero otherwise. Here, bi is a firing threshold, is the smoothness parameter of the frequency–current curve ( is the slope of the frequency–current curve at the firing threshold), and the total input to cell :
(3)
with xj the activity of EC input neuron , the feedforward weight from EC input neuron to DGC , and the weight from inhibitory neuron to DGC . The sum runs over all inhibitory neurons, but the weights are set to if the connection is absent. The firing rate is unit-free and normalized to a maximum of 1, which we interpret as a firing rate of 10 Hz. We take the synaptic weights as unit-less parameters such that is also unit-free.
The firing rate of inhibitory neuron , is defined as:
(4)
with a parameter which relates to the desired ensemble sparsity, and the total input toward interneuron , given as:
(5)
with the weight from DGC to inhibitory neuron . (We set if the connection is absent.) The feedback from inhibitory neurons ensures a sparse activity of model DGCs for each pattern. With we find that more than 70% of model DGCs are silent (firing rate < 1 Hz [Senzai and Buzsáki, 2017]) when an input pattern is presented, and less than 10% are highly active (firing rate > 1 Hz) (Figure 2c,d), consistent with the experimentally observed sparse activity in dentate gyrus (Chawla et al., 2005).
Plasticity rule
Projections from EC onto newborn DGCs exhibit Hebbian plasticity (Schmidt-Hieber et al., 2004; Ge et al., 2007; McHugh et al., 2007). Therefore, in our model, the connections from EC neurons to DGCs are plastic, following a Hebbian learning rule that exhibits LTD or LTP depending on the firing rate of the postsynaptic cell (Bienenstock et al., 1982; Artola et al., 1990; Sjöström et al., 2001; Pfister and Gerstner, 2006). Input patterns, , , are presented in random order. For each input pattern, we let the firing rate converge for a time where was chosen long enough to achieve convergence to a precision of 10−6. After presentations (i.e. at time ), the weight vector has value . We then present the next pattern and update at time (), according to the following plasticity rule (Equation (1), written here for convenience):
where xj is the firing rate of presynaptic EC input neuron , the firing rate of postsynaptic DGC , η the learning rate, θ marks the transition from LTD to LTP, and the relative strength α, γ of LTP and LTD depend on θ via and . The values of the parameters , , β, and θ are given in Table 1 (Biologically plausible network). The weights are hard-bounded from below at 0, i.e., if Equation (1) leads to a new weight smaller than zero, is set to zero. The first two terms of Equation (1) are a variation of the BCM rule (Bienenstock et al., 1982). The third term implements heterosynaptic plasticity (Chistiakova et al., 2014; Zenke and Gerstner, 2017) with three important features: first, heterosynaptic plasticity has a negative sign and therefore leads to synaptic depression; second, heterosynaptic plasticity sets in above a threshold () that is the same threshold as that for LTP, so that if LTP occurs at some synapses LTD is induced at other synapses; third, above threshold the dependence upon the postsynaptic firing rate is supra-linear. The interaction of the three different terms in the plasticity rule has several consequences. Because the first two terms of the plasticity rule are Hebbian (‘homosynaptic’) and proportional to the presynaptic activity xj, the active DGCs () update their feedforward weights in direction of the input pattern . Moreover, whenever LTP occurs at some synapses, all weights onto neuron are downregulated heterosynaptically by an amount that increases supra-linearly with the postsynaptic rate , implicitly controlling the length of the weight vector (see below) similar to synaptic homeostasis (Turrigiano et al., 1998) but on a rapid time scale (Zenke and Gerstner, 2017). Analogous to learning in a competitive network (Kohonen, 1989; Hertz et al., 1991), the vector of feedforward weights onto active DGCs will move toward the center of mass of the cluster of patterns they are selective for, as we will discuss now.
For a given input pattern , there are three fixed points for the postsynaptic firing rate: , , and (the negative root is omitted because due to Equation (2)). For , there is LTD, so the weights move toward zero: , while for , there is LTP, so the weights move toward (Figure 1c). The value of is defined implicitly by the network Equations (2–5). If a pattern is presented only for a short time these fixed points are not reached during a single pattern presentation.
Winners, losers, and quasi-orthogonal inputs
Request a detailed protocolWe define the winners as the DGCs that become strongly active () during presentation of an input pattern. Since the input patterns are normalized to have an L2-norm of 1 ( by construction), and the L2-norm of the feedforward weight vectors is bounded (see Section Direction and length of the weight vector), the winning units are the ones whose weight vectors (row of the feedforward connectivity matrix) align best with the current input pattern .
We emphasize that all synaptic weights and all presynaptic firing rates are non-negative: and . Thus, both the weight vectors and the vectors of input firing rates live in the positive quadrant. The angle between an input pattern and the weight vector of neuron can be at most ninety degrees. We say that an input pattern is ‘quasi-orthogonal’ to a weight vector if, in the stationary state, the input is not sufficient to activate neuron , i.e., . If an input pattern is quasi-orthogonal to a weight vector , then neuron does not fire in response to after the stimulus has been applied for a long enough time. Note that for a case without inhibitory neurons and with , we recover the standard orthogonality condition, but for finite quasi-orthogonality corresponds to angles larger than some reference angle.
Direction and length of the weight vector
Request a detailed protocolLet us denote the ensemble of patterns for which neuron is a winner by and call this the set of winning patterns (). Suppose that neuron is quasi-orthogonal to all other patterns, so that for all , we have . Then the feedforward weight vector of neuron converges in expectation to:
(6)
where and . Hence is a weighted average over all winning patterns.
The squared length of the feedforward weight vector can be computed by multiplying Equation (6) with :
(7)
Since input patterns have length one, the scalar product on the right-hand side can be rewritten as where α is the angle between the weight vector and pattern . Division by yields the L2-norm of the feedforward weight vector:
(8)
where the averages run, as before, over all winning patterns.
Let us now derive bounds for . First, since we have . Second, since for all winning patterns , where θ is the LTP threshold, we have . Thus the length of the weight vector is finite and bounded by:
(9)
It is possible to make the second bound tighter if we find the winning pattern with the smallest firing rate such that :
(10)
The bound is reached if neuron is winner for a single input pattern.
We can also derive a lower bound. For a pattern , let us write the firing rate of neuron as where is the mean firing rate of neuron averaged across all winning patterns and . We assume that the absolute size of is small, i.e., . Linearization of Equation (8) around yields:
(11)
Elementary geometric arguments for a neuron model with monotonically increasing frequency–current curve yield that the value of is positive (or zero) because an increase in the angle α lowers both the cosine and the firing rate, giving rise to a positive correlation. Since we are interested in a lower bound, we can therefore drop the term proportional to and evaluate the ratio to find:
(12)
where is the maximal firing rate of a DGC and is the angle of the winning pattern that has the largest angle with the weight vector. The first bound is tight and is reached if neuron is winner for only two patterns.
To summarize we find that the length of the weight vector remains bounded in a narrow range. Hence, for a reasonable distribution of input patterns and weight vectors, the value of is similar for different neurons , so that the weight vector will have, after convergence, similar lengths for all DGCs that are winners for at least one pattern. In our simulations with the MNIST data set, we find that the length of feedforward weight vectors lies in the range between 9.3 and 11.1 across all responsive neurons with a mean value close to 10; Figure 2e.
Early maturation phase
Request a detailed protocolDuring the early phase of maturation, the GABAergic input onto a newborn DGC with index has an excitatory effect. In the model, it is implemented as follows: with probability for any interneuron and otherwise (no connection). Since newborn cells do not project yet onto inhibitory neurons (Temprana et al., 2015), we have . Newborn DGCs are known to have enhanced excitability (Schmidt-Hieber et al., 2004; Li et al., 2017), so their threshold is kept at . Because the newborn model DGCs receive lateral excitation via interneurons and their thresholds are zero during the early phase of maturation, the lateral excitatory GABAergic input is always sufficient to activate them. Hence, if the firing rate of a newborn DGC exceeds the LTP threshold θ, the feedforward weights grow toward the presented input pattern, Equation (1).
Presentation of all patterns of the data set once (one epoch) is sufficient to reach convergence of the feedforward weights onto newborn DGCs. We define the end of the first epoch as the end of the early phase, i.e., simulation of one epoch of the model corresponds to about 3 weeks of biological time.
Late maturation phase
Request a detailed protocolDuring the late phase of maturation (starting at about 3 weeks [Ge et al., 2006]), the GABAergic input onto newborn DGCs switches from excitatory to inhibitory. In terms of our model, it means that all existing connections switch their sign to . Furthermore, since newborn DGCs develop lateral connections to inhibitory neurons in the late maturation phase (Temprana et al., 2015), we set with probability , and otherwise. The thresholds of newborn DGCs are updated after presentation of pattern μ at time () according to , where is a reference rate and a learning rate, to mimic the decrease of excitability as newborn DGCs mature (Table 1, Biologically plausible network). Therefore, the distribution of firing rates of newborn DGCs is shifted to the left (toward lower firing rates) at the end of the late phase of maturation compared to the early phase of maturation (Figure 2c,d). A sufficient condition for a newborn DGC to win the competition upon presentation of patterns of the novel cluster is that the scalar product between a pattern of the novel cluster and the feedforward weight vector onto the newborn DGC is larger than the scalar product between the pattern of the novel cluster and the feedforward weight vector onto any of the mature DGCs. Analogous to the early phase of maturation, presentation of all patterns of the data set once (one epoch) is sufficient to reach convergence of the feedforward weights onto newborn DGCs. We therefore consider that the late phase of maturation has been finished after one epoch.
Input patterns
Request a detailed protocolTwo different sets of input patterns are used. Both data sets have a number of clusters and several thousands of patterns per cluster. As a first data set, we use the MNIST 12 × 12 patterns (Lecun et al., 1998) (), normalized such that the L2-norm of each pattern is equal to 1. Normalization of inputs (be it implemented algorithmically as done here or by explicit inhibitory feedback) ensures that, once weight growth due to synaptic plasticity has ended and weights have stabilized, the overall strength of input onto DGCs is approximately identical for all cells (see Section Direction and length of the weight vector). Equalized lengths of weight vectors are, in turn, an important feature of classic soft or hard competitive networks (Kohonen, 1989; Hertz et al., 1991). The training set contains approximately 6000 patterns per digit, while the testing set contains about 1000 patterns per digit (Figure 1d). Both training patterns and test patterns contain a large variety of different writing styles indicating that the clusters of input patterns for each class are broadly distributed around their center of mass.
As a second data set, we use handmade artificial patterns designed such that the distance between the centers of any two clusters, or in other words their pairwise similarity, is the same. All clusters lie on the positive quadrant of the surface of a hypersphere of dimension . The cluster centers are Walsh patterns shifted along the diagonal (Figure 5b):
(13)
with a parameter that determines the spacing between clusters. c0 is a normalization factor to ensure that the center of mass of all clusters has an L2-norm of 1:
(14)
The number of input neurons is . The scalar product, and hence the angle Ω, between the center of mass of any pair of clusters and () is a function of ξ (Figure 5a):
(15)
We define the pairwise similarity of two clusters as: . Highly similar clusters have a large due to the small distance between their centers (hence a small ξ).
To make the artificial data set comparable to the MNIST 12 × 12 data set, we choose , so , and we generate 6000 noisy patterns per cluster for the training set and 1000 other noisy patterns per cluster for the testing set. Since our noisy high-dimensional input patterns have to be symmetrically distributed around the centers of mass , yet lie on the hypersphere, we have to use an appropriate sampling method. The patterns of a given cluster with center of mass are thus sampled from a Von Mises–Fisher distribution (Mardia and Jupp, 2009):
(16)
with an L2-normalized vector taken in the space orthogonal to . The vector is obtained by performing the singular-value decomposition of () and multiplying the matrix (after removing its first column), which corresponds to the left-singular vectors in the orthogonal space to , with a vector whose elements are drawn from the standard normal distribution. Then the L2-norm of the obtained pattern is set to 1, so that it lies on the surface of the hypersphere. A rejection sampling scheme is used to obtain (Mardia and Jupp, 2009). The sample is kept if , with κ a concentration parameter, , , drawn from a uniform distribution , , , and drawn from a beta distribution .
The concentration parameter κ characterizes the spread of the distribution around the center . In the limit where , sampling from the Von Mises–Fisher distribution becomes equivalent to sampling uniformly on the surface of the hypersphere, so the clusters become highly overlapping. In dimension , if , the probability of overlap between clusters is negligible. We use a value .
Classification performance (readout network)
Request a detailed protocolIt has been observed that classification performance based on DGC population activity is a good proxy for behavioral discrimination (Woods et al., 2020). Hence, to evaluate whether the newborn DGCs contribute to the function of the dentate gyrus network, we study classification performance. Once the feedforward weights have been adjusted upon presentation of many input patterns from the training set (Section Plasticity rule), we keep them fixed and determine classification on the test set using artificial readout units (RO).
To do so, the readout weights ( from model DGC to readout unit ) are initialized at random values drawn from a uniform distribution: , with . The number of readout units, , corresponds to the number of learned classes. To adjust the readout weights, all patterns of the training data set that belong to the learned classes are presented one after the other. For each pattern , we let the firing rate of the DGCs converge (values at convergence: ). The activity of a readout unit is given by:
(17)
As we aim to assess the performance of the network of DGCs, the readout weights are adjusted by an artificial supervised learning rule. The loss function, which corresponds to the difference between the activity of the readout units and a one-hot representation of the corresponding pattern label (Hertz et al., 1991),
(18)
with the element of a one-hot representation of the correct label of pattern , is minimized by stochastic gradient descent:
(19)
The readout units have a rectified hyperbolic tangent frequency-current curve: , whose derivative is: . We learn the weights of the readout units over 100 epochs of presentations of all training patterns with , which is sufficient to reach convergence.
Thereafter, the readout weights are fixed. Each test set pattern belonging to one of the learned classes is presented once, and the firing rates of the DGCs are let to converge. Finally, the activity of the readout units is computed and compared to the correct label of the presented pattern. If the readout unit with the highest activity value is the one that represents the class of the presented input pattern, the pattern is said to be correctly classified. Classification performance is given by the number of correctly classified patterns divided by the total number of test patterns of the learned classes.
Control cases
Request a detailed protocolIn our standard setting, patterns from a third digit are presented to a network that has previously only seen patterns from two digits. The question is whether neurogenesis helps when adding the third digit. We use several control cases to compare with the neurogenesis case. In the first control case, all three digits are learned in parallel (Figure 3a, control 1). In the two other control cases, we either keep all feedforward connections toward the DGCs plastic (Figure 3c, control 3) or fix the feedforward connections for all selective DGCs but keep unselective neurons plastic (as in the neurogenesis case) (Figure 3b, control 2). However, in both instances, the DGCs do not mature in the two-step process induced by the GABA-switch that is part of our model of neurogenesis.
Pretraining with two digits
Request a detailed protocolAs we are interested by neurogenesis at the adult stage, we pretrain the network with patterns from two digits, such that it already stores some memories before neurogenesis takes place. To do so, we randomly initialize the weights from EC neurons to DGCs: they are drawn from a uniform distribution (). The L2-norm of the feedforward weight vector onto each DGC is then normalized to 1, to ensure fair competition between DGCs during learning. Then we present all patterns from digits 3 and 4 in random order, as many times as needed for convergence of the weights. During each pattern presentation the firing rates of the DGCs are computed (Section Network architecture and neuronal dynamics) and their feedforward weights are updated according to our plasticity rule (Section Plasticity rule). We find that we need approximately 40 epochs for convergence of the weights and use 80 epochs to make sure that all weights are stable. At the end of pretraining, our network is considered to correspond to an adult stage, because some DGCs are selective for prototypes of the pretrained digits (Figure 1e).
Projection on pairwise discriminatory axes
Request a detailed protocolTo assess how separability of the DGC activation patterns develops during the late phase of maturation of newborn DGCs, we project the population activity onto axes which are optimized for pairwise discrimination (patterns from digit 3 versus patterns from digit 5, 4 versus 5, and 3 versus 4). Those axes are determined using Fisher linear discriminant analysis, as explained below.
We determine the vector of DGC firing rates, , at the end of the late phase of maturation of newborn DGCs upon presentation of each pattern, , from digits 3, 4, and 5 of the training MNIST dataset. The mean activity in response to all training patterns μ from digit , , is computed for each of the three digits ( is the number of training patterns of digit ). The pairwise Fisher linear discriminant is defined as the linear function that maximizes the distance between the means of the projected activity in response to two digits (e.g. and ), while normalizing for within-digit variability. The objective function to maximize is thus given as:
(20)
with the between-digit scatter matrix, and the within-digit scatter matrix ( is the covariance matrix of the DGC activity in response to pattern of digit , and is the covariance matrix of the DGC activity in response to pattern of digit ). It can be shown that the direction of the optimal discriminatory axis between digit and is given by the eigenvector of with the corresponding largest eigenvalue.
We arbitrarily set ‘axis 1’ as the optimal discriminatory axis between digit 3 and digit 5, ‘axis 2’ as the optimal discriminatory axis between digit 4 and digit 5, and ‘axis 3’ as the optimal discriminatory axis between digit 3 and digit 4. For each of the three discriminatory axes, we define its origin (i.e. projection value of 0) as the location of the average projection of all training patterns of the three digits on the corresponding axis. Figure 4 represents the projections of DGC activity upon presentation of testing patterns at the end of the early and late phase of maturation of newborn DGCs onto the above-defined axes.
Statistics
In the main text, we present a representative example with three digits from the MNIST data set (3, 4, and 5). It is selected from a set of 10 random combinations of three different digits. For each combination, one network is pretrained with two digits for 80 epochs. Then the third digit is added and neurogenesis takes place (one epoch of early phase of maturation, and one epoch of late phase of maturation). Furthermore, another network is pretrained directly with the three digits for 80 epochs. Classification performance is reported for all combinations (Supplementary file 1).
Simplified rate network
We use a toy network and the artificial data set to determine whether our theory of integration of newborn DGCs can explain why adult dentate gyrus neurogenesis helps for the discrimination of similar, but not for distinct patterns.
The rate network described above is simplified as follows. We use DGCs for clusters. Their firing rate is given by:
(21)
where is the Heaviside step function. As before, bi is the threshold, and the total input toward neuron :
(22)
with xj the input of presynaptic EC neuron , the feedforward weight between EC neuron and DGC , and the firing rate of DGC . Inhibitory neurons are modeled implicitly: each DGC directly connects to all other DGCs via inhibitory recurrent connections of value . During presentation of pattern , the firing rates of the DGCs evolve according to Equation (21). After convergence, the feedforward weights are updated: . The synaptic plasticity rule is the same as before, see Equation (1), but with the parameters reported in Table 1 (Simple network). They are different from those of the biologically plausible network because we now aim for a single winning neuron for each cluster. Note that for an LTP threshold all active DGCs update their feedforward weights because of the Heaviside function for the firing rate (Equation 21).
Assuming a single winner for each pattern presentation, the input (Equation 22) to the winner is:
(23)
while the input to the losers is:
(24)
Therefore, two conditions need to be satisfied for a solution with a single winner:
(25)
for the winner to actually be active, and:
(26)
to prevent non-winners to become active. The value of bi in the model is lower in the early phase than in the late phase of maturation to mimic enhanced excitability (Schmidt-Hieber et al., 2004; Li et al., 2017).
Similar versus distinct patterns with the artificial data set
Request a detailed protocolUsing the artificial data set with (Equation 13), the scalar product between the centers of mass of two different clusters, given by Equation (15), satisfies: . This corresponds to .
After stimulation with a pattern , it takes some time before the firing rates of the DGCs converge. We call two patterns ‘similar’ if they activate, at least initially, the same output unit, while we consider two patterns as ‘distinct’ if they do not activate the same output unit, not even initially. We now show that, with a large concentration parameter κ, patterns of different clusters are similar if and distinct if .
We first consider a DGC whose feedforward weight vector has converged toward the center of mass of cluster . If an input pattern from cluster is presented, it will receive the following initial input:
(27)
where is the angle between the pattern and the center of mass of the cluster to which it belongs. The larger the concentration parameter κ for the generation of the artificial data set, the smaller the dispersion of the clusters, and thus the larger . If instead, an input pattern from cluster is presented, that same DGC will receive a lower initial input:
(28)
The approximation holds for a small dispersion of the clusters (large concentration parameter κ). We note that there is no subtraction of the recurrent input yet because output units are initialized with zero firing rate before each pattern presentation. By definition, similar patterns stimulate (initially) the same DGCs. A DGC can be active for two clusters only if its threshold is:
(29)
Therefore, with a high concentration parameter κ, patterns of different clusters are similar if , while patterns of different clusters are distinct if .
Parameter choice
Request a detailed protocolThe upper bound of the expected L2-norm of the feedforward weight vector toward the DGCs at convergence can be computed, see Equation (10). With the parameters in Table 1 (Simple network), the value is . Moreover, the input patterns for each cluster are highly concentrated; hence, their angle with the center of mass of the cluster they belong to is close to 0, so we have . Therefore, at convergence, a DGC selective for a given cluster receives an input upon presentation of input patterns belonging to cluster . We choose to satisfy Equation (25). Given bi the threshold value for which two clusters are similar (and above which two clusters are distinct) can be determined by Equation (29) : . We created a handmade data set with for the case of similar clusters (therefore with similarity ), and a handmade data set with for the distinct case (hence with similarity ).
Let us suppose that the weights of DGC have converged and made this cell respond to patterns of cluster . If another DGC of the network is selective for cluster , cell gets the input upon presentation of input patterns belonging to cluster . Hence, to satisfy Equation (26), we need . We set .
Furthermore, a newborn DGC is born with a null feedforward weight vector so that at birth, its input consists only of the indirect excitatory input from mature DGCs, which vanishes if all DGCs are quiescent and takes a value if a mature DGC responds to the input. For the feedforward weight vector to grow, the newborn cell needs to be active. This could be achieved through spontaneous activity that could be implemented by setting the intrinsic firing threshold at birth to a value . In this case, a difference between similar and distinct patterns is not expected. Alternatively, activity of newborn cells can be achieved in the absence of spontaneous activity under the condition . For the simulations with the toy model, we set , which leads to weight growth in newborn cells for similar, but not distinct patterns.
Neurogenesis with the artificial data set
Request a detailed protocolTo save computation time, we initialize the feedforward weight vectors of two mature DGCs at two training patterns randomly chosen from the first two clusters, normalized such that they have an L2-norm of 1.5. We then present patterns from clusters 1 and 2 and let the feedforward weights evolve according to Equation (1) until they reach convergence.
We thereafter fix the feedforward weights onto the two mature cells and introduce a novel cluster of patterns as well as a newborn DGC in the network. The sequence of presentation of patterns from the three clusters (a novel one and two pretrained ones) is random. The newborn DGC is born with a null feedforward weight vector, and its maturation follows the same rules as before (plastic feedforward weights). In the early phase, GABAergic input has an excitatory effect (Ge et al., 2006) and the newborn DGC does not inhibit the mature DGCs (Temprana et al., 2015). This is modeled by setting for the connections from mature to newborn DGC, and for the connections from newborn to mature DGCs. The threshold of the newborn DGC starts at at birth, mimicking enhanced excitability (Schmidt-Hieber et al., 2004; Li et al., 2017), and increases linearly up to 1.2 (same threshold as that of mature DGCs) over 12,000 pattern presentations, reflecting loss of excitability with maturation. The exact time window is not critical. In the late phase of maturation of the newborn DGC, GABAergic input switches to inhibitory (Ge et al., 2006), and the newborn DGC recruits feedback inhibition onto mature DGCs (Temprana et al., 2015). It is modeled by switching the sign of the connection from mature to newborn DGC: and establishing connections from newborn to mature DGCs: . Each of the 6000 patterns is presented once during the early phase of maturation and once during the late phase of maturation.
The above paradigm is run separately for each of the two handmade data sets: the one where clusters are similar () and the one where clusters are distinct ().
Analytical computation of the L2-norm and angle
Request a detailed protocolWe consider the case where two mature DGCs have learned their synaptic connections, such that the first mature DGC with feedforward weight vector is selective for cluster 1 with normalized center of mass , and the second mature DGC with feedforward weight vector is selective for cluster 2 with normalized center of mass . After convergence, we have and , where is the expected L2-norm of the feedforward weight vector onto mature DGC that is selective for pretrained cluster . In addition, the upper bound for the L2-norm of the weight vectors of the mature DGCs can be determined . In our case, we obtain because of the dispersion of the patterns around their center of mass; hence, we will use this value for the numerical computations below.
We represent the feedforward weight vector onto a newborn DGC as an arrow of length (Figure 6—figure supplement 1). We compute analytically its L2-norm at the end of the early phase of maturation of the newborn DGC, as well as its angle φ with the center of mass of the novel cluster , to confirm the results obtained numerically (Figure 6, Figure 6—figure supplement 1).
In the early phase of maturation, the feedforward weight vector onto the newborn DGC grows. The norm stabilizes at a higher value in the case of similar patterns (, Figure 6—figure supplement 1) than in the case of distinct patterns (, Figure 6—figure supplement 1). It is due to the fact that the center of mass of three similar clusters lies closer to the surface of the sphere than the center of mass of two distinct clusters (see below). In the late phase of maturation, for similar clusters we observe a slight increase of the L2-norm of the feedforward weight vector onto the newborn DGC concomitantly with the decrease of angle with the center of mass of the novel cluster (Figure 6—figure supplement 1), because the center of mass of the novel cluster lies closer to the surface of the sphere than the center of mass of the three clusters.
Similar clusters
Request a detailed protocolThe angle between the center of mass of any pair of similar clusters (, ) is given by Equation (15):
(30)
Half the distance between the projections of the center of mass of any pair of two similar clusters on a concentric sphere with radius is given by (Figure 6—figure supplement 1):
(31)
The triangle that connects the centers of masses of the three clusters is equilateral, and separates one of its angle in two equal parts ( [rad] each). So the length can be calculated:
(32)
Using Pythagoras formula, we can thus determine the expected L2-norm of the feedforward weight vector onto the newborn DGC at the end of the early phase of maturation:
(33)
and finally its angle with the center of mass of the novel cluster:
(34)
The numerical values are as follows: and , which correspond to the values on Figure 6—figure supplement 1.
Distinct clusters
Request a detailed protocolIn the case of distinct patterns (, ), the angle between the center of mass of any pair of clusters is given by Equation (15):
(35)
We can directly compute the expected L2-norm of the feedforward weight vector onto the newborn DGC at the end of the early phase of maturation (Figure 6—figure supplement 1):
(36)
We can then calculate the length between the projection of the center of mass of one of the two pretrained clusters on a concentric sphere with radius and the feedforward weight vector onto the newborn DGC:
(37)
Analogous to the similar case, we observe that separates one angle of the equilateral triangle connecting the projections of the center of mass of the clusters on the sphere in two equal parts, consequently:
(38)
Finally, the angle between the center of mass of the novel cluster and the feedforward weight vector onto the newborn DGC at the end of the early phase of maturation is:
(39)
We obtain the following approximate values: and , which correspond to the values on Figure 6—figure supplement 1. The angle φ is smaller in the similar case than in the distinct case, hence the norm is larger in the similar case, as observed in Figure 6—figure supplement 1.
Effective dimensionality and participation ratio
Request a detailed protocolThe effective dimensionality of the input is measured as the participation ratio (PR) defined as , where is the covariance matrix of the input patterns, and denotes the trace of matrix (Mazzucato et al., 2016; Litwin-Kumar et al., 2017).
Data availability
Simulation and plotting scripts can be found at: https://github.com/ogozel/NeurogenesisModel (copy archived at https://archive.softwareheritage.org/swh:1:rev:e46f2dfc10c21d69ac057f31c5800f46644b004a).
-
THE MNIST DATABASEID yann.lecun.com/exdb/mnist/. The MNIST database of handwritten digits.
References
-
GABAergic cells are the major postsynaptic targets of mossy fibers in the rat HippocampusThe Journal of Neuroscience 18:3386–3403.https://doi.org/10.1523/JNEUROSCI.18-09-03386.1998
-
A theory of cerebellar functionMathematical Biosciences 10:25–61.https://doi.org/10.1016/0025-5564(71)90051-4
-
Transition to chaos in random networks with cell-type-specific connectivityPhysical Review Letters 114:088101.https://doi.org/10.1103/PhysRevLett.114.088101
-
The dentate gyrus: fundamental neuroanatomical organization (dentate gyrus for dummies)Progress in Brain Research 163:3–22.https://doi.org/10.1016/S0079-6123(07)63001-5
-
BookThe Hippocampus BookOxford University Press.https://doi.org/10.1093/acprof:oso/9780195100273.001.0001
-
Additive neurogenesis as a strategy for avoiding interference in a sparsely-coding dentate gyrusNetwork: Computation in Neural Systems 20:137–161.https://doi.org/10.1080/09548980902993156
-
Excitatory actions of gaba during development: the nature of the nurtureNature Reviews Neuroscience 3:728–739.https://doi.org/10.1038/nrn920
-
Adult neurogenesis produces a large pool of new granule cells in the dentate gyrusThe Journal of Comparative Neurology 435:406–417.https://doi.org/10.1002/cne.1040
-
Becoming a new neuron in the adult olfactory bulbNature Neuroscience 6:507–518.https://doi.org/10.1038/nn1048
-
GABA depolarization is required for experience-dependent synapse unsilencing in adult-born neuronsJournal of Neuroscience 33:6614–6622.https://doi.org/10.1523/JNEUROSCI.0781-13.2013
-
Heterosynaptic plasticity: multiple mechanisms and multiple rolesThe Neuroscientist : A Review Journal Bringing Neurobiology, Neurology and Psychiatry 20:483–498.https://doi.org/10.1177/1073858414529829
-
Connectivity reflects coding: a model of voltage-based STDP with homeostasisNature Neuroscience 13:344–352.https://doi.org/10.1038/nn.2479
-
Apoptosis, neurogenesis, and information content in Hebbian networksBiological Cybernetics 94:9–19.https://doi.org/10.1007/s00422-005-0026-8
-
Short-term and long-term survival of new neurons in the rat dentate gyrusThe Journal of Comparative Neurology 460:563–572.https://doi.org/10.1002/cne.10675
-
Hippocampal neurogenesis reduces the dimensionality of sparsely coded representations to enhance memory encodingFrontiers in Computational Neuroscience 12:99.https://doi.org/10.3389/fncom.2018.00099
-
New neurons and new memories: how does adult hippocampal neurogenesis affect learning and memory?Nature Reviews Neuroscience 11:339–350.https://doi.org/10.1038/nrn2822
-
ConferenceAdding a conscience to competitive learningIEEE International Conference on Neural Networks. pp. 117–124.https://doi.org/10.1109/ICNN.1988.23839
-
Clustering: a neural network approachNeural Networks 23:89–107.https://doi.org/10.1016/j.neunet.2009.08.007
-
Neurogenesis paradoxically decreases both pattern separation and memory interferenceFrontiers in Systems Neuroscience 9:136.https://doi.org/10.3389/fnsys.2015.00136
-
Neonatal maternal separation delays the GABA excitatory-to-inhibitory functional switch by inhibiting KCC2 expressionBiochemical and Biophysical Research Communications 493:1243–1249.https://doi.org/10.1016/j.bbrc.2017.09.143
-
BookNeuronal Dynamics: From Single Neurons to Networks and Models of CognitionCambridge University Press.https://doi.org/10.1017/CBO9781107447615
-
Single granule cells reliably discharge targets in the hippocampal CA3 network in vivoNature Neuroscience 5:790–795.https://doi.org/10.1038/nn887
-
Interneurons of the dentate gyrus: an overview of cell types, terminal fields and neurochemical identityProgress in Brain Research 163:217–232.https://doi.org/10.1016/S0079-6123(07)63013-1
-
On the role of the hippocampus in learning and memory in the ratBehavioral and Neural Biology 60:9–26.https://doi.org/10.1016/0163-1047(93)90664-4
-
Paradox of pattern separation and adult neurogenesis: a dual role for new neurons balancing memory resolution and robustnessNeurobiology of Learning and Memory 129:60–68.https://doi.org/10.1016/j.nlm.2015.10.013
-
Developmental changes in GABAergic actions and seizure susceptibility in the rat hippocampusEuropean Journal of Neuroscience 19:590–600.https://doi.org/10.1111/j.0953-816X.2003.03152.x
-
BookSelf-Organization and Associative MemorySpringer-Verlag.https://doi.org/10.1007/978-3-642-88163-3
-
Gradient-based learning applied to document recognitionProceedings of the IEEE 86:2278–2324.https://doi.org/10.1109/5.726791
-
Decoding neurotransmitter switching: the road forwardThe Journal of Neuroscience 40:4078–4089.https://doi.org/10.1523/JNEUROSCI.0005-20.2020
-
A theory of cerebellar cortexThe Journal of Physiology 202:437–470.https://doi.org/10.1113/jphysiol.1969.sp008820
-
Simple memory: a theory for archicortexPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 262:23–81.https://doi.org/10.1098/rstb.1971.0078
-
Stimuli reduce the dimensionality of cortical activityFrontiers in Systems Neuroscience 10:11.https://doi.org/10.3389/fnsys.2016.00011
-
Is there more to GABA than synaptic inhibition?Nature Reviews Neuroscience 3:715–727.https://doi.org/10.1038/nrn919
-
Triplets of spikes in a model of spike timing-dependent plasticityJournal of Neuroscience 26:9673–9682.https://doi.org/10.1523/JNEUROSCI.1425-06.2006
-
BookNeural Networks and Brain FunctionOxford: Oxford University Press.https://doi.org/10.1093/acprof:oso/9780198524328.001.0001
-
Feature discovery by competitive learningCognitive Science 9:75–112.https://doi.org/10.1207/s15516709cog0901_5
-
Young adult-born neurons improve odor coding by mitral cellsNature Communications 11:5867.https://doi.org/10.1038/s41467-020-19472-8
-
Defined types of cortical interneurone structure space and spike timing in the hippocampusThe Journal of Physiology 562:9–26.https://doi.org/10.1113/jphysiol.2004.078915
-
Running increases cell proliferation and neurogenesis in the adult mouse dentate gyrusNature Neuroscience 2:266–270.https://doi.org/10.1038/6368
-
Monosynaptic inputs to new neurons in the dentate gyrusNature Communications 3:1107.https://doi.org/10.1038/ncomms2101
-
Hebbian plasticity requires compensatory processes on multiple timescalesPhilosophical Transactions of the Royal Society B: Biological Sciences 372:20160259.https://doi.org/10.1098/rstb.2016.0259
Article and author information
Author details
Funding
Swiss National Science Foundation (200020 184615)
- Wulfram Gerstner
Horizon 2020 Framework Programme (785907)
- Wulfram Gerstner
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Josef Bischofberger and Laurenz Wiskott for great discussions and useful remarks, as well as Paul Miller and an anonymous reviewer for constructive comments and suggestions. This research was supported by the Swiss National Science Foundation (no. 200020 184615) and by the European Union Horizon 2020 Framework Program under grant agreement no. 785907 (HumanBrain Project, SGA2).
Copyright
© 2021, Gozel and Gerstner
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,237
- views
-
- 342
- downloads
-
- 9
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 9
- citations for umbrella DOI https://doi.org/10.7554/eLife.66463
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
A functional model of adult dentate gyrus neurogenesis
eLife 10:e66463.
https://doi.org/10.7554/eLife.66463




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}