Science Forum: Is preclinical research in cancer biology reproducible enough?
- Studies in Translation, Ethics and Medicine, Biomedical Ethics Unit, McGill University, Canada
Abstract
The Reproducibility Project: Cancer Biology (RPCB) was established to provide evidence about reproducibility in basic and preclinical cancer research, and to identify the factors that influence reproducibility more generally. In this commentary we address some of the scientific, ethical and policy implications of the project. We liken the basic and preclinical cancer research enterprise to a vast 'diagnostic machine' that is used to determine which clinical hypotheses should be advanced for further development, including clinical trials. The results of the RPCB suggest that this diagnostic machine currently recommends advancing many findings that are not reproducible. While concerning, we believe that more work needs to be done to evaluate the performance of the diagnostic machine. Specifically, we believe three questions remain unanswered: how often does the diagnostic machine correctly recommend against advancing real effects to clinical testing?; what are the relative costs to society of false positive and false negatives?; and how well do scientists and others interpret the outputs of the machine?
Main text
In 2012, reports from two major drug companies – Bayer and Amgen – claimed that fewer than a quarter of animal experiments submitted in support of clinical development could be reproduced by in-house researchers at the companies (Prinz et al., 2011; Begley and Ellis, 2012). These reports seemed to corroborate concerns raised by others around the same time: anti-cancer agents showing promise in animal models had often failed to deliver in clinical trials (Hay et al., 2014; Kola and Landis, 2004); preclinical cancer studies used methods that did not protect against bias and random variation (Hirst et al., 2013; Henderson et al., 2015); researchers reported difficulty replicating experiments (Mobley et al., 2013); negative preclinical findings often went unpublished (Henderson et al., 2015; Sena et al., 2010); and studies used too few animals to protect against false positive results (Button et al., 2013). Preclinical cancer research seemed to be in the throes of a 'reproducibility crisis'.
Although the Bayer and Amgen articles have garnered over 4,000 citations between them, they did not formalize a definition of reproducibility, or reveal the experiments they tried to repeat, or explain how they tried to repeat them. This raised the question of whether the two studies that questioned the reproducibility of research in cancer were themselves reproducible.
The Reproducibility Project: Cancer Biology (RPCB) set out to address some of the gaps in what we knew about the reproducibility of research in cancer biology. Building on a previous effort that attempted to replicate 100 studies in experimental psychology (Open Science Collaboration, 2015), a team of researchers at the Center for Open Science used an explicit method to sample 50 impactful publications in cancer biology (Errington et al., 2014). Then, working with Science Exchange (an organization that helps organizations to outsource R&D), they formalized their definitions of reproducibility, selected individual experiments within each of the 50 publications, and pre-specified protocols for repeating these experiments. These protocols were then peer reviewed by eLife and published as Registered Reports (https://www.cos.io/initiatives/registered-reports). An important part of the project was that data collection could not start before the Registered Report was accepted for publication. In the end, due to a combination of technical and budgetary problems, Registered Reports were published for 29 of the 50 publications.
The experiments were then performed, usually by contract research laboratories or core facilities at universities, as specified by the protocols in the relevant Registered Report. The RPCB team then wrote a Replication Study that contained: (a) the results of these experiments; (b) a discussion of how the results/effects compared with the results/effects reported in the original research article; and (c) a meta-analysis that combined the data from the original experiment and the replication. This Replication Study was peer-reviewed (usually undergoing revision) and then published. By the end of the project 17 Replication Studies had been published; Replication Studies were not published for 12 of Registered Reports due to technical and/or budgetary problems, but the results from eight partially completed replications have been published (Errington et al., 2021a; Pelech et al., 2021). The RPCB project has also published a paper containing a meta-analysis of all the replications (Errington et al., 2021b) and, separately, a paper that describes how the project was carried out and some of the challenges encountered during it (Errington et al., 2021c). The meta-analysis covers a total of 158 different effects from 50 experiments in 23 papers.
For each Replication Study the eLife editors handling the study added an assessment of the success or otherwise of the replication in the form of an Editors' Summary. According to these summaries: five of the replications reproduced important parts of the original research articles; six reproduced parts of the original research articles but also contained results that could not be interpreted or were not consistent with some parts of the original research article; two could not be interpreted; and four did not reproduce the parts of the original research articles that they attempted to reproduce.
In what follows, we consider some of the scientific, ethical and policy implications of the project, and discuss three key questions about reproducibility that are left unresolved.
Preclinical studies as diagnostic machines
To understand the implications of the RPCB it is important to appreciate two ways that the meaning of reproducibility in cancer biology differs from that in other areas in which large-scale reproducibility projects have been carried out (that is, psychology [Open Science Collaboration, 2015], experimental economics [Camerer et al., 2016], and the social sciences [Camerer et al., 2018]). First, research in psychology, economics and the social sciences is usually conducted on humans and the goal is to identify causal relationships that generalize to other humans. In contrast, research in cancer biology is conducted in tissue cultures and non-human animals, and the goal is to identify causal relationships that generalize to living humans. This means that the claims about causal relationships made by cancer biologists are always dependent on a more extensive set of assumptions – which are fallible – about the relationship between experimental systems and real-world settings.
Second, research in psychology and economics is generally geared toward generating, validating and comparing theories about causal relationships (for example, testing whether the violation of social norms leads to more norm violation). The purpose of replication in these fields, therefore, is to determine how much of what we think we know about these causal relationships is true. Pre-clinical cancer research, by contrast, is part of a broader enterprise tasked with finding treatments for diseases. The primary point of this research is to help decide which claims should be advanced into treatments, and which novel treatments should be advanced to further evaluation and rigorous testing in clinical trials. Thus, the replication question is a practical one: do contemporary research practices efficiently prioritize potential strategies for development and clinical testing, given the limits of existing model systems? (We appreciate that some biomedical research is pursued more in the spirit of fundamental inquiry rather than application but, nevertheless, we maintain that medical objectives dominate the motivations of private and public research sponsors).
In clinical testing, as many as 19 of 20 cancer drugs put into clinical development never demonstrate enough safety, efficacy or commercial promise to achieve licensure (Hay et al., 2014). Even those few that run the gauntlet from trialing to license often show underwhelming efficacy in trials (Davis et al., 2017). These failures exact enormous burdens on both the non-human animals that are sacrificed for this effort and the many patients who volunteer time, welfare and good will in offering their bodies and tissue samples for clinical trials. Futile research efforts also divert talent, patients and funding from more promising ones, often at the expense of the taxpayer in the form of drug reimbursement. The initial response of many researchers to the COVID-19 pandemic clearly showed how poorly planned, executed and reported research efforts can divert attention and resources from more productive endeavors (London and Kimmelman, 2020).
As one of us (JK) and Alex London have argued, many of these failures reflect the intrinsic challenges of conducting research at the cutting edge of what we understand about disease (London and Kimmelman, 2015). The failure of numerous drugs inspired by the amyloid cascade hypothesis, for example, in part reflects uncertainties about the pathogenesis of Alzheimer’s disease. When translation failures are due to theoretical uncertainties like this, properly designed and analyzed trials provide important feedback on experimental models and pathophysiological theories (Kimmelman, 2010). These types of 'failures' – which are natural and informative – are not the type of errors that the RPCB has (or should) set out to address.
The RPCB is instead concerned with the extent to which clinically interesting causal relationships discovered in laboratories are reproducible using the same experimental systems. Concluding that causal relationships are real when they are not represents a potentially 'unforced error' in drug development. If a treatment is advanced to clinical research based on such an error, medicine is deprived of an opportunity to develop an effective treatment and, furthermore, the research enterprise is deprived of the opportunity to learn something about the generalizability of our models and theories. These unforced errors are a sort of tax or friction that makes the research process significantly less efficient than it could be. Many of the issues that lead to such errors – haste, poor study design, biased reporting – are relatively easy and cheap to fix. And given the prevalence of preclinical studies that do not reproduce according to Amgen and Bayer, the gains of reducing such unforced errors could be substantial.
These unforced errors can come in two varieties. False positives occur when research communities mistakenly conclude that a clinically promising causal relationship exists when it does not. Projects looking into the reproducibility of research tend to focus on false positives because they are mostly interested in how valid our knowledge in a given field is. False negatives occur when a real and potentially impactful causal relationship is assumed to be too weak to be clinically promising, or the relationship is not observed in the first place. These tend to be ignored in reproducibility projects. However, in the context of preclinical cancer research, false negatives require serious consideration because the cost to society of missing out on impactful cancer treatments can be considerable, especially given that clinical development exists to cull false positives but can do little about false negatives.
One can think of the basic and preclinical research enterprise as a sprawling, multiplex diagnostic machine that helps researchers to decide if a clinical hypothesis should proceed to more rigorous development, such as a clinical trial. Clinical hypotheses are fed into the machine, which runs a series of experiments, and the results of these experiments are assembled into research articles, which are then submitted to journals. If the individual experiments within a research article converge on the same translational claim (which may be a claim about a particular molecule, or a claim about strategy), and if the article reports a large effect for a phenomenon judged by experts to be relevant to translation, the article is accepted for publication in a high-impact journal. However, if the individual experiments point in inconsistent directions, or if the effects are small, or if quality control flags a study, the article will not be published in a high-impact journal. The decision to proceed to a clinical trial (or to intensify research) will typically be made based on a small number of research articles (that is, on a few outputs of the diagnostic machine), other forms of evidence (such as safety information and trials involving related treatment strategies), and other extra-scientific considerations (such as commercial potential).
Some clarifications and provisos are needed before we proceed with our analysis. First, we acknowledge that analogizing cancer biology research as a diagnostic machine does not accommodate the spirit and goals of all the publications included in the RPCB. Like all models, ours strips away complexity to bring essential elements of a system to the fore (Borges, 1946). Nevertheless, as noted previously, every sponsor funding these efforts was probably motivated by the prospects of treating or preventing cancer. Even the most basic findings of studies in the RPCB have some prospect of being advanced in some fashion to clinical applications. Second, we recognize that positive outputs of the diagnostic machine will be used differently. In some cases they might be grounds to launch a clinical trial. In other cases, they will promote a clinical hypothesis to further work on a critical path towards translation (Emmerich et al., 2021) – perhaps by supporting the development of more pharmacologically attractive compounds that target the causal process described in a research article.
Furthermore, in our analogy, the outputs of the diagnostic machine are to be understood not as epistemic outputs (that is, positive outputs truly signal a hypothesis is promising; negative outputs signal the reverse). Instead, they are to be understood as sociological outputs, with a positive output signaling that various expert communities regard a hypothesis as worthy of further development. In this way, our analogy regards the RPCB as determining whether repetition of key experiments in original research articles would have produced results consistent with previous ones that generated a 'buzz' in the cancer biology community. In a well-functioning research system, sociological truths will track epistemic truths. However, the former will also be informed by non-epistemic variables, including views about clinical need. In the next sections, we consider what the RPCB results tell us about the performance of this diagnostic machine; Box 1 provides a primer on the terminology that will be used in our analysis (such as Positive Predictive Value and Negative Predictive Value).
A primer for assessing the performance of the diagnostic machine
At a high level we can think of diagnostic testing in terms of six factors.
Base rate: this is the prevalence or 'prior' of true clinical hypotheses among those fed into the diagnostic machine. This will vary by field: the base rate is very low in areas like Alzheimer’s disease, where we have few well-developed clinical hypotheses. However, the base rate is likely higher in, for example, hemophilia, where causal processes of disease are well understood.
Sensitivity: how frequently the diagnostic machine produces a positive output when it is testing a real causal relationship.
Specificity: how frequently the diagnostic machine produces a negative output when it is testing a null effect.
Positive Predictive Value (PPV): the frequency of real causal effects amongst positive outputs of the diagnostic machine.
Negative Predictive Value (NPV): the frequency of null effects amongst negative outputs of the diagnostic machine.
Likelihood ratio: this is the ratio of the probability the diagnostic machine produces a particular result when a real causal effect is being tested to the probability the diagnostic machine produces that same result when a null effect is being tested (Goodman, 1999). When we restrict the diagnostic machine to producing either a 'positive' or 'negative' result, there is a likelihood ratio corresponding to each. The positive likelihood ratio corresponds to the sensitivity divided by one minus the specificity, while the negative likelihood ratio is one minus the sensitivity divided by the specificity. A positive likelihood ratio of 1.0 indicates that a positive result is just as likely to occur when testing a null effect as a real causal effect. The higher the positive likelihood ratio, the more likely a positive output from the diagnostic machine indicates a true clinical hypothesis.
There are two points worth making about these numbers. First, the base rate, sensitivity and specificity determine the PPV and NPV (see Box 2): one can think of the PPV and NPV as properties that emerge when a test with a given sensitivity and specificity is applied to a population of hypotheses with a particular base rate of real causal effects. Second, although there is no mathematical requirement that sensitivity and specificity be linked, in practice there is often an inverse relationship between the two. For example, most scientists require a p value of less than 0.05 in order to reject a null hypothesis. Using a p value of 0.10 instead would make it easier to get a significant finding, thus raising the sensitivity. However, using a p value of 0.10 would also increase the number of false positives and lower the specificity.
The Positive Predictive Value is low for preclinical cancer studies
As specified by their sampling approach (and like other large-scale replication studies), the RPCB only selected research articles that the diagnostic machine had labeled as 'very positive'. All the papers selected for the project had received high numbers of citations, meaning that they had made an impact among cancer researchers: moreover, many of them had been published in high-profile journals such as Cell, Nature and Science, although this was not one of the selection criteria. Therefore, the principal diagnostic property directly assessed by the project was the Positive Predictive Value, which is defined as the number of outputs that replicated (true positives) divided by the total number of outputs tested.
As mentioned previously, only 17 out of the 50 originally planned Replication Studies were completed, with varying degrees of success: five reproduced important parts of the original research articles; six produced equivocal results; two could not be interpreted; and four did not reproduce the experiments they attempted to reproduce (an additional six replication reports were only partially completed). For simplicity we assume that 50% of the equivocal results would regress on repetition, leading the diagnostic machine to recommend advancing with three of these studies. Adding these three studies to the five studies that reproduced important parts of the original research articles, and dividing by 17 replication attempts, gives us an initial estimate of 47% for the Positive Predictive Value of the diagnostic machine. To put this number in context, replication rates for articles in three leading journals in psychology were (depending on how you count) 40% (Open Science Collaboration, 2015); the figure for articles in two leading journals in economics was 66% (Camerer et al., 2016); and for articles in the social sciences published in Nature and Science the figure was 67% (Camerer et al., 2018).
It is more likely than not, however, that an estimate of 47% for the Positive Predictive Value is charitable. As mentioned previously, according to the Editors' summaries, 2 of the 17 published Replication Studies reported findings that could not be interpreted (due to unexpected challenges in repeating the original experiments), and 33 studies were abandoned due to cost overruns, difficulties in securing research materials, or a lack of cooperation from the original authors. The RPCB team found that the original authors were bimodal in their helpfulness when it came to providing feedback and sharing data and materials: 26% were extremely helpful, but 32% were not at all helpful or did not respond (Errington et al., 2021c).
It might be tempting to view the 33 abandoned efforts as uninformative, but we may be able to actually learn from them because it is likely that the 17 published studies are biased in favor of work that is reproducible. Laboratories that were more confident about the reproducibility of their original publications, or more fastidious with their record keeping, might be more likely to cooperate with the RPCB than laboratories that were more doubtful or less fastidious (although the RPCB team did not observe a relationship between material sharing and replication rates; Errington et al., 2021b).
The RPCB also selected experiments that did not rely on unusual samples or techniques, which probably increased the chances of successful replication: experiments that require unusual samples or techniques are, it seems to us, more likely to require more attempts to get them 'to work', and therefore more likely to be prone to the problem of 'researcher degrees of freedom' (Simmons et al., 2011).
The problems the RPCB team experienced in terms of important information not being included in the original research articles, or the original authors not sharing data and/or reagents (Errington et al., 2021c), also points to a diagnostic machine whose workings are often opaque and that leaves a very patchy audit trail for its outputs.
In medicine, the number of people dropping out of a clinical trial (a process called attrition) is often regarded as a useful piece of information and is used when evaluating the results of the trial in 'intention to treat' analyses. Based on what has been reported thus far by the RPCB, eight replication studies produced results consistent with original research articles. The remaining 42 replication studies did not, thus providing a lower bound on the Positive Predictive Value of 16% – an estimate that is not far off from the proportion of studies Amgen reported reproducing years ago (Begley and Ellis, 2012).
As mentioned previously, the meta-analysis covered a total of 158 different effects. Most of the original effects were positive effects (136), and for these the RPCB team found that the median effect size in the replications was 85% smaller than the median effect size in the original experiments; moreover, in 92% of cases the effect size in the replication was smaller than in the original. If the original publications represented unbiased estimates of real effects, one would expect the replications to regress towards smaller effect sizes as often as they drifted towards larger effect sizes. Similar regression has been seen in other large-scale replication projects and noted by other commentators (Colquhoun, 2014).
The poor reproducibility of the individual experiments should influence our interpretation of the overall study results. According to our estimates, the abstracts of 13 of the 17 Replication Studies (that is, 76% of the studies) noted at least one experimental claim that did not reproduce the original effect (meaning that, had replication studies been submitted as original publications, their ’stories' would have been less coherent, putting them at higher risk of rejection by a journal).
Against despair, part I: Negative Predictive Value
So far, things are not looking good for our cancer biology diagnostic machine, but there is more to diagnosis than the Positive Predictive Value. The Negative Predictive Value is also important, given that any positive output will be further tested in clinical trials, but negative outputs will be turfed. Unfortunately the RPCB (and similar projects) only tried to reproduce papers asserting positive causal relationships, thus providing no information about how often the diagnostic machine falsely labels submissions as ‘negative’. (Although the 158 effects analyzed included 22 null effects, these were embedded in papers that contained mostly positive results, so they are unlikely to be representative of the broader population of negative results.) Given this limited information, it may be that the low PPV is balanced out by a high NPV, suggesting that at the very least we are not missing out on many potential valuable clinical hypotheses. On the other hand, the NPV may be as bad or worse than the PPV. Without further study of negative outputs from the diagnostic machine, we simply cannot know how reproducible they are.
Our diagnostic machine might return a falsely negative output for a number of reasons: an individual experiment might not be implemented using proper technique; a key individual experiment might be underpowered; a closely related rival clinical hypothesis might be accepted instead because of a biased individual experiment; or a journal might reject an article reporting a valid clinical hypothesis. To our knowledge there have been no attempts to assess the NPV of a field of research, possibly because many negative outputs are never written up, never mind submitted to a journal; indeed, according to one estimate, only 58% of animal studies are eventually published (Wieschowski et al., 2019). It might be possible to avoid this problem by asking a number of laboratories to blindly repeat a series of original research articles that support clinical hypotheses that have since been confirmed: the proportion of replication attempts that 'fail' would provide some insight into the NPV. However, this approach would require significant resources, and perhaps there are better ways to probe the NPV of preclinical research in cancer biology and give us a more complete understanding of the systems we currently rely on to prioritize clinical hypotheses for further development.
Against despair, part II: Decision rules
A second argument against despair concerns what are sometimes called 'decision rules'. In diagnosis, not all errors have the same practical or moral significance. The statistician Jerzy Neyman, writing in the 1950 s, offers the example of X-ray screening of healthy persons for tuberculosis. A false positive might cause anxiety while that individual waits for the results of further tests. However, a false negative means the person is denied an opportunity to undergo treatment early in a disease course (where management is more effective) and is likely to unwittingly spread the disease (Neyman, 1950). Decision rules illustrate one of the important ways that moral and social propositions are embedded within concepts and interpretations of reproducibility. Indeed, a richer criterion for 'reproducibility' would be whether a given experiment (or set of experiments), when repeated, provides similar levels of support for decisions that an original experiment (or set of experiments) aimed at informing.
What sort of decision rule is appropriate for weighting up false positives and false negatives from the diagnostic machine? As discussed above, preclinical research forms an intermediate step between theory and clinical trials. So long as we have mechanisms for intercepting false positives elsewhere in the research enterprise (ideally, before clinical trials begin), damage will be limited. Moreover, some of the costs associated with redesigning the diagnostic machine so that it produces fewer false positives are likely to be significant: for example, replacing our religious devotion to a p-value of 0.05 with an even more demanding value, such as 0.005 (Benjamin et al., 2018), would require researchers to use much larger sample sizes in their experiments. This might be fine for experiments in psychology and other areas that can use something like Amazon’s Mechanical Turk to recruit participants. In medicine, however, the total volume of human talent, tissue samples and non-human animals available to researchers is limited, so larger sample sizes would mean testing fewer clinical hypotheses, thus limiting our ability to scan the vast landscape of plausible hypotheses.
On the other hand, false negatives mean that populations are deprived of access to a potentially curative therapy, at least until errors are corrected. False negatives might take longer to correct because scientists have less motivation to repeat negative experiments. False negatives will be especially costly in underfunded research areas like neglected diseases and pediatric cancers, since errors will not be quickly corrected by competing labs conducting research in parallel. In well-funded areas where there are many research teams (such as, say, lung cancer), these costs may be small, as competing laboratories pick up on hypotheses rejected by other laboratories. So our decision rule – and the level of reproducibility we should demand for cancer preclinical research – depends on a set of moral and sociological conditions that are outside the scope of the RPCB.
Against despair, part III: Beliefs
Finally, diagnostic machines are simply tools to inform expert beliefs. Ultimately their utility can only be judged on how experts use them. For all 50 research articles identified by the RPCB, the diagnostic machine had originally recommended further development. Many outputs from the diagnostic machine appear, in retrospect, to have been biased in favor of accepting novel clinical hypotheses. This bias is undesirable from an ethical standpoint because non-human animals and scientific effort have been wasted on spurious hypotheses, but what matters most from the standpoint of science is that experts interpreted positive outputs from the diagnostic machine – that is, articles in high-impact journals – correctly and applied these outputs appropriately.
There are many reasons why experts contemplating studies like those in the RPCB might have interpreted and acted on the original research articles differently. The prior probability of a clinical hypothesis in one of the original research articles being true is likely to have depended on previous knowledge in that area of cancer biology. In cases where prior probabilities were higher (in diagnostics, the equivalent of having characteristic symptoms or a higher disease prevalence), a positive output may be sufficient to launch a clinical trial, whereas in cases where prior probabilities were lower, further evidence would be required. Experts might also interpret and act on positive outputs differently because of the methods used. Just as a positive PCR test on a patient might be viewed more skeptically if samples have not been fastidiously protected from contamination, an expert might ask for more evidence if the positive results in a research article were obtained with a method that is known to be temperamental or fallible. On this view, the decision of Amgen and Bayer to replicate preclinical work in house suggests that companies are well aware of the unreliability of many preclinical reports in the published literature.
The RPCB, like most other empirical studies of reproducibility, focused on the 'material' dimensions of reproducibility: the adequacy of the reagents and methods used and the completeness of the reporting in the original research articles, and the ability of independent scientists to implement the protocols described in these articles and obtain statistically similar results. Yet reproducibility has a cognitive dimension as well, namely the ability of experts to use evidence from various sources to predict if, how and to what extent experimental results will generalize. Little is understood about this aspect of reproducibility – and it may matter as much or more than the material dimensions. How well are competent experts able to read the methodology section of an article, and correctly infer that they can implement the exact same protocol in their own lab? How well can experts assess whether, if they implement the exact same protocol, they can obtain results that are statistically consistent with the original research article? How well can experts anticipate the extent to which variations in experimental conditions will extinguish previously detected cause and effect relationships? And how well can experts judge the extent to which phenomena detected under closely-controlled laboratory conditions will be recapitulated in the wilds of a clinical trial?
The little we know about this aspect of reproducibility provides mixed signals. On the one hand, forecast studies carried out by one of us (JK) and colleagues have found that: (i) preclinical researchers are unable to predict whether replication studies will reproduce experiments (Benjamin et al., 2017); (ii) cancer experts perform worse than chance in predicting which treatments tested in randomized trials will show efficacy (Benjamin et al., 2021); (iii) the predictions of cancer experts about trial outcomes are also heavily influenced by the format in which evidence is presented to them (Yu et al., 2021). However, these studies all have limitations and findings from other teams are more sanguine. For example, some studies suggest that expert communities are – in the aggregate – able to pick out which studies replicate in psychology (Dreber et al., 2015) and the social sciences (Camerer et al., 2018), and experts appropriately update their beliefs about an experimental phenomenon on seeing new and more powerful evidence (Ernst et al., 2018).
Future studies of reproducibility in the clinical translation process will need to use qualitative research and methods from decision science to characterize how decisions are made about starting clinical development, what experts believe about the prospects of successful translation, what sorts of evidence they rely on to form these beliefs, and how these beliefs are aggregated to arrive at the institutional decision of the sponsor.
Conclusions and next steps
For the sake of simplicity, let us assume that, across the field of cancer research, the base rate is 10%: that is, the prior for credible cancer research hypotheses being sufficiently true is 10%. Here the phrase ’sufficiently true' means that a hypothesis is close enough to being true that any adjustments that need to be made to the hypothesis can be made during clinical development. Let us also assume that 99% of negatives are true negatives, so the NPV is 99%. What then are the sensitivity and specificity of the diagnostic machine?
If we assume that the PPV is the higher of the two estimates we derived earlier, 47%, then the sensitivity of the diagnostic machine is 92% and the specificity is 88% (see Box 2 for the relevant formulae). This translates to a likelihood ratio for all positive preclinical studies of 8: that is, the diagnostic machine is eight times more likely to recommend clinical testing for real causal effects than for null effects. However, if we use the 'intention to treat' principle and adopt the lower estimate of the two estimates for PPV, 16%, the positive likelihood ratio drops to 1.7, driven by a sharp fall in the specificity.
Calculating sensitivity and specificity
We can write the Positive Predictive Value (PPV) and the Negative Predictive Value (NPV) in terms of the sensitivity, specificity and base rate (BR) as follows:
and
We can re-arrange these two equations to obtain the following expressions for the sensitivity and specificity:
and
We can then plug the expression for the specificity into the expression for sensitivity to obtain the following expression:
It is also possible obtain a similar expression for the specificity. The sensitivity and specificity can then be converted to likelihood ratios using the definition in Box 1.
Likewise, the likelihood ratios would be very different if we were to make different assumptions about the base rate and the NPV (see Figure 1). For example, if we were to assume the base rate of true hypotheses is 30% and the PPV is 47%, then the positive likelihood ratio drops to 2, which constitutes extremely weak evidence. Even with the most generous set of numbers, preclinical studies of the type sampled in the RPCB (that is, studies that receive high numbers of citations) provide only moderate evidence that a clinical hypothesis is true.
Figure 1
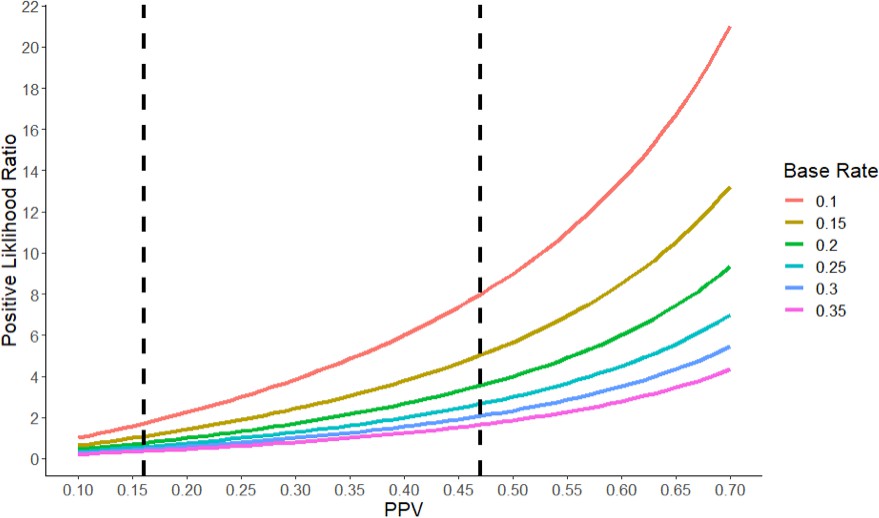
The positive likelihood ratio as a function of the Positive Predictive Value (PPV) and the base rate.
The positive likelihood ratio (y-axis) increases with the PPV (x-axis) for a given value of the base rate (see color code). However, for a given value of the PPV, the positive likelihood ratio decreases as the base rate increases. The vertical dashed lines represent the two estimates of the PPV (16% and 47%) we derived for the RPCB. Typically, a positive likelihood ratio between 1 and 2 is considered weak evidence, while ratios between 2 and 10 constitute moderate evidence, and ratios higher than 10 constitute strong evidence. A ratio of less than one indicates that a test is actively uninformative.
Several practical points about clinical translation follow from this analysis. First and most obviously, preclinical studies should never be interpreted in isolation from other theory and evidence. Instead, decision-makers should actively seek corroboratory and disconfirmatory evidence and interpret any claim in a preclinical study against what was known previously.
Second, as a general rule, positive preclinical publications should be understood in light of their role as providing exploratory evidence for future clinical work. This means we should understand the importance of both winnowing the field of potential hypotheses while also not removing any plausible hypotheses from consideration. Societies committed to improving patient outcomes and using healthcare resources wisely need to maintain strong mechanisms for subjecting clinical hypotheses to a re-test before they are advanced into clinical practice. Emmerich and co-authors offer a pathway for assessing new strategies for clinical development that is informed by 'validity threats' in preclinical research (Emmerich et al., 2021). There have also been call for researchers to label preclinical studies as exploratory, and for findings and hypotheses to be subject to confirmatory testing using principles of pre-specification (along the lines of registered reports) before they are advanced into clinical development (particularly if a hypothesis is likely to entail risk and burden [Mogil and Macleod, 2017; Dirnagl, 2019; Drude et al., 2021]).
Regulators, sponsors and ethics committees should expect that key preclinical studies be replicated in confirmatory studies where hypotheses and protocols are pre-specified and pre-registered (Kimmelman and Anderson, 2012) and proper statistical and experimental methods (such as randomization) are used. Governments should maintain strong pre-license drug regulatory standards, which provide powerful incentives for companies to confirm clinical hypotheses. Many recommendations in clinical practice guidelines are based on mechanistic evidence and expert judgment. Moreover, the journey from bench to bedside is becoming shorter with the emergence of precision medicine, techniques such as patient-derived xenografting (Kimmelman and Tannock, 2018; Yu et al., 2021; Byrne et al., 2017), and a weakening of drug regulation. RPCB findings, and our own studies of medical scientist expert prediction (Benjamin et al., 2017), provide grounds for believing that many such medical practices may sometimes result in costly and needlessly burdensome clinical practices.
Third, a complete understanding of the previous point requires accessing more information on the NPV and base rate of true hypotheses under consideration. Without this information we can only guess at whether the diagnostic machine is optimally tuned to maximize societal gains against the non-human animals, patients, and human capital we invest in operating it. Creativity and a great deal of cooperation from labs will likely be necessary for estimating these numbers.
Finally, we need to expand our inquiry into reproducibility by studying its non-material dimensions in greater detail. As we have tried to emphasize, defining and understanding reproducibility requires grappling not merely with what is done with pipettes and Eppendorf tubes, but also with the psychology of expert inference and decision-making, and how these judgments coalesce within research communities. It will require more thinking about ethical and pragmatic judgments embedded within decision rules. It will also require evidence and analysis concerning the efficiency of existing research systems, and the moral trade-offs between false positivity and false negativity. Though the RPCB has brought us much closer to knowing the extent to which we can trust conclusions in cancer preclinical studies, many evaluative judgments regarding the cancer biology research enterprise will have to await further scientific, sociological and moral inquiry.
Data availability
No data was generated for this work.
References
-
Redefine statistical significanceNature Human Behaviour 2:6–10.https://doi.org/10.1038/s41562-017-0189-z
-
Power failure: Why small sample size undermines the reliability of neuroscienceNature Reviews Neuroscience 14:365–376.https://doi.org/10.1038/nrn3475
-
Interrogating open issues in cancer precision medicine with patient-derived xenograftsNature Review Cancer 17:254–268.https://doi.org/10.1038/nrc.2016.140
-
An investigation of the false discovery rate and the misinterpretation of p-valuesRoyal Society Open Science 1:140216.https://doi.org/10.1098/rsos.140216
-
Rethinking research reproducibilityEMBO Journal 38:e101117.https://doi.org/10.15252/embj.2018101117
-
Improving target assessment in biomedical research: the GOT-IT recommendationsNature Reviews Drug Discovery 20:64–81.https://doi.org/10.1038/s41573-020-0087-3
-
Toward evidence-based medical statistics. 2: The Bayes factorAnnals of Internal Medicine 130:1005–1013.https://doi.org/10.7326/0003-4819-130-12-199906150-00019
-
Clinical development success rates for investigational drugsNature Biotechnology 32:40–51.https://doi.org/10.1038/nbt.2786
-
BookGene Transfer and the Ethics of First-in-Human ResearchCambridge University Press.https://doi.org/10.1017/CBO9780511642364
-
Should preclinical studies be registered?Nature Biotechnology 30:488–489.https://doi.org/10.1038/nbt.2261
-
The paradox of precision medicineNature Reviews Clinical Oncology 15:341–342.https://doi.org/10.1038/s41571-018-0016-0
-
Can the pharmaceutical industry reduce attrition rates?Nature Reviews Drug Discovery 3:711–715.https://doi.org/10.1038/nrd1470
-
Believe it or not: How much can we rely on published data on potential drug targets?Nature Reviews Drug Discovery 10:712.https://doi.org/10.1038/nrd3439-c1
-
Systematic review and narrative review lead experts to different cancer trial predictions: a randomized trialJournal of Clinical Epidemiology 132:116–124.https://doi.org/10.1016/j.jclinepi.2020.12.006
Decision letter
-
Peter RodgersSenior and Reviewing Editor; eLife, United Kingdom
In the interests of transparency, eLife publishes the most substantive revision requests and the accompanying author responses.
Note: This article underwent further editing and revision after it had been revised in response to feedback from the peer reviewers.
Thank you for sending your Feature Article "Is cancer biology research reproducible enough?" to eLife. Your article has been seen by two reviewers and their reports are below.
I asked the reviewers to comment on the following:
# Does the manuscript have any obvious weaknesses?
# Are there any topics you think the manuscript should mention but does not?
# Are there any topics that are covered at too great a length and could be shortened?
# Are there any parts of the article that need to be clearer?
Can you please revise your manuscript to address the comments in the reports and return the revised article to me, with a point-by-point response.
Reviewer 1:
Thanks for the opportunity to review the manuscript. We have both enjoyed reading it and think it makes important points. Though we generally agree with the conclusions provided by the authors, we have made a few remarks and suggestions below.
# Does the manuscript have any obvious weaknesses?
1. Our major concern with the manuscript is that the authors’ whole argument, although quite interesting from a theoretical point of view, is based on viewing preclinical research as a diagnostic machine. This might be a good analogy in some cases, when preclinical work corresponds more directly to the subsequent clinical research in its experimental design – e.g. one tests an intervention on animals, and depending on the result, you move to clinical trials with humans.
However, this does not seem to be the case for most preclinical research. Judging by their abstracts, the research within the RP:CB papers seems to be quite variable in terms of its proximity to clinical translation. Some articles are indeed about specific targets, or even about the efficacy of cancer drugs. However, others are about features of specific tumors or understanding signaling pathways. Thus, they are not all "preclinical" in the more strict sense of testing interventions in experimental models.
The authors do recognize this fact in isolated passages, but their reasoning seems to generally ignore the caveat. In their defense, they argue that “probably every sponsor funding these efforts was primarily motivated by the prospects of advancing health”. This is probably true, but the mapping from preclinical finding to clinical advancement is far from linear. One preclinical hypothesis could serve as a basis for many different interventions, especially if it's more fundamental research, further away from the intervention. Conversely, many preclinical findings might have to sum up to produce a candidate for clinical intervention.
This renders the discussion of positive and negative predictive values – which would require one-to-one mapping between preclinical finding and a clinical intervention – and the cost-benefit discussion that follows from it a bit artificial and overly simplistic. There might be no way around this, but the authors could be more clear on the fact that their model represents a crude approximation of a much more nuanced reality. For example, sentences such as “the RPCB results suggest that outputs for this “diagnostic machine” recommend advancing many non-reproducible findings to clinical testing” could probably be avoided in the absence of evidence that these recommendations are being made explicitly in the replicated articles.
[Note from editor: I think the best way to address this point is, as the referee suggests, to acknowledge that the diagnostic machine approach will work for some but not all kinds of preclinical research]
2. An associated problem is that the authors seem to equate citation impact and acceptance in prestigious journals (the basis for the selection of the papers included in RP:CB) with results warranting clinical investigation (e.g. “as specified by their sampling approach (and similar to other replication studies), the RPCB only selected “very positive” outputs from our diagnostic machine.”). Nevertheless, we are not sure that editors and reviewers indeed operate with a “diagnostic machine” mindset, and they could be very well selecting the papers on the basis of other issues (e.g. thoroughness, novelty, theoretical insight, prestige of the research group). Although we certainly agree that high-impact journals will tend to select for more positive findings, calling them all “very positive” in terms of clinical potential on the basis of publication venue and citation impact seems quite a leap.
In the same vein, we do not agree with passages such as “one imperfect way of going about assessing the NPV would be to replicate a sample of low impact original studies” or “another would be to trace the frequency and kinetics with which original reports bounced from high impact journals produce clinical hypotheses that are later vindicated in clinical trials”. Equating rejection at a high-impact journal (or publication in a low-impact venue) with findings being less promising in terms of direct clinical impact (i.e. a “negative” study from the point of view of the diagnostic machine) seems like a very crude and likely inaccurate approximation: there are certainly many positive findings which do not make their way to high-impact journals for other reasons, including low methodological rigor (which is likely to yield false-positive findings on its own).
3. The “intention-to-treat” analysis proposed by the authors seems to suggest that articles for which replication could not be completed should be taken as likely not to reproduce – on the basis of postulations such as “laboratories that were more confident of the reproducibility of their original publications, or more fastidious with record keeping, would be more likely to cooperate with RPCB investigators than laboratories that were more doubtful or less fastidious.” Although this is a possibility, as far as I understood cooperation from the original investigators was not a sine qua non for replications to be carried forward in the RP:CB. Similarly, not all unfinished replications fell by the wayside because of methodological troubles or lack of cooperation: many of them were left out merely because of budget concerns. The authors should thus discuss whether considering attrition as informative really makes sense – if correlation between attrition and non-reproducibility is low, the low predictive value of the intention-to-treat analysis might be largely exaggerating the problem.
# Are there any topics you think the manuscript should mention but does not?
1. As the authors seem to be quite concerned about false negatives and negative predictive values, one discussion that seems to be missing is about publication bias. When negative findings simply go missing (which is probably the case for many of them), estimating negative predictive values is basically impossible, so it is hard to discuss the potential accuracy of the diagnostic machine without taking this issue (i.e. where do negative findings actually end up and what fraction of them is accessible to the “machine”) into consideration. If the authors are concerned about negative predictive values (as they rightly should), ensuring that negative findings are indeed accessible seems like the most pressing issue to solve (and discuss).
2. In the “decision rules” session, the authors seem to suggest that there is a direct tradeoff between sensitivity and specificity. This is indeed the case when one uses a modifiable, quantitative threshold (such as a p value of 0.05) to analyze unbiased data. But is it the case that all false-positives arise because of “loose detection thresholds” considering weak evidence as positive – instead of the threshold itself actually biasing analyses to turn out positive (e.g. by p-hacking and other practices)? For instance, suppose that one or more RP:CB false-positives arose from fraud. If data were forged, changing such a threshold would make little difference (i.e. results would still be positive no matter where the threshold stands).
3. Also in the “decision rules” section, the authors should probably discuss more explicitly that error control for the “diagnostic machine” purposes does not necessarily need to be implemented at the publication level. Type I error rates could also be adjusted at the level of data synthesis – i.e. if companies require more than a few studies in order to move forward with human trials, one could eventually have acceptable error control even if positive predictive value is low at the level of the individual study (which is ultimately what the authors are discussing when referring to RP:CB). This possibility (which is hinted at in the conclusions) should at least be touched upon as an alternative for the diagnostic machine’s decision rules.
4. In some parts of the paper – particularly in the “beliefs” section, the authors engage in a lot of speculation on how the “diagnostic machine process” actually works in real life – e.g. what kind of heuristics companies actually use as evidence to launch a clinical trial. Although speculation is inevitable, as this process has not been charted systematically, it would be interesting if they could provide a clear list (perhaps in a Box 2) of data that could be collected to inform their model and drive the discussion forward.
5. Similarly, when authors make recommendations such as “Preclinical studies should generally be labeled as exploratory, and before advancing a hypothesis into clinical development (…) regulators, sponsors and ethics committees should expect that key preclinical studies be replicated in confirmatory studies where hypotheses and protocols are pre-specified and pre-registered and proper statistical and experimental methods (e.g. randomization) are used”, it might be worth discussing to what extent this might already be happening (or not) in some instances, or even provide examples of existing practices in specific agencies or committees, in case the authors are aware of any.
# Are there any topics that are covered at too great a length and could be shortened?
1. For the general reader, we’re not sure if likelihood ratios (which are an unfamiliar concept to most researchers in the life sciences) are necessary to understand the article’s points. Negative and positive predictive values are more intuitive and I get the feeling that these can largely be used to make the authors’ point without introducing an additional mathematical concept.
# Are there any parts of the article that need to be clearer?
1. The description of the RP:CB methodology is scattered through the paper (i.e. description of study selection and registered reports on page 2, description of the replication methodology on pages 4-5). Wouldn’t it be clearer to describe the methodology in a single session?
[Note from editor: I can deal with this point during editing]
2. The authors mention replication rates in different areas (“To put this number in context, replication rates for psychology were (depending on how you count) 40%, for economics they were 66%, and for the social sciences they were 67%.”) without mentioning the study selection process in each of these studies (i.e. the psychology and economy numbers come from specific specialty journals, the social sciences one from Science and Nature papers). It should be made clear that, as they refer to very specific samples of articles, these replication rates cannot be taken as representative of the whole scientific field.
3. The authors’ use of “inferential reproducibility” in the manuscript does not seem to be in line with the concept’s definition by Goodman et al. (cited to support it as ref. # 23). In that article, “inferential reproducibility” refers to whether two researchers performing similar studies or analyzing the same data will reach similar conclusions on the claims that can be made. This is quite different from “the ability of experts to predict if, how and to what experimental results will generalize” as defined in the current manuscript. Both are important topics to touch on, but they are very different concepts, and a different term should be used to describe the ability to predict the reproducibility of results.
4. When the authors perform calculations to illustrate their point, they assume a few numbers for prevalence rate and negative predictive values (i.e. “For the sake of simplicity, let’s assume that, across the field of cancer research, the “prevalence” or “prior” of credible cancer research hypotheses being sufficiently true (that is, close enough to being true that any adjustments to the hypothesis can be made during clinical development) is 10%. Let’s put an upper bound on the NPV of 99%, that is 99% of negatives are true negatives.”). As we don’t really have a clue on what these numbers really are, it is possible that assuming exact numbers – even for the sake of argument as the authors do – might give the idea of a nonexistent precision to the reader. If the authors do want to make the point – which we agree with – that different parameters lead to very different predictive values and likelihood ratios, it's worth considering whether a figure showing how this varies continuously depending on a wide range of parameter assumptions, without focusing on specific numbers, could be a better way to convey it.
Reviewer 2:
Kimmelman and Kane provide an excellent comment on the RPCB. They address three important issues (negative predictive value, decisions, and beliefs) in preclinical research that shape the environment where research is conducted. They also conduct a simple but very informative meta analysis on effect size shrinkage in the RPCB. I personally would be keen on knowing how much shrinkage there was on average as this would be a first prior for future sample size calculations in cancer biology. Perhaps this is also too much to ask at this point or is covered in other meta analyses by Tim Errington and colleagues. I give some more specific comments below that the authors may want to consider.
1. There are some references that already describe a diagnostic machine and make concrete examples. These could be added as they make several suggestions for criteria that could be diagnostic for decisions in this machinery.
- Emmerich et al. 2021 Improving target assessment in biomedical research: the GOT-IT recommendations. Nature Reviews Drug Discovery 20:64–81
– Drude et al. 2021 Improving preclinical studies through replications. eLife 10:e62101
(Note: I am a co-author on Drude et al., so please only cite it if you find it helpful.)
[Note from editor: Whether or not you cite either of this references, please mention the reproducibility projects in Brazil and Germany that are mentioned in Drude et al]
2. The authors state: “Experiments that require more finicky conditions seem more likely to require multiple attempts at the bench- thus increasing the prospect of original authors selecting those individual experimental results most flattering to the underlying hypothesis, a problem akin to phenomena elsewhere characterized in reproducibility studies as "researcher degrees of freedom."”
I find this not nuanced enough. Some techniques are only for specialised laboratories and advance our understanding of patho-mechanisms a lot. Examples are two-photon microscopy, organoids and their specific growth factors, single cell sequencing, etc. Not all information can be in the Materials and methods part. Alternative routes of detailed method dissemination are necessary and need higher awareness (eLife already promotes these). As it is it may read as if all complicated preclinical research is selective and entirely under researcher degrees of freedom.
3. High Impact Preclinical Experiments are Very Biased Against the Null
It may be helpful here to refer to Colquhoun, D. An investigation of the false discovery rate and the misinterpretation of p-values. Royal Society Open Science 1, 140216. Figure 7 here captures exactly the effect observed in the RPCB.
4. Against Despair, Part II: Decision Rules
The question for me is, was the RPCB designed to enable decision towards translation or was it designed to decide whether evidence is robust in the field of cancer biology. These are two different questions. It should be stated clearly which of these decisions RPCB was designed to make (the authors give a vague answer at the beginning of their comment).
For the question of translation, a field specific approach is necessary that takes all the variables into account that the authors refer to (prior probability, effect sizes in the field, ppv and npv, etc.). I think this question can be found through consensus in a field by combining expert knowledge and meta research and is not so much dependent on morality and sociological conditions as the authors claim in their last paragraph. These two words carry so much and at the same time little specific meaning here that I suggest to tone it down at this point.
5. Some mathematical descriptions could be a bit daunting for the average reader (e.g. paragraph after Box1). To help with that, calculations at the end of the paper could use a figure. It may be easier to understand if they do something similar to Figure 1 in Forstmeier W, Wagenmakers EJ, Parker TH. Detecting and avoiding likely false-positive findings – a practical guide. Biological Reviews of the Cambridge Philosophical Society. 2017 Nov;92(4):1941-1968. DOI: 10.1111/brv.12315.
https://doi.org/10.7554/eLife.67527.sa1Author response
Reviewer 1:
Thanks for the opportunity to review the manuscript. We have both enjoyed reading it and think it makes important points. Though we generally agree with the conclusions provided by the authors, we have made a few remarks and suggestions below.
# Does the manuscript have any obvious weaknesses?
1. Our major concern with the manuscript is that the authors’ whole argument, although quite interesting from a theoretical point of view, is based on viewing preclinical research as a diagnostic machine. This might be a good analogy in some cases, when preclinical work corresponds more directly to the subsequent clinical research in its experimental design – e.g. one tests an intervention on animals, and depending on the result, you move to clinical trials with humans.
However, this does not seem to be the case for most preclinical research. Judging by their abstracts, the research within the RP:CB papers seems to be quite variable in terms of its proximity to clinical translation. Some articles are indeed about specific targets, or even about the efficacy of cancer drugs. However, others are about features of specific tumors or understanding signaling pathways. Thus, they are not all "preclinical" in the more strict sense of testing interventions in experimental models.
The authors do recognize this fact in isolated passages, but their reasoning seems to generally ignore the caveat. In their defense, they argue that “probably every sponsor funding these efforts was primarily motivated by the prospects of advancing health”. This is probably true, but the mapping from preclinical finding to clinical advancement is far from linear. One preclinical hypothesis could serve as a basis for many different interventions, especially if it's more fundamental research, further away from the intervention. Conversely, many preclinical findings might have to sum up to produce a candidate for clinical intervention.
This renders the discussion of positive and negative predictive values – which would require one-to-one mapping between preclinical finding and a clinical intervention – and the cost-benefit discussion that follows from it a bit artificial and overly simplistic. There might be no way around this, but the authors could be more clear on the fact that their model represents a crude approximation of a much more nuanced reality. For example, sentences such as “the RPCB results suggest that outputs for this “diagnostic machine” recommend advancing many non-reproducible findings to clinical testing” could probably be avoided in the absence of evidence that these recommendations are being made explicitly in the replicated articles.
[Note from editor: I think the best way to address this point is, as the referee suggests, to acknowledge that the diagnostic machine approach will work for some but not all kinds of preclinical research]
We agree that our model and theory (like any model or theory) strips away complexity and nuance to get traction on a problem; some studies in the RPCB are indeed more basic than others. We also appreciate that the assumptions and implications embedded in our model were not as explicit as they could have been and could lead to confusion. Accordingly, we added a “provisos and clarifications” paragraph to the section that introduces the model that addresses three aspects of the model flagged by this referee- (a) the imperfection of the model; (b) the way diagnostic machine outputs might be used by different actors; (c) the precise meaning of what “positive” and “negative” means:
“Some clarifications and provisos before proceeding with our analysis. First, we acknowledge that analogizing cancer biology research as a diagnostic machine does not accommodate the spirit and goals of all original reports included in the RPCB. Like all models, ours strips away complexity to bring essential elements of a system to the fore. Nevertheless, every sponsor funding these efforts was probably motivated by the prospects of advancing health. Even the most basic findings of studies in the RPCB have some prospect of being advanced in some fashion to clinical applications. Second, we recognize that positive outputs of the diagnostic machine will be used differently. In some cases, they might be grounds to launch a clinical trial. In other cases, they will promote a clinical hypothesis to further work on a critical path towards translation – perhaps by supporting development of more pharmacologically attractive compounds that target the causal process fished out in an original report. Third, in our analogy, outputs of the diagnostic machine are to be understood not as epistemic outputs (e.g. positive outputs truly signal a hypothesis is promising; negative the reverse). Instead the outputs are to be understood as sociological- positive outputs signal that expert communities regard a hypothesis as worthy of further advancement. In this way, our analogy regards the RPCB as determining whether repetition of key experiments in original reports would have produced results consistent with previous ones that generated a buzz in the cancer biology community. In a well-functioning research system, sociological “truths” will track epistemic truths. However, the former will also be informed by nonepistemic variables, including views about clinical need. In the next sections, we consider what the RPCB results tell us about the performance of this sprawling clinical hypothesis diagnostic machine (Box 1 provides a primer on terminology that will be used in our analysis).”
We also clarify that we understand the process of medical translation is not about developing molecules per se, but rather unlocking the clinical utility of concepts and strategies that basic and preclinical research uncovers (that the first anti-angiogenesis compound, endostatin, failed clinical development does not take away from the enormous success of the paradigm in contemporary cancer management). This is reflected in the following passage (italics indicating text insertion):
“If individual experiments within each original publication converge on the same translational claim (which may not be a purely material claim about a particular molecule, but a claim about strategy) and produce large effects, the diagnostic machine recommends clinical development. If individual experiments point in inconsistent directions, if individual experiments effects are small, or if quality control flags a study, the diagnostic machine recommends against clinical development- at least for the time being.”
2. An associated problem is that the authors seem to equate citation impact and acceptance in prestigious journals (the basis for the selection of the papers included in RP:CB) with results warranting clinical investigation (e.g. “as specified by their sampling approach (and similar to other replication studies), the RPCB only selected “very positive” outputs from our diagnostic machine.”). Nevertheless, we are not sure that editors and reviewers indeed operate with a “diagnostic machine” mindset, and they could be very well selecting the papers on the basis of other issues (e.g. thoroughness, novelty, theoretical insight, prestige of the research group). Although we certainly agree that high-impact journals will tend to select for more positive findings, calling them all “very positive” in terms of clinical potential on the basis of publication venue and citation impact seems quite a leap.
Thank you for pressing us to be more precise. I don’t think we disagree. We intend “positive” in the broadest sense possible, namely that claims embedded in publications are deemed by the expert community to have some cluster of qualities (e.g. excitement, reliability, impact) that warrants the visibility bestowed by prestigious journals. We have clarified this in the paragraph addressing the referee’s first concern.
In the same vein, we do not agree with passages such as “one imperfect way of going about assessing the NPV would be to replicate a sample of low impact original studies” or “another would be to trace the frequency and kinetics with which original reports bounced from high impact journals produce clinical hypotheses that are later vindicated in clinical trials”. Equating rejection at a high-impact journal (or publication in a low-impact venue) with findings being less promising in terms of direct clinical impact (i.e. a “negative” study from the point of view of the diagnostic machine) seems like a very crude and likely inaccurate approximation: there are certainly many positive findings which do not make their way to high-impact journals for other reasons, including low methodological rigor (which is likely to yield false-positive findings on its own).
As we now discuss in our section on provisos and clarification (see above), there are two broad ways one might understand outputs of the diagnostic machine in our analogy. One is in an epistemic sense: positive outputs tell us what is truly a clinically impactful discovery. The other is in a sociological sense: positive outputs tell us what the machinery of science (which combines scientific processes, like the performance of assays, with sociological ones like peer review) tell us is an actionable discovery. Because we generally think science is well organized, we assume that latter will track the former, if imperfectly. In our analogy, we understand the diagnostic machine to be giving us a read out of the latter. What the RPCB is doing is activating those same machinery of scientific research and seeing if it produces results that are consistent with original findings that excited research communities (i.e., individual experimental results with large effect sizes, which when assembled together, offer a coherent picture about a causal process in cancer). To be clear, it is entirely possible, indeed likely, that many “positive” and “negative” findings are wrong in the epistemic sense. Some “positive” outputs might be artifacts of animal models. Some “negative” outputs might similarly reflect use of animal models that do not recapitulate human pathophysiology. However, we regard this mismatch between models and reality as a problem that is intrinsic to science itself.
As a result, when we say that studies published in low impact venues are less promising in terms of advancing cancer treatment, we do not mean that their findings are truly less important for developing cancer treatments. Instead, we mean that they are less likely to be interpreted by expert communities as likely to impact cancer care.
The idea behind our proposal is asking whether experiments that do not excite expert communities (hence published in lower impact venues), when repeated, acquire properties (i.e. individual experimental results with large effect sizes, which when assembled together, offer a coherent picture about a causal process in cancer) that excite expert communities.
3. The “intention-to-treat” analysis proposed by the authors seems to suggest that articles for which replication could not be completed should be taken as likely not to reproduce – on the basis of postulations such as “laboratories that were more confident of the reproducibility of their original publications, or more fastidious with record keeping, would be more likely to cooperate with RPCB investigators than laboratories that were more doubtful or less fastidious.” Although this is a possibility, as far as I understood cooperation from the original investigators was not a sine qua non for replications to be carried forward in the RP:CB. Similarly, not all unfinished replications fell by the wayside because of methodological troubles or lack of cooperation: many of them were left out merely because of budget concerns. The authors should thus discuss whether considering attrition as informative really makes sense – if correlation between attrition and non-reproducibility is low, the low predictive value of the intention-to-treat analysis might be largely exaggerating the problem.
We agree that it is impossible to know whether incomplete studies are less reproducible than ones that completed. We do, however, feel confident in saying that studies the RPCB were unable to repeat cannot be assumed to be missing at random, and we think there are numerous plausible reasons to entertain the possibility that completed studies are biased towards reproducibility. We have revised the manuscript to clarify that this intention to treat analysis is an attempt to create a lower bound, rather than the single correct estimate:
“The remaining 42 replication studies did not, thus providing a lower bound on the positive predictive value of 16%- an estimate that is not far off from the proportion of studies Amgen reported reproducing years ago.(1)”
# Are there any topics you think the manuscript should mention but does not?
1. As the authors seem to be quite concerned about false negatives and negative predictive values, one discussion that seems to be missing is about publication bias. When negative findings simply go missing (which is probably the case for many of them), estimating negative predictive values is basically impossible, so it is hard to discuss the potential accuracy of the diagnostic machine without taking this issue (i.e. where do negative findings actually end up and what fraction of them is accessible to the “machine”) into consideration. If the authors are concerned about negative predictive values (as they rightly should), ensuring that negative findings are indeed accessible seems like the most pressing issue to solve (and discuss).
We understand publication bias in the above to refer to circumstances where individual experiments are strung together into a potential original report, but because the potential original report is null, it is not advanced toward publication. So instead of showing up as a “low impact” publication, it stays in the file drawer. We agree this type of publication bias poses a major practical challenge for assessing NPV. We now acknowledge publication bias as presenting a challenge for two approaches we outline for assessing NPV by a) stating that “many negative findings are… never published (according to one estimate, only 58% of animal studies are eventually published).”(2) and (b) by adding the sentence “Both of these options would be limited by sampling bias, since many negative studies are never submitted for publication.”
2. In the “decision rules” session, the authors seem to suggest that there is a direct tradeoff between sensitivity and specificity. This is indeed the case when one uses a modifiable, quantitative threshold (such as a p value of 0.05) to analyze unbiased data. But is it the case that all false-positives arise because of “loose detection thresholds” considering weak evidence as positive – instead of the threshold itself actually biasing analyses to turn out positive (e.g. by p-hacking and other practices)? For instance, suppose that one or more RP:CB false-positives arose from fraud. If data were forged, changing such a threshold would make little difference (i.e. results would still be positive no matter where the threshold stands).
We respectfully disagree with the assertion that sensitivity and specificity don’t trade-off more generally. While there may be some areas in which a free lunch can be found, at least in the area of fraud, any enforcement mechanism used to detect fraudulent results will have its own false positives and false negatives, essentially recapitulating the same dynamic that applies to Gaussian curves.
3. Also in the “decision rules” section, the authors should probably discuss more explicitly that error control for the “diagnostic machine” purposes does not necessarily need to be implemented at the publication level. Type I error rates could also be adjusted at the level of data synthesis – i.e. if companies require more than a few studies in order to move forward with human trials, one could eventually have acceptable error control even if positive predictive value is low at the level of the individual study (which is ultimately what the authors are discussing when referring to RP:CB). This possibility (which is hinted at in the conclusions) should at least be touched upon as an alternative for the diagnostic machine’s decision rules.
We partly agree. In the previous version, we note that regulatory systems intercept false positives and thus reduce the “loss” associated with them. We revised this sentence to include other quality control processes (italics indicate additions):
“So long as we have mechanisms for intercepting false positives, such as effective drug regulators or quality control processes in research, errant acceptance of a clinical hypothesis will be quickly spotted in clinical testing.”
Our piece previously noted the importance of embedding new findings against what is known about a hypothesis; in revisions, we now also describe pathways that sponsors might consider in verifying strategies before putting them into clinical trials (see below).
On the other hand, we also think our point still stands. If Nature conditioned paper acceptance of all submitted papers on authors performing replications, it would have the same effect of upping the p-value. Namely, more resources would be expended per ‘buzz generating publication,’ with the consequence that some truly promising findings are missed because effect sizes in repeat experiments were insufficiently large (due to chance) for Nature to accept the piece. In many ways, the spirit of this comment is addressed in the next section (under “Beliefs”).
4. In some parts of the paper – particularly in the “beliefs” section, the authors engage in a lot of speculation on how the “diagnostic machine process” actually works in real life – e.g. what kind of heuristics companies actually use as evidence to launch a clinical trial. Although speculation is inevitable, as this process has not been charted systematically, it would be interesting if they could provide a clear list (perhaps in a Box 2) of data that could be collected to inform their model and drive the discussion forward.
We weren’t sure how to integrate these suggestions into our text without disturbing the flow. We added a few sentences to the end of the beliefs section that lays out a research agenda for better understanding the belief dimensions of drug development.
5. Similarly, when authors make recommendations such as “Preclinical studies should generally be labeled as exploratory, and before advancing a hypothesis into clinical development (…) regulators, sponsors and ethics committees should expect that key preclinical studies be replicated in confirmatory studies where hypotheses and protocols are pre-specified and pre-registered and proper statistical and experimental methods (e.g. randomization) are used”, it might be worth discussing to what extent this might already be happening (or not) in some instances, or even provide examples of existing practices in specific agencies or committees, in case the authors are aware of any.
This request echoes suggestions made by referee 2. We now cite two sources that describe pathways for validation of strategies before clinical development (Emmerich et al; Drude et al).
# Are there any topics that are covered at too great a length and could be shortened?
1. For the general reader, we’re not sure if likelihood ratios (which are an unfamiliar concept to most researchers in the life sciences) are necessary to understand the article’s points. Negative and positive predictive values are more intuitive and I get the feeling that these can largely be used to make the authors’ point without introducing an additional mathematical concept.
We appreciate this concern. However, we believe these concepts are important (and widespread) enough to be worth incorporated in the manuscript. We’ve done our best to provide context and explanation- and for the motivated reader- citations where they can follow up. Perhaps the new figure will at least help readers visually connect the relationship between PPV, priors, and strength of evidence.
# Are there any parts of the article that need to be clearer?
1. The description of the RP:CB methodology is scattered through the paper (i.e. description of study selection and registered reports on page 2, description of the replication methodology on pages 4-5). Wouldn’t it be clearer to describe the methodology in a single session?
[Note from editor: I can deal with this point during editing]
Great- thanks.
2. The authors mention replication rates in different areas (“To put this number in context, replication rates for psychology were (depending on how you count) 40%, for economics they were 66%, and for the social sciences they were 67%.”) without mentioning the study selection process in each of these studies (i.e. the psychology and economy numbers come from specific specialty journals, the social sciences one from Science and Nature papers). It should be made clear that, as they refer to very specific samples of articles, these replication rates cannot be taken as representative of the whole scientific field.
Thank you for noting this we have now provided more context on the journals involved in these replication projects.
3. The authors’ use of “inferential reproducibility” in the manuscript does not seem to be in line with the concept’s definition by Goodman et al. (cited to support it as ref. # 23). In that article, “inferential reproducibility” refers to whether two researchers performing similar studies or analyzing the same data will reach similar conclusions on the claims that can be made. This is quite different from “the ability of experts to predict if, how and to what experimental results will generalize” as defined in the current manuscript. Both are important topics to touch on, but they are very different concepts, and a different term should be used to describe the ability to predict the reproducibility of results.
Thank you for catching this; we regret the error. We removed the reference.
4. When the authors perform calculations to illustrate their point, they assume a few numbers for prevalence rate and negative predictive values (i.e. “For the sake of simplicity, let’s assume that, across the field of cancer research, the “prevalence” or “prior” of credible cancer research hypotheses being sufficiently true (that is, close enough to being true that any adjustments to the hypothesis can be made during clinical development) is 10%. Let’s put an upper bound on the NPV of 99%, that is 99% of negatives are true negatives.”). As we don’t really have a clue on what these numbers really are, it is possible that assuming exact numbers – even for the sake of argument as the authors do – might give the idea of a nonexistent precision to the reader. If the authors do want to make the point – which we agree with – that different parameters lead to very different predictive values and likelihood ratios, it's worth considering whether a figure showing how this varies continuously depending on a wide range of parameter assumptions, without focusing on specific numbers, could be a better way to convey it.
Thanks for this helpful suggestion. We have prepared a figure to address this comment.
Reviewer 2:
Kimmelman and Kane provide an excellent comment on the RPCB. They address three important issues (negative predictive value, decisions, and beliefs) in preclinical research that shape the environment where research is conducted. They also conduct a simple but very informative meta analysis on effect size shrinkage in the RPCB. I personally would be keen on knowing how much shrinkage there was on average as this would be a first prior for future sample size calculations in cancer biology. Perhaps this is also too much to ask at this point or is covered in other meta analyses by Tim Errington and colleagues. I give some more specific comments below that the authors may want to consider.
1. There are some references that already describe a diagnostic machine and make concrete examples. These could be added as they make several suggestions for criteria that could be diagnostic for decisions in this machinery.
- Emmerich et al. 2021 Improving target assessment in biomedical research: the GOT-IT recommendations. Nature Reviews Drug Discovery 20:64–81
– Drude et al. 2021 Improving preclinical studies through replications. eLife 10:e62101
(Note: I am a co-author on Drude et al., so please only cite it if you find it helpful.)
[Note from editor: Whether or not you cite either of this references, please mention the reproducibility projects in Brazil and Germany that are mentioned in Drude et al]
Thank you for these suggestions; we had not been aware of either of these publications and appreciate being alerted to each. We now cite the Emmerich et al. and Drude et al. in our closing section: “Emmerich et al. offer a pathway for assessing new strategies for clinical development that is informed by validity threats in preclinical research [EMMERICH et al] As other commentators have urged, it encourages researchers to label preclinical studies as exploratory.[DRUDE et al]”
2. The authors state: “Experiments that require more finicky conditions seem more likely to require multiple attempts at the bench- thus increasing the prospect of original authors selecting those individual experimental results most flattering to the underlying hypothesis, a problem akin to phenomena elsewhere characterized in reproducibility studies as "researcher degrees of freedom."”
I find this not nuanced enough. Some techniques are only for specialised laboratories and advance our understanding of patho-mechanisms a lot. Examples are two-photon microscopy, organoids and their specific growth factors, single cell sequencing, etc. Not all information can be in the Materials and methods part. Alternative routes of detailed method dissemination are necessary and need higher awareness (eLife already promotes these). As it is it may read as if all complicated preclinical research is selective and entirely under researcher degrees of freedom.
We agree that some techniques might require specialized labs. However, Errington et al. describe how they attempted to minimize failed replications due to the use of specialized techniques: “[we excluded studies] if they required specialized samples, techniques, or equipment that would be difficult or impossible to obtain,” and “a key part of matching experiments with laboratories is to identify labs with the appropriate expertise to maximize research quality. This is particularly important with new and innovative techniques, though most techniques called for in the selected experiments are standard techniques for which expertise is widely avail- able. As experiments are matched to labs, it is possible that no appropriate service provider can be identified. If appropriate expertise is not available, then the finding or paper will be excluded from the project.” We nevertheless acknowledge that RPCB might have erred in its judgments- now stated in revisions (italics indicating new text):
“RPCB states that they selected experiments that didn’t rely on unusual samples or techniques, and they attempted to match experiments to laboratories possessing competency with methods [ERRINGTON 2014]. Acknowledging the possibility RPCB selection and matching might have erred, studies involving standardized experimental techniques would be likely easier to reproduce than studies using less familiar ones, since there are likely to be more quality controls on standardized reagents.”
3. High Impact Preclinical Experiments are Very Biased Against the Null
It may be helpful here to refer to Colquhoun, D. An investigation of the false discovery rate and the misinterpretation of p-values. Royal Society Open Science 1, 140216. Figure 7 here captures exactly the effect observed in the RPCB.
Many thanks. Now cited in this section- also in the closing section.
4. Against Despair, Part II: Decision Rules
The question for me is, was the RPCB designed to enable decision towards translation or was it designed to decide whether evidence is robust in the field of cancer biology. These are two different questions. It should be stated clearly which of these decisions RPCB was designed to make (the authors give a vague answer at the beginning of their comment).
For the question of translation, a field specific approach is necessary that takes all the variables into account that the authors refer to (prior probability, effect sizes in the field, ppv and npv, etc.). I think this question can be found through consensus in a field by combining expert knowledge and meta research and is not so much dependent on morality and sociological conditions as the authors claim in their last paragraph. These two words carry so much and at the same time little specific meaning here that I suggest to tone it down at this point.
Thank you for these observations and suggestions. We agree consensus in a field can be found by combining expert knowledge and meta-research. But note that combining expert knowledge (and meta-research, for that matter) is itself a sociological exercise. To the former, we must begin by demarcating experts from nonexperts- which right off the bat is a sociological exercise. And we assume that part of what gives an individual their expertise involves both their commitment to certain values as well as their knowledge of the value environment in which they are working. For example, physician experts should have particular values (e.g. they should value a duty to not harm their patients, say) and they should also have an accurate read on what their patients value (what side effects they can live with; what disabilities they can’t abide). So, we stand by our core point, though we regret that elaborating on this might sidetrack the reader unduly and have thus elected to leave this point unchanged.
To the point at the start of this comment (objectives of the RPCB) we hope our revisions on the front end of the piece (section 2) go some way to addressing this.
5. Some mathematical descriptions could be a bit daunting for the average reader (e.g. paragraph after Box1). To help with that, calculations at the end of the paper could use a figure. It may be easier to understand if they do something similar to Figure 1 in Forstmeier W, Wagenmakers EJ, Parker TH. Detecting and avoiding likely false-positive findings – a practical guide. Biological Reviews of the Cambridge Philosophical Society. 2017 Nov;92(4):1941-1968. DOI: 10.1111/brv.12315.
Thank you for this suggestion and the citation. We’ve seen similar figures elsewhere- I believe in the Economist (or, fivethirtyeight.com). If the editors advise, we’d be happy to prepare such a figure; otherwise we now cite a paper in Nature (Mogul / Macleod) that uses this same graphic approach, and hope the figure we prepared in response to referee adds an additional graphical representation of our conclusions.
References
1) Begley CG, Ellis LM. Drug development: Raise standards for preclinical cancer research. Nature. 2012 Mar;483(7391):531–3.
2) Wieschowski S, Biernot S, Deutsch S, Glage S, Bleich A, Tolba R, et al. Publication rates in animal research. Extent and characteristics of published and non-published animal studies followed up at two German university medical centres. PLoS One [Internet]. 2019 Nov 26 [cited 2021 Jun 4];14(11). Available from: https://www.ncbi.nlm.nih.gov/pmc/articles/PMC6879110/
https://doi.org/10.7554/eLife.67527.sa2Article and author information
Author details
Patrick Bodilly Kane

Jonathan Kimmelman
Funding
Genome Quebec, Genome Canada
- Jonathan Kimmelman
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Selin Bicer for research assistance. This work was supported by funding from a large-scale applied research project grant from Genome Quebec, Genome Canada, the Government of Canada.
Publication history
- Received:
- Accepted:
- Version of Record published:
Copyright
© 2021, Kane and Kimmelman
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 2,147
- views
-
- 242
- downloads
-
- 15
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 15
- citations for umbrella DOI https://doi.org/10.7554/eLife.67527
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Science Forum: Is preclinical research in cancer biology reproducible enough?
eLife 10:e67527.
https://doi.org/10.7554/eLife.67527





{kind=link}