Task-dependent optimal representations for cerebellar learning
- Zuckerman Mind Brain Behavior Institute, Columbia University, United States
- Department of Computer Science, Western Washington University, United States
Abstract
The cerebellar granule cell layer has inspired numerous theoretical models of neural representations that support learned behaviors, beginning with the work of Marr and Albus. In these models, granule cells form a sparse, combinatorial encoding of diverse sensorimotor inputs. Such sparse representations are optimal for learning to discriminate random stimuli. However, recent observations of dense, low-dimensional activity across granule cells have called into question the role of sparse coding in these neurons. Here, we generalize theories of cerebellar learning to determine the optimal granule cell representation for tasks beyond random stimulus discrimination, including continuous input-output transformations as required for smooth motor control. We show that for such tasks, the optimal granule cell representation is substantially denser than predicted by classical theories. Our results provide a general theory of learning in cerebellum-like systems and suggest that optimal cerebellar representations are task-dependent.
Editor's evaluation
Models of cerebellar function and the coding of inputs in the cerebellum often assume that random stimuli are a reasonable stand-in for real stimuli. However, the important contribution of this paper is that conclusions about optimality and sparseness in these models do not generalize to potentially more realistic sets of stimuli, for example, those drawn from a low-dimensional manifold. The mathematical analyses in the paper are convincing and possible limitations, including the abstraction from biological details, are well discussed.
https://doi.org/10.7554/eLife.82914.sa0Introduction
A striking property of cerebellar anatomy is the vast expansion in number of granule cells compared to the mossy fibers that innervate them (Eccles et al., 1967). This anatomical feature has led to the proposal that the function of the granule cell layer is to produce a high-dimensional representation of lower-dimensional mossy fiber activity (Marr, 1969; Albus, 1971; Cayco-Gajic and Silver, 2019). In such theories, granule cells integrate information from multiple mossy fibers and respond in a nonlinear manner to different input combinations. Detailed theoretical analysis has argued that anatomical parameters such as the ratio of granule cells to mossy fibers (Babadi and Sompolinsky, 2014), the number of inputs received by individual granule cells (Litwin-Kumar et al., 2017; Cayco-Gajic et al., 2017), and the distribution of granule-cell-to-Purkinje-cell synaptic weights Brunel et al., 2004 have quantitative values that maximize the dimension of the granule cell representation and learning capacity. Sparse activity, which increases dimension, is also cited as a key property of this representation (Marr, 1969; Albus, 1971; Babadi and Sompolinsky, 2014; but see Spanne and Jörntell, 2015). Sparsity affects both learning speed (Cayco-Gajic et al., 2017) and generalization, the ability to predict correct labels for previously unseen inputs (Barak et al., 2013; Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017).
Theories that study the effects of dimension on learning typically focus on the ability of a system to perform categorization tasks with random, high-dimensional inputs (Barak et al., 2013; Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017; Cayco-Gajic et al., 2017). In this case, increasing the dimension of the granule cell representation increases the number of inputs that can be discriminated. However, cerebellar circuits participate in diverse behaviors, including dexterous movements, inter-limb coordination, the formation of internal models, and cognitive behaviors (Ito and Itō, 1984; Wolpert et al., 1998; Strick et al., 2009). Cerebellum-like circuits, such as the insect mushroom body and the electrosensory system of electric fish, support other functions such as associative learning (Modi et al., 2020) and the cancellation of self-generated sensory signals (Kennedy et al., 2014), respectively. This diversity raises the question of whether learning high-dimensional categorization tasks is a sufficient framework for probing the function of granule cells and their analogs.
Several recent studies have reported dense activity in cerebellar granule cells in response to sensory stimulation or during motor control tasks (Jörntell and Ekerot, 2006; Knogler et al., 2017; Wagner et al., 2017; Giovannucci et al., 2017; Badura and De Zeeuw, 2017; Wagner et al., 2019), at odds with classical theories (Marr, 1969; Albus, 1971). Moreover, there is evidence that granule cell firing rates differ across cerebellar regions (Heath et al., 2014; Witter and De Zeeuw, 2015). In contrast to this reported dense activity in cerebellar granule cells, odor responses in Kenyon cells, the analogs of granule cells in the Drosophila mushroom body, are sparse, with 5–10% of neurons responding to odor stimulation (Turner et al., 2008; Honegger et al., 2011; Lin et al., 2014).
We propose that these differences can be explained by the capacity of representations with different levels of sparsity to support learning of different tasks. We show that the optimal level of sparsity depends on the structure of the input-output relationship of a task. When learning input-output mappings for motor control tasks, the optimal granule cell representation is much denser than predicted by previous analyses. To explain this result, we develop an analytic theory that predicts the performance of cerebellum-like circuits for arbitrary learning tasks. The theory describes how properties of cerebellar architecture and activity control these networks’ inductive bias: the tendency of a network toward learning particular types of input-output mappings (Sollich, 1998; Jacot et al., 2018; Bordelon et al., 2020; Canatar et al., 2021b; Simon et al., 2021). The theory shows that inductive bias, rather than the dimension of the representation alone, is necessary to explain learning performance across tasks. It also suggests that cerebellar regions specialized for different functions may adjust the sparsity of their granule cell representations depending on the task.
Results
In our model, a granule cell layer of neurons receives connections from a random subset of mossy fiber inputs. Because in the cerebellar cortex and cerebellum-like structures (approximately and for the neurons presynaptic to a single Purkinje cell in the cat brain; Eccles et al., 1967), we refer to the granule cell layer as the expansion layer and the mossy fiber layer as the input layer (Figure 1A and B).
Figure 1
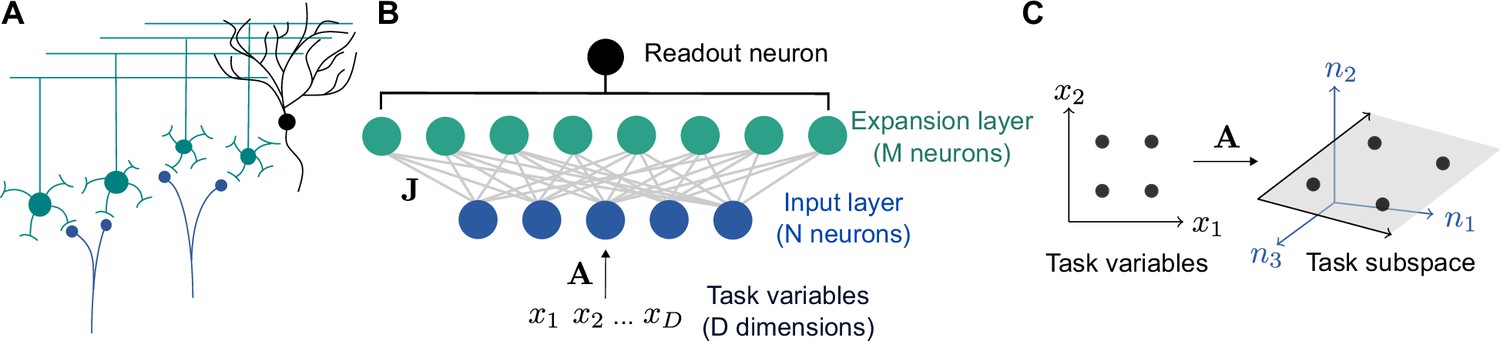
Schematic of cerebellar cortex model.
(A) Mossy fiber inputs (blue) project to granule cells (green), which send parallel fibers that contact a Purkinje cell (black). (B) Diagram of neural network model. task variables are embedded, via a linear transformation , in the activity of input layer neurons. Connections from the input layer to the expansion layer are described by a synaptic weight matrix . (C) Illustration of task subspace. Points in a -dimensional space of task variables are embedded in a -dimensional subspace of the -dimensional input layer activity (=2, =3 illustrated).
A typical assumption in computational theories of the cerebellar cortex is that inputs are randomly distributed in a high-dimensional space (Marr, 1969; Albus, 1971; Brunel et al., 2004; Babadi and Sompolinsky, 2014; Billings et al., 2014; Litwin-Kumar et al., 2017). While this may be a reasonable simplification in some cases, many tasks, including cerebellum-dependent tasks, are likely best-described as being encoded by a low-dimensional set of variables. For example, the cerebellum is often hypothesized to learn a forward model for motor control (Wolpert et al., 1998), which uses sensory input and motor efference to predict an effector’s future state. Mossy fiber activity recorded in monkeys correlates with position and velocity during natural movement (van Kan et al., 1993). Sources of motor efference copies include motor cortex, whose population activity lies on a low-dimensional manifold (Wagner et al., 2019; Huang et al., 2013; Churchland et al., 2010; Yu et al., 2009). We begin by modeling the low dimensionality of inputs and later consider more specific tasks.
We therefore assume that the inputs to our model lie on a -dimensional subspace embedded in the -dimensional input space, where is typically much smaller than (Figure 1B). We refer to this subspace as the ‘task subspace’ (Figure 1C). A location in this subspace is described by a dimensional vector , while the corresponding input layer activity is given by , with an matrix describing the embedding of the task variables in the input layer. An effective weight matrix , which describes the selectivity of expansion layer neurons to task variables, is determined by and the input-to-expansion-layer synaptic weight matrix . The activity of neurons in the expansion layer is given by:
(1)
where is a rectified linear activation function applied element-wise. Our results also hold for other threshold-polynomial activation functions. The scalar threshold is shared across neurons and controls the coding level, which we denote by , defined as the average fraction of neurons in the expansion layer that are active. We show results for , since extremely dense codes are rarely observed in experiments (Olshausen and Field, 2004; see Discussion). For analytical tractability, we begin with the case where the entries of are independent Gaussian random variables, as in previous theories (Rigotti et al., 2013; Barak et al., 2013; Babadi and Sompolinsky, 2014). This holds when the columns of are orthonormal (ensuring that the embedding of the task variables in the input layer preserves their geometry) and the entries of are independent and Gaussian. Later, we will show that networks with more realistic connectivity behave similarly to this case.
Optimal coding level is task-dependent
In our model, a learning task is defined by a mapping from task variables to an output , representing a target change in activity of a readout neuron, for example a Purkinje cell. The limited scope of this definition implies our results should not strongly depend on the influence of the readout neuron on downstream circuits. The readout adjusts its incoming synaptic weights from the expansion layer to better approximate this target output. For example, for an associative learning task in which sensory stimuli are classified into categories such as appetitive or aversive, the task may be represented as a mapping from inputs to two discrete firing rates corresponding to the readout’s response to stimuli of each category (Figure 2A). In contrast, for a forward model, in which the consequences of motor commands are computed using a model of movement dynamics, an input encoding the current sensorimotor state is mapped to a continuous output representing the readout neuron’s tuning to a predicted sensory variable (Figure 2B).
Figure 2 with 4 supplements see all
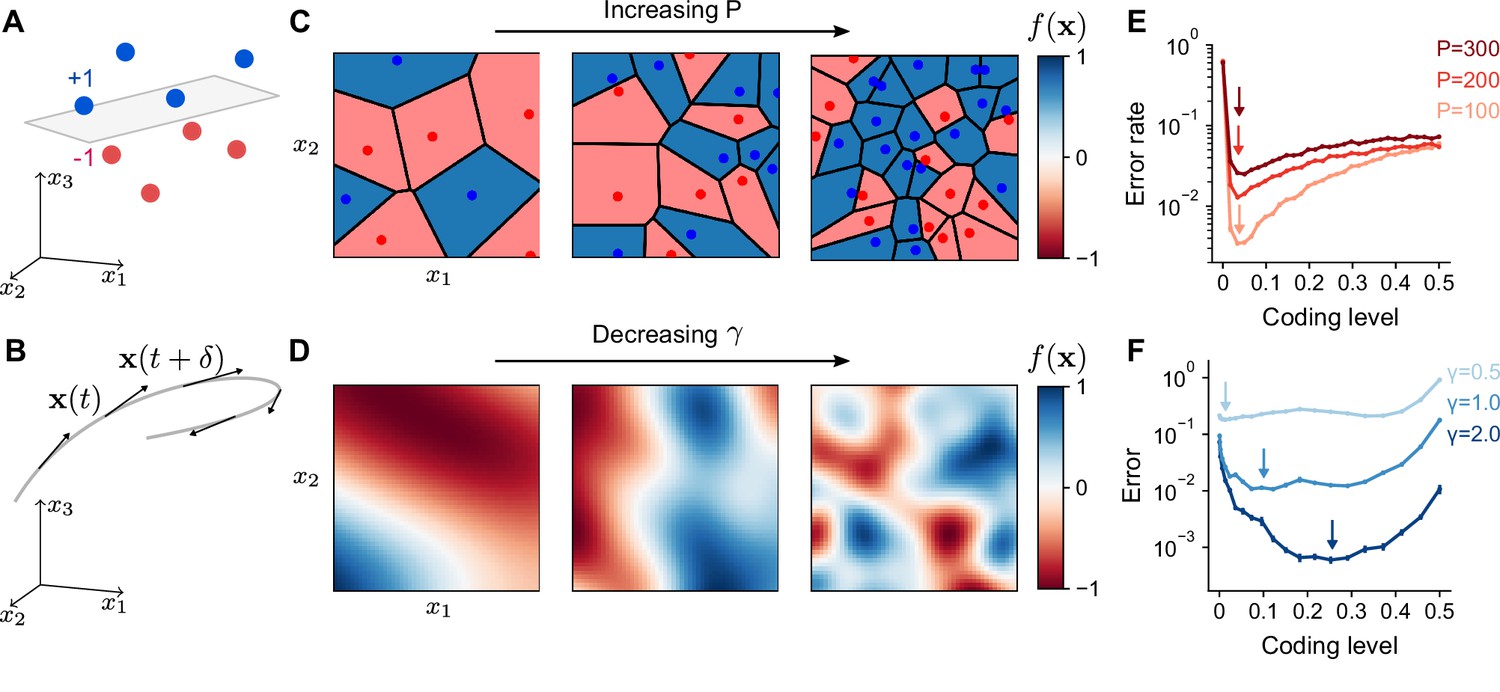
Optimal coding level depends on task.
(A) A random categorization task in which inputs are mapped to one of two categories (+1 or –1). Gray plane denotes the decision boundary of a linear classifier separating the two categories. (B) A motor control task in which inputs are the sensorimotor states of an effector which change continuously along a trajectory (gray) and outputs are components of predicted future states . (C) Schematic of random categorization tasks with input-category associations. The value of the target function (color) is a function of two task variables x1 and x2. (D) Schematic of tasks involving learning a continuously varying Gaussian process target parameterized by a length scale . (E) Error rate as a function of coding level for networks trained to perform random categorization tasks similar to (C). Arrows mark estimated locations of minima. (F) Error as a function of coding level for networks trained to fit target functions sampled from Gaussian processes. Curves represent different values of the length scale parameter . Standard error of the mean is computed across 20 realizations of network weights and sampled target functions in (E) and 200 in (F).
To examine how properties of the expansion layer representation influence learning performance across tasks, we designed two families of tasks: one modeling categorization of random stimuli, which is often used to study the performance of expanded neural representations (Rigotti et al., 2013; Barak et al., 2013; Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017; Cayco-Gajic et al., 2017), and the other modeling learning of a continuously varying output. The former we refer to as a ‘random categorization task’ and is parameterized by the number of input pattern-to-category associations learned during training (Figure 2C). During the training phase, the network learns to associate random input patterns for with random binary categories . The elements of are drawn i.i.d. from a normal distribution with mean 0 and variance . We refer to as ‘training patterns’. To assess the network’s generalization performance, it is presented with ‘test patterns’ generated by adding noise (parameterized by a noise magnitude ; see Methods) to the training patterns. Tasks with continuous outputs (Figure 2D) are parameterized by a length scale that determines how quickly the output changes as a function of the input (specifically, input-output functions are drawn from a Gaussian process with length scale for variations in as a function of ; see Methods). In this case, both training and test patterns are drawn uniformly on the unit sphere. Later, we will also consider tasks implemented by specific cerebellum-like systems. See Table 1 for a summary of parameters throughout this study.
Table 1
Summary of simulation parameters.
: number of expansion layer neurons. : number of input layer neurons. : number of connections from input layer to a single expansion layer neuron. : total number of connections from input to expansion layer. : expansion layer coding level. : number of task variables. : number of training patterns. : Gaussian process length scale. : magnitude of noise for random categorization tasks. We do not report and for simulations in which contains Gaussian i.i.d. elements as results do not depend on these parameters in this case.
| Figure panel | Network parameters | Task parameters |
|---|---|---|
| Figure 2E | ||
| Figures 2F, 4G and 5B (full) | ||
| Figure 5B and E | ||
| Figure 6A | ||
| Figure 6B | ||
| Figure 6C | ||
| Figure 6D | ||
| Figure 7A | ; see Methods | |
| Figure 7B | ||
| Figure 7C | see Methods | |
| Figure 7D | ; see Methods | |
| Figure 2—figure supplement 1 | See Figure | |
| Figure 2—figure supplement 2 | ||
| Figure 2—figure supplement 3 | ||
| Figure 2—figure supplement 4 | ||
| Figure 7—figure supplement 1 | ||
| Figure 7—figure supplement 2 |
We trained the readout to approximate the target output for training patterns and generalize to unseen test patterns. The network’s prediction is for tasks with continuous outputs, or for categorization tasks, where are the synaptic weights of the readout from the expansion layer. These weights were set using least squares regression. Performance was measured as the fraction of incorrect predictions for categorization tasks, or relative mean squared error for tasks with continuous targets: , where the expectation is across test patterns.
We began by examining the dependence of learning performance on the coding level of the expansion layer. For random categorization tasks, performance is maximized at low coding levels (Figure 2E), consistent with previous results (Barak et al., 2013; Babadi and Sompolinsky, 2014). The optimal coding level remains below 0.1 in the model, regardless of the number of associations , the level of input noise, and the dimension (Figure 2—figure supplement 1). For continuously varying outputs, the dependence is qualitatively different (Figure 2F). The optimal coding level depends strongly on the length scale, with learning performance for slowly varying functions optimized at much higher coding levels than quickly varying functions. This dependence holds for different choices of threshold-nonlinear functions (Figure 2—figure supplement 2) or input dimension (Figure 2—figure supplement 3) and is most pronounced when the number of training patterns is limited (Figure 2—figure supplement 4). Our observations are at odds with previous theories of the role of sparse granule cell representations (Marr, 1969; Albus, 1971; Babadi and Sompolinsky, 2014; Billings et al., 2014) and show that sparse activity does not always optimize performance for this broader set of tasks.
Geometry of the expansion layer representation
To determine how the optimal coding level depends on the task, we begin by quantifying how the expansion layer transforms the geometry of the task subspace. Later we will address how this transformation affects the ability of the network to learn a target. For ease of analysis, we will assume for now that inputs are normalized, , so that they lie on the surface of a sphere in dimensions. The set of neurons in the expansion layer activated by an input are those neurons for which the alignment of their effective weights with the input, , exceeds the activation threshold (Equation 1; Figure 3A). Increasing reduces the size of this set of neurons and hence reduces the coding level.
Figure 3
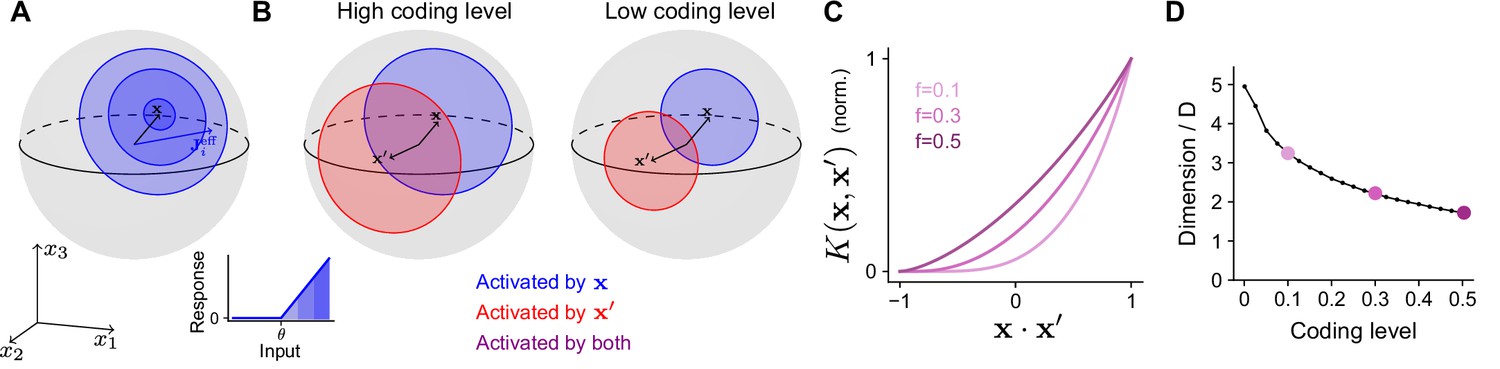
Effect of coding level on the expansion layer representation.
(A) Effect of activation threshold on coding level. A point on the surface of the sphere represents a neuron with effective weights . Blue region represents the set of neurons activated by , i.e., neurons whose input exceeds the activation threshold (inset). Darker regions denote higher activation. (B) Effect of coding level on the overlap between population responses to different inputs. Blue and red regions represent the neurons activated by and , respectively. Overlap (purple) represents the set of neurons activated by both stimuli. High coding level leads to more active neurons and greater overlap. (C) Kernel for networks with rectified linear activation functions (Equation 1), normalized so that fully overlapping representations have an overlap of 1, plotted as a function of overlap in the space of task variables. The vertical axis corresponds to the ratio of the area of the purple region to the area of the red or blue regions in (B). Each curve corresponds to the kernel of an infinite-width network with a different coding level . (D) Dimension of the expansion layer representation as a function of coding level for a network with and .
Different inputs activate different sets of neurons, and more similar inputs activate sets with greater overlap. As the coding level is reduced, this overlap is also reduced (Figure 3B). In fact, this reduction in overlap is greater than the reduction in number of neurons that respond to either of the individual inputs, reflecting the fact that representations with low coding levels perform ‘pattern separation’ (Figure 3B, compare purple and red or blue regions).
This effect is summarized by the ‘kernel’ of the network (Schölkopf and Smola, 2002; Rahimi and Recht, 2007), which measures overlap of representations in the expansion layer as a function of the task variables:
(2)
Equations 1 and 2 show that the threshold , which determines the coding level, influences the kernel through its effect on the expansion layer activity . When inputs are normalized and the effective weights are Gaussian, we compute a semi-analytic expression for the kernel of the expansion layer in the limit of a large expansion (; see Appendix). In this case, the kernel depends only on the overlap of the task variables, . Plotting the kernel for different choices of coding level demonstrates that representations with lower coding levels exhibit greater pattern separation (Figure 3C; Babadi and Sompolinsky, 2014). This is consistent with the observation that decreasing the coding level increases the dimension of the representation (Figure 3D).
Frequency decomposition of kernel and task explains optimal coding level
We now relate the geometry of the expansion layer representation to performance across the tasks we have considered. Previous studies focused on high-dimensional, random categorization tasks in which inputs belong to a small number of well-separated clusters whose centers are random uncorrelated patterns. Generalization is assessed by adding noise to previously observed training patterns (Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017; Figure 4A). In this case, performance depends only on overlaps at two spatial scales: the overlap between training patterns belonging to different clusters, which is small, and the overlap between training and test patterns belonging to the same cluster, which is large (Figure 4B). For such tasks, the kernel evaluated near these two values—specifically, the behavior of near and , where is a measure of within-cluster noise—fully determines generalization performance (Figure 4C; see Appendix). Sparse expansion layer representations reduce the overlap of patterns belonging to different clusters, increasing dimension and generalization performance (Figure 3D, Figure 2E).
Figure 4 with 2 supplements see all
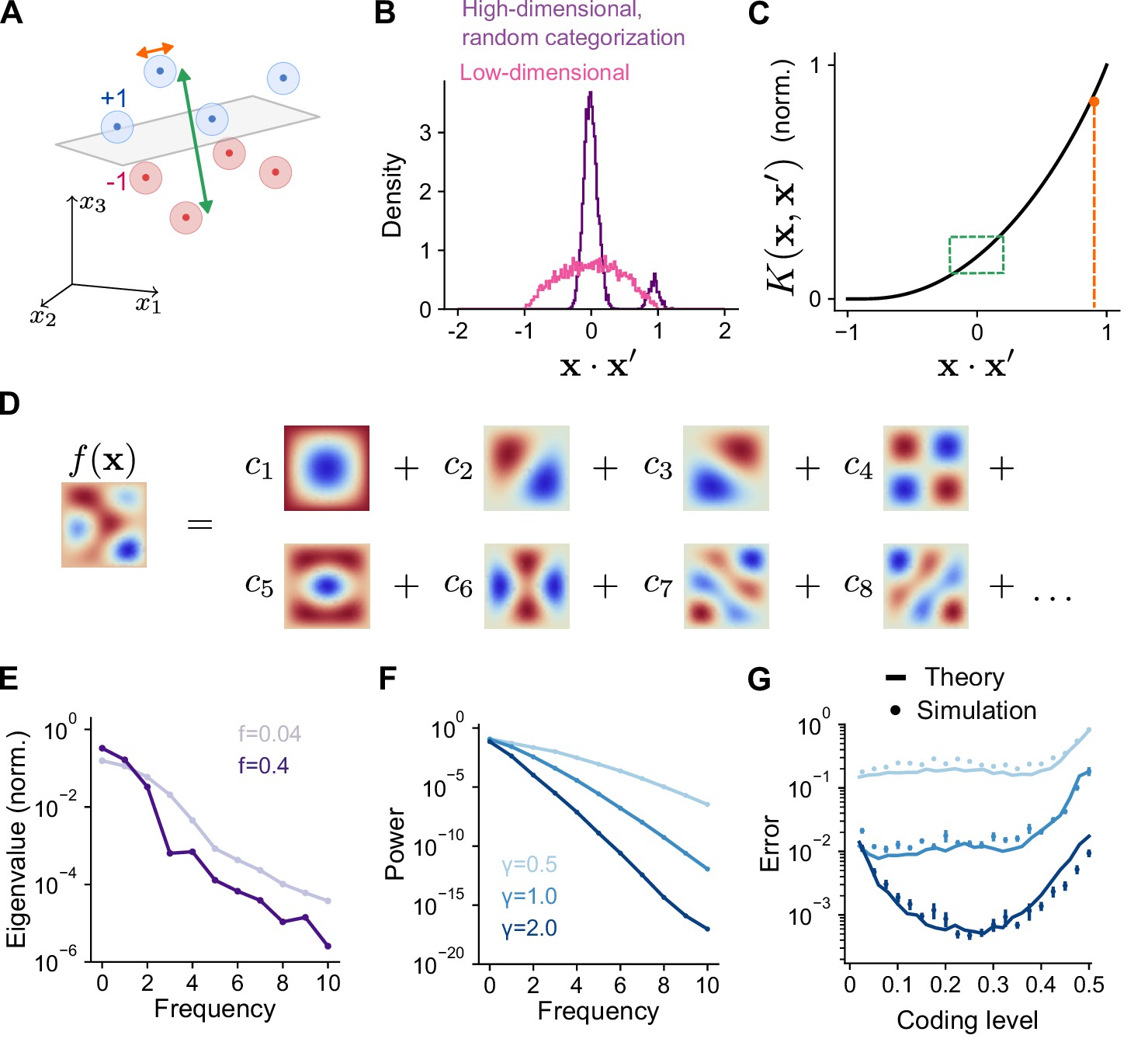
Frequency decomposition of network and target function.
(A) Geometry of high-dimensional categorization tasks where input patterns are drawn from random, noisy clusters (light regions). Performance depends on overlaps between training patterns from different clusters (green) and on overlaps between training and test patterns from the same cluster (orange). (B) Distribution of overlaps of training and test patterns in the space of task variables for a high-dimensional task () with random, clustered inputs as in (A) and a low-dimensional task () with inputs drawn uniformly on a sphere. (C) Overlaps in (A) mapped onto the kernel function. Overlaps between training patterns from different clusters are small (green). Overlaps between training and test patterns from the same cluster are large (orange). (D) Schematic illustration of basis function decomposition, for eigenfunctions on a square domain. (E) Kernel eigenvalues (normalized by the sum of eigenvalues across modes) as a function of frequency for networks with different coding levels. (F) Power as a function of frequency for Gaussian process target functions. Curves represent different values of , the length scale of the Gaussian process. Power is averaged over 20 realizations of target functions. (G) Generalization error predicted using kernel eigenvalues (E) and target function decomposition (F) for the three target function classes shown in (F). Standard error of the mean is computed across 100 realizations of network weights and target functions.
We study tasks where training patterns used for learning and test patterns used to assess generalization are both drawn according to a distribution over a low-dimensional space of task variables. While the mean overlap between pairs of random patterns remains zero regardless of dimension, fluctuations around the mean increase when the space is low dimensional, leading to a broader distribution of overlaps (Figure 4B). In this case, generalization performance depends on values of the kernel function evaluated across this entire range of overlaps. Methods from the theory of kernel regression (Sollich, 1998; Jacot et al., 2018; Bordelon et al., 2020; Canatar et al., 2021b; Simon et al., 2021) capture these effects by quantifying a network’s performance on a learning task through a decomposition of the target function into a set of basis functions (Figure 4D). Performance is assessed by summing the contribution of each mode in this decomposition to generalization error.
The decomposition expresses the kernel as a sum of eigenfunctions weighted by eigenvalues, . The eigenfunctions are determined by the network architecture and the distribution of inputs. As we show below, the eigenvalues determine the ease with which each corresponding eigenfunction —one element of the basis function decomposition—is learned by the network. Under our present assumptions of Gaussian effective weights and uniformly distributed, normalized input patterns, the eigenfunctions are the spherical harmonic functions. These functions are ordered by increasing frequency, with higher frequencies corresponding to functions that vary more quickly as a function of the task variables. Spherical harmonics are defined for any input dimension; for example, in two dimensions they are the Fourier modes. We find that coding level substantially changes the frequency dependence of the eigenvalues associated with these eigenfunctions (Figure 4E). Higher coding levels increase the relative magnitude of the low frequency eigenvalues compared to high-frequency eigenvalues. As we will show, this results in a different inductive bias for networks with different coding levels.
To calculate learning performance for an arbitrary task, we decompose the target function in the same basis as that of the kernel:
(3)
The coefficient quantifies the weight of mode in the decomposition. For the Gaussian process targets, we have considered, increasing length scale corresponds to a greater relative contribution of low versus high frequency modes (Figure 4F). Using these coefficients and the eigenvalues (Figure 4E), we obtain an analytical prediction of the mean-squared generalization error (‘Error’) for learning any given task (Figure 4G; see Methods):
(4)
where C1 and C2 do not depend on (Canatar et al., 2021b; Simon et al., 2021; see Methods). Equation 4 illustrates that for equal values of , modes with greater contribute less to the generalization error.
Our theory reveals that the optima observed in Figure 2F are a consequence of the difference in eigenvalues of networks with different coding levels. This reflects an inductive bias (Sollich, 1998; Jacot et al., 2018; Bordelon et al., 2020; Canatar et al., 2021b; Simon et al., 2021) of networks with low and high coding levels toward the learning of high and low frequency functions, respectively (Figure 4E, Figure 4—figure supplement 1). Thus, the coding level’s effect on a network’s inductive bias, rather than dimension alone, determines learning performance. Previous studies that focused only on random categorization tasks did not observe this dependence, since errors in such tasks are dominated by the learning of high frequency components, for which sparse activity is optimal (Figure 4—figure supplement 2).
Performance of sparsely connected expansions
To simplify our analysis, we have so far assumed full connectivity between input and expansion layers without a constraint on excitatory or inhibitory synaptic weights. In particular, we have assumed that the effective weight matrix contains independent Gaussian entries (Figure 5A, top). However, synaptic connections between mossy fibers and granule cells are sparse and excitatory (Sargent et al., 2005), with a typical in-degree of mossy fibers per granule cell (Figure 5A, bottom). We therefore analyzed the performance of model networks with more realistic connectivity. Surprisingly, when is sparse and nonnegative, both overall generalization performance and the task-dependence of optimal coding level remain unchanged (Figure 5B).
Figure 5
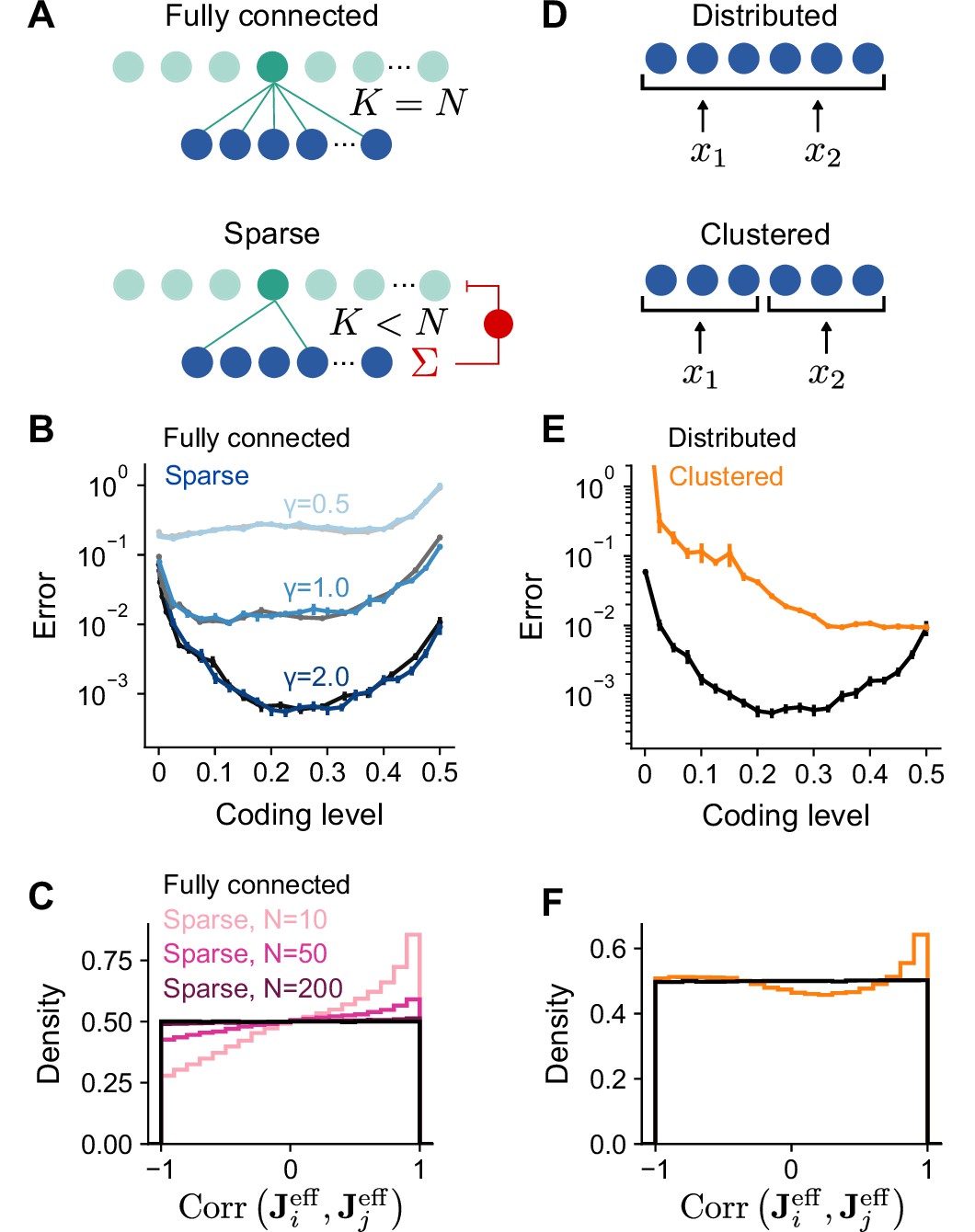
Performance of networks with sparse connectivity.
(A) Top: Fully connected network. Bottom: Sparsely connected network with in-degree and excitatory weights with global inhibition onto expansion layer neurons. (B) Error as a function of coding level for fully connected Gaussian weights (gray curves) and sparse excitatory weights (blue curves). Target functions are drawn from Gaussian processes with different values of length scale as in Figure 2. (C) Distributions of synaptic weight correlations , where is the ith row of , for pairs of expansion layer neurons in networks with different numbers of input layer neurons (colors) when and . Black distribution corresponds to fully connected networks with Gaussian weights. We note that when , the distribution of correlations for random Gaussian weight vectors is uniform on as shown (for higher dimensions the distribution has a peak at 0). (D) Schematic of the selectivity of input layer neurons to task variables in distributed and clustered representations. (E) Error as a function of coding level for networks with distributed (black, same as in B) and clustered (orange) representations. (F) Distributions of for pairs of expansion layer neurons in networks with distributed and clustered input representations when , , and . Standard error of the mean was computed across 200 realizations in (B) and 100 in (E), orange curve.
To understand this result, we examined how and shape the statistics of the effective weights onto the expansion layer neurons . A desirable property of the expansion layer representation is that these effective weights sample the space of task variables uniformly (Figure 3A), increasing the heterogeneity of tuning of expansion layer neurons (Litwin-Kumar et al., 2017). This occurs when is a matrix of independent random Gaussian entries. If the columns of are orthornormal and is fully-connected with independent Gaussian entries, has this uniform sampling property.
However, when is sparse and nonnegative, expansion layer neurons that share connections from the same input layer neurons receive correlated input currents. When is small and is random, fluctuations in lead to biases in the input layer’s sampling of task variables which are inherited by the expansion layer. We quantify this by computing the distribution of correlations between the effective weights for pairs of expansion layer neurons, . This distribution indeed deviates from uniform sampling when is small (Figure 5C). However, even when is moderately large (but much less than ), only small deviations from uniform sampling of task variables occur for low dimensional tasks as long as (see Appendix). In contrast, for high-dimensional tasks (), is sufficient, in agreement with previous findings (Litwin-Kumar et al., 2017). For realistic cerebellar parameters ( and ), the distribution is almost indistinguishable from that corresponding to uniform sampling (Figure 5C), consistent with the similar learning performance of these two cases (Figure 5B).
In the above analysis, an important assumption is that is dense and random, so that the input layer forms a distributed representation in which each input layer neuron responds to a random combination of task variables (Figure 5D, top). If, on the other hand, the input layer forms a clustered representation containing groups of neurons that each encode a single task variable (Figure 5D, bottom), we may expect different results. Indeed, with a clustered representation, sparse connectivity dramatically reduces performance (Figure 5E). This is because the distribution of deviates substantially from that corresponding to uniform sampling (Figure 5F), even as (see Appendix). Specifically, increasing does not reduce the probability of two expansion layer neurons being connected to input layer neurons that encode the same task variables and therefore receiving highly correlated currents. As a result, expansion layer neurons do not sample task variables uniformly and performance is dramatically reduced.
Our results show that networks with small , moderately large , and a distributed input layer representation approach the performance of networks that sample task variables uniformly. This equivalence validates the applicability of our theory to these more realistic networks. It also argues for the importance of distributed sensorimotor representations in the cortico-cerebellar pathway, consistent with the distributed nature of representations in motor cortex (Shenoy et al., 2013; Muscinelli et al., 2023).
Optimal cerebellar architecture is consistent across tasks
A history of theoretical modeling has shown a remarkable correspondence between anatomical properties of the cerebellar cortex and model parameters optimal for learning. These include the in-degree of granule cells (Marr, 1969; Litwin-Kumar et al., 2017; Cayco-Gajic et al., 2017), the expansion ratio of the granule cells to the mossy fibers (Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017), and the distribution of synaptic weights from granule cells to Purkinje cells (Brunel et al., 2004; Clopath et al., 2012; Clopath and Brunel, 2013). In these studies, model performance was assessed using random categorization tasks. We have shown that optimal coding level is dependent on the task being learned, raising the question of whether optimal values of these architectural parameters are also task-dependent.
Sparse connectivity (=4, consistent with the typical in-degree of cerebellar granule cells) has been shown to optimize learning performance in cerebellar cortex models (Litwin-Kumar et al., 2017; Cayco-Gajic et al., 2017). We examined the performance of networks with different granule cell in-degrees learning Gaussian process targets. The optimal in-degree is small for all the tasks we consider, suggesting that sparse connectivity is sufficient for high performance across a range of tasks (Figure 6A). This is consistent with the previous observation that the performance of a sparsely connected network approaches that of a fully connected network (Figure 5B).
Figure 6
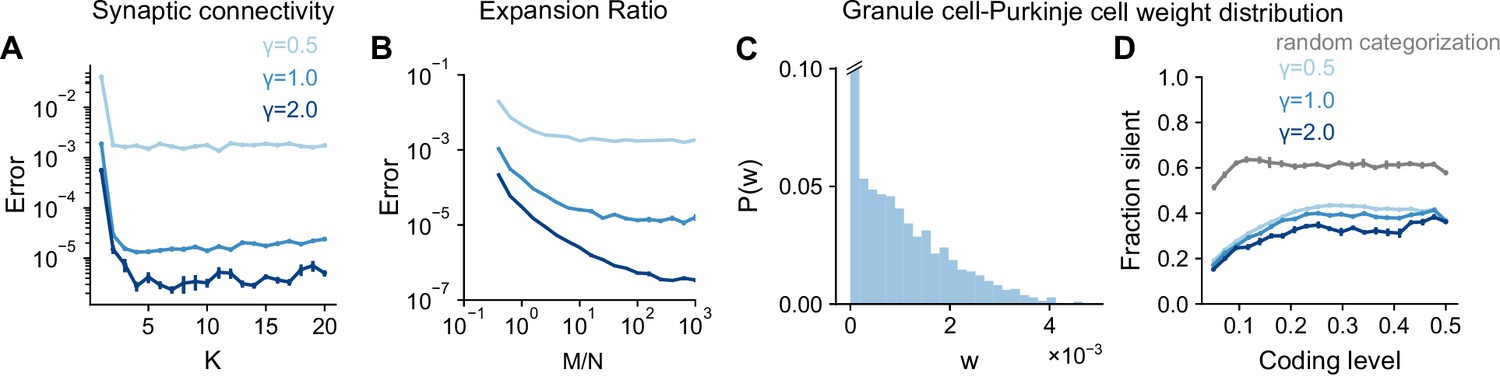
Task-independence of optimal anatomical parameters.
(A) Error as a function of in-degree for networks learning Gaussian process targets. Curves represent different values of , the length scale of the Gaussian process. The total number of synaptic connections is held constant. This constraint introduces a trade-off between having many neurons with small synaptic degree and having fewer neurons with large synaptic degree (Litwin-Kumar et al., 2017). , , . (B) Error as a function of expansion ratio for networks learning Gaussian process targets. , , . (C) Distribution of granule-cell-to-Purkinje cell weights for a network trained on nonnegative Gaussian process targets with , , . Granule-cell-to-Purkinje cell weights are constrained to be nonnegative (Brunel et al., 2004). (D) Fraction of granule-cell-to-Purkinje cell weights that are silent in networks learning nonnegative Gaussian process targets (blue) and random categorization tasks (gray).
Previous studies also showed that the expansion ratio from mossy fibers to granule cells controls the dimension of the granule cell representation (Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017). The dimension increases with expansion ratio but saturates as expansion ratio approaches the anatomical value ( when for the inputs presynaptic to an individual Purkinje cell). These studies assumed that mossy fiber activity is uncorrelated () rather than low-dimensional (). This raises the question of whether a large expansion is beneficial when is small. We find that when the number of training patterns is sufficiently large, performance still improves as approaches its anatomical value, showing that Purkinje cells can exploit their large number of presynaptic inputs even in the case of low-dimensional activity (Figure 6B).
Brunel et al., 2004 showed that the distribution of granule-cell-to-Purkinje cell synaptic weights is consistent with the distribution that maximizes the number of random binary input-output mappings stored. This distribution exhibits a substantial fraction of silent synapses, consistent with experiments. These results also hold for analog inputs and outputs (Clopath and Brunel, 2013) and for certain forms of correlations among binary inputs and outputs (Clopath et al., 2012). However, the case we consider, where targets are a smoothly varying function of task variables, has not been explored. We observe a similar weight distribution for these tasks (Figure 6C), with the fraction of silent synapses remaining high across coding levels (Figure 6D). The fraction of silent synapses is lower for networks learning Gaussian process targets than those learning random categorization tasks, consistent with the capacity of a given network for learning such targets being larger (Clopath et al., 2012).
Although optimal coding level is task-dependent, these analyses suggest that optimal architectural parameters are largely task-independent. Whereas coding level tunes the inductive bias of the network to favor the learning of specific tasks, these architectural parameters control properties of the representation that improve performance across tasks. In particular, sparse connectivity and a large expansion support uniform sampling of low-dimensional task variables (consistent with Figure 5C), while a large fraction of silent synapses is a consequence of a readout that maximizes learning performance (Brunel et al., 2004).
Modeling specific behaviors dependent on cerebellum-like structures
So far, we have considered analytically tractable families of tasks with parameterized input-output functions. Next, we extend our results to more realistic tasks constrained by the functions of specific cerebellum-like systems, which include both highly structured, continuous input-output mappings and random categorization tasks.
To model the cerebellum’s role in predicting the consequences of motor commands (Wolpert et al., 1998), we examined the optimal coding level for learning the dynamics of a two-joint arm (Fagg et al., 1997). Given an initial state, the network predicts the change in the future position of the arm (Figure 7A). Performance is optimized at substantially higher coding levels than for random categorization tasks, consistent with our previous results for continuous input-output mappings (Figure 2E and F).
Figure 7 with 2 supplements see all
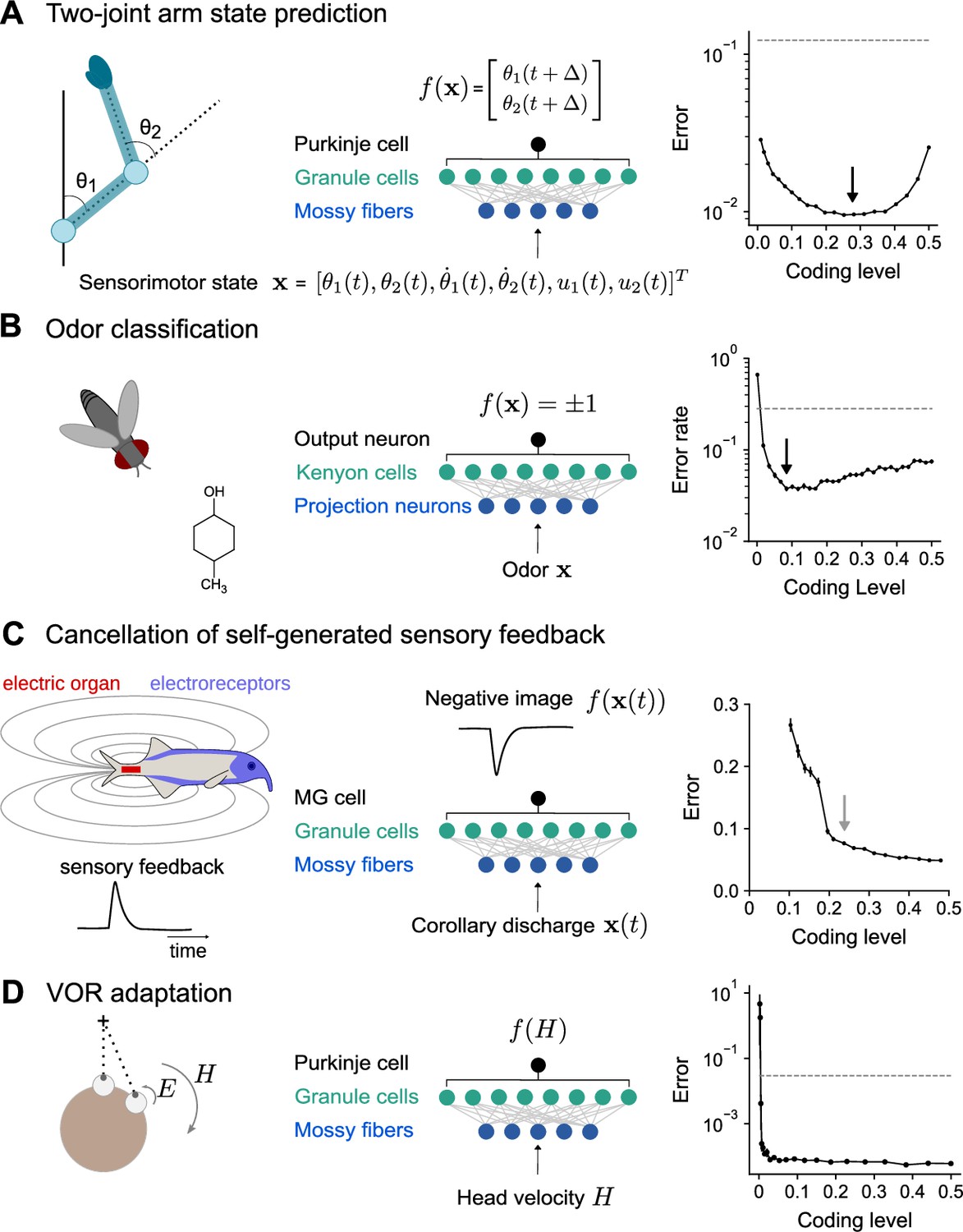
Optimal coding level across tasks and neural systems.
(A) Left: Schematic of two-joint arm. Center: Cerebellar cortex model in which sensorimotor task variables at time are used to predict hand position at time . Right: Error as a function of coding level. Black arrow indicates location of optimum. Dashed line indicates performance of a readout of the input layer. (B) Left: Odor categorization task. Center: Drosophila mushroom body model in which odors activate olfactory projection neurons and are associated with a binary category (appetitive or aversive). Right: Error rate, similar to (A), right. (C) Left: Schematic of electrosensory system of the mormyrid electric fish, which learns a negative image to cancel the self-generated feedback from electric organ discharges sensed by electroreceptors. Center: Electrosensory lateral line lobe (ELL) model in which MG cells learn a negative image. Right: Error as a function of coding level. Gray arrow indicates location of coding level estimated from biophysical parameters (Kennedy et al., 2014). (D) Left: Schematic of the vestibulo-cular reflex (VOR). Head rotations with velocity trigger eye motion in the opposite direction with velocity . During VOR adaptation, organisms adapt to different gains (). Center: Cerebellar cortex model in which the target function is the Purkinje cell’s firing rate as a function of head velocity. Right: Error, similar to (A), right.
The mushroom body, a cerebellum-like structure in insects, is required for learning of associations between odors and appetitive or aversive valence (Modi et al., 2020). This behavior can be represented as a mapping from random representations of odors in the input layer to binary category labels (Figure 7B). The optimal coding level in a model with parameters consistent with the Drosophila mushroom body is less than 0.1, consistent with our previous results for random categorization tasks (Figure 2E) and the sparse odor-evoked responses in Drosophila Kenyon cells (Turner et al., 2008; Honegger et al., 2011; Lin et al., 2014).
The prediction and cancellation of self-generated sensory feedback has been studied extensively in mormyrid weakly electric fish and depends on the electrosensory lateral line lobe (ELL), a cerebellum-like structure (Bell et al., 2008). Granule cells in the ELL provide a temporal basis for generating negative images that are used to cancel self-generated feedback (Figure 7C). We extended a detailed model of granule cells and their inputs (Kennedy et al., 2014) to study the influence of coding level on the effectiveness of this basis. The performance of this model saturated at relatively high coding levels, and notably the coding level corresponding to biophysical parameters estimated from data coincided with the value at which further increases in performance were modest. This observation suggests that coding level is also optimized for task performance in this system.
A canonical function of the mammalian cerebellum is the adjustment of the vestibulo-ocular reflex (VOR), in which motion of the head is detected and triggers compensatory ocular motion in the opposite direction. During VOR learning, Purkinje cells are tuned to head velocity, and their tuning curves are described as piecewise linear functions (Lisberger et al., 1994; Figure 7D). Although in vivo population recordings of granule cells during VOR adaptation are not, to our knowledge, available for comparison, our model predicts that performance for learning such tuning curves is high across a range of coding levels and shows that sparse codes are sufficient (although not necessary) for such tasks (Figure 7D).
These results predict diverse coding levels across different behaviors dependent on cerebellum-like structures. The odor categorization and VOR tasks both have input-output mappings that exhibit sharp nonlinearities and can be efficiently learned using sparse representations. In contrast, the forward modeling and feedback cancellation tasks have smooth input-output mappings and exhibit denser optima. These observations are consistent with our previous finding that more structured tasks favor denser coding levels than do random categorization tasks (Figure 2E and F).
Discussion
We have shown that the optimal granule cell coding level depends on the task being learned. While sparse representations are suitable for learning to categorize inputs into random categories, as predicted by classic theories, tasks involving structured input-output mappings benefit from denser representations (Figure 2). This reconciles such theories with the observation of dense granule cell activation during movement (Knogler et al., 2017; Wagner et al., 2017; Giovannucci et al., 2017; Badura and De Zeeuw, 2017; Wagner et al., 2019). We also show that, in contrast to the task-dependence of optimal coding level, optimal anatomical values of granule cell and Purkinje cell connectivity are largely task-independent (Figure 6). This distinction suggests that a stereotyped cerebellar architecture may support diverse representations optimized for a variety of learning tasks.
Relationship to previous theories
Previous studies assessed the learning performance of cerebellum-like systems with a model Purkinje cell that associates random patterns of mossy fiber activity with one of two randomly assigned categories (Marr, 1969; Albus, 1971; Brunel et al., 2004; Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017; Cayco-Gajic et al., 2017), a common benchmark for artificial learning systems (Gerace et al., 2022). In this case, a low coding level increases the dimension of the granule cell representation, permitting more associations to be stored and improving generalization to previously unseen inputs. The optimal coding level is low but not arbitrarily low, as extremely sparse representations introduce noise that hinders generalization (Barak et al., 2013; Babadi and Sompolinsky, 2014).
To examine a broader family of tasks, our learning problems extend previous studies in several ways. First, we consider inputs that may be constrained to a low-dimensional task subspace. Second, we consider input-output mappings beyond random categorization tasks. Finally, we assess generalization error for arbitrary locations on the task subspace, rather than only for noisy instances of previously presented inputs. As we have shown, these considerations require a complete analysis of the inductive bias of cerebellum-like networks (Figure 4). Our analysis generalizes previous approaches (Barak et al., 2013; Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017) that focused on dimension and noise alone. In particular, both dimension and noise for random patterns can be directly calculated from the kernel function (Figure 3C; see Appendix).
Our theory builds upon techniques that been developed for understanding properties of kernel regression (Sollich, 1998; Jacot et al., 2018; Bordelon et al., 2020; Canatar et al., 2021b; Simon et al., 2021). Kernel approximations of wide neural networks are a major area of current research providing analytically tractable theories (Rahimi and Recht, 2007; Jacot et al., 2018; Chizat et al., 2018). Prior studies have analyzed kernels corresponding to networks with zero (Cho and Saul, 2010) or mean-zero Gaussian thresholds (Basri et al., 2019; Jacot et al., 2018), which in both cases produce networks with a coding level of 0.5. Ours is the first kernel study of the effects of nonzero average thresholds. Our full characterization of the eigenvalue spectra and their decay rates as a function of the threshold extends previous work (Bach, 2017; Bietti and Bach, 2021). Furthermore, artificial neural network studies typically assume either fully-connected or convolutional layers, yet pruning connections after training barely degrades performance (Han et al., 2015; Zhang et al., 2018). Our results support the idea that sparsely connected networks may behave like dense ones if the representation is distributed (Figure 5), providing insight into the regimes in which pruning preserves performance.
Other studies have considered tasks with smooth input-output mappings and low-dimensional inputs, finding that heterogeneous Golgi cell inhibition can improve performance by diversifying individual granule cell thresholds (Spanne and Jörntell, 2013). Extending our model to include heterogeneous thresholds is an interesting direction for future work. Another proposal states that dense coding may improve generalization (Spanne and Jörntell, 2015). Our theory reveals that whether or not dense coding is beneficial depends on the task.
Assumptions and extensions
We have made several assumptions in our model for the sake of analytical tractability. When comparing the inductive biases of networks with different coding levels, our theory assumes that inputs are normalized and distributed uniformly in a linear subspace of the input layer activity. This allows us to decompose the target function into a basis in which we can directly compare eigenvalues, and hence learning performance, for different coding levels (Figure 4E–G). A similar analysis can be performed when inputs are not uniformly distributed, but in this case the basis is determined by an interplay between this distribution and the nonlinearity of expansion layer neurons, making the analysis more complex (see Appendix). We have also assumed that generalization is assessed for inputs drawn from the same distribution as used for learning. Recent and ongoing work on out-of-distribution generalization may permit relaxations of this assumption (Shen et al., 2021; Canatar et al., 2021a).
When analyzing properties of the granule cell layer, our theory also assumes an infinitely wide expansion. When is small enough that performance is limited by number of samples, this assumption is appropriate, but finite-size corrections to our theory are an interesting direction for future work. We also have not explicitly modeled inhibitory input provided by Golgi cells, instead assuming such input can be modeled as a change in effective threshold, as in previous studies (Billings et al., 2014; Cayco-Gajic et al., 2017; Litwin-Kumar et al., 2017). This is appropriate when considering the dimension of the granule cell representation (Litwin-Kumar et al., 2017), but more work is needed to extend our model to the case of heterogeneous inhibition.
Another key assumption concerning the granule cells is that they sample mossy fiber inputs randomly, as is typically assumed in Marr-Albus models (Marr, 1969; Albus, 1971; Litwin-Kumar et al., 2017; Cayco-Gajic et al., 2017). Other studies instead argue that granule cells sample from mossy fibers with highly similar receptive fields (Garwicz et al., 1998; Brown and Bower, 2001; Jörntell and Ekerot, 2006) defined by the tuning of mossy fiber and climbing fiber inputs to cerebellar microzones (Apps et al., 2018). This has led to an alternative hypothesis that granule cells serve to relay similarly tuned mossy fiber inputs and enhance their signal-to-noise ratio (Jörntell and Ekerot, 2006; Gilbert and Chris Miall, 2022) rather than to re-encode inputs. Another hypothesis is that granule cells enable Purkinje cells to learn piece-wise linear approximations of nonlinear functions (Spanne and Jörntell, 2013). However, several recent studies support the existence of heterogeneous connectivity and selectivity of granule cells to multiple distinct inputs at the local scale (Huang et al., 2013; Ishikawa et al., 2015). Furthermore, the deviation of the predicted dimension in models constrained by electron-microscopy data as compared to randomly wired models is modest (Nguyen et al., 2023). Thus, topographically organized connectivity at the macroscopic scale may coexist with disordered connectivity at the local scale, allowing granule cells presynaptic to an individual Purkinje cell to sample heterogeneous combinations of the subset of sensorimotor signals relevant to the tasks that Purkinje cell participates in. Finally, we note that the optimality of dense codes for learning slowly varying tasks in our theory suggests that observations of a lack of mixing (Jörntell and Ekerot, 2002) for such tasks are compatible with Marr-Albus models, as in this case nonlinear mixing is not required.
We have quantified coding level by the fraction of neurons that are above firing threshold. We focused on coding levels , as extremely dense codes are rarely found in experiments (Olshausen and Field, 2004), but our theory applies for as well. In general, representations with coding levels of and perform similarly in our model due to the symmetry of most of their associated eigenvalues (Figure 4—figure supplement 1 and Appendix). Under the assumption that the energetic costs associated with neural activity are minimized, the region is likely the biologically plausible one. We also note that coding level is most easily defined when neurons are modeled as rate, rather than spiking units. To investigate the consistency of our results under a spiking code, we implemented a model in which granule cell spiking exhibits Poisson variability and quantify coding level as the fraction of neurons that have nonzero spike counts (Figure 7—figure supplement 1; Figure 7C). In general, increased spike count leads to improved performance as noise associated with spiking variability is reduced. Granule cells have been shown to exhibit reliable burst responses to mossy fiber stimulation (Chadderton et al., 2004), motivating models using deterministic responses or sub-Poisson spiking variability. However, further work is needed to quantitatively compare variability in model and experiment and to account for more complex biophysical properties of granule cells (Saarinen et al., 2008).
For the Purkinje cells, our model assumes that their responses to granule cell input can be modeled as an optimal linear readout. Our model therefore provides an upper bound to linear readout performance, a standard benchmark for the quality of a neural representation that does not require assumptions on the nature of climbing fiber-mediated plasticity, which is still debated. Electrophysiological studies have argued in favor of a linear approximation (Brunel et al., 2004). To improve the biological applicability of our model, we implemented an online climbing fiber-mediated learning rule and found that optimal coding levels are still task-dependent (Figure 7—figure supplement 2). We also note that although we model several timing-dependent tasks (Figure 7), our learning rule does not exploit temporal information, and we assume that temporal dynamics of granule cell responses are largely inherited from mossy fibers. Integrating temporal information into our model is an interesting direction for future investigation.
Implications for cerebellar representations
Our results predict that qualitative differences in the coding levels of cerebellum-like systems, across brain regions or across species, reflect an optimization to distinct tasks (Figure 7). However, it is also possible that differences in coding level arise from other physiological differences between systems. In the Drosophila mushroom body, which is required for associative learning of odor categories, random and sparse subsets of Kenyon cells are activated in response to odor stimulation, consistent with our model (Figure 7B; Turner et al., 2008; Honegger et al., 2011; Lin et al., 2014). In a model of the electrosensory system of the electric fish, the inferred coding level of a model constrained by the properties of granule cells is similar to that which optimizes task performance (Figure 7C). Within the cerebellar cortex, heterogeneity in granule cell firing has been observed across cerebellar lobules, associated with both differences in intrinsic properties (Heath et al., 2014) and mossy fiber input (Witter and De Zeeuw, 2015). It would be interesting to correlate such physiological heterogeneity with heterogeneity in function across the cerebellum. Our model predicts that regions involved in behaviors with substantial low-dimensional structure, for example smooth motor control tasks, may exhibit higher coding levels than regions involved in categorization or discrimination of high-dimensional stimuli.
Our model also raises the possibility that individual brain regions may exhibit different coding levels at different moments in time, depending on immediate behavioral or task demands. Multiple mechanisms could support the dynamic adjustment of coding level, including changes in mossy fiber input (Ozden et al., 2012), Golgi cell inhibition (Eccles et al., 1966; Palay and Chan-Palay, 1974), retrograde signaling from Purkinje cells (Kreitzer and Regehr, 2001), or unsupervised plasticity of mossy fiber-to-granule cell synapses (Schweighofer et al., 2001). The predictions of our model are not dependent on which of these mechanisms are active. A recent study demonstrated that local synaptic inhibition by Golgi cells controls the spiking threshold and hence the population coding level of cerebellar granule cells in mice (Fleming et al., 2022). Further, the authors observed that granule cell responses to sensory stimuli are sparse when movement-related selectivity is controlled for. This suggests that dense movement-related activity and sparse sensory-evoked activity are not incompatible.
While our analysis makes clear qualitative predictions concerning comparisons between the optimal coding levels for different tasks, in some cases it is also possible to make quantitative predictions about the location of the optimum for a single task. Doing so requires determining the appropriate time interval over which to measure coding level, which depends on the integration time constant of the readout neuron. It also requires estimates of the firing rates and biophysical properties of the expansion layer neurons. In the electrosensory system, for which a well-calibrated model exists and the learning objective is well-characterized (Kennedy et al., 2014), we found that the coding level estimated based on the data is similar to that which optimizes performance (Figure 7C).
If coding level is task-optimized, our model predicts that manipulating coding level artificially will diminish performance. In the Drosophila mushroom body, disrupting feedback inhibition from the GABAergic anterior paired lateral neuron onto Kenyon cells increases coding level and impairs odor discrimination (Lin et al., 2014). A recent study demonstrated that blocking inhibition from Golgi cells onto granule cells results in denser granule cell population activity and impairs performance on an eye-blink conditioning task (Fleming et al., 2022). These examples demonstrate that increasing coding level during sensory discrimination tasks, for which sparse activity is optimal, impairs performance. Our theory predicts that decreasing coding level during a task for which dense activity is optimal, such as smooth motor control, would also impair performance.
While dense activity has been taken as evidence against theories of combinatorial coding in cerebellar granule cells (Knogler et al., 2017; Wagner et al., 2019), our theory suggests that the two are not incompatible. Instead, the coding level of cerebellum-like regions may be determined by behavioral demands and the nature of the input to granule-like layers (Muscinelli et al., 2023). Sparse coding has also been cited as a key property of sensory representations in the cerebral cortex (Olshausen and Field, 1996). However, recent population recordings show that such regions exhibit dense movement-related activity (Musall et al., 2019), much like in cerebellum. While the theory presented in this study does not account for the highly structured recurrent interactions that characterize cerebrocortical regions, it is possible that these areas also operate using inductive biases that are shaped by coding level in a similar manner to our model.
Methods
Network model
The expansion layer activity is given by where describes the selectivity of expansion layer neurons to task variables. For most simulations, is an matrix sampled with random, orthonormal columns and is an matrix with i.i.d. unit Gaussian entries. The nonlinearity is a rectified linear activation function applied element-wise. The input layer activity is given by
Sparsely connected networks
To model sparse excitatory connectivity, we generated a sparse matrix , where each row contains precisely nonzero elements at random locations. The nonzero elements are either identical and equal to 1 (homogeneous excitatory weights) or sampled from a unit truncated normal distribution (heterogeneous excitatory weights). To model global feedforward inhibition that balances excitation, , where is a dense matrix with every element equal to .
For Figure 5B, Figure 6A and B, Figure 7B, sparsely connected networks were generated with homogeneous excitatory weights and global inhibition. For Figure 5E, the network with clustered representations was generated with homogeneous excitatory weights without global inhibition. For Figure 5C and F, networks were generated with heterogeneous excitatory weights and global inhibition.
Clustered representations
For clustered input-layer representations, each input layer neuron encodes one task variable (that is, is a block matrix, with nonoverlapping blocks of elements equal to 1 for each task variable). In this case, in order to obtain good performance, we found it necessary to fix the coding level for each input pattern, corresponding to winner-take-all inhibition across the expansion layer.
Dimension
The dimension of the expansion layer representation (Figure 3D) is given by Abbott et al., 2011; Litwin-Kumar et al., 2017:
(5)
where are the eigenvalues of the covariance matrix of expansion layer responses (not to be confused with , the eigenvalues of the kernel operator). The covariance is computed by averaging over inputs .
Learning tasks
Random categorization task
In a random categorization task (Figure 2E, Figure 7B), the network learns to associate a random input pattern for with a random binary category . The elements of are drawn i.i.d. from a normal distribution with mean 0 and variance . Test patterns are generated by adding noise to the training patterns:
(6)
where . For Figure 2E, Figure 7B, and Figure 4—figure supplement 2, we set .
Gaussian process tasks
To generate a family of tasks with continuously varying outputs (Figure 2D and F, Figure 4F and G, Figure 5B, and Figure 6), we sampled target functions from a Gaussian process (Rasmussen and Williams, 2006), , with covariance
(7)
where determines the spatial scale of variations in . Training and test patterns are drawn uniformly on the unit sphere.
Learning of readout weights
With the exception of the ELL task and Figure 7—figure supplement 2, we performed unregularized least squares regression to determine the readout weights . For the ELL sensory cancellation task (Figure 7C), we used regularization, a.k.a. ridge regression:
(8)
where is the regularization parameter. Solutions were found using Python’s scikit-learn package (Pedregosa, 2011).
In Figure 7—figure supplement 2, we implement a model of an online climbing fiber-mediated plasticity rule. The climbing fiber activity is assumed to encode the error between the target and the network prediction . During each of training epochs, the training patterns are shuffled randomly and each pattern is presented one at a time. For each pattern µ, the weights are updated according to . Parameter values were .
Performance metrics
For tasks with continuous targets, the prediction of the network is given by , where are the synaptic weights of the readout from the expansion layer. Error is measured as relative mean squared error (an expectation across patterns in the test set): . In practice we use a large test set to estimate this error over drawn from the distribution of test patterns. For categorization tasks, the network’s prediction is given by . Performance is measured as the fraction of incorrect predictions. Error bars represent standard error of the mean across realizations of network weights and tasks.
Optimal granule–Purkinje cell weight distribution
We adapted our model to allow for comparisons with Brunel et al., 2004 by constraining readout weights to be nonnegative and adding a bias, . To guarantee that the target function is nonnegative, we set for the random categorization task and for the Gaussian process tasks. The weights and bias were determined with the Python convex optimization package cvxopt (Andersen et al., 2011).
Model of two-joint arm
We implemented a biophysical model of a planar two-joint arm (Fagg et al., 1997). The state of the arm is specified by six variables: joint angles and , angular velocities and , and torques u1 and u2. The upper and lower segments of the arm have lengths l1 and l2 and masses m1 and m2, respectively. The arm has the following dynamics:
(9)
where is the inertia matrix and is the matrix of centrifugal, Coriolis, and friction forces:
(10)
(11)
where is the center of mass of the lower arm, I1 and I2 are moments of inertia and D1 and D2 are friction terms of the upper and lower arm respectively. These parameters were , , , , , , , and .
The task is to predict the position of the hand based on the forward dynamics of the two-joint arm system, given the arm initial condition and the applied torques. More precisely, the network inputs were generated by sampling 6-dimensional Gaussian vectors with covariance matrix , to account for the fact that angles, angular velocities and torques might vary on different scales across simulations. For our results, we used and . Each sample was then normalized and used to generate initial conditions of the arm, by setting , , , and . Torques were generated by setting and . The target was constructed by running the dynamics of the arm forward in time for a time , and by computing the difference in position of the “hand” (i.e. the end of the lower segment) in Cartesian coordinates. As a result, the target in this task is two-dimensional, with each target dimension corresponding the one of the two Cartesian coordinates of the hand. The overall performance is assessed by computing the error on each task separately and then averaging the errors.
Model of electrosensory lateral line lobe (ELL)
We simulated 20,000 granule cells using the biophysical model of Kennedy et al., 2014. We varied the granule cell layer coding level by adjusting the spiking threshold parameter in the model. For each choice of threshold, we generated 30 different trials of spike rasters. Each trial is 160ms long with a 1ms time bin and consists of a time-locked response to an electric organ discharge command. Trial-to-trial variability in the model granule cell responses arises from noise in the mossy fiber responses. To generate training and testing data, we sampled 4 trials ( patterns) from the 30 total trials for training and 10 trials for testing (1600 patterns). Coding level is measured as the fraction of granule cells that spike at least once in the training data. We repeated this sampling process 30 times.
The targets were smoothed broad-spike responses of 15 MG cells time-locked to an electric organ discharge command measured during experiments (Muller et al., 2019). The original data set consisted of 55 MG cells, each with a 300ms long spike raster with a 1ms time bin. The spike rasters were trial-averaged and then smoothed with a Gaussian-weighted moving average with a 10ms time window. Only MG cells whose maximum spiking probability across all time bins exceeded 0.01 after smoothing were included in the task. The same MG cell responses were used for both training and testing. To match the length of the granule cell data, we discarded MG cell data beyond 160ms and then concatenated 4 copies of the 160ms long responses for training and 10 copies for testing. We measured the ability of the model to construct MG cell targets out of granule cell activity, generalizing across noise in granule cell responses. Errors for each MG cell target were averaged across the 30 repetitions of sampling of training and testing data, and then averaged across targets. Standard error of the mean was computed across the 30 repetitions.
Model of vestibulo-ocular reflex (VOR)
Recordings of Purkinje cell activity in monkeys suggest that these neurons exhibit piecewise-linear tuning to head velocity (Lisberger et al., 1994). Thus, we designed piecewise-linear target functions representing Purkinje cell firing rate as a function of head velocity , a one-dimensional input:
(12)
Inputs were sampled uniformly from 100 times. We generated 25 total target functions using all combinations of slopes m1 and m2 sampled from 5 equally spaced points on the interval . We set and .
Mossy fiber responses to head velocity input were modeled as exponential tuning curves:
(13)
where gj is a gain term, determines a mossy fiber preference for positive or negative velocities, and bj is the baseline firing rate. We generated 24 different tuning curves from all combinations of the following parameter values: The gain gj was sampled from 6 equally spaced points on the interval , rj was set to either –1 or 1, and bj was set to either 0 or 1. Qualitative results did not depend strongly on this parameterization. Mossy fiber to granule cell weights were random zero-mean Gaussians. Errors were averaged across targets.
Appendix 1
1 Connection between kernel and previous theories
Previous theories (Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017) studied generalization performance for random clusters of inputs associated with binary targets, where test patterns are formed by adding noise to training patterns (Figure 4A). The readout is trained using a supervised Hebbian rule with mean-subtracted expansion layer responses, , with . The net input to a readout in response to a test pattern from cluster µ is . The statistics of determine generalization performance. For a Hebbian readout, the error rate is expressed in terms of the signal-to-noise ratio (SNR) (Babadi and Sompolinsky, 2014):
(A1)
SNR is given in terms of the mean and variance of :
(A2)
The numerator of SNR is proportional to the average overlap of the expansion layer representations of training and test patterns belonging to the same cluster, which can be expressed in terms of the kernel function :
(A3)
For large networks with Gaussian i.i.d. expansion weights, , where , and the above equation reduces to , where is the typical overlap of training and test patterns belonging to the same cluster. When , can be written as , where Δ is a measure of within-cluster noise (Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017).
Babadi and Sompolinsky, 2014 demonstrated that, for random categorization tasks and when and are large, where is a constant and is given by
(A4)
assuming the entries of are zero-mean. for normalizes the overlaps to the typical overlap of a pattern with itself. The quantity is the ratio of the variance of overlaps between patterns belonging to different clusters in the expansion layer to that of the input layer. This describes the extent to which the geometry of the input layer representation is preserved in the expansion layer. When overlaps in the input layer are small, as they are for random clusters, as . This relation illustrates that, for random clusters and , is equal to the slope of the normalized kernel function evaluated at . Litwin-Kumar et al., 2017 also showed that the dimension of the expansion layer representation is equal to , where is a constant.
Thus, for the random categorization task studied in Babadi and Sompolinsky, 2014; Litwin-Kumar et al., 2017, dimension and readout SNR can be calculated by evaluating and the slope of at .
2 Dot-product kernels with arbitrary threshold
As , the normalized dot product between features (Equation 2) converges pointwise to
(A5)
where is a row of the weight matrix (without loss of generality, the first row) with entries drawn i.i.d. from a Gaussian distribution . Our goal is to compute Equation A5 for a given and inputs drawn on the unit sphere .
Because the Gaussian weight distribution is spherically symmetric, Equation A5 restricted to the unit sphere for any nonlinearity is only a function of the dot-product , making the kernel a dot-product kernel .
Denote by the entries of . Let and be the pre-activations for each input. Then are jointly Gaussian with mean 0, variance 1, and covariance . If , we can re-parameterize these pre-activations as the sum of an independent and shared component , where for and . In these coordinates, Equation A5 becomes
(A6)
where the second line follows from the conditional independence of and and the third from the fact that they are identically distributed. Similarly, if , we can write , .
We will use Equation A6 to solve for the kernel assuming is a ReLU nonlinearity. Let
(A7)
Using the fact that is nonzero only when , i.e. for , we obtain
(A8)
Performing a similar calculation for and collecting the results leads to:
(A9)
(A10)
(A11)
(A12)
3 Spherical harmonic decompositions
Our theory of generalization requires us to work in function spaces which are natural to the problem. The spherical harmonics are the natural basis for working with dot-product kernels on the sphere. For a thorough treatment of spherical harmonics, see Atkinson and Han, 2012, whose notation we generally follow. Both our kernel and Gaussian process (GP) tasks are defined over the sphere in dimensions
(A13)
A spherical harmonic —where indexes frequency and indexes modes of the same frequency—is a harmonic homogeneous polynomial of degree restricted to the sphere . For each frequency , there are linearly independent polynomials, where
(A14)
3.1 Decomposition of the kernel and target function
We remind the reader here of the setting for our theory:
Ridge regression using random features with a dot-product limiting kernel.
Data drawn uniformly from the unit sphere.
Let be the Lebesgue measure on . We will denote the surface area of the sphere as
(A15)
On the other hand, the uniform probability measure on the sphere, denoted by , must integrate to 1, so . Finally, we define the space of real-valued square integrable functions as the Hilbert space with inner product
(A16)
and . The space is defined analogously.
Eigendecompositions describe the action of linear operators, not functions, thus we must associate a linear operator with our kernel for its eigenvalues to make sense. The kernel eigenvalues that we will use to compute the error are the eigenvalues of the integral operator defined as
(A17)
This is because is the data distribution, and these eigenvalues are approximated by the eigenvalues of the kernel matrix evaluated on a large but finite dataset (Koltchinskii et al., 2000). Similarly, we define the analogous operator under the measure with eigenvalues . Since , the eigenvalues are related by
(A18)
and they share the same eigenfunctions, up to normalization. For the rest of this section we will study eigendecompositions of operator , which may be translated into statements about via (18) (These differences are liable to cause some confusion and pain when reading the literature).
Under mild technical conditions that our kernels satisfy, Mercer’s theorem states that positive semidefinite kernels can be expanded as a series in the orthonormal basis of eigenfunctions weighted by nonnegative eigenvalues :
(A19)
Again, are eigenpairs for the operator and form an orthonormal set under the inner product.
As stated earlier, the kernel (Equation A5) is spherically symmetric and thus a dot-product kernel. Because of this, we can take the eigenfunctions to be the spherical harmonics . The index is a multi-index into mode of frequency . Writing the Mercer decomposition in the spherical harmonic basis gives:
(A20)
Because our kernel is rotation invariant, all harmonics of frequency share eigenvalue .
Any function in can be expanded in the spherical harmonic basis as follows:
(A21)
The expansion is analogous to that of the Fourier series. In fact when , the spherical harmonics are sines and cosines on the unit circle.
3.2 Ultraspherical polynomials
Adding together all harmonics of a given frequency relates them to a polynomial in by the addition formula
(A22)
The polynomial is the th ultraspherical polynomial. These are also called Legendre or Gegenbauer polynomials, although these usually have different normalizations and can be defined more generally.
The ultraspherical polynomials form an orthogonal basis for
As special cases, and are the classical Chebyshev and Legendre polynomials, respectively. For any , the first two of these polynomials are and . We use the Rodrigues formula (Atkinson and Han, 2012), which holds for and , to generate these polynomials:
(A23)
Combining Equation A20 with the addition formula (Equation A22), we can express the kernel in terms of ultraspherical polynomials evaluated at the dot-product of the inputs:
(A24)
3.3 Computing kernel eigenvalues
The Funk-Hecke theorem states that
(A25)
Equation A25 implies that the eigenvalues of are given as
(A26)
For our kernels, the kernel eigenvalues can be conveniently computed using polar coordinates. When the entries of are i.i.d. unit Gaussian,
where and . The ReLU nonlinearity is positively homogeneous, so . We can write
(A27)
where we have introduced a new kernel which is times the dot-product kernel that arises when the weights are distributed uniformly on the sphere ( is not the probability measure). The above equation shows that the network restricted to inputs has different kernels depending on whether the weights are sampled according to a Gaussian distribution or uniformly on the sphere. Without the threshold, this difference disappears due to the positive homogeneity of the ReLU (Churchland et al., 2010).
Next we expand the nonlinearity in the spherical harmonic basis (following Bietti and Bach, 2021; Bach, 2017)
(A28)
where the th coefficient is given by the Funk-Hecke formula (Equation A25) as
(A29)
and we explicitly note the dependence on . Using the representation Equation A28, we can recover the eigendecomposition:
(A30)
which follows from orthonormality and the addition formula (Equation A22). We have that is the th eigenvalue of .
Using Equation A30 in Equation A27 leads to
(A31)
i.e. the eigenvalues satisfy
(A32)
3.3.1 Eigenvalues of
It is possible to compute analytically (Bietti and Bach, 2021; Bach, 2017). Letting
(A33)
we have that Equation A29 reduces to . Equation A33 requires , but in Equation A32 as . So we take , which still assures that Equation A29 is satisfied. For the rest of this section, assume wlog that .
Using Rodrigues’ formula (Equation A23) in Equation A33 gives
which may be integrated by parts. We will treat and 1 separately.
In the case of , since we have the integral of a derivative, so for
When we find that
For , we integrate by parts once and find that for ,
When , we have a straightforward integral
Finally, for , we obtain
3.3.2 Properties of the eigenvalues of
The above show that for
(A34)
Taking leads to , since fewer derivatives than appear in Equation A34, which reflects the fact that higher degree ultraspherical polynomials are orthogonal to a linear function. Furthermore, since is an even function, the parity of ak as a function of matches the parity of . However, ak appears squared in Equation A32, so will always be an even function of . This explains the parity symmetry of the eigenvalues with coding level for . Also, Equation A34 for gives when is odd, as was shown by Bach, 2017; Basri et al., 2019. This is because
because the and terms have opposite parity and cancel.
We may also compute the tail asymptotics of these eigenvalues for large . Let and , so we want to evaluate
for large at . The first line follows from Cauchy’s intergral formula for a counterclockwise contour encircling , and the second comes from defining
when is large and is constant. We will use the saddle point method (Butler, 2007) to evaluate the contour integral asymptotically, ignoring the term in the exponent. Note that the only singularity in the original integrand occurs at .
The function has derivatives
We find the saddle points by setting . This leads to a quadratic equation with two roots: . Since these are evaluated at with , both roots are complex, , and . Also, the saddle points avoid the singularity in the original integrand, so we can deform our contour to pass through these points and apply the standard approximation.
Applying the saddle point approximation, we obtain
for some which is constant in and depends on . In the last step, we use that since are conjugate pairs with magnitude 1.
Now recall the full equation for the coefficients:
Plugging in the result from the saddle point approximation, substituting , and dropping all terms that are constant in , we find that
where is a new constant. The rate of is the same decay rate found by Bach, 2017; Bietti and Bach, 2021 using a different mathematical technique for . These decay rates are important for obtaining general worst-case bounds for kernel learning of general targets; (Bach, 2012) is an example.
3.4 Gaussian process targets
Taking our target function to be a GP on the unit sphere with some covariance function , we can represent our target function by performing an eigendecomposition of the covariance operator . When itself is spherically symmetric and positive definite, this becomes
(A35)
where are the eigenvalues. Then a sample from the GP with this covariance function is a random series
(A36)
where by the Kosambi-Karhunen–Loève theorem (Kosambi, 1943). In other words, the coefficient of in the series expansion of is .
We take the squared exponential covariance on the sphere
(A37)
for and length scale .
3.5 Numerical details
All of our spherical harmonic expansions are truncated at frequency . This is typically for experiments in dimensions. In higher dimensions, grows very quickly in , requiring truncation at a lower frequency.
To compute the kernel eigenvalues , we can either numerically integrate the Funk-Hecke formula (Equation A25) or compute the coefficients semi-analytically, following Equation A34, then integrate Equation A32 with numerical quadrature and rescale by Equation A18.
We use the Funk-Hecke formula (Equation A25) and numerical quadrature to find . To compute the expected error using Equation A38, we use . After generating a sample from the GP, we normalize the functions by dividing the labels and coefficients by their standard deviation. This ensures that the relative mean squared error is equivalent to the mean squared error computed in the next section.
4 Calculation of generalization error
The generalization error of kernel ridge regression is derived in Canatar et al., 2021a; Simon et al., 2021; Gerace et al., 2021, which show that the mean squared error, in the absence of noise in the target, can be written as
(A38)
where depend on and the kernel but not on the target, and are the coefficients (Equation A21) of the target function in the basis . The exact form of this expression differs from that given in Canatar et al., 2021b due to differences in the conventions we take for our basis expansions. Specifically,
(A39)
where indexes the kernel eigenfunctions and
(A40)
(A41)
with the ridge parameter. Note that Equation A41 is an implicit equation for , which we solve by numerical root-finding.
Thus,
(A42)
with and .
5 Dense-sparse networks
To compare with more realistic networks, we break the simplifying assumption that is densely connected and instead consider sparse connections between the input and expansion layer. Consider a random matrix , where and , with and . The entries of are i.i.d. Gaussian, i.e. . In contrast, is a sparse matrix with exactly K nonzero entries per row, and nonzero entries equal to . With these scaling choices, the elements of are of order , which is appropriate when the input features xi are order 1. This is in contrast to the rest of this paper, where we considered features of order and therefore assumed order 1 weights. The current scaling allows us to study the properties of for different values of , and .
First, we examine properties of under these assumptions. Recall that the rows of are the weights of each hidden layer neuron. Since is Gaussian, any given row is marginally Gaussian and distributed identically to any other row. But the rows are not independent, since they are all linear combinations of the rows of . Thus, the kernel limit of an infinitely large dense-sparse network is equal to that of a fully dense network, but convergence to that kernel behaves differently and requires taking a limit of both . In this section, we study how finite introduces extra correlations among the rows of compared to dense networks.
The distribution of is spherically symmetric in the sense that and have the same distribution for any rotation matrix . In contrast, a densely connected network with weights drawn i.i.d. as will of course have independent rows and also be spherically symmetric. The spherical Gaussian is the only vector random variable which is spherically symmetric with independent entries (Nash and Klamkin, 1976). Furthermore, each row of may be rotated by a different orthogonal matrix and the resulting random variable would still have the same distribution.
With these symmetry considerations in mind, the statistics of the rows of can be described by their multi-point correlations. The simplest of these is the two-point correlation, which in the case of spherical symmetry is captured by the overlaps:
(A43)
The overlap is doubly stochastic: one source of stochasticity are the elements of , and the second one is the random sampling of nonzero elements of . Ideally, we are interested in studying the statistics of when varying and , i.e. when varies (since the rows of are sampled independently from each other). However, this will leave us with the quenched disorder given by the specific realization of . To obtain a more general and interpretable result, we want to compute the probability distribution
(A44)
Notice that the order in which we perform the averaging is irrelevant.
5.1Computation of the moment-generating function
Instead of computing directly the probability distribution in Equation A44, we compute the moment-generating function
(A45)
which fully characterizes the probability distribution of . We indicate the set of indices in which the -th row of takes nonzero values by such that , , and analogously for the -th row. We also indicate the intersection , i.e. the set of indices in which both the -th and the -th rows are nonzero. has size . Notice that setting causes deterministically. With this definitions, the overlap can be written as
(A46)
We start by perform swapping the averaging order in Equation A45 and averaging over .
where in the first equality we marginalized over all the elements of which do not enter the definition of , i.e. we went from having to integrate over variables to only variables. In the second equality we factorized the columns of .
We now explicitly compute integral for a fixed value of , by reducing it to a Gaussian integral:
where , which has a 3-by-3 block structure and can be written as
(A47)
where is the -by- identity matrix and is the -by- matrix of all ones (if is omitted, then it is -by-). Due to the block structure, the determinant of the matrix above is identical to the determinant of a 3-by-3 matrix
(A48)
By plugging this result into the expression for the moment-generating function, we have that
(A49)
This expression is our core result, and needs to be averaged over . This average can be written explicitly by noticing that, when , is a random variable that follows a hypergeometric distribution in which the number of draws is equal to number of success state and is equal to . By using the explicit expression of the probability mass function of a hypergeometric distribution, we have that
(A50)
Notice that the term yields the same moment-generating function (up to a factor) as for a fully-connected with Gaussian i.i.d. entries with variance . In contrast, when we obtain
(A51)
5.2 Computation of the moments of
In this section, we assume that and use the moment-generating function to compute the moments of . The non-central moments of the overlap are easily obtained from the moment-generating function as
(A52)
which can be computed in a symbolic manipulation tool.
We now explicitly compute the first two moments of .
(A53)
where we used the fact that the mean of is given by . For the second moment, we have
while to compute the variance we use the law of total variance
As we have that , which is the same variance of the overlap for a fully-connected with Gaussian i.i.d. entries. This is expected since when is large, the probability of and having common afferents goes to zero.
5.3 Comparison to clustered embedding
Instead of distributed embedding, i.e. being a Gaussian matrix, here we consider a clustered embedding by setting
(A54)
i.e. the Kronecker product of the -dimensional identity matrix and a vector of all ones and length . This means that we can separate the input layer of neurons in non overlapping subsets , each of size , and we can write
(A55)
In this case the overlap is given by
(A56)
where is the indicator function, i.e. it is one if the argument is true and zero if the argument is false. We indicate by the number of elements of which belongs to group , i.e. . The overlap can then be written as
(A57)
The vector follows a multivariate hypergeometric distribution with classes, draws, a population of size , and number of successes for each class equal to . Notice that and are independent from each other since each neuron samples its pre-synaptic partners independently. We can now compute explicitly the mean of using the fact that
(A58)
Similarly, we can write the second moment of as
(A59)
Once again, we can use known result for variance and covariance of multivariate hypergeometric variables to simplify the above expression. Indeed, we can write
(A60)
(A61)
from which we obtain the final expression for the second moment
(A62)
Data availability
The current manuscript is a computational study, so no data have been generated for this manuscript. Code implementing the model is available on github: https://github.com/marjoriexie/cerebellar-task-dependent (copy archived at Xie, 2023).
References
-
BookInteractions between intrinsic and stimulus-evoked activity in recurrent neural networksIn: Abbott LF, editors. The Dynamic Brain: An Exploration of Neuronal Variability and Its Functional Significance. Oxford University Press. pp. 65–82.https://doi.org/10.1093/acprof:oso/9780195393798.001.0001
-
A theory of cerebellar functionMathematical Biosciences 10:25–61.https://doi.org/10.1016/0025-5564(71)90051-4
-
BookInterior-point methods for large-scale cone programmingIn: Andersen M, editors. Optimization for Machine Learning. MIT Press. pp. 1–26.https://doi.org/10.7551/mitpress/8996.001.0001
-
BookSpherical Harmonics and Approximations on the Unit Sphere: An IntroductionBerlin, Heidelberg: Springer.https://doi.org/10.1007/978-3-642-25983-8
-
Breaking the curse of dimensionality with convex neural networksJournal of Machine Learning Research 18:1–53.
-
Cerebellar granule cells: dense, rich and evolving representationsCurrent Biology 27:R415–R418.https://doi.org/10.1016/j.cub.2017.04.009
-
The sparseness of mixed selectivity neurons controls the generalization-discrimination trade-offThe Journal of Neuroscience 33:3844–3856.https://doi.org/10.1523/JNEUROSCI.2753-12.2013
-
ConferenceThe convergence rate of neural networks for learned functions of different frequenciesAdvances in Neural Information Processing Systems. pp. 4761–4771.
-
Cerebellum-like structures and their implications for cerebellar functionAnnual Review of Neuroscience 31:1–24.https://doi.org/10.1146/annurev.neuro.30.051606.094225
-
ConferenceSpectrum dependent learning curves in kernel regression and wide neural networksInternational Conference on Machine Learning. pp. 1024–1034.
-
BookSaddlepoint Approximations with ApplicationsCambridge University Press.https://doi.org/10.1017/CBO9780511619083
-
Out-of-distribution generalization in kernel regressionAdvances in Neural Information Processing Systems 34:12600–12612.
-
Large-margin classification in infinite neural networksNeural Computation 22:2678–2697.https://doi.org/10.1162/NECO_a_00018
-
Stimulus onset quenches neural variability: a widespread cortical phenomenonNature Neuroscience 13:369–378.https://doi.org/10.1038/nn.2501
-
Storage of correlated patterns in standard and bistable Purkinje cell modelsPLOS Computational Biology 8:e1002448.https://doi.org/10.1371/journal.pcbi.1002448
-
Optimal properties of analog perceptrons with excitatory weightsPLOS Computational Biology 9:e1002919.https://doi.org/10.1371/journal.pcbi.1002919
-
The mossy fibre-granule cell relay of the cerebellum and its inhibitory control by Golgi cellsExperimental Brain Research 1:82–101.https://doi.org/10.1007/BF00235211
-
BookThe Cerebellum as a Neuronal MachineBerlin, Heidelberg: Springer.https://doi.org/10.1007/978-3-662-13147-3
-
ConferenceCerebellar learning for control of a two-link arm in muscle spaceProceedings of International Conference on Robotics and Automation. pp. 2638–2644.
-
Generalisation error in learning with random features and the hidden manifold model*Journal of Statistical Mechanics 2021:124013.https://doi.org/10.1088/1742-5468/ac3ae6
-
The expression pattern of a Cav3-Kv4 complex differentially regulates spike output in cerebellar granule cellsThe Journal of Neuroscience 34:8800–8812.https://doi.org/10.1523/JNEUROSCI.0981-14.2014
-
Cellular-resolution population imaging reveals robust sparse coding in the Drosophila mushroom bodyThe Journal of Neuroscience 31:11772–11785.https://doi.org/10.1523/JNEUROSCI.1099-11.2011
-
ConferenceNeural tangent kernel: Convergence and generalization in neural networksAdvances in Neural Information Processing Systems.
-
Properties of somatosensory synaptic integration in cerebellar granule cells in vivoThe Journal of Neuroscience 26:11786–11797.https://doi.org/10.1523/JNEUROSCI.2939-06.2006
-
A theory of cerebellar cortexThe Journal of Physiology 202:437–470.https://doi.org/10.1113/jphysiol.1969.sp008820
-
The Drosophila mushroom body: from architecture to algorithm in a learning circuitAnnual Review of Neuroscience 43:465–484.https://doi.org/10.1146/annurev-neuro-080317-0621333
-
Single-trial neural dynamics are dominated by richly varied movementsNature Neuroscience 22:1677–1686.https://doi.org/10.1038/s41593-019-0502-4
-
Optimal routing to cerebellum-like structuresNature Neuroscience 26:1630–1641.https://doi.org/10.1038/s41593-023-01403-7
-
A spherical characterization of the normal distributionJournal of Mathematical Analysis and Applications 55:156–158.https://doi.org/10.1016/0022-247X(76)90285-7
-
Sparse coding of sensory inputsCurrent Opinion in Neurobiology 14:481–487.https://doi.org/10.1016/j.conb.2004.07.007
-
BookCerebellar Cortex: Cytology and OrganizationBerlin, Heidelberg: Springer.https://doi.org/10.1007/978-3-642-65581-4
-
Scikit-learn: machine learning in pythonJournal of Machine Learning Research 12:2825–2830.
-
ConferenceRandom features for large-scale kernel machinesAdvances in Neural Information Processing Systems.
-
Stochastic differential equation model for cerebellar granule cell excitabilityPLOS Computational Biology 4:e1000004.https://doi.org/10.1371/journal.pcbi.1000004
-
BookLearning with Kernels: Support Vector Machines, Regularization, Optimization, and BeyondMIT press.
-
Cortical control of arm movements: A dynamical systems perspectiveAnnual Review of Neuroscience 36:337–359.https://doi.org/10.1146/annurev-neuro-062111-150509
-
ConferenceApproximate learning curves for Gaussian processes9th International Conference on Artificial Neural Networks.https://doi.org/10.1049/cp:19991148
-
Questioning the role of sparse coding in the brainTrends in Neurosciences 38:417–427.https://doi.org/10.1016/j.tins.2015.05.005
-
Cerebellum and nonmotor functionAnnual Review of Neuroscience 32:413–434.https://doi.org/10.1146/annurev.neuro.31.060407.125606
-
Olfactory representations by Drosophila mushroom body neuronsJournal of Neurophysiology 99:734–746.https://doi.org/10.1152/jn.01283.2007
-
Movement-related inputs to intermediate cerebellum of the monkeyJournal of Neurophysiology 69:74–94.https://doi.org/10.1152/jn.1993.69.1.74
-
Internal models in the cerebellumTrends in Cognitive Sciences 2:338–347.https://doi.org/10.1016/S1364-6613(98)01221-2
-
Softwarecerebellar-task-dependents, version swh:1:rev:f56a3522566ac2273a65e0cd1d5f717e034c9312Software Heritage.
-
Gaussian-process factor analysis for low-dimensional single-trial analysis of neural population activityJournal of Neurophysiology 102:614–635.https://doi.org/10.1152/jn.90941.2008
Article and author information
Author details
Samuel P Muscinelli

Kameron Decker Harris
Ashok Litwin-Kumar
Funding
National Institutes of Health (T32-NS06492)
- Marjorie Xie
Simons Foundation
- Samuel P Muscinelli
Swartz Foundation
- Samuel P Muscinelli
Washington Research Foundation
- Kameron Decker Harris
Burroughs Wellcome Fund
- Ashok Litwin-Kumar
Gatsby Charitable Foundation (GAT3708)
- Marjorie Xie
National Science Foundation (DBI-1707398)
- Marjorie Xie
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
The authors thank L F Abbott, N A Cayco-Gajic, N Sawtell, and S Fusi for helpful discussions and comments on the manuscript. The authors also thank S Muller for contributing data, code, and helpful discussions for analysis of ELL data. M X was supported by NIH grant T32-NS064929. S M was supported by the Simons and Swartz Foundations. K D H was supported by a grant from the Washington Research Foundation. A L-K was supported by the Simons and Burroughs Wellcome Foundations. M X, S M, and A L-K were also supported by the Gatsby Charitable Foundation and NSF NeuroNex award DBI-1707398.
Copyright
© 2023, Xie et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,822
- views
-
- 266
- downloads
-
- 13
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 13
- citations for umbrella DOI https://doi.org/10.7554/eLife.82914
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Task-dependent optimal representations for cerebellar learning
eLife 12:e82914.
https://doi.org/10.7554/eLife.82914




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}