Sequence co-evolution gives 3D contacts and structures of protein complexes
- Harvard University, United States
- Technische Universität München, Germany
- University of Tübingen, Germany
- Bijvoet Center for Biomolecular Research, Utrecht University, Netherlands
- Memorial Sloan Kettering Cancer Center, United States
Abstract
Protein–protein interactions are fundamental to many biological processes. Experimental screens have identified tens of thousands of interactions, and structural biology has provided detailed functional insight for select 3D protein complexes. An alternative rich source of information about protein interactions is the evolutionary sequence record. Building on earlier work, we show that analysis of correlated evolutionary sequence changes across proteins identifies residues that are close in space with sufficient accuracy to determine the three-dimensional structure of the protein complexes. We evaluate prediction performance in blinded tests on 76 complexes of known 3D structure, predict protein–protein contacts in 32 complexes of unknown structure, and demonstrate how evolutionary couplings can be used to distinguish between interacting and non-interacting protein pairs in a large complex. With the current growth of sequences, we expect that the method can be generalized to genome-wide elucidation of protein–protein interaction networks and used for interaction predictions at residue resolution.
https://doi.org/10.7554/eLife.03430.001eLife digest
DNA is often referred to as the ‘blueprint of life’, as this molecule contains the instructions that are required to build a living organism from a single cell. But these instructions largely play out through the proteins that DNA encodes; and most proteins do not work alone. Instead they come together in different combinations, or complexes, and a single protein may participate in many complexes with different activities.
Proteins are so small that it is difficult to get clear information about what they look like. Visualizing protein complexes is even harder. Most protein–protein interactions remain poorly understood, even in the best-studied organisms such as humans, yeast, and bacteria.
Proteins are made from smaller molecules, called amino acids, strung together one after the other. The order in which different amino acids are arranged in a protein determines the protein’s shape and ultimately its function. Like DNA, protein sequences can change over time. Sometimes, the sequence of one protein changes in a way that prevents it binding to another protein. If these two proteins must work together for an organism to survive, the second protein will often develop a compensating change that allows the protein–protein complex to reform.
Identifying pairs of changes in the sequences of pairs of proteins suggests that the two proteins interact and gives some information about how the proteins fit together. Different species can have copies of the same proteins that have slightly different sequences. Since the DNA sequences from many different organisms are already known, there are now many opportunities to find sites in pairs of proteins that have evolved together, or co-evolved, over time.
To find sites that seem to have co-evolved, Hopf et al. used a computer program based on an approach from statistical physics to look at pairs of proteins that were already known to form complexes. Co-evolving sites were found in over 300 pairs of proteins; including 76 where the structure of the complex was already known. When sites that were predicted to be co-evolving were then mapped to these known complex structures, the co-evolving sites were remarkably close to the true protein–protein contacts. This indicates that the information from the co-evolved sequences is sufficient to show how two proteins fit together.
Hopf et al. then turned their attention to 82 pairs of proteins that were thought to interact, but where a structure was unavailable. For 32 of these pairs, structures of the entire complex could be predicted, showing how the two proteins might interact. Furthermore, when other researchers subsequently worked out the structure of one of these complexes, the prediction was a good match to the solved complex structure.
The machinery of life is largely made up of proteins, which must interact in ever-changing but precise ways. The new methods developed by Hopf et al. provide a new way to discover and investigate the details of these interactions.
https://doi.org/10.7554/eLife.03430.002Introduction
A large part of biological research is concerned with the identity, dynamics, and specificity of protein interactions. There have been impressive advances in the three-dimensional (3D) structure determination of protein complexes which has been significantly extended by homology-inferred 3D models (Mosca et al., 2012; Webb et al., 2014) (Hart et al., 2006; Zhang et al., 2012). However, there is still little, or no, 3D information for ∼80% of the currently known protein interactions in bacteria, yeast, or human, amounting to at least ∼30,000/∼6000 incompletely characterized interactions in human and Escherichia coli, respectively (Mosca et al., 2012; Rajagopala et al., 2014). With the rapid rise in our knowledge of genetic variation at the sequence level, there is an increased interest in linking sequence changes to changes in molecular interactions, but current experimental methods cannot match the increase in the demand for residue-level information of these interactions. One way to address the knowledge gap of protein interactions has been the use of hybrid, computational–experimental approaches that typically combine 3D structural information at varying resolutions, homology models, and other methods (de Juan et al., 2013), with force field-based approaches such as RosettaDock, residue cross-linking, and data-driven approaches that incorporate various sources of biological information (Kortemme and Baker, 2002; Dominguez et al., 2003; Kortemme and Baker, 2004; Kortemme et al., 2004; Svensson et al., 2004; Chaudhury et al., 2011; Schneidman-Duhovny et al., 2012; Velazquez-Muriel et al., 2012; Karaca and Bonvin, 2013; Rodrigues et al., 2013; Webb et al., 2014). However, most of these approaches depend on the availability of prior knowledge and many biologically relevant systems remain out of reach, as additional experimental information is sparse (e.g., membrane proteins, transient interactions, and large complexes). One promising computational approach is to use evolutionary analysis of amino acid co-variation to identify close residue contacts across protein interactions, which was first used 20 years ago (Gobel et al., 1994; Pazos and Valencia, 2001), and subsequently used also to identify protein interactions (Pazos et al., 1997; Pazos and Valencia, 2002). Others have used some evolutionary information to improve a machine learning approach to developing docking potentials (Faure et al., 2012; Andreani et al., 2013; Andreani and Guerois, 2014). These previous approaches relied on a local model of co-evolution that is less likely to disentangle indirect and therefore incorrect correlations from the direct co-evolution, as has been described in work on residue–residue interactions in single proteins (Marks et al., 2012). More recently, reports using a global model have been successful in identifying residue interactions from evolutionary co-variation, for instance between histidine kinases and response regulators (Burger & van Nimwegen, 2008; Skerker et al., 2008; Weigt et al., 2009), and this approach has only recently been generalized and used to predict contacts between proteins in complexes of unknown structure, in an independent effort parallel to this work (Ovchinnikov et al., 2014). In principle, just a small number of key residue–residue contacts across a protein interface would allow computation of 3D models and provide a powerful, orthogonal approach to experiments.
Since the recent demonstration of the use of evolutionary couplings (ECs) between residues to determine the 3D structure of individual proteins (Marks et al., 2011; Morcos et al., 2011; Aurell and Ekeberg, 2012; Jones et al., 2012; Kamisetty et al., 2013), including integral membrane proteins (Hopf et al., 2012; Nugent and Jones, 2012), we reason that an evolutionary statistical approach such as EVcouplings (Marks et al., 2011) could be used to determine co-evolved residues between proteins. To assess this hypothesis, we built an evaluation set based on all known binary protein interactions in E. coli that have 3D structures of the complex as recently summarized (Rajagopala et al., 2014). We develop a score for every predicted inter-protein residue pair based on the overall inter-protein EC score distributions resulting in accurate predictions for the majority of top ranked inter-protein EC pairs (inter-ECs) and sufficient to calculate accurate 3D models of the complexes in the docked subset (Figure 1A). This approach was then used to predict evolutionary couplings for 32 complexes of unknown 3D structures that have a sufficient number of sequences. Predictions include the structurally unsolved interactions between the a-, b-, and c-subunits of ATP synthase, which are supported by previously published experimental results.
Figure 1 with 1 supplement see all
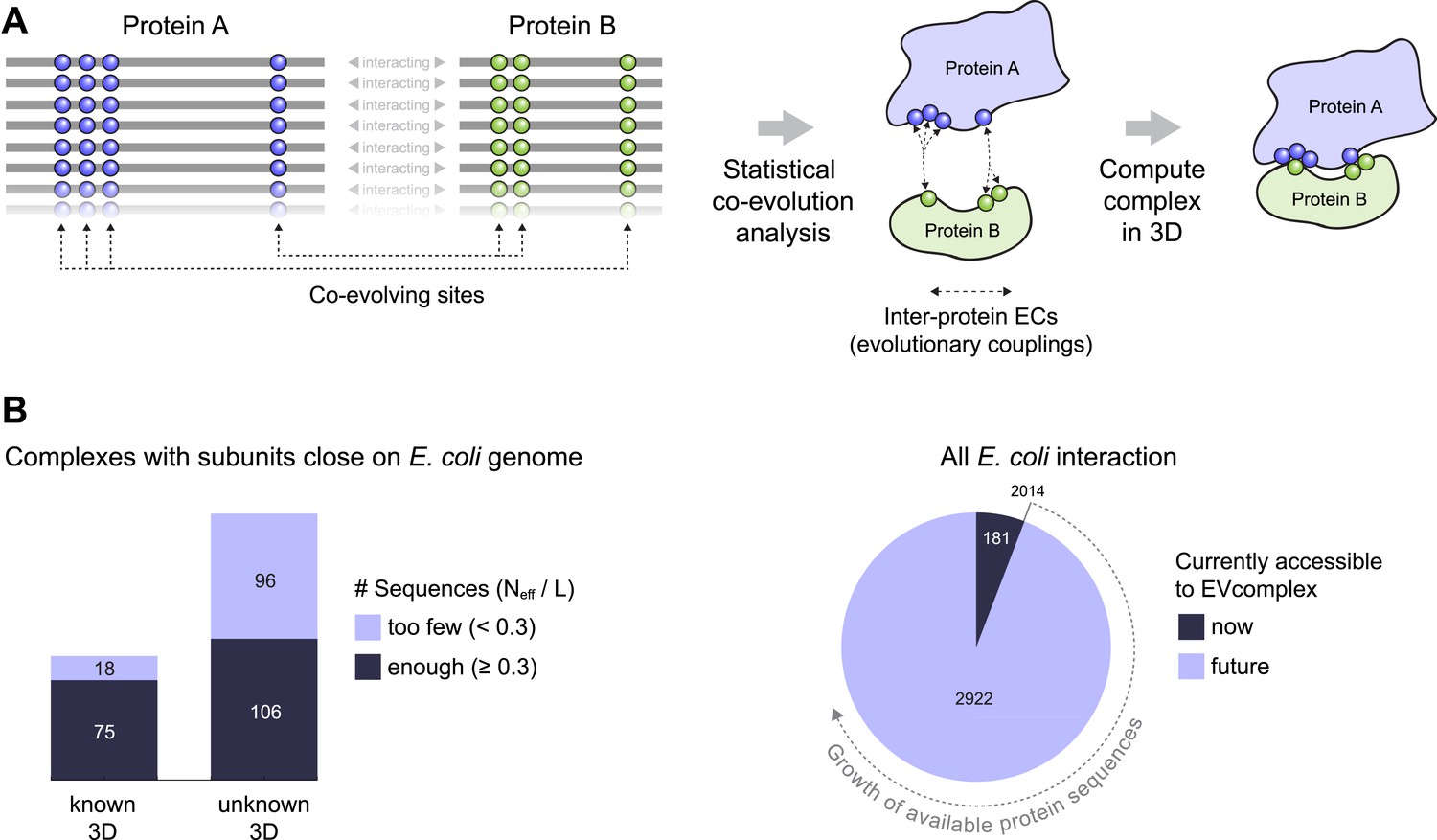
Co-evolution of residues across protein complexes from the evolutionary sequence record.
(A) Evolutionary pressure to maintain protein–protein interactions leads to the co-evolution of residues between interacting proteins in a complex. By analyzing patterns of amino acid co-variation in an alignment of putatively interacting homologous proteins (left), evolutionary couplings between co-evolving inter-protein residue pairs can be identified (middle). By defining distance restraints on these pairs, the 3D structure of the protein complex can be inferred using docking software (right). (B) Distribution of E. coli protein complexes of known and unknown 3D structure where both subunits are close on the bacterial genome (left), allowing sequence pair matching by genomic distance. For a subset of these complexes, sufficient sequence information is available for evolutionary couplings analysis (dark blue bars). As more genomic information is created through on-going sequencing efforts, larger fractions of the E. coli interactome become accessible for EVcomplex (right). A detailed version of the workflow used to calculate all E. coli complexes currently for which there is currently enough sequence information is shown in Figure1—figure supplement 1.
Results
We first investigated whether co-evolving residues between proteins are close in three dimensions by assessing blinded predictions of residue co-evolution against experimentally determined 3D complex structures. We follow this evaluation by then predicting co-evolved residue pairs of interacting proteins that have no known complex structure.
Extension of the evolutionary couplings method to protein complexes
To compute co-evolution across proteins, individual protein sequences must be paired up with each other that are presumed to interact, or being tested to see if they interact. Without this condition, proteins could be paired together that do not in fact interact with each other and therefore detection of co-evolution would be compromised. Given that the evolutionary couplings method depends on large numbers of diverse sequences (Hopf et al., 2012), some assumption must be made about which proteins interact with each other in homologous sequences in other species. Since it is challenging to know a priori whether particular interactions are conserved across many millions of years in thousands of different organisms, we use proximity of the two interacting partners on the genome as a proxy for this, with the goal of reducing incorrect pairings.
To assemble the broadest possible data sets to test the approach and make predictions, we take all known interacting proteins assembled in a published data set that contains ∼3500 high-confidence protein interactions in E. coli (Rajagopala et al., 2014). After removing redundancy and requiring close genome distance between the pairs of proteins this results in 326 interactions, see ‘Materials and methods’ (Figure 1B, Figure 1—figure supplement 1, Supplementary file 1 and 2),
The paired sequences are concatenated and statistical co-evolution analysis is performed using EVcouplings (Marks et al., 2011; Morcos et al., 2011; Aurell and Ekeberg, 2012), that applies a pseudolikelihood maximization (PLM) approximation to determine the interaction parameters in the underlying maximum entropy probability model (Balakrishnan et al., 2011; Ekeberg et al., 2013; Kamisetty et al., 2013), simultaneously generating both intra- and inter-EC scores for all pairs of residues within and across the protein pairs (Figure 1A). Evolutionary coupling calculations in previous work have indicated that this global probability model approach requires a minimum number of sequences in the alignment with at least 1 non-redundant sequence per residue (Marks et al., 2011; Morcos et al., 2011; Hopf et al., 2012; Jones et al., 2012; Kamisetty et al., 2013). Our current approach allows complexes with fewer available sequences to be assessed (minimum at 0.3 non-redundant sequences per residue) by using a new quality assessment score to assess the likelihood of the predicted contacts to be correct. The EVcomplex score is based on the knowledge that most pairs of residues are not coupled and true pair couplings are outliers in the high-scoring tail of the distribution (See ‘Materials and methods’, Figure 2A,B, Figure 2—figure supplement 1 and 2). The score can intuitively be understood as the distance from the noisy background of non-significant pair scores, normalized by the number of non-redundant sequences and the length of the protein (‘Materials and methods’, equations 1 and 2). If the number of sequences per residue is not controlled for, there is a large bias in the results, overestimating performance with low numbers of sequences (Figure 2B,C). The precise functional form of the correction for low numbers of sequences was chosen non-blindly after observing the dependencies in the test set.
Figure 2 with 8 supplements see all
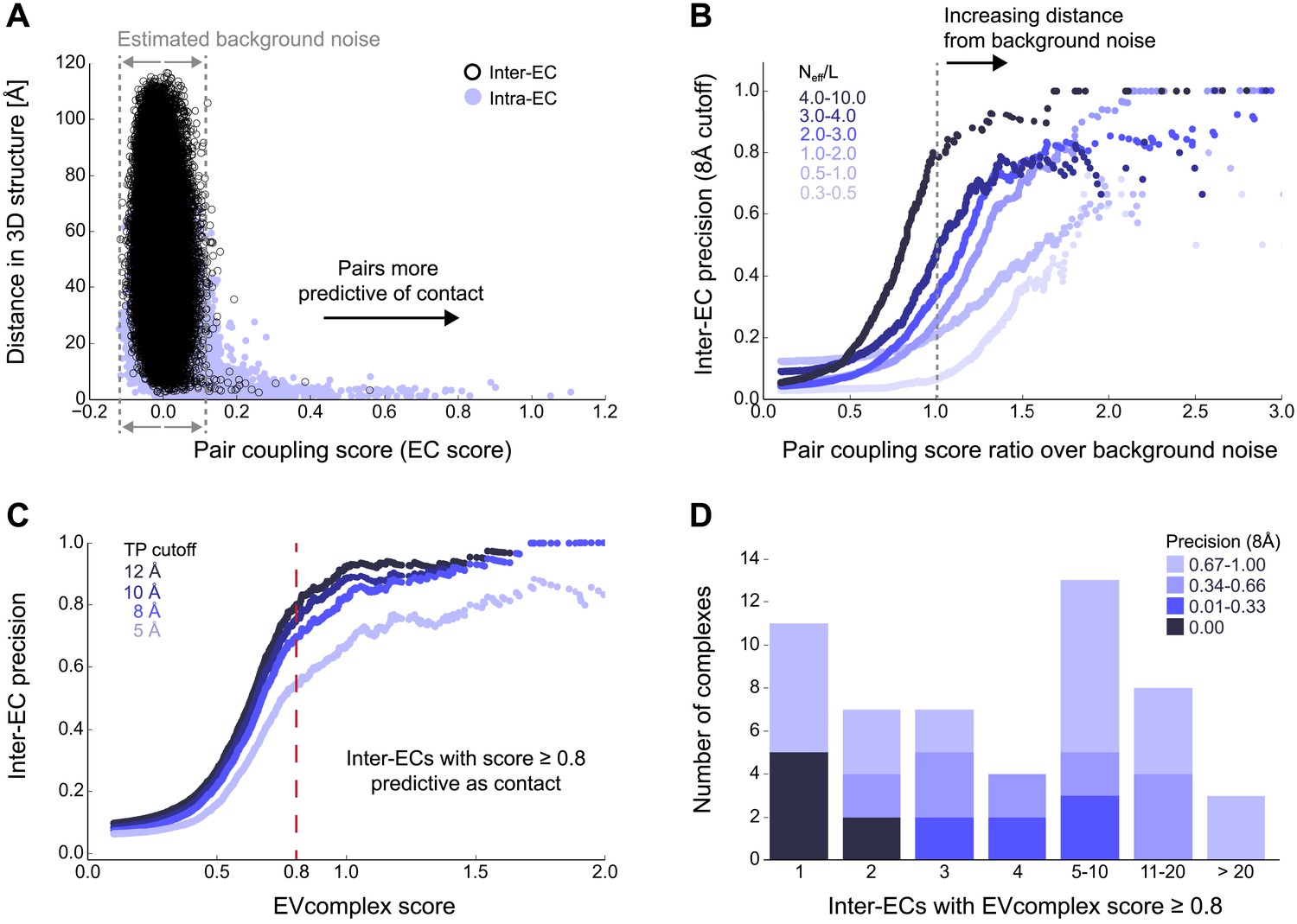
Evolutionary couplings capture interacting residues in protein complexes.
(A) Inter- and Intra-EC pairs with high coupling scores largely correspond to proximal pairs in 3D, but only if they lie above the background level of the coupling score distribution. To estimate this background noise a symmetric range around 0 is considered with the width being defined by the minimum inter-EC score. For the protein complexes in the evaluation set, this distribution is compared to the distance in the known 3D structure of the complex that is shown here for the methionine transporter complex, MetNI. (Plots for all complexes in the evaluation set are shown in Figure 2—figure supplement 1 and 2.) (B) A larger distance from the background noise (ratio of EC score over background noise line) gives more accurate contacts. Additionally, the higher the number of sequences in the alignment the more reliable the inferred coupling pairs are which then reduces the required distance from noise (different shades of blue). Residue pairs with an 8 Å minimum atom distance between the residues are defined as true positive contacts, and precision = TP/(TP + FP). The plot is limited to range (0,3) which excludes the histidine kinase—response regulator complex (HK–RR)—a single outlier with extremely high number of sequences. (C) To allow the comparison across protein complexes and to estimate the average inter-EC precision for a given score threshold independent of sequence numbers, the raw couplings score is normalized for the number of sequences in the alignment, resulting in the EVcomplex score. In this work, inter-ECs with an EVcomplex score ≥0.8 are used. Note: the shown plot is cut off at a score of 2 in order to zoom in on the phase change region and the high sequence coverage outlier HK-RR is excluded. (D) For complexes in the benchmark set, inter-EC pairs with EVcomplex score ≥0.8 give predictions of interacting residue pairs between the complex subunits to varying accuracy (8 Å TP distance cutoff). All predicted interacting residues for complexes in the benchmark set that had at least one inter-EC above 0.8 are shown as contact maps in Figure 2—figure supplement 3–8.
Blinded prediction of known complexes
Evolutionary covariation reveals inter-protein contacts
Of the 329 interactions identified that are close on the E. coli genome, 76 have a sufficient number of alignable homologous sequences and known 3D structures either in E. coli or in other species. This set was used to test the inter-protein evolutionary coupling predictions (Supplementary file 1). The relationship between the EVcomplex score and the precision of the corresponding inter-protein ECs suggests that on average 74% (69%) of the predicted pairs with EVcomplex score greater than 0.8 will be accurate to within 10 Å (8 Å) of an experimental structure of the complex (Figure 2C). Most complexes have at least one inter-protein predicted contact above the selected score threshold of 0.8 (53/76 complexes). Three complexes have more than 20 predicted inter-protein residue contacts which are over 80% accurate, namely the histidine kinase and response regulator system (78 residue pairs), t-RNA synthetase (32 residue pairs), and the vitamin B importer complex (21 residue pairs), with precision over 80% (complex numbers 330, 019, 130 respectively, Figure 2D, Figure 2—figure supplements 3–8, Supplementary file 1).
We suggest that users of EVcomplex consider predicted contacts that lie below the threshold of 0.8 in the context of other biological knowledge, where available, or in comparison to other higher scoring contacts for the same complex. In this way additional true positive inter-residue contacts can be distinguished from false positives. For instance, the ethanolamine ammonia-lyase complex (complex 065) has only 3 predicted inter-protein residue pairs above the score threshold, but in fact has 5 additional correct pairs with EVcomplex scores slightly below the threshold of 0.8 which cluster with the 3 high-scoring contacts on the monomers, indicating that they are also correct.
Some of the high confidence inter-protein ECs in the test set are not close in 3D space when compared to their known 3D structures. These false positives may be a result of assumptions in the method that are not always correct. This includes (1) the assumption that the interaction between paired proteins is conserved across species and across paralogs, and (2) that truly co-evolved residues across proteins are indeed always close in 3D, which is not always the case. In addition, the complexes may also exist in alternative conformations that have not necessarily all been captured yet by crystal or NMR structures, for instance in the case of the large conformational changes of the BtuCDF complex (Hvorup et al., 2007).
Docking is accurate with few pairs of predicted contacts
To test whether the computed inter-protein ECs are sufficient for obtaining accurate 3D structures of the whole complex, we selected 15 diverse examples (with 5 or more inter-protein residue contacts) for docking (Table 1, Figure 3, Figure 3—figure supplement 1, Supplementary file 3) with HADDOCK (Dominguez et al., 2003; de Vries et al., 2007). The docking procedure is fast and generates 100 3D models of each complex using all residue pairs with EVcomplex scores above the selection threshold. We additionally dock negative controls to assess the amount of information added to the docking protocol by evolutionary couplings (500 models per run, no constraints other than center of mass, see ‘Materials and methods’). The best models for all 15 complexes docked with evolutionary couplings have interface RMSDs under 6 Å, 12/15 have the best scoring model under 4 Å and the top ranked models for 11/15 are under 5 Å backbone interface RMSD compared to a crystal or NMR structure interface. Over 70% of the generated models are close to the experimental structures of the complexes (<4 Å backbone iRMSD), compared to less than 0.5% in the controls (and these were not high–ranked) (Figure 3—figure supplement 1, Supplementary file 3, ‘Supplementary data’). Not surprisingly complexes that have the largest numbers of true positive predicted contacts perform the best when docking. For example, the ribosomal proteins RS3 and RS14 have 11 true positive inter-protein ECs and result in a top ranked model only 1.1 Å iRMSD from the reference structure. More surprisingly, other complexes with a lower proportion of true positive inter-protein contacts, such as Ubiquinol oxidase (6 out of 11) or the epsilon and gamma subunits of ATP synthase (8 out of 15) also produced accurate predicted complexes, with an iRMSD of 1.8 and 1.4 Å respectively. The docking experiments therefore demonstrate that inter-protein ECs, even in the presence of incorrect predictions, can be sufficient to give accurate 3D models of protein complexes, but more work will be needed to quantify the likelihood of successful docking from the predicted contacts.
Table 1
EVcomplex predictions and docking results for 15 protein complexes
| EVcomplex contacts | Docking quality (iRMSD) | |||||
|---|---|---|---|---|---|---|
| Complex name | Subunits | Seqs† | ECs‡ | TP rate§ | Top ranked model# | Best model¶ |
| Carbamoyl-phosphate synthase | CarB:CarA | 2.3 | 17 | 0.88 | 1.9 | 1.9 |
| Aminomethyltransferase/Glycine cleavage system H protein | GcsH:GcsT | 2.9 | 5 | 0.2 | 5.4 | 5.4 |
| Histidine kinase/response regulator | KdpD:CheY (T. maritima) | 95.4 | 78 | 0.72 | 2.1 | 2.0 |
| Ubiquinol oxidase | CyoB:CyoA | 1.0 | 11 | 0.55 | 1.8 | 1.2 |
| Outer membrane usher protein/Chaperone protein | FimD:FimC | 3.6 | 6 | 0.83 | 3.2 | 3.0 |
| Molybdopterin synthase | MoaD:MoaE | 3.6 | 8 | 1.0 | 4.4 | 4.1 |
| Methionine transporter complex | MetN:MetI | 1.9 | 14 | 0.86 | 1.5 | 1.2 |
| Dihydroxyacetone kinase | DhaL:DhaK | 1.4 | 12 | 0.42 | 6.7 | 2.4 |
| Vitamin B12 uptake system | BtuC:BtuF | 3.2 | 5 | 0.6 | 2.8 | 2.8 |
| Vitamin B12 uptake system | BtuC:BtuD | 9.8 | 21 | 0.88 | 1.1 | 0.9 |
| ATP synthase γ and ε subunits | AtpE:AtpG | 2.9 | 15 | 0.53 | 1.4 | 1.4 |
| IIA-IIB complex of the N,N'-diacetylchitobiose (Chb) transporter | PtqA:PtqB | 3.1 | 5 | 0.2 | 7.2 | 5.5 |
| 30 S Ribosomal proteins | RS3:RS14 | 1.4 | 11 | 0.91 | 1.1 | 1.1 |
| Succinatequinone oxido-reductase flavoprotein/iron-sulfur subunits | SdhB:SdhA | 3.0 | 8 | 0.62 | 1.4 | 1.4 |
| 30 S Ribosomal proteins | RS10:RS14 | 1.2 | 6 | 1.0 | 5.3 | 2.5 |
-
†
Number of non-redundant sequences in concatenated alignment normalized by alignment length.
-
‡
Inter-ECs with EVcomplex score ≥0.8.
-
§
True Positive rate for inter-ECs above score threshold.
-
#
iRMSD positional deviation of model from known structure, for docked model with best HADDOCK score.
-
¶
Lowest iRMSD observed across all models.
Figure 3 with 1 supplement see all

Blinded prediction of evolutionary couplings between complex subunits with known 3D structure.
Inter-ECs with EVcomplex score ≥0.8 on a selection of benchmark complexes (monomer subunits in green and blue, inter-ECs in red, pairs closer than 8 Å by solid red lines, dashed otherwise). The predicted inter-ECs for these ten complexes were then used to create full 3D models of the complex using protein–protein docking. For the fifteen complexes for which 3D structures were predicted using docking, energy funnels are shown in Figure 3—figure supplement 1.
Conserved residue networks provide evidence of functional constraints
The top 10 inter-EC pairs between MetI and MetN are accurate to within 8 Å in the MetNI complex (PDB: 3tui [Johnson et al., 2012]), resulting in an average 1.4 Å iRMSD from the crystal structure for all 100 computed 3D models (Table 1, Supplementary file 3 and ‘Supplementary data’). The top 3 inter-EC residue pairs (K136-E108, A128-L105, and E74-R124, MetI-MetN respectively) constitute a residue network coupling the ATP-binding pocket of MetN to the membrane transporter MetI. This network calculated from the sequence alignment corresponds to residues identified experimentally that couple ATP hydrolysis to the open and closed conformations of the MetI dimer (Johnson et al., 2012) (Figure 4A). The vitamin B12 transporter (BtuC) belongs to a different structural class of ABC transporters, but also uses ATP hydrolysis via an interacting ATPase (BtuD). The top 5 inter-ECs co-locate the L-loop of BtuC close to the Q-loop ATP-binding domain of the ATPase, hence coupling the transporter with the ATP hydrolysis state in an analogous way to MetI-MetN. The identification of these coupled residues across the different subunits suggests that EVcomplex identifies not only residues close in space, but also particular pairs that are constrained by the transporter function of these complexes (Kadaba et al., 2008; Johnson et al., 2012).
Figure 4
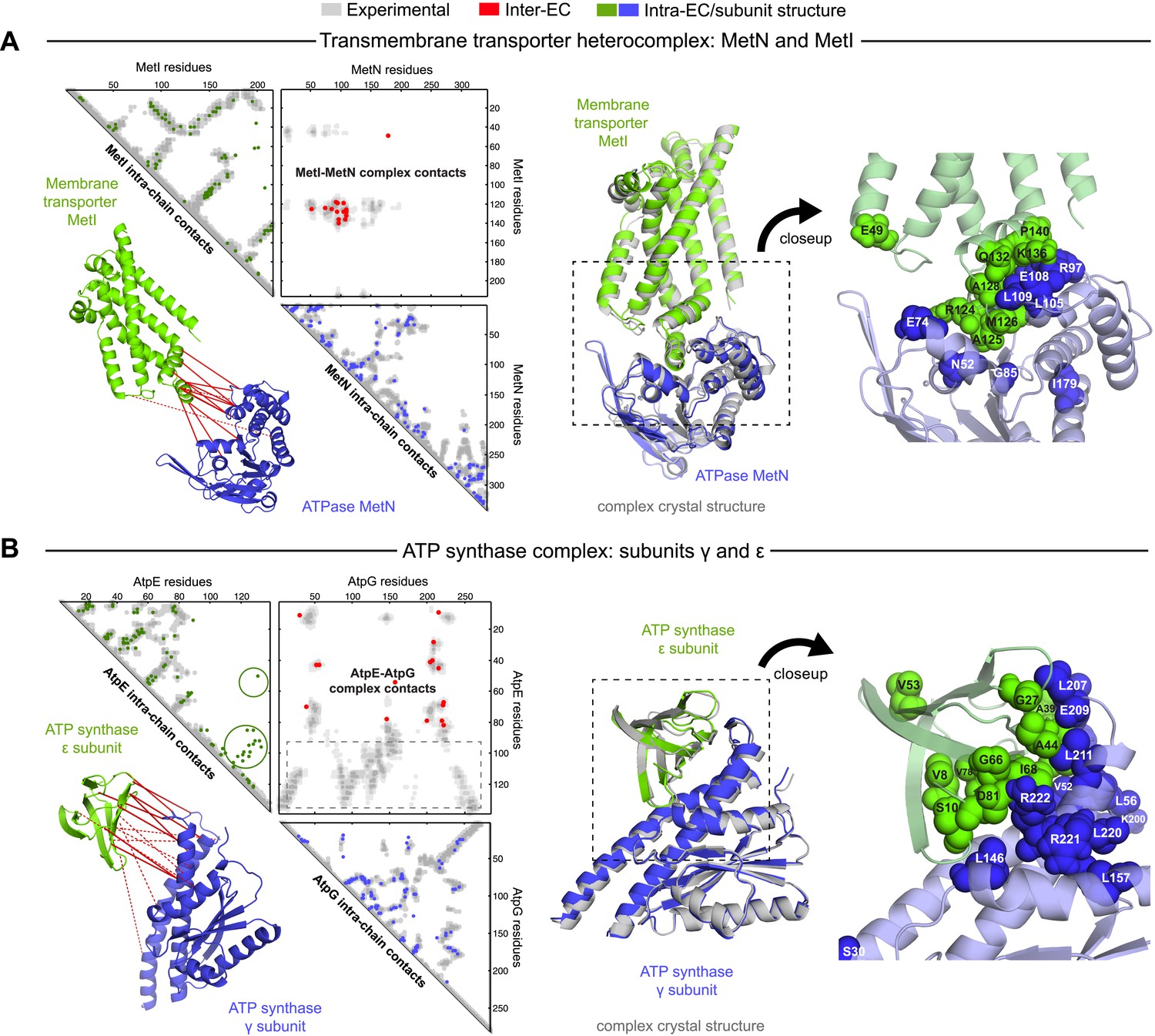
Evolutionary couplings give accurate 3D structures of complexes.
EVcomplex predictions and comparison to crystal structure for (A) the methionine-importing transmembrane transporter heterocomplex MetNI from E. coli (PDB: 3tui) and (B) the gamma/epsilon subunit interaction of E. coli ATP synthase (PDB: 1fs0). Left panels: complex contact map comparing predicted inter-ECs with EVcomplex score ≥0.8 (red dots, upper right quadrant) and intra-ECs (up to the last chosen inter-EC rank; green and blue dots, top left and lower right triangles) to close pairs in the complex crystal (dark/mid/light gray points for minimum atom distance cutoffs of 5/8/12 Å for inter-subunit contacts and dark/mid gray for 5/8 Å within the subunits). Inter-ECs with an EVcomplex score ≥0.8 are also displayed on the spatially separated subunits of the complex (red lines on green and blue cartoons, couplings closer than 8 Å in solid red lines, dashed otherwise, lower left). Right panels: superimposition of the top ranked model from 3D docking (green/blue cartoon, left) onto the complex crystal structure (gray cartoon) and close-up of the interface region with highly coupled residues (green/blue spheres).
The ATP synthase ε and γ subunit complex provides a challenge to our approach, since the ε subunit can take different positions relative to the γ subunit, executing the auto-inhibition of the enzyme by dramatic conformational changes (Cingolani and Duncan, 2011). In a real-world scenario, where we might not know this a priori, there may be conflicting constraints in the evolutionary record corresponding to the different positions of the flexible portion of ε subunit. EVcomplex accurately predicts 6 of the top 10 inter-EC pairs (within 8 Å in the crystal structure 1fs0 (Rodgers and Wilce, 2000) or 3oaa (Cingolani and Duncan, 2011)), with the top 2 inter-ECs εA45-γL215 and εA40-γL207 providing contact between the subunits along an inter-protein beta sheet. The location of the C-terminal helices of the ε subunit is significantly different across 3 crystal structures (PDB IDs: 1fs0 [Rodgers and Wilce, 2000], 1aqt [Uhlin et al., 1997], 3oaa [Cingolani and Duncan, 2011]). The top ranked intra-ECs support the conformation seen in 1aqt, with the C-terminal helices packed in an antiparallel manner and tucked against the N-terminal beta barrel (Figure 4B, green circles) and do not contain a high ranked evolutionary trace for the extended helical contact to the γ subunit seen in 1fs0 or 3oaa (Figure 4B, gray box). Docking with the top inter-ECs results in models with 1.4 Å backbone iRMSDs to the crystal structure for the interface between the N-terminal domain of the ε subunit and the γ subunit (Table 1, Supplementary file 3). εD82 and γR222 connect the ε-subunit via a network of 3 high-scoring intra-ECs between the N- and C-terminal helices to the core of the F1 ATP synthase. In summary, these examples suggest that inter-protein evolutionary couplings can provide residue relationships across the proteins that could aid identification of functional coupling pathways, in addition to obtaining 3D models of the complex.
De novo prediction of unknown complexes
Prediction of interactions for 32 protein pairs with high-scoring evolutionary couplings
A total of 82 protein complexes with unknown 3D structure of the interaction that satisfy the conditions for the current approach, i.e., have sufficient sequences and are close in all genomes, were predicted using EVcomplex (all residue–residue inter-protein evolutionary couplings scores are available in ‘Supplementary data’). 32 of these have high EVcomplex scores with at least one predicted contact (Figure 5, Figure 5—figure supplement 1 and 2, and Supplementary file 4). Analysis of the inter-EC predictions for known 3D complex structures shows that protein pairs with more high-scoring ECs (EVcomplex score ≥0.8) have a higher proportion of true positives (Figure 2D). Hence, the protein complexes in the set of unknown structures with more high-scoring inter-ECs are most likely to have predicted ECs that indicate residue pairs close in 3D (column Q, Supplementary file 2, the exact pairs can be found in Supplementary file 4). Three examples of predictions with multiple high-scoring inter-ECs include MetQ-MetI, UmuD-UmuC, and DinJ–YafQ. The top 15 inter-ECs between MetQ and MetI are from one interface of MetQ to the MetI periplasmic loops, or the periplasmic end of the helices, consistent with the known binding of MetQ to MetI in the periplasm.
Figure 5 with 3 supplements see all
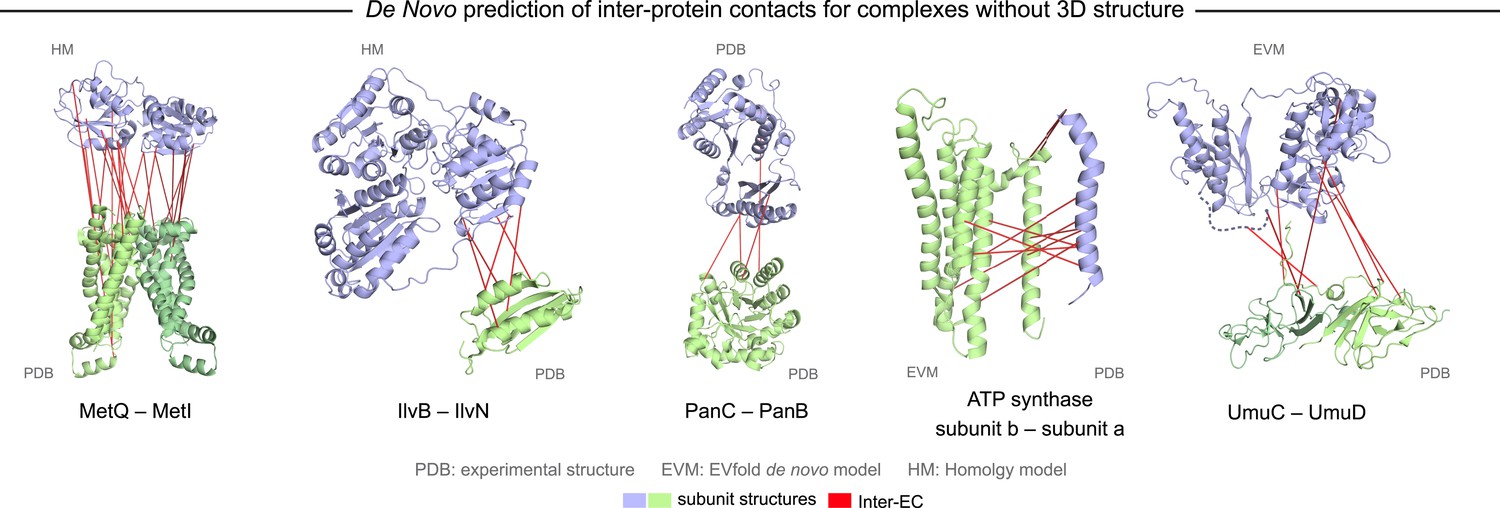
Evolutionary couplings in complexes of unknown 3D structure.
Inter-ECs for five de novo prediction candidates without E. coli or interaction homolog complex 3D structure (Subunits: blue/green cartoons; inter-ECs with EVcomplex score ≥0.8: red lines). For complex subunits which homomultimerize (light/dark green cartoon), inter-ECs are placed arbitrarily on either of the monomers to enable the identification of multiple interaction sites. Contact maps for all complexes with unsolved structures are provided in Figure 5—figure supplement 1 and 2. Left to right: (1) the membrane subunit of methionine-importing transporter heterocomplex MetI (PDB: 3tui) together with its periplasmic binding protein MetQ (Swissmodel: P28635); (2) the large and small subunits of acetolactate synthase IlvB (Swissmodel: P08142) and IlvN (PDB: 2lvw); (3) panthotenate synthase PanC (PDB: 1iho) together with ketopantoate hydroxymethyltransferase PanB (PDB: 1m3v); (4) subunits a and b of ATP synthase (model for a subunit a predict with EVfold-membrane, PDB: 1b9u for b subunit), for detailed information see Figure 6; and (5) the complex of UmuC (model created with EVfold) with one possible conformation of UmuD (PDB: 1i4v) involved in DNA repair and SOS mutagenesis. For alternative UmuD conformation, see Figure 5—figure supplement 3.
The UmuD and UmuC complex is induced in the stress/SOS response facilitating the cleavage of UmuD to UmuD’ (between C24 and G25) to form UmuD’2 which then interacts with UmuC (DNA polymerase V) in order to copy damaged DNA (Beuning et al., 2006). The truncated dimer form (UmuD’2) has at least two contrasting conformations where the N-terminal arm is placed on opposite sides of the dimer in one conformation or in close proximity in the alternative (Figure 5—figure supplement 3). For 6/7 ECs above the score threshold, residues in UmuD predicted to interface with UmuC are co-located on one face of the dimer. Two residues (Y33, I38) are located in the N-terminal arm of UmuD that, after cleavage of the 24 N-terminal amino acids, may become available for binding UmuC. Since UmuD switches functions after this cleavage and can then bind UmuC, these inter-ECs may identify the critical residues for translesion synthesis function (Beuning et al., 2006). Although the ECs from this UmuD arm to UmuC involve residues in two separate domains of UmuC (S 415 and Y 74), intra-monomer evolutionary couplings predict that these residues are close in UmuC (Figure 5—figure supplement 3A, black rectangles). The relative positions of the contacting residues within each monomer therefore support the plausibility of the accuracy of the interaction interface.
Whilst this manuscript was in review, the 3D structure of the previously unsolved biofilm toxin/antitoxin DinJ–YafQ complex was published (PDB: 3mlo (Liang et al., 2014)), showing the intertwining of subunits in a heterotetrameric complex. 17/19 predicted EC residue pairs are within 8 Å in this 3D structure (Supplementary file 4 and ‘Supplementary data’). In general, the agreement between our de novo predicted inter-protein ECs and available experimental data serves as a measure of confidence for the predicted residue pair interactions and suggests that EVcomplex can be used to reveal 3D structural details of yet unsolved protein complexes given sufficient evolutionary information.
EVcomplex predicts interacting protein pairs in a large complex
To investigate whether the EVcomplex score can also distinguish between interacting and non-interacting pairs of proteins, we use the E. coli ATP synthase complex as a test case. The ATP synthase structure is of wide biological interest (reviewed in Walker, 2013) with a remarkable 3D structural arrangement, but completion of all aspects of the 3D structure has remained experimentally challenging (Baker et al., 2012) (Figure 6A). As a demonstration exercise, we calculated evolutionary couplings for all 28 possible pair combinations of different ATP synthase subunits (centered around the E. coli ATP synthase) and transformed the ECs into EVcomplex scores for all inter-protein residue pairs (experimentally determined stoichiometry: α3β3γδεab2c10, Supplementary file 5 and ‘Supplementary data’). Using the default EVcomplex score threshold of 0.8 to discriminate between interacting and non-interacting pairs of subunits, 24 of the 28 possible interactions between the subunits are correctly classified as interacting or non-interacting. The four incorrect predictions (namely: ε and c, γ and c, ε and β, b and β, for which there is some experimental evidence) are not identified as interacting using the 0.8 EVcomplex threshold. Choosing a threshold lower than 0.8 does identify 2 of these as interacting but also introduces new false positives. The ε and β interaction in the crystal structure 3oaa (Cingolani and Duncan, 2011) is a special case in that it involves a highly extended conformation of the last two helices of the ε subunit that reach up into the enzyme making contacts with the β subunit. The false negative EVcomplex score for this pair could be a result of the transience of their interaction or reflect a more general problem of lack of conservation of this interaction across the aligned proteins from different species. In total 80% of the interacting residue pairs in the known 3D structure parts of the synthase complex (7 pairs of subunits) are correctly predicted (threshold: 10 Å minimum atom distance between two residues). This exercise of predicting the presence or absence of interaction between any two proteins indicates the potential of the EVcomplex method in helping to elucidate protein–protein interaction networks from evolutionary sequence co-variation and identify interacting subunits of large macromolecular complexes.
Figure 6 with 1 supplement see all
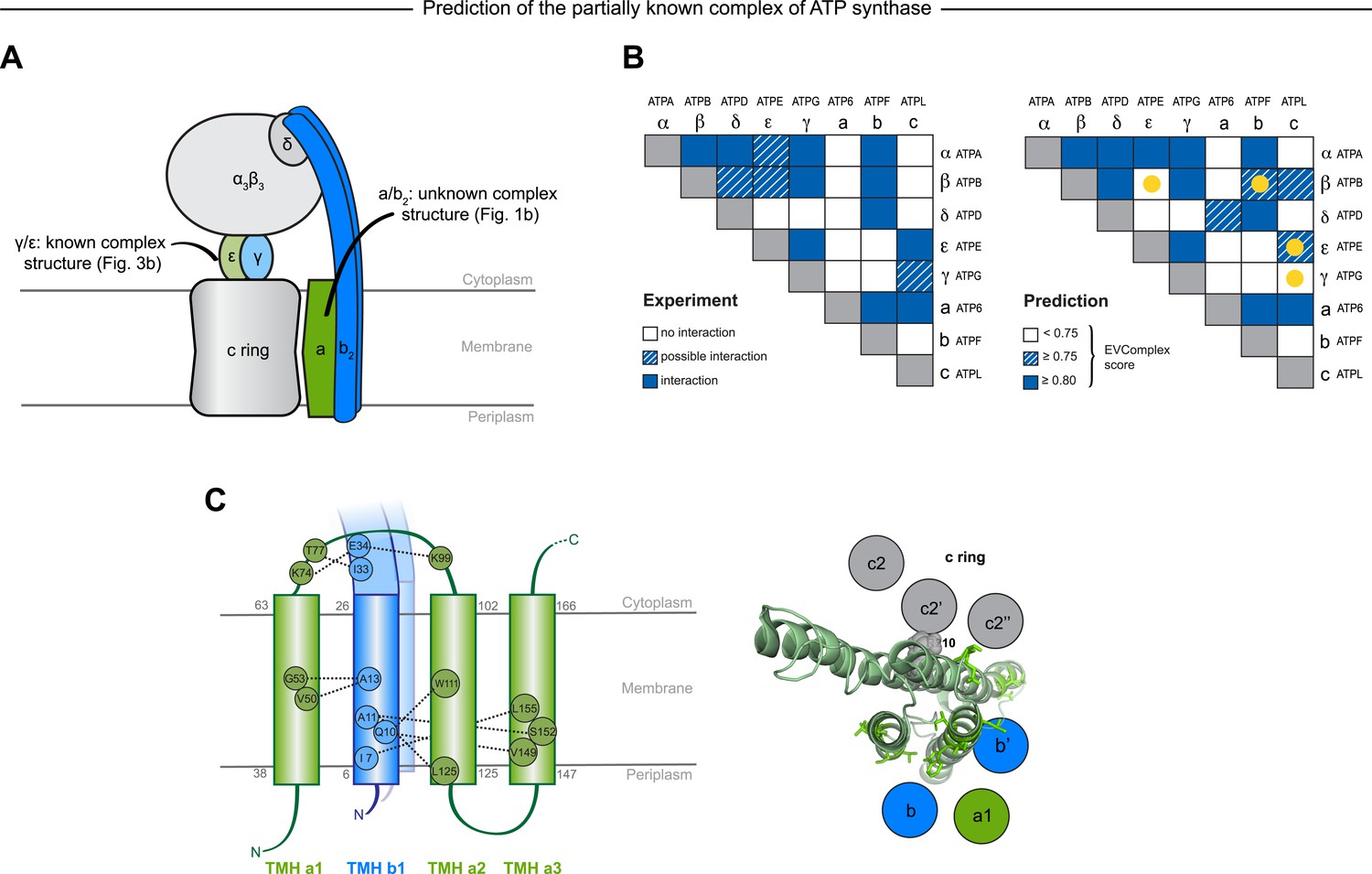
Predicted interactions between the a-, b-, and c-subunits of ATP synthase.
(A) The a- and b- subunits of E. coli ATP synthase are known to interact, but the monomer structure of subunits a and b and the structure of their interaction in the complex are unknown. (B) EVcomplex prediction (right matrix) for ATP synthase subunit interactions compared to experimental evidence (left matrix), which is either strong (left, solid blue squares) or indicative (left, crosshatched squares). Interactions that have experimental evidence, but are not predicted at the 0.8 threshold are indicated as yellow dots. (C) Left panel: residue detail of predicted residue–residue interactions (dotted lines) between subunit a and b (residue numbers at the boundaries of transmembrane helices in gray). Right panel: proposed helix–helix interactions between ATP synthase subunits a (green), b (blue, homodimer), and the c ring (gray). The proposed structural arrangement is based on analysis of the full map of inter-subunit ECs with EVcomplex score ≥0.8 (Figure 6—figure supplement 1).
EVcomplex predicts details of subunit interactions in ATP synthase
While much of the 3D structure of ATP synthase is known (Walker, 2013), the details of interactions between the a-, b-, and c-subunits have not yet been determined by crystallography. We analyse the details in these interactions, as the EVcomplex scores between these subunits are substantial (Figure 6B). We are fortunately able to provide a missing piece for this analysis, the unknown structure of the membrane-integral penta-helical a-subunit, using our previously described method for de novo 3D structure prediction of alpha-helical transmembrane proteins (Hopf et al., 2012). To our knowledge, there are no experimentally determined atomic resolution structures of the a-subunit of ATP synthase. A 3D model of the a-subunit is from 1999 (1c17(Rastogi and Girvin, 1999)) and was computed using five helical–helical interactions that were inferred from second suppressor mutation experiments, and then imposed as distance restraints for TMH2-5, revealing a four helical bundle (with no information for TMH1). Later, cross-linking experiments (Schwem and Fillingame, 2006) identified contacting residues from all pairs of helical combinations of TM2-TM5 (6 pairs), supporting the earlier 4 helical bundle topology. 7 of the 8 cross-linked pairs are either exactly the same pair (L120-I246) or adjacent to many pairs in the top L intra a-subunit evolutionary couplings (ECs).
In fact, the helix packing arrangement in the predicted structure of the a-subunit is consistent with the topology suggested on the basis of crosslinking studies (Long et al., 2002; DeLeon-Rangel et al., 2003; Fillingame and Steed, 2014), including the lack of contacts for transmembrane helix 1 with the other 4 helices (‘Supplementary data’).
The top inter-protein EC pair between subunits a and b, aK74–bE34, coincides with experimental crosslinking evidence of the interaction of aK74 with the b-subunit and the position of E34 of the b subunit emerging from the membrane on the cytoplasmic side (Long et al., 2002; DeLeon-Rangel et al., 2003). Indeed, 6 of the 13 high score ECs are in the same region as the experimental crosslinks, for instance between the cytoplasmic loop between the first two helices of the a-subunit and the b-subunit helix as it emerges from the membrane bilayer (DeLeon-Rangel et al., 2013), or between a239V in TM helix 5 and bL16 (Figure 6C, Figure 6—figure supplement 1, Supplementary file 6). Additionally, the top EC between the a- and c-subunits (aG213 – cM65) lies close to the functionally critical aR210–cD61 interaction (Dmitriev et al., 1999) on the same helical faces of the respective subunits (Figure 6C). This prediction of missing aspects of subunit interactions may help in the design of targeted experiments to complete the understanding of the intricate molecular mechanism of the ATP synthase complex.
Discussion
A primary limitation of our current approach is its dependence on the availability of a large number of evolutionarily related sequences. If a protein interaction is conserved across enough sequenced genomes, using a single pair per genome can give accurate predictions of the interacting residues. However, if the protein pair is present in limited taxonomic branches, there may be insufficient sequences at any given time to make confident predictions. A solution to this could be to include multiple paralogs of the interacting proteins from each genome, but this requires correct pairing of the interaction partners, which is in general hard to ascertain. In addition, details of interactions may have diverged for paralogous pairs. Hence, in this current version of the method, we have imposed a genome distance requirement across all genomes for all homolog pairs in order to be less sensitive to these complications.
As the need to use genome proximity to pair sequences becomes less important with the increasing availability of genome sequences, there will be a dramatic increase in the number of interactions that can be inferred from evolutionary couplings, including those unique to eukaryotes. With currently available sequences (May 2014 release of the UniProt database), EVcomplex is able to provide information for about 1/10th of the known 3000 protein interactions in the E. coli genome. Once there are ∼10,000 bacterial genome sequences of sufficient diversity, one would have enough information to test each potentially interacting pair of homologs for evidence of interaction and, given sufficiently strong evolutionary couplings, infer the 3D structure of each protein–protein pair, as well as of complexes with more than two proteins. For any set of species, e.g., vertebrates or mammals, one can imagine guiding sequencing efforts to optimize species diversity to facilitate the extraction of evolutionary couplings. This can open the doors for more comprehensive and more rapid determination of approximate 3D structures of proteins and protein complexes, as well as for the elucidation in molecular detail of the most strongly evolutionarily constrained interactions, pointing to functional interactions.
Determining the three-dimensional models of complexes from the predicted contacts was successful in many of the tested instances. Using minimal computing resources and a small number of inter-EC-derived contacts, low interface positional RMSDs relative to experimental structures can be achieved. However, a significant number of proteins exist as homomultimers within larger complexes. To determine models of these complexes one must deconvolute homomultimeric inter-ECs from the intra-protein signal, which is an important technical challenge for future work.
The analysis of subunit interactions in ATP synthase in this work is a ‘proof of principle’ study showing that methods such as EVcomplex can determine which proteins interact with each other at the same time as specific residue pair couplings across the proteins (as also shown in the work by the Baker lab on ribosomal protein interactions (Ovchinnikov et al., 2014)). Understanding the networks of protein interactions is of critical interest in eukaryotic systems, such as networks of protein kinases, GPCRs, or PDZ domain proteins. An understanding of the distributions of interaction specificities is of high interest to many fields. Although we do not know how well our evolutionary coupling approach will handle less obligate interactions, results on the two-component signaling system (histidine kinase/response regulator) both here and in other work (Skerker et al., 2008; Weigt et al., 2009) suggest optimism.
The approximately scale-free EVcomplex score is a heuristic based on the distribution of raw EC scores from the statistical model, their dependence on sequence alignment depth and the length of the concatenated sequences. The score provides a simple way of accounting for these dependencies such that a uniform threshold, say 0.8, can be used for any protein pair with the expectation of reasonably accurate predictions. Since cutoff thresholds can be useful but overly sharp, we recommend investigating predicted contacts below the threshold used in this work, especially where there is independent biological knowledge to validate the predictions.
The work presented here is in anticipation of a genome-wide exploration and, as a proof of principle, shows the accurate prediction of inter-protein contacts in many cases and their utility for the computation of 3D structures across diverse complex interfaces. As with single protein (intra-EC) predictions, evolutionarily conserved conformational flexibility and oligomerization can result in more than one set of contacts that must be de-convoluted. Can evolutionary information help to predict the details and extent for each complex? A key challenge will be the development of algorithms that can disentangle evolutionary signals caused by alternative conformations of single complexes, alternative conformations of homologous complexes, and effectively deal with false positive signals. Taken together, these issues highlight fruitful areas for future development of evolutionary coupling methods.
Despite conditions for the successful de novo calculation of co-evolved residues, the method described here may accelerate the exploration of the protein–protein interaction world and the determination of protein complexes on a genome-wide scale at residue level resolution. The use of co-evolutionary analysis in computational models to determine protein specificity and promiscuity, co-evolutionary dynamics and functional drift will open up exciting future research questions.
Materials and methods
Selection of interacting protein pairs for co-evolution calculation
Request a detailed protocolThe candidate set of complexes for testing and de novo prediction was derived starting from a data set of binary protein–protein interactions in E. coli including yeast two-hybrid experiments, literature-curated interactions and 3D complex structures in the PDB (Rajagopala et al., 2014). Three complexes not contained in the list were added based on our analysis of other subunits in the same complex, namely BtuC/BtuF, MetI/MetQ, and the interaction between ATP synthase subunits a and b. Since our algorithm for concatenating multiple sequence pairs per species assumes the proximity of the interacting proteins on the respective genomes of each species (See below), we excluded any complex with a gene distance >20 from further analysis. The gene distance is calculated as the number of genes between the interacting partners based on an ordered list of genes in the E. coli genome obtained from the UniProt database. The resulting list of pairs (∼350) was then filtered for pseudo-homomultimeric complexes based on the identification of Pfam domains in the interacting proteins (330). All remaining complexes with a known 3D structure (as summarized in Rajagopala et al., 2014) or a homologous interacting 3D structure (93) (identified by intersecting the results of HMMER searches against the PDB for both monomers) were used for evaluating the method, while complexes without known structure (236) were assigned to the de novo prediction set (Figure 1—figure supplement 1). The set with protein complexes of known 3D structure was further filtered for structures that only cover fragments (<30 amino acids) of one or both of the monomers and structures with very low resolution (>5 Å), which led to the re-assignment of Ribonucleoside-diphosphate reductase 1 (complex_002), Type I restriction-modification enzyme EcoKI (complex_012), RpoC/RpoB (complex_041), RL11/Rl7 (complex_165), the ribosome with SecY (complex_226, complex_250, and complex_255), and RS3/RS (complex_254) to the set of unknown complexes. Large proteins were run with the specific interacting domains informed by the known 3D structure, when the full sequence was too large for the number of retrieved sequences (for domain annotation see ‘Supplementary data’).
This set could serve as a benchmark set for future development efforts in the community.
Multiple sequence alignments
Request a detailed protocolEach protein from all pairs in our data set was used to generate a multiple sequence alignment (MSA) using jackhmmer (Johnson et al., 2010) to search the UniProt database (UniProt Consortium, 2014) with 5 iterations. To obtain alignments of consistent evolutionary depths across all the proteins, a bit score threshold of 0.5 * monomer sequence length was chosen as homolog inclusion criterion (-incdomT parameter), rather than a fixed E-value threshold which selects for different degrees of evolutionary divergence based on the length of the input sequence.
In order to calculate co-evolved residues across different proteins, the interacting pairs of sequences in each species need to be matched. Here, we assume that proteins in close proximity on the genome, e.g., on the same operon, are more likely to interact, as in the methods used previously matching histidine kinase and response regulator interacting pairs (Skerker et al., 2008; Weigt et al., 2009) (‘Supplementary data’). We retrieved the genomic locations of proteins in the alignments and concatenated pairs following 2 rules: (i) the CDS of each concatenated protein pair must be located on the same genomic contig (using ENA (Pakseresht et al., 2014) for mapping) and (ii) each pair must be the closest to one another on the genome, when compared to all other possible pairings in the same species. The concatenated sequence pairs were filtered based on the distribution of genomic distances to exclude outlier pairs with high genomic distances of more than 10k nucleotides (‘Supplementary data’). Alignment members were clustered together and reweighted if 80% or more of their residues were identical (thus implicitly removing duplicate sequences from the alignment). Supplementary file 1 and 2 report the total number of concatenated sequences, the lengths, and the effective number of sequences remaining after down-weighting in the evaluation and de novo prediction set, respectively.
Computation of evolutionary couplings
View detailed protocolInter- and intra-ECs were calculated on the alignment of concatenated sequences using a global probability model of sequence co-evolution, adapted from the method for single proteins (Marks et al., 2011; Morcos et al., 2011; Hopf et al., 2012) using a pseudo-likelihood maximization (PLM) (Balakrishnan et al., 2011; Ekeberg et al., 2013) rather than mean field approximation to calculate the coupling parameters. Columns in the alignment that contain more than 80% gaps were excluded and the weight of each sequence was adjusted to represent its cluster size in the alignment thus reducing the influence of identical or near-identical sequences in the calculation. For the evaluation set, we can then compare the predicted ECs for both within and between the proteins/domains to the crystal structures of the complexes (for contact maps and all EC scores, see ‘Supplementary data’).
Definition of a scale-free score for the assessment of interactions
Request a detailed protocolIn order to estimate the accuracy of the EC prediction, we evaluate the calculated inter-ECs based on the following observations: (1) most pairs of positions in an alignment are not coupled, i.e., have an EC score close to zero, and tend to be distant in the 3D structure; (2) the background distribution of EC scores between non-coupled positions is approximately symmetric around a zero mean; and (3) higher-scoring positive score outliers capture 3D proximity more accurately than lower-scoring outliers (See also Figure 2). The width of the (symmetric) background EC score distribution can be approximated using the absolute value of the minimal inter-EC score. The more a positive EC score exceeds the noise level of background coupling, the more likely it is to reflect true co-evolution between the coupled sites. For each inter-protein pair of sites i and j with pair coupling strength ECinter(i, j), we therefore calculate a raw reliability score ('pair coupling score ratio', Figure 2B) defined by
(1)
Since the accuracy of evolutionary couplings critically depends both on the number and diversity of sequences in the input alignment and the size of the statistical inference problem (Marks et al., 2011; Morcos et al., 2011; Jones et al., 2012), we incorporate a normalization factor to make the raw reliability score comparable across different protein pairs. The normalized EVcomplex score is defined as
(2)
where Neff is the effective number of sequences in the alignment after redundancy reduction, and L (total number of residues) is the length of the concatenated alignment. Previous work on single proteins has shown that the method requires a sufficient number of sequences in the alignment to be statistically meaningful. We thus filter for sequence sufficiency requiring Neff/L > 0.3 (Table 1, Supplementary files 1 and 2). Predictions of coupled residues in the evaluation set were evaluated against their residue distances in known structures of protein pairs (Rajagopala et al., 2014) (See Supplementary file 7) in order to determine the precision of the method.
To interpret the EVcomplex prediction of interaction between subunits a and b of the ATP synthase as well as UmuC and UmuD, individual monomer models were built de novo for the structurally unsolved a-subunit of ATP synthase and UmuC using the EVfold pipeline as previously published (Marks et al., 2011; Hopf et al., 2012). In both cases coupling parameters were calculated using PLM (Balakrishnan et al., 2011; Ekeberg et al., 2013) and sequences were clustered and weighted at 90% sequence identity (the resulting models are provided in ‘Supplementary data’).
Prediction of interactions in a set of subunits
Request a detailed protocolFollowing this same protocol EVcomplex scores were calculated for all possible 28 combinations of the 8 E. coli ATP synthase F0 and F1 subunits. Since we want to compare the computational predictions to some ‘ground truth’, as with the complexes for the rest of the manuscript, we used known 3D structures of the ATP synthase complex to assign whether or not the subunits interact (PDB: 3oaa, 1fs0, 2a7u; Supplementary file 7). Since we are also determining whether the subunits interact, not necessarily knowing full atomic detail residue interactions, we included subunit interactions that have been inferred from cryo-EM, crosslinking or other experiments, but do not necessarily have a crystal structure. These are represented as solid blue boxes, if the interaction is well established (DeLeon-Rangel et al., 2013; Schulenberg et al., 1999; Brandt et al., 2013; McLachlin and Dunn, 2000), or crosshatched blue if there is a lack of consensus in the community (Figure 6B, left panel).
For each possible interaction the EVcomplex score of the highest ranked inter-EC was considered as a proxy for the likelihood of interaction. Pairs with scores above 0.8 are considered likely to interact, between 0.75 and 0.8 weakly predicted, while interactions with scores below 0.75 are rejected as possible complexes (blue boxes, blue crosshatched, and white respectively in right panel of Figure 6B, and ‘Supplementary data’).
Computation of 3D structure of complexes
Request a detailed protocolA diverse set of 15 complexes was chosen from the 22 in the evaluation set that had at least 5 couplings above a complex score of 0.8 and was subsequently docked (Supplementary file 3). Proteins that have been crystallized together in a complex could bias the results of the docking, as they have complementary positions of the surface side chains. Therefore, where possible we used complexes that had a solved 3D structure of the unbound monomer, namely GcsH/GcsT, CyoA, FimC, DhaL, AtpE, PtqA/PtqB, RS10, and HK/RR, and in all other cases the side chains of the monomers were randomized either by using SCWRL4 (Krivov et al., 2009) or restrained minimization with Schrodinger Protein Preparation Wizard (Sastry et al., 2013) before docking. For ubiquinol oxidase (complex_054) the unbound structure of subunit 2 (CyoA) only covers the COX2 domain. In this case docking was performed using this unbound structure plus an additional run using the bound complex structure with perturbed side chains.
We used HADDOCK (Dominguez et al., 2003), a widely used docking program based on ARIA (Linge et al., 2003) and the CNS software (Brunger, 2007) (Crystallography and NMR System), to dock the monomers for each protein pair with all inter-ECs with an EVcomplex score of 0.8 or above implemented as distance restraints on the α-carbon atoms of the backbone.
Each docking calculation starts with a rigid-body energy minimization, followed by semi-flexible refinement in torsion angle space, and ends with further refinement of the models in explicit solvent (water). 500/100/100 models generated for each of the 3 steps, respectively. All other parameters were left as the default values in the HADDOCK protocol. Each protein complex was run using predicted ECs as unambiguous distance restraints on the Cα atoms (deff 5 Å, upper bound 2 Å, lower bound 2 Å; input files available in ‘Supplementary data’). As a negative control, each protein complex was also docked using center of mass restraints alone (ab initio docking mode of HADDOCK) (de Vries et al., 2007) and in this case generating 10,000/500/500 models.
Each of the generated models is scored using a weighted sum of electrostatic (Eelec) and van der Waals (Evdw) energies complemented by an empirical desolvation energy term (Edesolv) (Fernandez-Recio et al., 2004). The distance restraint energy term was explicitly removed from the equation in the last iteration (Edist3 = 0.0) to enable comparison of the scores between the runs that used a different number of ECs as distance restraints.
Comparison of predicted to experimental structures
Request a detailed protocolAll computed models in the docked set were compared to the cognate crystal structures by the RMSD of all backbone atoms at the interface of the complex using ProFit v.3.1 (http://www.bioinf.org.uk/software/profit/). The interface is defined as the set of all residues that contain any atom <6 Å away from any atom of the complex partner. For the AtpE–AtpG complex, we excluded the 2 C-terminal helices of AtpE as these helices are mobile and take many different positions relative to other ATP synthase subunits (Cingolani and Duncan, 2011). Similarly, since the DHp domain of histidine kinases can take different positions relative to the CA domain, the HK-RR complex was compared over the interface between the DHp domain alone and the response regulator partner. In the case of the unbound ubiquinol oxidase docking results, only the interface between COX2 in subunit 2 and subunit 1 was considered. Accuracy of the computed models with EC restraints was compared with computed models with center of mass restraints alone (negative controls) (Figure 3—figure supplement 1, Supplementary file 3).
Data analysis was conducted primarily using IPython notebooks (Perez and Granger, 2007). A webserver and all data are available at EVcomplex.org and the Dryad Digital Repository (Hopf et al., 2014).
Supplementary Data
Request a detailed protocol(Available at http://doi.org/10.5061/dryad.6t7b8 [Hopf et al., 2014])
Supplementary data 1: Concatenated alignments for complexes predicted in this work
Supplementary data 2: Genome distance distribution of concatenated sequences per alignment
Supplementary data 3: EVcomplex predictions for evaluation and de novo set
Supplementary data 4: Docking input files and top 10 predicted models for evaluation set
Supplementary data 5: ATP synthase predictions, ATP synthase subunit a model
Supplementary data 6: UmuC model
Data availability
-
Data from: Sequence co-evolution gives 3D contacts and structures of protein complexesPublicly available at Dryad Digital Repository.
-
Crystal structure of E. coli carbamoyl phosphate synthetase small subunit mutant C248D complexed with uridine 5'-monophosphateID 1T36. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin. This file contains the 50S subunit of the first 70S ribosome, with gentamicin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBA. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of an E.coli Chemotaxis Protein, ChezID 1KMI. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin. This file contains the 30S subunit of the second 70S ribosome, with gentamicin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBB. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the complex between the flagellar motor proteins FliG and FliMID 4FHR. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli at 3.5 A resolution. This file contains the 30S subunit of the second 70S ribosome. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2AW7. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli at 3.5 A resolution. This file contains the 50S subunit of one 70S ribosome. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2AW4. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with ribosome recycling factor (RRF). This file contains the 30S subunit of the second 70S ribosome. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBF. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin and ribosome recycling factor (RRF). This file contains the 50S subunit of the first 70S ribosome, with gentamicin and RRF bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBI. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin and ribosome recycling factor (RRF). This file contains the 30S subunit of the first 70S ribosome, with gentamicin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBH. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin and ribosome recycling factor (RRF). This file contains the 50S subunit of the second 70S ribosome, with gentamicin and RRF bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBK. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin and ribosome recycling factor (RRF). This file contains the 30S subunit of the second 70S ribosome, with gentamicin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBJ. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1P. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin. This file contains the 50S subunit of the second 70S ribosome, with gentamicin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBC. Publicly available at the RCSB Protein Data Bank.
-
Mercury-modified bacterial persistence regulator hipBAID 2WIU. Publicly available at the RCSB Protein Data Bank.
-
E. coli Quinol fumarate reductase FrdA E49Q mutationID 2B76. Publicly available at the RCSB Protein Data Bank.
-
RuvA-RuvB complexID 1IXR. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of NarGHI mutant NarG-R94SID 3IR7. Publicly available at the RCSB Protein Data Bank.
-
Structure of Carbamoyl Phosphate Synthetase Complexed with the ATP Analog AMPPNPID 1BXR. Publicly available at the RCSB Protein Data Bank.
-
MDT ProteinID 3DNV. Publicly available at the RCSB Protein Data Bank.
-
Structural Consequences of Effector Binding to the T State of Aspartate Carbamoyltransferase. Crystal Structures of the Unligated and ATP-, and CTP-Complexed Enzymes AT 2.6-Angstroms ResolutionID 5AT1. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli at 3.5 A resolution. This file contains the 30S subunit of one 70S ribosome. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2AVY. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the complete initiation complex of RecBCDID 3K70. Publicly available at the RCSB Protein Data Bank.
-
Inactivation of the Amidotransferase Activity of Carbamoyl Phosphate Synthetase by the Antibiotic AcivicinID 1KEE. Publicly available at the RCSB Protein Data Bank.
-
Structure of the Escherichia coli FlhDC complex, a prokaryotic heteromeric regulator of transcriptionID 2AVU. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of Thermus thermophilus Phenylalanyl-tRNA synthetase comlexed with L-dopaID 3TEH. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of E. coli Aspartate Transcarbamoylase P268A Mutant in the R-State in the Presence of N-Phosphonacetyl-L-AspartateID 1F1B. Publicly available at the RCSB Protein Data Bank.
-
The Crystal Structure of the E. coli Maltose TransporterID 2R6G. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structures of the HSLVU Peptidase-Atpase Complex Reveal an ATP-Dependent Proteolysis MechanismID 1G4A. Publicly available at the RCSB Protein Data Bank.
-
Carbamoyl Phosphate Synthetase: Caught in the Act of Glutamine HydrolysisID 1A9X. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from escherichia coli in complex with the antibiotic kasugamyin at 3.5a resolution. this file contains the 30s subunit of one 70s ribosome. the entire crystal structure contains two 70s ribosomes and is described in remark 400ID 1VS7. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Release Factor RF3 Trapped in the GTP State on a Rotated Conformation of the Ribosome (without viomycin)ID 3UOQ. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of processed TolB in complex with PalID 2W8B. Publicly available at the RCSB Protein Data Bank.
-
GroEL-GroES-ADP7ID s1SX4. Publicly available at the RCSB Protein Data Bank.
-
Crystal and Molecular Structures of Native and CTP-Liganded Aspartate Carbamoyltransferase from Escherichia ColiID 2ATC. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Release Factor RF3 Trapped in the GTP State on a Rotated Conformation of the RibosomeID 3SFS. Publicly available at the RCSB Protein Data Bank.
-
Ribonucleotide Reductase Dimanganese(II)-NrdF from Escherichia coli in Complex with NrdIID 3N39. Publicly available at the RCSB Protein Data Bank.
-
The Structure of Wild-Type E. Coli Aspartate Transcarbamoylase in Complex with Novel T State Inhibitors at 2.25 ResolutionID 2FZG. Publicly available at the RCSB Protein Data Bank.
-
Complex of FimC, FimF, FimG and FimHID 3JWN. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of ethanolamine ammonia-lyase from Escherichia coli complexed with CN-CBL and (S)-2-amino-1-propanolID 3AO0. Publicly available at the RCSB Protein Data Bank.
-
Solution Structure of the Enzyme I Dimer Complexed with HPr Using Residual Dipolar Couplings and Small Angle X-Ray ScatteringID 2XDF. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to chloramphenicol. This file contains the 30S subunit of the first 70S ribosomeID 3OFA. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to chloramphenicol. This file contains the 30S subunit of the second 70S ribosomeID 3OFB. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to chloramphenicol. This file contains the 50S subunit of the first 70S ribosome with chloramphenicol boundID 3OFC. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to chloramphenicol. This file contains the 50S subunit of the second 70S ribosomeID 3OFD. Publicly available at the RCSB Protein Data Bank.
-
FIMH adhesin-FIMC chaperone complex with D-mannoseID 1KLF. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of ethanolamine ammonia-lyase from escherichia coli complexed with CN-CBL and (R)-2-amino-1-propanolID 3ANY. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to clindamycin. This file contains the 30S subunit of the first 70S ribosomeID 3OFX. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to clindamycin. This file contains the 30S subunit of the second 70S ribosomeID 3OFY. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to clindamycin. This file contains the 50S subunit of the first 70S ribosome bound to clindamycinID 3OFZ. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to erythromycin. This file contains the 30S subunit of the second 70S ribosomeID 3OFP. Publicly available at the RCSB Protein Data Bank.
-
Chey-binding domain of chea in complex with cheyID 1A0O. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to erythromycin. This file contains the 50S subunit of the first 70S ribosome with erthromycin boundID 3OFR. Publicly available at the RCSB Protein Data Bank.
-
Structure of D236A mutant E. coli Aspartate Transcarbamoylase in presence of Phosphonoacetamide at 2.90 A resolutionID 2A0F. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the asymmetric chaperonin complex groel/groes/(ADP)7ID 1AON. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with spectinomycin and neomycin. This file contains the 30S subunit of the second 70S ribosome, with spectinomycin and neomycin bound. The entire crystal structure contains two 70S ribosomesID 2QP0. Publicly available at the RCSB Protein Data Bank.
-
Complex of enzyme IIAGLC and the histidine-containing phosphocarrier protein HPR from Escherichia coli NMR, restrained regularized mean structureID 1GGR. Publicly available at the RCSB Protein Data Bank.
-
Chey-binding domain of chea in complex with chey from crystals soaked in acetyl phosphateID 1FFS. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the FimD usher bound to its cognate FimC: FimH substrateID 3RFZ. Publicly available at the RCSB Protein Data Bank.
-
FimH adhesin Q133N mutant-FimC chaperone complex with methyl-alpha-D-mannoseID 1KIU. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli at 3.5 A resolution. This file contains the 50S subunit of the second 70S ribosome. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2AWB. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURES OF PHOSPHONOACETAMIDE LIGATED T AND PHOSPHONOACETAMIDE AND MALONATE LIGATED R STATES OF ASPARTATE CARBAMOYLTRANSFERASE AT 2.8-ANGSTROMS RESOLUTION AND NEUTRAL P*HID 1AT1. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of a pre-translocation state MBP-Maltose transporter complex bound to AMP-PNPID 3PUZ. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of an outward-facing MBP-Maltose transporter complex bound to ADP-BeF3ID 3PUX. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of an outward-facing MBP-Maltose transporter complex bound to AMP-PNP after crystal soaking of the pretranslocation stateID 3PUY. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of an outward-facing MBP-Maltose transporter complex bound to ADP-VO4ID 3PUV. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of an outward-facing MBP-Maltose transporter complex bound to ADP-AlF4ID 3PUW. Publicly available at the RCSB Protein Data Bank.
-
Structure of wild-type E. coli Aspartate Transcarbamoylase in the presence of N-phosphonacetyl-L-isoasparagine at 2.3A resolutionID 2H3E. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to clindamycin. This file contains the 50S subunit of the second 70S ribosomeID 3OG0. Publicly available at the RCSB Protein Data Bank.
-
STRUCTURAL CONSEQUENCES OF EFFECTOR BINDING TO THE T STATE OF ASPARTATE CARBAMOYLTRANSFERASE. CRYSTAL STRUCTURES OF THE UNLIGATED AND ATP-, AND CTP-COMPLEXED ENZYMES AT 2.6-ANGSTROMS RESOLUTIONID 4AT1. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with paromomycin and ribosome recycling factor (RRF). This file contains the 30S subunit of the second 70S ribosome, with paromomycin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2Z4M. Publicly available at the RCSB Protein Data Bank.
-
E. coli succinate:quinone oxidoreductase (SQR) with carboxin boundID 2WDQ. Publicly available at the RCSB Protein Data Bank.
-
CARBAMOYL PHOSPHATE SYNTHETASE FROM ESCHERICHIA COLIID 1JDB. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli succinate:quinone oxidoreductase ( SQR) SdhB His207Thr mutantID 2WP9. Publicly available at the RCSB Protein Data Bank.
-
crystal structure of heterohexameric TusBCD proteins, which are crucial for the tRNA modificationID 2D1P. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1O. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1N. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1M. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of NarGHI mutant NarG-H49CID 3IR5. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the resting state maltose transporter from E. coliID 3FH6. Publicly available at the RCSB Protein Data Bank.
-
NMR structure of the IIAchitobiose-IIBchitobiose phosphoryl transition state complex of the N,N'-diacetylchitoboise brance of the E. coli phosphotransferase systemID 2WY2. Publicly available at the RCSB Protein Data Bank.
-
Aspartate Transcarbamoylase Catalytic Chain Mutant E50A Complex with Phosphonoacetamide, Malonate, and Cytidine-5-Prime-Triphosphate (CTP)ID 1TUG. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1S. Publicly available at the RCSB Protein Data Bank.
-
Quinol-Fumarate Reductase with Menaquinol MoleculesID 1L0V. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1Q. Publicly available at the RCSB Protein Data Bank.
-
fatty acid beta-oxidation multienzyme complex from Pseudomonas fragi, form I (native2)ID 1WDK. Publicly available at the RCSB Protein Data Bank.
-
E. coli Quinol-Fumarate Reductase with Bound Inhibitor HQNOID 1KF6. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1Z. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Activated MPT SynthaseID 3BII. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of NarGH complexID 1R27. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURES OF PHOSPHONOACETAMIDE LIGATED T AND PHOSPHONOACETAMIDE AND MALONATE LIGATED R STATES OF ASPARTATE CARBAMOYLTRANSFERASE AT 2.8-ANGSTROMS RESOLUTION AND NEUTRAL PHID 2AT1. Publicly available at the RCSB Protein Data Bank.
-
CHEY-BINDING DOMAIN OF CHEA IN COMPLEX WITH CHEY AT 2.1 A RESOLUTIONID 1FFG. Publicly available at the RCSB Protein Data Bank.
-
Structures of the bacterial ribosome in classical and hybrid states of tRNA bindingID 3R8S. Publicly available at the RCSB Protein Data Bank.
-
E. coli succinate:quinone oxidoreductase (SQR) with an empty quinone- binding pocketID 2WDV. Publicly available at the RCSB Protein Data Bank.
-
E. coli Aspartate Transcarbamoylase complexed with N-phosphonacetyl-L-asparagineID 2IPO. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the entire respiratory complex I from Thermus thermophilusID 4HEA. Publicly available at the RCSB Protein Data Bank.
-
Structure of PDF binding helix in complex with the ribosomeID 2VHM. Publicly available at the RCSB Protein Data Bank.
-
X-RAY STRUCTURE OF THE FIMC-FIMH CHAPERONE ADHESIN COMPLEX FROM UROPATHOGENIC E.COLIID 1QUN. Publicly available at the RCSB Protein Data Bank.
-
Structure of regulatory chain mutant H20A of asparate transcarbamoylase from E. coliID 2QGF. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the apomolybdo-NarGHIID 1SIW. Publicly available at the RCSB Protein Data Bank.
-
Complex II (Succinate Dehydrogenase) From E. Coli with ubiquinone boundID 1NEK. Publicly available at the RCSB Protein Data Bank.
-
The structure of ubiquinol oxidase from Escherichia E. coliID 1FFT. Publicly available at the RCSB Protein Data Bank.
-
Complex II (Succinate Dehydrogenase) From E. Coli with Dinitrophenol-17 inhibitor co-crystallized at the ubiquinone binding siteID 1NEN. Publicly available at the RCSB Protein Data Bank.
-
ClpNS with fragmentsID 1R6Q. Publicly available at the RCSB Protein Data Bank.
-
E. coli succinate:quinone oxidoreductase (SQR) with pentachlorophenol boundID 2WDR. Publicly available at the RCSB Protein Data Bank.
-
Structure of a regulatory subunit mutant D19A of ATCase from E. coliID 2QG9. Publicly available at the RCSB Protein Data Bank.
-
Structure of mdt proteinID 3HZI. Publicly available at the RCSB Protein Data Bank.
-
Inward facing conformations of the MetNI methionine ABC transporter: CY5 SeMet soak crystal formID 3TUZ. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of a bifunctional aldolase-dehydrogenase: sequestering a reactive and volatile intermediateID 1NVM. Publicly available at the RCSB Protein Data Bank.
-
The subnanometer cryo-electron microscopy structure of the nitrogen assimilating enzyme glutamate synthase reveals a 1.2 MDa heterohexameric complexID 2VDC. Publicly available at the RCSB Protein Data Bank.
-
Aspartate Transcarbamylase (ATCase) of Escherichia coli: A New Crystalline R State Bound to PALA, or to Product Analogues Phosphate and CitrateID 1Q95. Publicly available at the RCSB Protein Data Bank.
-
Orthorhombic Crystal Form of Molybdopterin SynthaseID 1NVI. Publicly available at the RCSB Protein Data Bank.
-
Structure of PDF binding helix in complex with the ribosome. (Structure 2 of 4)ID 2VHN. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with gentamicin. This file contains the 30S subunit of the first 70S ribosome, with gentamicin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QB9. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of Nitrate Reductase A NarGHI, from Escherichia coliID 1Q16. Publicly available at the RCSB Protein Data Bank.
-
Inward facing conformations of the MetNI methionine ABC transporter: DM crystal formID 3TUJ. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Ribosome with messenger RNA and the Anticodon stem-loop of P-site tRNA. This file contains the 30s subunit of one 70s ribosome. The entire crystal structure contains two 70s ribosomes and is described in remark 400ID 2I2P. Publicly available at the RCSB Protein Data Bank.
-
Structure of D236A E. coli Aspartate Transcarbamoylase in the presence of phosphonoacetamide and l-Aspartate at 2.60 A resolutionID 2HSE. Publicly available at the RCSB Protein Data Bank.
-
Complex of the domain I and domain III of Escherichia coli transhydrogenaseID 2BRU. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Ribosome with messenger RNA and the Anticodon stem-loop of P-site tRNA. This file contains the 30s subunit of one 70s ribosome. The entire crystal structure contains two 70s ribosomes and is described in remark 400ID 2I2U. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of carbamoyl phosphate synthetase complexed at CYS269 in the small subunit with the tetrahedral mimic l-glutamate gamma-semialdehydeID 1CS0. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Ribosome with messenger RNA and the Anticodon stem-loop of P-site tRNA. This file contains the 50s subunit of one 70s ribosome. The entire crystal structure contains two 70s ribosomes and is described in remark 400ID 2I2V. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of a GTP-Regulated ATP Sulfurylase Heterodimer from Pseudomonas syringaeID 1ZUN. Publicly available at the RCSB Protein Data Bank.
-
ASPARTATE TRANSCARBAMOYLASE COMPLEXED WITH N-PHOSPHONACETYL-L-ASPARTATE (PALA)ID 1D09. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ammonia channel AMTB complexed with the signal transduction protein GLNKID 2NS1. Publicly available at the RCSB Protein Data Bank.
-
Ribonucleotide Reductase Dimanganese(II)-NrdF from Escherichia coli in Complex with Reduced NrdIID 3N3A. Publicly available at the RCSB Protein Data Bank.
-
A. fulgidus IscS-IscU complex structureID 4EB7. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to CEM-101. This file contains the 50S subunit of the second 70S ribosomeID 1VT2. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of the Ternary Complex of FIMD (N-Terminal Domain) with FIMC and the Pilin Domain of FIMHID 1ZE3. Publicly available at the RCSB Protein Data Bank.
-
E. coli Aspartate Transcarbamylase 240's Loop Mutant (K244N)ID 1SKU. Publicly available at the RCSB Protein Data Bank.
-
T-state Active Site of Aspartate Transcarbamylase: Crystal Structure of the Carbamyl Phosphate and L-alanosine Ligated EnzymeID 2AIR. Publicly available at the RCSB Protein Data Bank.
-
QUINOL-FUMARATE REDUCTASE WITH QUINOL INHIBITOR 2-[1-(4-CHLORO-PHENYL)-ETHYL]-4,6-DINITRO-PHENOLID 1KFY. Publicly available at the RCSB Protein Data Bank.
-
NMR solution structure of NapD in complex with NapA1-35 signal peptideID 2PQ4. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF MUTANT. R105A OF E. COLI ASPARTATE TRANSCARBAMOYLASEID 1I5O. Publicly available at the RCSB Protein Data Bank.
-
The crystal structure of the NarGHI mutant NarH C16AID 3EGW. Publicly available at the RCSB Protein Data Bank.
-
Structure of E. coli toxin RelE (R81A/R83A) mutant in complex with antitoxin RelBc (K47–L79) peptideID 2KC8. Publicly available at the RCSB Protein Data Bank.
-
Regulating the Escherichia coli ammonia channel: the crystal structure of the AmtB-GlnK complexID 2NUU. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Release Factor RF3 Trapped in the GTP State on a Rotated Conformation of the RibosomeID 3SGF. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to CEM-101. This file contains the 30S subunit of the first 70S ribosomeID 3OR9. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to erythromycin. This file contains the 50S subunit of the second 70S ribosomeID 3OFQ. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the ternary complex of FimD (N-Terminal Domain, FimDN) with FimC and the N-terminally truncated pilus subunit FimF (FimFt)ID 3BWU. Publicly available at the RCSB Protein Data Bank.
-
Structure of the E.coli F1-ATP synthase inhibited by subunit EpsilonID 3OAA. Publicly available at the RCSB Protein Data Bank.
-
Structures of the bacterial ribosome in classical and hybrid states of tRNA bindingID 3R8T. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to CEM-101. This file contains the 50S subunit of the first 70S ribosome bound to CEM-101ID 3ORB. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURES OF ASPARTATE CARBAMOYLTRANSFERASE LIGATED WITH PHOSPHONOACETAMIDE, MALONATE, AND CTP OR ATP AT 2.8-ANGSTROMS RESOLUTION AND NEUTRAL P*HID 7AT1. Publicly available at the RCSB Protein Data Bank.
-
The crystal structure of Nitrate Reductase A, NarGHI, in complex with the Q-site inhibitor pentachlorophenolID 1Y4Z. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I22. Publicly available at the RCSB Protein Data Bank.
-
MOLYBDOPTERIN SYNTHASE (MOAD/MOAE)ID 1FM0. Publicly available at the RCSB Protein Data Bank.
-
Inward facing conformations of the MetNI methionine ABC transporter: CY5 native crystal formID 3TUI. Publicly available at the RCSB Protein Data Bank.
-
The Structure of Wild-Type E. Coli Aspartate Transcarbamoylase in Complex with Novel T State Inhibitors at 2.50 ResolutionID 2FZK. Publicly available at the RCSB Protein Data Bank.
-
The structural basis of ClpS-mediated switch in ClpA substrate recognitionID 1MG9. Publicly available at the RCSB Protein Data Bank.
-
Structures of the bacterial ribosome in classical and hybrid states of tRNA bindingID 4GD2. Publicly available at the RCSB Protein Data Bank.
-
NMR structure of the IIAchitobiose-IIBchitobiose complex of the N, N'- diacetylchitoboise brance of the E. coli phosphotransferase systemID 2WWV. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of NarGHI mutant NarG-H49SID 3IR6. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I20. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I21. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with neomycin. This file contains the 30S subunit of the first 70S ribosome, with neomycin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QAL. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with neomycin. This file contains the 50S subunit of the first 70S ribosome, with neomycin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QAM. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with neomycin. This file contains the 30S subunit of the second 70S ribosome, with neomycin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QAN. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of Wild-Type E. Coli Asparate Transcarbamoylase at pH 8.5 at 2.80 A ResolutionID 3D7S. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with paromomycin and ribosome recycling factor (RRF). This file contains the 50S subunit of the first 70S ribosome, with paromomycin and RRF bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2Z4L. Publicly available at the RCSB Protein Data Bank.
-
ATCASE Y165F MUTANTID 9ATC. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with paromomycin and ribosome recycling factor (RRF). This file contains the 50S subunit of the second 70S ribosome, with paromomycin and RRF bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2Z4N. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with spectinomycin and neomycin. This file contains the 50S subunit of the first 70S ribosome, with neomycin bound. The entire crystal structure contains two 70S ribosomesID 2QOZ. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with paromomycin and ribosome recycling factor (RRF). This file contains the 30S subunit of the first 70S ribosome, with paromomycin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2Z4K. Publicly available at the RCSB Protein Data Bank.
-
Structural consequences of effector binding to the t state of aspartate carbamoyltransferase. Crystal structures of the unligated and atp-, and ctp-complexed enzymes at 2.6-angstroms resolutionID 6AT1. Publicly available at the RCSB Protein Data Bank.
-
4.3A resolution structure of a MinD-MinE(I24N) protein complexID 3R9J. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of ethanolamine ammonia-lyase from Escherichia coli complexed with CN-Cbl (substrate-free form)ID 3ABR. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of ethanolamine ammonia-lyase from Escherichia coli complexed with adeninylpentylcobalamin and ethanolamineID 3ABS. Publicly available at the RCSB Protein Data Bank.
-
Structures of the bacterial ribosome in classical and hybrid states of tRNA bindingID 4GD1. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of groEL-groESID 1PCQ. Publicly available at the RCSB Protein Data Bank.
-
Complex II (Succinate Dehydrogenase) From E. Coli with Atpenin A5 inhibitor co-crystallized at the ubiquinone binding siteID 2ACZ. Publicly available at the RCSB Protein Data Bank.
-
CHEY-BINDING (P2) DOMAIN OF CHEA IN COMPLEX WITH CHEY FROM ESCHERICHIA COLIID 1EAY. Publicly available at the RCSB Protein Data Bank.
-
The crystal structure of the NarGHI mutant NarI-H66YID 1Y5L. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with spectinomycin. This file contains the 50S subunit of the second 70S ribosome. The entire crystal structure contains two 70S ribosomesID 2QOX. Publicly available at the RCSB Protein Data Bank.
-
MOLYBDOPTERIN SYNTHASE (MOAD/MOAE)ID 1FMA. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of ethanolamine ammonia-lyase from Escherichia coli complexed with CN-Cbl and ethanolamineID 3ABO. Publicly available at the RCSB Protein Data Bank.
-
ARGININE 54 IN THE ACTIVE SITE OF ESCHERICHIA COLI ASPARTATE TRANSCARBAMOYLASE IS CRITICAL FOR CATALYSIS: A SITE-SPECIFIC MUTAGENESIS, NMR AND X-RAY CRYSTALLOGRAPHY STUDYID 1ACM. Publicly available at the RCSB Protein Data Bank.
-
The Structure of Wild-Type E. Coli Aspartate Transcarbamoylase in Complex with Novel T State Inhibitors at 2.10 ResolutionID 2FZC. Publicly available at the RCSB Protein Data Bank.
-
Ribonucleotide Reductase Dimanganese(II)-NrdF from Escherichia coli in Complex with Reduced NrdI with a Trapped PeroxideID 3N3B. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of the MukE-MukF ComplexID 3EUH. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with spectinomycin. This file contains the 50S subunit of the first 70S ribosome. The entire crystal structure contains two 70S ribosomesID 2QOV. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with spectinomycin. This file contains the 30S subunit of the second 70S ribosome, with spectinomycin bound. The entire crystal structure contains two 70S ribosomesID 2QOW. Publicly available at the RCSB Protein Data Bank.
-
Products in the T State of Aspartate Transcarbamylase: Crystal Structure of the Phosphate and N-carbamyl-L-aspartate Ligated EnzymeID 1R0C. Publicly available at the RCSB Protein Data Bank.
-
Aspartate Transcarbamylase (ATCase) of Escherichia coli: A New Crystalline R State Bound to PALA, or to Product Analogues Phosphate and CitrateID 1R0B. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from escherichia coli in complex with the antibiotic kasugamyin at 3.5A resolution. this file contains the 30s subunit of one 70s ribosome. the entire crystal structure contains two 70s ribosomes and is described in remark 400ID 1VS5. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from escherichia coli in complex with the antibiotic kasugamyin at 3.5A resolution. this file contains the 50s subunit of one 70s ribosome. the entire crystal structure contains two 70s ribosomes and is described in remark 400ID 1VS6. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of SufC-SufD complex involved in the iron-sulfur cluster biosynthesisID 2ZU0. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from escherichia coli in complex with the antibiotic kasugamyin at 3.5a resolution. this file contains the 50s subunit of one 70s ribosome. The entire crystal structure contains two 70s ribosomes and is described in remark 400ID 1VS8. Publicly available at the RCSB Protein Data Bank.
-
COMPLEX OF THE AMINO TERMINAL DOMAIN OF ENZYME I AND THE HISTIDINE-CONTAINING PHOSPHOCARRIER PROTEIN HPR FROM ESCHERICHIA COLI NMR, RESTRAINED REGULARIZED MEAN STRUCTUREID 3EZE. Publicly available at the RCSB Protein Data Bank.
-
COMPLEX OF THE AMINO TERMINAL DOMAIN OF ENZYME I AND THE HISTIDINE-CONTAINING PHOSPHOCARRIER PROTEIN HPR FROM ESCHERICHIA COLIID 3EZB. Publicly available at the RCSB Protein Data Bank.
-
COMPLEX OF THE AMINO TERMINAL DOMAIN OF ENZYME I AND THE HISTIDINE-CONTAINING PHOSPHOCARRIER PROTEIN HPR FROM ESCHERICHIA COLI NMR, RESTRAINED REGULARIZED MEAN STRUCTUREID 3EZA. Publicly available at the RCSB Protein Data Bank.
-
A1C12 SUBCOMPLEX OF F1FO ATP SYNTHASEID 1C17. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the CusBA heavy-metal efflux complex from Escherichia E. coliID 3NE5. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1T. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to CEM-101. This file contains the 30S subunit of the second 70S ribosomeID 3ORA. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of TolB/Pal complexID 2HQS. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of ethanolamine ammonia-lyase from Escherichia coli complexed with CN-Cbl and 2-amino-1-propanolID 3ABQ. Publicly available at the RCSB Protein Data Bank.
-
Molecular basis for bacterial class 1 release factor methylation by PrmCID 2B3T. Publicly available at the RCSB Protein Data Bank.
-
Structural basis for the negative regulation of bacterial stress response by RseBID 3M4W. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli 70S ribosome in an intermediate state of ratchetingID 3I1R. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with neomycin. This file contains the 50S subunit of the second 70S ribosome, with neomycin bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QAO. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF THE CARBAMOYL PHOSPHATE SYNTHETASE: SMALL SUBUNIT MUTANT C269S WITH BOUND GLUTAMINEID 1C3O. Publicly available at the RCSB Protein Data Bank.
-
E. coli Quinol fumarate reductase FrdA T234A mutationID 3CIR. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the maltose-binding protein/maltose transporter complex in an outward-facing conformation bound to MgAMPPNPID 3RLF. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli succinate:quinone oxidoreductase (SQR) SdhC His84Met mutantID 2WU2. Publicly available at the RCSB Protein Data Bank.
-
COMPLEX OF N-PHOSPHONACETYL-L-ASPARTATE WITH ASPARTATE CARBAMOYLTRANSFERASE. X-RAY REFINEMENT, ANALYSIS OF CONFORMATIONAL CHANGES AND CATALYTIC AND ALLOSTERIC MECHANISMSID 8ATC. Publicly available at the RCSB Protein Data Bank.
-
The crystal structure of the NarGHI mutant NarI-K86A in complex with pentachlorophenolID 1Y5N. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of MukE-MukF(residues 292-443)-MukB(head domain)-ATPgammaS complex, asymmetric dimerID 3EUK. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of methionine importer MetNIID 3DHW. Publicly available at the RCSB Protein Data Bank.
-
Aspartate Transcarbamoylase Catalytic Chain Mutant Glu50Ala Complexed with N-(Phosphonacetyl-L-Aspartate) (PALA)ID 1TTH. Publicly available at the RCSB Protein Data Bank.
-
The Structure of E. coli Aspartate Transcarbamoylase Q137A Mutant in The R-StateID 1XJW. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE ANALYSIS OF ClpSN WITH TRANSITION METAL ION BOUNDID 1MBX. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the C47A/A241C disulfide-linked E. coli Aspartate Transcarbamoylase holoenzymeID 3MPU. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF E. COLI ASPARTATE TRANSCARBAMOYLASE P268A MUTANT IN THE T-STATEID 1EZZ. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to telithromycin. This file contains the 50S subunit of the first 70S ribosome with telithromycin boundID 3OAT. Publicly available at the RCSB Protein Data Bank.
-
Structure of the N-terminal domain of the E. coli antitoxin MqsA (YgiT/b3021) in complex with the E. coli toxin MqsR (YgiU/b3022)ID 3HI2. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure Analysis of ClpSN heterodimerID 1MBU. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE ANALYSIS OF ClpSN HETERODIMER TETRAGONAL FORMID 1MBV. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to telithromycin. This file contains the 30S subunit of the first 70S ribosomeID 3OAQ. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of ET-EHred-5-CH3-THF complexID 3A8I. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of ET-EHred complexID 3A8J. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of ETD97N-EHred complexID 3A8K. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Escherichia coli sigmaE with the Cytoplasmic Domain of its Anti-sigma RseAID 1OR7. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli succinate:quinone oxidoreductase ( SQR) SdhD Tyr83Phe mutantID 2WS3. Publicly available at the RCSB Protein Data Bank.
-
CARBAMOYL PHOSPHATE SYNTHETASE FROM ESCHERICHIS COLI WITH COMPLEXED WITH THE ALLOSTERIC LIGAND IMPID 1CE8. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of the G359F (small subunit) Point Mutant of Carbamoyl Phosphate SynthetaseID 1M6V. Publicly available at the RCSB Protein Data Bank.
-
ABC-transporter BtuCD in complex with its periplasmic binding protein BtuFID 2QI9. Publicly available at the RCSB Protein Data Bank.
-
The crystal structure of the NarGHI mutant NarI-K86AID 1Y5I. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to erythromycin. This file contains the 30S subunit of the first 70S ribosomeID 3OFO. Publicly available at the RCSB Protein Data Bank.
-
Bacterial ABC Transporter Involved in B12 UptakeID 1L7V. Publicly available at the RCSB Protein Data Bank.
-
COMPLEX OF GAMMA/EPSILON ATP SYNTHASE FROM E.COLIID 1FS0. Publicly available at the RCSB Protein Data Bank.
-
Structure of a histidine kinase-response regulator complex reveals insights into Two-component signaling and a novel cis-autophosphorylation mechanismID 3DGE. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli succinate:quinone oxidoreductase (SQR) SdhD His71Met mutantID 2WU5. Publicly available at the RCSB Protein Data Bank.
-
Aspartate Transcarbamoylase Catalytic Chain Mutant E50A Complex with PhosphonoacetamideID 1TU0. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to telithromycin. This file contains the 50S subunit of the second 70S ribosomeID 3OAS. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of E.coli Dha kinase DhaK-DhaL complexID 3PNL. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with spectinomycin and neomycin. This file contains the 50S subunit of the second 70S ribosome, with neomycin bound. The entire crystal structure contains two 70S ribosomesID 2QP1. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the E. coli ribosome bound to telithromycin. This file contains the 30S subunit of the second 70S ribosomeID 3OAR. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with ribosome recycling factor (RRF). This file contains the 50S subunit of the first 70S ribosome, with RRF bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBE. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAB. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAC. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAA. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAF. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAG. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAD. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAE. Publicly available at the RCSB Protein Data Bank.
-
FORMATE DEHYDROGENASE N FROM E. COLIID 1KQG. Publicly available at the RCSB Protein Data Bank.
-
FORMATE DEHYDROGENASE N FROM E. COLIID 1KQF. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAH. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CTP-LIGATED T STATE ASPARTATE TRANSCARBAMOYLASE AT 2.5 ANGSTROMS RESOLUTION: IMPLICATIONS FOR ATCASE MUTANTS AND THE MECHANISM OF NEGATIVE COOPERATIVITYID 1RAI. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURES OF ASPARTATE CARBAMOYLTRANSFERASE LIGATED WITH PHOSPHONOACETAMIDE, MALONATE, AND CTP OR ATP AT 2.8-ANGSTROMS RESOLUTION AND NEUTRAL P*HID 8AT1. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of GroEL14-GroES7-(ADP-AlFx)7ID 1SVT. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of a pre-translocation state MBP-Maltose transporter complex without nucleotideID 3PV0. Publicly available at the RCSB Protein Data Bank.
-
ATP-dependent Clp protease ATP-binding subunit clpA/ATP-dependent Clp protease adaptor protein clpSID 1R6O. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Release Factor RF3 Trapped in the GTP State on a Rotated Conformation of the Ribosome (without viomycin)ID 3UOS. Publicly available at the RCSB Protein Data Bank.
-
RecBCD: DNA complexID 1W36. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with ribosome recycling factor (RRF). This file contains the 30S subunit of the first 70S ribosome. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBD. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURES OF PHOSPHONOACETAMIDE LIGATED T AND PHOSPHONOACETAMIDE AND MALONATE LIGATED R STATES OF ASPARTATE CARBAMOYLTRANSFERASE AT 2.8-ANGSTROMS RESOLUTION AND NEUTRAL PHID 3AT1. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of HypE-HypF complexID 3VTI. Publicly available at the RCSB Protein Data Bank.
-
Structural basis of ClpS-mediated switch in ClpA substrate recognitionID 1LZW. Publicly available at the RCSB Protein Data Bank.
-
Crystal Structure of Ribosome with messenger RNA and the Anticodon stem-loop of P-site tRNA. This file contains the 50s subunit of one 70s ribosome. The entire crystal structure contains two 70s ribosomes and is described in remark 400ID 2I2T. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with spectinomycin and neomycin. This file contains the 30S subunit of the first 70S ribosome, with spectinomycin and neomycin bound. The entire crystal structure contains two 70S ribosomesID 2QOY. Publicly available at the RCSB Protein Data Bank.
-
Structure of wild-type E. coli Aspartate Transcarbamoylase in the presence of CTP, carbamoyl phosphate at 2.50 A resolutionID 1ZA2. Publicly available at the RCSB Protein Data Bank.
-
Crystal structure of the bacterial ribosome from Escherichia coli in complex with ribosome recycling factor (RRF). This file contains the 50S subunit of the second 70S ribosome, with RRF bound. The entire crystal structure contains two 70S ribosomes and is described in remark 400ID 2QBG. Publicly available at the RCSB Protein Data Bank.
-
Structure of wild-type E. coli Aspartate Transcarbamoylase in the presence of CTP at 2.20 A resolutionID 1ZA1. Publicly available at the RCSB Protein Data Bank.
-
CRYSTAL STRUCTURE OF CARBAMOYL PHOSPHATE SYNTHETASE: SMALL SUBUNIT MUTATION C269SID 1C30. Publicly available at the RCSB Protein Data Bank.
-
ASPARTATE TRANSCARBOMYLASE REGULATORY CHAIN MUTANT (T82A)ID 1NBE. Publicly available at the RCSB Protein Data Bank.
References
-
Evolution of protein interactions: from interactomes to interfacesArchives of Biochemistry and Biophysics 554:65–75.https://doi.org/10.1016/j.abb.2014.05.010
-
Inverse Ising inference using all the dataPhysical Review Letters 108:090201.https://doi.org/10.1103/PhysRevLett.108.090201
-
Arrangement of subunits in intact mammalian mitochondrial ATP synthase determined by cryo-EMProceedings of the National Academy of Sciences of USA 109:11675–11680.https://doi.org/10.1073/pnas.1204935109
-
Learning generative models for protein fold familiesProteins 79:1061–1078.https://doi.org/10.1002/prot.22934
-
Individual interactions of the b subunits within the stator of the Escherichia coli ATP synthaseThe Journal of Biological Chemistry 288:24465–24479.https://doi.org/10.1074/jbc.M113.465633
-
Version 1.2 of the Crystallography and NMR systemNature Protocols 2:2728–2733.https://doi.org/10.1038/nprot.2007.406
-
Structure of the ATP synthase catalytic complex (F(1)) from Escherichia coli in an autoinhibited conformationNature Structural & Molecular Biology 18:701–707.https://doi.org/10.1038/nsmb.2058
-
Emerging methods in protein co-evolutionNature reviews. Genetics 14:249–261.https://doi.org/10.1038/nrg3414
-
The role of transmembrane span 2 in the structure and function of subunit a of the ATP synthase from Escherichia coliArchives of Biochemistry and Biophysics 418:55–62.https://doi.org/10.1016/S0003-9861(03)00391-6
-
Structure of the subunit c oligomer in the F1Fo ATP synthase: model derived from solution structure of the monomer and cross-linking in the native enzymeProceedings of the National Academy of Sciences of USA 96:7785–7790.https://doi.org/10.1073/pnas.96.14.7785
-
HADDOCK: a protein-protein docking approach based on biochemical or biophysical informationJournal of the American Chemical Society 125:1731–1737.https://doi.org/10.1021/ja026939x
-
Improved contact prediction in proteins: using pseudolikelihoods to infer Potts modelsPhysical Review. E, Statistical, Nonlinear, and Soft Matter Physics 87:012707.
-
InterEvol database: exploring the structure and evolution of protein complex interfacesNucleic Acids Research 40:D847–D856.https://doi.org/10.1093/nar/gkr845
-
Identification of protein-protein interaction sites from docking energy landscapesJournal of Molecular Biology 335:843–865.https://doi.org/10.1016/j.jmb.2003.10.069
-
Assessing the utility of coevolution-based residue-residue contact predictions in a sequence- and structure-rich eraProceedings of the National Academy of Sciences of USA 110:15674–15679.https://doi.org/10.1073/pnas.1314045110
-
A simple physical model for binding energy hot spots in protein-protein complexesProceedings of the National Academy of Sciences of USA 99:14116–14121.https://doi.org/10.1073/pnas.202485799
-
Computational design of protein-protein interactionsCurrent Opinion in Chemical Biology 8:91–97.https://doi.org/10.1016/j.cbpa.2003.12.008
-
Computational redesign of protein-protein interaction specificityNature Structural & Molecular Biology 11:371–379.https://doi.org/10.1038/nsmb749
-
Structural and functional Characterization of Escherichia coli toxin-antitoxin complex DinJ-YafQThe Journal of Biological Chemistry 289:21191–21202.https://doi.org/10.1074/jbc.M114.559773
-
Characterization of the first cytoplasmic loop of subunit a of the Escherichia coli ATP synthase by surface labeling, cross-linking, and mutagenesisThe Journal of Biological Chemistry 277:27288–27293.https://doi.org/10.1074/jbc.M202118200
-
Protein structure prediction from sequence variationNature Biotechnology 30:1072–1080.https://doi.org/10.1038/nbt.2419
-
Direct-coupling analysis of residue coevolution captures native contacts across many protein familiesProceedings of the National Academy of Sciences of USA 108:E1293–E1301.https://doi.org/10.1073/pnas.1111471108
-
Interactome3D: adding structural details to protein networksNature Methods 10:47–53.https://doi.org/10.1038/nmeth.2289
-
Accurate de novo structure prediction of large transmembrane protein domains using fragment-assembly and correlated mutation analysisProceedings of the National Academy of Sciences of USA 109:E1540–E1547.https://doi.org/10.1073/pnas.1120036109
-
Assembly information services in the European Nucleotide ArchiveNucleic Acids Research 42:D38–D43.https://doi.org/10.1093/nar/gkt1082
-
Similarity of phylogenetic trees as indicator of protein-protein interactionProtein Engineering 14:609–614.https://doi.org/10.1093/protein/14.9.609
-
Correlated mutations contain information about protein-protein interactionJournal of Molecular Biology 271:511–523.https://doi.org/10.1006/jmbi.1997.1198
-
IPython: a system for Interactive Scientific computingComputing in Science and Engineering 9:21–29.https://doi.org/10.1109/MCSE.2007.53
-
The binary protein-protein interaction landscape of Escherichia coliNature Biotechnology 32:285–290.https://doi.org/10.1038/nbt.2831
-
Structure of the gamma-epsilon complex of ATP synthaseNat Struct Biol 7:1051–1054.https://doi.org/10.1038/80975
-
Protein and ligand preparation: parameters, protocols, and influence on virtual screening enrichmentsJournal of Computer-aided Molecular Design 27:221–234.https://doi.org/10.1007/s10822-013-9644-8
-
The gammaepsilon-c subunit interface in the ATP synthase of Escherichia coli. cross-linking of the epsilon subunit to the c subunit ring does not impair enzyme function, that of gamma to c subunits leads to uncouplingThe Journal of Biological Chemistry 274:34233–34237.https://doi.org/10.1074/jbc.274.48.34233
-
Cross-linking between helices within subunit a of Escherichia coli ATP synthase defines the transmembrane packing of a four-helix bundleThe Journal of Biological Chemistry 281:37861–37867.https://doi.org/10.1074/jbc.M607453200
-
Activities at the Universal protein resource (UniProt)Nucleic Acids Research 42:D191–D198.https://doi.org/10.1093/nar/gkt1140
-
Assembly of macromolecular complexes by satisfaction of spatial restraints from electron microscopy imagesProceedings of the National Academy of Sciences of USA 109:18821–18826.https://doi.org/10.1073/pnas.1216549109
-
The ATP synthase: the understood, the uncertain and the unknownBiochemical Society Transactions 41:1–16.https://doi.org/10.1042/BST20110773
-
Modeling of proteins and their assemblies with the Integrative Modeling PlatformMethods in molecular biology 1091:277–295.https://doi.org/10.1007/978-1-62703-691-7_20
-
Identification of direct residue contacts in protein-protein interaction by message passingProceedings of the National Academy of Sciences of USA 106:67–72.https://doi.org/10.1073/pnas.0805923106
Article and author information
Author details
Charlotta P I Schärfe

Alexandre M J J Bonvin
Funding
National Institute of General Medical Sciences (R01 GM106303)
- Thomas A Hopf
- Debora S Marks
- Chris Sander
Fulbright Commission
- Charlotta P I Schärfe
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Copyright
© 2014, Hopf et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 19,610
- views
-
- 3,006
- downloads
-
- 473
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 473
- citations for umbrella DOI https://doi.org/10.7554/eLife.03430
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Sequence co-evolution gives 3D contacts and structures of protein complexes
eLife 3:e03430.
https://doi.org/10.7554/eLife.03430




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}