Resource-rational account of sequential effects in human prediction
- Department of Economics, Columbia University, United States
- Laboratoire de Physique de l’École Normale Supérieure, ENS, Université PSL, CNRS, Sorbonne Université, Université de Paris, France
- Cognitive Neuroimaging Unit, Institut National de la Santé et de la Recherche Médicale, Commissariat à l’Energie Atomique et aux Energies Alternatives, Centre National de la Recherche Scientifique, Université Paris-Saclay, NeuroSpin center, France
- Institut de neuromodulation, GHU Paris, Psychiatrie et Neurosciences, Centre Hospitalier Sainte-Anne, Pôle Hospitalo-Universitaire 15, Université Paris Cité, France
- Institute of Molecular and Clinical Ophthalmology Basel, Switzerland
- Faculty of Science, University of Basel, Switzerland
Abstract
An abundant literature reports on ‘sequential effects’ observed when humans make predictions on the basis of stochastic sequences of stimuli. Such sequential effects represent departures from an optimal, Bayesian process. A prominent explanation posits that humans are adapted to changing environments, and erroneously assume non-stationarity of the environment, even if the latter is static. As a result, their predictions fluctuate over time. We propose a different explanation in which sub-optimal and fluctuating predictions result from cognitive constraints (or costs), under which humans however behave rationally. We devise a framework of costly inference, in which we develop two classes of models that differ by the nature of the constraints at play: in one case the precision of beliefs comes at a cost, resulting in an exponential forgetting of past observations, while in the other beliefs with high predictive power are favored. To compare model predictions to human behavior, we carry out a prediction task that uses binary random stimuli, with probabilities ranging from 0.05 to 0.95. Although in this task the environment is static and the Bayesian belief converges, subjects’ predictions fluctuate and are biased toward the recent stimulus history. Both classes of models capture this ‘attractive effect’, but they depart in their characterization of higher-order effects. Only the precision-cost model reproduces a ‘repulsive effect’, observed in the data, in which predictions are biased away from stimuli presented in more distant trials. Our experimental results reveal systematic modulations in sequential effects, which our theoretical approach accounts for in terms of rationality under cognitive constraints.
Editor's evaluation
This valuable work addresses a long-standing empirical puzzle from a new computational perspective. The authors provide convincing evidence that attractive and repulsive sequential effects in perceptual decisions may emerge from rational choices under cognitive resource constraints rather than adjustments to changing environments. It is relevant to understanding how people represent uncertain events in the world around them and make decisions, with broad applications to economic behavior.
https://doi.org/10.7554/eLife.81256.sa0Introduction
In many situations of uncertainty, some outcomes are more probable than others. Knowing the probability distributions of the possible outcomes provides an edge that can be leveraged to improve and speed up decision making and perception (Summerfield and de Lange, 2014). In the case of choice reaction-time tasks, it was noted in the early 1950s that human reactions were faster when responding to a stimulus whose probability was higher (Hick, 1952; Hyman, 1953). In addition, faster responses were obtained after a repetition of a stimulus (i.e., when the same stimulus was presented twice in a row), even in the case of serially-independent stimuli (i.e., when the preceding stimulus carried no information on subsequent ones; Hyman, 1953; Bertelson, 1965). The observation of this seemingly suboptimal behavior has motivated in the following decades a profuse literature on ‘sequential effects’, i.e., on the dependence of reaction times on the recent history of presented stimuli (Kornblum, 1967; Soetens et al., 1985; Cho et al., 2002; Yu and Cohen, 2008; Wilder et al., 2009; Jones et al., 2013; Zhang et al., 2014; Meyniel et al., 2016). These studies consistently report a recency effect whereby the more often a simple pattern of stimuli (e.g. a repetition) is observed in recent stimulus history, the faster subjects respond to it. In tasks in which subjects are asked to make predictions about sequences of random binary events, sequential effects are also observed and they have given rise since the 1950s to a rich literature (Jarvik, 1951; Edwards, 1961; McClelland and Hackenberg, 1978; Matthews and Sanders, 1984; Gilovich et al., 1985; Ayton and Fischer, 2004; Burns and Corpus, 2004; Croson and Sundali, 2005; Bar-Eli et al., 2006; Oskarsson et al., 2009; Plonsky et al., 2015; Plonsky and Erev, 2017; Gökaydin and Ejova, 2017).
Sequential effects are intriguing: why do subjects change their behavior as a function of the recent past observations when those are in fact irrelevant to the current decision? A common theoretical account is that humans infer the statistics of the stimuli presented to them, but because they usually live in environments that change over time, they may believe that the process generating the stimuli is subject to random changes even when it is in fact constant (Yu and Cohen, 2008; Wilder et al., 2009; Zhang et al., 2014; Meyniel et al., 2016). Consequently, they may rely excessively on the most recent stimuli to predict the next ones. In several studies, this was heuristically modeled as a ‘leaky integration’ of the stimuli, that is, an exponential discounting of past observations (Cho et al., 2002; Yu and Cohen, 2008; Wilder et al., 2009; Jones et al., 2013; Meyniel et al., 2016). Here, instead of positing that subjects hold an incorrect belief on the dynamics of the environment and do not learn that it is stationary, we propose a different account, whereby a cognitive constraint is hindering the inference process and preventing it from converging to the correct, constant belief about the unchanging statistics of the environment. This proposal calls for the investigation of the kinds of choice patterns and sequential effects that would result from different cognitive constraints at play during inference.
We derive a framework of constrained inference, in which a cost hinders the representation of belief distributions (posteriors). This approach is in line with a rich literature that views several perceptual and cognitive processes as resulting from a constrained optimization: the brain is assumed to operate optimally, but within some posited limits on its resources or abilities. The ‘efficient coding’ hypothesis in neuroscience (Ganguli and Simoncelli, 2016; Wei and Stocker, 2015; Wei and Stocker, 2017; Prat-Carrabin and Woodford, 2021c) and the ‘rational inattention’ models in economics (Sims, 2003; Woodford, 2009; Caplin et al., 2019; Gabaix, 2017; Azeredo da Silveira and Woodford, 2019; Azeredo da Silveira et al., 2020) are examples of this approach, which has been called ‘resource-rational analysis’ (Griffiths et al., 2015; Lieder and Griffiths, 2019). Here, we investigate the proposal that human inference is resource-rational, i.e., optimal under a cost. As for the nature of this cost, we consider two natural hypotheses: first, that a higher precision in belief is harder for subjects to achieve, and thus that more precise posteriors come with higher costs; and second, that unpredictable environments are difficult for subjects to represent, and thus that they entail higher costs. Under the first hypothesis, the cost is a function of the belief held, while under the second hypothesis the cost is a function of the inferred environment. We show that the precision cost predicts ‘leaky integration’: in the resulting inference process, remote observations are discarded. Crucially, beliefs do not converge but fluctuate instead with the recent stimulus history. By contrast, under the unpredictability cost, the inference process does converge, although not to the correct (Bayesian) posterior, but rather to a posterior that implies a biased belief on the temporal structure of the stimuli. In both cases, sequential effects emerge as the result of a constrained inference process.
We examine experimentally the degree to which the models derived from our framework account for human behavior, with a task in which we repeatedly ask subjects to predict the upcoming stimulus in sequences of Bernoulli-distributed stimuli. Most studies on sequential effects only consider the equiprobable case, in which the two stimuli have the same probability. However, the models we consider here are more general than this singular case and they apply to the entire range of stimulus probability. We thus manipulate in separate blocks of trials the stimulus generative probability (i.e., the Bernoulli probability that parameterizes the stimulus) to span the range from 0.05 to 0.95 by increments of 0.05. This enables us to examine in detail the behavior of subjects in a large gamut of environments from the singular case of an equiprobable, maximally-uncertain environment (with a probability of 0.5 for both stimuli) to the strongly-biased, almost-certain environment in which one stimulus occurs with probability 0.95.
To anticipate on our results, the predictions of subjects depend on the stimulus generative probability, but also on the history of stimuli. We examine whether the occurrence of a stimulus, in past trials, increase the proportion of predictions identical to this stimulus (‘attractive effect’), or whether it decreases this proportion (‘repulsive effect’). The two costs presented above reproduce qualitatively the main patterns in subjects’ data, but they make distinct predictions as to the modulations of the recency effect as a function of the history of stimuli, beyond the last stimulus. We show that the responses of subjects exhibit an elaborate, and at times counter-intuitive, pattern of attractive and repulsive effects, and we compare these to the predictions of our models. Our results suggest that the brain infers a stimulus generative probability, but under a constraint on the precision of its internal representations; the inferred generative process may be more general than the actual one, and include higher-order statistics (e.g. transition probabilities), in contrast with the Bernoulli-distributed stimulus used in the experiment.
We present the behavioral task and we examine the predictions of subjects — in particular, how they vary with the stimulus generative probability, and how they depend, at each trial, on the preceding stimulus. We then introduce our framework of inference under constraint, and the two costs we consider, from which we derive two families of models. We examine the behavior of these models and the extent to which they capture the behavioral patterns of subjects. The models make different qualitative predictions about the sequential effects of past observations, which we confront to subjects’ data. We find that the predictions of subjects are qualitatively consistent with a model of inference of conditional probabilities, in which precise posteriors are costly.
Results
Subjects’ predictions of a stimulus increase with the stimulus probability
In a computer-based task, subjects are asked to predict which of two rods the lightning will strike. On each trial, the subject first selects by a key press the left- or right-hand-side rod presented on screen. A lightning symbol (which is here the stimulus) then randomly strikes either of the two rods. The trial is a success if the lightning strikes the rod selected by the subject (Figure 1a). The location of the lightning strike (left or right) is a Bernoulli random variable whose parameter (the stimulus generative probability) we manipulate across blocks of 200 trials: in each block, is a multiple of 0.05 chosen between 0.05 and 0.95. Changes of block are explicitly signaled to the subjects: each block is presented as a different town exposed to lightning strikes. The subjects are not told that the locations of the strikes are Bernoulli-distributed (in fact no information is given to them regarding how the locations are determined). Moreover, in order to capture the ‘stationary’ behavior of subjects, which presumably prevails after ample exposure to the stimulus, each block is preceded by 200 passive trials in which the stimuli (sampled with the probability chosen for the block) are successively shown with no action from the subject (Figure 1b); this is presented as a ‘useful track record’ of lightning strikes in the current town. (To verify the stationarity of subjects’ behavior, we compare their responses in the first and second halves of the 200 trials in which they are asked to make predictions. In most cases we find no significant differences. See Appendix.) We provide further details on the task in Methods.
Figure 1
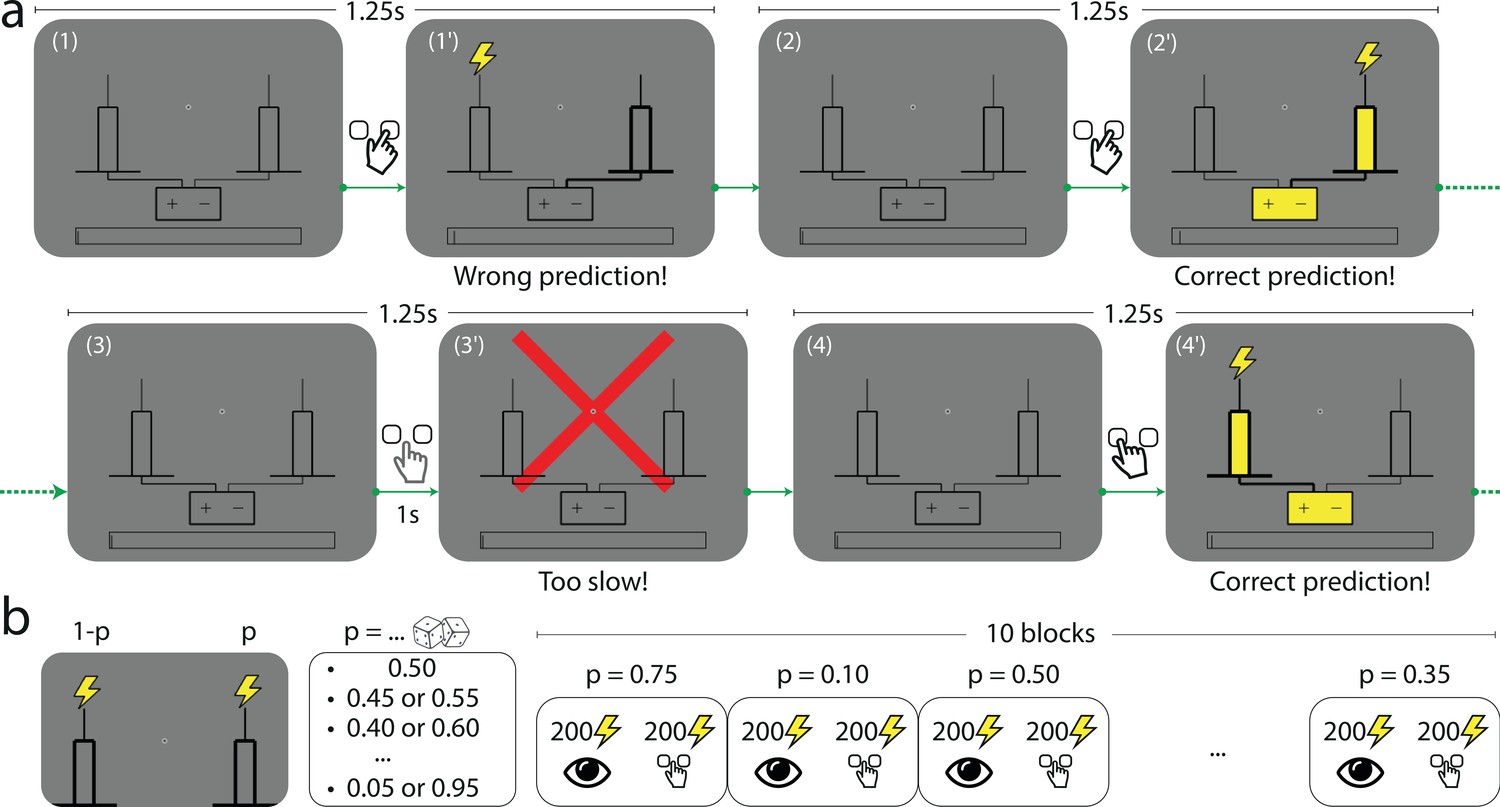
The Bernoulli sequential prediction task.
(a) In each successive trial, the subject is asked to predict which of two rods the lightning will strike. (1) A trial begins. (1’) The subject chooses the right-hand-side rod (bold lines), but the lightning strikes the left one (this feedback is given immediately after the subject makes a choice). (2) 1.25 s after the beginning of the preceding trial, a new trial begins. (2’) The subject chooses the right-hand-side rod, and this time the lightning strikes the rod chosen by the subject (immediate feedback). The rod and the connected battery light up (yellow), indicating success. (3) A new trial begins. (3’) If after 1 s the subject has not made a prediction, a red cross bars the screen and the trial ends. (4) A new trial begins. (4’) The subject chooses the left-hand-side rod, and the lightning strikes the same rod. In all cases, the duration of a trial is 1.25 s. (b) In each block of trials, the location of the lightning strike is a Bernoulli random variable with parameter , the stimulus generative probability. Each subject experiences 10 blocks of trials. The stimulus generative probability for each block is chosen randomly among the 19 multiples of 0.05 ranging from 0.05 to 0.95, with the constraint that if is chosen for a given block, neither nor can be chosen in the subsequent blocks; as a result for any value among these 19 probabilities spanning the range from 0.05 to 0.95, there is one block in which one of the two rods receives the lightning strike with probability . Within each block the first 200 trials consist in passive observation and the 200 following trials are active trials (depicted in panel a).
The behavior of subjects varies with the stimulus generative probability, . In our analyses, we are interested in how the subjects’ predictions of an event (left or right strike) vary with the probability of this event, regardless of its nature (left or right). Thus, for instance, we would like to pool together the trials in which a subject makes a rightward prediction when the probability of a rightward strike is 0.7, and the trials in which a subject makes a leftward prediction when the probability of a leftward strike is also 0.7. Therefore, throughout the paper, we do not discuss whether subjects predict ‘right’ or ‘left’, and instead we discuss whether they predict the event ‘A’ or the complementary event ‘B’: in different blocks of trials, A (and similarly B) may refer to different locations; but importantly, B always corresponds to the location opposite to A, and denotes the probability of A (thus B has probability ). This allows us, given a probability , to pool together the responses obtained in blocks of trials in which one of the two locations has probability . One advantage of this pooling is that it reduces the noise in data. Looking at the unpooled data, however, does not change our conclusions; see Appendix.
Turning to the behavior of subjects, we denote by the proportion of trials in which a subject predicts the event A. In the equiprobable condition (), the subjects predict either side on about half the trials (, subjects pooled; standard error of the mean (sem): 0.008; p-value of t-test of equality with 0.5: 0.59). In the non-equiprobable conditions, the optimal behavior is to predict A on none of the trials () if , or on all trials () if . The proportion of predictions A adopted by the subjects also increases as a function of the stimulus generative probability (Pearson correlation coefficient between and , subjects pooled: .97; p-value: 3.3e-6; correlation between the ‘logits’, : 0.994, p-value: 5.7e-9.), but not as steeply: it lies between the stimulus generative probability , and the optimal response 0 (if ) or 1 (if ; Figure 2a).
Figure 2
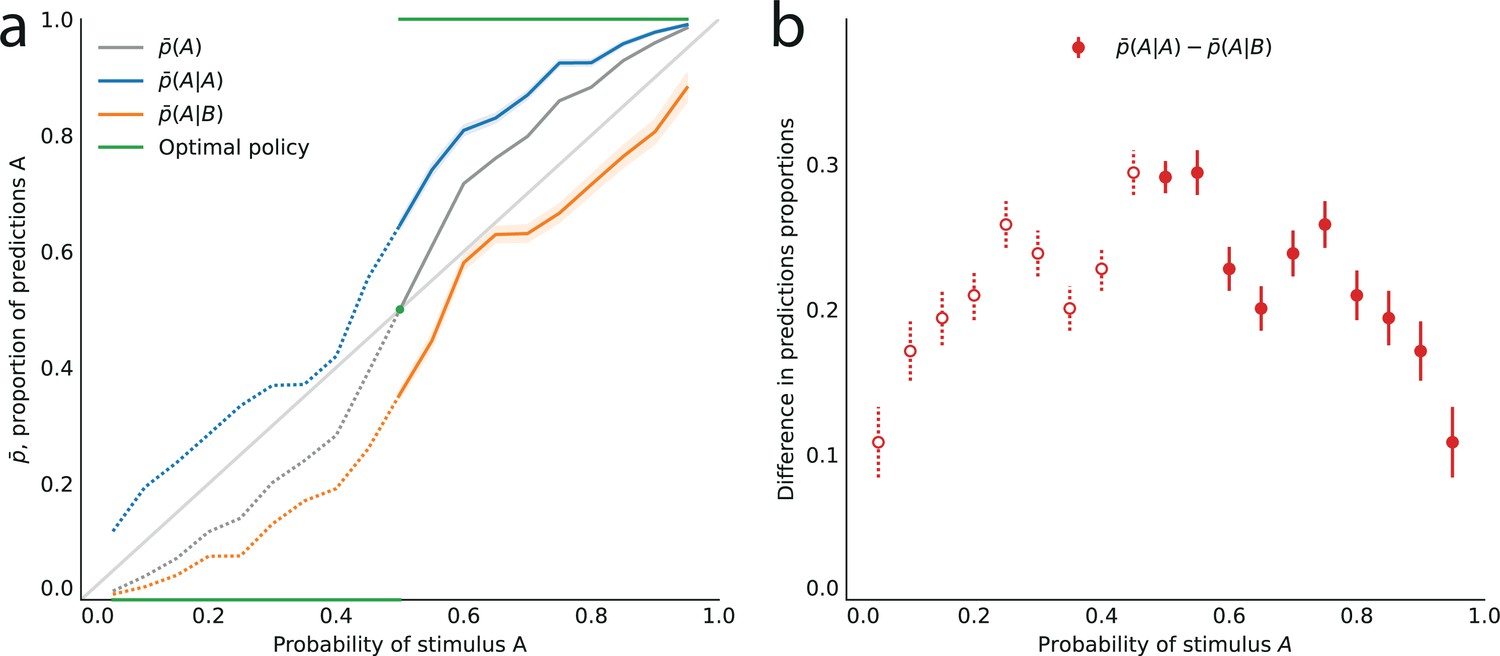
Across all stimulus generative probabilities, subjects are more likely than average to make a prediction equal to the preceding observation.
(a) Proportion of predictions A in subjects’ pooled responses as a function of the stimulus generative probability, conditional on observing an A (blue line) or a B (orange line) on the preceding trial, and unconditional (grey line). The widths of the shaded areas indicate the standard error of the mean (n = 178 to 3603). (b) Difference between the proportion of predictions A conditional on the preceding observation being an A, and the proportion of predictions A conditional on the preceding observation being a B. This difference is positive across all stimulus generative probabilities, that is, observing an A at the preceding trial increases the probability of predicting an A (p-values of Fisher’s exact tests, with Bonferroni-Holm-Šidák correction, are all below 1e-13). Bars are twice the square root of the sum of the two squared standard errors of the means (for each point, total n: 3582 to 3781). The binary nature of the task results in symmetries in this representation of data: in panel (a) the grey line is symmetric about the middle point and the blue and orange lines are reflections of each other, and in panel (b) the data is symmetric about the middle probability, 0.5. For this reason, for values of the stimulus generative probability below 0.5 we show the curves in panel (a) as dotted lines, and the data points in panel (b) as white dots with dotted error bars.
First-order sequential effects: attractive influence of the most recent stimulus on subjects’ predictions
The sequences presented to subjects correspond to independent, Bernoulli-distributed random events. Having shown that the subjects’ predictions follow (in a non-optimal fashion) the stimulus generative probability, we now test whether they also exhibit the non-independence of consecutive trials featured by the Bernoulli process. Under this hypothesis and in the stationary regime, the proportion of predictions A conditional on the preceding stimulus being A, , should be no different than the proportion of predictions A conditional on the preceding stimulus being B, . (Here and below, denotes the proportion of predictions X conditional on the preceding observation being Y, and not on the preceding response being Y. For the possibility that subjects’ responses depend on the preceding response, see Methods.)
In other words, conditioning on the preceding stimulus should have no effect. In subjects’ responses, however, these two conditional proportions are markedly different for all stimulus generative probabilities (Fisher exact test, subjects pooled: all p-values < 1e-10; Figure 2a). Both quantities increase as a function of the stimulus generative probability, but the proportions of predictions A conditional on an A are consistently greater than the proportions of predictions A conditional on a B, i.e., (Figure 2b). (We note that because the stimulus is either A or B, it follows that, symmetrically, the proportions of predictions B conditional on a B are consistently greater than the proportions of predictions B conditional on an A.) In other words, the preceding stimulus has an ‘attractive’ sequential effect. In addition, this attractive sequential effect seems stronger for values of the stimulus generative probability closer to the equiprobable case (p = 0.5), and to decrease for more extreme values ( closer to 0 or to 1; Figure 2b). The results in Figure 2 are obtained by pooling together the responses of the subjects. Results derived from an across-subjects analysis are very similar; see Appendix.
A framework of costly inference
The attractive effect of the preceding stimulus on subjects’ responses suggests that the subjects have not correctly inferred the Bernoulli statistics of the process generating the stimuli. We investigate the hypothesis that their ability to infer the underlying statistics of the stimuli is hampered by cognitive constraints. We assume that these constraints can be understood as a cost, bearing on the representation, by the brain, of the subject’s beliefs about the statistics. Specifically, we derive an array of models from a framework of inference under costly posteriors (Prat-Carrabin et al., 2021a), which we now present. We consider a model subject who is presented on each trial with a stimulus (where 0 and 1 encode for B and A, respectively) and who uses the sequence of stimuli to infer the stimulus statistics, over which she holds the belief distribution . A Bayesian observer equipped with this belief and observing a new observation would obtain its updated belief through Bayes’ rule. However, a cognitive cost hinders our model subject’s ability to represent probability distributions . Thus, she approximates the posterior through another distribution that minimizes a loss function defined as
(1)
where is a measure of distance between two probability distributions, and is a coefficient specifying the relative weight of the cost. (We are not proposing that subjects actively minimize this quantity, but rather that the brain’s inference process is an effective solution to this optimization problem.) Below, we use the Kullback-Leibler divergence for the distance (i.e. ). If , the solution to this minimization problem is the Bayesian posterior; if , the cost distorts the Bayesian solution in ways that depend on the form of the cost borne by the subject (we detail further below the two kinds of costs we investigate).
In our framework, the subject assumes that the preceding stimuli ( with ) and a vector of parameters jointly determine the distribution of the stimulus at trial , . Although in our task the stimuli are Bernoulli-distributed (thus they do not depend on preceding stimuli) and a single parameter determines the probability of the outcomes (the stimulus generative probability), the subject may admit the possibility that more complex mechanisms govern the statistics of the stimuli, for example transition probabilities between consecutive stimuli. Therefore, the vector may contain more than one parameter and the number of preceding stimuli assumed to influence the probability of the following stimulus, which we call the ‘Markov order’, may be greater than 0.
Below, we call ‘Bernoulli observer’ any model subject who assumes that the stimuli are Bernoulli-distributed (); in this case the vector consists of a single parameter that determines the probability of observing A, which we also denote by for the sake of concision. The bias and variability in the inference of the Bernoulli observer is studied in Prat-Carrabin et al., 2021a. We call ‘Markov observer’ any model subject who posits that the probability of the stimulus depends on the preceding stimuli (). In this case, the vector contains the conditional probabilities of observing A after observing each possible sequence of stimuli. For instance, with the vector is the pair of parameters denoting the probabilities of observing a stimulus A after observing, respectively, a stimulus A and a stimulus B. In the absence of a cost, the belief over the parameter(s) eventually converges towards the parameter vector that is consistent with the generative Bernoulli statistics governing the stimulus (except if the prior precludes this parameter vector). Below, we assume a uniform prior.
To understand how the costs contort the inference process, it is useful to have in mind the solution to the ‘unconstrained’ inference problem (with ), i.e., the Bayesian posterior, which we denote by . In the case of a Bernoulli observer (), after trials, the Bayesian posterior is a Beta distribution,
(2)
where is the number of stimuli observed up to trial , that is, , and . As more evidence is accumulated, the Bayesian posterior gradually narrows and converges towards the value of the stimulus generative probability (Figure 3c and d, grey lines).
Figure 3
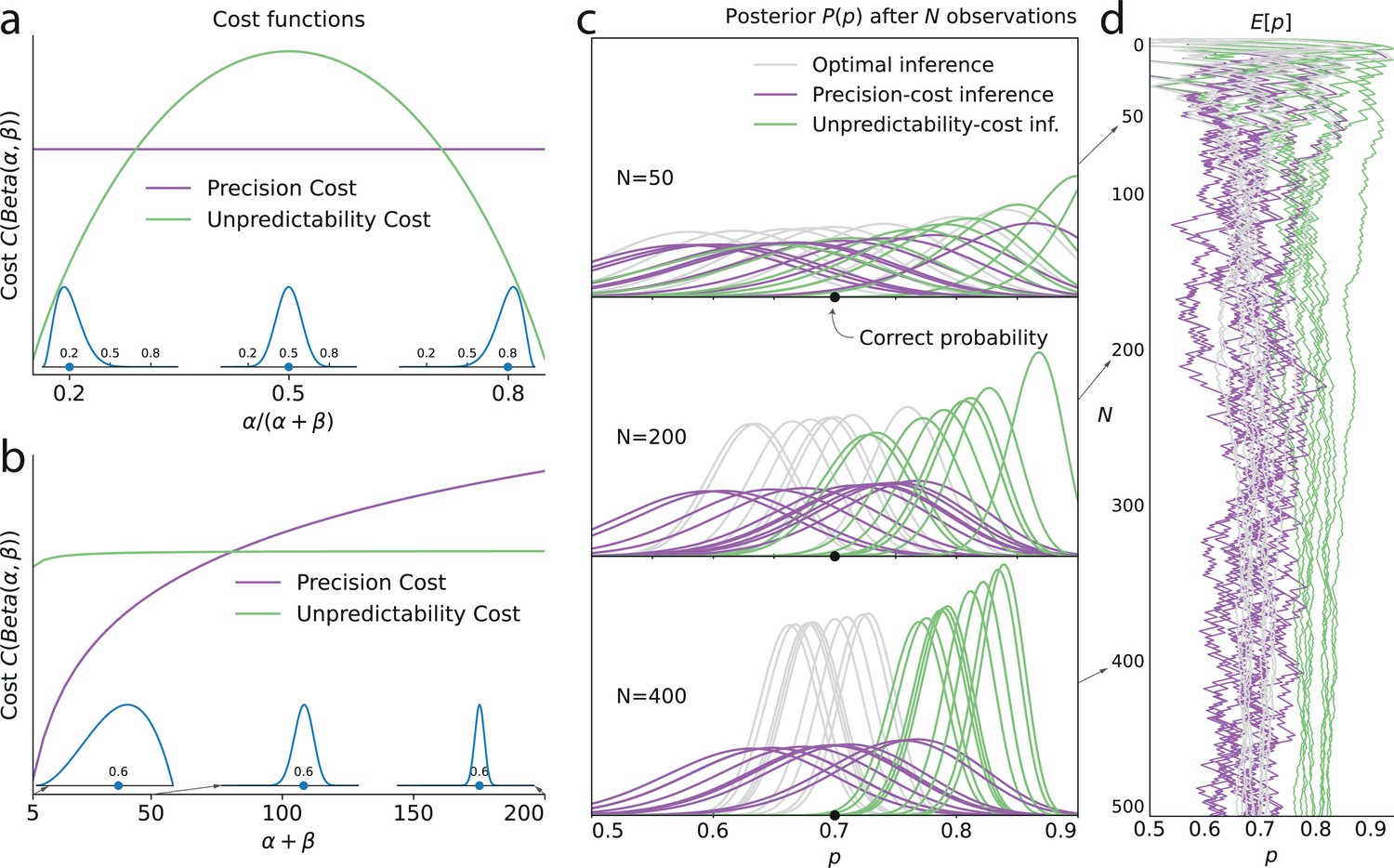
Illustration of the Bernoulli-observer models, with unpredictability and precision costs.
(a) Precision cost (purple) and unpredictability cost (green lines) of a Beta distribution with parameters and , as functions of the mean of the distribution, , and keeping the entropy constant. The precision cost is the negative of the entropy and it is thus constant, regardless of the mean of the distribution. The unpredictability cost is larger when the mean of the distribution is closer to 0.5 (i.e. when unpredictable environments are likely, under the distribution). Insets: Beta distributions with mean 0.2, 0.5, and 0.8, and constant entropy. (b) Costs as functions of the sample size parameter, . A larger sample size implies a higher precision and lower entropy, thus the precision cost increases as a function of the sample size, whereas the unpredictability cost is less sensitive to changes in this parameter. Insets: Beta distributions with mean 0.6 and sample size parameter, , equal to 5, 50, and 200. (c) Posteriors of an optimal observer (gray), a precision-cost observer (purple) and an unpredictability-cost observer (green lines), after the presentation of ten sequences of N = 50, 200, and 400 observations sampled from a Bernoulli distribution of parameter 0.7. The posteriors of the optimal observer narrow as evidence is accumulated, and the different posteriors obtained after different sequences of observations are drawn closer to each other and to the correct probability. The posteriors of the unpredictability-cost observer also narrow and group together, but around a probability larger (less unpredictable) than the correct probability. Precise distributions are costly to the precision-cost observer and thus the posteriors do not narrow after long sequences of observations. Instead, the posteriors fluctuate with the recent history of the stimuli. (d) Expected probability resulting from the inference. The optimal observer (gray) converges towards the correct probability; the unpredictability-cost observer (green) converges towards a biased (larger) probability; and the precision-cost observer (purple lines) does not converge, but instead fluctuates with the history of the stimuli.
The ways in which the Bayesian posterior is distorted, in our models, depend on the nature of the cost that weighs on the inference process. Although many assumptions could be made on the kind of constraint that hinders human inference, and on the cost it would entail in our framework, here we examine two costs that stem from two possible principles: that the cost is a function of the beliefs held by the subject, or that it is a function of the environment that the subject is inferring. We detail, below, these two costs.
Precision cost
A first hypothesis about the inference process of subjects is that the brain mobilizes resources to represent probability distributions, and that more ‘precise’ distributions require more resources. We write the cost associated with a distribution, , as the negative of its entropy,
(3)
which is a measure of the amount of certainty in the distribution. Wider (less concentrated) distributions provide less information about the probability parameter and are thus less costly than narrower (more concentrated) distributions (Figure 3b). As an extreme case, the uniform distribution is the least costly.
With this cost, the loss function (Equation 1) is minimized by the distribution equal to the product of the prior and the likelihood, raised to the exponent , and normalized, i.e.,
(4)
Since is strictly positive, the exponent is positive and lower than 1. As a result, the solution ‘flattens’ the Bayesian posterior, and in the extreme case of an unbounded cost () the posterior is the uniform distribution.
Furthermore, in the expression of our model subject’s posterior, the likelihood is raised after trials to the exponent , it thus decays to zero as the number of new stimuli increases. One can interpret this effect as gradually forgetting past observations. Specifically, we recover the predictions of leaky-integration models, in which remote patterns in the sequence of stimuli are discounted through an exponential filter (Yu and Cohen, 2008; Meyniel et al., 2016); here, we do not posit the gradual forgetting of remote observations, but instead we derive it as an optimal solution to a problem of constrained inference. We illustrate leaky integration in the case of a Bernoulli observer (): in this case, the posterior after trials, , is a Beta distribution,
(5)
where and are exponentially-filtered counts of the number of stimuli A and B observed up to trial , i.e.,
(6)
In other words, the solution to the constrained inference problem, with the precision cost, is similar to the Bayesian posterior (Equation 2), but with counts of the two stimuli that gradually ‘forget’ remote observations (in the absence of a cost, that is, , we have and , and thus we recover the Bayesian posterior). As a result, these counts fluctuate with the recent history of the stimuli. Consequently, the posterior is dominated by the recent stimuli: it does not converge, but instead fluctuates with the recent stimulus history (Figure 3c and d, purple lines; compare with the green and gray lines). Hence, this model implies predictions about subsequent stimuli that depend on the stimulus history, i.e., it predicts sequential effects.
Unpredictability cost
A different hypothesis is that the subjects favor, in their inference, parameter vectors that correspond to more predictable outcomes. We quantify the outcome unpredictability by the Shannon entropy (Shannon, 1948) of the outcome implied by the vector of parameters , which we denote by . (In the Bernoulli-observer case, ; for the Markov-observer cases, see Methods.) The cost associated with the distribution is the expectation of this quantity averaged over beliefs, i.e.,
(7)
which we call the ‘unpredictability cost’. For a Bernoulli observer, a posterior concentrated on extreme values of the Bernoulli parameter (toward 0 or 1), thus representing more predictable environments, comes with a lower cost than a posterior concentrated on values of the Bernoulli parameter close to 0.5, which correspond to the most unpredictable environments (Figure 3a).
After trials, the loss function (Equation 1) under this cost is minimized by the posterior
(8)
i.e., the product of the Bayesian posterior, which narrows with around the stimulus generative probability, and of a function that is larger for values of that imply less entropic (i.e. more predictable) environments (see Methods). In short, with the unpredictability cost the model subject’s posterior is ‘pushed’ towards less entropic values of .
In the Bernoulli case (), the posterior after stimuli has a global maximum, , that depends on the proportion of stimuli A observed up to trial . As the number of presented stimuli grows, the posterior becomes concentrated around this maximum. The proportion naturally converges to the stimulus generative probability, , thus our subject’s inference converges towards the value which is different from the true value , in the non-equiprobable case (). The equiprobable case () is singular, in that with a weak cost () the inferred probability is unbiased (), while with a strong cost () the inferred probability does not converge but instead alternates between two values above and below 0.5; see Prat-Carrabin et al., 2021a. In other words, except in the equiprobable case, the inference converges but it is biased, i.e., the posterior peaks at an incorrect value of the stimulus generative probability (Figure 3c and d, green lines). This value is closer to the extremes (0 and 1) than the stimulus generative probability, that is, it implies an environment more predictable than the actual one (Figure 3d).
In the case of a Markov observer (), the posterior also converges to a vector of parameters which implies not only a bias but also that the conditional probabilities of a stimulus A (conditioned on different stimulus histories) are not equal. The prediction of the next stimulus being A on a given trial depends on whether the preceding stimulus was A or B: this model therefore predicts sequential effects. We further examine below the behavior of this model in the cases of a Bernoulli observer and of different Markov observers. We refer the reader interested in more details on the Markov models, including their mathematical derivations, to the Methods section.
In short, with the unpredictability-cost models, when , the inference process converges to an asymptotic posterior which does not itself depend on the history of the stimulus, but that is biased (Figure 3c, d, green lines). In particular, for Markov observers (), the asymptotic posterior corresponds to an erroneous belief about the dependency of the stimulus on the recent stimulus history, which results in sequential effects in behavior.
Overview of the inference models
Although the two families of models derived from the two costs both potentially generate sequential effects, they do so by giving rise to qualitatively different inference processes. Under the unpredictability cost, the inference converges to a posterior that, in the Bernoulli case (), implies a biased estimate of the stimulus generative probability (Figure 3d, green lines), while in the Markov case () it implies the belief that there are serial dependencies in the stimuli: predictions therefore depend on the recent stimulus history. By contrast, the precision cost prevents beliefs from converging (Figure 3c, purple lines). As a result, the subject’s predictions vary with the recent stimulus history (Figure 3d). This inference process amounts to an exponential discount of remote observations, or equivalently, to the overweighting of recent observations (Equation 6).
To investigate in more detail the sequential effects that these two costs produce, we implement two families of inference models derived from the two costs. Each model is characterized by the type of cost (unpredictability cost or precision cost), and by the assumed Markov order (): we examine the case of a Bernoulli observer () and three cases of Markov observers (with 1, 2, and 3). We thus obtain models of inference. Each of these models has one parameter controlling the weight of the cost. (We also examine a ‘hybrid’ model that combines the two costs; see below.)
Response-selection strategy
We assume that the subject’s response on a given trial depends on the inferred posterior according to a generalization of ‘probability matching’ implemented in other studies (Battaglia et al., 2011; Yu and Huang, 2014; Prat-Carrabin et al., 2021b). In this response-selection strategy, the subject predicts A with the probability , where is the expected probability of a stimulus A derived from the posterior, i.e., . The single parameter controls the randomness of the response: with the subject predicts A and B with equal probability; with the response-selection strategy corresponds to probability matching, that is, the subject predicts A with probability ; and as increases toward infinity the choices become optimal, that is, the subjects predicts A if the expected probability of observing a stimulus A, , is greater than 0.5, and predicts B if it is lower than 0.5 (if the subject chooses A or B with equal probability). In our investigations, we also implement several other response-selection strategies, including one in which subjects have a propensity to repeat their preceding response, or conversely, to alternate; these analyses do not change our conclusions (see Methods).
Model fitting favors Markov-observer models
Each of our eight models has two parameters: the factor weighting the cost, , and the exponent of the generalized probability-matching, . We fit the parameters of each model to the responses of each subject, by maximizing their likelihoods. We find that 60% of subjects are best fitted by one of the unpredictability-cost models, while 40% are best fitted by one of the precision-cost models. When pooling the two types of cost, 65% of subjects are best fitted by a Markov-observer model. We implement a ‘Bayesian model selection’ procedure (Stephan et al., 2009), which takes into account, for each subject, the likelihoods of all the models (and not only the maximum among them) in order to obtain a Bayesian posterior over the distribution of models in the general population (see Methods). The derived expected probability of unpredictability-cost models is 57% (and 43% for precision-cost models) with an exceedance probability (i.e. probability that unpredictability-cost models are more frequent in the general population) of 78%. The expected probability of Markov-observer models, regardless of the cost used in the model, is 70% (and 30% for Bernoulli-observer models) with an exceedance probability (i.e. probability that Markov-observer models are more frequent in the general population) of 98%. These results indicate that the responses of subjects are generally consistent with a Markov-observer model, although the stimuli used in the experiment are Bernoulli-distributed. As for the unpredictability-cost and the precision-cost families of models, Bayesian model selection does not provide decisive evidence in favor of either model, indicating that they both capture some aspects of the responses of the subjects. Below, we examine more closely the behaviors of the models, and point to qualitative differences between the predictions resulting from each model family.
Before turning to these results, we validate the robustness of our model-fitting procedure with several additional analyses. First, we estimate a confusion matrix to examine the possibility that the model-fitting procedure could misidentify the models which generated test sets of responses. We find that the best-fitting model corresponds to the true model in at least 70% of simulations (the chance level is 12.5%=1/8 models), and actually more than 90% for the majority of models (see Appendix).
Second, we seek to verify whether the best-fitting cost factor, , that we obtain for each subject is consistent across the range of probabilities tested. Specifically, we fit separately the models to the responses obtained in the blocks of trials whose stimulus generative probability was ‘medium’ (between 0.3 and 0.7, included) on the one hand, and to the responses obtained when the probability was ‘extreme’ (below 0.3, and above 0.7) on the other hand; and we compare the values of the best-fitting cost factors in these two cases. More precisely, for the precision-cost family, we look at the inverse of the decay time, , which is the inverse of the characteristic time over which the model subject ‘forgets’ past observations. With both families of models, we find that on a logarithmic scale the parameters in the medium- and extreme-probabilities cases are significantly correlated across subjects (Pearson’s , precision-cost models: 0.75, p-value: 1e-4; unpredictability-cost models: , p-value: .036). In other words, if a subject is best fitted by a large cost factor in medium-probabilities trials, he or she is likely to be also best fitted by a large cost factor in extreme-probabilities trials. This indicates that our models capture idiosyncratic features of subjects that generalize across conditions instead of varying with the stimulus probability (see Appendix).
Third, as mentioned above we examine a variant of the response-selection strategy in which the subject sometimes repeats the preceding response, or conversely alternates and chooses the other response, instead of responding based on the inferred probability of the next stimulus. This propensity to repeat or alternate does not change the best-fitting inference model of most subjects, and the best-fitting values of the parameters and are very stable when allowing or not for this propensity. This analysis supports the results we present here, and speaks to the robustness of the model-fitting procedure (see Methods).
Finally, as the unpredictability-cost family and the precision-cost family of models both seem to capture the responses of a sizable share of the subjects, one might assume that the behavior of most subjects actually fall ‘somewhere in between’, and would be best accounted for by a hybrid model combining the two costs. In our investigations, we have implemented such a model, whereby the subject’s approximate posterior results from the minimization of a loss function that includes both a precision cost, with weight , and an unpredictability cost, with weight (and the response-selection strategy is the generalized probability matching, with parameter ). We do not find that most subjects’ responses are better fitted (as measured by the Bayesian Information Criterion Schwarz, 1978) by a combination of the two costs: instead, for more than two thirds of subjects, the best-fitting model features just one cost (see Methods). In other words, the two cost seems to capture different aspects of the behavior that are predominant in different subpopulations. Below, we examine the behavioral patterns resulting from each cost type, in comparison with the behavior of the subjects.
Models of costly inference reproduce the attractive effect of the most recent stimulus
We now examine the behavioral patterns resulting from the models. All the models we consider predict that the proportion of predictions A, , is a smooth, increasing function of the stimulus generative probability (when and ; Figure 4a–d, grey lines), thus we focus, here, on the ability of the models to reproduce the subjects’ sequential effects. With the unpredictability-cost model of a Bernoulli observer (), the belief of the model subject, as mentioned above, asymptotically converges in non-equiprobable cases to an erroneous value of the stimulus generative probability (Figure 3d, green lines). After a large number of observations (such as the 200 ‘passive’ trials, in our task), the sensitivity of the belief to new observations becomes almost imperceptible; as a result, this model predicts practically no sequential effects (Figure 4b), that is, . With the unpredictability-cost model of a Markov observer (e.g. ), the belief of the model subject also converges, but to a vector of parameters that implies a sequential dependency in the stimulus, that is, , resulting in sequential effects in predictions, that is, . The parameter vector yields a more predictable (less entropic) environment if the probability conditional on the more frequent outcome (say, A) is less entropic than the probability conditional on the less frequent outcome (B). This is the case if the former is greater than the latter, resulting in the inequality , that is, in sequential effects of the attractive kind (Figure 4d). (The case in which B is the more frequent outcome results in the inequality , i.e., , i.e., the same, attractive sequential effects.)
Figure 4
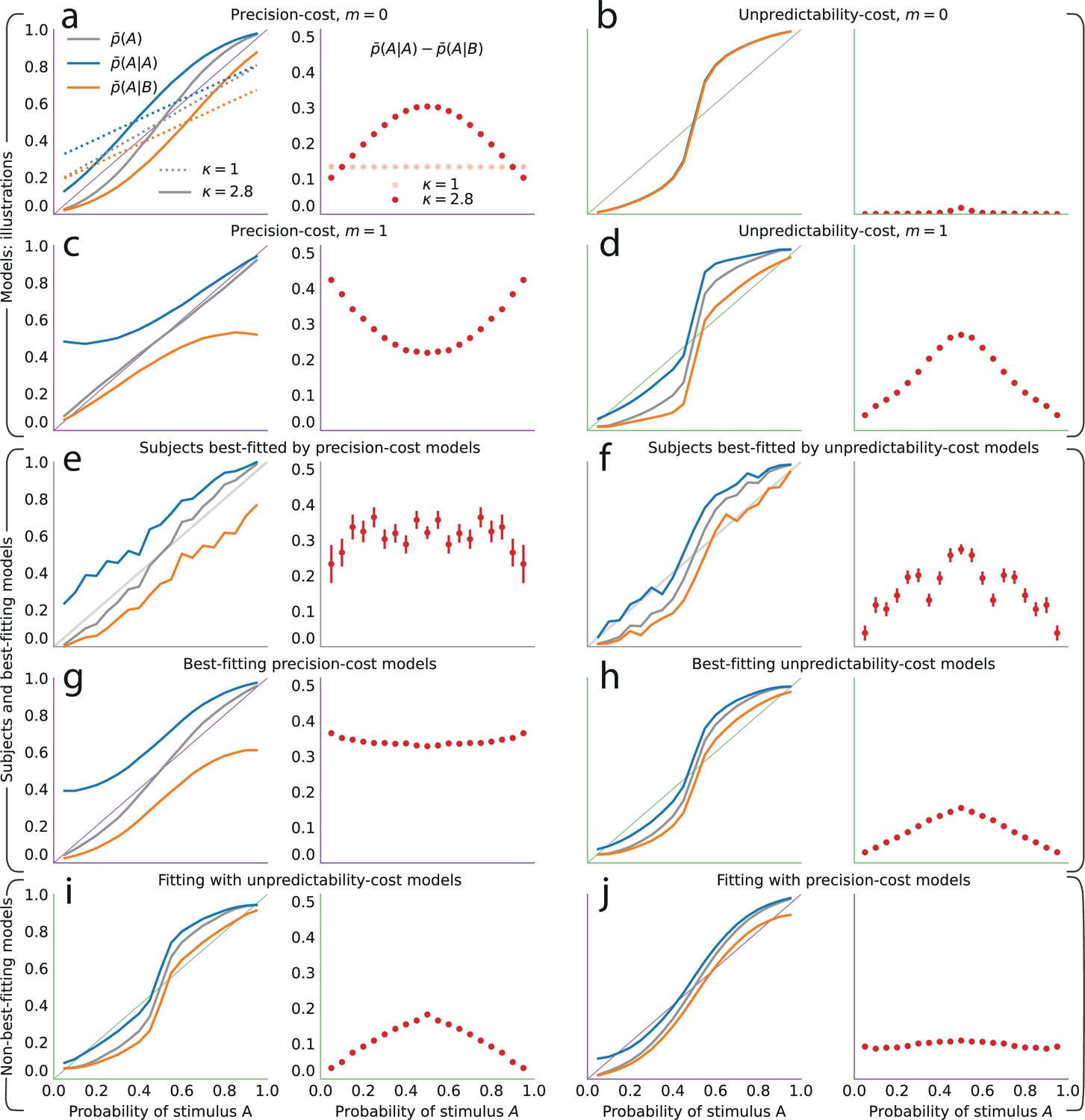
The precision-cost and unpredictability-cost models reproduce the subjects’ attractive sequential effects.
(a–h) Left subpanels: proportion of predictions A as a function of the stimulus generative probability, conditional on observing A (blue line) or B (orange line) on the preceding trial, and unconditional (grey line). Right subpanels: difference between the proportion of predictions A conditional on observing A, and conditional on observing B, . In all panels this difference is positive, indicating an attractive sequential effect (i.e. observing A at the preceding trial increases the probability of predicting A). (a–d) Models with the precision cost (a,c) or the unpredictability cost (b,d), and with a Bernoulli observer (; a,b) or a Markov observer with (c,d). (a) Behavior with the generalized probability-matching response-selection strategy with (solid lines, red dots) and with (dotted lines, light-red dots). (e,f) Pooled responses of the subjects best-fitted by a precision-cost model (e) or by an unpredictability-cost model (f). Right subpanels: bars are twice the square root of the sum of the two squared standard errors of the means (for each point, total n: e: 1393, f: 2189 to 2388). (g,h) Pooled responses of the models that best fit the corresponding subjects in panels (e,f). (i,j) Pooled responses of the unpredictability-cost models (i) and of the precision-cost models (j), fitted to the subjects best-fitted, respectively, by precision-cost models, and by unpredictability-cost models.
Turning to the precision-cost models, we have noted that in these models the posterior fluctuates with the recent history of the stimuli (Figure 3c): as a result, sequential effects are obtained, even with a Bernoulli observer (; Figure 4a). The most recent stimulus has the largest weight in the exponentially filtered counts that determine the posterior (Equation 6), thus the model subject’s prediction is biased towards the last stimulus, that is, the sequential effect is attractive (). With the traditional probability-matching response-selection strategy (i.e. ), the strength of the attractive effect is the same across all stimulus generative probabilities (i.e. the difference is constant; Figure 4a, dotted lines and light-red dots). With the generalized probability-matching response-selection strategy, if , proportions below and above 0.5 are brought closer to the extremes (0 and 1, respectively), resulting in larger sequential effects for values of the stimulus generative probability closer to 0.5 (Figure 4a, solid lines and red dots; the model is simulated with , a value representative of the subjects’ best-fitting values for this parameter). We also find stronger sequential effects closer to the equiprobable case in subjects’ data (Figure 2b).
The precision-cost model of a Markov observer () also predicts attractive sequential effects (Figure 4c). While the behavior of the Bernoulli observer (with a precision cost) is determined by two exponentially-filtered counts of the two possible stimuli (Equation 6), that of the Markov observer with depends on four exponentially filtered counts of the four possible pairs of stimuli. After observing a stimulus B, the belief that the following stimulus should be A or B is determined by the exponentially filtered counts of the pairs BA and BB. If is large, i.e., if the stimulus B is infrequent, then the BA and BB pairs are also infrequent and the corresponding counts are close to zero: the model subject thus behaves as if only very little evidence had been observed about the transitions B to A and B to B in this case, resulting in a proportion of predictions A conditional on a preceding B, , close to 0.5 (Figure 4c, orange line). Consequently, the sequential effects are stronger for values of the stimulus generative probabilities closer to the extreme (Figure 4c, red dots).
Both families of costs are thus able to produce attractive sequential effects, albeit with some qualitative differences. (In Figure 4a–d we show the behaviors resulting from the two costs for a Bernoulli observer and a Markov observer of order ; the Markov observers of higher order exhibit qualitatively similar behaviors; see Methods.) As the model fitting indicates that different groups of subjects are best fitted by models belonging to the two families, we examine separately the behaviors of the subjects whose responses are best fitted by each of the two costs (Figure 4e and f), in comparison with the behaviors of the corresponding best-fitting models (Figure 4g and h). This provides a finer understanding of the behavior of subjects than the group average shown in Figure 2. For the subjects best fitted by precision-cost models, the proportion of predictions A, , when the stimulus generative probability is close to 0.5, is a less steep function of this probability than for the subjects best-fitted by unpredictability-cost models (Figure 4e and f, grey lines); furthermore, their sequential effects are larger (as measured by the difference ), and do not depend much on the stimulus generative probability (Figure 4e and f, red dots). The corresponding models reproduce the behavioral patterns of the subjects that they best fit (Figure 4g and h). Each family of models seems to capture specific behaviors exhibited by the subjects: when fitting the unpredictability-cost models to the responses of the subjects that are best fitted by precision-cost models, and conversely when fitting the precision-cost models to the responses of the subjects that are best fitted by unpredictability-cost models, the models do not reproduce well the subjects’ behavioral patterns (Figure 4i and j). The precision-cost models, however, seem slightly better than the unpredictability-cost models at capturing the behavior of the subjects that they do not best fit (Figure 4, compare panel j to panel f, and panel i to panel e). Substantiating this observation, the examination of the distributions of the models’ BICs across subjects shows that when fitting the models onto the subjects that they do not best fit, the precision-cost models fare better than the unpredictability-cost models (see Appendix).
Beyond the most recent stimulus: patterns of higher-order sequential effects
Notwithstanding the quantitative differences just presented, both families of models yield qualitatively similar attractive sequential effects: the model subjects’ predictions are biased towards the preceding stimulus. Does this pattern also apply to the longer history of the stimulus, i.e., do more distant trials also influence the model subjects’ predictions? To investigate this hypothesis, we examine the difference between the proportion of predictions A after observing a sequence of length that starts with A, minus the proportion of predictions A after the same sequence, but starting with B, i.e., , where is a sequence of length , and and denote the same sequence preceded by A and by B. This quantity enables us to isolate the influence of the -to-last stimulus on the current prediction. If the difference is positive, the effect is ‘attractive’; if it is negative, the effect is ‘repulsive’ (in this latter case, the presentation of an A decreases the probability that the subjects predicts A in a later trial, as compared to the presentation of a B); and if the difference is zero there is no sequential effect stemming from the -to-last stimulus. The case corresponds to the immediately preceding stimulus, whose effect we have shown to be attractive, i.e., , in the responses both of the best-fitting models and of the subjects (Figures 2b, 4g and h).
We investigate the effect of the -to-last stimulus on the behavior of the two families of models, with , , and . We present here the main results of this investigation; we refer the reader to Methods for a more detailed analysis. With unpredictability-cost models of Markov order , there are non-vanishing sequential effects stemming from the -to-last stimulus only if the Markov order is greater than or equal to the distance from this stimulus to the current trial, i.e., if . In this case, the sequential effects are attractive (Figure 5).
Figure 5
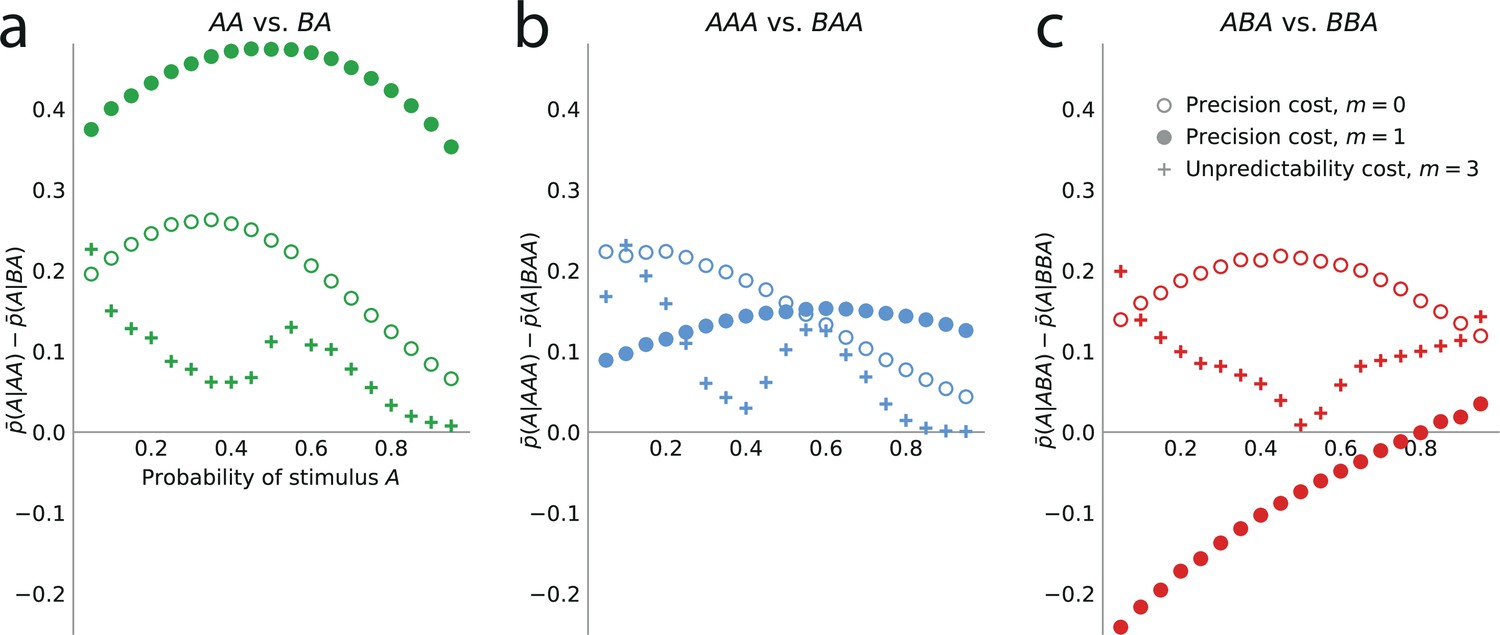
Higher-order sequential effects: the precision-cost model of a Markov observer predicts a repulsive effect of the third-to-last stimulus.
Sequential effect of the second-to-last (a) and third-to-last (b,c) stimuli, in the responses of the precision-cost model of a Bernoulli observer (; white circles), of the precision-cost model of a Markov observer with (filled circles), and of the unpredictability-cost model of a Markov observer with (crosses). (a) Difference between the proportion of prediction A conditional on observing AA, and conditional on observing BA, i.e., , as a function of the stimulus generative probability. With the three models, this difference is positive, indicating an attractive sequential effect of the second-to-last stimulus. (b) Difference between the proportion of prediction A conditional on observing AAA, and conditional on observing BAA, i.e., . The positive difference indicates an attractive sequential effect of the third-to-last stimulus in this case. (c) Difference between the proportion of prediction A conditional on observing ABA, and conditional on observing BBA, i.e., . With the precision-cost model of a Markov observer, the negative difference when the stimulus generative probability is lower than 0.8 indicates a repulsive sequential effect of the third-to-last stimulus in this case, while when the probability is greater than 0.8, and with the predictability-cost model of a Bernoulli observer and with the unpredictability-cost model of a Markov observer, the positive difference indicates an attractive sequential effect of the third-to-last stimulus.
With precision-cost models, the -to-last stimuli yield non-vanishing sequential effects regardless of the Markov order, . With , the effect is attractive, i.e., . With (second-to-last stimulus), the effect is also attractive, i.e., in the case of the pair of sequences AA and BA, (Figure 5a). By symmetry, the difference is also positive for the other pair of relevant sequences, AB and BB (e.g. we note that , and that when the probability of A is is equal to when the probability of A is . We detail in Methods such relations between the proportions of predictions A or B in different situations. These relations result in the symmetries of Figure 2, for the sequential effect of the last stimulus, while for higher-order sequential effects they imply that we do not need to show, in Figure 5, the effects following all possible past sequences of two or three stimuli, as the ones we do not show are readily derived from the ones we do.)
As for the third-to-last stimulus (), it can be followed by four different sequences of length two, but we only need to examine two of these four, for the reasons just presented. We find that for the precision-cost models, with all the Markov orders we examine (from 0 to 3), the probability of predicting A after observing the sequence AAA is greater than that after observing the sequence BAA, i.e., , that is, there is an attractive sequential effect of the third-to-last stimulus if the sequence following it is AA (and, by symmetry, if it is BB; Figure 5b). So far, thus, we have found only attractive effects. However, the results are less straightforward when the third-to-last stimulus is followed by the sequence BA. In this case, for a Bernoulli observer (), the effect is also attractive: (Figure 5c, white circles). With Markov observers (), over a range of stimulus generative probability , the effect is repulsive: , that is, the presentation of an A decreases the probability that the model subject predicts A three trials later, as compared to the presentation of a B (Figure 5c, filled circles). The occurrence of the repulsive effect in this particular case is a distinctive trait of the precision-cost models of Markov observers (); we do not obtain any repulsive effect with any of the unpredictability-cost models, nor with the precision-cost model of a Bernoulli observer ().
Subjects’ predictions exhibit higher-order repulsive effects
We now examine the sequential effects in subjects’ responses, beyond the attractive effect of the preceding stimulus (; discussed above). With (second-to-last stimulus), for the majority of the 19 stimulus generative probabilities , we find attractive sequential effects: the difference is significantly positive (Figure 6a; p-values <0.01 for 11 stimulus generative probabilities, <0.05 for 13 probabilities; subjects pooled). With (third-to-last stimulus), we also find significant attractive sequential effects in subjects’ responses for some of the stimulus generative probabilities, when the third-to-last stimulus is followed by the sequence AA (Figure 6b; p-values <0.01 for four probabilities, <0.05 for seven probabilities). When it is instead followed by the sequence BA, we find that for eight stimulus generative probabilities, all between 0.25 and 0.75, there is a significant repulsive sequential effect: (p-values <0.01 for six probabilities, <0.05 for eight probabilities; subjects pooled). Thus, in these cases, the occurrence of A as the third-to-last stimulus increases (in comparison with the occurrence of a B) the proportion of the opposite prediction, B. For the remaining stimulus generative probabilities, this difference is in most cases also negative although not significantly different from zero (Figure 6c). (An across-subjects analysis yields similar results; see Supplementary Materials.) Figure 6d summarizes subjects’ sequential effects, and exhibits the attractive and repulsive sequential effects in their responses (compare solid and dotted lines). (In this tree-like representation, we show averages across the stimulus generative probabilities; a figure with the individual ‘trees’ for each probability is provided in the Appendix.)
Figure 6
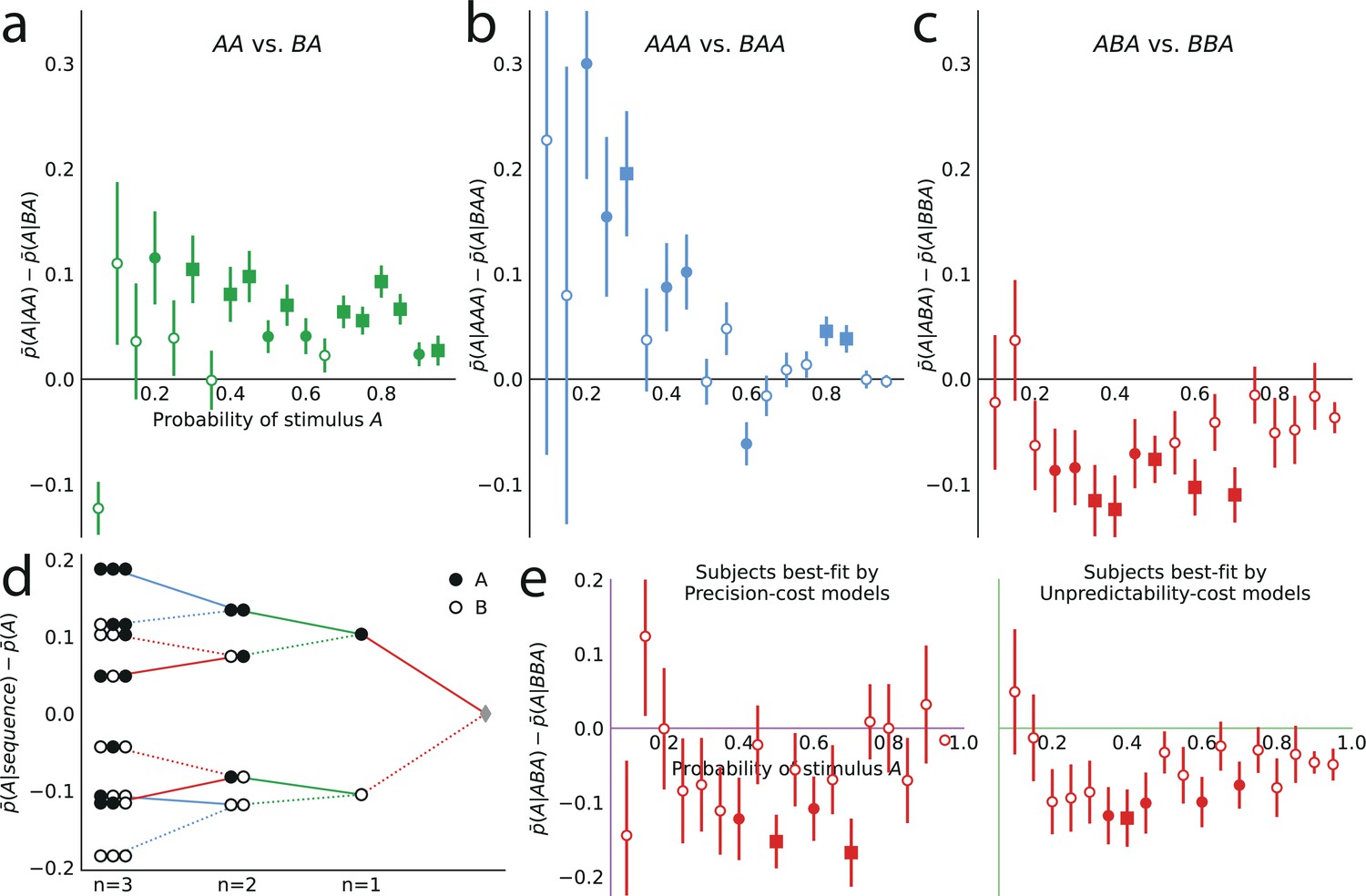
Patterns of attractive and repulsive sequential effects in subjects’ responses.
(a) Difference between the proportion of prediction A conditional on observing the sequence AA, and conditional on observing BA, i.e., , as a function of the stimulus generative probability. This difference is in most cases positive, indicating an attractive sequential effect of the second-to-last stimulus. (b) Difference between the proportion of prediction A conditional on observing AAA, and conditional on observing BAA, i.e., . This difference is positive in most cases, indicating an attractive sequential effect of the third-to-last stimulus. (c) Difference between the proportion of prediction A conditional on observing ABA, and conditional on observing BBA, i.e., . This difference is negative in most cases, indicating a repulsive sequential effect of the third-to-last stimulus. (d) Differences, averaged over all tested stimulus generative probabilities, between the proportion of predictions A conditional on sequences of up to three past observations, minus the unconditional proportion. The proportion conditional on a sequence is an average of the two proportions conditional on the same sequence preceded by another, ‘older’ observation, A or B, resulting in a binary-tree structure in this representation. If this additional past observation is A (respectively, B), we connect the two sequences with a solid line (respectively, a dotted line). In most cases, conditioning on an additional A increases the proportion of predictions A (in comparison to conditioning on an additional B), indicating an attractive sequential effect, except when the additional observation precedes the sequence BA (or its symmetric AB), in which cases repulsive sequential effects are observed (dotted line ‘above’ solid line). (e) Same as (c), with subjects split in two groups: the subjects best-fitted by precision-cost models (left) and the subjects best-fitted by unpredictability-cost models (right). In panels a-c and e, the filled circles indicate that the p-value of the Fisher exact test is below 0.05, and the filled squares indicate that the p-value with Bonferroni-Holm-Šidák correction is below 0.05. Bars are twice the square root of the sum of the two squared standard errors of the means (for each point, total n: a: 178 to 3584, b: 37 to 3394, c: 171 to 1868, e: 63 to 1184). In all panels, the responses of all the subjects are pooled together.
The repulsive sequential effect of the third-to-last stimulus in subjects’ predictions only occurs when the third-to-last stimulus is A followed by the sequence BA. It is also only in this case that the repulsive effect appears with the precision-cost models of a Markov observer (while it never appears with the unpredictability-cost models). This qualitative difference suggests that the precision-cost models offer a better account of sequential effects in subjects. However, model-fitting onto the overall behavior presented above showed that a fraction of the subjects is better fitted by the unpredictability-cost models. We investigate, thus, the presence of a repulsive effect in the predictions of the subjects best fitted by the precision-cost models, and of those best fitted by the unpredictability-cost models. For the subjects best fitted by the precision-cost models, we find (expectedly) that there is a significant repulsive sequential effect of the third-to-last stimulus (; p-values <0.01 for two probabilities, <0.05 for four probabilities; subjects pooled; Figure 6e, left panel). For the subjects best fitted by the unpredictability-cost models (a family of model that does not predict any repulsive sequential effects), we also find, perhaps surprisingly, a significant repulsive effect of the third-to-last stimulus (p-values <0.01 for three probabilities, <0.05 for five probabilities; subjects pooled), which demonstrates the robustness of this effect (Figure 6e, right panel). Thus, in spite of the results of the model-selection procedure, some sequential effects in subjects’ predictions support only one of the two families of model. Regardless of the model that best fits their overall predictions, the behavior of the subjects is consistent only with the precision-cost family of models with Markov order equal to or greater than 1, that is, with a model of inference of conditional probabilities hampered by a cognitive cost weighing on the precision of belief distributions.
Discussion
We investigated the hypothesis that sequential effects in human predictions result from cognitive constraints hindering the inference process carried out by the brain. We devised a framework of constrained inference, in which the model subject bears a cognitive cost when updating its belief distribution upon the arrival of new evidence: the larger the cost, the more the subject’s posterior differs from the Bayesian posterior. The models we derive from this framework make specific predictions. First, the proportion of forced-choice predictions for a given stimulus should increase with the stimulus generative probability. Second, most of those models predict sequential effects: predictions also depend on the recent stimulus history. Models with different types of cognitive cost resulted in different patterns of attractive and repulsive effects of the past few stimuli on predictions. To compare the predictions of constrained inference with human behavior, we asked subjects to predict each next outcome in sequences of binary stimuli. We manipulated the stimulus generative probability in blocks of trials, exploring exhaustively the probability range from 0.05 to 0.95 by increments of 0.05. We found that subjects’ predictions depend on both the stimulus generative probability and the recent stimulus history. Sequential effects exhibited both attractive and repulsive components which were modulated by the stimulus generative probability. This behavior was qualitatively accounted for by a model of constrained inference in which the subject infers the transition probabilities underlying the sequences of stimuli and bears a cost that increases with the precision of the posterior distributions. Our study proposes a novel theoretical account of sequential effects in terms of optimal inference under cognitive constraints and it uncovers the richness of human behavior over a wide range of stimulus generative probabilities.
The notion that human decisions can be understood as resulting from a constrained optimization has gained traction across several fields, including neuroscience, cognitive science, and economics. In neuroscience, a voluminous literature that started with Attneave, 1954 and Barlow, 1961 investigates the idea that perception maximizes the transmission of information, under the constraint of costly and limited neural resources (Laughlin, 1981; Laughlin et al., 1998; Simoncelli and Olshausen, 2001); related theories of ‘efficient coding’ account for the bias and the variability of perception (Ganguli and Simoncelli, 2016; Wei and Stocker, 2015; Wei and Stocker, 2017; Prat-Carrabin and Woodford, 2021c). In cognitive science and economics, ‘bounded rationality’ is a precursory concept introduced in the 1950s by Herbert Simon, who defines it as “rational choice that takes into account the cognitive limitations of the decision maker — limitations of both knowledge and computational capacity” (Simon, 1997). For Gigerenzer, these limitations promote the use of heuristics, which are ‘fast and frugal’ ways of reasoning, leading to biases and errors in humans and other animals (Gigerenzer and Goldstein, 1996; Gigerenzer and Selten, 2002). A range of more recent approaches can be understood as attempts to specify formally the limitations in question, and the resulting trade-off. The ‘resource-rational analysis’ paradigm aims at a unified theoretical account that reconciles principles of rationality with realistic constraints about the resources available to the brain when it is carrying out computations (Griffiths et al., 2015). In this approach, biases result from the constraints on resources, rather than from ‘simple heuristics’ (see Lieder and Griffiths, 2019 for an extensive review). For instance, in economics, theories of ‘rational inattention’ propose that economic agents optimally allocate resources (a limited amount of attention) to make decisions, thereby proposing new accounts of empirical findings in the economic literature (Sims, 2003; Woodford, 2009; Caplin et al., 2019; Gabaix, 2017; Azeredo da Silveira and Woodford, 2019; Azeredo da Silveira et al., 2020).
Our study puts forward a ‘resource-rational’ account of sequential effects. Traditional accounts since the 1960s attribute these effects to a belief in sequential dependencies between successive outcomes (Edwards, 1961; Matthews and Sanders, 1984) (potentially ‘acquired through life experience’ Ayton and Fischer, 2004), and more generally to the incorrect models that people assume about the processes generating sequences of events (see Oskarsson et al., 2009 for a review; similar rationales have been proposed to account for suboptimal behavior in other contexts, for example in exploration-exploitation tasks Navarro et al., 2016). This traditional account was formalized, in particular, by models in which subjects carry out a statistical inference about the sequence of stimuli presented to them, and this inference assumes that the parameters underlying the generating process are subject to changes (Yu and Cohen, 2008; Wilder et al., 2009; Zhang et al., 2014; Meyniel et al., 2016). In these models, sequential effects are thus understood as resulting from a rational adaptation to a changing world. Human subjects indeed dynamically adapt their learning rate when the environment changes (Payzan-LeNestour et al., 2013; Meyniel and Dehaene, 2017; Nassar et al., 2010), and they can even adapt their inference to the statistics of these changes (Behrens et al., 2007; Prat-Carrabin et al., 2021b). However, in our task and in many previous studies in which sequential effects have been reported, the underlying statistics are in fact not changing across trials. The models just mentioned thus leave unexplained why subjects’ behavior, in these tasks, is not rationally adapted to the unchanging statistics of the stimulus.
What underpins our main hypothesis is a different kind of rational adaptation: one, instead, to the ‘cognitive limitations of the decision maker’, which we assume hinder the inference carried out by the brain. We show that rational models of inference under a cost yield rich patterns of sequential effects. When the cost varies with the precision of the posterior (measured here by the negative of its entropy, Equation 3), the resulting optimal posterior is proportional to the product of the prior and the likelihood, each raised to an exponent (Equation 4). Many previous studies on biased belief updating have proposed models that adopt the same form except for the different exponents applied to the prior and to the likelihood (Grether, 1980; Matsumori et al., 2018; Benjamin, 2019). Here, with the precision cost, both quantities are raised to the same exponent and we note that in this case the inference of the subject amounts to an exponentially decaying count of the patterns observed in the sequence of stimuli, which is sometimes called ‘leaky integration’ in the literature (Yu and Cohen, 2008; Wilder et al., 2009; Jones et al., 2013; Meyniel et al., 2016). The models mentioned above, that posit a belief in changing statistics, indeed are well approximated by models of leaky integration (Yu and Cohen, 2008; Meyniel et al., 2016), which shows that the exponential discount can have different origins. Meyniel et al., 2016 show that the precision-cost, Markov-observer model with (named ‘local transition probability model’ in this study) accounts for a range of other findings, in addition to sequential effects, such as biases in the perception of randomness and patterns in the surprise signals recorded through EEG and fMRI. Here we reinterpret these effects as resulting from an optimal inference subject to a cost, rather than from a suboptimal erroneous belief in the dynamics of the stimulus’ statistics. In our modeling approach, the minimization of a loss function (Equation 1) formalizes a trade-off between the distance to optimality of the inference, and the cognitive constraints under which it is carried out. We stress that our proposal is not that the brain actively solves this optimization problem online, but instead that it is endowed with an inference algorithm (whose origin remains to be elucidated) which is effectively a solution to the constrained optimization problem.
By grounding the sequential effects in the optimal solution to a problem of constrained optimization, our approach opens avenues for exploring the origins of sequential effects, in the form of hypotheses about the nature of the constraint that hinders the inference carried out by the brain. With the precision cost, more precise posterior distributions are assumed to take a larger cognitive toll. The intuitive assumption that it is costly to be precise finds a more concrete realization in neural models of inference with probabilistic population codes: in these models, the precision of the posterior is proportional to the average activity of the population of neurons and to the number of neurons (Ma et al., 2006; Seung and Sompolinsky, 1993). More neural activity and more neurons arguably come with a metabolic cost, and thus more precise posteriors are more costly in these models. Imprecisions in computations, moreover, was shown to successfully account for decision variability and adaptive behavior in volatile environments (Findling et al., 2019; Findling et al., 2021).
The unpredictability cost, which we introduce, yields models that also exhibit sequential effects (for Markov observers), and that fit several subjects better than the precision-cost models. The unpredictability cost relies on a different hypothesis: that the cost of representing a distribution over different possible states of the world (here, different possible values of ) resides in the difficulty of representing these states. This could be the case, for instance, under the hypothesis that the brain runs stochastic simulations of the implied environments, as proposed in models of ‘intuitive physics’ (Battaglia et al., 2013) and in Kahneman and Tversky’s ‘simulation heuristics’ (Kahneman et al., 1982). More entropic environments imply more possible scenarios to simulate, giving rise, under this assumption, to higher costs. A different literature explores the hypothesis that the brain carries out a mental compression of sequences (Simon, 1972; Chekaf et al., 2016; Planton et al., 2021); entropy in this context is a measure of the degree of compressibility of a sequence (Planton et al., 2021), and thus, presumably, of its implied cost. As a result, the brain may prefer predictable environments over unpredictable ones. Human subjects exhibit a preference for predictive information indeed (Ogawa and Watanabe, 2011; Trapp et al., 2015), while unpredictable stimuli have been shown not only to increase anxiety-like behavior (Herry et al., 2007), but also to induce more neural activity (Herry et al., 2007; den Ouden et al., 2009; Alink et al., 2010) — a presumably costly increase, which may result from the encoding of larger prediction errors (Herry et al., 2007; Schultz and Dickinson, 2000).
We note that both costs (precision and unpredictability) can predict sequential effects, even though neither carries ex ante an explicit assumption that presupposes the existence of sequential effects. They both reproduce the attractive recency effect of the last stimulus exhibited by the subjects. They make quantitatively different predictions (Figure 4); we also find this diversity of behaviors in subjects.
The precision cost, as mentioned above, yields leaky-integration models which can be summarized by a simple algorithm in which the observed patterns are counted with an exponential decay. The psychology and neuroscience literature proposes many similar ‘leaky integrators’ or ‘leaky accumulators’ models (Smith, 1995; Roe et al., 2001; Usher and McClelland, 2001; Cook and Maunsell, 2002; Wang, 2002; Sugrue et al., 2004; Bogacz et al., 2006; Kiani et al., 2008; Yu and Cohen, 2008; Gao et al., 2011; Tsetsos et al., 2012; Ossmy et al., 2013; Meyniel et al., 2016). In connectionist models of decision-making, for instance, decision units in abstract network models have activity levels that accumulate evidence received from input units, and which decay to zero in the absence of input (Roe et al., 2001; Usher and McClelland, 2001; Wang, 2002; Bogacz et al., 2006; Tsetsos et al., 2012). In other instances, perceptual evidence (Kiani et al., 2008; Gao et al., 2011; Ossmy et al., 2013) or counts of events (Sugrue et al., 2004; Yu and Cohen, 2008; Meyniel et al., 2016) are accumulated through an exponential temporal filter. In our approach, leaky integration is not an assumption about the mechanisms underpinning some cognitive process: instead, we find that it is an optimal strategy in the face of a cognitive cost weighing on the precision of beliefs. Although it is less clear whether the unpredictability-cost models lend themselves to a similar algorithmic simplification, they consist in a distortion of Bayesian inference, for which various neural-network models have been proposed (Deneve et al., 2001; Ma et al., 2008; Ganguli and Simoncelli, 2014; Echeveste et al., 2020).
Turning to the experimental results, we note that in spite of the rich literature on sequential effects, the majority of studies have focused on equiprobable Bernoulli environments, in which the two possible stimuli both had a probability equal to 0.5, as in tosses of a fair coin (Soetens et al., 1985; Cho et al., 2002; Yu and Cohen, 2008; Wilder et al., 2009; Jones et al., 2013; Zhang et al., 2014; Ayton and Fischer, 2004; Gökaydin and Ejova, 2017). In environments of this kind, the two stimuli play symmetric roles and all sequences of a given length are equally probable. In contrast, in biased environments one of the two possible stimuli is more probable than the other. Although much less studied, this situation breaks the regularities of equiprobable environments and is arguably very frequent in real life. In our experiment, we explore stimulus generative probabilities from 0.05 to 0.95, thus allowing to investigate the behavior of subjects in a wide spectrum of Bernoulli environments: from these with ‘extreme’ probabilities (e.g. p = 0.95) to these only slightly different from the equiprobable case (e.g. p = 0.55) to the equiprobable case itself (p = 0.5). The subjects are sensitive to the imbalance of the non-equiprobable cases: while they predict A in half the trials of the equiprobable case, a probability of just p = 0.55 suffices to prompt the subjects to predict A in about in 60% of trials, a significant difference (; sem: 0.008; p-value of t-test against null hypothesis that : 1.7e-11; subjects pooled).
The well-known ‘probability matching’ hypothesis (Herrnstein, 1961; Vulkan, 2000; Gaissmaier and Schooler, 2008) suggests that the proportion of predictions A matches the stimulus generative probability: . This hypothesis is not supported by our data. We find that in the non-equiprobable conditions these two quantities are significantly different (all p-values <1e-11, when ). More precisely, we find that the proportion of prediction A is more extreme than the stimulus generative probability (i.e. when , and when ; Figure 2a). This result is consistent with the observations made by Edwards, 1961; Edwards, 1956 and with the conclusions of a more recent review (Vulkan, 2000).
In addition to varying with the stimulus generative probability, the subjects’ predictions depend on the recent history of stimuli. Recency effects are common in the psychology literature; they were reported from memory (Ebbinghaus et al., 1913) to causal learning (Collins and Shanks, 2002) to inference (Shanteau, 1972; Hogarth and Einhorn, 1992; Benjamin, 2019). Recency effects, in many studies, are obtained in the context of reaction tasks, in which subjects must identify a stimulus and quickly provide a response (Hyman, 1953; Bertelson, 1965; Kornblum, 1967; Soetens et al., 1985; Cho et al., 2002; Yu and Cohen, 2008; Wilder et al., 2009; Jones et al., 2013; Zhang et al., 2014). Although our task is of a different kind (subjects must predict the next stimulus), we find some evidence of recency effects in the response times of subjects: after observing the less frequent of the two stimuli (when ), subjects seem slower at providing a response (see Appendix). In prediction tasks (like ours), both attractive recency effects, also called ‘hot-hand fallacy’, and repulsive recency effects, also called ‘gambler’s fallacy’, have been reported (Jarvik, 1951; Edwards, 1961; Ayton and Fischer, 2004; Burns and Corpus, 2004; Croson and Sundali, 2005; Oskarsson et al., 2009). The observation of both effects within the same experiment has been reported in a visual identification task (Chopin and Mamassian, 2012) and in risky choices (‘wavy recency effect’ Plonsky et al., 2015; Plonsky and Erev, 2017). As to the heterogeneity of these results, several explanations have been proposed; two important factors seem to be the perceived degree of randomness of the predicted variable and whether it relates to human performance (Ayton and Fischer, 2004; Burns and Corpus, 2004; Croson and Sundali, 2005; Oskarsson et al., 2009). In any event, most studies focus exclusively on the influence of ‘runs’ of identical outcomes on the upcoming prediction, for example, in our task, on whether three As in a row increases the proportion of predictions A. With this analysis, Edwards (Edwards, 1961) in a task similar to ours concluded to an attractive recency effect (which he called ‘probability following’). Although our results are consistent with this observation (in our data three As in a row do increase the proportion of predictions A), we provide a more detailed picture of the influence of each stimulus preceding the prediction, whether it is in a ‘run’ of identical stimuli or not, which allows us to exhibit the non-trivial finer structure of the recency effects that is often overlooked.
Up to two stimuli in the past, the recency effect is attractive: observing A at trial or at trial induces, all else being equal, a higher proportion of predictions A at trial (in comparison to observing B; Figures 2 and 6a). The influence of the third-to-last stimulus is more intricate: it can yield either an attractive or a repulsive effect, depending on the second-to-last and the last stimuli. For a majority of probability parameters, , while an A followed by the sequence AA has an attractive effect (i.e. ), an A followed by the sequence BA has a repulsive effect (i.e. ; Figure 6b and c). How can this reversal be intuited? Only one of our models, the precision-cost model with a Markov order 1 (), reproduces this behavior; we show how it provides an interpretation for this result. From the update equation of this model (Equation 4), it is straightforward to show that the posterior of the model subject (a Dirichlet distribution of order 4) is determined by four quantities, which are exponentially-decaying counts of the four two-long patterns observed in the sequence of stimuli: BB, BA, AB, and AA. The higher the count of a pattern, the more likely the model subject deems this pattern to happen again. In the equiprobable case (), after observing the sequence AAA, the count of AA is higher than after observing BAA, thus the model subject believes that AA is more probable, and accordingly predicts A more frequently, i.e., . As for the sequences ABA and BBA, both result in the same count of AA, but the former results in a higher count of AB — in other words, the short sequence ABA suggests that A is usually followed by B, but the sequence BBA does not — and thus the model subject predicts more frequently B, i.e., less frequently A ().
In short, the ability of the precision-cost model of a Markov observer to capture the repulsive effect found in behavioral data suggests that human subjects extrapolate the local statistical properties of the presented sequence of stimuli in order to make predictions, and that they pay attention not only to the ‘base rate’ — the marginal probability of observing A, unconditional on the recent history — as a Bernoulli observer would do, but also to the statistics of more complex patterns, including the repetitions and the alternations, thus capturing the transition probabilities between consecutive observations. Wilder et al., 2009, Jones et al., 2013, and Meyniel et al., 2016 similarly argue that sequential effects result from an imperfect inference of the base rate and of the frequency of repetitions and alternations. Dehaene et al., 2015 argue that the knowledge of transition probabilities is a central mechanism in the brain’s processing of sequences (e.g. in language comprehension), and infants as young as 5 months were shown to be able to track both base rates and transition probabilities (see Saffran and Kirkham, 2018 for a review). Learning of transition probabilities has also been observed in rhesus monkeys (Meyer and Olson, 2011).
The deviations from perfect inference, in the precision-cost model, originate in the constraints faced by the brain when performing computation with probability distributions. In spite of the success of the Bayesian framework, we note that human performance in various inference tasks is often suboptimal (Nassar et al., 2010; Hu et al., 2013; Acerbi et al., 2014; Prat-Carrabin et al., 2021b; Prat-Carrabin and Woodford, 2022). Our approach suggests that the deviations from optimality in these tasks may be explained by the cognitive constraints at play in the inference carried out by humans.
Other studies have considered the hypothesis that suboptimal behavior in inference tasks results from cognitive constraints. Kominers et al., 2016 consider a model in which Bayesian inference comes with a fixed cost; the observer can choose to forgo updating her belief, so as to avoid the cost. In some cases, the model predicts ‘permanently cycling beliefs’ that do not converge; but in general the model predicts that subjects will choose not to react to new evidence that is unsurprising under the current belief. The significant sequential effects we find in our subjects’ responses, however, seem to indicate that they are sensitive to both unsurprising (e.g. outcome A when p>0.5) and surprising (outcome B when p>0.5) observations, at least across the values of the stimulus generative probability that we test (Figure 2). Graeber, 2020 considers costly information processing as an account of subjects’ neglect of confounding variables in an inference task, but concludes instead that the suboptimal behavior of subjects results from their misunderstanding of the information structure in the task. A model close to ours is the one proposed in Azeredo da Silveira and Woodford, 2019 and Azeredo da Silveira et al., 2020, in which an information-theoretic cost limits the memory of an otherwise optimal and Bayesian decision-maker, resulting, here also, in beliefs that fluctuate and do not converge, and in an overweighting, in decisions, of the recent evidence.
Taking a different approach, Dasgupta et al., 2020 implement a neural network that learns to approximate Bayesian posteriors. Possible approximate posteriors are constrained not only by the structure of the network, but also by the fact that the same network is used to address a series of different inference problems. Thus the network’s parameters must be ‘shared’ across problems, which is meant to capture the brain’s limited computational resources. Although this constraint differs from the ones we consider, we note that in this study the distance function (which the approximation aims to minimize) is the same as in our models, namely, the Kullback-Leibler divergence from the optimal posterior to the approximate posterior, . Minimizing this divergence (under a cost) allows the model subject to obtain a posterior as close as possible (at least by this measure) to the optimal posterior given the most recent stimulus and the subject’s belief prior to observing the stimulus, which in turn enables the subject to perform reasonably well in the task.
In principle, rewarding subjects with a higher payoff when they make a correct prediction would change the optimal trade-off (between the distance to the optimal posterior and the cognitive costs) formalized in Equation 1, resulting in ‘better’ posteriors (closer to the Bayesian posterior), and thus to higher performance in the task. At the same time, incentivization is known to influence, also in the direction of higher performance, the extent to which choice behavior is close to probability matching (Vulkan, 2000). The interesting question of the respective sensitivities of the subjects’ inference process and of their response-selection strategy in response to different levels of incentives is beyond the scope of this study, in which we have focussed on the sensitivity of behavior to different stimulus generative probabilities.
In any case, the approach of minimizing the Kullback-Leibler divergence from the optimal posterior to the approximate posterior is widely used in the machine learning literature, and forms the basis of the ‘variational’ family of approximate-inference techniques (Bishop, 2006). These techniques have inspired various cognitive models (Sanborn, 2017; Gallistel and Latham, 2022; Aridor and Woodford, 2023); alternatively, a bound on the divergence, known as the ‘evidence bound’, or, in neuroscience, as the negative of the ‘free energy’, is maximized (Moustafa, 2017; Friston et al., 2006; Friston, 2009). (We note that the ‘opposite’ divergence, , is minimized in a different machine-learning technique, ‘expectation propagation’ (Bishop, 2006), and in the cognitive model of causal reasoning of Icard and Goodman, 2015.) In these techniques, the approximate posterior is chosen within a convenient family of tractable, parameterized distributions; other distributions are precluded. This can be understood, in our framework, as positing a cost that is infinite for most distributions, but zero for the distributions that belong to some arbitrary family (Prat-Carrabin et al., 2021a). The precision cost and the unpredictability cost, in comparison, are ‘smooth’, and allow for any distribution, but they penalize, respectively, more precise belief distributions, and belief distributions that imply more unpredictable environments. Our study shows that inference, when subject to either of these costs, yields an attractive sequential effect of the most recent observation; and with a precision cost weighing on the inference of transition probabilities (i.e., ), the model predicts the subtle pattern of attractive and repulsive sequential effects that we find in subjects’ responses.
Methods
Task and subjects
The computer-based task was programmed using the Python library PsychoPy (Peirce, 2008). The experiment comprised ten blocks of trials, which differed by the stimulus generative probability, p, used in all the trials of each block. The probability p was chosen randomly among the ten values ranging from 0.50 to 0.95 by increments of 0.05, excluding the values already chosen; and with probability 1/2 the stimulus generative probability was used instead. Each block started with 200 passive trials, in which the subject was only asked to look at the 200 stimuli sampled with the block’s probability and successively presented. No action from the subject was required for these passive trials. The subject was then asked to predict, in each of 200 trials, the next location of the stimulus. Subjects provided their responses by a keypress. The task was presented as a game to the subjects: the stimulus was a lightning symbol, and predicting correctly whether the lightning would strike the left or the right rod resulted in the electrical energy of the lightning being collected in a battery (Figure 1). A gauge below the battery indicated the amount of energy accumulated in the current block of trials (Figure 1a). Twenty subjects (7 women, 13 men; age: 18–41, mean 25.5, standard deviation 6.2) participated in the experiment. All subjects completed the ten blocks of trials, except one subject who did not finish the experiment and was excluded from the analysis. The study was approved by the ethics committee Île de France VII (CPP 08–021). Participants gave their written consent prior to participating. The number of blocks of trials and the number of trials per block were chosen as a trade-off between maximizing the statistical power of the study, scanning the values of the generative probability parameter from 0.05 to 0.95 with a satisfying resolution, and maintaining the duration of the experiment under a reasonable length of time. The number of subjects was chosen consistently with similar studies and so as to capture individual variability. Throughout the study, we conduct Student’s t-tests when comparing the subjects’ proportion of predictions A to a given value (e.g. 0.5). When comparing two proportions of predictions A obtained under different conditions (e.g. depending on whether the preceding stimulus is A or B), we accordingly conduct Fisher exact tests. The trials in which subjects failed to respond within the limit of 1 s were not included in the analysis. They represented 1.27% of the trials, on average (across subjects); and for 95% of the subjects these trials represented less than 2.5% of the trials.
Sequential effects of the models
We run simulations of the eight models and look at the predictions they yield. To reproduce the conditions faced by the subjects, which included 200 passive trials, we start each simulation by showing to the model subject 200 randomly sampled stimuli (without collecting predictions at this stage). We then show an additional 200 samples, and obtain a prediction from the model subject after each sample. The sequential effects of the most recent stimulus, with the different models, are shown in Figure 7. With the precision-cost models, the posterior distribution of the model subject does not converge, but fluctuates instead with the recent history of the stimulus. This results in attractive sequential effects (Figure 7a), including for the Bernoulli observer, who assumes that the probability of A does not depend on the most recent stimulus. With the unpredictability-cost models, the posterior of the model subject does converge. With Markov observers, it converges toward a parameter vector that implies that the probability of observing A depends on the most recent stimulus, resulting in the presence of sequential effects of the most recent stimulus (Figure 7b, second to fourth row). With a Bernoulli observer, the posterior of the model subject converges toward a value of the stimulus generative probability that does not depend on the stimulus history. As more evidence is accumulated, the posterior narrows around this value but not without some fluctuations that depend on the sequence of stimuli presented. In consequence the model subject’s estimate of the stimulus generative probability is also subject to fluctuations, and depends on the history of stimuli (including the most recent stimulus), although the width of the fluctuations tend to zero as more stimuli are observed. After the 200 stimuli of the passive trials, the sequential effects of the most recent stimulus resulting from this transient regime appear small in comparison to the sequential effects obtained with the other models (Figure 7b, first row). The Figure 7 also shows the behaviors of the models when augmented with a propensity to repeat the preceding response: we comment on these in the section dedicated to these models, below.
Figure 7
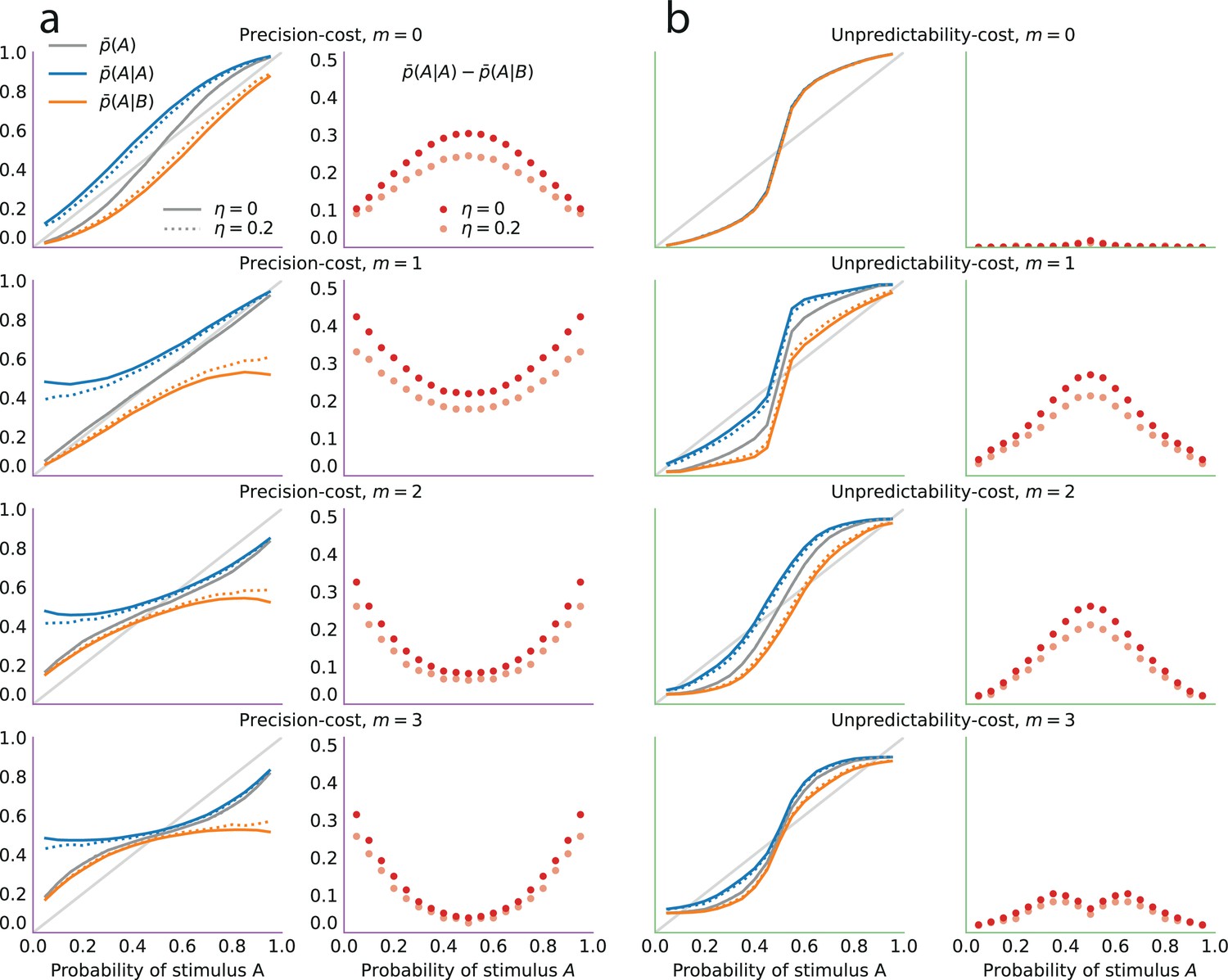
Sequential effects of the most recent stimulus in precision-cost and unpredictability-cost models.
(a) Precision-cost models. (b) Unpredictability-cost models. First row: Bernoulli observers (m = 0). Second to fourth rows: Markov observers (m = 1, 2, and 3). First column (each panel): proportion of predictions A in the models’ responses as a function of the stimulus generative probability, conditional on the preceding observation being A (blue line) or B (orange line), and unconditional (grey line); with repetition propensity (, dotted lines), and without (solid lines). Second column (each panel): difference between the proportion of predictions A conditional on the preceding observation being A, and the same proportion conditional on a B; with repetition propensity (dotted lines), and without (solid lines). A positive difference indicates an attractive sequential effect of the most recent stimulus.
Turning to higher-order sequential effects, we look at the influence on predictions of the second- and third-to-last stimulus (Figure 8). As mentioned, only precision-cost models of Markov observers yield repulsive sequential effects, and these occur only when the third-to-last-stimulus is followed by BA. They do not occur with the second-to-last stimulus, nor with the third-to-last-stimulus when it is followed by AA (Figure 8a); and they do not occur in any case with the unpredictability-cost models (Figure 8b).
Figure 8
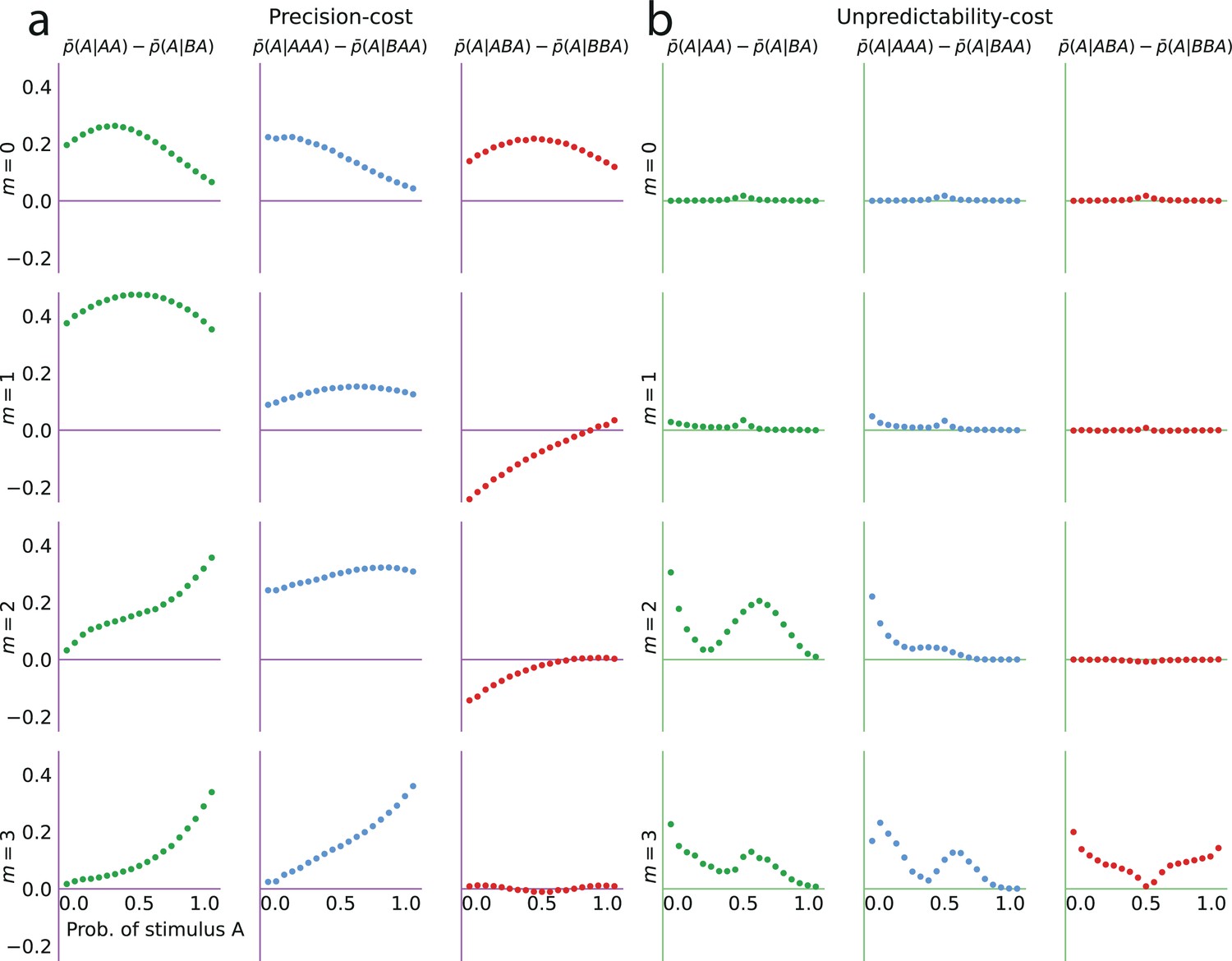
Sequential effects of the second- and third-to-last stimuli in precision-cost and unpredictability-cost models.
(a) Precision-cost models. (b) Unpredictability-cost models. First row: Bernoulli observers (m = 0). Second to fourth rows: Markov observers (m = 1, 2, and 3). First column (each panel): difference between the proportion of predictions A in the model subject’s responses, conditional on the two preceding observations being the sequence AA, and the same proportion conditional on the sequence BA. A positive difference indicates an attractive sequential effect of the second-to-last stimulus. Second column (each panel): difference between the proportion of predictions A in the model subject’s responses, conditional on the three preceding observations being the sequence AAA, and the same proportion conditional on the sequence BAA. Third column (each panel): difference between the proportion of predictions A in the model subject’s responses, conditional on the three preceding observations being the sequence ABA, and the same proportion conditional on the sequence BBA. The precision-cost models of Markov observers are the only models that yield a negative difference, i.e., a repulsive sequential effect of the third-to-last stimulus, in this case.
Derivation of the approximate posteriors
We derive the solution to the constrained optimization problem, in the general case of a ‘hybrid’ model subject who bears both a precision cost, with weight , and an unpredictability cost, with weight . Thus the subject minimizes the loss function
(9)
in which we have included a Lagrange multiplier, μ, corresponding to the normalization constraint, . Taking the functional derivative of and setting to zero, we obtain
(10)
and thus we write the approximate posterior as
(11)
where is the Bayesian update of the preceding belief, , i.e.,
(12)
Setting the weight of the unpredictability cost to zero (i.e., ), we obtain the posterior in presence of the precision cost only, as
(13)
The main text provides more details about the posterior in this case (Equation 4), in particular with a Bernoulli observer (; Equation 5, Equation 6).
For the hybrid model (in which both and are potentially different from zero), we obtain
(14)
With , the sum in the exponential is equal to , and the precision-cost posterior, , is the Bayesian posterior, , and thus we obtain the posterior in presence of the unpredictability cost only (see Equation 8).
Hybrid models
The hybrid model, described above, features both a precision cost and an unpredictability cost, with respective weights and . As with the models that include only one type of cost, we consider a Bernoulli observer (), and three Markov observers ( and 3). As for the response-selection strategy, we use, here also, the generalized probability-matching strategy parameterized by . We thus obtain four new models; each one has three parameters (, , and ), while the non-hybrid models (featuring only one type of cost) have only two parameters.
We fit these models to the responses of subjects. For 68% of subjects, the BIC of the best-fitting hybrid model is larger than the BIC of the best-fitting non-hybrid model, indicating a worse fit, by this measure. This suggests that for these subjects, allowing for a second type of cost result in a modest improvement of the fit that does not justify the additional parameter. For the remaining 32% of subjects, the hybrid models yield a better fit (a lower BIC) than the non-hybrid models, although for half of these, the difference in BICs is lower than 6, which is only weak evidence in favor of the hybrid models.
Moreover, we compute the exceedance probability, defined below in the section ‘Bayesian Model Selection’, of the hybrid models (together with the complementary probability of the non-hybrid models). We find that the exceedance probability of the hybrid models is 8.1% while that of the non-hybrid models is 91.9%, suggesting that subjects best-fitted by non-hybrid models are more prevalent.
In summary, we find that for more than two thirds of subjects, allowing for a second cost type does not improve much the fit to the behavioral data (the BIC is higher with the best-fitting hybrid model). These subjects are best-fitted by non-hybrid models, that is, by models featuring only one type of cost, instead of ‘falling in between’ the two cost types. This suggests that for most subjects, only one of the two costs, either the prediction cost or the unpredictability cost, dominates the inference process.
Alternative response-selection strategy, and repetition or alternation propensity
In addition to the generalized probability-matching response-selection strategy presented in the main text, in our investigations we also implement several other response-selection strategies. First, a strategy based on a ‘softmax’ function that smoothes the optimal decision rule; it does not yield, however, a behavior substantially different from that of the generalized probability-matching response-selection strategy. Second, we examine a strategy in which the model subject chooses the optimal response with a probability that is fixed across conditions, which we fit onto subjects’ choices. No subject is best-fitted by this strategy. Third, another possible strategy proposed in the game-theory literature (Nowak and Sigmund, 1993) is ‘win-stay, lose-shift’: it prescribes to repeat the same response as long as it proves correct and to change otherwise. In the context of our binary-choice prediction task, it is indistinguishable from a strategy in which the model subject chooses a prediction equal to the outcome that last occurred. This strategy is a special case of our Bernoulli observer hampered by a precision cost whose weight is large combined with the optimal response-selection strategy (). Since the generalized probability-matching strategy parameterized by the exponent appears either more general, better than or indistinguishable from those other response-selection strategies, we selected it to obtain the results presented in the main text.
Furthermore, we consider the possibility that subjects may have a tendency to repeat their preceding response, or, conversely, to alternate and choose the other response, independently from their inference of the stimulus statistics. Specifically, we examine a generalization of the response-selection strategy, in which a parameter , with , modulates the probability of a repetition or of an alternation. With probability , the model subject chooses a response with the generalized probability-matching response-selection strategy, with parameter . With probability , the model subject repeats the preceding response, if is positive; or chooses the opposite of the preceding response, if is negative. With , there is no propensity for repetition nor alternation, and the response-selection strategy is the same as the one we have considered in the main text. We have allowed for alternations () in this model for the sake of generality, but for all the subjects the best-fitting value of is non-negative, thus henceforth we only consider the possibility of repetitions, i.e., non-negative values of the parameter ().
We note that with a repetition probability , such that , the unconditional probability of a prediction A, which we denote by , is not different from the unconditional probability of a prediction A in the absence of a repetition probability , , as in the event of a repetition, the response that is repeated is itself A with probability ; formally, , which implies the equality .
Now turning to sequential effects, we note that with a repetition probability , the probability of a prediction conditional on an observation A is
(15)
In other words, when introducing the repetition probability , the resulting probability of a prediction A conditional on observing A is a weighted mean of the unconditional probability of a prediction A and of the conditional probability of a prediction A in the absence of a repetition probability. Figure 7 (dotted lines) illustrates this for the eight models, with . Consequently the sequential effects with this response-selection strategy are more modest (Figure 7, light-red dots).
We fit (by maximizing their likelihoods) our eight models now equipped with a propensity for repetition (or alternation) parameterized by . The average best-fitting value of , across subjects, is 0.21 (standard deviation: 0.19; median: 0.18); as mentioned, no subjects have a negative best-fitting value of . In order to assess the degree to which the models with repetition propensity are able to capture subjects’ data, in comparison with the models without such propensity, we use the Bayesian Information Criterion (BIC) (Schwarz, 1978), which penalizes the number of parameters, as a comparative metric (a lower BIC is better). For 26% of subjects, the BIC with this response-selection strategy (allowing for ) is higher than with the original response-selection strategy (which sets ,) suggesting that the responses of these subjects do not warrant the introduction of a repetition (or alternation) propensity. In addition, for these subjects the best-fitting inference model, characterized by a cost type and a Markov order, is the same when the response-selection strategy allows for repetition or alternation () and when it does not (). For 47% of subjects, the BIC is lower when including the parameter (suggesting that allowing for results in a better fit to the data), and importantly, here also the best-fitting inference model (cost type and Markov order) is the same with and with . For 11% of subjects, a better fit (lower BIC) is obtained with ; and the best-fitting inference models, with and with , belong to the same family of models, that is, they have the same cost type (precision cost or unpredictability cost), and only their Markov orders differ. Finally, only for the remaining 16% does the cost type change when allowing for . In other words, for 84% of subjects the best-fitting cost type is the same whether or not is allowed to differ from 0.
Furthermore, the best-fitting parameters and are also stable across these two cases. Among the 73% of subjects whose best-fitting inference model (including both cost type and Markov order) remains the same regardless of the presence of a repetition propensity, we find that the best-fitting values of , with and with , differ by less than 10% for 93% of subjects, and the best-fitting values of differ by less than 10% for 71% of subjects. For these two parameters, the correlation coefficient (between the best-fitting value with and the best-fitting value with ) is above 0.99 (with p-values lower than 1e-19).
The responses of a majority of subjects are thus better reproduced by a response-selection strategy that includes a probability of repeating the preceding response. The impact of this repetition propensity on sequential effects is relatively small in comparison to the magnitude of these effects (Figure 7). For most subjects, moreover, the best-fitting inference model, characterized by its cost type and its Markov order, is the same — with or without repetition propensity —, and the best-fitting parameters and are very close in the two cases. Therefore, this analysis supports the results of the model-fitting and model-selection procedure, and validates its robustness. We conclude that the models of costly inference are essential in reproducing the behavioral data, notwithstanding a positive repetition propensity in a fraction of subjects.
Computation of the models’ likelihoods
Model fitting is conducted by maximizing for each model the likelihood of the subject’s choices. With the precision-cost models, the likelihood can be derived analytically and thus easily computed: the model’s posterior is a Dirichlet distribution of order , whose parameters are exponentially filtered counts of the observed sequences of length . With a Bernoulli observer, i.e., , this is the Beta distribution presented in Equation 5. The expected probability of a stimulus A, conditional on the sequence of stimuli most recently observed, is a simple ratio involving the exponentially filtered counts, for example in the case of a Bernoulli observer. This probability is then raised to the power and normalized (as prescribed by the generalized probability-matching response-selection strategy) in order to obtain the probability of a prediction A.
As for the unpredictability-cost models, the posterior is given in Equation 8 up to a normalization constant. Unfortunately, the expected probability of a stimulus A implied by this posterior does not come in a closed-form expression. Thus we compute the (unnormalized) posterior on a discretized grid of values of the vector . The dimension of the vector is , and each element of is in the segment . If we discretize each dimension into bins, we obtain different possible values of the vector ; for each of these, at each trial, we compute the unnormalized value of the posterior (as given by Equation 8). As increases, this becomes computationally prohibitive: for instance, with bins and , the multidimensional grid of values of contains 1016 numbers (with a typical computer, this would represent 80,000 terabytes). In order to keep the needed computational resources within reasonable limits, we choose a lower resolution of the grid for larger values of . Specifically, for we choose a grid (over ) with increments of 0.01; for , increments of 0.02 (in each dimension); for , increments of 0.05; and for , increments of 0.1. We then compute the mean of the discretized posterior and pass it through the generalized probability-matching response-selection model to obtain the choice probability.
To find the best-fitting parameters and , the likelihood was maximized with the L-BFGS-B algorithm (Byrd et al., 1995; Zhu et al., 1997). These computations were run using Python and the libraries Numpy and Scipy (Harris et al., 2020; Virtanen et al., 2020).
Symmetries and relations between conditional probabilities
Throughout the paper, we leverage the symmetry inherent to the Bernoulli prediction task to present results in a condensed manner. Specifically, in our analysis, the proportion of predictions A when the probability of A (the stimulus generative probability) is , which we denote here by , is equal to the proportion of predictions B when the probability of A is , which we denote by ; i.e., . More generally, the predictions conditional on a given sequence when the probability of A is are equal to the predictions conditional on the ‘mirror’ sequence (in which A and B have been swapped), when the probability of A is , for example extending our notation, . Here, we show how this results in the symmetries in Figure 2, and in the fact that in Figures 5 and 6, it suffices to plot the sequential effects obtained with only a fraction of all the possible sequences of two or three stimuli.
First, we note that
(16)
which implies the symmetry of in Figure 2a (grey line). Turning to conditional probabilities (and thus sequential effects), we have
(17)
As a result, the lines representing (blue) and (orange) in Figure 2a are reflections of each other. In addition, these equations result in the equality
(18)
which implies the symmetry in Figure 2b.
As for the sequential effect of the second-to-last stimulus, we show in Figures 5a and 6a the difference in the proportions of predictions A conditional on two past sequences of two stimuli, AA and BA; i.e., . There are two other possible sequences of two stimuli: and . The difference in the proportions conditional on these two sequences is implied by the former difference, as:
(19)
As for the sequential effect of the third-to-last stimulus, we show in Figures 5b and 6b the difference in the proportions conditional on the sequences AAA and BAA, and in Figures 5c and 6c the difference in the proportions conditional on the sequences ABA and BBA. The differences in the proportions conditional on the sequences AAB and BAB, and conditional on the sequences ABB and BBB, are recovered as a function of the former two, as
(20)
Bayesian model selection
We implement the Bayesian model selection (BMS) procedure described in Stephan et al., 2009. Given models, this procedure aims at deriving a probabilistic belief on the distribution of these models among the general population. This unknown distribution is a categorical distribution, parameterized by the probabilities of the models, denoted by , with . With a finite sample of data, one cannot determine with infinite precision the values of the probabilities . The BMS, thus, computes an approximation of the Bayesian posterior over the vector , as a Dirichlet distribution parameterized by the vector , i.e., the posterior distribution
(21)
Computing the parameters of this posterior makes use of the log-evidence of each model for each subject, i.e., the logarithm of the joint probability, , of a given subject’s responses, , under the assumption that a given model, , generated the responses. We use the model’s maximum likelihood to obtain an approximation of the model’s log-evidence, as (Balasubramanian, 1997)
(22)
where denotes the parameters of the model, is the likelihood of the model when parameterized with , is the dimension of , and is the size of the data, that is, the number of responses. (The well-known Bayesian Information Criterion Schwarz, 1978 is equal to this approximation of the model’s log-evidence, multiplied by .)
In our case, there are models, each with parameters: . The posterior distribution over the parameters of the categorical distribution of models in the general population, , allows for the derivation of several quantities of interest; following Stephan et al., 2009, we derive two types of quantities. First, given a family of models, that is, a set of different models (for instance, the prediction-cost models, or the Bernoulli-observer models), the expected probability of this class of model, that is, the expected probability that the behavior of a subject randomly chosen in the general population follows a model belonging to this class, is the ratio
(23)
We compute the expected probability of the precision-cost models (and the complementary probability of the unpredictability-cost models), and the expected probability of the Bernoulli-observer models (and the complementary probability of the Markov-observer models; see Results).
Second, we estimate, for each family of models , the probability that it is the most likely, i.e., the probability of the inequality
(24)
which is called the ‘exceedance probability’. We compute an estimate of this probability by sampling one million times the Dirichlet belief distribution (Equation 21), and counting the number of samples in which the inequality is verified. We estimate in this way the exceedance probability of the precision-cost models (and the complementary probability of the unpredictability-cost models), and the exceedance probability of the Bernoulli-observer models (and the complementary probability of the Markov-observer models; see Results).
Unpredictability cost for Markov observers
Here we derive the expression of the unpredictability cost for Markov observers as a function of the elements of the parameter vector . For an observer of Markov order 1 (), the vector has two elements, which are the probability of observing A at a given trial conditional on the preceding outcome being A, and the probability of observing A at a given trial conditional on the preceding outcome being B, which we denote by and , respectively. The Shannon entropy, , implied by the vector , is the average of the conditional entropies implied by each conditional probability, i.e.,
(25)
where and are the unconditional probabilities of observing A and B, respectively (see below), and
(26)
where is A or B.
The unconditional probabilities and are functions of the conditional probabilities and . Indeed, at trial , the marginal probability of the event , , is a weighted average of the probabilities of this event conditional on the preceding stimulus, , as given by the law of total probability:
(27)
i.e.
(28)
Solving for , we find:
(29)
The entropy implied by the vector is obtained by substituting these quantities in Equation 25.
Similarly, for and 3, the elements of the vector are the parameters and , respectively, where , and where is the probability of observing A at a given trial conditional on the two preceding outcomes being the sequence ‘’, and is the probability of observing A at a given trial conditional on the three preceding outcomes being the sequence ‘’. The Shannon entropy, , implied by the vector , is here also the average of the conditional entropies implied by each conditional probability, as
(30)
(31)
where and are the unconditional probabilities of observing the sequence ‘’, and of observing the sequence ‘’, respectively. These unconditional probabilities verify a system of linear equations whose coefficients are given by the conditional probabilities. For instance, for , we have the relation
(32)
i.e.,
(33)
The system of linear equations can be written as
(34)
The solution is the eigenvector corresponding to the eigenvalue equal to 1 of the matrix in the equation above, with the additional constraint that the unconditional probabilities must sum to 1, i.e., . We find:
For , we find the relations:
Together with the normalization constraint , these relations allow determining the eight unconditional probabilities , and thus the expression of the Shannon entropy.
Appendix 1
Stability of subjects’ behavior throughout the experiment
Appendix 1—figure 1
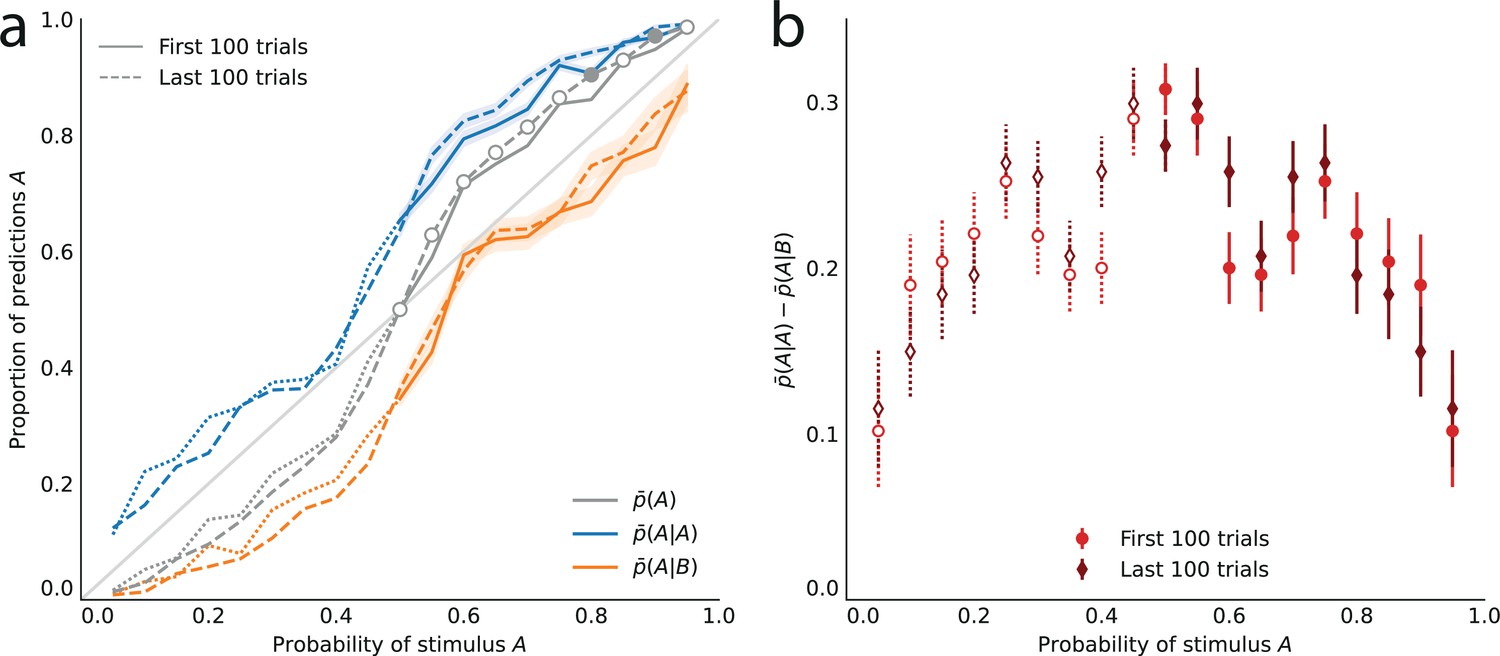
Subjects’ behavior in the first and second halves of the task.
(a) Proportion of predictions A as a function of the stimulus generative probability, conditional on observing A (blue lines) or B (orange lines), and unconditional (grey lines), in the first half of the experiment (solid lines) and in the second half (dashed lines). Filled circles indicate p-values of Fisher’s exact test (of the equality of the proportions in the first and second halves, with Bonferroni-Holm-Šidák correction) below .05. (b) Difference between the proportions of predictions A conditional on an A, and conditional on a B, in the first half of the experiment (red circles), and in the second half (dark-red diamonds). The p-values of Fisher’s exact tests (of equality of the conditional proportions, i.e., ), with Bonferroni-Holm-Šidák correction, are all below 1e-6. Bars indicate the standard error of the mean.
To validate the assumption that we capture, in our experiment, the ‘stationary’ behavior of subjects, we compare their responses in the first half of the task (first 100 trials) to their responses in the second half (last 100 trials). We find that the unconditional proportions of prediction A in these two cases are not significantly different, for most values of the stimulus generative probability. The sign of the difference (regardless of its statistical significance) implies that the proportions of predictions A in the second half of the experiment are slightly closer to 1 when the probability of the stimulus A is greater than 0.5; which would mean that the responses of subjects are slightly closer to optimality, in the second half of the experiment (Appendix 1—figure 1a, grey lines). Regarding the sequential effects, we also obtain very similar behaviors in the first and second halves of the experiment (Appendix 1—figure 1). We conclude that for our analysis it is reasonable to assume that the behavior of subjects is stationary throughout the task.
Robustness of the model fitting
To evaluate the ability of the model-fitting procedure to correctly identify the model that generated a given set of responses, we compute a confusion matrix of the eight models. For each model, we simulate 200 runs of the task (each with 200 passive trials followed by 200 trials in which a prediction is obtained), with values of and close to values typically obtained when fitting the subjects’ responses (for prediction-cost models, ; for unpredictability-cost models, ; and for both families of models). We then fit each of the eight models to each of these simulated datasets, and count how many times each model best fit each dataset (Appendix 1—figure 2a). To further test the robustness of the model-fitting procedure, we randomly introduce errors in the simulated responses: for 10% of the responses, randomly chosen in each dataset, we substitute the response by its opposite (i.e., B for A, and A for B), and compute a confusion matrix using these new responses (Appendix 1—figure 2b). In both cases, the model-fitting procedure identifies the correct model a majority of times (i.e., the best-fitting model is the model that generated the data; Appendix 1—figure 2).
Finally, to examine the robustness of the weight of the cost, , we consider for each subject its best-fitting model in each family (the precision-cost family and the unpredictability-cost family), and we fit separately each model to the subject’s responses obtained in trials in which the stimulus generative probability was medium () and those in which it was extreme (). The Appendix 1—figure 3 shows the correlation between the best-fitting parameters obtained in these two cases.
Appendix 1—figure 2
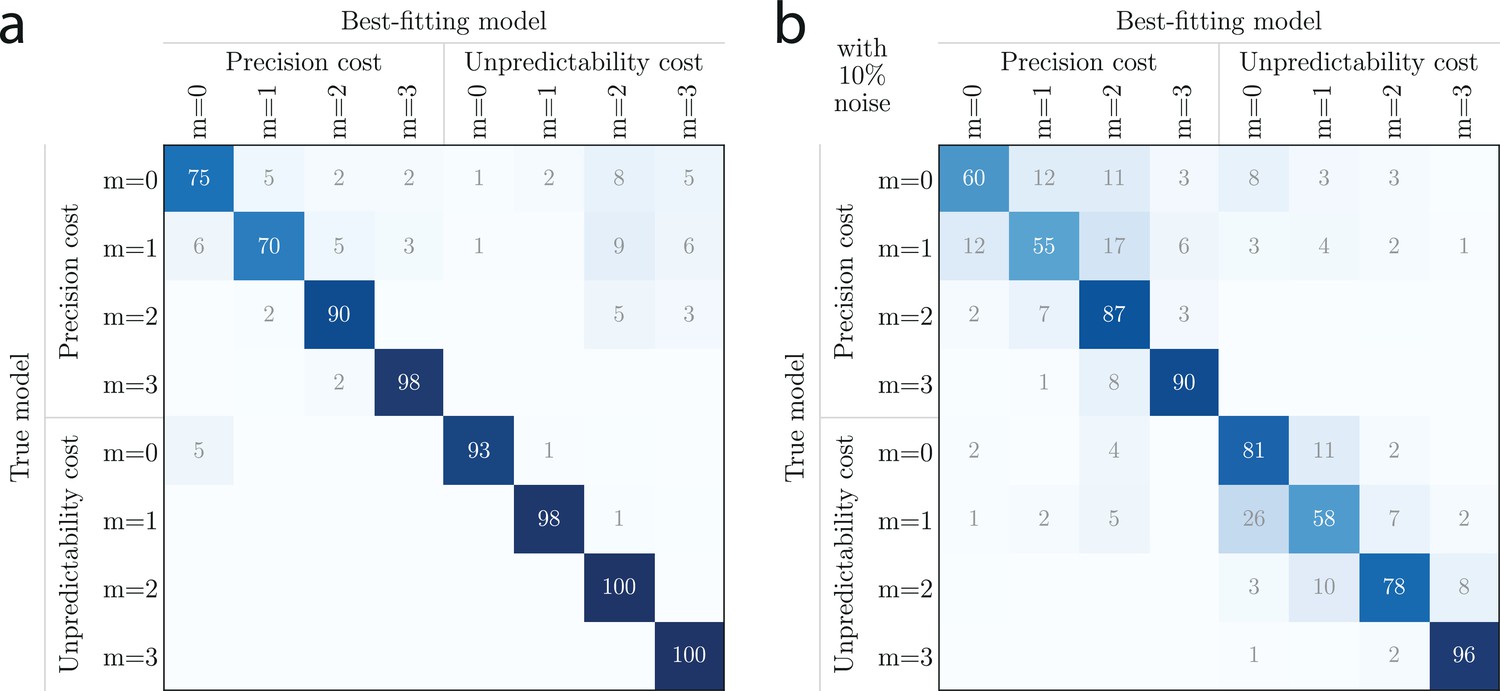
Model-fitting confusion matrix.
(a) For each row models (‘true model’), percentage of simulated datasets of 200 responses that were best fitted by column models (‘best-fitting model’). Example: when fitting data generated by the precision-cost model with , the best-fitting model was the correct model on 98% of the fits, and the precision-cost model with on 2% of the fits. (b) Same as (a), with 10% of responses (randomly chosen in each simulated dataset) replaced by the opposite responses.
Appendix 1—figure 3
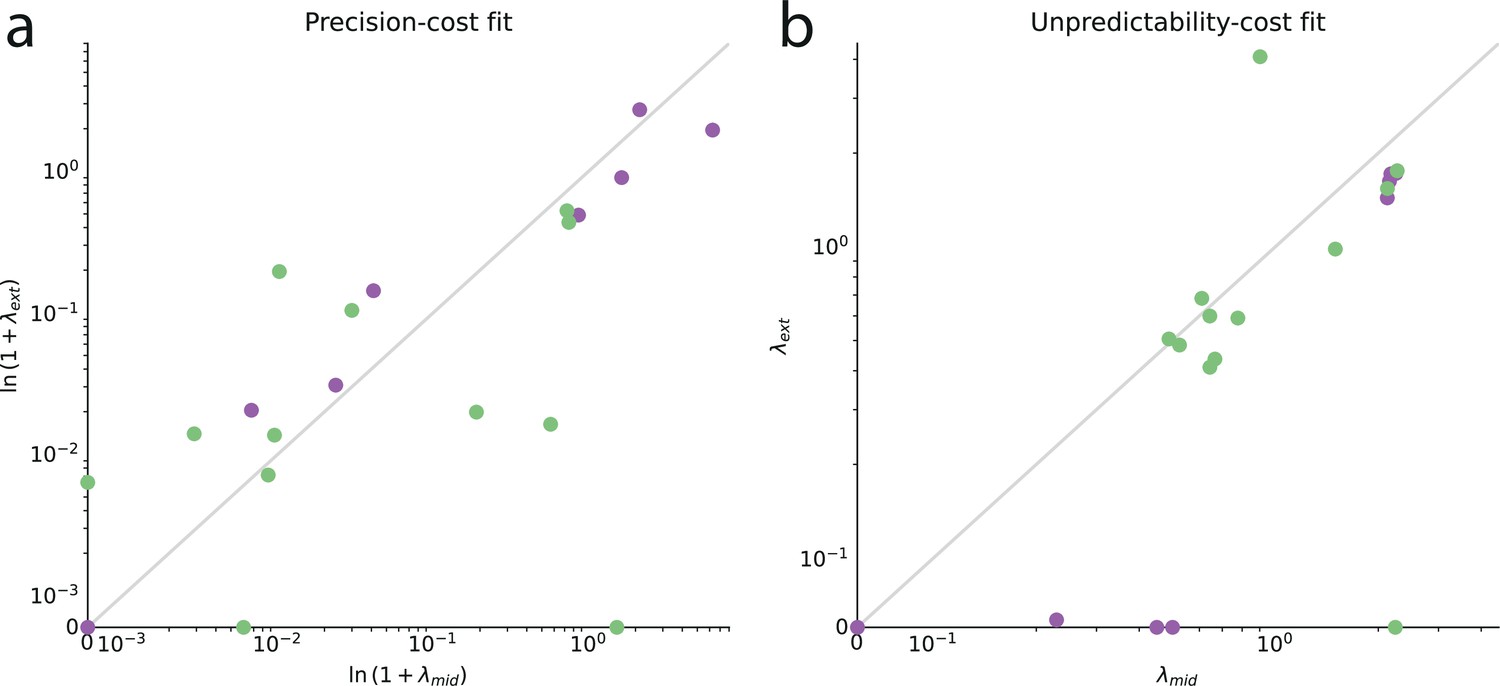
Stability of the cost-weight parameter across medium and extreme values of the stimulus generative probability.
Best-fitting parameters of individual subjects when fitting the data obtained in trials with extreme values of the stimulus generative probability (i.e., or in ), plotted against the best-fitting parameters when fitting the data obtained in trials with medium values of the stimulus generative probability (i.e., or in ), with (a) precision-cost models, and (b) unpredictability-cost models. Purple dots: subjects best-fitted by prediction-cost models. Green dots: subjects best-fitted by unpredictability-cost models. The plots are in log-log scale, except below (a) and (b), where the scale is linear (allowing in particular for the value 0 to be plotted.) For the precision-cost models, we plot the inverse of the characteristic decay time, . The grey line shows the identity function.
Distribution of subjects’ BICs
Appendix 1—figure 4
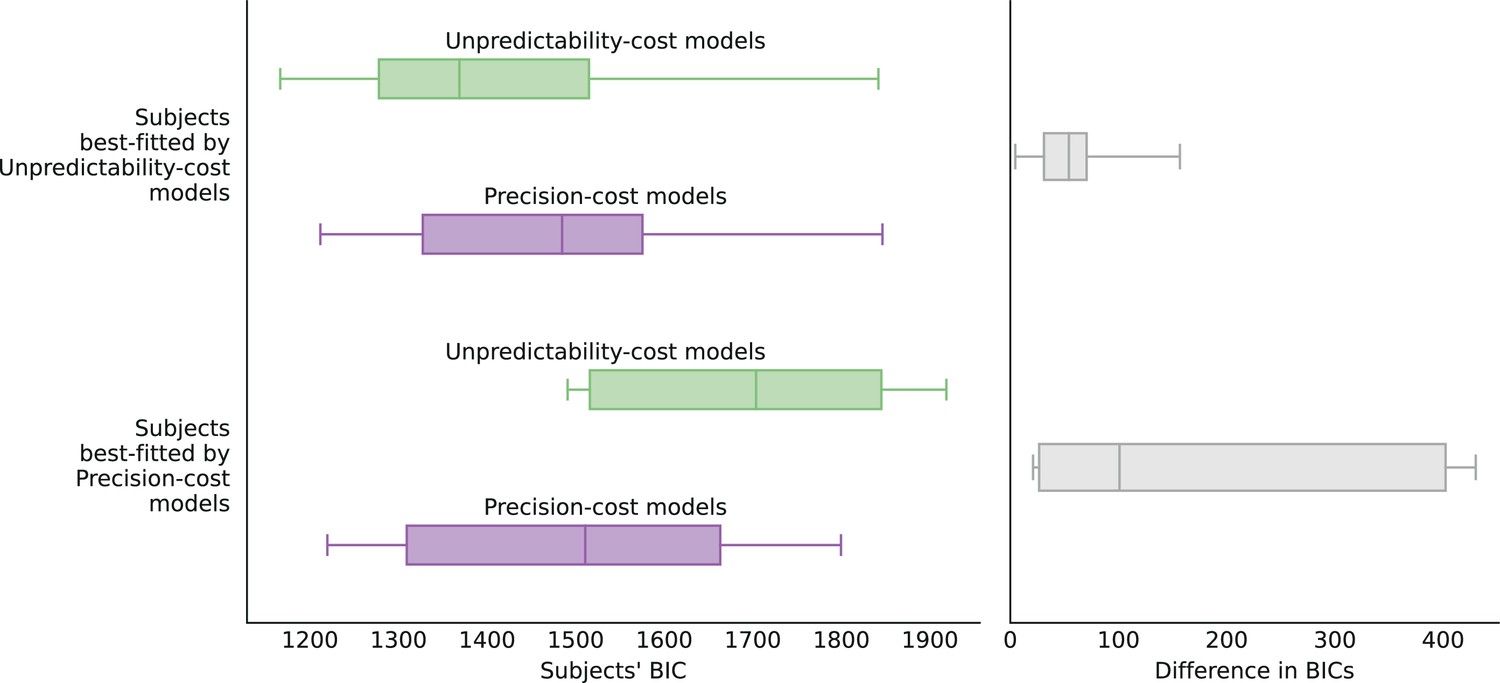
Distribution of subjects’ BICs.
(Left) Box-and-whisker plots showing the 5th and 95th percentiles (whiskers), the first and third quartiles (box), and the median (vertical line) of the BICs (across subjects) of the unpredictability-cost models (green boxes) and of the precision-cost models (purple boxes), fitted on the subjects best-fitted by the unpredictability-cost models (first two rows) and on the subjects best-fitted by the precision-cost models (last two rows). (Right) Box-and-whisker plots (same quantiles) showing the distribution of the difference, for each subject, between the BIC of the best model in the family that does not best fit the subject, and the BIC of the best-fitting model; for the subjects best-fitted by the unpredictability-cost models (top box) and for the subjects best-fitted by the precision-cost models (bottom box). The unpredictability-cost models, when fitted to the responses of the subjects best-fitted by the precision-cost models (bottom box), yield larger differences in the BIC with the best-fitting models, than the precision-cost models when fitted to the responses of the subjects best-fitted by the unpredictability-cost models (top box). This suggests that the precision-cost models are better than the unpredictability-cost models at capturing the responses of the subjects that they do not best fit.
Subjects’ sequential effects — tree representation
Appendix 1—figure 5
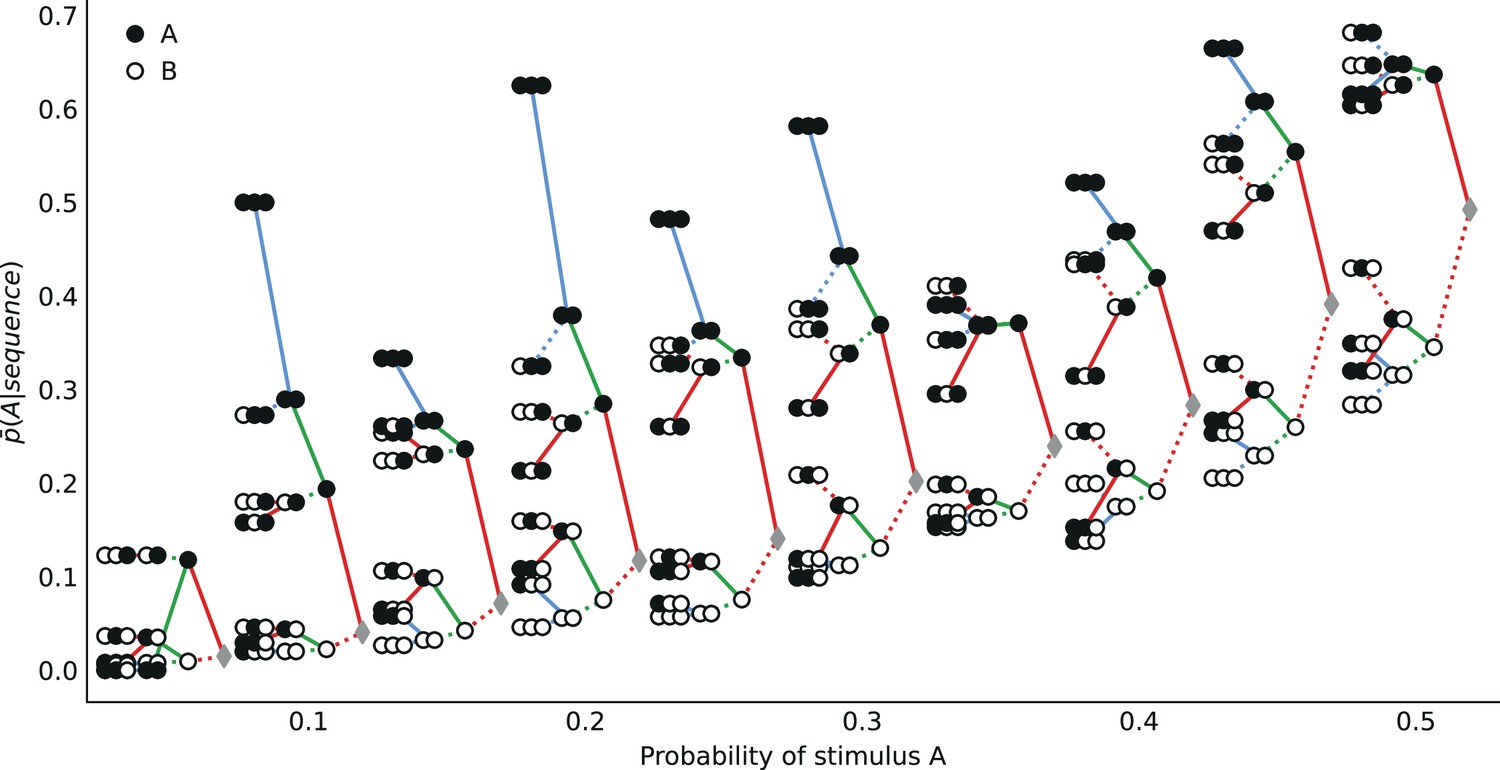
Composition of sequential effects in subjects’ responses.
Proportion of predictions A conditional on sequences of up to three past observations, as a function of the stimulus generative probability. See Figure 6d.
Subjects’ sequential effects — unpooled data
As mentioned in the main text, we pool together the predictions that correspond, in different blocks of trials, to either event (left or right), as long as these events have the same probability. The Appendix 1—figure 6, below, is the same as Figure 2, but without such pooling. Given a stimulus generative probability, , all the subjects experience one (and only one) block of trials in which either the event ‘right’ or the event ‘left’ had probability . For one group of subjects the ‘right’ event has probability and for the group of remaining subjects it is the ‘left’ event that has probability . The responses of these subjects are not pooled together in Appendix 1—figure 6, while they were in Figure 2. This also applies for any other stimulus generative probability, . However, we note that the two groups of subjects for whom was the probability of a ‘right’ event or a ‘left’ event are not the same as the two groups just mentioned in the case of the probability . As a result, from one proportion shown in Appendix 1—figure 6 to another, the underlying group of subjects changes. In Figure 2, each proportion is computed with the responses of all the subjects. This illustrates another advantage of the pooling that we use in the main text.
Appendix 1—figure 6
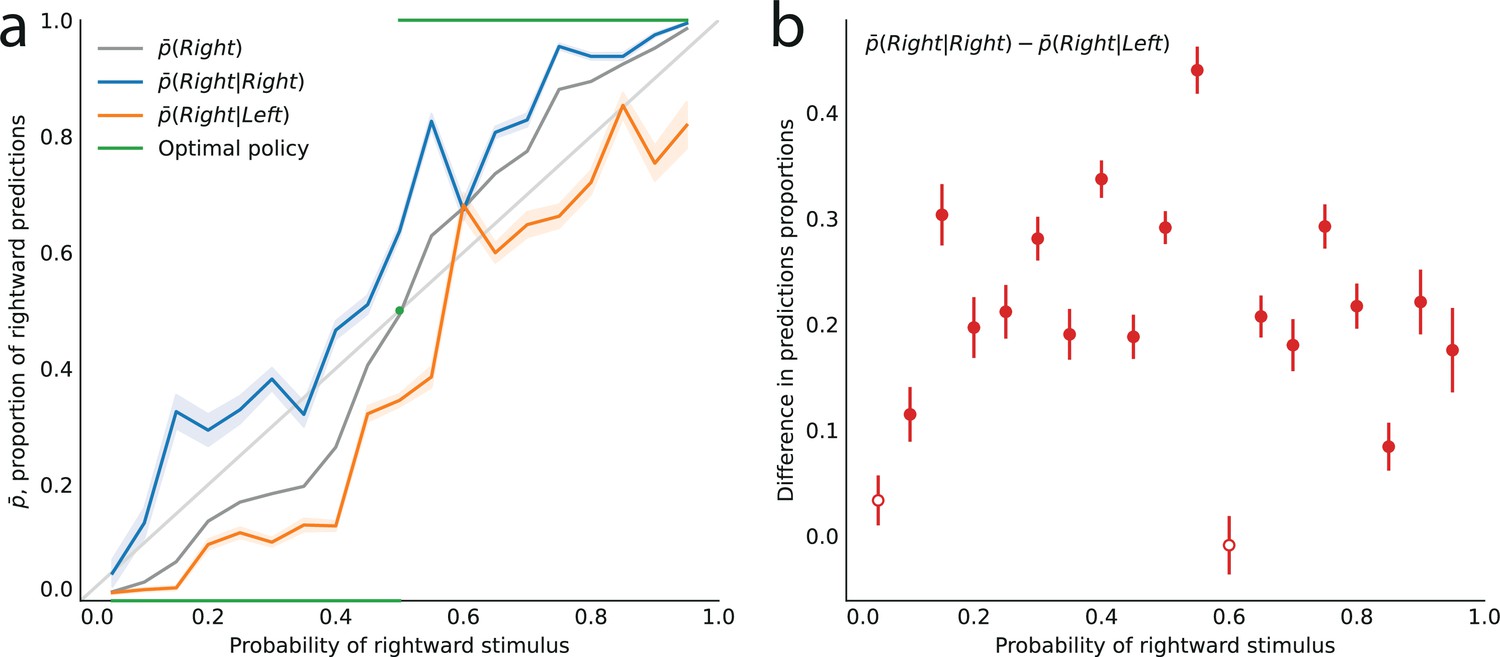
Sequential effects in subjects’ responses.
As Figure 2, but without pooling together the rightward and leftward predictions from different block of trials in which the corresponding stimuli have the same probability. See main text.
Subjects’ response times
Appendix 1—figure 7
Subjects’ response times.
Average response times conditional on having observed a stimulus A (blue line), a stimulus B (orange line), and unconditional (grey line), as a function of the stimulus generative probability. The stars indicate that the p-values below 0.05 of the -tests of equality between the response times after an A and after a B. The subjects seem slower after observing the less frequent stimulus (e.g., B, when ).
Across-subjects results
Appendix 1—figure 8
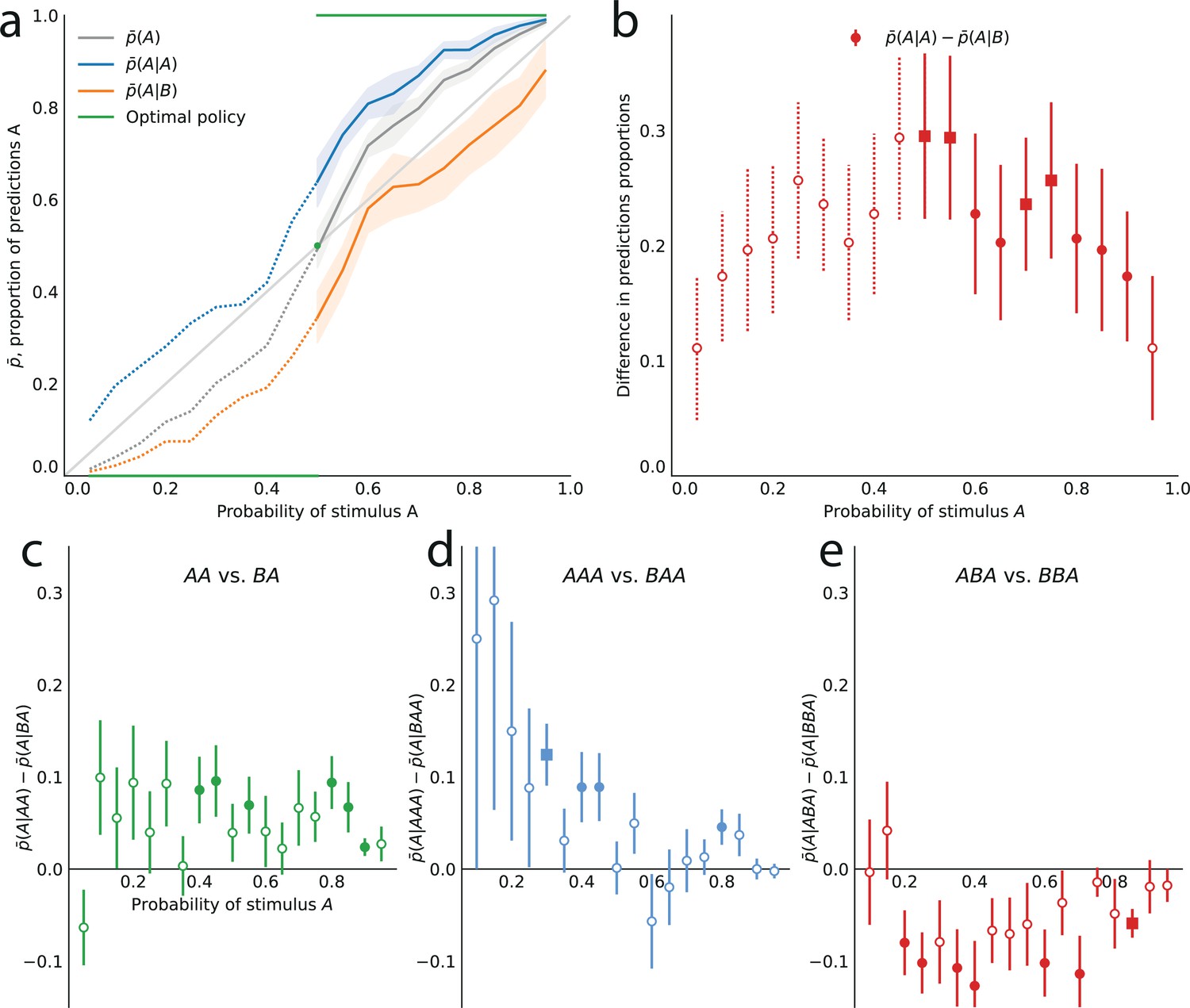
Subjects’ sequential effects — across-subjects analysis.
The statistics used for this figure are obtained by computing first the proportions of predictions A for each subject, and then computing the across-subject averages and standard errors of the mean (instead of pooling together the responses of all the subjects). (a,b) As in Figure 2, with across-subjects statistics. (c,d,e) As in Figure 6a, b and c, with across-subjects statistics. The filled circles indicate that the p-value of the Student’s t-test is below 0.05, and the filled squares indicate that the p-value with Bonferroni-Holm-Šidák correction is below 0.05.
Data availability
The behavioral data for this study and the computer code used for data analysis are freely and publicly available through the Open Science Framework repository at https://doi.org/10.17605/OSF.IO/BS5CY.
-
Open Science FrameworkResource-Rational Account of Sequential Effects in Human Prediction: Data & Code.https://doi.org/10.17605/OSF.IO/BS5CY
References
-
On the origins of suboptimality in human probabilistic inferencePLOS Computational Biology 10:e1003661.https://doi.org/10.1371/journal.pcbi.1003661
-
Stimulus predictability reduces responses in primary visual cortexThe Journal of Neuroscience 30:2960–2966.https://doi.org/10.1523/JNEUROSCI.3730-10.2010
-
Some informational aspects of visual perceptionPsychological Review 61:183–193.https://doi.org/10.1037/h0054663
-
The hot hand fallacy and the gambler’s fallacy: two faces of subjective randomness?Memory & Cognition 32:1369–1378.https://doi.org/10.3758/bf03206327
-
Noisy memory and over-reaction to newsAEA Papers and Proceedings 109:557–561.https://doi.org/10.1257/pandp.20191049
-
BookOptimally Imprecise Memory and Biased ForecastsNational Bureau of Economic Research.https://doi.org/10.2139/ssrn.3731244
-
Statistical inference, occam’s razor, and statistical mechanicsNeural Computation 368:349–368.https://doi.org/10.1162/neco.1997.9.2.349
-
Twenty years of “hot hand” research: Review and critiquePsychology of Sport and Exercise 7:525–553.https://doi.org/10.1016/j.psychsport.2006.03.001
-
BookPossible principles underlying the transformations of sensory messagesIn: Rosenblith Walter A, editors. Sensory Communication, Chapter 13. Cambridge, MA: The MIT Press. pp. 217–234.
-
How haptic size sensations improve distance perceptionPLOS Computational Biology 7:e1002080.https://doi.org/10.1371/journal.pcbi.1002080
-
Learning the value of information in an uncertain worldNature Neuroscience 10:1214–1221.https://doi.org/10.1038/nn1954
-
BookErrors in probabilistic reasoning and judgment biasesIn: Benjamin DJ, editors. Handbook of Behavioral Economics. Elsevier B.V. pp. 69–186.
-
Randomness and inductions from streaks: “gambler’s fallacy” versus “hot hand.”Psychonomic Bulletin & Review 11:179–184.https://doi.org/10.3758/bf03206480
-
A limited memory algorithm for bound constrained optimizationSIAM Journal on Scientific Computing 16:1190–1208.https://doi.org/10.1137/0916069
-
Rational inattention, optimal consideration sets, and stochastic choiceThe Review of Economic Studies 86:1061–1094.https://doi.org/10.1093/restud/rdy037
-
Mechanisms underlying dependencies of performance on stimulus history in a two-alternative forced-choice taskCognitive, Affective & Behavioral Neuroscience 2:283–299.https://doi.org/10.3758/cabn.2.4.283
-
Predictive properties of visual adaptationCurrent Biology 22:622–626.https://doi.org/10.1016/j.cub.2012.02.021
-
Momentary and integrative response strategies in causal judgmentMemory & Cognition 30:1138–1147.https://doi.org/10.3758/bf03194331
-
Dynamics of neuronal responses in macaque MT and VIP during motion detectionNature Neuroscience 5:985–994.https://doi.org/10.1038/nn924
-
The Gambler’s fallacy and the hot hand: empirical data from casinosJournal of Risk and Uncertainty 30:195–209.https://doi.org/10.1007/s11166-005-1153-2
-
Efficient computation and cue integration with noisy population codesNature Neuroscience 4:826–831.https://doi.org/10.1038/90541
-
A dual role for prediction error in associative learningCerebral Cortex 19:1175–1185.https://doi.org/10.1093/cercor/bhn161
-
BookMemory: A Contribution to Experimental PsychologyTeachers College Press.https://doi.org/10.1037/10011-000
-
Reward probability, amount, and information as determiners of sequential two-alternative decisionsJournal of Experimental Psychology 52:177–188.https://doi.org/10.1037/h0047727
-
Probability learning in 1000 trialsJournal of Experimental Psychology 62:385–394.https://doi.org/10.1037/h0041970
-
A free energy principle for the brainJournal of Physiology, Paris 100:70–87.https://doi.org/10.1016/j.jphysparis.2006.10.001
-
The free-energy principle: a rough guide to the brain?Trends in Cognitive Sciences 13:293–301.https://doi.org/10.1016/j.tics.2009.04.005
-
Efficient sensory encoding and bayesian inference with heterogeneous neural populationsNeural Computation 26:2103–2134.https://doi.org/10.1162/NECO_a_00638
-
Reasoning the fast and frugal way: Models of bounded rationalityPsychological Review 103:650–669.https://doi.org/10.1037/0033-295X.103.4.650
-
Bounded Rationality: The Adaptive ToolboxBounded rationality, Bounded Rationality: The Adaptive Toolbox, MIT Press, 10.7551/mitpress/1654.001.0001.
-
The hot hand in basketball: On the misperception of random sequencesCognitive Psychology 17:295–314.https://doi.org/10.1016/0010-0285(85)90010-6
-
ConferenceSequential effects in predictionProceedings of the Annual Conference of the Cognitive Science Society. pp. 397–402.
-
Bayes rule as a descriptive model: the representativeness heuristicThe Quarterly Journal of Economics 95:537.https://doi.org/10.2307/1885092
-
Rational use of cognitive resources: levels of analysis between the computational and the algorithmicTopics in Cognitive Science 7:217–229.https://doi.org/10.1111/tops.12142
-
Relative and absolute strength of response as a function of frequency of reinforcementJournal of the Experimental Analysis of Behavior 4:267–272.https://doi.org/10.1901/jeab.1961.4-267
-
Processing of temporal unpredictability in human and animal amygdalaThe Journal of Neuroscience 27:5958–5966.https://doi.org/10.1523/JNEUROSCI.5218-06.2007
-
On the rate of gain of informationQuarterly Journal of Experimental Psychology 4:11–26.https://doi.org/10.1080/17470215208416600
-
Order effects in belief updating: The belief-adjustment modelCognitive Psychology 24:1–55.https://doi.org/10.1016/0010-0285(92)90002-J
-
Nonparametric learning rules from bandit experiments: The eyes have it!Games and Economic Behavior 81:215–231.https://doi.org/10.1016/j.geb.2013.05.003
-
Stimulus information as a determinant of reaction timeJournal of Experimental Psychology 45:188–196.https://doi.org/10.1037/h0056940
-
ConferenceA Resource-Rational Approach to the Causal Frame ProblemProceedings of the 37th Annual Meeting of the Cognitive Science Society.
-
Probability learning and a negative recency effect in the serial anticipation of alternative symbolsJournal of Experimental Psychology 41:291–297.https://doi.org/10.1037/h0056878
-
Sequential effects in response time reveal learning mechanisms and event representationsPsychological Review 120:628–666.https://doi.org/10.1037/a0033180
-
A simple coding procedure enhances a neuron’s information capacityZeitschrift Für Naturforschung C 36:910–912.https://doi.org/10.1515/znc-1981-9-1040
-
Resource-rational analysis: Understanding human cognition as the optimal use of limited computational resourcesThe Behavioral and Brain Sciences 43:e1.https://doi.org/10.1017/S0140525X1900061X
-
Bayesian inference with probabilistic population codesNature Neuroscience 9:1432–1438.https://doi.org/10.1038/nn1790
-
Spiking networks for Bayesian inference and choiceCurrent Opinion in Neurobiology 18:217–222.https://doi.org/10.1016/j.conb.2008.07.004
-
A biased bayesian inference for decision-making and cognitive controlFrontiers in Neuroscience 12:734.https://doi.org/10.3389/fnins.2018.00734
-
Effects of causal and noncausal sequences of information on subjective predictionPsychological Reports 54:211–215.https://doi.org/10.2466/pr0.1984.54.1.211
-
Subjective probabilities for sex of next child: U.S. College students and Philippine villagersJournal of Population Behavioral, Social, and Environmental Issues 1:132–147.https://doi.org/10.1007/BF01277598
-
Human inferences about sequences: a minimal transition probability modelPLOS Computational Biology 12:e1005260.https://doi.org/10.1371/journal.pcbi.1005260
-
An approximately Bayesian delta-rule model explains the dynamics of belief updating in a changing environmentThe Journal of Neuroscience 30:12366–12378.https://doi.org/10.1523/JNEUROSCI.0822-10.2010
-
Implicit learning increases preference for predictive visual displayAttention, Perception & Psychophysics 73:1815–1822.https://doi.org/10.3758/s13414-010-0041-2
-
What’s next? Judging sequences of binary eventsPsychological Bulletin 135:262–285.https://doi.org/10.1037/a0014821
-
Generating stimuli for neuroscience using psychoPyFrontiers in Neuroinformatics 2:10.https://doi.org/10.3389/neuro.11.010.2008
-
A theory of memory for binary sequences: Evidence for A mental compression algorithm in humansPLOS Computational Biology 17:e1008598.https://doi.org/10.1371/journal.pcbi.1008598
-
Reliance on small samples, the wavy recency effect, and similarity-based learningPsychological Review 122:621–647.https://doi.org/10.1037/a0039413
-
Human inference in changing environments with temporal structurePsychological Review 128:879–912.https://doi.org/10.1037/rev0000276
-
ConferenceBias and variance of the Bayesian-mean decoderAdvances in Neural Information Processing Systems 34 (NeurIPS 2021). pp. 23793–23805.
-
Infant statistical learningAnnual Review of Psychology 69:181–203.https://doi.org/10.1146/annurev-psych-122216-011805
-
Types of approximation for probabilistic cognition: sampling and variationalBrain and Cognition 112:98–101.https://doi.org/10.1016/j.bandc.2015.06.008
-
Neuronal coding of prediction errorsAnnual Review of Neuroscience 23:473–500.https://doi.org/10.1146/annurev.neuro.23.1.473
-
Estimating the Dimension of a ModelThe Annals of Statistics 6:461–464.https://doi.org/10.1214/aos/1176344136
-
Descriptive versus normative models of sequential inference judgmentJournal of Experimental Psychology 93:63–68.https://doi.org/10.1037/h0032509
-
Complexity and the representation of patterned sequences of symbolsPsychological Review 79:369–382.https://doi.org/10.1037/h0033118
-
BookBounded rationalityIn: Simon HA, editors. Models of Bounded Rationality: Empirically Grounded Economic Reason. The MIT Press. pp. 291–294.https://doi.org/10.7551/mitpress/4711.001.0001
-
Natural image statistics and neural representationAnnual Review of Neuroscience 24:1193–1216.https://doi.org/10.1146/annurev.neuro.24.1.1193
-
Implications of rational inattentionJournal of Monetary Economics 50:665–690.https://doi.org/10.1016/S0304-3932(03)00029-1
-
Psychophysically principled models of visual simple reaction timePsychological Review 102:567–593.https://doi.org/10.1037/0033-295X.102.3.567
-
Expectancy or automatic facilitation? Separating sequential effects in two-choice reaction timeJournal of Experimental Psychology 11:598–616.https://doi.org/10.1037/0096-1523.11.5.598
-
Bayesian model selection for group studiesNeuroImage 46:1004–1017.https://doi.org/10.1016/j.neuroimage.2009.03.025
-
Expectation in perceptual decision making: neural and computational mechanismsNature Reviews. Neuroscience 15:745–756.https://doi.org/10.1038/nrn3838
-
Human preferences are biased towards associative informationCognition & Emotion 29:1054–1068.https://doi.org/10.1080/02699931.2014.966064
-
The time course of perceptual choice: the leaky, competing accumulator modelPsychological Review 108:550–592.https://doi.org/10.1037/0033-295x.108.3.550
-
An economist’s perspective on probability matchingJournal of Economic Surveys 14:101–118.https://doi.org/10.1111/1467-6419.00106
-
A Bayesian observer model constrained by efficient coding can explain “anti-Bayesian” perceptsNature Neuroscience 18:1509–1517.https://doi.org/10.1038/nn.4105
-
ConferenceSequential effects reflect parallel learning of multiple environmental regularitiesAdvances in Neural Information Processing Systems 22 - Proceedings of the 2009 Conference. pp. 2053–2061.
-
Information-constrained state-dependent pricingJournal of Monetary Economics 56:S100–S124.https://doi.org/10.1016/j.jmoneco.2009.06.014
-
Sequential effects: Superstition or rational behavior?Advances in Neural Information Processing Systems 21:1873–1880.
-
ConferenceSequential effects: A Bayesian analysis of prior bias on reaction time and behavioral choiceProceedings of the 36th Annual Conference of the Cognitive Science Society. pp. 1844–1849.
-
Algorithm 778: L-bfgs-b: Fortran subroutines for large-scale bound-constrained optimizationACM Transactions on Mathematical Software. Association for Computing Machinery 23:550–560.https://doi.org/10.1145/279232.279236
Article and author information
Author details
Arthur Prat-Carrabin

Rava Azeredo da Silveira
Funding
Albert P. Sloan Foundation (Grant G-2020-12680)
- Rava Azeredo da Silveira
CNRS (UMR8023)
- Rava Azeredo da Silveira
Fondation Pierre-Gilles de Gennes pour la recherche (Ph.D. Fellowship)
- Arthur Prat-Carrabin
The funders had no role in study design, data collection and interpretation, or the decision to submit the work for publication.
Acknowledgements
We thank Doron Cohen and Michael Woodford for inspiring discussions. This work was supported by the Alfred P Sloan Foundation through grant G-2020–12680 and the CNRS through UMR8023. A.P.C. was supported by a Ph.D. fellowship of the Fondation Pierre-Gilles de Gennes pour la Recherche. We acknowledge computing resources from Columbia University’s Shared Research Computing Facility project, which is supported by NIH Research Facility Improvement Grant 1G20RR030893-01, and associated funds from the New York State Empire State Development, Division of Science Technology and Innovation (NYSTAR) Contract C090171, both awarded April 15, 2010.
Ethics
The study was approved by the ethics committee Île de France VII (CPP 08-021). Participants gave their written consent prior to participating.
Copyright
© 2024, Prat-Carrabin et al.
This article is distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use and redistribution provided that the original author and source are credited.
Metrics
-
- 772
- views
-
- 114
- downloads
-
- 6
- citations
Views, downloads and citations are aggregated across all versions of this paper published by eLife.
Citations by DOI
-
- 6
- citations for umbrella DOI https://doi.org/10.7554/eLife.81256
Download links
A two-part list of links to download the article, or parts of the article, in various formats.
Downloads (link to download the article as PDF)
Open citations (links to open the citations from this article in various online reference manager services)
Cite this article (links to download the citations from this article in formats compatible with various reference manager tools)
Resource-rational account of sequential effects in human prediction
eLife 13:e81256.
https://doi.org/10.7554/eLife.81256




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}