Method for identification of condition-associated public antigen receptor sequences
- Shemyakin-Ovchinnikov Institute of Bioorganic Chemistry of the Russian Academy of Sciences, Russia
- Skolkovo Institute of Science and Technology, Russia
- Central European Institute of Technology, Czech republic
- Moscow State University, Russia
- CNRS, Sorbonne University, Paris-Diderot University, École Normale Supérieure, France
- CNRS, Sorbonne University, École Normale Supérieure, France
Abstract
Diverse repertoires of hypervariable immunoglobulin receptors (TCR and BCR) recognize antigens in the adaptive immune system. The development of immunoglobulin receptor repertoire sequencing methods makes it possible to perform repertoire-wide disease association studies of antigen receptor sequences. We developed a statistical framework for associating receptors to disease from only a small cohort of patients, with no need for a control cohort. Our method successfully identifies previously validated Cytomegalovirus and type one diabetes responsive TCR sequences .
https://doi.org/10.7554/eLife.33050.001Introduction
T-cell receptors (TCR) and B-cell receptors (BCR) are hypervariable immunoglobulins that play a key role in recognizing antigens in the vertebrate immune system. TCR and BCR are formed in the stochastic process of V(D)J recombination, creating a diverse sequence repertoire. These receptors consist of two hypervariable chains, the and chains in the case of TCR. Progress in high throughput sequencing now allows for deep profiling of TCR and TCR chain repertoires, by establishing a near-complete list of unique receptor chain sequences, or ‘clonotypes’, present in a sample. Most sequencing data available correspond to TCR only, but the same principles discussed below apply to TCR repertoires, or to paired repertoires.
Comparison of sequenced repertoires has revealed that in any pair of individuals, large numbers of TCR sequences have the same amino acid sequence (Venturi et al., 2011). Several mechanisms leading to the repertoire overlap have been identified so far. The first mechanism is convergent recombination. Due to biases in V(D)J recombination process, the probability of generation of some TCR sequences is very high, making them appear in almost every individual multiple times and repeatedly sampled in repertoire profiling experiments (Britanova et al., 2014). This sharing does not result from a common specificity or function of T-cells corresponding to the shared TCR clonotypes, and may in fact correspond to cells from the naive compartment in both donors (Quigley et al., 2010), or from functionally distinct subsets such as CD4 and CD8 T-cells. The second possible reason for TCR sequence sharing is specific to identical twins, who may share T cell clones as a consequence of cord blood exchange in utero via a shared placenta (Pogorelyy et al., 2017). Note that in that scenario both the and chains are shared together. The third and most interesting mechanism for sharing the sequence of either the or or both chains is convergent selection in response to a common antigen. From functional studies, such as sequencing of MHC-multimer specific T-cells, it is known that the antigen-specific repertoire is often biased, and the same antigen-specific TCR or chain sequences can be found in different individuals (Miles et al., 2011; Dash et al., 2017; Glanville et al., 2017).
Reproducibility of a portion of the antigen-specific T-cell repertoire in different patients creates an opportunity for disease association studies using TCR repertoire datasets (Faham et al., 2017; Emerson et al., 2017). These studies analyse the TCR sequence overlap in large cohorts of healthy controls and patients to identify shared sequences overrepresented in the patient cohort. Here we propose a novel computational method to identify clonotypes which are likely to be shared because of selection for their response to a common antigen, instead of convergent recombination. Our approach is based on a mechanistic model of TCR recombination and is applicable to small cohorts of patients, without the need for a healthy control cohort.
Results
As a proof of concept, we applied our method to two large publicly available TCR datasets from Cytomegalovirus (CMV)-positive (Emerson et al., 2017) and type one diabetes (T1D) (Seay et al., 2016) patients. In both studies the authors found shared public TCR clonotypes that are specific to CMV-peptides or self-peptides, respectively. Specificity of these clonotypes was defined using MHC-multimers. We show that TCR chain sequences functionally associated with CMV and T1D in these studies are identified as outliers by our method.
The main ingredient of our approach is to estimate the probability of generation of shared clonotypes, and to use this probability to determine the source of sharing (see Figure 1). Due to the limited sampling depth of any TCR sequencing experiment, chances to sample the same TCR clonotype twice are low, unless this clonotype is easy to generate convergently, with many independent generation events with the same TCR amino acid sequence in each individual (convergent recombination), or if corresponding T-cell clone underwent clonal expansion, making its concentration in blood high (convergent selection). Thus, we reasoned that convergently selected clonotypes should have a lower generative probability than typical convergently recombined clonotypes. To test this, we estimated the generative probability of the TCR’s Complementarity Determining Region 3 (CDR3) amino-acid sequences that were shared between several patients. Since no algorithm exists that can compute this generative probability directly, our method relies on the random generation and translation of massive numbers of TCR nucleotide sequences using a mechanistic statistical model of V(D)J recombination (Murugan et al., 2012), as can be easily performed for example using the IGoR software (Marcou et al., 2017).
Figure 1
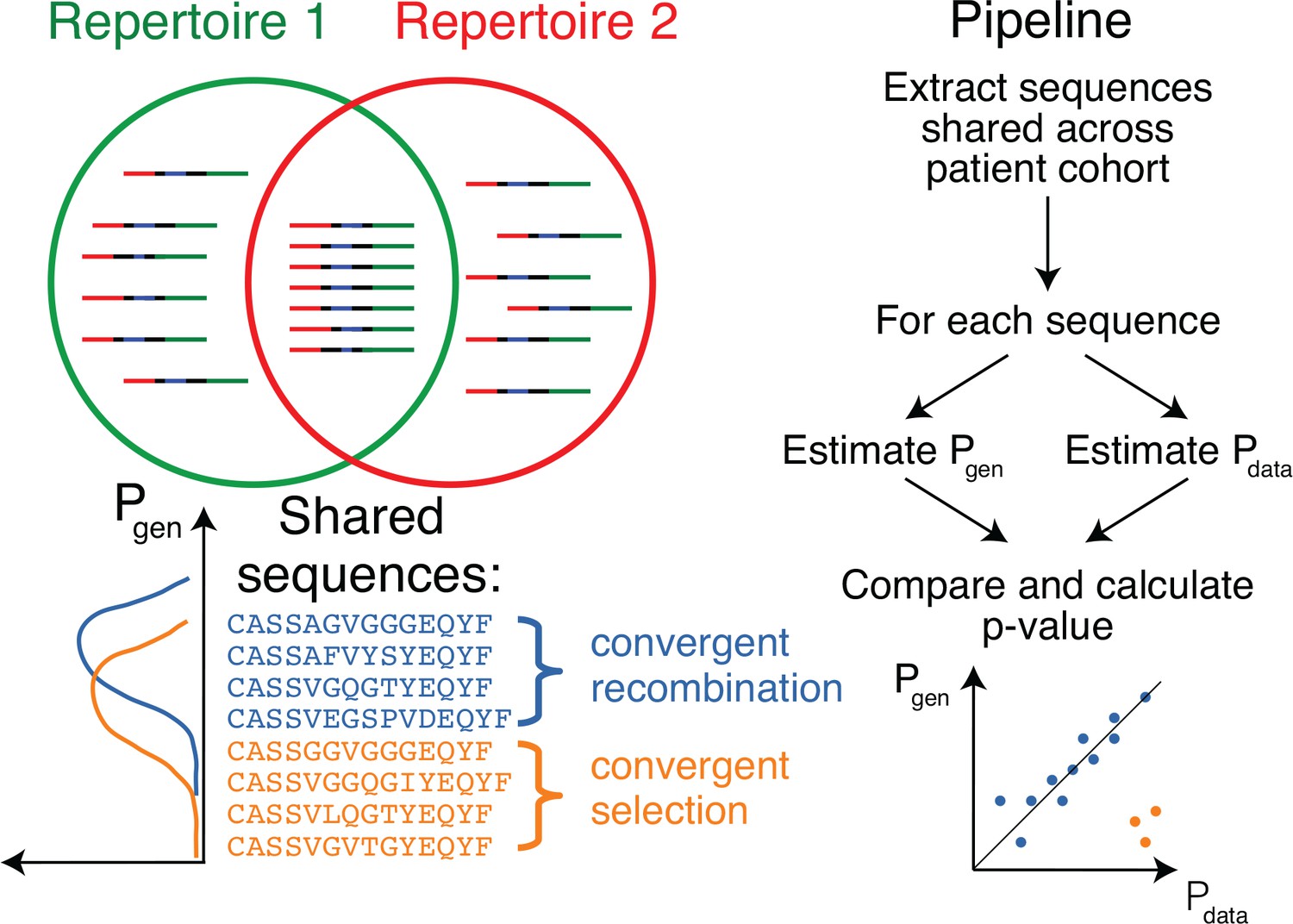
Method principle and pipeline.
(Top left) Sequence overlap between two TCR or BCR repertoires. (Bottom left) There are two major mechanisms for sequence sharing between two repertoires: convergent recombination and convergent selection. Because convergent recombination favors sequences with high generation probabilities, these two classes of sequences have different distributions of the generative probability, . (Right) We estimate the theoretical for each sequence and compare it to , which is empirically derived from the sharing pattern of that sequence in the cohort. Comparison of these two values allows us to calculate the analog of a p-value, namely the posterior probability that the sharing pattern is explained by the convergent recombination alone, with no selection for a common antigen.
In Figure 2A we plot for each clonotype the number of donors sharing that clonotype against its generation probability. Disease-specific TCR variants validated by functional tests in source studies are circled in red. Note that validated disease-specific TCR sequences have a much lower generation probability than the typical sequences shared by the same number of donors. We developed a method of axis transformation (see Materials and methods) to compare the model prediction with data values on the same scale (Figure 2B), so that outliers can be easily identified by their distance to identity line. Our method can be used to narrow down the potential candidates for further experimental validation of responsive receptors. Additional information, like the expansion of the identified TCR clonotype in the inflammation site, the presence of the same clonotype in the repertoire of activated or memory T-cells, or absence in a cohort of healthy controls, could provide additional evidence for functional association of identified candidates with a given condition.
Figure 2
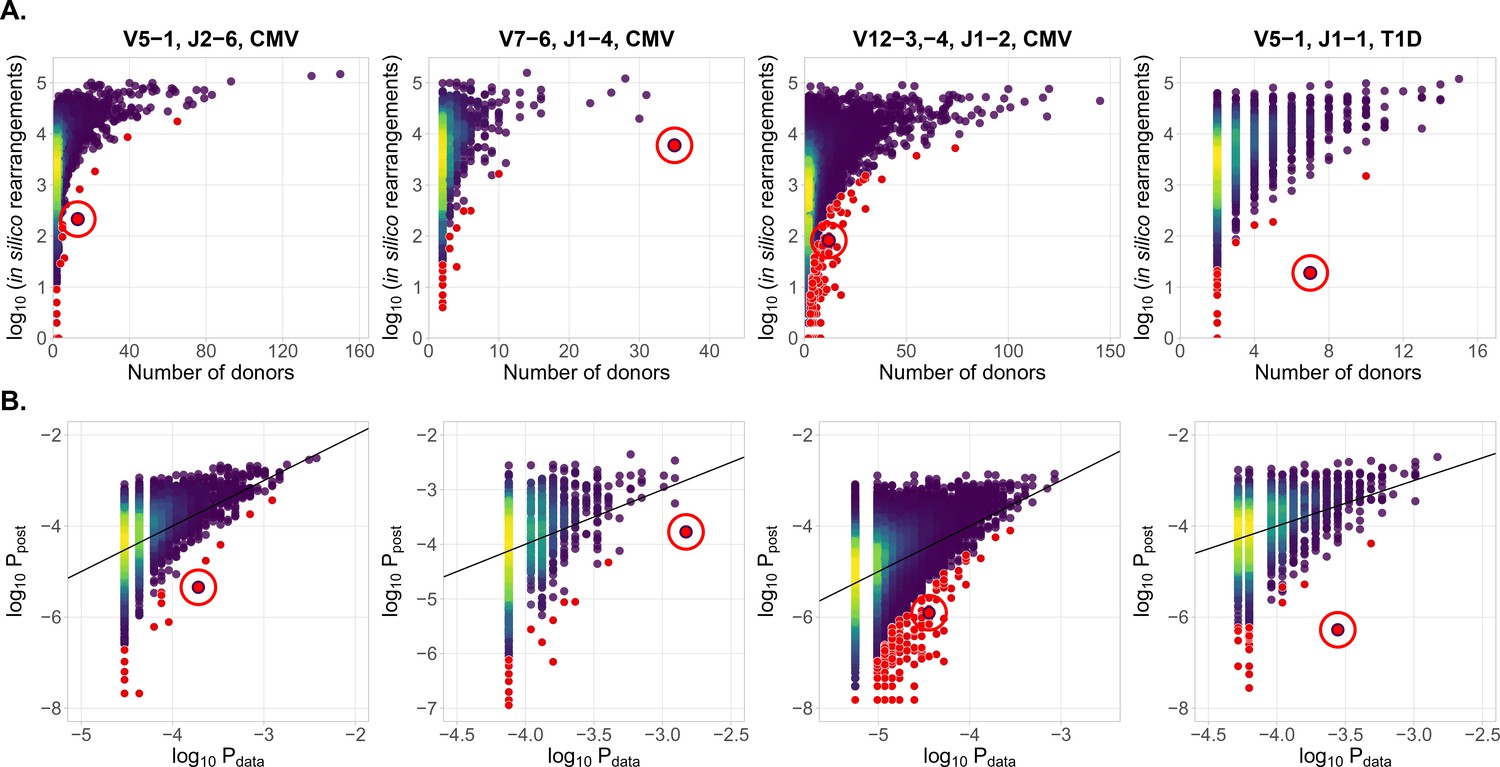
Identification of condition-associated clonotypes using generative probability
(A) CDR3aa of antigen specific clonotypes (red circles) have less generative probability than other clonotypes shared among the same number of donors. The number of in silico rearrangements obtained for each TCR sequence in our simulation (which is proportional to generation probability for each clonotype in a given VJ combination ), plotted against the number of patients with that TCR clonotype. (B) Model prediction of generative probabilities agrees well with data. To directly compare to data, we estimate the empirical probability of occurrence of sequences, , from its sharing pattern across donors (see Materials and methods). In A. and B. red dots indicate significant results (adjusted , Holm’s multiple testing correction), while red circles point to the responsive clonotypes identified in the source studies.
Our method also identifies other significant outliers than reported in the source studies (shown in red, and obtained after multiple-test correction – see Materials and methods), which may have three possible origins. First, they may be associated with the condition, but were missed by the source studies. Second, they may be due to other factors shared by the patients, such as features involved in thymic or peripheral selection, or reactivity to other common conditions than CMV (e.g. influenza infection). Third, they can be the result of intersample contamination. Our approach is able to diagnose the last explanation by estimating the likelihood of sharing at the level of nucleotide sequences (i.e. synonymously), as detailed in the Materials and methods section.
Discussion
Antigen receptor sequencing currently has little clinical applications. One of the most important ones is diagnostics and tracking of malignant T-cell and B-cell clones in lymphomas, where it allows for directly measuring the abundances of certain clones at different timepoints. Our method allows for a sequence-based theoretical prediction of T-cell abundances at the population level, and for the identification of T-cell clones associated with infectious and autoimmune conditions. Extensive databases of condition-associated clones can provide a means of disease diagnostics and extend the clinical utility of antigen receptor repertoire sequencing technologies.
This method may also be useful in the analysis of known antigen-specific TCR clonotypes. The typical source of such TCR sequences are MHC-multimer positive cells isolated from one or a few donors (Shugay et al., 2018; Tickotsky et al., 2017). Some of these antigen-specific clonotypes are private, and are hard to find in other patients, providing limited diagnostic value. Our method is able to distinguish these clones from publicly responding clonotypes that are likely to be shared by many patients using only their CDR3 amino acid sequences.
The cohort size necessary for the identification of antigen-specific clonotypes with our method varies (see ‘Designing the experiment’ subsection in Materials and methods). It depends on the strength and diversity of the response to the given antigen. CMV and other Herpesviridae (EBV, HSV), are able to cause a persistent infection, and a large fraction of the TCR repertoire of CMV-positive donors are believed to be specific to them—on average, up to 10% of CD8 +cells are specific to a single CMV epitope in elderly individuals (Khan et al., 2004). However, it was shown that in a human acute infection model of yellow fever vaccination, virus-specific T-cell clones are one of the most abundant in the TCR repertoire and occupy up to 12% of the CD8 +T cell repertoire. This response is short-lived and contracts significantly a month after immunization (Miller et al., 2008). So the peak of an immune response is the best timepoint to search for antigen-specific TCRs in acute infections using this method. T-cell response to herpesviruses is also not unique in terms of public clonotype involvement—in ankylosing spondylitis (Faham et al., 2017), 30–40% of patients share a certain TCR aminoacid sequence, which is more than the fraction of patients sharing CMV-specific clonotypes that we analysed in this study.
Our approach can be used on other hypervariable receptor chains (TCR, BCR heavy and light chains), as well as other species (mice, fish, etc.). Both and chains contribute to T-cell receptor specificity. Single-cell or paired sequencing technologies (Zemmour et al., 2018) could identify partner receptor chains for condition-associated TCR or chain sequences identified with our approach. Antigenic peptides recognized by complete T-cell receptors could then be recovered in vitro using yeast-display libraries of peptide-MHC (Gee et al., 2018). As paired sequencing becomes more widespread, our method can be extended to the analysis of full paired TCR by applying the exact same analysis using the joint recombination probability of clonotypes.
Recent advances in computational methods allow us to extract TCR repertoires from existing RNA-Seq data (Bolotin et al., 2017; Brown et al., 2015). Huge numbers of available RNA-Seq datasets from patients with various conditions can be used for analysis and identification of novel virus, cancer, and self reactive TCR variants using our method. The more immunoglobulin receptors with known specificity are found using this type of association mapping, the more clinically relevant information can be extracted from immunoglobulin repertoire data.
Materials and methods
Statistical analysis
Problem formulation
Request a detailed protocolOur framework is applicable to analyze the outcome of a next generation sequencing experiment probing the immune receptor repertoires of individuals with a given condition, for example CMV or Type one diabetes. We denote by the number of unique amino acid TCR sequences in patient , . For a given TCR amino acid sequence , we set to indicate that is present in patient ’s repertoire, and otherwise. For a given shared sequence , we want to know how likely its sharing pattern is under the null hypothesis of convergent recombination, correcting for the donors’ different sampling depths. In other words, is overrepresented in the population of interest? If is significantly overrepresented, we also want to quantify the size of this effect.
Overview
Under the null hypothesis, the presence of in a certain number of donors is explained by independent convergent V(D)J recombination events in each donor. Given the total number of recombination events that led to the sequenced sample of donor , , the presence of given amino acid sequence in donor is Bernoulli distributed with probability
(1)
(2)
where is the model probability that a recombined product found in a blood sample has sequence under the null hypothesis. It is formed by the product of , the probability to generate the sequence , estimated using a V(D)J recombination model (see the following subsection), and , a constant correction factor accounting for thymic selection (see Estimation of the correction factor subsection). The number of independent recombination events leading to the observed unique sequences in a sample is unknown, because of convergent recombination events within the sample, but it can be estimated from the number of unique sequences , using the model distribution (see Estimation of subsection).
We also calculate the posterior distribution of , corresponding to the empirical counterpart of in the cohort, inferred from the sharing pattern of across donors. We use information about the presence of in our donors, and the sequencing depth for each donor, (see Estimation of subsubsection), yielding the posterior density: .
Finally, we estimate the probability, given the observations, that the true value of is smaller than the theoretical value predicted using V(D)J recombination model, analogous to a p-value and used to identify significant effects:
(3)
To estimate the effect size we compare to ,
(4)
Estimation of , the probability of generation of a TCR CDR3 amino acid sequence
Request a detailed protocolTo procedure outlined above requires to calculate , the probability to generate a given CDR3 amino acid sequence. Methods exist to calculate the probability of TCR and BCR nucleotide sequences from a given recombination model (Murugan et al., 2012; Marcou et al., 2017), but are impractical to calculate the probability of amino acid sequences, because of the large number of codon combinations that can lead to the same amino acid sequence, , where is the sequence length, and the number of codons coding for amino acid . The number is about for a typical CDR3 length of 15 amino acid.
Instead, we estimated using a simple Monte-Carlo approach. We randomly generated a massive number () of recombination scenarios according to the validated recombination model (Murugan et al., 2012):
(5)
The resulting sequences were translated, truncated to only keep the CDR3, and counted. was approximated by the fraction of events thus generated that led to sequence . This approximation becomes more accurate as increases, with an error on scaling as .
Estimation of the correction factor
Request a detailed protocolNot all generated sequences pass selection in the thymus. systematically underestimates the frequency of recombination event that eventually make it into the observed repertoire. To correct for this effect, we estimate a correction factor , as was suggested in (Elhanati et al., 2014):
(6)
Contrary to (Elhanati et al., 2014), which learned a sequence-specific factor for each individual, here we assume that all observed sequences passed thymic selection. is a normalization factor accounting for the fact that just a fraction of sequences pass thymic selection. This factor is determined for each VJ-combination as an offset when plotting against (see the following subsection for definition of ), using least squares fitting.
Estimation of , the probability of sequence occurrence in data
Request a detailed protocolThe variable indicates the presence or absence of a given TCR amino acid sequence in the th dataset with recombination events per donor. We want to estimate , which is a fraction of recombination events leading to in the population of interest. According to Bayes’ theorem, for a given , the probability density function of reads:
(7)
The likelihood is given by a product of Bernouilli probabilities:
(8)
and a flat prior is used.
We estimate (shown in Figure 2B) as the maximum of the posterior distribution:
(9)
Estimation of , the number of recombination events
Request a detailed protocolThe total number of recombination events in th dataset is unknown, but we can count the number of unique CD3 acid sequences observed in the sequencing experiment. For a typical TRB experiment, convergent recombination is relatively rare and one could use as an approximation. However, for less diverse loci (e.g TRA), or for much higher sequencing depths, one should correct for convergent recombination, as the the observed number of unique aminoacid sequences could be much lower than the actual number of corresponding recombination events.
The average number of unique sequences resulting from recombination events is, in theory:
(10)
where is the set of sequences that can pass thymic selection. To estimate that number, we generate a very large number of recombinations, leading to unique CDR3 amino acid sequences for which is estimated as explained above. We take to be a random subset of unique sequences, , of size , and we apply Equation 8.
Using this equation we plot the calibration curve for the TRBV5-1 TRBJ2-6 VJ datasets in Figure 3. For comparison the case of no thymic selection () is shown in red. The inversion of this curve yields as a function of .
Figure 3
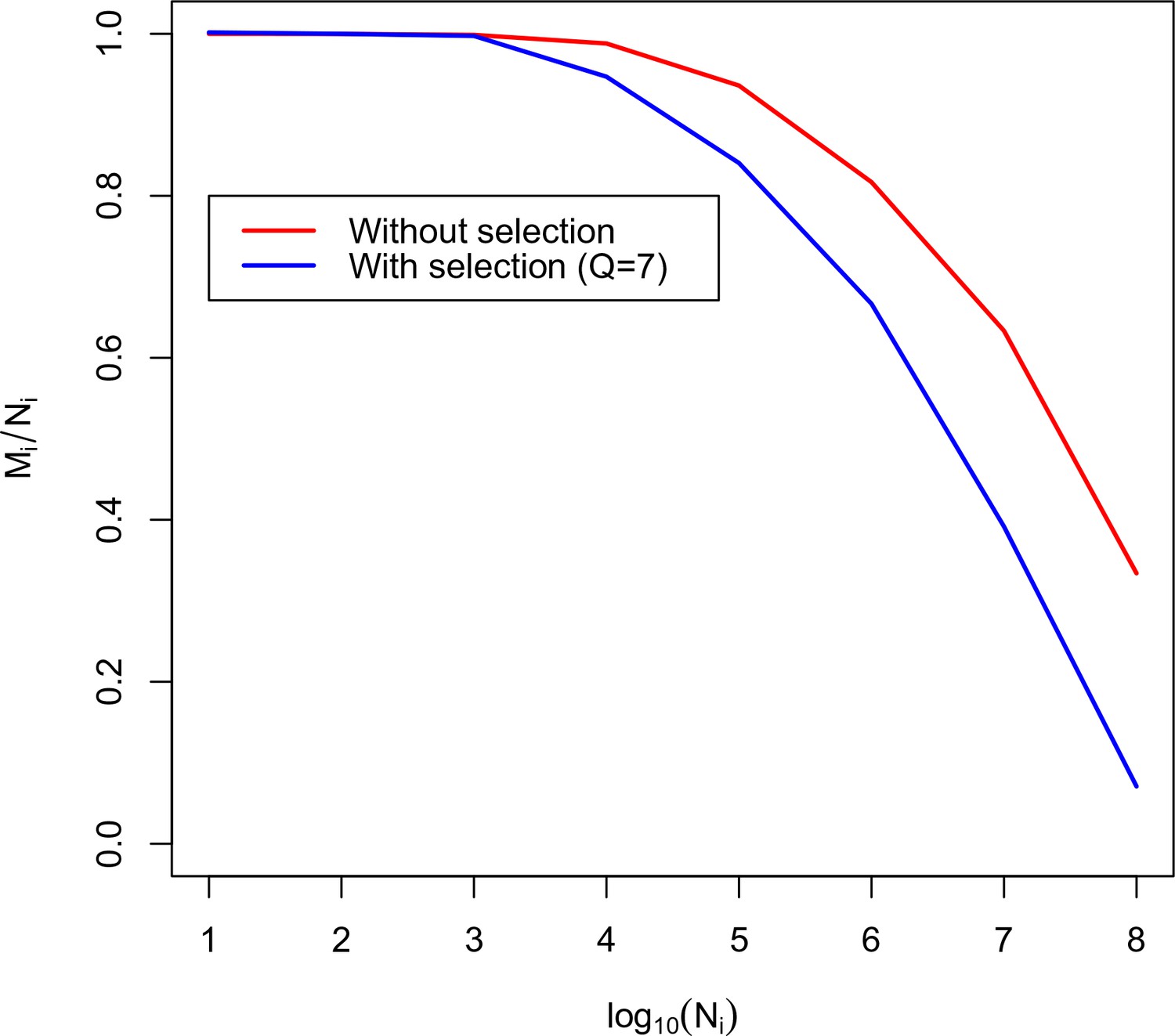
Calibration curve for TRBV5-1 TRBJ2-6 combination.
Here we plot the fraction of unique amino acid sequences to recombination events against the logarithm of the number of recombination events. The blue line corresponds to the theoretical solution with selection, the red line corresponds to the theoretical solution without selection.
Pipeline description
Request a detailed protocolIn this section we describe how to apply our algorithm to real data. All the code and data necessary to reproduce our analysis is available online on github (https://github.com/pogorely/vdjRec/; copy archived at https://github.com/elifesciences-publications/vdjRec/).
We start with annotated TCR datasets (CDR3 amino acid sequence, V-segment, J-segment), one per donor. Such datasets are produced by MiXCR (Bolotin et al., 2015), immunoseq (http://www.adaptivebiotech.com/immunoseq) and most other software for NGS repertoire data preprocessing. Data we used was in immunoseq format, publicly available from https://clients.adaptivebiotech.com/immuneaccess database.
We proceed as follows:
Split datasets by VJ combinations. The resulting datasets correspond to lists of unique CDR3 amino acid sequences for each donor and VJ combination. All following steps should be done independently for each VJ combination.
(Optional). Filter out sequences present in only one donor to speed up the downstream analysis.
Generate a large amount of simulated nucleotide TCR sequences for a given VJ combination. Extract and translate their CDR3, and count how many times each sequence appears in the simulated set (restricting to sequences actually observed in donors for better efficiency). The resulting number divided by the total number of simulated sequences is an estimate of .
Estimate for each sequence in the dataset, see Estimation of subsection.
Using and , estimate for each VJ combination the normalization by minimizing , see Estimation of the correction factor subsection, where , are the shared sequences.
Calculate . Calculate the p-value (Equation 1) and effect size (Equation 2).
Usage example
Data sources
Request a detailed protocolData from (Emerson et al., 2017) and (Seay et al., 2016) is publicly available from the immuneaccess database: https://clients.adaptivebiotech.com/immuneaccess. For our analysis, we only considered VJ combinations for which the authors identified condition-associated clonotypes with MHC-multimer proved specificity. CDR3 aminoacid sequences and V and J segment of these TCR clonotypes are given in Table 1.
Table 1
Published antigen-specific clonotypes used to test the algorithm.
https://doi.org/10.7554/eLife.33050.005| CDR3aa | V-segment | J-segment | Antigen source | Ref. |
|---|---|---|---|---|
| CASSLAPGATNEKLFF | TRBV07-06 | TRBJ1-4 | CMV | (Emerson et al., 2017) |
| CASSPGQEAGANVLTF | TRBV05-01 | TRBJ2-6 | CMV | (Emerson et al., 2017) |
| CASASANYGYTF | TRBV12-3,−4 | TRBJ1-2 | CMV | (Emerson et al., 2017) |
| CASSLVGGPSSEAFF | TRBV05-01 | TRBJ1-1 | self | (Seay et al., 2016; Gebe et al., 2009) |
Analysis results
Request a detailed protocolWe applied our pipeline to identify CMV-specific and self-specific TCR sequences listed in Table 1. For our analysis we used only case cohorts, without controls. For each dataset we followed our pipeline described in Pipeline description subsection. We found that sequences reported in the source studies as being both significantly enriched in the patient cohort, and antigen-specific according to MHC-multimers, were the most significant in 3 out of 4 datasets (See Table 2). In the remaining TRBV12 dataset, the sequence of interest was the top most significant out of sequences present in at least two CMV-positive donors.
Table 2
Output of the algorithm for sequences from Table 1.
https://doi.org/10.7554/eLife.33050.006| CDR3aa | V | J | Ag.source . | p-value rank | p-value | Effect size |
|---|---|---|---|---|---|---|
| CASSLAPGATNEKLFF | 07–06 | 1–4 | CMV | 1/1637 | 8.8 | |
| CASSPGQEAGANVLTF | 5–01 | 2–6 | CMV | 1/5549 | 42.3 | |
| CASASANYGYTF | 12–3,−4 | 1–2 | CMV | 40/27669 | 28.8 | |
| CASSLVGGPSSEAFF | 5–01 | 1–1 | self | 1/2646 | 524 |
Identifying contaminations
Request a detailed protocolIntersample contamination may complicate high-throughput sequencing data analysis in many ways. It could occur both during library preparation or the sequencing process itself (Sinha et al., 2017). Contaminations have the same nucleotide and amino acid sequence in all datasets, and so our method identifies them as outliers, because their sharing cannot be explained by a high recombination probability.
Our method provides a tool to diagnose contamination. Given an amino-acid sequence present in many donors, we measure its theoretical nucleotide diversity using the same simulation approach we used to calculate the generative probability of the amino acid sequence (see Estimation of subsection). If the diversity of the simulated nucleotide sequences is much larger than observed in the data, it is a sign of contamination.
We applied this approach to the CDR3 sequence CASSLVGGPSSEAFF associated to Type one diabetes, and found 19 recombination events consistent with that amino acid sequence out of our simulated dataset. We found 18 different nucleotide variants out of the 19 total possible. In contrast, in the data this clononotype had the same nucleotide variant in all of the eight donors in which it was present. That variant was absent from the simulated set. A one-sided Fisher exact test gives a probability of this happening by chance, indicating contamination as a likely source of sharing.
Designing the experiment
Request a detailed protocolOur approach also allows us to obtain important estimates for experiment design. A number of variables affect detection of an antigen-specific clone using our approach: the abundance of the clone in the general population (represented by in our approach), the cohort size, the sequencing depth in each donor in the cohort, and also the effect size. Fixing any two of these variables results in a constraint between the other two and the affects the probability to detect an antigen-specific clonotype, which translates into the statistical power of the method. As an example of such an analysis, we fix the cohort size at 10, 30 or 100 donors (see Figure 4A–C respectively) and the sequencing depth at unique clones sequenced per repertoire for a given VJ-combination in each donor in the cohort. We ask how frequently a disease specific clone with abundance in the population and effect size is detected with our method. To address this question for each value we perform a simulation: we simulate Bernoulli variables, each with a success probability. For a given value of and there is a single value of . Then we calculate
Figure 4
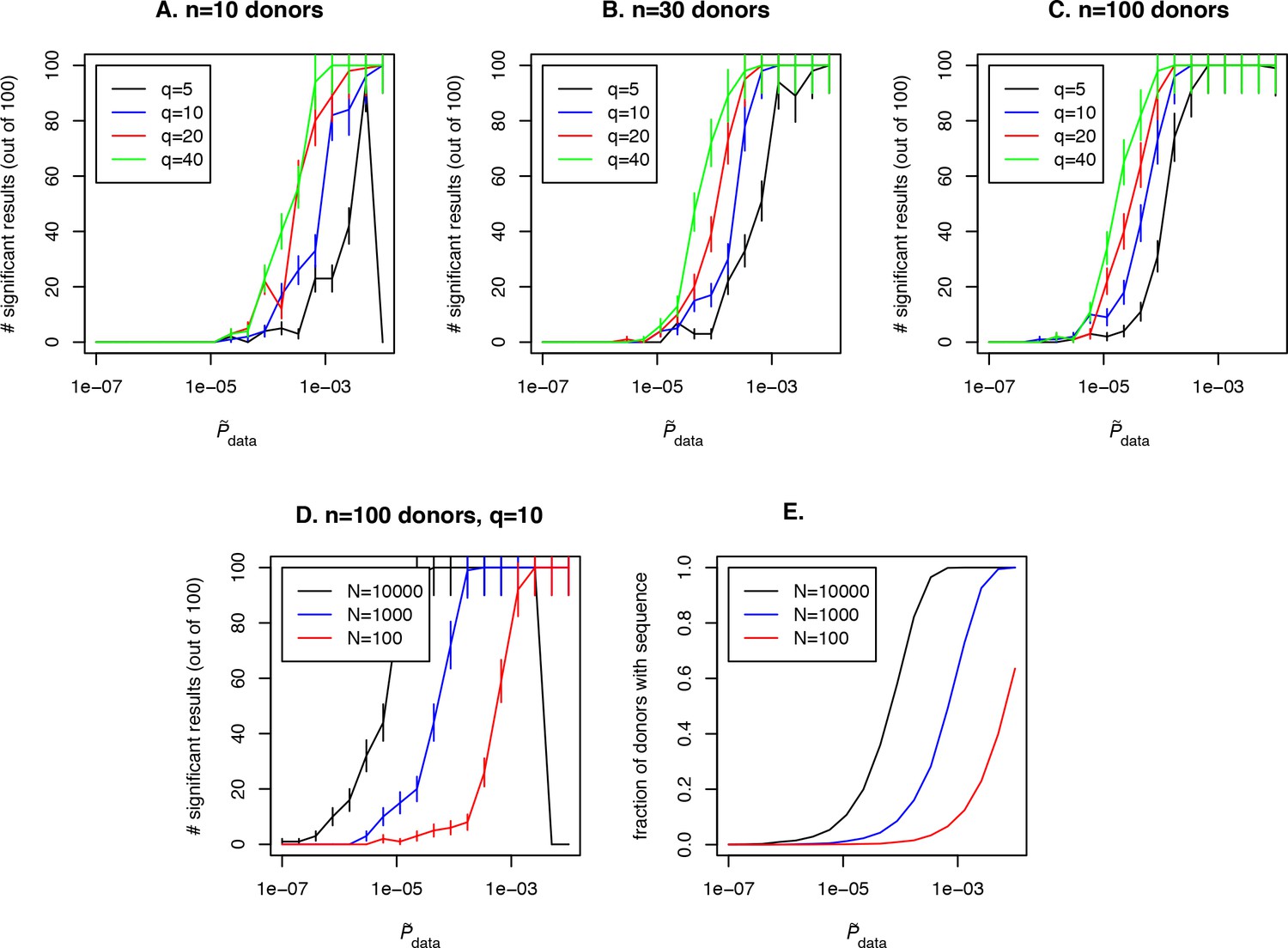
Simulation of the method performance with different cohort sizes, sequencing depths, effect sizes and target clone abundances in population.
In panels (A. B. C) we plot the number of simulations (out of 100) where a clone with a given effect size (line color, see legend) and (x-axis) is found to be significant using our approach, for cohort sizes of 10, 30 and 100 donors respectively. Larger cohort sizes and effect sizes make it possible to resolve clonotypes with lower abundance in the population. In panel (D) we show the effect of sequencing depth for fixed : larger numbers of clonotypes sequenced per donor allow us to resolve less frequent clones, since a clone of a given is detected in a larger fraction of donors (panel E).
(11)
where is the posterior density, and check if is below a significance threshold of 0.0001. Such a low significant threshold in this example is chosen to take into account the multiple testing correction: we assume that about 1000 shared clones would be tested in a such analysis and p¡0.01 after multiple testing is chosen as the significance threshold in this study, which gives p¡0.0001 before the Bonferroni multiple testing correction. Then we plot the number of simulations in which a significant result was obtained for given effect size and for the clone of interest and the fraction of donors with this sequence in the simulated cohort (see Figure 4E, blue curve). Unsurprisingly, the effect size plays a role in the probability to detect an antigen specific clone, and the detection is not possible at all if the clone is not shared between several donors in the cohort (in our example this happens for ) irrespective to the effect size. Larger cohort sizes can help to resolve clones with lower abundances, but sequencing depth also has a strong effect on the power of the approach. In Figure 4D and E we show simulation results for a fixed and different sequencing depths of 100, 1000 or 10000 clones per donor in a given VJ combination. Interestingly, a large sequencing depth (black curve) can lead to a situation when an abundant and frequently generated clone will not be detected by the algorithm, because it will be found in all donors in the cohort. An additional test that checks the predictions by lowering the sequencing depth in silico by downsampling can solve this problem.
Another complicated question is how is related to the number of clones and the fraction of the repertoire involved in the response to the infection in a given donor. If the same antigen-specific clone is present in every donor, is close to the average abundance of this clone in the repertoire. However one can imagine an opposite situation where the response is so diverse and private that different clones respond to a given antigen in each donor. It was previously shown that the diversity and publicness of responding T-cell clonotypes varies a lot across antigens (Dash et al., 2017). Our approach is restricted to the identification of public antigen-specific clonotypes, which may not exist for all antigens.
Data availability
-
Tissue distribution and clonal diversity of the T and B cell repertoire in type 1 diabetesPublicly available at ImmuneAccess.
References
-
Antigen receptor repertoire profiling from RNA-seq dataNature Biotechnology 35:908–911.https://doi.org/10.1038/nbt.3979
-
MiXCR: software for comprehensive adaptive immunity profilingNature Methods 12:380–381.https://doi.org/10.1038/nmeth.3364
-
Age-related decrease in TCR repertoire diversity measured with deep and normalized sequence profilingThe Journal of Immunology 192:2689–2698.https://doi.org/10.4049/jimmunol.1302064
-
Restricted autoantigen recognition associated with deletional and adaptive regulatory mechanismsThe Journal of Immunology 183:59–65.https://doi.org/10.4049/jimmunol.0804046
-
Bias in the αβ T-cell repertoire: implications for disease pathogenesis and vaccinationImmunology and Cell Biology 89:375–387.https://doi.org/10.1038/icb.2010.139
-
Persisting fetal clonotypes influence the structure and overlap of adult human T cell receptor repertoiresPLoS Computational Biology 13:e1005572.https://doi.org/10.1371/journal.pcbi.1005572
-
VDJdb: a curated database of T-cell receptor sequences with known antigen specificityNucleic Acids Research 46:D419–D427.https://doi.org/10.1093/nar/gkx760
-
A mechanism for TCR sharing between T cell subsets and individuals revealed by pyrosequencingThe Journal of Immunology 186:4285–4294.https://doi.org/10.4049/jimmunol.1003898
Article and author information
Author details
Mikhail V Pogorelyy

Dmitriy M Chudakov
Aleksandra M Walczak
Funding
Russian Science Foundation (15-15-00178)
- Dmitriy M Chudakov
- Ilgar Z Mamedov
- Yuri B Lebedev
European Research Council (724208)
- Aleksandra M Walczak
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
This work was supported by Russian Science Foundation grant 15-15-00178, and partially supported by European Research Council Consolidator Grant 724208.
Copyright
© 2018, Pogorelyy et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 3,289
- views
-
- 582
- downloads
-
- 61
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 61
- citations for umbrella DOI https://doi.org/10.7554/eLife.33050
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Method for identification of condition-associated public antigen receptor sequences
eLife 7:e33050.
https://doi.org/10.7554/eLife.33050




{kind=link}
{kind=link}
{kind=link}
{kind=link}