Combining mutation and recombination statistics to infer clonal families in antibody repertoires
- Laboratoire de physique de l’École normale supérieure, CNRS, PSL University, Sorbonne Université and Université de Paris, France
- Saber Bio SAS, Institut du Cerveau, iPEPS The Healthtech Hub, France
- Department of Organismic and Evolutionary Biology, Harvard University, United States
Abstract
B-cell repertoires are characterized by a diverse set of receptors of distinct specificities generated through two processes of somatic diversification: V(D)J recombination and somatic hypermutations. B-cell clonal families stem from the same V(D)J recombination event, but differ in their hypermutations. Clonal families identification is key to understanding B-cell repertoire function, evolution, and dynamics. We present HILARy (high-precision inference of lineages in antibody repertoires), an efficient, fast, and precise method to identify clonal families from single- or paired-chain repertoire sequencing datasets. HILARy combines probabilistic models that capture the receptor generation and selection statistics with adapted clustering methods to achieve consistently high inference accuracy. It automatically leverages the phylogenetic signal of shared mutations in difficult repertoire subsets. Exploiting the high sensitivity of the method, we find the statistics of evolutionary properties such as the site frequency spectrum and dN/dS ratio do not depend on the junction length. We also identify a broad range of selection pressures spanning two orders of magnitude.
Editor's evaluation
This fundamental study provides a new, high-performance algorithm for B-cell clonal family inference. The new algorithm is highly innovative and based on a rigorous probabilistic analysis of the relevant biological processes and their imprint on the resulting sequences. The strength of evidence regarding the algorithm's performance is convincing, as the algorithm has been benchmarked against two state-of-the-art methods for clonal family inference on two synthetic data sets generated with two independent, state-of-the-art methods for B cell repertoire simulation. This work will be fundamental to immunologists and important to any researcher or clinician utilizing B cell receptor repertoires in their field.
https://doi.org/10.7554/eLife.86181.sa0Introduction
B cells play a key role in the adaptive immune response through their diverse repertoire of immunoglobulins (Ig). These proteins recognize foreign pathogens in their membrane-bound form (called B-cell receptor [BCR]), and battle them in their soluble form (antibody). Each B cell expresses a unique BCR that can bind their antigenic targets with high affinity. The set of distinct BCR harbored by the organism is highly diverse (Briney et al., 2019), thanks to two processes of diversification: V(D)J recombination and somatic hypermutation. These stochastic processes ensure that repertoires can match a variety of potential threats, including proteins of bacterial and viral origin that have never been encountered before.
V(D)J recombination takes place during B-cell differentiation (Hozumi and Tonegawa, 1976; Schatz and Swanson, 2011). For each Ig chain, V, D, and J gene segments for the heavy chain, and V and J gene segments for the light chain, are randomly chosen and joined with random non-templated deletions and insertions at the junction, creating a long, hypervariable region, called the complementarity determining region 3 (CDR3) (Figure 1A). Cells are subsequently selected for the binding properties of their receptors and against autoreactivity. At this stage, the repertoire already covers a wide range of specificities. In response to antigenic stimuli, B cells with the relevant specificities are recruited to germinal centers, where they proliferate and their Ig-coding genes undergo somatic hypermutation (Victora and Nussenzweig, 2022) in the process of affinity maturation. Somatic hypermutation consists primarily of point substitutions, as well as insertions and deletions, restricted to Ig-coding genes (Feng et al., 2020). The mutants are selected for high affinity to the particular antigenic target, and the best binders further differentiate into plasma cells and produce high-affinity antibodies. A more diverse pool of variants forms the memory repertoire, leaving an imprint of the immune response that can be recalled upon repeated stimulation.
Figure 1

Clonal families and classes.
(A) Variable region of the immunoglobulin heavy chain (IgH)-coding gene. (B) A clonal family is a lineage of related B cells stemming from the same VDJ recombination event. The partition of the B-cell receptor (BCR) repertoire into clonal families is a refinement of the partition into classes, defined by sequences with the same V and J usage and the same complementarity determining region 3 (CDR3) length . (C–D) Properties of classes in donor 326651 from Briney et al., 2019. (C) Distribution of class sizes exhibits power-law scaling. The total number of pairwise comparisons in the largest classes is . (D) Distribution of the CDR3 length . The distribution is in yellow for in-frame CDR3 sequences ( multiple of 3), and in gray for out-of-frame sequences.
A clonal family is defined as a collection of cells that stem from a unique V(D)J rearrangement, and has diversified as a result of hypermutation, forming a lineage (Figure 1B). These families are the main building blocks of the repertoire. Since members of the same family usually share their specificities (De Boer et al., 2001), affinity maturation first competes families against each other for antigen binding in the early stages of the reaction, and then selects out the best binders within families in the later stages (Tas et al., 2016; Mesin et al., 2016).
High-throughput sequencing of single receptor chains offers unprecedented insight into the diversity and dynamics of the repertoire. Recent experiments have sampled the repertoires of the immunoglobulin heavy chain (IgH) of healthy individuals at great depth to reveal their structure (Briney et al., 2019). Disease-specific cohorts are now routinely subject to repertoire sequencing studies, which help to quantify and understand the dynamics of the B-cell response (Kreer et al., 2020; Nielsen et al., 2020).
Partitioning BCR repertoire sequence datasets into clonal families is a critical step in understanding the architecture of each sample and interpreting the results. Identifying these lineages allows for quantifying selection (Yaari and Uduman, 2012; Yaari and Kleinstein, 2015; Ruiz Ortega et al., 2023) and for detecting changes in longitudinal measurements (Nielsen et al., 2020; Turner et al., 2020). In recent years, many strategies have been developed that take advantage of CDR3 hypervariability (Abdollahi et al., 2020): it is generally unlikely that the same or a similar CDR3 sequence be generated independently multiple times (Elhanati et al., 2015; Ruiz Ortega et al., 2023). Other approaches make use of the information encoded in the intra-lineage patterns of divergence due to mutations (Briney et al., 2016; Nouri and Kleinstein, 2020). All inference techniques need to balance accuracy and speed. Simpler methods are fast but have low precision (also called positive predictive value) while more complex algorithms have long computation times that do not scale well with the number of sequences. This prohibits the analysis of recent large-scale data such as Briney et al., 2019.
In this work, we propose a new method for inferring clonal families from high-throughput sequencing data that is both fast and accurate. We use probabilistic models of junctional diversity to estimate the level of clonality in repertoire subsets, allowing us to tune the sensitivity threshold a priori to achieve a desired accuracy. We have developed two complementary algorithms. The first one (HILARy-CDR3) uses a very fast CDR3-based approach that avoids pairwise comparisons, while the second one (HILARy-full) additionally exploits information encoded in the phylogenetic signal outside of the junction. We compare our method with state-of-the-art approaches in a benchmark with realistic synthetic data.
Results
Analysis of pairwise distances within classes
A common strategy for partitioning a BCR repertoire dataset into clonal families is to go through all pairs of sequences and identify pairs of clonally related sequences. In the following, we call such related pairs positive, and pairs of sequences belonging to different families negative. Then, the partition is built by single-linkage clustering, which consists of recursively grouping all positive pairs. Two characteristics of the repertoire complicate the search for this partition: large total number of pairs and low proportion of positive pairs. In this section we analyze and model the statistics of pairs of sequences in natural repertoires to inform our choice of the clustering method and parameters. In the next section we will leverage that analysis to design an optimized clustering procedure. To help following notations, a summary of their definitions is provided in Table 1.
Table 1
Summary of notations used throughout the paper.
Hats ˆ denote estimates from the fit of the mixture model. Stars ∗ denote estimates after imposing 99% precision. The ‘post’ subscript denotes quantities after applying single-linkage clustering to obtain a partition from positive pairs.
| Definition | |
|---|---|
| Prevalence/fraction of positive pairs | |
| Precision = TP/(TP+FP) | |
| Sensitivity = TP/(TP+FN) | |
| Fallout = FP/(FP+TN) | |
| Threshold on CDR3 distance | |
| CDR3 length | |
| CDR3 Hamming distance of a pair | |
| Normalized CDR3 Hamming distance | |
| CDR3 Hamming distance, centered and scaled | |
| Shared mutations on V segment, centered and scaled | |
| Mean between positive pairs | |
| Model distribution for positive pairs | |
| Model distribution for negative pairs |
A pair of related sequences is expected to share the same V and J genes, as well as the same CDR3 length , as determined by alignment to the templates (Figure 1A). The methods developed here begin by partitioning the data into classes, defined as subsets of sequences with the same V and J gene usage, and CDR3 length (Figure 1B). For a description of the data preprocessing and alignment to the V and J gene templates, see Methods. Clustering will then be performed within each class independently. While this first step severely limits the number of unnecessary comparisons, some classes still exceed 105 sequences in large datasets, leading to the order of 1010 pairs (see Figure 1C for the distribution of the class sizes for donor 326651 of Briney et al., 2019).
The CDR3 plays an important role in encoding the signature of the VDJ rearrangement. As we will see, the CDR3 length has a strong impact on the difficulty of clonal family reconstruction. The distribution of CDR3 lengths observed in the data is shown in Figure 1D. In what follows we restrict our analysis to sequences with CDR3 lengths a multiple of 3 and between 15 and 105, relying on the common approximation that sequences with no frameshift in the CDR3 come from a productive naive ancestor. The number of sequences with length larger than 105 is too small to reach meaningful conclusions, and sequences of length smaller than 15 are likely nonfunctional (as evidenced by the similar number of in-frame and out-of-frame sequences in Figure 1D).
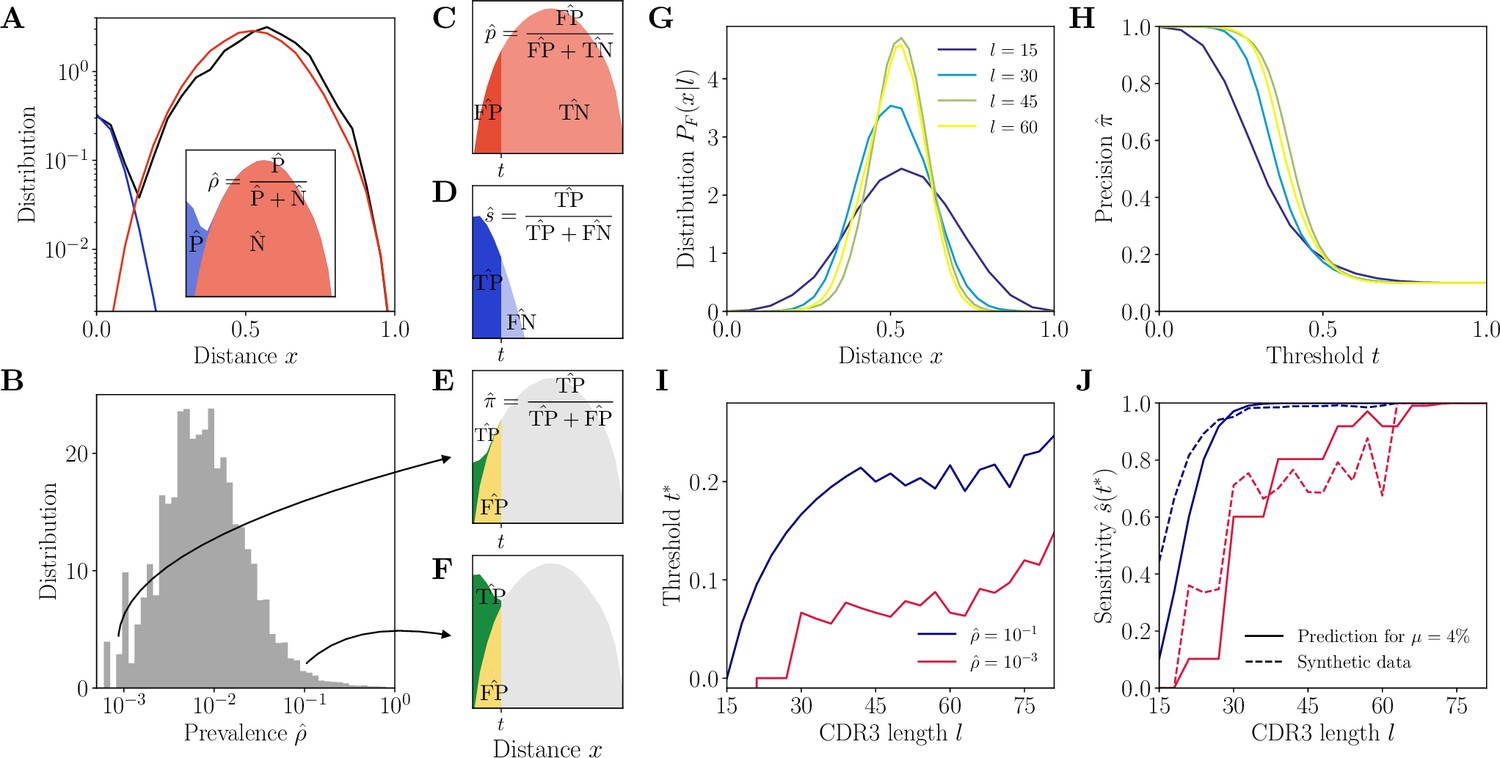
In each class, we call prevalence and denote by the proportion of positive pairs, i.e., the number of positive pairs divided by the total number of pairs. This quantity is unknown in the absence of the ground-truth partition. However, we can estimate it from the statistics of pairwise distances. We compute the Hamming distance of each pair of CDR3s, defined as the number of positions at which the two nucleotide sequences differ. The distribution of these distances normalized by the CDR3 length, denoted by , shows a clear bimodal structure in data (donor 326651 of Briney et al., 2019), with two identifiable components (Figure 2A): the contribution of positive pairs (of proportion ) peaks near and decays quickly, whereas the bell-shaped contribution of negative pairs (of proportion ) peaks around .
Figure 2 with 7 supplements see all
Complementarity determining region 3 (CDR3)-based inference method (HILARy-CDR3).
(A) Example distribution of normalized Hamming distances, , for one class with CDR3 length , V gene IGHV3-9 and J gene IGHJ4 (black). We fit the distribution by a mixture of positive pairs (belonging to the same family, in blue) and negative pairs (belonging to different families, in red). See Figure 2—figure supplement 5 for example fit results across different CDR3 lengths. Inset: the prevalence is defined as a fraction of positive pairs and was estimated to . Data from donor 326651 of Briney et al., 2019. (B) Distribution of the maximum likelihood estimates of prevalence across classes in donor 326651. (C–F) The choice of threshold on the normalized Hamming distance translates to the following a priori characteristics of inference (illustrated here for arbitrarily chosen and ). (C) Fallout rate . The null distribution of all negatives (N=FP + TN) is estimated using the soNNia sequence generation software. (D) Sensitivity . (E–F) Precision . For the same choice of threshold , a low prevalence of (E) leads to lower precision than high prevalence of (F). (G) Model distribution of distances between unrelated sequences, for , computed by the soNNia software. (H) Precision , computed a priori (i.e. before doing the inference) from the model with , , and (colors as in G), as a function of the threshold . For each class and its own inferred and , the threshold is chosen to achieve a desired . (I) High-precision threshold ensuring a priori, as a function of CDR3 length for different values of the prevalence , and , as predicted by the model. (J) Sensitivity at the high-precision threshold , as a function of CDR3 length for different values of the prevalence (colors as in I). Solid lines denote a priori prediction for intermediate mean distance , dashed lines denote actual performance of HILARy-CDR3 in a synthetic dataset.
The prevalence can be formally written as , where denote the sizes of the clonal families in the class, but we do not know these sizes before the partition into families is found. To overcome this issue, we developed a method to estimate a priori, without knowing the family structure (Methods). We do this by fitting the empirical distribution of as a mixture model, , where and are the distributions of distances between positive (T as true) and negative (F as false) pairs (Figure 2C and D), estimated as follows. is computed for each length by generating a large number of unrelated, same-length sequences with the soNNia model of recombination and selection (Isacchini et al., 2021), and calculating the distribution of their pairwise distances (Methods). is approximated by a Poisson distribution, , with adjustable parameter , which is proportional to the average hypermutation rate within the clone. The fit of by the mixture model is performed for each class with an expectation-maximization algorithm which finds maximum likelihood estimates of the prevalence and mean intra-family distance , the only free parameters of the mixture model.
The results of the fit to real data (donor 326651 of Briney et al., 2019) show that varies little between classes, around (Figure 2—figure supplement 1). In contrast, the prevalence varies widely across classes, spanning three orders of magnitude (Figure 2B). In addition, when we examine the classes with increasing CDR3 length , we find that the part of the model distribution corresponding to positive pairs, , varies little, whereas the model distribution over negative pairs becomes more and more peaked around 1/2 (Figure 2 and Figure 2—figure supplement 2), making the two categories more easily separable.
CDR3-based inference method with adaptive threshold
We want to build a classifier between positive and negative pairs using the normalized distance alone, by setting a threshold so that pairs are called positive if , and negative otherwise. Using our model for , for any given we can evaluate the number of true positives () and false negatives () among all positive pairs (), as well as true negatives () and false positives () among the negative pairs (), as schematized in Figure 2—figure supplement 2C and D.
Our goal is to set a threshold that ensures a high precision, , defined as a proportion of true positives among all pairs classified as positive (Figure 2E). In a single-linkage clustering approach, we will join two clusters with at least one pair of positive sequences between them. Therefore, it is critical to limit the number of false positives, which can cause the erroneous merger of large clusters. We can write:
(1)
(2)
and is the estimated sensitivity (Figure 2D), evaluated from the Poisson fit to (Methods):
(3)
Finally, the estimated prevalence is inferred from the distribution as explained above.
Figure 2H shows as a function of for different CDR3 lengths and a fixed value of . For each class, we define the threshold that reaches 99% precision, , by inverting Equation 1. This adaptive threshold depends on the class through the CDR3 length and the prevalence , and it increases with both (Figure 2I): low clonality (small ) means few positive pairs and a smaller adaptive threshold, while short CDR3 means less information and a stricter inclusion criterion.
The predicted sensitivity, , which tells us how much of the positives we are capturing, is shown in Figure 2J. We conclude that for a wide range of parameters, the method is predicted to achieve both high precision and high sensitivity. However, it is expected to fail when the prevalence and the CDR3 length are both low. At the extreme, for small values and , even joining together identical CDR3s () results in poor precision because of convergent recombination (reflected by ).
The resulting procedure, which we call HILARy-CDR3, can be applied to Ig repertoire data through the following steps: (1) group sequences by class; (2) in each class, fit the mixture model to the distribution of pairwise distance to infer and ; (3) invert Equations 1–3 to find the high-precision threshold ; (4) classify positive and negative pairs according to that threshold; (5) complete the partition by applying single-linkage clustering to positive pairs.
Tests on synthetic datasets
So far we have presented a method to set a high-precision threshold with predictable sensitivity, based on estimates from the distribution of distances only. To verify that these performance predictions hold in a realistic inference task, we designed a method to generate realistic synthetic datasets where the clonal family structure is known. This generative method will also be used in the next sections to create a benchmark for comparing different clustering algorithms.
We first estimated the distribution of clonal family sizes from the data of Briney et al., 2019, by applying HILARy-CDR3 with adaptive threshold as described above to classes for which the inference was highly reliable, i.e. for which the predicted sensitivity was . In that limit, clusters are clearly separated and the partition should depend only weakly on the choice of clustering method. The resulting distribution of clone sizes follows a power-law with exponent –2.3.
To create a synthetic lineage, we first draw a random progenitor using the soNNia model for IgH generation (Figure 2—figure supplement 4). We then draw the size of the lineage at random, using the power-law distribution above. Mutations are then randomly drawn on each sequence of the lineage in a way that preserves the mutation sharing patterns observed in families of comparable size from the partitioned data (Figure 2—figure supplement 5). We thus generated 104 lineages and 2.5 · 104 sequences. Note that, while that procedure is partially based on real data, in particular the distribution of lineage sizes and mutational co-occurence structure in the lineages, it uses completely random sequences and mutations. In addition, these empirical observables were inferred from classes that were easy to cluster, ensuring that they are not biased by our inference method, and therefore should not give it an unfair advantage. More details about the procedure are given in the Methods.
We applied the HILARy-CDR3 method to this synthetic dataset. The sensitivity achieved at roughly follows and sometimes even outperforms the predicted one across different values of and (Figure 2J, dashed line), validating the approach and the choice of the adaptive high-precision threshold (the discrepancy is due to the fact that is assumed to be constant in the prediction, while it varies in the dataset). These results also confirm the poor performance of the method at low prevalences and short CDR3s.
Incorporating phylogenetic signal
To improve the performance of HILARy-CDR3, we set out to include the phylogenetic signal encoded in the mutation spectrum of the templated regions of the sequences. Two sequences belonging to the same lineage are expected to share some part of the mutational histories, and therefore sequences with shared mutations are more likely to be in the same lineage.
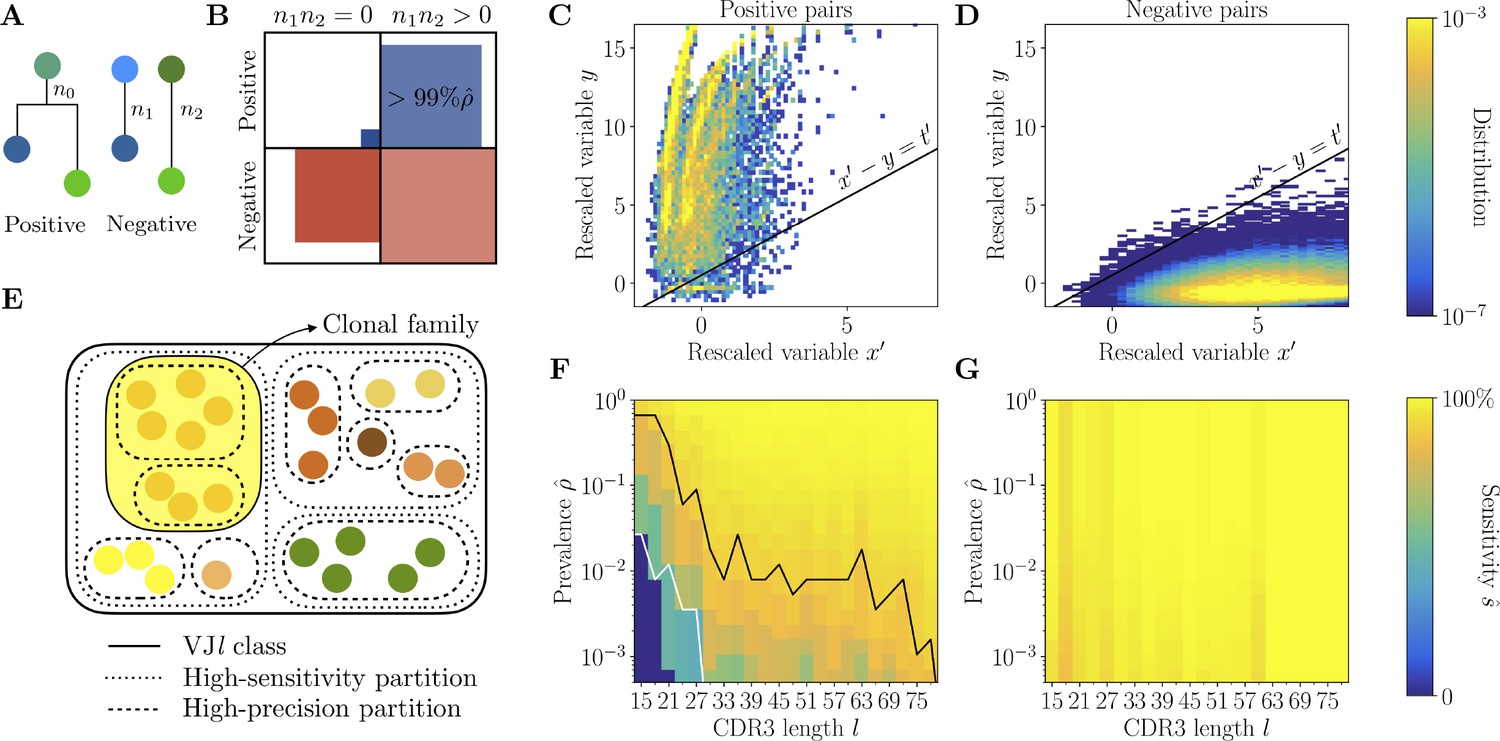
We focus on the template-aligned region of the sequence outside of the CDR3, where we can reliably identify substitutions with respect to the germline. We denote the length of this alignment by , so that the total length of the sequence is . For each pair of sequences, we define as the number of mutations along the templated alignment in the two sequences, the number of mutations shared by the two, and the number of non-shared mutations. Under the hypothesis of shared ancestry, the shared mutations fall on the shared part of the phylogeny, and are expected to be more numerous than under the null hypothesis of independent sequences, where they are a result of random co-occurrence (Figure 3A).
Figure 3 with 2 supplements see all
Full inference method with mutational information.
(A) For a pair of sequences, denote the numbers of mutations along the templated region (V and J), and is the number of shared mutations. For related sequences, corresponds to mutations on the initial branch of the tree, and is expected to be larger than for unrelated sequences, where corresponds to coincidental mutations. (B) Positive and negative pairs are called mutated if both sequences have mutations . Among positive pairs in the synthetic datasets, more than 99% are mutated. (C, D) Distributions of the rescaled variables and (Equation 4), for pairs of synthetic sequences belonging to the same lineage (positive pairs) and sequences belonging to different lineages (negative pairs). The separatrix marks a high-precision (99%) threshold choice. (E) To limit the number of pairwise comparisons we make use of high-precision and high-sensitivity complementarity determining region 3 (CDR3)-based partitions. High precision corresponds to the choice . High sensitivity corresponds to a coarser partition where is set to achieve 90% sensitivity. When the two partitions disagree, mutational information can be used to break the coarse, high-sensitivity partition into smaller clonal families. (F, G) Mutations-based methods achieve high sensitivity across all CDR3 lengths in the synthetic dataset (G), extending the range of applicability with respect to the CDR3-based method (F).
To balance the tradeoff between the information encoded in the templated part of the sequence and the recombination junction, we can compute characteristic scales for the two variables of interest: the number of shared mutations and the CDR3 distance n. Intuitively, in highly mutated sequences, we can expect substantial divergence in the CDR3. At the same time, the number of mutations in the templated regions would increase, possibly leading to more shared mutations. Conversely, sequences with few or no mutations carry no information in the templated region, but we also expect their CDR3 sequences to be nearly identical. To adapt a clustering threshold to the two variables, we compute their expectations under the two assumptions, and define the rescaled variables
(4)
where is the expected value of under the hypothesis that sequences belong to the same lineage (see Methods), and is the expected value of under the hypothesis that they do not. The standard deviations are likewise defined as and (Methods).
For more than 99% of positive pairs, both sequences are mutated, i.e., (Figure 3B). Without loss of sensitivity, we focus on the mutated part of the dataset, since we cannot use for non-mutated sequences. The distributions of and for positive and negative pairs (Figure 3C and D) are well separated, with positive pairs characterized by an overrepresentation of shared mutations. By adding the phylogenetic signal we can identify positive pairs of sequences that have significantly diverged in their CDR3 () but share significantly more mutations than expected (large ).
Computing for each pair of sequences is computationally expensive. To avoid examining all pairs, we first perform two different nested clusterings of each class using the CDR3-based method: the previously described HILARy-CDR3 ‘fine’ partition with threshold that ensures high precision ; and a ‘coarser’ clustering with a high threshold that ensures high estimated sensitivity (Methods and Figure 3E). When lineages are easily separable (e.g. for sufficiently large prevalence and CDR3 length ), these two partitions coincide, and we do not need to compute at all. When they do not coincide, we can use the phylogenetic signal to refine the coarse high-sensitivity partition. We only need to compute for pairs that belong to the same coarse cluster, but not to the same fine cluster: the phylogenetic signal is used to merge the fine-partition clusters into clonal families (Methods and Figure 3—figure supplement 1). This allows us to considerably reduce the number of pairwise comparisons that we need to make between the templated regions of the sequences.
Using and , we classify pairs of sequences as positive (i.e. belonging to the same family) if , and as negative otherwise. We can compute the expected sensitivity on the synthetic data, and find that it reaches values ≥90% across the whole range of prevalence and CDR3 lengths , outperforming HILARy-CDR3 in the low-, low- region (Figure 3F and G). This proves that using the phylogenetic signal significantly improves performance over HILARy-CDR3.
The procedure outlined above, which we call HILARy-full, may be summarized as follows: (1) group sequences by class; (2) apply HILARy-CDR3 twice, once with the high-precision threshold as before to get a fine partition, and once with a high-sensitivity threshold to get a coarse partition, thus obtaining two nested partitions; (3) compute and using Equation 4 only for pairs that belong to the same coarse cluster but to different fine clusters; (4) merge all fine clusters with at least one pair with .
Benchmark of the methods on heavy-chain datasets
We compare our approach to state-of-the-art methods. In addition to our two algorithms—HILARy-CDR3 and HILARy-full—our benchmark includes the alignment-free method of Lindenbaum et al., 2021, partis (Ralph and Matsen, 2016), and the spectral clustering method of SCOPer (Nouri and Kleinstein, 2018). The SCOPer method using V and J gene mutations (Nouri and Kleinstein, 2020) was also tested, but gave worse results (Figure 4—figure supplement 1). Details about the used versions and parameters are referenced in the data availability section. We tested all algorithms on two synthetic datasets: a dataset simulated by the partis package and used in Ralph and Matsen, 2022, to benchmark partis against increasing levels of somatic hypermutations, and the synthetic data described above. That dataset is more realistic in the sense that it represents well the statistics of mutation patterns and, perhaps more importantly, the long-tail distribution of clone sizes observed in the data, with its large impact on the diversity of prevalences, which play an important role in the inference. The partis dataset is generated from a population genetics model. It provides a more independent test since it is not based on data used to develop the method and allows to study performance across different mutation rates.
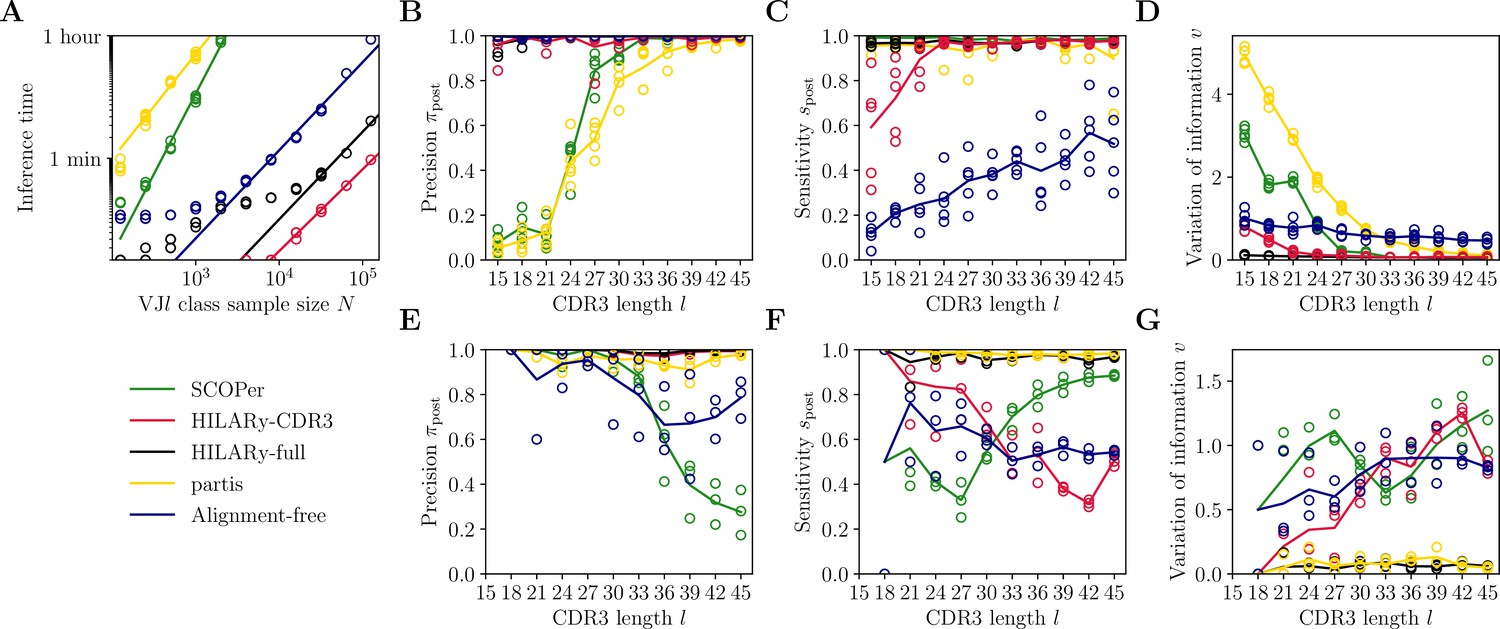
First, we measure the inference time of each algorithm on our synthetic dataset. We find that the inference time is primarily affected by the size of the largest class. Therefore, we measure the inference time using the largest class found in donor 326651 of Briney et al., 2019, with the size of unique sequences. We then apply the methods to a series of subsamples of this class to get the computational time as a function of the subsample size (Figure 4A). We only allowed for runtimes below 1 hr. We find that only three methods achieve satisfactory performance (under an hour): the two methods introduced here, and the alignment-free method. The other two methods, SCOPer and partis, are limited to classes of small size ( and , respectively).
Figure 4 with 2 supplements see all
Benchmark of the alternative methods on synthetic heavy-chain repertoires.
(A) Comparison of inference time using subsamples from the largest class found in donor 326651 from Briney et al., 2019. Comparisons were done on a computer with 14 double-threaded 2.60 GHz CPUs (28 threads in total) and 62.7 Gb of RAM. (B) Clustering precision (post single-linkage clustering of positive pairs), (C) sensitivity , and (D) variation of information as a function of complementarity determining region 3 (CDR3) length in the realistic synthetic dataset generated for this study. Solid lines represent the mean value averaged over five synthetic datasets. (E–G) Same as (B–D) but for the synthetic dataset from Ralph and Matsen, 2022, designed for the development and testing of the partis software. The solid lines represent the mean over the three datasets.
To compare the five algorithms in finite time, we test the accuracy of the methods using synthetic datasets with different CDR3 lengths, and with fixed mutation rate of 10% for the partis dataset (the mutation rate is not adjustable in our synthetic dataset as it mimics that of the data). We focus on short CDR3s, , which are the most challenging for lineage inference. Clonal families with longer CDR3s are easy to reconstruct, and simple methods such as single-linkage clustering with a threshold on mutational distance already work very well (Figure 4—figure supplement 2A–C). Each dataset contains 104 unique sequences, so that the dominant class is typically of size ∼103 and can be handled by all five algorithms. We measure performance using three metrics applied to the resulting partition: pairwise sensitivity (Figure 4B and E), pairwise precision (Figure 4C and F), and the variation of information (Figure 4D and G). Performance measures as a function of mutation rate in the partis dataset are presented in Figure 5. Pairwise sensitivity and precision are a posteriori analogs of the a priori estimates defined before in Equations 1 and 3, now computed after propagating links through the transitivity rule of single-linkage clustering. Their value reflects not only the accuracy of the adaptive threshold but is also affected by the propagation of errors in single-flinkage clustering. Variation of information is a global metric of clustering performance which measures the loss of information from the true partition to the inferred one, and is equal to zero for perfect inference and positive otherwise (Methods).
Figure 5
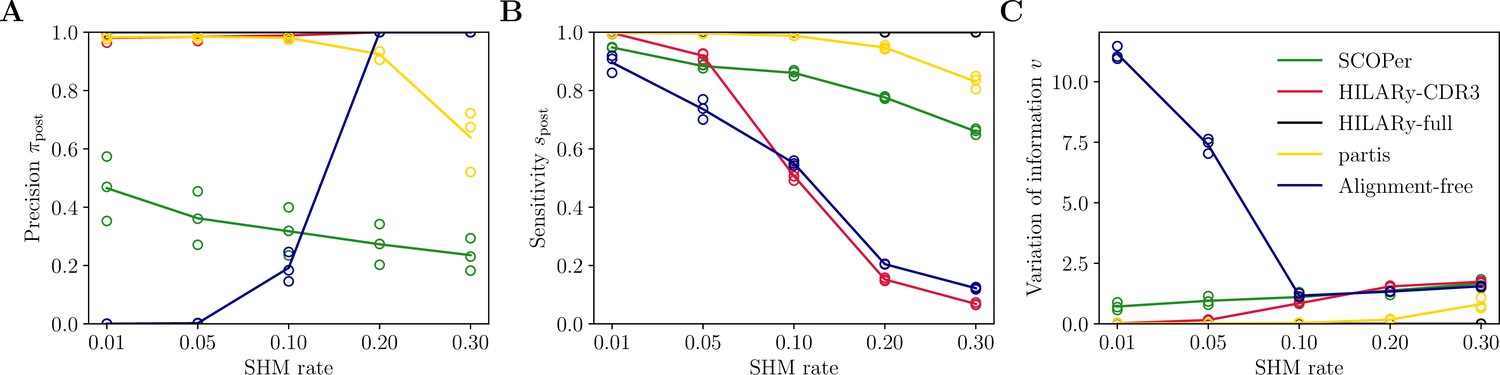
Performance of HILARy as a function of mutation rate for heavy chains, on synthetic data from Ralph and Matsen, 2022, designed for the development and testing of the partis software.
(A) Clustering precision (post single-linkage clustering of positive pairs), (B) sensitivity , and (C) variation of information as a function of mutation rate, using the heavy chain only. Solid lines represent the mean value averaged over the three datasets.
Out of the five tested methods, only HILARy-full achieved both high sensitivity and high precision across all CDR3 lengths and for both synthetic datasets. HILARy-full is the only method reaching both high precision and sensitivity for CDR3s shorter than or equal to 30 nucleotides (Figure 4B), which corresponds to ∼10% of a typical repertoire of productive IgGs (Figure 7A, inset).
The HILARy-CDR3 method achieves high precision everywhere by construction, but only reached good sensitivity for CDR3 lengths 24 and above. The alignment-free method also achieves high precision everywhere, but with low sensitivity, meaning that it erroneously breaks up clonal families into smaller subsets. These three methods achieve good precision, thanks to the use of a null model for the negative pairs. On the contrary, SCOPer has excellent sensitivity everywhere but only achieves high precision for large lengths (), suggesting that it erroneously merges short-CDR3 clonal families. Likewise, partis has high sensitivity but loses precision for short CDR3 on our realistic dataset, meaning that many clonal families are erroneously merged again. Note that our definition of precision and sensitivity differs from those used in Ralph and Matsen, 2022, which explains the differences between the performance measures reported here and in Ralph and Matsen, 2022. On the synthetic datasets from Ralph and Matsen, 2022, HILARy-full is the only method achieving high precision and sensitivity across mutation rates (Figure 5).
The variation of information offers a useful summary of the performance (Figure 4D and G and Figure 5C). According to that measure, only HILARy-full performs well across CDR3 lengths, mutation rates, and datasets. In particular, HILARy presents a clear advantage for challenging regions of the parameter space, such as CDR3 lengths below 30 nucleotides, and mutation rates of 20% and more.
For a typical repertoire, performance can be summarized into a global score by averaging over all CDR3 lengths in proportion of their abundance (assuming inference is perfect for CDR3 lengths larger than 45 regardless of the method). In this task, HILARy-full achieved 99.9% precision and 98.5% sensitivity; partis 93% and 96.9%; and SCOPer 96.6% and 99.1%. These scores are high because only a minority of lineages are difficult to infer. Nonetheless, HILARy-full provides a substantial gain in precision, while SCOPer presents a slight advantage in sensitivity.
We conclude that HILARy-CDR3 should be chosen for its consistently high sensitivity, specificity, and speed. In the case of the largest datasets, the faster HILARy-CDR3 is a useful alternative for long enough CDR3s in realistic repertoires.
Extension to heavy- and light-chain paired data
We added an extension of HILARy to infer lineages from paired-chain repertoires, i.e., with paired light- and heavy-chain sequences. To extend HILARy-CDR3, we generalize the class to a class, using the V and J genes from both the heavy and light chains, and the sum of their CDR3 lengths . We then apply HILARy-CDR3 using the sum of the Hamming distances between the heavy- and light-chain CDR3s, normalized by , as our new paired-chain . The null distribution used is computed with soNNia using a default generation model for paired heavy and light chains. We incorporate the phylogenetic signal of both chains by concatenating their respective template genes, to obtain the total mutation counts , and using as the sum of the lengths of the and genes.
In Figure 6A–C we compare our method to SCOPer and partis on the synthetic dataset from Ralph and Matsen, 2022, as a function of CDR3 length, as our method for generating synthetic sequences could not be easily extended to add random light chains. Performance comparison as a function of mutation rate is presented in Figure 6D–F. HILARy performs better than SCOPer and comparably to partis, which was designed and tested against this dataset.
Figure 6
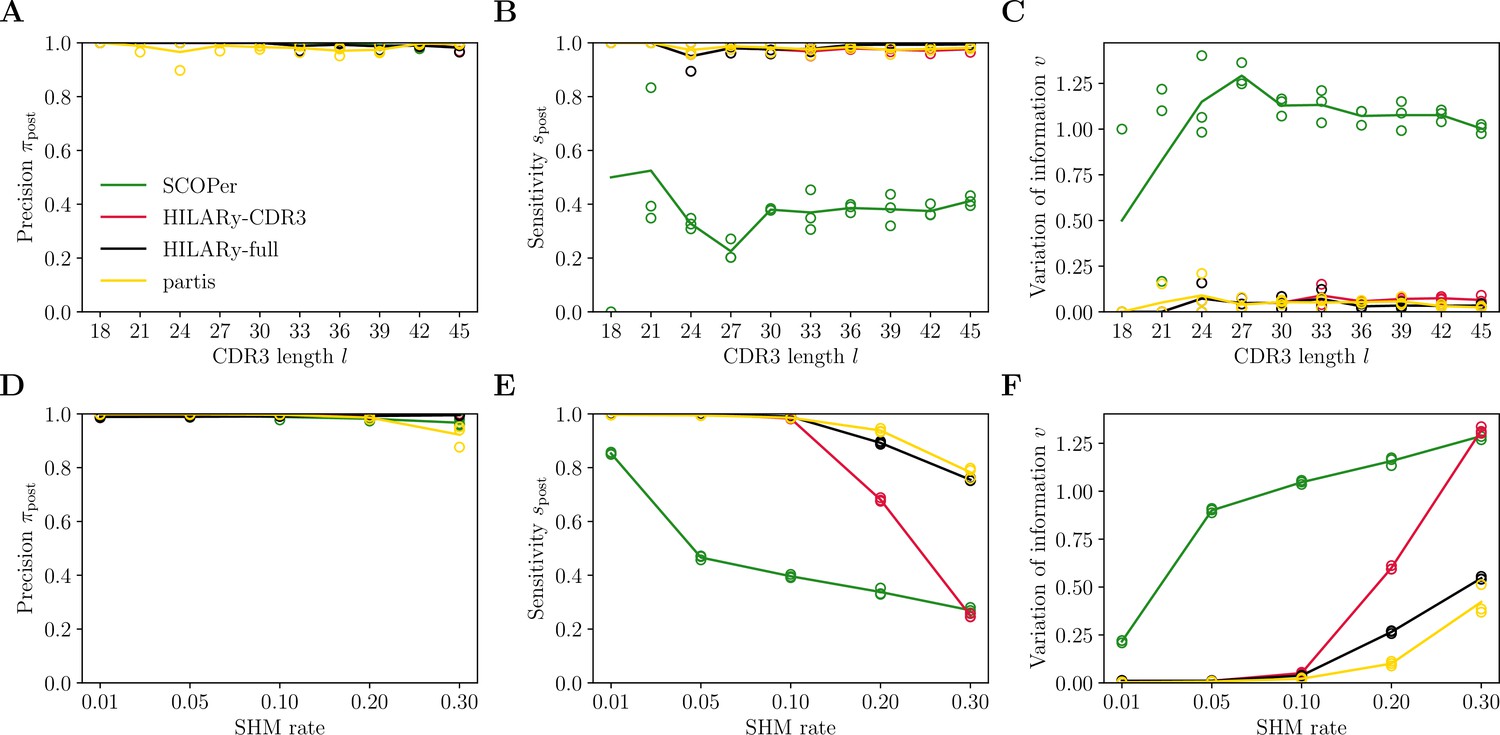
Benchmark of HILARy with paired light and heavy chains.
(A) Clustering precision (post single-linkage clustering of positive pairs), (B) sensitivity , and (C) variation of information as a function of complementarity determining region 3 (CDR3) length , on the synthetic datasets from Ralph and Matsen, 2022, designed for the development and testing of the partis software. (D–F): Same as (A–C) but as a function of mutation rate.
Inference of clonal families in a healthy repertoire
We next use our method to infer the clonal families of the heavy-chain IgG repertoires of healthy donors from Briney et al., 2019. Figure 7 summarizes key properties of the inferred clonal families of donor 326651. We take advantage of the consistency of our method across CDR3 lengths, as evidenced by the benchmark, to study how the lineage structure changes with the CDR3 length. To this end, we divide the dataset into nine quantiles, each containing ∼10% of the total number of sequences (Figure 7A, inset).
Figure 7
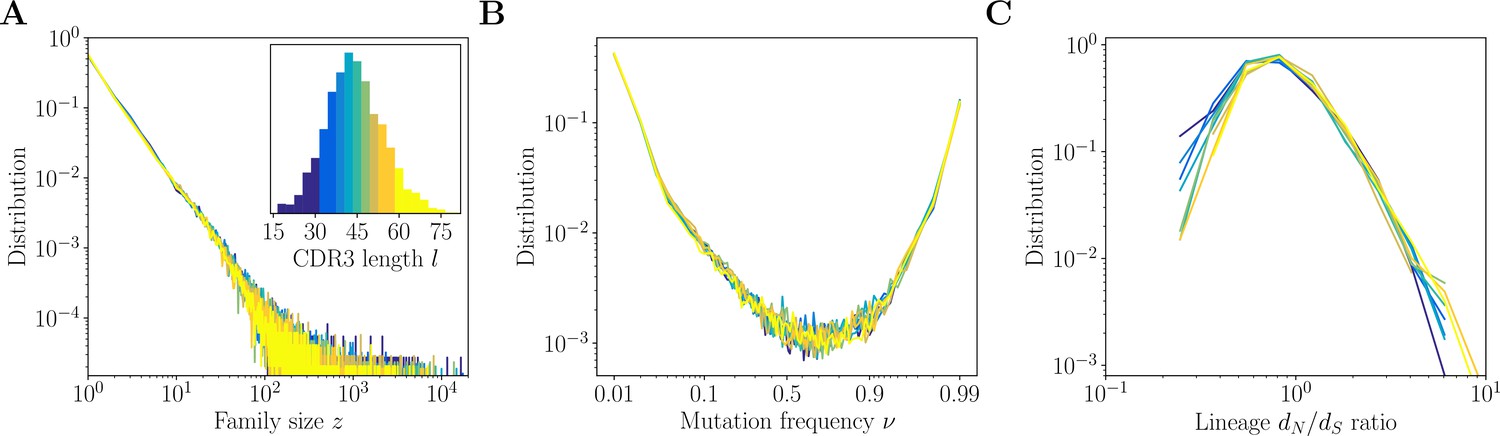
Inference results across complementarity determining region 3 (CDR3) lengths.
Inference results for donor 326651 of Briney et al., 2019, are presented for nine quantiles of the CDR3 distribution, each containing between 8% and 12% of the total number of sequences (corresponding to nine colors in the inset of A). (A) Distributions of family size . All CDR3 length quantiles exhibit universal power-law scaling with exponent −2.3. (B) Site frequency spectra estimated for families of sizes . Families of larger sizes were subsampled to to subtract the influence of varying family sizes. (C) Distribution of lineage ratios computed for polymorphisms in CDR3 regions over all lineages within each nine quantile.
We find that across the nine subsets of the data, the statistics of the lineage structure inferred with the mutations-based method are largely universal. The distribution of the clonal family sizes (Figure 7A) follows a power law across all CDR3 lengths under study, with no significant differences between different lengths. This results generalizes an earlier observation used above for generating synthetic datasets, but which was restricted to high-, high- classes, and justifies a posteriori the use of a universal power law in the generative model.
For the largest families, of size , we compute two intra-lineage summary statistics: the site frequency spectrum, which gives the distribution of frequencies of point mutations within lineages, and the distribution of ratios between non-synonymous and synonymous CDR3 polymorphisms within clonal families (estimated by counting). To avoid the bias of the varying family sizes, we subsampled all families to size .
Under models of neutral evolution with fixed population size, the distribution of point-mutation frequencies goes as . Here, we observe a non-neutral profile of the spectrum, with an upturn at large allele frequencies (Figure 7B). It is a known signature of selection or of rapid clonal expansion (Horns et al., 2019; Nourmohammad et al., 2019). We find that site frequency spectra are universal for all CDR3 lengths, suggesting that the dynamics that give rise to the structure of lineages and the subsequent dynamics that influence the sampling of family members do not depend on the CDR3 length.
The lineage ratio is also largely consistent across CDR3 lengths (Figure 7C), while spanning two orders of magnitude, suggesting a wide gamut of selection forces. We could have expected longer loops to be under stronger purifying selection (lower ) to maintain their specificity and folding. Instead, we observe that short CDR3s have more lineages with low . This may be due to different sequence context and codon composition in short versus long CDR3s. Short junctions are largely templated, whereas long junctions have long, non-templated insertions, and it was shown that templated regions have evolved their codons to minimize the possibility of non-synonymous mutations (Saini and Hershberg, 2015), which would lead to a lower , regardless of selection.
Discussion
Clonal families are the building blocks of memory repertoire shaped by VDJ recombination and subsequent somatic hypermutations and selection. Repertoire sequencing datasets enable new approaches to understand these processes. They allow us to model the different sources of diversity and measure the selection pressures involved. To take full advantage of this opportunity, we need to reliably identify independent lineages.
Here, we introduced a general framework for studying the methods for partitioning high-throughput sequencing of BCR repertoire datasets into clonal families. We have identified the main factors that influence the difficulty of this inference task: low clonality levels and short recombination junctions. We quantified the clonality level using the definition of pairwise prevalence and introduced a method to estimate it a priori, without knowing the partition. We found the prevalence levels across classes to span three orders of magnitude (Figure 2B), unraveling the varying degree of complexity.
We leveraged the soNNia model of VDJ recombination to quantify the CDR3 diversity and constructed a null expectation for the divergence of independent recombination products. This null model enabled the design of a CDR3-based clustering method with an adaptive threshold, HILARy-CDR3, that allows us to keep the precision of inference high across prevalences and CDR3 lengths. Owing to the prefix tree representation of the CDR3 sequences, this method is characterized by very short inference times, thanks to avoiding all pairwise comparisons in single-linkage clustering. As expected, we found that the adaptive threshold choice limits the sensitivity of inference in the regime of short junctions and low prevalence (Figure 3F, below the black line).
To remedy the limitations of the CDR3-based approach, we developed a mutation-based method (HILARy-full). We found that including the phylogenetic signal of shared mutations in highly mutated sequences allows us to properly classify them into lineages despite significant CDR3 divergence. We studied the performance of the method using synthetic data and found significant improvement with respect to HILARy-CDR3: we extended the range of high-precision and high-sensitivity performance to cover all values of prevalence and CDR3 lengths observed in productive data (Figure 3G).
We have compared the two methods developed here with state-of-the-art approaches: the partis (Ralph and Matsen, 2016) and SCOPer (Nouri and Kleinstein, 2018) algorithms, and the alignment-free method (Lindenbaum et al., 2021). Compared to these methods, HILARy relies on a probabilistic model of VDJ recombination and selection, which allows it to explicitly control for precision. This is not possible in partis, which relies on likelihood ratio test to merge candidate clusters together to form families. SCOPer also chooses a clustering threshold based on the pairwise distribution of distances, but without a null model. Another innovation of HILARy-full is to use a null expectation for the number of shared mutations. This feature makes the method robust to varying levels of mutation rates across sequences. HILARy achieves optimal efficiency by combining CDR3-based and mutation-based information. Typically, a large part of the dataset doesn’t require the use of the full method, allowing for greatly reduced inference times. HILARy relies on the soNNia model, which is based on a neural network, and benefits from its expressivity to quantify the purifying selection that modifies the VDJ recombination statistics. We found the performance of this model satisfactory when applied to healthy memory repertoires, in agreement with previous findings (Isacchini et al., 2021; Ruiz Ortega et al., 2023). For subsets of the repertoire with less challenging characteristics, such as low mutation rates, long CDR3s, or high pairwise prevalence , simpler methods can effectively reconstruct clonal families with high precision and sensitivity. As demonstrated in Balashova et al., 2024, single-linkage clustering outperforms state-of-the-art approaches for simulated samples based on real datasets with mutation rates ranging between 1.3% and 5.5%. As part of our clonal inference package, we provide our own implementation of single-linkage clustering based on mutational distance, which leverages a prefix tree representation method to speed up inference. We found this approach to be comparable to HILARy for long CDRs and low mutation rates (Figure 4—figure supplement 2).
Purifying selection is expected to be more pronounced in datasets of disease-specific cohorts and a default soNNia model may overestimate the diversity (Mayer and Callan, 2022) and lead to underestimation of the fallout rate. The inference framework introduced here could still be applied with more sophisticated models of selection, and take advantage of higher levels of clonality that characterize many disease-specific datasets (Nielsen et al., 2020; Turner et al., 2020).
We applied the mutations-based method to infer lineages in a repertoire of a healthy donor, sequenced at great depth (Briney et al., 2019). We took advantage of the consistency our method exhibits across CDR3 lengths to find that the statistics of lineages, including a heavy-tail distribution of family sizes as well as signatures of selection, are universal and independent of the CDR3 length. This result implies that the dynamics of expansion, mutation, and selection are independent of the CDR3 and suggests they are dictated by the rules of affinity maturation and memory formation rather than BCR specificity. It advocates for the use of RNA sequencing data to quantify these general principles (Mayer and Callan, 2022; Hoehn et al., 2019). Identifying clonal families with high accuracy is paramount in such approaches as it avoids the potential biases of different family sizes and varying levels of clonality.
The algorithm for clonal family identification presented here is a robust inference method that enables a reliable partition of a memory B-cell repertoire into independent lineages. Using synthetic datasets we demonstrated it is distinguished by consistently high precision and high sensitivity across different junction lengths and levels of clonality, while very fast compared to previous methods. It is therefore a useful tool to explore the diversity of the repertoires and improves our ability to interpret repertoire sequencing datasets.
Methods
Data preprocessing and alignment
We focus the analysis high-throughput RNA sequencing data of IgH-coding genes (Briney et al., 2019). The sequences were barcoded with unique molecular identifiers (UMIs) to correct for the PCR amplification bias and correct sequencing errors. We aligned raw sequences using presto of the Immcantation pipeline (Vander Heiden et al., 2014) with tools allowing for correcting errors in UMIs and deal with insufficient UMI diversity. Reads were filtered for quality and paired using default presto parameters. We selected only sequences aligned with the IgG primer and therefore the lineage analysis is limited to the IgG subset of the repertoire. Preprocessed data was then aligned to V, D, and J templates from IMGT (Giudicelli et al., 2006) database using IgBlast (Ye et al., 2013). After processing, all UMI count information is discarded and only unique nucleotide sequences are kept for further analysis.
Pairs of sequences stemming from the same VDJ recombination are expected to have the same CDR3 length and align to the same V and J templates. An exception could be caused by a insertion or deletion within the CDR3 that would alter its length as a result of the somatic hypermutation process. Such indel events are rare and generally selected against (Lupo et al., 2022), therefore in what follows we shall assume the effect of these events is negligible. The inference could also be affected by the misalignment of either V or J templates but we previously found the effect of alignment errors to be insignificant for identifying VJ classes (Spisak et al., 2020) (the alignment of the D template is error-prone and unreliable, hence not used in the inference procedure). Importantly, the two simplifications described here would result in decreased sensitivity of inference but are not expected to affect its precision.
Modeling junctional diversity
The extraordinary diversity of VDJ rearrangements can be efficiently described and quantified using probabilistic models of the recombination process as well as subsequent purifying selection. Sequence-based models can assign to each receptor sequence , its total probability of generation, (Murugan et al., 2012; Elhanati et al., 2015; Marcou et al., 2018) as well as a selection factor , inferred so as to match frequencies of the sequences with a model-based distribution (Elhanati et al., 2014; Sethna et al., 2020; Isacchini et al., 2021)
(5)
The model was inferred using unmutated out-of-frame sequences from Briney et al., 2019, using the IGoR software (Marcou et al., 2018). The selection function model was learned using unmutated productive IgM sequences from Briney et al., 2019, using the soNNia software (Isacchini et al., 2021).
The post-selection distribution describes the diversity of the CDR3 regions and in doing so provides an expectation of pairwise distances between unrelated, independently generated sequences of same length (Isacchini et al., 2021). As the soNNia software does not include somatic hypermutations, the underlying assumption is that additional diversity on the CDR3 caused by hypermutations doesn’t affect the distribution of pairwise distances. This assumption is justified by the quality of the fit. We can define
(6)
where stands for (Hamming) distance between sequences and . This definition of the null distribution is a straightforward recipe for its estimation using (Monte Carlo) samples from .
Should differ significantly from the empirical frequencies one can resolve to the following alternative
(7)
the equivalent of the negation distribution as defined in Lindenbaum et al., 2021, and used in our evaluation of the alignment-free method (Lindenbaum et al., 2021) in the method benchmark analysis.
Estimation of pairwise prevalence
Pairwise prevalence is defined as the ratio of pairs of related sequences to the total number of pairs of sequences in a given set. Related sequences share an ancestor and have diverged by independent somatic mutations, post-recombination. Low prevalence can be a major difficulty for any inference procedure as any misassignment (or fallout) will result in a drastic loss of sensitivity or precision. It is instrumental to have an a priori estimate of pairwise prevalence before the families are identified.
To estimate the prevalence from the distribution of distances for a given set of sequences (typically a class or class), we propose the following expectation-maximization procedure. We stipulate the distribution in question is a mixture distribution of two components, , the expectation for unrelated sequences defined as above, and , describing related sequences, modeled using a Poisson distribution
(8)
where μ is the mean divergence per base pair. If a particular CDR3 length is represented by unusually large number of classes, the resultant shape of the positive distribution is often closer to a geometric profile, and is then modeled using , where . In sum
(9)
In a standard fashion, we proceed iteratively by calculating the expected value of the log-likelihood (pairs of sequences indexed by i)
(10)
where the membership probabilities are defined as
(11)
(12)
(13)
We then find the maximum
(14)
and iterate the expectation and maximization steps until convergence, , to obtain .
Results for largest class within each class can be found in Figure 2—figure supplement 3 and results for classes using a geometric distribution can be found in Figure 2—figure supplement 6. Dependence of maximum likelihood prevalence estimates on class size is plotted in Figure 2—figure supplement 7.
HILARy-CDR3
The standard method for CDR3-based inference of lineages proceeds through single-linkage clustering with a fixed threshold on normalized Hamming distance divergence (fraction of differing nucleotides) (Kepler, 2013; Uduman et al., 2014; Yaari and Kleinstein, 2015; Nourmohammad et al., 2019). This crude method suffers from inaccuracy as it loses precision in the case of highly mutated sequences and junctions of short length (see Figure 4—figure supplement 2). If junctions are stored in a prefix tree data structure (Knuth, 2013) single-linkage clustering can be performed without comparing all pairs and hence is typically orders of magnitude faster than alternatives. The prefix tree is a search tree constructed such that all children of a given node have a common prefix, the root of the tree corresponding to an empty string, and leaves corresponding to unique sequences to be clustered. To find neighbors of a given sequence it suffices to traverse the prefix tree from the corresponding leaf upward and compute the Hamming distance at branchings. This method limits the number of unnecessary comparisons and greatly improves the speed of Hamming distance-based clustering (Boytsov, 2011). We implement the prefix tree structure to accommodate CDR3 sequences. Briefly, all the CDR3 sequences of identical length are stored in the leaves of a prefix tree (Navarro, 2001; Boytsov, 2011), implemented as a quaternary tree where each edge is labeled by a nucleobase (A, T, C, or G). The neighbors of a specific sequence are found by traversing the tree from top to bottom, exploring only the branches that are under a given Hamming distance from the sequence. Clusters are obtained by iterating this procedure and removing all the neighbors from the prefix tree until no sequences remain. The package is coded in C++ with a Python interface and is available independently. The time performance of this method for high-sensitivity and high-specificity partitions is studied as a part of the method benchmark analysis.
We take advantage of the speed of a prefix tree-based clustering to perform single-linkage clustering. Besides the algorithmic speed-up afforded by the prefix tree, the difference with previous methods is that we use an adaptive threshold. For any dataset, we define two CDR3-based partitions, high-sensitivity and high-precision clustering, corresponding to two choices of threshold.
The high-precision partition is obtained by setting the threshold to as the largest such , with (99% precision), where is given by Equation 1–3. To get the high-sensitivity partition, we set the threshold to , the smallest such that , where (90% sensitivity), where is given by Equation 3.
We apply these thresholds to the single-linkage clustering described above to generate the precise and sensitive partitions, which are then used by the mutations-based method to find an optimal partition that merges the fine clusters within the coarse clusters (Methods and Figure 3—figure supplement 1). We refer to the high-precision partition from the CDR3 alone as HILARy-CDR3, and the mutation-based method as HILARy-full.
Finally, the structure of families leads to propagation of errors that lowers the precision with respect to the a priori estimate . Denoting family size as , one error accounted for in causes, on average, extra errors by merging two families. If the a priori precision is high, we can neglect the second order effect of these two families simultaneously affected by other pairs. Therefore the expected precision (Equation 1) of the resulting partition reads
(15)
where we assumed . For and this formula gives .
Synthetic data generation
To generate synthetic data we make use of the statistics of tree topologies of the lineages identified in the high-sensitivity and high-precision regime of CDR3-based inference from the data (yellow region above the black line in Figure 3F). We denote the set of these lineages by . We assume that to good approximation the mutational process and the selection forces that shaped the mutational landscape in these lineages do not depend on the CDR3 length.
To test the performance of different inference methods across CDR3 lengths, we build synthetic datasets of fixed length.
In the first step, we choose the number of families . We then draw independent family sizes from the family size distribution of the form observed in healthy datasets
(16)
where . In the next step, we assign a naive progenitor to each lineage by sampling from the distribution, selecting sequences with a prescribed length (Figure 2—figure supplement 4). We then choose a lineage in the set of reconstructed lineages at random among lineages of size (or, for large sizes, the lineage of the closest size smaller than ). To create a lineage with the same mutation patterns as the real data, we then identify all unique mutations in the lineage from using standard alignment and tree recontruction methods described in Spisak et al., 2020, and for each mutation denote the labels of members of the lineage that carry it. For each mutation, this defines a configuration of labels, one of possible. We subsequently loop through observed configurations and choose new positions for all mutations to apply them to the synthetic progenitors of the ancestor, using the position- and context-dependent model of Spisak et al., 2020. The number of mutations assigned to a given configuration is rescaled by a factor where is the templated length of the synthetic ancestral sequence and is the templated length of the model lineage from .
This way a synthetic lineage preserves all properties of the lineages of long CDR3s found in the data, particularly the mutational spectra (Figure 2—figure supplement 5) except for the ancestral sequences and the identity of mutations.
HILARy-full
We compute the expected distributions of the CDR3 Hamming distance , and the number of shared mutations , under a uniform mutation rate assumption. In other words, we assume that the probability that a given position was mutated, given a mutation happened somewhere in a sequence of length , equals (we know this not to be true, see, e.g., Spisak et al., 2020, but it allows for simple computations). It follows that the probability that a given position has not mutated once in a series of mutations is .
Expectation of under the null hypothesis
For shared mutations, under the null hypothesis (we operate under the null hypothesis here since otherwise to estimate we would need to make assumptions about the law that governs B-cell phylogeny topologies), the likelihood reads
(17)
where the probability that the same position independently mutated in series of and mutations is
(18)
In the limit of large , we have at leading order
(19)
(20)
where the last approximation assumes , which holds when mutation rates are small. Therefore, may be approximated by a Poisson distribution of parameter , yielding:
(21)
Expectation of under the hypothesis of related sequences
The divergence of two CDR3s is interpreted as divergent mutations under the hypothesis that and are related. These mutations were harbored in parallel with mutations that occurred in the templated regions ( mutations arrived before the divergence of the two sequences began).
Under the assumption of a uniform mutation rate, the mutations inform the prediction of the number of mutations expected in the CDR3. Indeed, they are related through a hidden variable, the expected number of mutations per base pair, denoted . Integrating over this quantity we obtain
(22)
where we convolute the positive distribution (Equation 8),
(23)
and, using the Bayes rule under uniform prior over ,
(24)
The result is a negative binomial distribution,
(25)
with
(26)
Merging fine-partition clusters
HILARy-full relies on the results (Equation 26) and (Equation 21) to define the rescaled variables (Equation 4)
(27)
We expect , for unrelated sequences, and , for related sequences. So we expect for unrelated sequences, and for related sequences. We use as a distance for single-linkage clustering, with adaptive threshold to control performance. The threshold is chosen to achieve a desired precision of as in HILARy-CDR3. To this end we use soNNia-based estimate of null distribution (Equation 6), the data-derived distribution of the number of mutations, , and further assume to compute the null distribution . We can now choose a target and compute such that using Equations 1–3, the prevalence inferred as explained earlier in the CDR3-based method, and assuming . As the computation of depends on the inferred prevalence, we use this procedure only for classes with enough sequences for a reliable (Figure 3—figure supplement 2), namely for sizes larger than 100. For smaller sizes the threshold was set to the default value of 0.
To reduce the number of pairwise computations, we do not apply single-linkage clustering directly, but instead merge fine-partition clusters within coarse-partition clusters, where the fine and coarse partitions were previously obtained using the CDR3-based method (see section HILARy-CDR3). Specifically, we compute for all pairs of sequences that belong to the same coarse cluster, but to different fine clusters. Two fine-partition clusters are then merged if there exist any two sequences belonging to each of the two clusters for which . Note that this is equivalent to performing single-linkage clustering on all sequences using the distance for pairs inside a precise cluster and otherwise.
Evaluation methods
In this section, we introduce the variation of information , used for evaluating alternative methods for clonal family inference in the benchmark analysis. It is a useful summary statistic to quantify the performance of inference as it is affected by its precision as well as sensitivity (Brown et al., 2007). Variation of information measures the information loss from the true partition to the inference result (Zurek, 1989; Meilă, 2003). To define the variation of information we first introduce the entropy of a partition of sequences into clusters as
(28)
where denotes the number of sequences in cluster . The mutual information between two partitions and can then be computed as
(29)
where denotes the number of overlapping elements between cluster in partition and cluster in partition . Finally, variation of information is given by
(30)
Variation of information is a metric in the space of possible partitions since it is non-negative, , symmetric, , and obeys the triangle inequality, for any three partitions (Zurek, 1989).
Code and data availability
We used version 1.2.0 for spectral SCOPer, 1.3.0 for SCOper using the V and J mutation presented in Figure 4—figure supplement 1, version 1.2.0 for HILARy, version 0.16.0 for partis, and the code from this repository https://bitbucket.org/kleinstein/projects/src/master/Lindenbaum2020/Example.ipynb for the alignment-free method. The HILARy tool with Python implementations of the CDR3 and mutation-based methods introduced above can be found at https://github.com/statbiophys/HILARy (copy archived at Athènes, 2024). The standalone prefix tree implementation can be found at https://github.com/statbiophys/ATrieGC (copy archived at Dupic, 2024). A complete guide to our benchmark procedure can be found in the README of the folder https://github.com/statbiophys/HILARy/tree/main/data_with_scripts where we make available scripts to infer lineages and reproduce the benchmark figures of this article. We also upload this folder with all input and output data at https://zenodo.org/records/10676371.
Data availability
The current manuscript is a computational study, so no data have been generated for this manuscript. All data used is publicly available. The HILARy tool with Python implementations of the CDR3 and mutations-based methods introduced above can be found at https://github.com/statbiophys/HILARy (copy archived at Athènes, 2024). The standalone prefix tree implementation can be found at https://github.com/statbiophys/ATrieGC (copy archived at Dupic, 2024). A complete guide to our benchmark procedure can be found in the README of the folder https://github.com/statbiophys/HILARy/tree/main/data_with_scripts where we make available scripts to infer lineages and reproduce the benchmark figures of this article. We also upload this folder with all input and output data at https://zenodo.org/records/10676371.
-
ZenodoCombining mutation and recombination statistics to infer clonal families in antibody repertoires.https://doi.org/10.5281/zenodo.10676370
-
NCBI BioProjectID PRJNA406949. Uniqueness, commonality and exceptional diversity in the baseline human antibody repertoire.
References
-
Indexing methods for approximate dictionary searchingACM Journal of Experimental Algorithmics 16:1963191.https://doi.org/10.1145/1963190.1963191
-
Automated protein subfamily identification and classificationPLOS Computational Biology 3:e160.https://doi.org/10.1371/journal.pcbi.0030160
-
Resource competition determines selection of B cell repertoiresJournal of Theoretical Biology 212:333–343.https://doi.org/10.1006/jtbi.2001.2379
-
Inferring processes underlying B-cell repertoire diversityPhilosophical Transactions of the Royal Society of London. Series B, Biological Sciences 370:20140243.https://doi.org/10.1098/rstb.2014.0243
-
AID in antibody diversification: there and back againTrends in Immunology 41:586–600.https://doi.org/10.1016/j.it.2020.04.009
-
IMGT/LIGM-DB, the IMGT comprehensive database of immunoglobulin and T cell receptor nucleotide sequencesNucleic Acids Research 34:D781–D784.https://doi.org/10.1093/nar/gkj088
-
BookThe: generating all trees–history of combina torial generationIn: Knuth DE, editors. Art of Computer Programming. Addison-Wesley Professional. pp. 1–272.
-
Alignment free identification of clones in B cell receptor repertoiresNucleic Acids Research 49:e21.https://doi.org/10.1093/nar/gkaa1160
-
Learning the statistics and landscape of somatic mutation-induced insertions and deletions in antibodiesPLOS Computational Biology 18:e1010167.https://doi.org/10.1371/journal.pcbi.1010167
-
High-throughput immune repertoire analysis with IGoRNature Communications 9:561.https://doi.org/10.1038/s41467-018-02832-w
-
A guided tour to approximate string matchingACM Computing Surveys 33:31–88.https://doi.org/10.1145/375360.375365
-
Human B cell clonal expansion and convergent antibody responses to SARS-CoV-2Cell Host & Microbe 28:516–525.https://doi.org/10.1016/j.chom.2020.09.002
-
Fierce selection and interference in B-cell repertoire response to chronic HIV-1Molecular Biology and Evolution 36:2184–2194.https://doi.org/10.1093/molbev/msz143
-
Likelihood-based inference of B cell clonal familiesPLOS Computational Biology 12:e1005086.https://doi.org/10.1371/journal.pcbi.1005086
-
Inference of B cell clonal families using heavy/light chain pairing informationPLOS Computational Biology 18:e1010723.https://doi.org/10.1371/journal.pcbi.1010723
-
V(D)J recombination: mechanisms of initiationAnnual Review of Genetics 45:167–202.https://doi.org/10.1146/annurev-genet-110410-132552
-
Learning the heterogeneous hypermutation landscape of immunoglobulins from high-throughput repertoire dataNucleic Acids Research 48:10702–10712.https://doi.org/10.1093/nar/gkaa825
-
Germinal centersAnnual Review of Immunology 40:413–442.https://doi.org/10.1146/annurev-immunol-120419-022408
-
Quantifying selection in high-throughput immunoglobulin sequencing data setsNucleic Acids Research 40:e134.https://doi.org/10.1093/nar/gkn000
-
IgBLAST: an immunoglobulin variable domain sequence analysis toolNucleic Acids Research 41:W34–W40.https://doi.org/10.1093/nar/gkt382
Article and author information
Author details
Aleksandra M Walczak

Funding
European Research Council (COG 724208)
- Natanael Spisak
- Thomas Dupic
- Thierry Mora
- Aleksandra M Walczak
Agence Nationale de la Recherche (ANR-19-CE45-0018 `RESP- REP')
- Natanael Spisak
- Thomas Dupic
- Thierry Mora
- Aleksandra M Walczak
Deutsche Forschungsgemeinschaft (CRC 1310 `Predictability in Evolution'.)
- Natanael Spisak
- Gabriel Athènes
- Thomas Dupic
- Thierry Mora
- Aleksandra M Walczak
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
The study was supported by European Research Council COG 724208 and ANR-19-CE45-0018 ‘RESP- REP’ from the Agence Nationale de la Recherche grants and DFG grant CRC 1310 ‘Predictability in Evolution’.
Copyright
© 2024, Spisak et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 1,131
- views
-
- 174
- downloads
-
- 10
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 10
- citations for umbrella DOI https://doi.org/10.7554/eLife.86181
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Combining mutation and recombination statistics to infer clonal families in antibody repertoires
eLife 13:e86181.
https://doi.org/10.7554/eLife.86181




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}